Monaural Singing Voice and Accompaniment Separation Based on Gated Nested U-Net Architecture


Abstract
1. Introduction
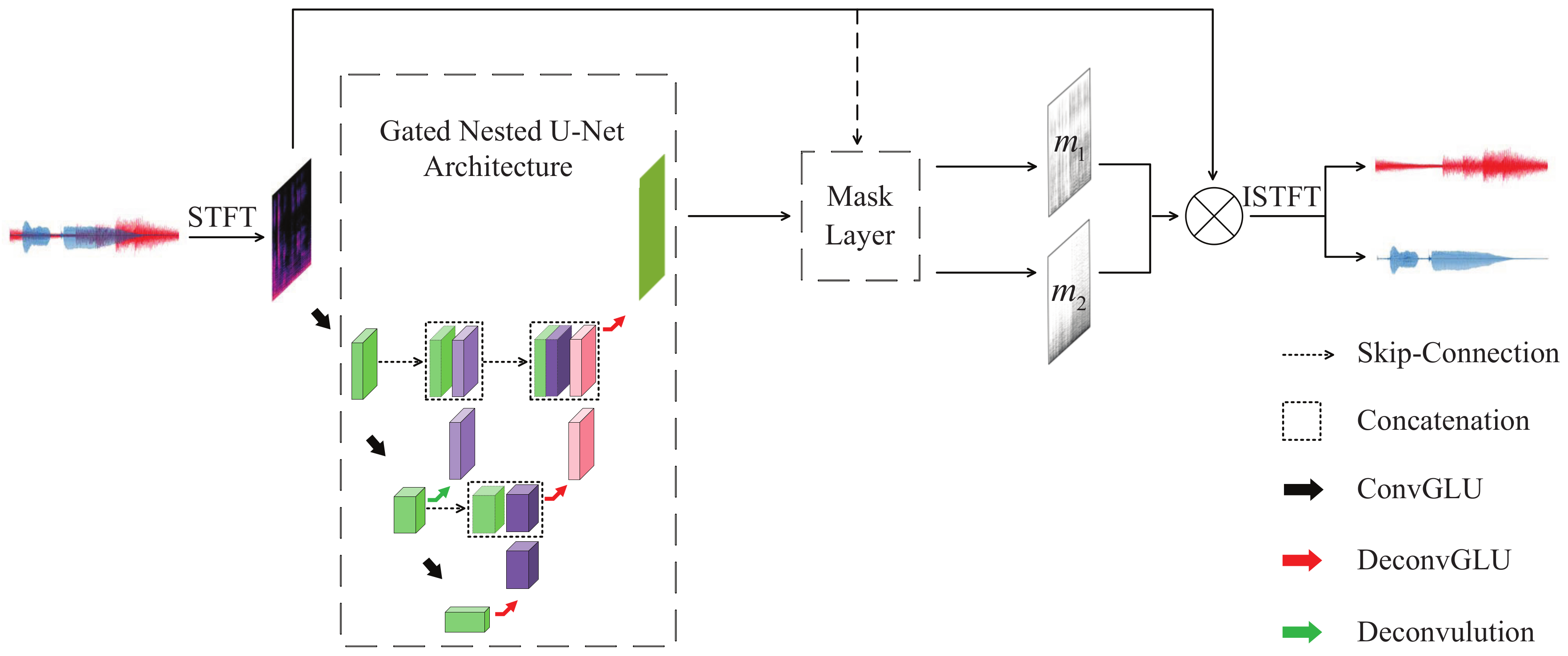
2. Gated Nested U-Net Separation Model
2.1. Proposed GNU-Net Separation Model
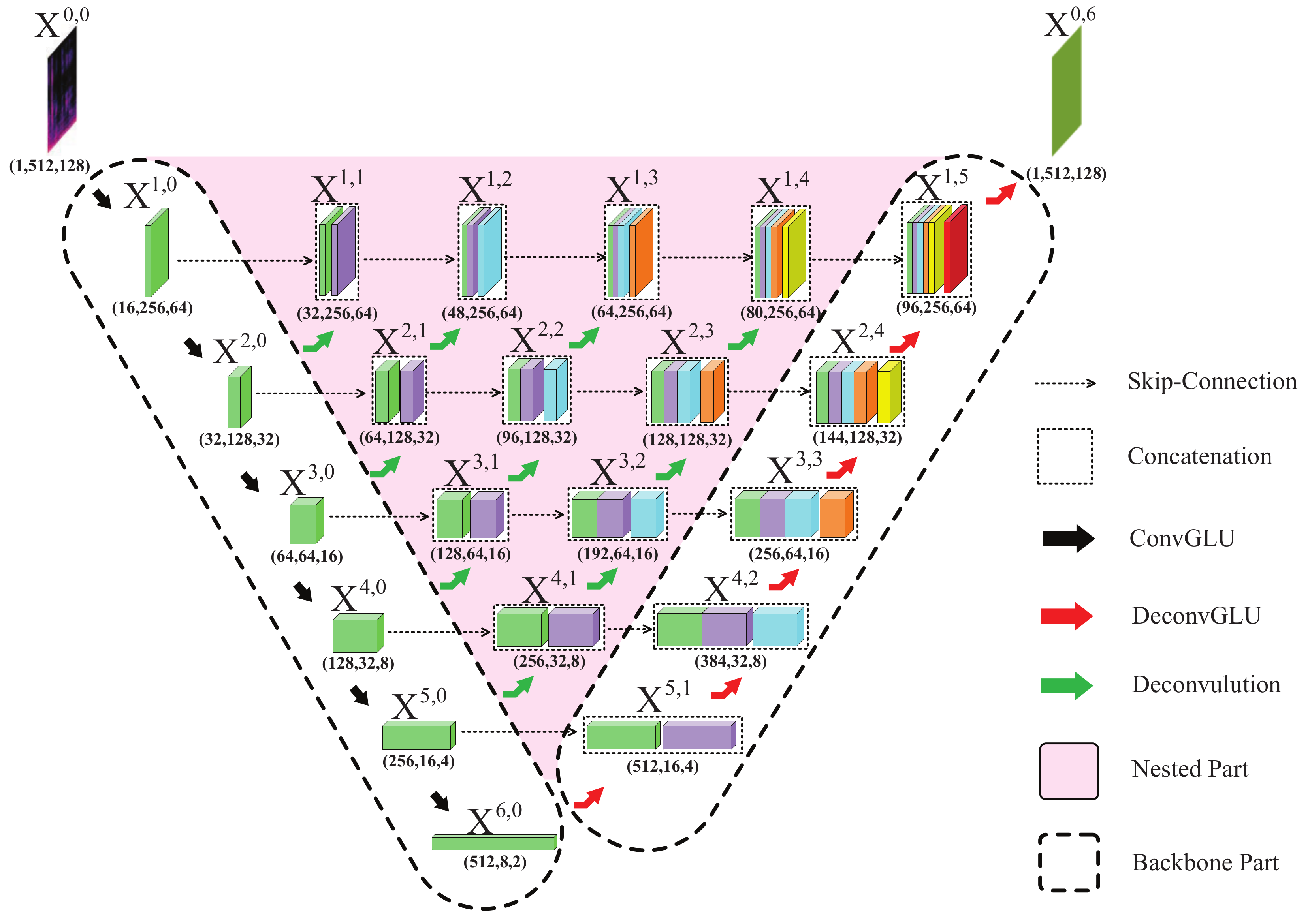
2.2. Gated Nested U-Net Architecture
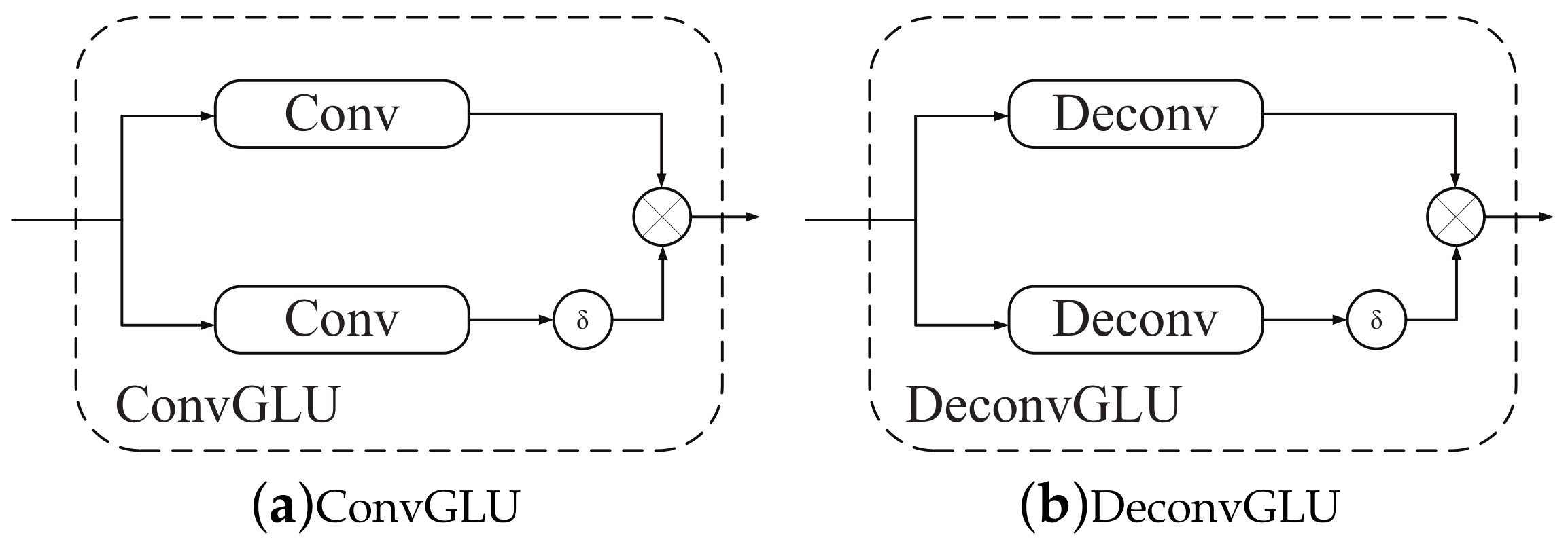
2.3. Gated Linear Unit
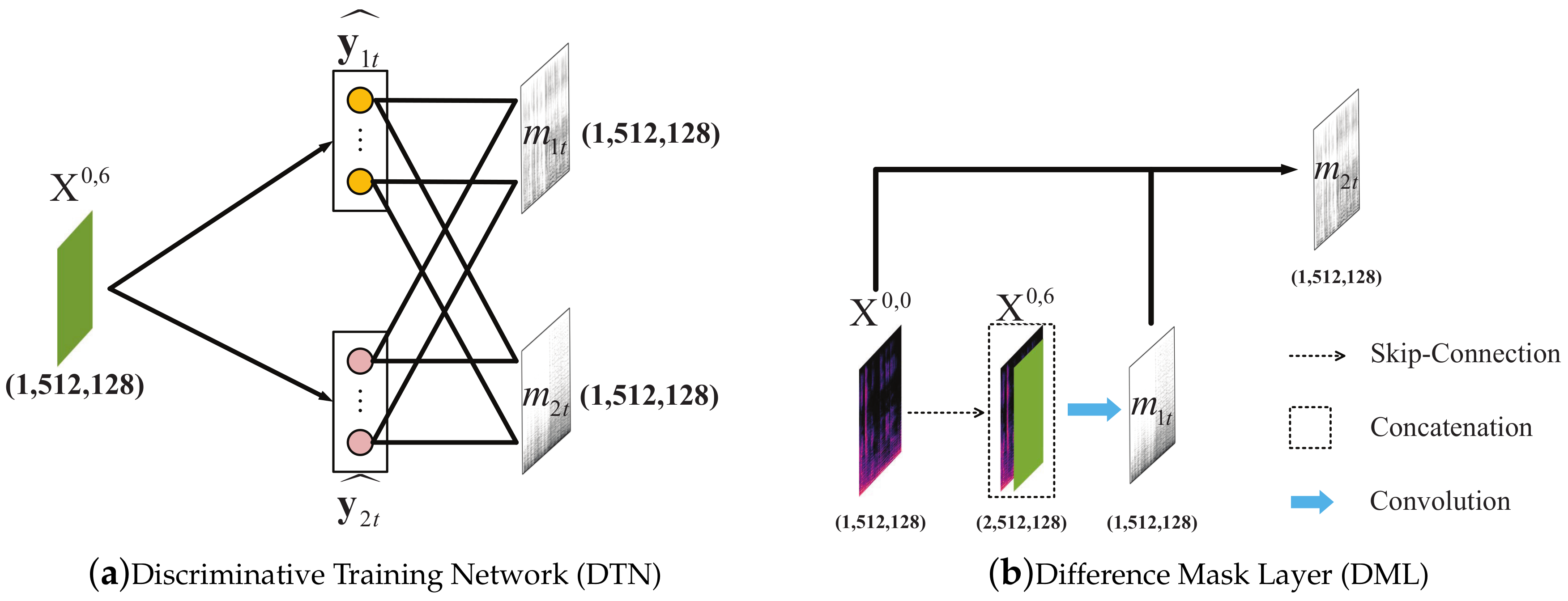
2.4. Mask Layer
3. Experiments
3.1. Dataset and Preprocessing
3.2. Evaluation Metrics
3.3. Experiment Configurations
3.4. Comparison with Ideal Time-Frequency Masks
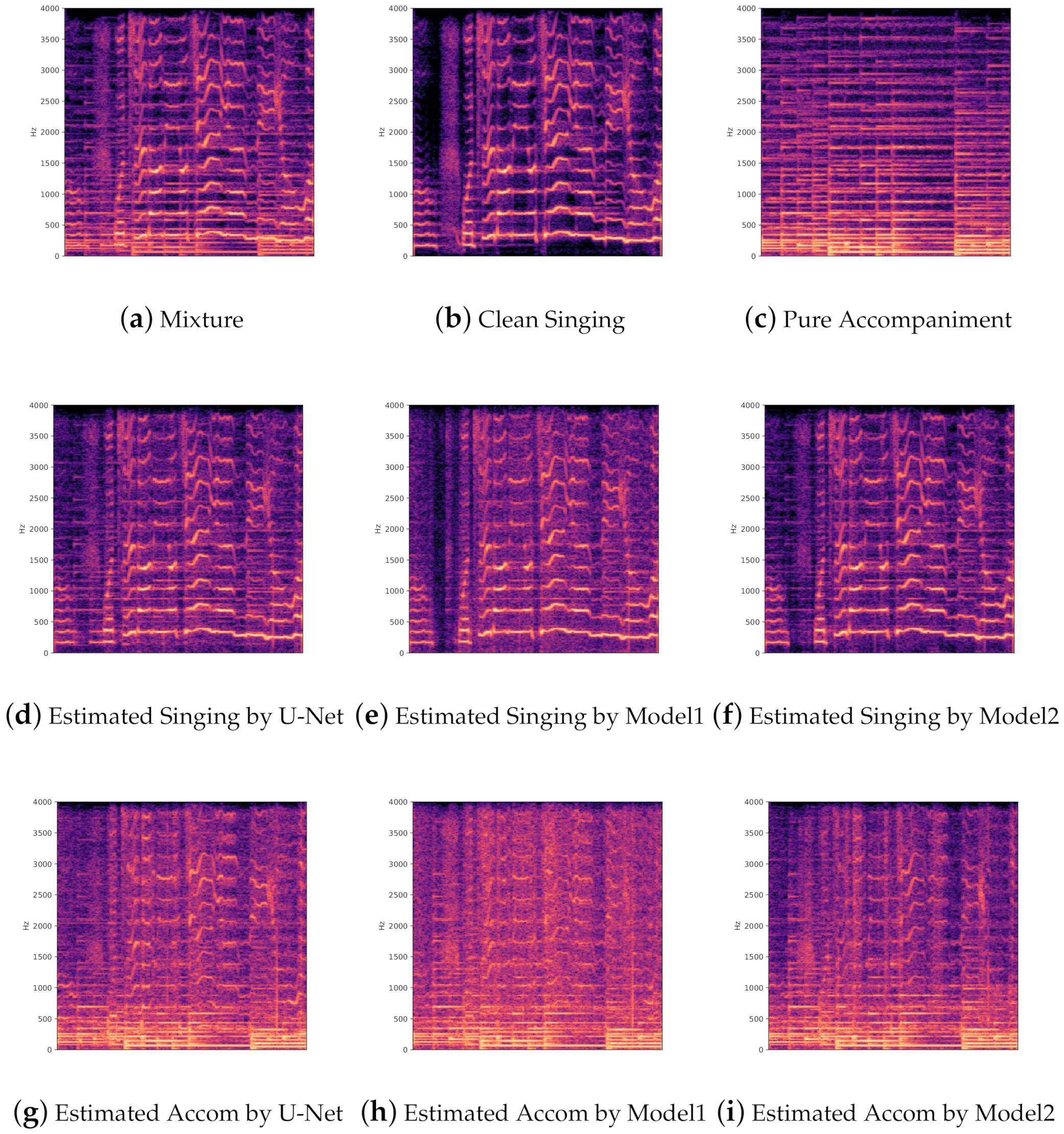
4. Results
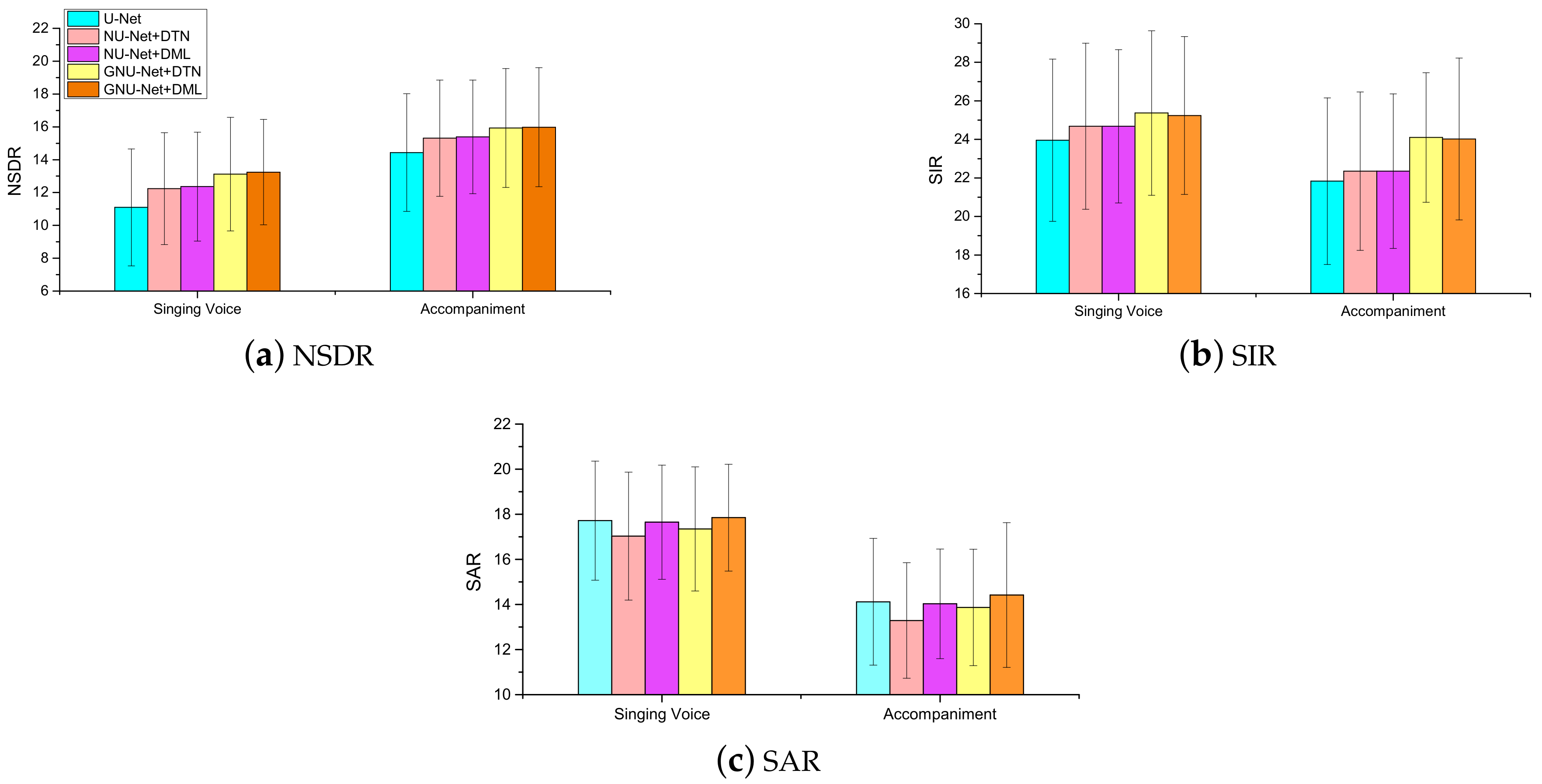
4.1. Optimizing the Network Model
- (i)
- Nested U-Net architecture outperforms U-Net architecture, this results verifies that the nested decoder subnetworks can remedy the information loss caused by previous downsampling operations.
- (ii)
- Introducing gated mechanisms can noticeably improve system performance.
- (iii)
- As mask layer, difference mask layer (DML) is superior to discriminative training network (DTN).
- (iv)
- On the whole, the NSDR scores of accompaniment outperform that of singing voice. This may be because in the most general case, the intensity of the accompaniment is greater than that of the singing voice, and accompaniment has more continuous components over time.
4.2. Comparison of Proposed Method with Previous Methods
5. Conclusions
- (i)
- The nested U-Net architecture outperforms U-Net architecture.
- (ii)
- Introducing gated mechanisms can improve system performance.
- (iii)
- DML is superior to DTN.
- (iv)
- Our proposed GNU-Net separation model outperforms three compared models on three evaluation metrics—NSDR, SIR, and SAR.
- (v)
- Our proposed GNU-Net approaches IBM on NSDR metric and even outperforms IBM on SAR.
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Sharma, B.; Das, R.K.; Li, H. On the importance of audio-source separation for singer identification in polyphonic music. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Hu, Y.; Liu, G. Separation of singing voice using nonnegative matrix partial co-factorization for singer identification. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 643–653. [Google Scholar] [CrossRef]
- Mesaros, A.; Virtanen, T.; Klapuri, A. Singer identification in polyphonic music using vocal separation and pattern recognition methods. ISMIR 2007, 375–378. [Google Scholar]
- Kruspe, A.M.; Fraunhofer, I. Retrieval of textual song lyrics from sung inputs. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 2140–2144. [Google Scholar]
- Mesaros, A.; Virtanen, T. Automatic recognition of lyrics in singing. EURASIP J. Audio Speech Music. Process. 2010, 546047. [Google Scholar] [CrossRef]
- Wang, Y.; Kan, M.Y.; Nwe, T.L.; Shenoy, A.; Yin, J. Lyrically: Automatic synchronization of acoustic musical signals and textual lyrics. In Proceedings of the 12th annual ACM international conference on Multimedia, New York, NY, USA, 10–16 October 2004; pp. 212–219. [Google Scholar]
- Ikemiya, Y.; Itoyama, K.; Yoshii, K. Singing voice separation and vocal f0 estimation based on mutual combination of robust principal component analysis and subharmonic summation. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2084–2095. [Google Scholar] [CrossRef]
- Lin, K.W.E.; Anderson, H.; Agus, N.; So, C.; Lui, S. Visualising singing style under common musical events using pitch-dynamics trajectories and modified traclus clustering. In Proceedings of the 2014 13th International Conference on Machine Learning and Applications, Detroit, MI, USA, 3–5 December 2014; pp. 237–242. [Google Scholar]
- Uhlich, S.; Giron, F.; Mitsufuji, Y. Deep neural network based instrument extraction from music. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 2135–2139. [Google Scholar]
- Yoo, J.; Kim, M.; Kang, K.; Choi, S. Nonnegative matrix partial co-factorization for drum source separation. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 1942–1945. [Google Scholar]
- Rafii, Z.; Liutkus, A.; Stoter, F.R.; Mimilakis, S.I.; FitzGerald, D.; Pardo, B. An overview of lead and accompaniment separation in music. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1307–1335. [Google Scholar] [CrossRef]
- Huang, P.S.; Chen, S.D.; Smaragdis, P.; Hasegawa-Johnson, M. Singing-voice separation from monaural recordings using robust principal component analysis. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 57–60. [Google Scholar]
- Wang, D.L.; Chen, J. Supervised speech separation based on deep learning: An overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef] [PubMed]
- Huang, P.S.; Kim, M.; Hasegawa-Johnson, M.; Smaragdis, P. Singing-voice separation from monaural recordings using deep recurrent neural networks. In Proceedings of the 15th International Society for Music Information Retrieval Conference (ISMIR 2014), Taipei, Taiwan, 27–31 October 2014; pp. 477–482. [Google Scholar]
- Huang, P.S.; Kim, M.; Hasegawa-Johnson, M.; Smaragdis, P. Joint optimization of masks and deep recurrent neural networks for monaural source separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 2136–2147. [Google Scholar] [CrossRef]
- Fan, Z.C.; Lai, Y.L.; Jang, J.S.R. Svsgan: Singing voice separation via generative adversarial network. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 726–730. [Google Scholar]
- He, B.; Wang, S.; Yuan, W.; Wang, J.; Unoki, M. Data augmentation for monaural singing voice separation based on variational autoencoder-generative adversarial network. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1354–1359. [Google Scholar]
- Stoller, D.; Ewert, S.; Dixon, S. Adversarial semi-supervised audio source separation applied to singing voice extraction. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2391–2395. [Google Scholar]
- Mimilakis, S.I.; Drossos, K.; Santos, J.F.; Schuller, G.; Virtanen, T.; Bengio, Y. Monaural singing voice separation with skip-filtering connections and recurrent inference of time-frequency mask. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 721–725. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Tan, K.; Wang, D.L. Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 28, 380–390. [Google Scholar] [CrossRef]
- Tan, K.; Chen, J.; Wang, D.L. Gated Residual Networks with Dilated Convolutions for Monaural Speech Enhancement. IEEE/ACM IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 189–198. [Google Scholar] [CrossRef] [PubMed]
- Shi, Z.; Lin, H.; Liu, L.; Liu, R.; Han, J.; Shi, A. Deep attention gated dilated temporal convolutional networks with intra-parallel convolutional modules for end-to-end monaural speech separation. Proc. Interspeech 2019, 3183–3187. [Google Scholar] [CrossRef]
- Xu, Y.; Kong, Q.; Wang, W.; Plumbley, M.D. Large-scale weakly supervised audio classification using gated convolutional neural network. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Jansson, A.; Humphrey, E.; Montecchio, N.; Bittner, R.; Kumar, A.; Weyde, T. Singing voice separation with deep u-net convolutional networks. In Proceedings of the 18th International Society for Music Information Retrieval Conference, ISMIR, Suzhou, China, 23–27 October 2017; pp. 23–27. [Google Scholar]
- Stoller, D.; Ewert, S.; Dixon, S. Wave-u-net: A multi-scale neural network for end-to-end audio source separation. arXiv 2018, arXiv:1806.03185. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Oord, A.V.D.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel Recurrent Neural Networks. arXiv 2016, arXiv:1601.06759. [Google Scholar]
- Chan, T.S.; Yeh, T.C.; Fan, Z.C.; Chen, H.W.; Su, L.; Yang, Y.H.; Jang, R. Vocal activity informed singing voice separation with the ikala dataset. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 718–722. [Google Scholar]
- Vincent, E.; Gribonval, R.; Févotte, C. Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1462–1469. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv preprint 2014, arXiv:1412.6980. [Google Scholar]
- Isik, Y.; Roux, J.L.; Chen, Z.; Watanabe, S.; Hershey, J.R. Single-channel multi-speaker separation using deep clustering. arXiv 2016, arXiv:1607.02173. [Google Scholar]
- Luo, Y.; Chen, Z.; Mesgarani, N. Speaker-independent speech separation with deep attractor network. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 787–796. [Google Scholar] [CrossRef]
- Luo, Y.; Chen, Z.; Ellis, D.P. Deep clustering for singing voice separation. MIREX, Task of Singing Voice Separation. 2016, pp. 1–2. Available online: https://www.music-ir.org/mirex/abstracts/2016/LCP1.pdf (accessed on 10 May 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Operation | Shape | |
|---|---|---|---|
| Input | = (1,512,128) | ||
| Encoder i = 1,…,L | ConvGLU2D() | = (512,8,2) | |
| Decoder i = L,…,1 | Nested Part | Concat[] | = (96,256,64) |
| Deconv2D() | |||
| Backbone Part | Concat[] | ||
| DeconvGLU2D() | |||
| Output | DeconvGLU2D(1) | = (1,512,128) |
| Singing Voice | Accompaniment | |||||
|---|---|---|---|---|---|---|
| NSDR | SIR | SAR | NSDR | SIR | SAR | |
| U-Net [26] | 11.09 | 23.96 | 17.72 | 14.44 | 21.83 | 14.12 |
| NU-Net+DTN | 12.24 | 24.68 | 17.03 | 15.31 | 22.35 | 13.29 |
| NU-Net+DML | 12.36 | 24.54 | 17.62 | 15.39 | 22.31 | 14.03 |
| GNU-Net+DTN | 13.12 | 25.37 | 17.37 | 15.93 | 24.10 | 13.87 |
| GNU-Net+DML | 13.24 | 25.24 | 17.85 | 15.98 | 24.02 | 14.42 |
| Model | Levels | Model Size | Singing Voice | Accompaniment | ||||
|---|---|---|---|---|---|---|---|---|
| NSDR | SIR | SAR | NSDR | SIR | SAR | |||
| U-Net | 4 | 0.61M | 9.71 | 22.72 | 15.15 | 13.22 | 17.78 | 12.22 |
| 5 | 2.45M | 10.37 | 23.25 | 16.87 | 14.96 | 21.24 | 13.53 | |
| 6 | 9.82M | 11.09 | 23.96 | 17.72 | 15.31 | 21.83 | 14.12 | |
| NU-Net+DML | 4 | 0.72M | 9.78 | 22.68 | 15.23 | 13.23 | 17.69 | 12.33 |
| 5 | 3.00M | 11.98 | 23.34 | 16.82 | 15.04 | 21.21 | 13.40 | |
| 6 | 12.07M | 12.36 | 24.54 | 17.62 | 15.39 | 22.31 | 14.03 | |
| GNU-Net+DML | 4 | 1.32M | 10.28 | 22.14 | 15.88 | 13.37 | 22.82 | 12.46 |
| 5 | 5.47M | 12.91 | 24.47 | 17.05 | 15.64 | 23.73 | 13.90 | |
| 6 | 22.21M | 13.24 | 25.24 | 17.85 | 15.98 | 24.02 | 14.42 | |
| SingingVoice | Accompaniment | |||||
|---|---|---|---|---|---|---|
| NSDR | SIR | SAR | NSDR | SIR | SAR | |
| RPCA [12] | 6.32 | 8.14 | 12.53 | 0.75 | 3.23 | 7.00 |
| Chimera [36] | 8.75 | 21.30 | 15.64 | 11.63 | 20.48 | 11.54 |
| U-Net [26] | 11.09 | 23.96 | 17.72 | 14.44 | 21.83 | 14.12 |
| NU-Net+DML | 12.36 | 24.54 | 17.62 | 15.39 | 22.31 | 13.03 |
| GNU-Net+DML | 13.24 | 25.24 | 17.85 | 15.98 | 24.02 | 14.42 |
| IBM | 14.06 | 29.00 | 16.80 | 16.56 | 32.78 | 14.18 |
| IRM | 15.25 | 26.45 | 18.34 | 17.48 | 22.18 | 16.02 |
| WFM | 15.66 | 28.57 | 18.55 | 18.23 | 29.18 | 16.00 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geng, H.; Hu, Y.; Huang, H. Monaural Singing Voice and Accompaniment Separation Based on Gated Nested U-Net Architecture. Symmetry 2020, 12, 1051. https://doi.org/10.3390/sym12061051
Geng H, Hu Y, Huang H. Monaural Singing Voice and Accompaniment Separation Based on Gated Nested U-Net Architecture. Symmetry. 2020; 12(6):1051. https://doi.org/10.3390/sym12061051
Chicago/Turabian StyleGeng, Haibo, Ying Hu, and Hao Huang. 2020. "Monaural Singing Voice and Accompaniment Separation Based on Gated Nested U-Net Architecture" Symmetry 12, no. 6: 1051. https://doi.org/10.3390/sym12061051
APA StyleGeng, H., Hu, Y., & Huang, H. (2020). Monaural Singing Voice and Accompaniment Separation Based on Gated Nested U-Net Architecture. Symmetry, 12(6), 1051. https://doi.org/10.3390/sym12061051