1. Introduction
Stress refers to physical, mental, or emotional reactions in response to changes that occur in the body. It is among the physiological symptoms that are frequently seen in people who work [
1]. It is one of the major problems in modern society. It is the body’s reaction to feeling threatened or under pressure. However, too much stress can affect our mood, our body and our relationships—especially when it feels out of control. It can make us feel anxious and irritable and affect our self-esteem. There are many possible causes of stress, for example, the pressure at work, school or home, illness, or difficult or sudden life events and many other things. Stress is responsible for abnormal responses in the autonomic nervous system (ANS), which is combined with the sympathetic nervous system (SNS) and the parasympathetic nervous system (PNS) under antagonistic control.
For millennia, we have understood that heart rate (HR) responds to stress. When we are overwhelmed with stress, in our body, adrenal glands are triggered to release the hormones cortisol and adrenaline. These can make our heart beat faster and raise our blood pressure. Many parameters can indicate stress levels in the body in medical contexts; these include heart rate variability (HRV), galvanic skin response, cortisol, blood pressure (BP), electroencephalogram (EEG), and respiratory activity [
1]. In this context, the heart rate variability (HRV), i.e., the variation in the time interval between heartbeats, is known to be a reliable non-invasive biomarker of the ANS. Using BP, heart rate, and HRV, it is possible to monitor the activity of the sympathetic and parasympathetic nervous systems [
2]. Apart from such physically observable phenomena or responses of the body, various technologies have also been developed to detect stress levels using physiological signals; for example, in a study conducted by Akane, they used wearable sensor and mobile phones to detect the stress. There are many novel wearable devices such as Olive, Spire, BreathAcoustics, and Gizmodo integrated with various biosensors that help people monitor stress and organise their daily life accordingly. In a study conducted by Vrijkotte, work stress was evaluated using BP, heart rate, and HRV [
3]. The study resulted that the high imbalance (a combination of high effort and low reward at work) was statistically correlated with a higher heart rate during work and higher systolic blood pressure during work and leisure time. Some of the studies are based on stress questionnaires, which are commonly used by psychologists to detect patients’ stress levels; for example, a research conducted by Sheldon Cohen used a questionnaire for the reliability and validity of a 14-item instrument, the Perceived Stress Scale (PSS), which is designed to measure the degree to which situations in one’s life are appraised as stressful [
1]. Heart rate is also used as a parameter in various studies on stress identification [
4].
Thus, we herein report the application of artificial intelligence to predict the effect of commute on BP and heart rate. We include as participants individuals who commute to and from work regularly. The participants are stratified based on how they commute to work (public transport, driving, or cycling/walking). Our approach will allow us to measure the effects during and after the period of commuting for a group of people. For this purpose, cutting-edge technology is used in this research: the MySignals device. We applied machine-learning approaches to predict the effect of a long commute on human heart rate and BP in the London area. Machine learning provides systems with the ability to learn and improve automatically from experience without being programmed explicitly. The value of machine learning in healthcare is its ability to process huge datasets beyond the scope of human capability and then reliably convert an analysis of that data ultimately leading to better outcomes. Machine learning provides systems with the ability to learn and improve automatically from the experience; it enables a broader range of scenarios (different commuting types, different environment, etc.) to be explored outside of the data. Moreover, it will help us provide a generalised module with the ability to help the employers provide the right support for their employees who have a long commute. In this process, we have chosen from among the various widely accepted artificial intelligence techniques those which are most relevant to our research.
2. Literature Review and the State of the Art
The Sano–Picard framework [
1] applied correlation analysis to find statistically significant features associated with stress and used machine learning to classify whether the participants were stressed or not. They collected five-day physiological and behavioural data, including skin conductance. They obtained over 75% accuracy for low and high perceived stress recognition using a combination of mobile phone usage and sensor data. In a study conducted by Vrijkotte, BP, heart rate, and HRV were used to evaluate work stress [
3]. The results of that study suggest that work stress can cause increased heart-rate reactivity to a stressful workday, an increase in systolic BP, and lower vagal tone. In another study, Hudson [
4] used a machine-learning approach to predict increases in BP.
As today’s world is moving towards intelligent systems, the demand for collaboration between various fields is increasing. Artificial intelligence techniques have been widely used in various forms of medical treatment. In this study, we are leveraging collaboration between AI and medical data analysis. By using artificial intelligence, this study aims to investigate how different psychophysical signals of healthy participants are collected to define a solid starting point for studying the impact of commuting on BP and heart rate.
Similarly, in a report produced by the Royal Society for Public Health (RSPH), the main findings were the health status, level of happiness, and satisfaction were lower for people who had longer commutes [
5]. In that report, factors such as how long the commute takes and the type of commute (e.g., by public transport, cycling, or driving) have an impact on how individuals feel about the commute. Commuting is one of the biggest lifestyle challenges in Greater London, as Londoners spend an average of 56 min travelling, rising to 79 min. For example, active commuting, which involves walking, cycling or using public transport, is associated with lower levels of stress, and long commutes tend to be associated with more stress. The number of people who spend more than two hours commuting to and from work every day has jumped by 72% over the past decade to more than three million, according to the Trade Union Congress (TUC), as published by
The Guardian. However, most of the studies on the effects of stress on commuting have been based on self-report questionnaires.
Machine learning is a new field that is focused on the development of systems that can automatically learn from data and create highly accurate predictive models. It has attracted considerable research interest towards developing smart digital health interventions. These interventions have the potential to revolutionise health care and lead to substantial outcomes for patients and medical professionals [
6]. It has already been implemented in many health-related studies such as obesity prediction. In that study, they created a framework that combines both the statistical and extraction-based methods with appropriate feature representation/selection strategy [
7]. In addition, software architecture was designed for the classification of information from patient electronic records; the architecture was formed by a classification layer that includes a linguistic module and machine learning classification modules [
8]. Artificial neural network (ANN) classification techniques are used to detect the region of tumours in the clinical datasets of patients with laryngeal tumours [
9].
Artificial intelligence has been trending in the field of medicine and health care. An overview of recent studies indicate that much artificial intelligence, machine learning, and deep learning techniques are being applied for various purposes, including the detection, prediction, diagnosis, and treatment of diseases, thereby reducing instances of human error in medical data analysis and processing. Variously, ANN techniques, regression and classification techniques, deep-learning convolutional neural networks, fuzzy logic, rule-based expert system techniques, and machine-learning techniques have been found to obtain better respective results when applied to detection systems, data analysis, data visualisation and classification methods. Feed-forward neural networks are the most popular static network. One study found that the feed-forward ANN technique has much better optimisation and precision when compared with the statistical multiple regression analysis techniques [
8]. In this paper, different algorithms, such as quasi-Newton, gradient descent, and genetic algorithms, were used to train the ANN. In another study, it was noted that an ANN technique performed better than multiple regression techniques [
10]. An ANN technique with a back-propagation algorithm was compared with statistical and machine-learning multiple-regression techniques to conduct a continuous estimation of blood pressure. Artificial intelligence technologies can provide better accuracy and save a significant amount of time on classification and quantification in positron emission tomography [
11]. ANN techniques were found to be highly reliable and more effective in a recent study on machine learning and stress assessment [
12]. Using risk factors such as stress, diabetes, obesity, smoking, salt intake, BP, and cholesterol as inputs, diagnosis of hypertension is easily predicted by applying ANN techniques. A decision tree algorithm was used for continuous BP measurement to predict BP at a continuous rate based on human physiological data from ECG signals and heart-rate reading [
13]. Finally, a support vector machine-based hardware platform was used for blood-pressure prediction. ANNs are one of the best artificial intelligence (AI) technologies with the capacity to classify, measure the region of interest precisely, and model the clinical evaluation [
14]. In this study, the support vector machine, recurrent neural networks, and the K-nearest neighbour algorithm are used to confirm whether heart rate and BP would be higher post-commute compared to pre-commute. Feed-forward neural networks, linear discriminant analysis (LDA), and decision tree techniques are used to confirm whether the systolic BP is higher in longer commutes versus shorter. Before applying these machine-learning techniques, a feature selection phase was conducted using several correlation methods.
Feed-forward neural networks are one of the most effective ANN techniques. In this technique, the information only moves in the forward direction. There are three main layers in this network: the input layer, the hidden layer, and the output layer. In a study, the classification of heart diseases using HRV signals was performed for normal patients and patients with congestive heart failure (CHF) and myocardial infarction. The data were taken from ECG recordings, and a multi-layer feed-forward neural network was used for their classification [
15]. Three different methods (time-domain, frequency-domain, and non-linear methods) were used to select the inputs to the neural network classifier. The results obtained based on the non-linear methods were used as a high accuracy rate for classifying heart diseases was achieved. A multi-layer feed-forward neural network consisting of an input layer, multiple hidden layers, and an output layer was used to predict the probability of occurrence of hypertension [
16]. This technique was also used in feature selection in ischemic heart disease identification [
17]. LDA is now a widely used technique in the field of artificial intelligence and machine learning and its associated methods, including statistical analysis, data analysis, pattern recognition, and classifier models. It can predict the value of the dependent variable using the values of predictor variables. This approach can achieve better results in metrics of accuracy, specificity, and sensitivity.
In previous research, the LDA technique was used to analyse medical datasets of blood-pressure recordings to predict post-induction hypotension (i.e., lower BP), and cross-validation and the receiver operating characteristic (ROC) curve were assessed with an accuracy of 95% when an LDA model was trained on the dataset [
18]. In a further study involving a dataset of elderly patients at high risk of heart failure, ECG recordings and features of respiratory breathing patterns and flow signals were used to train the LDA classification method. The technique was optimised and performed well with certain parameters applicable in the dataset. It obtained good levels of accuracy (82.4%), sensitivity (81.8%), and specificity (83.3%) [
19].
Decision tree learning, a supervised machine-learning technique that is also used as a classifier model, predicts the observations, decisions, and classifications regarding any problem until a target value is reached. A decision tree algorithm has been used for continuous BP measurement, that is, the predicting of BP at a continuous rate based on human physiological data from ECG signals and heart-rate readings. It has displayed higher accuracy in calculating the mean absolute error, applying the traditional least square method, calculating regression, and analysing the monitoring data for telemedicine applications. When the systolic BP of any single individual was predicted from the data, the accuracy rate was higher than 70%, and the diastolic BP was predicted with an accuracy rate higher than 64% when calculated with gradient-boosting decision tree algorithms [
18]. A decision tree is a flowchart-like tree structure in which each node represents a test on an attribute, each branch displays the output for the test, and each leaf node or terminal node holds a class label. This technique is also used for regression. It can achieve high accuracy and interpretability in many aspects. In one case study, this technique was used for the diagnosis of cardiovascular dysautonomia [
20].
A support vector machine (SVM) is a powerful machine-learning model that has outperformed most other systems in a wide variety of applications. In this technique, the learning machine is given a training set of examples (or inputs) belonging to two classes, with associated labels (or output values) [
21]. An SVM-based hardware platform was created to predict BP [
22]. In one study, a couple of heart rate turbulence denoising methodologies were proposed and attempted with uncommon meticulousness to reinforce SVM estimation [
23]. In an experiment conducted by a public heart sound database and released by the Texas Heart Institute, the kernels of heartbeat cycle segmentation and recognition were based on autocorrelation, short-time Fourier transform, and the SVM [
24]. An SVM has been used to classify heartbeat time series, whereas statistical methods and signal analysis techniques were used to extract features from the signals [
21].
A recurrent neural network (RNN) is a type of neural network in which the yields from past progress are a kind of nourishment that contributes to present progress. In customary neural systems, every one of the data sources and yields is free of one another. However, for example, when it is required to anticipate the next expression in a sentence, the past words are required and, consequently, there is a need to recall them. In such cases, a K-nearest neighbours algorithm is easy to implement, and a simple machine-learning algorithm can be used for both regression and classification problems, making it easy to handle missing values.
In the present work, to test our hypotheses, we use three different artificial intelligence techniques for each hypothesis. Further, various artificial intelligence techniques were applied to the medical data analyses in previous research papers and articles.
3. Data Collection and Research Hypotheses
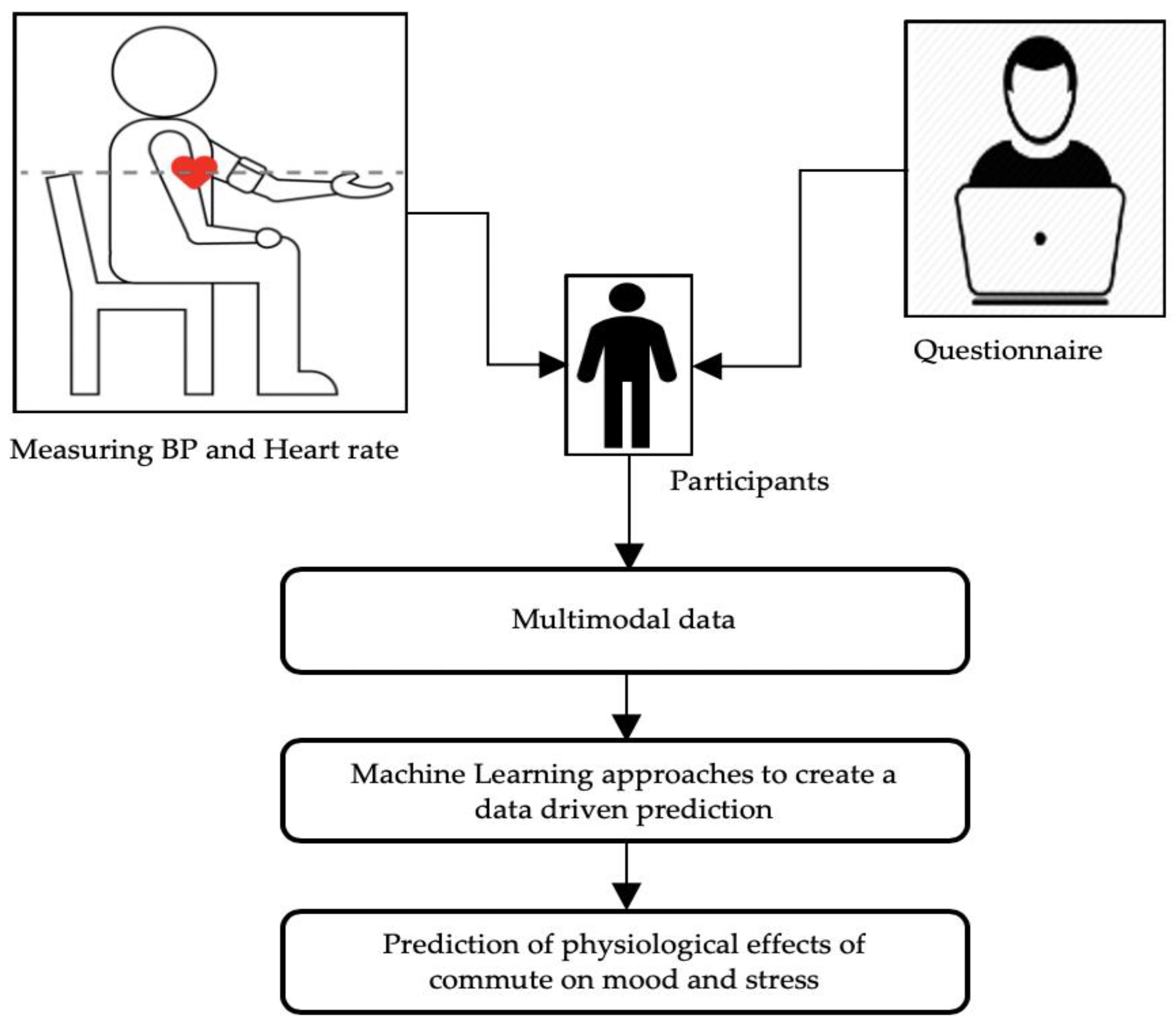
In this research, the data were collected from 16 participants who were employed and commuting regularly to work in London for five continuous working days. All participants signed an informed consent agreeing to participate in the research. Their participation in this study is entirely voluntary, and they were free to withdraw at any time during the research. They are from different parts of London, work in different places, and use different modes of commute. We collected two types of data—qualitative and quantitative—based on questionnaires (the Positive and Negative Affect Schedule [PANAS]) and bio-signals (BP and heart rate), respectively. Non-invasive wearable biosensor technology was employed to acquire the data from the research participants. The MySignals software-development platform was integrated into the system developed for the present research to measure blood pressure and heart rate. The normal BP measurement should be 120/80 mmHg systolic pressure over diastolic pressure. The BP monitor automatically measures the heart rate, where the normal reading should be between 60 and 100 beats per minute (bpm) [
25].
Figure 1 shows the data collection process and study design.
After the BP and heart-rate readings of each participant were recorded, other subjective factors and parameters were taken into consideration, such as age, gender, smoking, height, alcohol intake, any medication intake, medical health, location, and weather temperature. The full dataset contains data for five days, with readings taken twice a day for each participant. High BP levels can represent fluctuations due to certain risk factors, such as high alcohol intake, high sodium intake, high protein intake, low calcium levels, as well as low potassium and magnesium intake [
26].
Blood pressure is the pressure of the blood in the arteries as it is pumped around the body by the heart. When our heart beats, it contracts and pushes blood through arteries to the rest of our body. This force creates pressure on the arteries. Blood pressure is recorded as two numbers: the systolic pressure (as the heart beats) over the diastolic pressure (as the heart relaxes between beats). In this research, we recorded the bio-signal (systolic pressure, diastolic pressure and heart rate) before and after the commute from the participants.
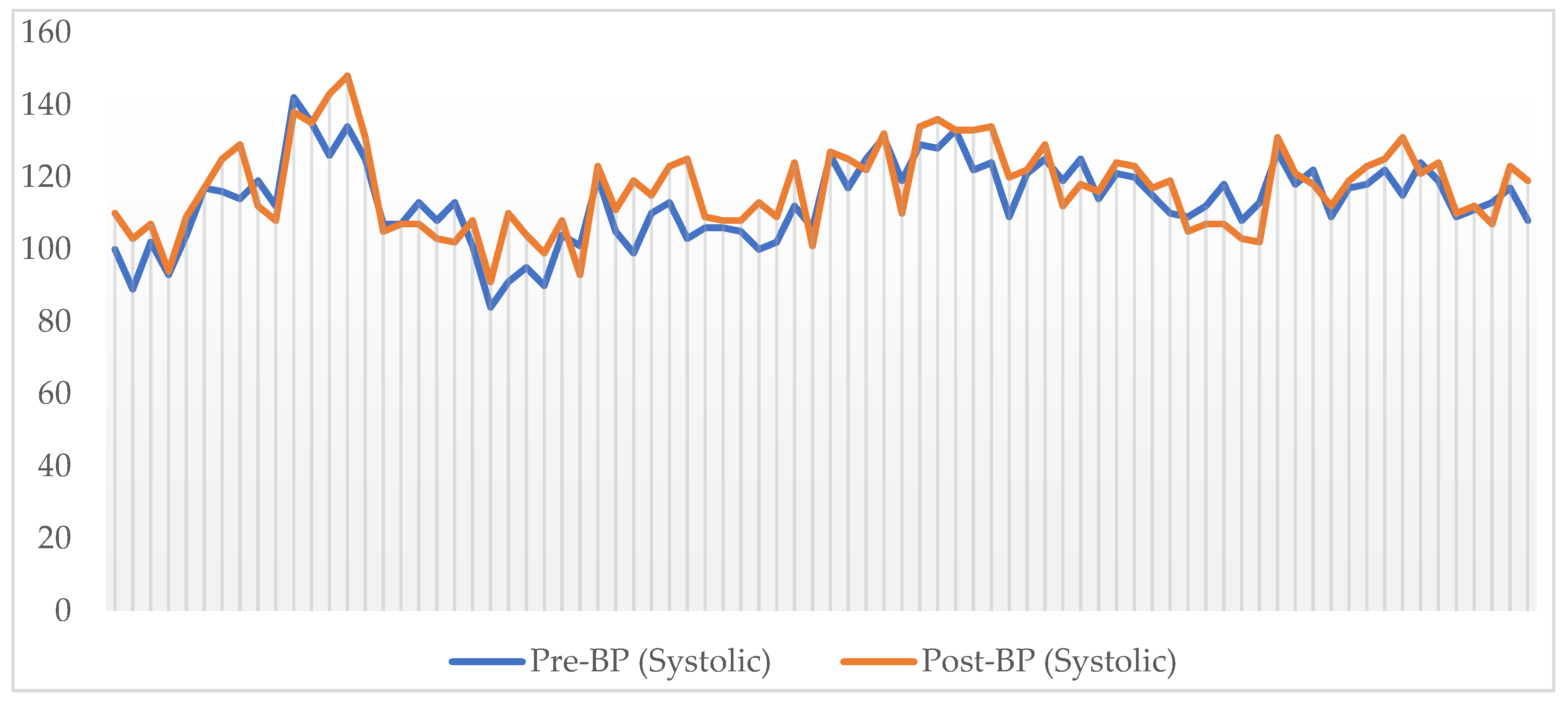
Figure 2 illustrates a comparison of the pre-systolic pressure over the post-systolic pressure. As pre-systolic refers to systolic pressure recorded before the journey and post refers to systolic pressure recorded after the journey. Meanwhile,
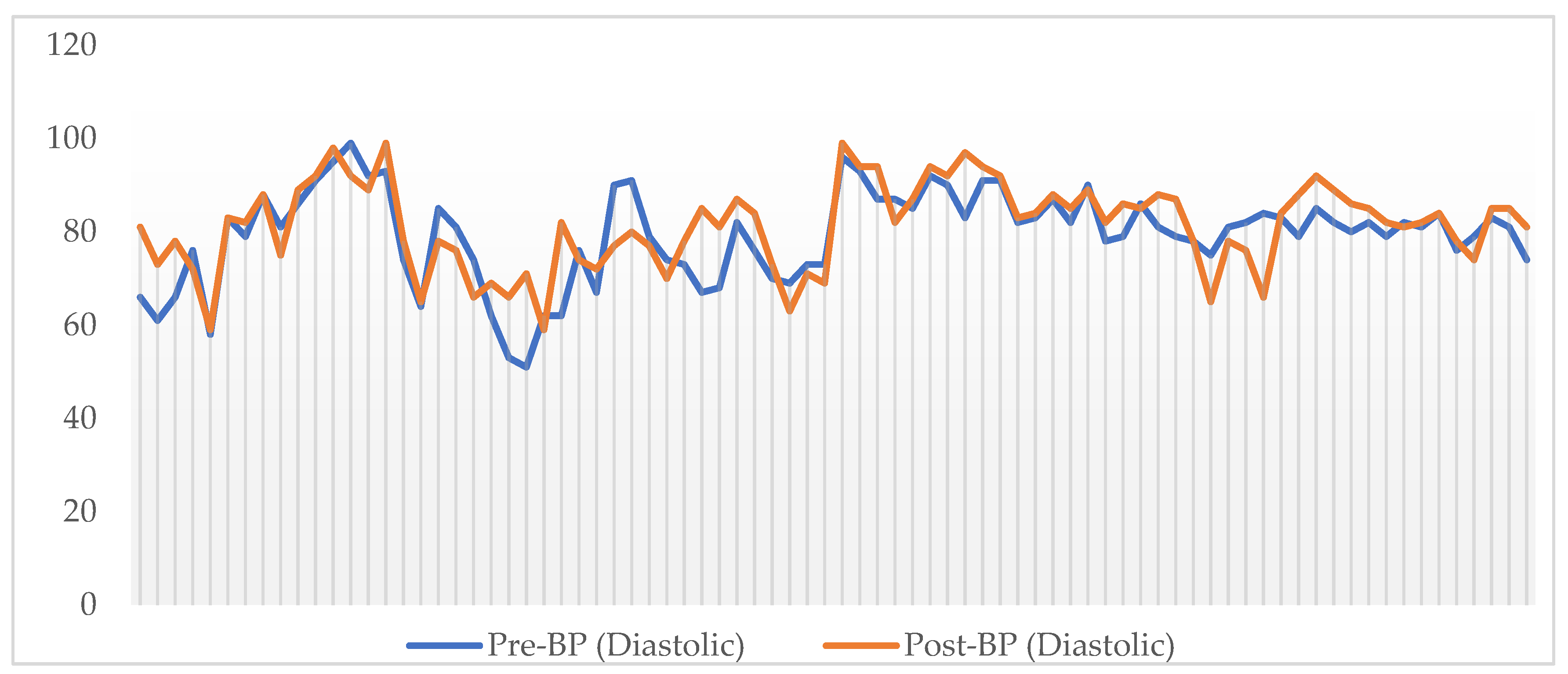
Figure 3 shows a comparison of diastolic pressure before and after the commute. Similarly,
Figure 4 compares the recorded heart rate before and after the commute.
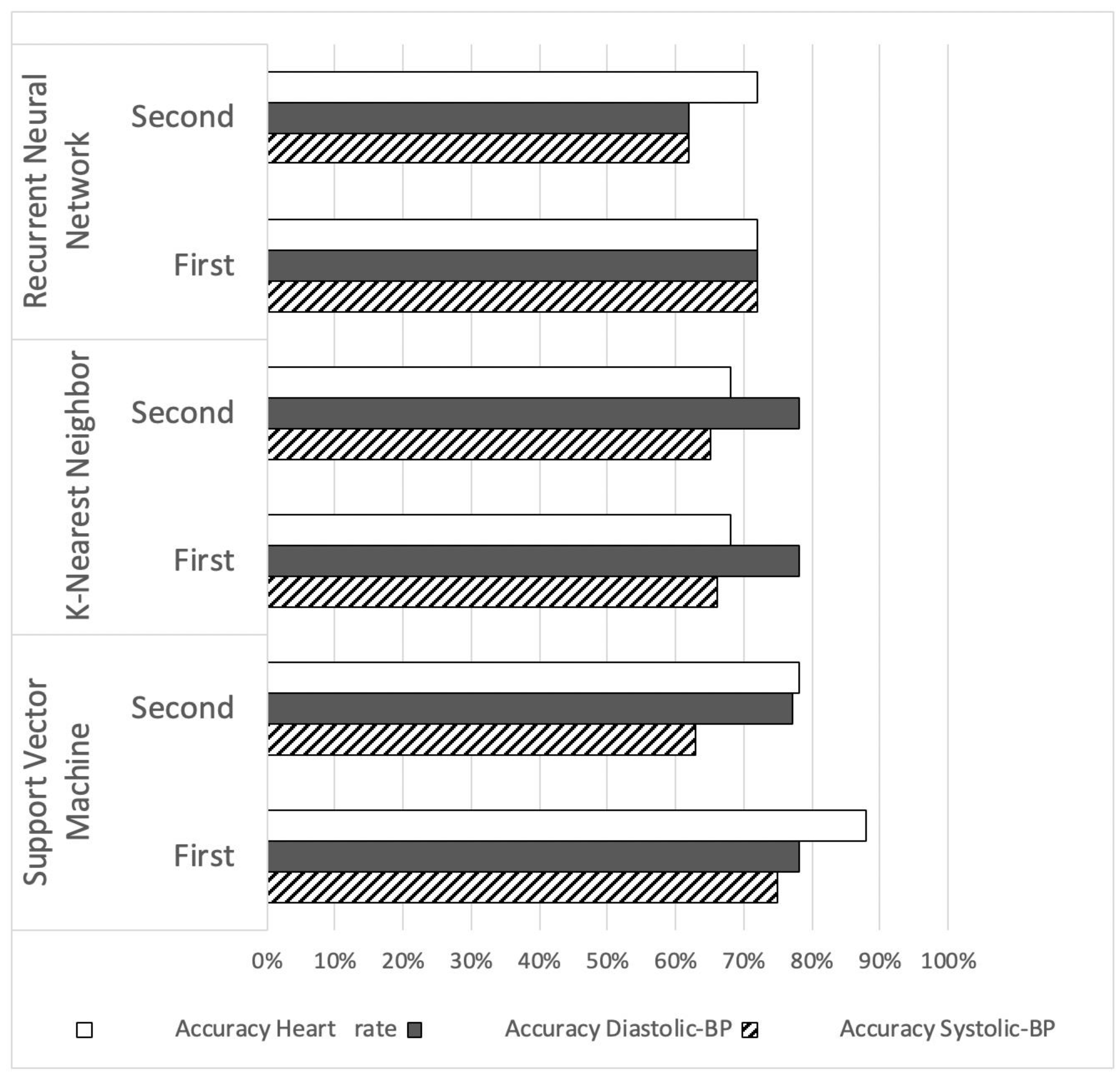
In this research, the data were divided into two categories. The first dataset contains only the relevant objective parameters (blood pressure and heart rate), and the second dataset includes all the subjective parameters such as age, height, weight, and alcohol consumption as well as the objective ones. Different machine-learning-based techniques are used in this study to objectively validate the proposed research hypotheses, which are as follows:
Systolic BP will be higher in longer versus shorter commutes; and
Objective bio-signals (heart rate, BP) for all participants will be higher post-commute than pre-commute.
We aim to analyse the biodata collected from the commuters in London and apply a machine-learning-based approach to predict the effect of a long commute on their heart rate and BP. The objectives of this research are thus as follows:
to record biodata (BP and heart rate) of London commuters using non-invasive wearable technology; and
to apply a machine-learning-based approach to predict the effect of a long commute on commuters’ heart rate and BP.
Questionnaires were used to gather the qualitative data, whereas the quantitative data are the biodata acquired from the participants via sensors. The research participants were asked to fill out a questionnaire form PANAS before and after commuting. The PANAS was developed in 1988 by researchers from the University of Minnesota and Southern Methodist University. Previous mood measures have shown correlations of variable strength between positive and negative affect, and these very measures are of questionable reliability and validity. Watson, Clark, and Tellegen developed the PANAS in an attempt to provide a better, purer measure of each of these dimensions [
27]. The PANAS form contains a scale of different words that describe feelings and emotions that vary depending on the situation, environment, and weather [
27]. It has been widely used as a self-report measure of effect in community and clinical contexts [
28]. In the present study, this method is used to demonstrate effect related to commuting from a subjective point of view. The words employed in PANAS form describe how the participant feels at the moment of answering, such as expressing positive or negative affect before and after the journey [
29]. In addition, we have a section in PANAS form for evaluation of the participant’s general stress levels; a participant needs to mention about any upcoming deadline at work, whether they slept well last night, anything annoying that occurred during a commute, and whether they considered yesterday to be a stressful day. In this questionnaire, the feelings and emotions were rated on a scale of 1 to 5, as illustrated in
Table 1.
In the beginning, all the participants went through the consent form and initial assessment questionnaire to check their suitability for the study. The participants recorded their feelings according to the proposed scale and rated them accordingly from 1 to 5, as shown in
Table 1. The participants expressed their subjective feelings twice a day—at the beginning of their commute and the end. After filling out the questionnaire form, the participants started recording their BP and heart-rate readings. All the forms were submitted online and exported to the database. Other factors and parameters are taken into consideration included age, gender, smoking, height, alcohol intake, any medication intake, medical health, location, and weather temperature, and all these data were also exported to the database.
To apply the relevant effective techniques to the data, the data first needed to be pre-processed into the training and testing data for each of the techniques to test the hypotheses. All the values of the parameters in the dataset are in numerical form. In this experiment, two datasets were created for each hypothesis. In the first dataset, only the main parameters related to the hypothesis were included so that we could determine the pure effect of commuting on heart rate and BP. Similarly, for the second dataset, we included the main parameters plus all other parameters collected from the participants. From the second dataset, we can identify the effect of other parameters on heart rate and BP.
For the first hypothesis, the dataset was divided into two subsets. The first one contained the main parameters, such as BP, heart-rate readings (pre- and post-commute), and the duration of the commute in minutes. The second dataset included the main parameters (BP, heart-rate readings [pre- and post-commute] and duration of the commute in minutes) along with the other parameters, such as age, weight, height, smoking, alcohol intake, and temperature according to the weather report in the morning.
Similarly, for the second hypothesis, the dataset was divided into two subsets: the first one with BP and heart-rate readings (pre- and post-commute), and the second one with all parameters (i.e., BP, heart-rate readings [pre- and post-commute], duration of the commute in minutes, age, weight, height, smoking, alcohol intake, and temperature according to the weather report in the morning).
4. Implementation
We developed a machine-learning approach for the implementation and execution of the dataset analysis. Machine learning-based techniques were implemented to create an effective model, and different patterns and training algorithms were created to optimise the performance. The analysis was conducted by treating the data with each technique to obtain outputs that could then be compared in light of the hypotheses of this study. The data were processed for the input and target files and loaded into the software either by importing them from the system or loading them manually from the workspace.
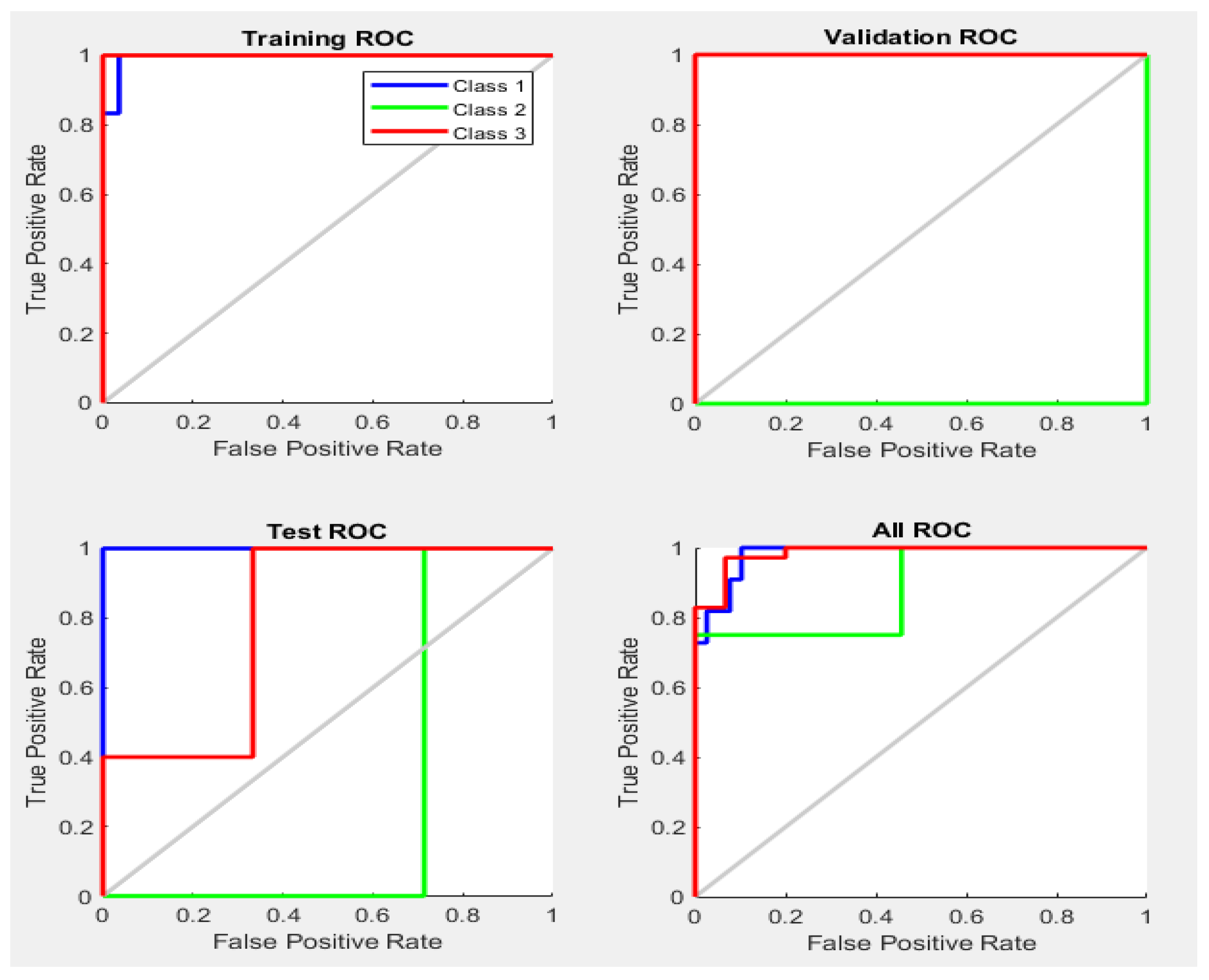
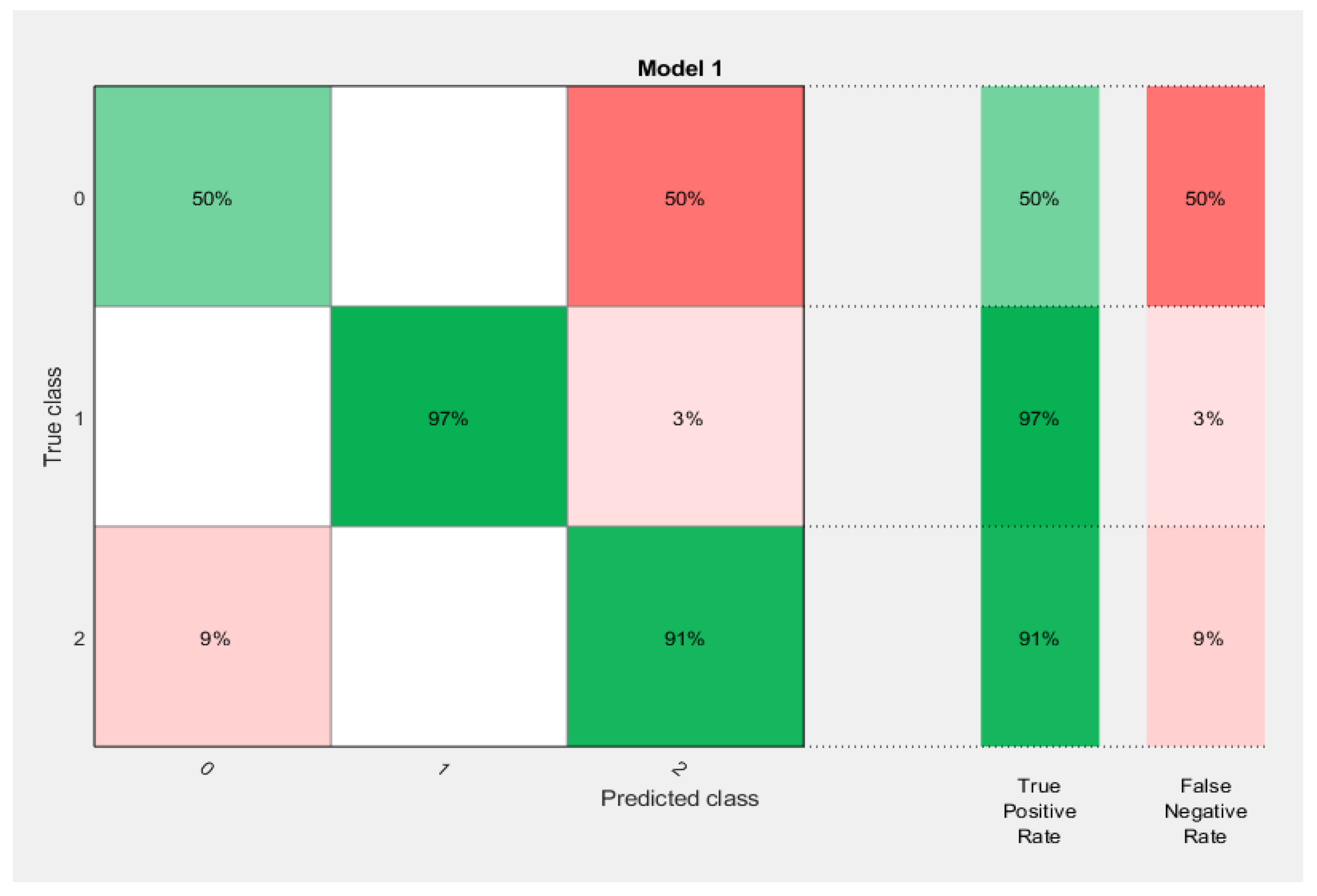
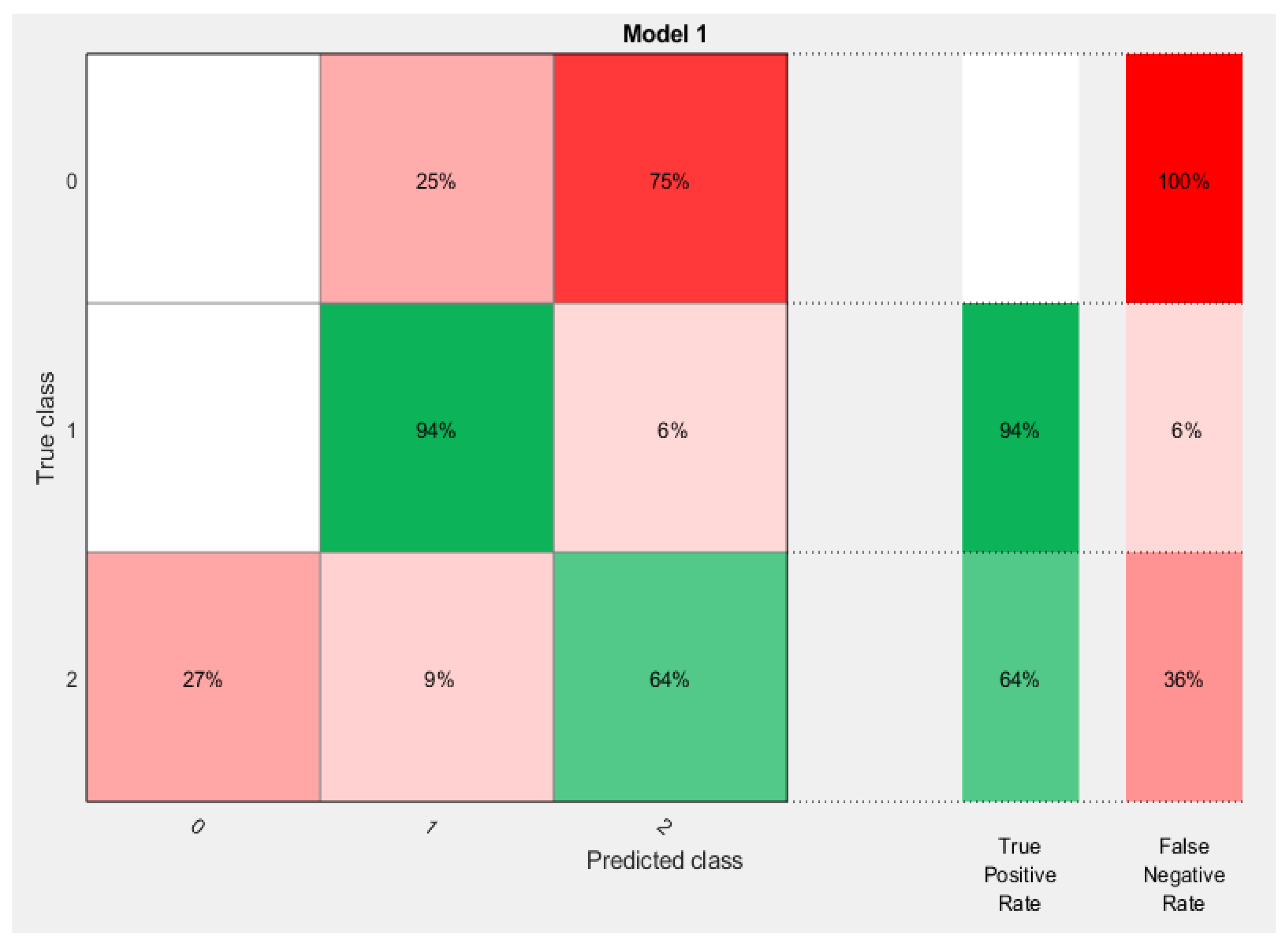
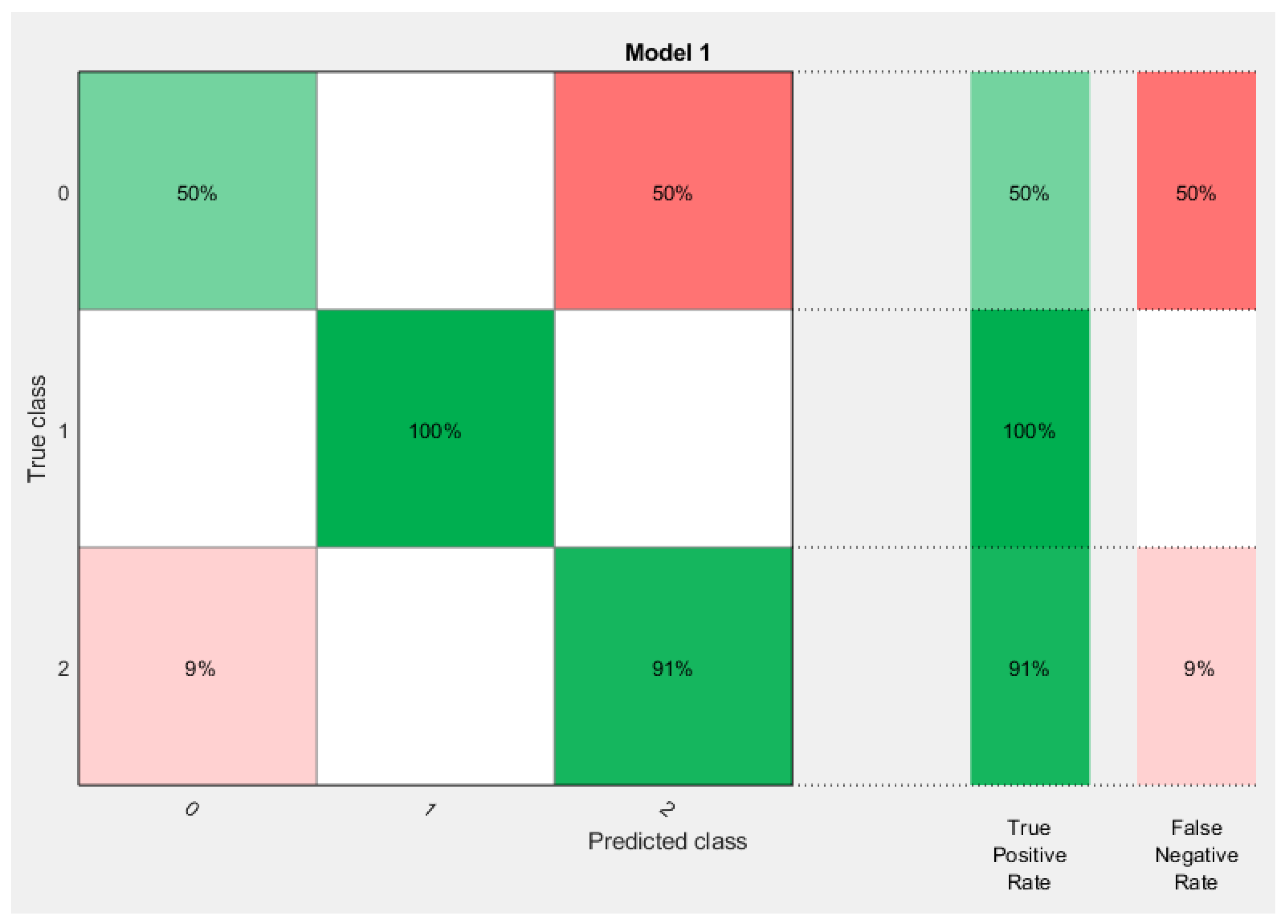
Model performance was evaluated using widely applied statistics, namely the area under the receiver-operator characteristics (ROC) curve or AUC statistic. The area under the ROC curve (AUC) has been used as a criterion to measure the performance of the classification algorithms even if the training data embraces an unbalanced class distribution and cost-sensitiveness [
30]. In each class, the ROC curve applies the threshold values to the output values so that for each threshold, the true-positive ratio (TPR) and the false-positive ratio (FPR) values are simplified. This also represents the specificity and sensitivity of the data based on the predictions and observations carried out on the model throughout the training process of the model [
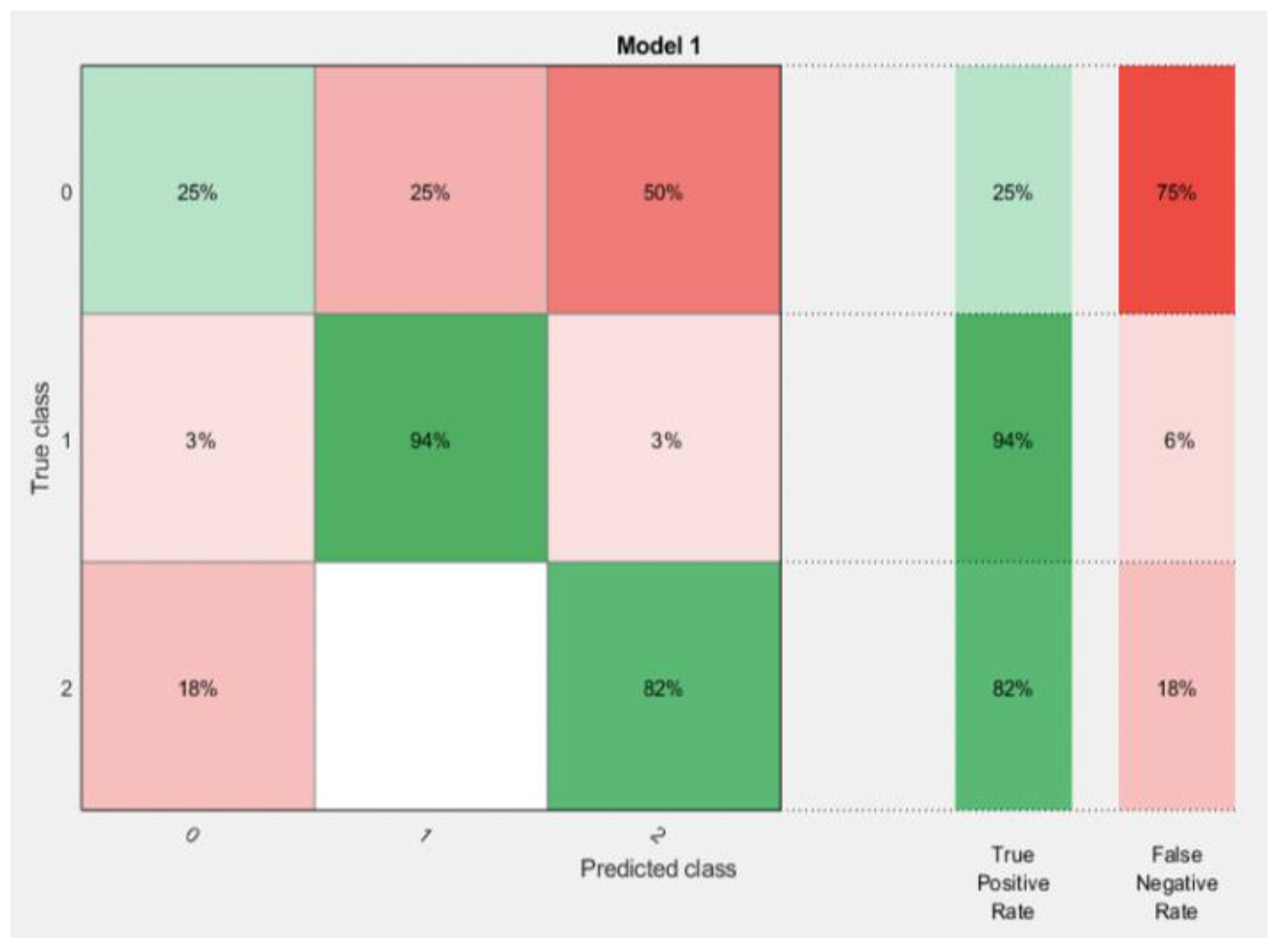
31]. The confusion matrix measures and displays the accuracy of a classification model or a training model by comparing both the actual class and predicted class values. It is used to describe the efficiency of a classifier. It is critical for supervised learning in the field of machine learning [
32].
To the relevant techniques to the data, the data must first be pre-processed to serve as training and testing data for each of the techniques to confirm the hypotheses. The data were divided into input data and target data. The input data are the values of the parameters from the dataset, and the target data were prepared by comparing the pre- and post-commute values from the data in the form of the numerical values 0, 1, and 2 for all the techniques. If the pre- and post-commute values are the same, then the target value is 0. If the pre-commute value is lower than the post-commute value, then the target value is 1. Finally, if the post-commute value is lower than the pre-commute value, then the target value is 2. In the feed-forward neural network technique, the target data value accepts binary values only. Therefore, the target data values for this technique were prepared in the form of a logical matrix with values of 0 and 1 only.
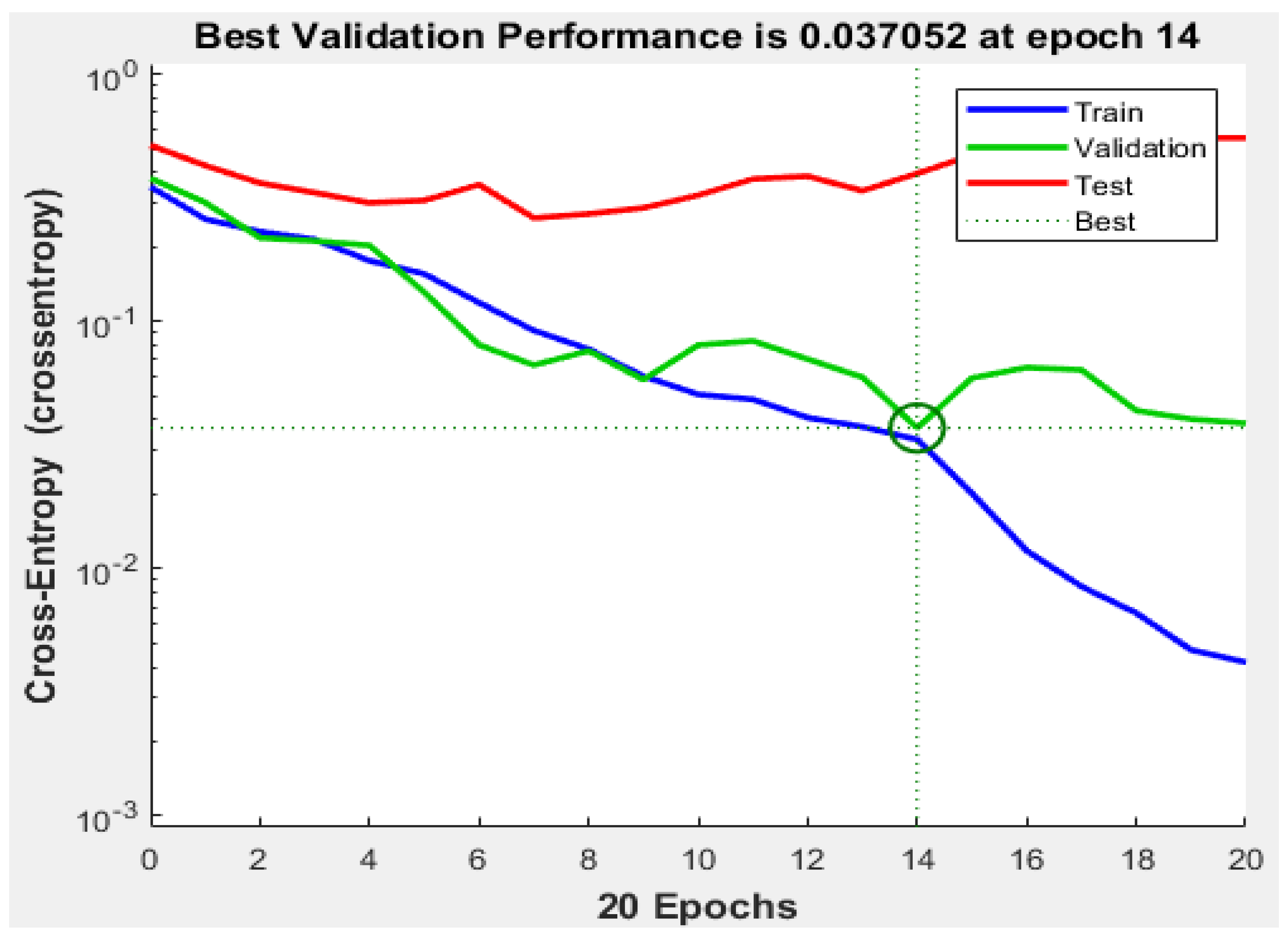
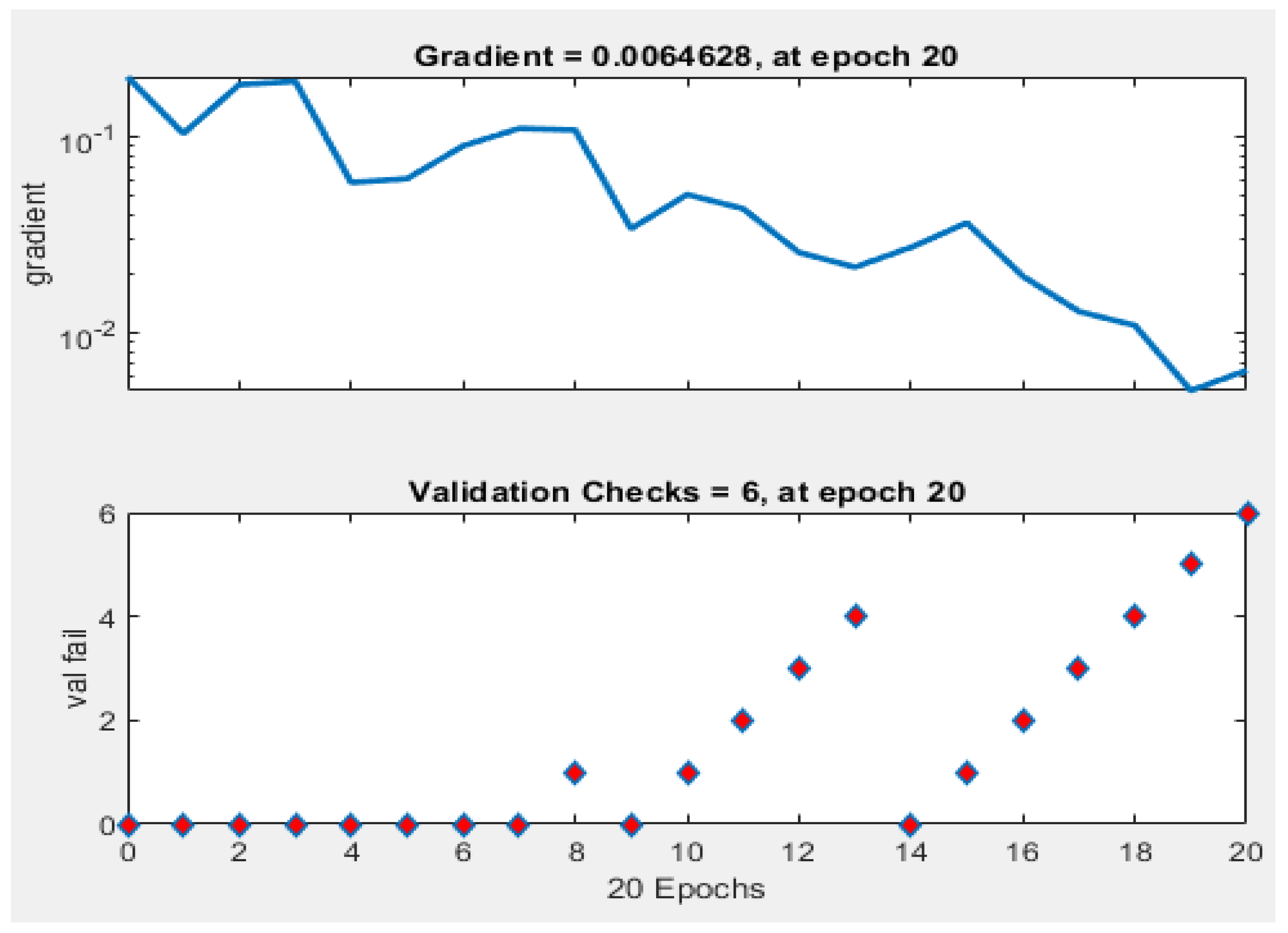
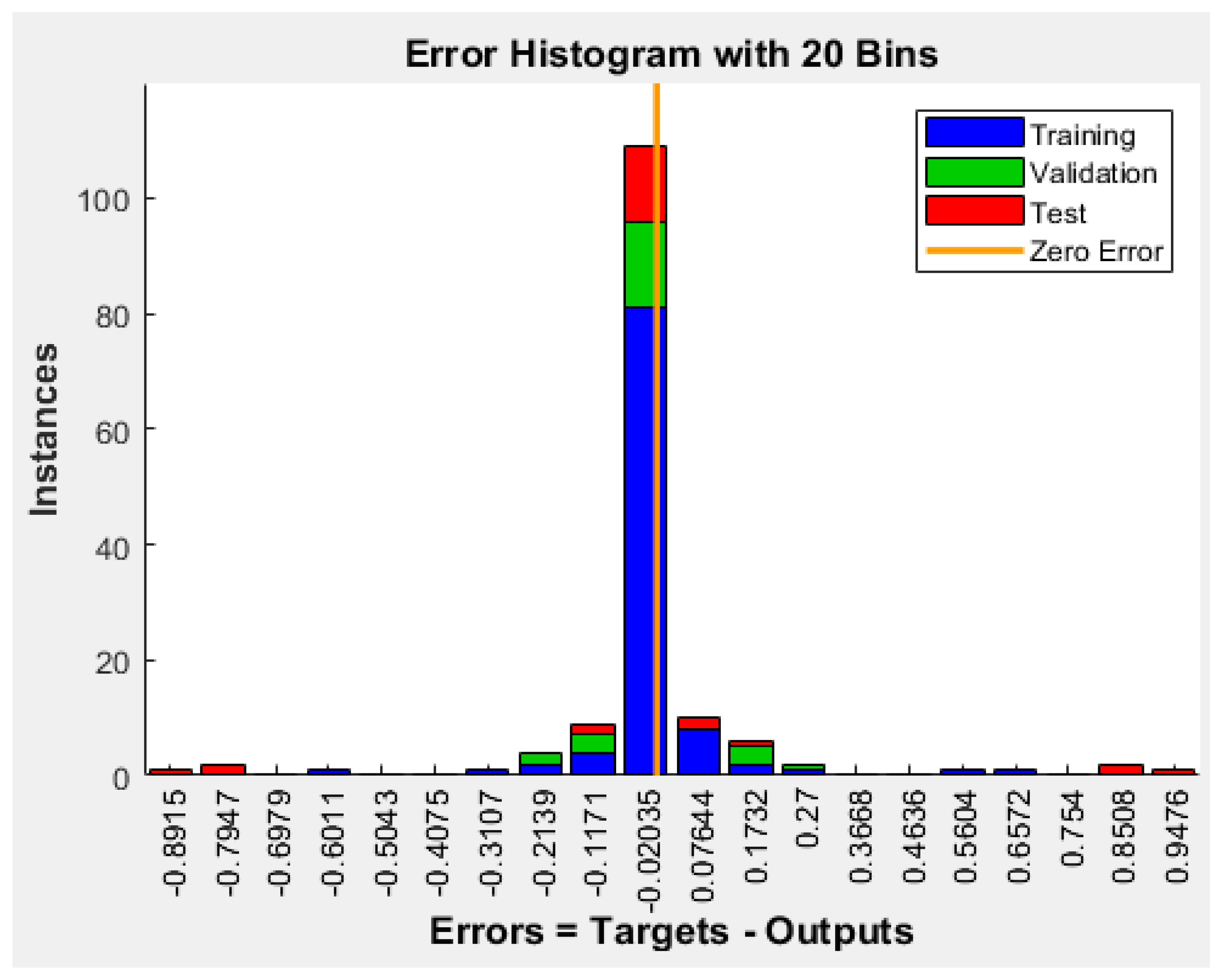
For each technique, the first input dataset and the target data were loaded into the workspace of the model. When the neural network pattern recognition application was opened, the datasets were then selected, and a training sample size of 70%, a validation sample size of 15%, and a testing sample size of 15% were selected under the training process. When the training started, the performance, training state, error histogram, confusion matrix, and ROC curve were plotted based on the data.
6. Conclusions
In this study, we developed an intelligent model based on different machine-learning approaches to predict the effect of commuting on heart rate and BP. Further, we used questionnaires (the PANAS) to demonstrate the impact of commuting on effect from a subjective point of view. When we applied the machine-learning based model, whether the commute duration was short or long, it was noticed that the systolic pressure was usually higher post-commute than pre-commute one, and we found the objective bio-signals (heart rate and BP) to be higher post-commute than pre-commute one. BP and heart rate are positively correlated to mood and stress. Based on this machine-learning approach, we were able to determine the participants’ level of stress after commuting.
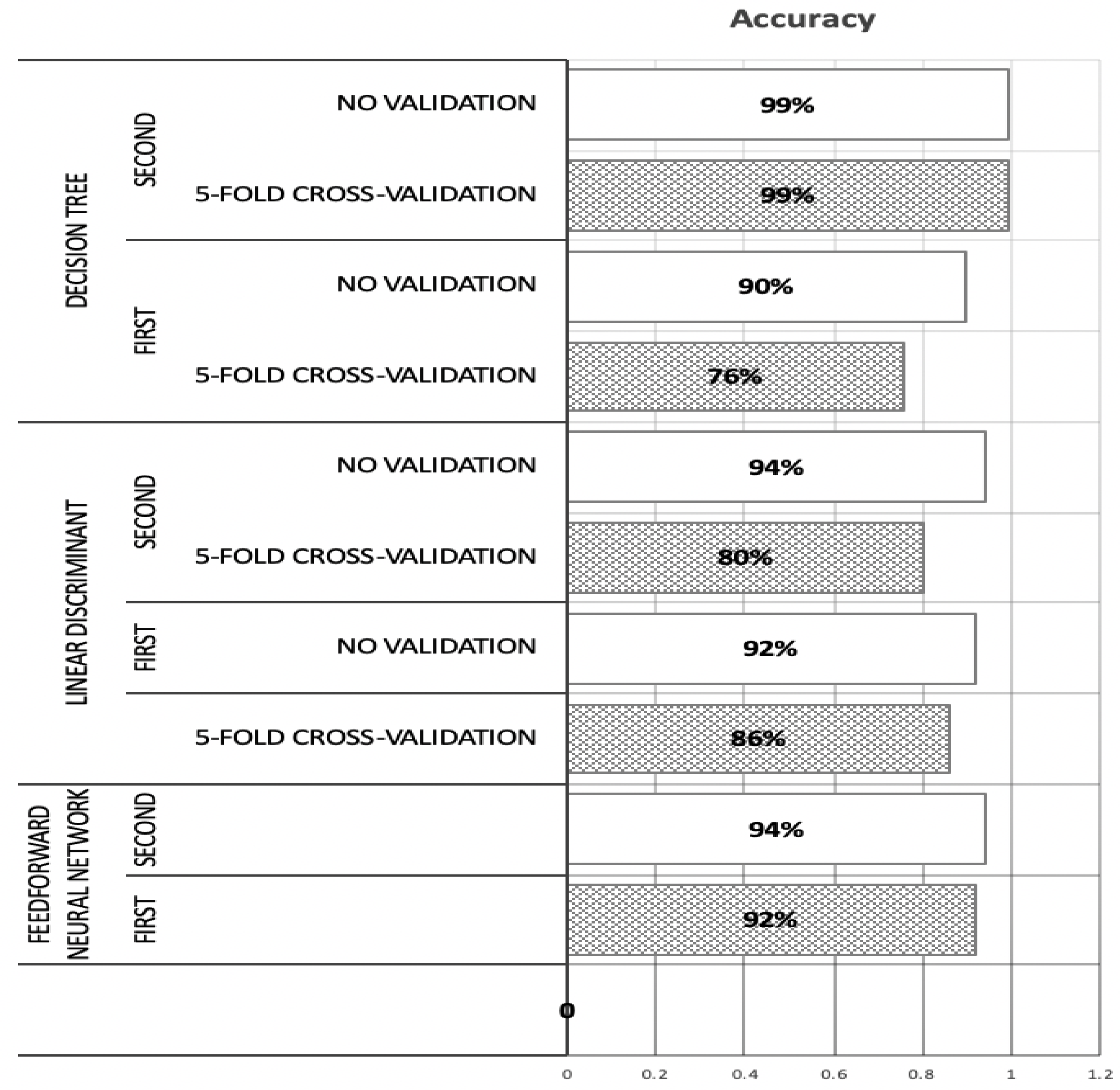
A comprehensive experiment was conducted to achieve the best structure for the feed-forward neural network, which suited the processed datasets. An accuracy level of 92% was obtained for the first dataset, which included only the main bio-signals, while an accuracy level of 94% was achieved for the second dataset, which included the main bio-parameters plus other subjective parameters collected from the participants. This increase in accuracy shows that the neural network was able to achieve better performance with the dataset containing both quantitative and qualitative parameters. The quantitative results confirmed the proposed hypothesis, which assumed that the systolic BP would be higher for longer commutes versus shorter ones, as it was found that the post-commute readings for systolic BP were higher, irrespective of the duration of the commute. Systolic BP was normally higher for shorter commutes than for longer ones.
Similarly, the results achieved by the fused machine-learning techniques confirmed the second hypothesis, which assumed that the bio-parameters (diastolic BP and heart rate) would be higher post-commute than pre-commute. The processed dataset was also partitioned into two datasets of parameters, one with only the relevant bio-parameters and the other with all the quantitative and qualitative parameters. In addition to the objective evaluation based on the machine-learning techniques, we used the PANAS survey, which has been widely utilised as a self-report measure of effect in both community and clinical contexts. From the PANAS results, it was determined that the positive affect of the participants was higher pre-commute than post-commute, which indicates that the mood and emotional state of the participants were more positive before commuting. Similarly, the negative affect of the participants was higher post-commute than pre-commute, which indicates that the participants were more stressed after the commute.
This research study forms a core work that gives us the ability to find the effect of commuting on people who commute to work five days a week. In this research, participants from all over Greater London were involved. Our future work in this area will leverage innovative machine-learning-based approaches to predict and evaluate the effect of commuting on productivity in the workplace as well as to study the psychological and physiological effects of commuting.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}