1. Introduction
Biological and artificial neural systems are composed of many local processors, such as neurons or microcircuits, that are interconnected to form various network architectures in which the connections are adaptable via various learning algorithms. The architectures of mammalian neocortex, and of the artificial nets trained by deep learning, have several hierarchical levels of abstraction. In mammalian neocortex there are also feedback and lateral connections within and between different levels of abstraction. The information processing capabilities of neural systems do not depend only on their learning algorithms and architectures, however. They also depend upon the transfer functions that relate each local processor’s outputs to its inputs. These transfer functions are often described in terms of the simple arithmetic operators, e.g., [
1,
2]. Distinguishing them on that basis can be misleading, however, because real physiological operations are rarely, if ever, that simple.
In biological systems feedback and lateral connections can modulate transmission of feedforward information in various ways. There is ample evidence that modulatory interactions are widespread in mammalian neocortex [
3,
4,
5,
6]. Many very different forms of interaction have been called ‘modulatory’, however, and our concern here is with a particular kind of context-dependent form of modulation for which there is direct evidence at the intracellular level. This evidence calls into question the common assumption that, from a computational point of view, neurons in general can be adequately thought of as being leaky integrate-and-fire point neurons [
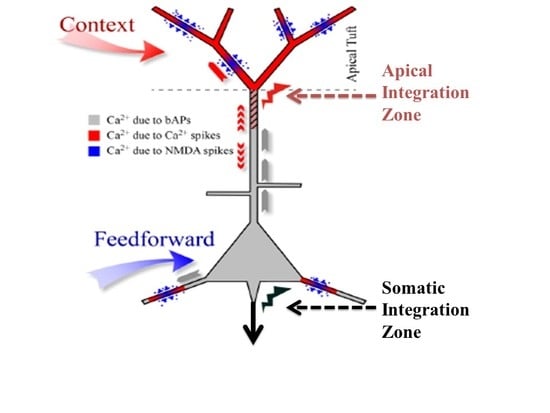
7]. They are called point neurons because it is assumed that all their inputs are integrated at the soma to compute the value of a single variable about which information is then transmitted to downstream cells. Though that assumption may indeed be adequate for many kinds of neuron it is not adequate for some principal pyramidal neurons in the cerebral cortex. There is now clear evidence from multi-site intracellular recordings for the existence of a second site of integration near the top of the apical trunk of some neocortical pyramidal cells, such as those in layer 5B. We refer to this second point of integration as the apical integration zone, but it is also sometimes referred to as the ‘nexus’. This second point of integration may be of crucial relevance to our understanding of contextual modulation in the neocortex because anatomical and physiological evidence suggests that activation of the apical integration zone serves as a context that modulates transmission of information about the integrated basal input. The analyses reported here add to our understanding of that theoretical possibility.
We have reviewed the anatomical, physiological, and computational evidence for context-sensitive two-point processors at length elsewhere, as noted below [
6] but give a summary here. Evidence for an intracellular mechanism that uses apical input to modulate neuronal output was first reported several years ago [
8,
9,
10,
11], though much remains to be learned about the far-reaching implications of such mechanisms. In vitro studies of rat somatosensory cortex show that in addition to the somatic sodium spike initiation zone that triggers axonal action potentials, layer 5 pyramidal cells have a zone of integration just below the main bifurcation point near the top of the apical trunk. If it receives adequate depolarization from the tuft dendrites and a backpropagated spike from the somatic sodium spike initiation zone it triggers calcium spikes that propagate to the soma [
8], where it has a strong modulatory effect on the cell’s response to weak basal inputs by converting a single axonal spike into a brief burst of from two to four spikes. Distal apical dendrites are well positioned to implement contextual modulation because they receive their inputs from a wide variety of sources, including non-specific thalamic nuclei, long-range descending pathways, and lateral pathways [
9]. Being so remote from the soma, however, input to the apical tuft of layer 5 cells has little effect on output unless propagated to the soma by active dendritic currents. A consequence of this is that input to the tuft alone usually has little or no effect on axonal action potentials, which we assume to be a crucial distinctive property of contextual modulation.
Contextual modulation is of fundamental importance to basic cognitive functions such as perceptual organization, contextual disambiguation, and background suppression [
6,
12,
13,
14,
15,
16,
17,
18,
19]. Many reviews show that selective attention also has modulatory effects (e.g., [
20]). There are several hypotheses concerning the neuronal mechanisms by which such modulation may be achieved [
21]. Some make use of the distinct anatomy and physiological functions of apical and basal inputs outlined above [
22,
23,
24], and our focus is on the basic information processing properties of such context-sensitive two-point processors.
The central goal of the work reported here is to use advanced forms of multivariate mutual information decomposition to analyze the information processing properties of such context-sensitive two-point processors and compare them with additive, subtractive, multiplicative and divisive interactions. It has been shown that artificial neural systems composed of such context-sensitive two-point neurons can learn to amplify or attenuate feedforward transmission within hierarchical architectures [
25,
26,
27], but the full computational potential of such systems has not yet been adequately explored. Though the primary concern of this paper is biological, we frequently relate it to machine learning using artificial neural nets because that provides clear evidence on the computational capabilities of the biological processes inferred.
To explore the fundamental information processing capabilities of this form of asymmetric contextual modulation this paper compares it with the arithmetic transfer functions that have previously been used to interpret data on ‘neuronal arithmetic’ [
1]. To this end we build upon recent extensions to the foundations of information theory that are called ‘partial information decomposition’ [
28,
29]. These recent advances enrich conceptions of ‘information processing’ by showing how the mutual information between two inputs and a local processor’s output can be decomposed into that unique to each of the two inputs, that shared with the two inputs, and that which depends upon both inputs, i.e., synergy [
29,
30,
31,
32]. Though decomposition is possible in principle when there are more than two inputs, the number of components rises more rapidly than exponentially as the number of inputs increase, limiting its applicability to cases where the contributions of only a few different input variables needs to be distinguished. This is not necessarily a severe limitation, however, because each input variable whose contribution to output is to be assessed can itself be computed from indefinitely many elementary input variables by either linear or non-linear functions. Here we show that decomposition in the case of only two integrated input variables is adequate to distinguish contextual modulation from the arithmetic operators.
As the term ‘modulation’ has been used to mean various different things it is important to note that the current paper is concerned with a well-defined conception of contextual modulation [
6,
25,
26,
27]. Though explicitly formulated in information-theoretic terms, this conception is close to that used in neurophysiology, e.g., [
12], and computational neuroscience, e.g., [
33]. The present paper further develops that conception by using multivariate mutual information decomposition to contrast the effects of contextual modulation with those of the simple arithmetic operators. Thus, when in the ensuing we refer simply to ‘modulation’ we mean contextual modulation. A simple example of our notion of contextual modulation is shown in
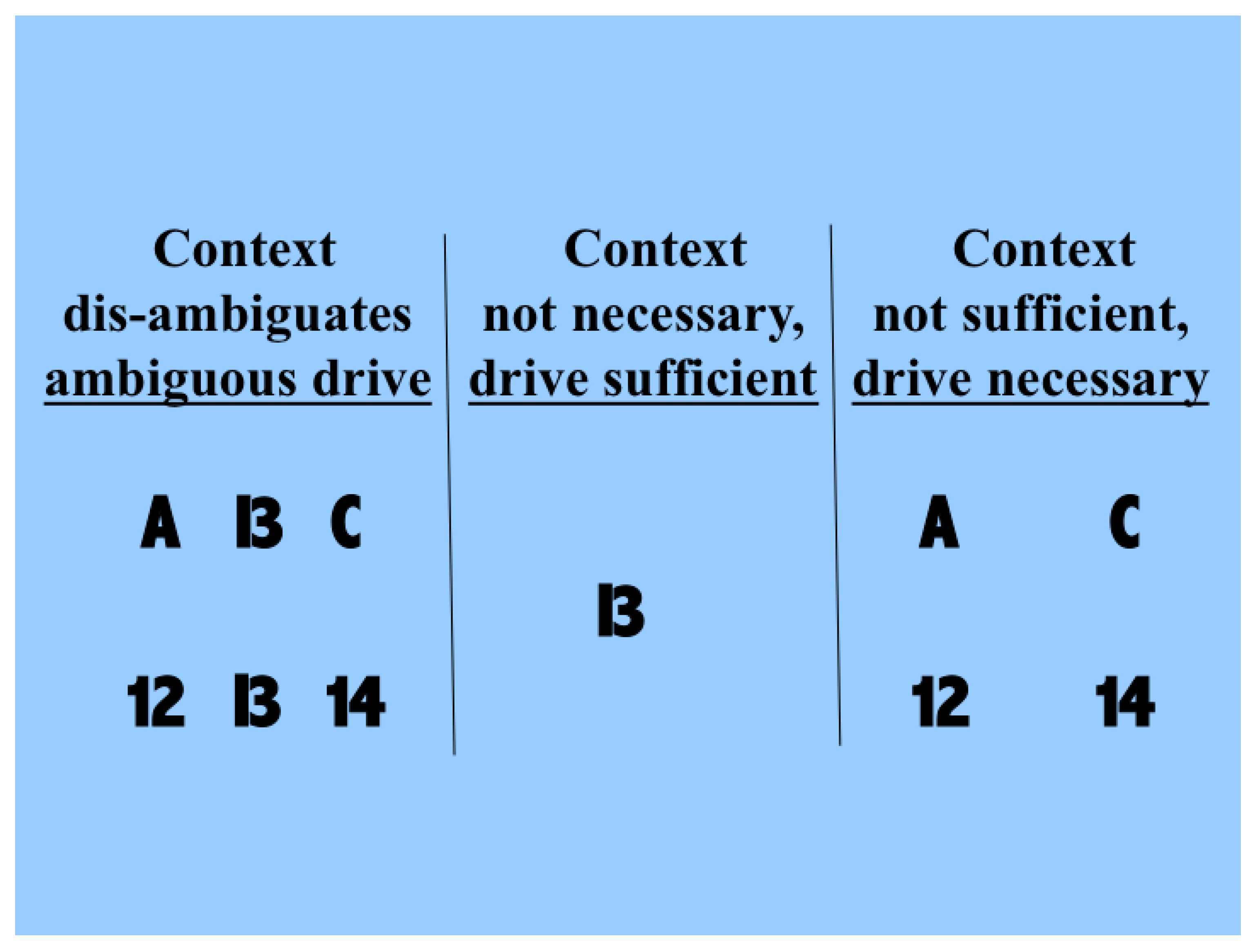
Figure 1. The driving information with which we are concerned here is that provided by the symbol that can be seen as either a B or a 13. Each of these possible interpretations is at less than full strength because of the ambiguity. The two rows in the left column show that the probabilities of making each of the possible interpretations can be influenced by the context in which the ambiguous figure is seen. The central column shows that drive alone is sufficient for some input information to be transmitted, and that context is not necessary because in its absence we can still see that a symbol that could be a B or a 13 is present. The right column shows that drive is necessary and that context is not sufficient, because when the information that is disambiguating in the left column is present in the absence of the driving information we do not see the B or 13 as being present. Though simple, and but one of indefinitely many, this demonstration shows that human neocortex uses context to interpret input in a way that is essentially asymmetric.
Therefore, contextual modulation cannot be implemented by purely multiplicative interactions, as often implied. Multiplication may indeed be involved in a more complex expression describing contextual modulation, as indeed it is for forms of contextual modulation advocated here. The crucial asymmetry does not arise by virtue of that multiplication, however, but by virtue of other things, such as asymmetric limitations on the interacting terms, or by adding one term but not the other to the result of the multiplication.
Though the information used for disambiguation in the example of
Figure 1 comes from nearby locations in space, contextual modulation is not identified with any particular location in space because modulatory signals can in principle come from anywhere, including other points in time as well as other locations in space. Furthermore, though the example given here is contrived to make the ambiguity to be resolved obvious to introspection, the ambiguities that we assume to be resolvable by context are more general, and include those due to weak signal to noise ratios, as well as those due to ambiguities of dynamic grouping and of task relevance. In short, we assume that contextual modulation uses other available information to amplify the transmission of ‘relevant’ signals without corrupting their semantic content, i.e., what they transmit information about. Here we use partial information decomposition to show how that is possible.
The information whose transmission is amplified or attenuated has been referred to as the ‘driving’ input, the ‘receptive field (RF)’ input, or the input that specifies the neuron’s ‘selective sensitivity’. Though none of these terms is wholly satisfactory, here we refer to the input about which information transmission is to be modulated as the driving receptive field (RF) input, and the modulatory input as the contextual field (CF) input.
One major contrast between hierarchies of abstraction in neocortex and those in deep learning systems is that intermediate levels of abstraction in neocortex typically have their own intrinsic utility, in addition to being on a path to even higher abstractions. There are outputs to subcortical sites from all levels of neocortical hierarchies, not only from a ‘top’ level. Furthermore, the functional and anatomical asymmetries that we emphasize are most clear for the class of pyramidal cells that provide those outputs from neocortex. Another major contrast is that contextual modulation in neocortex is provided by lateral and feedback connections, and it guides the current processing of all inputs; whereas in nets trained by deep learning back-propagation from higher levels is used only for training the system how to respond to later inputs. The work reported here contrasts with the simplifying assumption that neural systems are composed of leaky integrate-and-fire point neurons. Instead we emphasize functional capabilities that can arise in a local processor, or neuron, with two distinct sites of processing, i.e., two-point processors, as shown by partial information decomposition [
29,
32]. An anatomical asymmetry that may be associated with this functional asymmetry is obvious and long known. Pyramidal cells in mammalian neocortex have two distinct dendritic trees. One, the basal tree, feeds directly into the soma, from where the output signals are generated. The other is the apical dendritic tree, or tuft, which is much further from the soma and connected to it via the apical trunk. Inputs to these two trees come from very different sources, with the basal tree receiving the narrowly specified inputs about which the cell transmits information, while the apical tree receives information from a much broader context. Wide-ranging, but informal, reviews of evidence on this division of labor between driving and modulatory inputs within neocortical pyramidal cells indicate that it has fundamental implications for consciousness and cognition [
13,
34]
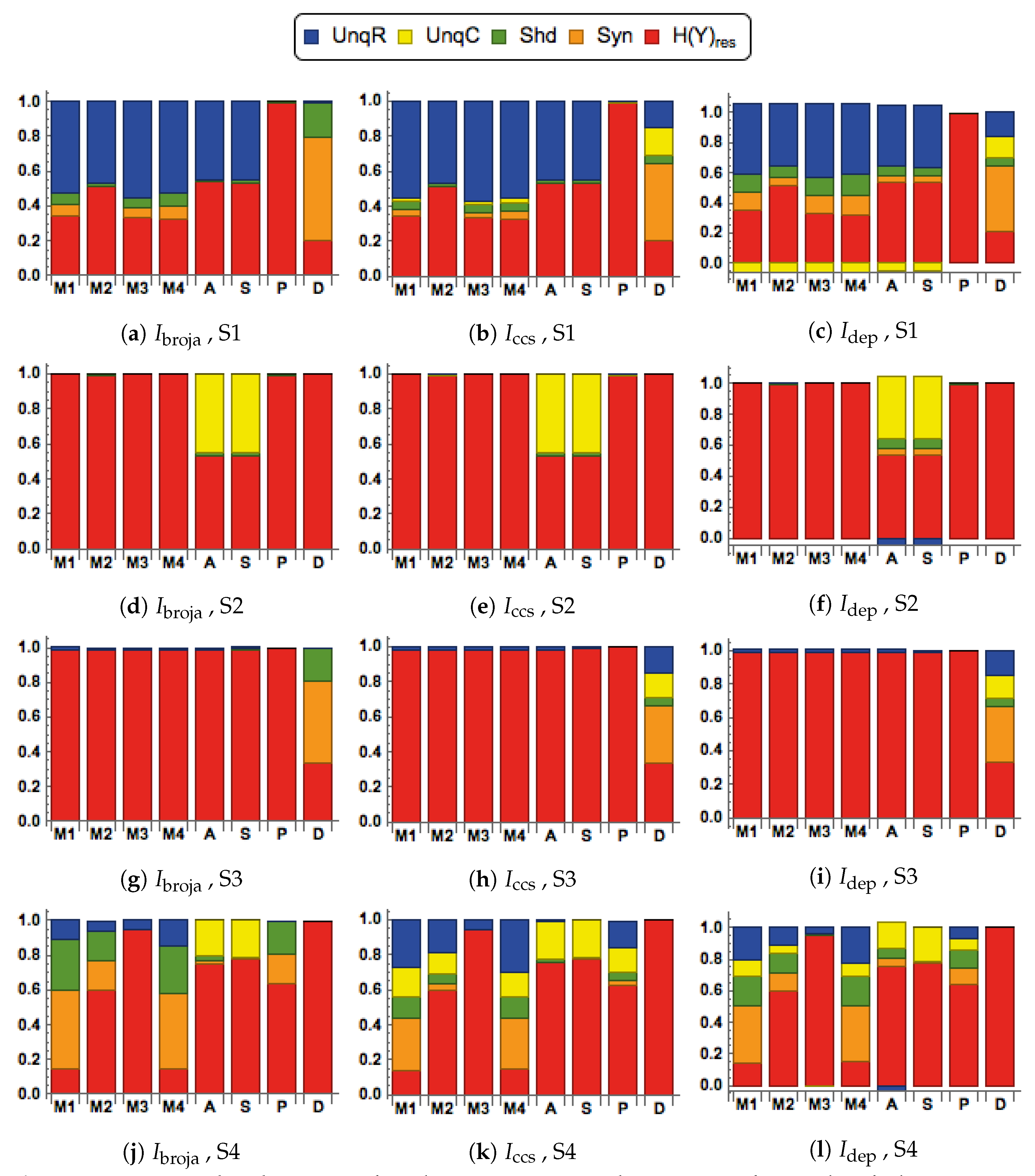
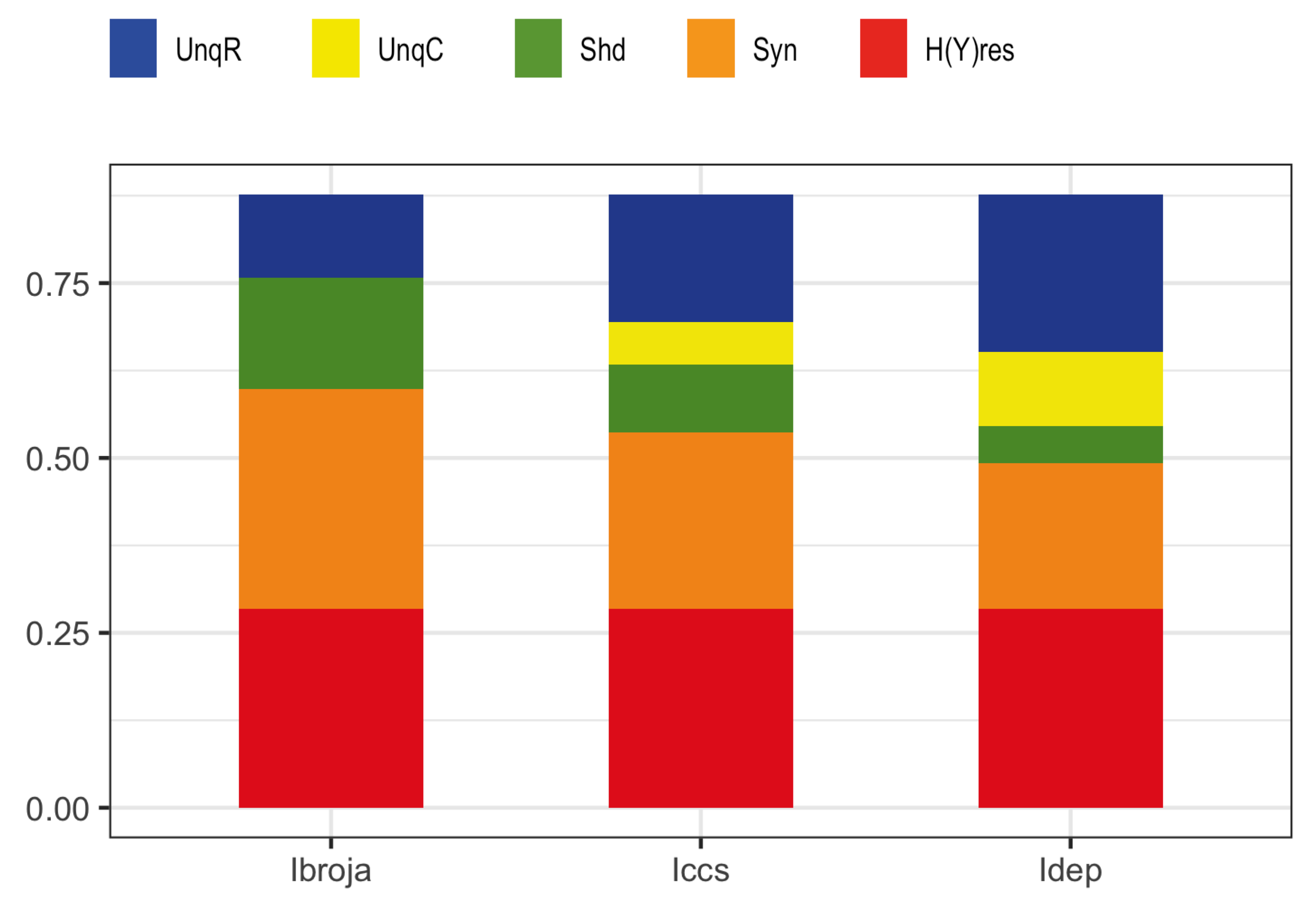
To further study these issues rigorously we use multivariate mutual information decomposition [
28] to analyze the information transmitted by one binary output variable, e.g., an output action potential or brief burst of action potentials, given two input variables, and we consider five different types of partial information decomposition. The partial information decompositions of four different forms of contextual modulation are studied. Those decompositions are compared with decompositions of purely additive, subtractive, multiplicative, or divisive transfer functions. Here we consider continuous inputs that are generated from multimodal and unimodal Gaussian probability models. The eight different forms of interaction are considered for each of four scenarios in which the signal strengths given to the two inputs are different. These strength scenarios are chosen to show the distinctive information processing properties of contextual modulation. These properties are as follows. First, information uniquely about the drive can be transmitted when contextual modulation is absent or very weak, and all of it is transmitted if the drive is strong enough. Second, little or no information or misinformation is transmitted uniquely about the modulatory input when drive is absent or very weak whatever the strength of the modulation. Third, modulatory inputs can amplify or attenuate the transmission of driving information that is weak or ambiguous. We show that this modulation is characterized by a synergistic component of the output that is present at intermediate levels of drive strength, but not at either very high or very low levels. Finally, we provide evidence that contextual modulation is asymmetric at the cellular level in neocortex by applying partial information decomposition to a highly detailed multi-compartmental model of a layer 5 pyramidal cell and showing that it functions in a way that approximates contextual modulation as defined above.
The work reported here builds on some long-established principles of cognition and neuroscience, but also offers a clear advance beyond them. Our conception of contextual modulation builds upon the view, long held by philosophers such as Immanuel Kant, that basic perception and other cognitive functions are in effect ‘unconscious inference’ [
35]. There is now ample evidence from psychophysics to neurophysiology to support and extend that view [
12,
36]. Though proposed by us more than 25 years ago, the conception of local processors as having two points of integration is not yet widely shared by those who work on systems neuroscience, many of whom remain fully committed to the assumption that, from the functional point of view, neurons in general can be adequately conceived of as leaky integrate-and-fire point neurons [
37]. That is beginning to change, however, because evidence from intracellular recordings at well-separated points on a single neuron is now becoming too strong to ignore [
9,
13]. Partial information decomposition is a very recent extension to the foundations of information theory. It has great potential for use in the cognitive and neurosciences, as well as in artificial intelligence and neuromorphic computing. Its application to such issues has just begun [
28], but it has far to go. Use of two-point processors in artificial neural nets is also beginning [
38], but not yet in the form of the context-sensitive two-point processors analyzed here. When context-sensitive two-point processors are used in such applications new light may be cast on well-established difficulties in the use of context, such as getting stuck in ‘local minima’ within the contextual landscape, and interference between competing contexts. This is the first paper in which partial information decomposition is used to explicitly distinguish the information processing properties of context-sensitive two-point processors from those of the simple arithmetic operators.
2. Methods
2.1. Notation and Definitions
A nomenclature of mathematical terms and acronyms is provided at the end of the paper.
In [
29], a local processor with two binary inputs and a binary output was discussed. Here, the inputs are instead continuous and have an absolutely continuous probability density function (p.d.f.), defined on
. We denote the inputs to the processor by the continuous random variables
R and
C (where R stands for the receptive field drive and C for the contextual input), and the output by the binary random variable,
Y, taking values in the set
. The conditional distribution of
Y, given that
is Bernoulli with conditional probability of the logistic form
where
is a continuous function defined on
.
We now define the standard information-theoretic terms that are required in this work and based on results in [
39,
40]. We denote by the function
H the usual Shannon entropy, and note that any term with zero probabilities makes no contribution to the sums involved. The joint mutual information that is shared by
Y and the pair
is given by,
The information that is shared between
Y and
R but not with
C is
and the information that is shared between
Y and
C but not with
R is
The information shared between
Y and
R is
and between
Y and
C is
The interaction information [
41] is a measure of information involving all three variables,
and is defined by
It has been employed as a measure of synergy [
42,
43].
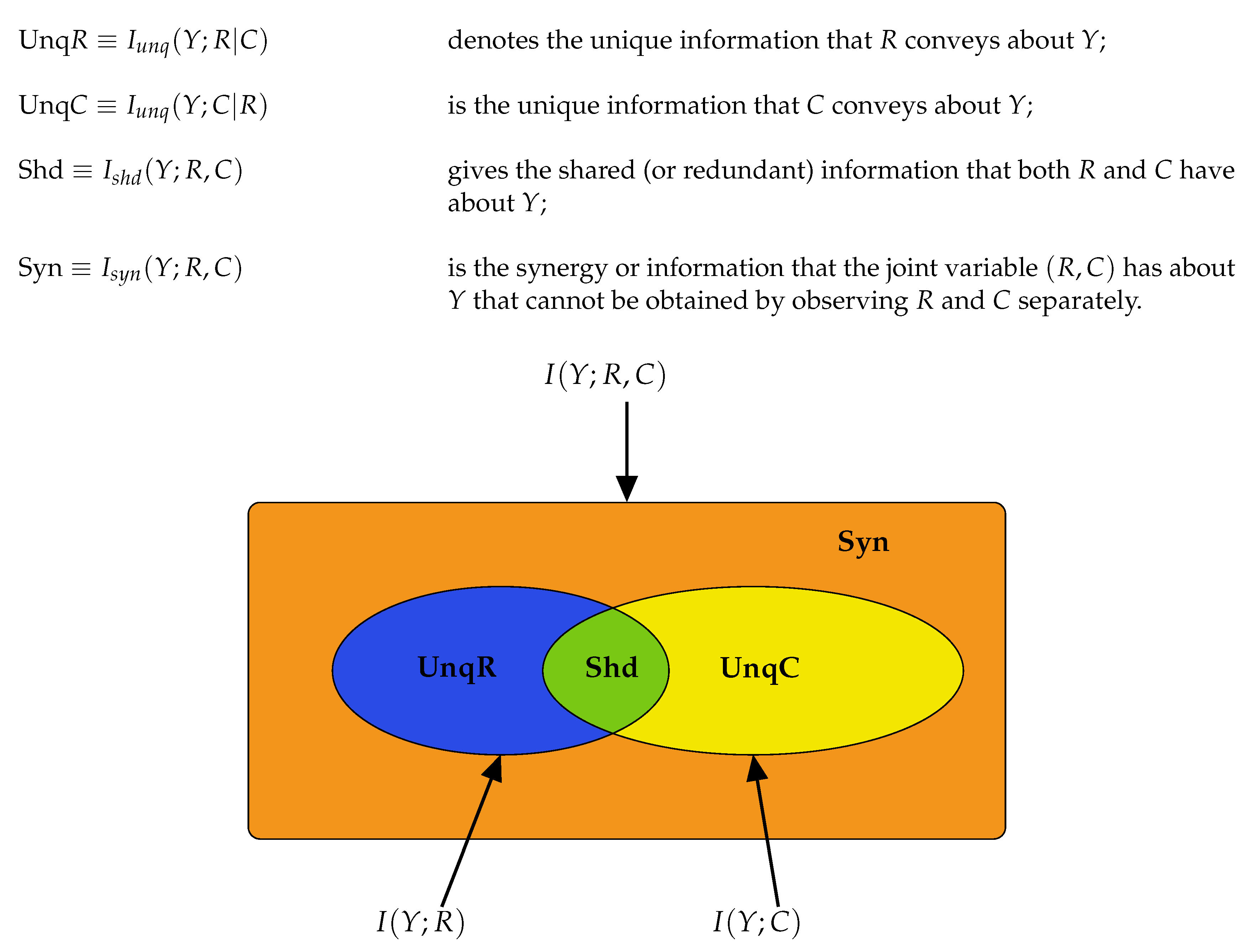
2.2. Partial Information Decompositions
Partial Information Decomposition (PID) was introduced by Williams and Beer [
30]. It provides a framework under which the mutual information, shared between the inputs and the output of a system, can be decomposed into components which measure four different aspects of the information: the unique information that each input conveys about the output; the shared information that both inputs possess regarding the output; the information that the inputs in combination have about the output. Partial information decomposition has been applied to data in neuroscience; see, e.g., [
31,
44,
45,
46]. For a recent overview, see [
28]. The PIDs were computed using the freely available Python package,
dit [
47].
Here there are two inputs,
, and one output,
Y. The information decomposition can be expressed as [
32]
Adapting the notation of [
32] we express our joint input mutual information in four terms as follows:
It is possible to make deductions about a PID by using the following four equations which give a link between the components of a PID and certain classical Shannon measures of mutual information. The following are in (Equations (4) and (5), [
32]), with amended notation; see also [
30].
The Equations (
8)–(10) are illustrated in graphical format in
Figure 2. Using (
8)–(10) we may deduce the following connections between classical information measures and partial information components.
When the partial information components are all non-negative, we may deduce the following from
,
and
. When the interaction information in
is positive, a lower bound on the synergy of a system is given by the interaction information [
41]. Also, the expression in
provides a lower bound for UnqR, when
. Thus, some deductions can be made without considering a PID. While such deductions can be useful in providing information bounds, it is only by computing a PID that the actual values of the partial information components can be obtained.
We consider here five of the different information decompositions that have been proposed. The five methods of decomposition are
[
30],
[
48],
[
49,
50],
[
51] and
[
52]. Although there are clear conceptual differences between them, our emphasis is upon aspects of the decompositions on which we find that they all agree.
In particular, all the PID methods, except
, produce PID components that are non-negative, whereas
can produce negative values. The PID
is a pointwise-based method in which local information measures are employed at the level of individual realizations. This is also the case with fully pointwise PIDs, such as [
53,
54]. Local mutual information is explained by Lizier in [
55]. If
are discrete random variables then the mutual information
shared between
U and
V can be written as an average of the local mutual information terms
, for each individual realization
of
, as follows
where
is the local mutual information associated with the realization
of
.
The local mutual information
is positive when
, so that “knowing the value of
v increased our expectation of (or positively informed us about) the value of the measurement
u” [
55]. The local mutual information
is negative when
, so that “knowing about the value of
v actually changed our belief
about the probability of occurrence of the outcome
u to a smaller value
, and hence we considered it less likely that
u would occur when knowing
v than when not knowing
v, in a case were
u nevertheless occurred” [
55]. Of course, the average of these local measures is the mutual information
, as in
, but when pointwise information measures are used to construct a PID there can be negative averages. For further details of how negative values of PID components can occur, see [
53,
54].
In the simulations, it will be found in some cases that the
PID has a negative value for the unique information due to context,
C. We interpret this to mean that the unique information provided by
C is, on average, less likely to result in predicting the correct value of the output
Y. We adopt the term ‘misinformation’ from [
53,
54], and describe this as ‘unique misinformation due to context,
C’.
We also consider residual output entropy defined by
. In addition to the four PID components, this residual measure is useful in expressing the information that is in
Y but not in
. It is also worth noting that these five terms add up to the output entropy
, and when plotted we refer to the decomposition as a spectrum.
When making comparisons between different systems it is sometimes necessary to normalize the five measures in
by dividing each term by their total, the output entropy,
. Such normalization was applied in some systems that are considered in
Section 3.1.
2.3. Transfer Functions
We consider eight different forms of transfer function when computing the conditional output probabilities in . These transfer functions provide different ways of combining the two inputs. The functions in define modulatory forms of interaction, whereas those in are arithmetic. One aim of this study is to compare the PIDs obtained when using the different functions.
There are four modulatory transfer functions that are defined as follows.
We also consider four transfer functions that correspond to arithmetic interactions between the inputs. They are given by
2.4. Different Signal-Strength Scenarios
The inputs to the processor, are composed as and , where are continuous random variables that have mean values of . Then the mean values of R are and the mean values of C are . The signal strengths, , are non-negative real parameters that characterize the strength of each input.
Four combinations of signal strengths are used in this study, as defined in
Table 1.
They are chosen to test for the key properties of contextual modulation. They are:
- CM1:
The drive, R, is sufficient for the output to transmit information about the input, so context, C, is not necessary.
- CM2:
The drive, R, is necessary for the output to transmit information about the input, so context, C, is not sufficient.
- CM3:
The output can transmit unique information about the drive, R, but little or no unique information or misinformation about the context, C.
- CM4:
The context can strengthen the transmission of information about R when R is weak.
2.5. Bivariate Gaussian Mixture Model (BGM)
In earlier work [
29], we considered units that are bipolar. The bivariate Gaussian mixture model offers a generalization to continuous inputs which reflect underlying binary events. We also consider a single bivariate Gaussian model for the inputs that is obviously more relevant to interactions between the two sites of integration within pyramidal cells. It is useful to know that two such different models for the inputs give essentially the same results on all the issues explored herein. We require the marginal distributions for the integrated receptive and contextual fields
R and
C to be bimodal, with the distribution of
R with modes at
and the distribution of
C with modes at
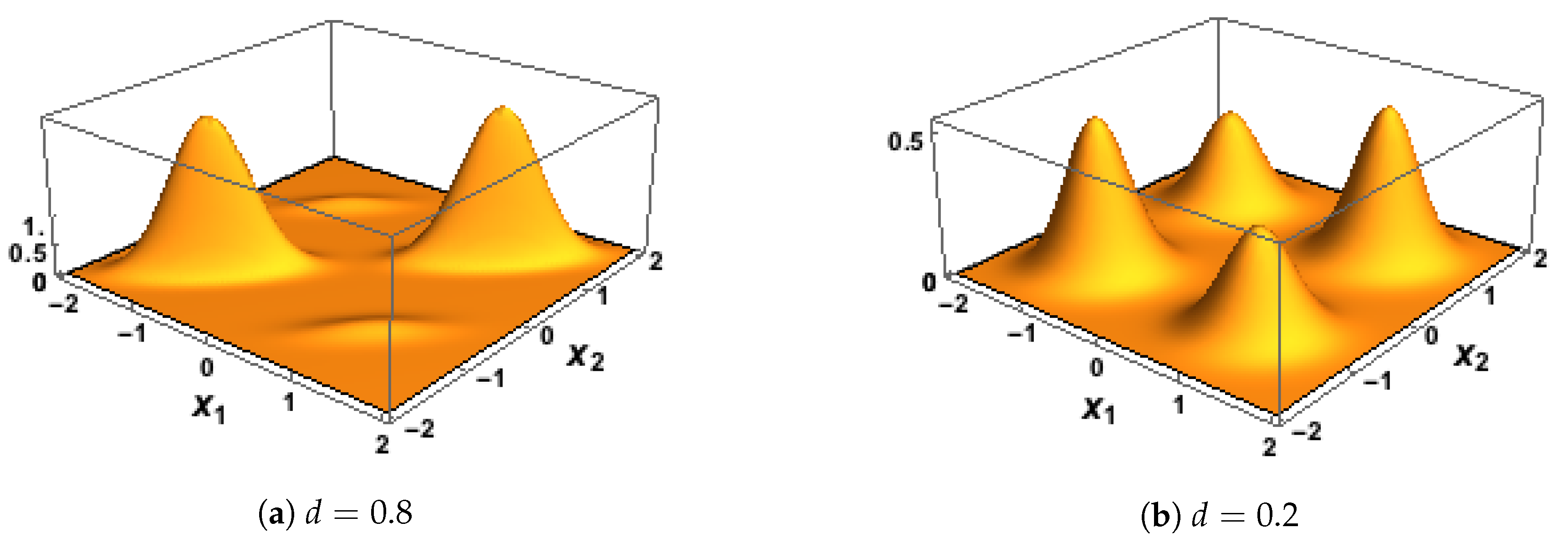
. We shall define a bivariate Gaussian mixture model for
which has four modes – at
and
. First we consider the bivariate Gaussian mixture model for
, with probability density function
where
and the
are the mixing proportions that are non-negative and sum to unity. For simplicity, we have assumed that the bivariate Gaussian pdfs, which form the four components of the mixture, have the same covariance matrix and also that the variances of
and
are equal. We note, in particular, that the correlation between
and
is equal to
in all four of the component distributions.
However, we require investigation of, the correlation of and for the mixture distribution defined by and, in particular, we need to find a way of setting this correlation to take any desired value in the simulations. We proceed as follows.
Consider the random vector
X given by
Then, with respect to the mixture model
,
X has mean vector
where we have used the law of iterated expectation. We make the simplifying assumption that
and that
which results in both components of
being equal to zero. This assumption also means that
We denote the covariance matrix of
X in the mixture model
by
K. Then
since
is the zero vector. Now, again using the law of iterated expectation, we have that
which simplifies to
Therefore, in the mixture model
, the Pearson correlation coefficient of
and
is
Setting this expression to be equal to the desired value of the correlation,
d, gives that
Taking
and using the equality
gives that
Hence, to generate values of
from the BGM model that have correlation
d we take
for some pre-selected value of
.
Now let
and
. Then
has the same correlation as
by the invariance of Pearson correlation under linear transformation, and it has a bivariate Gaussian mixture model with component means
and component covariance matrices all equal to
with mixing proportions
. It follows from the above discussion that in the bivariate Gaussian mixture model
has mean vector
and covariance matrix
K given by
Some plots of the BGM probability density function are given in
Figure 3. To complete the 3D specification of the joint distribution for
the conditional distribution of
Y, given that
and
, was assumed to be Bernoulli with probability equal to the logistic function applied to
, as in
.
2.6. Single Bivariate Gaussian Model (SBG)
While in our previous work [
29] bipolar inputs have been considered, and a continuous version considered in
Section 2.5, there are many datasets in neuroscience and in machine learning where the input variables are not bimodal. We extend our approach, therefore, by considering the input data to have been generated from a single bivariate Gaussian probability model. We take
to have a bivariate Gaussian distribution, with mean vector and covariance matrix
Then,
R and
C are bivariate Gaussian, with mean vector and covariance matrix
Taking , ensures that almost 100% of the generated values of lie within the unit square , and so the corresponding values of R and C are almost certainly positive.
Given positive inputs, it is necessary to introduce a bias term,
b, into each transfer function. Thus, the general
is replaced here by
where
b is taken to be the median of the values of
obtained by plugging in the generated values of
r and
c. This choice of
b ensures that the simulated outputs are equally likely to be
or
, so the output entropy
will be very close to its maximum value of 1. The conditional output probabilities are computed using
, with
replaced by
for each of the transfer functions in (
17) and (
18).
2.7. First Simulation, with Inputs Generated Using the BGM Model
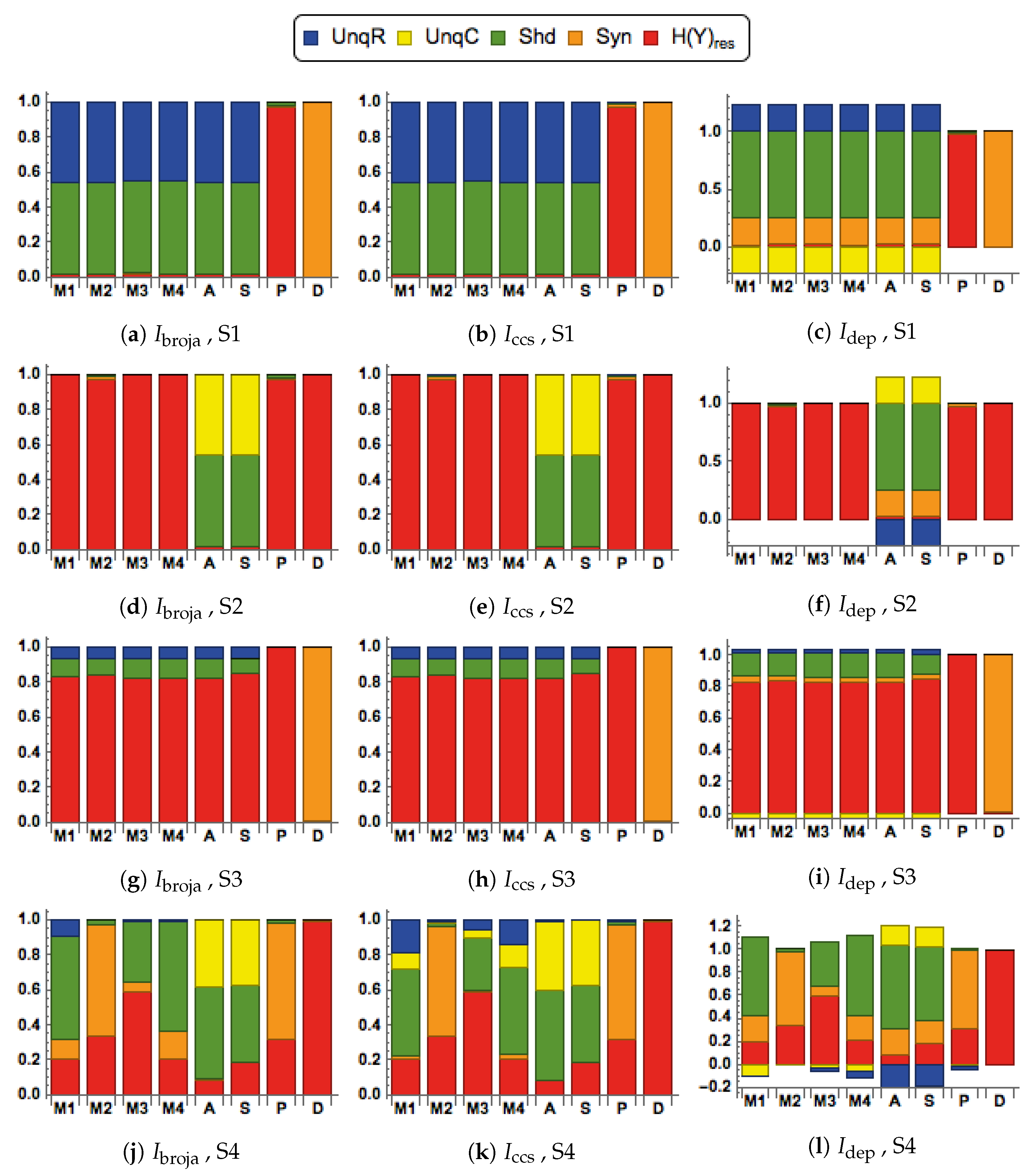
The first simulation study has four factors: transfer function, PID method, scenario and the correlation between the inputs. For each combination of the eight transfer functions, four signal-strength scenarios and two values of correlation (0.8, 0.2), data were generated using the following procedure.
One million samples of were generated from the bivariate Gaussian mixture model in for a given value of the correlation, d, a given combination of the signal strengths, and a given transfer function. In all cases the standard deviation of and was taken as .
For each sample, the values of R and C were computed as and , and these values were passed through the appropriate transfer function to compute the conditional output probability, in . For each value of a value of Y was simulated from the Bernoulli distribution with probability, , thus giving a simulated data set for .
Given the that PIDs have not yet been developed for this type of data, it is necessary to bin the data. For each data set, a hierarchical binning procedure was employed. The values of R were separated according to sign, and then the positive values were split equally into three bins using tertiles, and similarly for the negative values of R. The same procedure was used to define bins for the values of C.
The values of the binary output
Y were binned according to sign. Having defined the bins, the one million
observations were allocated to the appropriate bins. This procedure produced a
probability array that was used in each case as input for the computation of each of the five PIDs used in the study, making use of the package,
dit, which is available on GitHub (
https://github.com/dit/dit).
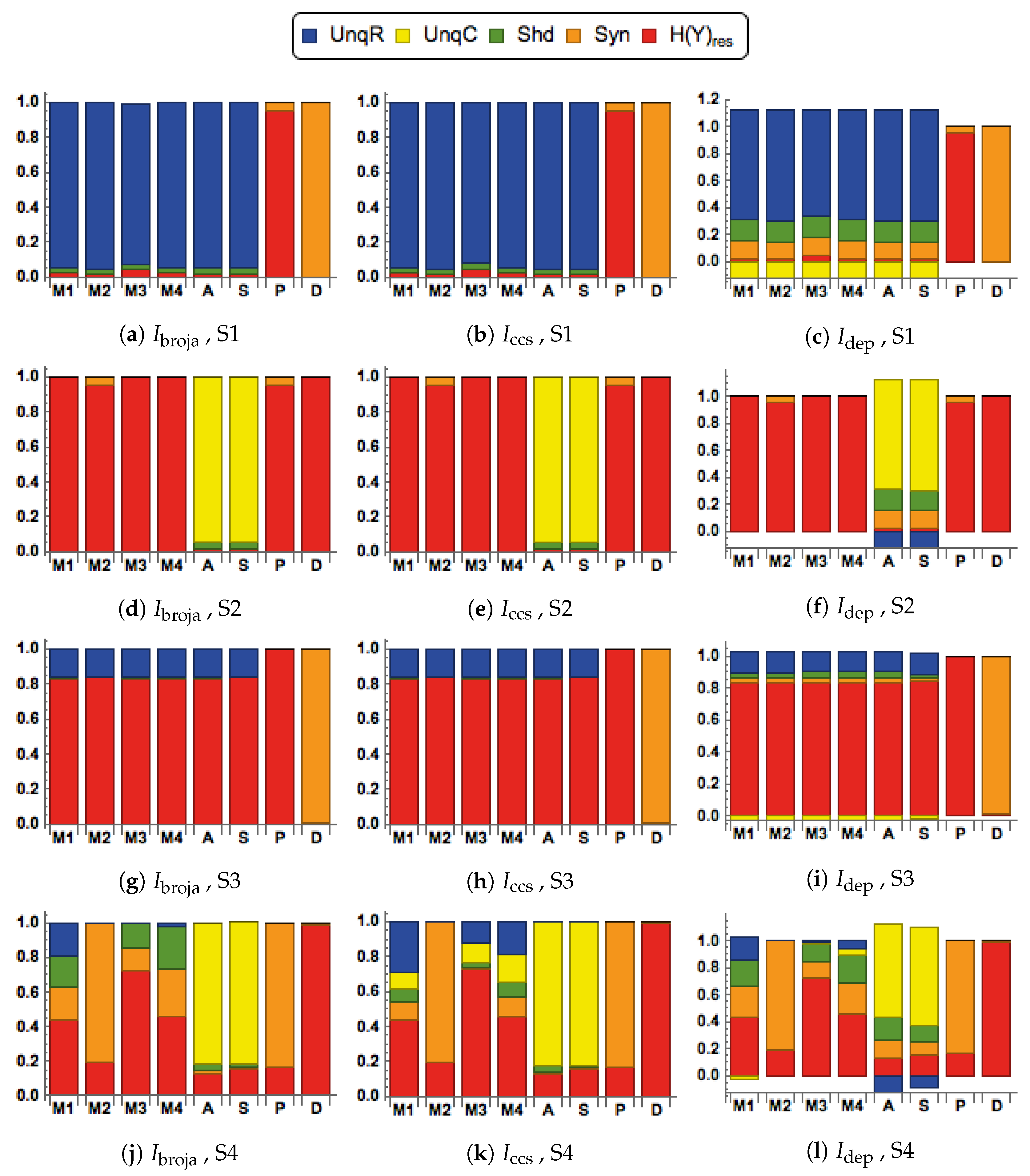
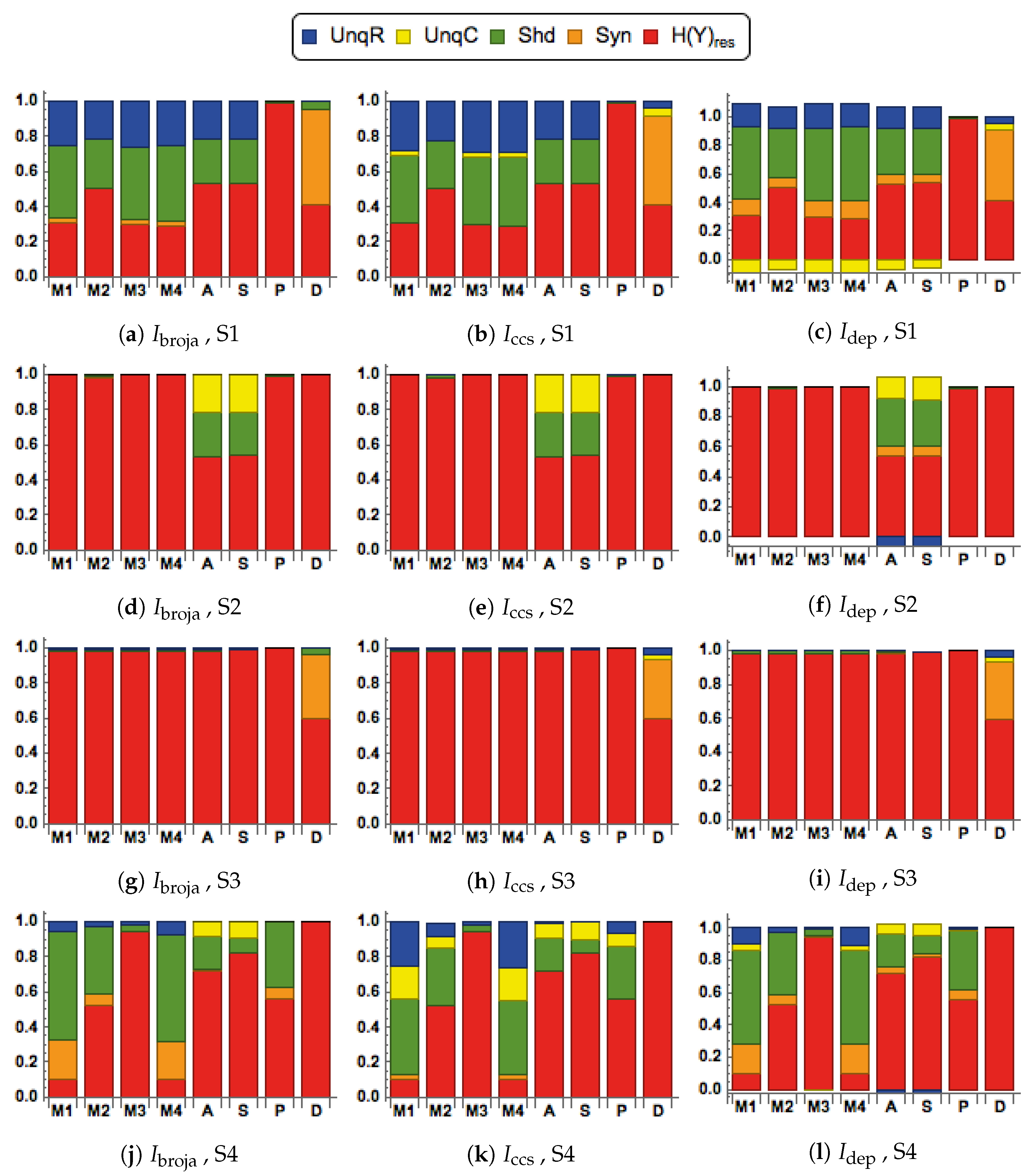
2.8. The Second Simulation, with Inputs Generated Using the SBG Model
The second simulation study is essentially a repeat of the first study, as described in
Section 2.6, with the continuous input data for
R and
C being generated using the SBG model of
Section 2.6 rather than the BGM model. The values of the binary output
Y were simulated in a similar way, with transfer functions of the form
used rather than
. The binning of the data was performed in a slightly different way. Given the absence of bipolarity here, the values of
R were divided equally into six bins defined by sextiles, and similarly for
C. The binary outputs were split according to sign. Thus, again here, a
probability array was created, and it was used in each case to compute the PIDs.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}