1. Introduction
The explosion of information on the internet is developing following the rapid advancement of internet technology. The recommender system is a simple mechanism to help users find the right information based on the wishes of internet users by referring to the preference patterns in the dataset. The purpose of the recommender system is to automatically generate proposed items (web pages, news, DVDs, music, movies, books, CDs) for users based on historical preferences and save time searching for them online by extracting worthwhile data. Some websites using the recommender system method include
yahoo.com,
ebay.com, and
amazon.com [
1,
2,
3,
4,
5,
6]. A movie recommender is an application most widely used to help customers select films from a large capacity film library. This algorithm can rank items and show users high-level items and good content to provide a movie recommended based on customer similarity. Customer similarity means collecting film ratings given by individuals based on genre or tags and then recommending films that promise to target customers based on individuals with identic tastes and preferences.
Traditional recommender systems always suffer from several inherent limits, such as poor scalability and data sparsity [
7]. Several works have evolved a model-based approach to overcome this problem and provide the benefits of the effectiveness of the existing recommender system. In the literature, many model-based recommender systems were developed by partitioning algorithms, such as
K-Means, and self-organizing maps (SOM) [
8,
9,
10,
11,
12].
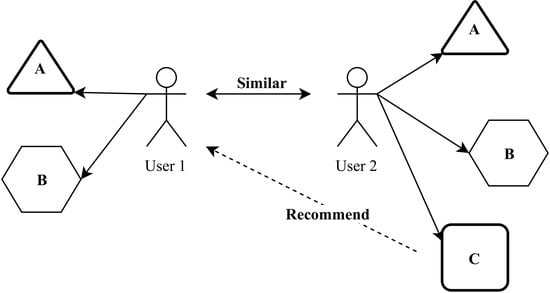
Other methods that can be used in the recommender system include the clarification method, association rules, and data grouping. The purpose of grouping is to separate users into different groups to form neighbors who are “like-minded” (closest) substitutes of searching the entire user space to increase system scalability [
13]. In essence, making high-quality film recommendations with good groupings remains a challenge and exploring those following efficient grouping methods is an important issue in the recommended system situation. A very useful feature in the recommender system becomes the ability to guess user preferences and needs in analyzing user behavior or other user behaviors to produce a personalized recommender [
14].
To overcome the challenges mentioned above, several methods are used to classify performance for the movie recommender system, such as
K-Means algorithm [
15,
16,
17], birch algorithm [
18], mini-batch
K-Means algorithm [
19], mean-shift algorithm [
20], affinity propagation algorithm [
21], agglomerative clustering algorithm [
22], and spectral clustering algorithm [
23]. In this article, we develop a grouping that can be optimized with several algorithms, then obtain the best algorithm in grouping user similarities based on genre, tags, and ratings on movies with the MovieLens dataset. Then, the proposed scheme optimizes
K for each cluster so that it can significantly reduce variance. To better understand this method, when we talk about variance, we are referring to mistakes. One way to calculate this error is by extracting the centroids of each group and then squaring this value to remove negative terms. Then, all of these values are added to obtain total error. To verify the quality of the recommender system, we use mean squared error (MSE), Dunn Matrix as Cluster Validity, and social network analysis (SNA). It also uses average similarity, computational time, rules of association with Apriori algorithms, and performance evaluation grouping as evaluation measures to compare the performance for recommender systems.
1.1. Prior Related Works
Zan Wang, X. Y. (2014) presented research on an improved collaborative movie recommender system to develop CF-based approaches for hybrid models to provide movie recommendations that combine dimensional reduction techniques with existing clustering algorithms. In a sparse data environment, “like-minded” selection based on the general ranking is a function of producing high-quality recommended films. Based on the MovieLens data set, an experimental evaluation approach can prove that it is capable of producing high predictive accuracy and more reliable film recommendations for existing user preferences compared to existing CF-based clustering [
13]. This study also applies the clustering method to find the nearest cluster and recommends a list of movies based on similarities among users. Our recommender system dataset refers to this research by using MovieLens dataset to establish the experiments, including 100,000 ratings by 943 users on 1682 movies, with a discrete scale of 1–5. Each user has rated at least 20 movies. Then, the dataset was randomly split into training and test data at an 80% to 20% ratio. Md. Tayeb Himel, M. N. (2017) researched the weight based movie recommender system using
K-Means algorithm [
14]. This research uses the
K-Means algorithm and explains the results. This research motivates us to use other methods as a comparison to identify the algorithm with better performance.
1.2. Problem Formulation
Information overload is a problem in information retrieval, and the recommendation system is one of the main techniques to deal with problems by advising users with appropriate and relevant items. At present, several recommendation systems have been developed for quite different domains; however, this is not appropriate enough to meet user information needs. Therefore, a high-quality recommendation system needs to be built. When designing these recommendations an appropriate method is needed. This paper investigates several appropriate clustering methods for research in developing high-quality recommendation systems with a proposed algorithm that determines similarities to define a people group to build a movie recommender system for users. Next, experiments are conducted to make performance comparisons with evaluation criteria on several clustering algorithms using the K-Means algorithm, birch algorithm, mini-batch K-Means algorithm, mean-shift algorithm, affinity propagation algorithm, agglomerative clustering algorithm, and spectral clustering algorithm. The best methods are identified to serve as a foundation to improve and analyze this movie recommender system.
1.3. Main Contributions
This study investigates several appropriate clustering methods to develop high-quality recommender systems with a proposed algorithm for finding the similarities within groups of people. Next, we conduct experiments to make comparisons on several clustering algorithms including K-Means algorithm, birch algorithm, mini-batch K-Means algorithm, mean-shift algorithm, affinity propagation algorithm, agglomerative clustering algorithm, and spectral clustering algorithm. After that, we find the best method from them as a foundation to improve and analyze this movie recommender system. We limit to using three tags and three genres because to analyze performance and get good visualization, the most stable results are three tags and three genres, before we have tried more than three but the visualization results obtained are not so good with some of the methods used in this study. We start losing the ability to visualize correctly when analyzing three or more dimensions. Then we limit it by using favorite genres and tags and more details on the algorithm comparison. The main contributions of this study are as follows:
Performance comparison of several clustering methods to generate a movie recommender system.
To optimize the K value in K-Means, mini-batch K-Means, birch, and agglomerative clustering algorithms.
To verify the quality of the recommender system, we employed social network analysis (SNA). We also used the average similarity to compare performance methods and association rules with the Apriori algorithm of recommender systems.
The remainder of this paper is organized as follows. In
Section 2, we present an overview of the recommender system and review the clustering algorithm and system design of the recommender system. We detail the algorithm design of the
K-Means algorithm, birch algorithm, mini-batch
K-Means algorithm, mean-shift algorithm, affinity propagation algorithm, agglomerative clustering algorithm, and spectral clustering algorithm. Additionally, we proposed a method to optimize
K in some of the methods. This session also explains the evaluation criteria. The experiments, dataset explanation, and results are illustrated in
Section 3. Evaluation results of algorithms via various test cases and discussions are shown in
Section 4. Finally,
Section 5 concludes this work.
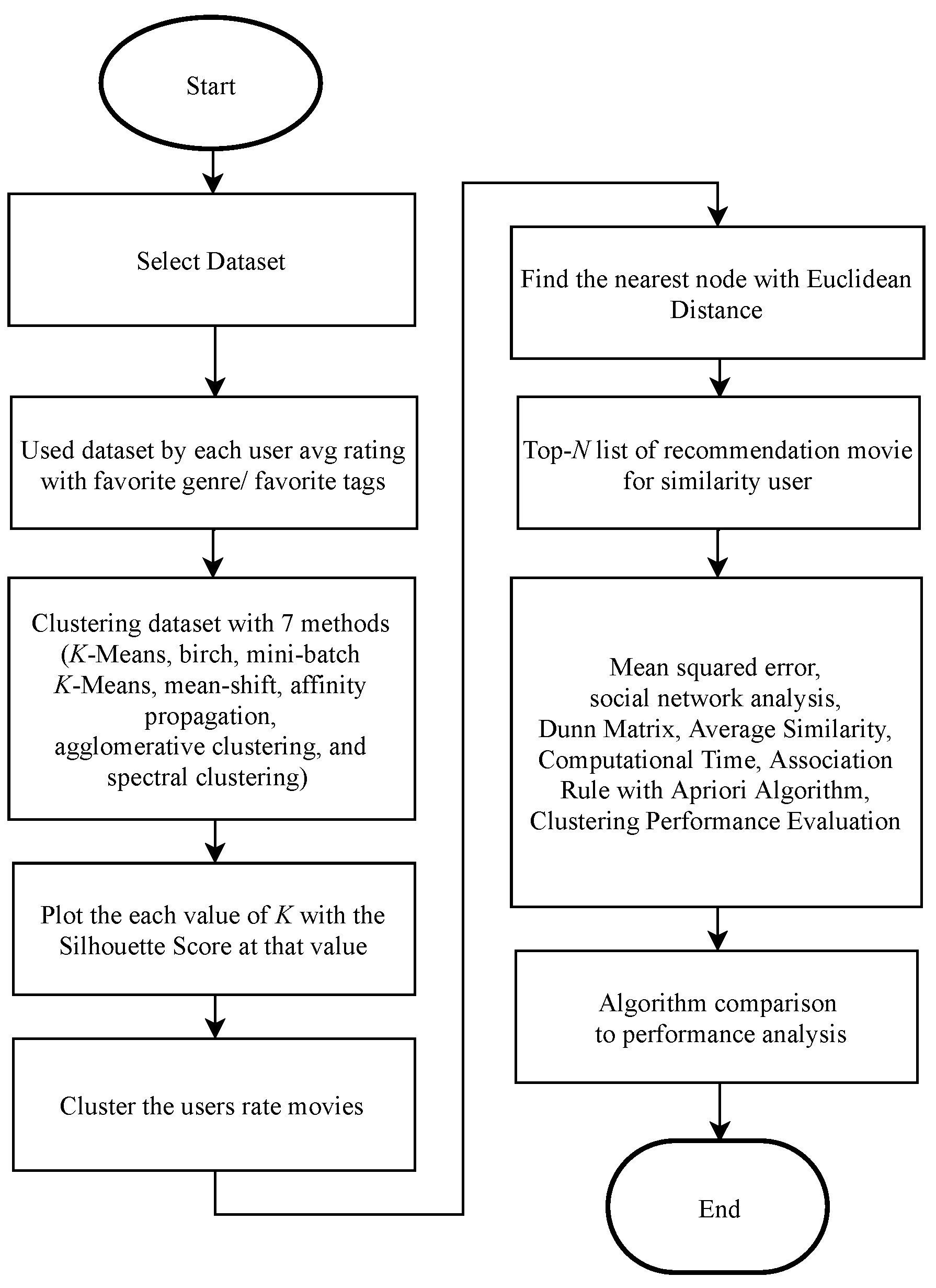
3. Experiment Results
In this part, the experimental design and empirical result of the proposed movie recommender algorithm via K-Means, birch, mini-batch K-Means, mean-shift, affinity propagation, agglomerative clustering, and spectral clustering technique are presented. To verify the quality of the recommender system, the mean squared error (MSE), Dunn Matrix as cluster validity indices, and social network analysis (SNA) are used. Average similarity, computational time, association rule with Apriori algorithm, and clustering performance evaluation are used as evaluation measures. Finally, the results are analyzed and discussed. These experiments were performed on Intel(R) Core(TM) i5-2400 CPU @ 3.10 GHz, 8.0 GB RAM computer and run Python 3 with Jupyter Notebook 5.7.8 version to simulate the algorithm.
3.1. Dataset
We use the MovieLens dataset to conduct an experiment and this dataset is also available online. The dataset is a stable benchmark dataset within 20 million ratings and 465,000 tag applications applied to 27,000 movies, including 19 genres, by 138,000 users. The tag data with 12 million relevance scores are incorporated across 1100 tags. Datasets are determined using a discrete scale of 1–5. We limit the use of clustering based on three genres and three tags to analyze the performance and get a good visualization. High dimensional could not be handled properly, so the visualization results were not suitable when using all tags and genres. Afterwards the dataset was randomly split into training and test data with a ratio of 80%/20%. The goal is to obtain similarities within groups of people to build a movie recommending system for users. Then, we analyze a dataset from MovieLens user ratings to examine the characteristics people share with regard to movie taste and use this information to rate the movie.
3.2. Algorithm Clustering Result
We try to establish different clustering algorithms using
K-Means, birch, mini-batch
K-Means, mean-shift, affinity propagation, agglomerative clustering, and spectral clustering techniques to discover similarities within groups of people to develop a movie recommendation system for users. Then, clustering based on three genres and three tags is used to analyze the performance, obtain good visualization, and sort movie ratings from high to less by assigning the dataset using a discrete scale of 1–5. Then, to overcome the above limitations,
K was optimized to select the right
K number of clusters. Euclidean distance was also used to find the closest neighbor or user in the cluster. Finally, this study recommends the list-
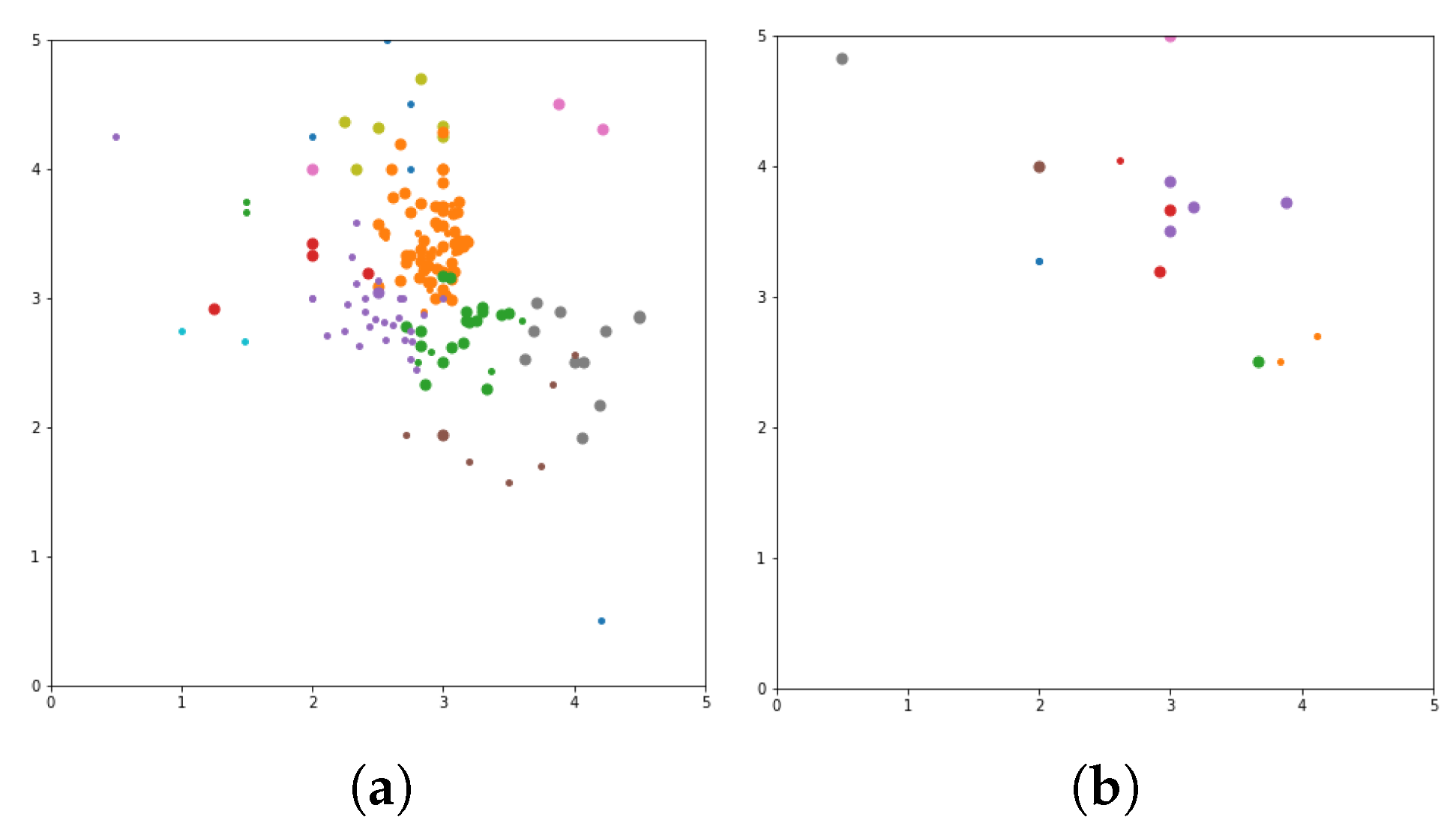
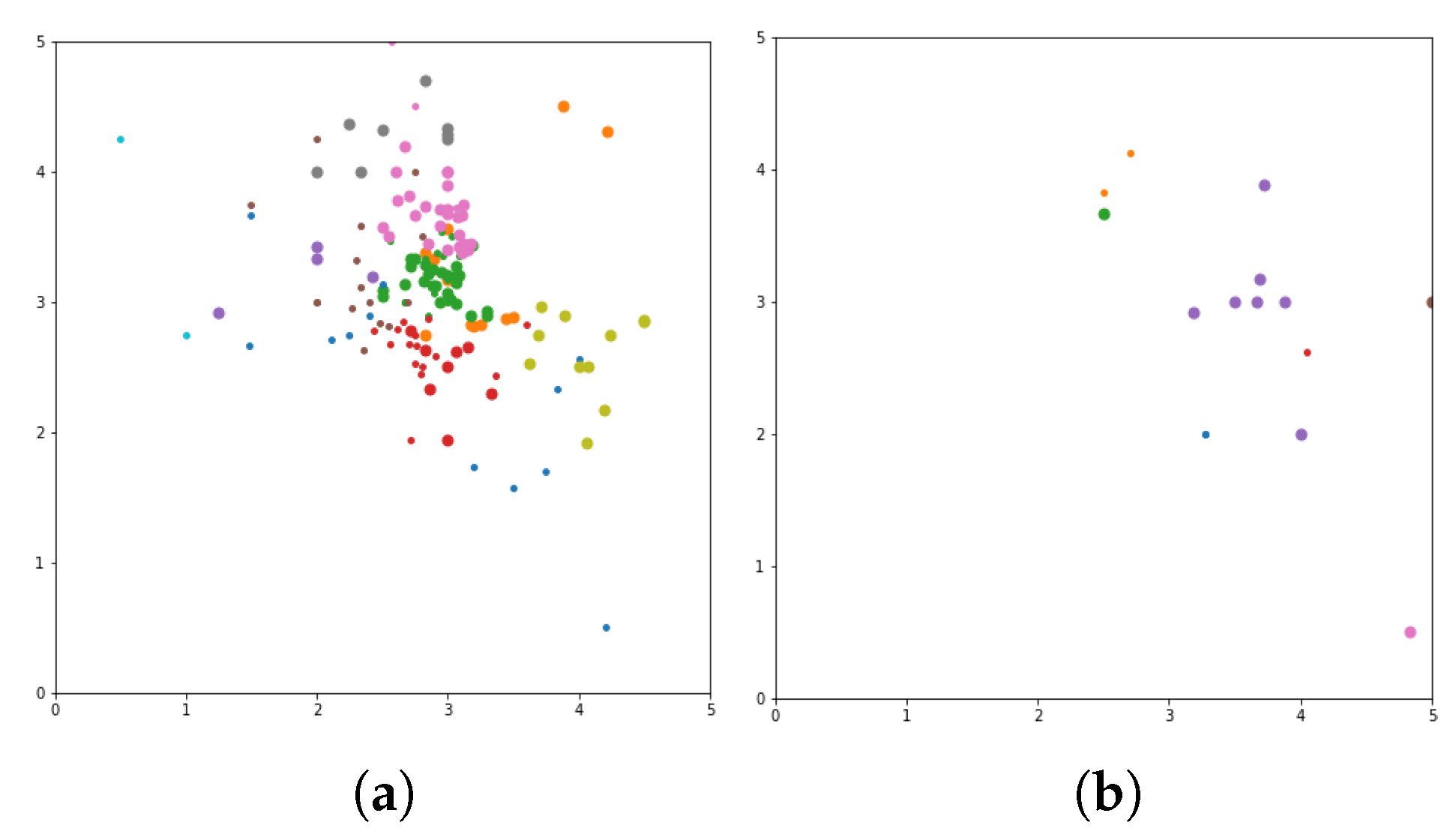
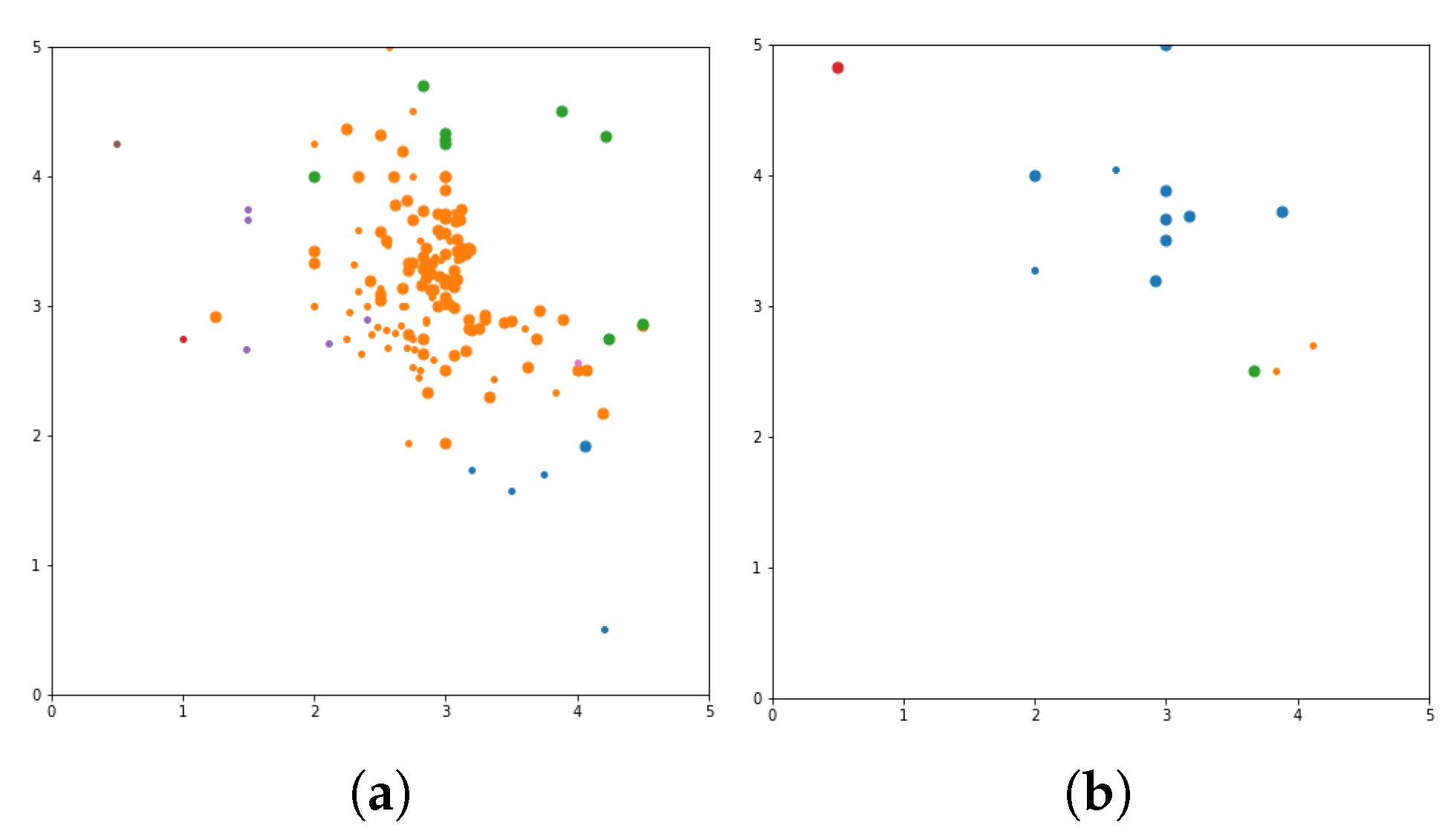
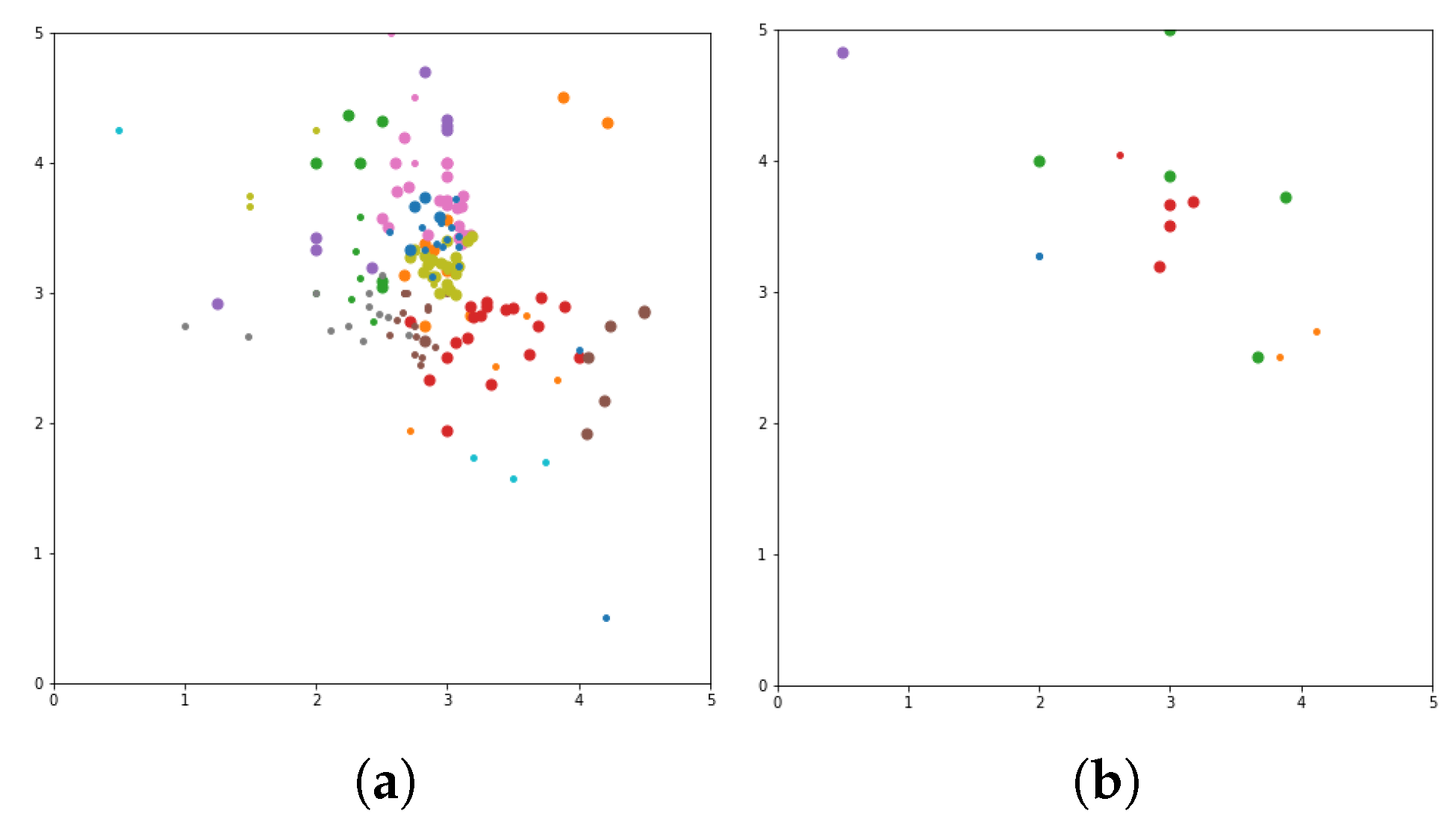
N of movie list based on user similarity. The visualization clustering results for seven different algorithms are presented (see
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
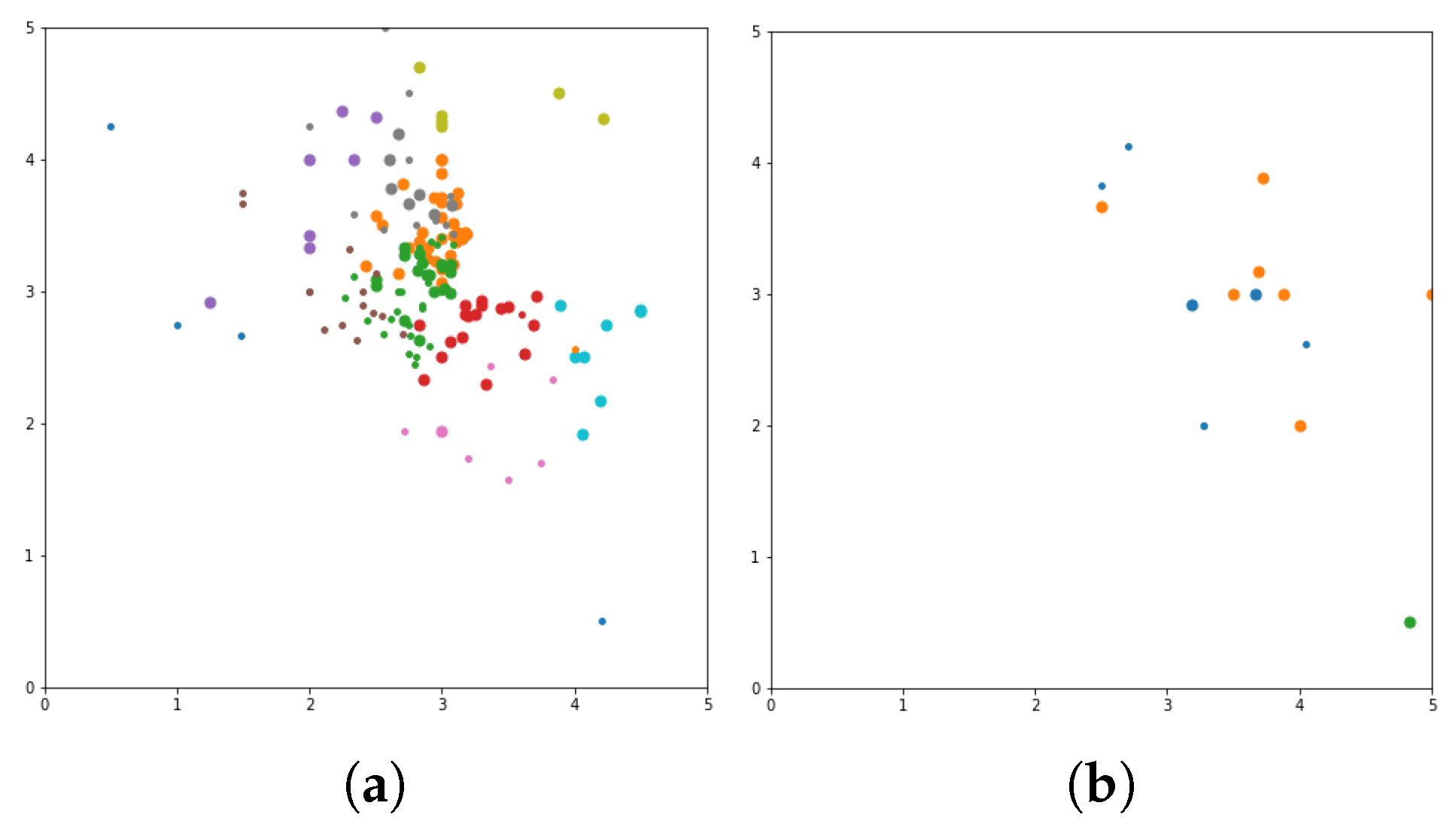
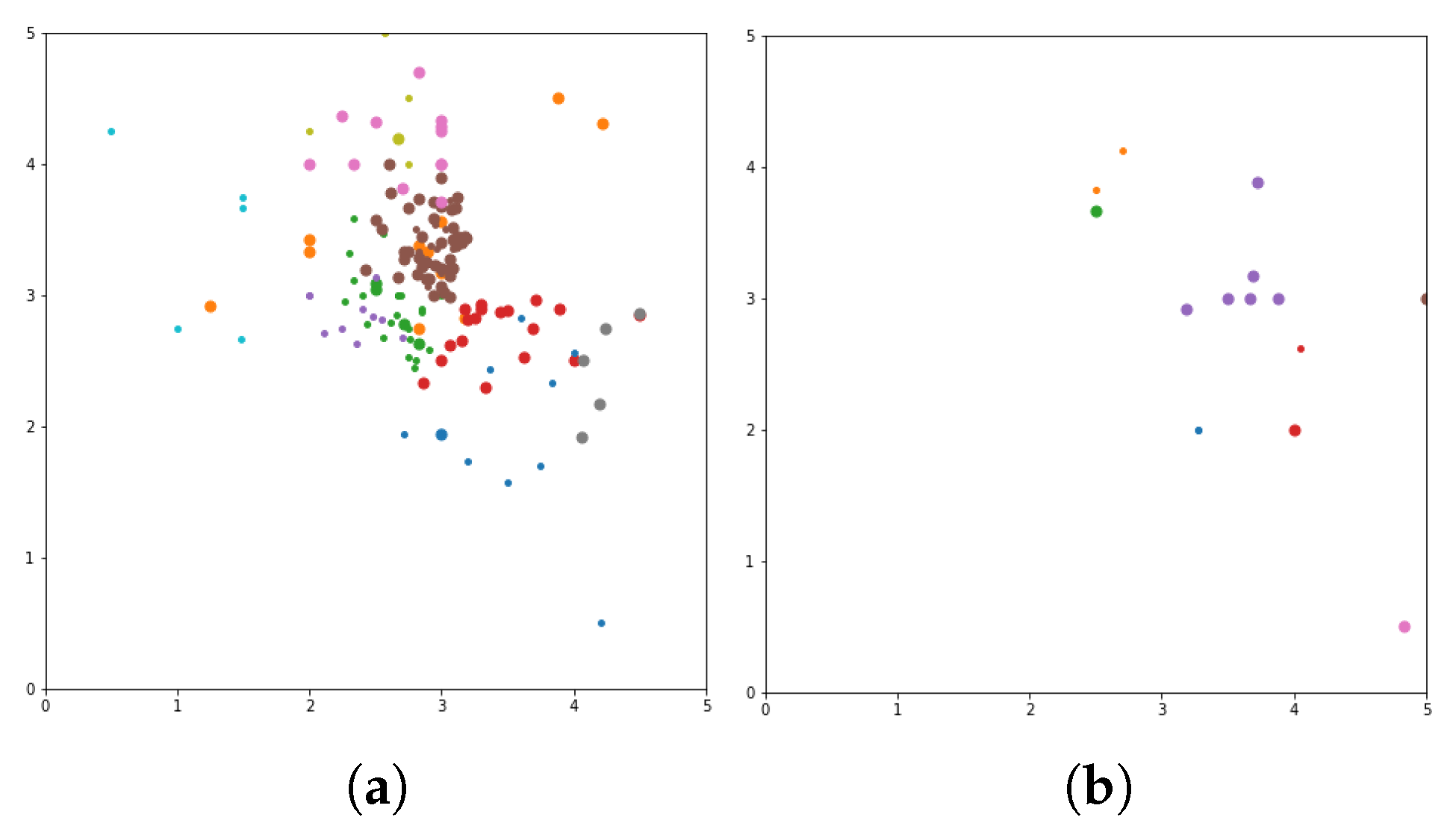
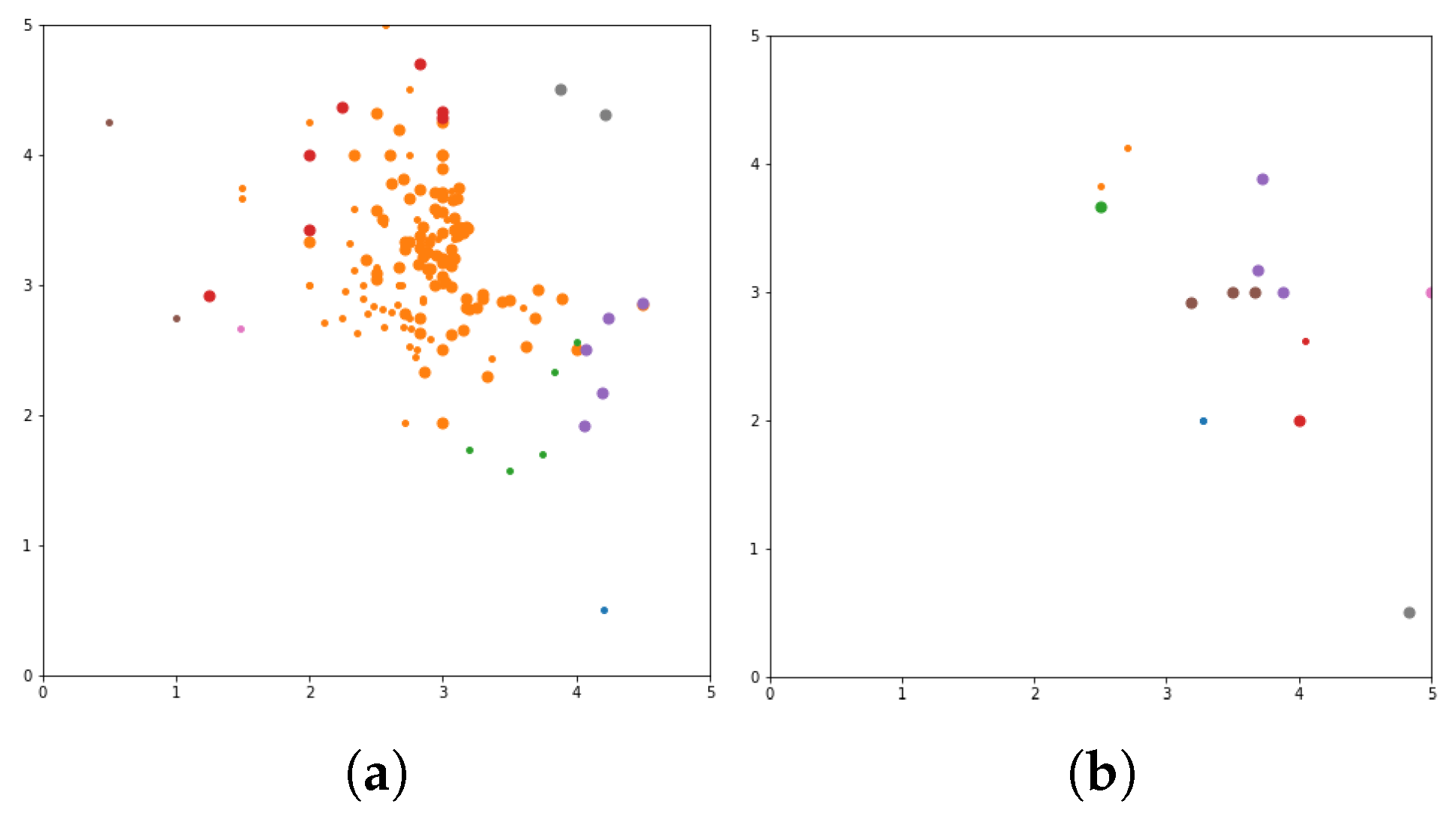
Figure 9). In these figures the X-axis for the first subfigures is the average romance rating, and the Y-axis is the average sci-fi rating. For the second subfigures, the X-axis is the average fantasy rating, and average funny rating is reported on the Y-axis.
To obtain a more delimited subset of people to study, grouping is performed to exclusively obtain ratings from those who like either romance or science fiction movies. X and Y-axes are romance and sci-fi ratings, respectively. In addition, the size of the dot represents the ratings of the adventure movies. The bigger the dot, the higher the adventure rating. The addition of the adventure genre significantly alters the clustering. The Top N-Movies lists several clustering algorithms with K-Means genre n cluster = 12, K-Means tag n cluster = 7, birch genre n cluster = 12, birch tags n cluster = 12, MiniBatch-K-Means genre n cluster = 12, MiniBatch-K-Means tags n clusters = 7, mean-shift genre, mean-shift tags, affinity propagation genre, affinity propagation tags, agglomerative clustering genre n cluster = 12, agglomerative clustering tag n cluster = 7, spectral clustering genre, spectral clustering tags are reported below.
Considering a subset of users and discovering what their favorite genre was, we define a function that would calculate each user’s average rating for all romance movies, science fiction movies, and adventure movies. To obtain a more delimited subset of people to study, we biased our grouping to exclusively obtain ratings from those users who who like either romance or science fiction movies. We used the
x and
y-axes of the romance and sci-fi ratings. In addition, the size of the dot represents the ratings of the adventure movies (the bigger the dot, the higher the adventure rating). The addition of the adventure genre significantly affects the clusters. The more data added to our model, the more similar the preferences of each group are. The final version is Top list of
N of movies (e.g., shown in
Figure 10). Additionally, we considered a subset of users and discovered their favorite tags. We defined a function that calculated each user’s average rating for all funny tag movies, fantasy tag movies, and mafia tag movies. To obtain a more delimited subset of people to study, we biased our grouping to exclusively obtain ratings from those users who like either funny or fantasy tags movies. We also determined that results obtained before the comparison algorithm are Top N movies to be given to similar users. The results of Top N movies before the comparison algorithm and Top N movies to give to similar users for interest in favorite genre and tags are presented.
Optimize K Number Cluster
From the results obtained, we can choose the best choices of the
K values. Choosing the right number of clusters is one of the key points of the
K-Means algorithm. We also use mini-batch
K-Means algorithm and birch algorithm. We do not apply to mean-shift and affinity propagation because the algorithm automatically sets the number of clusters. Increasing the number of clusters shows the range that resulted in the worst clusters based on the Silhouette Score. Optimize K is represented by a silhouette score. The X-axis represents the largest score, so the group is more varied to use and the Y axis represents the number of clusters. This is so that it can determine the right number of clusters to be used in displaying visualizations. The results to optimize
K in several clustering algorithms are presented in
Figure 11.
4. Evaluation and Discussion
This section contains the verification and evaluation results of the methodology. The best performing method is identified, and a discussion is presented.
4.1. Evaluation Result
The verification and evaluation results are presented below.
4.1.1. Mean Squared Error
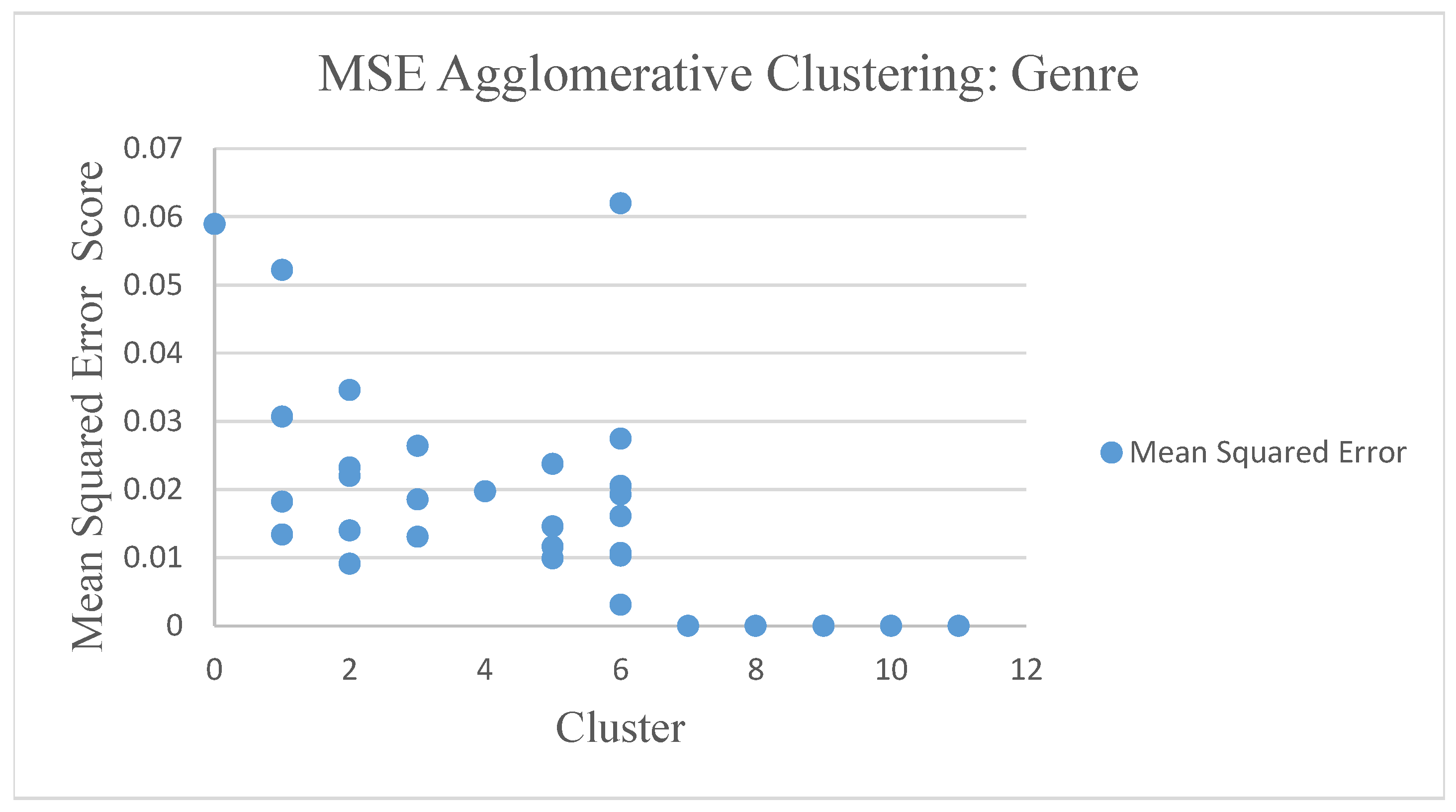
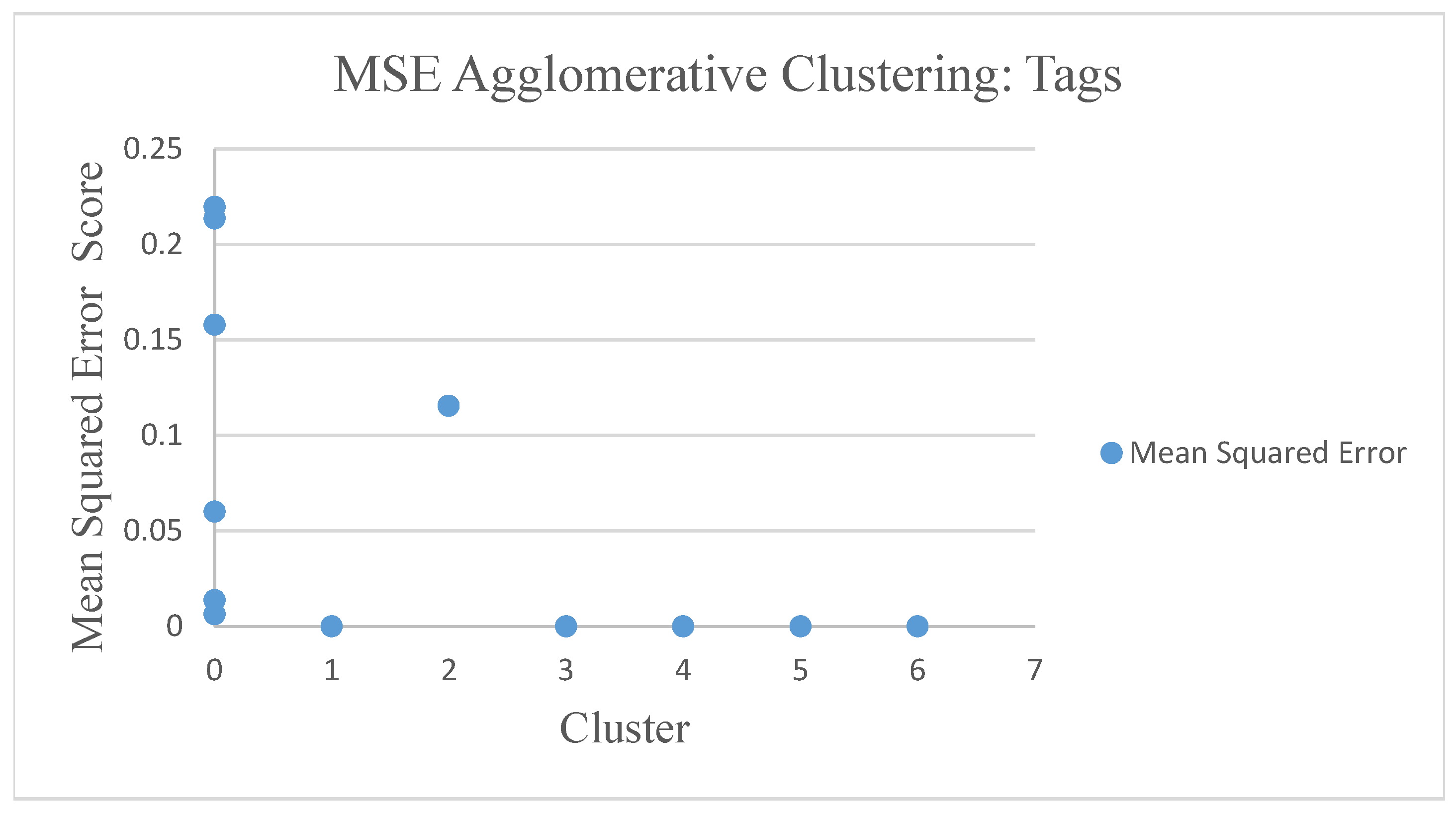
Shown in
Figure 12 and
Figure 13, the mean squared error (MSE) agglomerative method serves as an example among the seven clustering algorithms.
4.1.2. Cluster Validity Indices: Dunn Matrix
The Dunn matrix is used as a validity measure to compare performance methods of recommendation systems. The following Dunn matrix results are shown in
Table 1.
4.1.3. Average Similarity
The average similarity birch method example results from seven clustering algorithms are shown in
Table 2.
4.1.4. Social Network Analysis
Mean-shift results from seven clustering methods for social network analysis (SNA) are shown in
Table 3.
4.1.5. Association Rule: Apriori Algorithm
The association rule with Apriori algorithm is used as an evaluation measure to compare the method performance of the recommendation systems. An example of results for association rules with the Apriori algorithm from seven clustering algorithms is shown in the following section.
Rule: 12 Angry men (1957) -> Adventures of Priscilla, Queen of the Desert, The (1994) Support: 0.25 Confidence: 1.0 Lift: 4.0 ======================================== Rule: 12 Angry Men (1957) -> Airplane! (1980) Support: 0.25 Confidence 1.0 Lift: 4.0 ======================================== Rule: Amadeus (1984) -> 12 Angry men (1957) Support: 0.25 Confidence: 1.0 Lift: 4.0 ======================================== Rule: American Beauty (1999) -> 12 Angry Men (1957) Support: 0.25 Confidence: 1.0 Lift: 4.0 ======================================== Rule: Austin Powers: International Man of Mystery (1997) -> 12 Angry Men (1957) Support: 0.25 Confidence: 1.0 Lift: 4.0
|
4.1.6. Computational Time
The computational time is used as an evaluation measure to compare performance methods of recommendation systems. Computational time results are reported below (see
Table 4).
4.1.7. Clustering Performance Evaluation
Clustering performance evaluation (CPE) result of
K-Means and birch method examples from seven clustering algorithms are reported below (see
Table 5).
4.2. Discussion
A detailed explanation of the above-mentioned experiments is discussed in the subsequent section. In general, for all of these methods, the higher the value of the lift, support, and confidence, the better the link is for the recommender system. Further, the higher the Dunn index value, the better the grouping.
4.2.1. K-Means Performance
Movie recommender quality is evaluated with K-Means. MSE results from K-Means show different results for genre rating and rating tags. The rating tag results are relatively smaller with rating genre scores of 0–0.95 and rating tags scores of 0–0.28. K-Means has a Dunn Matrix that tends to be evenly distributed for genre and tags with values of 0.41. The higher the Dunn index value, the better the grouping. The average similarity in the genre showed that the value increases as the number of clusters decreases. The average similarity in K-Means tags shows that the high similarity value depends on the number of clusters. The association rule with Apriori algorithm in K-Means clustering approach 13% support for the genre and 25% for tags of customers who choose movies A and B. Support is an indication of how often the itemset appears in linkages. The confidence is 61% for the genre and 100% for tags of the customers who choose movie A and movie B. Lift represents the ratio of 3.3 for genre and 4.0 for tags of the observed support value. This is a conditional probability. Clustering performance evaluation showed that the K-Means method showed good performance with the Calinski-Harabaz Index with a score of 59.41.
4.2.2. Birch Performance
To evaluate the movie recommender quality with birch, mean squared error (MSE) results from birch showed relatively small results with a rating genre score range of 0–0.25 and tag scores of 0–0.17. Birch tag ratings have a Dunn Matrix value that tends to be greater than 0.64. The average similarity in the birch genre showed that the value increases, as the number of clusters decreases. The average similarity in birch tags revealed that the high similarity value depended on the number of clusters. The association rule with Apriori algorithm in the birch clustering approach provides 16% support for genre and 50% support for tags of customers who choose movies A and B. Support is an indication of how often the itemset appears in linkages. Confidence is 100% for the genre and 50% for tags of the customers who choose movie A and B. Lift represents the ratio of 4.0 for genre and 1.0 for tags of the observed support value. The performance evaluation showed that this method provides good performance with a score of 1.24 on the Davies–Bouldin Index.
4.2.3. Mini-Batch K-Means Performance
To evaluate movie recommender quality with mini-batch K-Means, MSE results from mini-batch K-Means showed different results in genre rating and rating tags. The rating tag results were relatively smaller with a rating genre score range of 0–0.69 and rating tag scores of 0–0.19. The mini-batch K-Means with genre rating has a Dunn Matrix value that tends to be greater than 0.38. The average similarity in the mini-batch K-Means genre showed that the high similarity value depended on the number of clusters. The average similarity in the mini-batch K-Means tags showed that the high similarity value depended on the number of clusters. The association rule with Apriori algorithm in mini-batch K-Means clustering approach provides 13% support for genre and 14% support for tags of customers who choose movies A and B. Support is an indication of how often the itemset appears in linkages. Confidence is 100% for the genre and 100% for tags of the customers who choose movie A and movie B. Lift represents the ratio of 3.75 for genre and 7.0 for tags of the observed support value. The evaluation showed that the mini-batch K-Means method performs well with Calinski-Harabaz Index with a score of 48.18.
4.2.4. Mean-Shift Performance
To evaluate the movie recommender quality with the mean-shift, the MSE results from the mean-shift showed relatively larger results with a genre rating score range of 0–1 and a tag score of 0–1. The mean-shift algorithm with rating tags has a Dunn Matrix value that tends to be greater than 0.63. The average similarity in the mean-shift genre showed that the value increases as the number of clusters decreases. The average similarity in tags mean-shift showed that the high similarity value depended on the number of clusters. The mean-shift in the genre has the best computational time at 13.75 ms. The association rule with Apriori algorithm in mean-shift clustering approach provides 12% support for genre and 9% for tags of customers who choose movies A and B. Support is an indication of how often the itemset appears in linkages. Confidence is 81% for the genre and 100% for tags of the customers who choose movie A and movie B. Lift represents a ratio of 3.06 for genre and 5.5 for tags of the observed support value. The above-mentioned evaluation depicts the affinity propagation method to provide sufficient performance with Calinski-Harabaz Index with a score of 20.14.
4.2.5. Affinity Propagation Performance
To evaluate the quality with affinity propagation movie, the results of the mean squared error (MSE) from affinity propagation showed different results for genre rating and rating tags. The rating genre results were relatively smaller with a genre rating score range of 0–0.17 and a rating tag score of 0–0.89. The affinity propagation algorithm with genre rating has a Dunn Matrix which tends to be higher at 1.06. The average similarity in the affinity propagation genre showed that the high similarity value depended on the number of clusters. The average similarity in affinity propagation tags showed that the high similarity value depended on the number of clusters. The association rule with Apriori algorithm in affinity propagation clustering approach provided 10.5% support for the genre and 20% support for tags of customers who choose movies A and B. Support is an indication of how often the itemset appears in linkages. Here, 66% confidence is noted for the genre and 100% for tags of the customers who choose movie A and movie B. Lift represents the ratio of 4.22 for genre and 5.0 for tags of the observed support value. Clustering performance evaluation also showed that the affinity propagation method showed good performance with the Calinski-Harabaz Index with a score of 53.49.
4.2.6. Agglomerative Clustering Performance
Now we evaluate the movie recommender quality with agglomerative clustering. MSE results from agglomerative clustering showed different results in genre rating and rating tags. The rating genre results were relatively smaller with rating genres scores of 0–0.06 and rating tags scores with 0–0.23. Agglomerative clustering algorithms with rating tags have Dunn Matrix results that tend to be greater than 0.45. The average similarity in the agglomerative clustering genre showed that the high similarity value depended on the number of clusters. The average similarity in agglomerative clustering tags showed that the high similarity value depended on the number of clusters. The association rule with the Apriori algorithm in agglomerative clustering approach provides 22% support for the genre and 16% for tags of customers who choose movies A and B. Support is an indication of how often the itemset appears in linkages. In addition, 22% confidence is noted for the genre and 16% for tags of customers who choose movie A and movie B. Lift represents a ratio of 1.0 for genre and 1.0 for tags of the observed support value. From the performance evaluation, we see that the agglomerative clustering method performs well with the Calinski-Harabaz Index with a score of 49.34.
4.2.7. Spectral Clustering Performance
Now we evaluate the movie recommender quality with spectral clustering. Mean squared error (MSE) results from spectral clustering showed differences in genre rating and rating tags. The rating tag results were relatively smaller with a rating genre score range of 0–0.62 and rating tags scores of 0–0.17. Spectral clustering algorithm with tag rating has the best Dunn Matrix results at 4.61 and the best spectral clustering algorithm results with genre at 2.09. The average similarity in the spectral clustering genre showed that the high similarity value depended on the number of clusters. The average similarity in spectral clustering tags showed that the high similarity value depended on the number of clusters. Spectral clustering in tags has the best computational time at 6.22 ms. The association rule with Apriori algorithm in spectral clustering approach provides 12% support for the genre and 33% support for tags of customers who choose movies A and B. Support is an indication of how often the itemset appears in linkages. Confidence is 75% for the genre and 100% for tags of the customers who choose movie A and movie B. Lift represents the ratio of 3.12 for genre and 3.0 for tags of the observed support values. Clustering performance evaluation showed that the spectral clustering method showed good performance with the Calinski-Harabaz Index with a score of 16.39.
5. Conclusions
In this study, seven clusterings were used to cluster performance comparison methods for movie recommendation systems, such as the K-Means algorithm, birch algorithm, mini-batch K-Means algorithm, mean-shift algorithm, affinity propagation algorithm, agglomerative clustering algorithm, and spectral clustering algorithm. The developed optimized groupings from several algorithms were then used to compare the best algorithms with regard to the similarity groupings of users on movie genre, tags, and rating using the MovieLens dataset. Then, optimizing K for each cluster did not significantly increase the variance. To better understand this method, variance refers to the error. One of the ways to calculate this error is to extract the centroid of its respective groups. Then, this value is squared (to remove the negative terms) and all those values are added to obtain the total error. To verify the quality of the recommender system, the mean squared error (MSE), Dunn Matrix as cluster validity indices and social network analysis (SNA) were used. In addition, average similarity, computational time, association rule with Apriori algorithm and clustering performance evaluation measures were used to compare the methods of performance systems.
Using the MovieLens dataset, experiment evaluation of the seven clustering methods revealed the following:
The best mean squared error (MSE) value is produced by the birch method with a relatively small squared error score in the rating genre and rating tags.
Spectral clustering algorithm with tag rating has the best Dunn Matrix results at 4.61 and the spectral clustering algorithm has the best genre results at 2.09. The higher the Dunn index value is, the better the grouping.
The closest distance to the social network analysis (SNA) is the mean-shift method, which indicates that the distance between clusters has a high linkage relationship invariance.
The birch method had a relatively high average similarly to increase the number of clusters, which showed a good level of similarity in clustering.
The best computational time is indicated by the mean-shift for genre at 13.75 ms and spectral clustering for tags at 6.22 ms.
Visualization of clustering and optimizing k for movie genre in algorithms is better than movie tags because fewer data are used for movie tags.
Mini-batch K-Means clustering approach is the best approach for the association rule with Apriori algorithm with a high score of support, 100% confidence, and 7.0 ratio of lift for item recommendations.
Clustering performance evaluation shows that the K-Means method exhibits good performance with the Calinski-Harabaz Index with a score of 59.41, and the birch algorithm with a score of 1.24, on the Davies–Bouldin Index.
Birch is the best method based on a comparison of several performance matrices.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}