1. Introduction
The Muth distribution is a one-parameter lifetime distribution introduced by [
1] demonstrating a certain interest in the modelling of some reliability phenomenon. As an essential mathematical definition, it has the following cumulative distribution function (cdf):
where
is a shape parameter. The popularity of the Muth distribution is explained by the combination of the following facts: (i) it corresponds to the classical exponential distribution with parameter 1 when
tends to 0, (ii) its probability mass in the right tail is less than those of the standard gamma, log-normal and Weibull distributions, (iii) it satisfies the variate generation property, (iv) it satisfies the mode-median-mean inequality and (v) it has enough flexibility to fit properly certain lifetime data sets, especially those resulting from the experiments of reliability. All these aspects are detailed in [
1,
2,
3]. Later, the Muth distribution has been extended through the power transform by [
4]. The perspective of generating new symmetric or asymmetric distributions from the Muth distribution has been explored in [
5] through the Muth generated (M-G) class of distributions.
Let us now present the M-G class constituting the basis of our study. First of all, it is defined by the following cdf:
where
is the cdf of a parental continuous distribution having
for parameter vector. This cdf comes from the combination of the second type of the T-X transformation by [
6] and the cdf of the Muth distribution. That is, we have
. With this construction, when
tends to 0,
is reduced to
. The probability density function (pdf) of the M-G class is specified by
where
refers to the pdf of the parental distribution, and the corresponding hazard rate function (hrf) follows:
Then, in order to illustrate the flexibility of the M-G class, Reference [
5] considered the following five special distributions: Muth uniform, Muth–Rayleigh, Muth–Lomax, Muth exponential and Muth–Weibull distributions. Graphics reveal diverse curvatures for the related pdfs and hrfs, proving their ability to model various types of phenomena. This is illustrated in [
5] with the Muth–Weibull distribution as the representative of the Muth class and the failure times aircraft windshield data by [
7]. In particular, Reference [
5] proved that these data are better adjusted by the Muth–Weibull model in comparison to several extensions of the Weibull models: the beta Weibull model by [
8], McDonald–Weibull model by [
9], and exponentiated Weibull model by [
10]. Other special Muth distributions can be constructed and studied, symmetric or not, following the spirits of [
11,
12,
13,
14].
In this study, we first discuss two new facts about the M-G class. One is about the possible values of
and the other is about the quantile function (qf). Next, we deepen the perspectives of the M-G class by extending it through the use of the quadratic rank transmutation map. More precisely, we introduce the transmuted Muth generated (TM-G) class of distributions defined by the following cdf:
where
,
is the quadratic rank transmutation map,
and
is the vector containing all the parameters. We thus apply the general approach developed by [
15] to the M-G class. The idea is to offer an intermediate class between the exponentiated generated class with power parameter 2 corresponding to
(see [
16]) and the Topp–Leone generated class with power parameter 1 corresponding to
(see [
17]), the former M-G class being obtained with
. The gain in transforming existing classes of distributions via the quadratic rank transmutation map is now well-established, improving the possible values of the mean and variance, while maintaining symmetry or creating skewness with varying kurtosis, etc. We may refer to [
18,
19,
20,
21,
22,
23]. We make a theoretical work on the TM-G class, determining its main functions, discussing the shape properties of the corresponding pdf and hrf, various moments through series techniques and mathematical inference on the parameter by using the maximum likelihood approach. Then, we illustrate the applicability of the new class by studying a special case based on the log-logistic distribution. We develop the related model to fit two real-life data sets, one with environmental data and the other with survival data. The adequacy of the model reveals to be quite acceptable, and better to competitors connected with the log-logistic model.
The outline of the study is as follows. In
Section 2, the new facts about the M-G class, as well as more information on the TM-G class, are provided. Technical results on the TM-G class are described in
Section 3. The practical side of the TM-G class is explored in
Section 4 through the analysis of real-life data.
Section 5 is the concluding section.
4. Practice of a Special TM-G Model
We are now focusing on a special distribution of the TM-G class, emphasizing its ability to adapt to real data.
4.1. Transmuted Muth Log-Logistic Distribution
There are as many distributions in the TM-G class as there are parental distributions. Here, we chose the log-logistic distribution as parental distribution, aiming to extend it for more statistical objectives. Basically, the log-logistic distribution is a continuous lifetime distribution used in the study of certain lifespan of an event, as for cancer mortality after diagnosis or treatment. It is also used in hydrology to model the flow of a river or the level of needs, and in economics to model income inequality. From a probabilistic point of view, the log-logistic distribution corresponds to the distribution of a random variable whose logarithm is distributed according to a logistic distribution. It closely resembles the log-normal distribution, but was distinguished by thicker tails. Moreover, its cdf admits an explicit expression, unlike the log-normal distribution. Further details on the log-logistic distribution can be found in [
29,
30,
31].
Here, we extend the log-logistic distribution by applying the transmuted Muth scheme, as described in
Section 2. First, we define the log-logistic distribution by the following cdf:
where
is a shape parameter, the corresponding pdf being given as
Then, based on (
6), we introduce the transmuted Muth log-logistic (TMLL) distribution defined by the following cdf:
where
. The corresponding pdf is obtained as
The hrf of the TMLL distribution is specified by
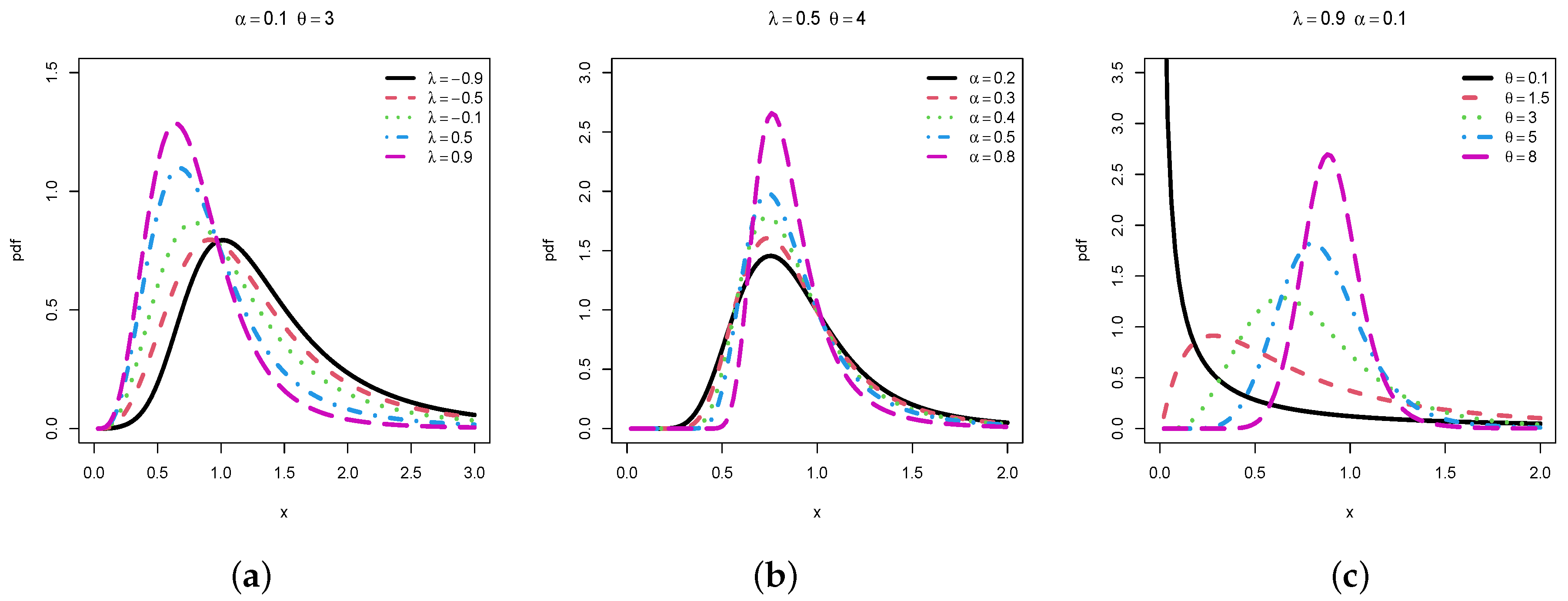
All the theory developed in the sections above can be applied to the TMLL distribution. Here, we go straight to the point by performing a graphical study on the critical points and possible shapes of
and
. First,
Figure 1 shows the possible shapes of
by varying only one of the parameters.
In particular, we see that the TMLL distribution is mainly unimodal, and is versatile in skewness and kurtosis. For the considered values of the parameters, mainly affects the degree of right-skewness, mainly impacts the peak of the pdf; we observe that increasing clearly inceases this peak, and shows a strong influence on the mode and the overall curvature, making the pdf possibly decreasing. The decreasing property is mainly observed for the small values of .
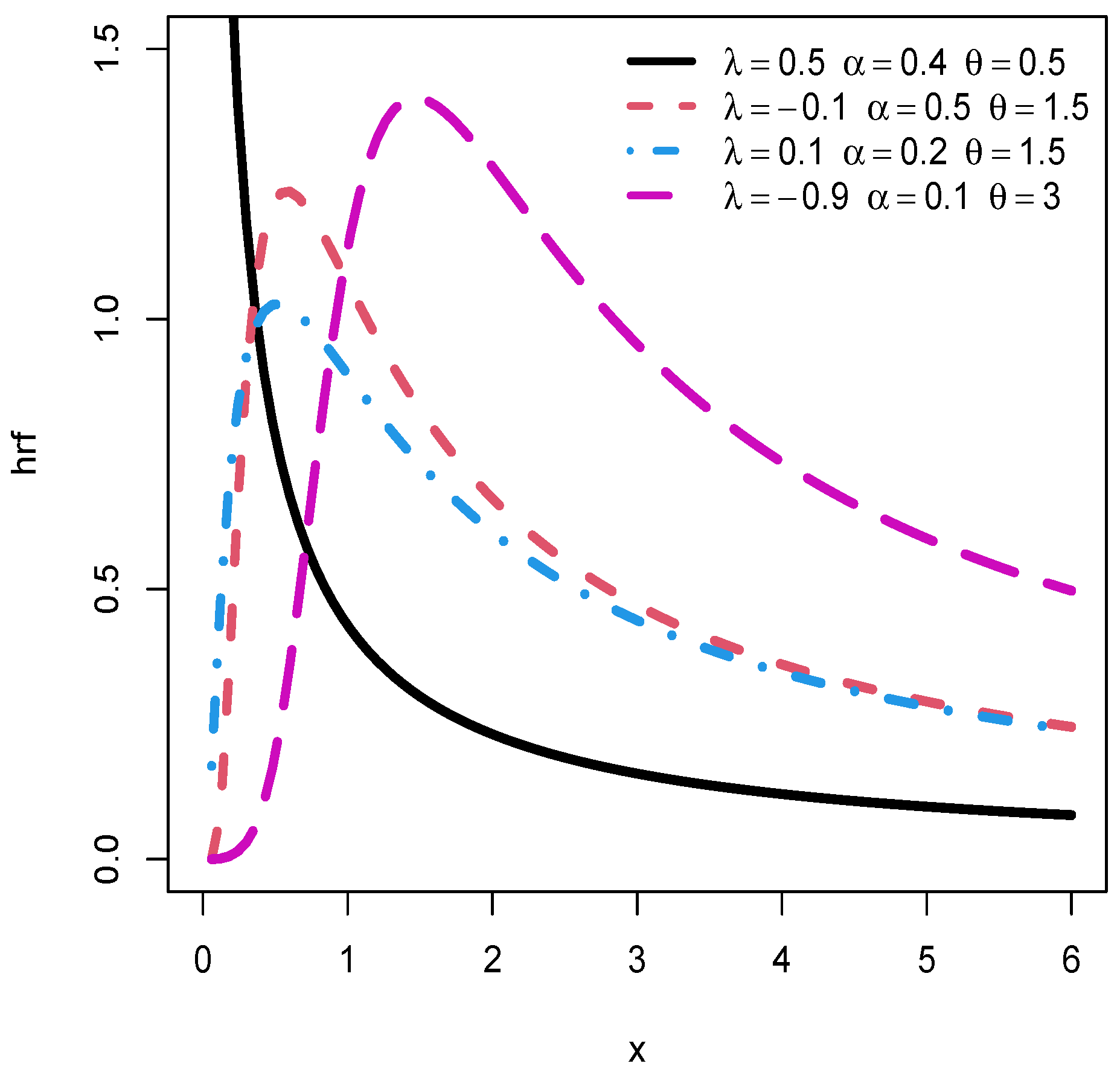
Figure 2 is about the possible shapes of
for four sets of parameters.
We observe in
Figure 2 that the hrf has decreasing, and increasing-decreasing shapes when a maximum is observed. These characteristics are desirable for the modelling in diverse lifetime phenomena, as discussed in [
25].
4.2. Parametric Estimation
The parameters of the TMLL model can be estimated through the ML approach, as developed in
Section 3.3. In order to check the convergence of the obtained estimates, we perform a simulation study with samples of varying sizes. We thus examine the numerical properties of the corresponding ML estimates, mean square errors (MSEs), and average lengths (ALs) and coverage probabilities (CPs) of CIs at a certain fixed level.
More precisely, we generate
random samples of
n values from the TMLL distribution defined with some (known) values of the parameters through the inverse transform sampling method. Then, we determine the average ML estimates, MSEs and average ALs of CIs at the levels
, and
. We do that for chosen increasing values of
n, that is
, 50, 100, 200, 300, and 1000, in order to see if (i) the ML estimates tend to the true values of the parameters, (ii) the MSEs decrease to 0, (iii) the ALs become smaller and (iv) the CPs tend to the expected values, i.e.,
or
, depending on the considered level. The obtained results are put in
Table 1,
Table 2 and
Table 3.
From
Table 1,
Table 2 and
Table 3, it is clear that the ML estimates converge to the corresponding values of the parameters. Furthermore, when
n increases, the MSEs decrease to 0, the ALs becomes smaller and the CPs tend to the considered level value. This motivates us to use the ML approach in estimation of the parameters of the TMLL model.
4.3. Applications
We now apply the TMLL model, along with the ML approach, to show its adequacy with environmental and survival data. The two considered data sets are described below.
Data set I: the first data set is obtained from [
32]. It contains 30 successive values of March precipitation (in inches) in Minneapolis. The data are as follows:
0.77; 1.74; 0.81; 1.20; 1.95; 1.20; 0.47; 1.43; 3.37; 2.20; 3.00; 3.09; 1.51; 2.10; 0.52; 1.62; 1.31; 0.32; 0.59; 0.81; 2.81; 1.87; 1.18; 1.35; 4.75; 2.48; 0.96; 1.89; 0.90; 2.05.
Data set II: the second data set is obtained from [
33]. It represents the survival times (in days) of 72 guinea pigs infected with mortal bacteria (tubercle bacilli). The data are as follows: 0.10; 0.33; 0.44; 0.56; 0.59; 0.72; 0.74; 0.77; 0.92; 0.93; 0.96; 1.00; 1.00; 1.02; 1.05; 1.07; 1.07; 1.08; 1.08; 1.08; 1.09; 1.12; 1.13; 1.15; 1.16; 1.20; 1.21; 1.22; 1.22; 1.24; 1.30; 1.34; 1.36; 1.39; 1.44; 1.46; 1.53; 1.59; 1.60; 1.63; 1.63; 1.68; 1.71; 1.72; 1.76; 1.83; 1.95; 1.96; 1.97; 2.02; 2.13; 2.15; 2.16; 2.22; 2.30; 2.31; 2.40; 2.45; 2.51; 2.53; 2.54; 2.54; 2.78; 2.93; 3.27; 3.42; 3.47; 3.61; 4.02; 4.32; 4.58; 5.55.
Table 4 presents the descriptive statistics of these data sets.
It is clear that the data sets mainly differ in their kurtosis nature. Now, we aim to compare the fit power of the TMLL model with those of the following famous models:
Burr XII (BXIII) with cdf defined by
where
and
.
Beta log-logistic (BLL) (see [
34]) with cdf specified by
where
denotes the classical beta function,
,
and
.
Muth (M) model with cdf given as (
1) with parameter
.
As a first step, we determine the ML estimates of all the parameters of the models in
Table 5 and
Table 6, for data sets I and II, respectively.
From these tables, concerning the TMLL model, we see that the parameter
is estimated “relatively far” to 0, motivating the use of the transmuted scheme. Furthermore, the parameter
is negatively estimated, attesting the importance of the new remarks formulated in
Section 2.1.
We now compare the models through the following well-established criteria: Akaike and Bayesian information criteria (AIC and BIC), Cramer–von Mises (W), and Anderson–Darling (A). Roughly speaking, the smaller the values of these criteria, the better the model is in the fit of the data. The R software is used, along with the package
AdequacyModel by [
28].
Table 7 and
Table 8 collect the obtained results.
Since it has the smallest values of AIC, BIC and A the TMLL model is the best among them all, for the two data sets. In particular, it outperforms the BLL model, and thus represents a better extension of the log-logistic model for the considered data sets.
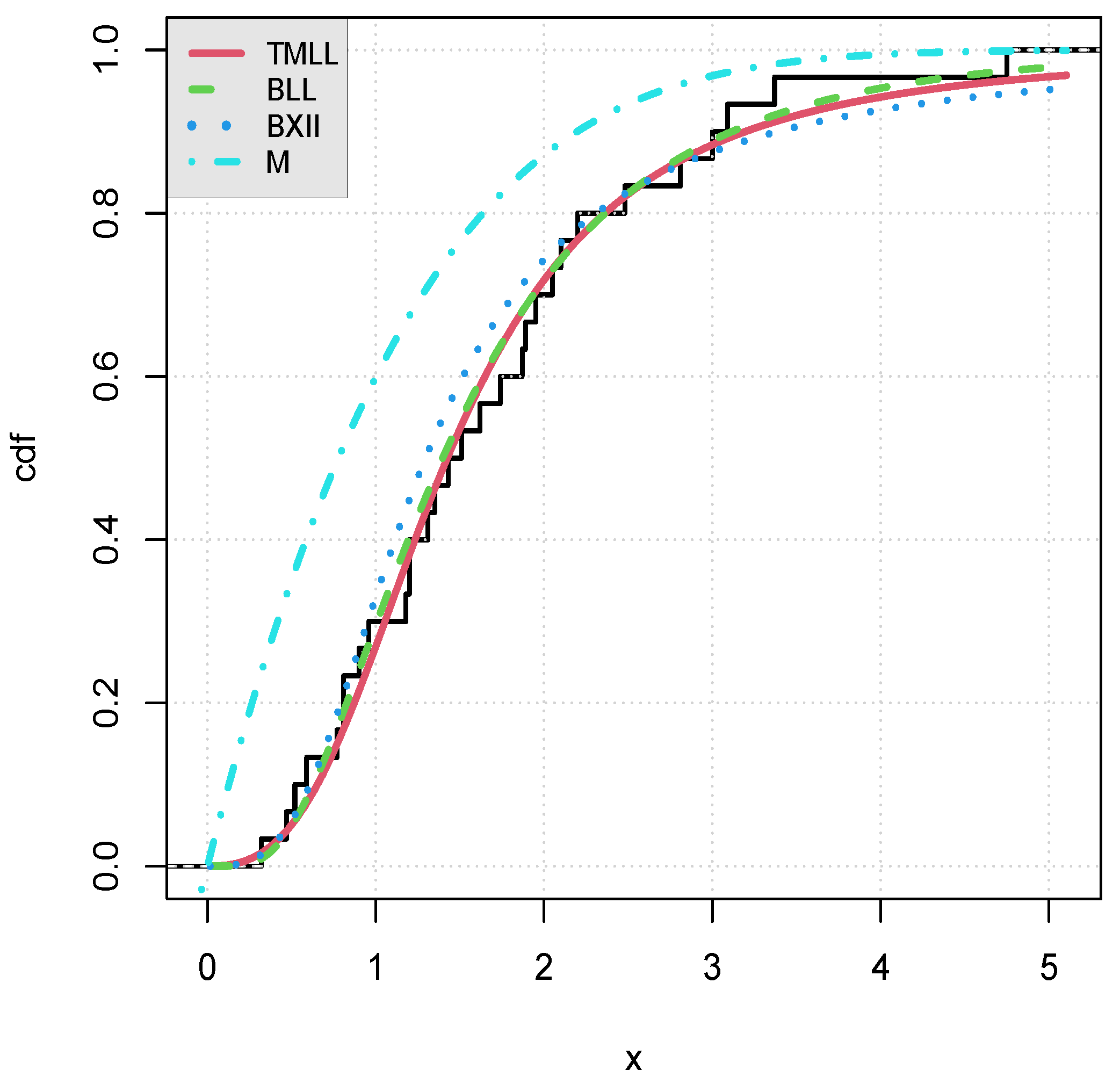
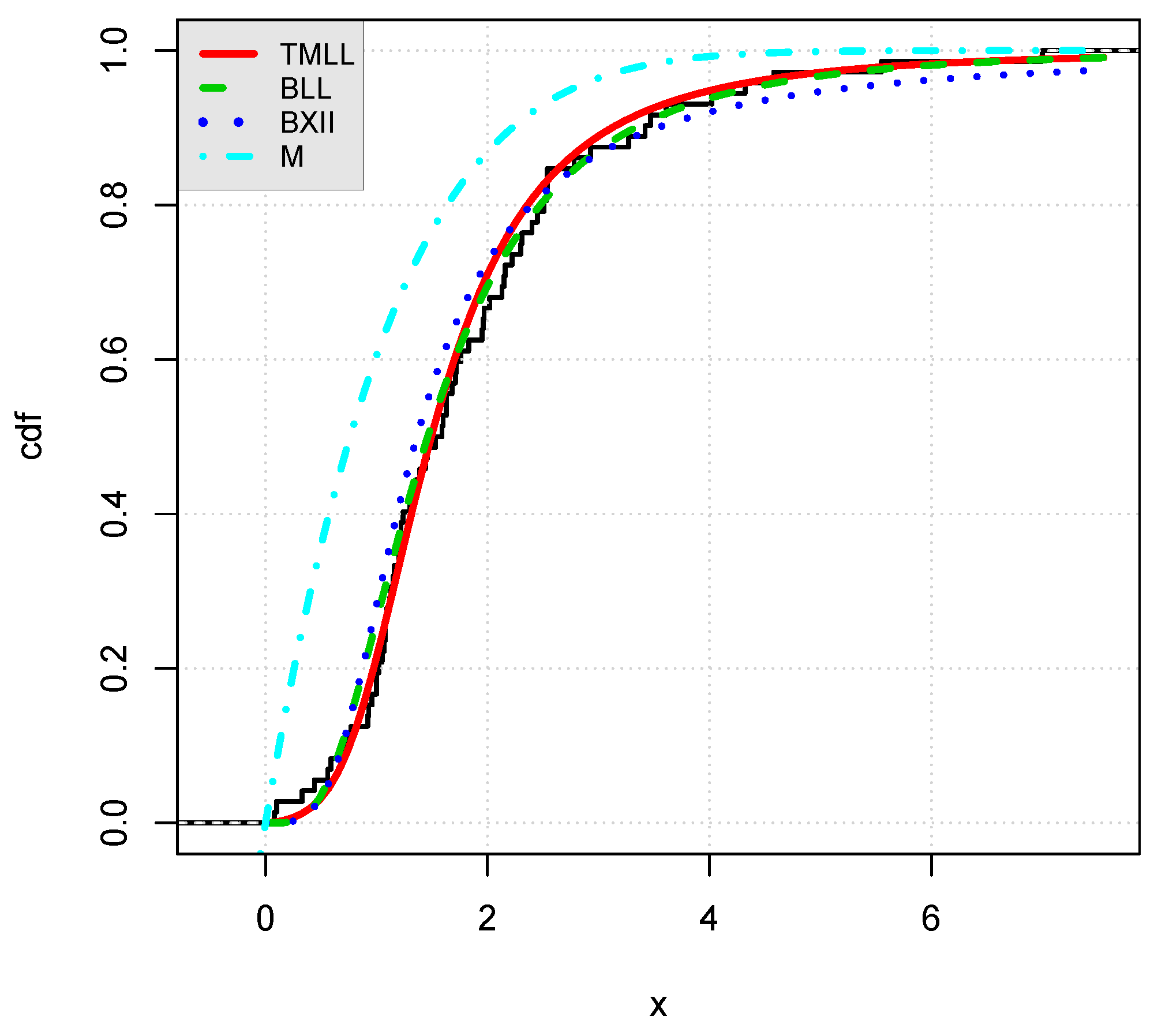
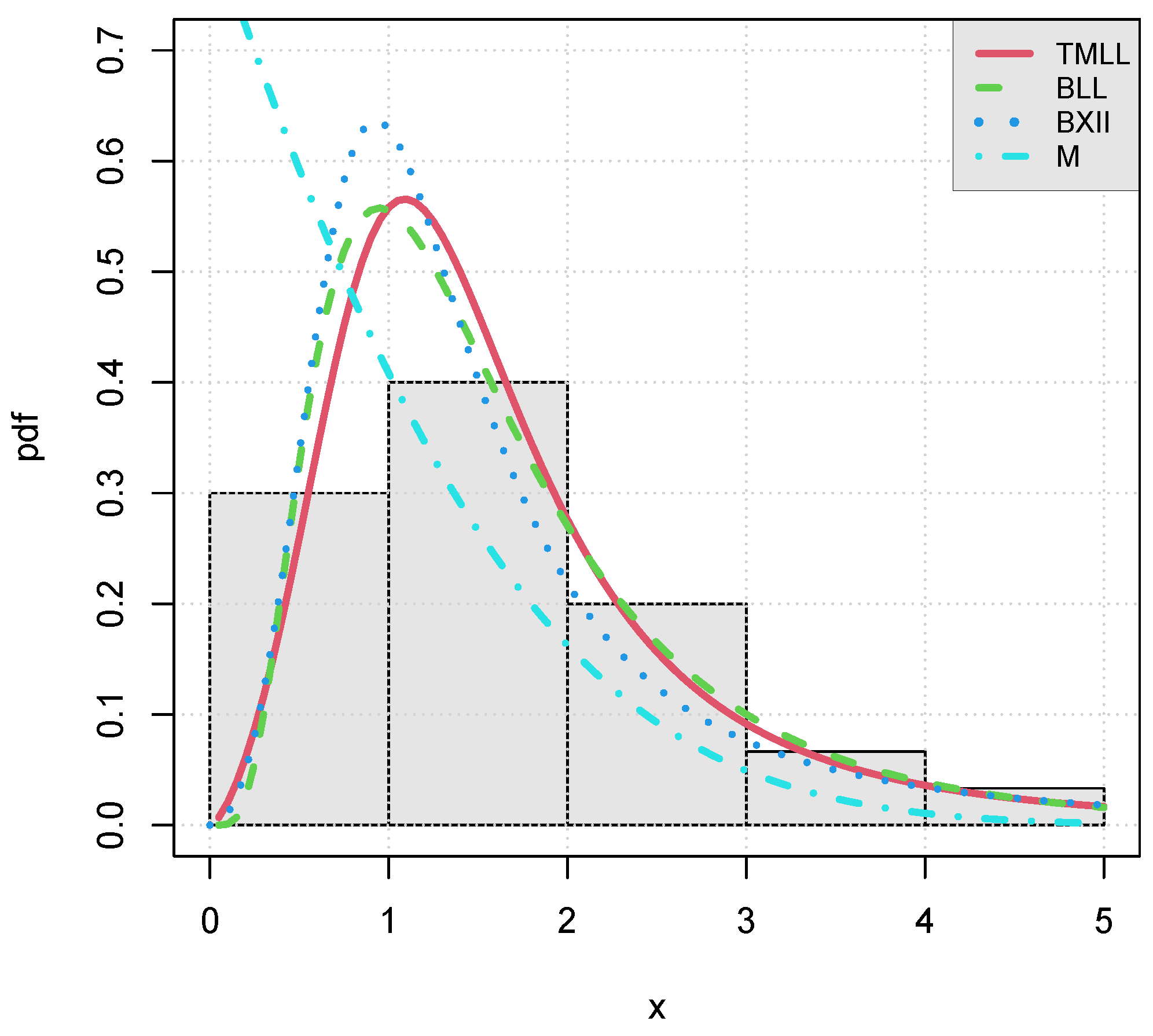
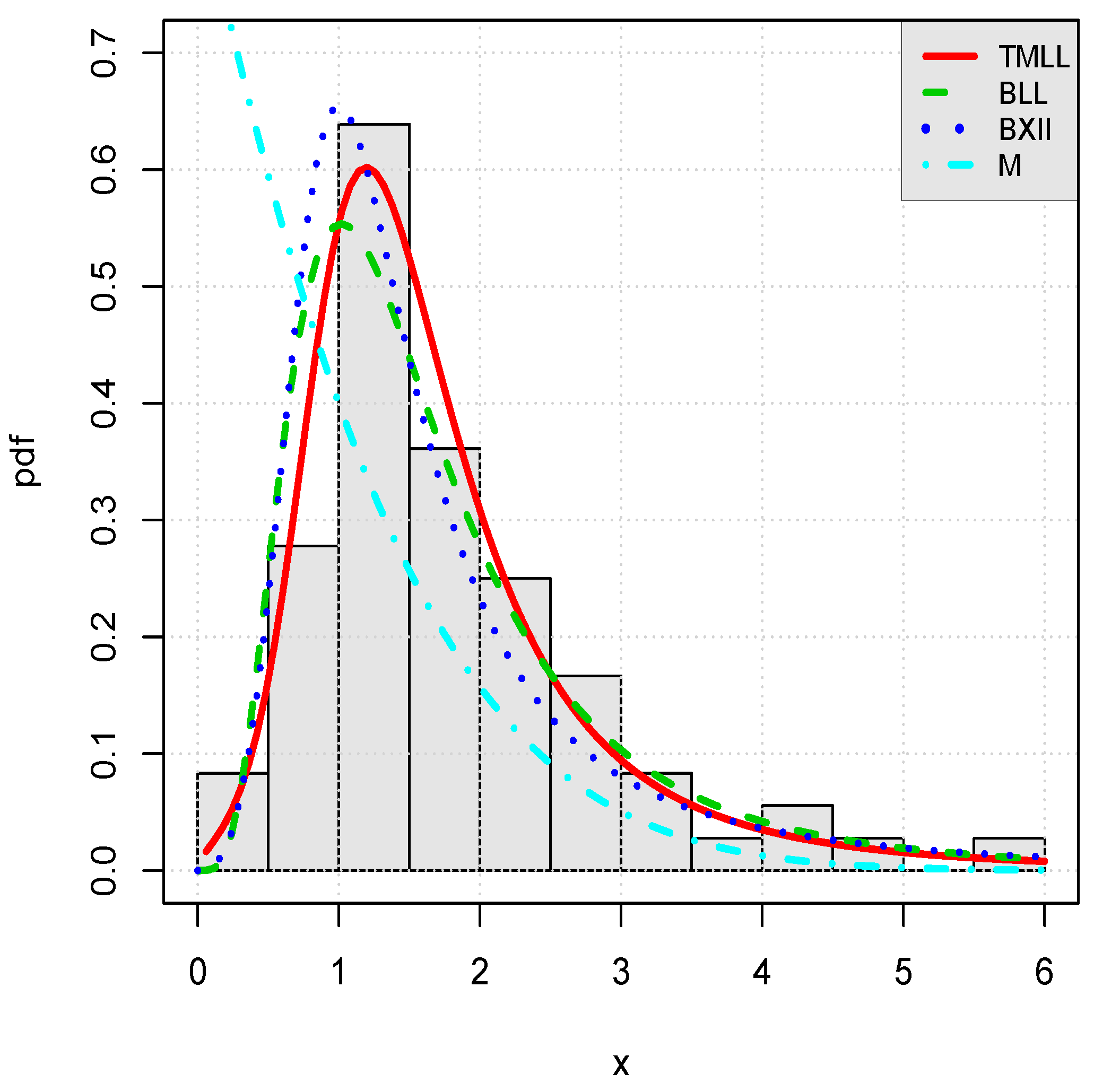
We now illustrate graphically the adequacy of the model by plotting the following objects:
The curve of the estimated cdf of the TMLL model, i.e.,
, as well as the curves of the estimated cdfs of the other models over the curve of the empirical cdf for data sets I and II in
Figure 3 and
Figure 4, respectively.
The curve of the estimated pdf of the TMLL model, i.e.,
, as well as the curves of the estimated pdfs of the other models, all over the histogram for data sets I and II in
Figure 5 and
Figure 6, respectively.
Visually, the fits of the TMLL model are quite satisfying, as anticipated.
5. Concluding Remarks and Perspectives
This study contributes to the development of the M-G class by showing new facts, and by proposing a motivated extending class, called the transmuted Muth generated class of distributions. We derive several of its probabilistic and analytical properties, including the expressions of the pdf and hrf, discussions on their critical points, expression of the qf, series expansions for various moments and theory on the parametric estimation of the parameters. Then, a focus is put on the special distribution of the TM-G class, called the transmuted Muth log-logistic distribution. We show that this distribution is flexible enough to fit various symmetrical or right-skewed data. Combined with the maximum likelihood approach, the fit behavior of the model is discussed through the analysis of two real data sets. The adequacy of the new model is quite satisfactory, beating the one of the famous beta log-logistic model. As further developments, one can investigate other special distributions of the TM-G class, as those having support in or , finding applications in diverse regression models. The regression aspect, however, needs further investigations in the future.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}