1. Introduction
The number of features increases with the growth of data. A large feature space can provide much information that is useful for decision-making [
1,
2,
3], but such a feature space includes many irrelevant or redundant features that are useless for a given concept. It is of necessity to remove the irrelevant features so that the curse of dimensionality can be relieved. This motivates some sort of research for feature selection methods. Feature selection, as a significant preprocessing step of data mining, can select a small subset, including the most significant and discriminative condition features [
4]. Traditional methods are developed based on the assumption that all features are available. Many typical approaches exist, such as ReliefF [
5], Fisher Score [
6], mutual information (MI) [
4], Laplacian Score [
7], LASSO [
8], and so on [
9]. The main benefits of feature selection include speeding up the model training, avoiding overfitting, and reducing the impact of dimensionality during the process of data analysis [
4].
However, features in many real-world applications are individually generated one-by-one over time. Traditional feature selection can no longer meet the required efficiency with the growing volume of features. For example, in the medical field, a doctor cannot easily obtain the entire features of a patient. In bioinformatic and clinical medicine situations, acquiring the entire features in a feature space is expensive and inefficient because of high-cost laboratory experiments [
10]. In addition, for the task of medical image segmentation, acquiring the entire features is infeasible due to the infinite number of filters [
11]. Furthermore, the symptom of a patient persistently changes over time during the treatment, and judging whether the feature contains useful information is essential for identifying the patient’s disease after a new feature has emerged [
12]. In these cases, waiting a long time until entire features are available and then performing the feature selection process is the primary method.
Online streaming feature selection (OSFS), presenting a feasible precept to solve feature streaming in an online way, has recently attracted wide concern [
13]. The OSFS method must meet the following three criteria [
14]: (1) Not all features are available, (2) the efficient incremental updating process for selected features is essential, and (3) accuracy is vital each time.
Many previous studies have proposed some different OSFS methods. For example, a grafting algorithm [
15], which employed a stagewise gradient descent approach to feature selection, during which a conjugate gradient procedure was used to carry out its parameters. However, as well as the grafting algorithm, both fast OSFS [
16] and a scalable and accurate online approach (SAOLA) [
13] need to specify some parameters, which requires the domain information in advance. Rough set (RS) theory [
17], which is an effective mathematic tool for features selection, rules extracting, or knowledge acquisition [
18], needs no domain knowledge other than the given datasets [
19]. In the real world, we usually encounter many numerical features in datasets, such as medical datasets. Under this circumstance, a neighborhood rough set is feasible to analyze discrete and continuous data [
20,
21]. Nevertheless, all these methods proposed have some adjustable parameters. Considering that selecting unified and optimal values for all different datasets is unrealistic [
22], a new OSFS method based on an adapted neighborhood rough set is proposed, in which the number of neighbors for each object is determined by its surrounding instance distribution [
22]. Furthermore, in the view of multi-granulation, multi-granulation rough sets is used to compute the neighborhoods of each sample and extract neighborhood size [
23]. For the above OSFS methods based on neighborhood relation, dependency degree calculation is a key step. However, very little work has considered the neighborhood structure in the granulation view during this calculation. In additional, the phenomenon of uneven distribution of some data, including medical data, is common, and few works focus on the challenge of the uneven distribution of data.
In this paper, focusing on the strength and weakness of the neighborhood rough set, we proposed a novel neighborhood relation. Further, a weighted dependency degree was developed by considering the neighborhood structure of each object. Finally, our approach, named OSFS-KW, was established. Our contributions were as follows:
- (1)
We proposed a novel neighborhood relation, and on this basis, we developed a weighted dependency computation method.
- (2)
We developed an OSFS framework, named OSFS-KW, which can select a small subset made up of the most significant and discriminative features.
- (3)
The OSFS-KW was established based on [
24] and can deal with the class imbalance problem.
- (4)
The results indicate that the OSFS-KW cannot only obtain better performance than traditional feature selection methods but, also, better than the state-of-the-art OSFS methods.
The remainder of the paper is organized as follows. In
Section 2, we briefly review the main concepts of neighborhood RS theory.
Section 3 discusses our new neighborhood relations and proposes the OSFS-KW. Then,
Section 4 performs some experiments and discusses the experimental results. Finally,
Section 5 concludes the paper.
2. Background
Neighborhood RS has been proposed to deal with numerical data or heterogeneous data. In general, a decision table (DT) for classification problem can be represented as
[
25], where
is a nonempty finite set of samples.
R can be divided condition attributes
C and decision attributes
D,
.
is a set of attributes domains, such that
denotes the domains of an attribute
r. For each
and
, a mapping
denotes an information function.
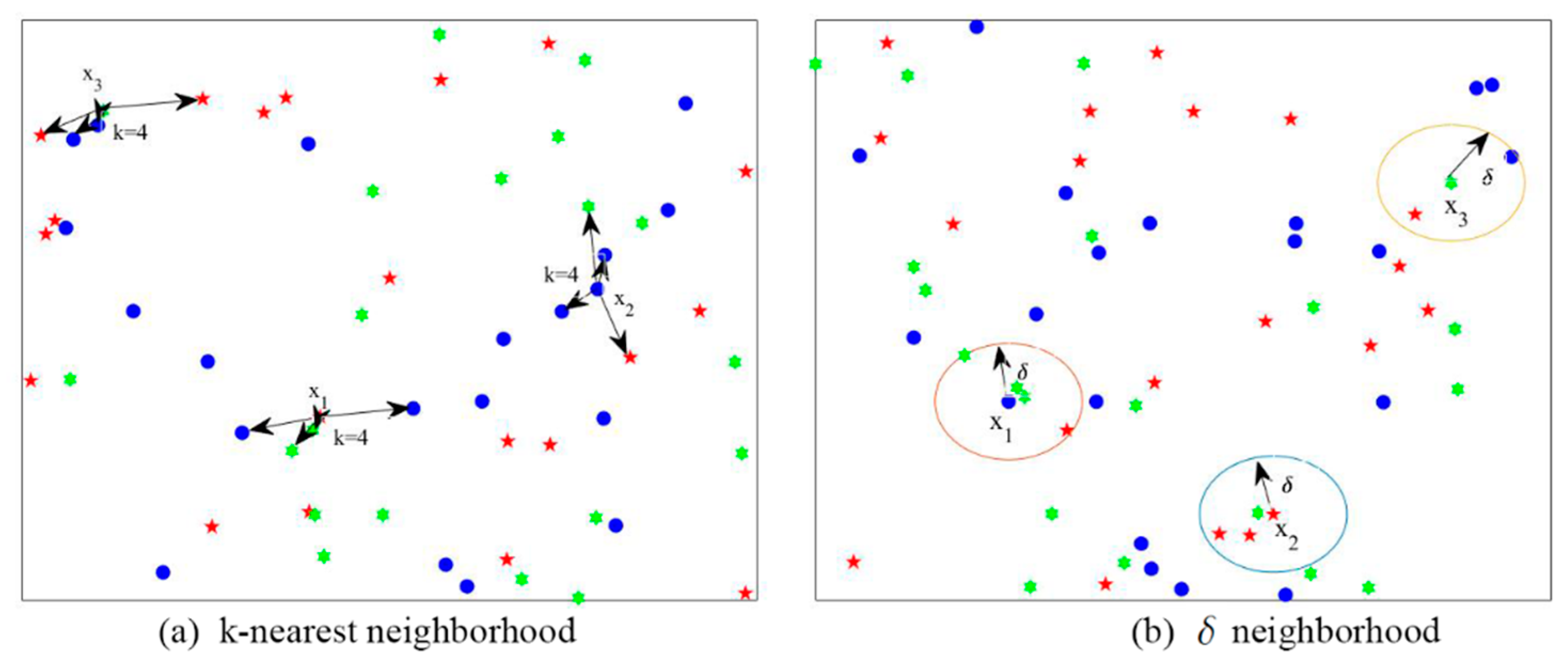
There are two main kinds of neighborhood relations: (1) the
k-nearest neighborhood relation shown in
Figure 1a and (2) the
neighborhood relation shown in
Figure 1b.
Definition 1 [
26].
Given DT, a metric is a distance function, and △(x, y) represents the distance between x and y. Then, for , it must satisfy the following:- (1)
, whenand,
- (2)
, and
- (3)
.
Definition 2 (
neighborhood [
22]).
Given DT, a feature subset , the neighborhood of any object is defined as follows:where is the distance radius, and satisfies:- (1)
,
- (2)
, wheredenotes the number of elements in the set, and
- (3)
.
Definition 3 (
k-nearest neighborhood [
22]).
Given DT and , the k-nearest neighborhood of any object on the feature subset is defined as follows: where represents the k neighbors closest to on a subset B, and satisfies:- (1)
,
- (2)
, and
- (3)
.
Then, the concepts of the lower and upper approximations of these two neighborhood relations are defined as follows:
Definition 4. Given DT, for any , two subsets of objects, called the lower and upper approximations ofwith regard to theneighborhood relation, are defined as follows [27]: If, thencertainly belongs to, but if, then it may or may not belong to.
Definition 5. Given DT, for any , the lower and upper approximations concerning the k-nearest neighborhood relation are defined as [24]: Figure 1a shows that the k-nearest neighbor (k = 4) samples of ,, and have different class labels. In detail, the k-nearest neighborhood samples of are from classwith the mark “·” and classwith the mark “🟌”; k-nearest neighborhood samples ofare from classes,,, andwith the mark “★”; the k-nearest neighbor samples ofare from classesand.
Figure 1b depicts that allneighbor samples of,,andalso come from different class labels. We define the samples of,, andas all the boundary objects. The size of the boundary area can increase the uncertain in DT, because it reflects the roughness ofin the approximate space. By Definition 5, The object space X can be partitioned into positive, boundary, and negative regions [28], which are defined as follows, respectively: In the data analysis, computing dependencies between attributes is an important issue. We give the definition of the dependency degree as follows:
Definition 6. Given DT, for any , the dependency degree ofto decision attribute setis defined as [22] The aim of the feature selection is to select a subsetfromand gain the maximal dependency degree ofto. Since the features are available one-by-one over time, it is a necessity to measure each feature’s importance in the candidate features.
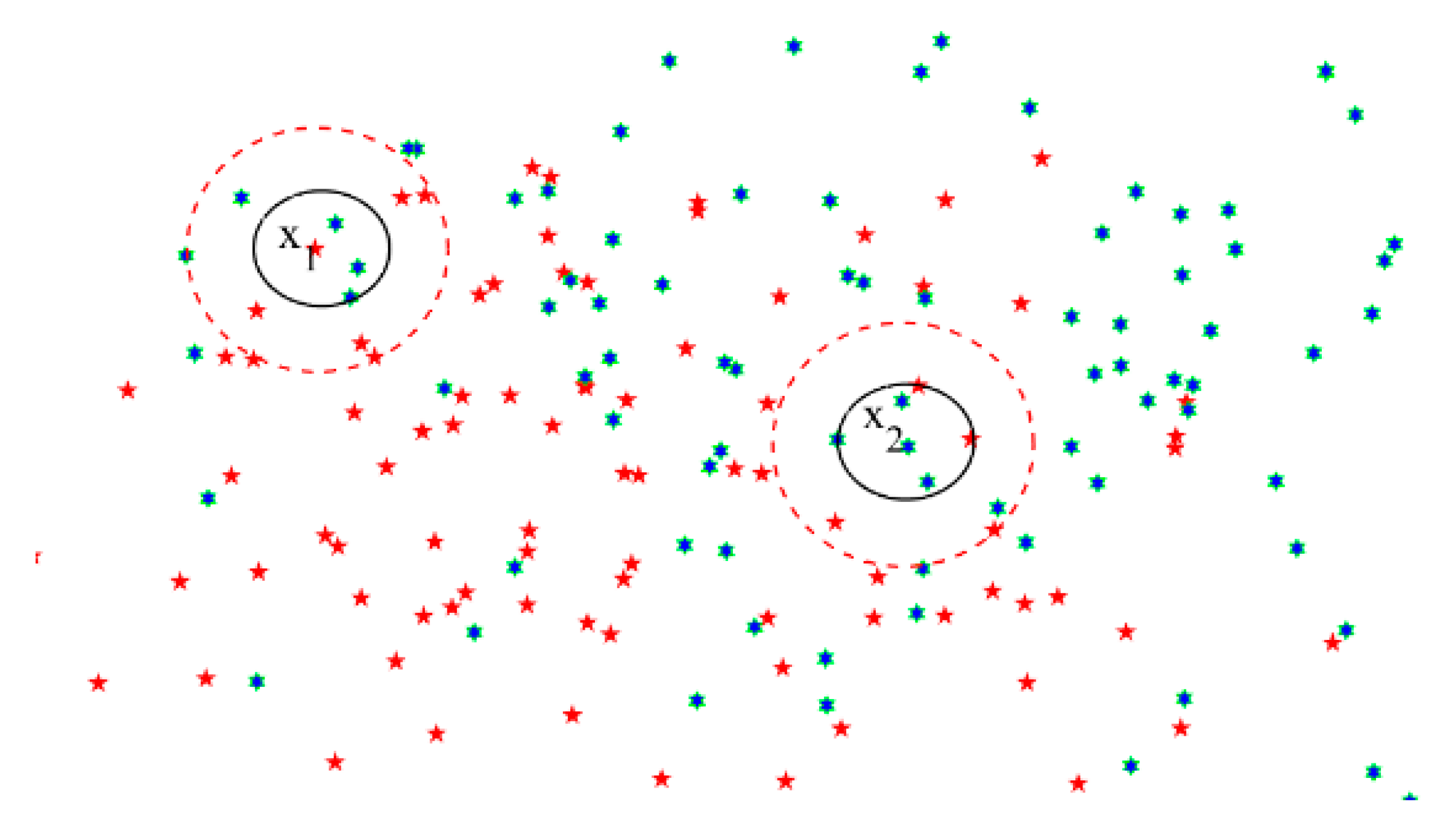
Definition 7. Given DT, forand, the significance of a featuretois defined as follows [22]: In a real application, specifically in the medical field, the instances are often unevenly distributed in the feature space; that is, the distribution around some example points is sparse, while the distribution around others is tight. Neither the
k-nearest neighborhood relation nor the
neighborhood relation can portray sample category information well, since the setting of the parameters like
r and
k can hardly meet both the sparse and tight distributions. For example, the feature space has two classes, as shown in
Figure 2—namely, red and green. Red and green represent two different classes respectively, which have different symbols including pentacle and hexagon as well. Around a sample point
, the sample distribution is sparse. The three nearest points to
all have different class from
. If applying the
k-nearest neighborhood relation (
k = 3),
will be misclassified. However, if we employ the δ neighborhood relation method, then the category of
is consistent with that of most samples in the neighbors of
. On the other hand, the sample distribution around point
is tight, and two class samples are included in its neighborhood, and sample
will be misclassified when applying the
neighborhood relation denoted by the red circle. In fact, if applying the
k-nearest neighborhood relation (
k = 3),
will be classified correctly. Therefore, in
Section 3, we proposed a novel neighborhood rough set combining the advantages of the
k-nearest neighborhood rough set and the
neighborhood rough set.
3. Method
In this section, we initially introduce a definition of OSFS. Then, we propose a new neighborhood relation and an approach of a weighted dependency degree. Based on three evaluation criteria—namely, maximal dependency, maximal relevance, and maximal significance—our new method OSFS-KW is presented finally.
3.1. Problem Statement
denotes the decision system (DS) at time t, where is a feature space including the condition feature and decision feature . is a nonempty finite set of objects. A new feature arrives individually, while the number of objects in is fixed. OSFS aims to derive a mapping of at each timestamp t, which obtains an optimal subset of features available so far.
Contrary to the traditional feature selection methods, we cannot access the full feature space in the scenarios of the OSFS. However, the two main neighborhood relations cannot make up the shortage caused by the uneven distribution data. Moreover, the class imbalanced issue of medical data is common. For example, abnormal cases attract more attention than the normal ones in the field of medical diagnosis. It is also crucial for the proposed framework to handle the class imbalanced problem.
3.2. Our New Neighborhood Relation
3.2.1. Neighborhood Relation
The standard European distance method is applied to eliminate the effect of variance on the distance among the samples. Given any samples
and
, and an attribute subset
, the distance between
and
is defined as follows:
where
denotes the values of
xi relative to the attribute
c, and
represents standard deviation of attribute
c.
To overcome the challenge of the uneven distribution of medical data, we proposed a novel neighborhood rough set as follows.
Definition 8. Given a decision system, whereis the finite sample set,is a condition attribute subset, andis the decision attribute set, theneighborhood relation is defined as follows:whereis defined as Definition 2, andis defined as Definition 3., whereis the number of instances. Meanwhile, based on [22],and Gmean are defined as follows: More specifically,represents the maximum distance fromto its neighbors, anddenotes the minimum distance from to its neighbors.
Definition 9. Givenand its neighborhood relationson, for, the lower and supper approximation regions ofin terms of theneighborhood relation are defined as follows: Similar to Definition 4,is also called the positive region, denoted by.
3.2.2. Weighted Dependency Computation
The traditional dependency degree only considers the samples correctly classified instead of that of neighborhood covering. To solve this problem, we propose an approach of weighted dependency degree, which considers the granular information for features.
Definition 10. Given, the weighted dependency ofis defined as follows:where Theorem 1. Given,. The weightis monotonic, defined as follows: Proof. According to the monotonicity of neighborhood relation defined in Definition 8, and . According to Equation (20), . Considering Definition 10, , , and . □
Theorem 2. Given,. Then,is equivalent to, and.
The proof of Theorem 2 is easy according to the monotonicity of the neighborhood relation and Theorem 1.
Definition 11. Givenand a decision attribute set, the significance of feature ctocan be rewritten as follows: 3.3. Three Evaluation Criteria
During the OSFS process, many irrelevant and redundant features should be removed for high-dimensional datasets. There are three evaluation criteria used during the process, such as max-dependency, max-relevance, and max-significance.
3.3.1. Max-Dependency
denotes the set of
m condition attributes. The task of OSFS is to find a feature subset
, which has the maximal dependency
on the decision attributes set
. At the moment, the number of features denoted as
d in the feature space should be as small as possible.
where
denotes the weighted dependency between the attribute subset
B and target class label
. The dependency
can be rewritten as
, where
. Hence, the increment search algorithm optimizes the following problem for selecting the
feature from the attribute set
:
which is also equivalent to optimizing the following problem:
The max-dependency maximizes either the joint dependency between the select feature subset and the decision attribute or the significance of the candidate feature to the already-selected features. However, the high-dimensional space has two limitations that lead to failure in generating the resultant equivalent classes: (1) the number of samples is often insufficient, and (2) during the multivariate density estimation process, computing the inverse of the high-dimensional covariance matric is generally an ill-posed problem [
29]. Specifically, these problems are evident for continuous feature variables in real-life applications, such as in the medical field. In addition, the computational speed of max-dependency is slow. Meanwhile, max-dependency is inappropriate for OSFS, because each timestamp can only know one feature instead of the entire feature space in advance.
3.3.2. Max-Relevance
Max-relevance is introduced as an alternative in selecting features, as implementing max-dependency is hard. The max-relevance search feature approximates
in Equation (23) with the mean value of all dependency values between individual feature
Bi and the decision attribute
.
where
is the already-selected feature subsets.
A rich redundancy likely exists among the features selected according to max-relevance. For example, if two features and among the large features space highly depend on each other, then after removing any one of them, the class differentiation ability of the other one would not substantially change. Therefore, the following max-significance criterion is added to solve the redundancy problem by selecting mutually exclusive features.
3.3.3. Max-Significance
Based on Equation (22), the importance of each candidate feature can be calculated. The max-significance can select mutually exclusive features as follows:
The feature flows individually over time for the OSFS. Testing all combinations of the candidate features and maximizing the dependency of the selected feature set are not appropriate. However, we can initially employ the “max-relevance” criteria to remove the irrelevant features. Then, we employ the “max-significance” criteria to remove the unimportant features in the selected feature set. Finally, the “max-dependency” criteria will be used to select the feature set with the maximal dependency. Based on the three criteria mentioned previously, in the next subsection, a novel online feature selection framework will be proposed.
3.4. OSFS-KW Framework
The proposed weighted dependency computation method based on the neighborhood RS in this study is shown in Algorithm 1. First, we calculate the card value of each sample and obtain the sum for the final weighted dependency at steps 5–14. The denotes the consistency between the decision attribute of and its neighbor’s decision attributes. The neighborhood relation is used to calculate the dependency of attribute subset . The value of reveals not only the distribution of labels nearby but, also, the structure granular structure information around .
In the real world, we generally encounter the issue of high-dimension class imbalance, specifically in medical diagnosis. Then, we employ the method proposed in [
24], named the class imbalance function, as shown in Algorithm 2. For imbalanced medical data, we apply Algorithm 2 to compute
at step 9 in Algorithm 1.
| Algorithm 1 Weighted dependency computation |
| Require: |
| B: The target attribute subset; |
| : Sample values on B; |
| Ensure: |
| 1: : Dependency between B and decision attribute D; |
| 2: : the number of positive samples on B, initial ; |
| 3: : the number of instances in universe U; |
| 4: SB: the number of instance of neighbors on B, initial |
| 5: for each in |
| 6: Calculate the distance from to other instances; |
| 7: Sort the neighbors of from the nearest to the farthest; |
| 8: Find the neighbor sample of as ; |
| 9: Calculate the card value of as ; |
| 10: ; |
| 11: Calculate the number of neighbors with the same class label of as ; |
| 12: ; |
| 13: end |
| 14: ; |
| 15: return |
In Algorithm 2,
denotes the large class, while
is the small class. The
sample is different from the
sample at steps 3–11. For
in the large class, if the number of neighbors with the same class label is more than 95% of the number of its total neighbors, then we will set the value of
to 1; otherwise, the value is set to 0. For
in the small class, we calculate the ratio of the number of neighbors with
to the total number of neighbors as the
. The method in Algorithm 2 can strengthen the consistency constraints of
and weaken the consistency constraints of
, so
is prevented from being overpowered by the samples in
.
| Algorithm 2 Class imbalance function |
| Require: |
| : The class label of ; |
| B: The target attribute subset; |
| Ensure: |
| : the card value of on B; |
| 1: : the number of neighbors with the same class label of ; |
| 2: : the number of neighbors of on B; |
| 3: if then |
| 4: if then |
| 5: =1; |
| 6: else |
| 7: ; |
| 8: end |
| 9: else then |
| 10: ; |
| 11: end |
| 12: return ; |
Based on the
neighborhood relation and the weighted dependency computation method mentioned above, we introduce our novel OSFS method, named “OSFS-KW”, as shown in Algorithm 3. The main aim of the OSFS-KW is to maximize
with the minimal number of feature subsets.
| Algorithm 3 OSFS-KW |
| Require: |
| C: the condition attribute set; |
| D: the decision attribute; |
| Ensure: |
| B: the selected attribute set |
| 1: B initialized to ; |
| 2: : the dependency between B and D, initialized to 0; |
| 3: : the mean dependency of attributes in B, initialized to 0; |
| 4: Repeat |
| 5: Get a new attribute of C at timestamp i; |
| 6: Calculated the dependency of as according to Algorithm 1; |
| 7: if then |
| 8: Discard attribute ; and go to Step 25; |
| 9: end |
| 10: if then |
| 11: ; |
| 12: ; |
| 13: ; |
| 14: else if then |
| 15: ; |
| 16: random the feature order in B; |
| 17: for each attribute in B |
| 18: calculate the significance of as ; |
| 19: if |
| 20: ; |
| 21: ; |
| 22: end |
| 23: end |
| 24: end |
| 25: Until no attributes are available; |
| 26: return B; |
Specifically, in Algorithm 1, we calculate the dependency of when a new attribute arrives at timestamp i. Then, the dependency of is compared with the mean dependency of the selected attribute subset B at step 7. If , then is added into B and goes to step 10. Otherwise, is discarded and goes to step 25 when due to the “max-relevance” constraint.
When satisfies the “max-relevance” constraint, , going to step 10 and comparing the dependency of the current attribute subset B with . If , then adding attribute into B will increase the dependency of B, so is added into B with the “max-dependency” constraint; that is, . On the other hand, if , then some redundant attributes exist in . In this condition, we add into B firstly. Then, we remove some redundant attributes by steps 16–24. With the “max-significance” constraint, we randomly select an attribute from B and compute its significance according to Equation (22). Some attributes with a significance equal to 0 will be removed from B. Ultimately, we can obtain the best feature subset for decision-making through the aforementioned three evaluation constraints.
3.5. Time Complexity of OFS-KW
In the process of OSFS-KW, the weighted dependency degree computation, shown in Algorithm 1, is a substantially important step. The number of examples in
DS is
n, and the number of attributes
C is
m. Table 1 shows the time complexity for different steps of OSFS-KW. In Algorithm 1, we compute the distance between
and its neighbors for each sample
. The time complexity of this process is
(
. Sorting all neighbors of
by instance is essential to find the neighbors of
. The time complex of the quick sorting process is
. Thus, the time complexity of Algorithm 1 is
.
At timestamp i, as a new attribute is present to the OSFS-KW, the time complexity of steps 6–9 is . If the dependency of is smaller than , then will be discarded. Otherwise, comparing the dependency of with B, the time complexity is also . If , then can be added into B, and step 25 is repeated. However, if , then the time complexity of steps 14–24 is . Thus, the complexity of the OSFS-KW is . Choosing all features in real-world datasets is impossible. Therefore, the time complexity will be smaller than .
5. Conclusions
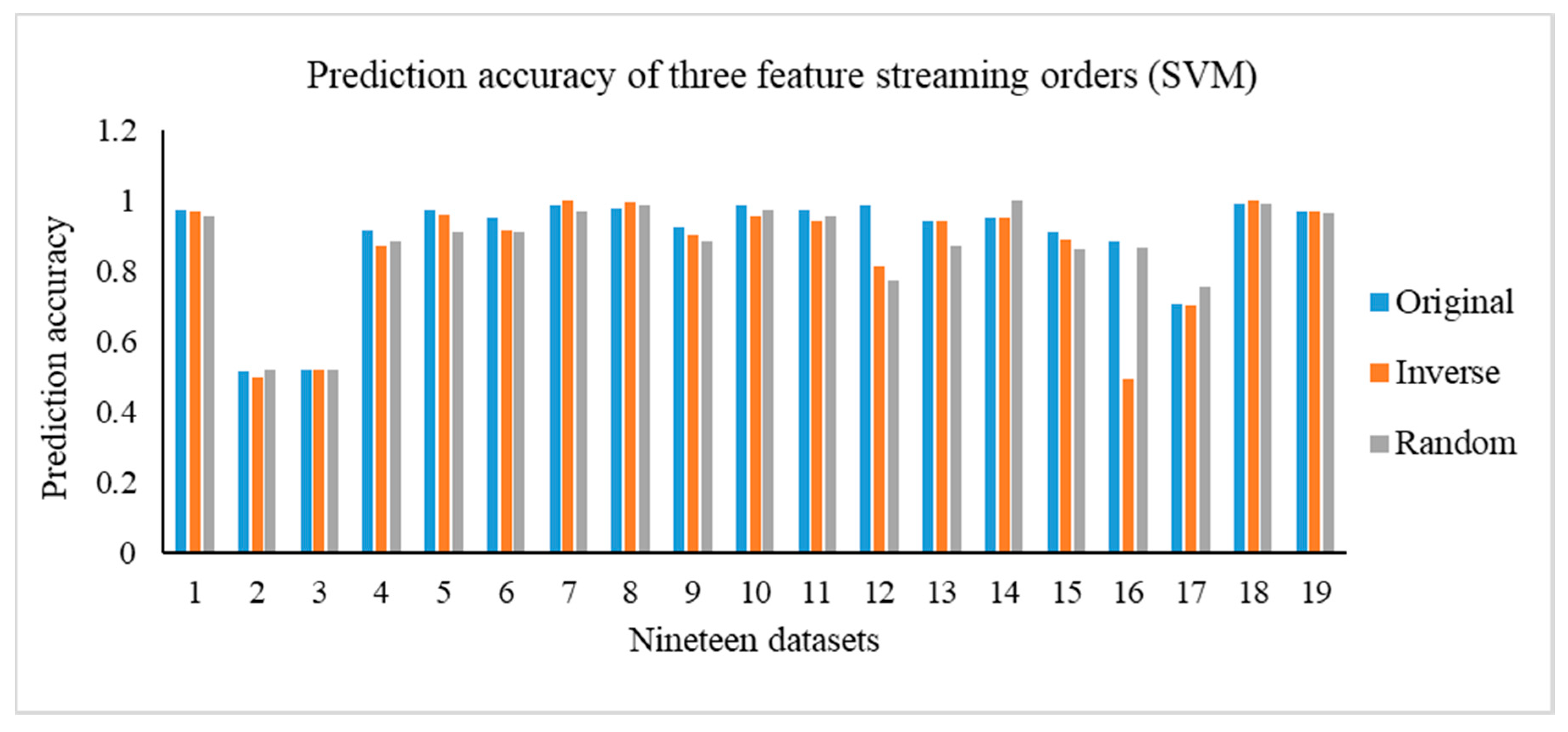
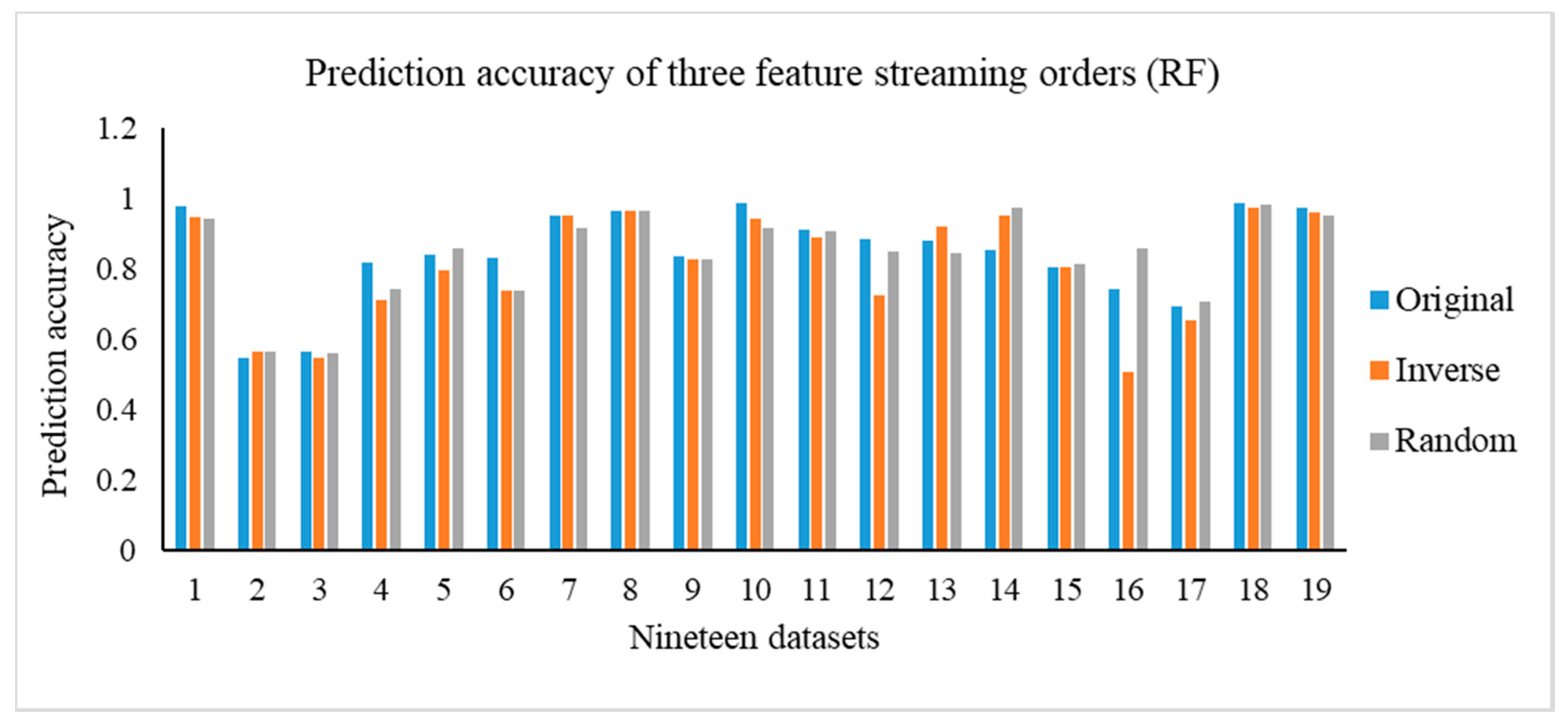
Most of the exiting OSFS methods cannot deal well with the problem of uneven distribution data. In this study, we defined a new neighborhood relation, combining the advantages of k-neighborhood relation and neighborhood relation. Then, we proposed a weighted dependency degree considering the structure of neighborhood covering. Finally, we proposed a new OSFS framework named OSFS-KW, which need not specify any parameters in advance. In addition, this method can also handle the problem of imbalance classes in medical datasets. With three evaluation criteria, this approach can select the optimal feature subset mapping decision attributes. Finally, we used KNN, SVM, and RF as the basic classifiers in conducting the experiments to validate the effectiveness of our method. The results of the Friedman test indicate that a significant difference exists between the OSFS-KW and other neighborhood relations on compactness and running time, but there was no significant difference on the predictive accuracy. Moreover, when comparing with the 11 traditional feature selection methods and five existing OSFS algorithms, the performance of OFS-KW is better than that of the traditional feature selection methods and outperforms that of the state-of-the-art OSFS. However, we only focused on the challenges of medical data and used only medical datasets to verify the validity of our approach. Virtually, our method can be applied into other similar fields, generally. In the future, we will test and evaluate this method using some multidisciplinary datasets.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





