Word Vector Models Approach to Text Regression of Financial Risk Prediction

Abstract
1. Introduction
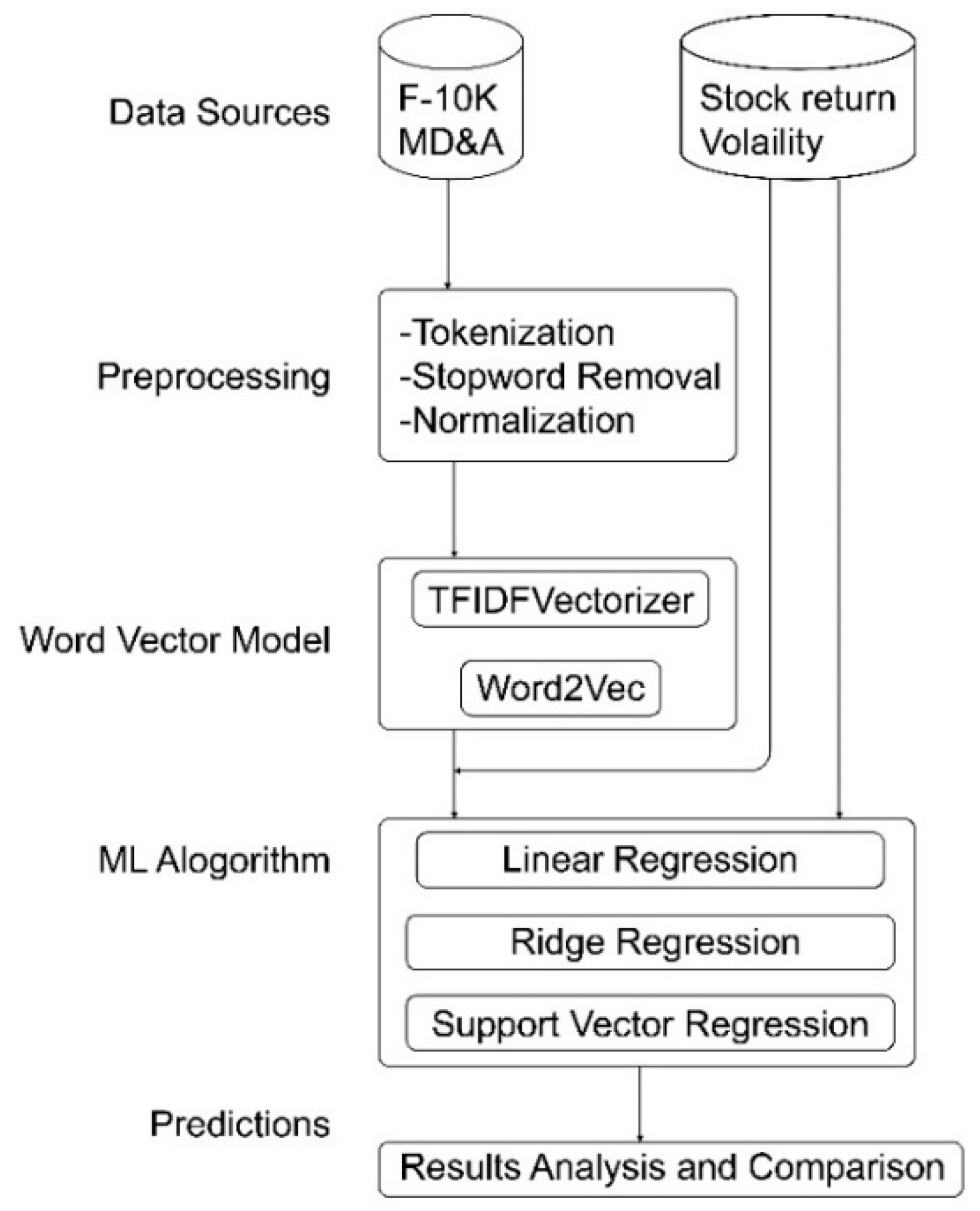
2. Material and Methods
2.1. Text Preprocessing
2.2. Stock Return Volatility
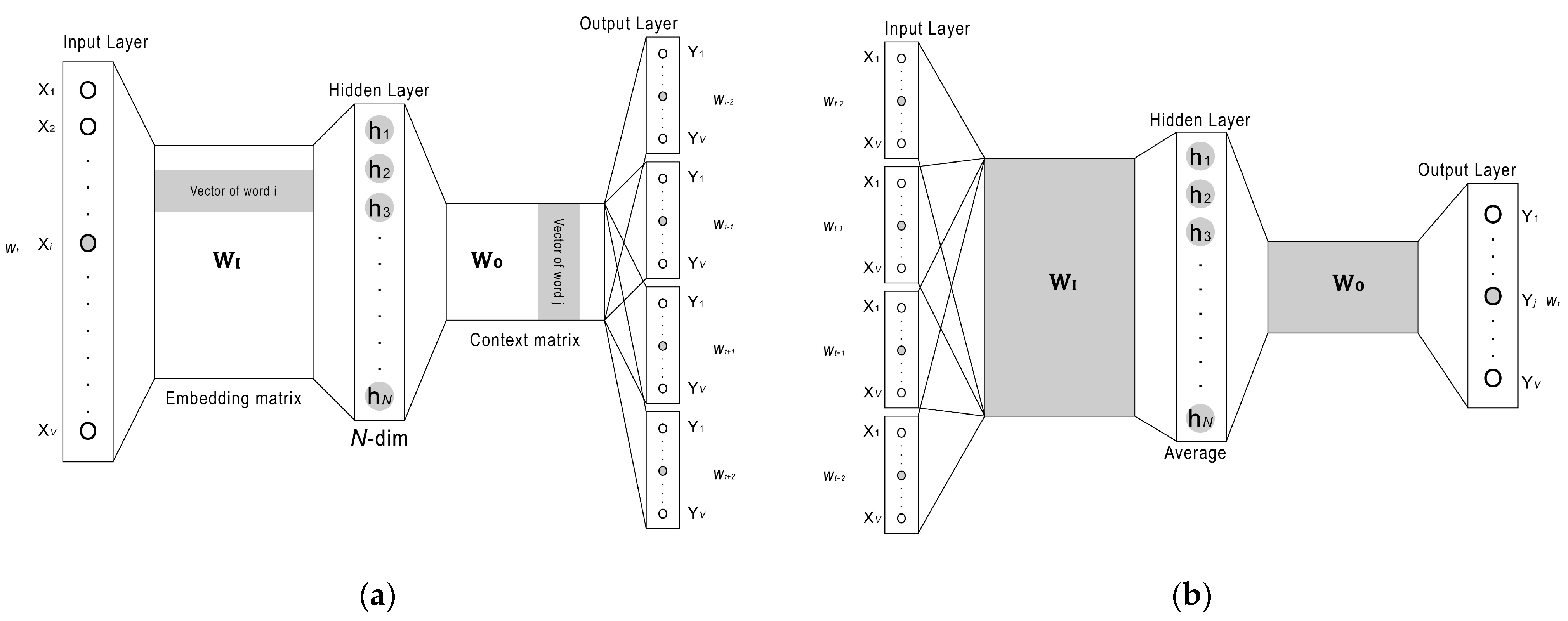
2.3. Word Vector Model Approach
- (1)
- TF-IDF. A document vector consists of words with TF-IDF weights, and each unique word is a different dimension in the document-word matrix.
- (2)
- Avg-Word2vec with pre-trained model. Many studies prefer to use pre-trained models because of the high computation and training time required for large text corpus. Each word has its own vector, and we average the vectors of words by dividing the number of the words appearing in a document.
- (3)
- Avg-Word2vec trained by our corpus (domain-specific word2vec). Word vectors learned from pre-trained model may not always suitable estimate of semantic similarity among words in target domain. Therefore, we generate domain-specific word2vec model learned from a given collected text corpus, a document vector is also obtained by taking the average of the word vectors appearing in a document.
2.4. Text Regression Problem
2.5. Evaluation Metrics
3. Experiments and Results
4. Discussion
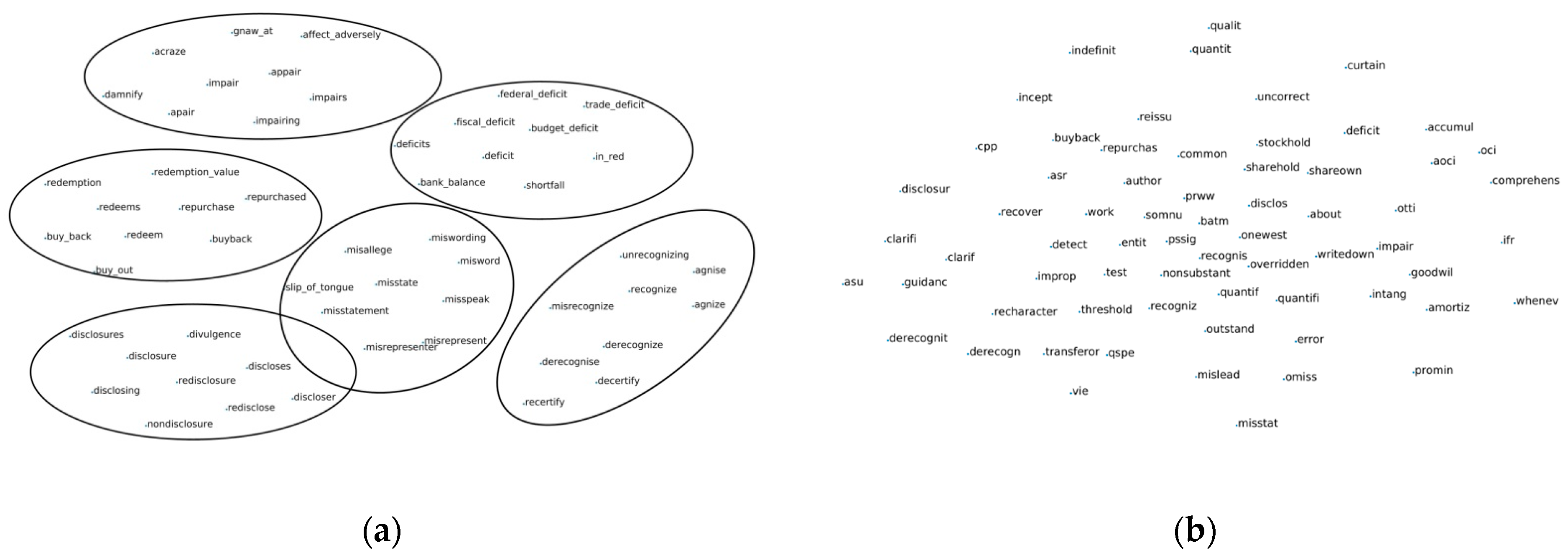
4.1. Content Analysis of Financial Reports
4.2. The Performance of Our Approach Comparing with State-of-the-Art Methods
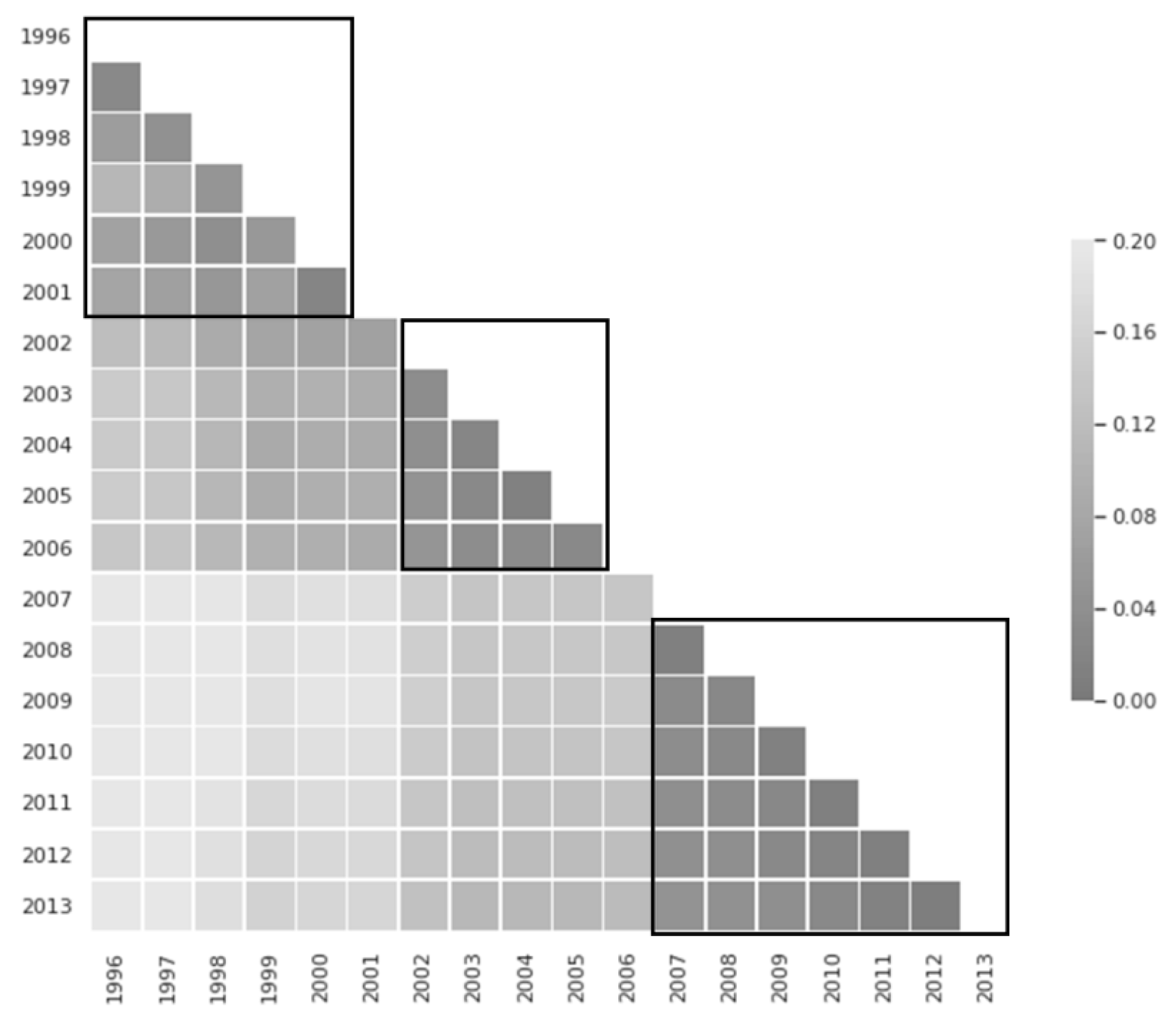
4.3. The Effects of the Training Data with Different Historical Periods
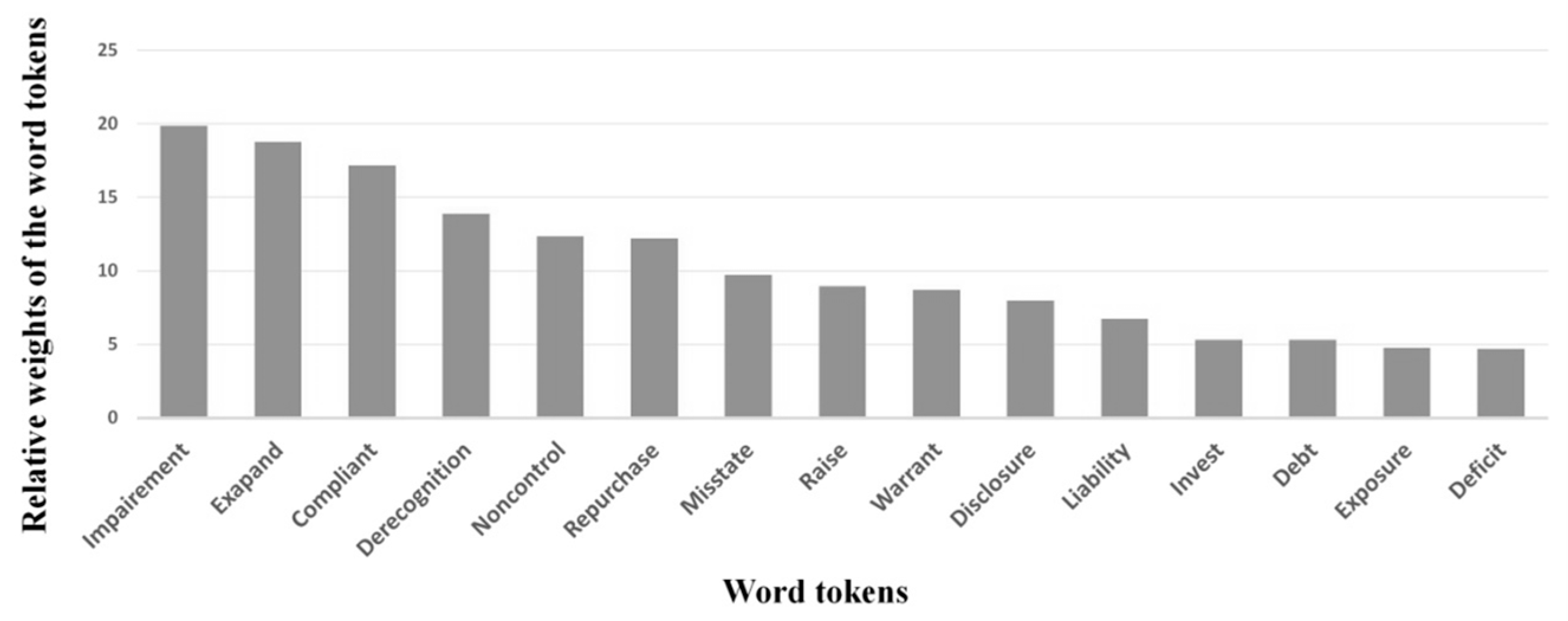
4.4. Word Cloud
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bodyanskiy, Y.; Popov, S. Neural network approach to forecasting of quasiperiodic financial time series. Eur. J. Oper. Res. 2006, 175, 1357–1366. [Google Scholar] [CrossRef]
- Lee, Y.S.; Tong, L.I. Forecasting time series using a methodology based on autoregressive integrated moving average and genetic programming. Knowl.-Based Syst. 2011, 24, 66–72. [Google Scholar] [CrossRef]
- Wong, W.K.; Xia, M.; Chu, W. Adaptive neural network model for time-series forecasting. Eur. J. Oper. Res. 2010, 207, 807–816. [Google Scholar] [CrossRef]
- Hung, J.C. A fuzzy asymmetric Garch model applied to stock markets. Inf. Sci. 2009, 179, 3930–3943. [Google Scholar] [CrossRef]
- Kim, K.J. Financial time series forecasting using support vector machines. Neurocomputing 2003, 55, 307–319. [Google Scholar] [CrossRef]
- Pejić Bach, M.; Krstić, Ž.; Seljan, S.; Turulja, L. Text mining for big data analysis in financial sector: A literature review. Sustainability 2019, 11, 1277. [Google Scholar] [CrossRef]
- Balakrishnan, R.; Qiu, X.Y.; Srinivasan, P. On the predictive ability of narrative disclosures in annual reports. Eur. J. Oper. Res. 2010, 202, 789–801. [Google Scholar] [CrossRef]
- Nopp, C.; Hanbury, A. Detecting Risks in the Banking System by Sentiment Analysis. In Proceedings of the Conference of Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015; pp. 591–600. [Google Scholar]
- Huang, K.W.; Li, Z. A multilabel text classification algorithm for labeling risk factors in sec form 10-K. ACM Trans. Manag. Inf. Syst. 2011, 2, 18. [Google Scholar] [CrossRef]
- Gidófalvi, G. Using News Articles to Predict Stock Price Movements. Ph.D. Thesis, Department of Computer Science and Engineering, University of California, San Diego, CA, USA, 2001. [Google Scholar]
- Luss, R.; d’Aspremont, A. Predicting abnormal returns from news using text classification. Quant. Financ. 2009. [Google Scholar] [CrossRef]
- Lin, M.-C.; Lee, A.J.T.; Kao, R.-T.; Chen, K.-T. Stockprice movement prediction using representative prototypes of financial reports. ACM Trans. Manag. Inf. Syst. 2008, 2. [Google Scholar] [CrossRef]
- Li, F. The information content of forward looking statements in corporate filings—A naive bayesian machine learning approach. J. Account. Res. 2010, 48, 1049–1102. [Google Scholar] [CrossRef]
- Loughran, T.; McDonald, B. When is a liability not a liability? Textual analysis, dictionaries, and 10-ks. J. Financ. 2011, 66, 35–65. [Google Scholar] [CrossRef]
- Tsai, M.F.; Wang, C.J. On the risk prediction and analysis of soft information in finance reports. Eur. J. Oper. Res. 2017, 257, 243–250. [Google Scholar] [CrossRef]
- Chen, M.P.; Chen, P.F.; Lee, C.C. Asymmetric effects of investor sentiment on industry stock returns: Panel data evidence. Emerg. Mark. Rev. 2013, 14, 35–54. [Google Scholar] [CrossRef]
- Kogan, S.; Levin, D.; Routledge, B.R.; Sagi, J.S.; Smith, N.A. Predicting risk from financial reports with regression. In Proceedings of the Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL ’09), Boulder, CO, USA, 1–3 June 2009; pp. 272–280. [Google Scholar]
- Tsai, M.F.; Wang, C.J. Financial keyword expansion via continuous word vector representations. In Proceedings of the Conference of Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1453–1458. [Google Scholar]
- Wang, C.J.; Tsai, M.F.; Liu, T.; Chang, C.T. Financial sentiment analysis for risk prediction. In Proceedings of the Joint Conference on Natural Language Processing (IJCNLP), Nagoya, Japan, 15 October 2013; pp. 802–808. [Google Scholar]
- Rekabsaz, N.; Lupu, M.; Baklanov, A.; Hanbury, A.; Duer, A.; Anderson, L. Volatility Prediction using Financial Disclosures Sentiments with Word Embedding-based IR Models. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL 2017), Vancouver, BC, Canada, 30 July 2017; pp. 1712–1721. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Jones, S. A Statistical Interpretation of Term Specificity and Its Application in Retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Robertson, S. Understanding Inverse Document Frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the International Conference on Learning Representations (ICLR 2013), Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Yoshua, B.; R’ejean, D.; Pascal, V.; Christian, J. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Holger, S. Continuous space language models. Comput. Speech Lang. 2007, 21, 492–518. [Google Scholar]
- Myers, J.L.; Well, A.; Lorch, R.F. Research Design and Statistical Analysis; Routledge: New York, NY, USA, 2010. [Google Scholar]
- Kendall, M. A new measure of rank correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Speer, R.; Chin, J.; Havasi, C. ConceptNet 5.5: An Open Multilingual Graph of General Knowledge. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the EMNLP, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Lison, P.; Tiedemann, J. OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the LREC, Potolo, Slovenia, 23–28 May 2016. [Google Scholar]
- Van der Maaten, J.P.; Hinton, G.E. Visualizing High-Dimensional Data Using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | # of Documents | # of Unique Terms | Year | # of Documents | # of Unique Terms |
|---|---|---|---|---|---|
| 1996 | 1203 | 18,291 | 2005 | 2698 | 44,303 |
| 1997 | 1705 | 22,506 | 2006 | 2564 | 44,303 |
| 1998 | 1940 | 25,487 | 2007 | 2495 | 41,433 |
| 1999 | 1971 | 26,422 | 2008 | 2509 | 41,924 |
| 2000 | 1884 | 26,027 | 2009 | 2567 | 42,919 |
| 2001 | 1825 | 26,602 | 2010 | 2439 | 42,948 |
| 2002 | 2023 | 32,280 | 2011 | 2416 | 43,404 |
| 2003 | 2866 | 43,041 | 2012 | 2406 | 42,995 |
| 2004 | 2861 | 44,642 | 2013 | 2336 | 43,513 |
| Linear Regression | Ridge Regression | SVR | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Word Vector Representation | MSE | Tau | Rho | MSE | Tau | Rho | MSE | Tau | Rho |
| Baseline | 0.131 | 0.583 | 0.777 | 0.131 | 0.583 | 0.777 | 0.131 | 0.583 | 0.777 |
| TF-IDF | >100 | 0.407 | 0.581 | 0.129 | 0.595 | 0.791 | 0.148 | 0.581 | 0.784 |
| Pre-trained word2vec | 0.131 | 0.586 | 0.780 | 0.125 | 0.598 | 0.792 | 0.131 | 0.586 | 0.780 |
| domain-specific word2vec (CBOW) | 0.119 | 0.611 | 0.802 | 0.121 | 0.608 | 0.799 | 0.130 | 0.598 | 0.782 |
| domain-specific word2vec (Skip-gram) | 0.126 | 0.598 | 0.790 | 0.122 | 0.603 | 0.795 | 0.126 | 0.598 | 0.790 |
| Year | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | Tau | MSE | Tau | MSE | Tau | MSE | Tau | MSE | Tau | MSE | Tau | |
| LOG1P (All words) | 0.180 | 0.622 | 0.172 | 0.636 | 0.172 | 0.585 | 0.129 | 0.593 | 0.130 | 0.597 | 0.143 | 0.576 |
| LOG1P (sentiment) | 0.185 | 0.633 | 0.164 | 0.623 | 0.158 | 0.605 | 0.128 | 0.590 | 0.130 | 0.603 | 0.140 | 0.583 |
| Our approach | 0.113 | 0.674 | 0.102 | 0.657 | 0.148 | 0.679 | 0.067 | 0.697 | 0.066 | 0.654 | 0.064 | 0.651 |
| Year | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Training Data | MSE | Tau | MSE | Tau | MSE | Tau | MSE | Tau | MSE | Tau | MSE | Tau |
| Fixed period | 0.113 | 0.674 | 0.106 | 0.657 | 0.180 | 0.678 | 0.118 | 0.696 | 0.100 | 0.652 | 0.092 | 0.650 |
| Varying period | 0.113 | 0.674 | 0.102 | 0.657 | 0.148 | 0.679 | 0.067 | 0.697 | 0.066 | 0.654 | 0.064 | 0.651 |
| Test Data | |||||||
|---|---|---|---|---|---|---|---|
| Year | 2011 | 2012 | 2013 | ||||
| Training Data | Period | MSE | Tau | MSE | Tau | MSE | Tau |
| 2007–2010 | 4 | 0.084 | 0.607 | 0.248 | 0.634 | 0.192 | 0.683 |
| 2007–2011 | 5 | - | - | 0.225 | 0.646 | 0.160 | 0.690 |
| 2007–2012 | 6 | - | - | - | - | 0.118 | 0.692 |
| Impairment | Derecognize | Repurchase | Misstate | |||||
|---|---|---|---|---|---|---|---|---|
| Word | Sim | Word | Sim | word | Sim | Word | Sim | |
| Pre-trained word2vec | chemofog | 0.69 | decertify | 0.89 | repurchased | 0.93 | misstatement | 0.69 |
| nonaging | 0.68 | misrecognize | 0.60 | buyback | 0.88 | misword | 0.68 | |
| impaired | 0.67 | agnise | 0.53 | buy_back | 0.87 | miswording | 0.63 | |
| domain-specific word2vec | goodwill | 0.67 | derecognition | 0.53 | buyback | 0.76 | uncorrect | 0.57 |
| write-down | 0.56 | transferor | 0.52 | reissue | 0.45 | quantifi | 0.54 | |
| intangible | 0.53 | non-substantial | 0.46 | onewest | 0.45 | error | 0.45 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeh, H.-Y.; Yeh, Y.-C.; Shen, D.-B. Word Vector Models Approach to Text Regression of Financial Risk Prediction. Symmetry 2020, 12, 89. https://doi.org/10.3390/sym12010089
Yeh H-Y, Yeh Y-C, Shen D-B. Word Vector Models Approach to Text Regression of Financial Risk Prediction. Symmetry. 2020; 12(1):89. https://doi.org/10.3390/sym12010089
Chicago/Turabian StyleYeh, Hsiang-Yuan, Yu-Ching Yeh, and Da-Bai Shen. 2020. "Word Vector Models Approach to Text Regression of Financial Risk Prediction" Symmetry 12, no. 1: 89. https://doi.org/10.3390/sym12010089
APA StyleYeh, H.-Y., Yeh, Y.-C., & Shen, D.-B. (2020). Word Vector Models Approach to Text Regression of Financial Risk Prediction. Symmetry, 12(1), 89. https://doi.org/10.3390/sym12010089