RDF 1.1: Knowledge Representation and Data Integration Language for the Web


Abstract
1. Introduction
- It is most fundamentally a surrogate.
- It is a collection of ontological commitments.
- It is a fragmental intelligent reasoning theory.
- It is a pragmatically efficient computation medium.
- It is a human expression medium.
1.1. Contributions
- To compare the RDF reification approaches.
- To analyze the RDF 1.1 interpretations, entailments and their complexity.
- To study the RDF blank nodes and their complexity.
- To compare the various RDF data integration approaches.
- To compare the RDF 1.1 serialization formats, including multiple graph syntaxes.
- To compare the RDF binary and compression formats.
1.2. Review Organization
2. Literature Review
- IRIs;
- literals;
- blank nodes.
- rdf:Bag is an unordered container and allows duplicates;
- rdf:Seq is an ordered container;
- rdf:Alt is considered to define a group of alternatives.
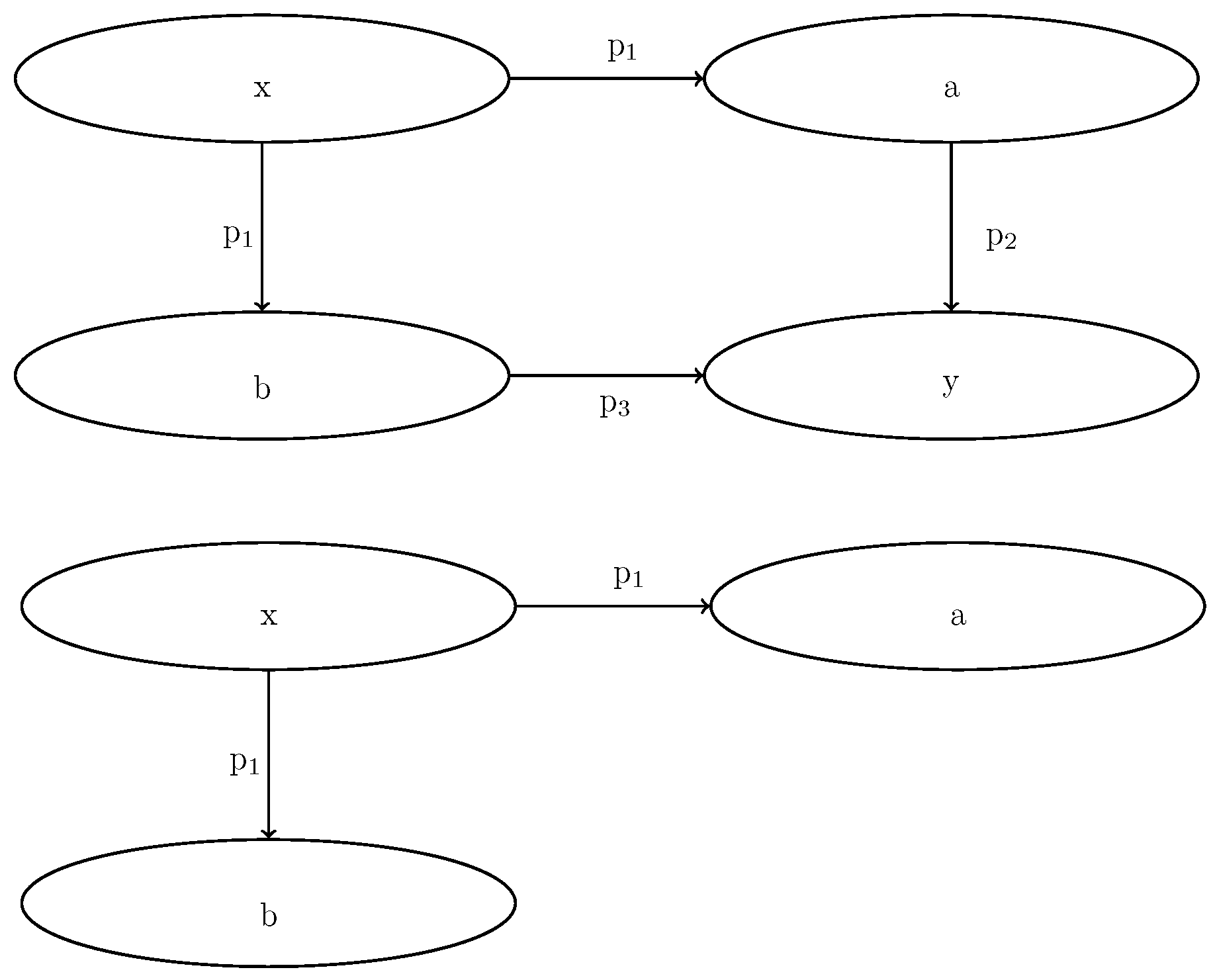
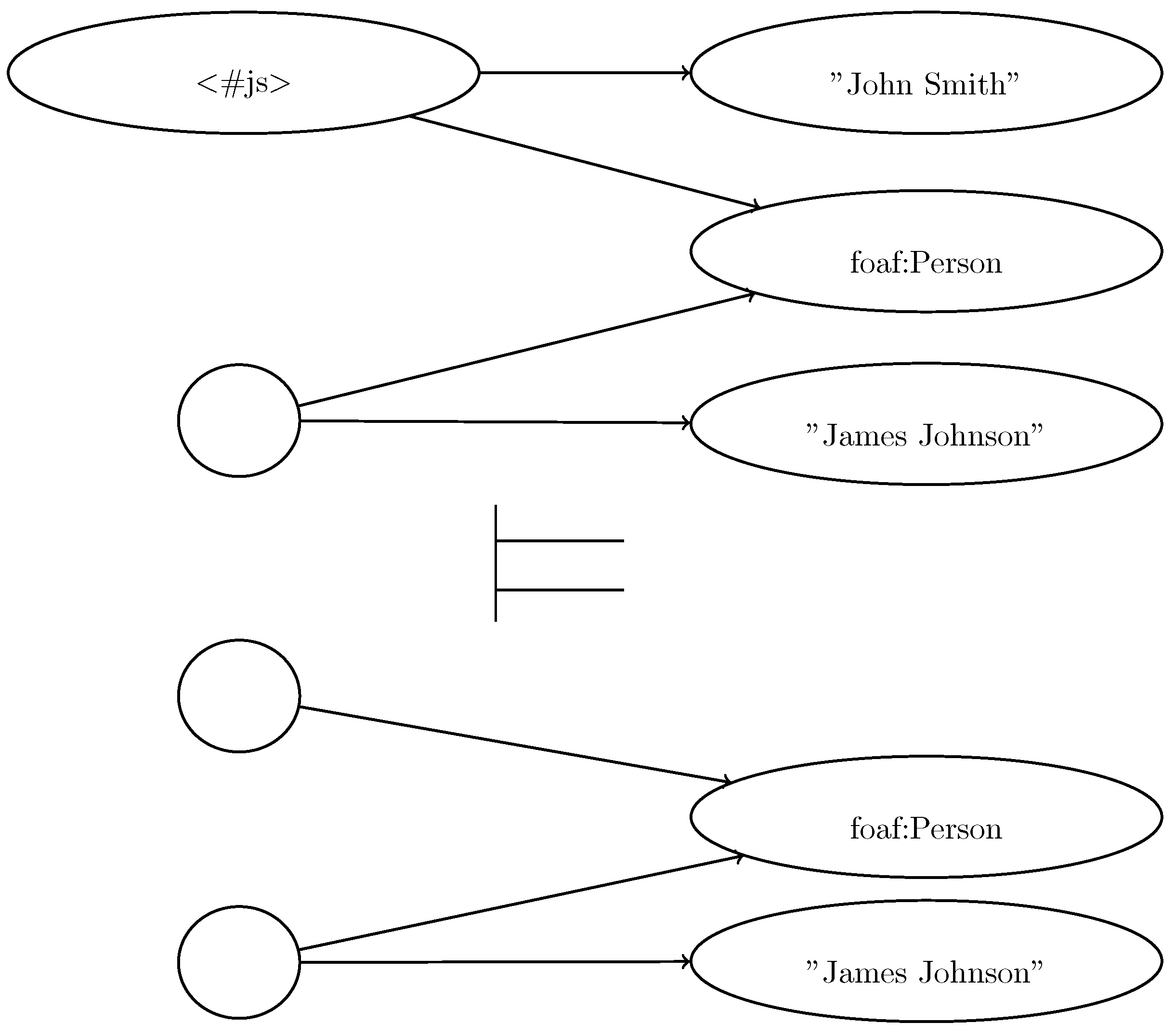
3. Modeling Blank Nodes
- Define the information to encapsulate the N-ary association;
- describe reification;
- offer protection of the inner data;
- describe multi-component structures (e.g., RDF containers);
- represent complex attributes without having to name explicitly the auxiliary node.
- 1.
- ;
- 2.
- , for all literals that are nodes of graph;
- 3.
- , for all RDF IRIs that are nodes of graph;
- 4.
- .
- 1.
- M is the identity map on RDF literals and IRIs, i.e.,;
- 2.
- for everysuch that,;
- 3.
- for every,;
- 4.
- .
- Disallow blank node;
- ground semantics;
- well-behaved RDF.
- 1.
- It can be serialized as Turtle without the use of explicit blank node identifiers;
- 2.
- it uses no deprecated features of RDF.
4. Entailments
- 1.
- is a (nonempty) set of named resources (the universe of I),
- 2.
- is a set, called the set of properties of I,
- 3.
- is an extension function used to associate properties with their property extension,,
- 4.
- is the interpretation function which assigns a resource or a property to every element of V such thatis the identity for literals,.
- 1.
- If rdf:langString, then for every language-tagged string E with lexical formand language tag,, whereistransformed to lower case,
- 2.
- For every other IRI,is the datatype identified by d, and for every literal “”^^d,(“”^^d) =, whereis a function from datatypes to their lexical-to-value mapping.
- rdf:Property ()–the class of RDF properties;
- rdf:type ()–the subject is an instance of a class;
- rdf:langString ()–the class of language-tagged string literal values.
- 1.
- ;
- 2.
- , whereis a value space.
- rdfs:Class ()–the class of classes;
- rdfs:Literal ()–the class of literal values;
- rdfs:Resource ()–the class resource, everything;
- rdfs:Datatype ()–the class of RDF datatypes;
- rdfs:subPropertyOf ()–the property that allows for stating that all things related by a given property x are also necessarily related by another property y;
- rdfs:subClassOf ()–the property that allows for stating that the extension of one class X is necessarily contained within the extension of another class Y;
- rdfs:domain ()–the property that allows for stating that the subject of a relation with a given property x is a member of a given class X;
- rdfs:range ()–the property that allows for stating that the object of a relation with a given property x is a member of a given class X;
- rdfs:ContainerMembershipProperty ()–the class of container membership properties, rdf:_i;
- rdfs:member ()–a member of the subject resource.
- 1.
- ,
- 2.
- ,
- 3.
- ,
- 4.
- ,
- 5.
- is a language-tagged string },
- 6.
- , whereis a value space,
- 7.
- 8.
- ,
- 9.
- ,
- 10.
- 11.
- ,
- 12.
- 13.
- 14.
- ,
- 15.
- ,
- 16.
- .
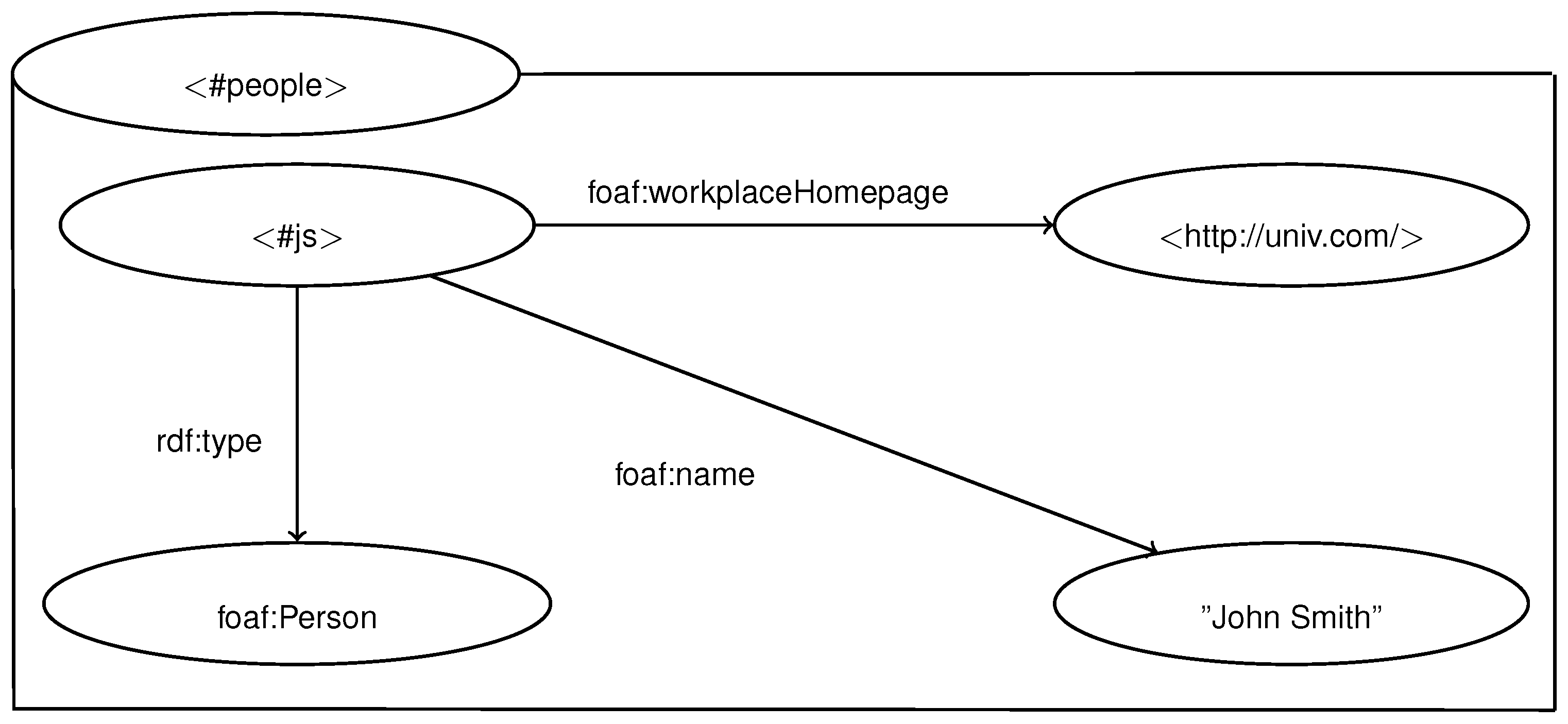
| rdf:type | ||
| foaf:name | ||
| foaf:workplaceHomepage | ||
| rdfs:label | ||
| <#js> | ||
| foaf:Person | ||
| “John Smith” | ||
| <http://univ.com/> | ||
| “University” |
5. RDF Data Integration
5.1. Bringing Relational Databases into the RDF
5.2. Bringing XML into the RDF
6. RDF Serializations
6.1. Single Graph Support
- about–an attribute that is an IRI or CURIE [41] specifying the resource the metadata is about (a RDF subject);
- rel and rev–attributes that expresses (reverse) relationships between two resources (a RDF predicate);
- property–an attribute that expresses relationships between a subject and some literal value (a RDF predicate);
- resource–an attribute for expressing a relationship’s partner resource that is not intended to be navigable (a RDF object);
- href–an attribute that expresses the partner resource of a relationship (a RDF resource object);
- src–an attribute that expresses a relationship’s partner resource when the resource is embedded (a RDF object that is a resource);
- content–an attribute that overrides the content of the element when using the property (a RDF object that is a literal);
- datatype–an attribute that specifies the datatype of a literal;
- typeof–an attribute that specifies the RDF types of the subject or the partner resource;
- inlist–an attribute that specifies that the object associated with property or rel attributes on the same element is to be pushed onto the list for that predicate;
- vocab–an attribute that specifies the mapping to be used when a RDF term is assigned in a value of attribute.
- rdf:RDF–a root element of RDF/XML documents;
- rdf:Description–an element that contains elements that describe the resource, it contains the description of the resource identified by the rdf:about attribute;
- rdf:Alt, rdf:Bag and rdf:Seq–elements that are containers used to describe a group of things (see Section 2);
- rdf:parseType="Collection"–an attribute that describe groups that can only contain the specified members;
- rdf:parseType="Resource"–an attribute that is used to omit blank nodes;
- xml:lang–an attribute that is used to allow content language identification;
- rdf:datatype–an attribute that is used to define a typed literal;
- rdf:nodeID–an attribute that identifies a blank node;
- rdf:ID and xml:base–attributes that abbreviate IRIs.
- The simplest triple statement consists of a sequence of subject, predicate, and object, separated by space, tabulation or other whitespace and terminated by a dot after each triple.
- Often, the same subject will be referenced by several predicates. In this situation, a series of predicates and objects are separated by a semicolon.
- As with predicates, objects are often repeated with the same subject and predicate. In this case, a comma should be used as a separator.
- IRIs may be written as relative or absolute IRIs or prefixed names. Both absolute and relative IRIs are enclosed in less-than sign and greater-than sign.
- Quoted literals have a lexical form followed by a datatype IRI, a language tag or neither. Literals should be delimited by apostrophe or double quotes.
- Blank nodes are expressed as underscore, colon and a blank node label that is a series of name characters. Blank nodes can be nested, abbreviated, and delimited by square brackets.
- Collections are enclosed by parentheses.
- The triple statement consists of a sequence of subject, predicate, and object, divided by whitespace, and terminated by a dot after each triple.
- IRIs should be represented as absolute IRIs and they are enclosed in less-than sign and greater-than sign.
- The representation of the lexical form is a sequence of a double quote (an initial delimiter), a list of characters or escape sequence, and a double quote (a final delimiter).
- Blank nodes are expressed as underscore, colon and a blank node label that is a series of name characters.
6.2. Multiple Graphs Support
- @context–set the short-hand names that are used throughout a document;
- @id–uniquely identify things that are being described in the document with blank nodes or IRIs;
- @value–specify the data that is associated with a particular property;
- @language–define the language for a particular string value or the default language of a document;
- @type–set the data type of an IRI, a blank node, a JSON-LD value or a list;
- @container–set the default container type for a short-hand string that expands to an IRI or a blank node identifier;
- @list–define an ordered set of data;
- @set–define an unordered set of data (values are represented as arrays);
- @reverse–used for reverse relationship expression between two resources;
- @index–specify that a container is used to index information;
- @base–define the base IRI against which relative IRIs are resolved;
- @vocab–expand properties and values in @type with a common prefix IRI;
- @graph–express a graph.
- A sequence of directives;
- RDF triples;
- graph statements which contain triple-generating statements.
7. RDF Compression
- Direct compression;
- adjacency list compression;
- a RDF split into the element dictionaries and the statements.
- A header, which includes metadata describing the RDF dataset;
- a dictionary, which organizes all the identifiers in the graph (it provides a list of the RDF terms such as literals, IRIs and blank nodes);
- a triples component, which consists of the underlying RDF graph pure structure.
8. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CURIE | compact URI expressions |
| DOM | Document Object Model |
| dRDF | domain-restricted RDF |
| EXI | Efficient XML Interchange |
| FOAF | Friend of a Friend |
| FOL | First-Order Logic |
| HDT | Header-Dictionary-Triples |
| HTTP | Hypertext Transfer Protocol |
| IRI | Internationalized Resource Identifier |
| JSON | JavaScript Object Notation |
| OWL | Web Ontology Language |
| QNames | qualified name |
| R2RML | RDB to RDF Mapping Language |
| RDF | Resource Description Framework |
| RDFS | Resource Description Framework Schema |
| SPARQL | SPARQL Protocol And RDF Query Language |
| SQL | Structured Query Language |
| URI | Uniform Resource Identifier |
| URL | Uniform Resource Locator |
| XML | Extensible Markup Language |
| XQuery | XML Query language |
| XSLT | Extensible Stylesheet Language Transformations |
References
- Sowa, J.F. Knowledge Representation: Logical, Philosophical, and Computational Foundations; Brooks/Cole Publishing Co.: Pacific Grove, CA, USA, 2000. [Google Scholar]
- Raimond, Y.; Schreiber, G. RDF 1.1 Primer: W3C Note; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Schwitter, R.; Tilbrook, M. Controlled Natural Language Meets the Semantic Web. In Proceedings of the Australasian Language Technology Workshop, Sydney, Australia, 8 December 2004; Volume 2, pp. 55–62. [Google Scholar]
- Crystal, D. The Cambridge Encyclopedia of Language, 3rd ed.; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar] [CrossRef]
- Lenzerini, M. Data Integration: A Theoretical Perspective. In Proceedings of the Twenty-first ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, PODS ’02, Madison, WI, USA, 3–5 June 2002; ACM: New York, NY, USA, 2002; pp. 233–246. [Google Scholar] [CrossRef]
- Ceri, S.; Tanca, L.; Zicari, R.V. Supporting Interoperability Between New Database Languages. In Proceedings of the 5th Annual European Computer Conference (CompEuro), Bologna, Italy, 13–16 May 1991; pp. 273–281. [Google Scholar] [CrossRef]
- Lassila, O.; Swick, R.R. Resource Description Framework (RDF) Model and Syntax Specification. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 1999. [Google Scholar]
- Decker, S.; Mitra, P.; Melnik, S. Framework for the Semantic Web: An RDF Tutorial. IEEE Int. Comput. 2000, 4, 68–73. [Google Scholar] [CrossRef]
- Champin, P.A. RDF Tutorial; Semantic Web Best Practices and Deployment Working Group; World Wide Web Consortium: Cambridge, MA, USA, 2001. [Google Scholar]
- Carroll, J.J. Matching RDF Graphs. In The Semantic Web—ISWC 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 5–15. [Google Scholar] [CrossRef]
- Pan, J.Z.; Horrocks, I. RDFS(FA) and RDF MT: Two semantics for RDFS. In The Semantic Web-ISWC 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 30–46. [Google Scholar] [CrossRef]
- Grau, B.C. A Possible Simplification of the Semantic Web Architecture. In Proceedings of the 13th International Conference on World Wide Web, WWW ’04, New York, NY, USA, 17–20 May 2004; ACM: New York, NY, USA, 2004; pp. 704–713. [Google Scholar] [CrossRef]
- Yang, G.; Kifer, M. Reasoning about Anonymous Resources and Meta Statements on the Semantic Web. J. Data Semant. 2003, 1, 69–97. [Google Scholar] [CrossRef]
- Kifer, M.; Lausen, G. F-logic: A Higher-order Language for Reasoning About Objects, Inheritance, and Scheme. SIGMOD Rec. 1989, 18, 134–146. [Google Scholar] [CrossRef]
- Berners-Lee, T.; Connolly, D.; Hawke, S. Semantic Web Tutorial Using N3. In Proceedings of the Twelfth International World Wide Web Conference, Budapest, Hungary, 20–24 May 2003. [Google Scholar]
- Marin, D. A Formalization of RDF. Master’s Thesis, École Polytechnique, Palaiseau, France, 2004. [Google Scholar]
- Manola, F.; Miller, E. RDF Primer. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2004. [Google Scholar]
- Gutierrez, C.; Hurtado, C.A.; Mendelzon, A.O. Foundations of Semantic Web Databases. In Proceedings of the Twenty-Third ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Paris, France, 14–16 June 2004; ACM: Paris, France, 2004; pp. 95–106. [Google Scholar] [CrossRef]
- De Bruijn, J.J.; Franconi, E.; Tessaris, S. Logical Reconstruction of RDF and Ontology Languages. In Principles and Practice of Semantic Web Reasoning; Springer: Berlin, Germany, 2005; pp. 65–71. [Google Scholar] [CrossRef]
- Franconi, E.; de Bruijn, J.; Tessaris, S. Logical Reconstruction of Normative RDF. In Proceedings of the CEUR Workshop Proceedings, Galway, Ireland, 11–12 November 2005; Volume 188. [Google Scholar]
- Feigenbaum, L.; Herman, I.; Hongsermeier, T.; Neumann, E.; Stephens, S. The Semantic Web in Action. Sci. Am. 2007, 297, 90–97. [Google Scholar] [CrossRef]
- Muñoz, S.; Pérez, J.; Gutierrez, C. Minimal Deductive Systems for RDF. In The Semantic Web: Research and Applications; Springer: Berlin/Heidelberg, Germany, 2007; pp. 53–67. [Google Scholar] [CrossRef]
- Munoz, S.; Perez, J.; Gutierrez, C. Simple and Efficient Minimal RDFS. Web Semant. 2009, 7, 220–234. [Google Scholar] [CrossRef]
- Pichler, R.; Polleres, A.; Wei, F.; Woltran, S. dRDF: Entailment for Domain-restricted RDF. In The Semantic Web: Research and Applications; Springer: Berlin/Heidelberg, Germany, 2008; pp. 200–214. [Google Scholar] [CrossRef]
- Hitzler, P.; Krotzsch, M.; Rudolph, S. Foundations of Semantic Web Technologies, 1st ed.; Chapman & Hall/CRC: London, UK, 2011. [Google Scholar]
- Antoniou, G.; Groth, P.; Van Harmelen, F.; Hoekstra, R. A Semantic Web Primer, 3rd ed.; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Curé, O.; Blin, G. RDF Database Systems: Triples Storage and SPARQL Query Processing; Morgan Kaufmann: Burlington, MA, USA, 2014. [Google Scholar]
- Zimmermann, A.; Lopes, N.; Polleres, A.; Straccia, U. A General Framework for Representing, Reasoning and Querying with Annotated Semantic Web Data. J. Web Semant. 2012, 11, 72–95. [Google Scholar] [CrossRef]
- Buneman, P.; Kostylev, E. Annotation algebras for RDFS. In Proceedings of the The Second International Workshop on the Role of Semantic Web in Provenance Management (SWPM-10), CEUR Workshop Proceedings, Shanghai, China, 7 November 2010; p. 32. [Google Scholar]
- Udrea, O.; Recupero, D.R.; Subrahmanian, V.S. Annotated RDF. In Proceedings of the 3rd European Conference on the Semantic Web: Research and Applications, ESWC’06, Budva, Montenegro, 11–14 June 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 487–501. [Google Scholar] [CrossRef]
- Straccia, U. A minimal deductive system for general fuzzy RDF. In Web Reasoning and Rule Systems; Springer: Berlin/Heidelberg, Germany, 2009; pp. 166–181. [Google Scholar] [CrossRef]
- Gutierrez, C.; Hurtado, C.; Vaisman, A. Temporal RDF. In The Semantic Web: Research and Applications; Springer: Berlin/Heidelberg, Germany, 2005; pp. 93–107. [Google Scholar] [CrossRef]
- Koubarakis, M.; Kyzirakos, K. Modeling and Querying Metadata in the Semantic Sensor Web: The Model stRDF and the Query Language stSPARQL. In ESWC (1); Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6088, pp. 425–439. [Google Scholar] [CrossRef]
- Tomaszuk, D.; Pak, K.; Rybinski, H. Trust in RDF Graphs. In ADBIS (2); Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2012; Volume 186, pp. 273–283. [Google Scholar]
- Sequeda, J.F.; Tirmizi, S.H.; Corcho, O.; Miranker, D.P. Survey of directly mapping SQL databases to the Semantic Web. Knowl. Eng. Rev. 2011, 26, 445–486. [Google Scholar] [CrossRef]
- Spanos, D.E.; Stavrou, P.; Mitrou, N. Bringing Relational Databases into the Semantic Web: A Survey. Semant. Web 2012, 3, 169–209. [Google Scholar] [CrossRef]
- Harth, A.; Hose, K.; Schenkel, R. Linked Data Management; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Thakkar, H.; Angles, R.; Tomaszuk, D.; Lehmann, J. Direct Mappings between RDF and Property Graph Databases. arXiv 2019, arXiv:1912.02127. [Google Scholar]
- Cyganiak, R.; Lanthaler, M.; Wood, D. RDF 1.1 Concepts and Abstract Syntax. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In The Semantic Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar] [CrossRef]
- Birbeck, M.; McCarron, S. CURIE Syntax 1.0: A syntax for expressing Compact URIs. In W3C Working Group Note; World Wide Web Consortium: Cambridge, MA, USA, 2010. [Google Scholar]
- Bray, T.; Hollander, D.; Layman, A.; Tobin, R. Namespaces in XML 1.1 (Second Edition). In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2006. [Google Scholar]
- Sperberg-McQueen, M.; Thompson, H.; Peterson, D.; Malhotra, A.; Biron, P.V.; Gao, S. W3C XML Schema Definition Language (XSD) 1.1 Part 2: Datatypes. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2012. [Google Scholar]
- Brickley, D.; Miller, L. FOAF Vocabulary Specification 0.99. Technical Report, FOAF Project. Available online: http://xmlns.com/foaf/spec/20140114.html (accessed on 1 December 2019).
- Carroll, J.J.; Bizer, C.; Hayes, P.; Stickler, P. Named Graphs, Provenance and Trust. In Proceedings of the 14th International Conference on World Wide Web, WWW ’05, Chiba, Japan, 10–14 May 2005; ACM: New York, NY, USA, 2005; pp. 613–622. [Google Scholar] [CrossRef]
- Zimmermann, A. RDF 1.1: On Semantics of RDF Datasets. In W3C Note; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Brickley, D.; Guha, R. RDF Schema 1.1. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Noy, N.; Rector, A. Defining N-ary Relations on the Semantic Web. In W3C Working Group Note; World Wide Web Consortium: Cambridge, MA, USA, 2006. [Google Scholar]
- Hartig, O.; Thompson, B. Foundations of an Alternative Approach to Reification in RDF. arXiv 2014, arXiv:1406.3399. [Google Scholar]
- Nguyen, V.; Bodenreider, O.; Sheth, A. Don’t Like RDF Reification?: Making Statements About Statements Using Singleton Property. In Proceedings of the 23rd International Conference on World Wide Web, WWW ’14, Seoul, Korea, 7–11 April 2014; ACM: New York, NY, USA, 2014; pp. 759–770. [Google Scholar] [CrossRef]
- Groth, P.; Gibson, A.; Velterop, J. The anatomy of a Nano-publication. Inf. Serv. Use 2010, 30, 51–56. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, H.; Chen, Y.; Guo, W. Blank Nodes in RDF. J. Softw. 2012, 7, 1993–1999. [Google Scholar] [CrossRef]
- Mallea, A.; Arenas, M.; Hogan, A.; Polleres, A. On Blank Nodes. In The Semantic Web–ISWC 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 421–437. [Google Scholar] [CrossRef]
- Hogan, A. Skolemising Blank Nodes While Preserving Isomorphism. In Proceedings of the 24th International Conference on World Wide Web, WWW’15, Florence, Italy, 18–22 May 2015; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2015; pp. 430–440. [Google Scholar] [CrossRef]
- Nottingham, M.; Hammer-Lahav, E. Defining Well-Known Uniform Resource Identifiers (URIs). In RFC 5785, Request for Comments; Internet Engineering Task Force: Fremont, CA, USA, 2010. [Google Scholar]
- Hogan, A.; Arenas, M.; Mallea, A.; Polleres, A. Everything You Always Wanted to Know About Blank Nodes. J. Web Semant. 2014, 27–28, 42–69. [Google Scholar] [CrossRef]
- Booth, D. Well Behaved RDF: A Straw-Man Proposal for Taming Blank Nodes. Available online: http://dbooth.org/2013/well-behaved-rdf/Booth-well-behaved-rdf.pdf (accessed on 1 December 2019).
- Gutierrez, C.; Hurtado, C.A.; Mendelzon, A.O.; Jorge, P. Foundations of Semantic Web Databases. J. Comput. Syst. Sci. 2011, 77, 520–541. [Google Scholar] [CrossRef]
- Patel-Schneider, P.; Hayes, P. RDF 1.1 Semantics. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Ter Horst, H.J. Completeness, Decidability and Complexity of Entailment for RDF Schema and a Semantic Extension Involving the OWL Vocabulary. J. Web Semant. 2005, 3, 79–115. [Google Scholar] [CrossRef]
- Data, C. An Introduction to Database Systems; Addison-Wesley Publ.: Boston, MA, USA, 1975. [Google Scholar]
- Hayes, P. RDF 1.0 Semantics. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2004. [Google Scholar]
- Corby, O.; Faron-Zucker, C. A Transformation Language for RDF based on SPARQL. In Web Information Systems and Technologies; Springer: Cham, Switzerland, 2016; pp. 318–340. [Google Scholar] [CrossRef]
- Corby, O.; Faron-Zucker, C.; Gandon, F. A Generic RDF Transformation Software and Its Application to an Online Translation Service for Common Languages of Linked Data. In International Semantic Web Conference (2); Lecture Notes in Computer Science; Springer: Berlin, Germany, 2015; Volume 9367, pp. 150–165. [Google Scholar]
- Alkhateeb, F.; Laborie, S. Towards extending and using SPARQL for modular document generation. In Proceedings of the Eighth ACM Symposium on Document Engineering, DocEng ’08, Sao Paulo, Brazil, 16–19 September 2008; ACM: New York, NY, USA, 2008; pp. 164–172. [Google Scholar] [CrossRef]
- Quan, D.; Karger, D.R.; Berners-Lee, T.; Connolly, D.; Hawke, S. Xenon: An RDF Stylesheet Ontology. In Proceedings of the International World Wide Web Conference, Chiba, Japan, 10–14 May 2005. [Google Scholar]
- Peroni, S.; Vitali, F. RSLT: RDF Stylesheet Language Transformations. In Proceedings of the ESWC Developers Workshop, CEUR Workshop Proceedings, Portoroz, Slovenia, 31 May–4 June 2015; Volume 1361, pp. 7–13. [Google Scholar]
- Tandy, J.; Herman, I.; Kellogg, G. Generating RDF from Tabular Data on the Web. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2015. [Google Scholar]
- Dimou, A.; Vander Sande, M.; Colpaert, P.; Verborgh, R.; Mannens, E.; Van de Walle, R. RML: A Generic Language for Integrated RDF Mappings of Heterogeneous Data. In Proceedings of the 7th Workshop on Linked Data on the Web, CEUR Workshop Proceedings, Seoul, Korea, 7–11 April 2014; Volume 1184. [Google Scholar]
- Horrocks, I.; Patel-Schneider, P.F.; Harmelen, F.V. Reviewing the Design of DAML+OIL: An Ontology Language for the Semantic Web. In Eighteenth National Conference on Artificial Intelligence; American Association for Artificial Intelligence: Menlo Park, CA, USA, 2002; pp. 792–797. [Google Scholar]
- Auer, S.; Dietzold, S.; Lehmann, J.; Hellmann, S.; Aumueller, D. Triplify: Light-weight Linked Data Publication from Relational Databases. In Proceedings of the 18th International Conference on World Wide Web, WWW ’09, Madrid, Spain, 20–24 April 2009; ACM: New York, NY, USA, 2009; pp. 621–630. [Google Scholar] [CrossRef]
- Salas, P.E.; Breitman, K.K.; Viterbo F., J.; Casanova, M.A. Interoperability by Design Using the StdTrip Tool: An a Priori Approach. In Proceedings of the 6th International Conference on Semantic Systems, I-SEMANTICS ’10, Graz, Austria, 1–3 September 2010; ACM: New York, NY, USA, 2010; pp. 43:1–43:3. [Google Scholar] [CrossRef]
- Vavliakis, K.N.; Grollios, T.K.; Mitkas, P.A. RDOTE-Publishing Relational Databases into the Semantic Web. J. Syst. Softw. 2013, 86, 89–99. [Google Scholar] [CrossRef]
- Astrova, I. Reverse Engineering of Relational Databases to Ontologies. In The Semantic Web: Research and Applications; Springer: Berlin/Heidelberg, Germany, 2004; pp. 327–341. [Google Scholar] [CrossRef]
- Astrova, I. Rules for Mapping SQL Relational Databases to OWL Ontologies. In MTSR; Springer: Boston, MA, USA, 2007; pp. 415–424. [Google Scholar] [CrossRef]
- Cerbah, F. Learning Highly Structured Semantic Repositories from Relational Databases: The RDBToOnto Tool. In The Semantic Web: Research and Applications; ESWC’08; Springer: Berlin/Heidelberg, Germay, 2008; pp. 777–781. [Google Scholar] [CrossRef]
- Cerbah, F. Mining the Content of Relational Databases to Learn Ontologies with Deeper Taxonomies. Web Intelligence. IEEE Comput. Soc. 2008, 1, 553–557. [Google Scholar] [CrossRef]
- Bizer, C.; Cyganiak, R. D2RQ-Lessons Learned. In Proceedings of the W3C Workshop on RDF Access to Relational Databases, Cambridge, MA, USA, 25–26 October 2007. [Google Scholar]
- Curino, C.; Orsi, G.; Panigati, E.; Tanca, L. Accessing and Documenting Relational Databases Through OWL Ontologies. In Proceedings of the 8th International Conference on Flexible Query Answering Systems, FQAS ’09, Roskilde, Denmark, 26–28 October 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 431–442. [Google Scholar] [CrossRef]
- Buccella, A.; Penabad, M.R.; Rodriguez, F.J.; Farina, A.; Cechich, A. From relational databases to OWL ontologies. In Proceedings of the 6th National Russian Research Conference, Pushchino, Russia, 29 September–1 October 2004. [Google Scholar]
- Hu, W.; Qu, Y. Discovering Simple Mappings Between Relational Database Schemas and Ontologies. In The Semantic Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 225–238. [Google Scholar] [CrossRef]
- Būmans, G.; Čerāns, K. RDB2OWL: A Practical Approach for Transforming RDB Data into RDF/OWL. In Proceedings of the 6th International Conference on Semantic Systems, I-SEMANTICS ’10, Graz, Austria, 1–3 September 2010; ACM: New York, NY, USA, 2010; pp. 25:1–25:3. [Google Scholar] [CrossRef]
- Li, M.; Du, X.; Wang, S. A Semi-automatic Ontology Acquisition Method for the Semantic Web. In Advances in Web-Age Information Management, WAIM’05; Springer: Berlin/Heidelberg, Germany, 2005; pp. 209–220. [Google Scholar] [CrossRef]
- Byrne, K. Having Triplets–Holding Cultural Data as RDF. In Proceedings of the ECDL 2008 Workshop on Information Access to Cultural Heritage, Aarhus, Denmark, 14–19 September 2008. [Google Scholar]
- Calvanese, D.; De Giacomo, G.; Lembo, D.; Lenzerini, M.; Poggi, A.; Rodriguez-Muro, M.; Rosati, R.; Ruzzi, M.; Savo, D.F. The MASTRO System for Ontology-based Data Access. Semant. Web 2011, 2, 43–53. [Google Scholar] [CrossRef]
- Erling, O.; Mikhailov, I. RDF Support in the Virtuoso DBMS. In Networked Knowledge-Networked Media: Integrating Knowledge Management, New Media Technologies and Semantic Systems; Springer: Berlin/Heidelberg, Germany, 2009; pp. 7–24. [Google Scholar] [CrossRef]
- Ghawi, R.; Cullot, N. Database-to-Ontology Mapping Generation for Semantic Interoperability. In Proceedings of the Third International Workshop on Database Interoperability (InterDB 2007), Dijon, France, 23–27 September 2007. [Google Scholar]
- Hert, M.; Reif, G.; Gall, H.C. Updating Relational Data via SPARQL/Update. In Proceedings of the 2010 EDBT/ICDT Workshops, EDBT ’10, Lausanne, Switzerland, 22–26 March 2010; ACM: New York, NY, USA, 2010; pp. 24:1–24:8. [Google Scholar] [CrossRef]
- Nyulas, C.; OConnor, M.; Tu, S. DataMaster–a plug-in for importing schemas and data from relational databases into Protege. In Proceedings of the 10th International Protege Conference, Budapest, Hungary, 15–18 July 2007. [Google Scholar]
- Polfliet, S.; Ichise, R. Automated Mapping Generation for Converting Databases into Linked Data. In Proceedings of the ISWC Posters & Demos, CEUR Workshop Proceedings, Shanghai, China, 7–11 November 2010; Volume 658. [Google Scholar]
- Sahoo, S.S.; Bodenreider, O.; Rutter, J.L.; Skinner, K.J.; Sheth, A.P. An Ontology-driven Semantic Mashup of Gene and Biological Pathway Information: Application to the Domain of Nicotine Dependence. J. Biomed. Inf. 2008, 41, 752–765. [Google Scholar] [CrossRef]
- Shen, G.; Huang, Z.; Zhu, X.; Zhao, X. Research on the Rules of Mapping from Relational Model to OWL. In Proceedings of the OWLED, CEUR Workshop Proceedings, Athens, GA, USA, 10–11 November 2006; Volume 216. [Google Scholar]
- Stojanovic, L.; Stojanovic, N.; Volz, R. Migrating Data-intensive Web Sites into the Semantic Web. In Proceedings of the 2002 ACM Symposium on Applied Computing, SAC ’02, Madrid, Spain, 11–14 March 2002; ACM: New York, NY, USA, 2002; pp. 1100–1107. [Google Scholar] [CrossRef]
- Tirmizi, S.H.; Sequeda, J.; Miranker, D. Translating SQL Applications to the Semantic Web. In Database and Expert Systems Applications; DEXA ’08; Springer: Berlin/Heidelberg, Germany, 2008; pp. 450–464. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, H.; Wang, H.; Wang, Y.; Mao, Y.; Tang, J.; Zhou, C. Dartgrid: A Semantic Web Toolkit for Integrating Heterogeneous Relational Databases. In Proceedings of the Semantic Web Challenge at 4th International Semantic Web Conference, Beijing, China, 27–29 November 2005. [Google Scholar] [CrossRef]
- Seaborne, A.; Steer, D.; Williams, S. SQL-RDF. Available online: http://www.w3.org/2007/03/RdfRDB/papers/seaborne.html (accessed on 1 December 2019).
- Lopes, N.; Bischof, S.; Decker, S.; Polleres, A. On the Semantics of Heterogeneous Querying of Relational, XML and RDF Data with XSPARQL. In Proceedings of the 15th Portuguese Conference on Artificial Intelligence (EPIA 2011), Lisbon, Portugal, 10–13 October 2011. [Google Scholar]
- Bischof, S.; Lopes, N.; Polleres, A. Improve Efficiency of Mapping Data Between XML and RDF with XSPARQL. In Proceedings of the 5th International Conference on Web Reasoning and Rule Systems, RR’11, Galway, Ireland, 29–30 August 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 232–237. [Google Scholar] [CrossRef]
- De Laborda, C.P.; Conrad, S. Relational.OWL: A Data and Schema Representation Format Based on OWL. In Proceedings of the 2Nd Asia-Pacific Conference on Conceptual Modelling-Volume 43, APCCM ’05, Newcastle, Australia, 30 January–4 February 2005; Australian Computer Society, Inc.: Darlinghurst, Australia, 2005; pp. 89–96. [Google Scholar]
- Das, S.; Cyganiak, R.; Sundara, S. R2RML: RDB to RDF Mapping Language. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2012. [Google Scholar]
- Priyatna, F.; Alonso-Calvo, R.; Paraiso-Medina, S.; Padron-Sanchez, G.; Corcho, O. R2RML-based Access and Querying to Relational Clinical Data with Morph-RDB. In Proceedings of the 8th Semantic Web Applications and Tools for Life Sciences International Conference, Cambridge, UK, 7–10 December 2015; pp. 142–151. [Google Scholar]
- Sequeda, J.F.; Miranker, D.P. Ultrawrap Mapper: A Semi-Automatic Relational Database to RDF (RDB2RDF) Mapping Tool. In Proceedings of the International Semantic Web Conference (Posters & Demos), Bethlehem, PA, USA, 11–15 October 2015. [Google Scholar]
- Erling, O.; Mikhailov, I. RDF Support in the Virtuoso DBMS. In Networked Knowledge-Networked Media; Springer: Berlin, Germany, 2009; pp. 7–24. [Google Scholar]
- Barrasa, J.; Corcho, Ó.; Gómez-pérez, A. R2O, an Extensible and Semantically based Database-to-Ontology Mapping Language. In Proceedings of the 2nd Workshop on Semantic Web and Databases (SWDB2004), Toronto, ON, Canada, 29–30 August 2004; pp. 1069–1070. [Google Scholar] [CrossRef]
- Kay, M. XSL Transformations (XSLT) Version 3.0. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2017. [Google Scholar]
- Snelson, J.; Chamberlin, D.; Dyck, M.; Robie, J. XML Path Language (XPath) 3.1. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2017. [Google Scholar]
- Amann, B.; Beeri, C.; Fundulaki, I.; Scholl, M. Ontology-Based Integration of XML Web Resources. In The Semantic Web—ISWC 2002; ISWC ’02; Springer: Berlin/Heidelberg, Germany, 2002; pp. 117–131. [Google Scholar] [CrossRef]
- Battle, S. Gloze: XML to RDF and back again. In Proceedings of the Jena User Conference, Bristol, UK, 10–11 May 2006. [Google Scholar]
- Bedini, I.; Matheus, C.; Patel-Schneider, P.F.; Boran, A.; Nguyen, B. Transforming XML Schema to OWL Using Patterns. In Proceedings of the 2011 IEEE Fifth International Conference on Semantic Computing, ICSC ’11, Palo Alto, CA, USA, 18–21 September 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 102–109. [Google Scholar] [CrossRef]
- Berrueta, D.; Labra, J.E.; Herman, I. XSLT+SPARQL: Scripting the Semantic Web with SPARQL Embedded into XSLT Stylesheets. In Proceedings of the 4th Workshop on Scripting for the Semantic Web, Tenerife, Spain, 1 June 2008. [Google Scholar]
- Bikakis, N.; Gioldasis, N.; Tsinaraki, C.; Christodoulakis, S. Querying XML Data with SPARQL. In Database and Expert Systems Applications; DEXA ’09; Springer: Berlin/Heidelberg, Germany, 2009; pp. 372–381. [Google Scholar] [CrossRef]
- Bischof, S.; Decker, S.; Krennwallner, T.; Lopes, N.; Polleres, A. Mapping between RDF and XML with XSPARQL. J. Data Semant. 2012, 1, 147–185. [Google Scholar] [CrossRef]
- Bohring, H.; Auer, S. Mapping XML to OWL Ontologies. Leipz. Inf.-Tage 2005, 72, 147–156. [Google Scholar]
- Connolly, D. Gleaning Resource Descriptions from Dialects of Languages (GRDDL). In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2007. [Google Scholar]
- Cruz, C.; Nicolle, C. Ontology Enrichment and Automatic Population From XML Data. In Proceedings of the 4th International VLDB Workshop on Ontology-Based Techniques for DataBases in Information Systems and Knowledge Systems, ODBIS 2008, Auckland, New Zealand, 34 August 23 2008; pp. 17–20. [Google Scholar]
- Deursen, D.V.; Poppe, C.; Martens, G.; Mannens, E.; Walle, R.V.D. XML to RDF Conversion: A Generic Approach. In Proceedings of the 2008 International Conference on Automated Solutions for Cross Media Content and Multi-channel Distribution, AXMEDIS ’08, Florence, Italy, 17–19 November 2008; IEEE Computer Society: Washington, DC, USA, 2008; pp. 138–144. [Google Scholar] [CrossRef]
- Droop, M.; Flarer, M.; Groppe, J.; Groppe, S.; Linnemann, V.; Pinggera, J.; Santner, F.; Schier, M.; Schöpf, F.; Staffler, H.; et al. Bringing the XML and Semantic Web Worlds Closer: Transforming XML into RDF and embedding XPath into SPARQL. In Enterprise Information Systems; Springer: Berlin/Heidelberg, Germany, 2009; pp. 31–45. [Google Scholar] [CrossRef]
- Farrell, J.; Lausen, H. Semantic Annotations for WSDL and XML Schema. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2007. [Google Scholar]
- Ferdinand, M.; Zirpins, C.; Trastour, D. Lifting XML schema to OWL. In Web Engineering; Springer: Berlin/Heidelberg, Germany, 2004; pp. 354–358. [Google Scholar] [CrossRef]
- Garcia, R.; Celma, O. Semantic Integration and Retrieval of Multimedia Metadata. In Proceedings of the 5th International Workshop on Knowledge Markup and Semantic Annotation, Galway, Ireland, 7 November 2005; pp. 69–80. [Google Scholar]
- Ghawi, R.; Cullot, N. Building Ontologies from XML Data Sources. In Proceedings of the 2009 20th International Workshop on Database and Expert Systems Application, DEXA ’09, Linz, Austria, 31 August–4 September 2009; IEEE Computer Society: Washington, DC, USA, 2009; pp. 480–484. [Google Scholar] [CrossRef]
- Klein, M.C.A. Interpreting XML Documents via an RDF Schema Ontology. In Proceedings of the 13th International Workshop on Database and Expert Systems Applications, DEXA ’02, Aix-en-Provence, France, 6 September 2002; IEEE Computer Society: Washington, DC, USA, 2002; pp. 889–894. [Google Scholar] [CrossRef]
- Koffina, I.; Serfiotis, G.; Christophides, V.; Tannen, V. Mediating RDF/S Queries to Relational and XML Sources. Int. J. Semant. Web Inf. Syst. 2006, 2, 68. [Google Scholar] [CrossRef]
- Lehti, P.; Fankhauser, P. XML Data Integration with OWL: Experiences and Challenges. In Proceedings of the 2004 International Symposium on Applications and the Internet, Tokyo, Japan, 26–30 January 2004; pp. 160–167. [Google Scholar] [CrossRef]
- O’Connor, M.J.; Das, A. Acquiring OWL Ontologies from XML Documents. In Proceedings of the Sixth International Conference on Knowledge Capture, K-CAP ’11, Banff, AB, Canada, 26–29 June 2011; ACM: New York, NY, USA, 2011; pp. 17–24. [Google Scholar] [CrossRef]
- Reif, G.; Jazayeri, M.; Gall, H. Towards Semantic Web Engineering: WEESA-Mapping XML Schema to Ontologies. In Proceedings of the WWW Workshop on Application Design, Development and Implementation Issues in the Semantic Web, New York, NY, USA, 18 May 2004. [Google Scholar]
- Rodrigues, T.; Rosa, P.; Cardoso, J. Moving from Syntactic to Semantic Organizations Using JXML2OWL. Comput. Ind. 2008, 59, 808–819. [Google Scholar] [CrossRef]
- Shapkin, P.; Shumsky, L. A Language for Transforming the RDF Data on the Basis of Ontologies. In Proceedings of the 11th International Conference on Web Information Systems and Technologies, Lisbon, Portugal, 20–22 May 2015; pp. 504–511. [Google Scholar] [CrossRef]
- Stavrakantonakis, I.; Tsinaraki, C.; Bikakis, N.; Gioldasis, N.; Christodoulakis, S. SPARQL2XQuery 2.0: Supporting Semantic-based queries over XML data. In Proceedings of the 2010 Fifth International Workshop Semantic Media Adaptation and Personalization, Limmassol, Cyprus, 9–10 December 2010; pp. 76–84. [Google Scholar]
- Thuy, P.T.T.; Lee, Y.K.; Lee, S. DTD2OWL: Automatic Transforming XML Documents into OWL Ontology. In Proceedings of the 2nd International Conference on Interaction Sciences: Information Technology, Culture and Human, ICIS ’09, Seoul, Korea, 24–26 November 2009; ACM: New York, NY, USA, 2009; pp. 125–131. [Google Scholar] [CrossRef]
- Thuy, P.T.; Lee, Y.K.; Lee, S. A Semantic Approach for Transforming XML Data into RDF Ontology. Wirel. Pers. Commun. 2013, 73, 1387–1402. [Google Scholar] [CrossRef]
- Tsinaraki, C.; Christodoulakis, S. Interoperability of XML Schema Applications with OWL Domain Knowledge and Semantic Web Tools. In Proceedings of the 2007 OTM Confederated International Conference on On the Move to Meaningful Internet Systems: CoopIS, DOA, ODBASE, GADA, and IS-Volume Part I, OTM’07, Vilamoura, Portugal, 25–30 November 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 850–869. [Google Scholar] [CrossRef]
- Xiao, H.; Cruz, I.F. Integrating and Exchanging XML Data Using Ontologies. In Journal on Data Semantics VI; Springer: Berlin/Heidelberg, Germany, 2006; pp. 67–89. [Google Scholar]
- Yahia, N.; Mokhtar, S.A.; Ahmed, A. Automatic Generation of OWL Ontology from XML Data Source. arXiv 2012, arXiv:1206.0570. [Google Scholar]
- Harris, S.; Seaborne, A. SPARQL 1.1 Query Language. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2013. [Google Scholar]
- Robie, J.; Dyck, M. XQuery 3.1: An XML Query Language. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2017. [Google Scholar]
- De Laborda, C.P.; Conrad, S. Querying Relational Databases with RDQL. In Proceedings of the Berliner XML Tage, Podebrady, Czech Republic, 2–6 October 2006; pp. 161–172. [Google Scholar]
- Chinnici, R.; Moreau, J.J.; Ryman, A.; Weerawarana, S. Web Services Description Language (WSDL) Version 2.0 Part 1: Core Language. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2007. [Google Scholar]
- McCarron, S.; Adida, B.; Birbeck, M.; Herman, I. RDFa Core 1.1 - Third Edition. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2015. [Google Scholar]
- Gandon, F.; Schreiber, G. RDF 1.1 XML Syntax. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Prud’hommeaux, E.; Carothers, G. RDF 1.1 Turtle. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Carothers, G.; Seaborne, A. RDF 1.1 N-Triples. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Sporny, M.; Lanthaler, M.; Kellogg, G. JSON-LD 1.0. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Seaborne, A.; Carothers, G. RDF 1.1 TriG. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Carothers, G. RDF 1.1 N-Quads. In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Carroll, J.J.; Stickler, P. RDF triples in XML. In Proceedings of the 13th International World Wide Web Conference on Alternate Track Papers & Posters, WWW Alt. ’04, New York, NY, USA, 19–21 May 2004; ACM: New York, NY, USA, 2004; pp. 412–413. [Google Scholar] [CrossRef]
- Tomaszuk, D. Named graphs in RDF/JSON serialization. Zesz. Naukowe Politech. Gdań. 2011, 2, 273–278. [Google Scholar]
- Tomaszuk, D. Flat triples approach to RDF graphs in JSON. In W3C Workshop–RDF Next Steps; World Wide Web Consortium: Cambridge, MA, USA, 2010. [Google Scholar]
- Fernández, J.D.; Gutierrez, C.; Martínez-Prieto, M.A. RDF Compression: Basic Approaches. In Proceedings of the 19th International Conference on World Wide Web, WWW ’10, Raleigh, NC, USA, 26–30 April 2010; ACM: New York, NY, USA, 2010; pp. 1091–1092. [Google Scholar] [CrossRef]
- Fernández, J.D.; Martínez-Prieto, M.A.; Gutiérrez, C.; Polleres, A.; Arias, M. Binary RDF Representation for Publication and Exchange (HDT). J. Web Semant. 2013, 19, 22–41. [Google Scholar] [CrossRef]
- Fernández, J.D. Binary RDF for Scalable Publishing, Exchanging and Consumption in the Web of Data. In Proceedings of the 21st International Conference on World Wide Web, WWW ’12 Companion, Lyon, France, 16–20 April 2012; ACM: New York, NY, USA, 2012; pp. 133–138. [Google Scholar] [CrossRef]
- Verborgh, R.; Hartig, O.; De Meester, B.; Haesendonck, G.; De Vocht, L.; Vander Sande, M.; Cyganiak, R.; Colpaert, P.; Mannens, E.; Van de Walle, R. Querying Datasets on the Web with High Availability. In The Semantic Web–ISWC 2014; Springer: Cham, Switzerland, 2014; pp. 180–196. [Google Scholar] [CrossRef]
- Fernández, J.D.; Llaves, A.; Corcho, O. Efficient RDF Interchange (ERI) Format for RDF Data Streams. In The Semantic Web–ISWC 2014; Springer: Cham, Switzerland, 2014; pp. 244–259. [Google Scholar] [CrossRef]
- Álvarez-García, S.; Brisaboa, N.R.; Fernández, J.D.; Martínez-Prieto, M.A.; Navarro, G. Compressed Vertical Partitioning for Efficient RDF Management. Knowl. Inf. Syst. 2015, 44, 439–474. [Google Scholar] [CrossRef]
- Fernández, N.; Arias, J.; Sánchez, L.; Fuentes-Lorenzo, D.; Corcho, Ó. RDSZ: An approach for lossless RDF stream compression. In The Semantic Web: Trends and Challenges; Springer: Cham, Switzerland, 2014; pp. 52–67. [Google Scholar] [CrossRef]
- Le-Phuoc, D.; Quoc, H.N.M.; Le Van, C.; Hauswirth, M. Elastic and Scalable Processing of Linked Stream Data in the Cloud. In The Semantic Web–ISWC 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 280–297. [Google Scholar] [CrossRef]
- Fisteus, J.A.; Garcia, N.F.; Fernandez, L.S.; Fuentes-Lorenzo, D. Ztreamy: A middleware for publishing semantic streams on the Web. J. Web Semant. 2014, 25, 16–23. [Google Scholar] [CrossRef]
- Urbani, J.; Maassen, J.; Drost, N.; Seinstra, F.; Bal, H. Scalable RDF data compression with MapReduce. Concurr. Comput. Pract. Exp. 2013, 25, 24–39. [Google Scholar] [CrossRef]
- Urbani, J.; Maassen, J.; Bal, H. Massive Semantic Web Data Compression with MapReduce. In Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, HPDC ’10, Chicago, IL, USA, 21–25 June 2010; ACM: New York, NY, USA, 2010; pp. 795–802. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Giménez-García, J.M.; Fernández, J.D.; Martínez-Prieto, M.A. HDT-MR: A scalable solution for RDF compression with HDT and MapReduce. In The Semantic Web. Latest Advances and New Domains; Springer: Cham, Switzerland, 2015; pp. 253–268. [Google Scholar] [CrossRef]
- Käbisch, S.; Peintner, D.; Anicic, D. Standardized and Efficient RDF Encoding for Constrained Embedded Networks. In The Semantic Web. Latest Advances and New Domains; Springer: Cham, Switzerland, 2015; pp. 437–452. [Google Scholar] [CrossRef]
- Schneider, J.; Kamiya, T.; Peintner, D.; Kyusakov, R. Efficient XML Interchange (EXI) Format 1.0 (Second Edition). In W3C Recommendation; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Peintner, D.; Brutzman, D. EXI for JSON (EXI4JSON). In W3C Working Group Note; World Wide Web Consortium: Cambridge, MA, USA, 2018. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | sr | nr | rdr | sp | ng |
|---|---|---|---|---|---|
| Standard | ☑ | ☒ | ☒ | ☑ | |
| RDF syntax only | ☑ | ☑ | ☒ | ☒ | □ |
| Extra statements | |||||
| W3C Working Group Note | |||||
| Counted as n-tripleX | |||||
| Counted as n-quads | |||||
| Rule ID | Body | Head |
|---|---|---|
| rdf1 | “”^^d . | ⇒ _:n . _:n d . |
| rdf2 | . | ⇒ . |
| Rule ID | Body | Head |
|---|---|---|
| rdfs1 | any IRI | ⇒ . |
| rdfs2 | . . | ⇒ . |
| rdfs3 | . . | ⇒ . |
| rdfs4a | . | ⇒ . |
| rdfs4b | . | ⇒ . |
| rdfs5 | . . | ⇒ . |
| rdfs6 | . | ⇒ . |
| rdfs7 | . . | ⇒ . |
| rdfs8 | ⇒ . | |
| rdfs9 | . . | ⇒ . |
| rdfs10 | . | ⇒ . |
| rdfs11 | . . | ⇒ . |
| rdfs12 | . | ⇒ . |
| rdfs13 | . | ⇒ . |
| Entailment | Current Semantics | No Blank Nodes |
|---|---|---|
| simple | NP-complete | PTIME |
| D* | NP-complete | PTIME |
| RDF | NP-complete | PTIME |
| RDFS | NP-complete | PTIME |
| Approaches | Mapping Represent. | Schema Represent. | Automatic |
|---|---|---|---|
| [74,75] | n/a | RDFS, OWL, F-Logic | □ |
| [71] | SQL | RDFS | ☒ |
| [76,77] | Constraint rules | RDFS, OWL | □ |
| [78] | D2RQ | RDFS | ☑ |
| [79] | RDF, Rel.OWL | RDFS, OWL | ☑ |
| [80] | n/a | RDFS, OWL | □ |
| [81] | FOL, Horn | RDFS, OWL | ☑ |
| [82] | SQL | RDFS, OWL | ☒ |
| [83] | Logic rules | RDFS, OWL | □ |
| [84] | n/a | RDFS | □ |
| [85] | XML | RDFS, OWL | ☒ |
| [86] | SPARQL | RDFS | |
| [87] | R2O | RDFS, OWL | ☑ |
| [88] | RDF | RDFS | ☒ |
| [89] | RDF, Rel.OWL | RDFS, OWL | ☑ |
| [90] | D2RQ | RDFS, OWL | □ |
| [91] | XPath (XSLT) | RDFS, OWL | ☒ |
| [72] | SQL | RDFS, OWL | □ |
| [92] | n/a | RDFS, OWL | ☑ |
| [93] | n/a | RDFS, F-Logic | □ |
| [94] | FOL | RDFS, OWL | ☑ |
| [73] | SQL | RDFS, OWL | ☒ |
| [95] | RDF/XML | RDFS, OWL | ☒ |
| [96] | RDF (Direct) | RDFS | |
| [97,98] | XQuery | n/a | □ |
| Approaches | Existing Vocabulary | Schema Representation | Auto- Matic |
|---|---|---|---|
| [107] | ☒ | RDFS, DAML+OIL | ☒ |
| [108] | ☒ | RDFS, OWL | ☑ |
| [109] | ☒ | RDFS, OWL | ☑ |
| [110] | ☒ | n/a | ☑ |
| [111] | ☒ | RDFS, OWL | ☑ |
| [98,112] | ☒ | n/a | □ |
| [113] | ☒ | RDFS, OWL | ☑ |
| [114] | ☒ | RDFS, OWL | □ |
| [115] | ☑ | RDFS, OWL | ☑ |
| [116] | ☑ | RDFS, OWL | □ |
| [69] | ☒ | RDFS, OWL | □ |
| [117] | ☒ | n/a | □ |
| [118] | ☒ | n/a | □ |
| [119] | ☒ | RDFS, OWL | ☑ |
| [120] | ☒ | RDFS, OWL | ☑ |
| [121] | ☑ | RDFS, OWL | ☑ |
| [122] | ☒ | RDFS | ☑ |
| [123] | ☒ | RDFS | ☑ |
| [124] | ☒ | RDFS, OWL | ☑ |
| [125] | ☒ | RDFS, OWL | □ |
| [126] | ☑ | RDFS, OWL | ☑ |
| [127] | ☑ | RDFS, OWL | ☑ |
| [128] | ☒ | RDFS, OWL | ☑ |
| [129] | ☒ | RDFS, OWL | ☑ |
| [130,131] | ☒ | RDFS, OWL | □ |
| [132] | ☒ | n/a | ☑ |
| [133] | ☒ | RDFS | ☑ |
| [134] | ☒ | RDFS, OWL | ☑ |
| Feature | ttl | nt | tg | nq | jld | rdfa | xml |
|---|---|---|---|---|---|---|---|
| Standard | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ |
| Human readable | ☑ | □ | ☑ | □ | ☑ | ☑ | □ |
| Efficient | ☒ | ☒ | ☒ | ☒ | □ | ☒ | □ |
| Normalized | ☒ | ☑ | ☒ | ☑ | □ | ☒ | ☒ |
| Turtle family | ☑ | ☑ | ☑ | ☑ | ☒ | ☒ | ☒ |
| XML family | ☒ | ☒ | ☒ | ☒ | ☒ | ☑ | ☑ |
| Multiple graphs | ☒ | ☒ | ☑ | ☑ | ☑ | ☒ | ☒ |
| Feature | hdt | eri | rdsz | cqels | ztr | mr |
|---|---|---|---|---|---|---|
| Standard | ☒ | ☒ | ☒ | ☒ | ☒ | |
| Binary format | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ |
| Streamable | ☒ | ☑ | ☑ | ☑ | ☑ | ☑ |
| Scalable | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ |
| Zlib | ☒ | ☒ | ☑ | ☒ | ☑ | ☑ |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tomaszuk, D.; Hyland-Wood, D. RDF 1.1: Knowledge Representation and Data Integration Language for the Web. Symmetry 2020, 12, 84. https://doi.org/10.3390/sym12010084
Tomaszuk D, Hyland-Wood D. RDF 1.1: Knowledge Representation and Data Integration Language for the Web. Symmetry. 2020; 12(1):84. https://doi.org/10.3390/sym12010084
Chicago/Turabian StyleTomaszuk, Dominik, and David Hyland-Wood. 2020. "RDF 1.1: Knowledge Representation and Data Integration Language for the Web" Symmetry 12, no. 1: 84. https://doi.org/10.3390/sym12010084
APA StyleTomaszuk, D., & Hyland-Wood, D. (2020). RDF 1.1: Knowledge Representation and Data Integration Language for the Web. Symmetry, 12(1), 84. https://doi.org/10.3390/sym12010084