Use of Nonconventional Dispersion Measures to Improve the Efficiency of Ratio-Type Estimators of Variance in the Presence of Outliers



Abstract
1. Introduction
2. Background of the Ratio-Type Estimators of Variance
3. Proposed Estimators of Variance
- Inter-decile Range: The inter-decile range is the difference between the largest decile and smallest decile . Symbolically it is given as
- Probability Weighted Moment Estimator: The probability weighted moment estimator of dispersion suggested by Downton [21] is based on the ordered sample statistics and it is defined aswhere denotes the th order sample statistics.
- Downton’s Estimator: Another estimator of dispersion, similar to , was proposed by Downton [21] and defined as
- Gini Mean Difference Estimator: Gini [22] introduced a dispersion estimator which is also based on the sample order statistics. It is given as
- Median Absolute Deviation from Median: Hampel [23] suggested an estimator of dispersion based on absolute deviation from the median. It is defined as, where is the median.
- The Median of Pairwise Distances: Shamos [24] (p. 260) and Bickel and Lehmann [25] (p. 38) suggested an estimator of dispersion which is based on the median of pairwise distances as . Rousseeuw and Croux [26] suggested to pre-multiply it by 1.0483 to achieve consistency under the Gaussian distribution, and the resultant estimator can be defined as.
- Median Absolute Deviation from Mean: Wu et al. [27] defined another estimator which is also based on absolute deviation from the mean. It is given as
- Mean Absolute Deviation from Mean: Wu et al. [27] suggested an estimator of dispersion which is based on absolute deviation from the mean. It is given as
- Average Absolute Deviation from Median: Wu et al. [27] suggested an estimator of dispersion which is based on the average of absolute deviation from the median. It is given as
- The Ordered Statistic of Subranges: A robust estimator of dispersion based on the order of subranges was introduced by Croux and Rousseeuw [28], defined as, where the symbol [·] represents the integer part of a fraction.
- Trimmed Mean of Median of Pairwise Distances: Croux and Rousseeuw [28] defined another robust estimator of dispersion which is based on the trimmed mean of the median of pairwise distances. It is given as, where for each , we compute the median of that yields values, and the average of the first order statistics gives the final estimate , where , which is roughly half of the number of observations.
- The 0.25-quantile of Pairwise Distances: Another incorporated in this study as a non-conventional dispersion measure is due to Rousseeuw and Croux [26] and is defined aswhere is the constant factor and its default value is to make it a consistent estimator under normality, while and . Thus, the th order statistic of the interpoint distances yields the desired estimator.
- The Median of the Median of Distances: This study also includes a robust estimator of dispersion defined in Rousseeuw and Croux [26]. It is given as, where is a constant used for consistency and under a normal population its value is usually set to .
3.1. The Suggested Estimators of Class-I
Efficiency Conditions for Class-I Estimators
- ▪
- The estimators of class-I perform better than the traditional estimator of Isaki [4] for estimating the population variance ifor
- ▪
- The estimators defined in class-I will achieve greater efficiency as compared to the estimators defined in Section 2, i.e., ifor
- ▪
- The suggested class-I estimators will outperform the Upadhyaya and Singh [17] modified ratio-type estimator of population variance in terms of efficiency ifor
- ▪
- The estimators envisaged in the proposed class will exhibit superior performance as compared to the Subramani and Kumarapandiyan [16] modified class of estimators ifor
3.2. The Suggested Estimators of Class-II
Efficiency Conditions for Class-II Estimators
- ▪
- The estimators in class-II will perform better than the Isaki [4] traditional ratio estimator of population variance ifor
- ▪
- The estimators defined in class-II will be superior in terms of efficiency as compared to the estimators defined in Section 2, i.e., ifor
- ▪
- The suggested class-II estimators will outperform the Upadhyaya and Singh [17] modified ratio-type estimator of population variance in terms of efficiency ifor
- ▪
- The estimators envisaged in the proposed class-II will exhibit superior performance as compared to the Subramani and Kumarapandiyan [16] modified class of estimators ifor
4. Empirical Study
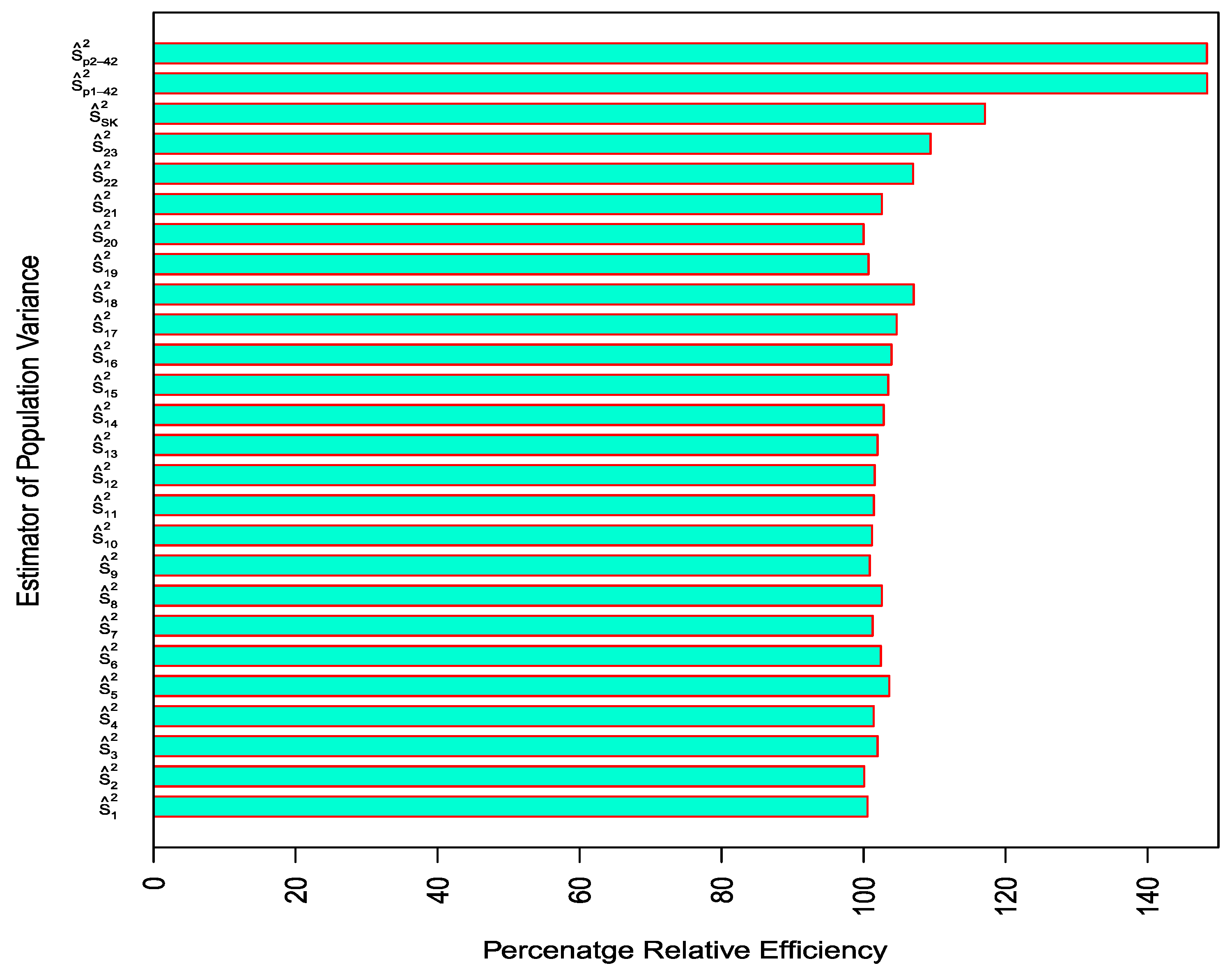
- The estimators proposed in class-I and class-II have higher PREs as compared to the existing estimators for both the populations considered in this study, which reveals the supremacy of the proposed classes of estimators in the presence of outliers in the data (cf. Table 5, Table 6, Table 7 and Table 8 and Figure 3 and Figure 4). For instance, the suggested estimators of class-I and class-II are at least 38% more efficient as compared to the traditional ratio estimator for population-I. For population-II, the efficiency of the suggested estimators exceeds 44%. All existing estimators are at most 11% and 17% more efficient as compared to the traditional ratio estimator for population-I and population-II, respectively.
- The estimator which is based on inter-decile range and the correlation coefficient between the study and auxiliary variables turned out to be the most efficient estimator.
- It was also observed that the performance of existing estimators in comparison with the traditional ratio estimators is not much superior in the presence of outliers in the data (cf. Table 5 and Table 6), whereas the suggested estimators perform quite well as compared to the existing and the traditional ratio estimators (cf. Table 7 and Table 8). These findings highlight the significance of using nonconventional measures in estimating the population variance in the presence of outliers.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley and Sons: New York, NY, USA, 1977. [Google Scholar]
- Singh, H.P. Estimation of normal parent parameters with known coefficient of variation. Gujarat Stat. Rev. 1986, 13, 57–62. [Google Scholar]
- Wolter, K.M. Introduction to Variance Estimation, 2nd ed.; Springer: New York, NY, USA, 1985. [Google Scholar]
- Isaki, C.T. Variance estimation using auxiliary information. J. Am. Stat. Assoc. 1983, 78, 117–123. [Google Scholar] [CrossRef]
- Kadilar, C.; Cingi, H. Ratio estimators for population variance in simple and stratified sampling. Appl. Math. Comput. 2006, 173, 1047–1058. [Google Scholar] [CrossRef]
- Khan, M.; Shabbir, J. A ratio type estimator for the estimation of population variance using quartiles of an auxiliary variable. J. Stat. Appl. Probab. 2013, 2, 319–325. [Google Scholar] [CrossRef]
- Maqbool, S.; Javaid, S. Variance estimation using linear combination of tri-mean and quartile average. Am. J. Biol. Environ. Stat. 2017, 3, 5–9. [Google Scholar] [CrossRef]
- Muneer, S.; Khalil, A.; Shabbir, J.; Narjis, G. A new improved ratio-product type exponential estimator of finite population variance using auxiliary information. J. Stat. Comput. Simul. 2018, 88, 3179–3192. [Google Scholar] [CrossRef]
- Naz, F.; Abid, M.; Nawaz, T.; Pang, T. Enhancing the efficiency of the ratio-type estimators of population variance with a blend of information on robust location measures. Sci. Iran. 2019. [Google Scholar] [CrossRef]
- Solanki, R.S.; Singh, H.P.; Pal, S.K. Improved ratio-type estimators of finite population variance using quartiles. Hacet. J. Math. Stat. 2015, 44, 747–754. [Google Scholar] [CrossRef]
- Subramani, J.; Kumarapandiyan, G. Variance estimation using median of the auxiliary variable. Int. J. Probab. Stat. 2012, 1, 36–40. [Google Scholar] [CrossRef]
- Estimation of Variance Using Deciles of an Auxiliary Variable. Available online: https://www.researchgate.net/publication/274008488_7_Subramani_J_and_Kumarapandiyan_G_2012c_Estimation_of_variance_using_deciles_of_an_auxiliary_variable_Proceedings_of_International_Conference_on_Frontiers_of_Statistics_and_Its_Applications_Bonfring_ (accessed on 10 November 2019).
- Subramani, J.; Kumarapandiyan, G. Variance estimation using quartiles and their functions of an auxiliary variable. Int. J. Stat. Appl. 2012, 2, 67–72. [Google Scholar] [CrossRef]
- Upadhyaya, L.N.; Singh, H.P. An estimator for population variance that utilizes the kurtosis of an auxiliary variable in sample surveys. Vikram Math. J. 1999, 19, 14–17. [Google Scholar]
- Yaqub, M.; Shabbir, J. An improved class of estimators for finite population variance. Hacet. J. Math. Stat. 2016, 45, 1641–1660. [Google Scholar] [CrossRef]
- Subramani, J.; Kumarapandiyan, G. A class of modified ratio estimators for estimation of population variance. J. Appl. Math. Stat. Inform. 2015, 11, 91–114. [Google Scholar] [CrossRef]
- Subramani, J.; Kumarapandiyan, G. Estimation of variance using known coefficient of variation and median of an auxiliary variable. J. Mod. Appl. Stat. Methods 2013, 12, 58–64. [Google Scholar] [CrossRef]
- Upadhyaya, L.N.; Singh, H.P. Estimation of population standard deviation using auxiliary information. Am. J. Math. Manag. Sci. 2001, 21, 345–358. [Google Scholar] [CrossRef]
- Riaz, M. A dispersion control chart. Commun. Stat.—Simul. Comput. 2008, 37, 1239–1261. [Google Scholar] [CrossRef]
- Nazir, H.Z.; Riaz, M.; Does, R.J.M.M. Robust CUSUM control charting for process dispersion. Qual. Reliab. Eng. Int. 2015, 31, 369–379. [Google Scholar] [CrossRef]
- Downton, F. Linear estimates with polynomial coefficients. Biometrika 1966, 53, 129–141. [Google Scholar] [CrossRef]
- Gini, C. Variabilità e mutabilità. In Memorie di Metodologica Statistica; Pizetti, E., Salvemini, T., Eds.; Libreria Eredi Virgilio Veschi: Rome, Italy, 1912. [Google Scholar]
- Hampel, F.R. The influence curve and its role in robust estimation. J. Am. Stat. Assoc. 1974, 69, 383–393. [Google Scholar] [CrossRef]
- Shamos, M.I. Geometry and statistics: problems at the interface. In New Directions and Recent Results in Algorithms and Complexity; Traub, J.F., Ed.; Academic Press: New York, NY, USA, 1976; pp. 251–280. [Google Scholar]
- Bickel, P.J.; Lehmann, E.L. Descriptive statistics for nonparametric models IV. spread. In Contributions to Statistics, Hajek Memorial Volume; Jureckova, J., Ed.; Academia: Prague, Czechia, 1979; pp. 33–40. [Google Scholar] [CrossRef]
- Rousseeuw, P.J.; Croux, C. Alternatives to the median absolute deviation. J. Am. Stat. Assoc. 1993, 88, 1273–1283. [Google Scholar] [CrossRef]
- Wu, C.; Zhao, Y.; Wang, Z. The median absolute deviations and their applications to Shewhart control charts. Commun. Stat.—Simul. Comput. 2002, 31, 425–442. [Google Scholar] [CrossRef]
- Croux, C.; Rousseeuw, P.J. A class of high-breakdown scale estimators based on subranges. Commun. Stat.—Theory Methods 1992, 21, 1935–1951. [Google Scholar] [CrossRef]
- Abid, M.; Abbas, N.; Nazir, H.Z.; Lin, Z. Enhancing the mean ratio estimators for estimating population mean using non-conventional location parameters. Rev. Colomb. Estadística 2016, 39, 63–79. [Google Scholar] [CrossRef]
- Searls, D.T. Utilization of known coefficient of kurtosis in the estimation procedure of variance. J. Am. Stat. Assoc. 1964, 59, 1225–1226. [Google Scholar] [CrossRef]
- Singh, D.; Chaudhary, F.S. Theory and Analysis of Sample Survey Designs; New Age International Publisher: New Dehli, India, 1986. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimator | Proposed By | B(.) | MSE(.) |
|---|---|---|---|
| Upadhyaya and Singh [14] | ; where | ||
| Kadilar and Cingi [5] | ; where | ||
| Subramani and Kumarapandiyan [11] | ; where | ||
| Subramani and Kumarapandiyan [13] | ; where | ||
| Subramani and Kumarapandiyan [13] | ; where | ||
| Subramani and Kumarapandiyan [13] | ; where | ||
| Subramani and Kumarapandiyan [13] | ; where | ||
| Subramani and Kumarapandiyan [13] | ; where | ||
| Subramani and Kumarapandiyan [12] | ; where | ||
| Subramani and Kumarapandiyan [12] | ; where | ||
| Subramani and Kumarapandiyan [12] | ; where | ||
| Subramani and Kumarapandiyan [12] | ; where | ||
| Subramani and Kumarapandiyan [12] | ; where | ||
| Subramani and Kumarapandiyan [12] | ; where | ||
| Subramani and Kumarapandiyan [12] | ; where | ||
| Subramani and Kumarapandiyan [12] | ; where | ||
| Subramani and Kumarapandiyan [12] | ; where | ||
| Subramani and Kumarapandiyan [12] | ; where | ||
| Kadilar and Cingi [5] | ; where | ||
| Kadilar and Cingi [5] | ; where | ||
| Subramani and Kumarapandiyan [17] | ; where | ||
| Khan and Shabbir [6] | ; where | ||
| Upadhyaya and Singh [18] |
| Estimator | Value of Constant | |||
|---|---|---|---|---|
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | ||||
| 1 | 1 | |||
| . | ||||
| Estimator | Value of Constant | |||
|---|---|---|---|---|
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
| 1 | 1 | |||
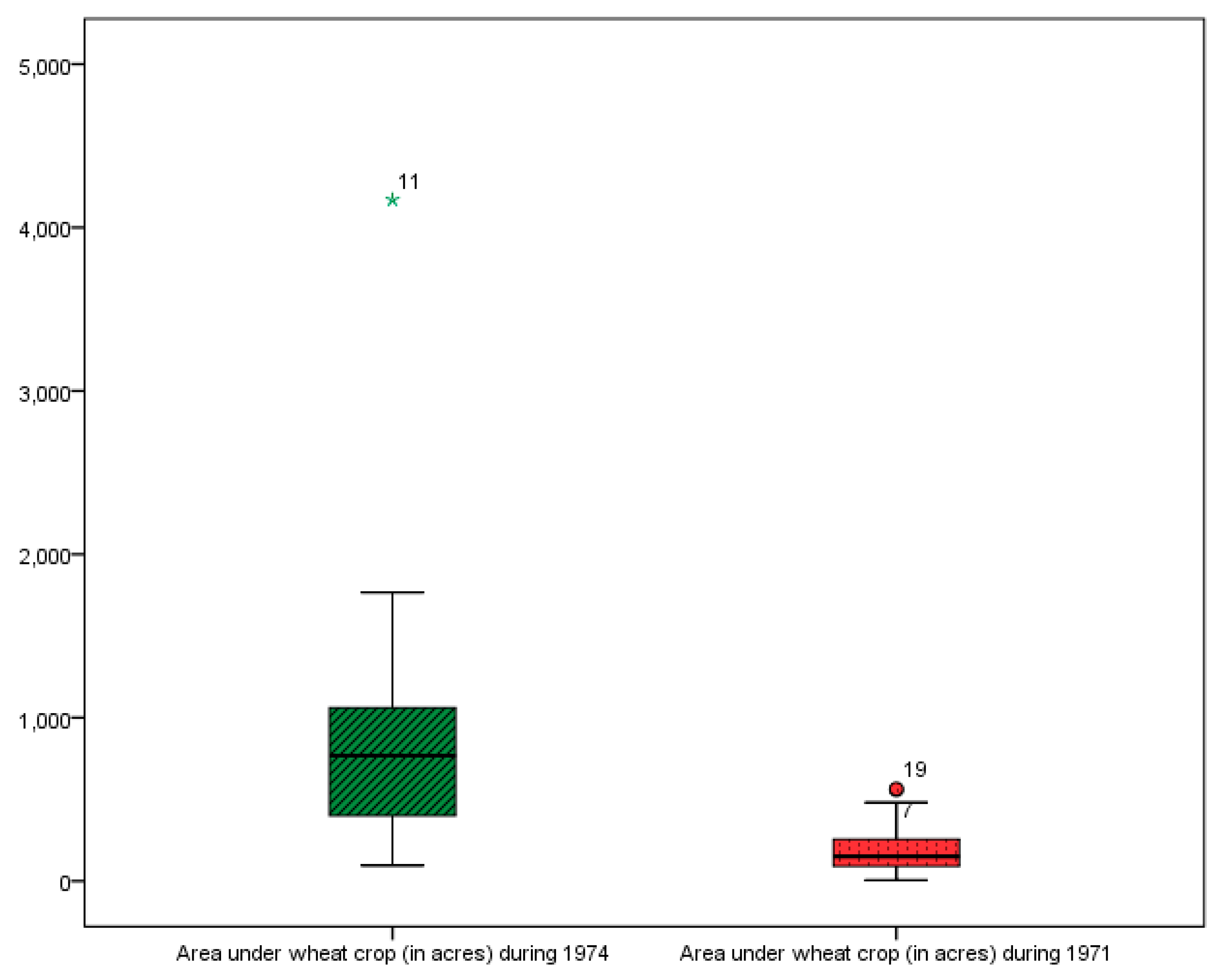
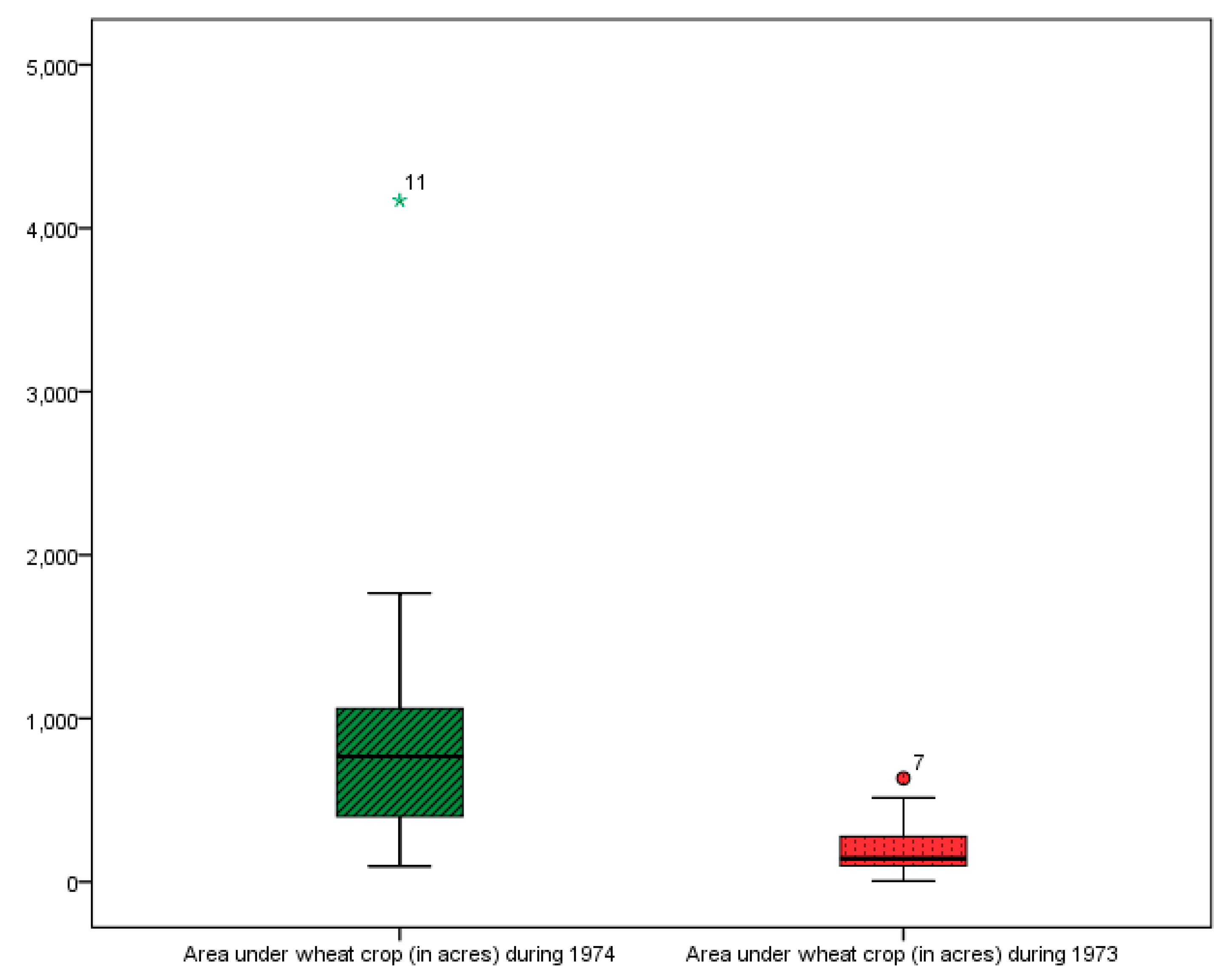
| Characteristic | Population-I | Population-II | Characteristic | Population-I | Population-II |
|---|---|---|---|---|---|
| 34 | 34 | 12.94 | 11.12 | ||
| 20 | 20 | 15.00 | 14.25 | ||
| 85.64 | 85.64 | 22.72 | 21.02 | ||
| 20.89 | 19.94 | 25.04 | 26.45 | ||
| 73.31 | 73.31 | 33.56 | 30.44 | ||
| 0.86 | 0.86 | 43.61 | 37.32 | ||
| 15.05 | 15.02 | 56.40 | 63.40 | ||
| 0.72 | 0.75 | 14.28 | 14.02 | ||
| 0.87 | 1.28 | 16.60 | 16.30 | ||
| 2.91 | 3.73 | 14.72 | 14.45 | ||
| 13.37 | 13.37 | 18.28 | 18.40 | ||
| 1.15 | 1.22 | 15.24 | 15.16 | ||
| −0.31 | −0.29 | 11.70 | 11.33 | ||
| 15.00 | 14.25 | 10.95 | 9.79 | ||
| 9.43 | 9.93 | 12.23 | 11.79 | ||
| 25.48 | 27.80 | 13.78 | 12.66 | ||
| 16.05 | 17.88 | 12.05 | 11.21 | ||
| 8.03 | 8.94 | 13.21 | 14.05 | ||
| 17.45 | 18.86 | 11.66 | 10.49 | ||
| 7.03 | 6.06 | 12.90 | 10.67 | ||
| 7.68 | 8.30 | 36.58 | 31.26 | ||
| 10.82 | 10.27 | 16.05 | 8.94 |
| Estimator | PRE | Estimator | PRE | Estimator | PRE | Estimator | PRE |
|---|---|---|---|---|---|---|---|
| 100.32 | 100.08 | 101.53 | 100.99 | ||||
| 102.47 | 101.63 | 100.85 | 101.76 | ||||
| 100.75 | 100.82 | 101.13 | 101.34 | ||||
| 101.53 | 102.23 | 102.43 | 103.12 | ||||
| 103.85 | 104.69 | 100.44 | 100.03 | ||||
| 102.06 | 104.71 | 104.81 | 111.56 |
| Estimator | PRE | Estimator | PRE | Estimator | PRE | Estimator | PRE |
|---|---|---|---|---|---|---|---|
| 100.55 | 100.11 | 102.00 | 101.43 | ||||
| 103.65 | 102.47 | 101.29 | 102.59 | ||||
| 100.89 | 101.20 | 101.47 | 101.59 | ||||
| 102.00 | 102.86 | 103.50 | 103.95 | ||||
| 104.68 | 107.07 | 100.73 | 100.03 | ||||
| 102.60 | 106.99 | 109.46 | 117.10 |
| Proposed Class-I | Proposed Class-II | ||||||
|---|---|---|---|---|---|---|---|
| Estimator | PRE | Estimator | PRE | Estimator | PRE | Estimator | PRE |
| 140.53 | 141.28 | 140.47 | 141.23 | ||||
| 140.71 | 141.37 | 140.65 | 141.32 | ||||
| 140.57 | 141.30 | 140.51 | 141.25 | ||||
| 140.81 | 141.42 | 140.76 | 141.37 | ||||
| 140.61 | 141.32 | 140.55 | 141.27 | ||||
| 140.28 | 141.14 | 140.21 | 141.09 | ||||
| 140.19 | 141.08 | 140.12 | 141.03 | ||||
| 140.34 | 141.17 | 140.27 | 141.12 | ||||
| 140.49 | 141.26 | 140.43 | 141.21 | ||||
| 140.32 | 141.16 | 140.25 | 141.11 | ||||
| 140.44 | 141.23 | 140.37 | 141.18 | ||||
| 140.27 | 141.14 | 140.21 | 141.09 | ||||
| 140.41 | 141.21 | 140.34 | 141.16 | ||||
| 141.36 | 141.64 | 141.32 | 141.61 | ||||
| 140.90 | 139.04 | 140.84 | 138.96 | ||||
| 141.04 | 139.25 | 140.98 | 139.17 | ||||
| 140.93 | 139.08 | 140.87 | 139.00 | ||||
| 141.12 | 139.39 | 141.07 | 139.31 | ||||
| 140.96 | 139.13 | 140.91 | 139.05 | ||||
| 140.69 | 138.77 | 140.63 | 138.68 | ||||
| 140.61 | 138.68 | 140.55 | 138.60 | ||||
| 140.73 | 138.83 | 140.68 | 138.74 | ||||
| 140.86 | 138.99 | 140.80 | 138.91 | ||||
| 140.72 | 138.81 | 140.66 | 138.72 | ||||
| 140.82 | 138.93 | 140.76 | 138.85 | ||||
| 140.68 | 138.77 | 140.62 | 138.68 | ||||
| 140.79 | 138.90 | 140.74 | 138.82 | ||||
| 141.51 | 140.37 | 141.47 | 140.31 | ||||
| Proposed Class-I | Proposed Class-II | ||||||
|---|---|---|---|---|---|---|---|
| Estimator | PRE | Estimator | PRE | Estimator | PRE | Estimator | PRE |
| 147.30 | 148.08 | 147.23 | 148.03 | ||||
| 147.48 | 148.17 | 147.42 | 148.12 | ||||
| 147.33 | 148.10 | 147.27 | 148.05 | ||||
| 147.62 | 148.23 | 147.56 | 148.18 | ||||
| 147.39 | 148.13 | 147.33 | 148.08 | ||||
| 147.01 | 147.92 | 146.94 | 147.87 | ||||
| 146.79 | 147.80 | 146.72 | 147.74 | ||||
| 147.06 | 147.95 | 147.00 | 147.90 | ||||
| 147.16 | 148.01 | 147.10 | 147.96 | ||||
| 146.99 | 147.91 | 146.92 | 147.86 | ||||
| 147.30 | 148.08 | 147.24 | 148.03 | ||||
| 146.89 | 147.86 | 146.82 | 147.80 | ||||
| 146.92 | 147.87 | 146.85 | 147.82 | ||||
| 148.07 | 148.41 | 148.02 | table | ||||
| 147.63 | 145.32 | 147.57 | 145.23 | ||||
| 147.78 | 145.54 | 147.73 | 145.45 | ||||
| 147.66 | 145.37 | 147.61 | 145.28 | ||||
| 147.89 | 145.73 | 147.84 | 145.64 | ||||
| 147.71 | 145.44 | 147.66 | 145.35 | ||||
| 147.38 | 145.03 | 147.32 | 144.94 | ||||
| 147.20 | 144.85 | 147.13 | 144.76 | ||||
| 147.43 | 145.09 | 147.37 | 144.99 | ||||
| 147.52 | 145.18 | 147.46 | 145.09 | ||||
| 147.37 | 145.02 | 147.31 | 144.93 | ||||
| 147.63 | 145.33 | 147.57 | 145.24 | ||||
| 147.29 | 144.94 | 147.22 | 144.84 | ||||
| 147.31 | 144.96 | 147.25 | 144.86 | ||||
| 148.23 | 146.56 | 148.19 | 146.48 | ||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naz, F.; Nawaz, T.; Pang, T.; Abid, M. Use of Nonconventional Dispersion Measures to Improve the Efficiency of Ratio-Type Estimators of Variance in the Presence of Outliers. Symmetry 2020, 12, 16. https://doi.org/10.3390/sym12010016
Naz F, Nawaz T, Pang T, Abid M. Use of Nonconventional Dispersion Measures to Improve the Efficiency of Ratio-Type Estimators of Variance in the Presence of Outliers. Symmetry. 2020; 12(1):16. https://doi.org/10.3390/sym12010016
Chicago/Turabian StyleNaz, Farah, Tahir Nawaz, Tianxiao Pang, and Muhammad Abid. 2020. "Use of Nonconventional Dispersion Measures to Improve the Efficiency of Ratio-Type Estimators of Variance in the Presence of Outliers" Symmetry 12, no. 1: 16. https://doi.org/10.3390/sym12010016
APA StyleNaz, F., Nawaz, T., Pang, T., & Abid, M. (2020). Use of Nonconventional Dispersion Measures to Improve the Efficiency of Ratio-Type Estimators of Variance in the Presence of Outliers. Symmetry, 12(1), 16. https://doi.org/10.3390/sym12010016