1. Introduction
Improving the management and effectiveness of employees’ learning processes in manufacturing companies is one of the needs of manufacturing enterprises in the context of Industry 4.0. Expert workers, that is, technical specialists, acquire a unique knowledge about production processes over the years [
1]. The transfer of such specialist knowledge to new employees, without the involvement of experienced employees, requires the development of solutions supporting this process. Automating the process of transferring specialist knowledge, within an enterprise, is not only a modern solution to employees’ learning processes, but also allows business managers to retain the knowledge of employees who leave a company. The process of acquiring knowledge, and then formalising and transferring it into a useful form, is difficult. In this article, the proposed model for the generation of workplace procedures, using Convolutional Neural Networks with a Support Vector Machine (CNN-SVM) architecture, combines the acquisition of specialist knowledge, on the one hand, and also allows the formalisation and recording of this knowledge in such a way that it is useful for new employees in the company, according to the two essential elements of a knowledge-based system (KBS) [
2]. In our approach, specialist knowledge is acquired using video recordings of company specialists in action. These recordings will allow any knowledge about the activities performed to be passed on.
The second element of our approach is the formalisation of the acquired knowledge with the help of a video recording and its further distribution in the company. In the context of such as image data analysis, Support Vector Machine (SVM), Principal Component Analysis (PCA), and Linear Discriminant Analysis (LDA) have been used [
3]. New object recognition models, such as the HMAX [
4,
5], the convolutional networks [
6], and a number of deep learning models [
7], have been successfully applied in solutions supporting employees in manufacturing companies in the context of Industry 4.0. Convolutional Neural Networks (CNNs) and Support Vector Machines (SVMs) are introduced to solve the problem of generating of real-time workplace procedures, in order to support the learning processes in a company where the lack of resources prevents the teaching of new employees.
The main focus of this work was to use a Convolutional Neural Network with a Support Vector Machine (CNN-SVM), in order to generate workplace instructions. In this paper, we used the CNN neural network with an SVM classifier, so that the knowledge of an experienced worker can be extracted and classified based on the video material. In our case, this process was done to study the repair of a solid fuel boiler. In the first step, the video material is divided into stages, according to established rules that will allow individual images to be assigned to a given step. Next, based on the features obtained for a given step in the video material, and using CNN-SVM, a reference model of the features will be constrcuted for each step of the work performed at work. In addition, a model of the characteristics of the station instructions (illustration) will be built with the help of CNN. In order to obtain an automatic workplace instruction, an algorithm for establishing an activity scenario has been proposed, the use of which allows comparison of the models both of the features and of the automatic generation of workstation instructions.
This paper is organised as follows.
Section 2 describes an analysis of the research literature;
Section 3 shows the research model. In
Section 4, the research experiments are presented along with the results and an evaluation of the performance. In
Section 5, the relevant discussion is presented.
Section 6 provides the conclusions and direction for further work.
2. Methods and Techniques for Generating Workplace Procedures
Industry 4.0 provides new opportunities to support the training process of new employees in the company. The use, in manufacturing, of virtual reality (VR), augmented reality (AR), and mixed reality (MR) in the education process [
8] has undoubted advantages, including providing operators with adequate feedback for their actions [
9]. However, it also makes it necessary for a company to invest in such solutions. Our proposed approach allows the expert operators’ specialist knowledge of assembly tasks to be transferred to new operators using a friendly set of instructions for the new employees in the form of a sequence of animated images.
In order to formalise the acquired specialist knowledge with the use of video recordings, it is necessary to apply image analysis methods. Previously, such methods dealt with the extraction of data or information from images [
10]. The result of this type of analysis is not the image but the data received, such as in the numerical form [
11,
12]. There are several techniques to analyse images for their distinguishing features. These techniques include Principal Component Analysis (PCA), the Singular Value Decomposition algorithm (SVD), and Linear Discriminant Analysis (LDA). PCA is a method for reducing dimensions and is used to reduce the size of large data sets by converting a set of variables to a smaller set that contains most of the information of the large set [
10,
13,
14,
15]. PCA relies on processing a large amount of information contained in mutually correlated input data into a set of new data, with orthogonally corresponding features. SVD decomposes the given matrix into three parts: the left singular matrix, the right singular matrix, and a singular matrix [
16,
17]. LDA is a dimension reduction technique in machine learning. It is a supervised learning method where labelled data are used for training [
18]. LDA is most commonly used as a dimensionality reduction technique in the pre-processing step for pattern-classification and machine learning applications. In this method, the dimensions of the projection subspace are related to the number of data classes and remain independent of the data’s dimensions. Linear discriminant analysis is the projection of the normal vector in the linear discriminant hyperplane and renders the distance between the classes as the largest and the distance within the classes as the smallest [
18].
SVD has been successfully applied to signal processing (speaker verification systems) [
19], image processing (noise filtering, watermarking) [
20], image compression [
21], and big data, e.g., in genomic signal processing (transforming genome-wide expression data and analysis of genome-scale data) [
22,
23]. PCA is also used in signal processing (diagnosing and predicting machine damage) [
24,
25], image processing (extracting image features) [
26], and analysis (pattern recognition and image compression) [
27]. The case for LDA looks very similar. Here, this technique is also applied to image processing and analysis (facial recognition) [
28,
29]. There is a research gap in the literature on the application of SVD, PCA, and LDA techniques to the generation of workstation instructions based on previously recorded video material.
In the context of the image analysis needed in companies compatible with the concept of Industry 4.0, the most frequent methods used are classification algorithms, the Decision Tree (DT), K-Nearest Neighbour (KNN), Perceptron, Random Forest, Bayes Algorithm, and the Support Vector Machine (SVM). DTs are tree-structured models for classification and regression [
30]. The Decision Tree is a tree in which the nodes correspond to the tests carried out on the values of the attributes of the rules. The branches are possible results of such tests, and the leaves represent the decision part. A decision tree is a structure in which each internal node, not the leaf, is labelled with an input feature. The arcs coming from a node labelled with this feature are labelled with each of the possible values of the feature. Each leaf of the tree is labelled with a class or a probability distribution over the classes [
31]. The K Nearest Neighbours method belongs to the group of lazy algorithms, i.e., those that do not form the internal representation of the training data but look for a solution only when the test pattern appears for such as classification. This method stores all training patterns for which the distance of the test pattern is determined [
32]. When using a neural network as a classifier, the input signals are image features that have been previously detected. The number of input neurons is equal to the number of features analysed, while the outputs are as numerous as the image classes. The connection of the input vector with the neurons of the output layer is usually complete, i.e., each input node is connected to each output neuron. Connections are represented by the matrix of connection weights W [
33,
34]. Random Forest is a machine learning method for classification, regression and other tasks that involve the construction of many decision trees during learning and generating a class that influences or controls the classes (classification) or predicted means (regression) of individual trees [
35]. The Algorithm of bi- and multi-class classification is also known as Random Forest and Decision Forest. In both cases, the idea of functioning is almost identical and is based on classification using a group of decision trees; the biggest difference in the construction of both algorithms is the so-called bootstrap. The simple Bayesian classifier is an uncomplicated, probabilistic classifier used in machine learning methods to solve the problems of sorting and classification [
36,
37]. The task of the Bayes classifier is to assign a new case to one of the decision classes, while the set of decision classes must be finite and defined a priori.
Decision trees, Perceptron, Random Forest, The Bayesian Classifier, SVM, and K-Nearest Neighbour are commonly used techniques for image classification. Decision Tree, SVM, and K-NN are used for satellite image classification [
38]. Decision trees are used for image processing and image mining (that is, the mining of large datasets of different image types) [
39]. Random Forest is used for image analysis (that is, landscape analysis and the analysis of satellite images) [
40], and processing, which is a tool in medicine to diagnose disease [
41] by classifying images according to the object categories they contain, in the case of a large number of object categories [
42]. The Bayes Classifier is used in medicine [
43]. The K-NN technique is used for image recognition, in areas such as facial recognition [
44]. Perceptron, K-NN, and the Bayes Classifier are also used in weather forecasting [
45]. The Bayes Classifier and K-NN are also used in fraud detection [
46]. In the context of improving the management and effectiveness of employee learning processes in manufacturing companies, we did not find any sources that presented the use of these techniques for generating workstation instructions based on pre-recorded video material.
In order to address the above issues, our work proposes a new methodology for the generation of workplace procedures, in which CNN-SVM architecture is also applied. To the best of our knowledge, there is no existing work available on enabling CNNs and SVMs to generate workplace procedures. One important positive aspect of CNNs are their “learning features”, i.e., omitting the manual functions that are necessary for other types of networks. Feature extraction is an important element in the success of a recognition system [
47]. CNN features are automatically taught. One of the strengths of CNN is that they can be invariant, in the case of transformations like translation, scaling, and rotation. Invariance, rotation, and scale are three of the most important assets of CNN, especially in problems with image recognition, such as object detection, because they allow the abstraction of identity, so the network can effectively recognise the object in cases where the real pixel values in the image can vary significantly. In the case of problems with facial recognition, CNN has changed the facial recognition field, thanks to its learning characteristics and the transformation of its features. For example, Google FaceNet and Facebook DeepFace are based on CNNs. The CNN is arguably the most popular deep learning architecture, with CNNs now being the go-to model for every image related problem; in terms of accuracy, they have no peer. CNNs have also been successfully applied to recommender systems, natural language processing, and more. CNNs have also been used in the realm of networking and, more specifically, in the traffic classification of mobile applications [
48].
The main advantage of the CNN, compared to its predecessors, is that it automatically detects [
49] important features without any human supervision. For example, given many pictures of cats and dogs, it learns distinctive features for each class by itself. A CNN is also computationally efficient. It uses special convolution and pooling operations and performs parameter sharing. This enables CNN models to run on any device, making them universally attractive. CNN is a very powerful and efficient model, which performs automatic feature extraction in order to achieve superhuman accuracy to the point where, now, CNN models classify images better than humans do. Another main feature of CNNs is their weight sharing. In terms of performance, CNNs outperform NNs in conventional image recognition and many other tasks. For a completely new task or problem, CNNs are very good feature extractors. This means that useful attributes can be extracted from an already trained CNN, with its trained weights, by feeding data to each level and slightly tuning the CNN to the specific task, such as by adding a classifier after the last layer with labels specific to the task. This is also called pre-training, and CNNs are very efficient in such tasks compared to NNs. Another advantage of this pre-training is that we avoid training in CNNs and, thus, save memory and time. Convolutional Neural Networks take advantage of local spatial coherence in the input (often images), which allow them to have fewer weights, as some parameters are shared. This process, taking the form of convolutions, makes CNNs especially well-suited to extracting relevant information at low computational costs [
50].
For classification processes, most “deep learning” models employ the Softmax activation function for predictions and to minimise cross-entropy loss [
51,
52]. Replacing Softmax with linear SVMs gives significant gains for the popular deep learning datasets, MNIST, CIFAR-10, and the 2013 ICML representation Learning Workshop’s facial expression recognition challenge. SVM is a widely used alternative to Softmax for classification processes. First, a deep convolutional net is trained using supervised/unsupervised objectives to learn good, invariant, hidden, latent representations. The variables of the data samples are then treated as input and fed into linear SVMs. This technique can improve performance in the classification process. CNN-SVM was used during the development of a water leakage detection system [
53] and was also used to identify the spatiotemporal motion characteristics of a human [
54]. A comparison with state-of-the-art alternatives devised for image analysis applied to manufacturing (in the context of generating workstation instructions) is also done (
Table 1), illustrating the novel contributions of our approach.
In this paper, we limit the provisions of our experiments according to the structure of the CNN, to extract the frames’ features and the CNN-SVM for object classification. However, the principles behind the transformation of the underlying data and the overall EDLT framework are valid for other types of deep learning methods. As already pointed out, the proposed model allows knowledge of assembly tasks to be acquired from specialists and transferred to new people in the form of workplace procedures.
3. Model for Generating Workplace Procedures, in Real-Time, Using CNN-SVM Architecture
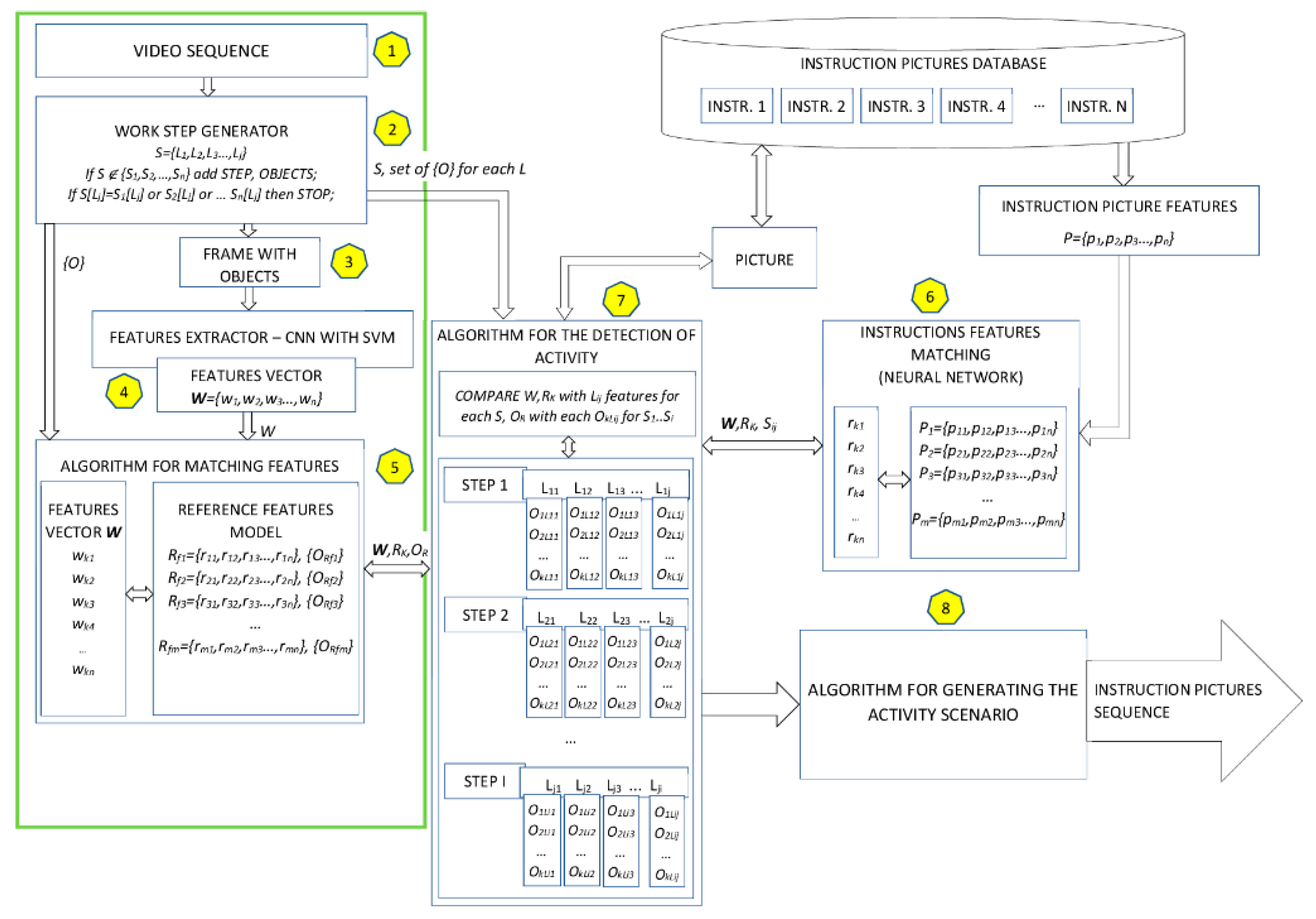
The proposed research model for generating workplace instructions using the convolutional neural network and SVM is presented below (
Figure 1).
where:
W—frame features vector, k, n ∈ N
Rm—reference features vector, f, m ∈ N
Sn—step (S) number (m) and work (L) number (j), n, j ∈ N
O—set of {O} for each L, L ∈ N
P—instruction features vector, n, m ∈ N.
At first, the employee’s specialist knowledge is obtained through video recording (Stage 1,
Figure 1). Next (Stage 2,
Figure 1), the conditions that allow the extraction of individual stages from the actions recorded on video are defined. It has been assumed that the rules are created according to:
- (1)
If S ∉ {S1, S2, …, Sn} add STEP, OBJECTS;
- (2)
If S[Lj] = S1[Lj] or S2[Lj] or … Sn[Lj] then STOP;
where:
Sn—is a step number
Lj—is a work number
n, j ∈ N.
Next, the frame for the video sequence was subjected to the input of the neural network. For each of the frames, a feature vector and the set of objects thereupon were generated.
In Stage 4 (
Figure 1), the architecture of CNN-SVM was employed as Resnet18 architecture, where: For experiments, the classification layer was changed from Softmax to SVM. The CNN network expresses the mapping between the objects on images and their classes. Conventionally, the Softmax function is the classifier used in the last layer of that kind of network. However, there have been studies in which a linear support vector machine (SVM) was used in an artificial neural network architecture. Studies proved that the CNN-SVM model was able to achieve a test accuracy of ≈99.04% using the MNIST dataset [
51].
conv1
conv2_x
conv3_x
conv4_x
conv5_x
average pool
fully connected
SVM
The total time complexity of all convolutional layers (1) is [
55]:
where
l is the index of a convolutional layer and
d is the depth (number of convolutional layers).
nl is the number of filters (also known as “width”) in the
l-th layer.
nl−1 is also known as the number of input channels of the
l-th layer.
sl is the spatial size (length) of the filter.
ml is the spatial size of the output feature map. The computational complexity of the SVM algorithm is between O(n
2) a O(n
3) [
56]. More specifically, the complexity is O(max(n,d) min (n,d)^2), where n is the number of points, and d is the number of dimensions [
57].
In Stage 5, an algorithm for matching features (
Table 2) was developed. The use of this algorithm enables the features of the individual frames of the analysed and defined video sequence to be determined according to the characteristics of the reference frames stored in the system.
where:
i,j—loop counters
m—number of reference features vector
n—number of reference features vector elements
matching[]—a matrix of compatibility of vectors elements
wj—frame vector element
rij—reference features vector element
z—index of matching[] matrix.
The computational complexity of this algorithm is O(nm) + O(n).
In Stage 6 (
Figure 1), the database contains examples of animated illustrations matching the task for which the real-time workplace procedure generation was built. Next to be extracted (using CNN for each image feature) were:
where:
Pm—instruction features vector
pn—is a single feature of a vector frame
rkn—is a feature of the reference frame features vector R, where Rk1 = {rk1, rk2, rk3 …, rkn}
n, m ∈ N
In Stage 7 (
Figure 1), an algorithm for the detection of activity (
Table 3) was developed. The task of this algorithm is to analyse the characteristics of individual frames in the video sequence along with the reference features of these sequences and compare them with the characteristics of each step of the the service activity performed. In addition, information about the objects registered in the reference model and objects of a particular service step is compared.
where:
i,j—loop counters
x—number of steps
y—number of works
Step—index of step
Work—index of work
wj—frame vector element
rij—reference of features vector element
Si[Lij]—the element of the features vector for i step
OR—a set of objects for analysed frame
OLij—a set of objects for work
The computational complexity of this algorithm is O (nm).
An algorithm for generating the activity scenario (Stage 8,
Figure 1) enables analysis of the model video material to be carried out which, in turn, allows the video frames responsible for the various stages of service activities to be identified. The algorithm that creates the activity scenario (
Table 4) will generate a set of graphical instructions on the output depending on the activity currently performed by the employee.
where:
i,j,k—loop counters
S[]—a matrix of steps
Ls[]—a matrix of works for each step
scenario[]—a matrix instruction picture
z—index of the picture
LSij—element of work feature vector for each step
Pk—element of instruction feature vector
The computational complexity of this algorithm is O (nmk).
As the result of the use of the proposed algorithm, we can obtain a sequence of instruction pictures for a workplace procedure. Our whole proposed approach enables acquired specialist knowledge to be transformed into a useful form for new employees in the company. The use of our model eliminates the need for an experienced employee to participate in the process of educating new employees and shows increased effectiveness for this process in the company.
In our research model (
Figure 1), the area marked in green includes elements of the model used during the experiment, while individual elements, marked with numbers, are explained in the description of the experiments and placed under the picture (based on the example of the repair of a solid fuel boiler).
4. Research Experiments
The aim of this experiment was to determine features and information about the occurrence of objects on each frame of video material and compare them with a test recording. In the next stage, the features of individual video frames were analysed for similarities. This whole process will allow future comparison of the video sequence obtained from the camera that recorded the employee’s actions within a reference sequence. This, in turn, will be the basis of the algorithm for generating the activity scenario.
The experiment was videoed and presents the implementation of a single service operation, namely the procedure for repairing a solid fuel boiler.
In the first stage (
Figure 1), the following sets of learning data were prepared (with the network being trained based on these sets):
Reference material in the form of a video sequence, from which single frames were extracted as reference objects for the frames of the test material.
Test video material, lasting about 13 s, also processed to form single frames (30 frames per second) from the 407 images. In addition to the collection, modified single frames were added that did not contain some of the objects, viz., they had no key and no bucket. Also inserted were several sets of frames, which were the final stages of the service activity performed (that is, a set of frames depicting the activity performed from the back). This collection totaled 597 frames. Assuming 30 frames per second, the video material obtained in this way takes about 20 s.
The training set of the 3000 images from the network containing objects consisted of a hand, a flat key, a geared motor, an organizer, a burner auger, and a bucket.
For research purposes, the reference frames came from the same video material as the test frames. However, the reference frames were removed from the test set.
In Stage 2 (
Figure 1), the conditions that allow the extraction of individual stages in the action recorded on the video are defined:
Motoreductor + hand—START CONDITION
Motoreductor + hand + bucket
Motoreductor + hand + bucket + key
Motoreductor + hand + bucket + organiser
Motoreductor + hand + bucket + organiser + burner auger
Motoreductor + hand + bucket + organizer—STOP CONDITION
Conditions were defined manually.
Next, the frame of the test video sequence was subjected to the input of the neural network. For each frame, a feature vector and the set of objects on it were generated.
In Stage 4 (
Figure 1), an experiment was carried out in the MATLAB 2019a programme using the ResNet-18 network structure, in which the classification layer was changed from Softmax to SVM. SVM is designed for classification and regression tasks. For linearly separable data, the Support Vector Machine method allows a hyperplane to be established, thereby dividing the data set into two classes with a maximum separation margin. For linearly non-separable data a hyperplane that classifies objects with a minimum of error can be defined. When creating a hyperplane, keep in mind that the maximum margin of trust or margin of separation is the distance of the hyperplane from the nearest data [
51,
52].
In the next stage, the vectors of the referenced frame features, along with the set of objects for these frames and the vectors of the test frames (also with the set of objects on these frames) were compared using the algorithm for matching features (Stage 5,
Figure 1).
Reference frames with objects representing individual activities are shown in
Table 5.
Results for the comparison of features are presented in
Table 6.
Results for the comparison of sets of objects for CNN -SVM are presented in
Table 7.
Results for the comparison of sets of objects for CNN-Softmax are presented in
Table 8.
The accuracy test was carried out on a set consisting of 3000 images. The network was trained and then subjected to class object prediction tests from photos. For the CNN with an SVM classifier, the accuracy was 98.14%. For the CNN with Softmax, the accuracy was 97.83%
The results of the experiment indicate that the video material, which is the basis upon which the system is taught and tested at the same time, is able to meet the task of controlling the work performed based on similarities of the features of individual system frames. However, how exactly the system will behave for other video materials recorded at the workstation should be determined.
For the analysis of objects occurring in individual frames, the CNN-SVM detected three types of objects out of six possible objects. CNN-Softmax detected only 1 object. Objects that were detected on the image by CNN-SVM were the hand, the motoreductor, and the bucket. Objects that were not detected correctly by CNN-SVM were the key, the burner auger, and the organiser. For CNN-Softmax, the only detected object was the bucket.
In the case of the burner auger and the organiser, the system classified the objects detected as the motoreductors. In the case of the key, the system detected the hand. This situation may have arisen on account of the:
The presence of another object or part thereof on the frame analysed;
The small size of the object appearing on the frame (this being the key);
Too few training samples (500 for each class);
The low resolution of the analysed image; in the CNN network used, it was 227 × 227 pixels.





{kind=link}