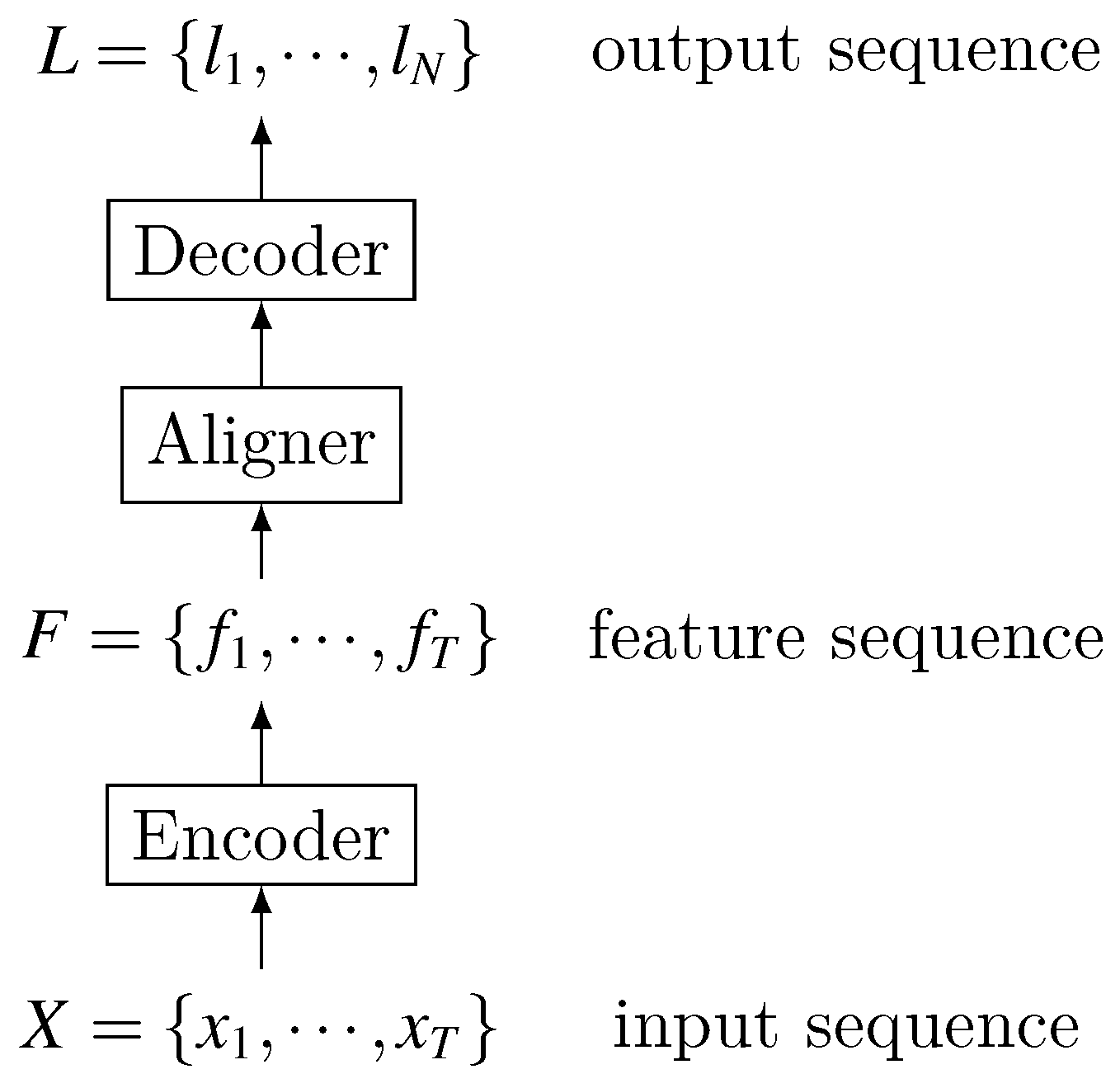
An Overview of End-to-End Automatic Speech Recognition


Abstract
1. Introduction
2. Background of Automatic Speech Recognition
2.1. History of ASR
2.2. Models for LVCSR
2.2.1. HMM-Based Model
- Acoustic model : It indicates the probability of observing X from hidden sequence S. According to the probability chain rule and the observation independence hypothesis in HMM (observations at any time depend only on the hidden state at that time), can be decomposed into the following form:In the acoustic model, is the observation probability, which is generally represented by GMM. The posterior probability distribution of hidden state can be calculated by DNN method. These two different calculations of result into two different models, namely HMM-GMM and HMM-DNN. For a long time, HMM-GMM model is a general structure for speech recognition. With the development of deep learning technology, DNN is introduced into speech recognition for acoustic modeling [19]. The role of DNN is to calculate the posterior probability of the HMM state, which may be transformed into likelihoods, replacing the conventional GMM observation probability [18]. Thus, HMM-GMM model is developed into HMM-DNN, which achieves better results than HMM-GMM and becomes state-of-the-art ASR model.
- Pronunciation model : this is also called the dictionary. Its role is to achieve the connection between acoustic sequence and language sequence. The dictionary includes various levels of mapping, such as pronunciation to phone, phone to trip-hone. The dictionary is not only used to achieve structural mapping, but also to map the probability calculation relationship.
- Language model : is trained by a large amount of corpus, using order Markov hypothesis to generate a m-gram language model.
- The training process is complex and difficult to be globally optimized. HMM-based model often uses different training methods and data sets to train different modules. Each module is independently optimized with their own optimization objective functions which are generally different from the true LVCSR performance evaluation criteria. So the optimality of each module does not necessarily mean the global optimality [21,22].
- Conditional independent assumptions. To simplify the model’s construction and training, the HMM-based model uses conditional independence assumptions within HMM and between different modules. This does not match the actual situation of LVCSR.
2.2.2. End-to-End Model
- Multiple modules are merged into one network for joint training. The benefit of merging multiple modules is that there is no need to design many modules to realize the mapping between various intermediate states [23]. Joint training enables the end-to-end model to use a function that is highly relevant to the final evaluation criteria as a global optimization goal, thereby seeking globally optimal results [22].
- It directly maps input acoustic signature sequence to the text result sequence, and does not require further processing to achieve the true transcription or to improve recognition performance [24], whereas in the HMM-based models, there is usually an internal representation for pronunciation of a character chain. Nevertheless, character level models are known with some traditional architectures, too.
- CTC-based: CTC first enumerates all possible hard alignments (represented by the concept path), then it achieves soft alignment by aggregating these hard alignments. CTC assumes that output labels are independent of each other when enumerating hard alignments.
- RNN-transducer: it also enumerates all possible hard alignments and then aggregates them for soft alignment. But unlike CTC, RNN-transducer does not make independent assumptions about labels when enumerating hard alignments, so it is different from CTC in terms of path definition and probability calculation.
- Attention-based: this method no longer enumerates all possible hard alignments, but uses Attention mechanism to directly calculate the soft alignment information between input data and output label.
3. CTC-Based End-to-End Model
- Data alignment problem. CTC no longer needs to segment and align training data. This solves the alignment problem so that DNN can be used to model time-domain features, which greatly enhances DNN’s role in LVCSR tasks.
- Directly output the target transcriptions. Traditional models often output phonemes or other small units, and further processing is required to obtain the final transcriptions. CTC eliminates the need for small units and direct output in final target form, greatly simplifying the construction and training of end-to-end model.
3.1. Key Ideas of CTC
3.1.1. Path Probability Calculation
3.1.2. Path Aggregation
- Merge the same contiguous labels. If consecutive identical labels appear in the path, merge them and keep only one of them. For example, for two different paths “c-aa-t-” and “c-a-tt-”, they are aggregated according to the above principles to give the same result: “c-a-t-”.
- Delete the blank label “-” in the path. Since label “-” indicates that there is no output, it should be deleted when the final label sequence is generated. The above sequence “c-a-t-”, after being aggregated according to the present principle, becomes final sequence “cat”.
3.2. CTC-Based Works
3.2.1. Model Structure
3.2.2. Large-Scale Data Training
3.2.3. Language Model
4. RNN-Transducer End-to-End Model
- CTC cannot model interdependencies within the output sequence because it assumes that output elements are independent of each other. Therefore, CTC cannot learn the language model. The speech recognition network trained by CTC should be treated as only an acoustic model.
- CTC can only map input sequences to output sequences that are shorter than it. For scenarios where output sequence is longer, CTC is powerless. This can be easily analyzed from CTC’s calculation process.
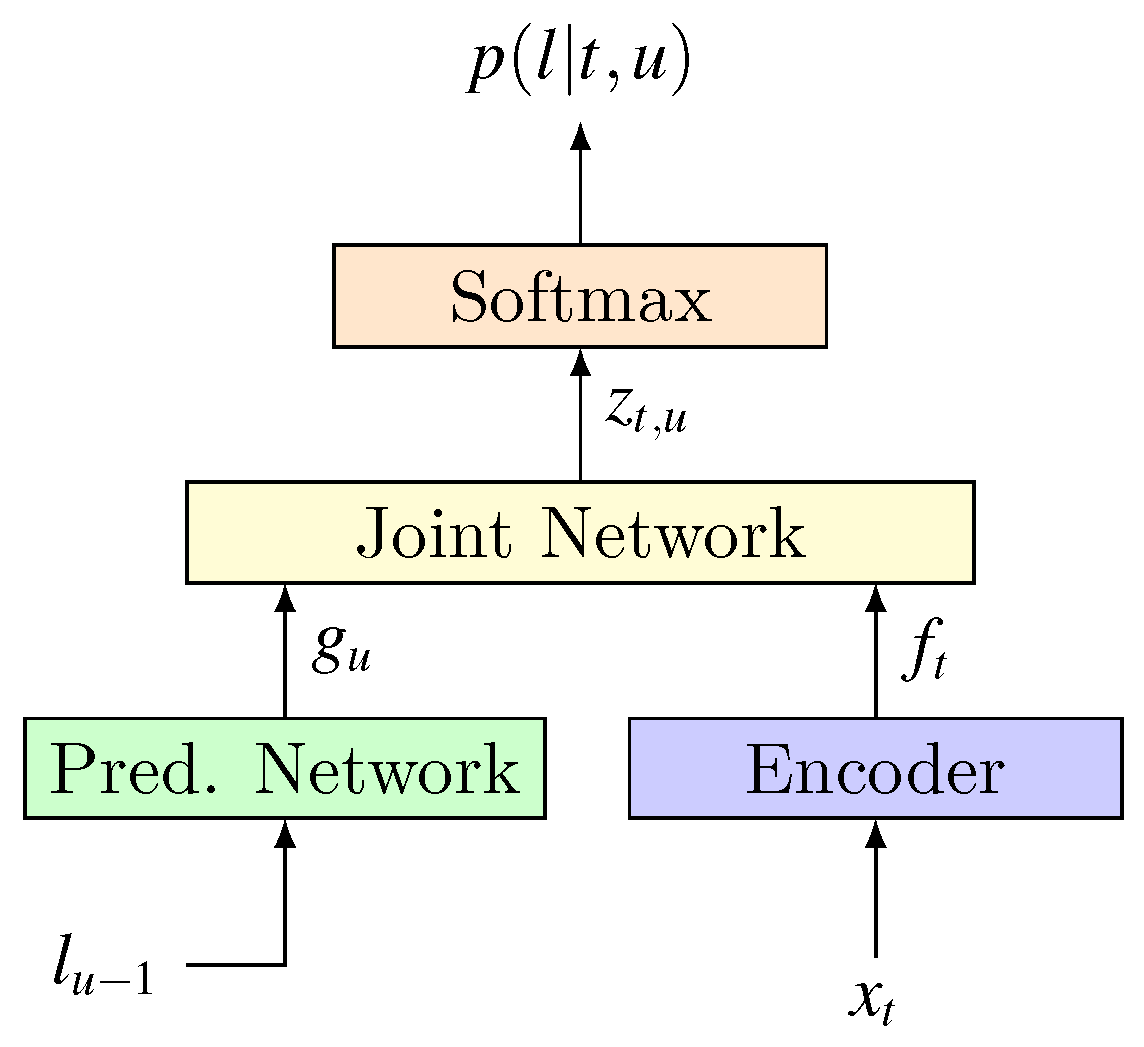
4.1. Key Ideas of RNN-Transducer
- Transcription network (): this is the encoder, which plays the role of an acoustic model. Regardless of sub sampling technique, for an acoustic input sequence of length T, map it to a feature sequence . Correspondingly, for input value at any time t, Transcription network is used as an acoustic model with an output value , which is a dimensional vector.
- Prediction network (): It’s part of the Decoder that plays the role of language model. As an RNN network, it models the interdependencies within output label sequence (while transcription network models the dependencies within acoustic input). maintains a hidden state and an output value for any label location . Their loop calculation process isLater in the analysis of joint networks we will point out that the calculation of depends on . So the above loop process actually means using the output sequence in the first positions to determine the choice of . For simplicity, we can express this relationship as . is also a dimension vector.
- Joint network (): it does the alignment job between input and output sequence. For any , , the joint network uses the transcription network’s output and the prediction network’s output to calculate the label distribution at output location u:As we can see, is a function of and . Since comes from , comes from the sequence , so the joint network’s role is: for a given historical output sequence and input at time t, it calculates the label distribution at the output location u, which provides probability distribution information for decoding process.
- Since one input data can generate a label sequence of arbitrary length, theoretically, the RNN-transducer can map input sequence to an output sequence of arbitrary length, whether it is longer or shorter than the input.
- Since the prediction network is an RNN structure, each state update is based on previous state and output labels. Therefore, the RNN-transducer can model the interdependence within output sequence, that is, it can learn the language model knowledge.
- Since Joint Network uses both language model and acoustic model output to calculate probability distribution, RNN-Transducer models the interdependence between input sequence and output sequence, achieving joint training of language model and the acoustic model.
4.2. RNN-Transducer Works
- Experiments show that the RNN-transducer is not easy to train. Therefore, it is necessary for each part to be pre-trained, which is very important for improving performance.
- Thd RNN-transducer’s calculation process includes many obviously unreasonable paths. Even if there are some improving works, it is still unavoidable. In fact, all speech recognitions that first enumerate all possible paths and then aggregate them face this problem, including CTC.
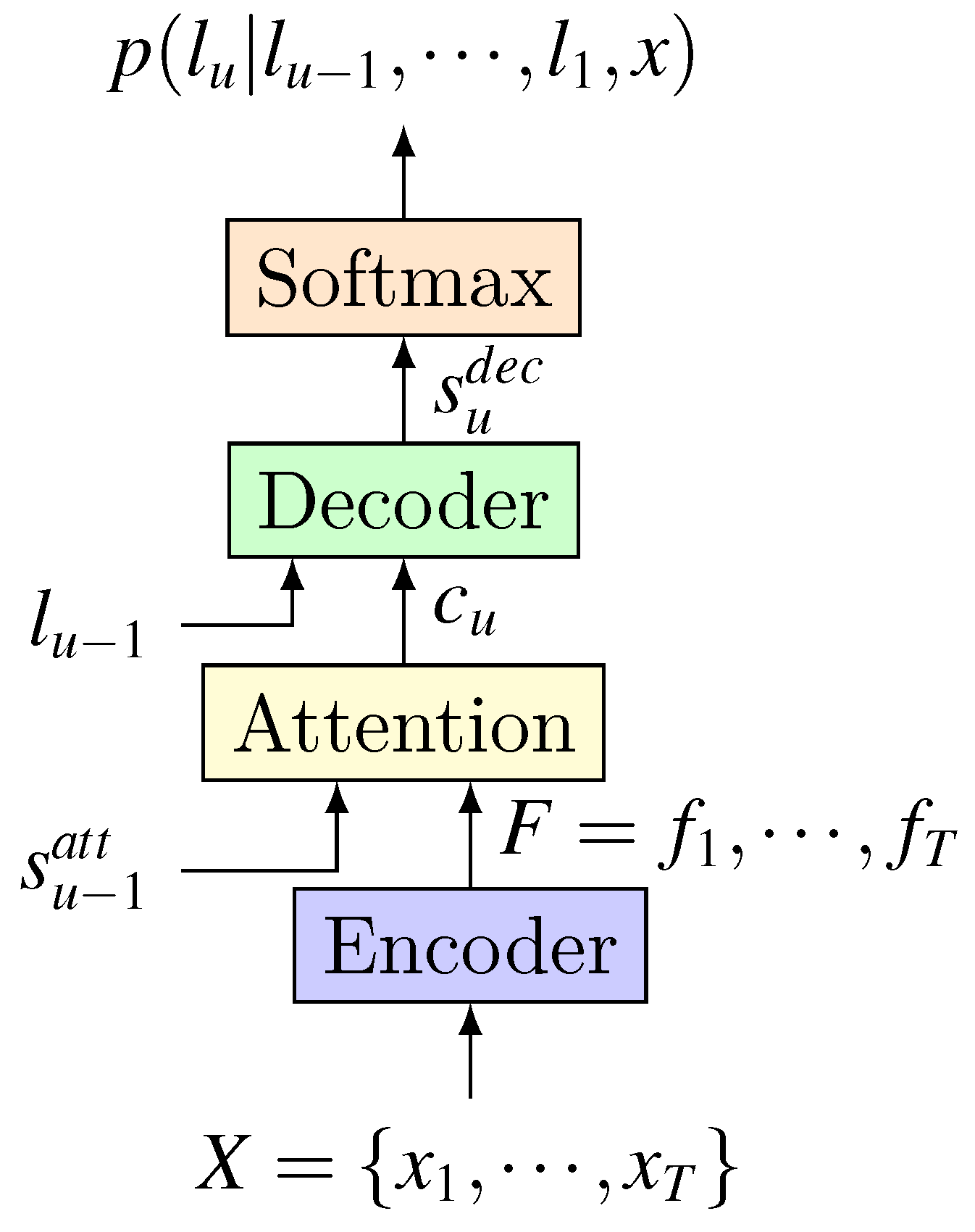
5. Attention-Based End-to-End Model
- Speech recognition is also a sequence-to-sequence process that recognizes the output sequence from the input sequence. So it is essentially the same as translation task.
- The encoder–decoder method using an attention mechanism does not require pre-segment alignment of data. With attention, it can implicitly learn the soft alignment between input and output sequences, which solves a big problem for speech recognition.
- Encoding result is no longer limited to a single fixed-length vector, the model can still have a good effect on long input sequence, so it is also possible for such model to handle speech input of various lengths.
5.1. Works on the Encoder
5.1.1. Delay and Information Redundancy
5.1.2. Network Structure
5.2. Works on Attention
- Context-based: it uses only the input feature sequence F and the previous hidden state to calculate the weight at each position. Ref. [46] used this method. Its problem is that it does not use position information. For a feature’s different appearances in the feature sequence, context-based attention will give them same weights, which is called similarity speech fragment problem.
- Location-based: the previous weight is utilized as location information at each step to calculate current weight . But since it does not use the input feature sequence F, it is not sufficient for input features.
- Hybrid: as the name implies, it takes into account the input feature sequence F, the previous weight , and the previous hidden state , which enables it to combine advantages of context-based and location-based attention.
5.2.1. Continuity Problem
5.2.2. Monotonic Problem
5.2.3. Inaccurate Extraction of Key Information
- In the weights calculated by softmax, every item is greater than zero, which means that every feature of the feature sequence will be retained in the context information obtained by attention. This introduces unnecessary noise characteristics and retains some information that should not be retained in .
- Softmax itself concentrates the probability on the largest item, causing attention to focus mostly on one feature, while other features that have positive effects and should be retained are not fully preserved.
- It introduced a scale value greater than unity in softmax operation, which can enlarge greater weight and shrink smaller one. This method can attenuate the problem of noise characteristics, but makes the probability distribution more concentrated to the feature items with higher probability.
- After having calculated the weight of softmax, it only retains the largest k values and then normalizes them again. This method increases the amount of attention calculation.
- Window method. A calculation window and a window sliding strategy are set in advance, and attention’s weights are calculated by softmax only for data in the window.
5.2.4. Delay
5.3. Works on Decoder
6. Comparison and Conclusions
6.1. Model Characteristics Comparison
- Delay: the forward-backward algorithm used by CTC can adjust the probability of decoding results immediately after receiving a encoding result without waiting for other information, so CTC-based model has the shortest delay. RNN-Transducer model is similar to CTC in that it also adjusts the probability of decoding results immediately after each acquisition of an encoding result. However, since it uses not only the encoding result but also the previous decoding output in the forward-backward calculation at each step, its delay is higher compared to CTC. But, they all support streaming speech recognition, where recognition results are generated the same time speech signals are produced. Attention-based model has the longest delay because it needs to wait until all the encoding results are generated before soft alignment and decoding can start. So streaming speech recognition is not supported unless some corresponding compromise is made.
- Computational complexity: In the process of calculating the probability of L of length N based on X of length T, CTC technology needs to do a softmax on each input time step with a complexity of . RNN-transducer technology requires a softamx operation on each input/output pair with a complexity of . The primitive attention, like RNN-transducer, also requires a softamx operation on each input/output pair with complexity. However, as more and more attention mechanism uses window mechanisms, attention-based model only needs to perform softmax operation on the input segments in the window when outputting each label, and its complexity is reduced to , .
- Language modeling capabilities: CTC assumes that output labels are independent of each other, so it has no ability to model language. RNN-transducer enables models with language model ability through the joint network, while attention-based models achieves this through decoder network.
- Training difficulty: CTC is essentially a loss function, and there is no weight to train in itself. Its role is to train an acoustic model. Therefore, the CTC-based network model can quickly achieve optimal results. Attention mechanism and the joint network in RNN-transducer model introduce weights and functions that require training, and because of the joint training of language model and acoustic model, they are much more difficult to train than CTC-based models. In addition, RNN-transducer’s joint network will generate a lot of unreasonable data alignment between input and output. So it is more difficult to train than attention-based models. Generally, it needs to pre-train the prediction network and transcription network to have better performance.
- Recognition accuracy: due to the modeling of linguistic knowledge, recognition accuracies of RNN-Transducer and attention-based model are much higher than that of CTC-based model. In most cases, the accuracy of attention-based model is higher than RNN-transducer.
6.2. Model Recognition Performance Comparison
- Without external language model, CTC-based model has the worst effect, and the gap between it and other models is very large. This is consistent with our analysis and expectation of CTC: it makes a conditional independent assumption of the output and cannot learn language model knowledge itself.
- Compared with CTC, RNN-transducer has been greatly improved on all test sets because compared to CTC, it uses Prediction network to learn language knowledge.
- Attention-based model is the best of all end-to-end, and the two-layer decoder is better than the one-layer Decoder. This shows that decoder’s depth also has an impact on the results.
7. Future Works
- Model delay. CTC-based and RNN-transducer models are monotonic and support streaming decoding, so they are suitable for online scenarios with low latency. However, their recognition performance is limited. Attention-based models can effectively improve the recognition performance, but it is not monotonous and has long delay. Although there are methods such as “window” to reduce the delay of attention, they may reduce the recognition performance to a certain extent [65]. Therefore, reducing latency while ensuring performance is an important research issue for the end-to-end model.
- Language knowledge learning. HMM-based model uses additional language models to provide a wealth of language knowledge, while all the language knowledge of the end-to-end model comes only from training data’s transcriptions, whose coverage is very limited. This leads to great difficulties in dealing with scenes with large linguistic diversity. Therefore, the end-to-end model needs to improve its learning of language knowledge while maintaining the end-to-end structure.
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| LPC | Linear predictive coding |
| TIMIT | Texas Instruments, Inc. and the Massachusetts Institute of Technology |
| PER | Phoneme error rate |
| WSJ | Wall street journal |
| HMM | Hidden Markov model |
| GMM | Gaussian mixed model |
| DNN | Deep neural network |
| CTC | Connectionist temporal classification |
| RNN | Recurrent neural network |
| ASR | Automatic speech recognition |
| LVCSR | Large vocabulary continuous speech recognition |
| CD | Context-dependent |
| CNN | Convolutional neural network |
| LSTM | Long short time memory |
| GPU | Graphics processing unit |
| OpenMPI | Open message passing interface |
| LM | Language model |
| WER | Word error rate |
| LAS | Listen, attend and spell |
| CDF | Cumulative distribution function |
| BLSTM | Bi-directional long short time memory |
| GRU | Gated recurrent unit |
References
- Bengio, Y. Markovian models for sequential data. Neural Comput. Surv. 1999, 2, 129–162. [Google Scholar]
- Chengyou, W.; Diannong, L.; Tiesheng, K.; Huihuang, C.; Chaojing, T. Automatic Speech Recognition Technology Review. Acoust. Electr. Eng. 1996, 49, 15–21. [Google Scholar]
- Davis, K.; Biddulph, R.; Balashek, S. Automatic recognition of spoken digits. J. Acoust. Soc. Am. 1952, 24, 637–642. [Google Scholar] [CrossRef]
- Olson, H.F.; Belar, H. Phonetic typewriter. J. Acoust. Soc. Am. 1956, 28, 1072–1081. [Google Scholar] [CrossRef]
- Forgie, J.W.; Forgie, C.D. Results obtained from a vowel recognition computer program. J. Acoust. Soc. Am. 1959, 31, 1480–1489. [Google Scholar] [CrossRef]
- Juang, B.H.; Rabiner, L.R. Automatic speech recognition–a brief history of the technology development. Georgia Inst. Technol. 2005, 1, 67. [Google Scholar]
- Suzuki, J.; Nakata, K. Recognition of Japanese vowels—Preliminary to the recognition of speech. J. Radio Res. Lab. 1961, 37, 193–212. [Google Scholar]
- Sakai, T.; Doshita, S. Phonetic Typewriter. J. Acoust. Soc. Am. 1961, 33, 1664. [Google Scholar] [CrossRef]
- Nagata, K.; Kato, Y.; Chiba, S. Spoken digit recognizer for Japanese language. Audio Engineering Society Convention 16. Audio Engineering Society. 1964. Available online: http://www.aes.org/e-lib/browse.cfm?elib=603 (accessed on 4 August 2018).
- Itakura, F. A statistical method for estimation of speech spectral density and formant frequencies. Electr. Commun. Jpn. A 1970, 53, 36–43. [Google Scholar]
- Vintsyuk, T.K. Speech discrimination by dynamic programming. Cybern. Syst. Anal. 1968, 4, 52–57. [Google Scholar] [CrossRef]
- Atal, B.S.; Hanauer, S.L. Speech analysis and synthesis by linear prediction of the speech wave. J. Acoust. Soc. Am. 1971, 50, 637–655. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.F. On large-vocabulary speaker-independent continuous speech recognition. Speech Commun. 1988, 7, 375–379. [Google Scholar] [CrossRef]
- Tu, H.; Wen, J.; Sun, A.; Wang, X. Joint Implicit and Explicit Neural Networks for Question Recommendation in CQA Services. IEEE Access 2018, 6, 73081–73092. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Luo, L.; Huang, D.F.; Wen, M.; Zhang, C.Y. Exploiting a depth context model in visual tracking with correlation filter. Front. Inf. Technol. Electr. Eng. 2017, 18, 667–679. [Google Scholar] [CrossRef]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 30–42. [Google Scholar] [CrossRef]
- Rao, K.; Sak, H.; Prabhavalkar, R. Exploring architectures, data and units for streaming end-to-end speech recognition with RNN-transducer. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 193–199. [Google Scholar] [CrossRef]
- Lu, L.; Zhang, X.; Cho, K.; Renals, S. A study of the recurrent neural network encoder-decoder for large vocabulary speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3249–3253. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. DeepSpeech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Miao, Y.; Gowayyed, M.; Metze, F. EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 167–174. [Google Scholar] [CrossRef]
- Zhang, Y.; Pezeshki, M.; Brakel, P.; Zhang, S.; Laurent, C.; Bengio, Y.; Courville, A. Towards End-to-End Speech Recognition with Deep Convolutional Neural Networks. arXiv 2017. [Google Scholar] [CrossRef]
- Graves, A.; Jaitly, N. Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21 June–26 June 2014; pp. 1764–1772. [Google Scholar]
- Hori, T.; Watanabe, S.; Zhang, Y.; Chan, W. Advances in Joint CTC-Attention Based End-to-End Speech Recognition with a Deep CNN Encoder and RNN-LM. arXiv 2017, arXiv:1706.02737, 949–953. [Google Scholar]
- Kim, S.; Hori, T.; Watanabe, S. Joint CTC-attention based end-to-end speech recognition using multi-task learning. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4835–4839. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Eyben, F.; Wöllmer, M.; Schuller, B.; Graves, A. From speech to letters-using a novel neural network architecture for grapheme based asr. In Proceedings of the 2009 IEEE Workshop on Automatic Speech Recognition & Understanding, Merano/Meran, Italy, 13–17 December 2009; pp. 376–380. [Google Scholar]
- Li, J.; Zhang, H.; Cai, X.; Xu, B. Towards end-to-end speech recognition for Chinese Mandarin using long short-term memory recurrent neural networks. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3615–3619. [Google Scholar]
- Hannun, A.Y.; Maas, A.L.; Jurafsky, D.; Ng, A.Y. First-pass large vocabulary continuous speech recognition using bi-directional recurrent DNNs. arXiv 2014, arXiv:1408.2873. [Google Scholar]
- Maas, A.; Xie, Z.; Jurafsky, D.; Ng, A. Lexicon-free conversational speech recognition with neural networks. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 345–354. [Google Scholar]
- Sak, H.; Senior, A.W.; Rao, K.; Beaufays, F. Fast and accurate recurrent neural network acoustic models for speech recognition. arXiv 2015, arXiv:1507.06947, 1468–1472. [Google Scholar]
- Song, W.; Cai, J. End-to-end deep neural network for automatic speech recognition. Standford CS224D Rep. 2015. Available online: https://cs224d.stanford.edu/reports/SongWilliam.pdf (accessed on 14 August 2019).
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 173–182. [Google Scholar]
- Soltau, H.; Liao, H.; Sak, H. Neural Speech Recognizer: Acoustic-to-Word LSTM Model for Large Vocabulary Speech Recognition. arXiv 2017, arXiv:1610.09975, 3707–3711. [Google Scholar]
- Zweig, G.; Yu, C.; Droppo, J.; Stolcke, A. Advances in all-neural speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4805–4809. [Google Scholar] [CrossRef]
- Audhkhasi, K.; Ramabhadran, B.; Saon, G.; Picheny, M.; Nahamoo, D. Direct Acoustics-to-Word Models for English Conversational Speech Recognition. arXiv 2017, arXiv:1703.07754, 959–963. [Google Scholar]
- Li, J.; Ye, G.; Zhao, R.; Droppo, J.; Gong, Y. Acoustic-to-word model without OOV. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 111–117. [Google Scholar] [CrossRef]
- Audhkhasi, K.; Kingsbury, B.; Ramabhadran, B.; Saon, G.; Picheny, M. Building Competitive Direct Acoustics-to-Word Models for English Conversational Speech Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4759–4763. [Google Scholar] [CrossRef]
- Prabhavalkar, R.; Rao, K.; Sainath, T.N.; Li, B.; Johnson, L.; Jaitly, N. A comparison of sequence-to-sequence models for speech recognition. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 939–943. [Google Scholar]
- Hwang, K.; Sung, W. Character-level incremental speech recognition with recurrent neural networks. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5335–5339. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, L.; Zhang, B.; Li, Z. End-to-End Mandarin Recognition based on Convolution Input. In Proceedings of the MATEC Web of Conferences, Lille, France, 8–10 October 2018; Volume 214, p. 01004. [Google Scholar]
- Graves, A. Sequence Transduction with Recurrent Neural Networks. Comput. Sci. 2012, 58, 235–242. [Google Scholar]
- Zue, V.; Seneff, S.; Glass, J. Speech database development at MIT: TIMIT and beyond. Speech Commun. 1990, 9, 351–356. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.r.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Sak, H.; Shannon, M.; Rao, K.; Beaufays, F. Recurrent Neural Aligner: An Encoder-Decoder Neural Network Model for Sequence to Sequence Mapping. In Proceedings of the INTERSPEECH, ISCA, Stockholm, Sweden, 20–24 August 2017; pp. 1298–1302. [Google Scholar]
- Dong, L.; Zhou, S.; Chen, W.; Xu, B. Extending Recurrent Neural Aligner for Streaming End-to-End Speech Recognition in Mandarin. arXiv 2018, arXiv:1806.06342, 816–820. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Cho, K.; Bengio, Y. End-to-end continuous speech recognition using attention-based recurrent nn: First results. In Proceedings of the NIPS 2014 Workshop on Deep Learning, Montreal, QC, Canada, 12 December 2014. [Google Scholar]
- Chorowski, J.K.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; pp. 577–585. [Google Scholar]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-end attention-based large vocabulary speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4945–4949. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Chan, W.; Lane, I. On Online Attention-Based Speech Recognition and Joint Mandarin Character-Pinyin Training. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 3404–3408. [Google Scholar]
- Chan, W.; Zhang, Y.; Le, Q.V.; Jaitly, N. Latent Sequence Decompositions. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Watanabe, S.; Hori, T.; Kim, S.; Hershey, J.R.; Hayashi, T. Hybrid CTC/attention architecture for end-to-end speech recognition. IEEE J. Sel. Top. Signal Process. 2017, 11, 1240–1253. [Google Scholar] [CrossRef]
- Hayashi, T.; Watanabe, S.; Toda, T.; Takeda, K. Multi-Head Decoder for End-to-End Speech Recognition. arXiv 2018, arXiv:1804.08050. [Google Scholar]
- Zhang, Y.; Chan, W.; Jaitly, N. Very deep convolutional networks for end-to-end speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4845–4849. [Google Scholar]
- Chorowski, J.; Jaitly, N. Towards better decoding and language model integration in sequence to sequence models. arXiv 2016, arXiv:1612.02695. [Google Scholar]
- Lu, L.; Zhang, X.; Renais, S. On training the recurrent neural network encoder-decoder for large vocabulary end-to-end speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5060–5064. [Google Scholar] [CrossRef]
- Chiu, C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-Art Speech Recognition with Sequence-to-Sequence Models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar] [CrossRef]
- Weng, C.; Cui, J.; Wang, G.; Wang, J.; Yu, C.; Su, D.; Yu, D. Improving Attention Based Sequence-to-Sequence Models for End-to-End English Conversational Speech Recognition. In Proceedings of the Interspeech ISCA, Hyderabad, Indian, 2–6 September 2018; pp. 761–765. [Google Scholar]
- Hou, J.; Zhang, S.; Dai, L. Gaussian Prediction Based Attention for Online End-to-End Speech Recognition. In Proceedings of the INTERSPEECH, ISCA, Stockholm, Sweden, 20–24 August 2017; pp. 3692–3696. [Google Scholar]
- Prabhavalkar, R.; Sainath, T.N.; Wu, Y.; Nguyen, P.; Chen, Z.; Chiu, C.; Kannan, A. Minimum Word Error Rate Training for Attention-Based Sequence-to-Sequence Models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4839–4843. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kingsbury, B. Lattice-based optimization of sequence classification criteria for neural-network acoustic modeling. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 3761–3764. [Google Scholar]
- Battenberg, E.; Chen, J.; Child, R.; Coates, A.; Li, Y.G.Y.; Liu, H.; Satheesh, S.; Sriram, A.; Zhu, Z. Exploring neural transducers for end-to-end speech recognition. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 206–213. [Google Scholar] [CrossRef]






{kind=link}
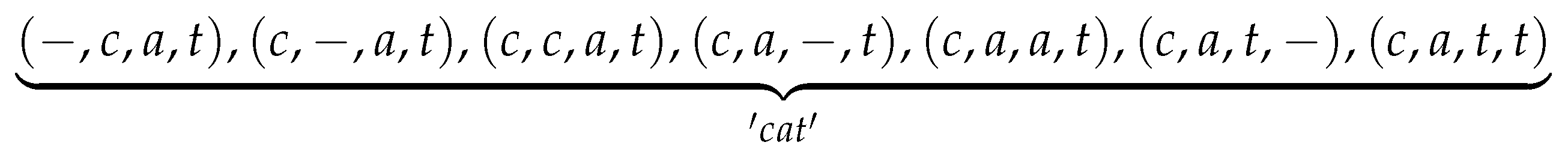{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Delay | Computation Complexity | Language Model Ability | Training Difficulty | Recognition Accuracy |
|---|---|---|---|---|---|
| CTC-based | × | ||||
| RNN-Transducer | √ | ||||
| Attention-based | √ |
| Model | Clean | Noisy | Numeric | ||
|---|---|---|---|---|---|
| Dict | vs | Dict | vs | ||
| Baseline Uni.CDP | 6.4 | 9.9 | 8.7 | 14.6 | 11.4 |
| Baseline BiDi.CDP | 5.4 | 8.6 | 6.9 | - | 11.4 |
| End-to-End systems | |||||
| CTC-Grapheme | 39.4 | 53.4 | - | - | - |
| RNN Transducer | 6.6 | 12.8 | 8.5 | 22.0 | 9.9 |
| RNN Trans.with att. | 6.5 | 12.5 | 8.4 | 21.5 | 9.7 |
| Att. 1-layer dec. | 6.6 | 11.7 | 8.7 | 20.6 | 9.0 |
| Att. 2-layer dec. | 6.3 | 11.2 | 8.1 | 19.7 | 8.7 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Wang, X.; Lv, S. An Overview of End-to-End Automatic Speech Recognition. Symmetry 2019, 11, 1018. https://doi.org/10.3390/sym11081018
Wang D, Wang X, Lv S. An Overview of End-to-End Automatic Speech Recognition. Symmetry. 2019; 11(8):1018. https://doi.org/10.3390/sym11081018
Chicago/Turabian StyleWang, Dong, Xiaodong Wang, and Shaohe Lv. 2019. "An Overview of End-to-End Automatic Speech Recognition" Symmetry 11, no. 8: 1018. https://doi.org/10.3390/sym11081018
APA StyleWang, D., Wang, X., & Lv, S. (2019). An Overview of End-to-End Automatic Speech Recognition. Symmetry, 11(8), 1018. https://doi.org/10.3390/sym11081018