Ranking of Normality Tests: An Appraisal through Skewed Alternative Space

Abstract
1. Introduction
2. Stringency Framework
3. Tests and Alternative Distributions
4. Discussion of Results
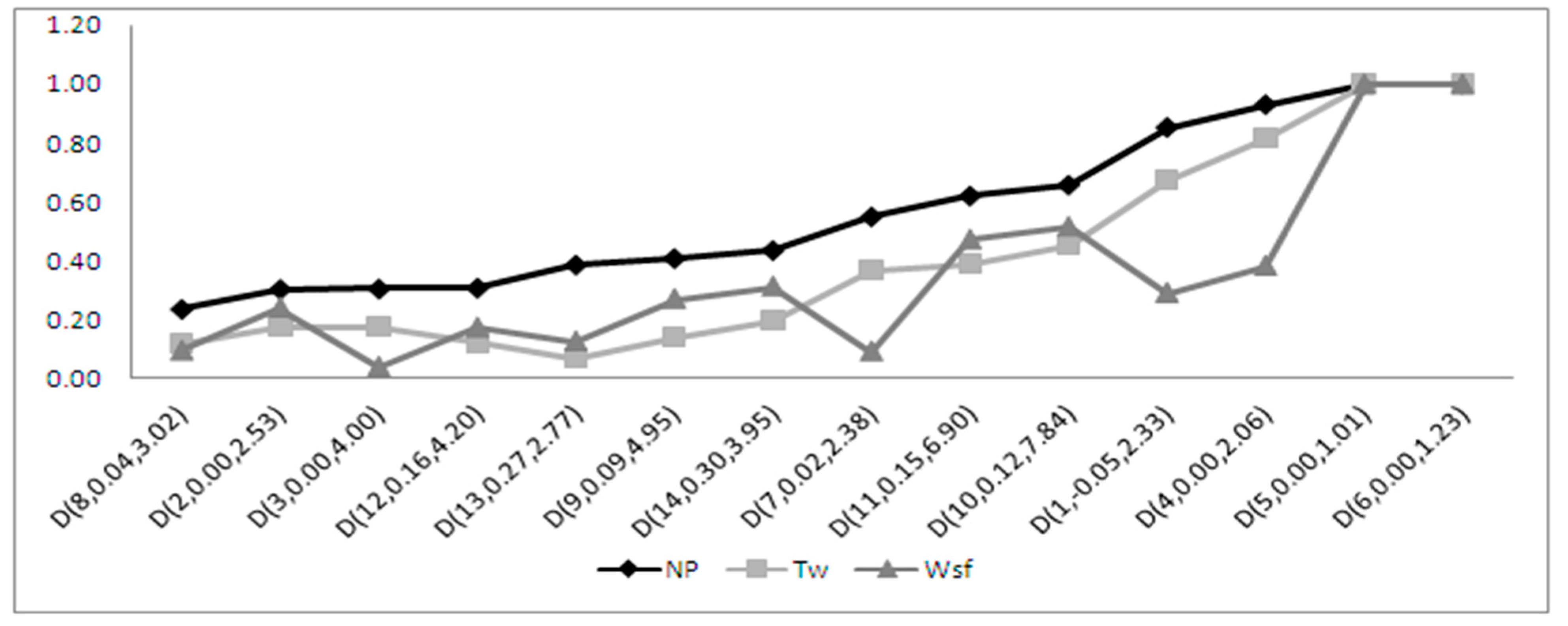
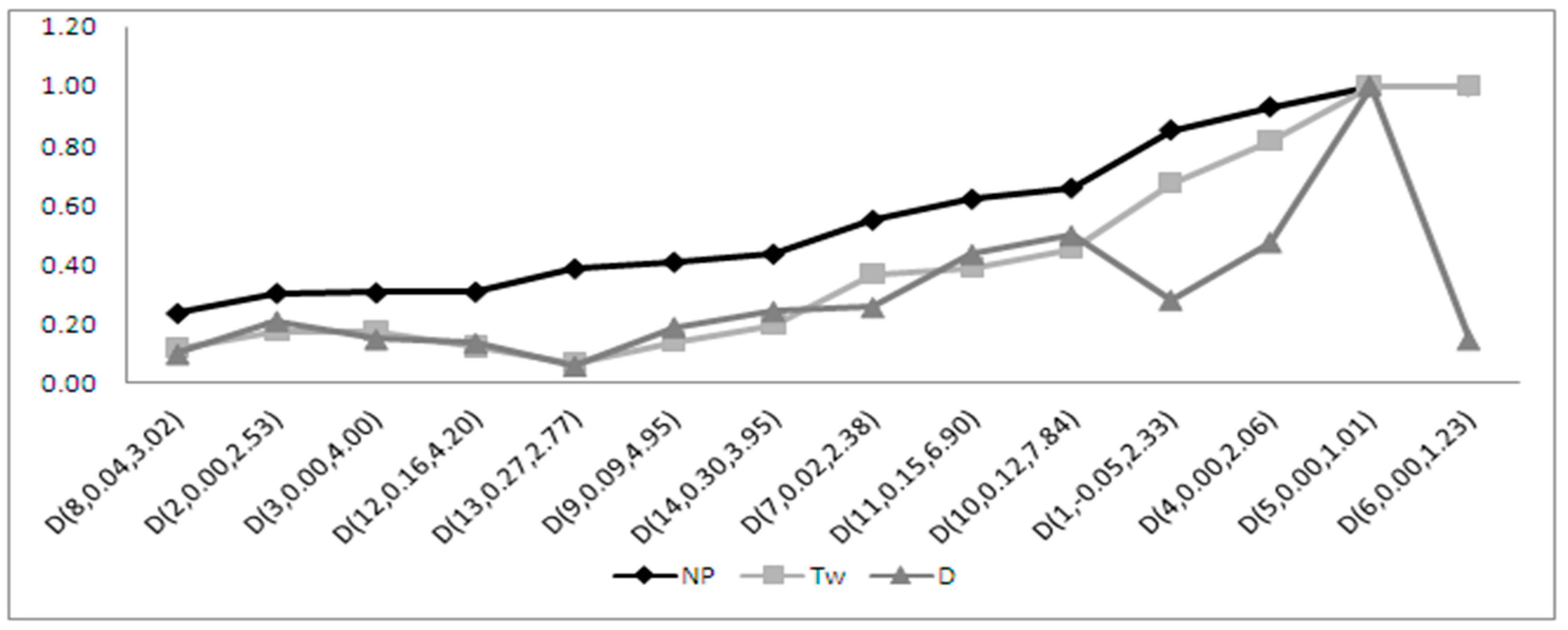
4.1. Slightly Skewed Alternatives
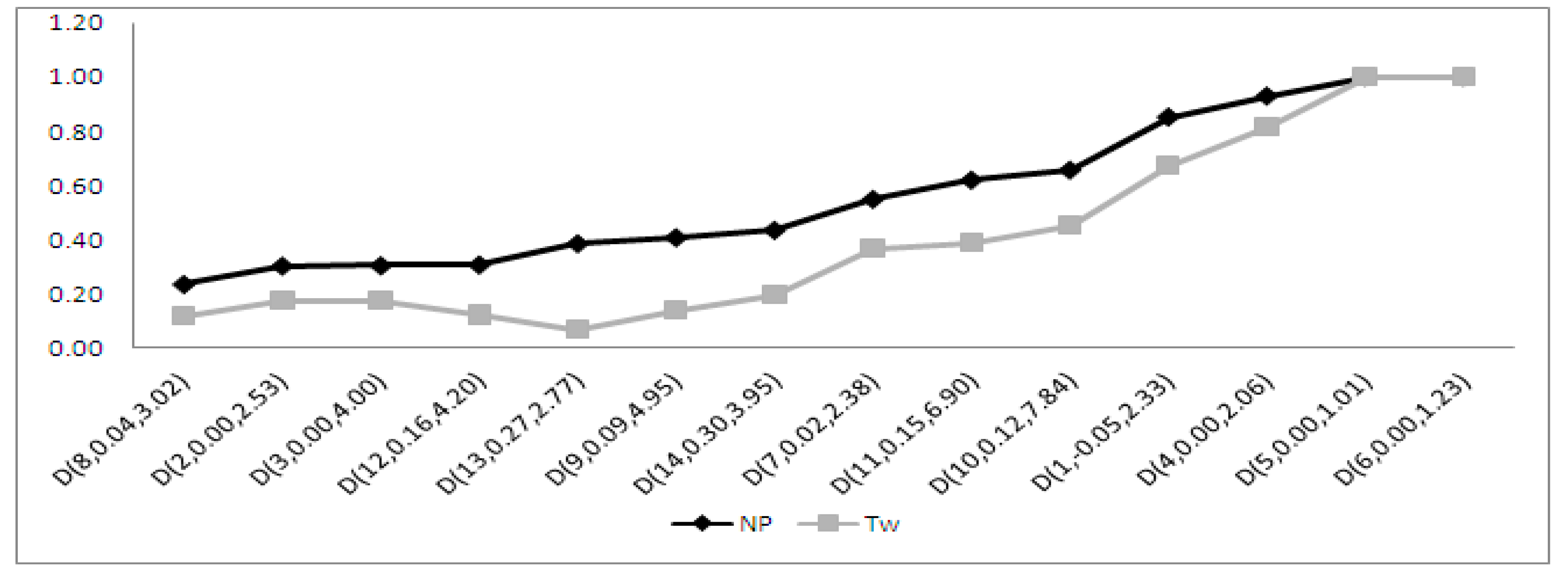
4.1.1. Performance of the Moments-Based Tests
4.1.2. Performance of the Regression and Correlation Tests
4.1.3. Performance of the ECDF Tests
4.1.4. Performance of the Special Test
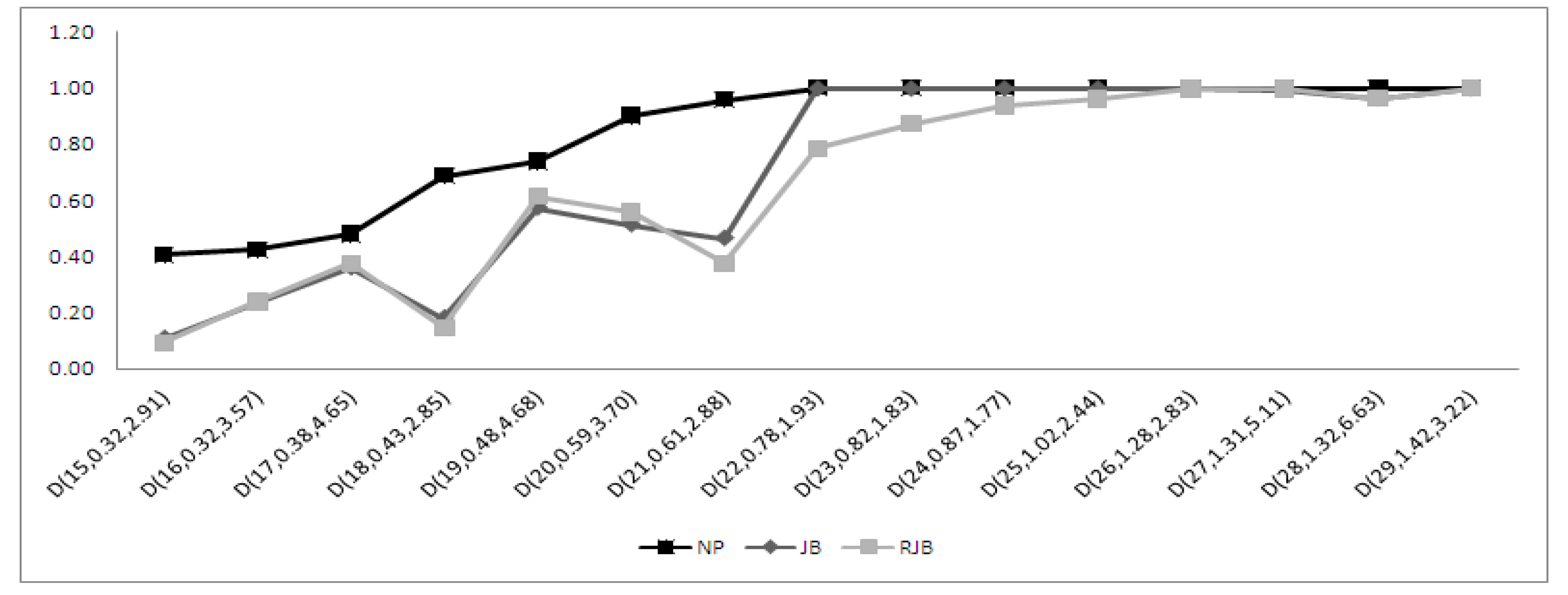
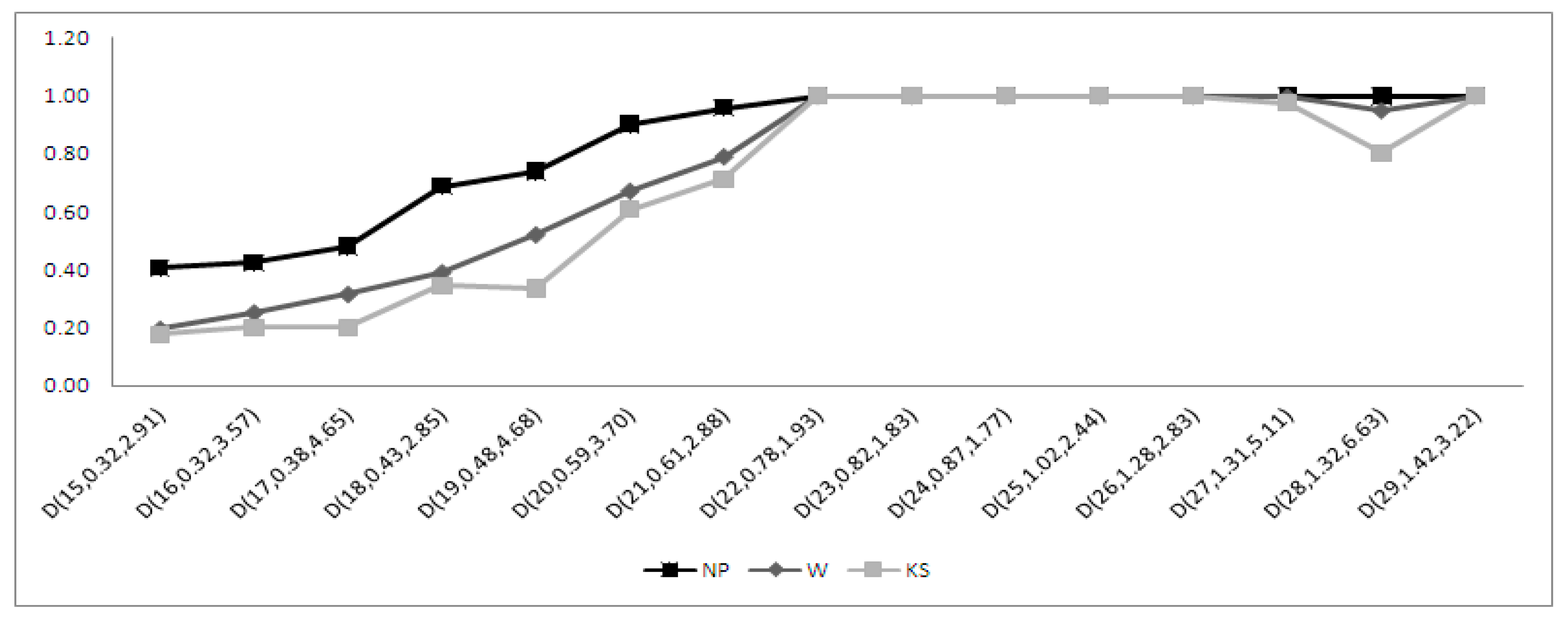
4.2. Moderately Skewed Alternatives
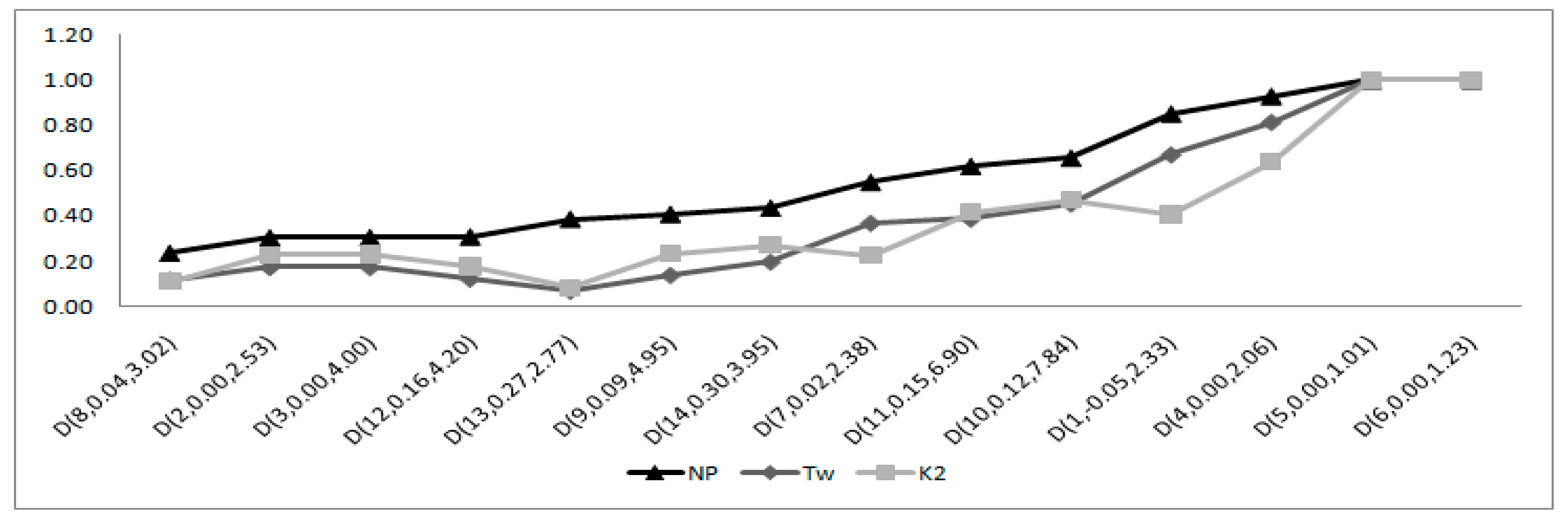
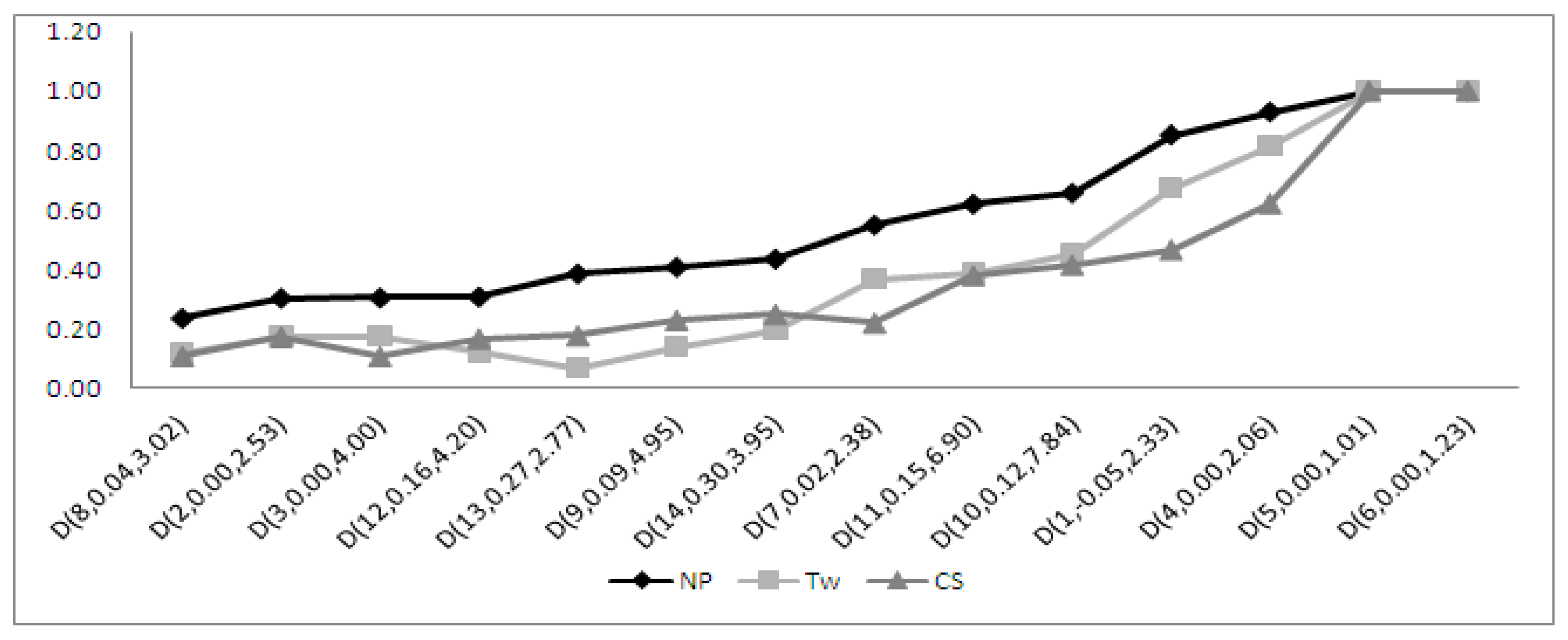
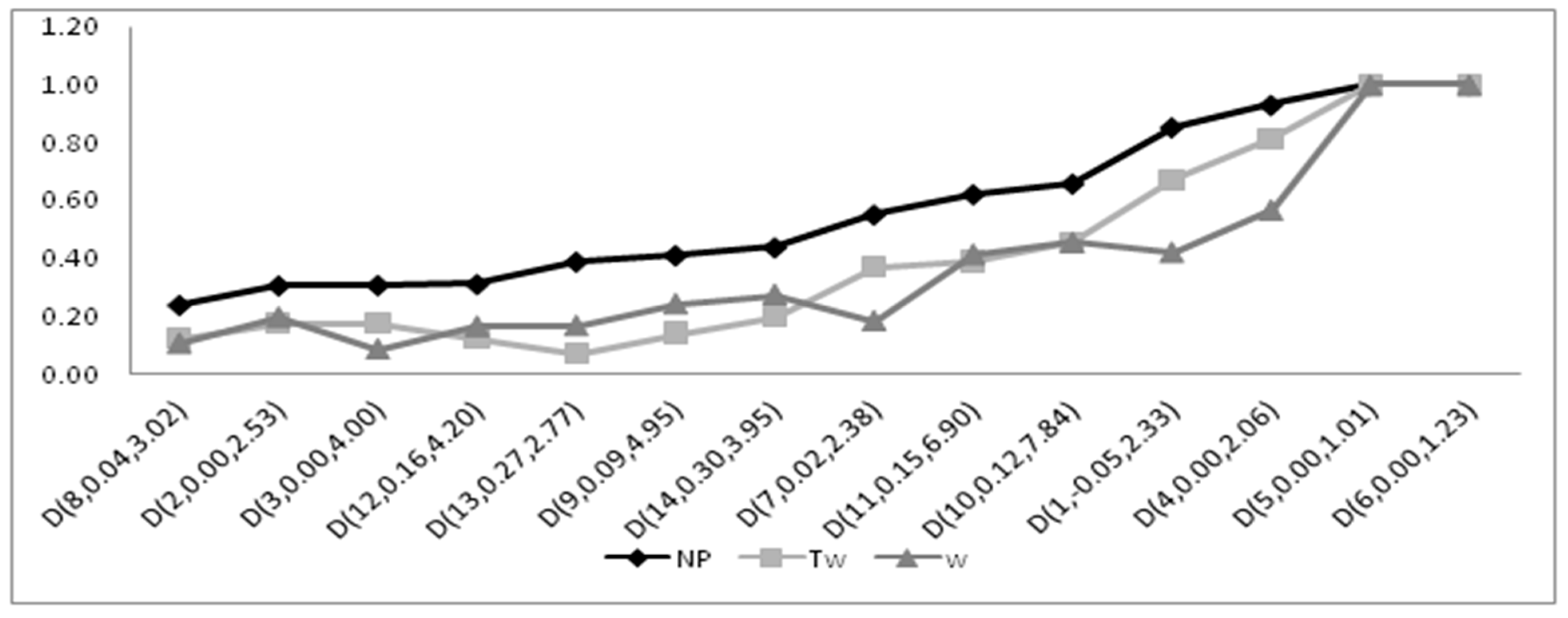
4.2.1. Performance of the Moments-Based Tests
4.2.2. Performance of the Regression and Correlation Tests
4.2.3. Performance of the ECDF Tests
4.2.4. Performance of the Other Tests
4.3. Highly Skewed Alternatives
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sr. No | Student t Distribution | Mixture Distribution | |||||||
|---|---|---|---|---|---|---|---|---|---|
| t1 | t2 | ||||||||
| d.f | Mean | d.f | Mean | Alpha | Mean | SD | β1 | β2 | |
| 1 | 8 | 2.0 | 12 | 5.0 | 0.50 | 3.50 | 1.88 | −0.05 | 2.33 |
| 2 | 100 | 4.0 | 75 | 6.0 | 0.50 | 5.00 | 1.42 | 0.00 | 2.53 |
| 3 | 10 | 0.0 | .. | .. | 1.00 | 0.00 | 1.12 | 0.00 | 4.00 |
| 4 | 100 | −1.5 | 75 | 1.5 | 0.50 | 0.00 | 1.81 | 0.00 | 2.06 |
| 5 | 10 | 3.0 | 5 | 50.0 | 0.50 | 26.50 | 23.53 | 0.00 | 1.01 |
| 6 | 100 | −4.0 | 75 | 4.0 | 0.50 | 0.00 | 4.13 | 0.00 | 1.23 |
| 7 | 50 | −1.2 | 25 | 1.2 | 0.50 | 0.00 | 1.58 | 0.02 | 2.38 |
| 8 | 8 | 5.0 | 10 | 3.0 | 0.50 | 4.00 | 1.51 | 0.04 | 3.02 |
| 9 | 5 | 2.0 | 7 | 4.0 | 0.70 | 2.60 | 1.56 | 0.09 | 4.95 |
| 10 | 5 | 10.0 | 6 | 12.0 | 0.95 | 10.10 | 1.36 | 0.12 | 7.84 |
| 11 | 5 | 10.0 | 7 | 12.0 | 0.90 | 10.20 | 1.41 | 0.15 | 6.90 |
| 12 | 10 | 5.0 | 5 | 7.0 | 0.50 | 6.00 | 1.57 | 0.16 | 4.20 |
| 13 | 100 | 4.0 | 75 | 6.0 | 0.70 | 4.60 | 1.36 | 0.27 | 2.77 |
| 14 | 8 | 5.0 | 10 | 3.0 | 0.10 | 3.20 | 1.27 | 0.30 | 3.95 |
| 15 | 100 | −1.0 | 75 | 1.0 | 0.75 | −0.50 | 1.33 | 0.32 | 2.91 |
| 16 | 8 | 5.0 | 10 | 3.0 | 0.20 | 3.40 | 1.38 | 0.32 | 3.57 |
| 17 | 10 | 5.0 | 5 | 7.0 | 0.90 | 5.20 | 1.29 | 0.38 | 4.65 |
| 18 | 100 | −1.2 | 75 | 1.2 | 0.75 | −0.60 | 1.45 | 0.43 | 2.85 |
| 19 | 8 | −1.0 | 10 | 2.0 | 0.95 | −0.85 | 1.33 | 0.48 | 4.68 |
| 20 | 8 | −1.0 | 12 | 2.0 | 0.85 | −0.55 | 1.57 | 0.59 | 3.70 |
| 21 | 100 | −1.5 | 75 | 1.5 | 0.77 | −0.81 | 1.62 | 0.61 | 2.88 |
| 22 | 100 | −4.0 | 75 | 4.0 | 0.70 | −1.60 | 3.80 | 0.78 | 1.93 |
| 23 | 5 | 10.0 | 7 | 25.0 | 0.70 | 14.50 | 6.99 | 0.82 | 1.83 |
| 24 | 10 | 3.0 | 5 | 50.0 | 0.70 | 17.10 | 21.57 | 0.87 | 1.77 |
| 25 | 100 | −4.0 | 75 | 4.0 | 0.75 | −2.00 | 3.61 | 1.02 | 2.44 |
| 26 | 8 | −10.0 | 12 | 5.0 | 0.78 | −6.70 | 6.32 | 1.28 | 2.83 |
| 27 | 8 | 0.0 | 12 | 5.0 | 0.90 | 0.50 | 1.89 | 1.31 | 5.11 |
| 28 | 8 | 0.0 | 12 | 5.0 | 0.95 | 0.25 | 1.59 | 1.32 | 6.63 |
| 29 | 8 | −10.0 | 12 | 5.0 | 0.80 | −7.00 | 6.11 | 1.42 | 3.22 |
| 30 | 8 | −10.0 | 12 | 5.0 | 0.82 | −7.30 | 5.88 | 1.57 | 3.71 |
| 31 | 8 | −1.0 | 12 | 5.0 | 0.90 | −0.40 | 2.14 | 1.58 | 5.60 |
| 32 | 5 | 5.0 | 7 | 15.0 | 0.85 | 6.50 | 3.79 | 1.62 | 4.45 |
| 33 | 5 | 5.0 | 6 | 15.0 | 0.90 | 6.00 | 3.26 | 2.06 | 6.73 |
| 34 | 100 | −4.0 | 75 | 4.0 | 0.90 | −3.20 | 2.60 | 2.09 | 6.69 |
| 35 | 5 | 10.0 | 7 | 25.0 | 0.90 | 11.50 | 4.68 | 2.36 | 7.35 |
| 36 | 8 | −10.0 | 12 | 5.0 | 0.90 | −8.50 | 4.64 | 2.42 | 7.48 |
| 37 | 10 | 3.0 | 5 | 50.0 | 0.90 | 7.70 | 14.15 | 2.64 | 8.06 |
| Distribution | Skew | Kurt | JB | RJB | Best Test |
|---|---|---|---|---|---|
| D(5,0.00,1.01) | 0.00 | 1.01 | 0.27 | 0.04 | 1.00 |
| D(6,0.00,1.23) | 0.00 | 1.23 | 0.03 | 0.02 | 1.00 |
| Beta(0.5,0.5) | 0.00 | 1.50 | 0.00 | 0.00 | 0.91 |
| Beta(1,1) | 0.00 | 1.80 | 0.00 | 0.00 | 0.44 |
| Tukey(2) | 0.00 | 1.80 | 0.00 | 0.00 | 0.44 |
| D(4,0.00,2.06) | 0.00 | 2.06 | 0.01 | 0.00 | 0.54 |
| Tukey(0.5) | 0.00 | 2.08 | 0.00 | 0.00 | 0.14 |
| Beta (2,2) | 0.00 | 2.14 | 0.00 | 0.00 | 0.11 |
| D(2,0.00,2.53) | 0.00 | 2.53 | 0.02 | 0.01 | 0.16 |
| Tukey(5) | 0.00 | 2.90 | 0.03 | 0.07 | 0.14 |
Appendix B













References
- Delong, J.B.; Summers, L.H. Are Business Cycle Symmetrical in American Business Cycle: Continuity and Change; University of Chicago Press: Chicago, IL, USA, 1985; pp. 166–178. [Google Scholar]
- Henderson, A.R. Testing experimental data for univariate normality. Clin. Chim. Acta 2006, 366, 112–129. [Google Scholar] [CrossRef]
- Blanca, M.J.; Arnau, J.; López-Montiel, D.; Bono, R.; Bendayan, R. Skewness and Kurtosis in Real Data Samples. Methodology 2013, 9, 78–84. [Google Scholar] [CrossRef]
- Bonett, D.G.; Seier, E. A test of normality with high uniform power. Comput. Stat. Data Anal. 2002, 40, 435–445. [Google Scholar] [CrossRef]
- D’Agostino, R.; Pearson, E.S. Tests for departure from normality. Empirical results for the distributions of b2 and b1. Biometrika 1973, 60, 613–622. [Google Scholar] [CrossRef]
- Gel, Y.R.; Gastwirth, J.L. A robust modification of the Jarque–Bera test of normality. Econ. Lett. 2008, 99, 30–32. [Google Scholar] [CrossRef]
- Jarque, C.M.; Bera, A.K. A Test for Normality of Observations and Regression Residuals. Int. Stat. Rev. 1987, 55, 163–172. [Google Scholar] [CrossRef]
- Bispo, R.; Marques, T.A.; Pestana, D. Statistical power of goodness-of-fit tests based on the empirical distribution function for type_I right-censored data. J. Stat. Comput. Simul. 2012, 82, 21–38. [Google Scholar] [CrossRef][Green Version]
- Shapiro, S.S.; Francia, R.S. An approximate analysis of variance test for normality. J. Am. Stat. Assoc. 1972, 67, 215–216. [Google Scholar] [CrossRef]
- Shapiro, S.S.; Wilk, M.B. An analysis of variance test for the exponential distribution (Complete samples). Biometrika 1965, 54, 591–611. [Google Scholar] [CrossRef]
- Anderson, T.W.; Darling, D.A. A test of goodness of fit. J. Am. Stat. Assoc. 1954, 49, 765–769. [Google Scholar] [CrossRef]
- Yazici, B.; Yolacan, S. A comparison of various tests of normality. J. Stat. Comput. Simul. 2007, 77, 175–183. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, Y. Likelihood-ration tests for normality. Comput. Stat. Data Anal. 2005, 49, 709–721. [Google Scholar] [CrossRef]
- Gel, Y.R.; Miao, W.; Gastwirth, J.L. Robust directed tests of normality against heavy-tailed alternatives. Comput. Stat. Data Anal. 2007, 51, 2734–2746. [Google Scholar] [CrossRef]
- Önder, A.Ö.; Zaman, A. Robust tests for normality of errors in regression models. Econ. Lett. 2005, 86, 63–68. [Google Scholar] [CrossRef]
- Islam, T.U. Stringency-based ranking of normality tests. Commun. Stat. Simul. Comput. 2017, 46, 655–668. [Google Scholar] [CrossRef]
- Lehmann, E.L.; Stein, C. On the Theory of Some Non-Parametric Hypotheses. Ann. Math. Stat. 1949, 20, 28–45. [Google Scholar] [CrossRef]
- Shapiro, S.S.; Wilk, M.B.; Chen, H.J. A comparative study of various tests for normality. J. Am. Stat. Assoc. 1968, 63, 1343–1372. [Google Scholar] [CrossRef]
- Thorsten, T.; Buning, H. Jarque-Bera Test and its Competitors for Testing Normality-A Power Comparison. J. Appl. Stat. 2007, 34, 87–105. [Google Scholar]
- Yap, B.W.; Sim, C.H. Comparisons of various types of normality tests. J. Stat. Comput. Simul. 2011, 81, 1–15. [Google Scholar] [CrossRef]
- Romao, X.; Delgado, R.; Costa, A. An empirical power comparison of univariate goodness-of-fit tests for normality. J. Stat. Comput. Simul. 2010, 80, 1–47. [Google Scholar] [CrossRef]
- Bowman, K.O.; Shenton, L.R. Omnibus test contours for departures from normality based on b1 and b2. Biometrika 1975, 62, 243–250. [Google Scholar] [CrossRef]
- Coin, D. A goodness-of-fit test for normality based on polynomial regression. Comput. Stat. Data Anal. 2008, 52, 2185–2198. [Google Scholar] [CrossRef]
| Test | Class of Test |
|---|---|
| Za, Zc, AD, and KS | ECDF |
| JB, RJB, K, and Tw | Moments |
| W, Wsf, D, CS, BCMR, and COIN | Correlation and Regression |
| Rsj | Special |
| n = 25 | n = 50 | n = 75 | ||||||
|---|---|---|---|---|---|---|---|---|
| Test | Rank | Gap | Test | Rank | Gap | Test | Rank | Gap |
| Tw | 1 | 24.0% | Tw | 1 | 22.9% | Tw | 1 | 31.8% |
| COIN | 2 | 34.6% | Rsj | 2 | 26.4% | Rsj | 1 | 32.4% |
| AD | 2 | 34.7% | AD | 3 | 38.0% | AD | 1 | 32.6% |
| CS | 2 | 34.8% | CS | 3 | 39.8% | CS | 2 | 38.6% |
| Rsj | 3 | 36.1% | COIN | 4 | 42.5% | W | 3 | 43.3% |
| W | 3 | 37.5% | K2 | 4 | 44.8% | K2 | 3 | 44.7% |
| KS | 3 | 38.1% | W | 4 | 45.5% | KS | 3 | 45.1% |
| Zc | 3 | 39.0% | Zc | 5 | 48.0% | COIN | 3 | 45.2% |
| BCMR | 3 | 39.9% | BCMR | 5 | 48.3% | BCMR | 3 | 46.1% |
| K2 | 4 | 42.6% | KS | 5 | 49.9% | Zc | 4 | 50.5% |
| Za | 4 | 43.1% | Za | 6 | 51.9% | Za | 4 | 51.4% |
| Wsf | 4 | 46.5% | Wsf | 7 | 61.3% | Wsf | 5 | 56.2% |
| D | 5 | 91.6% | JB | 8 | 80.5% | D | 6 | 85.3% |
| JB | 6 | 97.2% | D | 9 | 90.9% | JB | 7 | 88.0% |
| RJB | 6 | 98.2% | RJB | 10 | 99.5% | RJB | 8 | 92.9% |
| n = 25 | n = 50 | n = 75 | ||||||
|---|---|---|---|---|---|---|---|---|
| Tests | Rank | Gap | Test | Rank | Gap | Test | Rank | Gap |
| CS | 1 | 28.5% | AD | 1 | 25.0% | AD | 1 | 26.7% |
| W | 1 | 29.0% | W | 2 | 28.3% | CS | 1 | 28.9% |
| AD | 1 | 29.5% | BCMR | 2 | 28.7% | W | 1 | 29.5% |
| BCMR | 1 | 29.8% | CS | 2 | 29.8% | BCMR | 1 | 31.4% |
| Za | 2 | 32.8% | Wsf | 3 | 34.9% | Wsf | 2 | 35.8% |
| Wsf | 2 | 33.5% | KS | 3 | 35.2% | Za | 2 | 36.2% |
| Zc | 2 | 33.5% | Za | 3 | 36.5% | Zc | 2 | 38.2% |
| KS | 3 | 42.2% | Zc | 3 | 38.3% | KS | 2 | 40.4% |
| K2 | 4 | 46.7% | JB | 4 | 59.8% | JB | 3 | 50.6% |
| D | 5 | 49.8% | RJB | 4 | 61.9% | K2 | 4 | 57.9% |
| Rsj | 6 | 55.5% | K2 | 5 | 64.6% | RJB | 4 | 58.0% |
| Tw | 6 | 55.7% | D | 6 | 74.6% | D | 5 | 81.3% |
| JB | 7 | 59.0% | Rsj | 6 | 75.6% | Rsj | 5 | 83.9% |
| RJB | 8 | 64.4% | Tw | 7 | 78.4% | Tw | 6 | 88.0% |
| COIN | 9 | 68.8% | COIN | 7 | 79.8% | COIN | 6 | 88.7% |
| n = 25 | n = 50 | n = 75 | ||||||
|---|---|---|---|---|---|---|---|---|
| Test | Rank | Gap | Test | Rank | Gap | Test | Rank | Gap |
| Wsf | 1 | 8.8% | Wsf | 1 | 0.6% | RJB | 1 | 0.0% |
| BCMR | 1 | 9.3% | BCMR | 1 | 0.7% | Zc | 1 | 0.0% |
| W | 1 | 10.1% | Zc | 1 | 0.7% | JB | 1 | 0.0% |
| CS | 1 | 10.4% | W | 1 | 0.7% | Wsf | 1 | 0.0% |
| Za | 1 | 10.9% | JB | 1 | 0.7% | W | 1 | 0.1% |
| Zc | 1 | 11.0% | RJB | 1 | 0.7% | CS | 1 | 0.1% |
| AD | 1 | 11.9% | CS | 1 | 0.8% | D | 1 | 0.1% |
| RJB | 1 | 12.5% | Za | 1 | 0.9% | BCMR | 1 | 0.1% |
| JB | 1 | 13.9% | D | 1 | 1.0% | K2 | 1 | 0.1% |
| D | 2 | 16.1% | K2 | 1 | 1.2% | Za | 1 | 0.1% |
| K2 | 3 | 20.4% | AD | 1 | 1.3% | AD | 1 | 0.2% |
| KS | 3 | 21.2% | Rsj | 1 | 2.1% | Rsj | 1 | 0.2% |
| Rsj | 3 | 21.5% | KS | 1 | 3.6% | KS | 1 | 0.5% |
| Tw | 4 | 46.9% | Tw | 2 | 45.3% | Tw | 2 | 42.5% |
| COIN | 5 | 61.4% | COIN | 3 | 69.1% | COIN | 3 | 72.0% |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, T.U. Ranking of Normality Tests: An Appraisal through Skewed Alternative Space. Symmetry 2019, 11, 872. https://doi.org/10.3390/sym11070872
Islam TU. Ranking of Normality Tests: An Appraisal through Skewed Alternative Space. Symmetry. 2019; 11(7):872. https://doi.org/10.3390/sym11070872
Chicago/Turabian StyleIslam, Tanweer Ul. 2019. "Ranking of Normality Tests: An Appraisal through Skewed Alternative Space" Symmetry 11, no. 7: 872. https://doi.org/10.3390/sym11070872
APA StyleIslam, T. U. (2019). Ranking of Normality Tests: An Appraisal through Skewed Alternative Space. Symmetry, 11(7), 872. https://doi.org/10.3390/sym11070872