3.1. Periodic Binary Sequences Inside the Prime Characteristic Function
The occurrence of pieces of periodic binary sequences inside the prime characteristic function is discussed here. To this end, both the Sieve procedure and a modified version of it are investigated step-by-step, where each step is labelled with the progressive index , with denoting the beginning of the two procedures. The difference between the modified and the true Sieve procedure is simply that in the Sieve procedure, in each step , only the multiplies of the prime are struck out, but not the prime itself, whereas in the modified Sieve procedure the prime itself is also deleted. As previously stated, the status of each integer (0→deleted, 1→undeleted) is stored in a N-size vector, which is initialized with all values. The outputs of the Sieve procedure and its modified version are denoted as and , respectively, for each step . Consequently, the deletion of an integer from the true or the modified Sieve procedure simply means that a value replaces a value in the two previous sequences. In the case of the Sieve procedure, the sequence is an approximation at the step of the prime characteristic function .
At the beginning of the procedures (
), we have two equal periodic sequences of all
values, that is,
and
, whose period is
. In the first step of the modified Sieve procedure (
), the multiples of
are struck out, including
itself. Consequently, we obtain a sequence
, which is still periodic, with alternating
and
symbols. The period of
is given by the prime value
itself, that is,
. In the following,
will denote the period of the sequence
. Conversely, in the Sieve procedure, the prime
is not deleted. In this case, the output sequence
is not periodic, but includes a piece of the periodic sequence
, by starting from the square
. Before such a value, the previous sequence
is preserved, which coincides with
. It follows that
is a mixed sequence, being composed by pieces of both
and
, that is,
Similarly, in the second step of the modified Sieve procedure (
), every multiple of
, which is not yet struck out, is deleted, including the prime itself, to give the new sequence
. Therefore, this sequence comes from the deletion of all the multiplies of the primes
and
, including the primes themselves. It follows that the sequence
is periodic, with a period equal to the product of
and
, as it will be demonstrated in Theorem 1. If we consider the second step of the Sieve procedure, where the primes
and
have not been deleted, we obtain the sequence
. This is again a mixed sequence, where a piece of the periodic sequence
is introduced, by starting from the square
, whereas the previous binary values are saved before this square. Consequently, we have
In general, the multiples of the prime
, which are not yet struck out in the previous steps, are deleted in the
k-th step of the modified Sieve procedure, including the prime
itself. Consequently, after performing all the first
steps, we obtain the periodic sequence
, as shown in Theorem 1. In the case of the original Sieve procedure, after the
k-th step, we obtain the sequence
, which is an approximation of the prime characteristic function until the prime
. Such an approximation differs from the previous one
, only by starting from the square
. In fact, after this point, a piece of the periodic sequence
is recognizable. It follows that
can be eventually written as a mixed sequence, which is a generalization of Equations (
15) and (
16), that is,
By evaluating the expression (
17), we can recognize that subsets of the periodic binary sequences
are present, for each
, in the related intervals
of the prime characteristic function. This happens until the end of the Sieve procedure, because each
interval is not influenced by the deletions done in the following steps. We now show that the sequences
are periodic and that their periods are given by the product of all the primes up to
.
Theorem 1. Let be given the binary sequences , which are generated by the deletion of the multiplies of all the primes up to , including the primes themselves. Then, the sequences are periodic, and their periods are given by the product of all the primes up to , that is, Proof. The deletion of the multiplies of all the primes up to
gives all the sets, as a function of
, of reduced residue systems modulo
, where
is given by Equation (
18). Each set is composed by all the positive integers relatively prime to
, that is, by all the numbers such that
. The quantity of integers in each set is given by the Euler phi function
, which computes the number of positive integers less than
and relatively prime to
. However, the sets of reduced residue systems are abelian groups, so that each of them is associated to a principal Dirichlet character function. This is an arithmetical function
, which is nothing but
, being defined as
In [
8], it is proven that
is a periodic sequence, and in particular that
This completes the proof. ☐
Table 1 reports the periods
of the sequences
,
, in comparison with the sizes
of the intervals
, where subsets of each
are recognizable. The pseudo-prime
is put in brackets.
By considering the ratios , it is evident that the periods increase much faster than the width of the intervals . This makes sense because the periodicity of the sequences is hardly recognizable by simply investigating the subsets of each in the intervals .
3.3. The Relation Between the Primes in an Interval and the Runs in a Period
For evidencing the relation between each period
and the correspondent number of runs of zeroes
, we report in
Table 3 the scores of
for
.
Such scores also give the number of the integers that have not been struck out by the modified Sieve procedure in the period , which in turn can be related to the number of undeleted integers (and consequently of the primes) in the correspondent interval . We will show in Theorem 2 that a correlation exists between and , in such a way the number of primes in each interval can be inferred. According on the theory of congruences, Theorem 2 gives the quantity of the integers that have not been struck out (i.e., ) in each period , that is,
Theorem 2. Let be given the periodic binary sequences defined in Theorem 1, and whose periods are . Then, the number of undeleted integers, that is, the number of runs of zeroes , in a period , for , is given by Proof. The number of undeleted integers in each period
is given by the number of integers in the reduced residue systems modulo
, that is, the number of positive integers less than
and relatively prime to
. Such a value is given by the Euler phi function
, once computed in
, that is [
8]
where
, are the primes dividing
. ☐
By starting from
,
Table 1 shows that the interval
is included in the first period of the sequence
. Consequently, a subset of the undeleted integers
in each period
lies in the correspondent interval
, where they are just primes. Therefore, we can infer the quantity of primes
in each
, by starting from the quantity
in the correspondent period
. As a first approximation, a simple proportional relationship is investigated. Let us consider the local density
of the undeleted integers in the period
, where
is computed in sliding intervals
whose size is the same of
, that is,
. In this context, the index
represents the starting point of each
. If such intervals span the whole period
, we assume that the density
is not a function of
. In this case, it is equal to the average density
over
, and we have
It is noteworthy that the product structure in Equation (
23) is the same as in Equation (
12). Let us suppose that the previous assumption holds. Then, an estimation of the local density
in each interval
(that is, for
), will be just the average density
over the period
. Consequently, we can write
Therefore, by starting from Equation (
23), we can estimate the quantity of primes
in each interval
, for
. To this end, the average density
is multiplied by the size
, that is,
Evidently, Equation (
25) is analogous to Equation (
12), apart from the size
of the global interval
, where
, that is changed into the size
of the local interval
.
3.5. The Corrected LINPES Estimation by Using the Equivalence with the Function
We want now to show that Equations (
3) and (
26) are related. To this end, we write the logarithmic integral function
as a summation of integrals, each of them is computed in the interval
, that is,
where the first term starts from
to cope with a possible improper integral, and
is the greatest square of a prime less than
. Consequently, the
function is expressed by Equation (
27) as a succession of estimations
, in a similar way to Equation (
26), that is,
where
,
, and
We now apply the Mean Value Theorem to each interval
in Equation (
27), that is,
where
,
,
, and
,
. In order to show the equivalence between the Equations (
26) and (
30), we also consider the lower bound
of the interval
. By taking, in the two summations, the ratio between the two terms multiplying the interval size
, we can write
From Equation (
13), we have
where
, so that its maximum distance from
is
. However, we know that the
prime
is given asymptotically by
[
9]. Therefore,
and
, so that for each point
we have
. It follows that
and consequently Equation (
31) gives, for each fixed
,
It follows that the trends of the two estimations (
26) and (
30) are the same as
, apart from the constant coefficient
. Due to this multiplicative factor, the proposed estimation (
26) overestimates the prime number function
with respect to Equation (
30), and in this sense it is similar to the heuristic procedure described in
Section 2. However, it has to be noticed that this last one is completely probabilistic, whereas the proposed method is also based on an analytical procedure, that is, the recognition of an infinite number of binary periodical sequences and related intervals of the prime characteristic function. In order to correct this discrepancy, we relax the conjecture of
Section 3.3, in such a way the trend of the local density
becomes a function of
. Experimentally, the values of the local density
in the interval
are lower than those of the average density
. The following conjecture is then proposed, which links
and
by means of the constant
of the Third Mertens’ Theorem [
11].
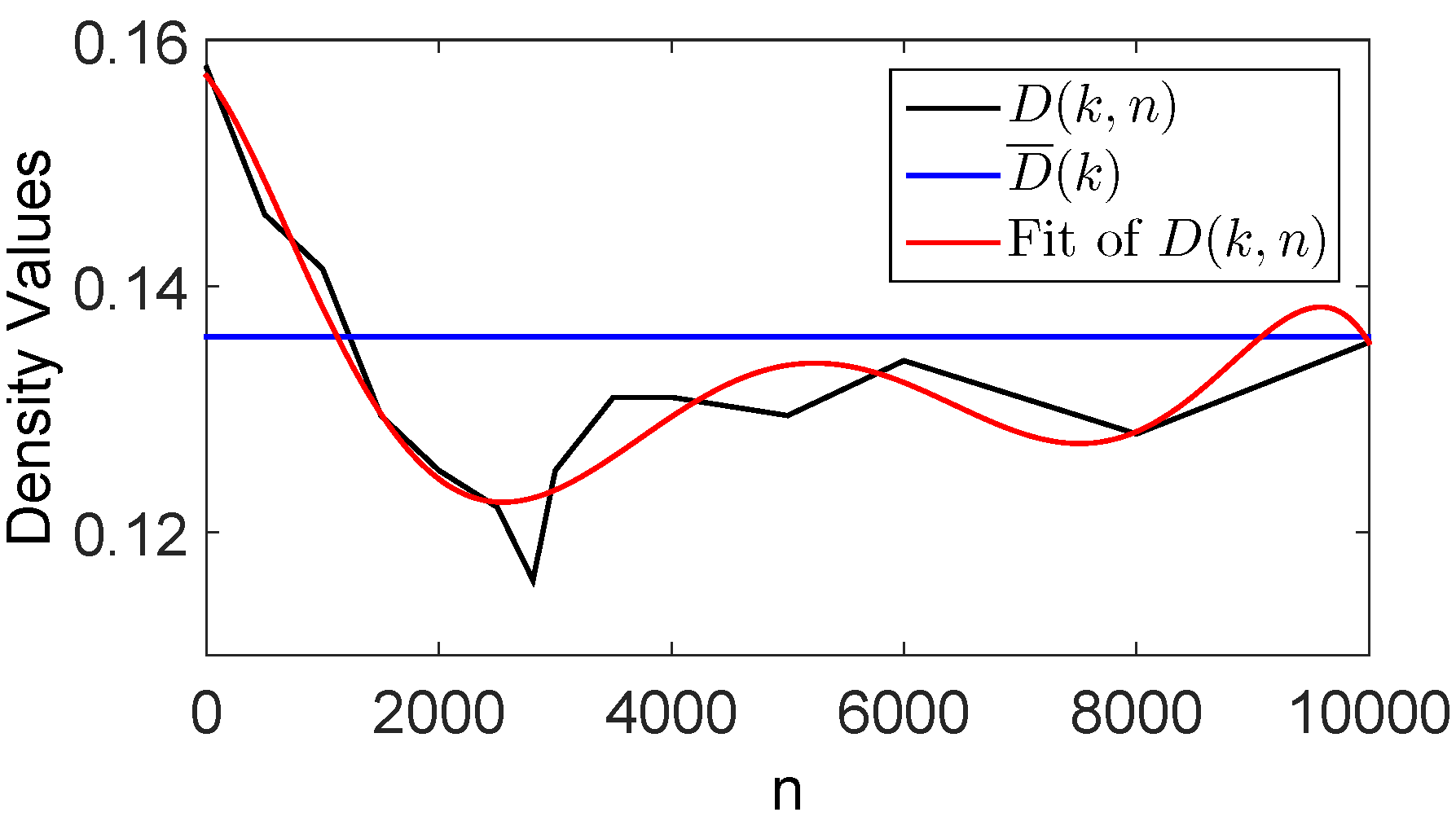
Conjecture 1. The local density of the undeleted integers in the period , if computed in sliding intervals whose size is the same of , is a function of the starting point of the sliding interval. In particular, the average density is greater than the local density in the interval , in such a way the succession of their ratios exceeds the unity. Moreover, the limit value as of is equal to the constant of the Third Mertens’ Theorem, that is, The typical trend of
, for
and varying
, is plotted in
Figure 1, together with the average density
in the period
. Let us notice that, as it will be discussed in the following, such a trend is less appreciable for small values of the primes.
Figure 1 can be explained as follows. Let us consider the sequences
defined in
Section 3.1, where the multiples of the primes up to
have been struck out, included the primes themselves. In each of these sequences, all the undeleted integers are just primes in the range
, whereas the undeleted integers greater than
can be indifferently primes or composites, because the multiples of the primes greater than
have not yet been struck out.
At the beginning of the modified Sieve procedure (), the local density of the undeleted integers is not a function of , because no integer has been still struck out. In the first step (), only the even integers (i.e., the multiplies of ) have been struck out, so that is still a constant value up to infinity. Noticeably, the multipliers (i.e. the integers multiplying to give the deleted multiplies) are equal to the undeleted integers when the procedure starts (i.e., all the integers). This rule also holds for the following steps, that is, the multipliers of the prime in the step of the modified Sieve procedure are equal to the undeleted integers in the previous step. It follows that the multipliers of are all the odd integers, whose distribution is again uniform. Some of these multipliers (that is, ) are just primes in the interval , but they can also be composites beyond . In this case, the distribution of the composite multipliers exactly compensate the decreasing trend of the distribution of the multipliers that are also prime numbers. If the primes are sufficiently small, such a compensation happens quickly, because it starts from . In these cases, the distribution of the local density is still approximately uniform. However, as grows, a transient state is noticeable, because, for such values of and small values of , the local density is greater than the average density . In fact, for such values, only a portion of the multiplies of the primes , have been struck out, because the deletion of the multiplies of the prime , starts only from , apart from the prime itself. This means that the deletion of the multiplies of , is completed only at the lower bound of the interval , that is, . Consequently, after this point, the transient state ends and the stationary state begins, where the local density fluctuates around the average density .
Figure 1 shows the trend of the local density
in the case of
. Starting approximately from this value of
, we can notice a minimum value
for the distribution of
, which is located immediately after the transient state, that is, at the lower bound of the interval
. Such a minimum value is about a 10 percent lower than the average density
. In fact, as previously explained, the multipliers of the prime
are just primes up to
, whereupon they can be even composites. It follows that the distribution of the composite multipliers compensate the decreasing distribution of the multipliers that are prime numbers only starting from the multiple
. Therefore, as
, such a compensation is delaying, in such a way the ratio between
and
more and more grows up to the
value of Equation (
35). As a matter of fact, if all the multipliers were primes, their distribution would decrease by following a logarithmic trend, so that
would augment with the same trend, by starting from the minimum value in the interval
. In the real case, however, the compensation given by the composite multipliers has the effect that the local density does not grow indefinitely, but tends to the limit value
. Let us notice that, if we stop the procedure to a finite value of
, the ratio between
and
is
, where the succession
is increasing and tends to the limit value
as
.
In order to evaluate the effect of the compensation delay for the small primes
,
, in comparison with the case of
,
Table 4 reports: a) the multipliers
such that the multiples
lie in the interval
, and b) the first multiplier that is a composite number, that is,
, whose correspondent multiple is
. Evidently, as
grows, the difference between the upper bound
of
and
becomes so large that the compensation effect of the composite multipliers is no longer noticeable in the interval itself.
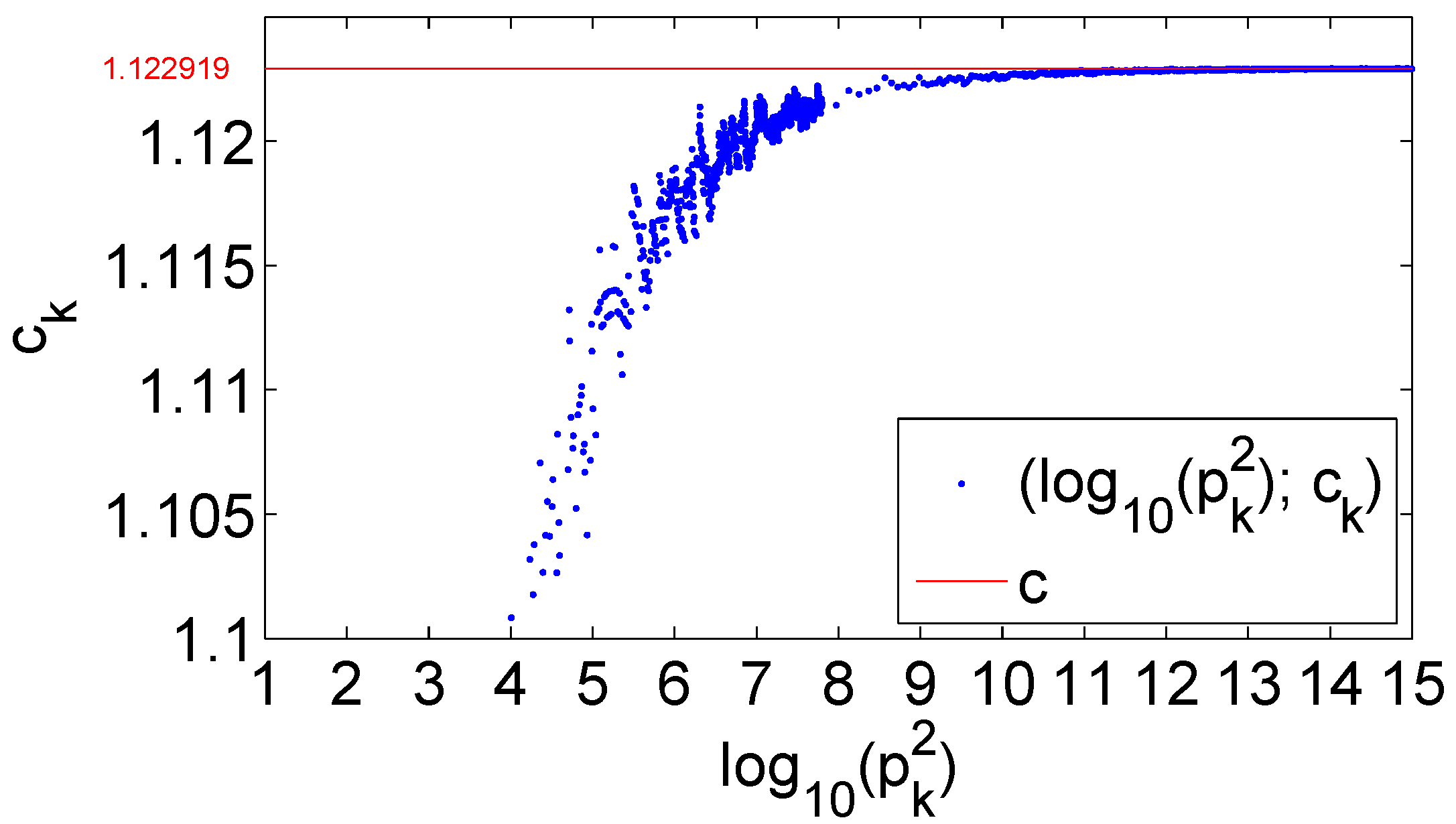
Figure 2 shows the trend of the succession
, as
approaches infinity. Evidently, such a succession tends to the constant value
. The x-axis is in a logarithmic scale, in such a way the values of
can be visualized up to
.
Finally,
Table 5 highlights the equivalence between the proposed estimation (
26) and the logarithmic-integral one (
3). To this end, a number of linear regressions have been computed between the occurrences
(
25) in each interval
of the proposed estimation versus the correspondent ones
(
29) of the integral-logarithmic function. Each row of
Table 5 is referred to the prime squares
ranging from a power-of-ten to the following one, except the first raw, which includes all the squares lower than
, in order to elaborate a sufficient number of points. For each of these ranges, we report the coefficients
and
of the linear regressions
, together with the coefficient of determination
, which is a measure of the fitting between the two estimations. Evidently, the coefficient of determination tends very fast to its optimal value, that is
, despite that the number of observations has increased. Let us notice that the intercept
is practically negligible with respect to the full-scale level, whereas the slope
is approaching the constant value
.
For comparison,
Table 5 also reports the parameters and the coefficient of determination in the case of the linear regressions
concerning the occurrences
versus the targets
. These scores are defined as the number of primes in each interval
. Even in this case, the fitting between
and
is impressive, as shown by the coefficient of determination
. Noticeably, the slope
still approaches the value
, because the P.N.T. guarantees that the logarithmic-integral function and the prime number function goes to infinity in the same way.
From the previous analysis, it follows that, for a given
, the proposed approximation
overestimates the prime number function
by a factor
, which can be computed by considering that we have an overestimation for each interval
that can be computed by considering a factor in the finite set
, where
is such that
(see Equation (
34)). If
, the overestimation factor
tends to the constant
. Being
unknown, an adjusted version (
36) of (
26) can be defined by means of the correction factor
, that is,
Clearly, the corrected version
is able to give better estimations than
as
approaches infinity. In order to give a quantitative assessment,
Table 6 reports the scores of
(
26) and of its adjusted version
(
36), in comparison with the logarithmic integral estimation
(
27), and with the prime number function
. The range of each row of
Table 6 starts from a power-of-ten and ends to the following one up to
.
It can be noticed that the scores of
slightly underestimate both the true number of primes
and the logarithmic integral function
, which, in turn, is such that the sign of its difference with
changes infinitely many times [
17,
18], by showing some irregularities in the distribution of the primes [
19], which have been investigated by considering differences in some subsets of the primes themselves [
20]. Concerning the previous underestimation, this is due to the fact that the limit value
is an upper bound for the succession
. Evidently,
would be perfectly accurate if the terms
were available for the computation of (
36), by considering the real number of primes in each interval
.







{kind=link}
{kind=link}
{kind=link}