A Semi-Supervised Monocular Stereo Matching Method

Abstract
:1. Introduction
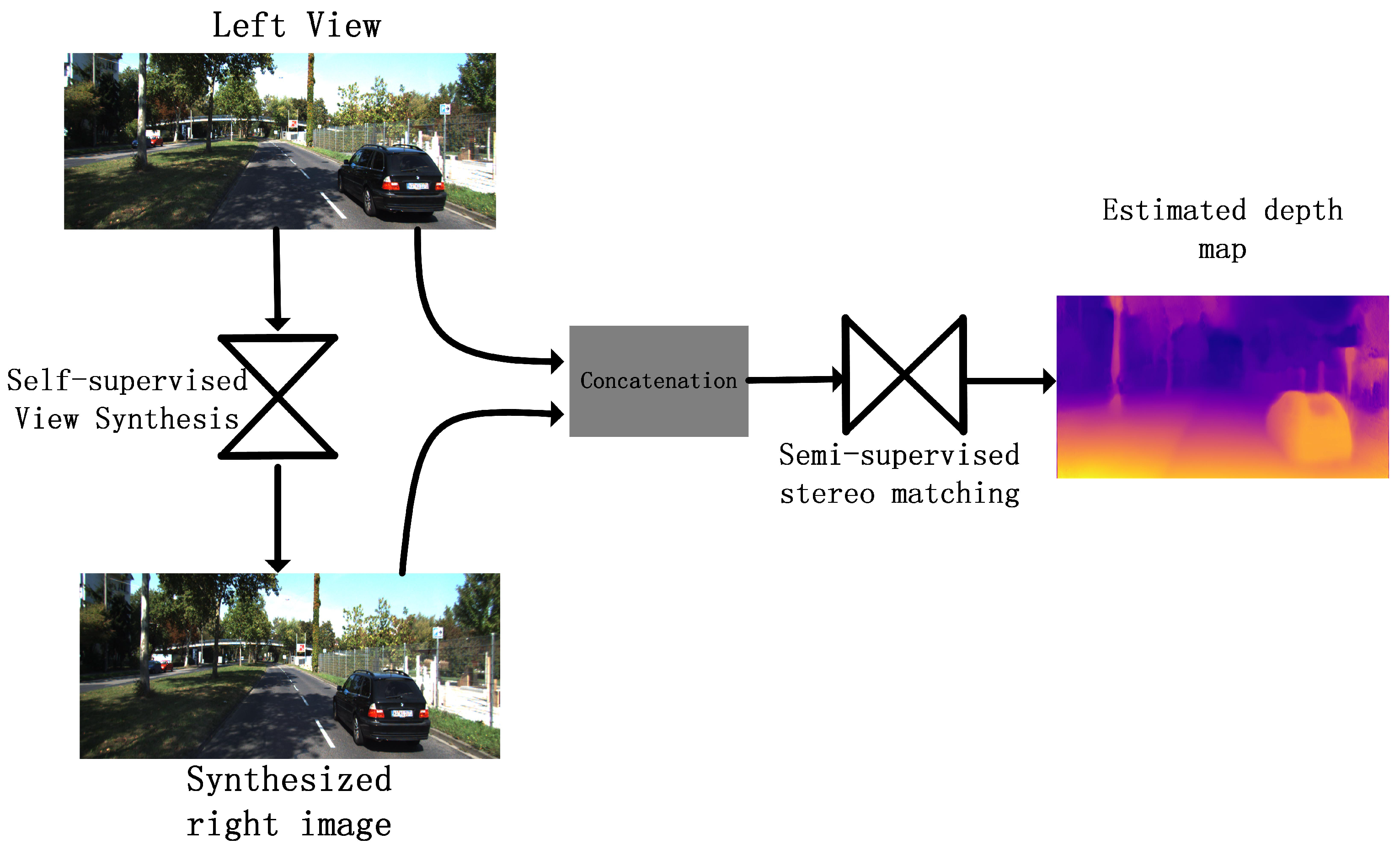
- This paper proposes a novel monocular depth estimation method without using ground truth depth data, which uses the combinative model of the view synthesis network and stereo matching network to achieve a high-quality depth map from a single image. The model not only follows the geometric principles, but also improves the estimation accuracy.
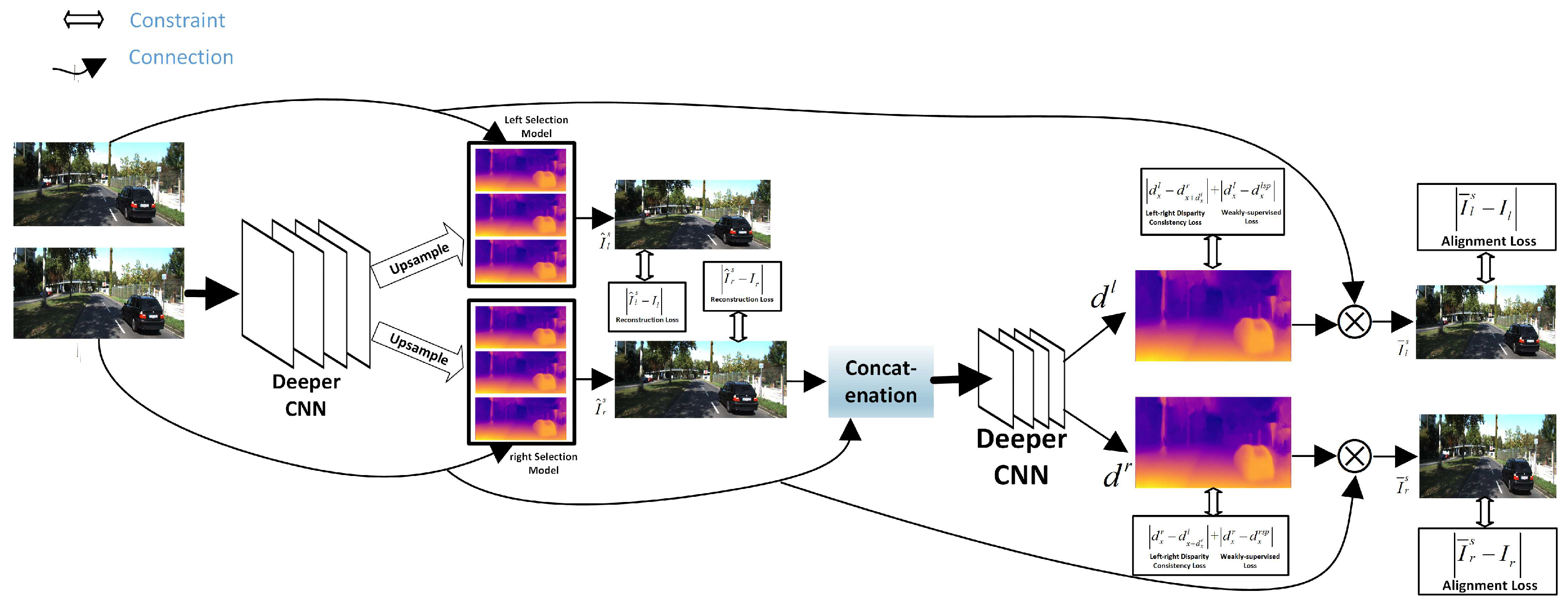
- To raise the quality of the reconstructed right view, the paper improves the existing view synthesis network Deep3D model by adding a left-right consistency constraint and a smoothness constraint.
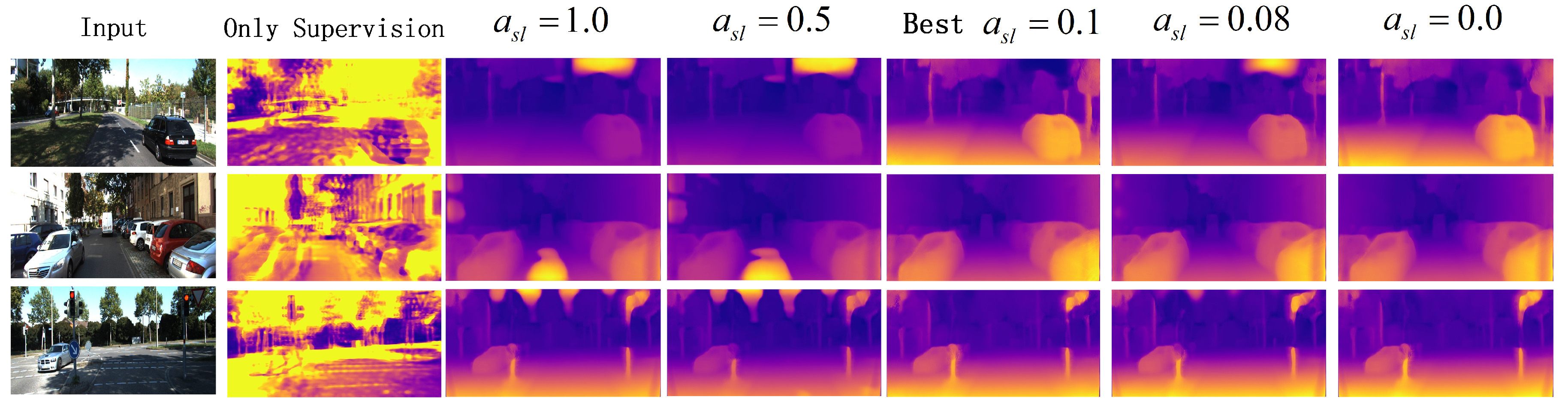
- In order to improve the estimation accuracy and reduce the impact of the reconstruction error from the right view, we propose a semi-supervised stereo matching method to predict the depth.
2. Related Work
2.1. Stereo Matching
2.2. Monocular Depth Estimation
3. Method
3.1. Analysis of Depth Estimation Method
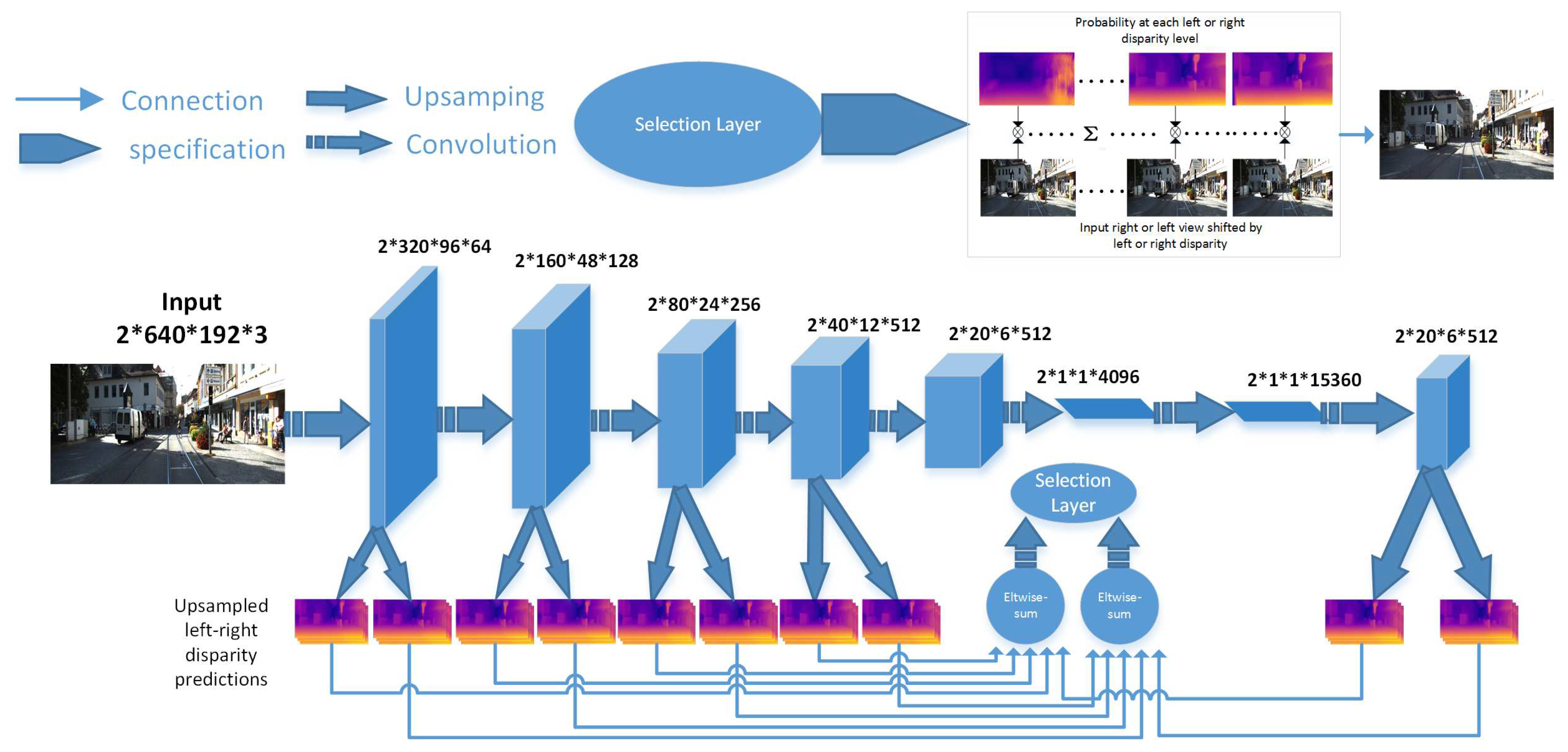
3.2. View Synthesis Network
3.2.1. Network Architecture
3.2.2. Loss Function
3.3. Stereo Matching Network
3.3.1. Network Architecture
3.3.2. Loss Function
Supervised Loss
Self-Supervised Loss
4. Experiments
4.1. Evaluation Metrics
4.1.1. Reconstruction Metrics of the View Synthesis Model
4.1.2. Evaluation Metrics of the Stereo Matching Model
4.2. Dataset
4.3. Implementation Details
4.4. Performance Analysis
4.5. Results
4.5.1. Comparison of the View Synthesis Network Model
4.5.2. Comparison of Stereo Matching Model
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Furukawa, Y. Multi-View Stereo: A Tutorial; Now Publishers Inc.: Delft, The Netherlands, 2015; pp. 1–148. [Google Scholar]
- Ladický, L.; Christian, H.; Pollefeys, M. Learning the Matching Function. arXiv 2015, arXiv:1502.00652. [Google Scholar]
- Sturm, P.; Triggs, B. A factorization based algorithm for multi-image projective structure and motion. In Proceedings of the 4th European Conference on Computer Vision (ECCV’96), Cambridge, UK, 14–18 April 1996; Volume 1065, pp. 709–720. [Google Scholar]
- Hernández, E.C.; Vogiatzis, G.; Cipolla, R. Multiview photometric stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 548. [Google Scholar] [CrossRef] [PubMed]
- Saxena, A.; Chung, S.H.; Ng, A.Y. 3-D Depth Reconstruction from a Single Still Image. Int. J. Comput. Vis. 2008, 76, 53–69. [Google Scholar] [CrossRef]
- Luo, W.; Schwing, A.G.; Urtasun, R. Efficient Deep Learning for Stereo Matching. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5695–5703. [Google Scholar]
- Lecun, Y. Stereo Matching by Training A Convolutional Neural Network to Compare Image Patches. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Chen, W.; Fu, Z.; Yang, D.; Deng, J. Single-Image Depth Perception in the Wild. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2016; pp. 730–738. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3D: Learning 3D Scene Structure from a Single Still Image. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 824–840. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Ren, J.; Lin, M.; Pang, J.; Sun, W.; Li, H.; Lin, L. Single View Stereo Matching. arXiv 2018, arXiv:1803.02612. [Google Scholar]
- Godard, C.; Aodha, O.M.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6602–6611. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Deep3D: Fully Automatic 2D-to-3D Video Conversion with Deep Convolutional Neural Networks; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Kuznietsov, Y.; Stückler, J.; Leibe, B. Semi-Supervised Deep Learning for Monocular Depth Map Prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2215–2223. [Google Scholar]
- Geiger, A. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Mayer, N.; Ilg, E.; Häusser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Dosovitskiy, A.; Fischery, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Smagt, P.V.D.; Cremers, D.; Brox, T. FlowNet: Learning Optical Flow with Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Pang, J.; Sun, W.; Ren, J.S.; Yang, C.; Yan, Q. Cascade Residual Learning: A Two-stage Convolutional Neural Network for Stereo Matching. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 878–886. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-scale Convolutional Architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper Depth Prediction with Fully Convolutional Residual Networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning Depth from Single Monocular Images Using Deep Convolutional Neural Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed]
- Ummenhofer, B.; Zhou, H.U.J.; Mayer, N. DeMoN: Depth and motion network for learning monocular stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wu, Y.; Ying, S.; Zheng, L. Size-to-Depth: A New Perspective for Single Image Depth Estimation. arXiv 2018, arXiv:1801.04461. [Google Scholar]
- Garg, R.; Vijay, K.B.G.; Carneiro, G.; Reid, I. Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue. In Proceedings of the ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 740–756. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2015; pp. 2017–2025. [Google Scholar]
- Li, R.; Wang, S.; Long, Z.; Gu, D. UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 21–25 May 2018; pp. 2017–2025. [Google Scholar]
- Zhan, H.; Garg, R.; Weerasekera, C.S.; Li, K.; Agarwal, H.; Reid, I. Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6612–6619. [Google Scholar]
- Byravan, A.; Fox, D. SE3-Nets: Learning Rigid Body Motion using Deep Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 173–180. [Google Scholar]
- Vijayanarasimhan, S.; Ricco, S.; Schmid, C.; Sukthankar, R.; Fragkiadaki, K. SfM-Net: Learning of Structure and Motion from Video. arXiv 2017, arXiv:1704.07804. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G. Digging Into Self-Supervised Monocular Depth Estimation. arXiv 2018, arXiv:1806.01260. [Google Scholar]
- Yin, Z.; Shi, J. GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Yang, Z.; Peng, W.; Wei, X.; Liang, Z.; Nevatia, R. Unsupervised Learning of Geometry with Edge-aware Depth-Normal Consistency. arXiv 2017, arXiv:1711.03665. [Google Scholar]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5667–5675. [Google Scholar]
- Wang, C.; Buenaposada, J.M.; Zhu, R.; Lucey, S. Learning Depth from Monocular Videos using Direct Methods. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2022–2030. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G. Deep Convolutional Neural Fields for Depth Estimation from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–23 June 2018; pp. 5162–5170. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. Software available from tensorflow.org. 2016. Available online: https://cse.buffalo.edu/~chandola/teaching/mlseminardocs/TensorFlow.pdf (accessed on 17 May 2019).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Mode | RMSE | RMSE(log) | ARD | SRD | |||
|---|---|---|---|---|---|---|---|---|
| (Lower Is Better) | (Higher Is Better) | |||||||
| Monocular-VGG16 [12] | self-supervised | 6.125 | 0.217 | 0.124 | 1.388 | 0.841 | 0.936 | 0.975 |
| Stereo-VGG16 [12] | 4.434 | 0.146 | 0.067 | 0.899 | 0.947 | 0.978 | 0.988 | |
| Monocular-ResNet50 [12] | 5.764 | 0.203 | 0.114 | 1.246 | 0.854 | 0.947 | 0.979 | |
| Stereo-ResNet50 [12] | 4.593 | 0.150 | 0.070 | 1.039 | 0.946 | 0.977 | 0.988 | |
| Supervised Method [11] | supervised | 4.252 | 0.177 | 0.094 | 0.626 | 0.891 | 0.965 | 0.984 |
| RMSE | RMSE(log) | ARD | SRD | |||||
|---|---|---|---|---|---|---|---|---|
| (Lower Is Better) | (Higher Is Better) | |||||||
| Only-Supervision | 18.469 | 2.269 | 0.8469 | 12.928 | 0.010 | 0.023 | 0.039 | |
| 5.845 | 0.335 | 0.151 | 1.372 | 0.786 | 0.887 | 0.927 | ||
| 5.203 | 0.220 | 0.117 | 1.085 | 0.837 | 0.935 | 0.971 | ||
| 5.191 | 0.208 | 0.112 | 1.032 | 0.848 | 0.942 | 0.979 | ||
| 5.163 | 0.193 | 0.107 | 1.015 | 0.858 | 0.951 | 0.982 | ||
| 5.194 | 0.194 | 0.108 | 1.041 | 0.856 | 0.950 | 0.982 | ||
| 5.205 | 0.195 | 0.108 | 1.039 | 0.856 | 0.950 | 0.982 | ||
| 5.231 | 0.195 | 0.108 | 1.034 | 0.856 | 0.949 | 0.982 | ||
| Method | Dataset | Train | Cap | RMSE | RMSE(log) | ARD | SRD | |||
|---|---|---|---|---|---|---|---|---|---|---|
| (Lower Is Better) | (Higher Is Better) | |||||||||
| Stereo Matching | K | Stereo | 1–80 m | 4.392 | 0.146 | 0.066 | 0.835 | 0.947 | 0.978 | 0.989 |
| Stereo Matching | Stereo | 1–50 m | 3.997 | 0.140 | 0.063 | 0.629 | 0.945 | 0.979 | 0.990 | |
| Eigen et al. [9] coarse | K | Depth | 1–80 m | 6.215 | 0.271 | 0.204 | 1.598 | 0.695 | 0.897 | 0.960 |
| Eigen et al. [9] Fine | Depth | 1–80 m | 6.138 | 0.265 | 0.195 | 1.531 | 0.734 | 0.904 | 0.966 | |
| Liu et al. [37] | Depth | 1–80 m | 6.471 | 0.273 | 0.201 | 1.584 | 0.680 | 0.898 | 0.967 | |
| Kuznietsov et al. [14] | Depth | 1–80 m | 4.621 | 0.189 | 0.113 | 0.741 | 0.862 | 0.960 | 0.980 | |
| Luo et al. [11] | Depth | 1–80 m | 4.252 | 0.177 | 0.094 | 0.626 | 0.891 | 0.965 | 0.984 | |
| Godard et al. [12] | K | Stereo | 1–80 m | 5.764 | 0.203 | 0.114 | 1.246 | 0.854 | 0.947 | 0.979 |
| Godard et al. [32] | Stereo | 1–80 m | 5.164 | 0.212 | 0.115 | 1.010 | 0.858 | 0.946 | 0.974 | |
| Zhan et al. [28] | Temporal + Stereo | 1–80 m | 5.869 | 0.241 | 0.144 | 1.391 | 0.803 | 0.928 | 0.969 | |
| Godard et al. [32] | Temporal + Stereo | 1–80 m | 5.029 | 0.203 | 0.114 | 0.991 | 0.864 | 0.951 | 0.978 | |
| Ours | Stereo | 1–80 m | 5.180 | 0.200 | 0.110 | 1.141 | 0.854 | 0.948 | 0.980 | |
| Ours (Post-processing) | Stereo | 1–80 m | 5.163 | 0.193 | 0.107 | 1.002 | 0.858 | 0.951 | 0.982 | |
| Garg et al. [25] | K | Stereo | 1–50 m | 5.104 | 0.273 | 0.169 | 1.080 | 0.740 | 0.904 | 0.962 |
| Godard et al. [12] | Stereo | 1–50 m | 5.431 | 0.199 | 0.110 | 1.034 | 0.854 | 0.949 | 0.980 | |
| Zhou et al. [29] | Mono | 1–50 m | 6.709 | 0.270 | 0.183 | 1.595 | 0.734 | 0.902 | 0.959 | |
| Zhan et al. [28] | Temporal + Stereo | 1–50 m | 4.366 | 0.225 | 0.135 | 0.905 | 0.818 | 0.937 | 0.973 | |
| Ours | Stereo | 1–50 m | 5.106 | 0.196 | 0.107 | 0.941 | 0.854 | 0.950 | 0.981 | |
| Ours (Post-processing) | Stereo | 1–50 m | 5.098 | 0.190 | 0.105 | 0.863 | 0.857 | 0.952 | 0.983 | |
| Layer | Feature Map (I/O) | Scaling | Inputs |
|---|---|---|---|
| 3/32 | 1 | Input (RGB) | |
| 32/32 | 2 | ||
| 32/32 | 1 | ||
| 32/32 | 1 | ||
| 32/32 | 1 | ||
| 32/32 | 2 | ||
| 32/64 | 2 | ||
| 64/64 | 4 | ||
| 64/64 | 2 | ||
| 64/128 | 4 | ||
| 128/256 | 4 | ||
| 256/256 | 8 | ||
| 256/512 | 8 | ||
| 512/512 | 16 | ||
| 512/512 | 16 | ||
| 512/512 | 32 | ||
| 512/512 | 64 | ||
| 512/512 | 64 | ||
| 512/512 | 128 | ||
| 512/512 | 128 | ||
| 7 | 512/512 | 64 | |
| 512/512 | 32 | ||
| 512/256 | 16 | ||
| 256/128 | 8 | ||
| 128/64 | 4 | ||
| 64/32 | 2 | ||
| 32/16 | 2 | ||
| Method | PSNR | SSIM |
|---|---|---|
| Deep3D [13] | 20.209 | 0.781 |
| Deep3Ds [11] | 22.310 | 0.810 |
| Godard et al. [12] | 24.510 | 0.820 |
| Ours | 25.065 | 0.831 |
| Method | Dataset | Supervised | Cap | RMSE | RMSE (log) | ARD | SRD | |||
|---|---|---|---|---|---|---|---|---|---|---|
| (Lower Is Better) | (Higher Is Better) | |||||||||
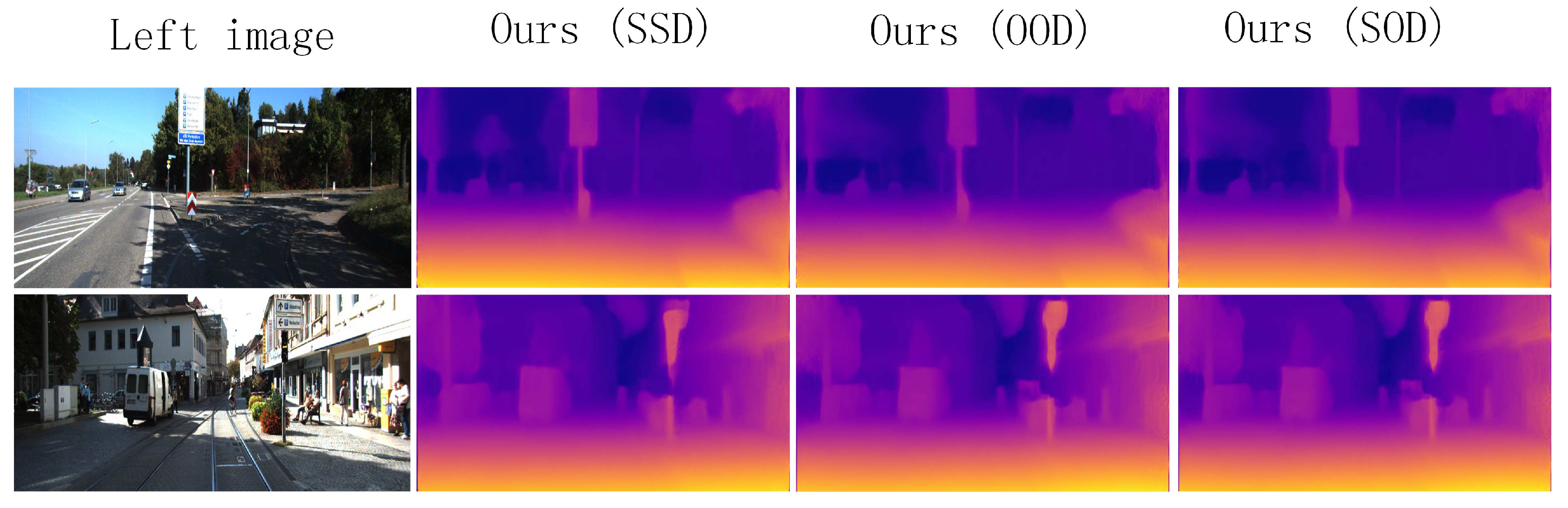
| Ours (SSD) | K | N | 0–80 m | 5.205 | 0.203 | 0.113 | 1.240 | 0.850 | 0.946 | 0.979 |
| Ours (OOD) | N | 0–80 m | 5.190 | 0.202 | 0.113 | 1.002 | 0.850 | 0.946 | 0.980 | |
| Ours (SOD) | N | 0–80 m | 5.163 | 0.193 | 0.107 | 1.002 | 0.858 | 0.951 | 0.982 | |
| Ours (SSD) | K | N | 0–50 m | 5.167 | 0.193 | 0.110 | 0.875 | 0.854 | 0.949 | 0.980 |
| Ours (OOD) | N | 0–50 m | 5.158 | 0.192 | 0.111 | 0.873 | 0.854 | 0.950 | 0.981 | |
| Ours (SOD) | N | 0–50 m | 5.098 | 0.190 | 0.105 | 0.863 | 0.857 | 0.952 | 0.983 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Qiao, J.; Lin, S. A Semi-Supervised Monocular Stereo Matching Method. Symmetry 2019, 11, 690. https://doi.org/10.3390/sym11050690
Zhang Z, Qiao J, Lin S. A Semi-Supervised Monocular Stereo Matching Method. Symmetry. 2019; 11(5):690. https://doi.org/10.3390/sym11050690
Chicago/Turabian StyleZhang, Zhimin, Jianzhong Qiao, and Shukuan Lin. 2019. "A Semi-Supervised Monocular Stereo Matching Method" Symmetry 11, no. 5: 690. https://doi.org/10.3390/sym11050690
APA StyleZhang, Z., Qiao, J., & Lin, S. (2019). A Semi-Supervised Monocular Stereo Matching Method. Symmetry, 11(5), 690. https://doi.org/10.3390/sym11050690