1. Introduction
Hand pose estimation has made rapid progress in recent years. The increased accuracy can be attributed to two aspects: depth camera and convolution neural networks (CNN). Firstly, commodity depth sensors, such as the Microsoft Kinect and the Intel RealSense, have an attractive price and stable performance. Moreover, depth cameras have been embedded in mobile devices. For example, Apple Inc. has adopted TrueDepthCameraSystem for face identification (FaceID) and extension of the selfie. With the help of depth information, algorithms can resolve many of the ambiguities compared to RGB images. Secondly, deep learning has significantly changed the way of solving the vision problem. Many backbones and networks play essential roles in different visual fields.
Deep neural networks (DNNs) have been successfully applied to 3D hand pose estimation [
1,
2,
3,
4]. 2.5D depth data can be treated both as 2D images and volumetric representations. Wan [
5] designed careful parameterization to combine holistic 3D regression with 3D detection and outperformed all previous state-of-arts on three public datasets. However, they used the hourglass network [
6] as the backbone and two repeated stacks to improve accuracy. With this structure, we found that the inference time still cannot meet the real-time performance requirement even in the case of one NVIDIA TITAN X and the requirement for expensive graphics processing units (GPUs) is a barrier to deployment on mobile devices. It is probably because previous work mainly focused on model accuracy alone while overlooking the importance of model efficiency and the deployed platform.
Nevertheless, deep learning should embrace more resources-limited devices for a broader application scenario. Deep learning networks with large depth and width are resource-intensive in the training and inference process. The industrial world has plenty of attempts for model speedup, such as binary neural network [
7], knowledge distillation [
8] and network compression [
9]. With these network compressions and speed up technology, a small sacrifice of accuracy can result in significant time-saving. For hand pose estimation, as an interactive task, real-time performance is crucial as long as the error is within the acceptable range.
In this study, we carefully make two-level network pruning to improve hand pose estimation efficiency without accuracy degradation. First, we observe that the following stacked modules (such as [
5,
6]) contribute much less to the overall accuracy than the previous modules. It allows us to keep a high accuracy when pruning the latter blocks (also called: depth pruning). Secondly, we treat the hourglass block as a variant of U-Net with nested and dense skip connections. Therefore, we can further prune the hourglass block at inference time if it is trained using deep supervision modules. In the experiments, we find deep supervision significantly helps to overcome the underfit problem of a smaller network compared to knowledge distillation. Moreover, deep supervision can mitigate the overfitting of model and outperform its original model. The proposed pruned network enables much faster inference time with remarkably smaller (49%) model size while only 1.67mm mean joint error increase.
Our contributions can be summarized as follows:
We investigate the less-studied hourglass network efficiency problem. Different from the most previous researches, we also focus on the model’s inference cost while keeping the accuracy performance.
We treat the hourglass network as a variant of U-Net and propose a new training strategy using deep supervision. It has a better generalization performance and allows us for finer-grained pruning.
We implement the two-level pruning strategy in the public NYU and ICVL datasets and achieve satisfactory accuracy rates compared to the previous state-of-the-art approaches. We also extensively examine the redundancy of the hand pose estimation design and find the significant benefits brought from deep supervision. We apply our model using OpenVINO toolkit to accelerate the inference process on the CPUs and it runs faster in contrast to GPUs.
2. Related Work
2.1. Network Pruning
Determining the proper size of a neural network is recognized as crucial and has a long history. Early work can be traced back to 1997 [
10] and it proposed the method of iteratively eliminating units and adjusting the remaining weight. After 2006, with the popularity of CNNs [
11], researchers [
12,
13] reduced parameters of AlexNet [
14] and VGG-16 [
15] using connection pruning. However, most of the reduction is achieved on fully-connected layers and it has no apparent speedup of convolutional layers. Many new designs use fewer FCNs (Fully Convolutional Networks), for example, only 3.99% of the parameters of ResNet-152 [
16] are from FCNs. Then, to reduce the cost of the convolution layers, several works [
17,
18] have studied removing the redundant filters from a well-trained network. Polyak et al. [
18] removed the less frequently activated feature maps using input samples. Li [
19] removed the whole filters and their connections based on L1-norm and this method did not depend on excessive hyperparameters and resulted in sparse connectivity patterns. In our method, we also focus on convolutional layers pruning. We make coarser-grained layers pruning based on the deep characteristics of the model. Our study is similar to that described in Reference [
20] but we choose to prune instead of knowledge distillation [
8]. Therefore, our method needs no additional training overhead compared to knowledge distillation and can achieve a satisfactory result.
2.2. Hand Pose Estimation
There is huge progress in hand pose estimation based on the deep learning method. The current best-performing methods [
21,
22,
23] are all single stage (holistic pose regression), probably because they take full advantage of joint correlations. Wan’s work [
5] well exploits the 2D and 3D properties of depth images and achieves evident performance increases. However, these prior works focus only on accuracy by using stacked structures and expensive models while mostly ignoring the inference cost. Therefore, it will restrict their scalability in real-time applications. In our paper, we present a fast hand pose estimation model based on dense regression and the proposed model is more lightweight and usable in the real world.
2.3. Hourglass and U-Net
U-Net [
24] was introduced by Ronneberger et al. and achieves good performance with biomedical image segmentation. U-Net concatenates the up-sampled features with features skipped from the encoder and adds convolutions layers between each up-sampling step. Inspired by DenseNet [
25], much research has attempted to modify the skip connections: Li proposed H-denseunet [
26] for liver segmentation and Drozdzal [
27] introduced short skip connections within the encoder. Similar to UNet++ [
28], an hourglass network has the encoder and decoder sub-networks connected through nested, dense and skip pathways. Opposite to fusing semantically dissimilar feature maps from different sub-networks, we exploit the semantic similarity to build an easier-learning task. Explicitly, we add supervision modules to every decoder and average their losses.
2.4. Deep Supervision
To train a deeper network more efficiently, many studies adopt the idea of adding auxiliary classifiers after some of the intermediate convolutional layers [
29,
30,
31,
32]. Deep supervision helps to relieve gradient disappearance and explosion and increase the transparency of hidden layers. Reference [
31] raised the idea that a discriminative classifier trained using hidden layer feature maps can serve as a proxy for the quality of those hidden layers and further the upper layers. Inspired by these guidelines, we use deep supervision in an hourglass network and enabling it as (1) an accurate model since the overall loss is averaged from all branches and (2) a fast model since we can select the last branch and speed up the inference process.
3. Method
We leverage the redundancy of the hourglass network (hourglass is widely used, such as References [
33,
34,
35,
36]) and make a two-level pruning to the dense 3D regression for hand pose estimation. With empirical examination, we revealed that a half number of stages suffices to keep over 96% accuracy on the NYU dataset. Later, the resulting network, with deep supervision, can be further pruned to the
network and suffice to achieve over 86% mean accuracy.
3.1. Compact Network Architecture
Hourglass is one of the most common building block units for hand pose estimation. The hourglass architecture uses repeated bottom-up and top-down processing to extract features from different scales and the pose predictions are generated after passing through each hourglass module. Subsequent hourglass modules allow the high-level features to be processed again and can correct the mistakes made earlier by the network.
Figure 1 shows the architecture of the compact network. It consists of stack pruning (
Figure 1a) and level pruning (
Figure 1b). We use the dense 3D regression as the original network because it is highly precise. The 2D, 3D joint heatmaps and unit vector fields (yellow blocks) are estimated by hourglass in a multi-task learning manner and sequentially the 3D hand pose is estimated by enforcing consensus between the 3D detection and 3D estimation. In our pruning strategy, we decrease the number of stacks in half. Although a tiny network is attractive, it is not easy to train a small network that can achieve a similar accuracy target to the larger one. Reference [
18] argued that training the small pruned network from scratch can almost always achieve a comparable or higher level of accuracy. However, in our situation, we find that training a one-stack tiny network performs poorly and it is most likely because the tiny network does not have enough generalization ability (learning power) and is more difficult to train. It can explain why most researchers attempt to stack identical structures to achieve better performance.
3.2. Hourglass with Deep Supervision
We propose using deep supervision in the hourglass module.
Figure 1b shows the varying model complexity determined by the different choice of selected (pruned) branch. According to the hourglass module, different levels generate different resolution feature maps representing multiple semantic levels. We add supervision behind {
}. We update the loss function with all the branch’s losses and the loss function is described as:
where
represent the ground-truth 2D heat map, 3D heat maps and vector offsets of joint
and
are the corresponding estimates from
th branch (level).
Owing to the skip connection (blue circles), the loss of accuracy caused by down-sampling can be compensated for and all the pruned networks have asymmetrical encoder-decoder architectures. The main drop of accuracy comes from the missing (pruned) decoder. However, in our experiment, we find the loss of accuracy is still always acceptable and the result can be explained in two aspects. Firstly, we average the loss with all semantics levels outputs and treat them equally importantly. The special position where we insert the deep supervision makes every decoder’s feature maps as a proxy for the quality. By making appropriate use of the feature quality feedback, we can directly influence the update process of weights to get a highly discriminative feature map. This is the source of why deep supervision helps to increase performance. Secondly, there are no criteria for how deep an hourglass network should be. In general, higher resolution images should have a deeper network structure (128*128 for 4 ranks, 256*256 for 5 ranks). However, in a simpler regression task (for example the hand poses are not complicated and less self-occlusion), a deep network is sometimes redundant in the inference process. Therefore, we propose the compact network to trade off accuracy and efficiency.
3.3. Inference Optimization with OpenVINO
Different from most previous work, we mainly focus on the performance of CPUs because it is more practical if deep learning applications can be deployed on embedded devices or normal PCs and have fast execution during inference. Instead of depending on the expensive GPUs, we transform to leverage the resources of CPUs. The main advantage of GPUs over CPUs is the parallelism. However, the AVX (advanced vector extensions) instructions have extended the parallel execution capability. For example, with AVX-512, applications can pack 32 double precision and 64 single precision floating point operations per second per clock cycle within the 512-bit vectors, as well as eight 64-bit and sixteen 32-bit integers, with up to two 512-bit fused-multiply add (FMA) units. Thus, it is possible to speed up the DNN without any GPUs.
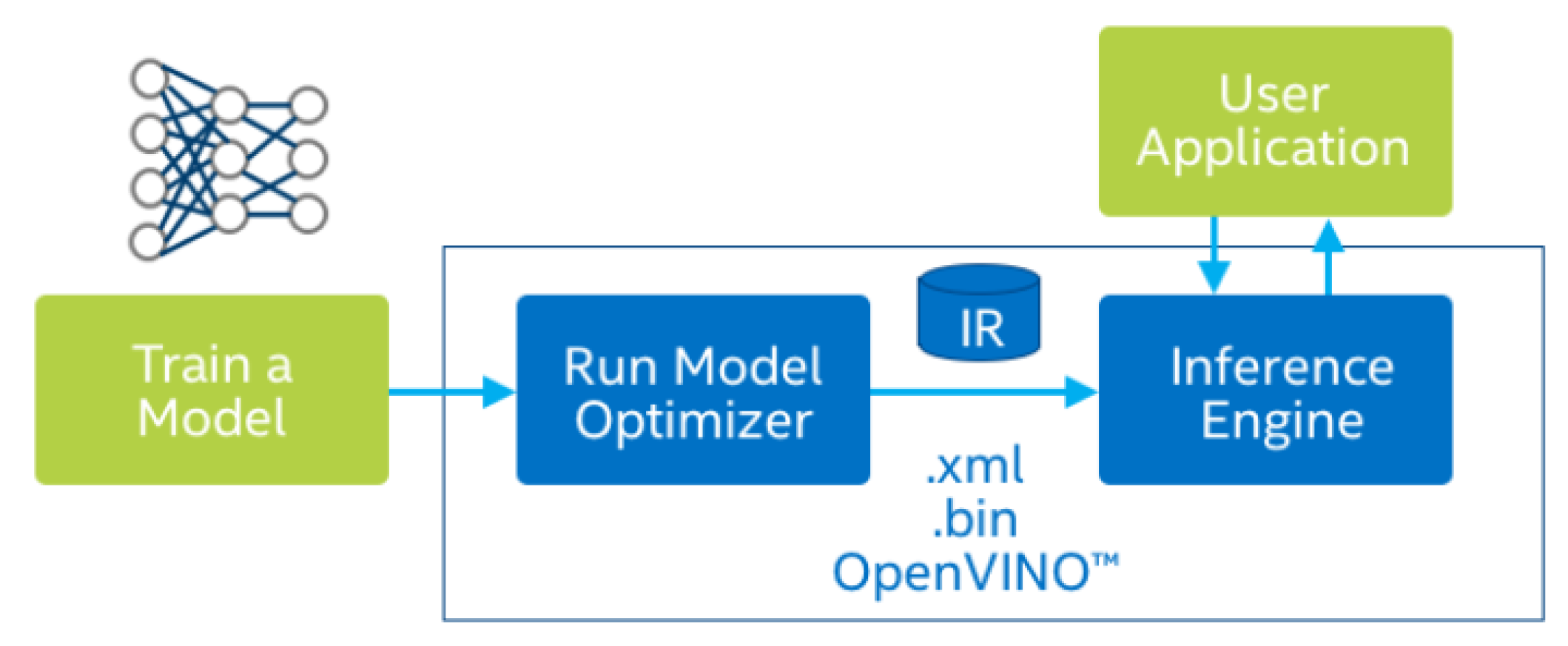
OpenVINO is a deep learning deployment toolkit which allows the deployment pre-trained deep learning models through a high-level Python or C++ inference engine API and supports many Intel platforms such as CPUs, VPU and FPGA and so forth. As shown in
Figure 2, the toolkit comprises two components: model optimizer and inference engine. Model optimizer contains many state-of-the-art network optimization techniques such as path folding, batch normalization fusion, node merging, dead/no-op elimination and so forth. The inference engine contains the high-level inference API which can deliver the best hardware performance for each hardware type. The model optimizer converts the trained model to the intermediate representation (IR) and then runs on the inference engine.
3.4. Implementation Details
In stack pruning, we cut off the second network stack without any training process. In level pruning, we add three supervision modules and retrain the one stack network. The network is implemented with Tensorflow and optimized using the Adam. We choose the checkpoint file carefully with the help of the validation set. We use a single NVIDIA Titan X for training and the Intel Core CPU (i9-7900X, 3.30GHz) during the testing to simulate the actual application scenarios. During training, we randomly rotate the image and change the aspect ratio for simple data augmentation.
During inference, the resulting network achieves a mean running time of 32 ms (31.25 FPS, the original is 22.7 FPS) and is 49% parameters size of the original one with only 16.3% loss increase (according to
Table 1). Moreover, we implement the pipeline with the help of OpenVINO optimizer. It boosts the execution performance on Intel platforms and we will explain the details in
Section 4.3.
4. Experiments
We conduct experiments on two publicly available datasets, that is, NYU and ICVL. We choose the NYU dataset to conduct the level-pruning and ablation experiments because it has broader coverage of hand poses as opposed to ICVL. We also implement the network with Intel OpenVINO toolkit. The toolkit extends workloads across Intel hardware and greatly maximizes performance.
To evaluate the efficiency of the model, we measure the parameters size and the running time per frame. To evaluate the accuracy quantitatively, we use two metrics: mean joint error (in mm) averaged over all joints and all frames and the percentage of frames in which all joints are below a certain threshold (in mm). To evaluate the whole pipeline performance, we break it down to three parts: pre-processing (crop, padding, etc.), regression network, the mean-shift algorithm (network output to estimated pose) and measure their efficiency separately. The results illustrate the Intel OpenVINO toolkit can optimize the pipeline’s inference process in Intel CPUs and achieve the similar or even better performance than NVIDIA Titan X.
4.1. Baseline
In this section, we analyze the redundancy of models and the reasons why our pruning strategy works. Besides, we investigate the dominant layers and the benefits brought from deep supervision.
4.1.1. What Dominates the Accuracy of the Stacked Hourglass?
We examined the design of the popular stacked-hourglass network regarding feature number and stack number. To this end, we mainly tested two dimensions: depth (layers) and width (the channel/feature number). We revealed that the channel number has less impact on the accuracy than layer number.
From
Table 2, we find that the half feature number only leads to quite limited performance degradation (when the stack number is the same). However, the half stack leads a relatively large performance collapse. As we discussed before, the result proved that training a small model from scratch is challenging and cannot always achieve the similar accuracy target as a complicated model because of the lack of generalization capability for large amounts of data. This is one of the reasons why we use network pruning: we want to exploit both the generalization capability from large models and the lightweight from small models.
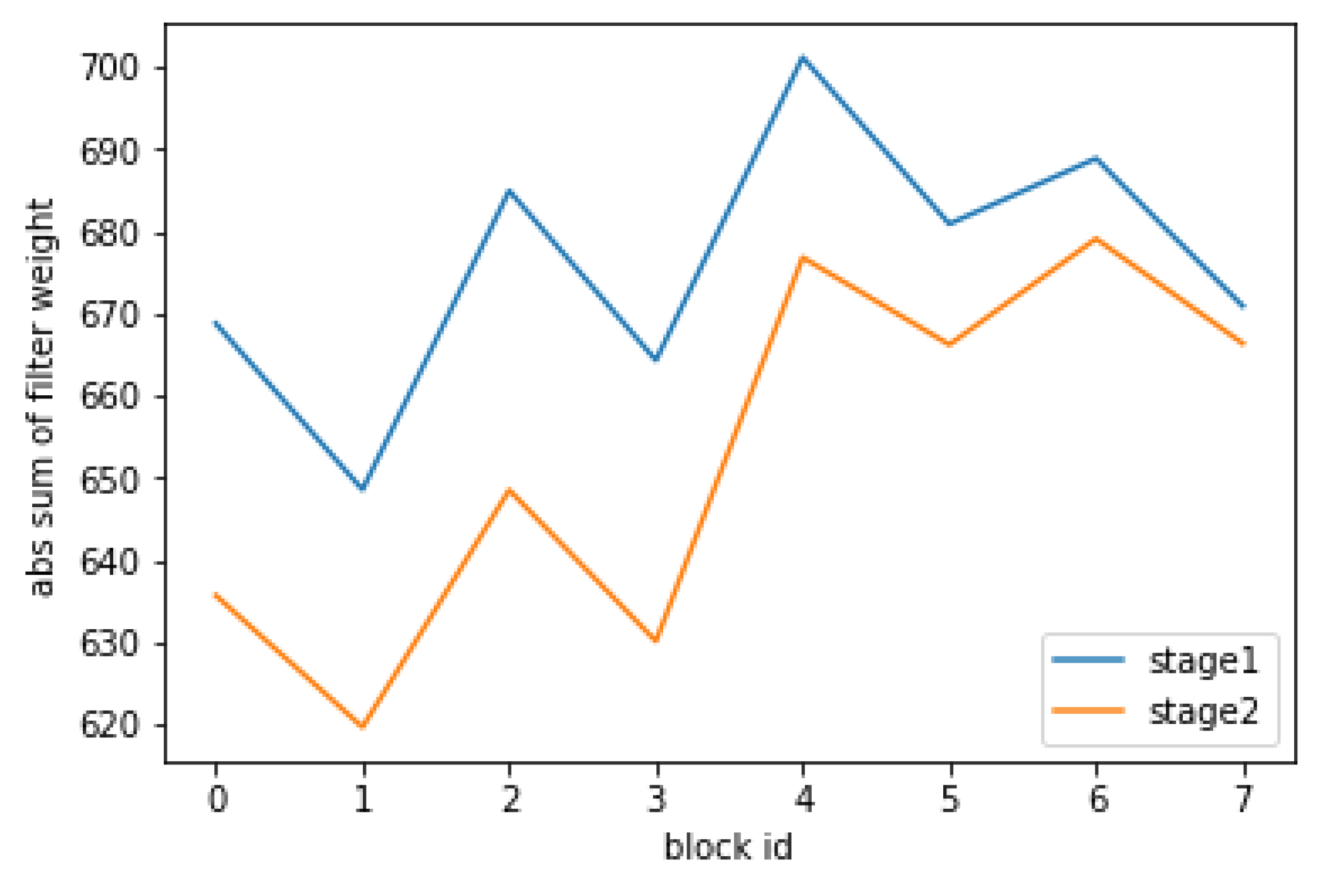
We investigated which part of the hourglass should be pruned. In general, we should remove weights with small magnitudes (less important). According to
Figure 3, we compare the L1-norm between different stages of the original network and decide to prune the second stack which has the smaller L1-norm. L1-norm measures the importance of layers by calculating the sum of its absolute weights
(
is the index of any kernel matrix). We use L1-norm because it is a good criterion for data-free selection [
19].
4.1.2. Impact of Deep Supervision
To explore the impact of deep supervision, we implement it and retrain the one-stack network. The results from
Table 3 show how the
prune and retrain technique can complement the error increase caused by pruning. Training from scratch performed worse than retraining from pruned network. Instead, retraining with or without deep supervision has a similar accuracy performance (the difference is only 0.062mm).
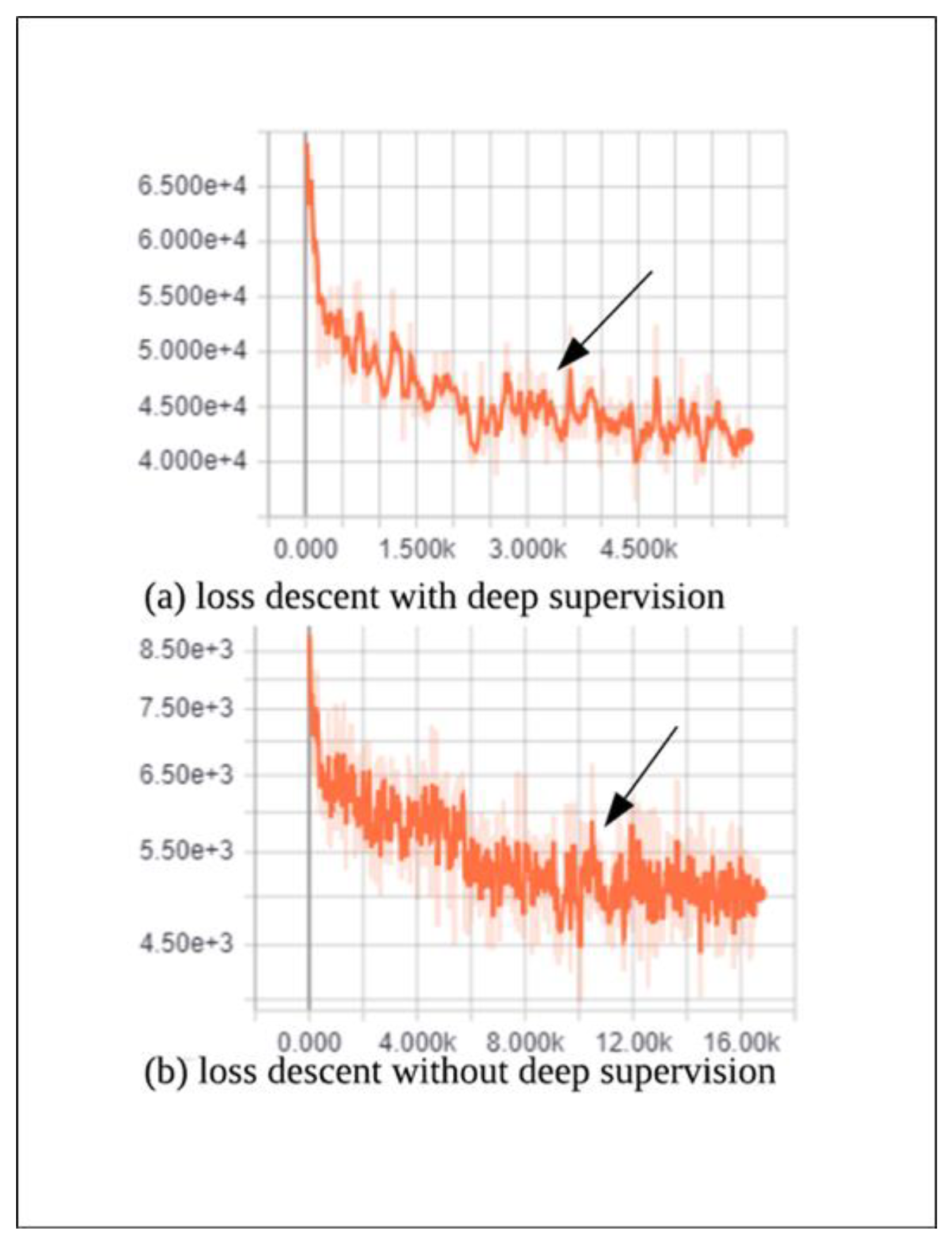
We deeply analyze the retraining process. As shown in
Figure 4, although the network with deep supervision has a higher initial loss, the convergence rate is bigger than that without deep supervision. For example, as shown in
Figure 4 (where the arrow points), the training process with deep supervision converges at step 4K and that without deep supervision only converges at step 10K. The reason why the
Figure 4a has higher loss is that the two strategies have different loss function which can be found in Equation 1. The loss function of
Figure 4a is the sum of different level branches, so it has a bigger loss than
Figure 4b.
Thus, the strategy of deep supervision can not only provide the possibility of further pruning but also performs the shorter training process.
4.2. Comparision of State-of-the-Art
We evaluated our proposed lightweight hand pose estimation method against the state-of-the-art methods on the NYU and ICVL dataset. The results show that our pruned network has traded off the accuracy and efficiency and achieve a satisfactory target on both datasets.
NYU Dataset [
1]: The NYU hand dataset contains 72,757 training and 8252 testing samples (each view). The depth data are captured using MS Kinects from three points of view (left, right and middle). It covers a wide range of hand poses and also some noisy depth images which makes the dataset challenging. We only use 14 joints and one view (middle) for both training and testing despite that the dataset has 36 key hand locations.
We compare our method with the original regression network. According to
Table 1, the 1-stack-
w/DS method gets 6 FPS boost with only 4% ((10.64-10.23)/10.23) error increase. Also, 1-stack-
w/DS achieve 9 FPS boost with 16.3% error increase, which is an acceptable trade-off. Similar to
Table 3, deep supervision helps to converge faster but still has approximate error. As shown in
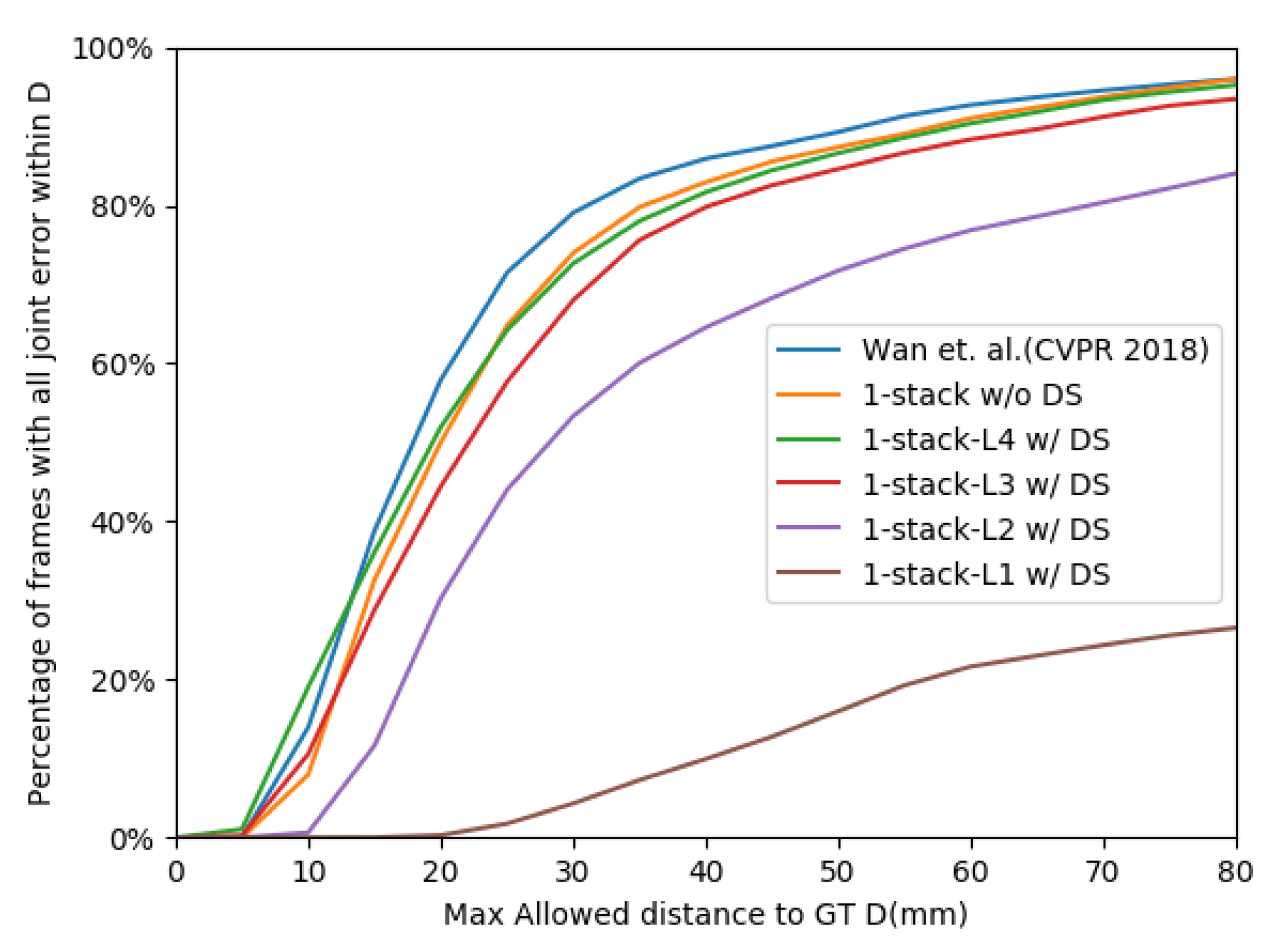
Figure 5, our pruned network increases the percentage on the threshold of 10mm and has the close max joint error percentage compared to the original network.
However, we notice that a large level-pruning has the lousy result (1-stack-
w/DS). It is because the
branch only has a
resolution, which is not enough for an accurate prediction. We also present the qualitative results in
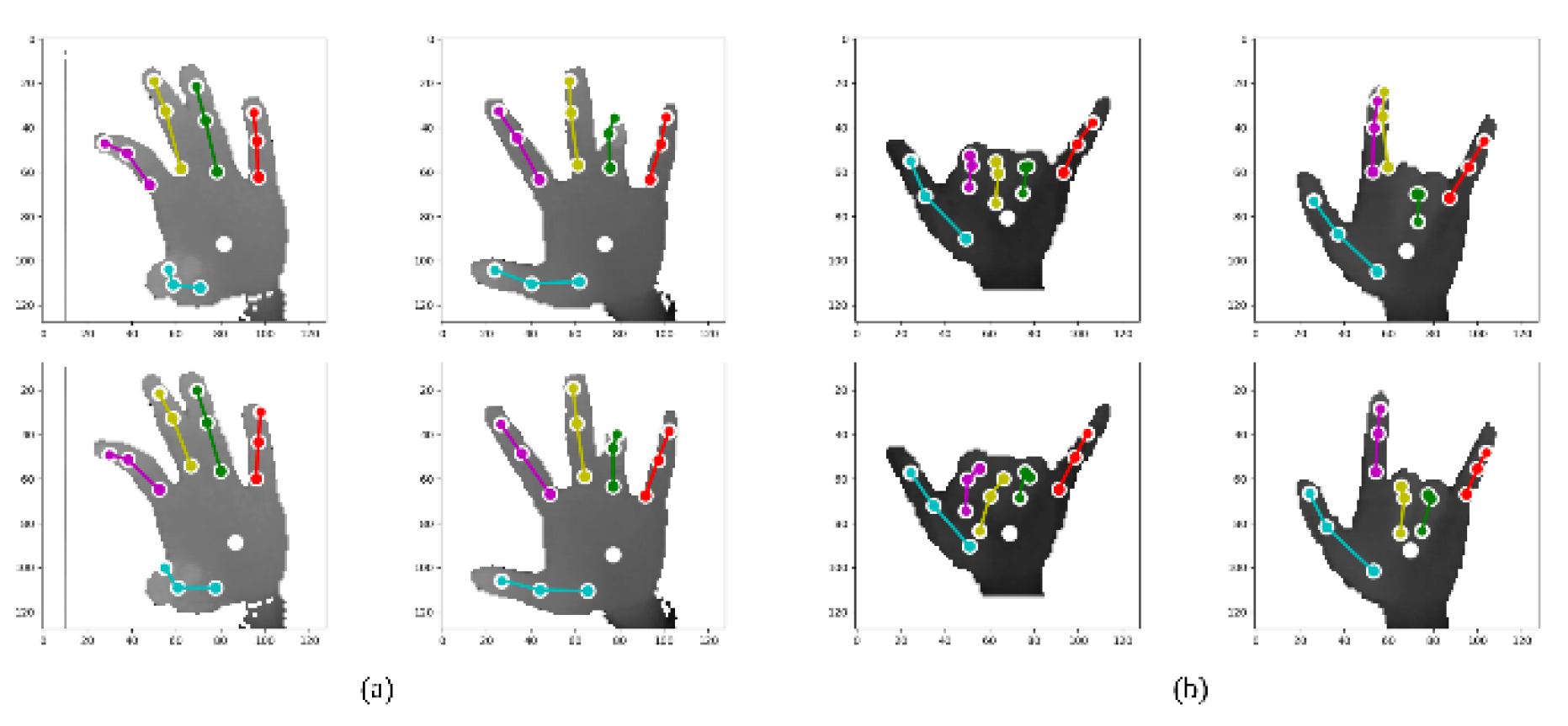
Figure 6. Failure cases include noisy images and severe self-occlusions shown in
Figure 6b.
ICVL Dataset [
13]: The ICVL 3D hand posture dataset has 22K depth images for training and 1.5K for testing. The richness of pose is much smaller than the NYU dataset. ICVL has 16 joint locations from each frame and the data is captured using Intel Creative depth sensor. This dataset has less noisy input, owing to the sensor. We also select 14 joints to be consistent with the NYU dataset.
As is shown in
Table 4, our method has a stable performance in the ICVL dataset.
Table 4 shows that 0.17mm average 3D error sacrifice can bring 20% speed boost. Similar to NYU dataset, the reason for failure samples is severe self-occlusions (as shown in
Figure 7). According to
Figure 8, the percentage of max joint error is very close compared to the original network.
4.3. OpenVINO Optimization
We break down the pipeline into three parts: pre-processing (crop, align and normalization), regression network (regression for heat map estimation) and mean-shift algorithm (coordinate 2D and 3D heat map to restructure hand poses). We find that the regression network is not the only impact of inference time. From
Table 5, we find the mean-shift algorithm takes much time on GPU, which is even longer than the time of regression network (17.6 ms versus 3.6 ms). This is because the mean-shift algorithm cannot benefit much from parallel computing and requires fast data transmission. That can also explain why some small networks can perform better on CPU than on GPU.
As shown in
Table 6, we compare the execution time on different framework and device for our proposed network (1-stack-
w/DS). The results show that the OpenVINO framework can boost the inference process of regression network on CPUs (row 2 and 3). Moreover, the benefits brought by faster mean-shift algorithm execution speed can further decrease the total inference time of the pipeline (row 1 and 3). Therefore, our method runs faster on CPUs (56 FPS versus 44 FPS).
Compared to state-of-the-art methods shown in
Table 6, our method achieves comparable accuracy and the real-time goal.
4.4. Exploration Studies
We implement the existing network compression technique (knowledge distillation [
8]) to compare it with our method. Knowledge distillation is the approach of training student networks from the supervision of a teacher network. We consider the 2-stack network as the teacher model and 1-stack network as the resulting student model. Subsequently, the student network is trained under the supervision of a teacher network. The results are appended to
Table 2 and show an even worse result than training from scratch. A possible explanation is that knowledge distillation is inadequate for the multi-task regression problem instead of for the classification problem. Previous network compression works mainly focus on compressing universal networks such as VGG-16, ResNet and so forth. However, we notice the general-purpose compression methods may not apply to all kinds of networks, more dedicated strategies should be considered for better performance targets.
5. Conclusions and Discussion
We propose a lightweight architecture for real-time 3D hand pose estimation from depth images. Given the original network, we make two-level pruning under deep supervision and further boost the inference performance on the CPU platform. This is made possible to scale up hand pose estimation applications in reality. We have carried out extensive comparative evaluations on two 3D hand pose datasets and different hardware. The results show our network gains both cost-effectiveness and high accuracy. For practical applications, we prune the pre-trained network before inference and retrain to improve the reduced accuracy. Subsequently, we use the structure-optimized network in inference time.
Also, the inference time on CPUs can outperform that on GPUs with the help of new instructions and a newly proposed toolkit. Further optimization directions include pipeline throughput, heterogeneous computation and batch process.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}