Global Image Thresholding Adaptive Neuro-Fuzzy Inference System Trained with Fuzzy Inclusion and Entropy Measures



Abstract
:1. Introduction
2. ANFIS, Global Thresholding Techniques and the Main Parts of Our Previous Research
2.1. Global Thresholding Methods and Neural Networks in Image Segmentation
2.2. Fuzzy Subsethood and Entropy Measures
| if and only ifin Zadeh’s sense, | (S1) |
| Ifin Zadeh’s sense, then, | (S2) |
| If, then, | (S3) |
| and if, then |
| If , then | (S3) |
| and if , then |
2.3. Global and Local Thresholding Using Fuzzy Inclusion and Entropy Measures
| Algorithm 1: (Global) |
|
- Group 1 N with and (very dark),
- Group 2 N with and
- Group 3 N with and
- Group 4 N with and
- Group 5 N with and (very bright)
- Group 6 N with and
- Group 7 N with and
- Group 8 N with and
| Algorithm 2: (Local) |
|
2.4. Why ANFIS
3. First Global Thresholding ANFIS
3.1. Data Construction and Initial Evaluation
3.2. G(lobal) ANFIS 1—Adjusting Otsu’s Targets
4. Second Global Thresholding ANFIS—Experimenting on Public Databases
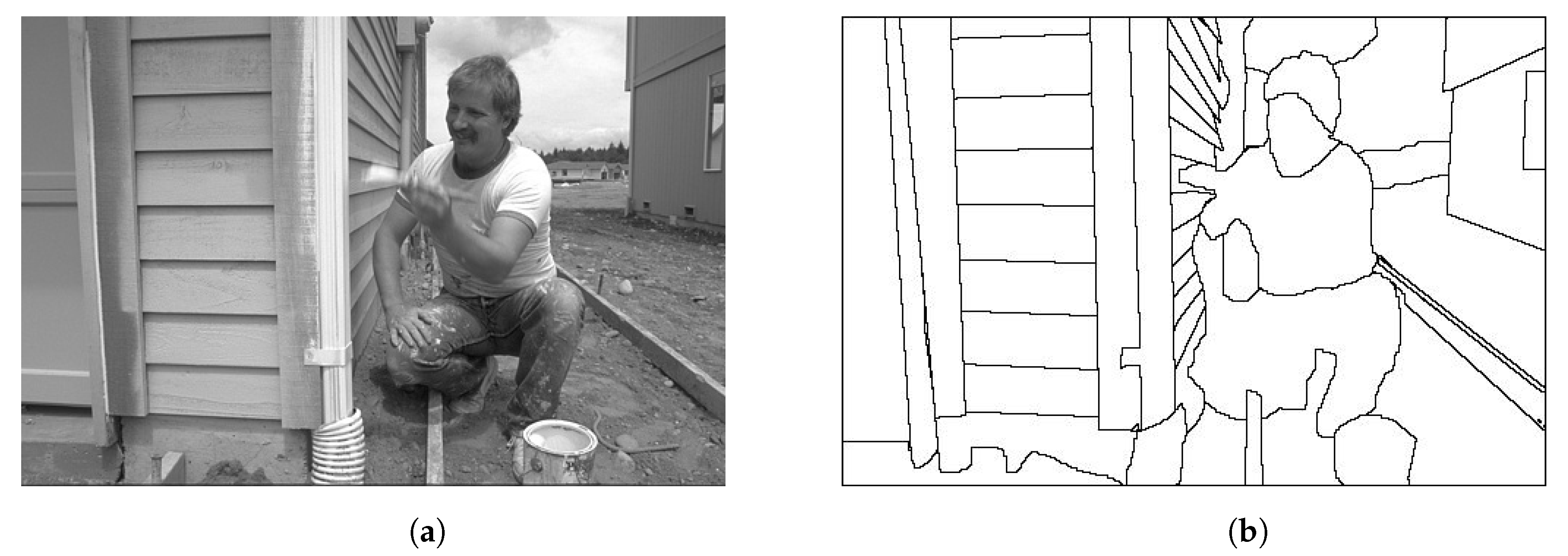
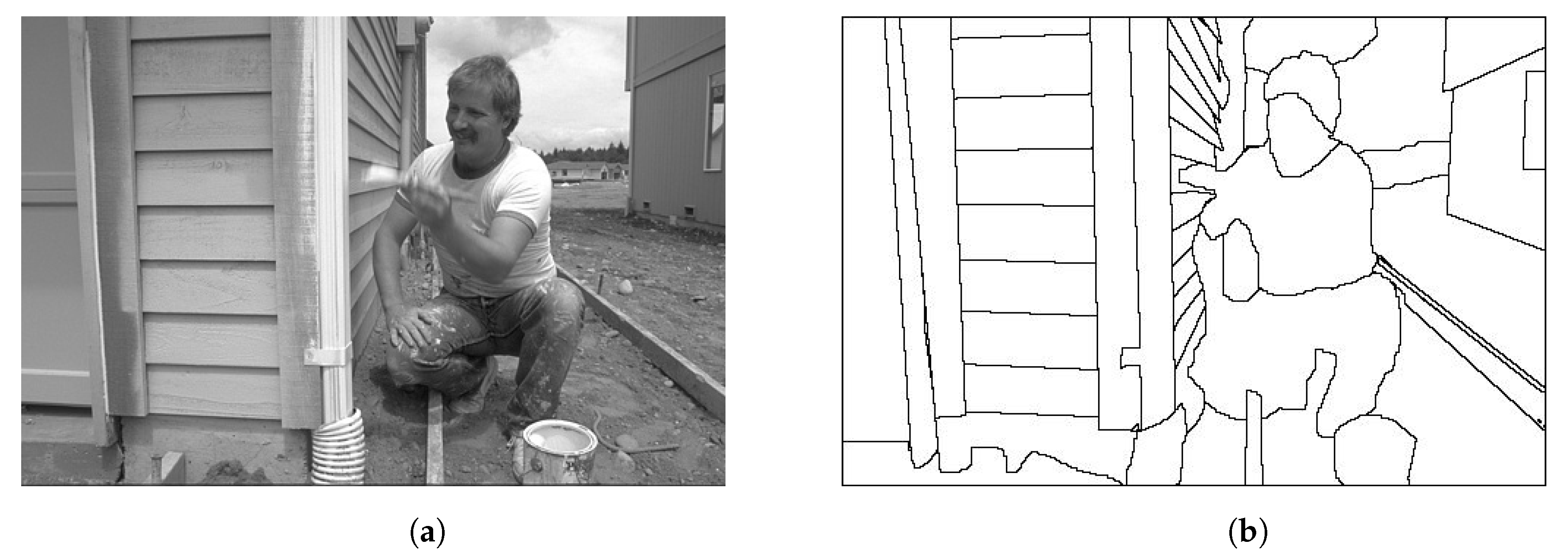
4.1. Public Databases Which We Used
4.2. Data Set Construction of G(lobal) ANFIS 2
4.3. Testing of G ANFIS 2
- 211 cases where (the difference varied from 0.76 to 0.01).
- 24 cases where (the difference varied from 0.17 to 0.01).
- 6 cases where the difference of and was zero.
- 202 cases where (the difference varied from 0.53 to 0.01),
- 20 cases where (the difference varied from 0.11 to 0.01),
- 19 cases where the difference of and was zero.
5. Summary and Some Further Remarks
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| ANFIS | Adaptive Neuro-Fuzzy Inference System |
References
- Sezgin, M.; Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146–168. [Google Scholar] [CrossRef]
- Bogiatzis, A.; Papadopoulos, B. Producing Fuzzy Inclusion and Entropy Measures and Their Application on Global Image Thresholding. B.K. Evol. Syst. 2018, 9, 331–353. [Google Scholar] [CrossRef]
- Young, V.R. Fuzzy subsethood. Fuzzy Sets Syst. 1996, 77, 371–384. [Google Scholar] [CrossRef]
- Kosko, B. Fuzzy Thinking: The New Science of Fuzzy Logic; Hyperion: New York, NY, USA, 1993; ISBN 0-7868-8021-X. [Google Scholar]
- Kosko, B.; Isaka, S. Fuzzy Logic. Sci. Am. 1993, 269, 76–81. [Google Scholar] [CrossRef]
- Kosko, B. Neural Networks and Fuzzy Systems: A Dynamical Systems Approach to Machine Intelligence; Prentice-Hall: Englewood Cliffs, NJ, USA, 1992; ISBN 9780136114352. [Google Scholar]
- Boulmakoul, A.; Laarabi, M.H.; Sacile, R.; Garbolino, E. An original approach to ranking fuzzy numbers by inclusion index and Bitset Encoding. Fuzzy Optim. Decis. Mak. 2017, 16, 23–49. [Google Scholar] [CrossRef]
- Bronevich, A.G.; Rozenberg, I.N. Ranking probability measures by inclusion indices in the case of unknown utility function. Fuzzy Optim. Decis. Mak. 2014, 13, 49–71. [Google Scholar] [CrossRef]
- Burillo, P.; Frago, N.; Fuentes, R. Inclusion grade and fuzzy implication operators. Fuzzy Set. Syst. 2000, 114, 417–429. [Google Scholar] [CrossRef]
- Cheng, W.C. Conditional Fuzzy Entropy of Maps in Fuzzy Systems. Theory Comput. Syst. 2011, 48, 767–780. [Google Scholar] [CrossRef]
- Cornelis, C.; Van der Donck, C.; Kerre, E. Sinha–Dougherty approach to the fuzzification of set inclusion revisited. Fuzzy Set. Syst. 2003, 134, 283–295. [Google Scholar] [CrossRef]
- Dey, V.; Pratihar, D.K.; Datta, G.L. Genetic algorithm-tuned entropy-based fuzzy C-means algorithm for obtaining distinct and compact clusters. Fuzzy Optim. Decis. Mak. 2011, 10, 153–166. [Google Scholar] [CrossRef]
- Jung, D.; Choi, J.W.; Park, W.J.; Lee, S. Quantitative comparison of similarity measure and entropy for fuzzy sets. J. Cent. South Univ. Technol. 2011, 18, 2045–2049. [Google Scholar] [CrossRef]
- Lukka, P. Feature selection using fuzzy entropy measures with similarity classifier. Expert Syst. Appl. 2011, 38, 4600–4607. [Google Scholar] [CrossRef]
- Palanisamy, C.; Selvan, S. Efficient subspace clustering for higher dimensional data using fuzzy entropy. J. Syst. Sci. Syst. Eng. 2009, 18, 95–110. [Google Scholar] [CrossRef]
- Scozzafava, R.; Vantaggi, B. Fuzzy inclusion and similarity through coherent conditional probability. Fuzzy Sets Syst. 2009, 160, 292–305. [Google Scholar] [CrossRef]
- Sussner, P.; Valle, M.E. Classification of Fuzzy Mathematical Morphologies Based on Concepts of Inclusion Measure and Duality. J. Math. Imaging Vis. 2008, 32, 139–159. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, S. Inclusion measure for typical hesitant fuzzy sets, the relative similarity measure and fuzzy entropy. Soft Comput. 2016, 20, 1277–1287. [Google Scholar] [CrossRef]
- Zhou, R.; Yang, Z.; Yu, M.; Ralescu, D.A. A portfolio optimization model based on information entropy and fuzzy time series. Fuzzy Optim. Decis. Mak. 2015, 1, 381–397. [Google Scholar] [CrossRef]
- Bogiatzis, A.; Papadopoulos, B. Local Thresholding of Degraded or Unevenly Illuminated Documents Using Fuzzy Inclusion and Entropy Measures. B.K. Evol. Syst. 2019. [Google Scholar] [CrossRef]
- Bogiatzis, A.; Papadopoulos, B. Binarization of Texts with Varying Lighting Conditions Using Fuzzy Inclusion and Entropy Measures. AIP Conf. Proc. 2018, 1978. [Google Scholar] [CrossRef]
- Halada, L.; Osokov, G.A. Histogram concavity analysis by quasicurvature. Comput. Artif. Intell. 1987, 6, 523–533. [Google Scholar]
- Rosenfeld, A.; De la Torre, P. Histogram concavity analysis as an aid in threshold selection. IEEE Trans. Syst. Man Cybern. 1983, 13. [Google Scholar] [CrossRef]
- Sahasrabudhe, S.C.; Gupta, K.S.D. A valley-seeking threshold selection technique. Comput. Vis. Image Underst. 1992, 56, 55–65. [Google Scholar]
- Weszka, J.; Rosenfeld, A. Histogram modification for threshold selection. IEEE Trans. Syst. Man Cybern. 1979, 9, 38–52. [Google Scholar] [CrossRef]
- Weszka, J.; Rosenfeld, A. Threshold evaluation techniques. IEEE Trans. Syst. Man Cybern. 1978, 8, 622–629. [Google Scholar] [CrossRef]
- Carlotto, M.J. Histogram analysis using a scale-space approach. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 9, 121–129. [Google Scholar] [CrossRef] [PubMed]
- Olivo, J.C. Automatic threshold selection using the wavelet transform. Graph. Models Image Process. 1994, 56, 205–218. [Google Scholar] [CrossRef]
- Sezan, M.I. A peak detection algorithm and its application to histogram-based image data reduction. Comput. Vis. Graph. Image Process. 1990, 49, 36–51. [Google Scholar] [CrossRef]
- Cai, J.; Liu, Z.Q. A new thresholding algorithm based on all-pole model. In Proceedings of the Fourteenth International Conference on Pattern Recognition, Brisbane, Queensland, Australia, 20 August 1998; Volume 1, pp. 34–36. [Google Scholar] [CrossRef]
- Guo, R.; Pandit, S.M. Automatic threshold selection based on histogram modes and a discriminant criterion. Mach. Vis. Appl. 1998, 10, 331–338. [Google Scholar] [CrossRef]
- Kampke, T.; Kober, R. Nonparametric optimal binarization. In Proceedings of the Fourteenth International Conference on Pattern Recognition, Brisbane, Queensland, Australia, 20 August 1998; Volume 1, pp. 27–29. [Google Scholar] [CrossRef]
- Ramesh, N.; Yoo, J.H.; Sethi, I.K. Thresholding based on histogram approximation. Proc. Vis. Image Signal Process. 1995, 142, 271–279. [Google Scholar] [CrossRef]
- Leung, C.K.; Lam, F.K. Performance analysis of a class of iterative image thresholding algorithms. Pattern Recogn. 1996, 29, 1523–1530. [Google Scholar] [CrossRef]
- Ridler, T.W.; Calvard, C. Picture thresholding using an iterative selection method. IEEE Trans. Syst. Man Cybern. 1978, 8, 630–632. [Google Scholar] [CrossRef]
- Trussel, H.J. Comments on picture thresholding using iterative selection method. IEEE Trans. Syst. Man Cybern. 1979, 9, 311. [Google Scholar] [CrossRef]
- Yanni, M.K.; Horne, E. A new approach to dynamic thresholding. In Proceedings of the EUSIPCO’94: 9th European European Signal Processing Conference, Edinburgh, UK, 13–16 September 1994; Volume 1, pp. 34–41. [Google Scholar]
- Cho, S.; Haralick, R.; Yi, S. Improvement of Kittler and Illingworths’s minimum error thresholding. Pattern Recogn. 1989, 22, 609–617. [Google Scholar] [CrossRef]
- Kittler, J.; Illingworth, J. Minimum error thresholding. Pattern Recogn. 1986, 19, 41–47. [Google Scholar] [CrossRef]
- Jawahar, C.V.; Biswas, P.K.; Ray, A.K. Investigations on fuzzy thresholding based on fuzzy clustering. Pattern Recogn. 1997, 30, 1605–1613. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Pal, S.K.; King, R.A.; Hashim, A.A. Automatic gray level thresholding through index of fuzziness and entropy. Pattern Recogn. Lett. 1983, 1, 141–146. [Google Scholar] [CrossRef]
- Johannsen, G.; Bille, J. A threshold selection method using information measures. In Proceedings of the ICPR’82: 6th International Conference on Pattern Recognition, Munich, Germany, 19–22 October 1982; pp. 140–143. [Google Scholar]
- Kapur, J.N.; Sahoo, P.K.; Wong, A.K.C. A new method for gray-level picture thresholding using the entropy of the histogram. Graph. Models Image Process. 1985, 29, 273–285. [Google Scholar] [CrossRef]
- Pun, T. Entropic thresholding: A new approach. Comput. Graph. Image Process. 1981, 16, 210–239. [Google Scholar] [CrossRef]
- Sahoo, P.; Wilkins, C.; Yeager, J. Threshold selection using Renyi’s entropy. Pattern Recogn. 1997, 30, 71–84. [Google Scholar] [CrossRef]
- Yen, J.C.; Chang, F.J.; Chang, S. A new criterion for automatic multilevel thresholding. IEEE Trans. Image Process. 1995, 4, 370–378. [Google Scholar] [CrossRef] [PubMed]
- Brink, A.D.; Pendock, N.E. Minimum cross entropy threshold selection. Pattern Recogn. 1996, 29, 179–188. [Google Scholar] [CrossRef]
- Li, C.H.; Tam, P.K.S. An iterative algorithm for minimumcross-entropy thresholding. Pattern Recogn. Lett. 1998, 19, 771–776. [Google Scholar] [CrossRef]
- Li, C.H.; Lee, C.K. Minimum cross-entropy thresholding. Pattern Recogn. 1993, 26, 617–625. [Google Scholar] [CrossRef]
- Pal, N.R. On minimum cross-entropy thresholding. Pattern Recogn. 1996, 29, 575–580. [Google Scholar] [CrossRef]
- Hertz, L.; Schafer, R.W. Multilevel thresholding using edge matching. Comput. Vis. Graph. Image Process. 1988, 44, 279–295. [Google Scholar] [CrossRef]
- Cheng, S.C.; Tsai, W.H. A neural network approach of the moment-preserving technique and its application to thresholding. IEEE Trans. Comput. 1993, 42, 501–507. [Google Scholar] [CrossRef]
- Delp, E.J.; Mitchell, O.R. Moment-preserving quantization. IEEE Trans. Commun. 1991, 39, 1549–1558. [Google Scholar] [CrossRef]
- Tsai, W.H. Moment-preserving thresholding: A new approach. Graph. Models Image Process. 1985, 29, 377–393. [Google Scholar] [CrossRef]
- Pal, S.K.; Rosenfeld, A. Image enhancement and thresholding by optimization of fuzzy compactness. Pattern Recogn. Lett. 1988, 7, 77–86. [Google Scholar] [CrossRef]
- Rosenfeld, A. The fuzzy geometry of image subsets. Pattern Recogn. Lett. 1984, 2, 311–317. [Google Scholar] [CrossRef]
- O’Gorman, L. Binarization and multithresholding of document images using connectivity. Graph. Models Image Process. 1994, 56, 494–506. [Google Scholar] [CrossRef]
- Liu, Y.; Srihari, S.N. Document image binarization based on texture analysis. Proc. SPIE 1994, 2181, 254–263. [Google Scholar] [CrossRef]
- Pikaz, A.; Averbuch, A. Digital image thresholding based on topological stable state. Pattern Recogn. 1996, 29, 829–843. [Google Scholar] [CrossRef]
- Murthy, C.A.; Pal, S.K. Fuzzy thresholding: A mathematical framework, bound functions and weighted moving average technique. Pattern Recogn. Lett. 1990, 11, 197–206. [Google Scholar] [CrossRef]
- Ramar, K.; Arunigam, S.; Sivanandam, S.N.; Ganesand, L.; Manimegalai, D. Quantitative fuzzy measures for threshold selection. Pattern Recogn. Lett. 2000, 21, 1–7. [Google Scholar] [CrossRef]
- Kirby, R.L.; Rosenfeld, A. A Note on the Use of (Gray Level, Local Average Gray Level) Space as an Aid in Threshold Selection. IEEE Trans. Syst. Man Cybern. 1979, 9, 860–864. [Google Scholar]
- Fekete, G.; Eklundh, J.O.; Rosenfeld, A. Relaxation: Evaluation and applications. IEEE Trans. Pattern Anal. Mach. Intell. 1981, 3, 459–469. [Google Scholar] [CrossRef] [PubMed]
- Rosenfeld, A.; Smith, R. Thresholding using relaxation. IEEE Trans. Pattern Anal. Mach. Intell. 1981, 3, 598–606. [Google Scholar] [CrossRef] [PubMed]
- Wu, A.Y.; Hong, T.H.; Rosenfeld, A. Threshold selection using quadtrees. IEEE Trans. Pattern Anal. Mach. Intell. 1982, 4, 90–94. [Google Scholar] [CrossRef] [PubMed]
- Ahuja, N.; Rosenfeld, A. A note on the use of second-order gray level statistics for threshold selection. IEEE Trans. Syst. Man Cybern. 1978, 8, 895–898. [Google Scholar] [CrossRef]
- Chanda, B.; Majumder, D.D. A note on the use of gray level co-occurrence matrix in threshold selection. Signal Process. 1988, 15, 149–167. [Google Scholar] [CrossRef]
- Chang, C.; Chen, K.; Wang, J.; Althouse, M.L.G. A relative entropy based approach in image thresholding. Pattern Recogn. 1994, 27, 1275–1289. [Google Scholar] [CrossRef]
- Lie, W.N. An efficient threshold-evaluation algorithm for image segmentation based on spatial gray level cooccurrences. Signal Process. 1993, 33, 121–126. [Google Scholar] [CrossRef]
- Abutaleb, A.S. Automatic thresholding of gray-level pictures using two-dimensional entropy. Comput. Vis. Graph. Image Process. 1989, 47, 22–32. [Google Scholar] [CrossRef]
- Brink, A.D. Minimum spatial entropy threshold selection. IEE Proc. Vis.Image Signal Process. 1995, 142, 128–132. [Google Scholar] [CrossRef]
- Brink, A.D. Thresholding of digital images using two-dimensional entropies. Pattern Recogn. 1992, 25, 803–808. [Google Scholar] [CrossRef]
- Cheng, H.D.; Chen, Y.H. Thresholding based on fuzzy partition of 2D histogram. In Proceedings of the Fourteenth International Conference on Pattern Recognition, Brisbane, Queensland, Australia, 20 August 1998; pp. 1616–1618. [Google Scholar] [CrossRef]
- Li, L.; Gong, J.; Chen, W. Gray-level image thresholding based on fisher linear projection of two-dimensional histogram. Pattern Recogn. 1997, 30, 743–749. [Google Scholar] [CrossRef]
- Pal, N.R.; Pal, S.K. Entropic thresholding. Signal Process. 1989, 16, 97–108. [Google Scholar] [CrossRef]
- Brink, A.D. Gray level thresholding of images using a correlation criterion. Pattern Recogn. Lett. 1989, 9, 335–341. [Google Scholar] [CrossRef]
- Cheng, H.D.; Chen, Y.H. Fuzzy partition of two-dimensional histogram and its application to thresholding. Pattern Recogn. 1999, 32, 825–843. [Google Scholar] [CrossRef]
- Leung, C.K.; Lam, F.K. Maximum a posteriori spatial probability segmentation. IEE Proc. Vis. Image Signal Process. 1997, 144, 161–167. [Google Scholar] [CrossRef]
- Friel, N.; Molchanov, I.S. A new thresholding technique based on random sets. Pattern Recogn. 1999, 32, 1507–1517. [Google Scholar] [CrossRef]
- Bernsen, J. Dynamic thresholding of gray level images. In Proceedings of the International Conference on Pattern Recognition (ICPR’86), Berlin, Germany, 27–31 October 1986; pp. 1251–1255. [Google Scholar]
- Niblack, W. An Introduction to Image Processing; Prentice-Hall: Englewood Cliffs, NJ, USA, 1986; ISBN 0134806743. [Google Scholar]
- Sauvola, J.; Pietaksinen, M. Adaptive document image binarization. Pattern Recogn. 2000, 33, 225–236. [Google Scholar] [CrossRef]
- Yanowitz, S.D.; Bruckstein, A.M. A new method for image segmentation. Comput. Graph. Image Process. 1989, 46, 82–95. [Google Scholar] [CrossRef]
- Othman, A.A.; Tizhoosh, H.R. Image thresholding using neural network. In Proceedings of the 10th International Conference on Intelligent Systems Design and Applications, Cairo, Egypt, 29 November–1 December 2010; pp. 1159–1164. [Google Scholar] [CrossRef]
- Ahmed, M.N.; Farag, A.A. Two-stage neural network for volume segmentation of medical images. Pattern Recogn. Lett. 1997, 18, 1143–1151. [Google Scholar] [CrossRef]
- Chang, C.Y.; Chung, P.C. Medical image segmentation using a contextual-constraint-based Hopfield neural cube. Image Vis. Comput. 2001, 19, 669–678. [Google Scholar] [CrossRef]
- Mustafa, N.; Khan, S.A.; Li, J.; Khalil, M.; Kumar, K.; Giess, M. Medical image De-noising schemes using wavelet transform with fixed form thresholding. In Proceedings of the 11th International Computer Conference on Wavelet Actiev Media Technology and Information Processing(ICCWAMTIP, Chengdu, China, 19–21 December 2014; pp. 397–402. [Google Scholar] [CrossRef]
- Kurugollu, F.; Sankur, B.; Harmancı, A. Image segmentation by relaxation using constraint satisfaction neural network. Image Vis. Comput. 2002, 20, 483–497. [Google Scholar] [CrossRef]
- Nuneza, J.; Llacerb, J. Astronomical image segmentation by self-organizing neural networks and wavelets. Neural Netw. 2003, 16, 411–417. [Google Scholar] [CrossRef]
- Bogiatzis, A.; Papadopoulos, B. Producing Fuzzy Inclusion and Entropy Measures. In Computation, Cryptography, and Network Security; Springer: Cham, Switzerland, 2015; pp. 51–74. [Google Scholar]
- Klir, G.J. Fuzzy Sets and Fuzzy Logic: Theory and Applications; Klir, G.J., Yuan, B., Eds.; Prentice Hall: Upper Saddle River, NJ, USA, 1995. [Google Scholar]
- Wirth, M.; Nikitenko, D. Worn-out Images in Testing Image Processing Algorithms. In Proceedings of the Canadian Conference on Computer and Robot Vision, St. Johns, NL, Canada, 25–27 May 2011; pp. 183–190. [Google Scholar] [CrossRef]
- Jang, R. ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Alhasa, K.M.; Nadzir, M.S.M.; Olalekan, P.; Latif, M.T.; Yusup, Y.; Faruque, M.R.I.; Ahamad, F.P.K.; Hamid, H.H.A.; Aiyub, K.; Ali, S.H.M.; et al. Calibration Model of a Low-Cost Air Quality Sensor Using an Adaptive Neuro-Fuzzy Inference System. Sensors 2018, 18, 4380. [Google Scholar] [CrossRef] [PubMed]
- Arun Shankar, V.K.; Subramaniam, U.; Sanjeevikumar, P.; Paramasivam, S. Adaptive Neuro-Fuzzy Inference System (ANFIS) based Direct Torque Control of PMSM driven centrifugal pump. Int. J. Renew. Energy Res. 2017, 7, 1437–1447. [Google Scholar]
- Chen, W.; Panahi, M.; Tsangaratos, P.; Shahabi, H. Applying population-based evolutionary algorithms and a neuro-fuzzy system for modeling landslide susceptibility. Catena 2019, 172, 212–231. [Google Scholar] [CrossRef]
- Ebtehaj, I.; Bonakdari, H.; Sadegh Es-haghi, M. Design of a Hybrid ANFIS–PSO Model to Estimate Sediment Transport in Open Channels. Iran. J. Sci. Technol. Trans. Civ. Eng. 2018. [Google Scholar] [CrossRef]
- Le Chau, N.; Nguyen, M.Q.; Nguyen, M.; Dao, T.P.; Huang, S.-C.; Hsiao, T.-C.; Dinh-Cong, D.; Dang, V.A. An effective approach of adaptive neuro-fuzzy inference system-integrated teaching learning-based optimization for use in machining optimization of S45C CNC turning. Optim. Eng. 2018. [Google Scholar] [CrossRef]
- Lukichev, D.V.; Demidova, G.L.; Kuzin, A.Y.; Saushev, A.V. Application of adaptive Neuro Fuzzy Inference System (ANFIS) controller in servodrive with multi-mass object. In Proceedings of the 25th International Workshop on Electric Drives: Optimization in Control of Electric Drives, Moscow, Russia, 31 January–2 February 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Prasojo, R.A.; Diwyacitta, K.; Suwarno; Gumilang, H. Transformer Paper Expected Life Estimation Using ANFIS Based on Oil Characteristics and Dissolved Gases (Case Study: Indonesian Transformers). Energies 2017, 10, 1135. [Google Scholar] [CrossRef]
- Ramakrishna Reddy, K.; Meikandasivam, S. Load Flattening and Voltage Regulation using Plug-In Electric Vehicle’s Storage capacity with Vehicle Prioritization using ANFIS. IEEE Trans. Sustain. Energy 2018. [Google Scholar] [CrossRef]
- Şahin, M.; Erol, R. A Comparative Study of Neural Networks and ANFIS for Forecasting Attendance Rate of Soccer Games. Math. Comput. Appl. 2017, 22. [Google Scholar] [CrossRef]
- Tiwari, S.; Babbar, R.; Kaur, G. Performance Evaluation of Two ANFIS Models for Predicting Water Quality Index of River Satluj (India). Adv. Civ. Eng. 2018, 2018, 8971079. [Google Scholar] [CrossRef]
- Yusuf, D.; Sayuti, M.; Sarhan, A.; Ab SHukor, H.B. Prediction of specific grinding forces and surface roughness in machining of AL6061-T6 alloy using ANFIS technique. Ind. Lubr. Tribol. 2018. [Google Scholar] [CrossRef]
- Özkan, G.; İnal, M. Comparison of neural network application for fuzzy and ANFIS approaches for multi-criteria decision making problems. Appl. Soft Comput. 2014, 24, 232–238. [Google Scholar] [CrossRef]
- Shariati, S.; Haghighi, M.M. Comparison of anfis Neural Network with several other ANNs and Support Vector Machine for diagnosing hepatitis and thyroid diseases. In Proceedings of the 2010 International Conference on Computer Information Systems and Industrial Management Applications (CISIM), Krackow, Poland, 8–10 October 2010; pp. 596–599. [Google Scholar] [CrossRef]
- Li, F.-F.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental Bayesian approach tested on 101 object categories. IEEE. CVPR 2004, Workshop on Generative-Model Based Vision, 2004. Available online: http://www.vision.caltech.edu/Image_Datasets/Caltech_101/Caltech101/ (accessed on 22 February 2019).
- Griffin, G.; Holub, A.D.; Perona, P. The Caltech 256. Available online: http://www.vision.caltech.edu/Image_Datasets/Caltech256/ (accessed on 22 February 2019).
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour Detection and Hierarchical Image Segmentation. IEEE TPAMI 2011, 33, 898–916. Available online: https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/resources.html (accessed on 22 February 2019). [CrossRef] [PubMed]
- Heitz, G.; Gould, S.; Saxena, A.; Koller, D. Cascaded Classification Models: Combining Models for Holistic Scene Understanding. Proc. Adv. Neural Inf. Process. Syst. (NIPS) 2008. Available online: http://dags.stanford.edu/projects/scenedataset.html (accessed on 22 February 2019).
- Bardamova, M.; Konev, A.; Hodashinsky, I.; Shelupanov, A. A Fuzzy Classifier with Feature Selection Based on the Gravitational Search Algorithm. Symmetry 2018, 10, 609. [Google Scholar] [CrossRef]
- Cross, V. Relating Fuzzy Set Similarity Measures. Adv. Intell. Syst. Comput. 2018, 9. [Google Scholar] [CrossRef]
- Hulianytskyi, L.F.; Riasna, I.I. Automatic Classification Method Based on a Fuzzy Similarity Relation. Cybern. Syst. Anal. 2016, 52, 30–37. [Google Scholar] [CrossRef]
- Lan, R.; Fan, J.L.; Liu, Y.; Zhao, F. Image Thresholding by Maximizing the Similarity Degree Based on Intuitionistic Fuzzy Sets. In Proceedings of the 4th International Conference on Quantitative Logic and Soft Computing (QLSC2016), Hangzhou, China, 14–17 October 2016. [Google Scholar] [CrossRef]
- Li, X.; Zhu, Z.-C.; Rui, G.-C.; Cheng, D.; Shen, G.; Tang, Y. Force Loading Tracking Control of an Electro-Hydraulic Actuator Based on a Nonlinear Adaptive Fuzzy Backstepping Control Scheme. Symmetry 2018, 10, 155. [Google Scholar] [CrossRef]
- Luo, M.; Liang, J. A Novel Similarity Measure for Interval-Valued Intuitionistic Fuzzy Sets and Its Applications. Symmetry 2018, 10, 441. [Google Scholar] [CrossRef]
- Mansoori, E.G.; Shafiee, K.S. On fuzzy feature selection in designing fuzzy classifiers for high–dimensional data. Evol. Syst. 2016, 7, 255–265. [Google Scholar] [CrossRef]
- Ullah, K.; Mahmood, T.; Jan, N. Similarity Measures for T-Spherical Fuzzy Sets with Applications in Pattern Recognition. Symmetry 2018, 10, 193. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lines of data matrix 1 used as testing samples | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2 | 5 | 7 | 11 | 14 | 18 | 20 | 21 | 25 | 33 |
| 34 | 35 | 36 | 41 | 43 | 50 | 63 | 65 | 87 | 89 |
| 101 | 111 | 115 | 123 | 124 | 128 | 132 | 137 | 142 | 152 |
| 155 | 177 | 178 | 184 | 190 | 193 | 201 | 204 | 209 | 210 |
| 213 | 220 | 222 | 229 | 231 | 238 | 239 | 240 | 247 | 251 |
| Sample | Difference | Sample | Difference | ||||
|---|---|---|---|---|---|---|---|
| 292066 | 0.87 | 0.11 | 0.76 | 90076 | 0.83 | 0.09 | 0.74 |
| 21077 | 0.81 | 0.14 | 0.67 | 135037 | 0.91 | 0.29 | 0.62 |
| 27059 | 0.72 | 0.13 | 0.59 | 108041 | 0.86 | 0.30 | 0.56 |
| 188063 | 0.90 | 0.39 | 0.51 | 106020 | 0.68 | 0.18 | 0.50 |
| 101087 | 0.82 | 0.33 | 0.49 | 109053 | 0.75 | 0.26 | 0.49 |
| 69020 | 0.88 | 0.39 | 0.48 | 46076 | 0.84 | 0.37 | 0.47 |
| 20008 | 0.67 | 0.21 | 0.46 | 385028 | 0.71 | 0.25 | 0.46 |
| 216066 | 0.81 | 0.36 | 0.45 | 100075 | 0.76 | 0.30 | 0.46 |
| 368078 | 0.68 | 0.25 | 0.43 | 103070 | 0.70 | 0.28 | 0.42 |
| 274007 | 0.74 | 0.33 | 0.41 | 55075 | 0.83 | 0.42 | 0.41 |
| 155060 | 0.72 | 0.31 | 0.41 | 216053 | 0.72 | 0.31 | 0.41 |
| 38082 | 0.86 | 0.47 | 0.39 | 187003 | 0.64 | 0.25 | 0.39 |
| 163085 | 0.77 | 0.38 | 0.39 | 23080 | 0.76 | 0.37 | 0.39 |
| 229036 | 0.68 | 0.30 | 0.38 | 138078 | 0.73 | 0.35 | 0.38 |
| 22013 | 0.62 | 0.25 | 0.37 | 183055 | 0.74 | 0.38 | 0.36 |
| 227046 | 0.70 | 0.33 | 0.37 | 216081 | 0.63 | 0.27 | 0.36 |
| 65132 | 0.72 | 0.36 | 0.36 | 41069 | 0.81 | 0.46 | 0.35 |
| 45077 | 0.72 | 0.36 | 0.36 | 105025 | 0.86 | 0.51 | 0.35 |
| 159008 | 0.72 | 0.37 | 0.35 | 178054 | 0.88 | 0.54 | 0.34 |
| 376043 | 0.60 | 0.26 | 0.34 | 69040 | 0.75 | 0.42 | 0.33 |
| … | … | … | … | … | … | … | … |
| 227092 | 0.54 | 0.69 | −0.15 | 198023 | 0.12 | 0.29 | −0.17 |
| Sample | Difference | Sample | Difference | ||||
|---|---|---|---|---|---|---|---|
| 108041 | 0.59 | 0.06 | 0.53 | 90076 | 0.58 | 0.06 | 0.52 |
| 135037 | 0.65 | 0.18 | 0.47 | 188063 | 0.61 | 0.16 | 0.45 |
| 61060 | 0.82 | 0.42 | 0.40 | 21077 | 0.43 | 0.06 | 0.37 |
| 27059 | 0.39 | 0.04 | 0.35 | 100075 | 0.44 | 0.09 | 0.35 |
| 69020 | 0.41 | 0.07 | 0.34 | 292066 | 0.40 | 0.07 | 0.33 |
| 101087 | 0.57 | 0.25 | 0.32 | 65132 | 0.42 | 0.10 | 0.32 |
| 38082 | 0.42 | 0.10 | 0.32 | 46076 | 0.56 | 0.25 | 0.31 |
| 105025 | 0.53 | 0.22 | 0.31 | 55075 | 0.53 | 0.24 | 0.29 |
| 94079 | 0.42 | 0.15 | 0.27 | 138032 | 0.33 | 0.06 | 0.27 |
| 156065 | 0.40 | 0.13 | 0.27 | 368078 | 0.35 | 0.08 | 0.27 |
| 163085 | 0.37 | 0.11 | 0.26 | 239096 | 0.42 | 0.15 | 0.27 |
| 106020 | 0.32 | 0.06 | 0.26 | 385028 | 0.33 | 0.08 | 0.25 |
| 159008 | 0.42 | 0.16 | 0.26 | 48055 | 0.57 | 0.32 | 0.25 |
| 109053 | 0.30 | 0.05 | 0.25 | 130026 | 0.31 | 0.06 | 0.25 |
| 41069 | 0.29 | 0.05 | 0.24 | 103070 | 0.35 | 0.10 | 0.25 |
| 176039 | 0.40 | 0.16 | 0.24 | 187003 | 0.30 | 0.07 | 0.23 |
| 225017 | 0.29 | 0.06 | 0.23 | 254054 | 0.30 | 0.07 | 0.23 |
| 143090 | 0.46 | 0.23 | 0.23 | 216053 | 0.38 | 0.16 | 0.22 |
| 62096 | 0.44 | 0.23 | 0.21 | 183055 | 0.40 | 0.18 | 0.22 |
| 178054 | 0.49 | 0.28 | 0.21 | 24063 | 0.55 | 0.35 | 0.20 |
| … | … | … | … | … | … | … | … |
| 227092 | 0.27 | 0.38 | −0.11 | 151087 | 0.39 | 0.50 | −0.11 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bogiatzis, A.; Papadopoulos, B. Global Image Thresholding Adaptive Neuro-Fuzzy Inference System Trained with Fuzzy Inclusion and Entropy Measures. Symmetry 2019, 11, 286. https://doi.org/10.3390/sym11020286
Bogiatzis A, Papadopoulos B. Global Image Thresholding Adaptive Neuro-Fuzzy Inference System Trained with Fuzzy Inclusion and Entropy Measures. Symmetry. 2019; 11(2):286. https://doi.org/10.3390/sym11020286
Chicago/Turabian StyleBogiatzis, Athanasios, and Basil Papadopoulos. 2019. "Global Image Thresholding Adaptive Neuro-Fuzzy Inference System Trained with Fuzzy Inclusion and Entropy Measures" Symmetry 11, no. 2: 286. https://doi.org/10.3390/sym11020286
APA StyleBogiatzis, A., & Papadopoulos, B. (2019). Global Image Thresholding Adaptive Neuro-Fuzzy Inference System Trained with Fuzzy Inclusion and Entropy Measures. Symmetry, 11(2), 286. https://doi.org/10.3390/sym11020286