An Upgraded Version of the Binary Search Space-Structured VQ Search Algorithm for AMR-WB Codec

Abstract
:1. Introduction
2. ISF Quantization in AMR-WB
2.1. Linear Prediction Analysis
2.2. Quantization of ISF Coefficients
3. Proposed Search Algorithm
3.1. The BSS-VQ Search Algorithm
| Algorithm1 Encoding procedure of BSS-VQ |
| Step 1. Given a TQA, Mk(TQA) satisfying (12) is found directly in the lookup table in bssk. |
| Step 2. Referencing Table 2 and by means of (9) and (10), an input vector is assigned to a subspace bssk in an efficient manner. |
| Step 3. A full search for the best-matched codeword is performed among the top Mk(TQA) sorted codewords in bssk, and then the index of the found codeword is output. |
| Step 4. Repeat Steps 2 and 3 until all the input vectors are encoded. |
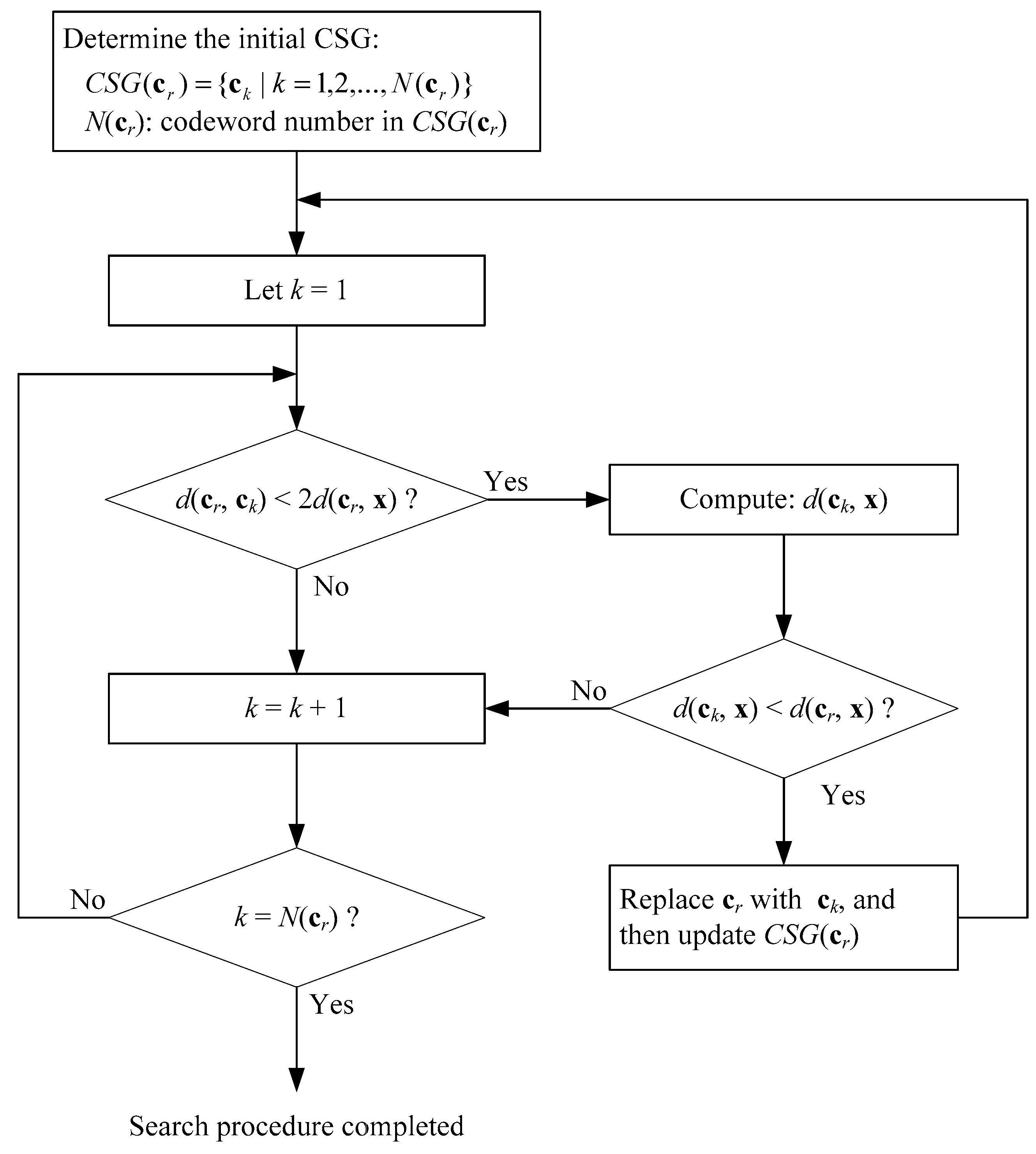
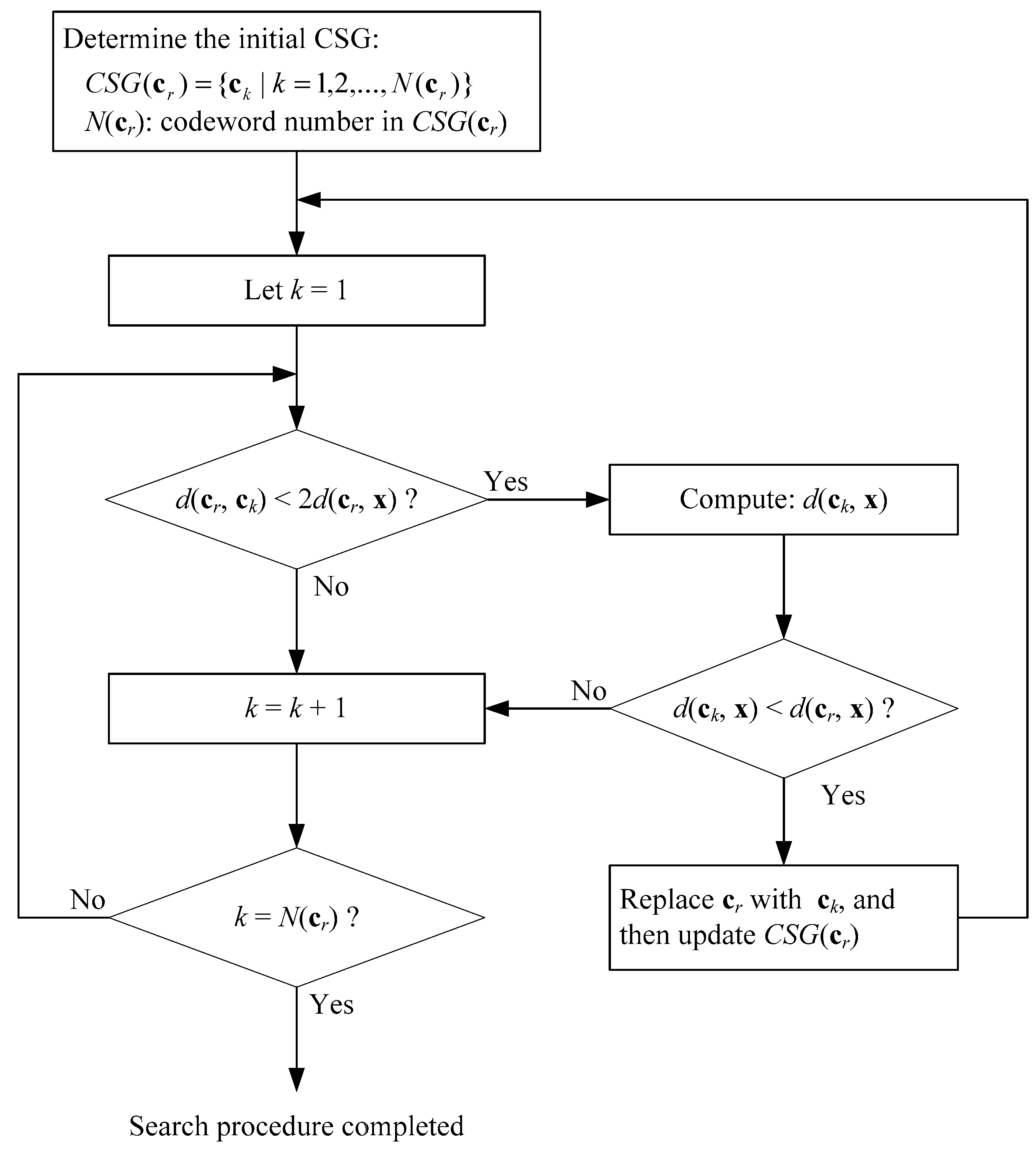
3.2. The ITIE Search Algorithm
| Algorithm2 Search procedure of ITIE |
| Step 1. Build a TIE lookup table. |
| Step 2. Given a cr, compute d(cr, x), and then CSG(cr) is found directly in the TIE lookup table, that is, |
CSG(cr) = {ck | k = 1,2,...,N(cr)},
|
| Step 3. Starting at k = 1, obtain d(cr, ck) from the lookup table. |
| Step 4. If (d(cr, ck) < 2d(cr, x)), then compute d(ck, x), and perform Step 5. |
| Otherwise, let k = k + 1, and then repeat Step 4, until k = N(cr). |
| Step 5. If (d(ck, x) < d(cr, x)), then replace cr with ck, update new CSG(cr), let k = 1, and repeat Step 3. |
| Otherwise, let k = k + 1, and then repeat Step 4, until k = N(cr). |
3.3. Upgraded Version of the BSS-VQ Search Algorithm
| Algorithm3 Search mechanism of the upgraded version |
| Step 1. Initial setting: Given a TQA, Mk(TQA) satisfying (12) is found directly in the lookup table in bssk. A TIE lookup table is also built. |
| Step 2. Referencing Table 2 and through (9) and (10), an input vector is efficiently assigned to a subspace bssk. And then a set, composed of the top Mk(TQA)-sorted codewords in bssk, is denoted by CSG(bssk) and formulated as |
CSG(bssk) = {ck | k = 1,2,...,Mk(TQA)}.
|
| Step 3. Starting at k = 1, set cr = ck | k = 1 in (15), then compute d(cr, x). |
| Step 4. Let k = k + 1, then obtain d(cr, ck) from the TIE lookup table. |
| Step 5. If (d(cr, ck) < 2d(cr, x)), then compute d(ck, x), and perform Step 6. |
| Otherwise, let k = k + 1, and then repeat Step 5, until k = Mk(TQA). |
| Step 6. If (d(ck, x) < d(cr, x)), then replace cr with ck, and repeat Step 4. |
| Otherwise, let k = k + 1, and then repeat Step 5, until k = Mk(TQA). |
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- 3rd Generation Partnership Project (3GPP). Adaptive Multi-Rate—Wideband (AMR-WB) Speech Codec; Transcoding Functions; TS 26.190; 3GPP: Valbonne, France, 2012. [Google Scholar]
- Ojala, P.; Lakaniemi, A.; Lepanaho, H.; Jokimies, M. The adaptive multirate wideband speech codec: System characteristics, quality advances, and deployment strategies. IEEE Commun. Mag. 2006, 44, 59–65. [Google Scholar] [CrossRef]
- Varga, I.; De Lacovo, R.D.; Usai, P. Standardization of the AMR wideband speech codec in 3GPP and ITU-T. IEEE Commun. Mag. 2006, 44, 66–73. [Google Scholar] [CrossRef]
- Bessette, B.; Salami, R.; Lefebvre, R.; Jelínek, M.; Rotola-Pukkila, J.; Vainio, J.; Mikkola, H.; Järvinen, K. The adaptive multirate wideband speech codec (AMR-WB). IEEE Trans. Speech Audio Process. 2002, 10, 620–636. [Google Scholar] [CrossRef]
- Salami, R.; Laflamme, C.; Adoul, J.P.; Kataoka, A.; Hayashi, S.; Moriya, T.; Lamblin, C.; Massaloux, D.; Proust, S.; Kroon, P.; et al. Design and description of CS-ACELP: A toll quality 8 kb/s speech coder. IEEE Trans. Speech Audio Process. 1998, 6, 116–130. [Google Scholar] [CrossRef]
- Wang, L.; Chen, Z.; Yin, F. A novel hierarchical decomposition vector quantization method for high-order LPC parameters. IEEE Trans. Audio Speech Lang. Process. 2015, 23, 212–221. [Google Scholar] [CrossRef]
- Salah-Eddine, C.; Merouane, B. Robust coding of wideband speech immittance spectral frequencies. Speech Commun. 2014, 65, 94–108. [Google Scholar] [CrossRef]
- Ramirez, M.A. Intra-predictive switched split vector quantization of speech spectra. IEEE Signal Process. Lett. 2013, 20, 791–794. [Google Scholar] [CrossRef]
- Chatterjee, S.; Sreenivas, T.V. Optimum switched split vector quantization of LSF parameters. Signal Process. 2008, 88, 1528–1538. [Google Scholar] [CrossRef]
- Yeh, C.Y. An Efficient VQ Codebook Search Algorithm Applied to AMR-WB Speech Coding. Symmetry 2017, 9, 54. [Google Scholar] [CrossRef]
- Lu, Z.M.; Sun, S.H. Equal-average equal-variance equal-norm nearest neighbor search algorithm for vector quantization. IEICE Trans. Inf. Syst. 2003, 86, 660–663. [Google Scholar]
- Xia, S.; Xiong, Z.; Luo, Y.; Dong, L.; Zhang, G. Location difference of multiple distances based k-nearest neighbors algorithm. Knowl. Based Syst. 2015, 90, 99–110. [Google Scholar] [CrossRef]
- Chen, S.X.; Li, F.W. Fast encoding method for vector quantisation of images using subvector characteristics and Hadamard transform. IET Image Process. 2011, 5, 18–24. [Google Scholar] [CrossRef]
- Chen, S.X.; Li, F.W.; Zhu, W.L. Fast searching algorithm for vector quantisation based on features of vector and subvector. IET Image Process. 2008, 2, 275–285. [Google Scholar] [CrossRef]
- Yao, B.J.; Yeh, C.Y.; Hwang, S.H. A search complexity improvement of vector quantization to immittance spectral frequency coefficients in AMR-WB speech codec. Symmetry 2016, 8, 104. [Google Scholar] [CrossRef]
- Hwang, S.H.; Chen, S.H. Fast encoding algorithm for VQ-based image coding. Electron. Lett. 1990, 26, 1618–1619. [Google Scholar]
- Hsieh, C.H.; Liu, Y.J. Fast search algorithms for vector quantization of images using multiple triangle inequalities and wavelet transform. IEEE Trans. Image Process. 2000, 9, 321–328. [Google Scholar] [CrossRef] [PubMed]
- Yeh, C.Y. An Efficient Iterative Triangular Inequality Elimination Algorithm for Codebook Search of Vector Quantization. IEEJ Trans. Electr. Electron. Eng. 2018, 13, 1528–1529. [Google Scholar] [CrossRef]
- 3rd Generation Partnership Project (3GPP). Codec for Enhanced Voice Services (EVS); Detailed Algorithmic Description; TS 26.445; 3GPP: Valbonne, France, 2015. [Google Scholar]

{kind=link}
| Structure of S-MSVQ | |||||
|---|---|---|---|---|---|
| Stage 1 | CB1: r1 (1–9 order of r) (8 bits) | CB2: r2 (10–16 order of r) (8 bits) | |||
| Stage 2 | CB11: r(2)1,1–3 (6 bits) | CB12: r(2)1,4–6 (7 bits) | CB13: r(2)1,7–9 (7 bits) | CB21: r(2)2,1–3 (5 bits) | CB22: r(2)2,4–7 (5 bits) |
| jth-Order | Mean |
|---|---|
| 0 | 15.3816 |
| 1 | 19.0062 |
| 2 | 15.4689 |
| 3 | 21.3921 |
| 4 | 26.8766 |
| 5 | 28.1561 |
| 6 | 28.0969 |
| 7 | 21.6403 |
| 8 | 16.3302 |
| Codebooks | Full Search | EEENNS | DI-TIE | ITIE | |
|---|---|---|---|---|---|
| Stage 1 | CB1 | 256 | 58.82 | 42.46 | 58.01 |
| CB2 | 256 | 63.87 | 42.79 | 62.03 | |
| Stage 2 | CB11 | 64 | 14.17 | 12.31 | 13.10 |
| CB12 | 128 | 22.91 | 14.40 | 15.32 | |
| CB13 | 128 | 21.01 | 13.50 | 14.40 | |
| CB21 | 32 | 11.08 | 8.95 | 9.48 | |
| CB22 | 32 | 17.44 | 12.42 | 13.21 | |
| TQA | Average Number of Searches in Various Codebooks | ||||||
|---|---|---|---|---|---|---|---|
| CB1 | CB2 | CB11 | CB12 | CB13 | CB21 | CB22 | |
| 0.90 | 15.40 | 26.45 | 12.47 | 19.96 | 19.93 | 7.11 | 6.66 |
| 0.91 | 16.10 | 27.52 | 12.86 | 20.84 | 20.62 | 7.11 | 6.72 |
| 0.92 | 16.80 | 28.85 | 12.99 | 21.50 | 21.19 | 7.64 | 6.91 |
| 0.93 | 17.79 | 30.23 | 13.52 | 21.84 | 22.02 | 7.64 | 7.15 |
| 0.94 | 18.87 | 31.71 | 14.04 | 22.85 | 22.72 | 8.00 | 7.57 |
| 0.95 | 20.03 | 33.58 | 14.61 | 23.85 | 23.72 | 8.26 | 7.84 |
| 0.96 | 21.36 | 35.81 | 15.04 | 24.76 | 24.95 | 8.87 | 8.21 |
| 0.97 | 23.18 | 38.37 | 15.86 | 25.93 | 26.24 | 9.27 | 8.51 |
| 0.98 | 25.71 | 41.82 | 16.73 | 27.60 | 27.86 | 10.00 | 9.33 |
| 0.99 | 29.71 | 47.12 | 18.21 | 29.61 | 29.99 | 10.49 | 10.15 |
| TQA | Average Number of Searches in Various Codebooks | ||||||
|---|---|---|---|---|---|---|---|
| CB1 | CB2 | CB11 | CB12 | CB13 | CB21 | CB22 | |
| 0.90 | 10.56 | 15.82 | 6.55 | 8.48 | 8.21 | 4.06 | 4.69 |
| 0.91 | 10.99 | 16.26 | 6.62 | 8.56 | 8.30 | 4.06 | 4.72 |
| 0.92 | 11.40 | 16.79 | 6.63 | 8.65 | 8.38 | 4.22 | 4.82 |
| 0.93 | 11.86 | 17.36 | 6.73 | 8.70 | 8.49 | 4.22 | 4.90 |
| 0.94 | 12.40 | 17.89 | 6.80 | 8.76 | 8.54 | 4.28 | 5.10 |
| 0.95 | 13.00 | 18.57 | 6.89 | 8.84 | 8.60 | 4.34 | 5.19 |
| 0.96 | 13.67 | 19.44 | 6.95 | 8.91 | 8.68 | 4.41 | 5.32 |
| 0.97 | 14.53 | 20.27 | 7.10 | 8.98 | 8.73 | 4.50 | 5.43 |
| 0.98 | 15.71 | 21.50 | 7.16 | 9.09 | 8.85 | 4.68 | 5.74 |
| 0.99 | 17.46 | 23.28 | 7.33 | 9.22 | 8.97 | 4.75 | 6.04 |
| Method | LR in CB1 (%) | LR in CB2 (%) | Overall Search Load | Overall LR (%) | |
|---|---|---|---|---|---|
| Full Search | Benchmark | Benchmark | 5280 | Benchmark | |
| EEENNS | 77.03 | 75.05 | 1253.76 | 76.26 | |
| DI-TIE | 83.42 | 83.29 | 878.88 | 83.36 | |
| ITIE | 77.34 | 75.77 | 1165.99 | 77.92 | |
| Original version of BSS-VQ (TQA) | 0.90 | 93.98 | 89.67 | 528.78 | 89.99 |
| 0.91 | 93.71 | 89.25 | 548.77 | 89.61 | |
| 0.92 | 93.44 | 88.73 | 570.76 | 89.19 | |
| 0.93 | 93.05 | 88.19 | 595.34 | 88.72 | |
| 0.94 | 92.63 | 87.61 | 624.92 | 88.16 | |
| 0.95 | 92.18 | 86.88 | 657.95 | 87.54 | |
| 0.96 | 91.66 | 86.01 | 696.62 | 86.81 | |
| 0.97 | 90.95 | 85.01 | 743.15 | 85.93 | |
| 0.98 | 89.96 | 83.66 | 808.06 | 84.70 | |
| 0.99 | 88.39 | 81.60 | 902.67 | 82.90 | |
| Upgraded version (TQA) | 0.90 | 95.88 | 93.82 | 306.41 | 94.20 |
| 0.91 | 95.71 | 93.65 | 314.19 | 94.05 | |
| 0.92 | 95.55 | 93.44 | 323.09 | 93.88 | |
| 0.93 | 95.37 | 93.22 | 332.32 | 93.71 | |
| 0.94 | 95.15 | 93.01 | 342.42 | 93.51 | |
| 0.95 | 94.92 | 92.75 | 353.80 | 93.30 | |
| 0.96 | 94.66 | 92.40 | 367.20 | 93.05 | |
| 0.97 | 94.32 | 92.08 | 382.26 | 92.76 | |
| 0.98 | 93.86 | 91.60 | 404.15 | 92.35 | |
| 0.99 | 93.18 | 90.91 | 435.10 | 91.76 | |
| TQA | BSS-VQ (Benchmark) | Proposed | LR (%) |
|---|---|---|---|
| 0.90 | 528.78 | 306.41 | 42.05 |
| 0.91 | 548.77 | 314.19 | 42.75 |
| 0.92 | 570.76 | 323.09 | 43.39 |
| 0.93 | 595.34 | 332.32 | 44.18 |
| 0.94 | 624.92 | 342.42 | 45.21 |
| 0.95 | 657.95 | 353.80 | 46.23 |
| 0.96 | 696.62 | 367.20 | 47.29 |
| 0.97 | 743.15 | 382.26 | 48.56 |
| 0.98 | 808.06 | 404.15 | 49.99 |
| 0.99 | 902.67 | 435.10 | 51.80 |
| Memory Size (Byte) | BSS Space | Dichotomy Position | TIE | Sum |
|---|---|---|---|---|
| CB1 | 524,288 | 36 | 326,400 | 850,724 |
| CB2 | 131,072 | 28 | 326,400 | 457,500 |
| CB11 | 2048 | 12 | 20,160 | 22,220 |
| CB12 | 4096 | 12 | 81,280 | 85,388 |
| CB13 | 4096 | 12 | 81,280 | 85,388 |
| CB21 | 1024 | 12 | 4960 | 5996 |
| CB22 | 2048 | 16 | 4960 | 7024 |
| Sum | 668,672 | 128 | 845,440 | 1,514,240 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeh, C.-Y.; Huang, H.-H. An Upgraded Version of the Binary Search Space-Structured VQ Search Algorithm for AMR-WB Codec. Symmetry 2019, 11, 283. https://doi.org/10.3390/sym11020283
Yeh C-Y, Huang H-H. An Upgraded Version of the Binary Search Space-Structured VQ Search Algorithm for AMR-WB Codec. Symmetry. 2019; 11(2):283. https://doi.org/10.3390/sym11020283
Chicago/Turabian StyleYeh, Cheng-Yu, and Hung-Hsun Huang. 2019. "An Upgraded Version of the Binary Search Space-Structured VQ Search Algorithm for AMR-WB Codec" Symmetry 11, no. 2: 283. https://doi.org/10.3390/sym11020283
APA StyleYeh, C.-Y., & Huang, H.-H. (2019). An Upgraded Version of the Binary Search Space-Structured VQ Search Algorithm for AMR-WB Codec. Symmetry, 11(2), 283. https://doi.org/10.3390/sym11020283