Hyperbolic Function Embedding: Learning Hierarchical Representation for Functions of Source Code in Hyperbolic Space


 ,
,
Abstract
1. Introduction
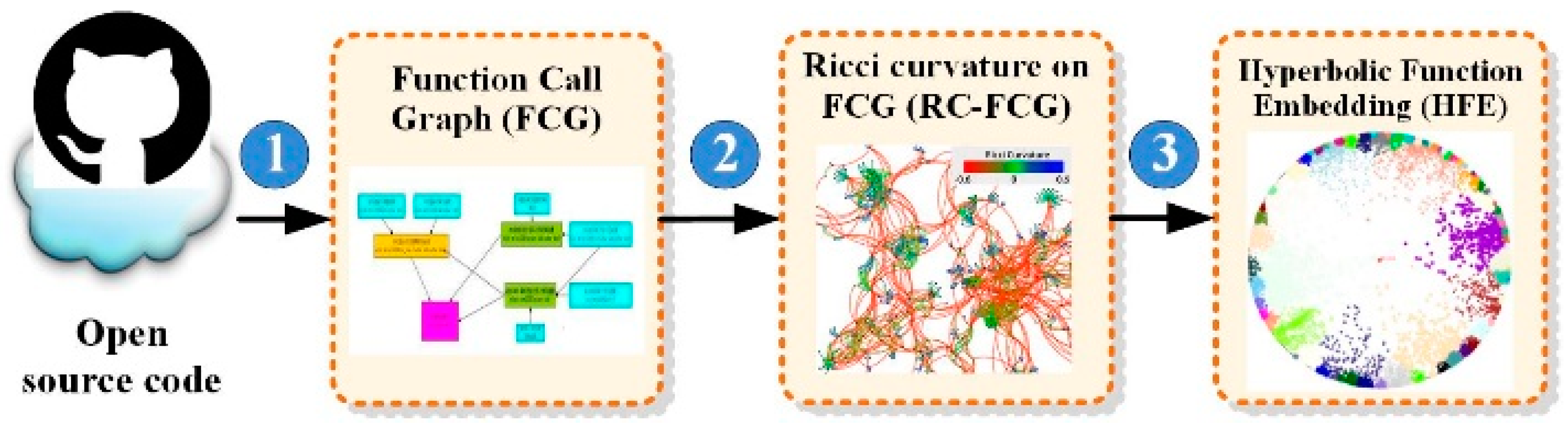
- We build an FCG model to describe the function-call relations.
- We use Ricci curvature [15] to estimate the geometric structure of the FCG and identify that the curvature for most of the edges in the FCG are negative. This phenomenon suggests hyperbolic space instead of Euclidean space as a natural embedding space for FCG since hyperbolic space is usually associated with constant negative curvature [16]. Based on this observation, the original edge weights of the FCG are replaced by Ricci curvatures to form a new graph called RC-FCG, where the weight of each edge denotes the curvature from one node to the other node. The modified edge weights encode more information than the original edge weights.
- Based on the RC-FCG, we propose a Poincaré disk-based hyperbolic function embedding (HFE) method to learn a hierarchical representation for RC-FCG in hyperbolic space. Our method achieves up to 7.6% performance improvement (especially in low-dimension situations) compared with the chosen state-of-the-art embedding methods, namely, Node2vec [17] and Struc2vec [18].
2. Related Works
3. Hyperbolic Function Embedding
3.1. Overview
- Build a function call graph (FCG) from source code. Each node in the FCG denotes a function, and each edge in the FCG means a function-call relation. FCG can model the way in which a function is called in a context, i.e., a function-call semantic of code fragments (see Section 3.2 for more detail).
- Once the FCG is built, the Ricci curvature will be calculated for each pair of connected functions, and the calculated curvatures will replace the weight of each edge. The modified FCG is called RC-FCG. We believe that the Ricci curvature of each edge in the FCG carries much more information than the original one, and is suitable for hyperbolic space (see Section 3.3 for more detail).
- We learn a hyperbolic function embedding via the Poincaré ball model for RC-FCG (see Section 3.4 for more detail).
3.2. Function Call Graphs
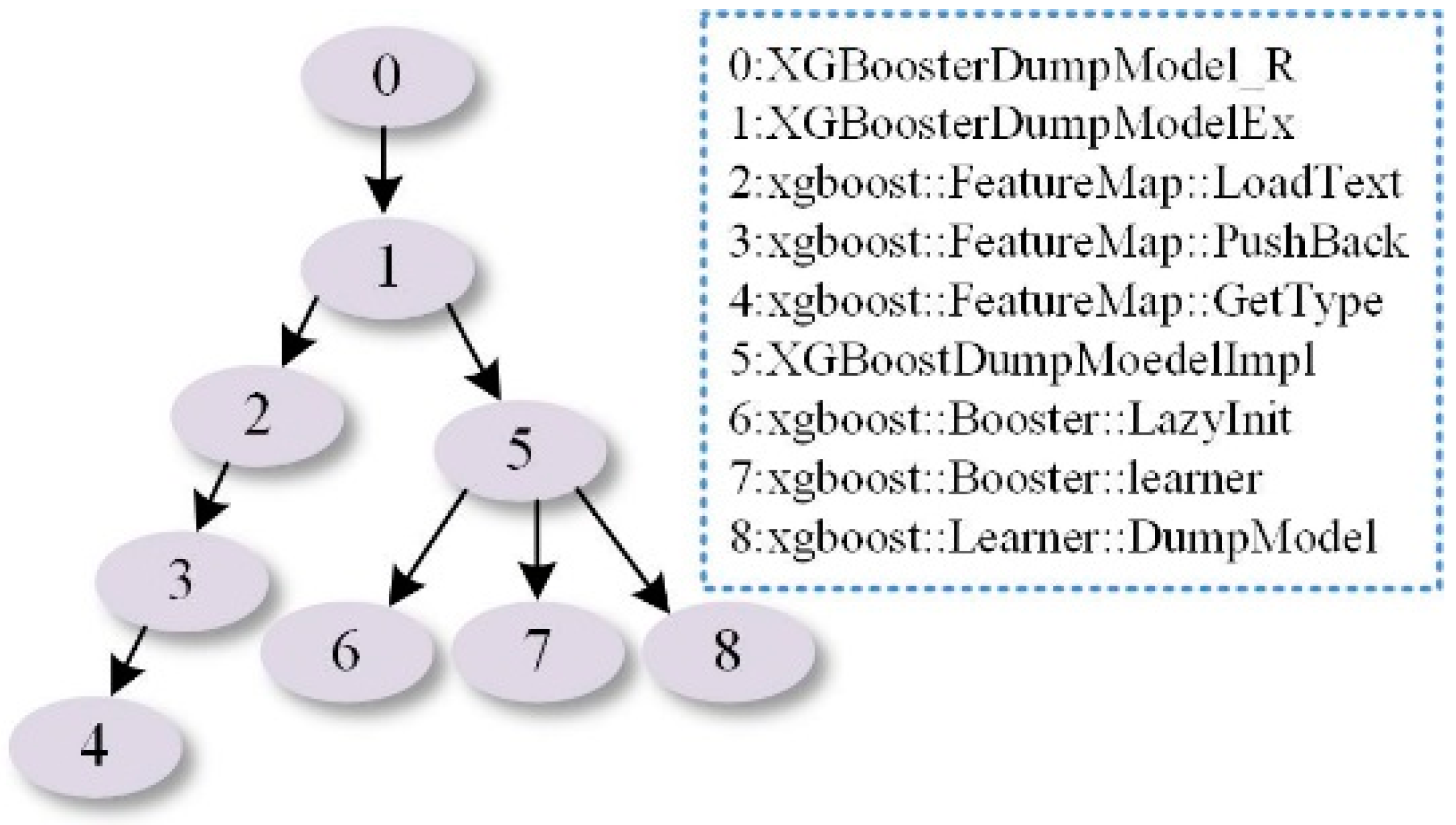
- Step 1.
- The software tool Doxygen (http://www.stack.nl/~dimitri/doxygen/) is used to extract functions from source code. In this step, the name space is used to uniquely identify each function. Each function can be encoded by a hash function for tightening storage and fast search. Additionally, the other parts of the code, such as variable definition or assignment, can be mitted.
- Step 2.
- A sub-gragh is constructed for each function and the associated functions called inside. Then, the sub-graghs are merged into a larger graph called FCG. As mentioned before, the weight for each edge is the call frequency for two functions. We believe FCG can catch the call semantic relationship between functions.
- Step 3.
- Certain high-frequency functions, such as the set functions and the type-obtaining functions, are deleted to balance the global frequency of the whole graph.
3.3. FCG, Ricci Curvature, and Hyperbolic Space
3.3.1. FCG and Ricci Curvature
3.3.2. RC-FCG and Hyperbolic Space
3.4. Learning HFE via the Poincaré Ball Model
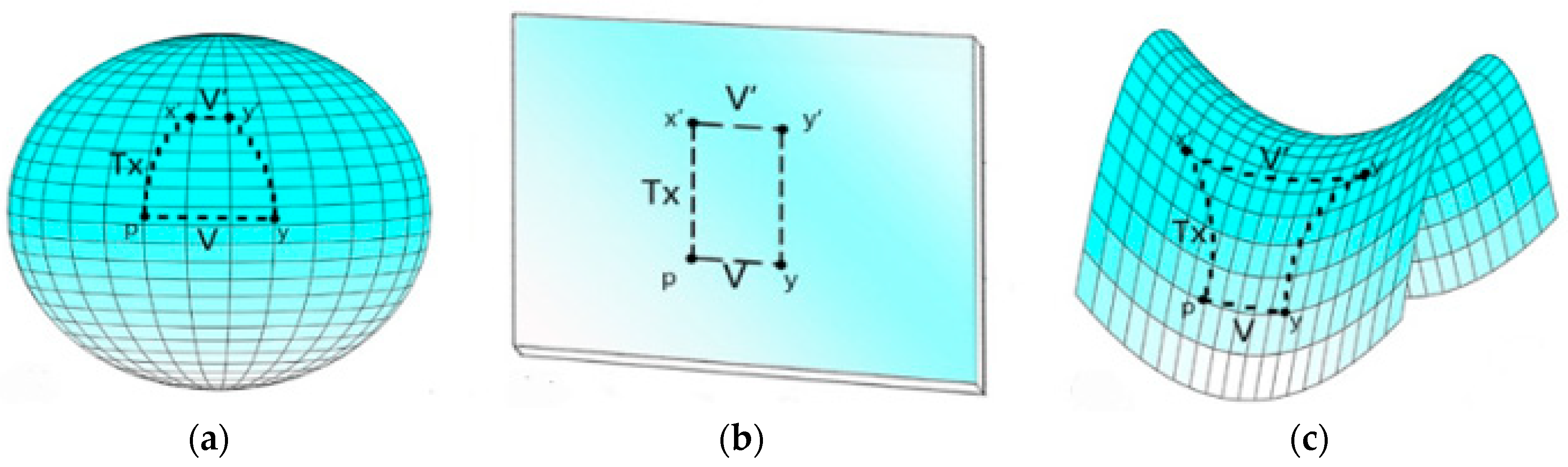
3.4.1. Hyperbolic Space and the Poincaré Ball Model
3.4.2. Hyperbolic Distance for the Poincaré Ball Model
3.4.3. Loss Function and Optimization
4. Experiments and Analysis
4.1. Dataset and Baseline
4.1.1. Dataset
4.1.2. Baselines
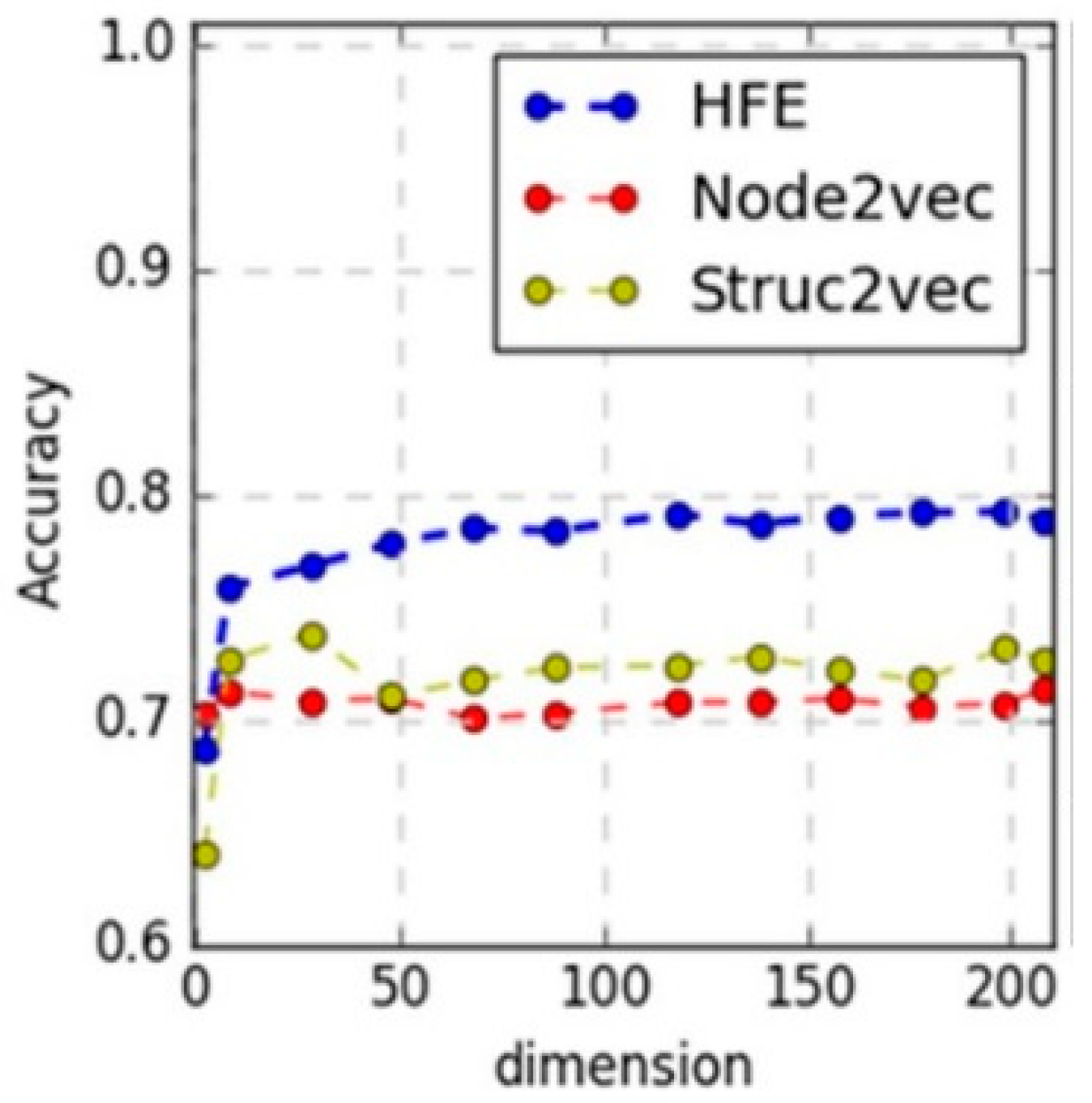
4.2. Performance Comparison and Analysis
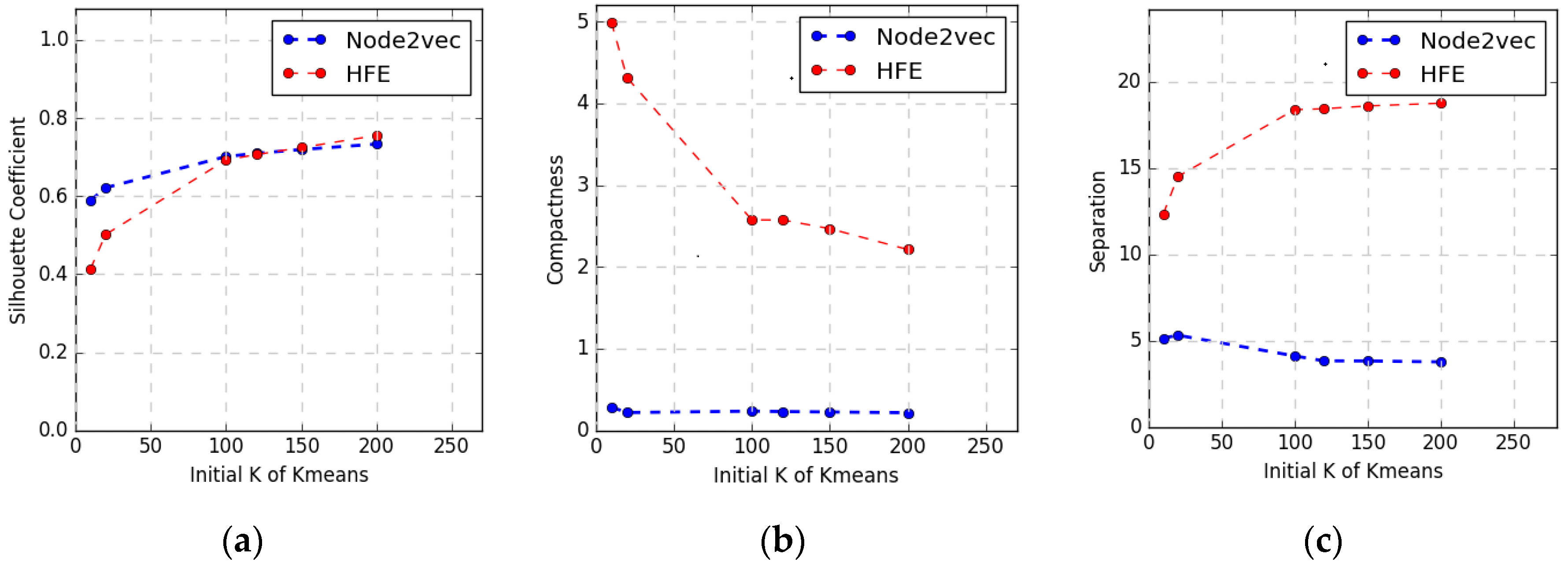
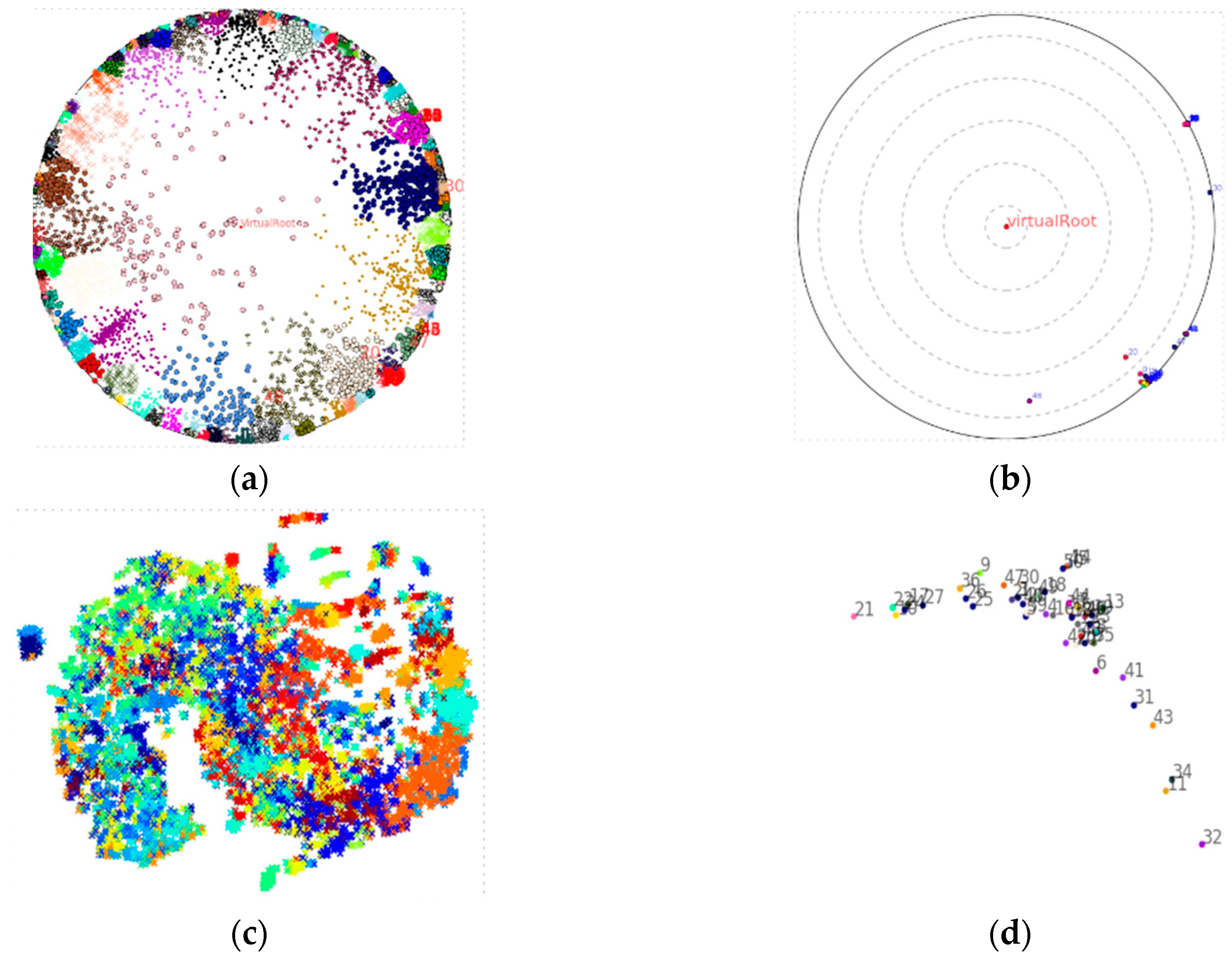
4.2.1. Clustering
4.2.2. Link Prediction
4.3. Visualization
5. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Allamanis, M.; Barr, E.T.; Devanbu, P.; Sutton, C. A Survey of Machine Learning for Big Code and Naturalness. ACM Comput. Surv. 2018, 51, 1–37. [Google Scholar] [CrossRef]
- Gupta, R.; Pal, S.; Kanade, A.; Shevade, S. DeepFix: Fixing Common C Language Errors by Deep Learning. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 1345–1351. [Google Scholar]
- Hu, X.; Wei, Y.; Li, G.; Jin, Z. CodeSum: Translate Program Language to Natural Language. arXiv, 2017; arXiv:1708.01837. [Google Scholar]
- Knuth, D.E. Literate Programming. Comput. J. 1984, 27, 97–111. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Gu, X.; Zhang, H.; Zhang, D.; Kim, S. Deep API Learning. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering 2016, Seattle, WA, USA, 13–19 November 2016. [Google Scholar]
- Iyer, S.; Konstas, I.; Cheung, A.; Zettlemoyer, L. Summarizing source code using a neural attention model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 2073–2083. [Google Scholar]
- Piech, C.; Huang, J.; Nguyen, A.; Phulsuksombati, M.; Sahami, M.; Guibas, L. Learning Program Embeddings to Propagate Feedback on Student Code. arXiv, 2015; arXiv:1505.05969. [Google Scholar]
- Nguyen, T.D.; Nguyen, A.T.; Phan, H.D.; Nguyen, T.N. Exploring API Embedding for API Usages and Applications. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017. [Google Scholar]
- Mou, L.; Li, G.; Zhang, L.; Wang, T.; Jin, Z. Convolutional Neural Networks over Tree Structures for Programming Language Processing. In Proceedings of the AAAI, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Chamberlain, B.P.; Clough, J.; Deisenroth, M.P. Neural Embeddings of Graphs in Hyperbolic Space. arXiv, 2017; arXiv:1705.10359. [Google Scholar]
- Krioukov, D.; Papadopoulos, F.; Kitsak, M.; Vahdat, A.; Boguná, M. Hyperbolic Geometry of Complex Networks. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2010, 82, 036106. [Google Scholar] [CrossRef] [PubMed]
- Verbeek, K.; Suri, S. Metric Embedding, Hyperbolic Space, and Social Networks; Elsevier Science Publishers, B.V.: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Nickel, M.; Kiela, D. Poincaré Embeddings for Learning Hierarchical Representations. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Lohkamp, J. Metrics of Negative Ricci Curvature. Ann. Math. 1994, 140, 655–683. [Google Scholar] [CrossRef]
- Ollivier, Y. Ricci curvature of Markov chains on metric spaces. J. Funct. Anal. 2009, 256, 810–864. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. Node2vec: Scalable Feature Learning for Networks. In Proceedings of the ACM Sigkdd International Conference on Knowledge Discovery & Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Ribeiro, L.F.R.; Saverese, P.H.P.; Figueiredo, D.R. Struc2vec: Learning Node Representations from Structural Identity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Vilnis, L.; Mccallum, A. Word Representations via Gaussian Embedding. arXiv, 2014; arXiv:1412.6623. [Google Scholar]
- Allamanis, M.; Peng, H.; Sutton, C. A Convolutional Attention Network for Extreme Summarization of Source Code. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016. [Google Scholar]
- Dam, H.K.; Tran, T.; Pham, T.T.M. A deep language model for software code. arXiv, 2016; arXiv:1608.02715. [Google Scholar]
- Allamanis, M.; Brockschmidt, M.; Khademi, M. Learning to Represent Programs with Graphs. arXiv, 2017; arXiv:1711.00740. [Google Scholar]
- Allamanis, M.; Chanthirasegaran, P.; Kohli, P.; Sutton, C. Learning Continuous Semantic Representations of Symbolic Expressions. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated Graph Sequence Neural Networks. arXiv, 2015; arXiv:1511.05493. [Google Scholar]
- Jürgen, J.; Liu, S. Ollivier’s Ricci Curvature, Local Clustering and Curvature-Dimension Inequalities on Graphs. Discr. Comput. Geometry 2014, 51, 300–322. [Google Scholar] [CrossRef]
- Villani, C. Optimal Transport. Grundlehren Der Mathematischen Wissenschaften. In The Analysis of Linear Partial Differential Operators; Springer: New York, NY, USA, 2009. [Google Scholar]
- Ollivier, Y.; Villani, C. A Curved Brunn--Minkowski Inequality on the Discrete Hypercube, Or: What Is the Ricci Curvature of the Discrete Hypercube? SIAM J. Discr. Math. 2012, 26, 983–996. [Google Scholar] [CrossRef]
- Shi, J.; Zhang, W.; Wang, Y. Shape Analysis with Hyperbolic Wasserstein Distance. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Santambrogio, F. Optimal transport for applied mathematicians. In Progress in Nonlinear Differential Equations & Their Applications; Springer: Birkäuser, NY, USA, 2015; pp. 99–102. [Google Scholar]
- Gromov, M. Hyperbolic groups. In Essays in Group Theory; Springer: New York, NY, USA, 1987. [Google Scholar]
- Zhang, H.; Reddi, S.J.; Sra, S. Riemannian SVRG: Fast Stochastic Optimization on Riemannian Manifolds. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Bonnabel, S. Stochastic Gradient Descent on Riemannian Manifolds. IEEE Trans. Autom. Control 2013, 58, 2217–2229. [Google Scholar] [CrossRef]
- Jonckheere, E.; Lou, M.; Bonahon, F.; Baryshnikov, Y. Euclidean versus Hyperbolic Congestion in Idealized versus Experimental Networks. Internet Math. 2011, 7, 1–27. [Google Scholar] [CrossRef]
- Wang, C.; Jonckheere, E.; Brun, T. Differential geometric treewidth estimation in adiabatic quantum computation. Quant. Inf. Process. 2016, 15, 3951–3966. [Google Scholar] [CrossRef]
- Gulcehre, C.; Denil, M.; Malinowski, M.; Razavi, A.; Pascanu, R.; Hermann, K.M.; Battaglia, P.; Bapst, V.; Raposo, D.; Santoro, A.; et al. Hyperbolic Attention Networks. arXiv, 2010; arXiv:1805.09786. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | RC-FCG | |
|---|---|---|
| Accuracy | ||
| 8-dim | 2018-dim | |
| Node2vec | 0.7047 | 0.7131 |
| Struc2vec | 0.7269 | 0.7271 |
| HFE | 0.7519 | 0.7891 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, M.; Liu, Y.; Li, H.; Tan, D.; He, X.; Bi, W.; Li, W. Hyperbolic Function Embedding: Learning Hierarchical Representation for Functions of Source Code in Hyperbolic Space. Symmetry 2019, 11, 254. https://doi.org/10.3390/sym11020254
Lu M, Liu Y, Li H, Tan D, He X, Bi W, Li W. Hyperbolic Function Embedding: Learning Hierarchical Representation for Functions of Source Code in Hyperbolic Space. Symmetry. 2019; 11(2):254. https://doi.org/10.3390/sym11020254
Chicago/Turabian StyleLu, Mingming, Yan Liu, Haifeng Li, Dingwu Tan, Xiaoxian He, Wenjie Bi, and Wendbo Li. 2019. "Hyperbolic Function Embedding: Learning Hierarchical Representation for Functions of Source Code in Hyperbolic Space" Symmetry 11, no. 2: 254. https://doi.org/10.3390/sym11020254
APA StyleLu, M., Liu, Y., Li, H., Tan, D., He, X., Bi, W., & Li, W. (2019). Hyperbolic Function Embedding: Learning Hierarchical Representation for Functions of Source Code in Hyperbolic Space. Symmetry, 11(2), 254. https://doi.org/10.3390/sym11020254