MAIAD: A Multistage Asymmetric Information Attack and Defense Model Based on Evolutionary Game Theory


Abstract
1. Introduction
2. The Multistage Asymmetric Information Attack and Defense Model
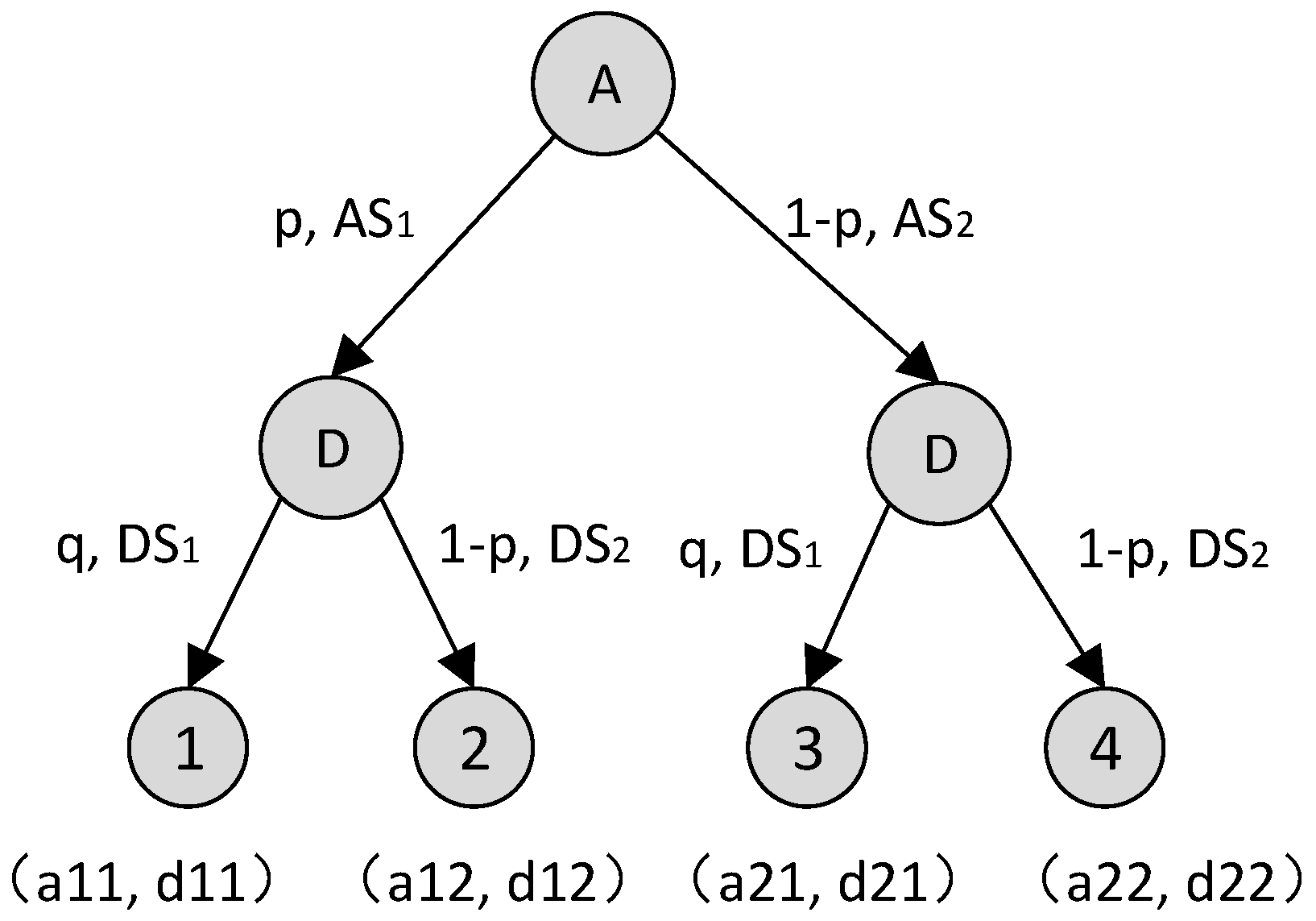
2.1. Analysis of Attack and Defense Game Processes
2.2. Definition of the MAIAD
- 1.
- N represents the set of participants in the game, and the participants in the offensive and defensive game are the subject of the strategy choice and the strategist. Na stands for the attacker set of the IoT system and is a follower. Nd is the leader of the defenders.
- 2.
- θ represents the type space of the defender and the attacker. Depending on the defensive capabilities, the type of defender can be divided into a high level defender θh, medium level defender θm, and low level defender θl, θd = (θh,θm,θl). The type information of the defender is private information. The attacker has only one type θa= (η).
- 3.
- S represents the set of policies of the attacker and defender, where DS represents the defender’s policy set, DS = {ai | i = 1,2,…}, AS represents the attacker’s policy set, AS = { dj | j = 1,2,…}.
- 4.
- M represents the defense signal space. The defender selects and releases the false defense signal according to the preset signal release mechanism. For the convenience of representation, the signal name is consistent with the name of the defender type. M ≠ ∅, M = (mh, mm, ml). For the purpose of deterrence, deception, and inducement of an attacker, the true type of defense signal and defender is not necessarily consistent.
- 5.
- T represents the number of stages in a multistage game, i.e., T = {1,2,…,n}.
- 6.
- P represents a set of game beliefs. In stage T, pi represents the probability of selecting the attack strategy ASi, qi represents the probability of selecting the defense strategy DSi, , .
- 7.
- δT is a discount factor, which indicates that as the game progresses, the proportion of the defender’s return is smaller than the initial stage’s discount ratio in the process of increasing T, 0 ≤ δT ≤ 1. When T = 1, δ1 = 1, it means that in the initial game stage, the released false defense signal has no attenuation. At this time, the defense signal has the strongest ability to deter, deceive, and induce the attacker, and the defense party gains. When 1 < T < n, 1 < δT < n, δT has a monotonously decreasing characteristic, that is, as the game evolves, the false defense signal will decay and the attenuation will increase, and the defense party will decrease; when T = n, δn = 0, which means that after the game between the two parties reaches a certain level, the influence of the false defense signal on the game result completely disappears, and the multistage dynamic attack and defense game degenerates into the static game problem under the condition of incomplete information.
- 8.
- U = {Ua, Ud} is a collection of utility functions for attackers and defenders. It indicates the gain or loss obtained by the offensive and defensive sides from the game. Ua is the utility function of the attacker. Ud is the utility function of the defender. When the offensive and defensive sides use different attack and defense strategies to play the game, they will get different income values.
2.3. Quantification of Attack and Defense Strategy Cost/Benefit
3. Optimal Strategy Selection
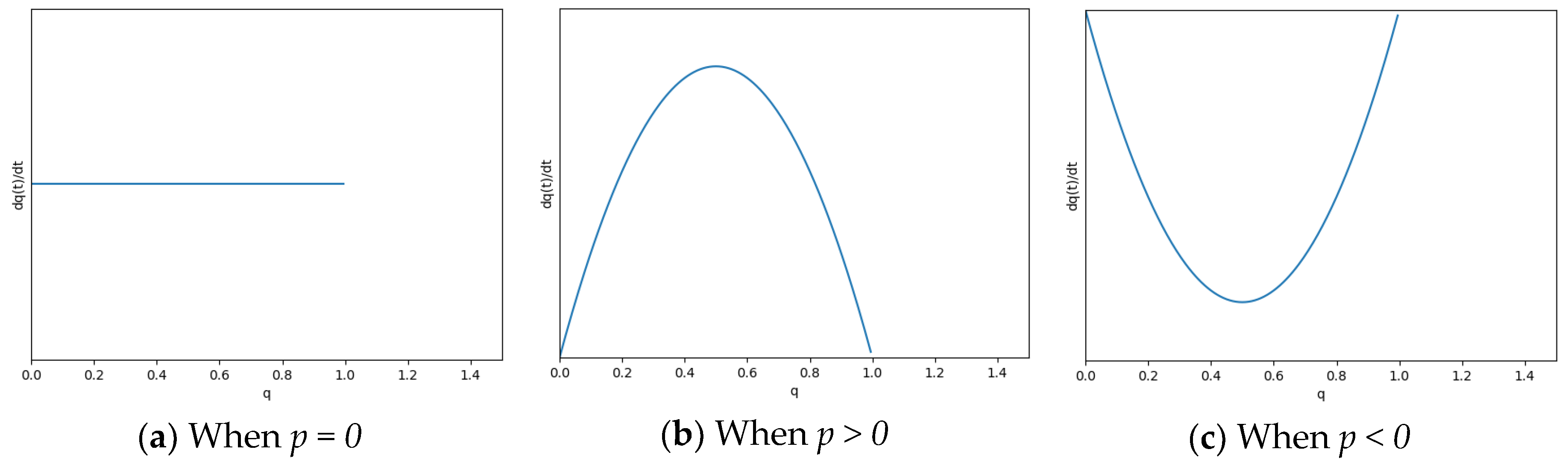
3.1. Evolutionary Game Equilibrium
3.2. Optimal Strategy Selection
4. Experimental Verification
4.1. Attack and Defense Strategy Set
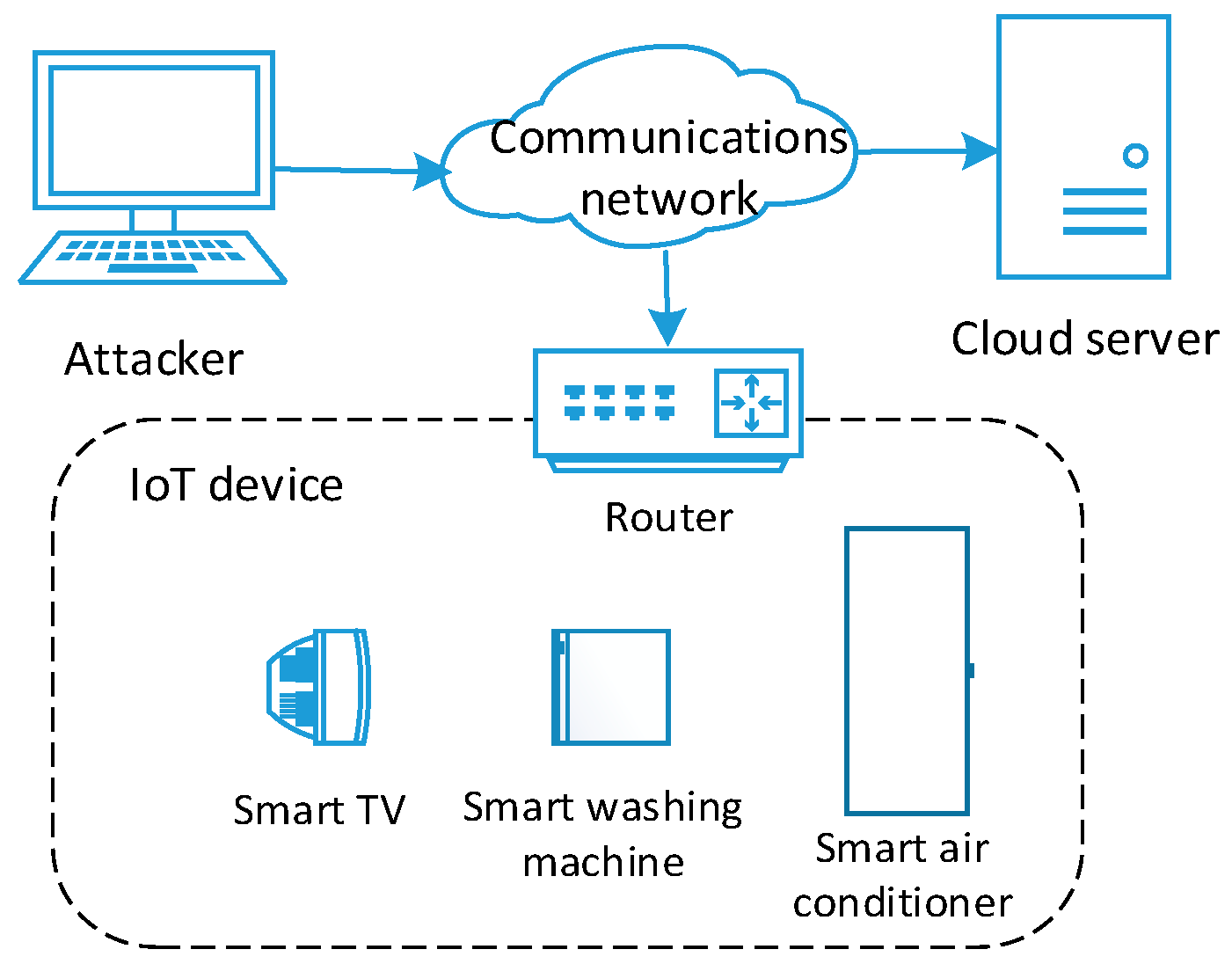
4.1.1. Smart Home Network
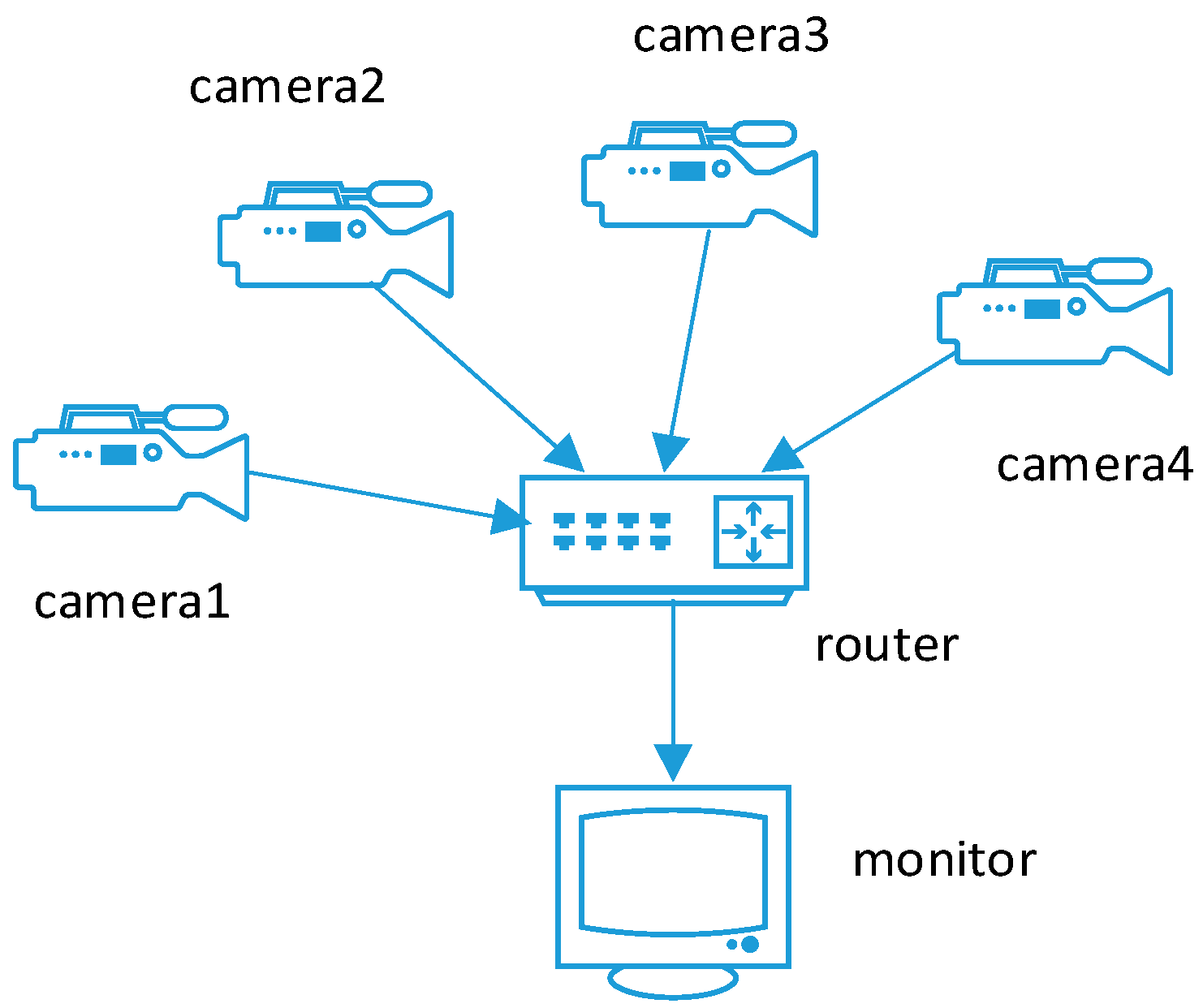
4.1.2. Smart Camera Network
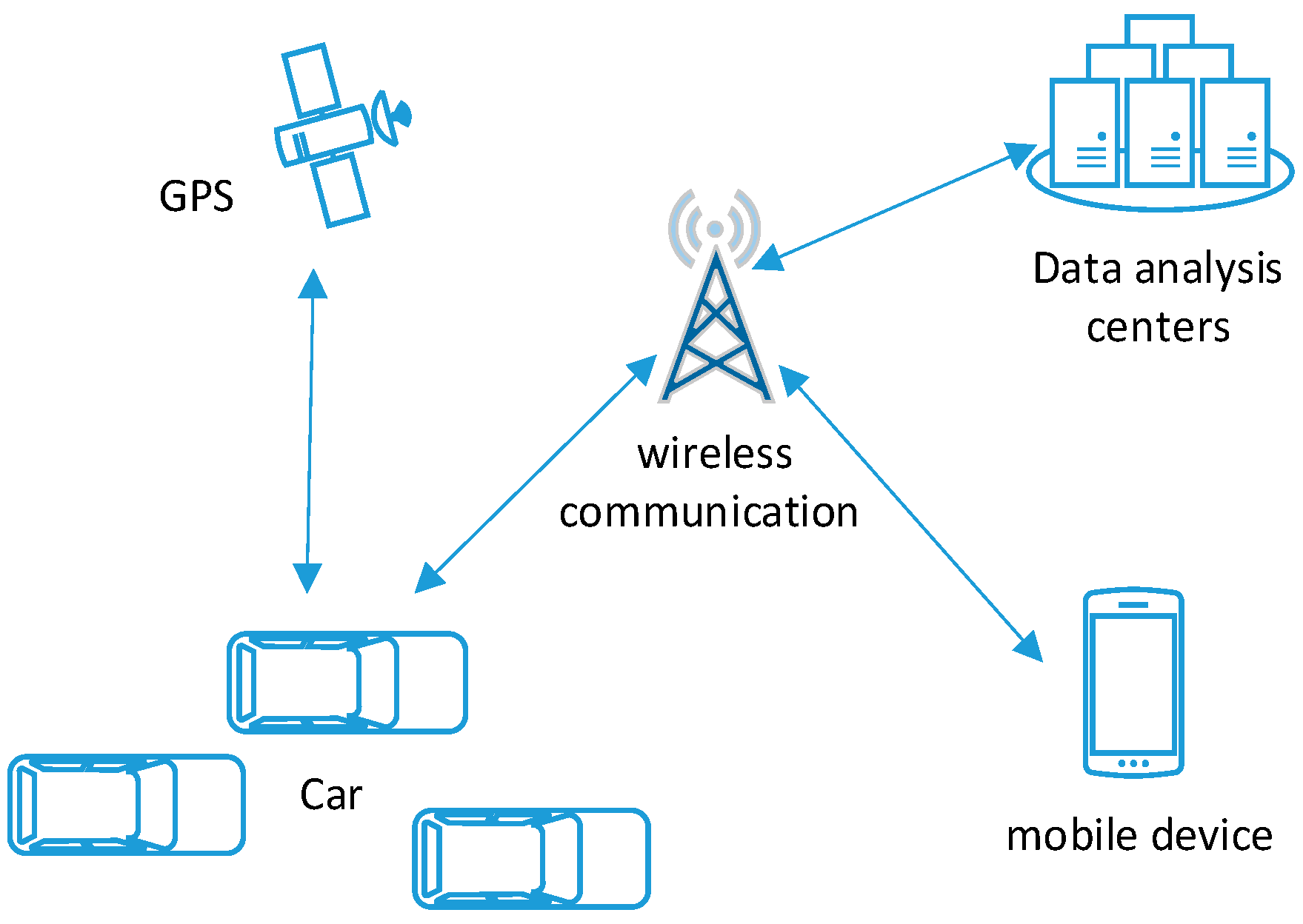
4.1.3. Smart Transportation System
4.2. Optimal Strategy Calulation
4.2.1. Smart Home Network
4.2.2. Smart Camera Network
4.2.3. Smart Transportation System
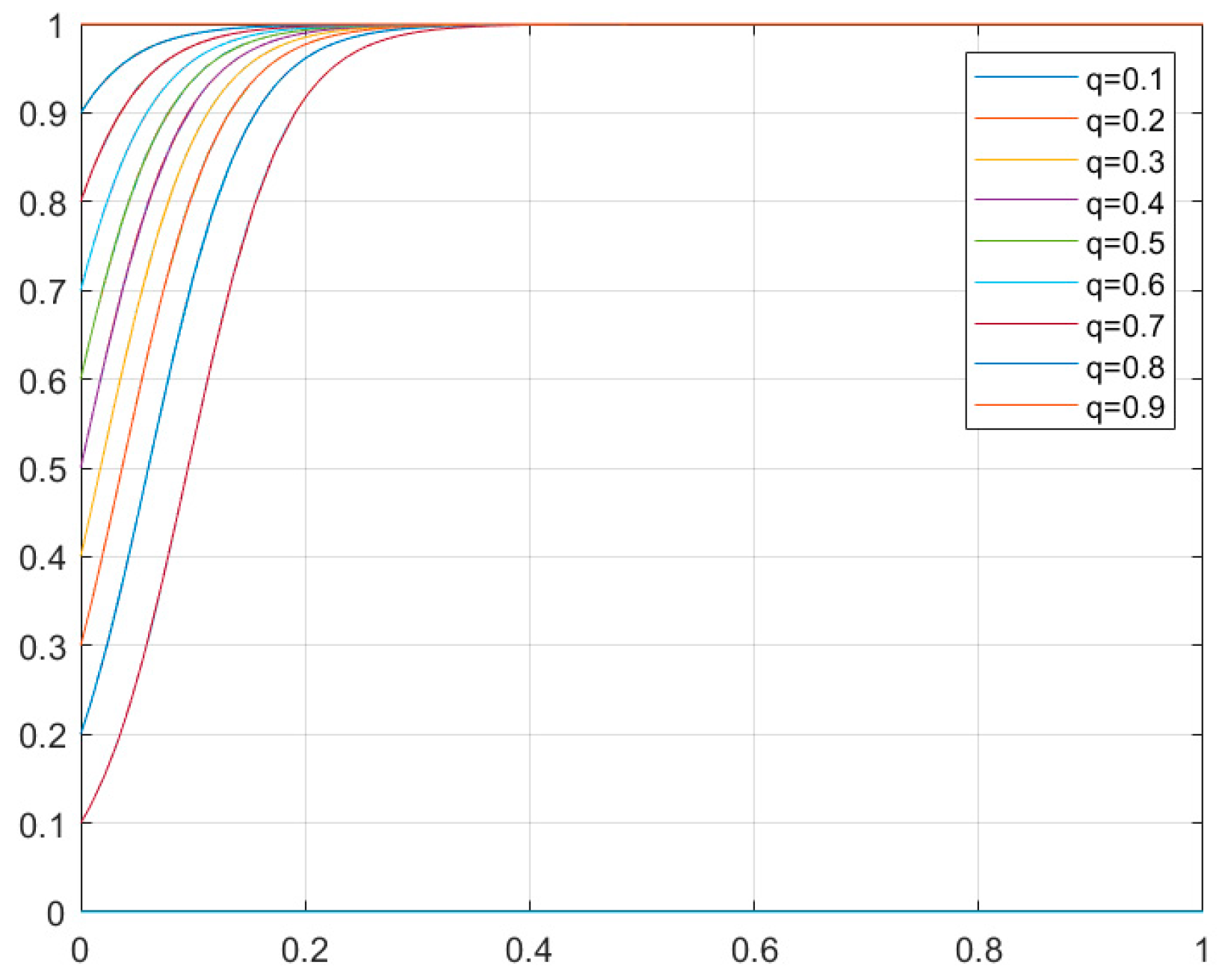
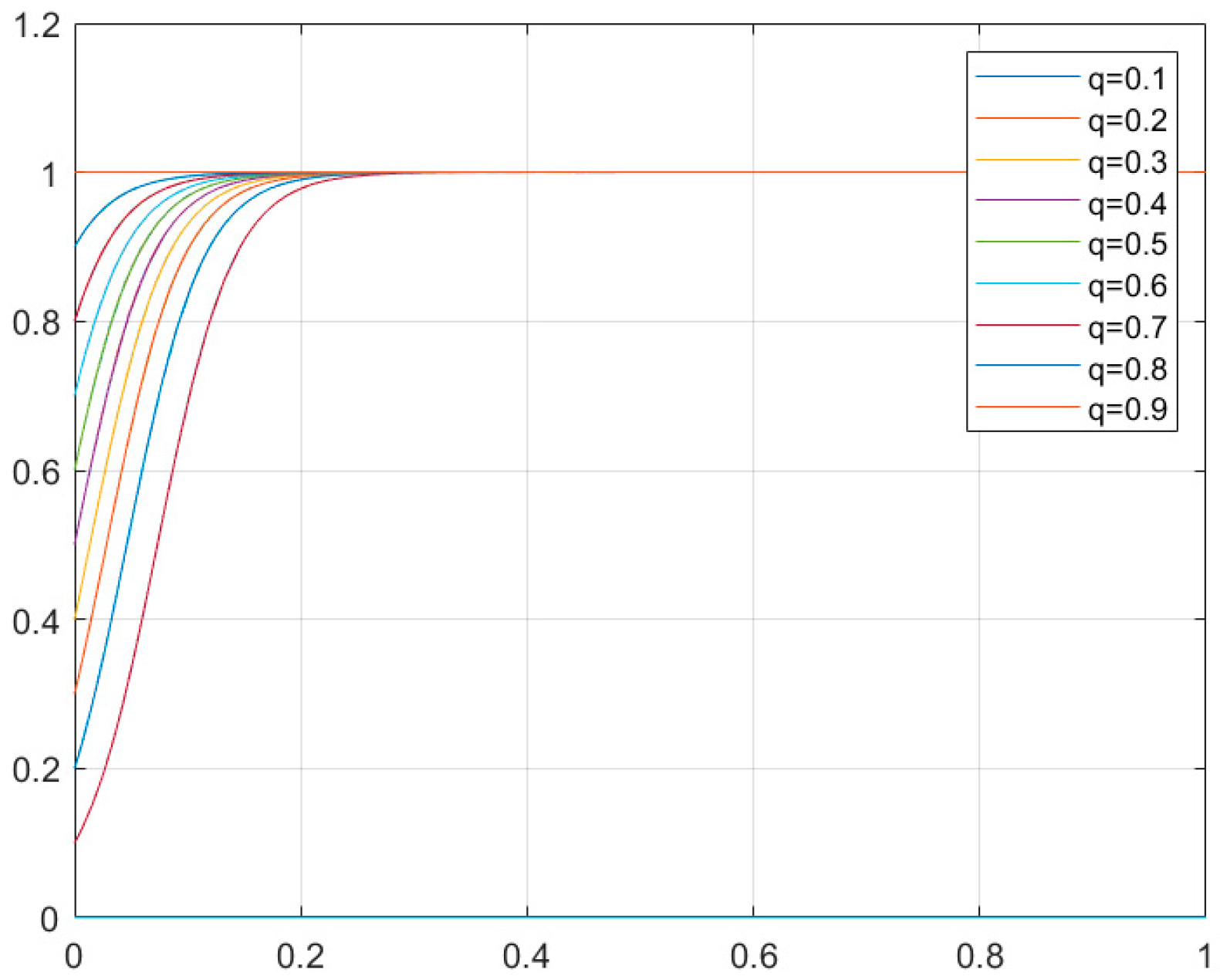
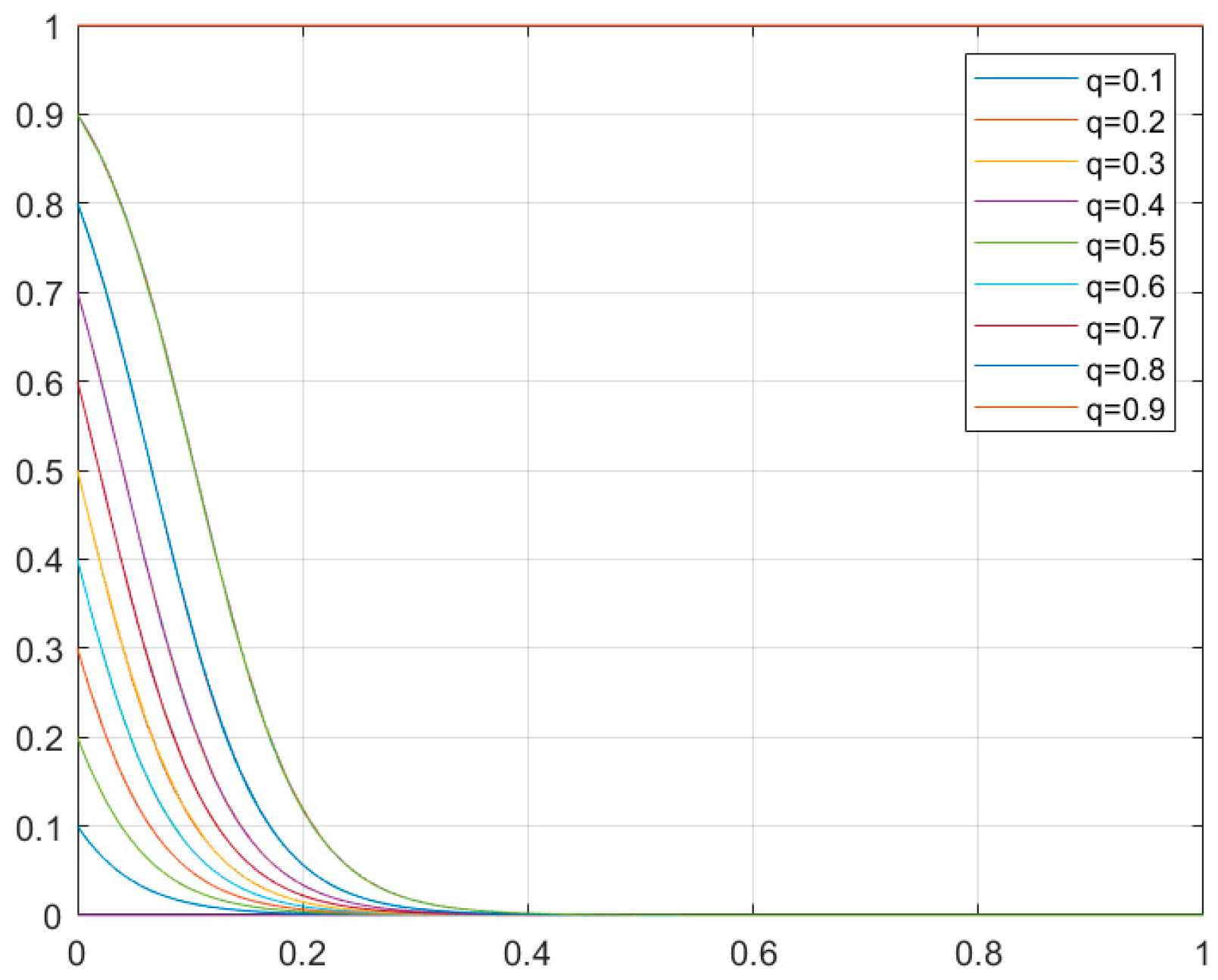
4.3. Simulation Results
4.3.1. Smart Home Network
4.3.2. Smart Camera Network
4.3.3. Smart Transportation System
5. Conclusions and Future Research Directions
Author Contributions
Funding
Conflicts of Interest
References
- Hong, X.; Li, F.; Zhan, B.H. Information Security Assessment and Risk Assessment; Electronic Industry Press: Beijing, China, 2012. [Google Scholar]
- Lye, K.W.; Wing, J.M. Game strategies in network security. Int. J. Inf. Secur. 2005, 4, 71–86. [Google Scholar] [CrossRef]
- Ryutov, T.; Orosz, M.; Blythe, J.; von Winterfeldt, D. A Game Theoretic Framework for Modeling Adversarial Cyber Security Game among Attackers, Defenders, and Users; Security and Trust Management; Springer International Publishing: New York, NY, USA, 2015; pp. 274–282. [Google Scholar]
- Solan, E.; Vieille, N. Correlated equilibrium in stochastic games. Game Econ. Behav. 2002, 38, 362–399. [Google Scholar] [CrossRef]
- Fudenberg, D.; Tirole, J. Game Theory; Massachusettes Institute of Technology Press: Boston, MA, USA, 2012. [Google Scholar]
- Jiang, Y.; Zhang, H.; Song, X.; Jiao, X.; Hung, W.N.; Gu, M.; Sun, J. Bayesian-Network-Based Reliability Analysis of PLC Systems. IEEE Trans. Ind. Electron. 2013, 60, 5325–5336. [Google Scholar] [CrossRef]
- Cheng, D.; He, F.; Qi, H.; Xu, T. Modeling, analysis and control of networked evolutionary games. IEEE Trans. Autom. Control 2015, 60, 2402–2415. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, H.; Wang, J. Defense strategies selection based on attack–defense evolutionary game model. J. Commun. 2017, 38, 168–176. [Google Scholar]
- Shan, X.; Zhuang, J. Modeling Cumulative Defensive Resource Allocation against a Strategic Attacker in a Multiperiod Multitarget Game. Reliab. Eng. Syst. Saf. 2018, 179, 12–26. [Google Scholar] [CrossRef]
- Jose, V.R.; Zhuang, J. Technology Adoption, Accumulation, and Competition in Multiperiod Attacker-Defender Games. Adv. Mater. Res. 2013, 18, 1178–1181. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, H.; Wang, J. Markov Evolutionary Games for Network Defense Strategy Selection. IEEE Access 2017, 5, 19505–19516. [Google Scholar] [CrossRef]
- Hu, H.; Liu, Y.; Zhang, H.; Pan, R. Optimal Network Defense Strategy Selection Based on Incomplete Information Evolutionary Game. IEEE Access 2018, 6, 29806–29821. [Google Scholar] [CrossRef]
- Basar, T.; Olsder, G. Mixed Stackelberg strategies in continuous-kernel games. In Proceedings of the IEEE Conference on Decision & Control Including the Symposium on Adaptive Processes, New Orleans, LA, USA, 12–14 December 2007. [Google Scholar]
- Jiang, W.; Fang, B.X.; Tian, Z.H.; Zhang, H.L. Evaluating Network Security and Optimal Active Defense Based on Attack–defense Game Model. Chin. J. Comput. 2009, 32, 817–827. [Google Scholar] [CrossRef]
- Jiang, Y.; Song, H.; Wang, R.; Gu, M.; Sun, J.; Sha, L. Data-centered runtime verification of wireless medical cyber-physical system. IEEE Trans. Ind. Inform. 2017, 13, 1900–1909. [Google Scholar] [CrossRef]
- Wang, B.; Cai, J.; Zhang, S.; Li, J. A network security assessment model based on attack–defense game theory. In Proceedings of the International Conference on Computer Application & System Modeling, Taiyuan, China, 22–24 October 2010. [Google Scholar]
- Jin-Dong, W.A.; Ding-Kun, Y.; Hengwei, Z.H. Active defense strategy selection based on the static Bayesian game. In Proceedings of the IET International Conference on Cyberspace Technology, Beijing, China, 7 April 2016. [Google Scholar]
- Jiang, Y.; Zhang, H.; Zhang, H.; Liu, H.; Song, X.; Gu, M.; Sun, J. Design of Mixed Synchronous/Asynchronous Systems with Multiple Clocks. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 2220–2232. [Google Scholar] [CrossRef]
- Zhuang, J.; Bier, V.M. Secrecy and Deception at Equilibrium, with Applications to Anti-Terrorism Resource Allocation. Def. Peace Econ. 2011, 22, 43–61. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Real Type | Camouflage Type | SDE Level | Quantization Assignment |
|---|---|---|---|
| High level defender | High level defender | SDE0 | 10 |
| Medium level defender | SDE1 | 40 | |
| Low level defender | SDE2 | 70 | |
| Medium level defender | High level defender | SDE1 | 40 |
| Medium level defender | SDE0 | 10 | |
| Low level defender | SDE1 | 40 | |
| Low level defender | High level defender | SDE2 | 70 |
| Medium level defender | SDE1 | 40 | |
| Low level defender | SDE0 | 10 |
| Serial Number | Attack Action Description | AL | Quantitative Assignment |
|---|---|---|---|
| a1 | Remote code execution | AL1 | 10 |
| a2 | Unsigned firmware update | AL2 | 40 |
| a3 | Database rights | AL3 | 70 |
| Serial Number | Defense Action Description | DL | Quantitative Assignment |
|---|---|---|---|
| d1 | system update | DL1 | 10 |
| d2 | Behavior filtering | DL2 | 40 |
| d3 | Abnormal field identification | DL1 | 10 |
| Serial Number | Attack Action Description | AL | Quantitative Assignment |
|---|---|---|---|
| a1 | Weak password | AL1 | 10 |
| a2 | Data plaintext transmission | AL1 | 10 |
| a3 | Rewritten update location | AL2 | 40 |
| Serial Number | Defense Action Description | DL | Quantitative Assignment |
|---|---|---|---|
| d1 | Access control | DL1 | 10 |
| d2 | Behavior filtering | DL2 | 40 |
| d3 | Access authentication | DL3 | 70 |
| Serial Number | Attack Action Description | AL | Quantitative Assignment |
|---|---|---|---|
| a1 | SQL injection | AL1 | 10 |
| a2 | Unsafe key storage | AL2 | 40 |
| a3 | Violent enumeration | AL2 | 40 |
| Serial Number | Defense Action Description | DL | Quantitative Assignment |
|---|---|---|---|
| d1 | Injection tool detection | DL1 | 10 |
| d2 | key update | DL2 | 40 |
| d3 | Access authentication | DL3 | 70 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Che, B.; Zeng, Y.; Cheng, Y.; Li, C. MAIAD: A Multistage Asymmetric Information Attack and Defense Model Based on Evolutionary Game Theory. Symmetry 2019, 11, 215. https://doi.org/10.3390/sym11020215
Yang Y, Che B, Zeng Y, Cheng Y, Li C. MAIAD: A Multistage Asymmetric Information Attack and Defense Model Based on Evolutionary Game Theory. Symmetry. 2019; 11(2):215. https://doi.org/10.3390/sym11020215
Chicago/Turabian StyleYang, Yu, Bichen Che, Yang Zeng, Yang Cheng, and Chenyang Li. 2019. "MAIAD: A Multistage Asymmetric Information Attack and Defense Model Based on Evolutionary Game Theory" Symmetry 11, no. 2: 215. https://doi.org/10.3390/sym11020215
APA StyleYang, Y., Che, B., Zeng, Y., Cheng, Y., & Li, C. (2019). MAIAD: A Multistage Asymmetric Information Attack and Defense Model Based on Evolutionary Game Theory. Symmetry, 11(2), 215. https://doi.org/10.3390/sym11020215