A New Design for Alignment-Free Chaffed Cancelable Iris Key Binding Scheme


Abstract
:1. Introduction
- Unlinkability: The protected biometric templates from the same subject should not be differentiable to prevent cross-matching across various applications.
- Revocability: It should be computationally infeasible to derive its original data from multiple protected templates.
- Non-invertibility: It should be computationally infeasible to derive its original biometric data from the protected template and/or the helper data.
- Performance: The accuracy of the cancelable template in recognition performance must be approximately preserved with respect to its original counterparts without the template protection scheme.
2. Related Work
2.1. Fuzzy Commitment
2.2. Fuzzy Vault
2.3. Cancelable Biometrics
2.4. Motivation and Contribution
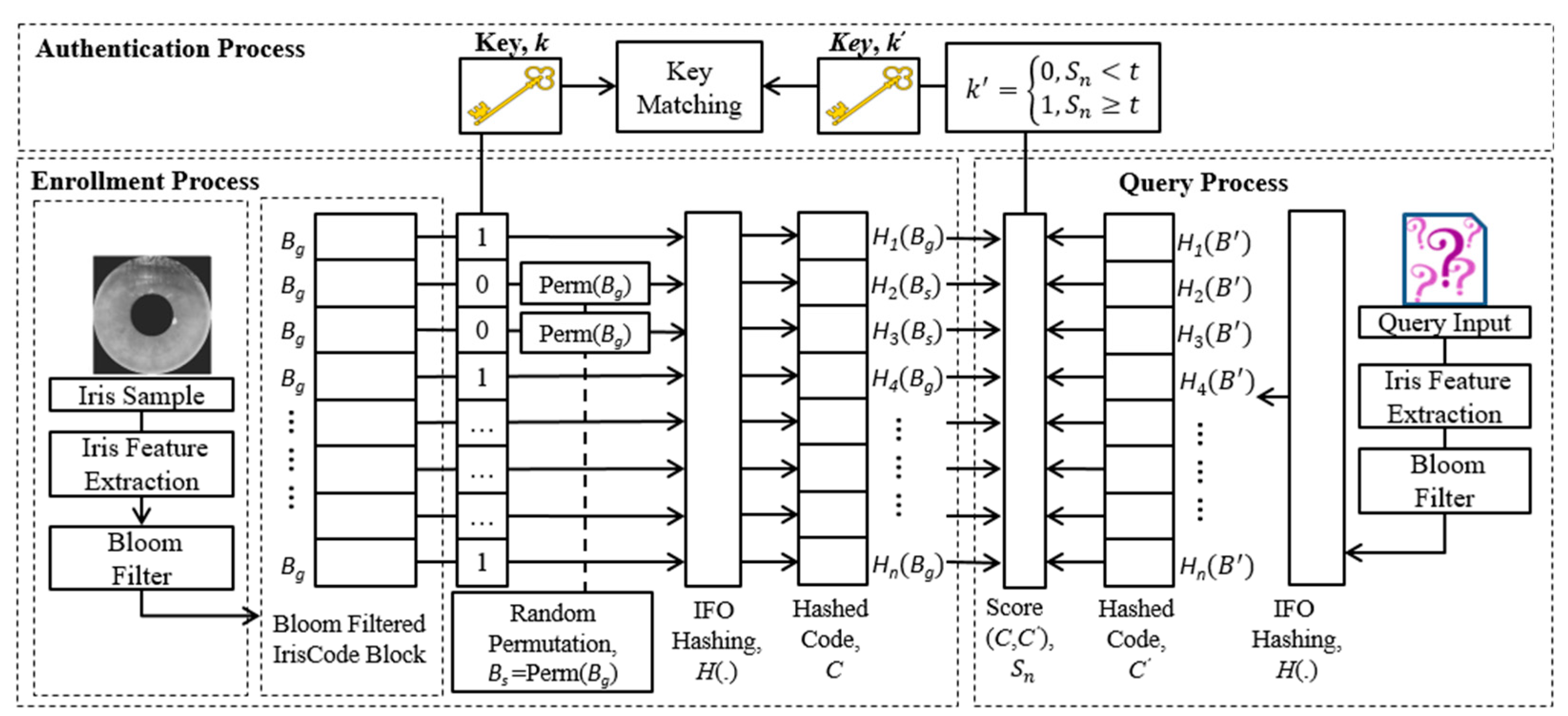
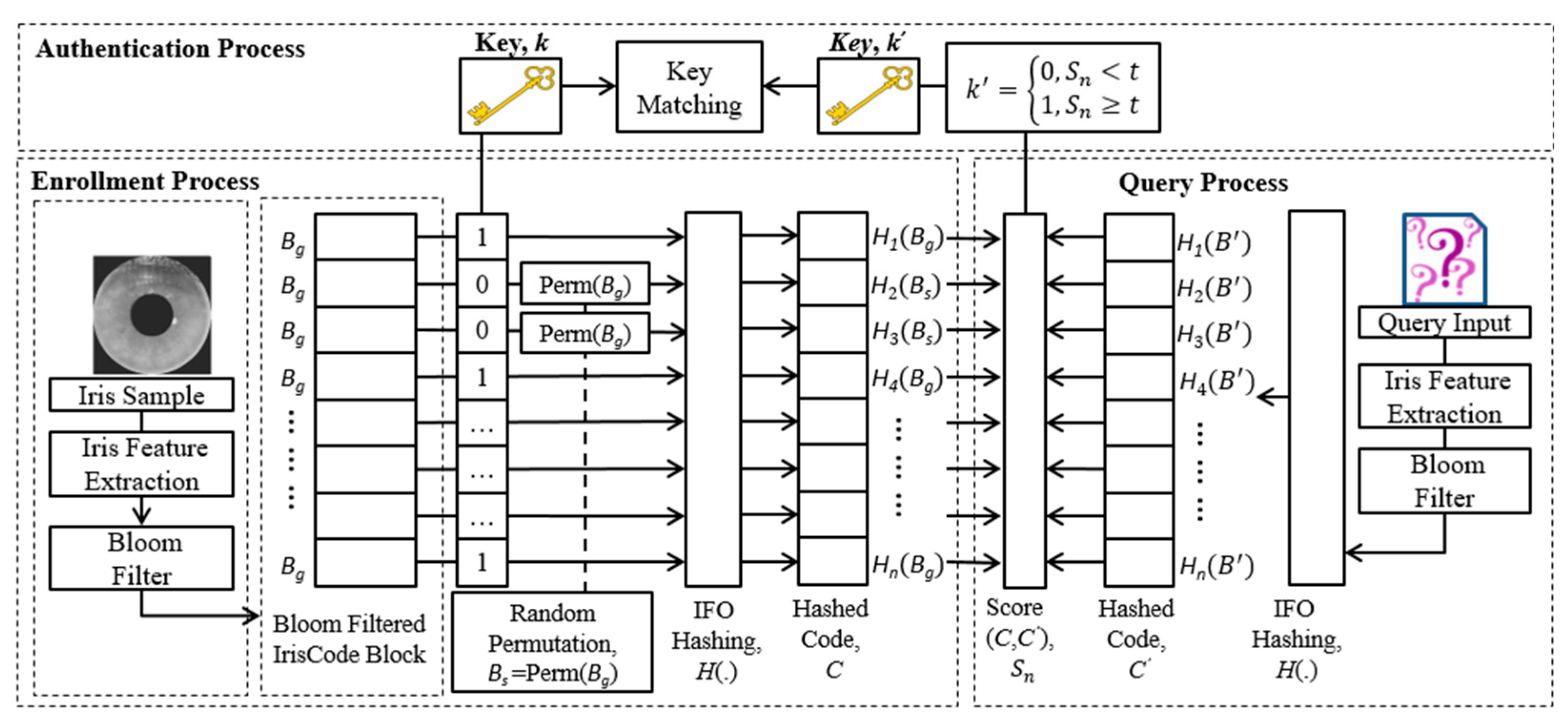
3. Methodology
3.1. Key Binding
- Cryptographic key generation: A random binary cryptographic key is generated where and is the input parameter determining the cryptographic key length.
- Genuine and synthetic template generation: IrisCode goes through feature transformation to generate a genuine iris template (Bloom filtered IrisCode) while a synthetic iris template can be generated through permutation as .
- Key binding: Given a key, , we can define number of IFO hash groups Each hash group (for ) is used to generate the -th IFO hashed code based on the input matrix of either genuine or synthetic Bloom filtered IrisCode. For example, if , the j-th hashed code can be described as , where ; otherwise (if ), the -th hashed code is described as .
- Hashed code generation: number of hashed codes are constructed and stored in the database instead of the corresponding cryptographic key .
- Storage: The collection of output IFO hashed codes are then stored together with the collection of IFO hash groups used in the process of key binding.
3.2. Key Retrieval
- Genuine template generation: has to go through a similar transformation to first generate a query Bloom filtered IrisCode matrix, which can then be described as .
- Query hashed code generation: By using the same IFO hash groups with their respective permutations, number of query hashed codes can be generated.
- Key retrieval: To prepare for key retrieval, we first generate an empty array denoted as where and is the cryptographic key length generated via the matching between the query and the reference hashed codes. Given any pre-defined threshold , matching can be carried out by calculating the similarity score between the reference hashed code and the query hashed code If , set , otherwise, .
- Eventually, a final key can be retrieved.
3.3. The Relation of Key Retrieval Rate to Jaccard Similarity
3.4. Example
4. Performance Evaluation
4.1. Performance of Original IrisCode and Bloom Filter IrisCode
4.2. Performance of the Proposed Key Binding Method
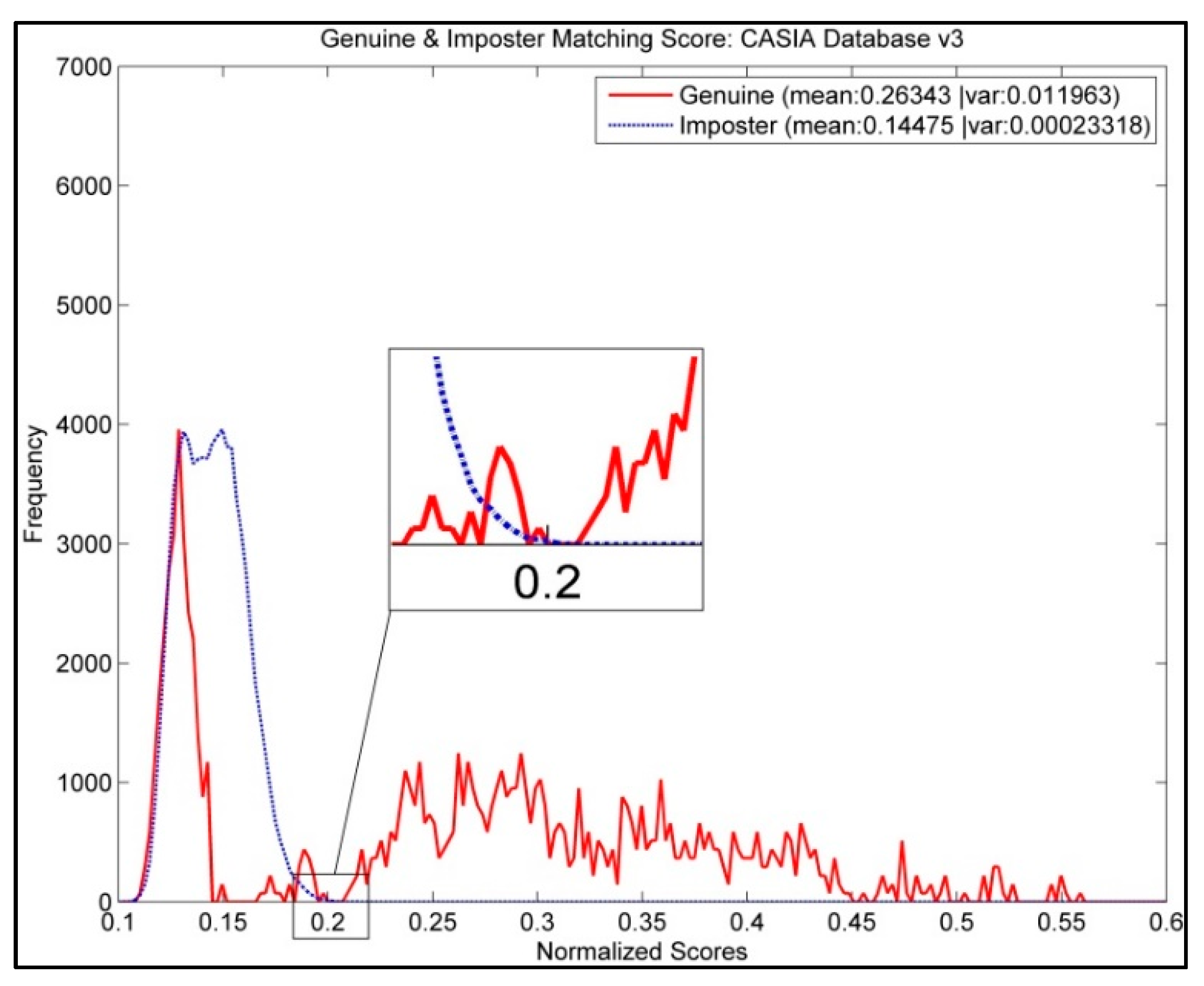
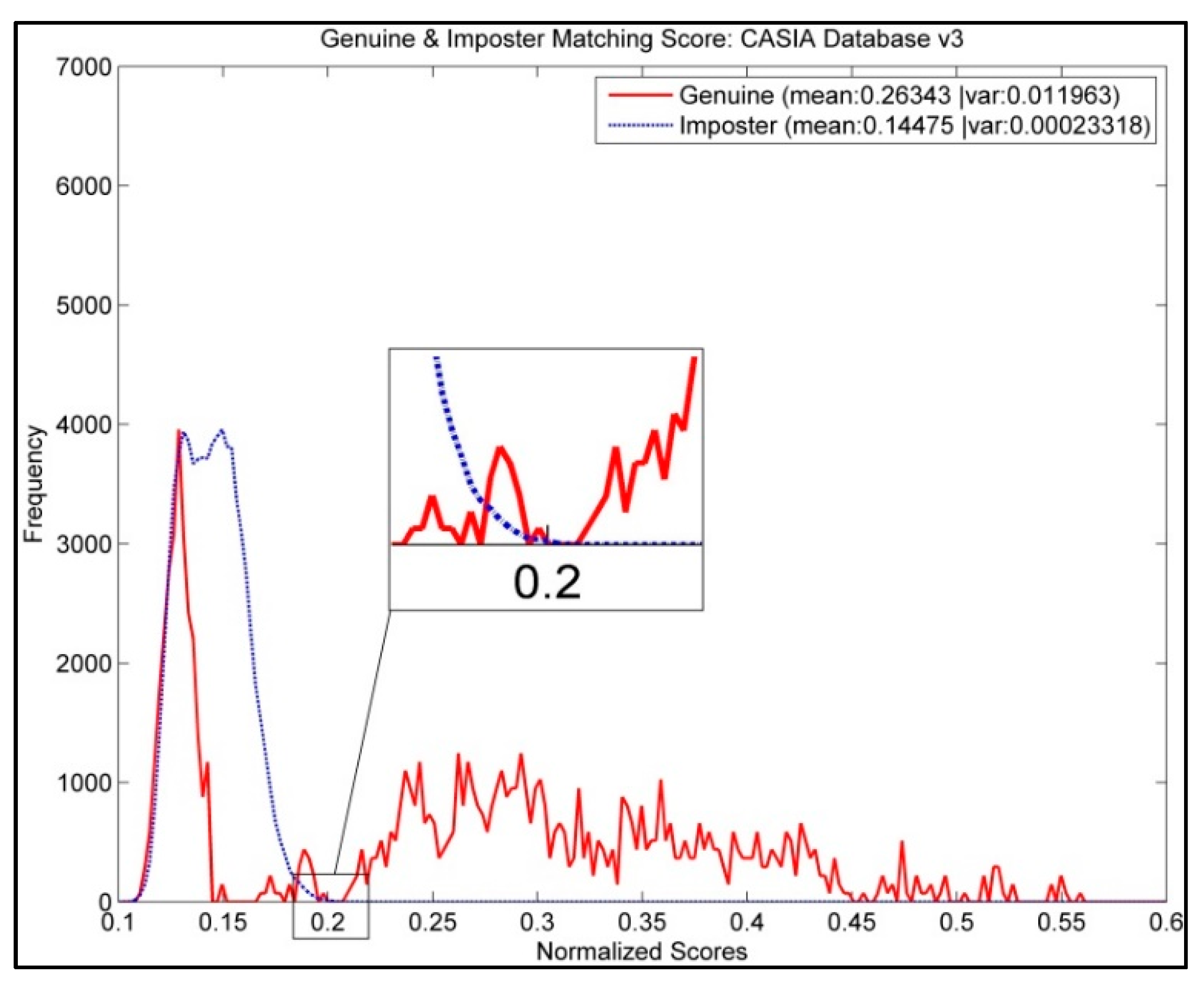
4.3. Evaluation on Similarity Score Threshold,
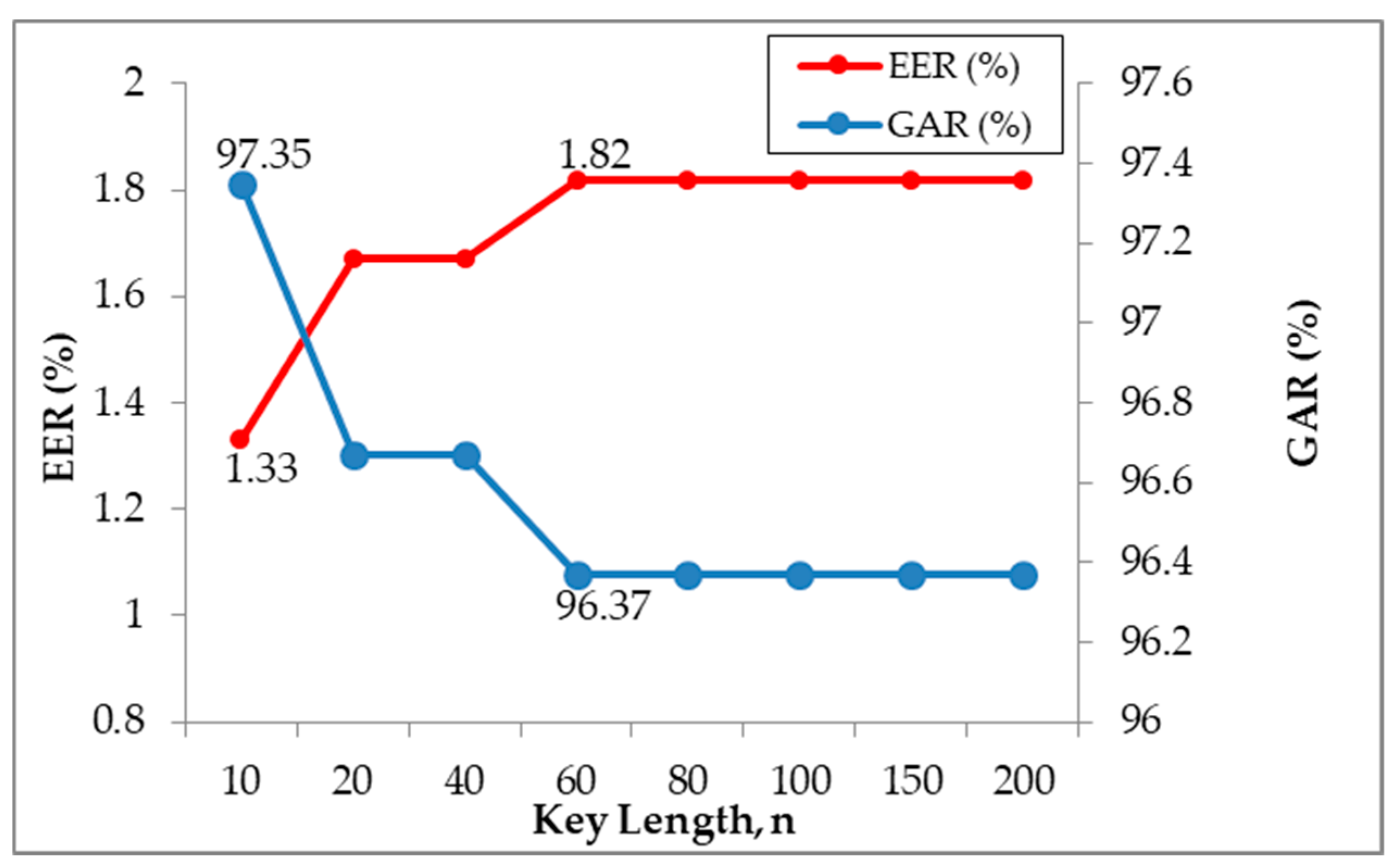
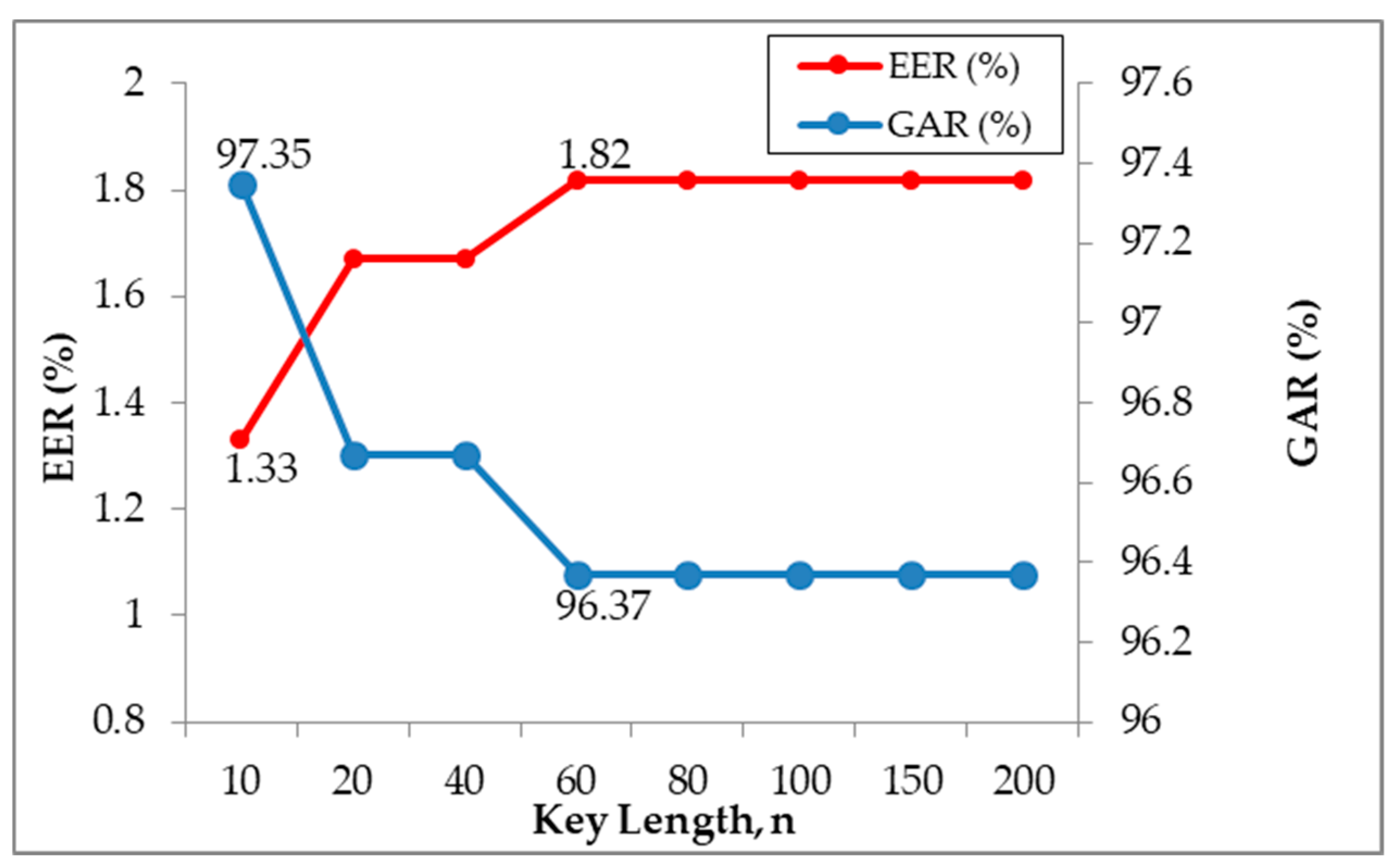
4.4. Evaluation on Cryptographic Key Length, n
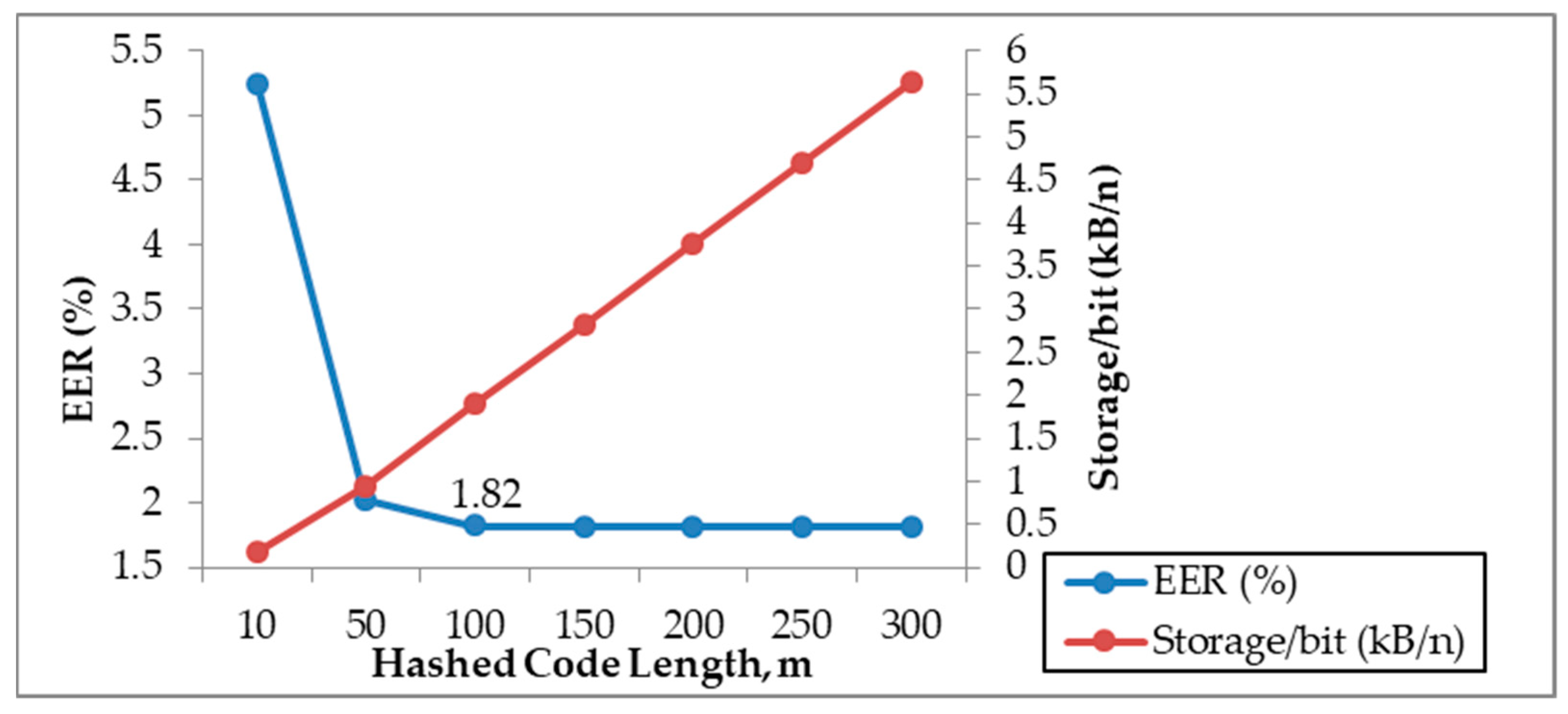
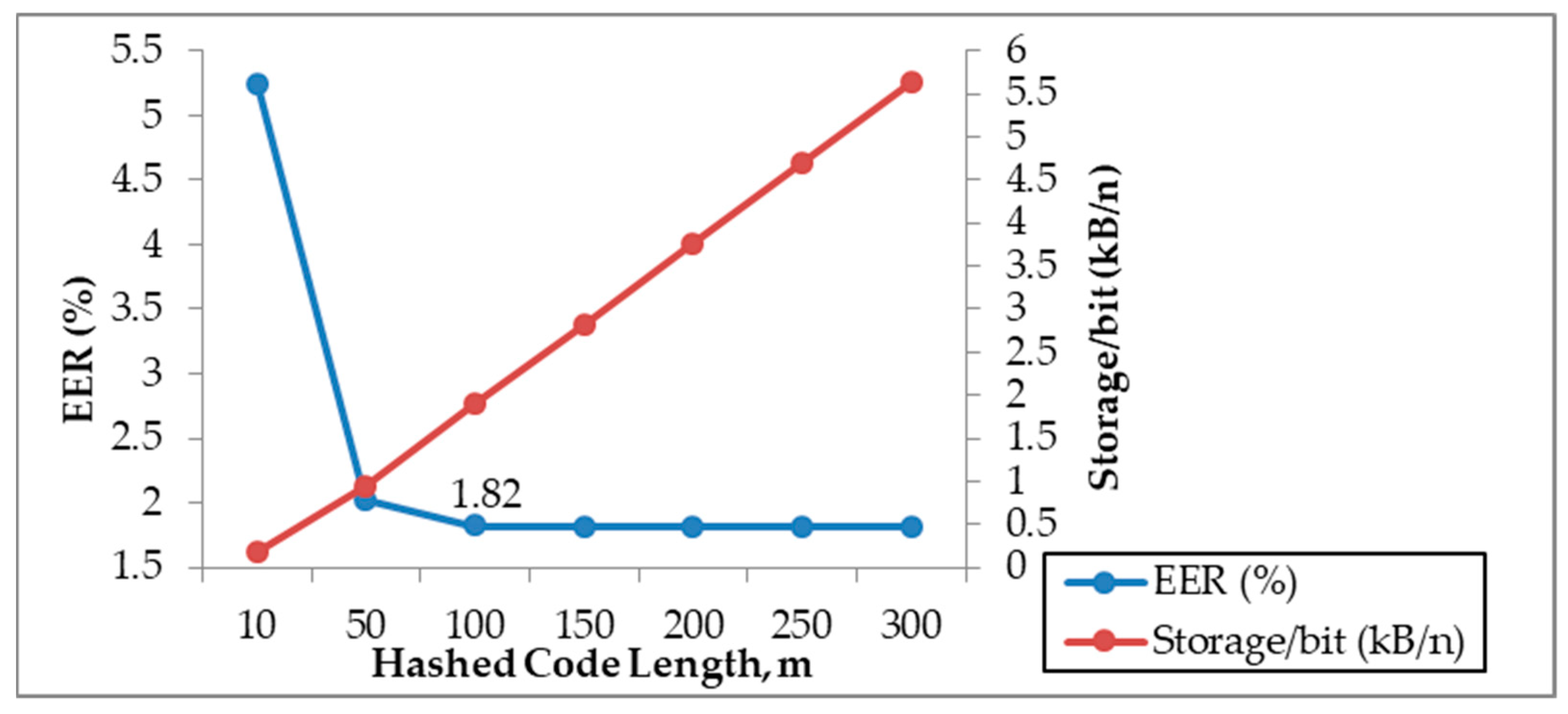
4.5. Evaluation on Hashed Code Length, m
5. Security Analysis
5.1. Indistinguishability Between Genuine and Synthetic Templates
- To start the game, given a group IFO hash function the challenger allows the adversary to choose any class/individual from the database.
- After a class is chosen by the adversary, the challenger selects a random Bloom filtered IrisCode of that individual and generates
- The challenger can then produce the IFO hashed code and give to the adversary.
- After that, the challenger flips a fair coin . If , the challenger selects another Bloom filtered IrisCode of the selected person with a threshold , such that and generates . In addition, hashed code . can also be generated by adding random noise to the filtered IrisCode as long as . If , the challenger permutes the Bloom filtered IrisCode and generates . Then challenger gives to the adversary.
- The adversary outputs a word and wins if .
5.2. Cancelability and Renewal
5.3. Potential Attacks
5.3.1. Brute Force Attack
5.3.2. False Accept Attack
5.4. Comparison
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Daugman, J. How iris recognition works. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 21–30. [Google Scholar] [CrossRef]
- Sasse, M.A. Red-eye blink, bendy shuffle, and the yuck factor: A user experience of biometric airport systems. IEEE Secur. Priv. 2007, 5. [Google Scholar] [CrossRef]
- Cimato, S.; Gamassi, M.; Piuri, V.; Sassi, R.; Scotti, F. Privacy in Biometrics. Available online: https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=cimato+Privacy+in+biometrics&btnG= (accessed on 17 December 2018).
- Klein, D.V. Foiling the cracker: A survey of, and improvements to, password security. In Proceedings of the 2nd USENIX Security Workshop, Boston, MA, USA, 6–10 August 1990; pp. 5–14. [Google Scholar]
- Jain, A.K.; Ross, A.; Pankanti, S. Biometrics: A tool for information security. IEEE Trans. Inf. Forensics Secur. 2006, 1, 125–143. [Google Scholar] [CrossRef]
- Juels, A.; Wattenberg, M. A fuzzy commitment scheme. In Proceedings of the 6th ACM conference on Computer and communications security, Singapore, 1–4 November 1999; pp. 28–36. [Google Scholar] [CrossRef]
- Jain, A.K.; Nandakumar, K.; Nagar, A. Biometric template security. Eurasip J. Adv. Signal Process. 2008, 2008, 113. [Google Scholar] [CrossRef]
- Jain, A.K.; Ross, A.; Prabhakar, S. An introduction to biometric recognition. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 4–20. [Google Scholar] [CrossRef]
- Dodis, Y.; Reyzin, L.; Smith, A. Fuzzy extractors: How to generate strong keys from biometrics and other noisy data. In International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2004; pp. 523–540. [Google Scholar]
- Verbitskiy, E.A.; Tuyls, P.; Obi, C.; Schoenmakers, B.; Skoric, B. Key extraction from general nondiscrete signals. IEEE Trans. Inf. Forensics Secur. 2010, 5, 269–279. [Google Scholar] [CrossRef]
- Juels, A.; Sudan, M. A fuzzy vault scheme. Des. Codes Cryptogr. 2006, 38, 237–257. [Google Scholar] [CrossRef]
- Ratha, N.K.; Chikkerur, S.; Connell, J.H.; Bolle, R.M. Generating cancelable fingerprint templates. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 561–572. [Google Scholar] [CrossRef]
- Cavoukian, A.; Stoianov, A. Biometric encryption. In Encyclopedia of Cryptography and Security; Springer: Berlin/Heidelberg, Germany, 2011; pp. 90–98. [Google Scholar]
- Hao, F.; Anderson, R.; Daugman, J. Combining crypto with biometrics effectively. IEEE Trans. Comput. 2006, 55, 1081–1088. [Google Scholar]
- Bringer, J.; Chabanne, H.; Cohen, G.; Kindarji, B.; Zemor, G. Theoretical and practical boundaries of binary secure sketches. IEEE Trans. Inf. Forensics Secur. 2008, 3, 673–683. [Google Scholar] [CrossRef]
- Phillips, P.J.; Bowyer, K.W.; Flynn, P.J.; Liu, X.; Scruggs, W.T. The iris challenge evaluation 2005. In Proceedings of the 2nd IEEE International Conference on Biometrics: Theory, Applications and Systems, BTAS 2008, Arlington, VA, USA, 29 September–1 October 2008; pp. 1–8. [Google Scholar]
- Rathgeb, C.; Uhl, A. Context-based biometric key generation for Iris. IET Comput. Vis. 2011, 5, 389–397. [Google Scholar] [CrossRef]
- Maiorana, E.; Campisi, P.; Neri, A. IRIS template protection using a digital modulation paradigm. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3759–3763. [Google Scholar]
- Kelkboom, E.J.; Breebaart, J.; Kevenaar, T.A.; Buhan, I.; Veldhuis, R.N. Preventing the decodability attack based cross-matching in a fuzzy commitment scheme. IEEE Trans. Inf. Forensics Secur. 2011, 6, 107–121. [Google Scholar] [CrossRef]
- Teoh, A.B.J.; Kim, J. Secure biometric template protection in fuzzy commitment scheme. IEICE Electron. Express 2007, 4, 724–730. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, Z.; Tan, T.; Hu, S. Robust biometric key extraction based on iris cryptosystem. In International Conference on Biometrics; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1060–1069. [Google Scholar]
- Zhou, X.; Kuijper, A.; Veldhuis, R.; Busch, C. Quantifying privacy and security of biometric fuzzy commitment. In Proceedings of the 2011 International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; pp. 1–8. [Google Scholar]
- Rathgeb, C.; Uhl, A. Statistical attack against iris-biometric fuzzy commitment schemes. In Proceedings of the 2011 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Colorado Springs, CO, USA, 20–25 June 2011; pp. 23–30. [Google Scholar]
- Scheirer, W.J.; Boult, T.E. Cracking fuzzy vaults and biometric encryption. In Proceedings of the Biometrics Symposium, Baltimore, MD, USA, 11–13 September 2007; pp. 1–6. [Google Scholar]
- Carter, F.; Stoianov, A. Implications of biometric encryption on wide spread use of biometrics. In Proceedings of the EBF Biometric Encryption Seminar (June, 2008), Amsterdam, The Netherlands, 24 June 2008. [Google Scholar]
- Ignatenko, T.; Willems, F.M. Information leakage in fuzzy commitment schemes. IEEE Trans. Inf. Forensics Secur. 2010, 5, 337–348. [Google Scholar] [CrossRef]
- Kelkboom, E.J.; Breebaart, J.; Buhan, I.; Veldhuis, R.N. Maximum key size and classification performance of fuzzy commitment for gaussian modeled biometric sources. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1225–1241. [Google Scholar] [CrossRef]
- Lee, Y.J.; Park, K.R.; Lee, S.J.; Bae, K.; Kim, J. A new method for generating an invariant iris private key based on the fuzzy vault system. IEEE Trans. Syst. Man Cybern. Part B 2008, 38, 1302–1313. [Google Scholar] [CrossRef]
- Chinese Academy of Sciences’ Institute of Automation: CASIA Iris Image Database V3.0—Interval. 2002. Available online: http://biometrics.idealtest.org (accessed on 8 September 2015).
- Reddy, E.S.; Babu, I.R. Performance of iris based hard fuzzy vault. In Proceedings of the IEEE 8th International Conference on Computer and Information Technology Workshops, CIT Workshops 2008, Sydney, QLD, Australia, 8–11 July 2008; pp. 248–253. [Google Scholar] [CrossRef]
- Chinese Academy of Sciences’ Institute of Automation: CASIA Iris Image Database V1.0. 2002. Available online: http://biometrics.idealtest.org (accessed on 8 September 2015).
- Multimedia University: MMU Iris Image Database. 2004. Available online: http://pesona.mmu.edu.my/ccteo (accessed on 8 September 2015).
- Mariño, R.Á.; Alvarez, F.H.; Encinas, L.H. A crypto-biometric scheme based on iris-templates with fuzzy extractors. Inf. Sci. 2012, 195, 91–102. [Google Scholar] [CrossRef]
- Fouad, M.; El Saddik, A.; Zhao, J.; Petriu, E. A fuzzy vault implementation for securing revocable iris templates. In Proceedings of the 2011 the IEEE International on Systems Conference (SysCon), Montreal, QC, Canada, 4–7 April 2011; pp. 491–494. [Google Scholar]
- Kholmatov, A.; Yanikoglu, B. Realization of correlation attack against the fuzzy vault scheme. In Proceedings of the Security, Forensics, Steganography, and Watermarking of Multimedia Contents X, San Jose, CA, USA, 27–31 January 2008; p. 68190O. [Google Scholar]
- Tams, B.; Mihăilescu, P.; Munk, A. Security considerations in minutiae-based fuzzy vaults. IEEE Trans. Inf. Forensics Secur. 2015, 10, 985–998. [Google Scholar] [CrossRef]
- Nandakumar, K.; Jain, A.K.; Pankanti, S. Fingerprint-based fuzzy vault: Implementation and performance. IEEE Trans. Inf. Forensics Secur. 2007, 2, 744–757. [Google Scholar] [CrossRef]
- Quan, F.; Fei, S.; Anni, C.; Feifei, Z. Cracking cancelable fingerprint template of Ratha. In Proceedings of the International Symposium on Computer Science and Computational Technology, ISCSCT’08, Shanghai, China, 20–22 December 2008; pp. 572–575. [Google Scholar]
- Savvides, M.; Kumar, B.V.; Khosla, P.K. Cancelable biometric filters for face recognition. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, 2004, Cambridge, UK, 26 August 2004; pp. 922–925. [Google Scholar]
- Chin, C.S.; Jin, A.T.B.; Ling, D.N.C. High security iris verification system based on random secret integration. Comput. Vis. Image Underst. 2006, 102, 169–177. [Google Scholar] [CrossRef]
- Zuo, J.; Ratha, N.K.; Connell, J.H. Cancelable iris biometric. In Proceedings of the 19th International Conference on Pattern Recognition, ICPR 2008, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Pillai, J.K.; Patel, V.M.; Chellappa, R.; Ratha, N.K. Sectored random projections for cancelable iris biometrics. In Proceedings of the 2010 IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 1838–1841. [Google Scholar]
- Kong, A.; Cheung, K.-H.; Zhang, D.; Kamel, M.; You, J. An analysis of BioHashing and its variants. Pattern Recognit. 2006, 39, 1359–1368. [Google Scholar] [CrossRef]
- Lacharme, P.; Cherrier, E.; Rosenberger, C. Preimage attack on biohashing. In Proceedings of the 2013 International Conference on Security and Cryptography (SECRYPT), Reykjavik, Iceland, 29–31 July 2013; pp. 1–8. [Google Scholar]
- Hämmerle-Uhl, J.; Pschernig, E.; Uhl, A. Cancelable Iris Biometrics Using Block Re-mapping and Image Warping. In Proceedings of the ISC, Pisa, Italy, 7–9 September 2009; pp. 135–142. [Google Scholar]
- Jenisch, S.; Uhl, A. Security analysis of a cancelable iris recognition system based on block remapping. In Proceedings of the 2011 18th IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 3213–3216. [Google Scholar]
- Ouda, O.; Tsumura, N.; Nakaguchi, T. On the security of bioencoding based cancelable biometrics. IEICE Trans. Inf. Syst. 2011, 94, 1768–1777. [Google Scholar] [CrossRef]
- Lacharme, P. Analysis of the iriscodes bioencoding scheme. Int. J. Comput. Sci. Softw. Eng. 2012, 6, 315–321. [Google Scholar]
- Rathgeb, C.; Breitinger, F.; Busch, C. Alignment-free cancelable iris biometric templates based on adaptive bloom filters. In Proceedings of the 2013 International Conference on Biometrics (ICB), Madrid, Spain, 4–7 June 2013; pp. 1–8. [Google Scholar]
- Hermans, J.; Mennink, B.; Peeters, R. When a bloom filter is a doom filter: Security assessment of a novel iris biometric template protection system. In Proceedings of the 2014 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 10–12 September 2014; pp. 1–6. [Google Scholar]
- Bringer, J.; Morel, C.; Rathgeb, C. Security analysis of bloom filter-based iris biometric template protection. In Proceedings of the 2015 International Conference on Biometrics (ICB), Phuket, Thailand, 19–22 May 2015; pp. 527–534. [Google Scholar]
- Gomez-Barrero, M.; Rathgeb, C.; Galbally, J.; Busch, C.; Fierrez, J. Unlinkable and irreversible biometric template protection based on bloom filters. Inf. Sci. 2016, 370, 18–32. [Google Scholar] [CrossRef]
- Dwivedi, R.; Dey, S. Cancelable iris template generation using look-up table mapping. In Proceedings of the 2015 2nd International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 19–20 February 2015; pp. 785–790. [Google Scholar]
- Umer, S.; Dhara, B.C.; Chanda, B. A novel cancelable iris recognition system based on feature learning techniques. Inf. Sci. 2017, 406, 102–118. [Google Scholar] [CrossRef]
- Lai, Y.-L.; Jin, Z.; Teoh, A.B.J.; Goi, B.-M.; Yap, W.-S.; Chai, T.-Y.; Rathgeb, C. Cancellable iris template generation based on Indexing-First-One hashing. Pattern Recognit. 2017, 64, 105–117. [Google Scholar] [CrossRef]
- Lai, Y.-L.; Goi, B.-M.; Chai, T.-Y. Alignment-free indexing-first-one hashing with bloom filter integration. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; pp. 78–82. [Google Scholar]
- Jin, Z.; Teoh, A.B.J.; Goi, B.-M.; Tay, Y.-H. Biometric cryptosystems: A new biometric key binding and its implementation for fingerprint minutiae-based representation. Pattern Recognit. 2016, 56, 50–62. [Google Scholar] [CrossRef]
- Rivest, R.L. Chaffing and winnowing: Confidentiality without encryption. Cryptobytes 1998, 4, 12–17. [Google Scholar]
- Gács, P.; Körner, J. Common information is far less than mutual information. Probl. Control Inf. Theory 1973, 2, 149–162. [Google Scholar]
- Li, P.; Yang, X.; Cao, K.; Tao, X.; Wang, R.; Tian, J. An alignment-free fingerprint cryptosystem based on fuzzy vault scheme. J. Netw. Comput. Appl. 2010, 33, 207–220. [Google Scholar] [CrossRef]
- Rathgeb, C.; Uhl, A. The State-of-the-Art in Iris Biometric Cryptosystems. Available online: http://cdn.intechopen.com/pdfs/16590/InTech-The_state_of_the_art_in_iris_biometric_cryptosystems.pdf (accessed on 17 December 2018).
- Rathgeb, C.; Uhl, A. Context-based texture analysis for secure revocable iris-biometric key generation. In Proceedings of the 3rd International Conference on Imaging for Crime Detection and Prevention (ICDP 2009), London, UK, 3 December 2009. [Google Scholar]
- Rathgeb, C.; Tams, B.; Wagner, J.; Busch, C. Unlinkable improved multi-biometric iris fuzzy vault. Eurasip J. Inf. Secur. 2016, 2016, 26. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CASIA v3 Database [29] | Equal Error Rate (EER %) |
|---|---|
| IrisCode | 0.38 |
| Bloom filtered IrisCode | 0.50 |
| Bloom filtered IrisCode (IFO applied) | 0.58 |
| FRR (%) | FAR (%) | EER (%) | |
|---|---|---|---|
| 0.16 | 0.15 | 12.14 | 6.97 |
| 0.17 | 0.31 | 3.23 | 1.77 |
| 0.18 | 0.62 | 0.62 | 0.62 |
| 0.19 | 1.65 | 0.05 | 0.85 |
| 0.20 | 2.65 | 0.00 | 1.33 |
| 0.21 | 3.80 | 0.00 | 1.90 |
| 0.22 | 5.61 | 0.00 | 2.81 |
| 0.23 | 8.26 | 0.00 | 4.13 |
| 0.24 | 11.56 | 0.00 | 5.78 |
| 0.25 | 15.40 | 0.00 | 7.70 |
| GAR (%) | FAR (%) | EER (%) | |
|---|---|---|---|
| 10 | 97.35 | 0.00 | 1.33 |
| 20 | 96.67 | 0.00 | 1.67 |
| 40 | 96.67 | 0.00 | 1.67 |
| 60 | 96.37 | 0.00 | 1.82 |
| 80 | 96.37 | 0.00 | 1.82 |
| 100 | 96.37 | 0.00 | 1.82 |
| 150 | 96.37 | 0.00 | 1.82 |
| 200 | 96.37 | 0.00 | 1.82 |
| GAR (%) | FAR (%) | EER (%) | ||
|---|---|---|---|---|
| 10 | 89.51 | 0 | 5.25 | 0.19 |
| 50 | 95.97 | 0 | 2.02 | 0.94 |
| 100 | 96.37 | 0 | 1.82 | 1.90 |
| 150 | 96.37 | 0 | 1.82 | 2.81 |
| 200 | 96.37 | 0 | 1.82 | 3.75 |
| 250 | 96.37 | 0 | 1.82 | 4.69 |
| 300 | 96.37 | 0 | 1.82 | 5.63 |
| 0.16 | ||||
| 0.17 | ||||
| 0.18 | ||||
| 0.19 | 0.0058 | 0.29 | 0.58 | 1.16 |
| 0.195 | ||
| 0.196 | ||
| 0.197 | ||
| 0.198 | ||
| 0.199 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chai, T.-Y.; Goi, B.-M.; Tay, Y.-H.; Jin, Z. A New Design for Alignment-Free Chaffed Cancelable Iris Key Binding Scheme. Symmetry 2019, 11, 164. https://doi.org/10.3390/sym11020164
Chai T-Y, Goi B-M, Tay Y-H, Jin Z. A New Design for Alignment-Free Chaffed Cancelable Iris Key Binding Scheme. Symmetry. 2019; 11(2):164. https://doi.org/10.3390/sym11020164
Chicago/Turabian StyleChai, Tong-Yuen, Bok-Min Goi, Yong-Haur Tay, and Zhe Jin. 2019. "A New Design for Alignment-Free Chaffed Cancelable Iris Key Binding Scheme" Symmetry 11, no. 2: 164. https://doi.org/10.3390/sym11020164
APA StyleChai, T.-Y., Goi, B.-M., Tay, Y.-H., & Jin, Z. (2019). A New Design for Alignment-Free Chaffed Cancelable Iris Key Binding Scheme. Symmetry, 11(2), 164. https://doi.org/10.3390/sym11020164