Abstract
The traditional multi-attribute group decision making (MAGDM) method needs to be improved to the integration of assessment information under multi-granular probabilistic linguistic environments. Some novel distance measures between two multi-granular probabilistic linguistic term sets (PLTSs) are proposed, and distance measures are proved to be reasonable. To calculate the weights of the alternative attributes, the extended cross-entropy method for multi-granular probabilistic linguistic term sets is proposed. Then, a novel extended MAGDM algorithm based on prospect theory (PT) is proposed. Two case studies of decision making (DM) on purchasing a car is provided to illustrate the application of the extended MAGDM algorithm. The case analyses are proposed to illustrate the novelty, feasibility, and application of the proposed MAGDM algorithm by comparing the other three algorithms based on TOPSIS, VIKOR, and Pang Qi et al.’s method. The analyses results demonstrate that the proposed algorithm based on PT is superior.
1. Introduction
MAGDM is a hot issue, which aims at finding the optimal alternative with multi-attributes [1]. MAGDM is applied in the real world widely, such as in enterprise strategy planning [2], in the choosing of appropriate hospitals [3], in quality assessments [4], in the selection of investment strategies [5], and so on. Integrating decision makers’ (DMs’) preferences information on different attributes is an important prerequisite [6]. Since Zadeh proposed the fuzzy set as the basic fuzzy decision-making model first in 1965 [7], more and more authors have focused on fuzzy MAGDM. In practical DM problems, the DMs express their preferences on the considered alternatives by linguistic terms, such as “bad”, “medium”, or “good”, and so on. Then they make the optimal decision by some appropriate DM methods.
In practice, the same object may be assessed on different platforms, or the same object is described on the same platform by different granular fuzzy linguistic information in the real world. The traditional method of group decision making (GDM) under only the same granular linguistic information cannot be used to integrate hybrid assessment information. Therefore, multi-granular linguistic term sets need to be described efficiently. Then, the basic distance measures of probabilistic linguistic term sets (PLTSs) with multi-granular probabilistic linguistic information are proposed firstly. Under the distance measures methods, a novel algorithm of MAGDM based on prospect theory (PT) is given in this paper. Then, two practical case studies on purchasing a car are employed to illustrate the application of the extended algorithm based on PT. The three other algorithms based on TOPSIS and VIKOR are given to compare.
Until now, there has been lots of research on linguistic decision making (LDM) [8]. For example, Herrera and Verdegay [9] proposed the linguistic assessments in GDM in 1993. Then, Herrera et al. [10,11] made some GDM models with linguistic settings. Later, Xu proposed the goal programming model for multi-attribute decision making (MADM) under a linguistic environment [12]. Ben-Arieh and Chen [13] gave the aggregation of opinions and consensus measures in linguistic GDM. Xu [14] gave a method based on the uncertain linguistic ordered weighted geometric (LOWG) and the uncertain LOWG operators to GDM with uncertain multiplicative linguistic preference relations. Liu et al. [15] gave a MAGDM approach based on a prioritized aggregation operator with hesitant intuitionistic fuzzy linguistic environments. Liao et al. [16] proposed another MAGDM approach under two intuitionistic multiplicative distance measures.
However, DMs express their preferences inaccurately under linguistic environment because of fuzziness and uncertainties of human beings’ thinking. DMs may be hesitant between some possible linguistic terms. Then, Rodriguez et al. [17] gave hesitant fuzzy linguistic term sets (HFLTSs) under hesitant fuzzy sets (HFSs) [18] and linguistic term sets (LTSs) [19], which allows a DM to give several possible values for a linguistic variable. In most of the current research of HFLTSs, the DMs give all possible values with equal importance or weight. Obviously, it is different from the real world. In the problems of both individual DM and GDM, the DMs can prefer some of the possible linguistic terms leading to the set of possible values with different importance degrees. Then, the assessment information includes both several possible linguistic terms and the associated probabilistic information. This information can be described as probabilistic distribution [20,21,22], importance degree [23], belief degree [24,25], and so on. The ignorance of this information may lead to erroneous decision results. We can get accurate preference information of the DMs under the probabilistic linguistic term sets (PLTSs). Then, Wang and Hao [26] proposed two proportional linguistic terms. Under a general form of probabilistic distributions, Zhang et al. [22] and Wu and Xu [21] improved the model. Moreover, Yang and Xu [25] proposed partial ignorance as well with the framework of evidential reasoning. Therefore, lots of research results of PLTSs in MAGDM have been proposed now [27,28]. Xu and Zhou [29,30] improved a group of DMs under the hesitant probabilistic fuzzy environment. Kobina et al. [31] made the operators of probabilistic linguistic power aggregation for Multi-Criteria Group Decision Making (MCGDM).
Some methods have been proposed with multi-granularity linguistic information in GDM [32,33]. However, there are few researches on MAGDM with multi-granular probabilistic linguistic information. Then, how do we measure two PLTSs? Although, there have been lots of research about the distance measures, such as fuzzy sets [6], interval-valued fuzzy sets [34], intuitionistic fuzzy sets [35], interval-valued intuitionistic fuzzy sets [36], hesitant fuzzy sets [18], interval-valued hesitant fuzzy sets [37], hesitant fuzzy linguistic term sets [17], and so on, there are still few researches on the distance measures of the PLTSs with multi-granular linguistic information. In order to solve these problems, distance measures of PLTSs with multi-granular linguistic information are proposed. Based on the feasibility of prospect theory, many scholars use prospect theory (PT) to solve practical problems. For example, Wang et al. [38] proposed a GDM method based on PT for emergency situations. Yao et al. [39] solved the GDM problem for the green supply chain. In this paper, a novel algorithm for MAGDM based on PT is proposed.
2. Preliminaries
DMs can use LTSs to express their preferences on the considered objects. The additive LTS is used most widely, which is defined as follows [40]:
where is a -granular fuzzy linguistic set, is a linguistic variable with and denoting the lower and upper limits of the linguistic terms, and is a positive integer. The linguistic term has the characteristics as follows:
The ordered set is defined if , ; the negation operator is defined neg, where .
Because the DMs may hesitate in several possible values in DM, Rodriguez et al. [23] proposed the definitions of HFLTSs as follows.
Definition 1.
Let be an LTS; then, a HFLTs is an ordered finite subset of the consecutive linguistic terms of S [41].
Definition 2.
Let be an LTS. A PLTS can be defined as
where is the linguistic term associated with the probability and is the number of all the different linguistic terms in [27].
If , then we get the complete information on the probabilistic distribution with all the possible linguistic terms; if , then partial ignorance exists because of current insufficient assessment information. Especially, means complete ignorance. Therefore, handling the ignorance of is crucial research for the application of PLTSs.
Definition 3.
Given a PLTS with , then the associated PLTS is defined by
where for all [27].
The numbers of linguistic terms in PLTSs are usually different for a DM. Therefore, the number of linguistic terms for the PLTSs need to be added, which numbers are relatively small. Then, the numbers of linguistic terms are the same.
3. Main Results
3.1. Definitions of Multi-Granular Probabilistic Linguistic Term Sets
Inspired by Reference [27], some definitions of multi-granular probabilistic linguistic term sets are proposed as follows.
Definition 4.
Let be -granular LTS and be -granular LTS. and are two different granular PLTSs on the attribute set ; multi-granular PLTSs can be defined as
where is the linguistic term associated with the probability is the linguistic term associated with the probability .
The numbers of are denoted as respectively. If , then linguistic terms are added to , leading to the numbers of and to be equal. The added linguistic terms are the smallest ones in , and the probabilities of all the linguistic terms are zero.
Definition 5.
Let and be two multi-granular PLTSs, then the normalization processes are as follows:
- (1)
- If , then by Equation (2), we calculate
- (2)
- If , then by Definition 4, we add some elements to the one with the smaller number of elements.
The PLTSs obtained by Definition 5 are named by the normalized PLTSs. Conveniently, the normalized PLTSs are denoted by as well.
Because the positions of elements in a PLTS are arbitrary, we need to get the ordered PLTSs first, which leads to the operational results in PLTSs being determined directly.
Definition 6.
Let be -granular LTS. Given a PLTS, , and () is the subscript of linguistic term . is named an ordered multi-granular PLTS if the linguistic terms are arranged by the values of in descending order.
3.2. Distance Measures between Multi-Granular PLTSs
According to the normalized distance measures, the normalized distance measures are extended and the generalized distance measures between two multi-granular PLTSs in discrete cases are proposed as follows.
Definition 7.
Let and be two PLTSs, then the distance measures between them is defined as [27], which satisfies the following three conditions:
- (1)
- 0 1;
- (2)
- 0, if and only if ; and
- (3)
- .
If and are normalized ordered PLTSs as in Definition 5 and Definition 6, then the distance measured between two multi-granular PLTSs are defined as follows.
Definition 8.
Let and be two PLTEs as in Definition 4, then the distance measured between them is defined as
where is the subscript of linguistic term and is the subscript of linguistic term .
Obviously, Definition 8 satisfies the three conditions of the distance definition as in Definition 7.
Definition 9.
Let and be two PLTEs on the attribute set , where is the th attribute of the alternatives and ; then, the generalized Hamming distance measured between and is defined as
where .
The generalized Euclidean distance between and can be given as
Inspired by the generalized idea proposed by Yager [42], this paper gives the generalized distance as
where
Especially if , then the generalized distance reduces to the generalized Hamming distance. If , then it reduces to the generalized Euclidean distance. Then, Definition 9 extends the normalized Hamming distance and Euclidean distance.
3.3. A MAGDM Algorithm Based on PT
A MAGDM problem with multi-granular probabilistic linguistic information is described as follows.
There are a set of alternatives, , and the weight vector of attributes , where is the th attribute of the alternatives and where and . The DMs assess alternatives on attributes by utilizing linguistic term set to get a set of linguistic decision matrices.
Then, the assessment linguistic information is used to make up a multi-granular probabilistic linguistic decision matrix as follows:
where is a multi-granular PLTS denoting the degree of the alternative on the attribute , is a -granular fuzzy linguistic set, and is the subscript of the linguistic term , which is associated with the probability , , .
Since all the numbers of the probabilistic linguistic elements of the PLTSs in are different usually, the PLTSs should be normalized by Definition 5. Then, suppose is an ordered PLTS as in Definition 6.
In MAGDM problems, the attributes can be classified into two types: benefits and costs. The higher a benefit attribute is, the better the situation is, while a cost attribute is the reverse [43]. In this paper, we suppose the attributes are benefits.
Definition 10.
Prospect Theory [44]: implies the gain () or the loss () of the outcome relative to the reference point (RP). The prospect value function V() is given by
where is a parameter that represents the decision maker’s sensitivity degree on gain, is a parameter that represents the decision maker’s sensitivity degree on loss, and , is a parameter that represents the decision maker’s loss aversion degree.
Inspired by the definition of RP, the theory of TOPSIS is extended as follows.
Definition 11.
Generalized prospect value function ) based on TOPSIS is given by
where and are normalized ordered multi-granular PLTSs.
Under Definition 11, a novel MAGDM algorithm based on PT diagram is shown as follows. See Figure 1.
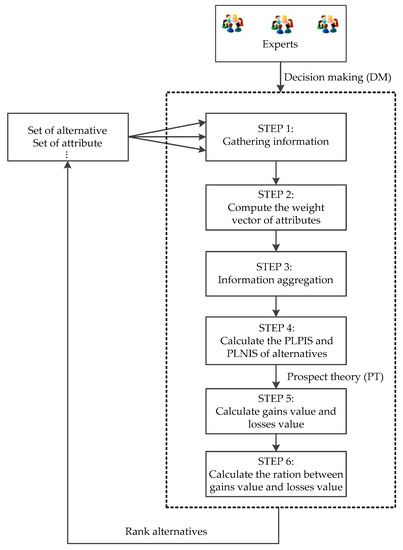
Figure 1.
The algorithm diagram.
The specific steps of the algorithm are as follows.
Step 1. Information gathering process: individual reference points (RPs) over the alternatives on different attributes provided by experts are gathered as by Equation (9).
Inspired by Reference [45], the extended cross-entry method is proposed to calculate the attributes’ weights.
Step 2. Compute the weight vector of attributes as follows. See Equation (12).
where is the th attribute of the alternatives, and . In this paper, let [46].
Step 3. Aggregation process: get weighted DM matrix . See Equation (13).
where ,
Step 4. Calculate the positive ideal solution and the negative ideal solution respectively.
Then, the definitions of the probabilistic linguistic positive ideal solution (PLPIS) and the probabilistic linguistic negative ideal solution (PLNIS) are defined respectively as follows.
The PLPIS of the alternatives is
where .
The PLNIS of the alternatives is
where .
In order to select a preferred alternative or to rank all the alternatives, we should compute the distance between and and the distance between and . Certainly, a better should be closer to and also farther from .
Step 5. Calculate the gains value and the losses value: gains and losses are calculated with respect to the group reference points of the different alternatives.
Then, the prospect value is
where 2.25, 0.88, and 0.88 [47].
Step 6. Calculate the ration between the gains value and the losses value of each alternative.
Rank the alternatives by the values of . Certainly, the bigger the closeness degree is, the better the alternative is.
4. Case Studies
With the popularity of the Internet, e-commerce has become an indispensable field in daily life. For example, if people want to purchase a car, they will be concerned with all kinds of information about cars on the Internet. People take all kinds of information into consideration to decide which car to buy, such as scoring data, word-of-mouth data, forum reviews, and so on. For example, there are seven new energy cars to choose. People collect assessment information of these cars from users by the three ways (scoring data, word-of-mouth data, and forum reviews) on eight attributes, which are space, power, manipulate, power consumption, comfort, appearance, interior decoration, and cost performance on the “Auto Home” website. Note them as and respectively. The seven cars are ZhiXuan (), WeiChiFS (), LiWei (), FeiDu (), RuiNa RV (), KiaK2 (), and JinRui () respectively. Since scoring data online is a 5-point system, the scoring data to assessment information is operated to 5-granular linguistic term sets. The word-of-mouth data of the overall assessment for cars can be mapped to 7-granular linguistic term sets. Due to the complexity of the community review information, this information can be operated to 9-granular linguistic term sets.
4.1. The Applications of the Algorithm
The applications of the algorithm based on PT are shown as follows.
Step 1. Collect the users’ assessment information on the “Auto Home” website until May 20 in 2018. See Table 1, Table 2 and Table 3.

Table 1.
The assessment information from scoring data by .
Table 2.
The assessment information from word-of-mouth data by .
Table 3.
The assessment information from forum reviews data by .
Here, the scoring data (see Table 1) are the final average values of the seven cars on eight attributes from the scoring data. The assessment information (see Table 2) is the general impression from the word-of-mouth data. The assessment information (see Table 3) is from forum reviews data. These data are obtained on the “Auto Home” website.
Then, we get the users’ overall assessment probabilistic linguistic term sets. See Table 4.
Table 4.
The assessment probabilistic linguistic assessment matrix.
Then, we get the normalized DM matrix by Definition 5. See Table 5.
Table 5.
The normalized decision-making (DM) matrix.
Here, is defined as follows: For example, .
Step 2. Calculate the weight vector on the eight attributes by Equation (12). See Table 6.
Table 6.
The weights of the attributes.
Step 3. Get a weighted DM matrix. See Table 7.
Table 7.
The weighted normalized DM matrix.
Here, in order to calculate conveniently, we only note instead of .
Step 4. Calculate the PLPIS and PLNIS respectively.
The normalized PLPIS is as follows (see Table 8):
Table 8.
The positive ideal solution.
The normalized PLNIS is as follows (see Table 9):
Table 9.
The negative ideal solution.
Table 10.
The results of .
Table 11.
The results of .
Step 6. Calculate the closeness coefficient of by Equation (18). The results are as follows. See Table 12 and Figure 2.
Table 12.
The ration of .
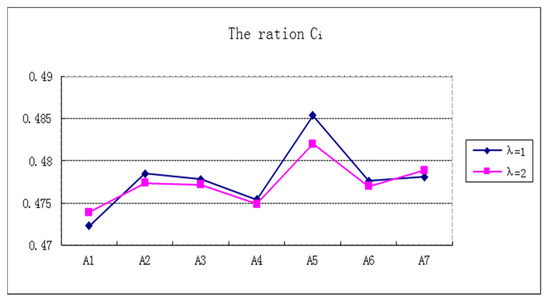
Figure 2.
The ration of .
Rank the alternatives by the values of . See Table 13.
Table 13.
The ranking of .
4.2. Sensitivity Analysis
In order to analyze the sensitivity of the parameters, take the different parameters [38] and rank by the algorithm based on PT as in Section 4.1. Then, the results are as follows.
Calculate the closeness coefficient of each alternative by Equation (18). See Table 14.
Table 14.
The ration of .
Rank the alternatives by the values of . See Table 15.
Table 15.
The ranking of .
From Table 14 and Table 15, we can find the rankings of the alternatives are different but only when , , and () and , , and , respectively; the results are coincident by the algorithm based on PT. The ranking results are different as the parameters ( are changed. This result is consistent with the meaning of the parameters (. Here, are power parameters related to gains and losses, respectively. is the risk-aversion parameter, which has the characteristic of being steeper for losses than for gains when : The larger the value, the greater the degree of risk. Then the ranking of is different. Therefore, the algorithm based on PT proposed in Section 4.1 is scientific.
4.3. Comparative Analysis
In order to illustrate the feasibility and efficiency of the algorithm-based PT, we calculate the other results by the other three algorithms based on TOPSIS, VIKOR, and Pang Qi et al.’s method respectively.
The results of the algorithm based on TOPSIS are as follows:
The closeness coefficient of is
The parameter represents the risk preferences of the decision maker. If then it means that the DMs are optimistic. If , then it means they are pessimistic. The value of should be given by DMs beforehand. Here, let . The higher is, the better the alternative is.
Calculate the closeness coefficient by Equation (19), and the results are as follows. See Table 16 and Figure 3.
Table 16.
The closeness coefficient .
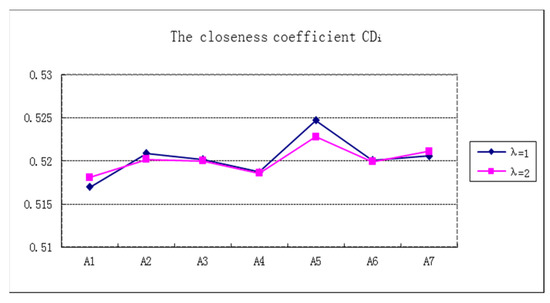
Figure 3.
The Closeness coefficient .
Rank the alternatives by the values of (). See Table 17.
Table 17.
The ranking of .
The results of the algorithm based on VIKOR are as follows:
The compromise index:
The whole benefit index:
The compromise index:
where , , . The parameter denotes the weight of the strategy of the maximum whole benefits, where is the weight of the individual regret strategy. Here, let The higher is, the better the alternative is.
We calculate the compromise index of () by Equations (20)–(22) and obtain the results. See Table 18 and Figure 4.
Table 18.
The compromise index of
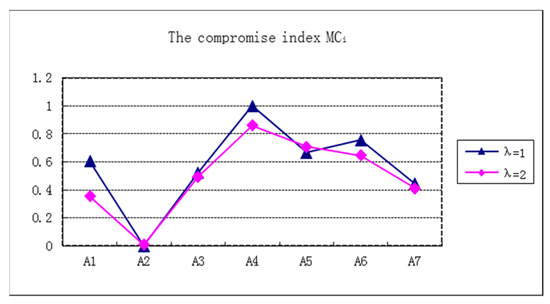
Figure 4.
The compromise index .
Rank the alternatives by the compromise index of (). See Table 19.
Table 19.
The ranking of .
The results of the algorithm based on Pang Qi et al.’s method [27] are as follows:
The closeness coefficient of is
Calculate the closeness coefficient by Equation (23), and obtain the results. See Table 20 and Figure 5.
Table 20.
The closeness coefficient .
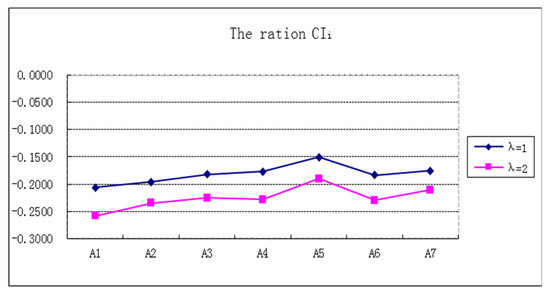
Figure 5.
The closeness coefficient .
Rank the alternatives by the closeness coefficient of (). See Table 21.
Table 21.
The ranking of
From the comparative analysis, we can find when , the ranking of () is “” and when , the ranking of () is “”, which illustrates the ranking results of the algorithm based on PT are consistent with that of the algorithm based on TOPSIS. See Table 13 and Table 17. Although the parameters are changed, the ranking of are still “” () and “” () respectively. See Table 15 and Table 17. However, the rankings of are different in the other three algorithms. See Table 19 and Table 21. The comparative analysis results demonstrate the algorithm based on PT is superior to the other three traditional algorithms.
4.4. The Second Case Study
In order to illustrate the feasibility and validity of the algorithm based on PT better, a second case study is given. There are seven cars to choose on the “Auto Home” website. The seven cars are ATENZA (), CAMRY (), ACCORD (), LAMANDO (), SAGITAR (), LAVIDA(), and BORA (). The computational and analytical processes are the same as in Section 4.1.
Collect the users’ assessment information on the “Auto Home” website until January 5 in 2019. See Table 22, Table 23 and Table 24.
Table 22.
The assessment information from scoring data by .
Table 23.
The assessment information from word-of-mouth data by .
Table 24.
The assessment information from forum reviews data by .
By the same method of Section 4.1, the weight vector on the eight attributes is given by Equation (12). See Table 25.
Table 25.
The weights of the attributes.
Get the weighted DM matrix. See Table 26.
Table 26.
The weighted normalized DM matrix.
Since the calculation process of this example is the same as that of Section 4.1, then only the final calculation results are given as follows. See Table 27.
Table 27.
The relative values of .
The ranking of is as follows. See Table 28.
Table 28.
The ranking of .
This paper proposes a generalized distance measures method between two PLTs with multi-granular linguistic information, which are helpful to deal with multi-granular MAGDM problems. These distance measures improve the accuracy of multi-granular linguistic information in the MAGDM problems, even some assessment information is null. Especially, the parameter λ of the extended distance measures method is a variable, which can be used to obtain different distance measures formula according to people’s need. Under these distance measures, the extended MAGDM algorithm based on PT is proposed. From the sensitivity analyses of the parameters (θ, α, and β), we can find the ranking of the alternatives are different but only when , , and for and , , and for ; the results are coincident by the algorithm based on PT.
The ranking results are different when the parameters ( are changed. This result is consistent with the meaning of
the parameters (. Therefore, the algorithm based on PT proposed in Section 4.1 is illustrated to be scientific. Two case studies of purchasing a car is given to demonstrate the algorithm based on PT is valid and applied by comparing the extended TOPSIS, VIKOR, and Pang Qi et al.’s algorithms. Here, the parameters of and can be selected by what we need in actual problems. From the comparative analyses, we can find when , the ranking of () is “” and when , the ranking of () is “”, which illustrates the ranking results of the algorithm based on PT are consistent with that of the algorithm based on TOPSIS. See Table 13 and Table 17. Although the parameters are changed, the ranking of are still “” () and “” () respectively. However, the rankings of are different in the other three algorithms. Therefore, the comparing analyses demonstrate the novelty, feasibility, and validity of the proposed MAGMD method based on PT. The novel method of MAGMD in this paper can be used to deal with some practical MAGDM problems under multi-granular probabilistic linguistic environments.
The MAGDM algorithm based on PT proposed in this paper also has some limitations: If there are too many attributes or alternatives, the size of Section 4.1 might be quite big. However, we can use some software packages to solve it, such as by crawler technology, matlab, python, and so on, so this is not a big problem in the use of this method. Whether there are more appropriate ways to measure the distances between two PLTs with multi-granular linguistic information is a valued question. There are some directions for further investigation: Firstly, how to select an appropriate parameter λ to calculate the distance between two PLTSs is a valued problem; secondly, the applications of these distance measures are interesting to research in other fields, such as cluster analysis, MCGDM problems, and so on; and finally, the linguistic information is also expressed by hesitant fuzzy numbers, interval fuzzy number, etc. to represent the fitting accuracy. These issues should be focused on further in the future.
Funding
This study was funded by the Major Program of the National Natural Science Foundation of China (71490725), the Foundation for Innovative Research Groups of the National Natural Science Foundation of China (71521001), the National Natural Science Foundation of China (71722010,91546114,91746302,71501057), the National Key Research and Development Program of China (2017YF80803303), the National Natural Science Foundation of China (71571002), and the Key Projects of Natural Science Research in Anhui Colleges and Universities (KJ2016A151).
Conflicts of Interest
The author declares that there are no conflicts of interest regarding the publication of this paper. This research does not involve any human or animal participation.
References
- Zhou, L.G.; Chen, H.Y. Continous ordered linguistic distance measure and its application to multiple attribute group decision making. Group Decis. Negot. 2013, 22, 739–758. [Google Scholar] [CrossRef]
- Parreiras, R.O.; Ekel, P.Y.; Martni, J.S.C.; Palhares, R.M. A flexible consensus scheme for multicriteria group decision making under linguistiic assessments. Inf. Sci. 2010, 180, 1075–1089. [Google Scholar] [CrossRef]
- Grossglauser, M.; Saner, H. Data–driven healthcare: From patterns to actions. Eur. J. Prev. Cardiol. 2014, 21, 14–17. [Google Scholar] [CrossRef]
- Celotto, A.; Loia, V.; Senatore, S. Fuzzy linguistic approach to quality assessment model for electricity network infrastructure. Inf. Sci. 2015, 304, 1–15. [Google Scholar] [CrossRef]
- Tao, Z.F.; Chen, H.Y.; Zhou, L.G.; Liu, J.P. 2-Tuple linguistic soft set and its application to group decision making. Soft Comput. 2015, 19, 1201–1213. [Google Scholar] [CrossRef]
- Sengupta, A.T.; Pal, K.; Zhou, L.G.; Chen, H.Y. Fuzzy Preference Ordering of Interval Numbers in Decision Problems; Springer: Heidelberg, Germany, 2009; Volume 238, pp. 140–143. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 3, 338–353. [Google Scholar] [CrossRef]
- Xu, Z.S. Linguistic Decision Making: Theory and Methods; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Herrera, F.; Verdegay, J.L. Linguistic assessments in group decision. In Proceedings of the First European Congress on Fuzzy and Intelligent Technologies, Aachen, Germany, 7–10 September 1993; pp. 941–948. [Google Scholar]
- Herrera, F.; Herrera-Viedma, E.; Verdegay, J.L. A model of consensus in group decision making under linguistic assessments. Fuzzy Sets Syst. 1996, 78, 73–87. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E.; Verdegay, J.L. A rational consensus model in group decision making using linguistic assessments. Fuzzy Sets Syst. 1997, 88, 31–49. [Google Scholar] [CrossRef]
- Xu, Z.S. A method for multiple attribute decision making with incomplete weight information in linguistic setting. Knowl.-Based Syst. 2007, 20, 719–725. [Google Scholar] [CrossRef]
- Arieh, D.B.; Chen, Z. Linguistic group decision-making: Opinion aggregation and measures of consensus. Fuzzy Opt. Decis. Mak. 2006, 5, 371–386. [Google Scholar] [CrossRef]
- Xu, Z.S. An approach based on the uncertain LOWG and induced uncertain LOWG operators to group decision making with uncertain multiplicative linguistic preference relations. Decis. Support Syst. 2006, 41, 488–499. [Google Scholar] [CrossRef]
- Liu, P.D.; Mahmood, T.; Khan, Q. Multi-Attribute Decision-Making Based on Prioritized Aggregation Operator under Hesitant. Symmetry 2017, 9, 11. [Google Scholar] [CrossRef]
- Liao, H.C.; Zhang, C.; Luo, L. A multiple attribute group decision making method based on two novel intuitionistic multiplicative distance measures. Inf. Sci. 2018, 467, 766–783. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. Hesitant fuzzy linguistic term sets for decision making. IEEE Trans. Fuzzy Syst. 2012, 20, 109–119. [Google Scholar] [CrossRef]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Dong, Y.C.; Wu, Y.Z.; Zhang, H.J.; Zhang, G.Q. Multi-granular unbalanced linguistic distribution assessments with interval symbolic proportions. Knowl.-Based Syst. 2015, 82, 139–151. [Google Scholar] [CrossRef]
- Wu, Z.B.; Xu, J.P. Possibility distribution-based approach for MAGDM with hesitant fuzzy linguistic information. IEEE Trans. Cybern. 2016, 46, 694–705. [Google Scholar] [CrossRef]
- Zhang, G.Q.; Dong, Y.C.; Xu, Y.F. Consistency and consensus measures for linguistic preference relations based on distribution assessments. Inf. Fusion 2014, 17, 46–55. [Google Scholar] [CrossRef]
- Liu, H.B.; Rodriguez, R.M. A fuzzy envelope for hesitant fuzzy linguistic term set and its application to multi-criteria decision making. Inf. Sci. 2014, 258, 220–238. [Google Scholar] [CrossRef]
- Yang, J.B. Rule and utility based evidential reasoning approach for multi-attribute decision analysis under uncertainties. Eur. J. Oper. Res. 2001, 131, 31–61. [Google Scholar] [CrossRef]
- Yang, J.B.; Xu, D.L. On the evidential reasoning algorithm for multiple attribute decision analysis under uncertainty. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2002, 32, 289–304. [Google Scholar] [CrossRef]
- Wang, J.H.; Hao, J.Y. A new version of 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans. Fuzzy Syst. 2006, 14, 435–445. [Google Scholar] [CrossRef]
- Pang, Q.; Wang, H.; Xu, Z.S. Probabilistic linguistic term sets in multi-attribute group decision making. Inf. Sci. 2016, 369, 128–143. [Google Scholar] [CrossRef]
- Lin, M.W.; Xu, Z.S.; Zhai, Y.L.; Yao, Z.Q. Multi-attribute group decision-making under probabilistic uncertain linguistic environment. J. Oper. Res. Soc. 2017, 1–15. [Google Scholar] [CrossRef]
- Xu, Z.S.; Zhou, W. Consensus building with a group of decision makers under the hesitant probabilistic fuzzy environment. Fuzzy Opt. Decis. Mak. 2017, 16, 481–503. [Google Scholar] [CrossRef]
- Lin, M.W.; Xu, Z.S. Probabilistic Linguistic Distance Measures and Their Applications in Multi-criteria Group Decision Making. In Soft Computing Applications for Group Decision-Making and Consensus Modeling; Springer: Cham, Switzerland, 2018; Volume 357, pp. 411–440. [Google Scholar]
- Kobina, A.; Liang, D.C. Probabilistic linguistic power aggregation operators for multi-criteria group decision making. Symmetry 2017, 9, 12. [Google Scholar] [CrossRef]
- Xu, Z.S.; Wang, H. Managing multi-granularity linguistic information in qualitative group decision making: An overview. Granul. Comput. 2016, 1, 21–35. [Google Scholar] [CrossRef]
- Wang, H.; Xu, Z.S.; Zeng, X.J. Hesitant fuzzy linguistic term sets for linguistic decision making: Current developments, issues and challenges. Inf. Fusion 2018, 43, 1–12. [Google Scholar] [CrossRef]
- Gorzalczany, M.B. An interval-valued fuzzy inference method-some basic properties. Fuzzy Sets Syst. 1989, 31, 243–251. [Google Scholar] [CrossRef]
- Atanassov, K.T. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Atanassov, K.T.; Gargov, G. Interval–valued intuitionistic fuzzy sets. Fuzzy Sets Syst. 1989, 31, 343–349. [Google Scholar] [CrossRef]
- Chen, N.; Xu, Z.S.; Xia, M.M. Interval-valued hesitant preference relations and their applications to group decision making. Knowl-Based Syst. 2013, 37, 528–540. [Google Scholar] [CrossRef]
- W, L.; W, Y.M.; Martinez, L. A group decision method based on prospect theory for emergency situations. Inf. Sci. 2017, 418, 119–135. [Google Scholar]
- Yao, S.; Yu, D.; Song, Y.; Yao, H.; Hu, Y.; Guo, B. Dry bulk carrier investment selection through a dual group decision fusing mechanism in the green supply chain. Sustainability 2018, 10, 4528. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E.; Verdegay, J.L. A sequential selection process in group decision making with a linguistic assessment approach. Inf. Sci. 1995, 85, 223–239. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. A group decision making model dealing with comparative linguistic expressions based on hesitant fuzzy linguistic term sets. Inf. Sci. 2013, 241, 28–42. [Google Scholar] [CrossRef]
- Yager, R.R. Generalized OWA aggregation operators. Fuzzy Opt. Decis. Mak. 2004, 3, 93–107. [Google Scholar] [CrossRef]
- Ma, J.; Fan, Z.P.; Huang, L.H. A subjective and objective integrated approach to determine attribute weights. Eur. J. Oper. Res. 1999, 112, 397–404. [Google Scholar] [CrossRef]
- Kahneman, D.; Tversky, A. Prospect theory: An analysis of decision under risk. Econometrica 1979, 47, 263–292. [Google Scholar] [CrossRef]
- Xu, Z.S.; Xia, M.M. Hesitant Fuzzy entropy and cross-entropy and their use in multi-attribute decision-making. Int. J. Intell. Syst. 2012, 27, 799–822. [Google Scholar] [CrossRef]
- Wang, L.Z.; Zhang, X.; Wang, Y.M. A prospect theory-based interval dynamic reference point method for emergency decision making. Expert Syst. Appl. 2015, 42, 9379–9388. [Google Scholar] [CrossRef]
- Zhang, X.L.; Xu, Z.S. The TODIM analysis approach based on novel measured functions under hesitant fuzzy environment. Knowl.-Based Syst. 2014, 61, 48–58. [Google Scholar] [CrossRef]
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).