1. Introduction
In the life testing field, different data collection models are created to simulate various realistic situations. Conventional censoring methods, type-I and type-II censoring schemes have evolved into progressive forms and have been explored and applied extensively.
Theoretically, these data sets take the unintentional loss of observed units into consideration, but in experiments, these conventional data sets are difficult to implement. Especially when the units work for a long time, it has been proved that the sample size of the type-I censored data set is usually small. At the same time, the progressive type-II censoring data set is difficult to realize as it may last for a long time.
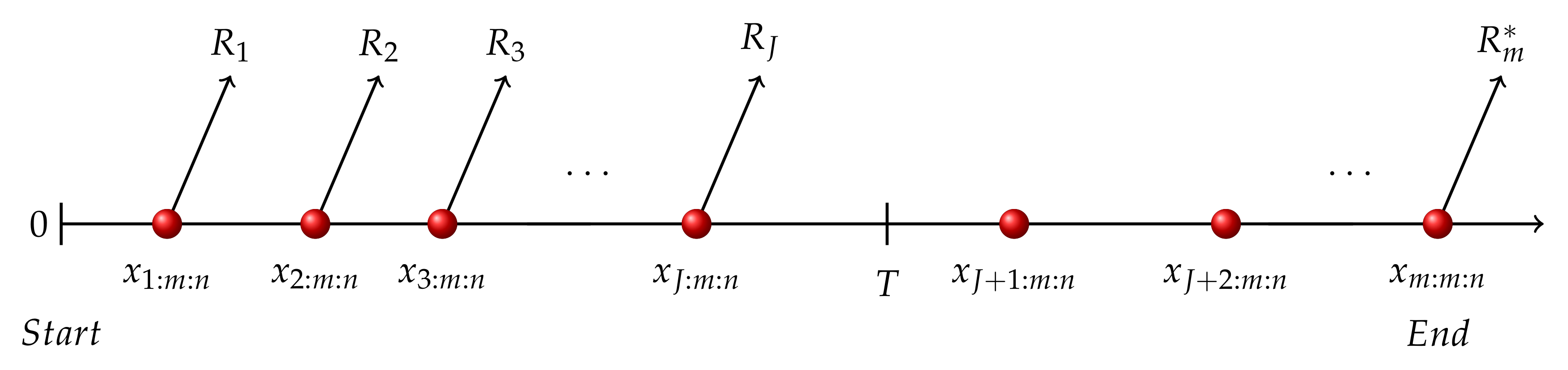
Suppose the experimenter provides a time T, which is the ideal total test time, but they allow the experiment to last beyond it. If the number of failures that occur before time T reaches the expectation, the experiment will stop earlier than T. Otherwise, once the experimental time exceeds the time T, but the number of observed failures is still lower than m, we hope to terminate the experiment as soon as possible. In response to this expectation, the experimenter would prefer a design that ensures that m observed failure times are obtained to assure the efficiency of statistical inference while the total test time is not too far from the ideal time T. According to the basic characteristic of the censored sample, the smaller censored size, the shorter the experimental time. Therefore, if we want to terminate the experiment earlier while fixing sample size m, we should keep as many surviving items as possible in the test.
Introduced by the authors of [
1], the adaptive type-II progressive hybrid censoring scheme was designed to satisfy such an expectation, thus reasonably and effectively shortening the experiment period. On the basis of the traditional type-II progressive censoring scheme, which removes some of the remaining individuals at each failure time, the adaptive type-II progressive hybrid actively adjusts the experimental time by responding to the experimenter’s expected duration of the experiment. It considers a traditional type-I censoring method that censors according to a specific time. Therefore, this kind of censoring scheme speeds up the experiment after the certain time
T, improving the efficiency of the experiment.
In this kind of data set, at each failure time , of remaining units will be removed. Although observed failures m and censored sample size are preset according to n and , the censoring scheme varies depends on the performance of each individual and constraint time T. After setting threshold time T, appearances of adaptive type-II progressive hybrid censoring schemes under different cases depend on whether the m-th failure occurs beyond T (case I) or before T (case II).
In case I, see
Figure 1, the
m-th failure happens after certain time
T and the last failure before time
T occurs at
, where
and
. In this situation,
are set as
, meanwhile
.
In case II, see
Figure 2, the
m-th failure happens before time T. Therefore, adaptive type-II progressive hybrid censoring scheme degenerates into usual progressive type-II censoring data set, terminating at time
.
Given the descriptions of these two schemes above, the likelihood functions of two cases can be written as
where
,
.
Detailed in [
2], one of the basic properties of order statistics is that the fewer operating items are withdrawn, the shorter total test time is expected. Thus, once the experiment lasts beyond expected time, the procedure will be accelerated. Through these changes, the experimenter can control the test time within a relatively short time interval without losing the number of observed failures.
Several distributions have been investigated under the adaptive type-II progressive hybrid censoring scheme. The authors of [
3] compared estimations of parameters of generalized Pareto distribution and analyzed their creditable intervals using this kind of data samples. The authors of [
1] contributed to computation of expected total test time and estimated failure rate for failure times under exponential distribution using this kind of data set. In addition, the authors of [
4] estimated parameters, reliability functions, and hazard functions under adaptive type-II progressive hybrid censoring schemes for exponentiated Weibull distribution.
Inverse Weibull distribution plays an important role in reliability engineering and life testing, which was proposed to describe failures of mechanical components affected by degradation phenomenon. It has been investigated from various aspects. Reference [
5] applied classical and Bayesian estimation procedures for estimations of parameters from Inverse Weibull distribution based on the progressive type-II censored data set. Especially considering Bayesian method, References [
6] compared simulated risks of different estimators. References [
7,
8] devoted their efforts to its extensive versions investigations, including generalized inverse Weibull distribution as well as exponentiated generalized inverse Weibull distribution.
Inverse Weibull distribution has been explored from different perspectives. Many properties of this distribution are presented graphically and mathematically by [
9], including variance and coefficients for variation, skewness, and kurtosis. Reference [
10] estimated inverse Weibull distribution under a new prior distribution, including the considerations in the range of shape parameter and expected value of a quantile (reliable life) of the sampling distribution. Further extension of involving two inverse Weibull distributions into hybrid model was especially detailed in [
11].
Obtaining a random variable
x from inverse Weibull distribution, we display its cumulative distribution function and probability density function as
In which, shape parameter
and scale parameter
ensure the flexibility and suitability of inverse Weibull distribution in numerous applications.
Nowadays, in the application field, the inverse Weibull distribution is still suitable for fitting numerous kinds of data resources. Depending on the value of the shape parameter, the hazard function of the inverse Weibull distribution can be reduced or increased. Therefore, the inverse Weibull distribution model is more appropriate in many conditions. The superiority of this distribution in providing a satisfactory parameter fit is often emphasized in articles when the nonmonotonic and unimodal hazard rate functions are strongly indicated in the data set. Reference [
12] established analysis models for the first-order reaction of lignocellulosic biomass through inverse Weibull distribution. Regardless of various pre-exponential factors and activation energies, inverse Weibull distributions perform better in reaction sequences description. Reference [
13] preferred the hybrid model based on inverse Weibull distribution to analyze the capacity of a cellular network in a cellular system employing multi-input multi-output beam-forming in rich and limited scattering environments. Such wide applications of inverse Weibull distribution are attributed to its flexible scale and shape parameters.
Entropy, raised by Shannon during investigation on communication (see [
14]), constitutes the framework of information theory. The well-known Shannon entropy pioneers the information measurement field and has been widely used and studied today. This entropy of lifetime distribution can be calculated through
Entropy describes the uncertainty expressed by probability density function. Various distributions have different entropy values, describing distributions from another perspective and grabbing extensive attention to it. However, only numerical description of the entropy can be used to improve the practical experiments. Therefore, its calculation and estimation of different distributions are important. Reference [
15], focused on entropy estimations of multivariate normal distribution. Reference [
16] discussed estimations of Rayleigh distribution against criteria of bias, root mean squared error and Kullback–Leibler divergence values. Also, the authors of [
17] contributed to the entropy estimations of Weibull distribution using generalized progressive hybrid censored samples.
Using inverse Weibull distribution, we derive the Shannon entropy of it directly from Equations (
4) and (
5) as follows.
where
denotes the Euler–Mascheroni constant
In this paper, we focus on the entropy estimation of inverse Weibull distribution when samples derived under adaptive type-II progressive hybrid censoring schemes. Maximum likelihood estimation and Bayes estimation with multiple loss functions are studied.
The rest of the article is organized as follows. In
Section 2, maximum likelihood estimations in different cases are obtained, including point estimation and approximate confidence interval estimation. Then, in
Section 3, Bayes estimations of entropy are also proposed. Three loss functions and their balanced extension are considered. Lindley’s approximation method is used for calculation of Bayesian estimates. Through Monte Carlo simulation, in
Section 4, we present comparisons of different estimators in tables and figures. In
Section 5, a real data set is applied for illustrative purposes. Finally,
Section 6 summarizes with a short conclusion.
2. Maximum Likelihood Estimation
Using general likelihood functions (
1) and (2), and functions of inverse Weibull distribution, the likelihood functions of the censored sample are given by
When considering various schemes, likelihood functions can be written as an expression with different coefficients.
where
and
denotes different cases, within which schemes have different appearances beyond
.
In case I, , , and are also required besides the prerequisite .
In case II, and (where ) can be defined randomly as long as they meet the sum requirement.
Therefore, the log-likelihood function is
The corresponding score equations are
where
.
2.1. Point Estimation of Entropy
However, it is difficult to derive explicit numerical solutions using Equations (
11) and (12). Thus, a numerical method should be used to figure out the values.
To begin with, through transformations, we obtain functional expressions of
and
through
Having the initial guess,
, we assume
. Following such recurrence, a sequence of
as
is produced. Stop the procedure once
, where
is a preset tolerance. Taking
as the estimated value
, we derive
as the estimation of
as well. Once we have
and
, the maximum likelihood estimation of entropy can be easily derived as
2.2. Approximate Confidence Intervals of Entropy
In statistics, the delta method is the result of an approximate probability distribution of the asymptotic normal statistical estimator function from the limit variance of the estimator. This method is well known for its generality in deriving the variances and approximate confidence intervals of estimators by creating a linear approximation of maximum likelihood function. Reference [
18] used the Delta method for estimation of new Weibull–Pareto distribution based on progressive Type-II censored sample. Reference [
19] also used this method for estimation of the two-parameter bathtub lifetime model. Different loss functions for Bayes estimation are considered and realized through Monte Carlo method.
In this section, the Delta method is used to derive the confidence intervals of entropy in the following Algorithm 1.
In Algorithm,
D is calculated through
| Algorithm 1. Entropy estimation using Delta method. |
- 1:
Derive vector D as . - 2:
Calculate estimated variance of as , where is the transpose of matrix D. - 3:
Calculate the approximate confidence interval of .
|
denotes the Fisher information matrix of the parameters, which could be further calculated through the derivation in Equations (
11) and (12).
Within which the
and
represent the partial derivatives of equation
for
and
, respectively.
3. Bayes Estimations
The Bayesian method provides a solution to derive the estimation of certain distribution based on the prior information and the sample information. Prior information is processed into prior distribution. Therefore, it can be combined with likelihood function to derive posterior distribution. During this process, different estimators are evaluated through loss functions, which determine the criterion for selecting the optimal estimator.
Prior distribution is an important factor in Bayes estimation since its influence cannot be completely eliminated. In this paper, Gamma distributions are prior distributions for parameters
and
of inverse Weibull distribution. We assume that
follows Gamma distribution with hyperparameters
, meanwhile
follows the Gamma distribution with hyperparameters
. Thus, their joint prior distribution can be derived directly.
Based on Equation (
9), the joint prior distribution of
,
, and
is
Given
, the posterior distribution of
and
is apparently.
In this section, we first use squared error loss function, Linex loss function, and general entropy loss function to carry out Bayes estimations of inverse Weibull distribution under Gamma prior distribution. On this basis, balanced loss function is also considered to promote the estimation. Then, we use Lindley’s approximation to calculate results.
3.1. Three Loss Functions
The loss function determines the choosing of best estimator to a certain degree. In this section, we consider three different loss functions and derive their estimation results of entropy for comparing different Bayes estimations.
3.1.1. Squared Error Loss Function
Squared error loss (SEL) function is applicable when considering symmetric loss functions. The loss function is shown as
where
is the estimation of parameter
.
Therefore, under the squared error loss function, the Bayes estimates can be obtained theoretically as
3.1.2. Linex Loss Function
The Linex loss function is applied when considering asymmetric loss functions. It plays an important role in engineering evaluation when positive and negative errors have unequal influence on the estimation. On the basis of discussions given in [
20], the Linex loss function is shown as
The constant h denotes the weight of errors on different directions. If , the positive errors are more serious than negative ones. If , the lower estimations are more significant than higher estimations. If h is close to 0, the Linex loss function is close to squared loss function.
The Bayes estimator using the Linex loss function is described as
Therefore, under the Linex loss function, Bayes estimates can be obtained theoretically as
3.1.3. General Entropy Loss Function
General entropy loss function is also a widely used asymmetric loss function introduced in [
21] and extended in [
22]. Endowing flexibility to location parameter and scale parameter in measurement, this modified Linex function is also popular in lots of fields. The general entropy loss function is shown as
The constant q also denotes how much influence that an error will have. If , positive errors cause more serious consequences than negative ones. On the other hand, if , negative errors affect the consequences more seriously.
The Bayes estimator using General entropy loss function is described as
Therefore, under the general entropy loss function, Bayes estimates can be obtained theoretically as
3.2. Bayes Estimation Using Balanced Loss Function
Based on the different loss functions, general balanced loss function gives out an uniform expression of different Bayes estimates. Such loss function is in the form of
where
is a general expression of any conventional loss function and
is a target estimator of
.
With transformations of expression in balanced loss function, all the estimators mentioned above, including maximum likelihood estimation, symmetric, and asymmetric Bayes estimation, can be presented as special cases. When
denotes different functions, such as
,
, or
, function (
33) describes the squared error estimation, Linex loss function, and general entropy loss function.
In addition, through different values of
w, the balanced loss function reflects the proximity of estimation towards target estimator
or unknown parameter
. Thus, this loss function is more general, as artificial preferences can be attached to this kind of function. Wide applications of it can be detected through [
23,
24].
According to [
17], the approximate Bayes estimations based on the balanced loss functions are given as
3.3. Lindley’s Approximation
All the initial appearances of Bayes estimation above are ratio of two integrals which are not feasible to obtain the explicit results directly. Therefore, Lindley’s approximation is used to figure out the numerical solutions. This method has been used extensively (see [
25,
26]) as it gives out numerical result through simplifying transformation.
In the two-parameter case, according to the authors of [
17], Lindley’s approximation is written as
where
denotes the
-th element of the matrix
,
l denotes the log-likelihood function, and
Based on these equations, we can calculate the Lindley’s approximation of entropy estimation of inverse Weibull distribution:
and
are first and second derivative of
by
, respectively; also,
and
are the first and second derivative of
by
, respectively. For convenience of illustration, we display
.
Using the Lindley’s approximation shown above, we can calculate the approximation results of Bayes estimates against different loss functions.
Under the squared error loss function,
Using Equation (
37), the approximate Bayes estimation
can be derived as
Under the Linex loss function,
Using Equation (
37), the approximate Bayes estimation
can be derived as
Under the general entropy loss function,
Using Equation (
37), the approximate Bayes estimation
can be derived as
4. Simulation Results
Monte Carlo method is an important procedure of statistical analysis that provides a certain method for simulation through generating random variables under a certain distribution. In this section, we compare the performances of different estimations using this method.
At the beginning, we derive Algorithm 2 to generate adaptive type-II progressive hybrid censored sample under inverse Weibull distribution following the method proposed in [
1].
| Algorithm 2 Generating adaptive type-II progressive hybrid censoring data under inverse Weibull distribution. |
- 1:
For each i ∈ [1,m], generate following uniform distribution. - 2:
For each i ∈ [1,m], generate through relationship with and as , , , . - 3:
For each i ∈ [1,m], generate through relationship with as , , , . - 4:
For each i ∈ [1,m], derive following where denotes the inverse Weibull distribution’s inverse cumulative functional expression with parameters (,).() - 5:
When , set index J and record - 6:
Record , as first order statistics following truncated distribution with sample size .
|
Without loss of generality, we set parameters of the inverse Weibull distribution to .
Next, we create adaptive type-II progressive hybrid censoring schemes by setting the schemes and threshold time T. It is used to display the estimation appearances under different cases of adaptive type-II progressive hybrid censoring data set. Therefore, we take different T into consideration by setting them to , respectively.
Meanwhile, this paper also considers various adaptive type-II progressive hybrid censored data set through three kinds of censoring schemes. Schemes themselves have different versions in case I and case II. However, for illustration convenience, they are displayed in
Table 1. As the proportions of the censored samples and observed samples also influence the entropy values, various
m and
n are set to
,
. Also, to avoid over censoring, we chose
when
, while
when
.
Finally, in the computation of each estimation, we use noninformative prior distribution with parameters h and q set to (for Linex loss function); (for general entropy loss function); and (for balanced loss function).
In interval estimation, we derive the variances of estimated entropy, indicating the approximate interval of entropy of different progressive type-II censoring schemes. Under different conditions, the lengths of estimation interval are tabulated in
Table 2.
According to results, it is reasonable to assume that the censoring pattern, the censored size, and the time limitation T are apparently related to the interval estimation.
With the growth of time constraint T, the lengths of approximate confidence intervals of entropy decrease.
When observed failure amount increases while sample size is fixed, the lengths of approximate confidence intervals of entropy decrease.
Censoring scheme c. usually leads to shorter estimation intervals.
In point estimation, following the method for computation using descriptions of
and
as in Equations (
13) and (
14), we derive the estimates under maximum likelihood estimations method and Bayes estimation methods against squared error loss function, Linex loss function, and general entropy loss function. According to discussions in
Section 3, balanced loss function-based estimations against three loss functions above are also calculated through Lindley’s approximation. Using Monte Carlo method, we replicate the procedures 1000 times in each case to present the comparisons. All the estimations are compared by presenting their mean squared error (MSE) (units is 0.1) and bias (units is 0.1) in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10.
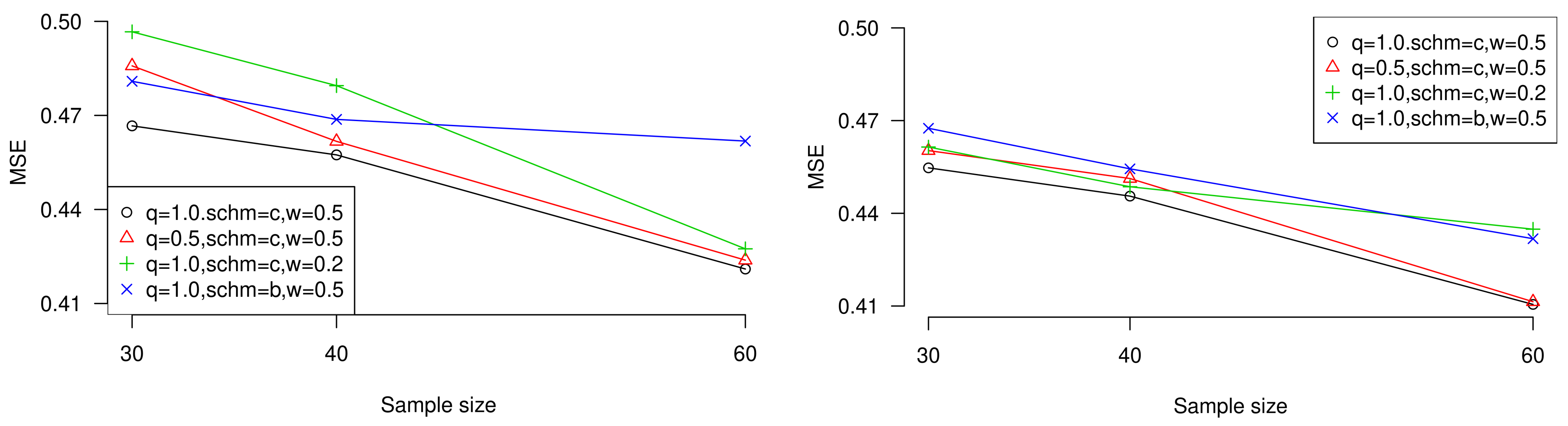
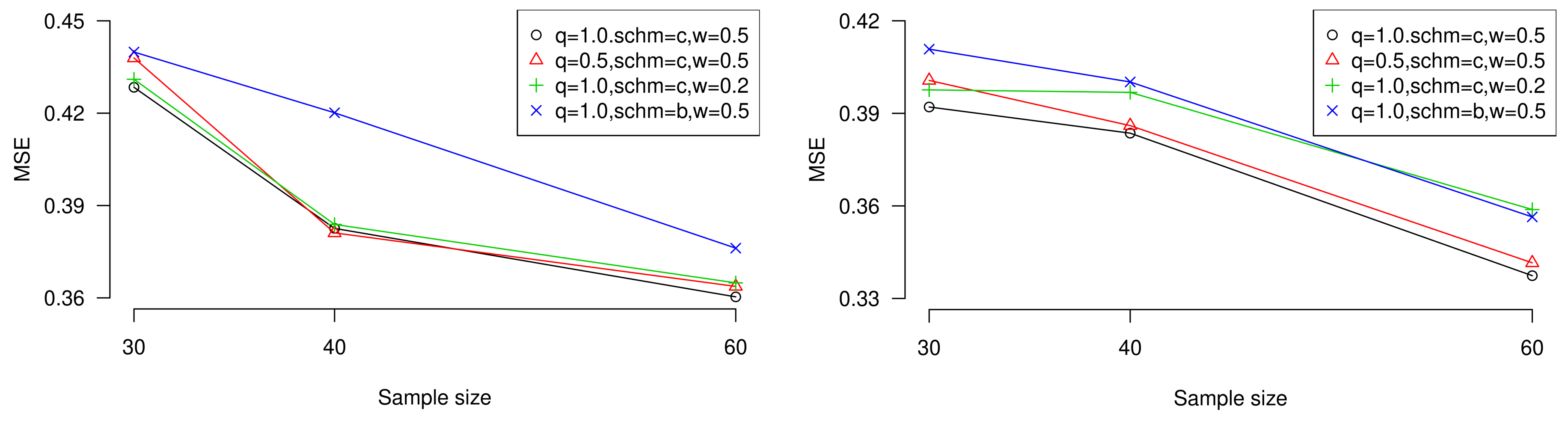
As can be seen from tables, the properties of the estimates under all of the above conditions are as follows.
All the maximum likelihood estimates and Bayesian estimates are lower than true values.
With the growth of time constraint T, the estimates seem to be more accurate.
When sample size increases while observed failures amount is fixed, the MSE values show a decreasing tendency.
When the observed failure amount increases while sample size is fixed, the MSE values decrease generally.
is more appropriate value of general entropy loss function for estimation.
is more suitable for balanced loss function under the noninformative prior inverse Weibull distribution.
Censoring scheme c. usually performs better.
General entropy estimation performs better under most conditions.
To display the conclusions, we plot the performances of MSE when sample size is increasing with different censored sizes, censoring schemes, weight of errors, and proximity of estimation towards target estimator or unknown parameter. Besides, the influence of expected experiment time
T can also be observed in the figures. Trends are shown in
Figure 3 and
Figure 4 (values come from
Table 3,
Table 5,
Table 7, and
Table 9).
5. Real Data Analysis
To illustrate the estimations intuitively, we use a data set obtained through realistic experiment. The research started when people realized that guinea pigs are highly susceptible to human tuberculosis. Although guinea pigs do acquire resistance, even a few deadly tubercle bacilli will cause progressive disease and death. The initial focus of this investigation was the relation between numbers of tubercle bacilli infected individuals and survival time. Reference [
27] used this data to test whether they can be regarded as samples from inverse Weibull distribution. According to the result, it is reasonable to use inverse Weibull distribution to analyze.
The listed values are the survival times (in days) of the guineas placed in the environment of 4.0 × 106 bacillary units per 0.5 mL. Those 72 observations are shown as follows; 12, 15, 22, 24, 24, 32, 32, 33, 34, 38, 38, 43, 44, 48, 52, 53, 54, 54, 55, 56, 57, 58, 58, 59, 60, 60, 60, 60, 61, 62, 63, 65, 65, 67, 68, 70, 70, 72, 73, 75, 76, 76, 81, 83, 84, 85, 87, 91, 95, 96, 98, 99, 109, 110, 121, 127, 129, 131, 143, 146, 146, 175, 175, 211, 233, 258, 258, 263, 297, 341, 341, 376.
We first generate progressive type-II censoring scheme with , and the sample is 15, 22, 32, 43, 48, 56, 60, 65, 68, 76, 87, 99, 121, 127, 146, 175, 233, 297.
For case I data set, we assume , , while and .
For case II data set, we assume and scheme changes into .
Some other values about the inverse Weibull distribution and the loss function must be given before estimations. Without informative prior, we choose . Meanwhile, the influence of overestimation and underestimation are inexplicit, so against different loss functions, for consistency, we use the same h and q in simulation analysis, such that , . In addition, we still use to carry out different balanced loss functions for estimations.
Table 11 presents the estimations of entropy under adaptive type-II progressive hybrid censoring schemes, considering all the conditions mentioned above. For convenience, we display the interval estimation entropy derived by maximum likelihood method in the same tabel.
According to the simulation study, we prefer the general entropy loss function-based Bayes estimation, where and to estimate the entropy of progressive type-II censored data reported by the infected tubercle bacilli, which has been tested to follow the inverse Weibull distribution.
6. Conclusions
Entropy of inverse Weibull distribution under different conditions are calculated and estimated in this paper. Adaptive type-II progressive hybrid censoring schemes are focused on, as they satisfy the experiment time limitation and can also be used to simulate different practical situations. Theoretically, maximum likelihood estimations, including point estimation as well as interval estimation, and Bayes estimations using three kinds of loss function, including squared error loss function, Linex loss function, and general entropy loss function, are given. Also, in general condition, considering the preference of the proximity of the target estimator to the unknown parameters, balanced loss function-based Bayes estimates are also computed. As these estimations are difficult to obtain by direct calculation, Lindley’s approximation method is applied to solve the problem numerically.
In expectation of clear comparison among all the estimations, we compute the interval length, MSE, as well as bias of them by simulation. From the results, some suggestions about estimation choices for inverse Weibull distribution without informative prior information under adaptive type-II progressive censoring schemes can be obtained. Finally, for illustration, a real data set, which has been proved following inverse Weibull distribution, is used for estimation application.
Macroscopically, although all the estimation errors are within a short interval, the ratio between observed failures and censored samples as well as supposed time limitation T are influential factors of estimates. The higher ratio of observed failures against censored samples, the larger T, the more accurate estimation is.
More specifically, under both MSE and bias criteria, Scheme c. is usually superior to other schemes and is more suitable for balanced loss function under the noninformative prior inverse Weibull distribution. Furthermore, for noninformative inverse Weibull distribution, Bayes estimations are preferable in most conditions and general entropy estimation with parameter is usually the most reasonable estimation.








{kind=link}
{kind=link}
{kind=link}
{kind=link}