A Decision Support System Using Text Mining Based Grey Relational Method for the Evaluation of Written Exams


Abstract
:1. Introduction
2. Background
2.1. The Evaluation of Exams
2.1.1. Written Exams
2.2. Data Mining
2.3. Text Mining
- Clustering: It is the method to organize similar contents from unstructured data sources such as documents, news, images, paragraphs, sentences, comments, or terms in order to enhance retrieval and support browsing. It is the process to group the contents based on fuzzy information, such as words or word phrases in a set of documents. The similarity is computed using a similarity function. Measurement methods such as Cosine distance, Manhattan distance, and Euclidean distance are used for the clustering process. Besides, there is a wide variety of different clustering algorithms, such as hierarchical algorithms, partitioning algorithms, and standard parametric modeling-based methods. These algorithms are grouped along different dimensions based either on the underlying methodology of the algorithm, leading to agglomerative or partitional approaches, or on the structure of the final solution, leading to hierarchical or non-hierarchical solutions [35,38,43].
- Classification: It is a data mining approach to the grouping of the data according to the specified characteristics. It is carried out in two stages as learning and classification. In the first stage, a part of the data set is used for training purposes to determine how data characteristics will be classified. In the second stage, all datasets are classified by these rules. Supervised machine learning algorithms are used for classification methods. These algorithms include decision trees, I Bayes, nearest neighbor, classification and regression trees, support vector machines, and genetic algorithms [31,35,43].
- Summarization: It is used for documents and aims to determine the meanings, words, and phrases that can represent a document. It is carried out based on the language-specific rules that textual data belongs to. NLP approaches, which are one of the complex processes in terms of computer systems, are used in applications such as speech recognition, language translation, automated response systems, text summarization, and sentiment analysis [31,35,43].
2.4. Educational Data Mining (EDM)
3. Grey Relational Analysis (GRA)
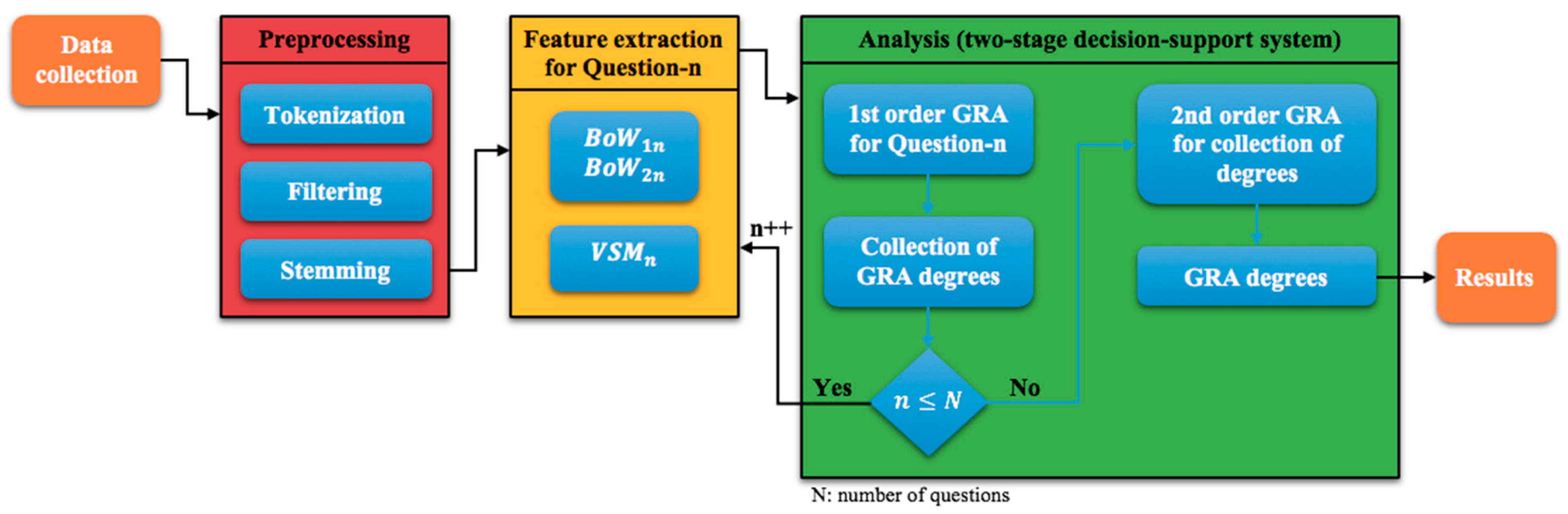
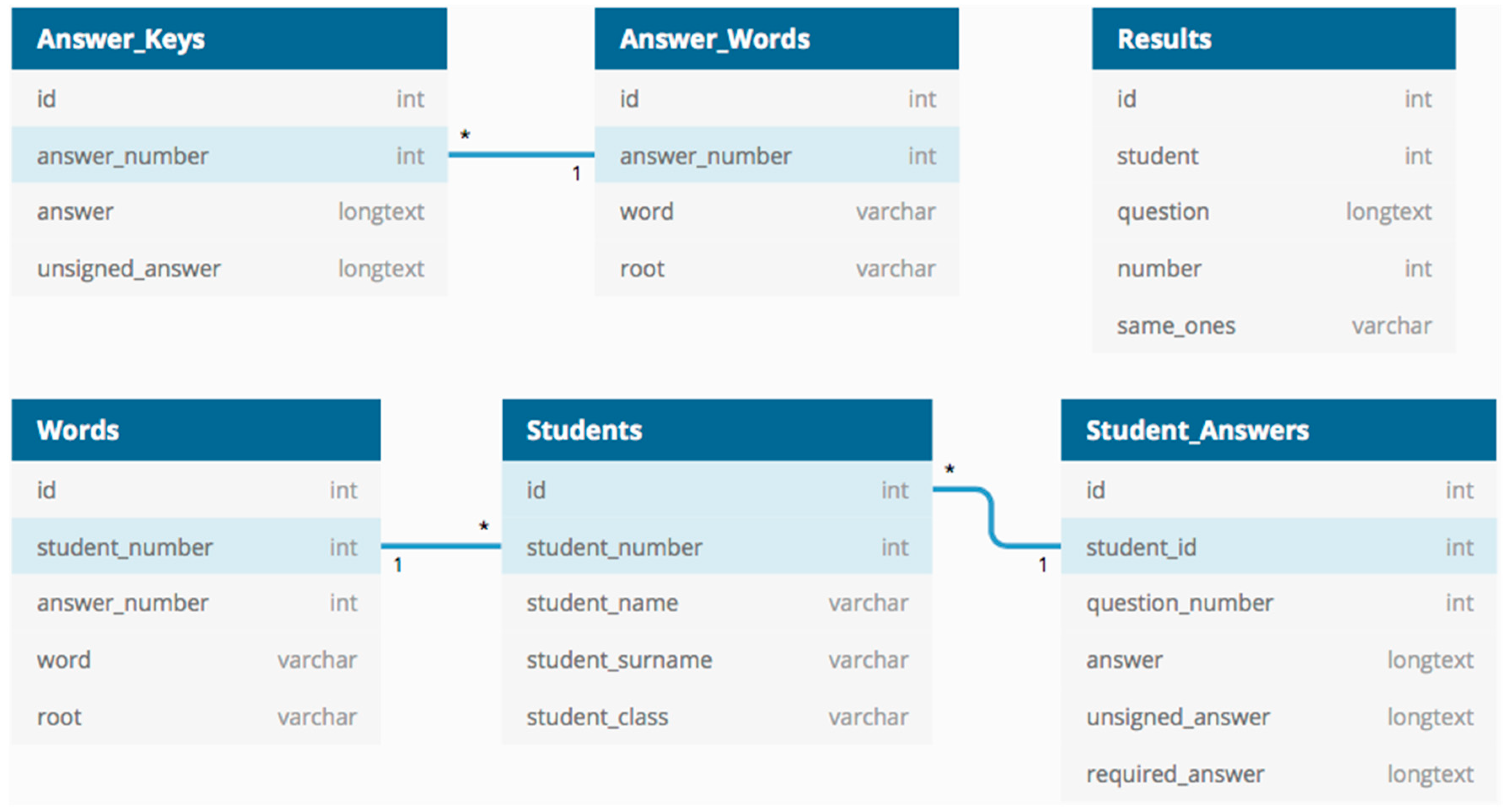
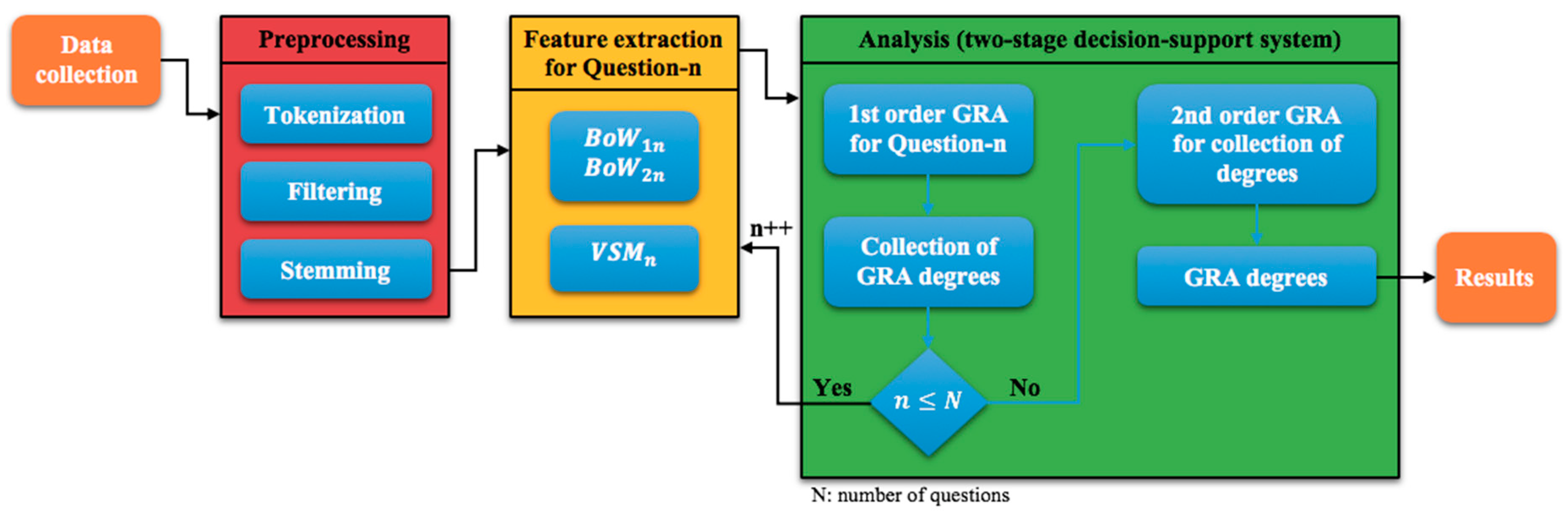
4. Proposed Method
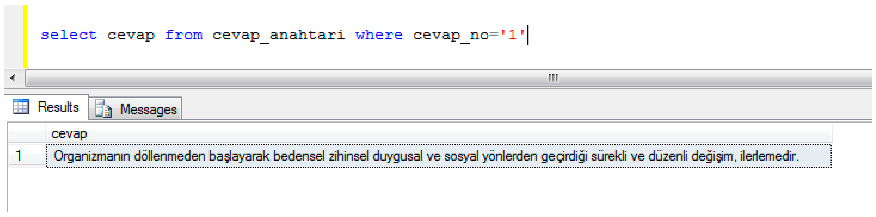
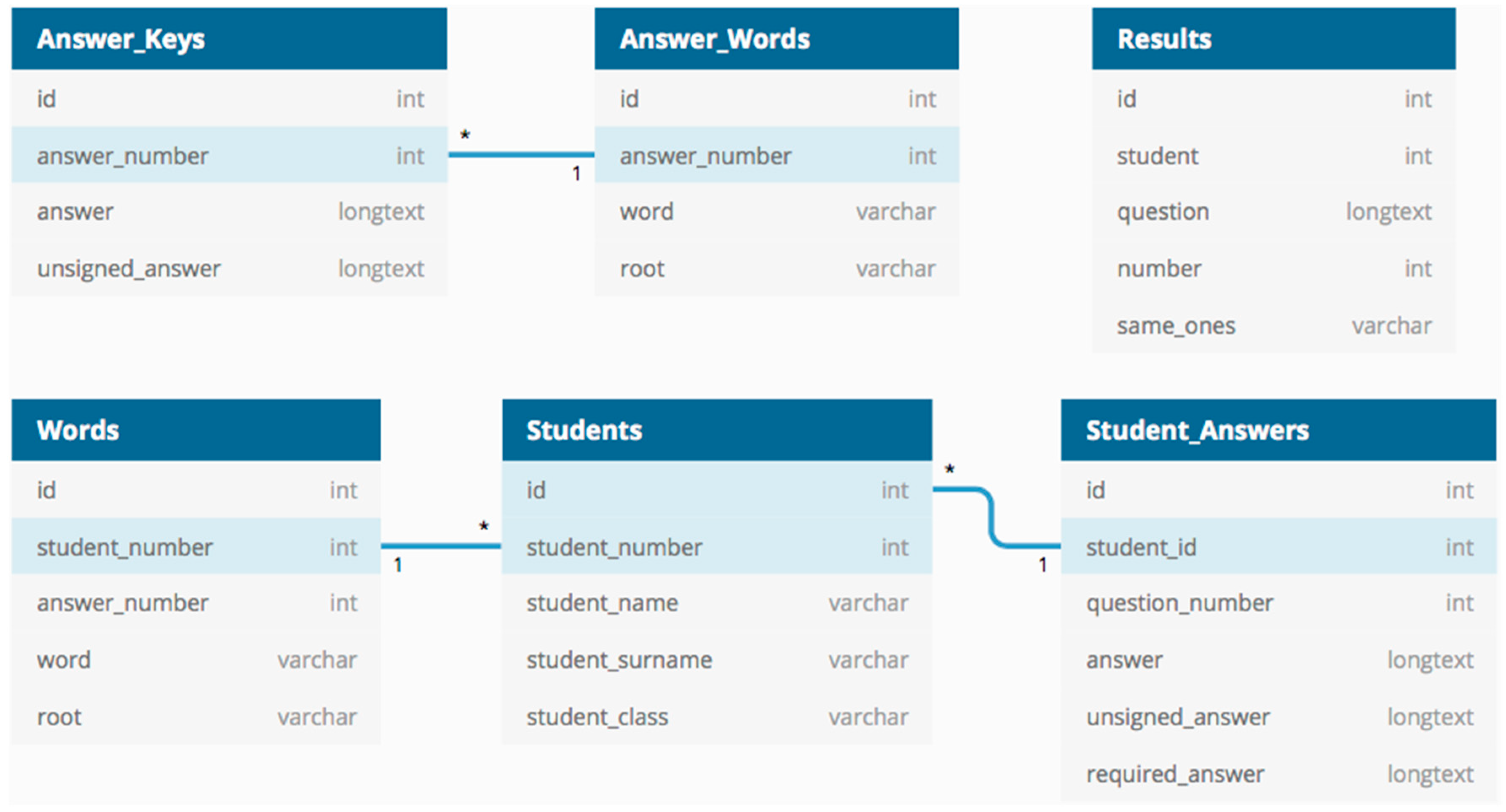
4.1. Data Collection
4.2. Data Preprocessing
4.3. Feature Extraction
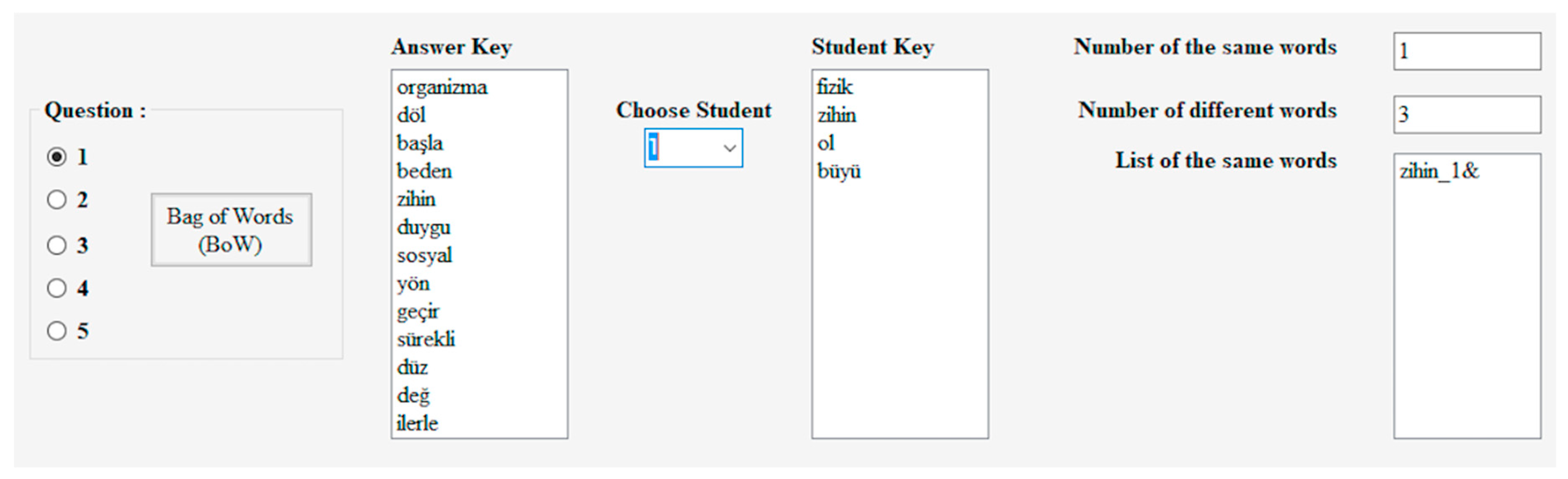
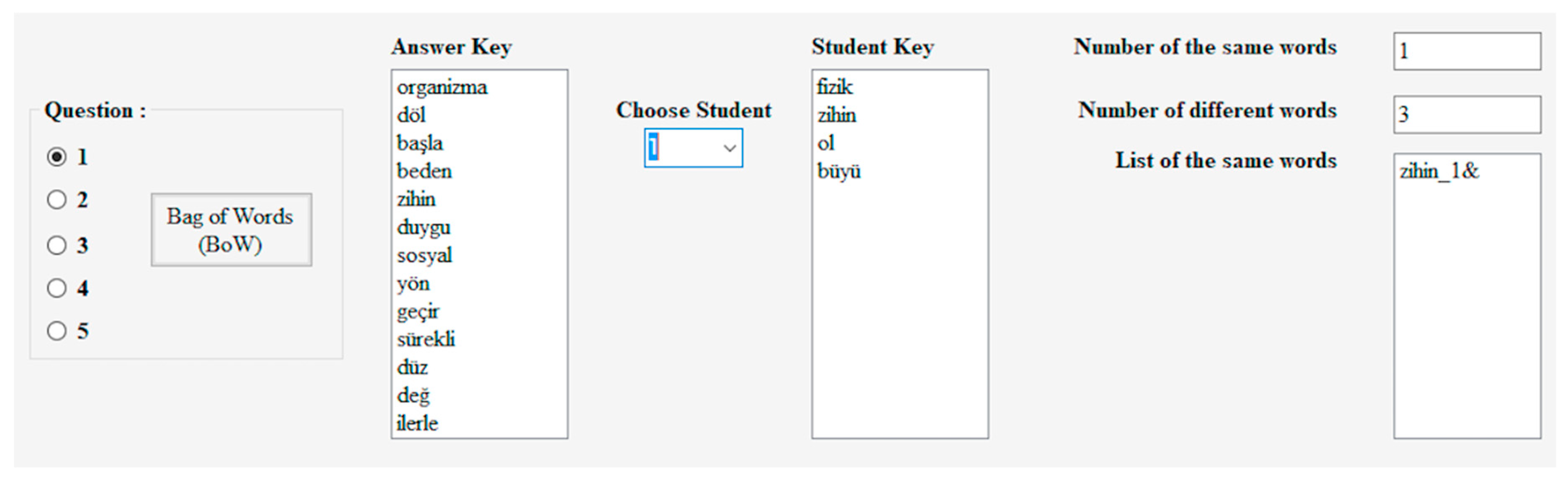
4.3.1. Bag of Words (BoW)
| Algorithm 1. BoW Generation |
|
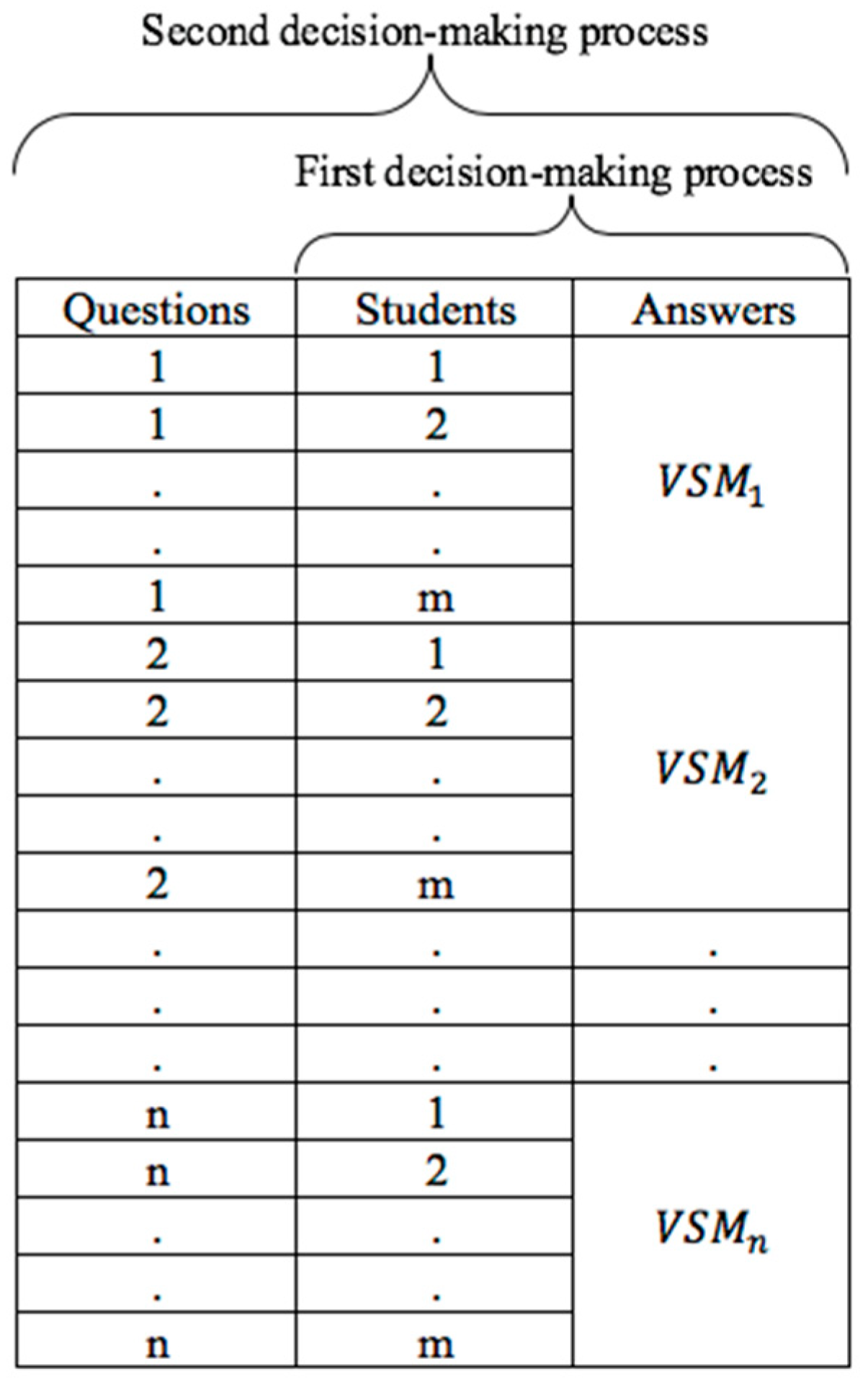
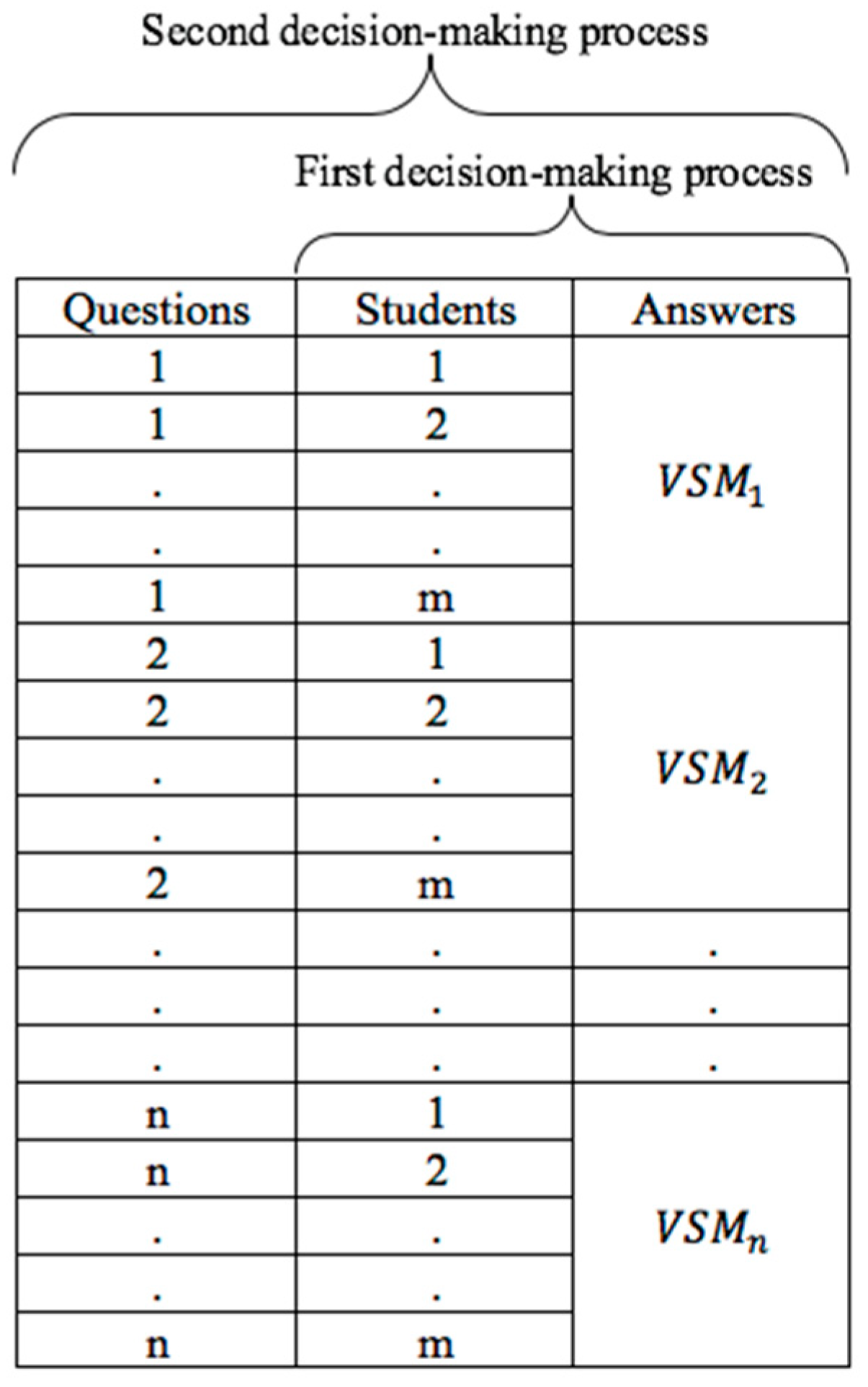
4.3.2. Vector Space Model (VSM)
4.4. Analysis
5. Experimental Results
5.1. BoW Findings
5.2. VSM Findings
5.3. Grey Relational Degree Findings
6. Discussion and Suggestions
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A


Appendix B
| S | Q | Words (in both Turkish and English) |
| 1 | 1 | zihin_1& (mental_1&) |
| 3 | 1 | sosyal_1& (social_1&) |
| 6 | 1 | organizma_1&döl_1&başla_1& (organism_1&seed_1&start_1&) |
| 7 | 1 | başla_1&duygu_1& (start_1&emotion_1&) |
| 10 | 1 | döl_1&başla_1&sosyal_1&yön_1& (seed_1&start_1&social_1&direction_1&) |
| 13 | 1 | organizma_1&döl_1&başla_1&beden_1&zihin_1&sosyal_1&yön_1&geçir_1&sürekli_1&düz_1&değ_1&(organism_1&seed_1&start_1&body_1&mental_1&social_1&direction_1&pass_1&continuous_1&straight_1&touch_1&) |
| 14 | 1 | organizma_1&döl_1&başla_1&beden_1&zihin_1&duygu_1&sosyal_1&yön_1&geçir_1&sürekli_1&düz_2&ilerle_1&(organism_1&seed_1&start_1&body_1&mental_1&emotion_1&social_1&direction_1&pass_1&continuous_1&straight_2&move_1&) |
| 15 | 1 | döl_1&başla_1&sürekli_1& (seed_1&start_1&continuous_1&) |
| 18 | 1 | zihin_1& (mental_1&) |
| 19 | 1 | sosyal_1&yön_2& (social_1&direction_2&) |
| 20 | 1 | beden_1& (body_1&) |
| 21 | 1 | sosyal_1& (social_1&) |
| 24 | 1 | başla_1&zihin_1&sosyal_1& (start_1&mental_1&social_1&) |
| 25 | 1 | döl_1&başla_1& (seed_1&start_1&) |
| 26 | 1 | sürekli_1&düz_1&ilerle_1& (continuous_1&straight_1&move_1&) |
| 27 | 1 | organizma_1&döl_1&başla_1&sosyal_1&yön_1&geçir_1&sürekli_1&düz_1&değ_1&(organism_1&seed_1&start_1&social_1&direction_1&pass_1&continuous_1&straight_1&touch_1& |
| 29 | 1 | geçir_1& (pass_1&) |
| 31 | 1 | organizma_1&döl_1&başla_1&zihin_1&sosyal_1&yön_1&(organism_1&seed_1&start_1&mental_1&sosyal_1&yön_1&) |
| 32 | 1 | beden_1&zihin_1&sosyal_1&yön_1&geçir_1&sürekli_1&düz_1&değ_1&(body_1&mental_1&social_1&direction_1&pass_1&continuous_1&straight_1&touch_1&) |
| 33 | 1 | döl_1&başla_1&düz_1&ilerle_1& (seed_1&start_1& straight_1&move_1&) |
| 34 | 1 | başla_1&duygu_1&sosyal_1& (start_1&emotion_1&social_1&) |
| 37 | 1 | başla_1& (start_1&) |
| 39 | 1 | başla_1& (start_1&) |
| 40 | 1 | sosyal_1&yön_1& (social_1&direction_1&) |
| 43 | 1 | sürekli_1& (continuous_1&) |
| 44 | 1 | başla_1& (start_1&) |
| 45 | 1 | sürekli_1& (continuous_1&) |
| 46 | 1 | başla_2&duygu_1&sosyal_1& (start_2&emotion_1&social_1&) |
| 47 | 1 | duygu_1&sosyal_1&yön_1& (emotion_1&social_1&direction_1&) |
| 48 | 1 | döl_1&başla_1&sürekli_1&değ_1& (seed_1&start_1&continuous_1&touch_1&) |
| 49 | 1 | sosyal_1&yön_2& (social_1& direction_2&) |
| 50 | 1 | başla_1&duygu_1&sosyal_1&yön_1& (start_1&emotion_1&social_1&direction_1&) |
| Words (in both Turkish and English) | ||||||||||||||
| Q | S | Organizma (organism) | Döl (seed) | Başla (start) | Beden (body) | Zihin (mental) | Duygu (emotion) | Sosyal (social) | Yön (direction) | Geçir (pass) | Sürekli (continuous) | Düz (straight) | Değ (touch) | Ilerle (move) |
| 1 | 0 * | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 6 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 7 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 10 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 13 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 1 | 14 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 0 | 1 |
| 1 | 15 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 16 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 18 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 19 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | 0 |
| 1 | 20 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 21 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 22 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 24 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 25 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 26 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 |
| 1 | 27 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 1 | 28 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 29 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 30 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 31 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 32 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 1 | 33 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 34 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 35 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 36 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 37 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 38 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 39 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 40 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 41 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 42 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 43 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 44 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 45 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 46 | 0 | 0 | 2 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 47 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 48 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 1 | 49 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | 0 |
| 1 | 50 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
Appendix C
| Question | Student | Words | ||||||||||||
| 1 | Answer Key | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | Reference | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 2 | 1 | 2 | 2 | 1 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Question | Student | Words | ||||||||||||
| 1 | Reference | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 3 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 4 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 5 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| Question | Student | Words | ||||||||||||
| 1 | Reference | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 3 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 4 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 5 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| Question | Student | Words | ||||||||||||
| 1 | Reference | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 | 0.333 | 1 | 0.333 | 1 | 1 | 0.333 | 1 | 0.333 | 0.333 | 1 | 1 |
| 1 | 2 | 1 | 1 | 0.333 | 1 | 1 | 1 | 1 | 0.333 | 1 | 0.333 | 0.333 | 1 | 1 |
| 1 | 3 | 1 | 1 | 0.333 | 1 | 1 | 1 | 0.333 | 0.333 | 1 | 0.333 | 0.333 | 1 | 1 |
| 1 | 4 | 1 | 1 | 0.333 | 1 | 1 | 1 | 1 | 0.333 | 1 | 0.333 | 0.333 | 1 | 1 |
| 1 | 5 | 1 | 1 | 0.333 | 1 | 1 | 1 | 1 | 0.333 | 1 | 0.333 | 0.333 | 1 | 1 |
Appendix D
| S | Q-1 | Q-2 | Q-3 | Q-4 | Q-5 | Degrees |
| 1 | 0.4117 | 0.4189 | 0.5241 | 0.3874 | 0.3422 | 0.4169 |
| 2 | 0.3684 | 0.6305 | 0.4517 | 0.367 | 0.3859 | 0.4407 |
| 3 | 0.4117 | 0.4406 | 0.5863 | 0.4118 | 0.3692 | 0.4439 |
| 4 | 0.3684 | 0.6072 | 0.3692 | 0.4367 | 0.3913 | 0.4346 |
| 5 | 0.3684 | 1 | 0.4236 | 0.4011 | 0.3523 | 0.5091 |
| 6 | 0.4117 | 0.4006 | 0.4745 | 0.3697 | 0.3778 | 0.4069 |
| 7 | 0.3684 | 0.4521 | 0.5029 | 0.3741 | 0.4045 | 0.4204 |
| 8 | 0.3684 | 0.709 | 0.4264 | 0.4037 | 0.3822 | 0.4579 |
| 9 | 0.3684 | 0.4106 | 0.6004 | 0.3964 | 0.377 | 0.4306 |
| 10 | 0.3684 | 0.7275 | 1 | 0.3923 | 0.4133 | 0.5803 |
| 11 | 0.3684 | 0.4362 | 0.4236 | 0.3695 | 0.4592 | 0.4114 |
| 12 | 0.3684 | 0.4545 | 0.6159 | 0.3846 | 0.3488 | 0.4344 |
| 13 | 0.5385 | 0.6535 | 0.3446 | 0.4022 | 0.48 | 0.4838 |
| 14 | 1 | 0.621 | 0.5699 | 1 | 1 | 0.8382 |
| 15 | 0.3333 | 0.7404 | 0.3486 | 0.3864 | 0.3913 | 0.44 |
| 16 | 0.3684 | 0.4757 | 0.6159 | 0.3641 | 0.4059 | 0.446 |
| 17 | 0.3684 | 0.4812 | 0.5029 | 0.3991 | 0.3536 | 0.421 |
| 18 | 0.4117 | 0.5224 | 0.5132 | 0.3854 | 0.3488 | 0.4363 |
| 19 | 0.4117 | 0.5224 | 0.5221 | 0.42 | 0.3505 | 0.4453 |
| 20 | 0.4117 | 0.3812 | 0.4402 | 0.3966 | 0.3818 | 0.4023 |
| 21 | 0.4117 | 0.4524 | 0.4008 | 0.4123 | 0.3333 | 0.4021 |
| 22 | 0.3684 | 0.4295 | 0.4668 | 0.3623 | 0.3711 | 0.3996 |
| 23 | 0.3684 | 0.4247 | 0.4891 | 0.3978 | 0.381 | 0.4122 |
| 24 | 0.4117 | 0.4298 | 0.4531 | 0.4123 | 0.379 | 0.4172 |
| 25 | 0.3684 | 0.6078 | 0.4813 | 0.443 | 0.4433 | 0.4688 |
| 26 | 0.3333 | 0.5224 | 0.3535 | 0.4123 | 0.3987 | 0.404 |
| 27 | 0.4117 | 0.7312 | 0.3333 | 0.4393 | 0.3523 | 0.4536 |
| 28 | 0.3684 | 0.3812 | 0.3566 | 0.3741 | 0.3863 | 0.3733 |
| 29 | 0.4117 | 0.5949 | 0.4252 | 0.4084 | 0.4045 | 0.4489 |
| 30 | 0.3684 | 0.4423 | 0.5627 | 0.4123 | 0.379 | 0.4329 |
| 31 | 0.4666 | 0.3954 | 0.3867 | 0.3333 | 0.4374 | 0.4039 |
| 32 | 0.4666 | 0.3826 | 0.3513 | 0.4051 | 0.3673 | 0.3946 |
| 33 | 0.3684 | 0.616 | 0.6004 | 0.3944 | 0.3913 | 0.4741 |
| 34 | 0.4117 | 0.6444 | 0.4531 | 0.3856 | 0.4348 | 0.4659 |
| 35 | 0.3684 | 0.4278 | 0.5728 | 0.3792 | 0.5389 | 0.4574 |
| 36 | 0.3684 | 0.4329 | 0.3805 | 0.3968 | 0.3913 | 0.394 |
| 37 | 0.3333 | 0.4683 | 0.5404 | 0.3964 | 0.3913 | 0.4259 |
| 38 | 0.3684 | 0.616 | 0.3627 | 0.3921 | 0.3913 | 0.4261 |
| 39 | 0.3333 | 0.5224 | 0.5358 | 0.4492 | 0.4068 | 0.4495 |
| 40 | 0.3684 | 0.4112 | 0.6159 | 0.4123 | 0.3913 | 0.4398 |
| 41 | 0.3684 | 0.6305 | 0.5378 | 0.4196 | 0.3818 | 0.4676 |
| 42 | 0.3684 | 0.4647 | 0.4319 | 0.4239 | 0.3913 | 0.416 |
| 43 | 0.3333 | 0.4647 | 0.4382 | 0.4227 | 0.3913 | 0.41 |
| 44 | 0.3333 | 0.4647 | 0.4833 | 0.3731 | 0.3913 | 0.4091 |
| 45 | 0.3333 | 0.4861 | 0.3928 | 0.4123 | 0.422 | 0.4093 |
| 46 | 0.4666 | 0.3974 | 0.4929 | 0.4013 | 0.3913 | 0.4299 |
| 47 | 0.4117 | 0.5291 | 0.5241 | 0.4123 | 0.355 | 0.4464 |
| 48 | 0.3684 | 0.549 | 0.4467 | 0.4123 | 0.4245 | 0.4402 |
| 49 | 0.4117 | 0.3812 | 0.3952 | 0.4256 | 0.3987 | 0.4025 |
| 50 | 0.3684 | 0.3333 | 0.4097 | 0.4013 | 0.3913 | 0.3808 |
| Evaluator Scores | GRA Results | |||||||||
| S | Q-1 | Q-2 | Q-3 | Q-4 | Q-5 | Total | Rank | Degrees | Rank | Suggestion |
| 1 | 5 | 8 | 5 | 0 | 2 | 20 | 33 | 0.4169 | 33 | do not change |
| 2 | 0 | 10 | 10 | 15 | 0 | 35 | 25 | 0.4407 | 18 | increase the score |
| 3 | 15 | 12 | 10 | 0 | 0 | 37 | 24 | 0.4439 | 17 | increase the score |
| 4 | 5 | 0 | 15 | 15 | 0 | 35 | 26 | 0.4346 | 23 | increase the score |
| 5 | 0 | 20 | 12 | 13 | 20 | 65 | 8 | 0.5091 | 3 | increase the score |
| 6 | 10 | 8 | 10 | 15 | 10 | 53 | 13 | 0.4069 | 40 | decrease the score |
| 7 | 15 | 15 | 20 | 15 | 2 | 67 | 7 | 0.4204 | 31 | decrease the score |
| 8 | 0 | 0 | 10 | 15 | 10 | 35 | 27 | 0.4579 | 9 | increase the score |
| 9 | 10 | 20 | 0 | 0 | 2 | 32 | 29 | 0.4306 | 26 | increase the score |
| 10 | 20 | 20 | 20 | 20 | 20 | 100 | 1 | 0.5803 | 2 | decrease the score |
| 11 | 0 | 15 | 20 | 15 | 20 | 70 | 6 | 0.4114 | 36 | decrease the score |
| 12 | 0 | 15 | 0 | 10 | 15 | 50 | 14 | 0.4344 | 24 | decrease the score |
| 13 | 15 | 20 | 20 | 15 | 15 | 85 | 3 | 0.4838 | 4 | decrease the score |
| 14 | 20 | 20 | 12 | 15 | 20 | 87 | 2 | 0.8382 | 1 | increase the score |
| 15 | 10 | 10 | 5 | 5 | 10 | 40 | 16 | 0.44 | 20 | decrease the score |
| 16 | 0 | 15 | 20 | 0 | 5 | 40 | 17 | 0.446 | 15 | increase the score |
| 17 | 0 | 5 | 0 | 0 | 0 | 5 | 48 | 0.421 | 30 | increase the score |
| 18 | 0 | 0 | 5 | 15 | 5 | 25 | 32 | 0.4363 | 22 | increase the score |
| 19 | 10 | 0 | 0 | 0 | 0 | 10 | 45 | 0.4453 | 16 | increase the score |
| 20 | 5 | 8 | 0 | 5 | 0 | 18 | 37 | 0.4023 | 44 | decrease the score |
| 21 | 15 | 2 | 20 | 0 | 2 | 39 | 21 | 0.4021 | 45 | decrease the score |
| 22 | 0 | 15 | 5 | 10 | 10 | 40 | 18 | 0.3996 | 46 | decrease the score |
| 23 | 0 | 8 | 0 | 0 | 0 | 8 | 46 | 0.4122 | 35 | increase the score |
| 24 | 0 | 8 | 5 | 0 | 0 | 13 | 42 | 0.4172 | 32 | increase the score |
| 25 | 10 | 10 | 15 | 15 | 15 | 65 | 9 | 0.4688 | 6 | increase the score |
| 26 | 10 | 0 | 10 | 0 | 10 | 30 | 31 | 0.404 | 41 | decrease the score |
| 27 | 20 | 20 | 20 | 15 | 10 | 85 | 4 | 0.4536 | 11 | decrease the score |
| 28 | 10 | 8 | 5 | 10 | 0 | 33 | 28 | 0.3733 | 50 | decrease the score |
| 29 | 0 | 18 | 0 | 8 | 5 | 31 | 30 | 0.4489 | 13 | increase the score |
| 30 | 0 | 10 | 10 | 0 | 0 | 20 | 34 | 0.4329 | 25 | increase the score |
| 31 | 18 | 10 | 20 | 20 | 15 | 83 | 5 | 0.4039 | 42 | decrease the score |
| 32 | 18 | 15 | 10 | 5 | 2 | 50 | 15 | 0.3946 | 47 | decrease the score |
| 33 | 10 | 15 | 10 | 20 | 0 | 55 | 11 | 0.4741 | 5 | increase the score |
| 34 | 10 | 4 | 10 | 20 | 10 | 54 | 12 | 0.4659 | 8 | increase the score |
| 35 | 10 | 0 | 0 | 10 | 10 | 40 | 19 | 0.4574 | 10 | increase the score |
| 36 | 0 | 5 | 10 | 0 | 0 | 15 | 40 | 0.394 | 48 | decrease the score |
| 37 | 10 | 2 | 0 | 0 | 0 | 12 | 43 | 0.4259 | 29 | increase the score |
| 38 | 0 | 18 | 0 | 0 | 0 | 18 | 38 | 0.4261 | 28 | increase the score |
| 39 | 0 | 0 | 10 | 5 | 5 | 20 | 35 | 0.4495 | 12 | increase the score |
| 40 | 0 | 5 | 0 | 0 | 0 | 5 | 49 | 0.4398 | 21 | increase the score |
| 41 | 0 | 12 | 0 | 0 | 0 | 12 | 44 | 0.4676 | 7 | increase the score |
| 42 | 0 | 6 | 0 | 0 | 0 | 6 | 47 | 0.416 | 34 | increase the score |
| 43 | 0 | 6 | 14 | 0 | 0 | 20 | 36 | 0.41 | 37 | decrease the score |
| 44 | 0 | 5 | 0 | 0 | 0 | 5 | 50 | 0.4091 | 39 | increase the score |
| 45 | 0 | 10 | 20 | 0 | 10 | 40 | 20 | 0.4093 | 38 | decrease the score |
| 46 | 10 | 18 | 5 | 5 | 0 | 38 | 22 | 0.4299 | 27 | decrease the score |
| 47 | 0 | 8 | 5 | 0 | 2 | 15 | 41 | 0.4464 | 14 | increase the score |
| 48 | 20 | 15 | 15 | 0 | 10 | 60 | 10 | 0.4402 | 19 | decrease the score |
| 49 | 0 | 8 | 10 | 0 | 0 | 18 | 39 | 0.4025 | 43 | decrease the score |
| 50 | 10 | 8 | 15 | 5 | 0 | 38 | 23 | 0.3808 | 49 | decrease the score |
References
- Turgut, M.F.; Baykul, Y. Eğitimde Ölçme ve Değerlendirme; Pegem Akademi: Ankara, Turkey, 2012. [Google Scholar]
- Dikli, S. Assessment at a distance: Traditional vs. alternative assessments. Turk. Online J. Educ. Technol. 2003, 2, 13–19. [Google Scholar]
- Yılmaz, A. Ölçme ve Değerlendirme; Pegem Akademi: Ankara, Turkey, 2009. [Google Scholar]
- Miller, M.D.; Linn, R.L.; Gronlund, N.E. Measurement and Assessment in Teaching; Pearson: Boston, MA, USA, 2013. [Google Scholar]
- Fraenkel, J.R.; Wallen, N.E. How to Design and Evaluate Research in Education; McGraw-Hill: New York, NY, USA, 2005. [Google Scholar]
- Kurgan, L.A.; Musilek, P. A survey of knowledge discovery and data mining process models. Knowl. Eng. Rev. 2006, 21, 1–24. [Google Scholar] [CrossRef]
- Kahraman, C.; Onar, S.C. Intelligent Techniques in Engineering Management, Theory and Applications; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Nenonen, N. Analysing factors related to slipping, stumbling, and falling accidents at work: Application of data mining methods to Finnish occupational accidents and diseases statistics database. Appl. Ergon. 2013, 44, 215–224. [Google Scholar] [CrossRef] [PubMed]
- Gurbuz, F.; Ozbakir, L.; Yapici, H. Classification rule discovery for the aviation incidents resulted in fatality. Knowl. Based Syst. 2009, 22, 622–632. [Google Scholar] [CrossRef]
- Yuksel, M.E. Agent-based evacuation modeling with multiple exits using NeuroEvolution of Augmenting Topologies. Adv. Eng. Inform. 2018, 35, 30–55. [Google Scholar] [CrossRef]
- Ji, H.; Park, K.; Jo, J.; Lim, H. Mining students activities from a computer supported collaborative learning system based on peer to peer network. Peer Peer Netw. Appl. 2016, 9, 465–476. [Google Scholar] [CrossRef]
- Sailesh, S.B.; Lu, K.J.; Aali, M.A. Profiling Students on Their Course-Taking Patterns in Higher Educational Institutions (HEIs). In Proceedings of the International Conference on Information Science, Kochi, India, 12–13 August 2016. [Google Scholar]
- Scheuer, O.; McLaren, B.M. Educational Data Mining, In the Encyclopedia of the Sciences of Learning; Springer: Boston, MC, USA, 2011. [Google Scholar]
- Tsai, C.Y.; Tsai, M.H. A Dynamic Web Service Based Data Mining Process System. In Proceedings of the 5th International Conference on Computer and Information Technology, Shanghai, China, 21–23 September 2005. [Google Scholar]
- Rygielski, C.; Wang, J.C.; Yen, D.C. Data mining techniques for customer relationship management. Technol. Soc. 2002, 24, 483–502. [Google Scholar] [CrossRef]
- Ramakrishnan, R.; Gehrke, J. Database Management Systems; McGraw-Hill Education: New York, NY, USA, 2003. [Google Scholar]
- Dunham, M.H. Data Mining: Introductory and Advanced Topics; Prentice-Hall: New Jersey River, NJ, USA, 2003. [Google Scholar]
- Harish, B.S.; Guru, D.S.; Manjunath, S. Representation and classification of text documents: A brief review. Int. J. Comput. Appl. Spec. Issue Recent Trends Image Process. Pattern Recognit. 2010, 2, 110–119. [Google Scholar]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. A brief survey of text mining: Classification, clustering and extraction techniques. arXiv 2017, arXiv:1707.02919. [Google Scholar]
- Pan, W.; Zhong, E.; Yang, Q. Transfer learning for text mining. In Mining Text Data; Aggarwal, C., Zhai, C., Eds.; Springer: Boston, MA, USA, 2012; pp. 223–257. [Google Scholar]
- Korde, V.; Mahender, C.N. Text classification and classifiers: A survey. Int. J. Artif. Intell. Appl. 2012, 3, 85–99. [Google Scholar]
- Xia, T.; Chai, Y. An improvement to TF-IDF: Term distribution based term weight algorithm. J. Softw. 2011, 6, 413–420. [Google Scholar] [CrossRef]
- Tasci, S.; Gungor, T. Comparison of text feature selection policies and using an adaptive framework. Expert Syst. Appl. 2013, 40, 4871–4886. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, Z.; Long, J.; Zhang, H. Turning from TF-IDF to TF-IGM for term weighting in text classification. Expert Syst. Appl. 2016, 66, 245–260. [Google Scholar] [CrossRef]
- Cakan, M. Eğitimde Ölçme ve Değerlendirme; Pegem Akademi: Ankara, Turkey, 2008. [Google Scholar]
- Atilgan, H.; Kan, A.; Dogan, N. Eğitimde Ölçme ve Değerlendirme; Ani Yayincilik: Ankara, Turkey, 2009. [Google Scholar]
- Stiggins, R. Assessment Manifesto: A Call for the Development of Balanced Assessment Systems; ETS Assessment Training Institute: Portland, OR, USA, 2008. [Google Scholar]
- Gecit, Y. Eğitimde Ölçme ve Değerlendirme; Nobel Yayincilik: Ankara, Turkey, 2012. [Google Scholar]
- Tekindal, S. Okullarda Ölçme ve Değerlendirme Yöntemleri; Nobel Yayincilik: Ankara, Turkey, 2014. [Google Scholar]
- Ozcelik, D.A. Okullarda Ölçme ve Değerlendirme Öğretmen El Kitabı; Pegem Akademi: Ankara, Turkey, 2010. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining Concepts and Techniques; Morgan Kaufmann: Waltham, MC, USA, 2012. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Waltham, MC, USA, 2017. [Google Scholar]
- Ozkan, Y. Veri Madenciliği Yöntemleri; Papatya Bilim: Istanbul, Turkey, 2016. [Google Scholar]
- Zheng, Y. Trajectory data mining: An overview. ACM Trans. Intell. Syst. Technol. 2015, 6, 29. [Google Scholar] [CrossRef]
- Berry, M.W. Survey of Text Mining: Clustering, Classification, and Retrieval; Springer: New York, NY, USA, 2004. [Google Scholar]
- Hebrail, G.; Marsais, J. Experiments of textual data analysis at Electricite de France. In New Approaches in Classification and Data Analysis. Studies in Classification, Data Analysis, and Knowledge Organization; Diday, E., Lechevallier, Y., Schader, M., Bertrand, P., Burtschy, B., Eds.; Springer: Heidelberg, Germany, 1994; pp. 569–576. [Google Scholar]
- Feldman, R.; Dagan, I. Knowledge Discovery in Textual Databases. In Proceedings of the First International Conference on Knowledge Discovery and Data Mining, Montreal, QC, Canada, 20–21 August 1995. [Google Scholar]
- Weiss, S.M.; Indurkhya, N.; Zhang, T. Fundamentals of Predictive Text Mining; Springer: London, UK, 2015. [Google Scholar]
- Beliga, S.; Mestrovic, A.; Ipsic, M.S. An overview of graph based keyword extraction methods and approaches. J. Inf. Organ. Sci. 2015, 39, 1–20. [Google Scholar]
- Zhang, W.; Yoshida, T.; Tang, X. Text classification based on multi-word with support vector machine. Knowl. Based Syst. 2008, 21, 879–886. [Google Scholar] [CrossRef]
- Ravi, K.; Ravi, R. A survey on opinion mining and sentiment analysis: Tasks, approaches and applications. Knowl. Based Syst. 2015, 89, 14–46. [Google Scholar] [CrossRef]
- Montoyo, A.; Barco, P.M.; Balahur, A. Subjectivity and sentiment analysis: An overview of the current state of the area and envisaged developments. Decis. Support Syst. 2012, 53, 675–679. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Zhai, C.X. Mining Test Data; Springer: New York, NY, USA, 2012. [Google Scholar]
- Romero, C.; Ventura, S.; Pechenizkiy, M.; Baker, R.S. Handbook of Educational Data Mining; CRC Press, Taylor & Francis Group: Boca Raton, FL, USA, 2010. [Google Scholar]
- Baker, R.S. Educational data mining: An advance for intelligent systems in education. IEEE Intell. Syst. 2014, 29, 78–82. [Google Scholar] [CrossRef]
- Liu, S.; Lin, Y. Grey Information Theory and Practical Applications; Springer: New York, NY, USA, 2006. [Google Scholar]
- Deng, J.L. Control problems of grey systems. Syst. Control Lett. 1982, 1, 288–294. [Google Scholar]
- Liu, S.; Forrest, J.; Yang, Y. A brief introduction to grey systems theory. Grey Syst. Theory Appl. 2012, 2, 89–104. [Google Scholar] [CrossRef]
- Yildirim, B.F. Gri ilişkisel analiz. In Çok Kriterli Karar Verme Yöntemleri; Yildirim, B.F., Onder, E., Eds.; Dora Yayincilik: Bursa, Turkey, 2015; pp. 229–236. [Google Scholar]
- Fidan, H. Association rules-based grey relational approach for e-commerce recommender system. In Machine Learning Techniques for Improved Business Analytics; Kumar, G.D., Ed.; IGI Global: Hershey, PA, USA, 2019; pp. 64–93. [Google Scholar]
- Fidan, H. Grey relational classification of consumers’ textual evaluations in e-commerce. J. Theor. Appl. Electron. Commer. Res. 2020, 15, 48–65. [Google Scholar] [CrossRef]
- Fidan, H. Grey relational clustering analysis of e-commerce customers loyalty. Online Acad. J. Inf. Technol. 2018, 9, 163–182. [Google Scholar]
- Ertugrul, I.; Oztas, T.; Ozcil, A.; Oztas, G.Z. Grey relational analysis approach in academic performance comparison of university: A case study of Turkish universities. Eur. Sci. J. 2016, 128–139. [Google Scholar]
- Tsai, C.H.; Chang, C.L.; Chen, L. Applying grey relational analysis to the vendor evaluation model. Int. J. Comput. Internet Manag. 2003, 11, 45–53. [Google Scholar]
- Turney, P.D.; Pantel, P. From frequency to meaning: Vector space models of semantics. J. Artif. Intell. Res. 2010, 37, 141–188. [Google Scholar] [CrossRef]
- Ropero, J.; Gomez, A.; Carrasco, A.; Leon, C.; Luque, J. Term weighting for information retrieval using fuzzy logic. In Fuzzy Logic-Algorithms, Techniques and Implementations; Elmer, P.D., Ed.; Intech: London, UK, 2012; pp. 173–192. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Advantages | Disadvantages |
|---|---|
|
|
| Advantages | Disadvantages |
|---|---|
|
|
| Advantages | Disadvantages |
|---|---|
|
|
| Question | Student | Words (in Both Turkish and English) | |||
|---|---|---|---|---|---|
| Zihin (Mental) | Sosyal (Social) | Duygu (Emotion) | |||
| Answer key | 1 | 0 | 1 | 1 | 1 |
| 1 | 1 | 1 | 0 | 0 | |
| 1 | 2 | 0 | 0 | 0 | |
| 1 | 3 | 0 | 1 | 0 | |
| 1 | 4 | 0 | 0 | 0 | |
| 1 | 5 | 0 | 0 | 0 | |
| Student | Question-1 | Question-2 | Question-3 | Question-4 | Question-5 |
|---|---|---|---|---|---|
| 1 | 0.7436 | 0.8921 | 0.7357 | 0.8317 | 0.9022 |
| 2 | 0.7949 | 0.789 | 0.7532 | 0.8423 | 0.8903 |
| 3 | 0.7436 | 0.8769 | 0.7241 | 0.8204 | 0.8945 |
| 4 | 0.7949 | 0.7968 | 0.7815 | 0.8102 | 0.889 |
| 5 | 0.7949 | 0.7136 | 0.7616 | 0.8252 | 0.8992 |
| Student | Question-1 | Question-2 | Question-3 | Question-4 | Question-5 | Degrees |
|---|---|---|---|---|---|---|
| 1 | 0.4117 | 0.4189 | 0.5241 | 0.3874 | 0.3422 | 0.4169 |
| 2 | 0.3684 | 0.6305 | 0.4517 | 0.367 | 0.3859 | 0.4407 |
| 3 | 0.4117 | 0.4406 | 0.5863 | 0.4118 | 0.3692 | 0.4439 |
| 4 | 0.3684 | 0.6072 | 0.3692 | 0.4367 | 0.3913 | 0.4346 |
| 5 | 0.3684 | 1 | 0.4236 | 0.4011 | 0.3523 | 0.5091 |
| Evaluator Scores | Analysis Results | ||||||
|---|---|---|---|---|---|---|---|
| Student | Question-1 | Question-2 | Question-3 | Question-4 | Question-5 | Total | GRA Degrees |
| 1 | 5 | 8 | 5 | 0 | 2 | 20 | 0.4169 |
| 2 | 0 | 10 | 10 | 15 | 0 | 35 | 0.4407 |
| 3 | 15 | 12 | 10 | 0 | 0 | 37 | 0.4439 |
| 4 | 5 | 0 | 15 | 15 | 0 | 35 | 0.4346 |
| 5 | 0 | 20 | 12 | 13 | 20 | 65 | 0.5091 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuksel, M.E.; Fidan, H. A Decision Support System Using Text Mining Based Grey Relational Method for the Evaluation of Written Exams. Symmetry 2019, 11, 1426. https://doi.org/10.3390/sym11111426
Yuksel ME, Fidan H. A Decision Support System Using Text Mining Based Grey Relational Method for the Evaluation of Written Exams. Symmetry. 2019; 11(11):1426. https://doi.org/10.3390/sym11111426
Chicago/Turabian StyleYuksel, Mehmet Erkan, and Huseyin Fidan. 2019. "A Decision Support System Using Text Mining Based Grey Relational Method for the Evaluation of Written Exams" Symmetry 11, no. 11: 1426. https://doi.org/10.3390/sym11111426
APA StyleYuksel, M. E., & Fidan, H. (2019). A Decision Support System Using Text Mining Based Grey Relational Method for the Evaluation of Written Exams. Symmetry, 11(11), 1426. https://doi.org/10.3390/sym11111426