A Robust Framework for Self-Care Problem Identification for Children with Disability



Abstract
1. Introduction
2. Related Works
3. Materials and Methods
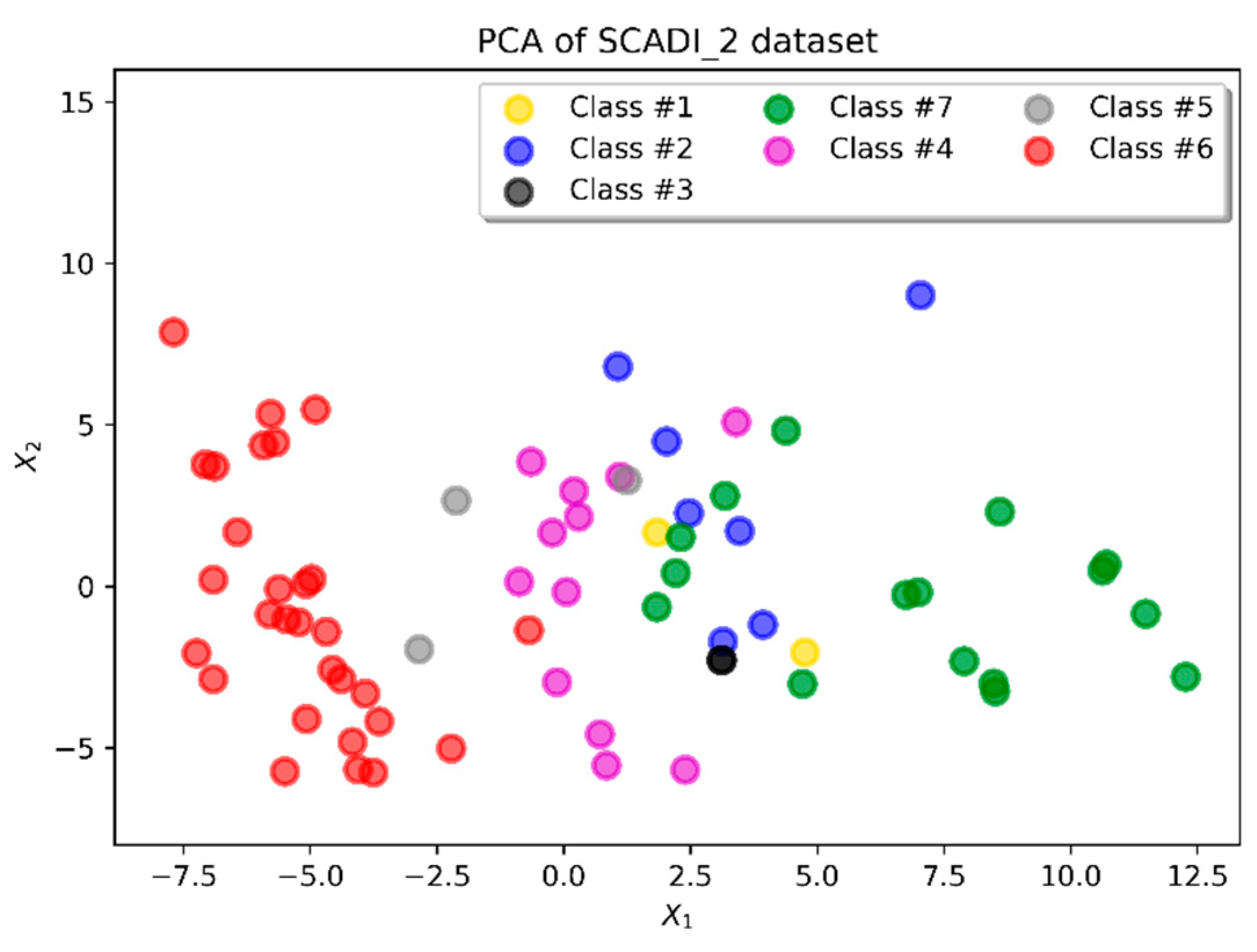
3.1. SCADI Dataset
3.2. Preprocessing
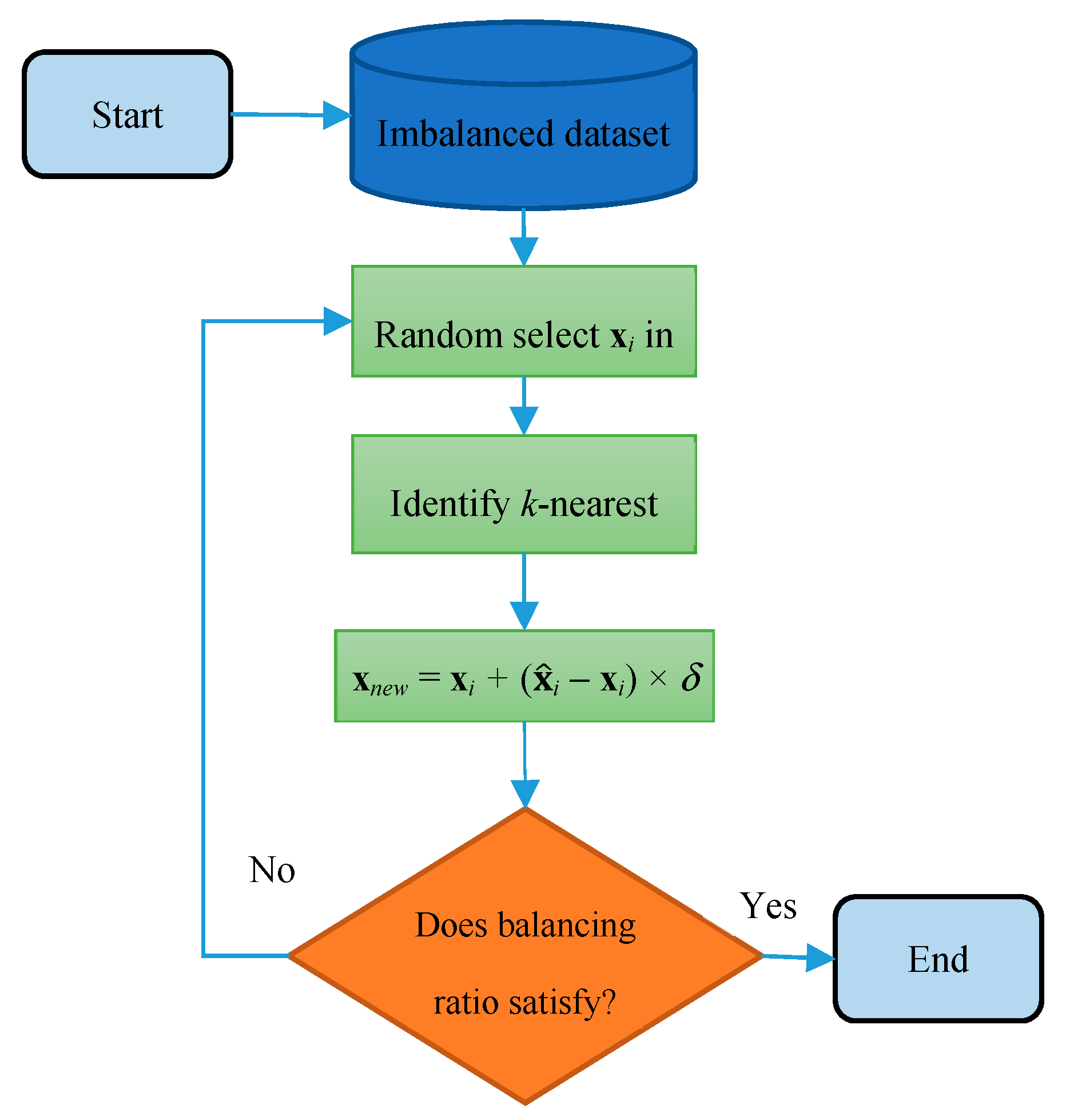
3.3. SMOTE Algorithm
3.4. Extreme Gradient Boosting
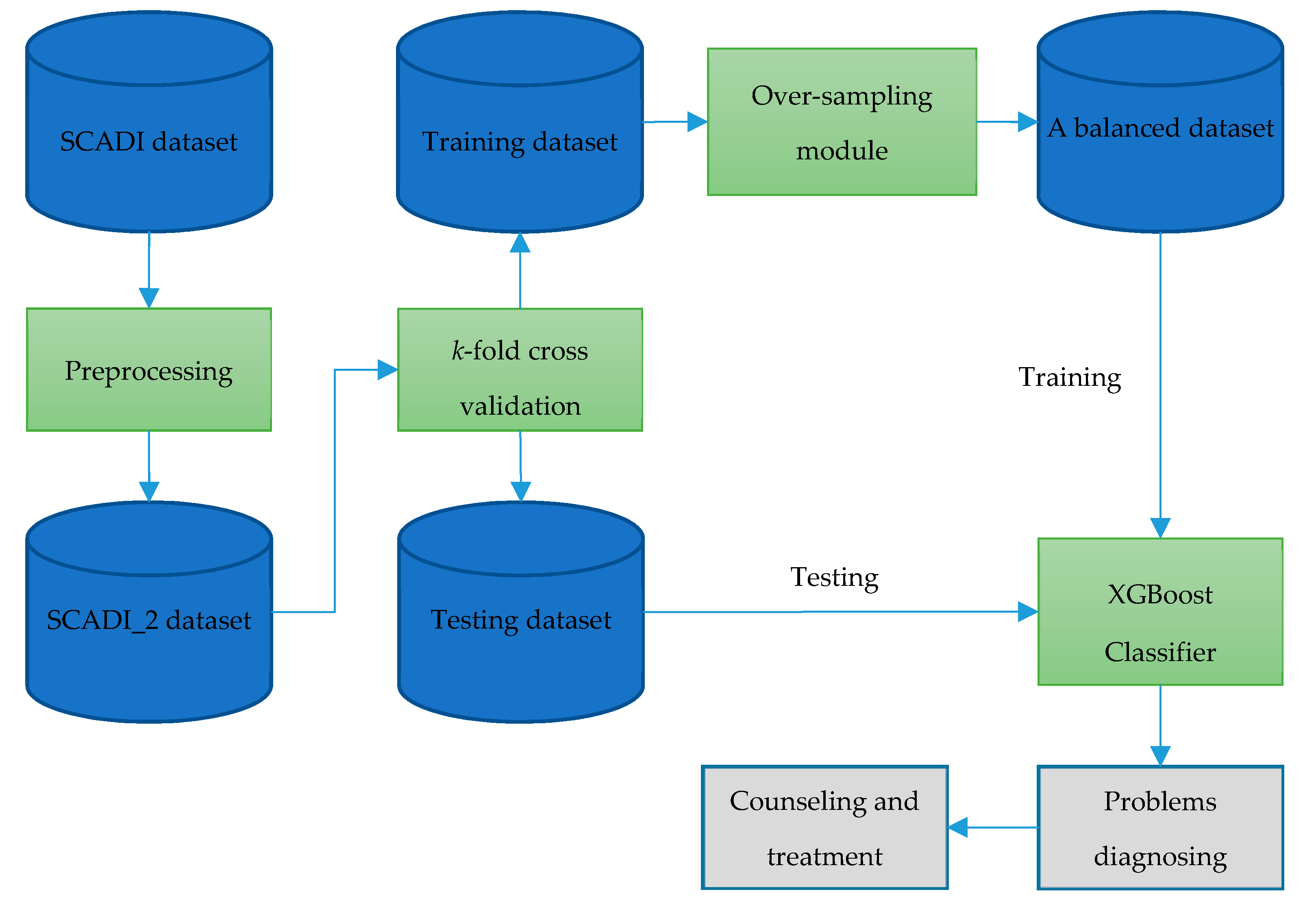
3.5. The Robust Framework
| Algorithm 1. FSX framework | |
| Input: The SCADI dataset | |
| Output: The best model for self-care problem identification and the best AUC value | |
| 1 | Let R = {0.4, 0.6, 0.8, 1.0} |
| 2 | Let the ACCbest be 0 and Mbest is ermty |
| 3 | For each r in R: |
| 4 | Spliting the SCADI dataset using k-fold cross validation. |
| 5 | Balancing the training set using SMOTE with the balancing ratio equals to r. |
| 6 | Using the balanced dataset in the previous step for training the XGBr. |
| 7 | Evaluating XGBr using the testing set and obtaining the ACCr. |
| 8 | If ACCr > ACCbest then |
| 9 | ACCbest = ACCr |
| 10 | Mbest = XGBr |
| 11 | End for |
| 12 | Return Mbest and ACCbest |
4. Results
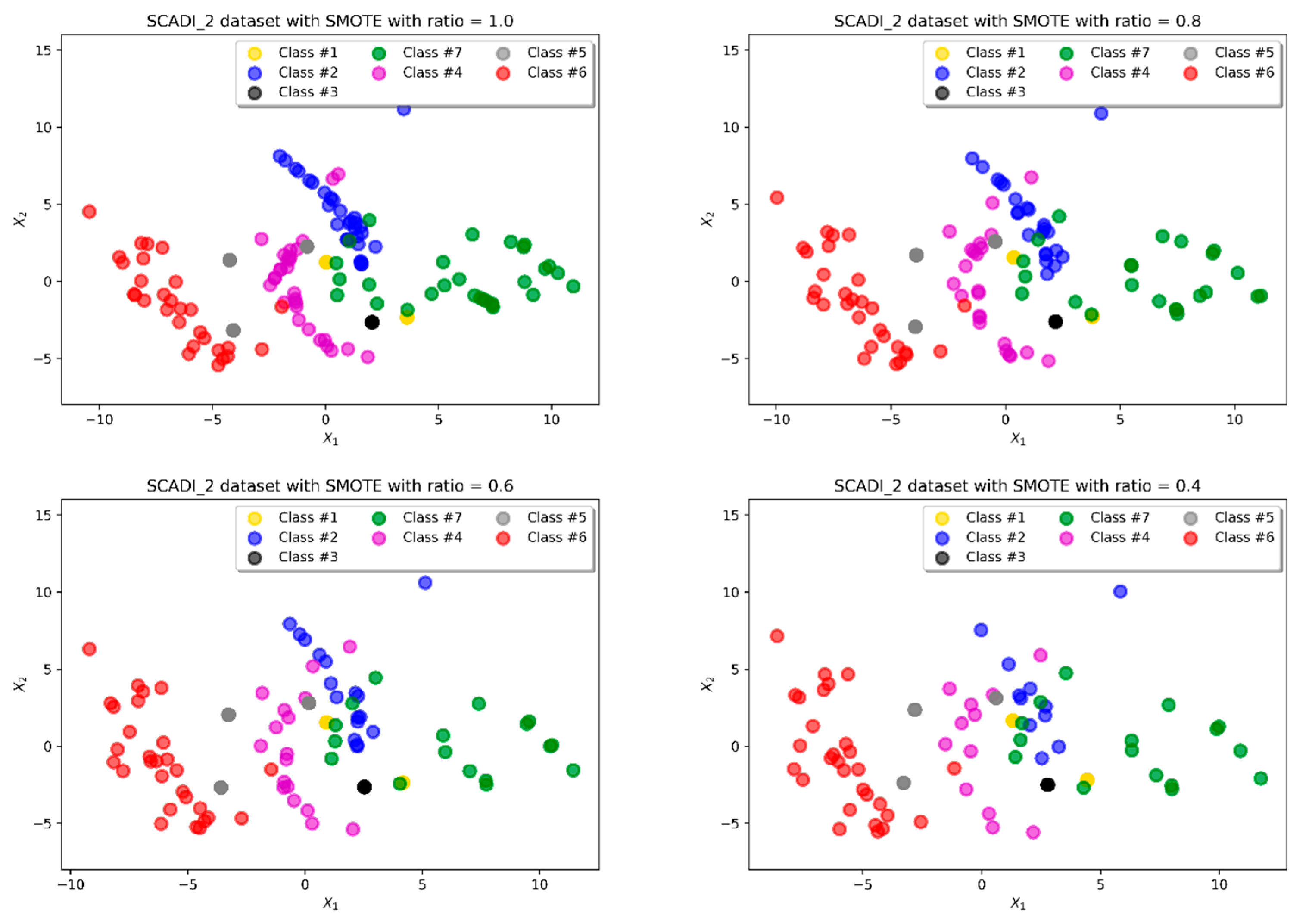
4.1. Oversampling Comparision
4.2. Performance Evaluation
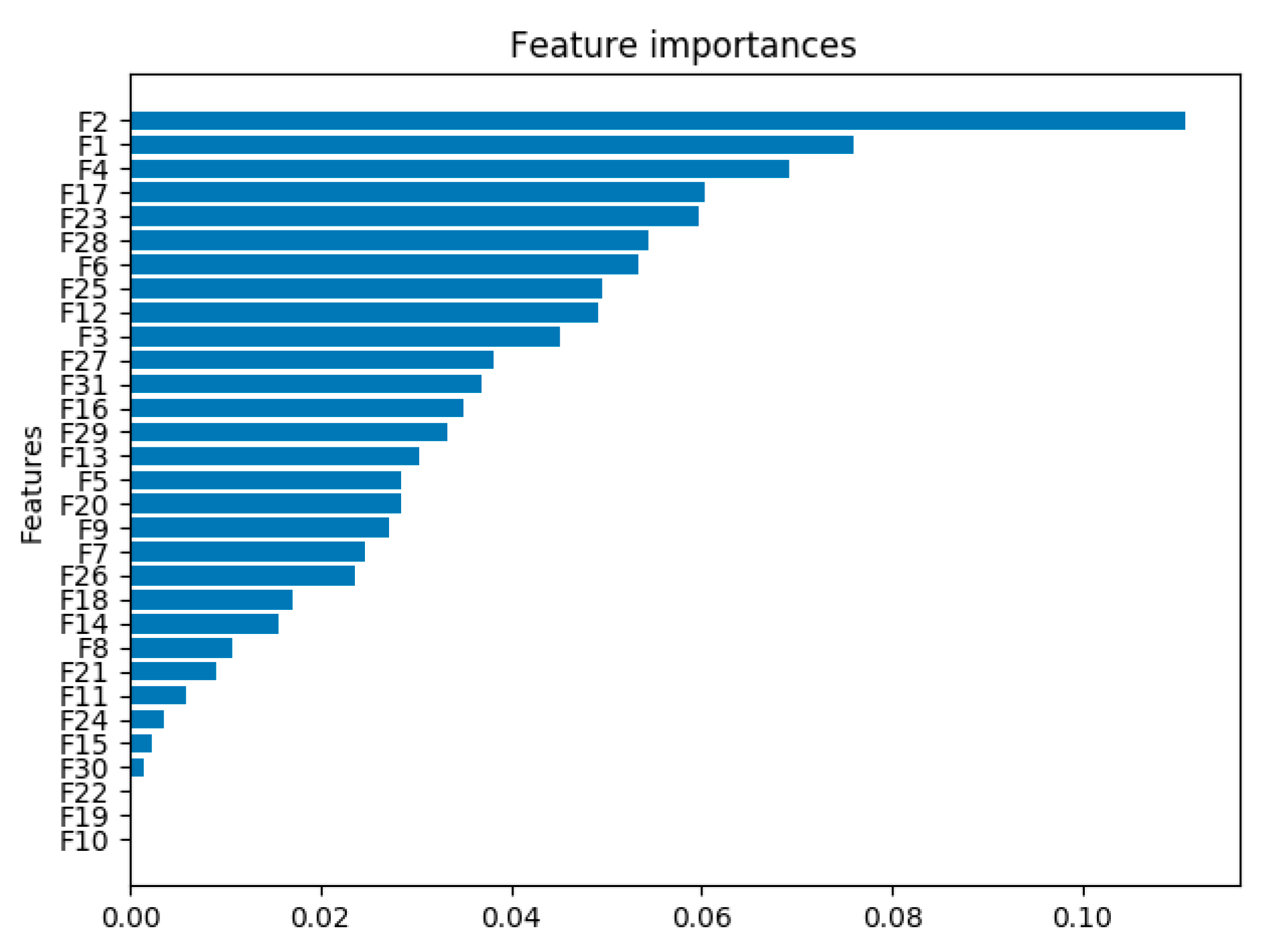
4.3. Feature Importance
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Le, T.; Le, H.S.; Vo, M.T.; Lee, M.Y.; Baik, S.W. A Cluster-Based Boosting Algorithm for Bankruptcy Prediction in a Highly Imbalanced Dataset. Symmetry 2018, 10, 250. [Google Scholar] [CrossRef]
- Le, T.; Lee, M.Y.; Park, J.R.; Baik, S.W. Oversampling techniques for bankruptcy prediction: Novel features from a transaction dataset. Symmetry 2018, 10, 79. [Google Scholar] [CrossRef]
- Le, T.; Vo, B.; Baik, S.W. Efficient algorithms for mining top-rank-k erasable patterns using pruning strategies and the subsume concept. Eng. Appl. Artif. Intell. 2018, 68, 1–9. [Google Scholar] [CrossRef]
- Roan, T.N.; Ali, M.; Le, H.S. δ-equality of intuitionistic fuzzy sets: A new proximity measure and applications in medical diagnosis. Appl. Intell. 2018, 48, 499–525. [Google Scholar]
- Le, H.S.; Tran, M.T.; Fujita, H.; Dey, N.; Ashour, A.S.; Vo, T.N.N.; Le, Q.A.; Chu, D.T. Dental diagnosis from X-Ray images: An expert system based on fuzzy computing. Biomed. Signal Process. Control 2018, 39, 64–73. [Google Scholar]
- Ali, M.; Le, H.S.; Khan, M.; Nguyen, T.T. Segmentation of dental X-ray images in medical imaging using neutrosophic orthogonal matrices. Expert Syst. Appl. 2018, 91, 434–441. [Google Scholar] [CrossRef]
- Vajda, S.; Karargyris, A.; Jäger, S.; Santosh, K.C.; Candemir, S.; Xue, Z.; Antani, S.K.; Thoma, G.R. Feature Selection for Automatic Tuberculosis Screening in Frontal Chest Radiographs. J. Med. Syst. 2018, 42, 146. [Google Scholar] [CrossRef]
- Lan, K.; Wang, D.; Fong, S.; Liu, L.; Wong, K.; Dey, N. A Survey of Data Mining and Deep Learning in Bioinformatics. J. Med. Syst. 2018, 42, 139. [Google Scholar] [CrossRef]
- Goshvarpour, A.; Goshvarpour, A. A Novel Feature Level Fusion for Heart Rate Variability Classification Using Correntropy and Cauchy-Schwarz Divergence. J. Med. Syst. 2018, 42, 109. [Google Scholar] [CrossRef]
- Pham, N.T.; Lee, J.W.; Kwon, G.R.; Park, C.S. Efficient image splicing detection algorithm based on markov features. Multimed. Tools Appl. 2018. [Google Scholar] [CrossRef]
- Le, D.H.; Pham, V.H. HGPEC: A Cytoscape app for prediction of novel disease-gene and disease-disease associations and evidence collection based on a random walk on heterogeneous network. BMC Syst. Biol. 2017, 11, 61. [Google Scholar] [CrossRef] [PubMed]
- Le, D.H.; Dao, L.T.M. Annotating Diseases Using Human Phenotype Ontology Improves Prediction of Disease-Associated Long Non-coding RNAs. J. Mol. Biol. 2018, 430, 2219–2230. [Google Scholar] [CrossRef] [PubMed]
- Malmir, B.; Amini, M.; Chang, S.I. A medical decision support system for disease diagnosis under uncertainty. Expert Syst. Appl. 2017, 88, 95–108. [Google Scholar] [CrossRef]
- Eshtay, M.; Faris, H.; Obeid, N. Improving Extreme Learning Machine by Competitive Swarm Optimization and its application for medical diagnosis problems. Expert Syst. Appl. 2018, 104, 134–152. [Google Scholar] [CrossRef]
- Turgeman, L.; May, J.; Sciulli, R. Insights from a machine learning model for predicting the hospital length of stay (los) at the time of admission. Expert Syst. Appl. 2017, 78, 376–385. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, Y.; Tzeng, G.H. Identification of key factors in consumers’ adoption behavior of intelligent medical terminals based on a hybrid modified MADM model for product improvement. Int. J. Med. Inform. 2017, 105, 68–82. [Google Scholar] [CrossRef]
- Mustaqeem, A.; Anwar, S.M.; Khan, A.R.; Majid, M. A statistical analysis-based recommender model for heart disease patients. Int. J. Med. Inform. 2017, 108, 134–145. [Google Scholar] [CrossRef]
- Lucini, F.R.; Fogliatto, F.S.; Silveira, G.J.C.; Neyeloff, J.; Anzanello, M.J.; Kuchenbecker, R.S.; Schaan, B.D. Text mining approach to predict hospital admissions using early medical records from the emergency department. Int. J. Med. Inform. 2017, 100, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Lewis Brown, R.; Turner, R.J. Physical disability and depression: Clarifying racial/ ethnic contrasts. J. Aging Health 2010, 22, 977–1000. [Google Scholar] [CrossRef]
- Lollar, D.J.; Simeonsson, R.J. Diagnosis to function: Classification for children and youths. J. Dev. Behav. Pediatrics 2005, 26, 323–330. [Google Scholar] [CrossRef]
- Lee, A.M. Using the ICF-CY to organise characteristics of children’s functioning. Disabil. Rehabil. 2011, 33, 605–616. [Google Scholar] [CrossRef] [PubMed]
- Ståhl, Y.; Granlund, M.; Gäre-Andersson, B.; Enskär, K. Review article: Mapping of children’s health and development data on population level using the classification system ICF-CY. Scand. J. Public Health 2011, 39, 51–57. [Google Scholar] [CrossRef] [PubMed]
- Organization, W.H. International Classification of Functioning, Disability, and Health: Children & Youth Version: ICF-CY; World Health Organization: Geneva, Switzerland, 2007. [Google Scholar]
- Case-Smith, J. Self-care Strategies for Children with Developmental Disabilities. In Ways of Living: Self-Care Strategies for Special Needs, 2nd ed.; Christiansen, C., Ed.; American Occupational Therapy Association: Bethesda, MD, USA, 2000; pp. 83–121. [Google Scholar]
- Ijaz, M.; Alfian, G.; Syafrudin, M.; Rhee, J. Hybrid Prediction Model for Type 2 Diabetes and Hypertension Using DBSCAN-Based Outlier Detection, Synthetic Minority Over Sampling Technique (SMOTE), and Random Forest. Appl. Sci. 2018, 8, 1325. [Google Scholar] [CrossRef]
- Bang, J.; Hur, T.; Kim, D.; Lee, J.; Han, Y.; Banos, O.; Kim, J.I.; Lee, S. Adaptive Data Boosting Technique for Robust Personalized Speech Emotion in Emotionally-Imbalanced Small-Sample Environments. Sensors 2018, 18, 3744. [Google Scholar] [CrossRef]
- Zarchi, M.S.; Fatemi Bushehri, S.M.M.; Dehghanizadeh, M. SCADI: A standard dataset for self-care problems classification of children with physical and motor disability. Int. J. Med. Inform. 2018, 114, 81–87. [Google Scholar] [CrossRef] [PubMed]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Berlin, Germany, 2018; pp. 1–377. ISBN 978-3-319-98073-7. [Google Scholar]
- Lin, Y.; Lee, Y.; Wahba, G. Support vector machines for classification in nonstandard situations. Mach. Learn. 2002, 46, 191–202. [Google Scholar] [CrossRef]
- Liu, B.; Ma, Y.; Wong, C. Improving an association rule-based classifier. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, PKDD, Lyon, France, 13–16 September 2000; pp. 293–317. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Lemaitre, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Chawla, N.; Cieslak, D.; Hall, L.; Joshi, A. Automatically countering imbalance and its empirical relationship to cost. Data Min. Knowl. Discov. 2008, 17, 225–252. [Google Scholar] [CrossRef]
- Ling, C.; Sheng, V.; Yang, Q. Test strategies for cost-sensitive decision trees. IEEE Trans. Knowl. Data Eng. 2006, 18, 1055–1067. [Google Scholar] [CrossRef]
- Galar, M.; Fernández, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for class imbalance problem: Bagging, boosting and hybrid-based approaches. IEEE Trans. Syst. Man Cybern. Part C 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Batista, G.; Prati, R.C.; Monard, M.C. A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, T. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cat No. | Self-Care Category | Activity No. | Description | Feature Name |
|---|---|---|---|---|
| I | Washing oneself | 1 | Washing body parts | F3 |
| 2 | Washing whole body | F4 | ||
| 3 | Drying oneself | F5 | ||
| II | Caring for body parts | 4 | Caring for skin | F6 |
| 5 | Caring for teeth | F7 | ||
| 6 | Caring for hair | F8 | ||
| 7 | Caring for fingernails | F9 | ||
| 8 | Caring for toenails | F10 | ||
| 9 | Caring for nose | F11 | ||
| III | Toileting | 10 | Indicating need for urination | F12 |
| 11 | Carrying out urination appropriately | F13 | ||
| 12 | Indicating need for defecation | F14 | ||
| 13 | Carrying out defecation appropriately | F15 | ||
| 14 | Menstrual care | F16 | ||
| IV | Dressing | 15 | Putting on clothes | F17 |
| 16 | Taking off clothes | F18 | ||
| 17 | Putting on footwear | F19 | ||
| 18 | Taking off footwear | F20 | ||
| 19 | Choosing appropriate clothing | F21 | ||
| V | Eating | 20 | Indicating need for eating | F22 |
| 21 | Carrying out eating appropriately | F23 | ||
| VI | Drinking | 22 | Indicating need for drinking | F24 |
| 23 | Indicating need for drinking | F25 | ||
| VII | Looking after one’s health | 24 | Ensuring one’s physical comfort | F26 |
| 25 | Managing diet and fitness | F27 | ||
| 26 | Managing medications and following health advice | F28 | ||
| 27 | Seeking advice or assistance from caregivers or professionals | F29 | ||
| 28 | Avoiding risks of abuse of drugs or alcohol | F30 | ||
| VIII | Looking after one’s safety | 29 | Looking after one’s safety | F31 |
| No. | Description | Notation |
|---|---|---|
| 1 | Caring for body parts problem | Class #1 |
| 2 | Toileting problem | Class #2 |
| 3 | Dressing problem | Class #3 |
| 4 | Washing oneself and caring for body parts and dressing problem | Class #4 |
| 5 | Washing oneself, caring for body parts, toileting and dressing problem | Class #5 |
| 6 | Eating, Drinking, washing oneself, caring for body parts, toileting, dressing, looking after one’s health and looking after one’s safety problem | Class #6 |
| 7 | No Problem | Class #7 |
| Oversampling Technique | Balancing Ratio | Accuracy |
|---|---|---|
| SMOTE | 0.4 | 0.837 |
| 0.6 | 0.837 | |
| 0.8 | 0.854 | |
| 1.0 | 0.839 | |
| SMOTE-ENN | 0.4 | 0.724 |
| 0.6 | 0.812 | |
| 0.8 | 0.822 | |
| 1.0 | 0.807 | |
| SMOTE-Tomek | 0.4 | 0.837 |
| 0.6 | 0.837 | |
| 0.8 | 0.853 | |
| 1.0 | 0.839 |
| Fold | ANN | FSX | SVM | RF |
|---|---|---|---|---|
| Fold 1 | 0.727 | 0.727 | 0.818 | 0.636 |
| Fold 2 | 1.000 | 0.800 | 0.75 | 1.000 |
| Fold 3 | 0.857 | 0.857 | 0.857 | 1.000 |
| Fold 4 | 1.000 | 1.000 | 0.833 | 0.833 |
| Fold 5 | 0.857 | 0.857 | 0.857 | 0.857 |
| Fold 6 | 0.571 | 0.771 | 0.714 | 0.714 |
| Fold 7 | 0.800 | 1.000 | 0.800 | 1.000 |
| Fold 8 | 0.667 | 0.889 | 0.667 | 0.667 |
| Fold 9 | 1.000 | 0.800 | 0.800 | 1.000 |
| Fold 10 | 0.667 | 0.833 | 0.833 | 0.667 |
| Average | 0.815 | 0.854 | 0.793 | 0.837 |
| Fold | Sensitivity | Specificity | ||||||
|---|---|---|---|---|---|---|---|---|
| ANN | FSX | SVM | RF | ANN | FSX | SVM | RF | |
| Fold 1 | 0.643 | 0.875 | 0.714 | 0.428 | 0.948 | 0.958 | 0.966 | 0.935 |
| Fold 2 | 1.000 | 0.700 | 0.600 | 1.000 | 1.000 | 0.975 | 0.950 | 1.000 |
| Fold 3 | 0.875 | 1.000 | 0.875 | 1.000 | 0.938 | 1.000 | 0.958 | 1.000 |
| Fold 4 | 1.000 | 0.583 | 0.889 | 0.889 | 1.000 | 0.955 | 0.933 | 0.930 |
| Fold 5 | 0.600 | 0.572 | 0.600 | 0.750 | 0.971 | 0.944 | 0.971 | 0.958 |
| Fold 6 | 0.500 | 0.667 | 0.625 | 0.625 | 0.875 | 0.889 | 0.917 | 0.917 |
| Fold 7 | 0.889 | 0.600 | 0.667 | 1.000 | 0.917 | 0.967 | 0.950 | 1.000 |
| Fold 8 | 0.572 | 1.000 | 0.571 | 0.571 | 0.940 | 1.000 | 0.946 | 0.940 |
| Fold 9 | 1.000 | 1.000 | 0.500 | 1.000 | 1.000 | 1.000 | 0.950 | 1.000 |
| Fold 10 | 0.600 | 0.572 | 0.800 | 0.600 | 0.910 | 0.939 | 0.960 | 0.920 |
| Average | 0.768 | 0.757 | 0.684 | 0.786 | 0.950 | 0.963 | 0.950 | 0.960 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, T.; Baik, S.W. A Robust Framework for Self-Care Problem Identification for Children with Disability. Symmetry 2019, 11, 89. https://doi.org/10.3390/sym11010089
Le T, Baik SW. A Robust Framework for Self-Care Problem Identification for Children with Disability. Symmetry. 2019; 11(1):89. https://doi.org/10.3390/sym11010089
Chicago/Turabian StyleLe, Tuong, and Sung Wook Baik. 2019. "A Robust Framework for Self-Care Problem Identification for Children with Disability" Symmetry 11, no. 1: 89. https://doi.org/10.3390/sym11010089
APA StyleLe, T., & Baik, S. W. (2019). A Robust Framework for Self-Care Problem Identification for Children with Disability. Symmetry, 11(1), 89. https://doi.org/10.3390/sym11010089