4.1. Illustrative Examples for DHFEs
In this section, we will make some analyses on the differences and similarities of the three weighting methods by using specific DHFEs.
Example 1. For a decision-making problem, nine expertsare invited to evaluate the performance of the employee A for his/her annual work, and the experts’ opinions are expressed in the form of DHFEs as follows: Then, we need to deal with the decision information, and there are two steps for the implementation of the proposed method presented as follows:
Step 1. Calculate the mean and the standard deviation according to the Euclidean distance Equation(4), respectively: = {{0.544,0.411,0.389}, {0.411,0.389,0.367}}, and = 0.189.
Step 2. Determine the experts’ weights by using Equations (8), (10) and (13) respectively. Thus, the gained weights for
are listed in
Table 1.
From
Table 1, it is clear that the weighting strategies of the three methods are similar. They all assign the highest weights to
which is the nearest to the mean
and assign the lowest weights to
which is the furthest one to the mean
. To get a full understanding of these methods, in the following, some comparisons among them will be shown as follows:
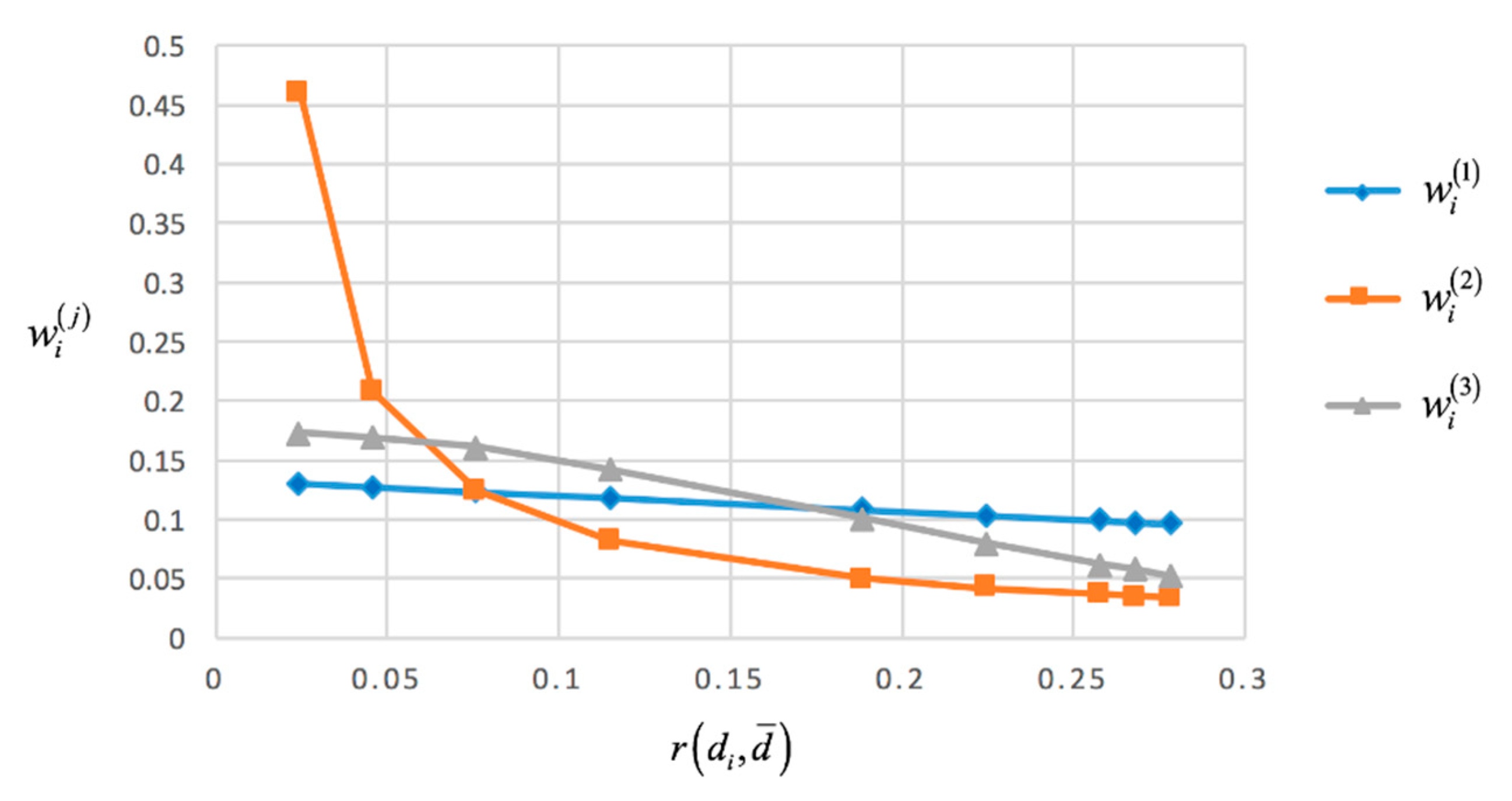
Case 1. Comparisons among the three methods with respect to the distances
. To provide a clear analysis of them, we put the weights of the DHFEs
obtained from these three proposed methods, respectively, into
Figure 1.
From
Figure 1, we can find some similarities and differences between the three weighting methods: (1) For all of the three methods, the weights decrease when the distances increase, that is to say, the further the distance between
and
is, the lower the weight is; (2) It is obvious that the degrees of the divergence of these weights
derived from different methods are different. Among them, the degree of the divergence of
is the biggest one and the degree of the divergence of
is the smallest one, correspondingly, the degree of the divergence of
derived by Equation(13) is in the middle.
It is also clear from
Figure 1 that both the highest weight
= 0.461 and the lowest weight
= 0.034 are obtained by Equation (10). Meanwhile, for
, the highest weight is
= 0.130 and the lowest weight is
= 0.096. The main reason for this difference is that
are inverse proportional functions which are sensitive to small numbers and
are small numbers within 0 and 1. On the contrary,
are linear functions which are less sensitive to even tiny change. Generally, if you want to emphasize the DHFEs near to the mean (mid one(s)), the method based on the inverse proportional function is available. On the other hand, if you want to emphasize both the whole and some individuals, the method based on the linear function is better.
In the existing literature, a classical weighting method called normal distribution weighting method [
36] (for convenience, here we call it Xu’s method), which is designed for the OWA operator primordially, has been widely used for determining the weights. Its main idea that assigns higher weights to the mid one(s) and assigns lower weights to the biased ones is similar to the above three methods. Therefore, in the following, we will take some comparisons among them.
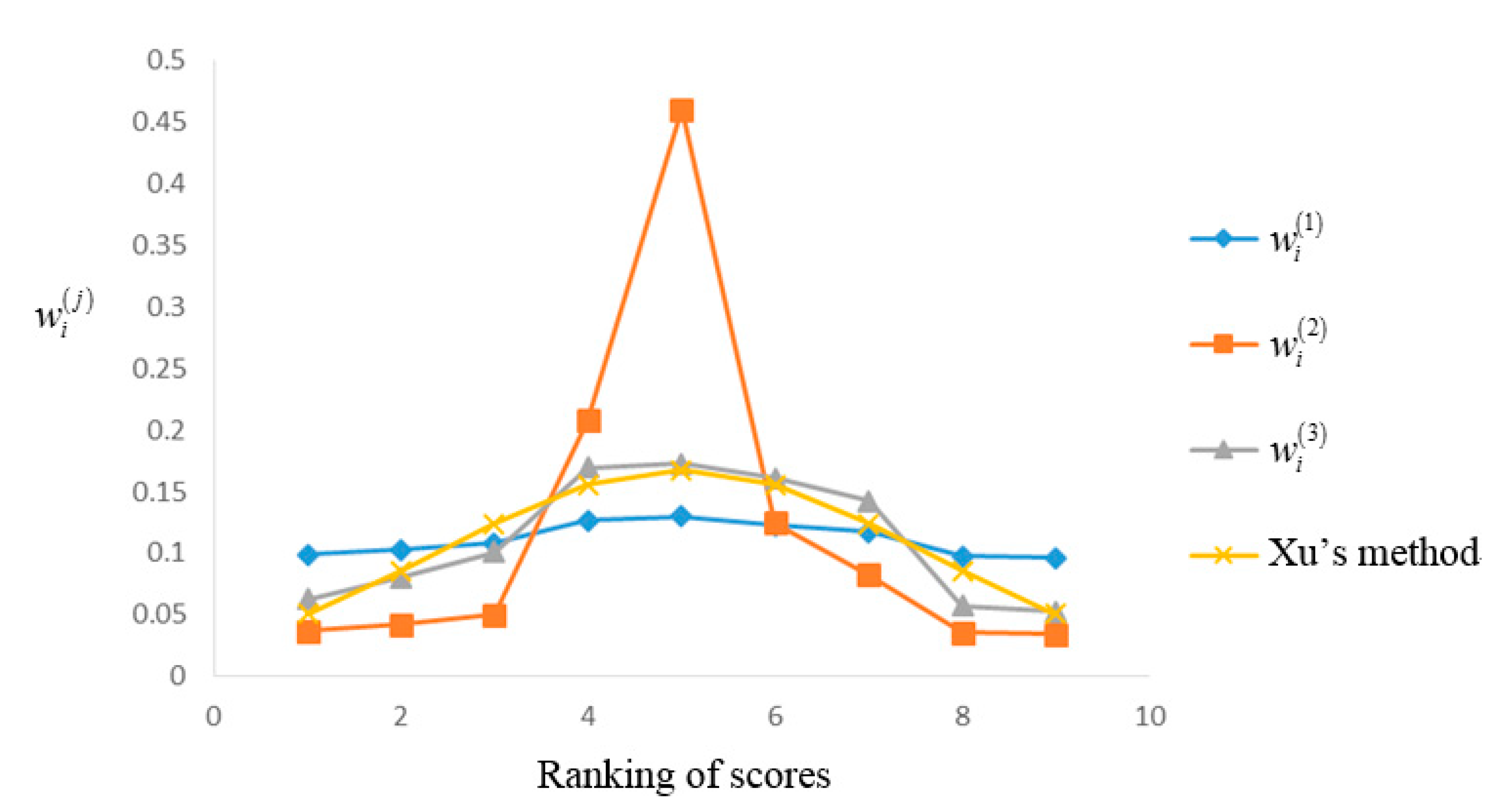
Case 2. Comparisons among the three methods and Xu’s method with respect to the ranking of scores. Since Xu’s method is designed for the OWA operator, then in order to conduct some comparisons, we first rank the DHFEs
based on the technique [
4] as follows:
.
Then, according to Xu’s method, the vector of these DHFEs’ weights is
= (0.051, 0.086, 0.124, 0.156, 0.168, 0.156, 0.124, 0.086, 0.051) relying on the ranking of the scores. Thus, we can describe the relationships among the four weighting methods in
Figure 2.
Based on
Figure 2, it is clear that the method based on the normal distribution for DHFEs is similar to Xu’s method, for example, the weights assigned by the two methods to the mid one
are 0.173 and 0.168 respectively. Furthermore, compared with the three weighting methods, when the number of arguments is known, the weight vector of Xu’s method is certain and its graph is symmetrical, while the weight vectors of our proposed three methods are uncertain and the weights will change a little with the values of the attributes. In general, among the four methods, the graph of the inverse proportional function-based method is the sharpest, and the linear function-based method is the smoothest.
Example 2. The decision strategy for recruitment interview of product manager. The product manager is a position to discover and guide a product that is valuable, usable, and feasible which is also the main bridge between business, technology, and user experience, especially in technology companies [47]. It is so crucial for an enterprise to choose the right person for this position that his decisions will not only help enterprise to create great wealth but also conciliate the opportunities of scientific development for the enterprise. Normally, the recruitment interview for the right person are done by several decision-makers from different positions. Due to their diversities in knowledge backgrounds, cognitive levels, psychological states, etc., their opinions are susceptible to the cognitive bias, and are always hesitant and vague. In this situation, (1) DHFS is an effective tool for the description of the hesitant and vague data. For example, Sahin and Liu [48] applied the DHFSs to solve the investment decision-making problems, Ren and Wei [12] used the DHFSs to describe the indexes in teacher evaluation system. With the use of the dual hesitant fuzzy information, Liang et al. further developed the three-way Decisions [11]. (2) The distribution-based weighting methods mentioned above will be feasible to reduce the negative effect caused by the biased data. Therefore, in the decision strategy for recruitment interview of product manager, according to the dual hesitant fuzzy data provided by the experts, we can use the distribution-based weighting methods to obtain the weight of each expert, then calculate the final scores of the candidates, and finally get the right person for this position. Assume that there are five candidates
to be selected, and the decision committee includes four experts from different departments: (1)
is from board of directors; (2)
is from the technology department; (3)
is a product manager from the same level; and (4)
is from personal department. The assessments of the five candidates
provided by the four experts are in the form of DHFEs
(
) listed in
Table 2 (i.e., the decision matrix
).
Part 1. Evaluation process to choose the appropriate product manager.
The solving method is presented as follows:
Step 1. Calculating weights. Using the hamming distance in Equation (3), we can get the weights of the experts derived from Equations (8), (10) and (13) respectively as follows:
As shown in
Table 3,
Table 4 and
Table 5, these weights of the experts
are determined respectively according to the assessed values of the five candidates.
Step 2. Evaluations. We use Equations (1) and (2) to calculate the final scores of the candidates
. For convenience, we assume that
,
and
represent the aggregated values obtained by the DHFWA operator using
,
and
respectively, and
,
and
are obtained by the DHFWG operator using
,
and
correspondingly. The results are shown in
Table 6:
According to the ranking results in
Table 7, it is clear that the candidate
is more suitable than others for this enterprise no matter using what weighting method and aggregation operator, meanwhile, the ranking results for the five candidates are similar.
Part 2. Discussion
In this section, we shall analyze the influence of the weighting methods. To do so, we compare the entropy-based method [
49] with our distribution-based methods.
(1) General analysis
As is shown in
Table 7, the ranking results using the DHFWA operator are the same. Since the same operators are adopted, then the ranking results are greatly influenced by the weight values. Based on
Table 3,
Table 4 and
Table 5, no matter which weight formulas are used, the change trends of the weights are the same. So, we get the same rankings according to the DHFWA operator. However, there is also little difference among the rankings obtained by the DHFWG operator. The main reason is that the DHFWG operator is more sensitive to small numbers between 0 and 1.
(2) Comparative analysis
The traditional entropy method [
49] which assigns low weight values to the attributes with high entropies can also be applied in this decision-making problem. So, we make some comparisons between the entropy-based methods [
49] and the proposed distribution-based methods.
First, we calculate the entropies for DHFEs in
Table 2, and the entropy formula [
9] is shown below:
What needs to be explained is that if
, then we extend
by repeating its maximum element until it has the same length with
. Conversely, if
, then an extension of
is to repeat its minimum element until it has the same length with
[
9].
Then, we calculate the entropy weights basing on the classical formula shown as:
To distinguish these entropy weights from others, we use the symbol
for them which are listed in
Table 8:
Using the DHFWA operator, the final ranking result in
Table 9. is
and
is taken for the best person for the product manager position.
Compared with the rankings in
Table 7, there are two different decisions for the right person. The main reason is that the entropy-based method focuses on reducing the uncertainty in the decision-making process; however, the distribution-based method aims to relieve the impact of the bias information.
Generally speaking, from the above examples, it can be concluded that the three weighting methods highlighting the mid one(s), which coincide with the majority rule in the real life, are valid for DHFEs. Therefore, in the following, we will explore whether these weighting methods can be extended to accommodate the HFEs.
4.2. Illustrative Examples for HFEs
To detect the validity of our methods for HFEs, we transform the DHFEs in Examples 1 and 2 into HFEs, and then take some comparisons.
Example 3. In this example, we want to find out whether the proposed weighting methods mentioned before are valid when the opinions of experts are expressed by the HFEs. Therefore, first, we should reduce the DHFEs in Example 1 to HFEs as follows: Then, following the procedure in Example 1, we get the following steps:
Step 1. Calculate the mean
and the variance
of these HFEs:
and the Euclidean distance Equation (16) is adopted.
Step 2. With using Equations (19), (21) and (22), the appropriate weights of
are determined, which are listed in
Table 7.
Analyzing
Table 10, we find that the weighting results for the HFEs are similar to the weighting results for the DHFEs, while they all assign the highest weight to the expert
and assign the lowest weight to the expert
. Moreover, both the highest weight
= 0.463 and the lowest weight
= 0.041 are derived from the method based on the inverse proportional function. However, for the loss of some information, there is also little difference among the methods for the HFEs and the methods for the DHFEs. For example, the ranking of the weights for
is the sixth in the methods for HFEs, while it is the eighth in the methods for DHFEs.
Example 4. We attempt to use the new weighting methods to solve the decision-making problem which is mentioned in Example 2 supposing that the decision-making information is in the form of HFSs. The main process is to obtain the weights of experts using the distribution-based weighting methods, then aggregate these data provided by these experts to calculate the final scores for these candidates. First, the experts’ opinions which are demonstrated with DHFEs should be reduced to HFEs, and then we get the hesitant fuzzy decision matrix as shown in Table 11. Because the HFEs which are lack of the non-membership degree information can be seen as the special cases of DHFEs, our discussion will focus on the two aspects as: (1) detecting the effectiveness of the three weighting methods for HFEs, and (2) discussing whether less information will influence the ranking results or not.
Using Equations (19), (21) and (22) and the HFWA operator and the HFWG operator defined in Ref. [
29], we can calculate the aggregation results and the rankings of arguments
. For convenience, let the
and the
be the aggregation values obtained from the HFWA operator and the HFWG operator, using the Hamming distances for HFEs, respectively. In the end, the ranking results which are derived from Ref. [
29] are got, as listed in
Table 12.
With the results in
Table 13, it is certain that the three weighting methods based on HFEs are valid in decision-making, and the candidate
is deemed to be the best choice which is the same as the results in
Table 7. Secondly, when the HFWA operator is used, the rankings getting from different weights are coincident. As for the HFWG operator, the ranking results vary with the weight vectors slightly. Finally, compared with the results in
Table 7, although they reach an agreement on the right person, the rankings of the other arguments are not the same. The primary reason can be ascribed to the loss of the negation information which always play great role in decision-making.





{kind=link}
{kind=link}