Neural Relation Classification Using Selective Attention and Symmetrical Directional Instances


Abstract
:1. Introduction
- *
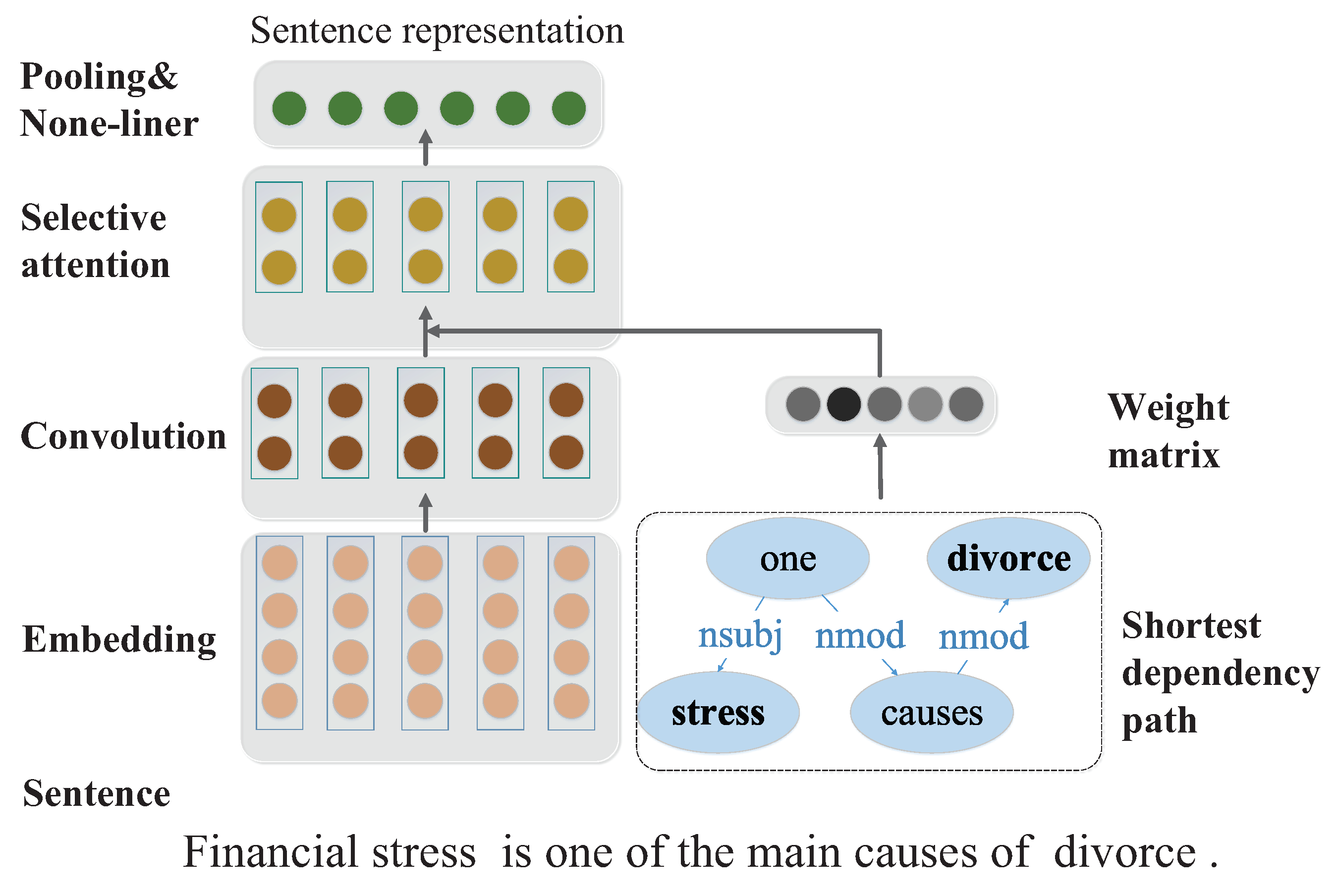
- For the first limitation, we propose a CNN-based sentence encoder integrated with a selective attention layer, which leverages the shortest dependency path to help find keywords closely related to desired relations.
- *
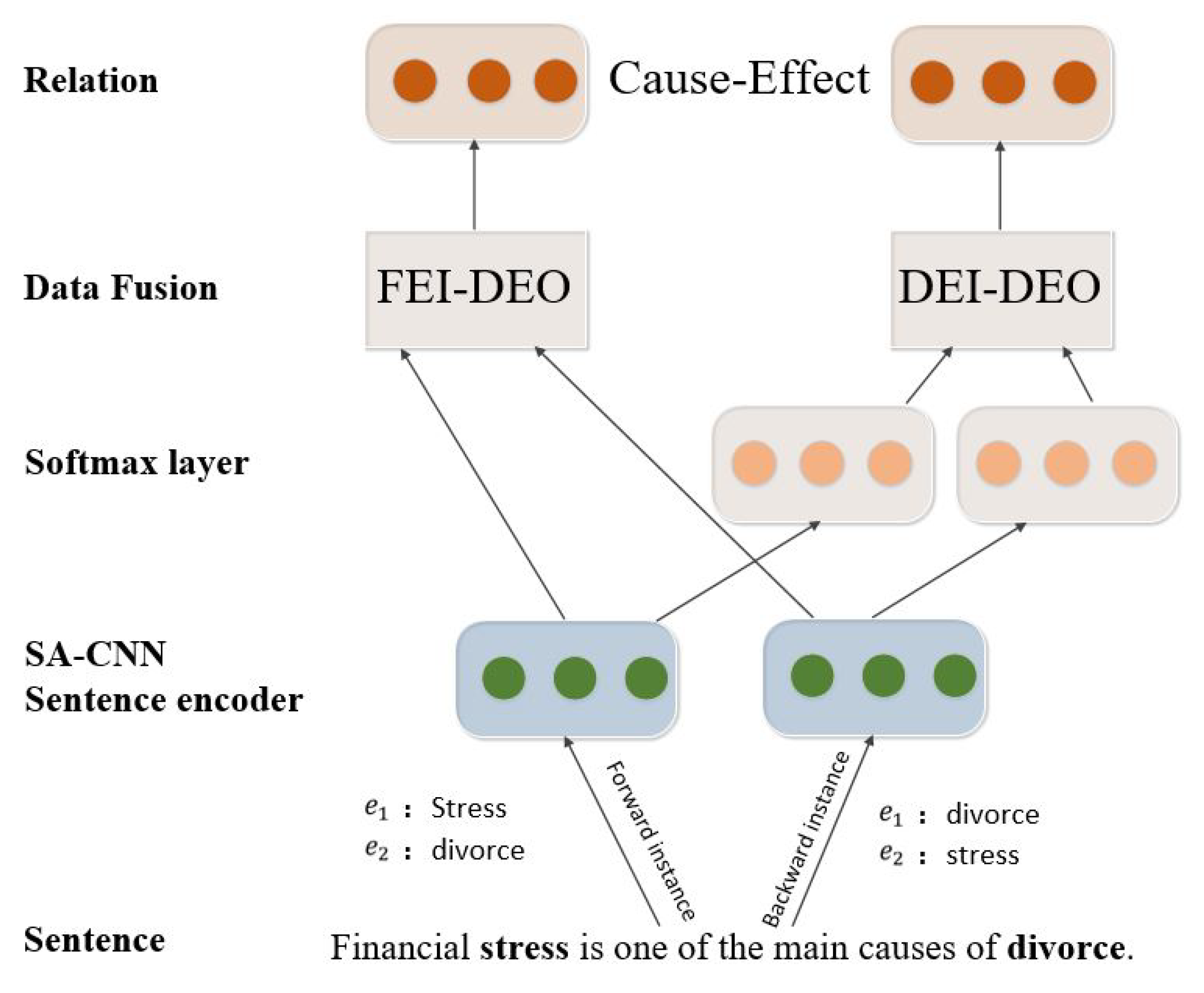
- For the second limitation, we reconstruct the multi-classification framework via information fusion for accurate RC, such that symmetrical directional instances are consolidated for data argumentation.
- *
- The proposed techniques constitute a novel method, and comprehensive experimental study indicates that the proposed model achieves state-of-the-art results on F1 score over the SemEval-2010 Task 8 dataset.
2. Related Work
3. Proposed Method
3.1. Sentence Encoder
3.2. Classification Framework
4. Experiment
4.1. Baselines
- *
- SVM [1] leverages hand-designed features to describe sentence features and then uses the SVM classifier to judge the relation type between different entities.
- *
- FCM [24] utilizes word embedding, dependency parse, NERtools and multi-layer perceptron (MLP) to extract latent features, and then, a softmax layer is leveraged to predict the output relation label.
- *
- CNN [2] is a simple and effective model that comprises a standard convolution layer with filters of four window sizes, followed by a softmax layer for classification.
- *
- CR-CNN [13] is an improved model that designs a ranking-based classifier with a novel pairwise loss function to reduce the impact of “Other” classes.
- *
- depLCNN+ NS [14] proposes a straightforward negative sampling to reduce irrelevant information introduced when subjects and objects are at a long distance.
- *
- Bi-LSTM-RNN [22] utilizes a bi-directional long-short-term-memory recurrent-neural network (Bi-LSTM-RNN) model based on low-cost sequence features to extract latent features where the features are divided into five parts: two entities and their three contexts.
- *
- RNN [21] leverages a hierarchical recurrent neural network with attention mechanism to extract the latent features between entities, and a softmax function is used to predict the relation type.
- *
- ATT-Bi-LSTM [19] leverages attention-based Bi-LSTM to capture semantic information and judge the importance of each position in a sentence.
4.2. Analysis of the Proposed Method
4.3. Evaluation against State-of-the-Art Competitors
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rink, B.; Harabagiu, S.M. UTD: Classifying Semantic Relations by Combining Lexical and Semantic Resources. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala University, Uppsala, Sweden, 15–16 July 2010; pp. 256–259. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation Classification via Convolutional Deep Neural Network. In Proceedings of the 25th International Conference on Computational Linguistics (COLING 2014), Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Kambhatla, N. Combining lexical, syntactic, and semantic features with maximum entropy models for extracting relations. In Proceedings of the ACL 2004 on Interactive Poster and Demonstration Sessions, Barcelona, Spain, 21–26 July 2004. [Google Scholar]
- Bunescu, R.C.; Mooney, R.J. Subsequence Kernels for Relation Extraction. In Proceedings of the Advances in Neural Information Processing Systems 18 (NIPS 2005), Vancouver, BC, Canada, 5–8 December 2005; pp. 171–178. [Google Scholar]
- Zelenko, D.; Aone, C.; Richardella, A. Kernel Methods for Relation Extraction. J. Mach. Learn. Res. 2003, 3, 1083–1106. [Google Scholar]
- Zhao, X.; Xiao, C.; Lin, X.; Zhang, W.; Wang, Y. Efficient structure similarity searches: A partition-based approach. VLDB J. 2018, 27, 53–78. [Google Scholar] [CrossRef]
- Culotta, A.; Sorensen, J.S. Dependency Tree Kernels for Relation Extraction. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; pp. 423–429. [Google Scholar]
- Bunescu, R.C.; Mooney, R.J. A Shortest Path Dependency Kernel for Relation Extraction. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing (HLT/EMNLP 2005), Vancouver, BC, Canada, 6–8 October 2005; pp. 724–731. [Google Scholar]
- Zhou, G.; Zhang, M.; Ji, D.; Zhu, Q. Tree Kernel-Based Relation Extraction with Context-Sensitive Structured Parse Tree Information. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL 2007), Prague, Czech Republic, 28–30 June 2007; pp. 728–736. [Google Scholar]
- Ren, F.; Li, Y.; Zhao, R.; Zhou, D.; Liu, Z. BiTCNN: A Bi-Channel Tree Convolution Based Neural Network Model for Relation Classification. In Proceedings of the Natural Language Processing and Chinese Computing-7th CCF International Conference (NLPCC 2018), Hohhot, China, 26–30 August 2018; pp. 158–170. [Google Scholar]
- Suárez-Paniagua, V.; Segura-Bedmar, I.; Aizawa, A. UC3M-NII Team at SemEval-2018 Task 7: Semantic Relation Classification in Scientific Papers via Convolutional Neural Network. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 793–797. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Dos Santos, C.N.; Xiang, B.; Zhou, B. Classifying Relations by Ranking with Convolutional Neural Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1, pp. 626–634. [Google Scholar]
- Xu, K.; Feng, Y.; Huang, S.; Zhao, D. Semantic Relation Classification via Convolutional Neural Networks with Simple Negative Sampling. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP 2015), Lisbon, Portugal, 17–21 September 2015; pp. 536–540. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation Extraction: Perspective from Convolutional Neural Networks. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, VS@NAACL-HLT 2015, Denver, CO, USA, 31 May–5 June 2015; pp. 39–48. [Google Scholar]
- Shen, Y.; Huang, X. Attention-Based Convolutional Neural Network for Semantic Relation Extraction. In Proceedings of the 26th International Conference on Computational Linguistics (COLING 2016), Osaka, Japan, 11–16 December 2016; pp. 2526–2536. [Google Scholar]
- Xu, Y.; Mou, L.; Li, G.; Chen, Y.; Peng, H.; Jin, Z. Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Paths. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP 2015), Lisbon, Portugal, 17–21 September 2015; pp. 1785–1794. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Combining Neural Networks and Log-linear Models to Improve Relation Extraction. arXiv, 2015; arXiv:1511.05926. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 2. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1. [Google Scholar]
- Xiao, M.; Liu, C. Semantic Relation Classification via Hierarchical Recurrent Neural Network with Attention. In Proceedings of the 26th International Conference on Computational Linguistics (COLING 2016), Osaka, Japan, 11–16 December 2016; pp. 1254–1263. [Google Scholar]
- Li, F.; Zhang, M.; Fu, G.; Qian, T.; Ji, D. A Bi-LSTM-RNN Model for Relation Classification Using Low-Cost Sequence Features. arXiv, 2016; arXiv:1608.07720. [Google Scholar]
- Hashimoto, K.; Miwa, M.; Tsuruoka, Y.; Chikayama, T. Simple Customization of Recursive Neural Networks for Semantic Relation Classification. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP 2013), Seattle, WA, USA, 18–21 October 2013; pp. 1372–1376. [Google Scholar]
- Yu, M.; Gormley, M.; Dredze, M. Factor-based compositional embedding models. In Proceedings of the NIPS Workshop on Learning Semantics, Montreal, QC, Canada, 8–13 December 2014; pp. 95–101. [Google Scholar]
- Socher, R.; Huval, B.; Manning, C.D.; Ng, A.Y. Semantic Compositionality through Recursive Matrix-Vector Spaces. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL 2012), Jeju Island, Korea, 12–14 July 2012; pp. 1201–1211. [Google Scholar]
- Liu, Y.; Li, S.; Wei, F.; Ji, H. Relation Classification Via Modeling Augmented Dependency Paths. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1589–1598. [Google Scholar] [CrossRef]
- Wang, L.; Cao, Z.; de Melo, G.; Liu, Z. Relation Classification via Multi-Level Attention CNNs. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1. [Google Scholar]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv, 2012; arXiv:1212.5701. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Additional Features | F1 |
|---|---|---|
| POS, prefixes, morphological, WordNet, | ||
| SVM [1] | Levin classed, ProBank, FramNet, NomLex-Plus, | 82.2 |
| Google n-gram, paraphrases, TextRunner | ||
| FCM [24] | word, dependency parsing, NER | 83.0 |
| CNN [2] | words around entities, WordNet | 82.7 |
| CR-CNN [13] | words, word position | 84.1 |
| depLCNN+ NS [14] | WordNet, words around entities | 85.6 |
| RNN [21] | words, position indicators | 79.6 |
| Bi-LSTM-RNN [22] | word, char, POS, WordNet, dependency, POS | 83.1 |
| ATT-Bi-LSTM [19] | WordNet, grammar | 83.7 |
| SA-CNN + DI | words, dependency | 85.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, Z.; Li, B.; Huang, P.; Ge, B.; Xiao, W. Neural Relation Classification Using Selective Attention and Symmetrical Directional Instances. Symmetry 2018, 10, 357. https://doi.org/10.3390/sym10090357
Tan Z, Li B, Huang P, Ge B, Xiao W. Neural Relation Classification Using Selective Attention and Symmetrical Directional Instances. Symmetry. 2018; 10(9):357. https://doi.org/10.3390/sym10090357
Chicago/Turabian StyleTan, Zhen, Bo Li, Peixin Huang, Bin Ge, and Weidong Xiao. 2018. "Neural Relation Classification Using Selective Attention and Symmetrical Directional Instances" Symmetry 10, no. 9: 357. https://doi.org/10.3390/sym10090357
APA StyleTan, Z., Li, B., Huang, P., Ge, B., & Xiao, W. (2018). Neural Relation Classification Using Selective Attention and Symmetrical Directional Instances. Symmetry, 10(9), 357. https://doi.org/10.3390/sym10090357