1. Introduction
Detailed knowledge of the characteristics of probability models is desirable (if not essential) if data are to be modeled properly. In studying these properties, many authors have considered orderings within probability distribution families, according to diverse measuring criteria. The usual approach taken by researchers in this field is to evaluate or measure one or more theoretical characteristics of a given distribution and to study the effect produced by the value of its parameters on this measurement. In actuarial science, stochastic orders are widely used in order to make risk comparisons [
1].
Some parametric distributions can be ordered according to the evaluation made of a given property, merely by comparing some of its parameters. Although most related orders are actually preorders, each one presents interesting applications. Many studies have been conducted in this area, and the following are particularly significant: Lehmann (1955) [
2], which is of seminal importance; Arnold (1987) [
3], who compared random variables according to stochastic ordering in a particular Lorenz order; Shaked and Shanthikumar (2006) [
1], on stochastic orders; Nanda and Shaked (2001) [
4], on reversed hazard rate orders; Ramos-Romero and Sordo-Díaz (2001) [
5], on the likelihood ratio order; and Gupta and Aziz (2010) [
6], on convex orders.
In this paper, we study the relationship between the skewness of some parametric distributions and the value of one of their parameters. The first question to be addressed is that of measuring the skewness. In this respect, Oja (1981) [
7] introduced a set of axioms to be verified by any measurement of skewness considered. These axioms were established for indexes of skewness with one main constraint: that the skewness of a distribution should be evaluated by a single real number. This point is discussed below.
Many authors have proposed and obtained different descriptive elements to measure skewness (see, for instance, [
8,
9,
10,
11,
12,
13]). Ref [
10] suggested a measurement of skewness corresponding to the (unique) mode,
M, given by the following index:
Ref [
10] applied this index to ordering the gamma, log-logistic, lognormal and Weibull families of distributions by their skewness, taking into account the feasible values of their respective parameters. Index (
1), which is proven to satisfy those axioms derived from Oja (1981) [
7], is also recommended in [
14] as a (very) good index of skewness. However, notice that (
1) only compares the probability weight on the left side of a central point (the mode) with the value
, but it does not account for how the weights are distributed to each side of the centre.
García et al. (2015) [
15] introduced some further elements to be incorporated into the list of skewness measurements of a probability distribution. According to these authors, given a unimodal probability distribution
, its skewness is considered to be a local function of a given distance,
z, from the mode,
M. For such a distance, and given the interval
, the aggregate skewness function,
, compares the probability weight of
F at either side of the interval:
where
. Thus, the (maximum) right skewness of the distribution
F and its (minimum) left skewness are respectively given by
The distances, and , where these extreme values are achieved, are termed the critical distances to the mode. As the skewness function is bounded inside the interval and , the bivariate index belongs to . A given distribution function F such that for all is said to be only skewed to the right; and if for all , it is said to be only skewed to the left.
The relationship (F precedes G) means that is a convex function. For a continuous distribution F, the bivariate measurement of skewness verifies the following properties, where and mean the distributions of the corresponding transformation of a random variable that is distributed:
for any symmetric distribution F.
, for all , .
.
If , then understood as vector dominance.
These properties can be considered as a vectorial interpretation of the axioms given by Oja (1981) [
7].
As it is easily proven that
, we can establish that (
2) and (
3) give considerably clearer and more complete information than (
1) about the skewness of any distribution function.
Most families of continuous distributions are only skewed to the right (or only to the left), while doubles-sign skewness is abundant within the discrete families, as shown in [
15]. Nevertheless, the joint use of the function (
2) and the bivariate index (
3) makes it possible to improve the ordering of the skewness-based distribution discussed in [
10], as can be seen in the following example.
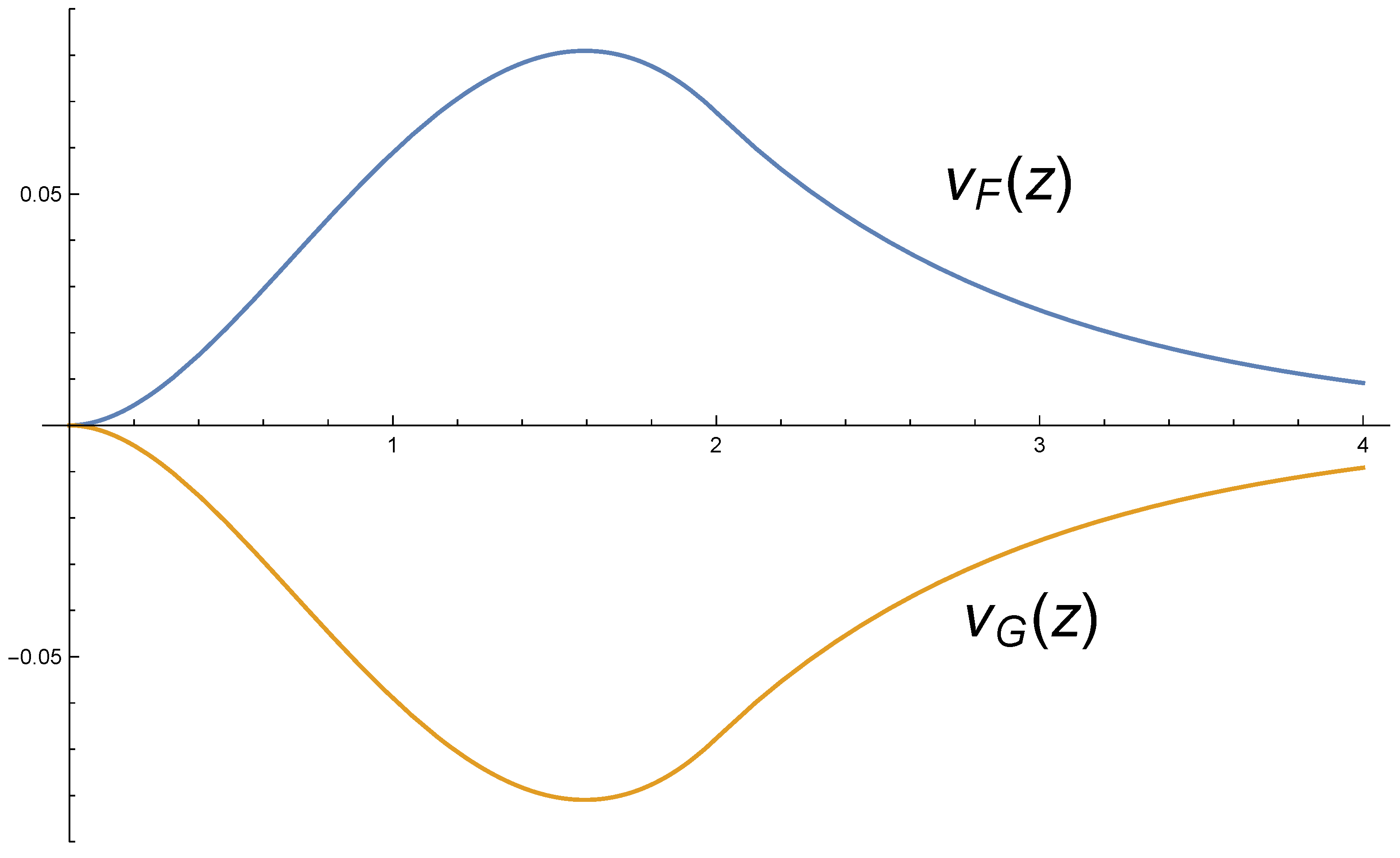
Example 1. Assume the following random variable with PDF given by: Assume also the PDF, of . Then, That is, according to coefficient , both distributions have the same null skewness, although they do not even have a symmetric support set.
However, using expression (2), we find thatand for all . These functions are plotted in Figure 1, where it can be seen that for all , and . Clearly, the information about skewness obtained from the aggregate skewness function and the indices and is considerably more comprehensive than that obtained from . Outline
In applied statistical analysis, it is useful to have a large catalogue of plausible distributions with which to fit the data. According to García et al. (2015) [
15], common measures of skewness can be complemented with a bivariate index of positive–negative skewness, and the authors show that the mode is the relevant central value to study both right and left skewness. In this paper, we extend the tool-box approach to fit data from probability distributions, introducing two orderings that are deduced from the skewness measures given in [
15]. The first of those orderings is based on the positive part of the bivariate index of skewness, which in many instances coincides with the well known
. Nevertheless, the differences can be highly significant, as in the previous example. The second, more noteworthy, order is based on the skewness function
and meets the first of the conditions, but not the reciprocal.
There are two reasons for ordering a family of distributions according to a given measurement of skewness. Firstly, as a property of the distribution, this ordering allows us to control its skewness by the appropriate selection of the parameter. When this is done (and the parameter is readily determined), the theoretical results have immediate applications in the data-fitting process. Secondly, when a given family of distributions is conceived as being more or less skewed according to the value of a parameter, and a measurement of skewness ratifies the ordering, it may be concluded that the functioning of this measurement provides a reasonably good fit with an intuitive conception of skewness.
The rest of this paper is organized as follows. In
Section 2, we study the aggregate skewness function and the resultant skewness-based ordering of the gamma, log-logistic, lognormal, Weibull and asymmetric Laplace families of continuous probability distributions. In
Section 3, we study the ordering of two of the most well-known distributions commonly used in PERT methods: the beta and the asymmetric triangular distributions. Finally, conclusions are presented in
Section 4.
2. Families of Uniparametric Distributions Ordered by Skewness
Let F and G be unimodal distribution functions, with no centre or scale parameters, and modes and respectively. We compare their respective skewness by two different criteria.
Definition 1. Ifthen we say that F has equal or more aggregate skewness to the right at any point than We denote this by . Definition 2. If and G are both skewed only to the right, we say that F has equal or more maximum aggregate skewness to the right than G whenand we denote this by . With these definitions, it immediately follows that:
Proposition 1. If then
The reverse implication is not true in general.
Proof. The proof follows immediately from the definitions given in (
4) and (
5). ☐
In the next section, we consider some well known uniparametric families of continuous distributions, with no centre or scale parameters but depending on a skewness parameter, and examine whether they are ordered by aggregate skewness, or by maximum aggregate skewness. The gamma family is a very broad one, which includes many other well known distributions as particular cases. A study of the log-logistic, lognormal, Weibull and asymmetric Laplace families, one by one and in turn, when not included inside the previous one, will produce widely varying results.
2.1. Uniparametric Gamma Distributions
Let
X be a uniparametric gamma distributed random variable,
. That is, its CDF
is given by
for
, where
, and the mode is given by
. Then, for
, the density function decreases on
x along the positive real line and we obtain that
In these cases,
is a decreasing function on
z, and
Proposition 2. Let and be gamma distributions with CDF as in (6). Then: - 1.
If , then
- 2.
If , then
Proof. Part 1. We can write
By denoting
,
, and then considering
we obtain
Therefore,
when
is negative for
, and positive for
. Also,
,
. Then,
is the integral of a negative function, so it is negative, and the proof is complete.
Part 2. For
, we have that
and,
Then, clearly we have that
for all
. For
, if we denote
then the sign of
is the sign of
. As
,
, and
we conclude that
is a decreasing function on
and
where
is the incomplete Gamma function, and then
is a decreasing function on
, when
. Nevertheless, a simple plotting of the functionals
for any
shows that both functionals cross each other and that they are not ordered by ”
”. Thus, the proof is completed. ☐
2.2. Log–Logistic Distributions
The CDF of a uniparametric log–logistic distributed random variable
X is given by
for
, with
. The mode of these distributions depends on
. If
, then
, and
and
. The functionals
for different values of
inside the rank cross each other at
, and these distributions are ordered neither by skewness function nor by skewness indexes. Nevertheless, for
, the mode is
Notice that
M is an increasing function of
when
because
When
, it is also known from Arnold and Groeneveld (1995) that
As is a decreasing function, it is then stated that implies . Furthermore, the skewness functions are ordered, as we prove below.
Proposition 3. Let be and log-logistic distributions with CDF as in (7), where . Then, Proof. If we consider
, such that the respective modes verify
, we can then denote
and consider the function
h given by
with
M as in (
8). Then,
For this implies that , . With this notation, we can write as follows.
Firstly, for
,
Secondly, for
, we only need to compare
, because
Hence, the proof is completed. ☐
2.3. Lognormal Variance Distributions
for
, where
is the standard normal distribution function. The mode is given by
and
Proposition 4. Let and be lognormal distributions with CDF as in (11), where . Then, Proof. For
the corresponding modes are
, and
because
is a strictly increasing function. Thus, we obtain that
for all
and the proof is completed. ☐
2.4. Uniparametric Weibull Distributions
Consider the uniparametric Weibull distributions family given by the CDF
The mode is known to be at 0, for
(as a limit, when
) and at
for
. The expression for
is given by
On the one hand, when , note that , so all these functions intersect at this point. Graphically, it can be seen that there is no ordering by “”, and also that , when . On the other hand, for , the following result is obtained.
Proposition 5. Let and be Weibull distributions with and CDF as in (12). Then, Proof. For
, the corresponding modes are
. Then, for
because each part of the expression inside brackets
is positive. If we take
, then
for a similar reason. Finally, if we take
, then
and the proof is completed. ☐
2.5. Asymmetric Laplace Distributions
The asymmetric Laplace distribution has been introduced in the literature by different ways ([
16,
17]). In this paper we will use Kozubowski and Podgórski (2002) [
18] (later refined in [
19]) to refer it. This distribution is obtained by using the scheme introduced by Fernández and Steel (1998) [
20] to produce skewness on a symmetric distribution. In this way, the pdf of a skewed or asymmetric Laplace distribution can be written in the form
where
, and
. Then, we assign values
to the centre and scale parameters (
and
, respectively) in order to study the aggregate skewness function, and the extreme right and left skewness indices then depend only on the skewness parameter
. Thus, it is easily proven that:
The aggregate skewness function of an
distribution can be written as
is an increasing negative function of
z when
, and it is a decreasing positive function of
z when
.
, for all
. That is, any
distribution is skewed only to the right or to the left, depending on
. In any case, the function verifies
but, when
, the function never reaches that limit value. To prove these results, it is sufficient to note that
At
, the skewness function takes the following value:
Then,
is the value for
or
, depending on its sign.
is a strictly decreasing function on
. This is easily shown by means of
for all
, and all
.
As a conclusion, we can enunciate the following Proposition, whose proof is straightforward and hence omitted.
Proposition 6. Assume , and let and be the respective asymmetric Laplace distributions. Then:
- 1.
- 2.
If , then is skewed only to the right.
- 3.
If , then is skewed only to the left.
3. The Beta and the AST Distributions
The methods for Project Management and Review Technique (PERT) are well known and widely applied when the needed activities for a given project must be ordered according to precedence in time. Some of these methods require modelling the time length of each activity as a random variable, following an expert’s opinion. The beta and the asymmetric triangular distributions are commonly used by engineers to describe these time lengths. In any case, the indications of the experts can be related to a maximum and a minimum values and a mode, often completed with further considerations about the shape and skewness of the PDF of the time random variable. Then, a deep study of the skewness of both families of probability distributions would be welcome to improve the model fit.
On the one hand, the asymmetric standard triangular distribution (ASTD) , free of center and scale parameters, depends on only one parameter
, and has the pdf:
There is a large body of literature that shows the use of the ASTD in PERT methods (see [
21] and [
19] and cites therein). Note that cases
are members of the beta family of distributions.
For
, the
CDF can be written as follows:
As the mode is found to be at
, its skewness function is found to be
for
In the case
, the skewness function is null. Then, for
and
,
In the case
, for
,
and it is easily found that
for
.
Some algebra allows to prove that, being ,
If , then , and .
If , then and .
Therefore, the skewness of the ASTD distributions is completely controlled by the parameter
On the other hand, the pdf of a beta distribution is given by
where
, and
is the beta function. Given that its CDF
verifies that
and the sign of its skewness depends only on the condition
or
, we can study only the case
.
We are interested on the cases
, where there is an unique mode
Hence, we only consider cases where , where there exists a right skewness; the cases , with left skewness, can be immediately deducted by taking the parameters in reverse.
Notice that
requires
, and that
requires
. Then,
where,
is the well known Beta Regularized function.
Firstly, observe that
and
where
is the approximate median of the distribution.
Secondly, if
then
which is negative within the rank of
z. For
,
Hence, for , is a strictly decreasing continuous function with and
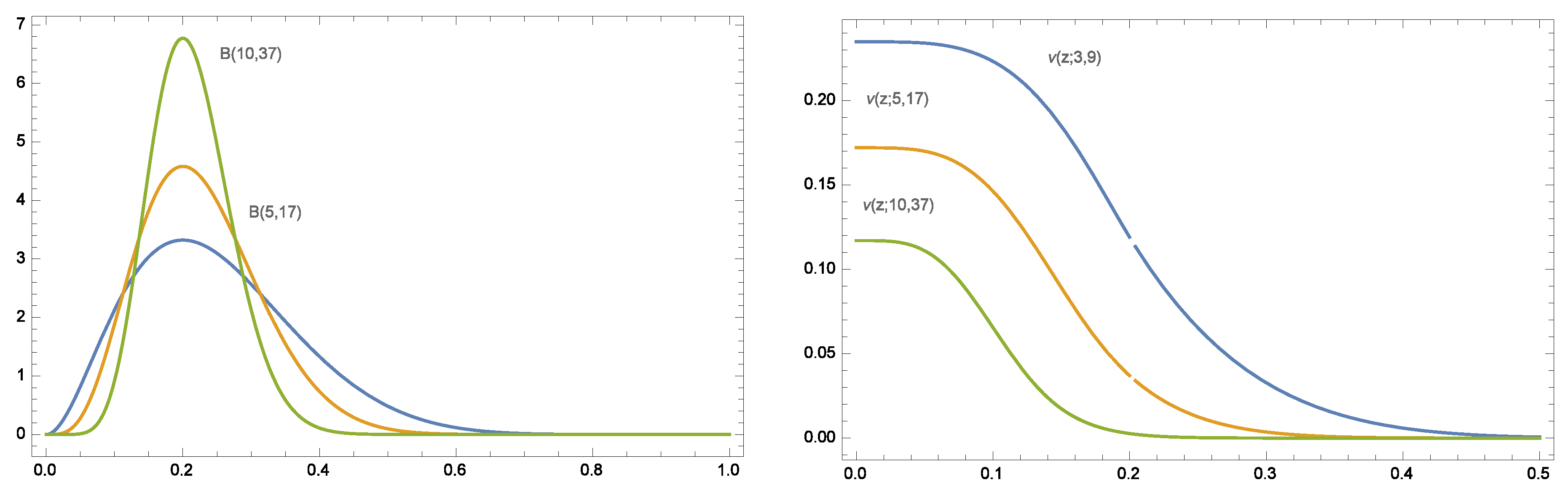
Now we focus on the family of Beta distributions with given mode,
M. That is, we consider the subfamily of Beta distributions:
with
. Then, with the aid of a proper software (we have used Wolfram Mathematica 10), one can obtain the derivative
and maximize this function, in two cases:
First case, the constrains are The maximum value of the function is 0, and it is achieved when , , .
Second case, the constrain are The maximum value of the function is , and it is achieved when , , .
With these results, we can conclude that
decreases with the feasible values of
. That way, the subsets of Beta distributions with fixed mode are ordered on skewness (see
Figure 2). As the parameter values increase, these Beta distributions become less skewed.
4. Conclusions
In this paper two main objectives are achieved: on the one hand, the given examples show that the skewness function orders the mesh in good accordance with the intuitive conception of skewness. Moreover, these examples show that the skewness of a distribution obtained from certain parametric families can be controlled by reference to their parameters.
As we show, the function facilitates the description of a random variable by means of a probability distribution, by making any skewness in the model easily observable and should be undertaken to examine the use of these properties in data fitting.
In practice, much can be learned from this model, but there remains the risk that it may be wrongly specified in real applications. Thus, in practice we must be willing to assume that the underlying distribution has a unique mode and belongs to a uniparametric family of distributions.
In many practical situations, the maximum skewness index coincides with the well known , but this second index only takes into account the difference of probability weights at each side of the mode, while the first takes a value from the point where this difference is maximum. Moreover, the aggregate skewness function gives more accurate information about how the probability weight is distributed along both sides of the mode. Accordingly, the condition provides highly valuable information.


{kind=link}
{kind=link}

