Automatic Grading of Palsy Using Asymmetrical Facial Features: A Study Complemented by New Solutions


Abstract
:1. Introduction
- Build a large facial palsy dataset;
- Demonstrate a deep learning based facial palsy-specific features extraction strategy in conjunction with CNNs;
- Address the problem of overfitting of CNNs by generating additional face images using GANs;
- Show that such a method tested on a large dataset will be suitable for large scale facial palsy grading applications, such as primary health care.
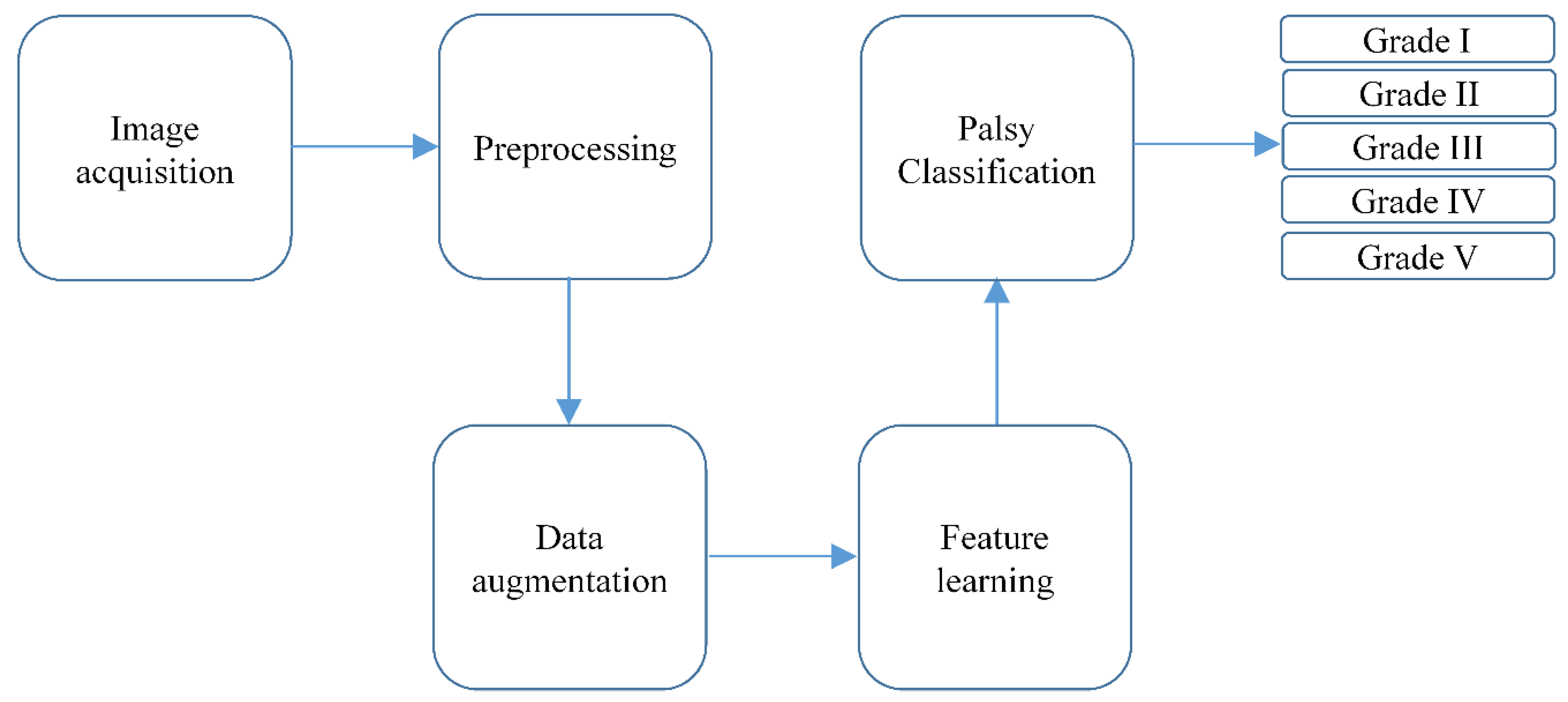
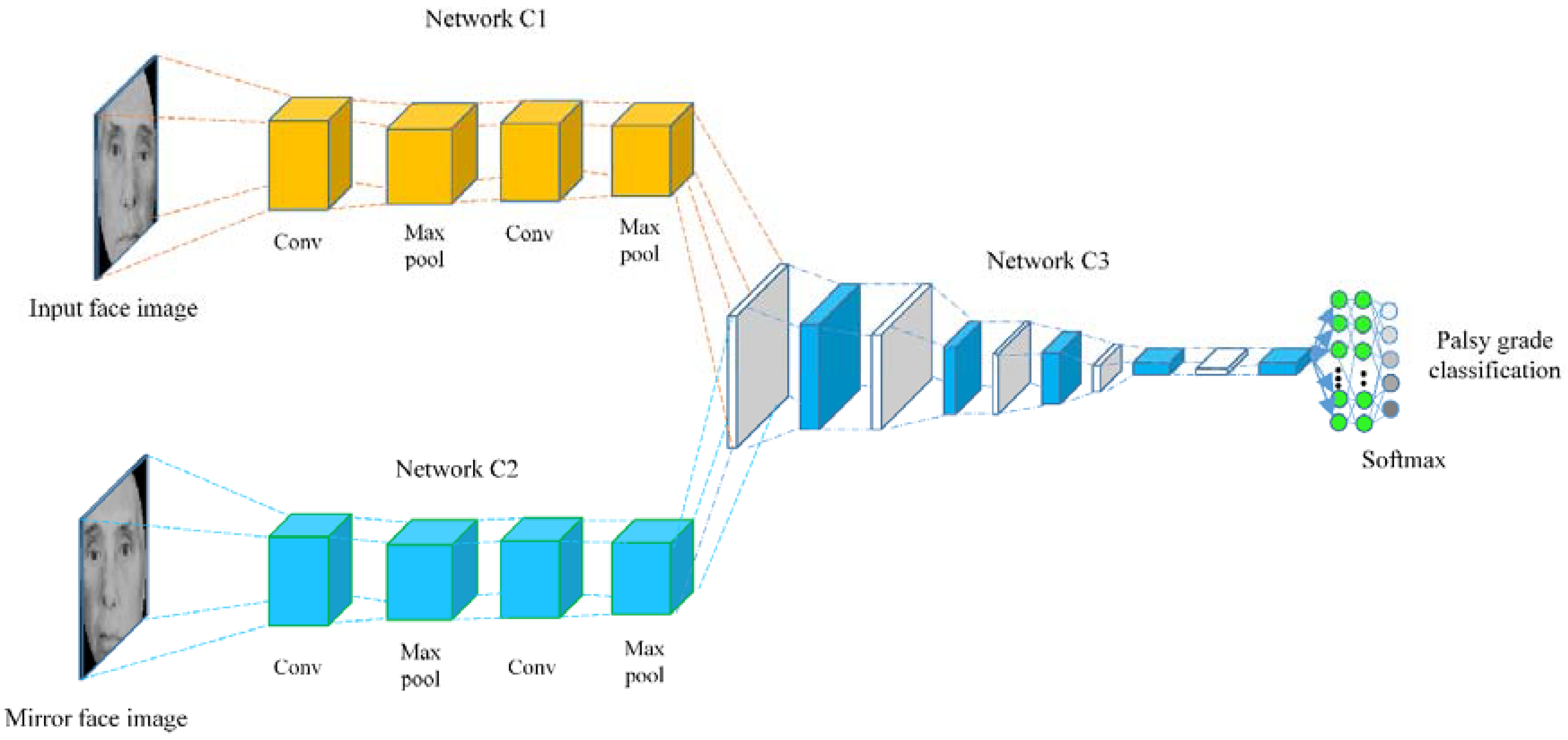
2. Proposed Methodology
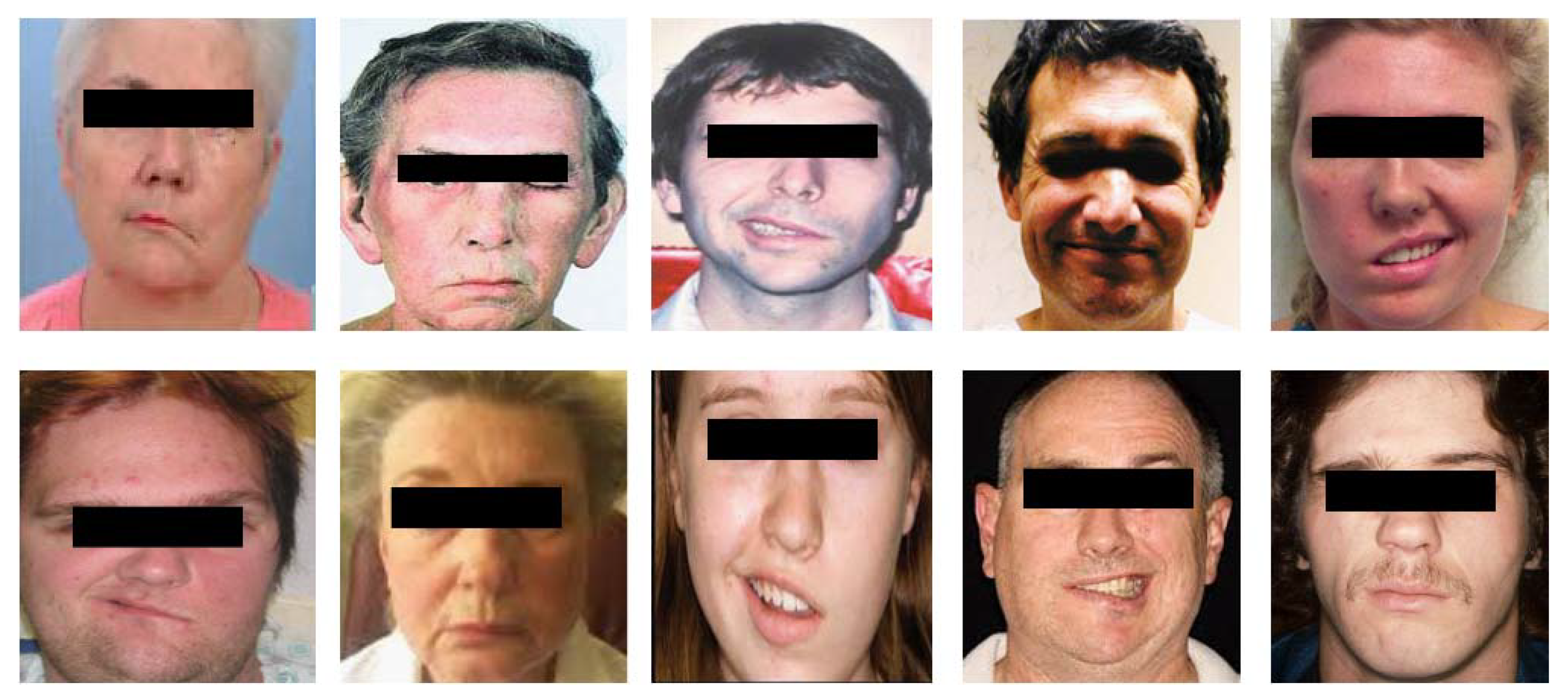
2.1. Image Acquisition or Dataset Collection
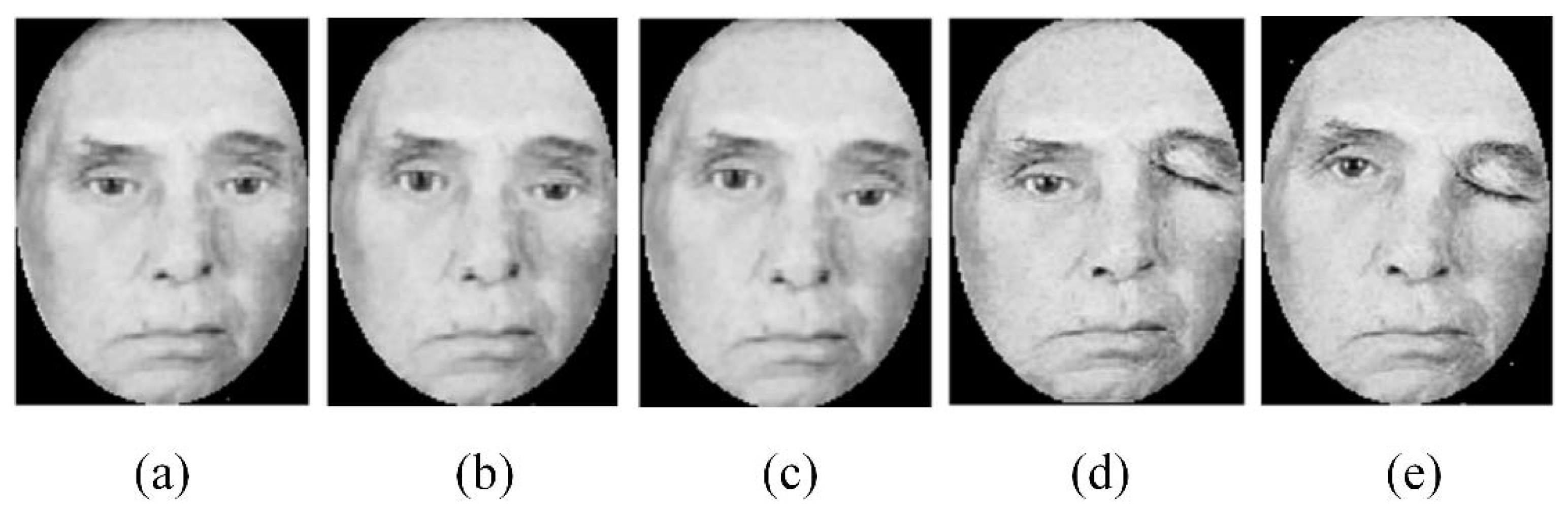
2.2. Preprocessing
- Face images are aligned such that these are upright;
- Color face images are converted into gray scale to eliminate unwanted color cast;
- Histogram equalization is used to remove shadows and illumination variations;
- Finally, the face images are cropped to 200 × 200 pixels with a 100 pixel interpupillary distance [25]. A binary elliptical mask is then applied to remove unwanted hair and background variations.
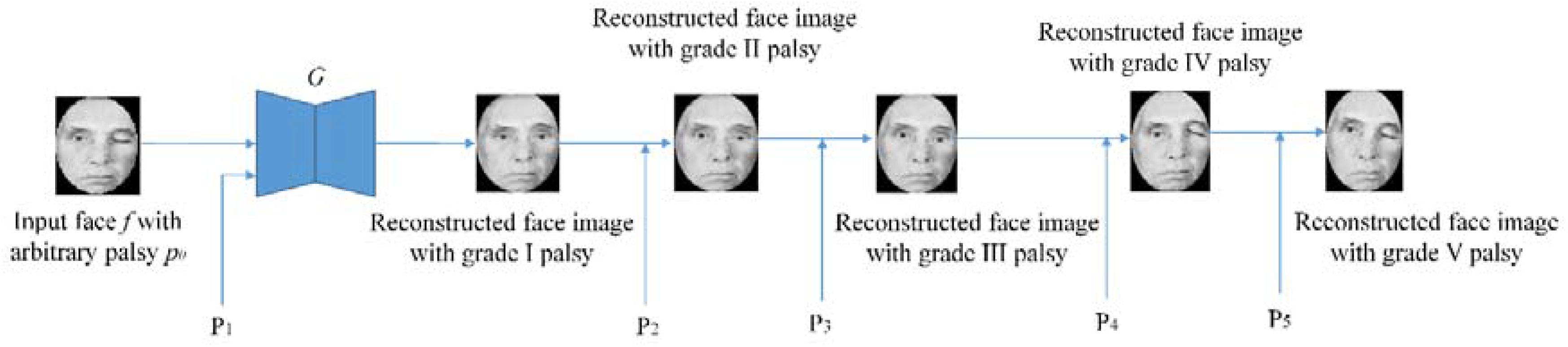
2.3. Data Augmentation
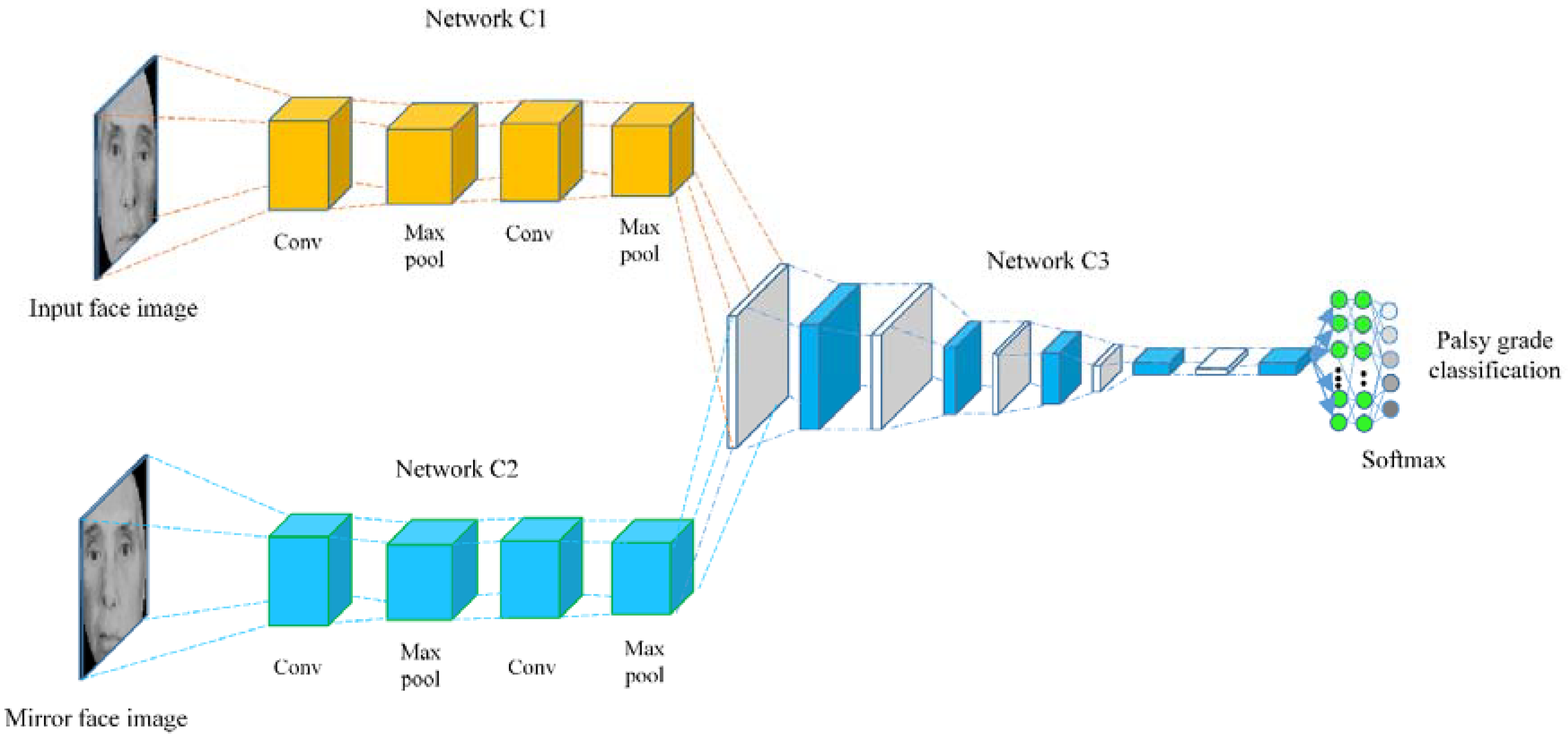
2.4. Feature Learning
2.5. Classification
3. Experiments and Results
3.1. Experimental Protocol
3.2. Experimental Results and Evaluation
- Accuracy: The metric which represents correct predictions out of total predictions, i.e.,where, TP, TN, FP, and FN represent true positive, true negative, false positive and false negatives respectively.
- Precision: The precision metric represents the correctly predicted labels out of total true predictions as:
- Sensitivity: The recall metric is used to quantify the cases that are predicted correctly; predicted labels over all positive observations, i.e.,
- F1 score: The weighted average of precision and sensitivity is called F1 score as:
4. Results and Related Discussion
- Compared with traditional hand-crafted features, the palsy grading method in this paper is more effective and robust. This is because CNNs have been used to encode palsy-specific face features automatically. In traditional methods such as [1,2,3,4], both the landmark detection and feature extraction strategies are hand-crafted which limit the classification accuracy owing to non-optimal feature representation and landmark detection. In contrast, this method uses automatic face features to encode face representation and thus achieve superior classification accuracy across a range of facial palsy severity.
- To the best of our knowledge, this is the first study to perform palsy grade classification on a large dataset containing 2000 face images. In contrast, the existing methods performed the similar task on quite smaller datasets. For example only 36 subjects have been analyzed in [1] for palsy classification. The smaller datasets have two main limitations. First, these datasets are less diverse in representing severity of palsy disease. Second they are not suitable to perform classification task using CNNs, owing to inherent problem of overfitting for small datasets. Recall that overfitting means lower training loss and higher validation loss due to poor generalization of the CNN models. Since our model is designed for large dataset, such an approach is useful for large scale applications such as primary health care, where smart-phones based palsy grading systems are not adequate.
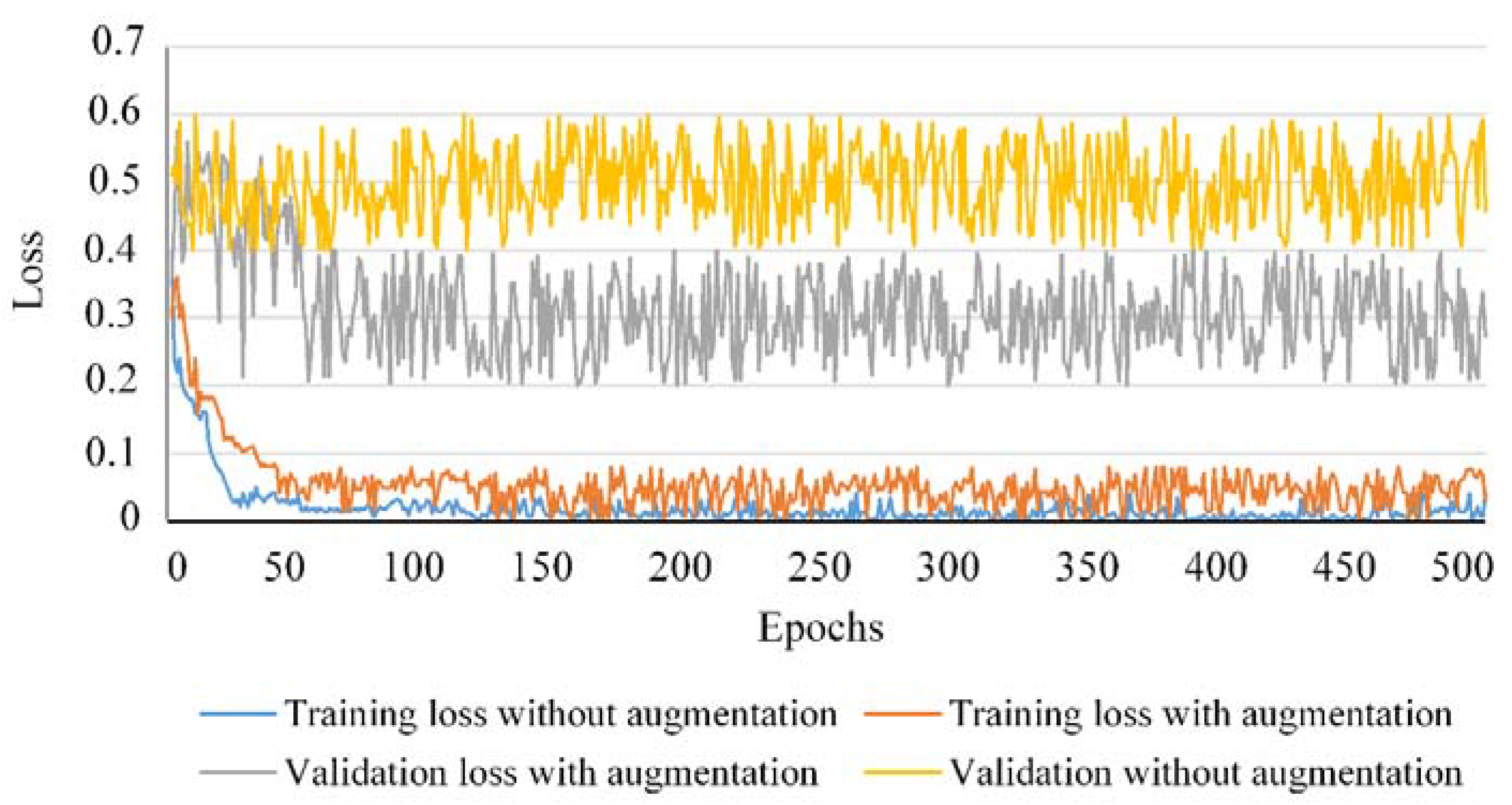
- To prevent overfitting, a data augmentation strategy suitable for the underlying task of palsy grading has been proposed. To analyze the impact of the proposed data augmentation on classification accuracy, the training and validation losses for 500 epochs have been traced as shown in Figure 7. One can observe that the rate of overfitting is greatly reduced when the data augmentation strategy is applied compared to the scenario when no data augmentation was applied to train our classification model. The smaller difference between training and test losses caused by data augmentation shows how this strategy is useful for the classification model to learn the most discriminative features for the desired task. More precisely, the model works across a variety of palsy grades and preserves the discriminative information in the training stage. In the testing stage, a face image with arbitrary level of palsy severity can be easily classified into the true grading level. This suggests the efficacy of our method to prevent the classification model from overfitting and provides robustness for classification accuracy against varying nature of facial palsy disease.
- Generally speaking, a single evaluation metric can lead to inappropriate classification results due to the presence of some imbalanced classes in the dataset or too small or large a number of training labels. To this end, some existing methods such as [1] expressed relevant classification performance in terms of accuracy metric only. In contrast, we reported the classification performance of our model using four distinct evaluation metrics including accuracy, precision, sensitivity and F1 score. The experimental results displayed in Table 3 show the consistent performance of our model in palsy grade classification across a variety of evaluation metrics, i.e., accuracy, precision, sensitivity and F1 score. This suggests the effectiveness of our method for underlying task in the presence of a wide variety of palsy disease ranging from mild to total paralysis of face.
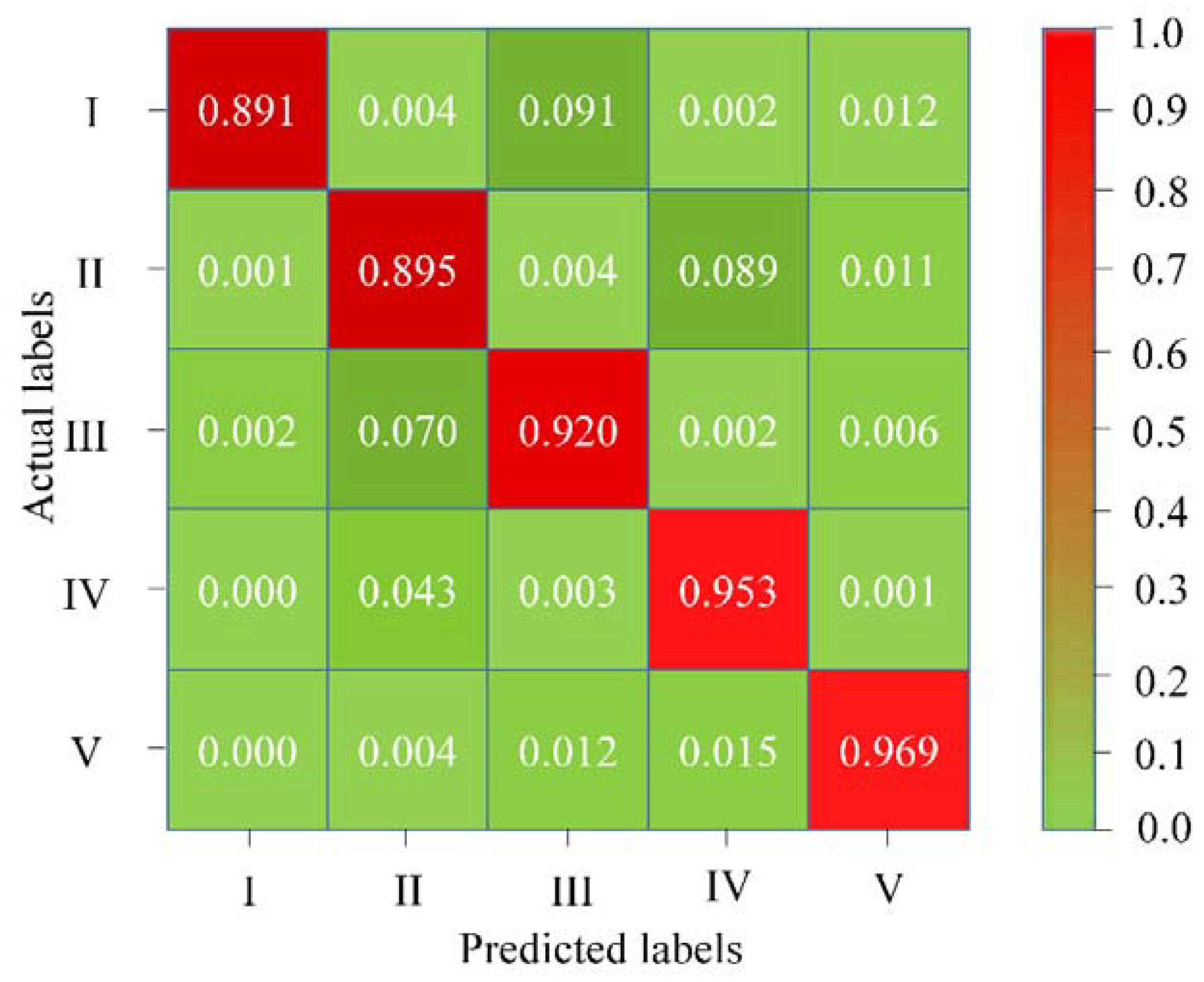
- The confusion matrix displayed in Figure 6 shows that if the facial palsy is more obvious, the classification ability of our model is also stronger. For example, the classification accuracy for grade V palsy is the highest (96.90%) among all grades. This is because this type of facial palsy can be expressed more effectively by the underlying model. In contrast, the classification performance for mild and moderate facial palsy for grade I and II respectively, is relatively lower (89.10% and 89.50%) owing to lesser palsy-specific discriminative information presented to the model.
- The literature review of the existing methods on palsy grade classification reveals that inherent in these methods is a major limitation in terms of repeatability. Repeatability is a very important factor for a reliable classification system and can be evaluated through an experiment under repeated measurements of the same subject over a short period. For example, the study presented in [1] describes the unavailability of repeatability as one of its main limitations. This issue has been addressed in this study by leveraging the advantage of the data augmentation strategy suitable for a particular scenario of palsy grade classification. More precisely, face photos of a given image are generated across a variety of palsy severities ranging from mild to total paralysis. This type of data augmentation makes our model capable of learning varying palsy severities which can substitute the repeated measurements and thus helpful in the repeatability of the classification system.
- The CNN-based classification model is the core of this article with GAN-based face image generation as the necessary step to achieve the overall robust classification of palsy grades. The proposed model has managed to classify facial palsy into one of the five major types benchmarked by House and Brackmann [23]. The practical significance is proved through the performance indicators in Figure 6 and Table 3. Compared with existing methods, we break the restrictions of dividing face images into regions for classification purposes. For example, the study presented in [12] proposed to train artificial neural networks on bilateral displacements and regional mean intensities to quantify the damage caused by facial palsy. In contrast, our model achieves the palsy grade classification based on the automatic asymmetry feature extraction. The most important advancement is the integral analysis of patients’ faces instead of regions on a large dataset.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, H.S.; Kim, S.Y.; Kim, Y.H.; Park, K.S. A smartphone-based automatic diagnosis system for facial nerve palsy. Sensors 2015, 15, 26757–26768. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Dong, J.; Sun, X.; Zhang, S.; Wang, S. Automatic recognition of facial movement for paralyzed face. Biomed. Mater. Eng. 2014, 24, 2751–2760. [Google Scholar] [PubMed]
- He, S.; Soraghan, J.J.; O’Reilly, B.F.; Xing, D. Quantitative analysis of facial paralysis using local binary patterns in biomedical videos. IEEE Trans. Biomed. Eng. 2009, 56, 1864–1870. [Google Scholar] [CrossRef] [PubMed]
- Delannoy, J.R.; Ward, T.E. A preliminary investigation into the use of machine vision techniques for automating facial paralysis rehabilitation therapy. In Proceedings of the IET Irish Signals and Systems Conference (ISSC 2010), Cork, Ireland, 23–24 June 2010. [Google Scholar]
- Walley, J.; Lawn, J.E.; Tinker, A.; de Francisco, A.; Chopra, M.; Rudan, I.; Black, R.E. Primary health care: Making Alma-Ata a reality. Lancet 2008, 372, 1001–1007. [Google Scholar] [CrossRef]
- Sumithra, R.; Suhil, M.; Guru, D.S. Segmentation and classification of skin lesions for disease diagnosis. Procedia Comput. Sci. 2015, 45, 76–85. [Google Scholar] [CrossRef]
- Yuan, X.; Situ, N.; Zouridakis, G. A narrow band graph partitioning method for skin lesion segmentation. Pattern Recognit. 2009, 42, 1017–1028. [Google Scholar] [CrossRef]
- Manoorkar, P.B.; Kamat, D.K.; Patil, P.M. Analysis and classification of human skin diseases. In Proceedings of the 2016 International Conference on Automatic Control and Dynamic Optimization Techniques (ICACDOT), Pune, India, 9–10 September 2016. [Google Scholar]
- El abbadi, N.K.; Dahir, N.; Al-Dhalimi, M.; Restom, H. Psoriasis detection using skin color and texture features. J. Comput. Sci. 2010, 6, 648–652. [Google Scholar] [CrossRef]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Sermanet, P.; Chintala, S.; LeCun, Y. Convolutional neural networks applied to house numbers digit classification. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012. [Google Scholar]
- McGrenary, S.; O’Reilly, B.F.; Soraghan, J.J. Objective grading of facial paralysis using artificial intelligence analysis of video data. In Proceedings of the 18th IEEE Symposium on Computer-Based Medical Systems, Dublin, Ireland, 23–24 June 2005. [Google Scholar]
- Wang, K.; Luo, J. Detecting visually observable disease symptoms from faces. EURASIP J. Bioinf. Syst. Biol. 2016, 2016, 13. [Google Scholar] [CrossRef] [PubMed]
- Liao, H.; Li, Y.; Luo, J. Skin disease classification versus skin lesion characterization: Achieving robust diagnosis using multi-label deep neural networks. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Ge, Z.; Demyanov, S.; Bozorgtabar, B.; Abedini, M.; Chakravorty, R.; Bowling, A.; Garnavi, R. Exploiting local and generic features for accurate skin lesions classification using clinical and dermoscopy imaging. In Proceedings of the 14th International Symposium on Biomedical Imaging, Melbourne, VIC, Australia, 18–21 April 2017. [Google Scholar]
- Shen, X.; Zhang, J.; Yan, C.; Zhou, H. An automatic diagnosis method of facial acne ulgaris based on convolutional neural network. Sci. Rep. 2018, 8, 5839. [Google Scholar] [CrossRef] [PubMed]
- Goldberg, C.; Catalog of Clinical Images. UCSD School of Medicine and VA Medical Center. Available online: http://meded.ucsd.edu/clinicalimg/ (accessed on 25 May 2018).
- The Primary Care Dermatology Society (PCDS). Available online: http://www.pcds.org.uk (accessed on 20 May 2018).
- Wang, K.; Luo, J. Clinical Images for Symptoms on Face, University of Rochester. 2015. Available online: http://tinyurl.com/h77ty86 (accessed on 20 May 2018).
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv, 2012; arXiv:1207.0580. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- House, J.W.; Brackmann, D.E. Facial nerve grading system. Otolaryngol. Head Neck Surg. 1985, 93, 146–147. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Han, H.; Otto, C.; Liu, X.; Jain, A.K. Demographic estimation from face images: Human vs. machine performance. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1148–1161. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 8 April 2018).
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Smart augmentation learning an optimal data augmentation strategy. IEEE Access 2017, 5, 5858–5869. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. A Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Brachmann, A.; Redies, C. Using convolutional neural network filters to measure left-right mirror symmetry in images. Symmetry 2016, 8, 144. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 11, 2278–2324. [Google Scholar] [CrossRef]
- Moayedikia, A.; Ong, K.L.; Boo, Y.L.; Yeoh, W.G. Feature selection for high dimensional imbalanced class data using harmony search. Eng. Appl. Artif. Intell. 2017, 57, 38–49. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Song, I.; Yen, N.Y.; Vong, J.; Diederich, J.; Yellowlees, P. Profiling Bell’s Palsy based on House-BrackMann score. J. Artif. Intell. Soft Comput. Res. 2013, 3, 41–50. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
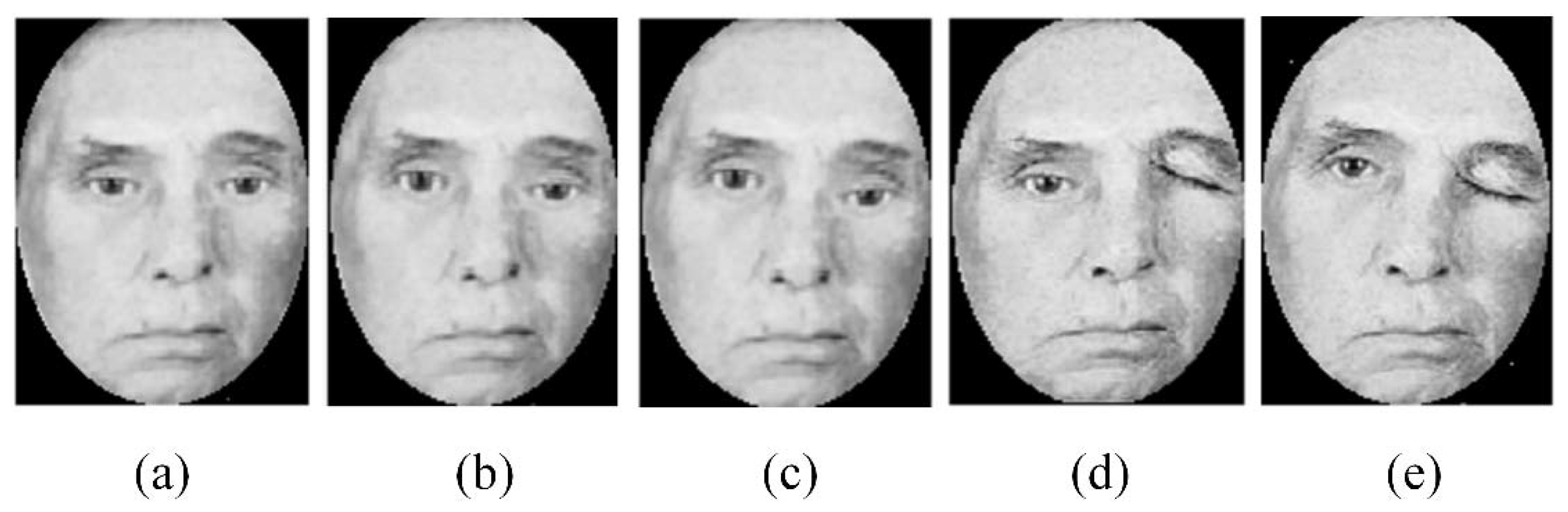
| Palsy Grade | Severity | Description |
|---|---|---|
| I | Mild | The forehead, eyes and mouth show moderate to good function with slight facial asymmetry. |
| II | Moderate | Slight to moderate changes around mouth and eyes, with slight facial asymmetry. |
| III | Moderately severe | Eyes are not completely closed despite efforts, and mouth exhibits asymmetry with maximum effort. |
| IV | Severe | Eyes show incomplete closure and mouth shows asymmetry. |
| V | Total paralysis | Remarked facial asymmetry without movement. |
| Data Subset | Palsy Grades | |||||
|---|---|---|---|---|---|---|
| I | II | III | IV | V | Total | |
| Training (augmented subset) | 2066 | 1756 | 912 | 894 | 372 | 6000 |
| Validation | 151 | 109 | 111 | 81 | 56 | 500 |
| Testing | 144 | 116 | 103 | 78 | 51 | 500 |
| Total | 2361 | 1981 | 1126 | 1053 | 479 | 7000 |
| Approach | Features | Average Classification Accuracy (%) | Precision | Sensitivity | F1 Score |
|---|---|---|---|---|---|
| Reference [1] | Bilateral facial landmarks with support vector machine (SVM) and linear discriminant analysis (LDA) as classifiers | 88.90 | 87.11 | 90.07 | 86.66 |
| Reference [34] | Emergent self-organizing map and SVM classifier | 89.00 | 89.23 | 88.49 | 88.00 |
| VGG-16 Net (Our method) | Deep feature learning on augmented dataset | 92.60 | 92.91 | 93.14 | 93.00 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sajid, M.; Shafique, T.; Baig, M.J.A.; Riaz, I.; Amin, S.; Manzoor, S. Automatic Grading of Palsy Using Asymmetrical Facial Features: A Study Complemented by New Solutions. Symmetry 2018, 10, 242. https://doi.org/10.3390/sym10070242
Sajid M, Shafique T, Baig MJA, Riaz I, Amin S, Manzoor S. Automatic Grading of Palsy Using Asymmetrical Facial Features: A Study Complemented by New Solutions. Symmetry. 2018; 10(7):242. https://doi.org/10.3390/sym10070242
Chicago/Turabian StyleSajid, Muhammad, Tamoor Shafique, Mirza Jabbar Aziz Baig, Imran Riaz, Shahid Amin, and Sohaib Manzoor. 2018. "Automatic Grading of Palsy Using Asymmetrical Facial Features: A Study Complemented by New Solutions" Symmetry 10, no. 7: 242. https://doi.org/10.3390/sym10070242
APA StyleSajid, M., Shafique, T., Baig, M. J. A., Riaz, I., Amin, S., & Manzoor, S. (2018). Automatic Grading of Palsy Using Asymmetrical Facial Features: A Study Complemented by New Solutions. Symmetry, 10(7), 242. https://doi.org/10.3390/sym10070242