Towards Real-Time Facial Landmark Detection in Depth Data Using Auxiliary Information


Abstract
1. Introduction
- We introduce a new Kinect One [11] dataset, namely KOED to overcome data deficiency in this domain.
- We propose a novel and automated real-time 3D facial landmarks detection method.
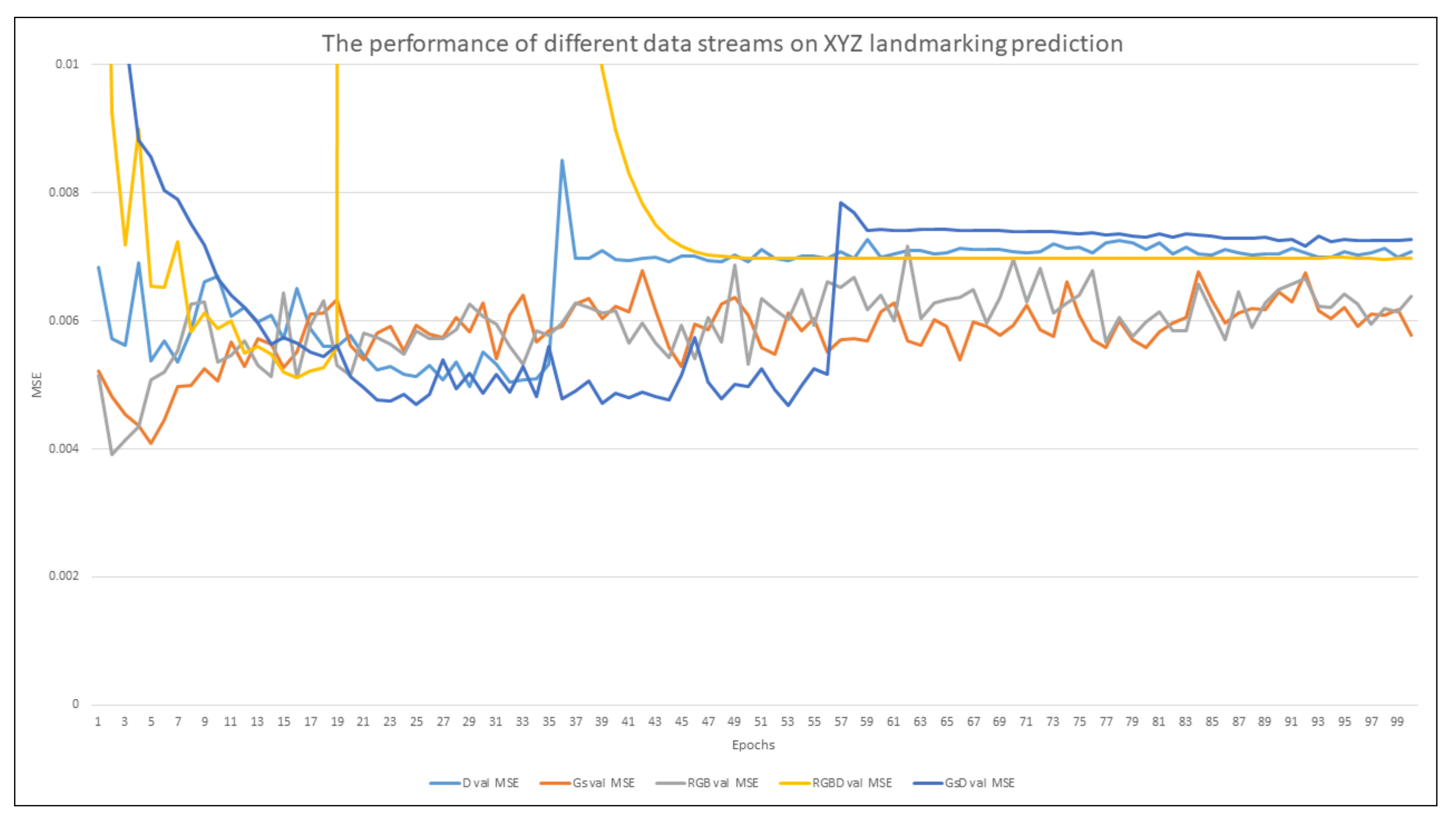
- We conduct a complete investigation on the effect of different data streams, such as Gs, RGB, GsD, RGBD in 2D and 3D facial landmarks detection.
2. Related Work
2.1. Facial Landmarking with Neural Networks
2.2. Merging Visual and Depth
2.3. Existing Datasets
- Face Warehouse [26]: is a large-scale dataset containing 150 participants with an age range of 7–80. The dataset contains RGB images (), Depth maps () and 3D models with 74 UV landmarks. The dataset focuses solely on posed expressions giving one model and image when the participant displays the expression. Furthermore, for capture they use the Kinect version 1 [27]. The dataset is captured under different lighting and in different places. As only the expressions peak is captured, there is not a significant amount of data for training deep learning and it is at a low resolution compared to modern cameras. Overall, the Face Warehouse is a good 3D face dataset providing a wide assortment of expressions with landmark annotations, but with no onset or offset of the expression.
- Biwi Kinect Head Pose [28]: is a small-scale Kinect version 1 dataset containing 20 participants, four of the participants were recorded twice. During the recording, keeping a neutral face, the participants would look around the room only moving their heads. The recordings are different lengths. The Depth data has been pre-processed to remove the background of all no face sections. The recording contains no facial landmarks, but the centre of the head and rotation is noted per frame. Although the recording was done in the same environment, the participants can be positioned in different sections of the room changing the background; the lighting remains consistent. Overall, the Biwi Kinect dataset was not suitable for the experiment as it contained no facial expressions and was recorded using the Kinect version 1.
- Eurocom Kinect [29]: is a medium-sized dataset containing 52 participants, each participant was recorded twice with around two weeks in between. Participants were recorded by having single images of them performing nine different expressions. The images were taken using the Kinect version 1 and images were pre-processed to segment the heads. The coordinates for the cropping are given as well as six facial landmarks. The Eurocom dataset contains few images for a deep learning network and is recorded with the Kinect version 1, making it unsuitable for the experiment.
- VAP face database [30]: is a small size dataset containing 31 participants. The dataset was recorded using an updated Kinect version 1 for Windows, this version gives a bigger RGB image (1280 × 1024) and larger Depth map (), but at the cost of reduced frame rates. The recording was also done using the Kinects ‘near-mode’ which allows for the increased resolution described. Each participant has 51 images of the face taken at different head angles performing a neutral face and some frontal face with expressions. The recordings were done in the same place with consistent lighting. As the dataset contains single images and few participants performing facial expressions, it is unsuitable for the experiment, but for head pose estimation it would be appropriate.
- 3D Mask Attack [31]: is a small to medium scale dataset containing 17 participants, but a large collection of recordings. The participant is recorded in three different sessions; in each session the participant is recorded five times for 300 frames per recording, holding a neutral expression. The recording uses the Kinect version 1. The eyes are annotated every 60 frames with interpolation for the other frames. The recordings were done under consistent lighting and background. The 3D Mask Attack dataset contains a vast number of frames, but all use the neutral expression, face the camera and use the older Kinect making it unsuitable for the experiment.
- Deep learning requires large-scale datasets containing many thousands of training examples.
- Facial expression is key for robust landmarking systems, including the onset and offset of expressions.
- Facial Landmarks, in both 2D and 3D.
- As facial movement can be subtle, high-resolution images are required, which is why Kinect version 2 with both higher accuracy and resolution is needed.
- Real-time frame rates, as most systems target 30 Frames Per Second (FPS).
3. Proposed Method
3.1. Kinect One Expression Dataset (KOED)
3.1.1. Experimental Protocol
- Happy
- Sad
- Surprise
- Anger
- Fear
- Contempt
- Disgust
3.1.2. Emotional Replication Training
3.1.3. Ethics
3.1.4. Equipment and Experimental Set up
3.1.5. Camera
3.1.6. Lighting
3.1.7. Frame Rate and Storage
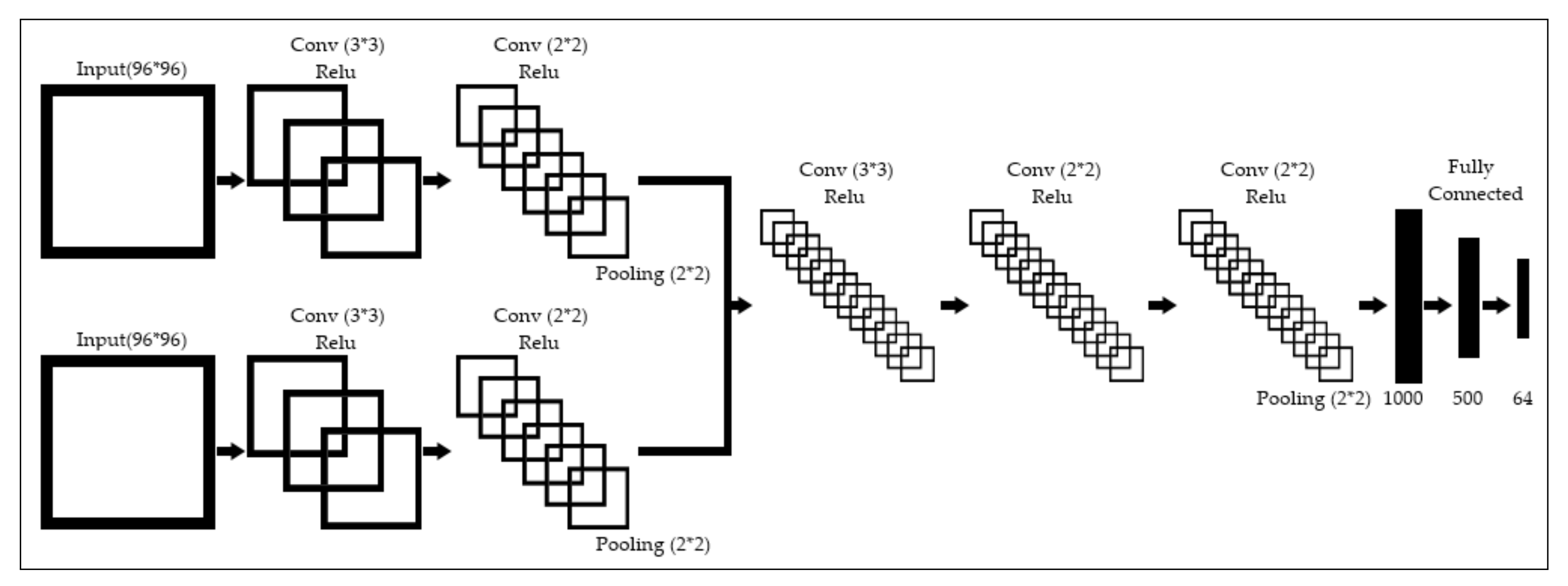
3.2. Methodology
- The UV coordinates, in pixels
- The XYZ coordinates, in meters
- The UVXYZ coordinates
- n is the number of samples in the training batches.
- is the ground truth for the training image.
- is the predicted output for the training image.
- n is the number of samples in the training batches.
- is the ground truth for the training image.
- is the predicted output for the training image.
4. Results
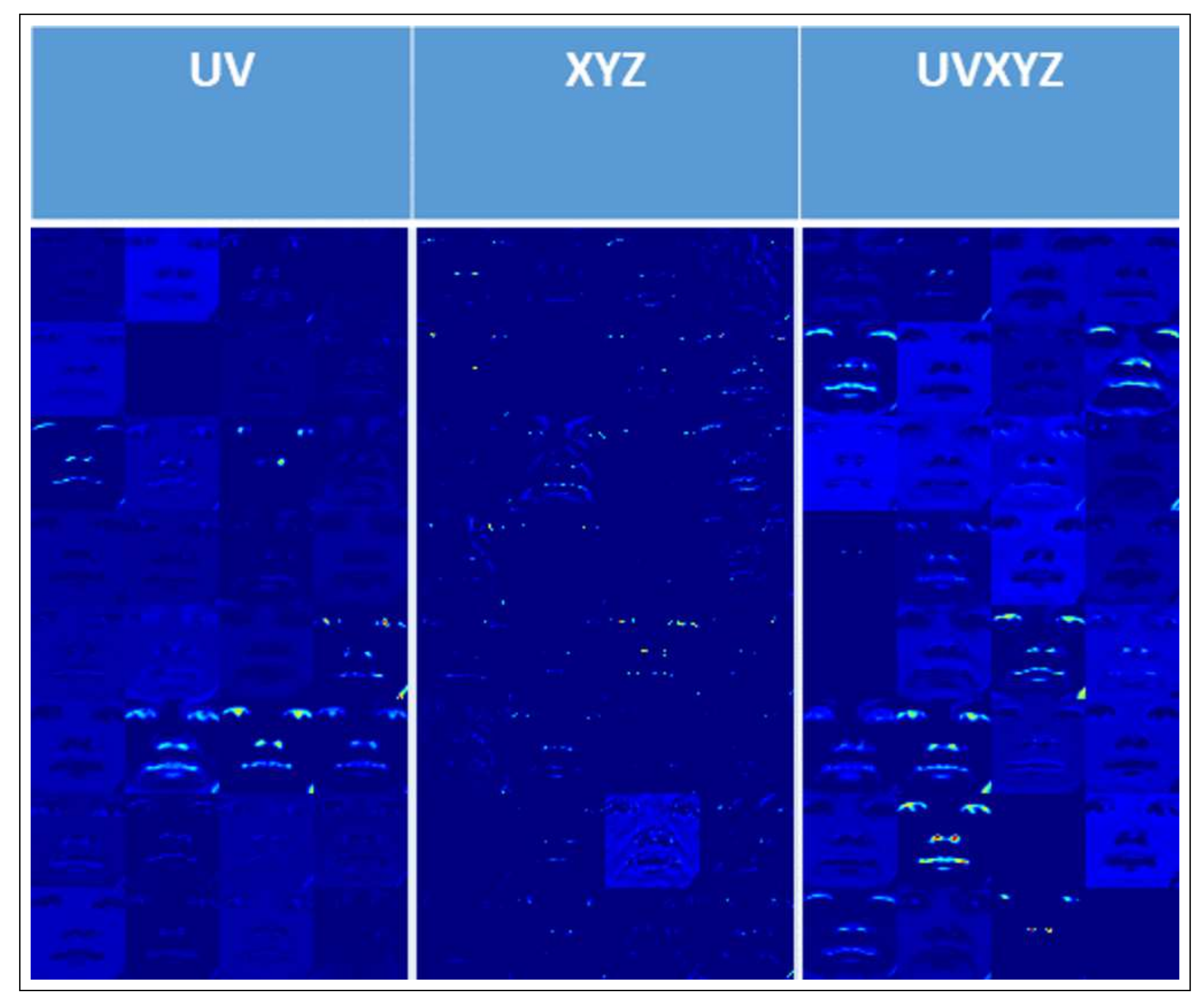
- In the UV only prediction, the results are visually similar, but there is some deviation between each of the networks. When using Depth as the input stream, the predictions of both the right eye and lip corners are predicted less precise than the other input streams; this could be directly affected by the noise in the Depth maps, as when merged with a visual stream, performance is improved.
- For UVXYZ, there is no noticeable difference between the UV results.
- For the XYZ only predictions we see much larger discriminations in the predicted facial landmarks. Some of the major changes are:
- -
- From the frontal view there is a variation in the mouth width, with Gs being the smallest and Depth being the widest.
- -
- Nose landmarks shifts in GsD were the nose tip and right nostril are predicted close to each other.
- -
- Eye shape changes between networks, Gs and RGBD produce round smooth eyes. Whereas others are more jagged and uneven.
- -
- From the side view, we see the profile of the face change with the forehead and nose shape varying greatly between networks.
- In contrast to the UV results in the UVXYZ network, with the addition of auxiliary information the resulting geometric landmarks on the mouth, nose, eye and eyebrows, become more precise and consistent. In most of the cases the eyes are smoother, the eyebrows are more evenly spaced, the nose irregularity in GsD no longer occurs and the mouth width consistency has improved greatly. These results show that, as UV is easier for the networks to learn as all streams manage similar results, when used as auxiliary information, they aid to standardise the 3D locations as well. However, there are still some variations in the profile of the nose and in RGB the right eye is predicted to be shut.
- Combined loss, which is the sum of UV and XYZ layers loss.
- UV loss, the loss of the UV layers alone.
- XYZ loss, the loss of the XYZ layers alone.
5. Discussion and Conclusions
6. Materials and Methods
Supplementary Materials
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| LSTM | Long Short-Term Memory |
| RNN | Recurrent Neural Network |
| ReLU | Rectified Linear Unit |
| RGB | Red Blue Green |
| RGBD | Red Blue Green Depth |
| Gs | Greyscale |
| GsD | Greyscale Depth |
| D | Depth |
| 2D | Two Dimensional |
| 3D | Three Dimensional |
| KOED | Kinect One Expressional Dataset |
| HD | High Definition |
| MSE | Mean Squared Error |
| MAE | Mean Absolute Error |
References
- Vicon Motion Systems Ltd. Capture Systems; Vicon Motion Systems Ltd.: Oxford, UK, 2016. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Ranjan, R.; Patel, V.M.; Chellappa, R. HyperFace: A Deep Multi-task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 1. [Google Scholar] [CrossRef]
- Bui, H.M.; Lech, M.; Cheng, E.; Neville, K.; Burnett, I.S. Using grayscale images for object recognition with convolutional-recursive neural network. In Proceedings of the 2016 IEEE Sixth International Conference on Communications and Electronics (ICCE), Ha Long, Vietnam, 27–29 July 2016; pp. 321–325. [Google Scholar] [CrossRef]
- Zhou, E.; Fan, H.; Cao, Z.; Jiang, Y.; Yin, Q. Extensive facial landmark localization with coarse-to-fine convolutional network cascade. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 386–391. [Google Scholar] [CrossRef]
- Jourabloo, A.; Liu, X. Large-Pose Face Alignment via CNN-Based Dense 3D Model Fitting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4188–4196. [Google Scholar] [CrossRef]
- Han, X.; Yap, M.H.; Palmer, I. Face recognition in the presence of expressions. J. Softw. Eng. Appl. 2012, 5, 321. [Google Scholar] [CrossRef]
- Faceware Technologies Inc. Faceware; Faceware Technologies Inc: Sherman Oaks, CA, USA, 2015. [Google Scholar]
- Feng, Z.H.; Kittler, J. Advances in facial landmark detection. Biom. Technol. Today 2018, 2018, 8–11. [Google Scholar] [CrossRef]
- Phillips, P.J.; Flynn, P.J.; Scruggs, T.; Bowyer, K.W.; Chang, J.; Hoffman, K.; Marques, J.; Min, J.; Worek, W. Overview of the Face Recognition Grand Challenge. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE Computer Society: Washington, DC, USA, 2005; Volume 1, pp. 947–954. [Google Scholar] [CrossRef]
- Microsoft. Microsoft Kinect; Microsoft: Redmond, WA, USA, 2013. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Facial landmark detection by deep multi-task learning. In Lecture Notes in Computer Science; (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Germany, 2014; Volume 8694, pp. 94–108. [Google Scholar]
- Hand, E.M.; Chellappa, R. Attributes for Improved Attributes: A Multi-Task Network for Attribute Classification. arXiv, 2016; arXiv:1604.07360. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Learning Deep Representation for Face Alignment with Auxiliary Attributes. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 918–930. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Wang, X.; Tang, X. Deep convolutional network cascade for facial point detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3476–3483. [Google Scholar] [CrossRef]
- Lai, H.; Xiao, S.; Pan, Y.; Cui, Z.; Feng, J.; Xu, C.; Yin, J.; Yan, S. Deep Recurrent Regression for Facial Landmark Detection. arXiv, 2015; arXiv:1510.09083. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Lu, J.; Feng, J.; Zhou, J. Learning Deep Sharable and Structural Detectors for Face Alignment. IEEE Trans. Image Process. 2017, 26, 1666–1678. [Google Scholar] [CrossRef] [PubMed]
- Angeline, P.J.; Angeline, P.J.; Saunders, G.M.; Saunders, G.M.; Pollack, J.B.; Pollack, J.B. An evolutionary algorithm that constructs recurrent neural networks. IEEE Trans. Neural Netw. 1994, 5, 54–65. [Google Scholar] [CrossRef] [PubMed]
- Dibeklioglu, H.; Salah, A.A.; Akarun, L. 3D Facial Landmarking under Expression, Pose, and Occlusion Variations. In Proceedings of the 2008 IEEE Second International Conference on Biometrics: Theory, Applications and Systems, Arlington, VA, USA, 29 September–1 October 2008; pp. 3–8. [Google Scholar]
- Nair, P.; Cavallaro, A. 3-D Face Detection, Landmark Localization, and Registration Using a Point Distribution Model. IEEE Trans. Multimed. 2009, 11, 611–623. [Google Scholar] [CrossRef]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal Deep Learning. In Proceedings of the 28th International Conference on Machine Learning (ICML), Orlando, FL, USA, 3–7 November 2014; pp. 689–696. [Google Scholar] [CrossRef]
- Park, E.; Han, X.; Tamara, L.; Berg, A.C. Combining Multiple Sources of Knowledege in Deep CNNs for Action Recognition. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016; pp. 1–8. [Google Scholar]
- Socher, R.; Huval, B. Convolutional-recursive deep learning for 3D object classification. In Advances in Neural Information Processing Systems 9: Proceedings of the 1996 Conference; MIT Press Ltd.: Cambridge, MA, USA, 2012; pp. 1–9. [Google Scholar]
- Liu, L.; Shao, L. Learning discriminative representations from RGB-D video data. IJCAI 2013, 1, 1493. [Google Scholar]
- Cao, C.; Weng, Y.; Zhou, S.; Tong, Y.; Zhou, K. FaceWarehouse: A 3D facial expression database for visual computing. IEEE Trans. Vis. Comput. Graph. 2014, 20, 413–425. [Google Scholar] [CrossRef] [PubMed]
- Microsoft. Microsoft Kinect 360; Microsoft: Redmond, WA, USA, 2010. [Google Scholar]
- Fanelli, G.; Dantone, M.; Gall, J.; Fossati, A.; Van Gool, L. Random Forests for Real Time 3D Face Analysis. Int. J. Comput. Vis. 2013, 101, 437–458. [Google Scholar] [CrossRef]
- Min, R.; Kose, N.; Dugelay, J.L. KinectFaceDB: A Kinect Face Database for Face Recognition. IEEE Trans. Syst. Man Cybern. A 2014, 44, 1534–1548. [Google Scholar] [CrossRef]
- Hg, R.I.; Jasek, P.; Rofidal, C.; Nasrollahi, K.; Moeslund, T.B.; Tranchet, G. An RGB-D database using microsoft’s kinect for windows for face detection. In Proceedings of the 2012 8th International Conference on Signal Image Technology and Internet Based Systems, (SITIS’2012), Naples, Italy, 25–29 November 2012; pp. 42–46. [Google Scholar] [CrossRef]
- Erdogmus, N.; Marcel, S. Spoofing in 2D face recognition with 3D masks and anti-spoofing with Kinect. In Proceedings of the 2013 IEEE 6th International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013. [Google Scholar] [CrossRef]
- Kendrick, C.; Tan, K.; Walker, K.; Yap, M.H. The Application of Neural Networks for Facial Landmarking on Mobile Devices. In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISAPP), Funchal, Portugal, 27–29 January 2018; INSTICC/SciTePress: Setúbal, Portugal, 2018; Volume 4, pp. 189–197. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. Osdi 2016, 16, 265–283. [Google Scholar]
- Chollet, F. Keras. 2016. Available online: https://keras.io/ (accessed on 15 June 2018).
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. arXiv, 2015; arXiv:1412.6980v8. [Google Scholar]
- Kendrick, C.; Tan, K.; Williams, T.; Yap, M.H. An Online Tool for the Annotation of 3D Models. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 362–369. [Google Scholar] [CrossRef]
- Intel. RealSense SR300; Intel: Santa Clara, CA, USA, 2016. [Google Scholar]
- Carfagni, M.; Furferi, R.; Governi, L.; Servi, M.; Uccheddu, F.; Volpe, Y. On the Performance of the Intel SR300 Depth Camera: Metrological and Critical Characterization. IEEE Sens. J. 2017, 17, 4508–4519. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Data | UV MSE | XYZ MSE | UVXYZ MSE (Combined) | UVXYZ MSE (UV) | UVXYZ MSE (XYZ) |
|---|---|---|---|---|---|
| Gs | 1.8192 | 0.0023 | 1.3695 | 1.3676 | 0.0019 |
| Depth | 6.4672 | 0.0023 | 6.6509 | 6.6482 | 0.0027 |
| Gs Depth | 2.1845 | 0.0022 | 1.8933 | 1.8911 | 0.0022 |
| RGB Depth | 2.1561 | 0.0022 | 2.8744 | 2.8752 | 0.0022 |
| RGB | 1.7488 | 0.0023 | 1.5612 | 1.5592 | 0.0019 |
| Input Data | UV MAE | XYZ MAE | UVXYZ MAE (Combined) | UVXYZ MAE (UV) | UVXYZ MAE (XYZ) |
|---|---|---|---|---|---|
| Gs | 1.0052 | 0.0341 | 0.9127 | 0.8797 | 0.0330 |
| Depth | 1.9150 | 0.0361 | 1.9705 | 1.9322 | 0.0382 |
| Gs Depth | 1.1210 | 0.0379 | 1.0617 | 1.0246 | 0.0371 |
| RGB Depth | 1.0848 | 0.0367 | 1.3056 | 1.2685 | 0.0371 |
| RGB | 0.9553 | 0.0346 | 0.9685 | 0.9388 | 0.0297 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kendrick, C.; Tan, K.; Walker, K.; Yap, M.H. Towards Real-Time Facial Landmark Detection in Depth Data Using Auxiliary Information. Symmetry 2018, 10, 230. https://doi.org/10.3390/sym10060230
Kendrick C, Tan K, Walker K, Yap MH. Towards Real-Time Facial Landmark Detection in Depth Data Using Auxiliary Information. Symmetry. 2018; 10(6):230. https://doi.org/10.3390/sym10060230
Chicago/Turabian StyleKendrick, Connah, Kevin Tan, Kevin Walker, and Moi Hoon Yap. 2018. "Towards Real-Time Facial Landmark Detection in Depth Data Using Auxiliary Information" Symmetry 10, no. 6: 230. https://doi.org/10.3390/sym10060230
APA StyleKendrick, C., Tan, K., Walker, K., & Yap, M. H. (2018). Towards Real-Time Facial Landmark Detection in Depth Data Using Auxiliary Information. Symmetry, 10(6), 230. https://doi.org/10.3390/sym10060230