1. Introduction
Generalized Principal Component Analysis (PCA) is an important research tool in the Symbolic Data Analysis (SDA) [
1]. PCA is a statistical procedure that uses orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components (PCs) [
2,
3,
4]. PCA is commonly used for dimension reduction [
5,
6] by specifying a few PCs that account for as much of the variability in the original dataset as possible. It is well known that PCA has been primarily developed for single-valued variables. However, the explosion of big data from a wide range of application domains presents new challenges for traditional PCA, as it is difficult to gain insight from mass observation even in a low-dimensional space. Symbolic data analysis [
7,
8,
9,
10] has developed a new path for solving this problem.
Symbolic data was first introduced by [
7] and aims to summarize large-scale data with conceptual observations described by symbolic descriptors, such as interval data, histogram, and continuous distribution data. Application fields of symbolic data include economic management, finance, and sociodemographic surveys. Thus, some researchers devoted themselves to studying new PCA methods for symbolic data. Here, we are interested in PCA for histogram data, where each variable value for each unit is a set of weights associated with the bins of variable values. The weights can be considered to be the frequency or probability of their associated bin for the corresponding unit. The sum of the weights is equal to 1.
Several studies contribute to the extension of PCA to histogram data. Reference [
11] attempted to analyze a symbolic dataset for dimensionality reduction when the features are of histogram type. This approach assumes that the modal variables have the same number of ordered bins and uses the PCA of tables associated with each bin. References [
12,
13] assumed that the same number of bins was ordered for each variable. References [
1,
14] proposed approaches based on distributions of histogram transformation, which is not possible in the case of nonordinal bins. Nevertheless, the Ichino method solves this case by ranking bins by their frequency among the whole population of individuals. Reference [
15] presented a strategy for extending standard PCA to histogram data. This method uses metabins that mix bins from different bar charts and enhance interpretability. Then it proposes Copular PCA to handle the probabilities and underlying dependencies. The method presented by [
1] builds metabins and metabin trajectories for each individual from the nominal histogram variables. Reference [
15] also proved that the method proposed by [
1] is an alternate solution to Copular PCA. Reference [
16] expressed an accurate distribution of linear combination of quantitative symbolic variables by convolutions of their probability distribution functions. Reference [
17] use Multiple Factor Analysis (MFA) approach for the analysis of data described by distributional variables. Each distributional variable induces a set new numeric variable related to the quantiles of each distribution. Reference [
18] deals with the current situation of histogram use through histogram PCA.
Despite the number of experts who study PCA for histogram data, there are still many challenging issues that have not been fully addressed in previous publications. In PCA methods for histogram data, projection results are approximated based on Moore’s algebra [
19] and fail to reflect the data’s true structure, mainly because methods of linear combinations of histogram data are imprecise and not unified. The PSPCA method proposed by [
16] can obtain precise projections, but the process of calculating convolutions is very complicated and time consuming, requiring a more efficient method of PCA for histogram data.
In this paper, we investigate a sampling-based PCA method for histogram data to solve the dimension reduction problem of histogram data. This method can project observations onto the space spanned by PCs more accurately and rapidly using a MapReduce framework. Assuming orthogonal dimensions for every observation [
20], as in existing literature, to project observations onto the space spanned by PCs, we first sample from the original histogram variables to acquire single-valued data on which linear combination operations can be performed. Then, the projection of observations can be described by a linear combination of loading vectors and single-valued samples. Lastly, the projection is summarized to histogram data. As random sampling is used in this process, the projection results of different samplings may be different, resulting in the projection results of the proposed method being only close to accurate projections. However, we have proved that for a sufficiently large sample size, the projection results tend towards stability and are close to the accurate projections.
Because this method uses complex algorithms and large-scale data, it is quite time consuming. To speed up the method, we undertake a parallel implementation of the new method through a multicore MapReduce framework. MapReduce is a popular parallel programming model for cloud computing platforms and has been effective in processing large datasets using multicore or multiprocessor systems [
21,
22,
23,
24,
25]. We conducted a simulation experiment to confirm that the new method is effective and can be substantially accelerated.
It should be emphasized that we only propose the MapReduce framework for sampling-based histogram PCA for big data. When there is sufficient data, we can use a big data platform like Hadoop and adopt parallel computing methods, such as GPU computing and MPI (Message Passing Interface). In this paper, we simply consider a multicore MapReduce parallel implementation.
The remainder of this paper is organized as follows. In
Section 2, we propose a sampling-based Histogram PCA method.
Section 3 describes the implementation of the new method in a multicore MapReduce framework. Next, in
Section 4, a simulation study of the new method and its parallel implementation are presented. We also compare the execution times of serial and parallel processing. In
Section 5, we report the results of our empirical study. Finally,
Section 6 outlines our conclusions.
2. Sampling-Based Histogram PCA
In this section, we first define the inner product operator for histogram-valued data, then derive histogram PCA, and finally project the observations onto the space spanned by principal components using sampling.
2.1. Basic Operators
Let
be a data matrix that can be expressed as a vector of observations or of variables.
where
denotes the
ith observation and
,
denotes the
jth variable. Additionally, the random variable
represents the
jth variable of the
ith observation, with realization
in the classical case and
in the symbolic case.
Next, we give the empirical distribution functions and descriptive statistics for histogram data. For further detail, refer to [
9,
26].
Let
,
i = 1, …,
n, be a random sample. Let the
jth variable have a histogram-valued realization
,
where
is the
lth subinterval of
and
is its associated relative frequency. Let
denote the number of subintervals in
. Then,
for all
l = 1, …,
, and
.
Reference [
27] extended the empirical distribution function derived by [
26] for interval data to histogram data. Based on the assumption that all values within each subinterval
are uniformly distributed, they defined the empirical distribution of a point
within subinterval
as
Furthermore, assume that each object is equally likely to be observed with probability
; then, the empirical distribution function of
W is
where
. The empirical density function of
W is defined as
The symbolic sample mean derived from the density function shown in Equation (
5) is
Accordingly, the centralization of
is given by
After centralization, the symbolic sample variance and covariance are, respectively,
and
2.2. The PCA Algorithm of Histogram Data
Based on the operators above, we begin to derive histogram-valued PCs. For simplicity of notation, we assume that all histogram-valued data units have been centralized.
The
kth histogram-valued PC
is a linear combination of
,
where
is subject to
and
. Then, the symbolic sample variance of
can be derived from
where
represents the sample covariance matrix as
, in which
and
are present in Equations (
8) and (
9).
The following process is the same as that for classical PCA. (for details, see the original sources).
Set
as the eigenvectors of
, corresponding to the eigenvalues
. The derivation of PC coefficients is transformed into the eigendecomposition of the covariance matrix. The contribution rate(
) of the
mth PC to the total variance can be measured by
2.3. The Projection Process
In existing PCA methods for histogram data, the projection results are approximated based on Moore’s algebra [
19] and fail to reflect true data structures, mainly because there are no precise, unified methods for linearly combining histogram data.
In this paper, we project observations onto the space spanned by PCs with a sampling method. Using the concept of symbolic data, histogram-valued data can be generated from a mass of numerical data. Retroactively, we can also sample from histogram-valued data to obtain numerical data on which linear combination operations can be performed. As PC coefficients and numerical variables corresponding to the original histogram-valued variables are obtained, we can calculate the numerical projections by linearly combining them. Then, histogram-valued projections of the original observations can be summarized from numerical projections.
Let
represent the
ith observation unit of the
jth variable
in histogram-valued matrix
.
in Equation (
2) is a realization of
. Based on the assumption that all values within each subinterval
are uniformly distributed, to obtain numerical data corresponding to
, we select
samples from those subintervals of
through random sampling. To maintain the coherence of the numerical sample matrix, the sample sizes of different variables from the same observation are assumed to be equal. After the random sampling process, the numerical sample matrix corresponding to the original histogram-valued matrix, which we call matrix
, can be obtained. As the dimension of
is
, the dimension of
is
.
According to Equation (
10), the
kth numerical PC
is a linear combination of
,
The calculation in Equation (
13) can be performed because
are numerical variables. The projection approach in Equation (
13) is similar to the classic PCA approach. Finally, we obtain histogram-valued PCs through generating numerical PCs. In this way, histogram-valued observations are successfully projected onto the space spanned by PCs.
The above analysis can be summarized by the following algorithm:
Step 1: Centralize the histogram-valued matrix
in Equation (
1) and keep the notations consistent for simplicity.
Step 2: Calculate the covariance matrix
of
using Equations (
8) and (
9).
Step 3: Eigendecompose for orthonormalized eigenvectors in accordance with the eigenvalues , which are PC coefficients and PC variances, respectively.
Step 4: Obtain numerical matrix through random sampling from .
Step 5: Compute the numerical PCs
using Equation (
13).
Step 6: Generate histogram-valued PCs by summarizing numerical PCs , .
During this procedure, it is crucial to guarantee that any column of the matrix obtained by sampling has the same distribution as the corresponding column in , or that the distance between these two distributions is small enough to be negligible. Considering the empirical cumulative distribution approximates the true cumulative distribution favorably, we can determine that the difference between these two distributions converges as the sample size goes to infinity. Here, we give some key conclusions from the perspective of asymptotic theory.
Kolmogorov-Smirnov distance is a useful measure of global closeness between distributions
and
The asymptotic properties of Kolmogorov-Smirnov distance
have been studied and many related conclusions have been built. Extreme fluctuations in the convergence of
to 0 can be characterized by [
28]
Here, we deal with histogram data, in which case
is not continuous; thus, we cannot give
. According to Equation (
15),
converges with a rate slower than
by a factor
From the pointwise closeness of
to
we can easily observe that
where
is asymptotic normality.
Therefore, global and local differences between the histogram obtained from sampling data and the original can be controlled when the sample size is large, illustrating the feasibility of the proposed sampling method. It should be noted that the original histogram data, which is not continuous, is treated as the true distribution, but the conclusions above can cover discontinuous cases, although the formula expression may be complex. Related theoretical issues will be considered in the future.
3. MapReduce for Multicore, Sampling-Based Histogram PCA
The sampling-based histogram PCA approach presented in
Section 2 involves complex algorithms and large-scale data, which makes the method time-consuming and degrades its computation efficiency. To speed up the method, we undertake its parallel implementation using a multicore MapReduce framework in this section.
MapReduce is a programming model for processing large datasets with a parallel, distributed algorithm on a cluster. A MapReduce program is composed of a map procedure that filters and sorts data and a reduce procedure that performs a summary operation [
21]. Reference [
22] show that algorithms that can be written in a “summation form” can be easily parallelized on multicore computers. Coincidentally, Equations (
8), (
9) and (
13) are written in this form. In addition, the random sampling procedure can also be parallelized. Consequently, we adapt the MapReduce paradigm to implement our histogram PCA algorithm.
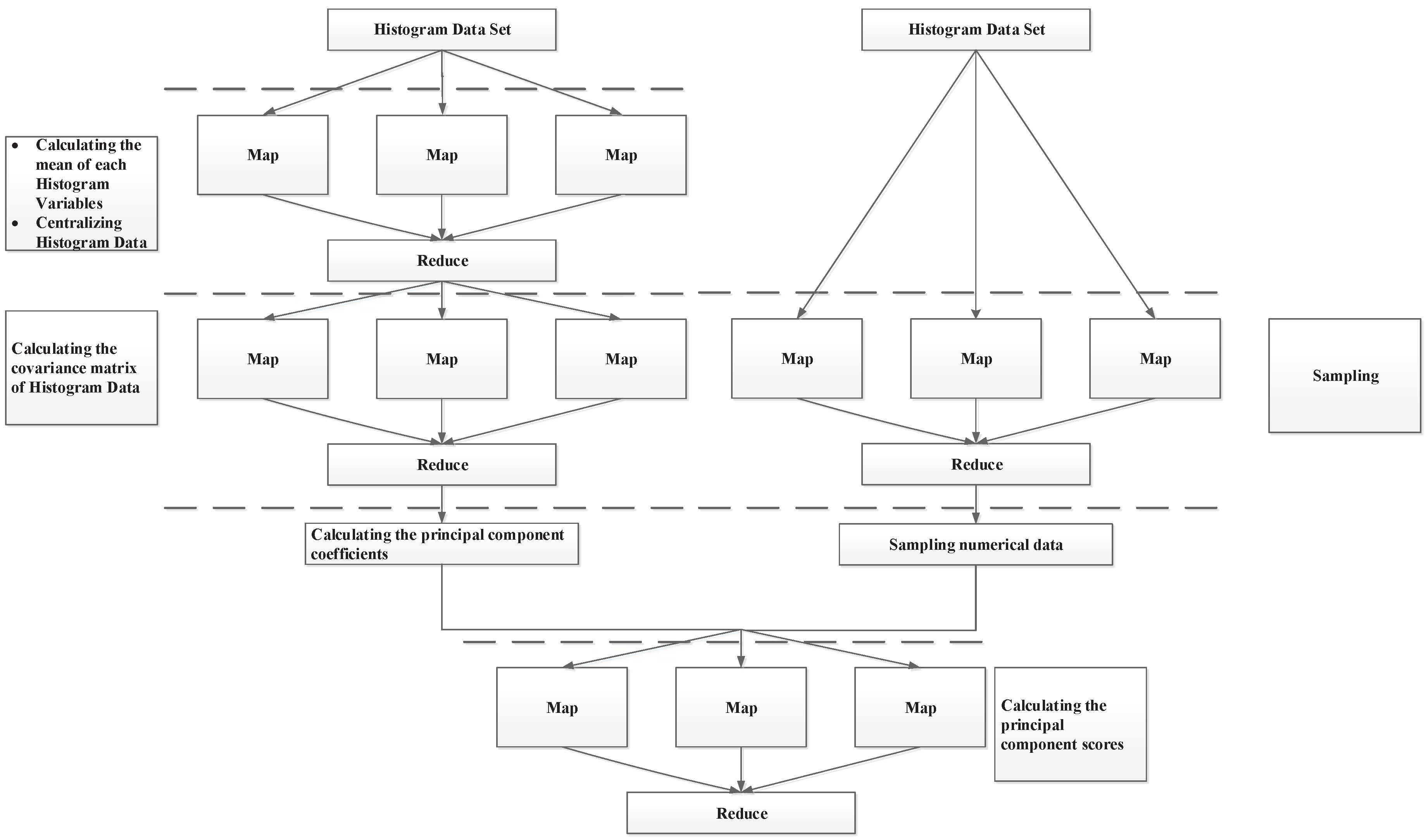
The multicore MapReduce frame for histogram PCA is presented in
Figure 1, which shows a high- level view of our architecture and how it processes the data. In
Step 1, the MapReduce engine calculates the mean of each histogram variable using Equation (
6) using pseudocode shown in Algorithm 1.
| Algorithm 1 MapReduce for calculating the mean of each histogram variable |
| 1: | function map1 () |
| 2: | |
| 3: | : row ID of the observation in |
| 4: | |
| 5: | : observations in |
| 6: | |
| 7: | for each element in do |
| 8: | |
| 9: | |
| 10: | |
| 11: | end for |
| 12: | |
| 13: | return () : coordinates of elements in |
| 14: | |
| 15: | end function |
| 16: | |
| 17: | function reduce1 () |
| 18: | |
| 19: | for do |
| 20: | |
| 21: | Calculating the mean of each histogram variable |
| 22: | |
| 23: | end for |
| 24: | |
| 25: | return (_) |
| 26: | |
| 27: | end function |
Then, the variables are centralized using Equation (
7). Every variable has its own engine instance, and every MapReduce task is delegated to its engine. Similarly, calculating the covariance matrix of histogram data using Equations (
8) and (
9) in
Step 2, random sampling from
in
Step 4, and computing the numerical principal components
using Equation (
13) in
Step 5 can also be delegated to MapReduce engines. The map and reduce functions are presented in Algorithms 2 and 3.
| Algorithm 2 MapReduce for centralizing histogram data and calculating the covariance matrix of histogram data |
| 1: | function map2 () |
| 2: | |
| 3: | : row ID of the observation in |
| 4: | |
| 5: | : observations in |
| 6: | |
| 7: | for each element in do |
| 8: | |
| 9: | Centralizing histogram data |
| 10: | |
| 11: | |
| 12: | |
| 13: | end for |
| 14: | |
| 15: | return () : coordinates of elements in |
| 16: | |
| 17: | end function |
| 18: | |
| 19: | function reduce2 () |
| 20: | |
| 21: | for do |
| 22: | |
| 23: | for do |
| 24: | |
| 25: | if then |
| 26: | |
| 27: | |
| 28: | |
| 29: | else |
| 30: | |
| 31: | |
| 32: | |
| 33: | Calculating the covariance matrix of histogram data |
| 34: | |
| 35: | end if |
| 36: | |
| 37: | end for |
| 38: | |
| 39: | end for |
| 40: | |
| 41: | return (_) _: coordinates of elements in |
| 42: | |
| 43: | end function |
| Algorithm 3 MapReduce for sampling-based histogram PCA |
| 1: | function map3 () |
| 2: | |
| 3: | : row ID of the observation in |
| 4: | |
| 5: | : observations in |
| 6: | |
| 7: | for each element in do |
| 8: | |
| 9: | Randomly sampling numerical data from , the sample size is K. |
| 10: | |
| 11: | end for |
| 12: | |
| 13: | return () |
| 14: | |
| 15: | end function |
| 16: | |
| 17: | function reduce3 () |
| 18: | |
| 19: | for each element in do |
| 20: | |
| 21: | |
| 22: | |
| 23: | Calculating the ith observation of the kth numerical PC |
| 24: | |
| 25: | Summarizing numerical PCs to obtain histogram PCs |
| 26: | |
| 27: | end for |
| 28: | |
| 29: | return (_) : the kth histogram PC |
| 30: | |
| 31: | end function |
| 32: | |
4. Simulation Study
To analyze the performance of the new histogram PCA method and demonstrate whether MapReduce parallelization can speed it up, we carried out a simulation study involving three examples.
Of the examples, Example 1 investigates the histogram PCA accuracy in
Section 2.2, Example 2 evaluates the precision of the sampling-based projection process of histogram PCA in
Section 2.3, and Example 3 compares the method’s execution time in parallel and serial systems.
The environment in which we conducted experiments is a PC with 8 Core Intel i7-6700K 4.00 GHz CPU and 8 GB RAM running Windows 7.
4.1. Example 1
With Example 1, we aim to investigate the accuracy of the histogram PCA algorithm. The simulated symbolic data tables are built as in [
29]. Based on the concept of symbolic variables, to obtain
n observations associated with a histogram-valued variable
, we simulate
K real values
corresponding to each unit. These values are then organized in histograms that represent the empirical distribution for each unit. The distribution of the microdata that allow histogram generation, corresponding to each observation of the variables
, is randomly selected from a mixture of distributions. Without loss of generality, in all observations, the widths of the subintervals in each histogram are the same.
Thus, we generate n histogram observations and the corresponding single-value data points. The single-value data points can be viewed as the original data, which we aim to approximate using histogram-valued data. Consequently, experimental PCA results obtained from single-value data can work as an evaluation benchmark for the histogram PCA algorithm.
The detailed process of Example 1 is as follows:
(1) Generate a synthetic histogram dataset with p variables and n observations and the corresponding single-value dataset, denoted as .
(2) Adopt the new histogram PCA method on and perform classical PCA on . The obtained PC coefficients are denoted as and , and the corresponding PC variances are represented by and , .
(3) Compute the following two indicators [
30]:
(a) Absolute cosine value (
) of PC coefficients:
Since cosine measures the angle between two vectors,
describes the similarity between PC coefficients
and the benchmark
. A higher
indicates a better performance of the new histogram PCA method. (b) Relative error (
) of PC variances:
Taking PC variances obtained from as a benchmark, the lower the is, the better the new histogram PCA method has performed.
The parameters for the experiments are set as follows: , .
We can compare the performance of the new histogram PCA method with the single-value benchmark based on the resulting PC coefficients and variances.
The comparative results of the PC coefficients are shown in
Table 1 using the
measure, and the comparative results of PC variances are shown in
Table 2 using the
measure. In general, the new histogram method yields fairly good results. The
values are all very close to 1, which indicates that the PC coefficients of the new histogram PCA method are similar to the benchmark PC coefficients. The values of
all fluctuate near zero, which verifies that the PC variances of the new histogram PCA method have only small differences with benchmark PC variances.
Furthermore,
Table 1 and
Table 2 show that the values of
and
change little, as the number of single-value data points
K increases. Additionally, there is no obvious regularity between the indicators and
K. Consequently, it can be concluded that the performance of the new histogram PCA method is accurate and not influenced by
K.
4.2. Example 2
In this example, we consider the precision of the sampling-based projection process. The simulated symbolic data tables were built in the same way as in Example 1. To obtain
n observations associated with histogram-valued variable
, we simulated 5000 real values
corresponding to each unit. These values were then organized in histograms. The distribution of the microdata was also randomly selected from a mixture of distributions:
As in Example 1, for all observations, the widths of the subintervals in each histogram are the same.
Thus, we generate
n histogram observations and the corresponding
single-value data points. The histogram dataset was adopted for comparing our sampling-based histogram PCA with the PSPCA method proposed by [
16]. Single-value data points can also be viewed as the original data we aim to approximate using histogram-valued data. Consequently, experimental PCA results obtained from single-value data can work as the evaluation benchmark for the results of the histogram PCA algorithm.
Per
Section 2.3, during the projection process, we select
single-value samples from the
ith observation. In this example, we assume that the sizes of single-value samples in each observation are all the same and are denoted as
M. The detailed process of Example 2 follows:
(1) Generate a synthetic histogram dataset with p variables and n observations and the corresponding single-value data set, denoted as .
(2) Adopt sampling-based histogram PCA and PSPCA methods to . The obtained histogram PCs are denoted as and respectively, where M is the sample size of each histogram unit. Classical PCA is performed on . The obtained histogram PCs are .
(3) Compute the Wasserstein distance
between
and
[
31].
(4) Compute the Wasserstein distance
between
and
.
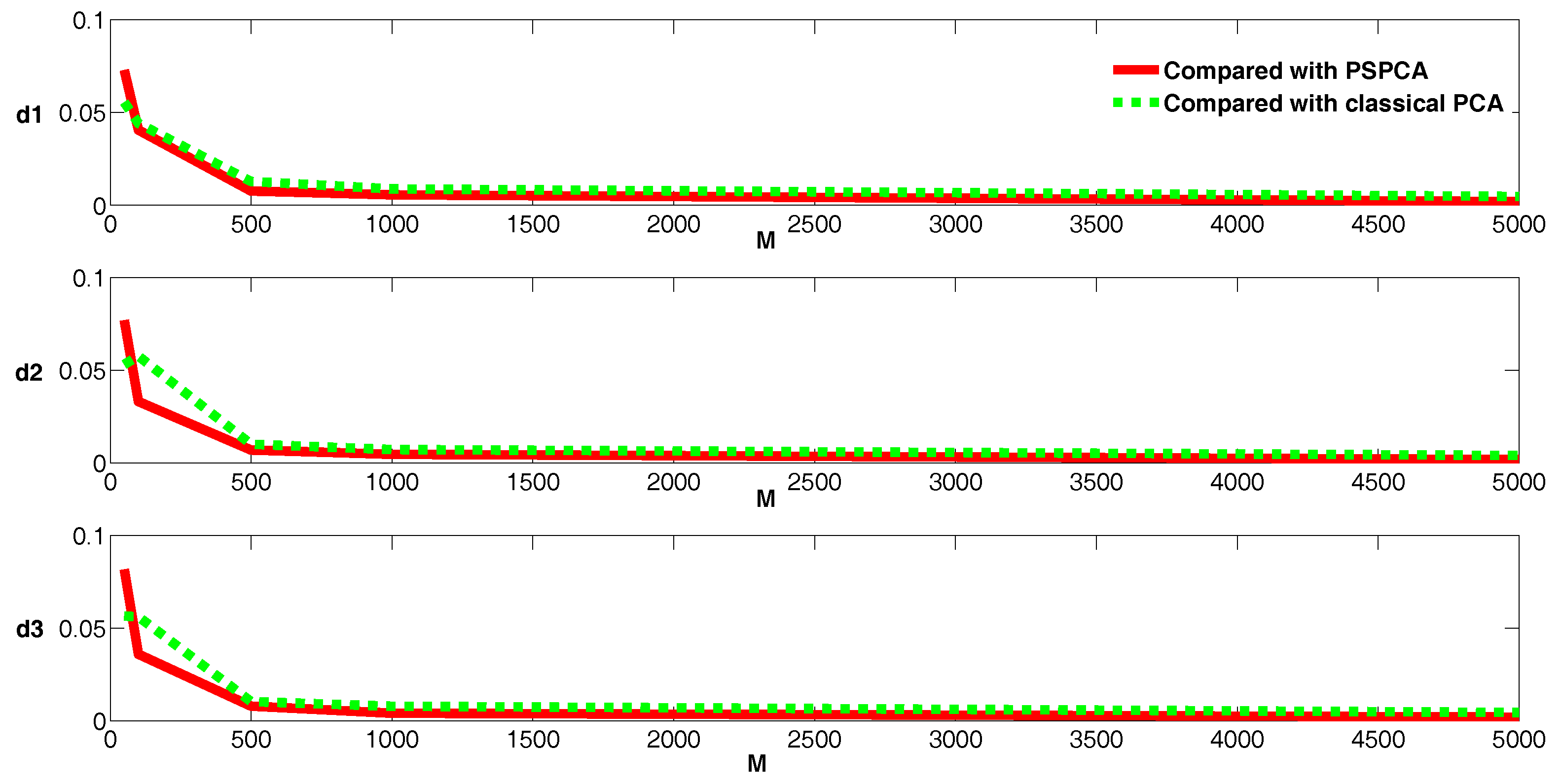
The parameters for the experiments are set as , and , .
Then, we can compare the performance of our sampling-based histogram PCA method with the single-value benchmark and the PSPCA method with the resulting PCs, as shown in
Figure 2.
The solid line shows the Wasserstein distance between and and the dotted line denotes the Wasserstein distance between and . The results shown in this figure indicate that the projections of sampling-based histogram PCA, PSPCA, and the single-value benchmarks are generally close. More specifically, the distances decrease as the random sampling size increases during sampling-based projection; when the sample size is more than 1000, the difference is close to zero. These results demonstrate the accuracy of sampling-based histogram PCA projection.
4.3. Example 3
In the third example, we verify the time-saving effects of the multicore MapReduce implementation of the new histogram PCA method. First, we generated observations of the histogram-valued variables . Then, we implemented the method in two different versions: one running MapReduce and the other a serial implementation without the new framework. The execution times of both approaches are compared. Here, we compare results using 1, 2, 4 and 8 cores.
First, we create observations for each histogram-valued variable . The simulated symbolic data tables are built as in Examples 1 and 2.
Based on the concept of symbolic variables, to obtain n observations associated with a histogram-valued variable , we simulate 5000 real values corresponding to each unit. These values are then organized in histograms that represent the empirical distribution for each unit. In all observations, the widths of the histograms subintervals are the same.
To perform the simulation experiment, symbolic tables that illustrate different situations were created. In this study, a full factorial design is employed, with the following factors:
Distribution of the microdata that allow histogram generation corresponding to each observation of the variables :
Mixture of distributions: Randomly selected from
Number of histogram-valued variables: p = 3; 5.
Observation size: n = 100; 500; 1000; 3000.
Based on the simulated histogram-valued variables, we conducted the new histogram PCA method in both parallel and serial. The random sampling size from histogram-valued variables in
Step 4 is also 5000, the same as the number of real values we began with to simulate histogram-valued variables. Index
and
are computed using Equation (
12) to analyze the behavior of the new histogram PCA method.Moreover, the execution time of both approach are compared to evaluate the speedup effect.
As the conclusion of different situations is almost the same, for the sake of brevity, in this section, we only provide the results for p = 3 and the uniform distribution.
Table 3 shows the contribution rate of the 1th and 2th PCs. As can be seen from the table,
and
explain most of the original information contained in the histogram-valued matrix, indicating that the new histogram PCA method performs well.
Figure 3 demonstrates the speedup of the method for 1, 2, 4 and 8 processing cores under the MapReduce frame. In
Figure 3, we can see that for a given number of cores, execution time increases with sample size. In addition, when sample size is constant, the execution time of the parallel and serial approaches is nearly equivalent when using 1 core. As the number of cores increases, the execution time of the serial approach is essentially unchanged, whereas the execution time of the parallel approach is gradually reduced; the ratio of the execution time between the serial and parallel approaches is nearly the same as the core number. We conclude that the speed increase using a parallel approach with a multicore MapReduce frame is significant.
5. Empirical Study
Nowadays, the rapid development of the Internet has created opportunities for the development of movie sites. The major functions of movie sites are to calculate movie ratings based on user rating data and to then recommend high-quality movies. Since the set of user rating data is massive, symbolic data can be utilized.
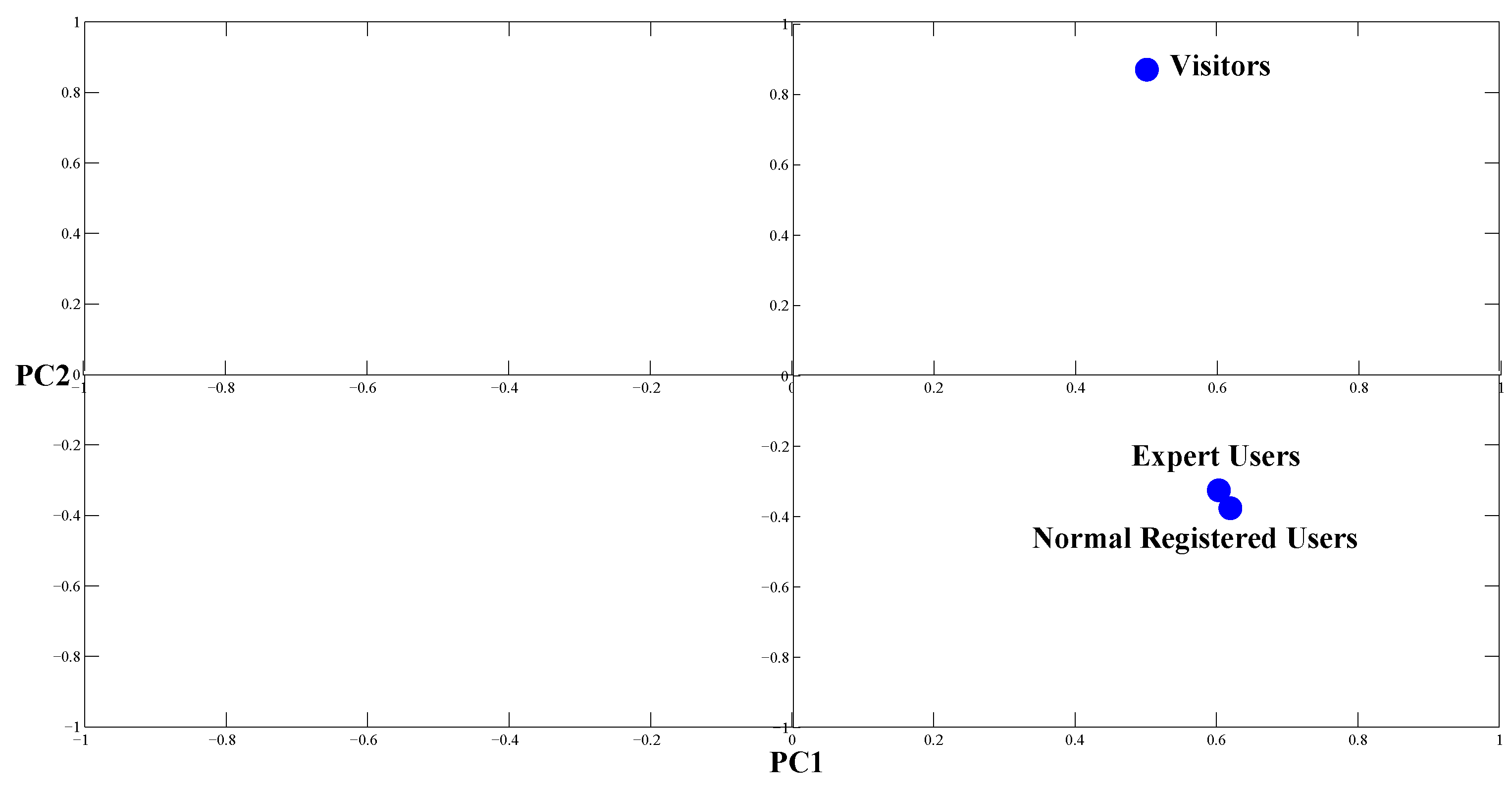
In this section, we use real data to evaluate the performance of sampling-based histogram PCA. The data consists of 198,315 ratings from a Chinese movie site from October 2009 to May 2014. The ratings come from three different types of users: visitors, normal registered users, and expert users. In the first step, we summarize movie ratings from the different user types to obtain scoring histograms for each type of user for a movie. Then, the dataset becomes a histogram symbolic table of 500 observations and 3 variables. Finally, sampling-based histogram PCA can be conducted on the generated histogram symbolic table. We computed the
index of each PC and show the loading plot of the first and the second PCs in
Table 4 and
Figure 4.
The results show that the first PC summarizes 73.87% of the total information carried by the original variables. The first PC is positively associated with visitors’, normal registered users’, and expert users’ rating histograms. Thus, we could simply use the first PC as an integrated embodiment of the three types of user ratings, simplifying the evaluation and comparison of different movies.
Next, we verify the performance of the sampling-based projection process using the projection results on the first PC. As the explanatory power of the first PC is very good, if the scores of the first PC can identify the different characteristics of the movies, the projection results are reasonable.
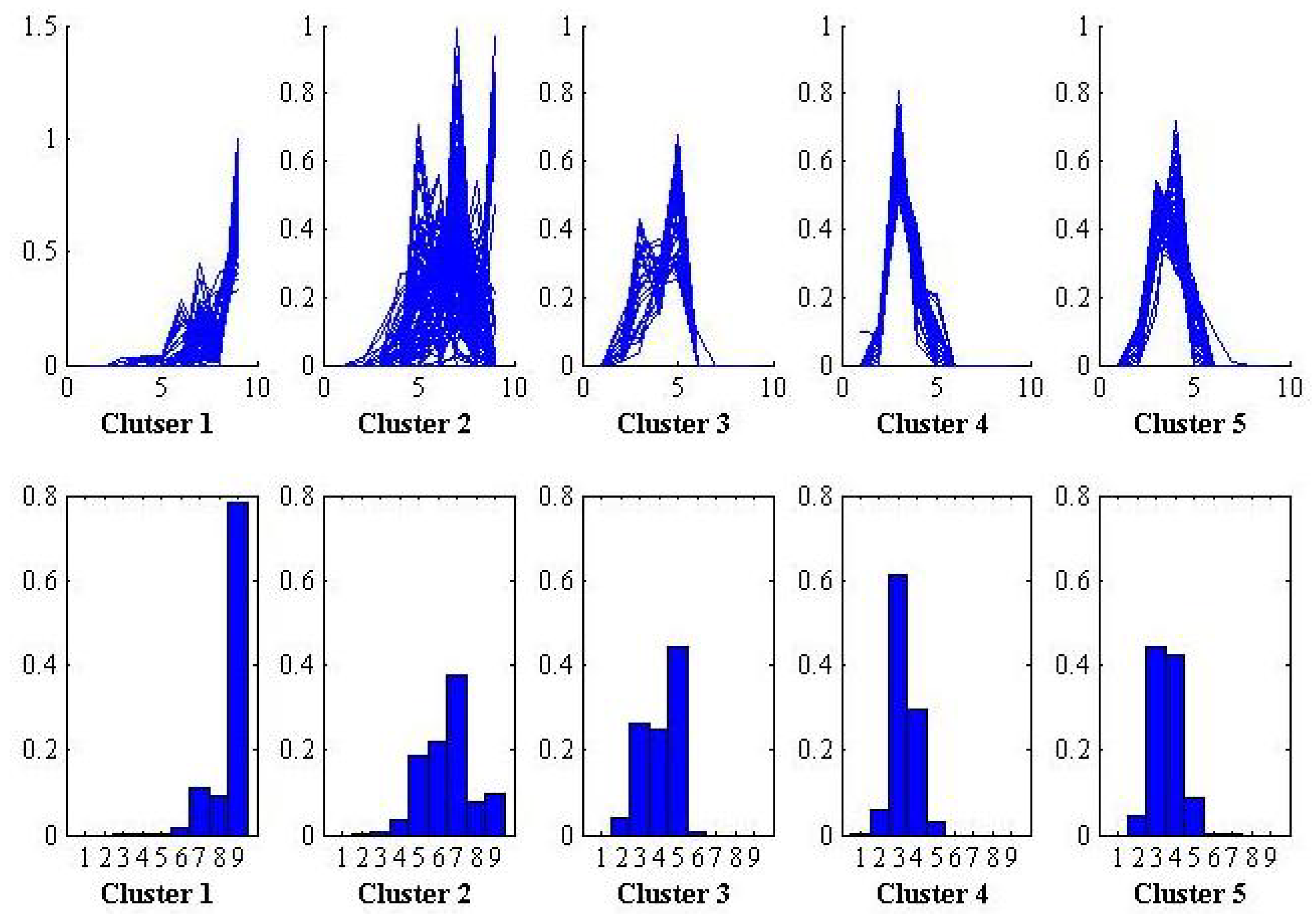
In this empirical study, clustering analysis is implemented on these movies based on the Wasserstein distances [
31] between pairs of projections on the first PC and movies are divided into five clusters. During the projection process, we randomly sample 1000 single-value samples from each histogram observation. The projection results of the clusters are showed in
Figure 5, where the curves in the first row are the projections of the movies in each cluster. For convenience, we use curve instead of histogram to show the a movie’s scoring probabilities in each score section. The histograms in the second row are the centers of the five clusters in the first row.
The results show that the characteristics of different categories of movie are different. The movies in Cluster 1 receive high ratings; movies in Cluster 2 are distributed relatively equally across score sections; movies in Cluster 3 are distributed relatively equally among low-score sections; and the movies in Clusters 4 and 5 are low grade, mainly distributed in 3 and 3-4 point ratings, respectively.
As can be seen, the final ratings histograms clearly reflect different types of movies, which indicate that the method proposed in this paper performs effectively.
6. Conclusions
As there is no precise, unified method of linear combination of histogram-valued symbolic data, the paper presents a more accurate histogram PCA method, which can project observations onto the space spanned by PCs by random sampling numerical data from the histogram-valued variables. Furthermore, considering that the sampling algorithm is time-consuming and that the sampling can be done separately, we adopt a MapReduce paradigm to implement the new histogram PCA algorithm. A simulation study and an empirical study were performed to analyze the behavior of the new histogram PCA method and to demonstrate the effect of MapReduce parallel implementation. The new method performs well and can be sped up significantly through a multicore MapReduce framework.
In practice, the sampling method for the linear combination of histogram data proposed in the paper can be popularized and applied widely on other multivariable statistical models for histogram data, such as linear regression model, linear discriminant analysis model, and so on. Using sampling method will provide a new perspective for these methods, but further research is needed in the future.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}