3.1. Architecture and Procedure of the Proposed System
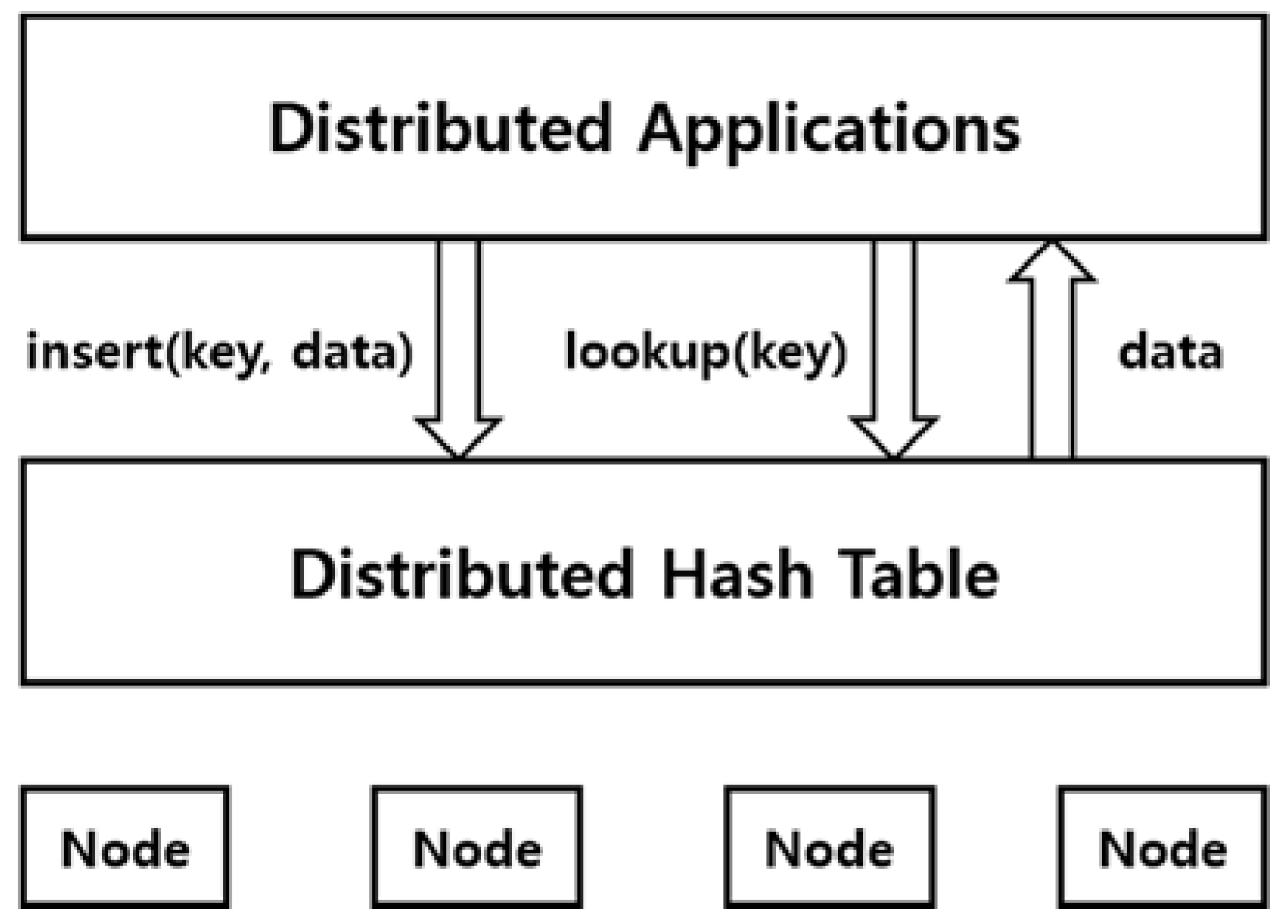
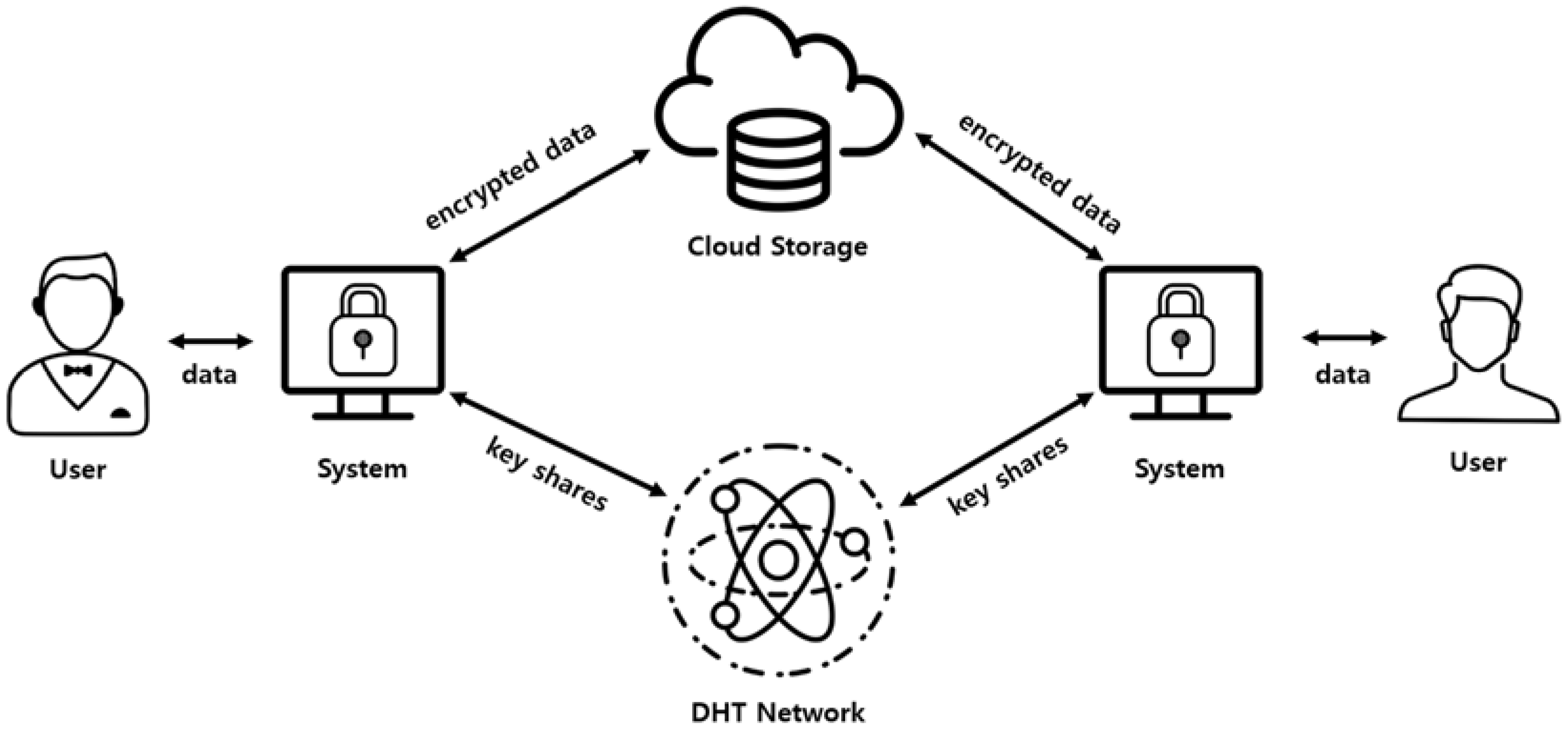
Figure 6 shows an overview of the overall system using the self-destructing scheme. The proposed system can be installed and operated on all users’ equipment using the cloud service, and can be used for cloud storage, email system, instant messages and so on. In addition, the overall system configuration and data flow are not significantly different from those using existing self-destructing schemes. The system installed in the equipment encrypts the user’s data and structures it as a new data object based on the additional information required by the system. The additional information needed at this time is mentioned in the self-destructing scheme. The encryption key is divided into several key shares using Shamir’s Secret Sharing technique, and each of the key shares are distributed and stored on the nodes in the DHT network. The structure of the data object stored in the cloud storage is in the form of (
,
,
,
) and the decryption process is performed in the reverse order of the encryption process. Naturally, all parameters are needed to decrypt the encapsulated data again.
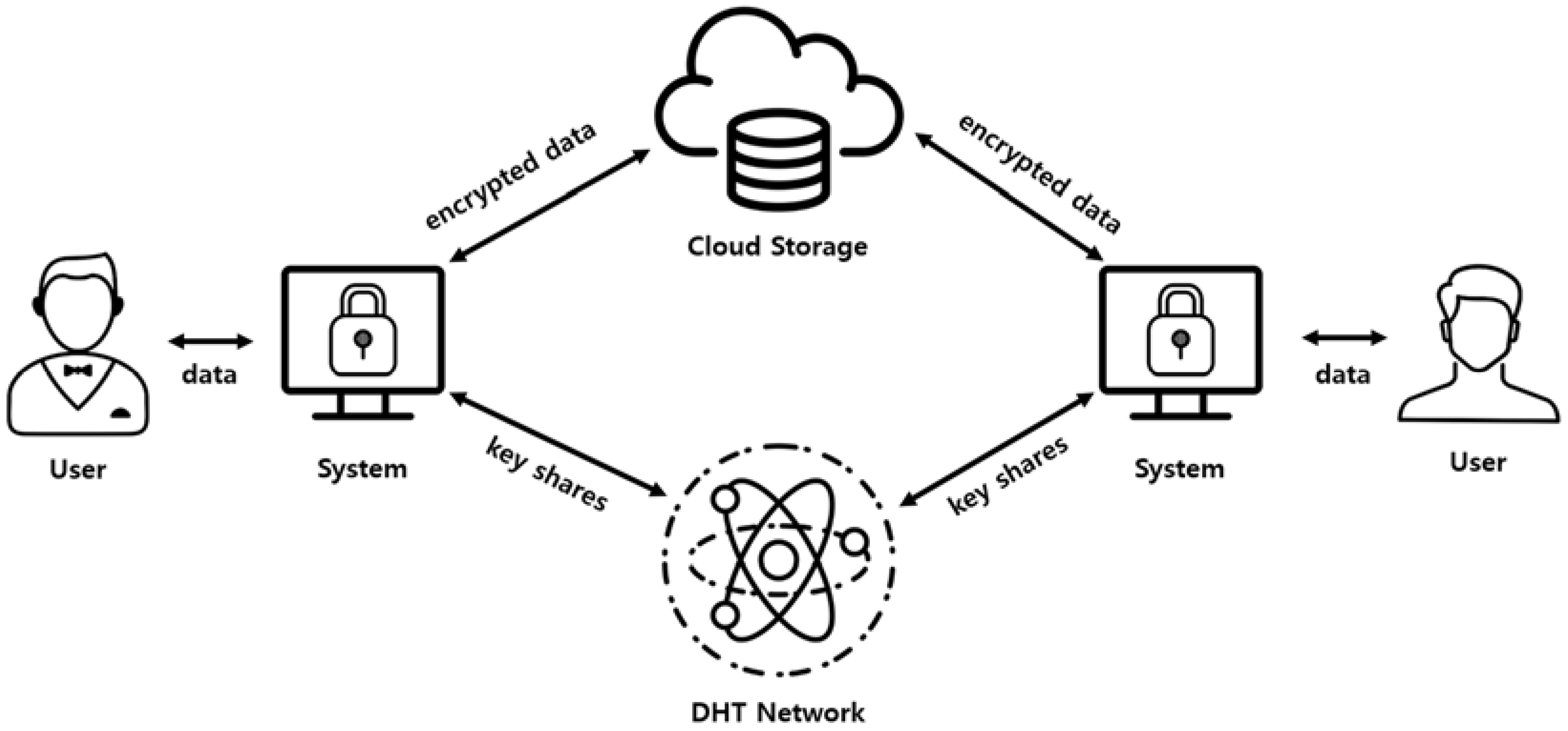
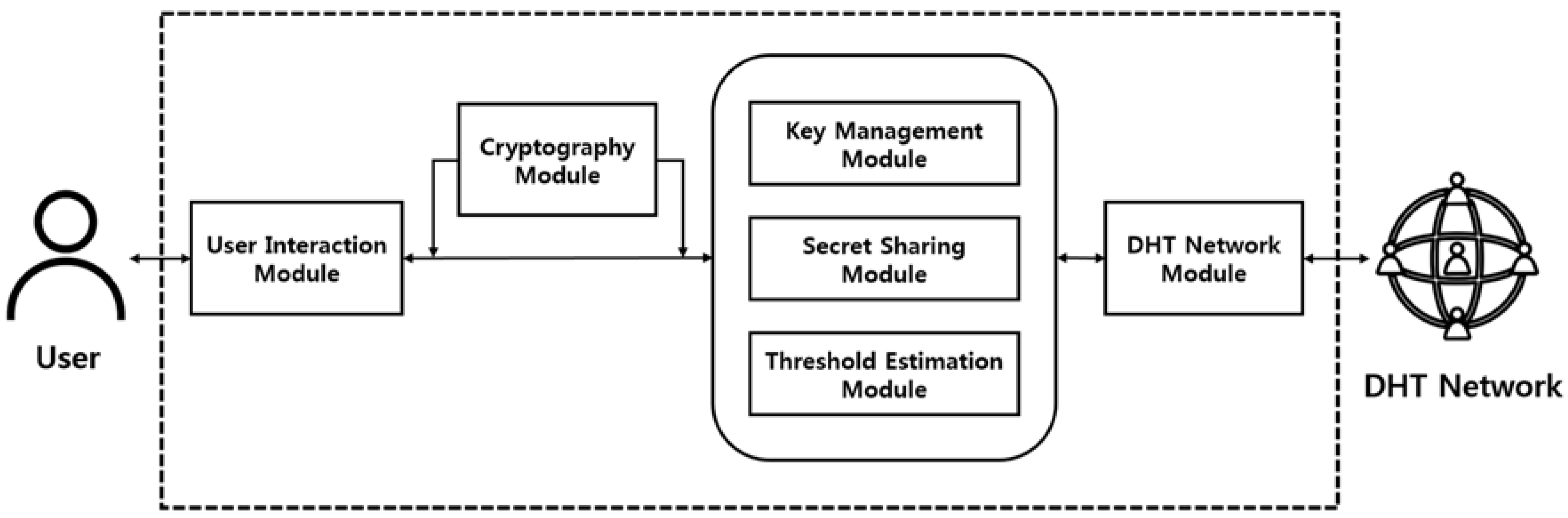
Figure 7 shows the overall structure of the system using the proposed self-destructing scheme. The system consists of a User Interaction Module for receiving data and access time information from the user, a Cryptography Module for performing encryption of data, and a Key Management Module for managing the keys required for encryption. The Secret Sharing Module for dividing the encryption key into several pieces using Shamir’s Secret Sharing, the Threshold Estimation Module for setting the optimal parameters(
,
) based on the similarity measurement between the reinforcement learning and the data availability graph, and a DHT Network Module for distributing the generated key shares to the DHT network.
A user who wants to protect sensitive data by using the proposed self-destructing scheme inputs corresponding data through the interface. The system receives an encryption key() from the certificate authority (CA) to encrypt the user’s data and creates a ciphertext(). The encryption algorithm uses the Advanced Encryption Standard (AES) algorithm based on a symmetric key algorithm, Cipher Block Chaining (CBC) mode. The key used in the AES-CBC encryption algorithm is 128 bits in size. The Secret Sharing Module divides the encryption key into several shares using Shamir’s Secret Sharing technique. We use the number of total key shares(N) and the minimum number of key shares needed to get the original key back() as parameters.
In addition, the Threshold Estimation Module periodically measures the availability of data in the DHT network environment and finds the ideal graph and parameters with higher similarity based on the reinforcement learning and similarity of the graph. The generated key shares are distributed to the DHT network by the DHT Network Module.
3.2. Measuring Similarity of the Data Availability Graph
In the proposed data self-destruction scheme, data availability is calculated by obtaining the key for decrypting the encrypted data. In this process, MAPE is used as a method to measure the similarity with the ideal state (all data is available during the user-specified time). For example, a user divides 10 encryption keys into 10 key shares and distributes a total of 100 key shares to the DHT. If the user gets five encryption keys based on the key shares from DHT at a particular time, then the data availability is 0.5.
As mentioned in
Figure 5, in the self-destructing scheme, the availability graph of the data is measured differently according to the number of the key shares and the threshold value. Therefore, in this paper, we compare the availability graph of ideal data with the availability graph of measured data in actual DHT network environment using Mean Absolute Percentage.
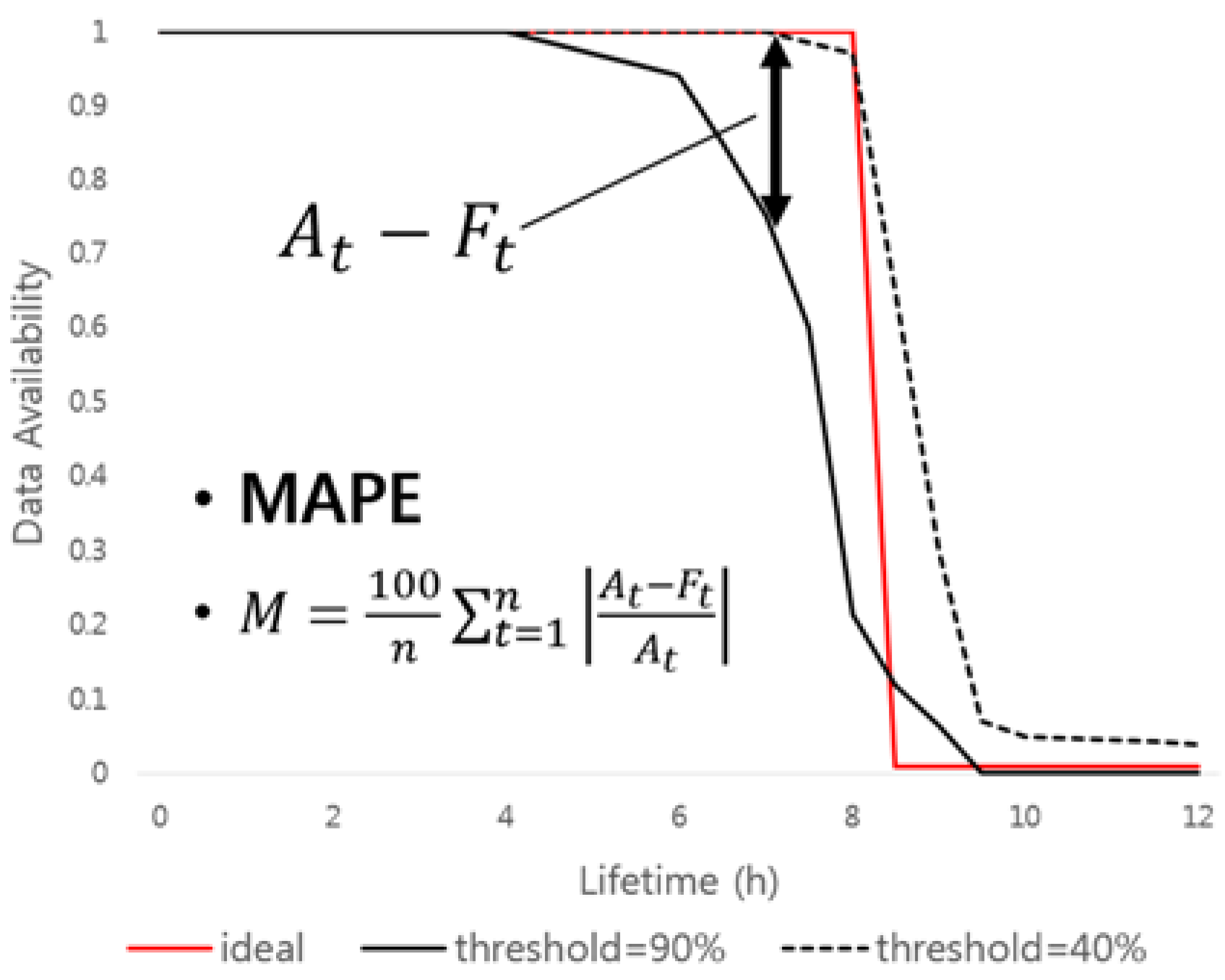
Figure 8 shows how to measure the similarity to the ideal graph, which guarantees the use of data only for a user-specified time. The proposed scheme uses MAPE, which is calculated by adding the difference of the result value according to the input value in the similarity measurement process. The result value (
y-axis) along the input value (
x-axis) is below the ideal graph, meaning that key shares are self-destructed before the user-specified time, which means that data availability is low. On the other hand, if the result value is above the ideal graph, meaning that key shares are not self-destructed and remain in the DHT network. This may cause system performance degradation or privacy problems. We find optimal key sharing parameters that are similar to the ideal graph by using MAPE, and apply them to the data self-destruction scheme.
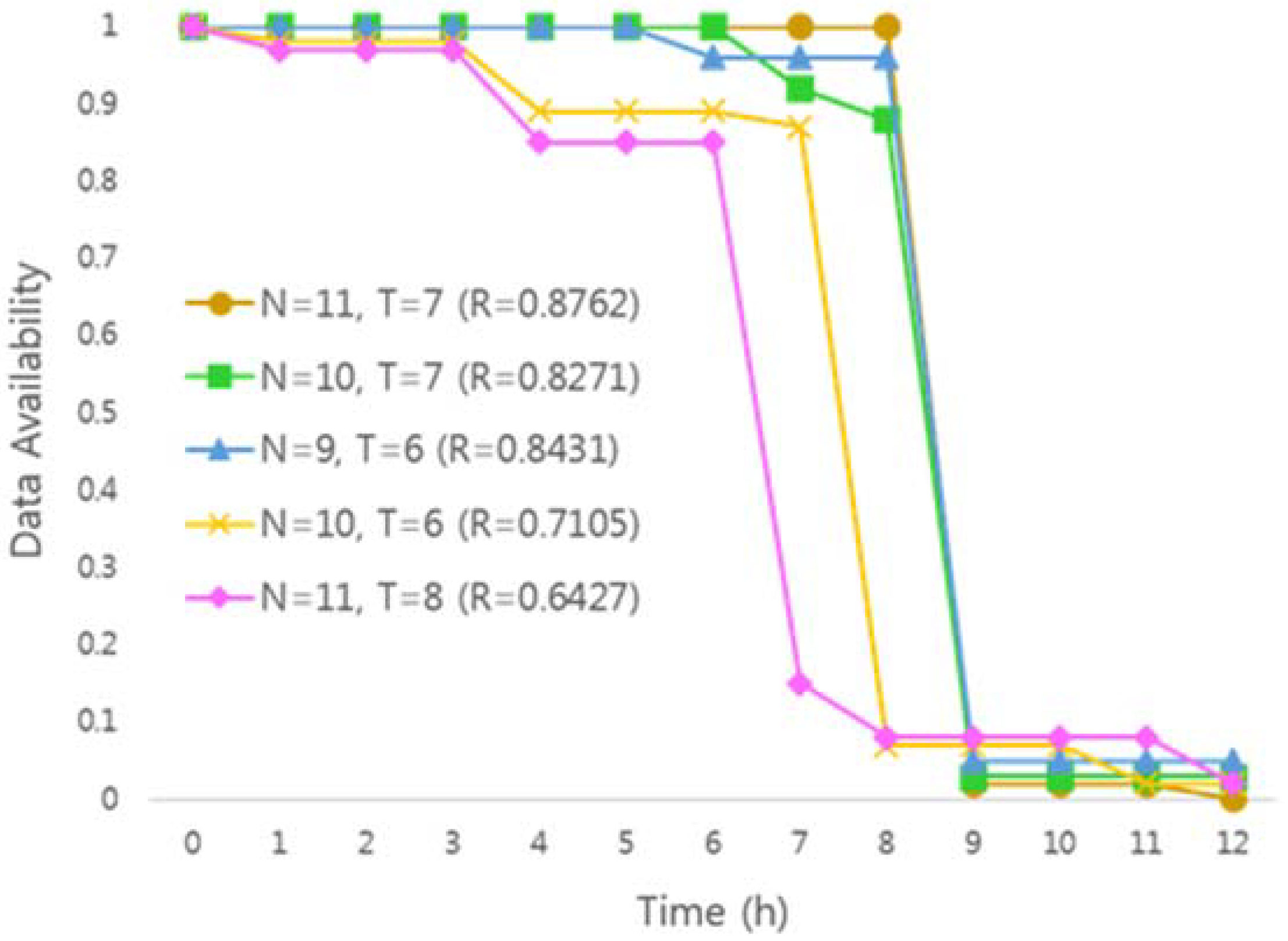
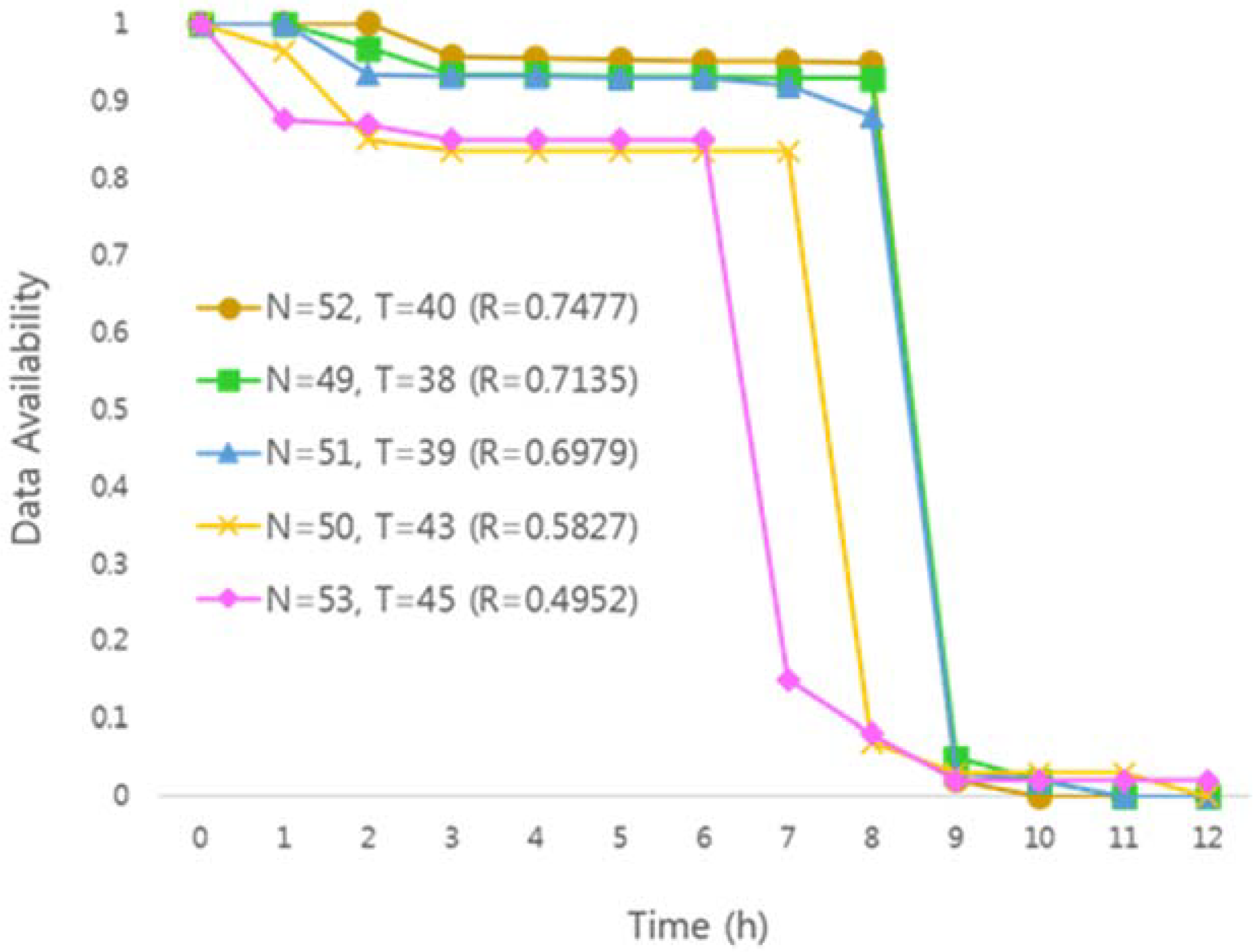
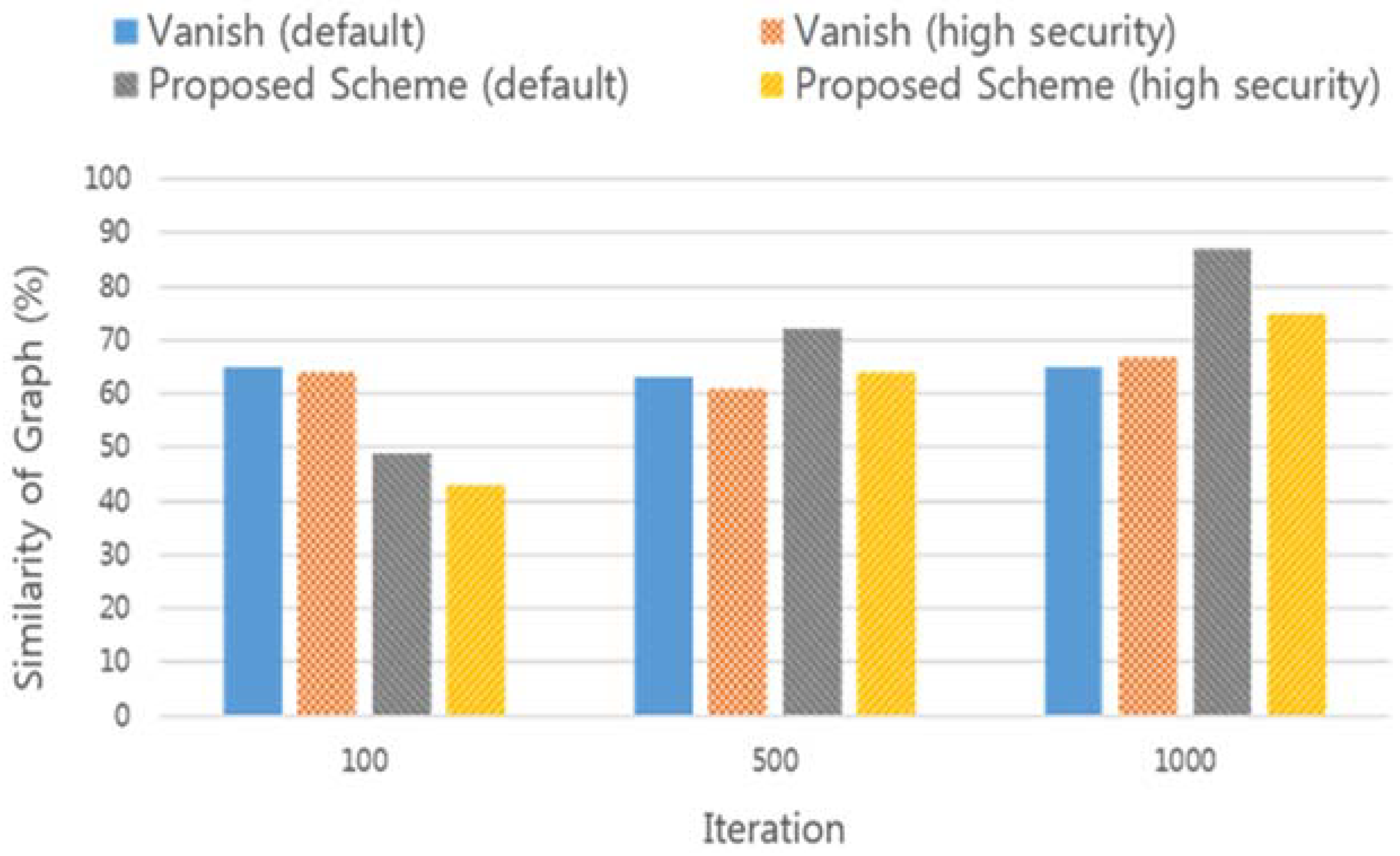
The following is an example of an ideal graph and similarity measure using MAPE for the availability graph of data according to different threshold values in VuzeDHT environment. In this case, the total number of key shares is 10, and the threshold values are 40 and 90, respectively. The data availability graph divides the keys required to encrypt each of the 100 data pieces and distributes them to the DHT network. After 12 h, each key shares are checked to see if the original encryption key can be recovered or not.
Table 2 is an example of measuring the similarity of the graph using the data of
Figure 8. The total number of key shares(N) is equal to 10, and is the result of the MAPE value and similarity when the minimum number of key shares(T) to obtain the original encryption key is 4 and 9, respectively. In case of T = 9, the similarity with the ideal graph was found to be lower than in the case of T = 4. In the above example, the total number of values used in the MAPE calculation is 120 (1 in 6 min, 10 in 1 h), and the more the values are used, the higher the accuracy of the calculation. However, due to the nature of the DHT network, which is heavily distributed all over the world, there is a clear limit to minimize the time required for the lookup operation. In addition, if the availability graph of the data is measured before the lookup operation is completed, a situation may arise in which the key fragment does not receive an accurate result even though it exists in the DHT node. Therefore, an operation that takes a value for measuring the similarity of a graph must be performed after the LOOKUP operation is definitely finished.
3.3. Reinforcement Learning Algorithm for Key Sharing Parameters
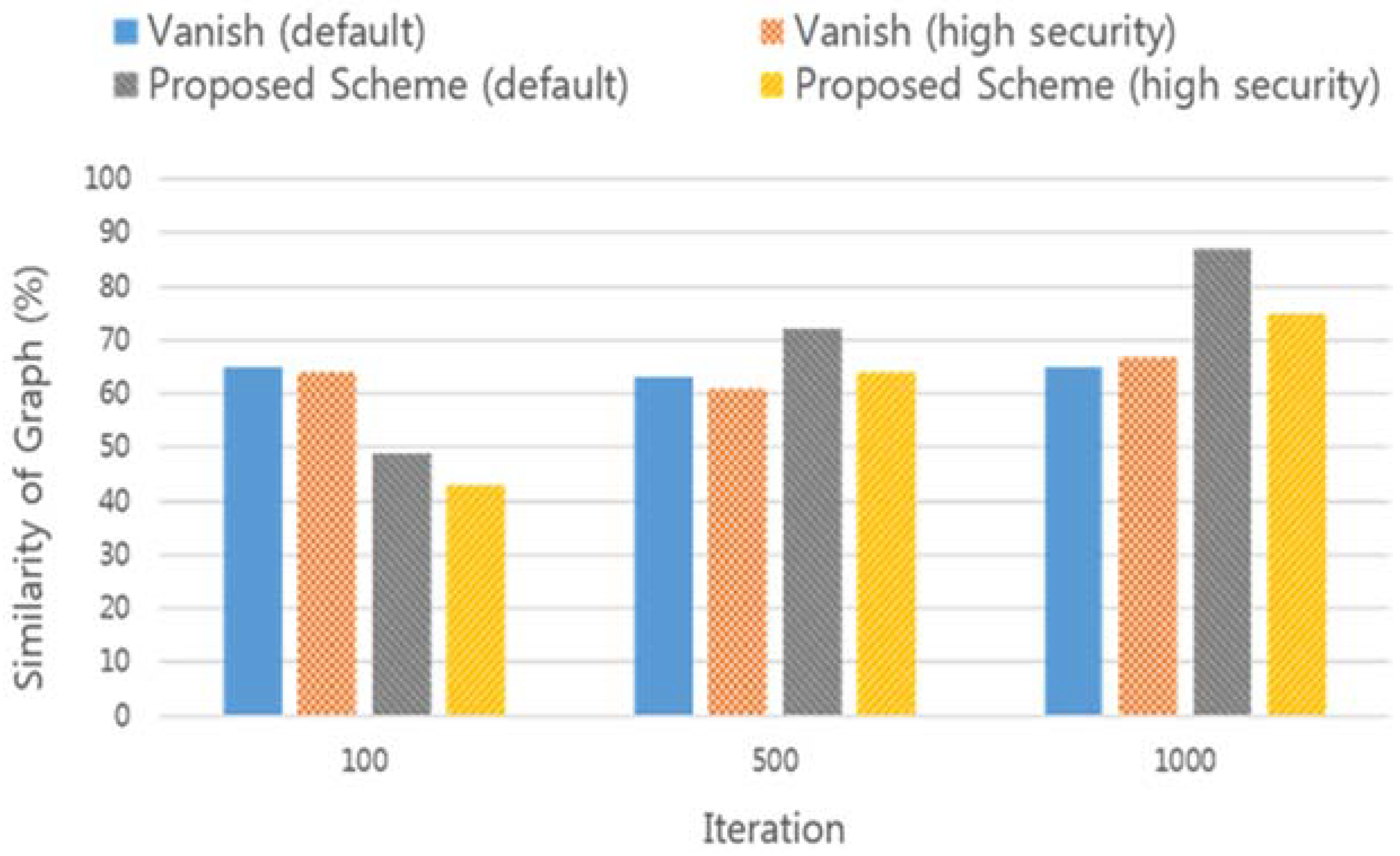
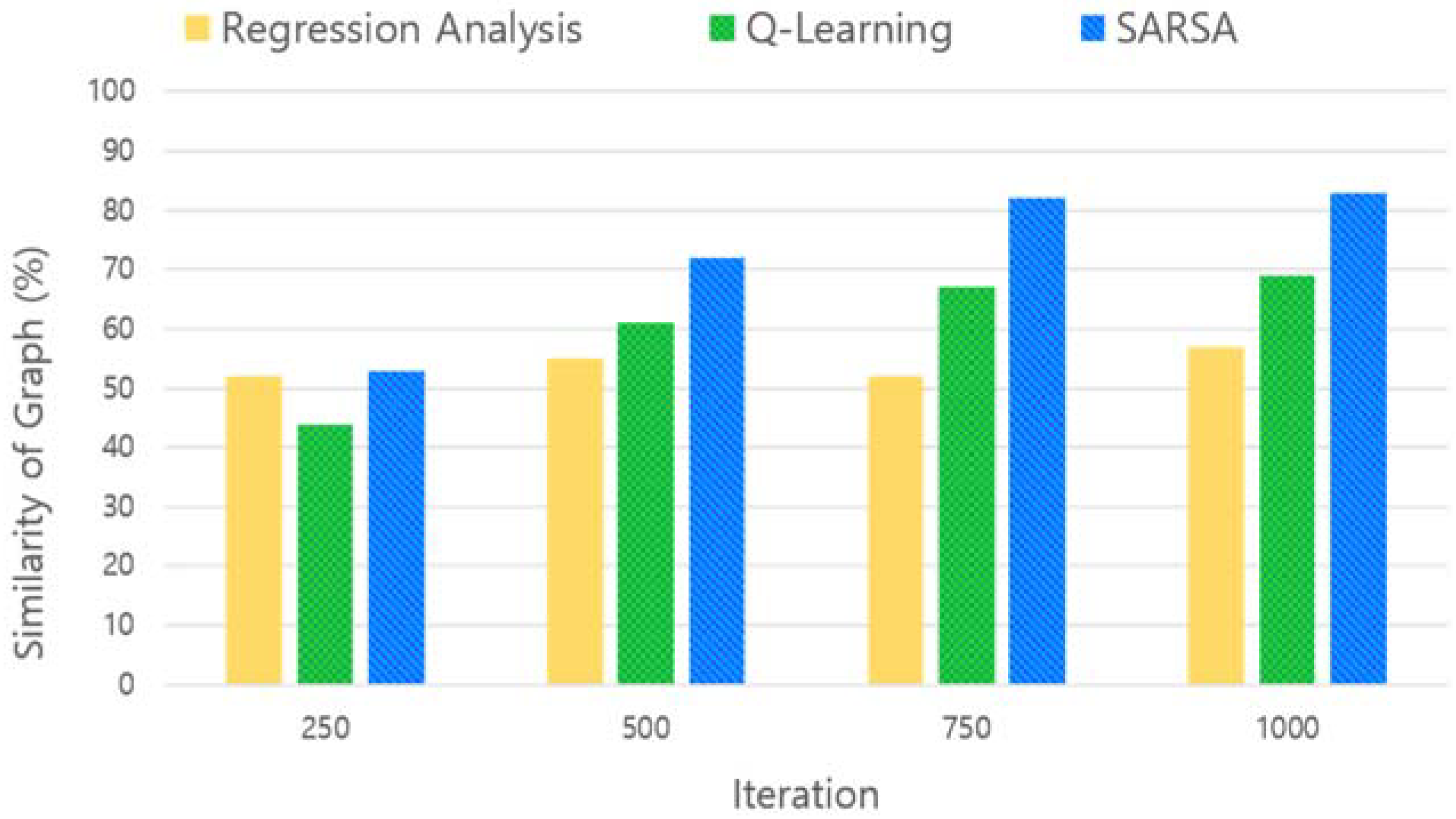
We apply reinforcement learning as a method for setting optimal parameters for Shamir’s Secret Sharing considering the availability and security of data in the self-destructing scheme environment. The characteristics of reinforcement learning are expected to be better by defining the state and choosing the action that can obtain the best result at a certain point in time. In this process, we update the reward that each state and action can have. A state-action table (Q-table) is updated until a target value of the same value is finally found for a state and an action.
In the self-destructing scheme proposed in this paper, the optimal threshold is found based on the security and availability of data based on the reinforcement learning model. We define the state according to the data availability graph in the environment of the DHT network, and, based on the defined state as the structure of DHT network changes, the similarity of graph according to the action that determines the number of key shares and threshold value for finding the optimal key sharing parameters with the reward and distribute the key shares to the DHT network. Due to the continuously changing characteristic of DHT, data availability of the same key sharing parameter is not kept constant. Therefore, the similarity measuring process with the ideal state should be done very quickly. MAPE is a simple method for comparing the result according to the input value, and the key sharing parameters having high similarity, which is found through the iterative process and applied to the system.
The state for applying reinforcement learning has data availability in the form of a matrix over time for a specific parameter(N, T). This includes the availability of data at each time in units of time intervals to measure the similarity of the graph. Action is the process of selecting specific parameters defined in State. This process requires a proper balance between exploration applying new values and exploitation applying existing values.
The reason for choosing reinforcement learning to set the key sharing parameters required for the self-destructing scheme is that the optimal values to be applied at each point in time vary depending on the dynamic change of the DHT network environment. In addition, since the initial default parameters are expected to yield results similar to the final goal, the parameters defined by the state and action sets are in the form of normal distributions for the default values.
Table 3 shows the parameters for applying reinforcement learning. In order to apply reinforcement learning algorithm, state, action, and reward must be defined basically. State is defined as the availability of data on the number of key shares() and the time that key shares generated by the threshold() are distributed to the DHT network.
State stores the availability value of data for a specific time unit in the form of a simple one-dimensional array. It is in the nature of the data availability graph that state is defined as a discrete array rather than a continuous form of expression. The data availability graph in the DHT network environment is independent from the measured values in relation to the measured time units.
Therefore, it is very inefficient to define and apply the formula for each measurement time unit. In addition, it is much more efficient to store only the measured values without defining the state as a formula because it requires only the measurement values according to time unit in the process of measuring the similarity of the graph using MAPE. However, if the state is defined as a discrete form, only the measured values for the fixed time interval can be applied.
Action is a process of selecting the maximum reward value among the defined states. There are exploration methods for applying the new value to the result and exploitation for applying the existing value as it is. The method of selecting two methods is to apply decaying ε-greedy to perform exploration at a high probability in the initial stage and increase the probability of performing exploitation over time.
In the Self-Destructing Scheme environment, the smaller the time unit of measuring the availability graph of data, the more accurate the result, but it can be a disadvantage in terms of calculation time. This is also related to the time required for the lookup operation to query the data in the DHT network. In this paper, we measure the availability of data 10 times in 1 h (once every 6 min):
The process for updating the Q-table constructed at the time based on the defined state and action is defined as shown in Equation (2).
returns the probability for the next state based on state and action in time. α means learning rate, and, as this value increases, existing information is updated with new information. This is related to learning rate and has a value between 0 and 1.This means reward that is a compensation as it changes from a specific time. Moreover, it determines how much the reward at the discount rate is worth the future reward. This can be reflected in lesser and lesser rewards expected to come in the future:
Reward is defined based on MAPE at the time and converted to the appropriate form for applying to the Q-table. In order to meet the requirements of the self-destructing scheme, the difference between the ideal graph and the total number of key shares and the data availability graph measured by the threshold is calculated by the MAPE as a percentage, so the result subtracted from 100 is the degree of similarity between two graphs. In addition, convert the result calculated as a percentage to a decimal point to apply to the Q-table.
The initial Q-table for applying the reinforcement learning algorithm is defined as Q_1(s,a) with default values of N = 10, T = 7 and Q_2(s,a) with N = 50, T = 45 as default values. Each Q-table should not be duplicated in the normal distribution form based on the default value.
Figure 9 shows the process for setting the total number of key shares(N) and threshold(T). First, key fragments are generated and distributed to the DHT network. In addition, it measures the availability graph of user’s data in the DHT network environment. After that, we check the similarity with the ideal data availability graph, which is the target value finally, and select another parameter(N, T) in the process of generating the key shares. Through this iterative process, the degree of similarity with the ideal graph, that is, the reward being large, will be selected.
This iterative process ends when the data availability graph according to the parameters predicted through reinforcement learning matches perfectly with the ideal data availability graph. However, due to the nature of the ever-changing DHT network, it is virtually impossible to perfectly match the availability graphs of two different data. Therefore, while the self-destructing scheme is running, the above iterative process will be performed continuously in the background.
Algorithm 1 represents our proposed solution for finding optimal parameters by applying reinforcement learning in a system of self-destructing scheme. The initial Q(s,a) value is generated to have an arbitrary normal distribution without duplication based on the values N = 10, T = 7 or N = 50, T = 45. In the reinforcement learning process, the data availability graph for the corresponding state and action is measured to obtain the reward. The reason for having a normal distribution here is that it assumes that the key shares are generated with a default value in the system utilizing the existing self-destructing scheme and have relatively high availability and security. In addition, the weights are set differently for each variable, so that the deviation of the threshold values is set to be larger than the total number of key pieces.
| Algorithm 1. Reinforcement Learning |
| Algorithm: Reinforcement Learning based Threshold Estimation |
| Initialize: Q(s, a) arbitrarily |
| Repeat (for each episode) |
| Initialize s |
| Chose a from s using Q (ε-greedy) |
| Repeat (for each step of episode) |
| Take action a, observe r, s’ |
| Choose a’ from s’ using Q (ε-greedy) |
| Q(s, a) ← Q(s, a) + α[r + γQ(s’, a’) − Q(s, a)] |
| s ← s’; a ← a’ |
| Until s is terminal |

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}