PV Forecasting Using Support Vector Machine Learning in a Big Data Analytics Context





Abstract
1. Introduction
2. Literature Review
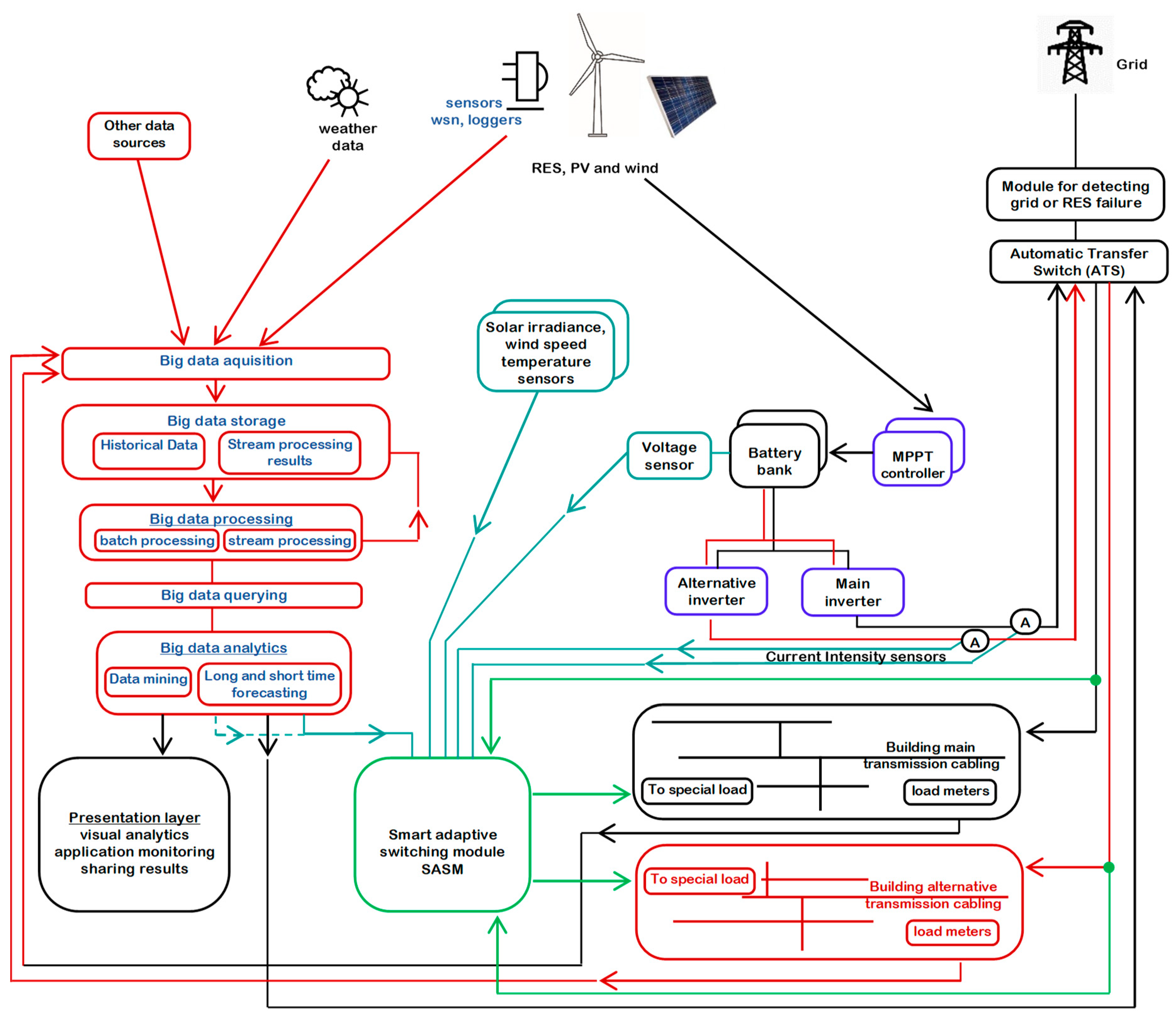
3. Methodology
3.1. Sensor Data
- -
- Simple sensors mounted near the renewable energy sources, such as: solar light sensors, temperature, humidity or even video cameras;
- -
- Advanced sensors for on-site monitoring [37], where an embedded device, based on a microcontroller, is added to a photovoltaic panel to measure the voltage and the power. Arduino-related sensors are similarly implemented. In both cases, data can be collected via wireless or LAN technologies and sent to a server.
- -
- High integrated sensors that are recently offered by RES equipment producers (solar and wind) and generate special “loggers.” These devices are connected to solar controllers via the RS485 interface, retrieve on a custom time interval all the voltage and the power parameters and locally store them for a specific time period, three months or one month, depending on the storage capacity. An example of such a logger is EPEVER eLOG01 for EPEVER MPPT solar controllers. Other producers have similar loggers directly integrated in the solar controllers.
- -
- Wireless Sensor Networks (WSN) represent a small module, which contains sensors, microcontrollers and radio transceivers. All principles related to WSN apply to PV, wind turbine or RES [38,39,40,41]. They provide a central data storage, access control, transmission techniques, multichannel and optimal sensor locations, energy efficiency sensors and transmission criteria. In the case of RES, WSN can contain one or more sensors for temperature, solar radiation and wind speed. However, in order to reduce the costs, only the back-panel temperature sensors can be used for PV, and only the wind speed sensor can be used for the wind turbines. Based on these two sensors, the generated power can be predicted. Another particularity of RES is that a relatively high number of WSN modules are necessary (in comparison with the logger modules), especially because it is desirable to monitor every element. Thus, it generates a huge data volume. The data collection, the aggregation and the analysis are highly dependent on technology, with the recommendation being to use big data.
- -
- Monitoring units that contain sensors for PV temperature, ambient temperature, solar radiation and a main unit. These units collect primary data and send them to a web portal from where the data can be processed in a big data environment (for example, the SM2-MU main unit). This situation is mentioned in [42,43]: to analyze large volumes of data, SM2-MU connects to a web portal to send data. The portal can have, in the background, the possibility of analyzing data. By extrapolation, it is possible to write data using a customized code into a repository or even into a big data system, where big data analytical features can be used.
- -
- Standalone sensors such as the PV-100 PV monitoring package, which contains PV temperature, ambient temperature and solar radiation sensors, plus a radiation shield to prevent errors. PV-100 PV is working on an SMA cluster controller. It is a SMA company product mentioned here since it implements a distinct monitoring principle for monitoring the PV system. As described in [44], the SMA cluster controller is a central unit that works with many SMA inverters and sensors, such as the previously mentioned PV-100 PV. SMA cluster records data from inverters and sensors and assures the monitoring and the control of the PV plant. It can interact with a web portal that allows for large-scale integration. The SMA cluster controller consists of an intelligent part of monitoring that collects and transmits data for many applications, providing seamless sensor integration.
- A logger used with one solar charge controller that records at 15-min frequencies: in one day, it generates 132 records, each with 27 attributes, stored in a .csv file of 20 KB. In one month, it stores 3960 records into a .csv file of 620 KB.
- Loggers used on a PV RES rooftop of 3kW with an array of 10 PV panels, each one of 300 W. If we consider, for example, 10 micro-inverters, each with an MPPT solar controller, and 10 loggers: in one day, they generate 1320 records stored in a .csv file of 200 KB. In one month, it stores 39,600 records into a .csv file of 6200 MB.
- Loggers used on a PV RES rooftop of 12 kW with an array of 40 PV panels, each one of 300 W, 40 micro-inverters/MPPT solar controller and 40 loggers: in one day, they generate 5320 records, stored in a .csv file of 800 KB. In one month, it stores 15,840 records in a .csv file of 24,800 MB.
- Loggers used on a PV RES rooftop of 24 kW with an array of 80 PV panels, each one of 300 W, 80 micro-inverters/MPPT solar controller and 80 loggers: in one day, they generate 10,640 records, stored in a .csv file of 1600 KB. In one month, it stores 31,680 records in a .csv file of 49,600 MB.
- Loggers used on a 100 kW PV system within a RES. Multiplying by 4 the data from the previous sample, in one day, it generates 42,560 records, stored in a .csv file of 6400 KB. In one month, it stores 126,720 records in a .csv file of 198,400 MB.
- Loggers used on 1 MW PV system within RES. Multiplying by 10 the data from the previous sample, in one day, it generates 425,600 records, stored in a .csv file of 64 MB. In one month, it stores 1,267,200 records in a .csv file of 1,980,400 GB.
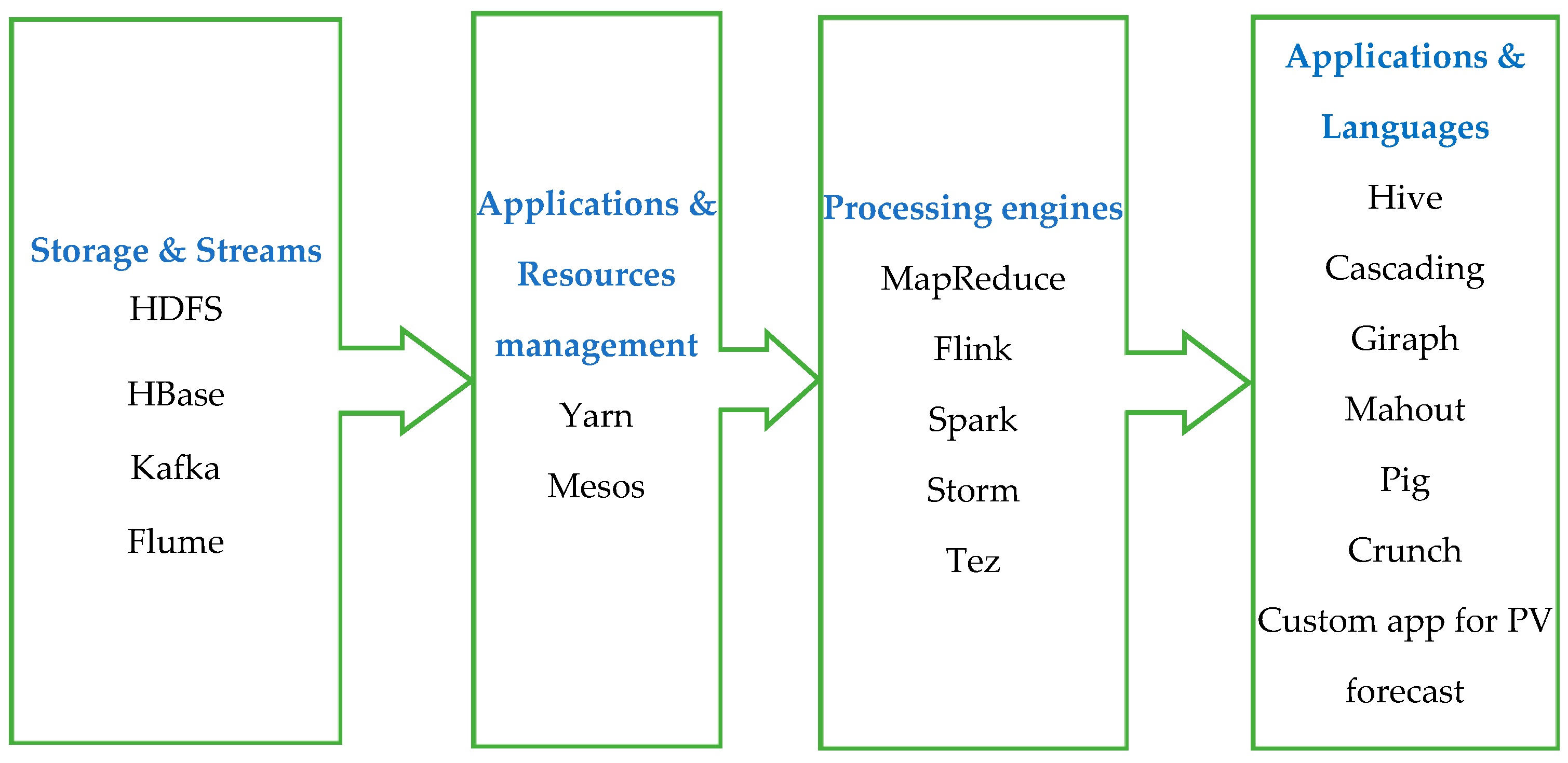
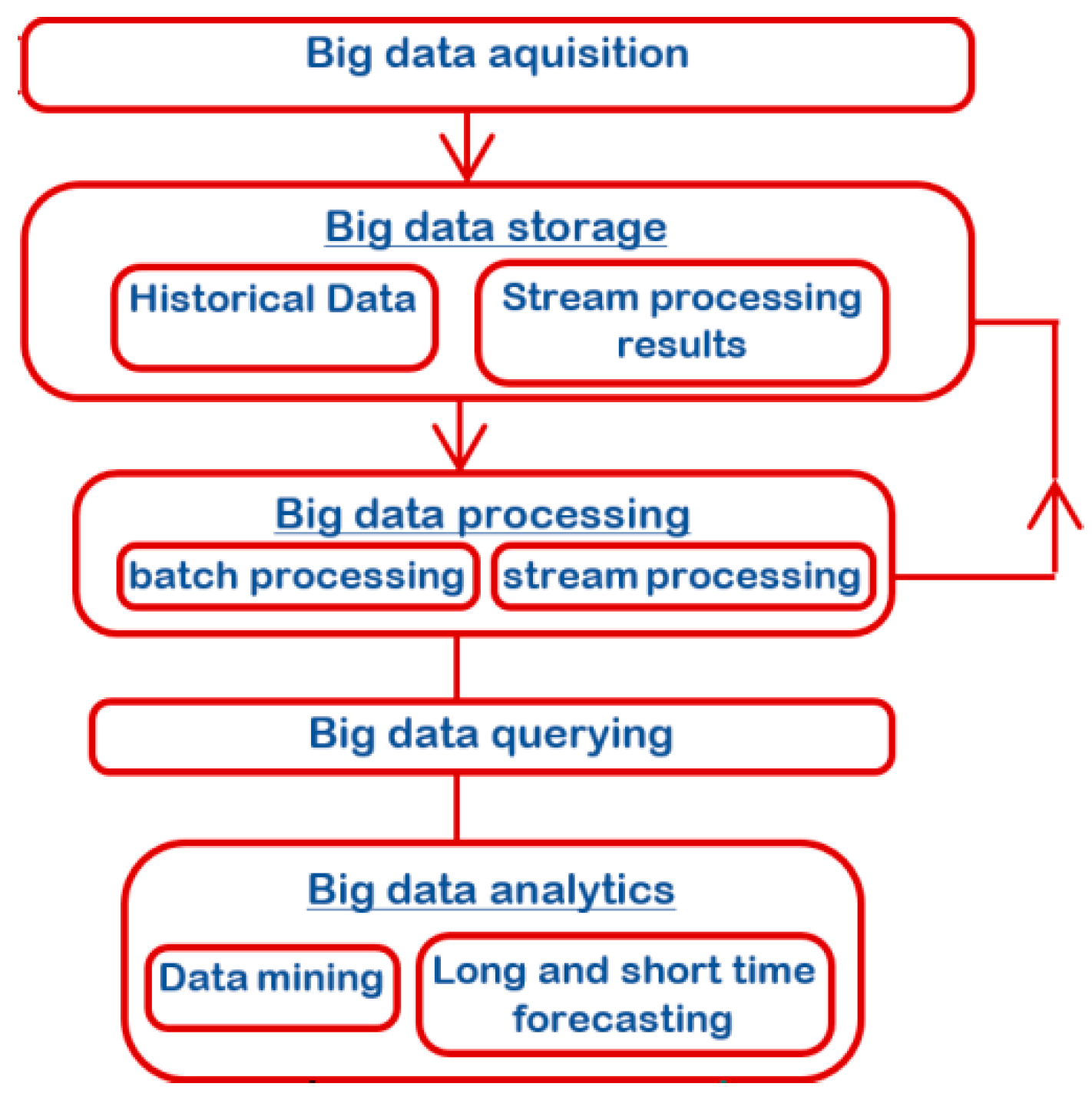
3.2. Big Data Processing and Analytics
3.2.1. Storage and Streams
- -
- the ability to work with stream processing, since the data from sensors is coming continuously;
- -
- ability to work with large volumes of datasets from sensors; based on application logic, a large volume of data can accumulate over time.
- -
- the ability to work with many files or data sources; thus, for the PV, data that come from many sensors or sources can be successfully handled.
3.2.2. Applications and Resource Management
3.2.3. Processing Engines
3.2.4. Applications and Languages
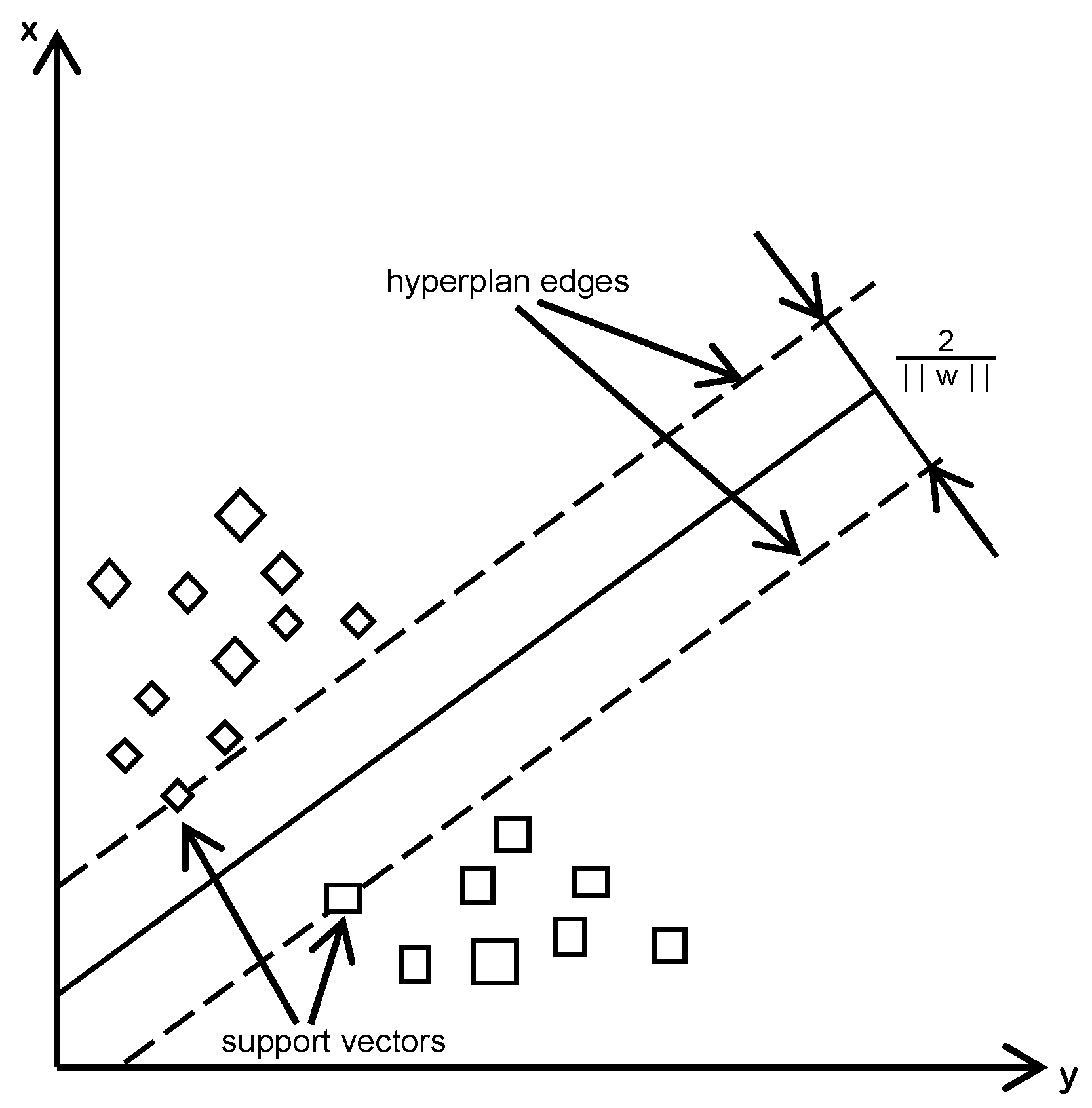
3.3. SVM Forecast Model Depiction
4. Results of the Case Study—A Sample Use of Data Generated by Loggers
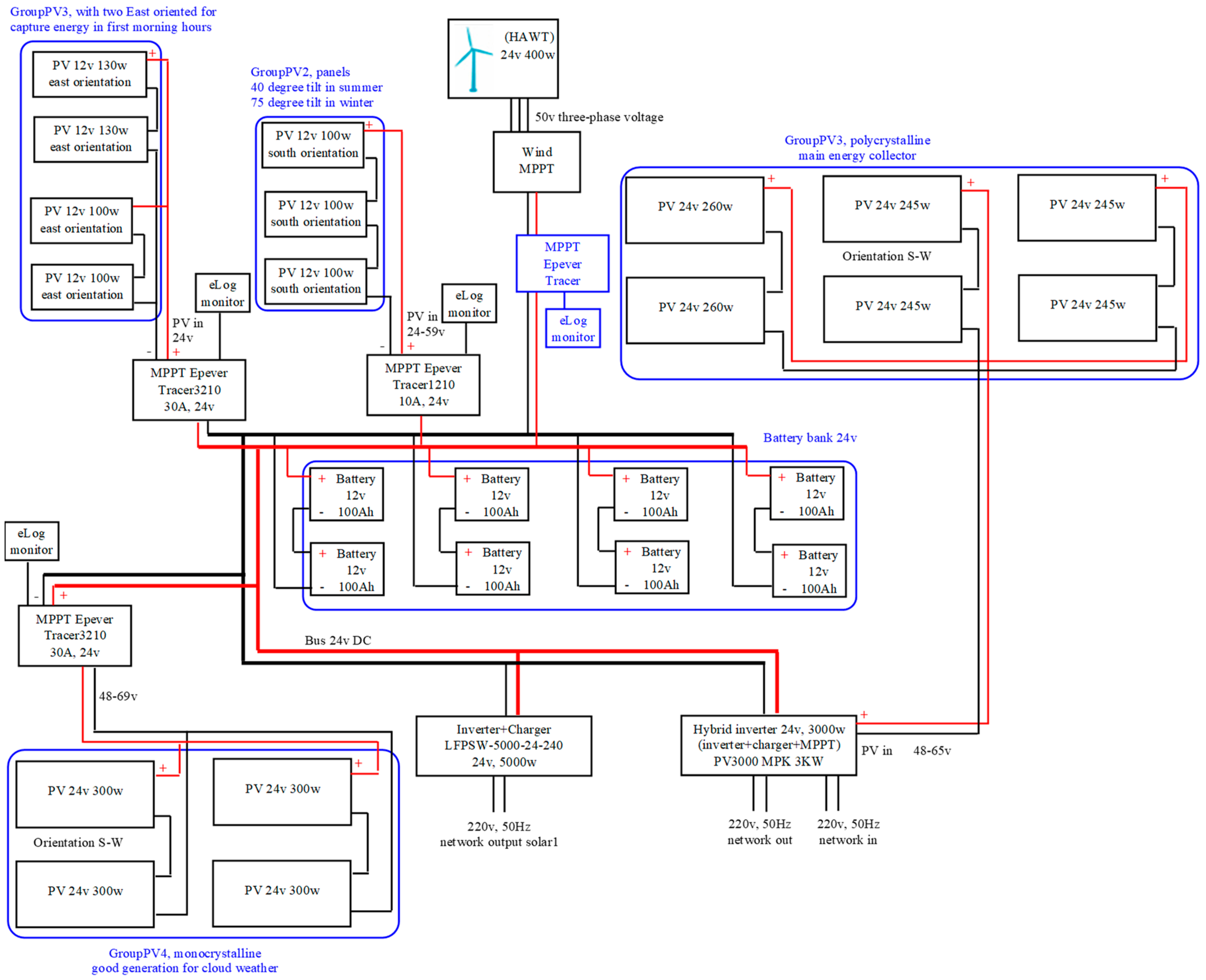
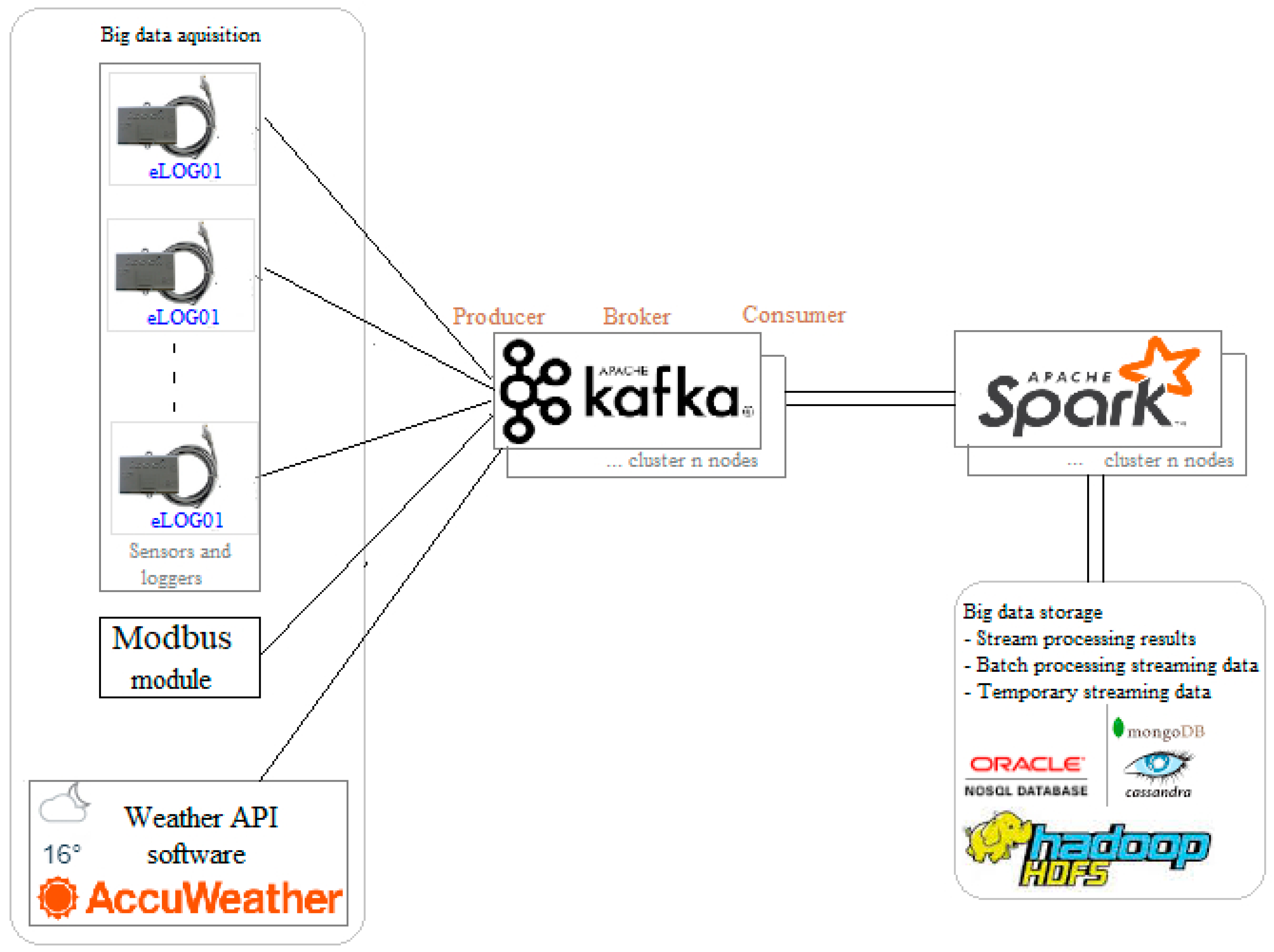
4.1. Case Study RES System Architecture
- -
- Photovoltaic panels:5 × 12 V 100 W monocrystalline panels2 × 12 V 130 W monocrystalline panels3 × 24 V 245 W polycrystalline panels Photowatt PW2450F3 × 24 V 260 W polycrystalline panels KDM Kingdom Solar KD-P260W4 × 24 V 300 W monocrystalline panels Q.ANTUM Q.PEAK-G4.1 300
- -
- Solar controllers:2 × MPPT EPEVER Tracer32101 × MPPT EPEVER Tracer12101 × MPPT included in MUST PV3000 MPK 3 kW (hybrid solar Inverter/Charger)Wind controller: JW-MPPT 600 W Wind Solar Hybrid Charge Controller
- -
- Inverters:Power Jack LFPSW-5000-24-240 (24 V 5000 W off grid inverter)MUST PV3000 MPK 3 kW (24 V 3000 W hybrid solar Inverter/Charger)
- -
- Batteries:8 × Sorgeti Deep Cycle 100 Ah, 12 V
- -
- Loggers:3 × Epever eLOG01
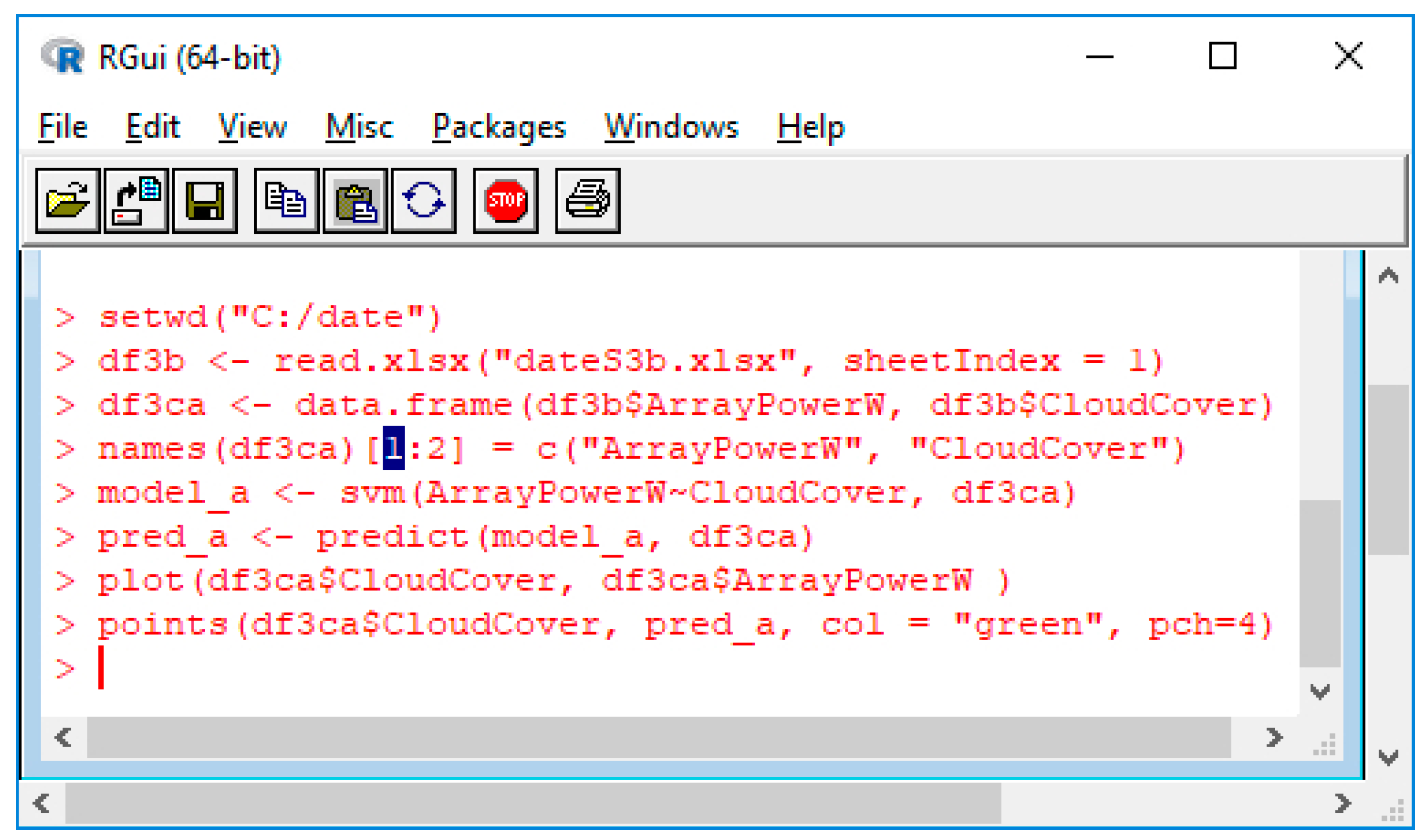
4.2. Predicting PV Output with SVM Regression
4.3. Predicting RES Output with SVM Regression
- p1 = 95 (estimation for generated power);
- p2 = 50 (electricity demand);
- p3 = 100 (sunny day);
- p4 = 30 (wind);
- p5 = 40 (temperature);
- p6 = 14.2 (energy in batteries);
- p7 = 4 (actual consumption, inverter1 is low);
- p8 = 5 (actual consumption, inverter2 is low).
- p1 = 82 (estimation output);
- p2 = 50 (medium demand);
- p3 = 80 (sunny day);
- p4 = 34 (wind);
- p5 = 40 (temperature);
- p6 = 28.5 (energy in batteries);
- p7 = 5 (actual consumption, inverter1 is low);
- P8 = 6 (actual consumption, inverter2 is low).
- p1 = 70 (estimation for output);
- p2 = 35 (smaller electricity demand comparing to winter scenarios);
- p3 = 65 (partly sunny day);
- p4 = 0 (no wind);
- p5 = 100 (temperature);
- p6 = 27.8 (energy in batteries/batteries are not too loaded);
- p7 = 5(actual consumption, inverter1 is low);
- p8 = 5 (actual consumption, inverter2 is low).
5. Discussion
- -
- The off-grid system has a limited way to balance generation and consumption in comparison with large power systems, as it has limited reservoirs or reserve power capacities. In general, this is an energy storage that can be of different sources and sizes, from well-known batteries to air reservoir, water reservoir placed at altitude, big capacitors. There are many other types, but as a general feature, the size is smaller and the possibility to extend it is limited by costs.
- -
- In most cases, if the hybrid RES cannot properly balance for a limited period of time, then it can switch to the grid.
6. Limitations
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A.
Example 1: Comparison of the Power Generated between Days

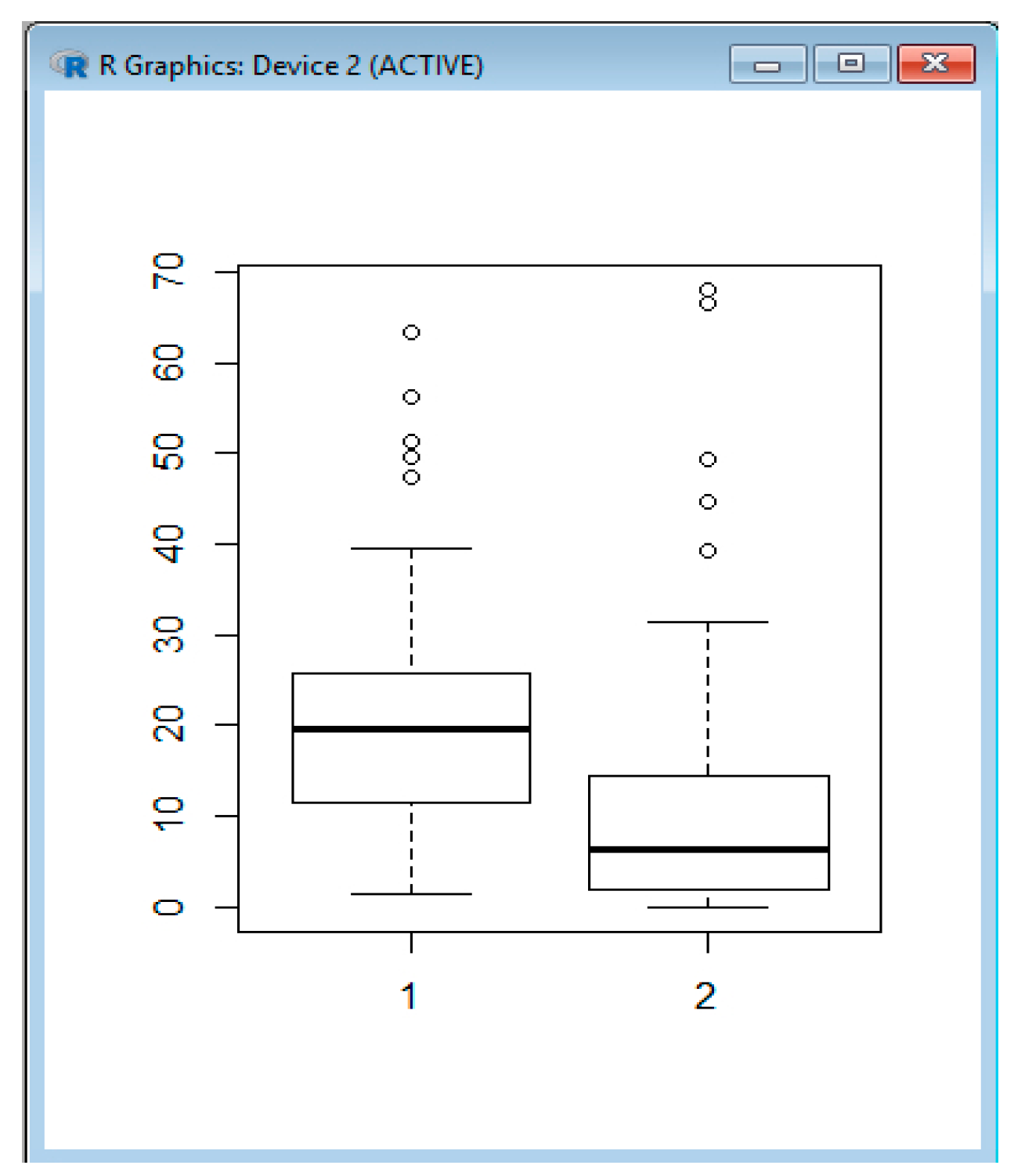
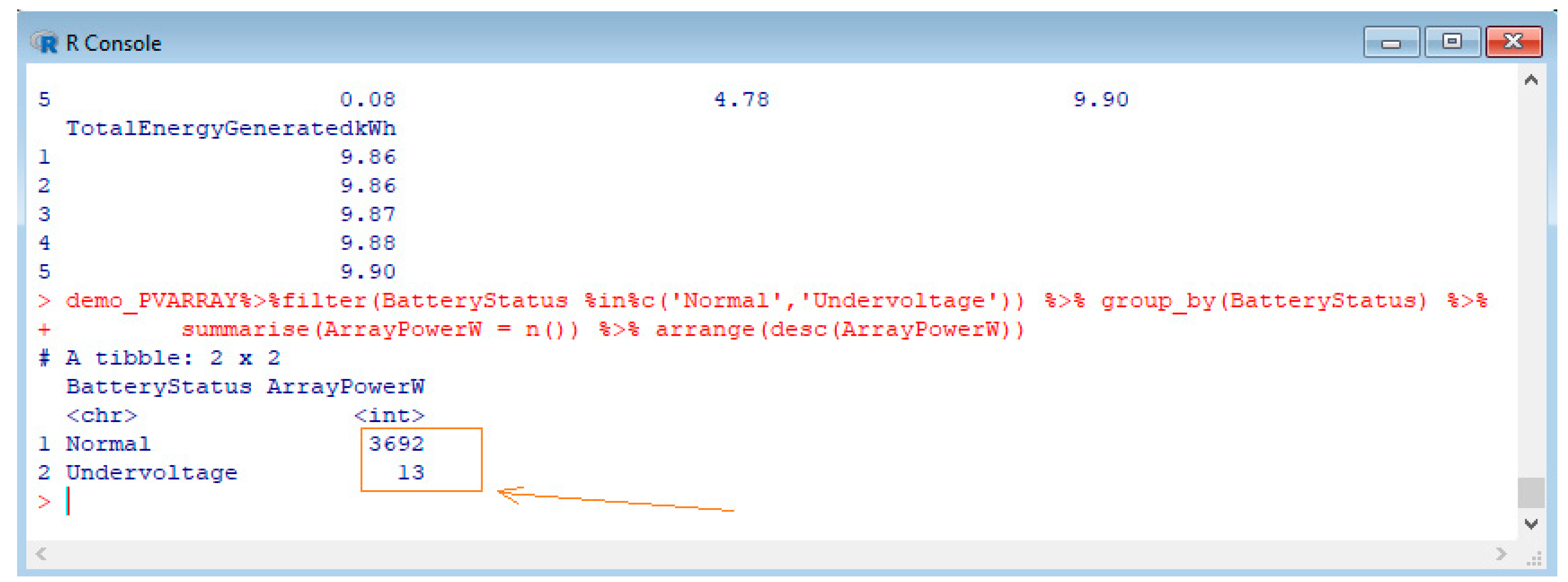
Example 2: Analyzing the Battery Status in a Photovoltaic System

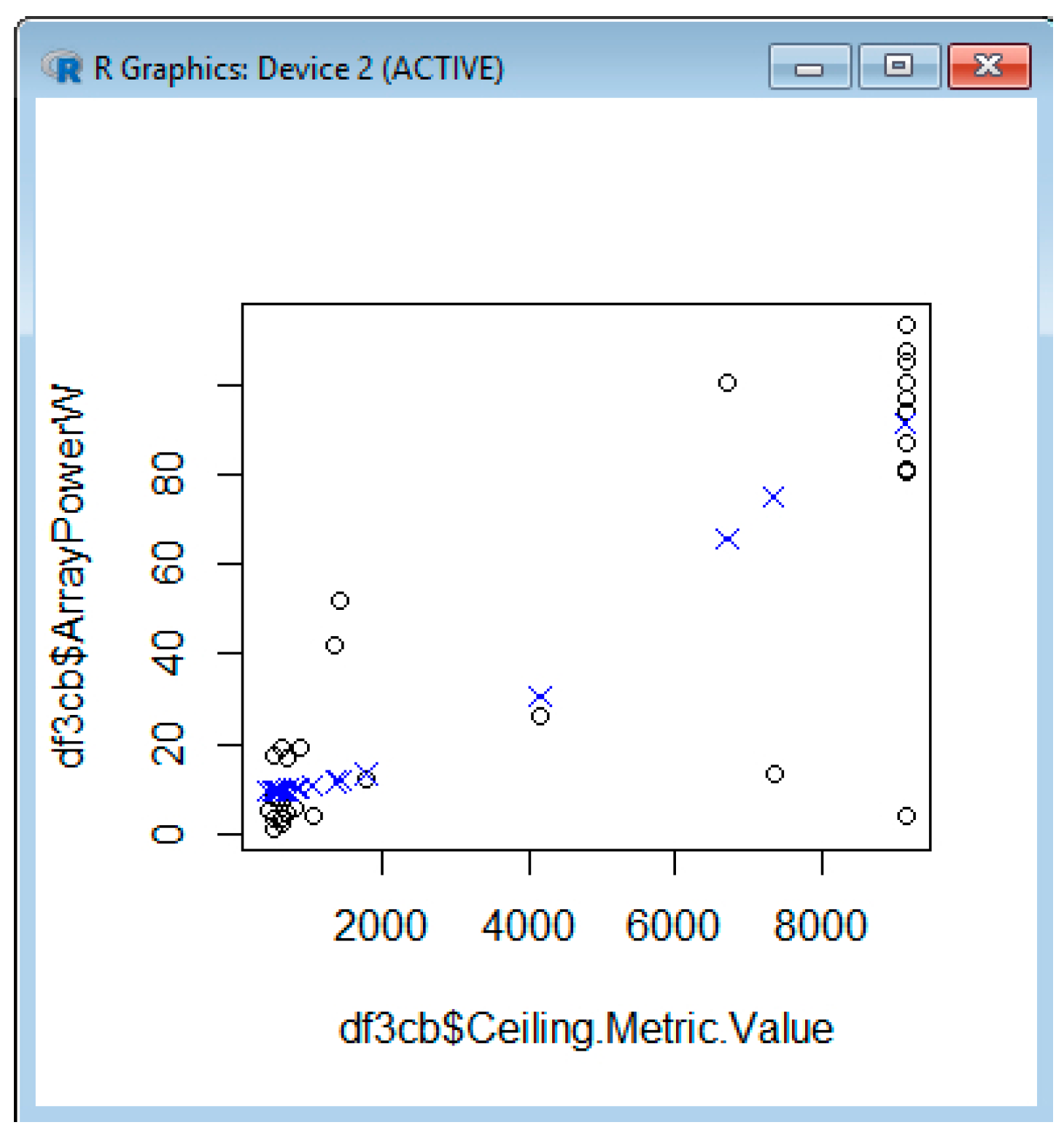
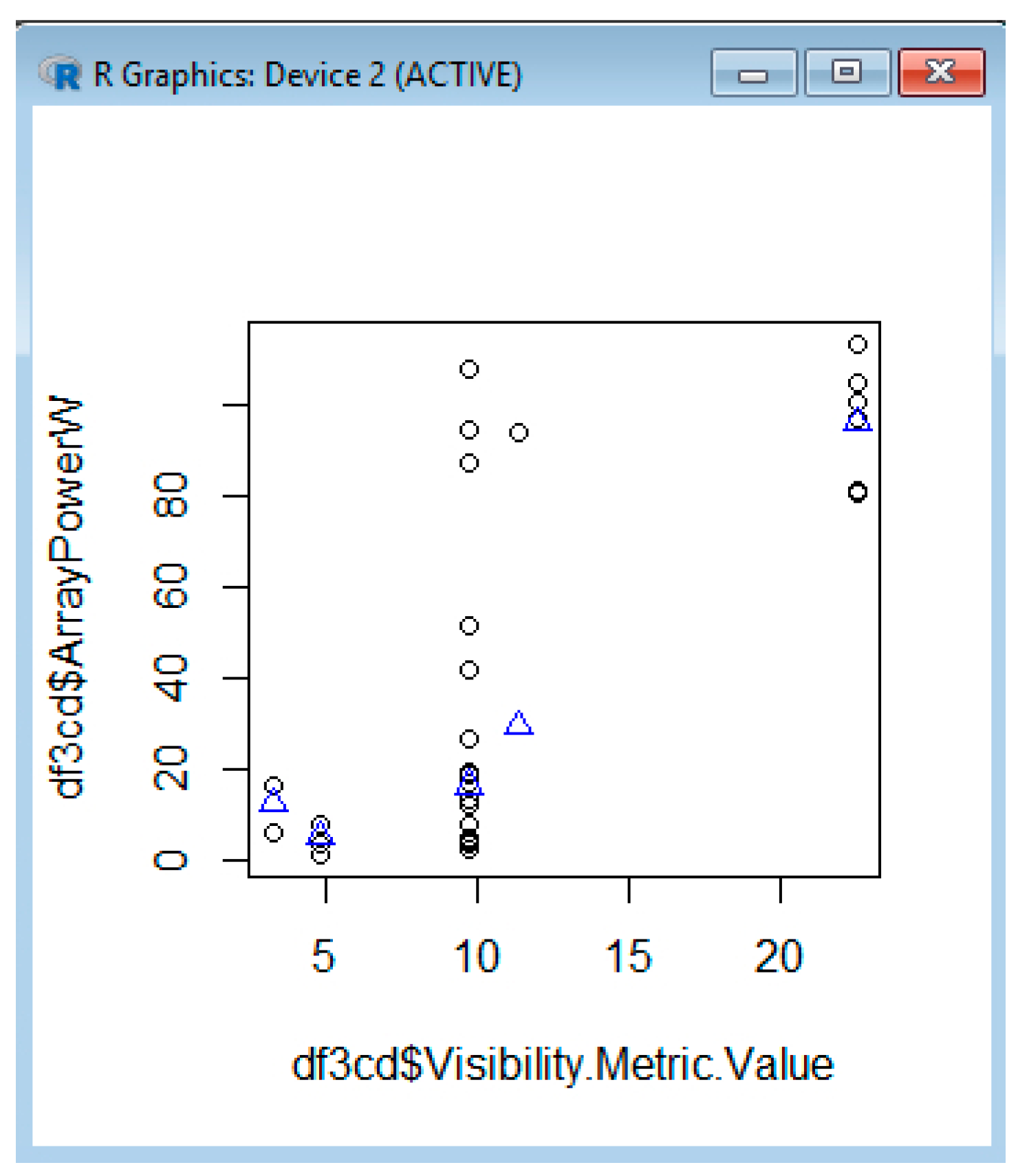
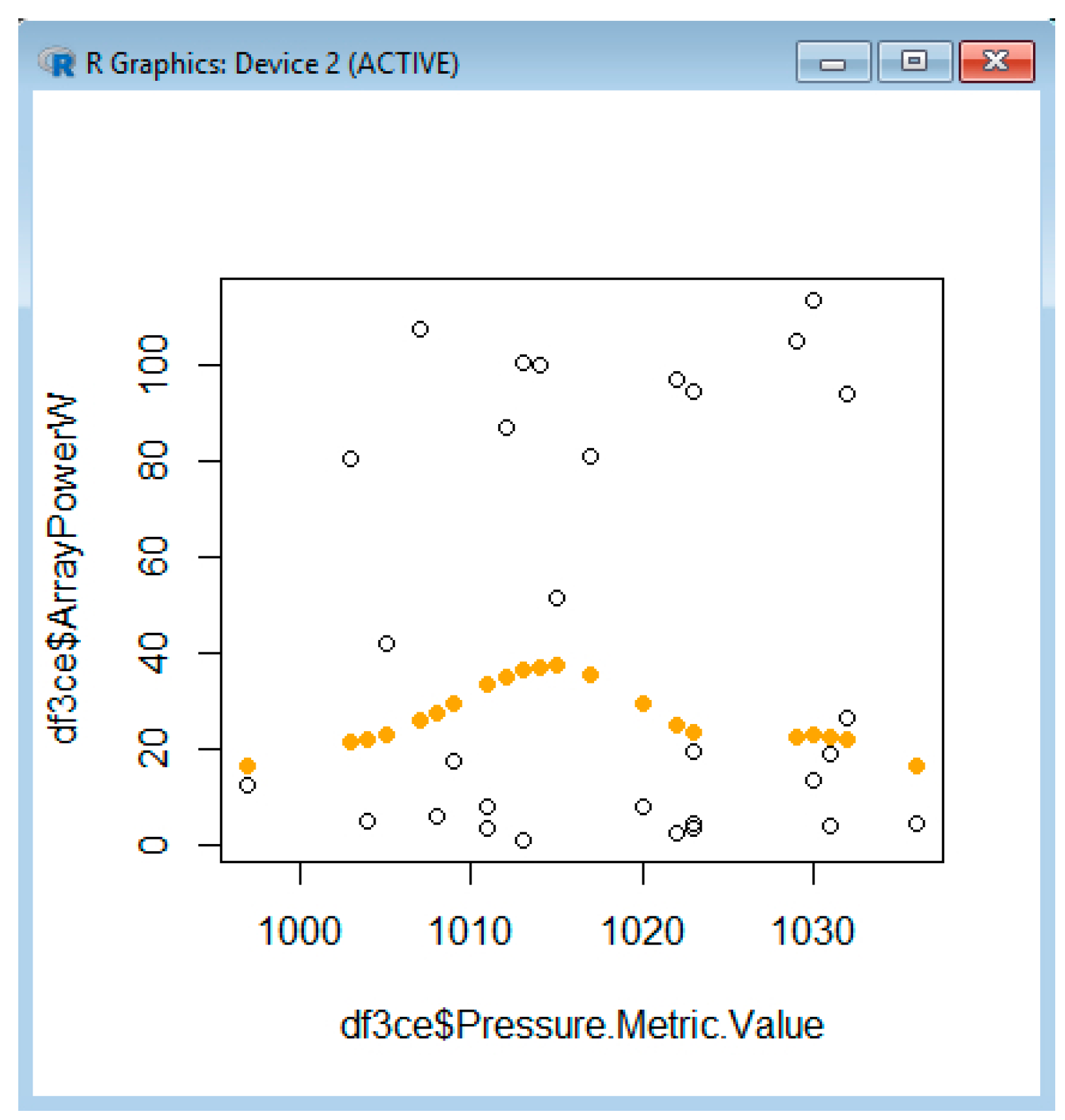
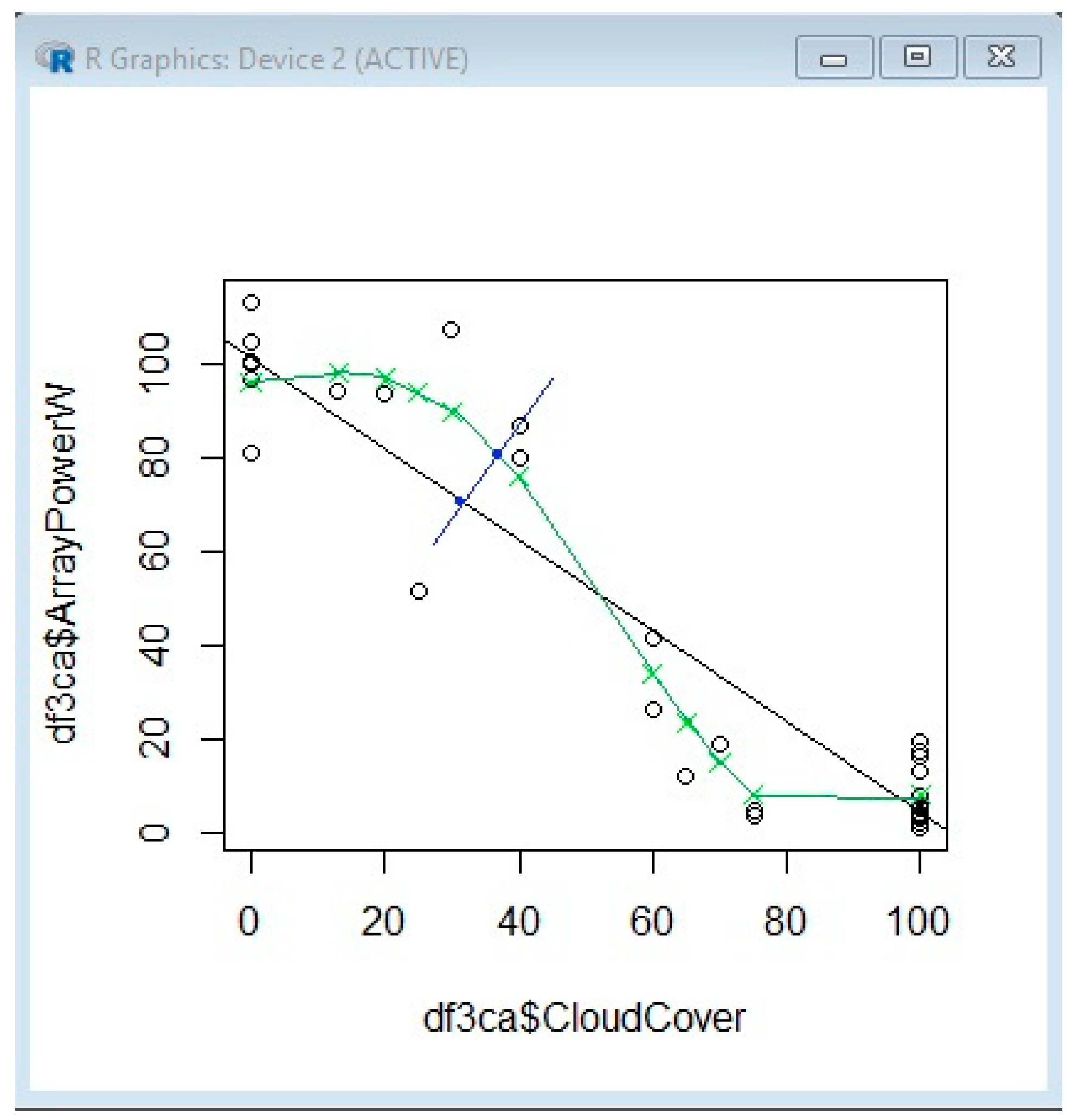
Example 3: Analyzing the Array Power versus the Battery Status

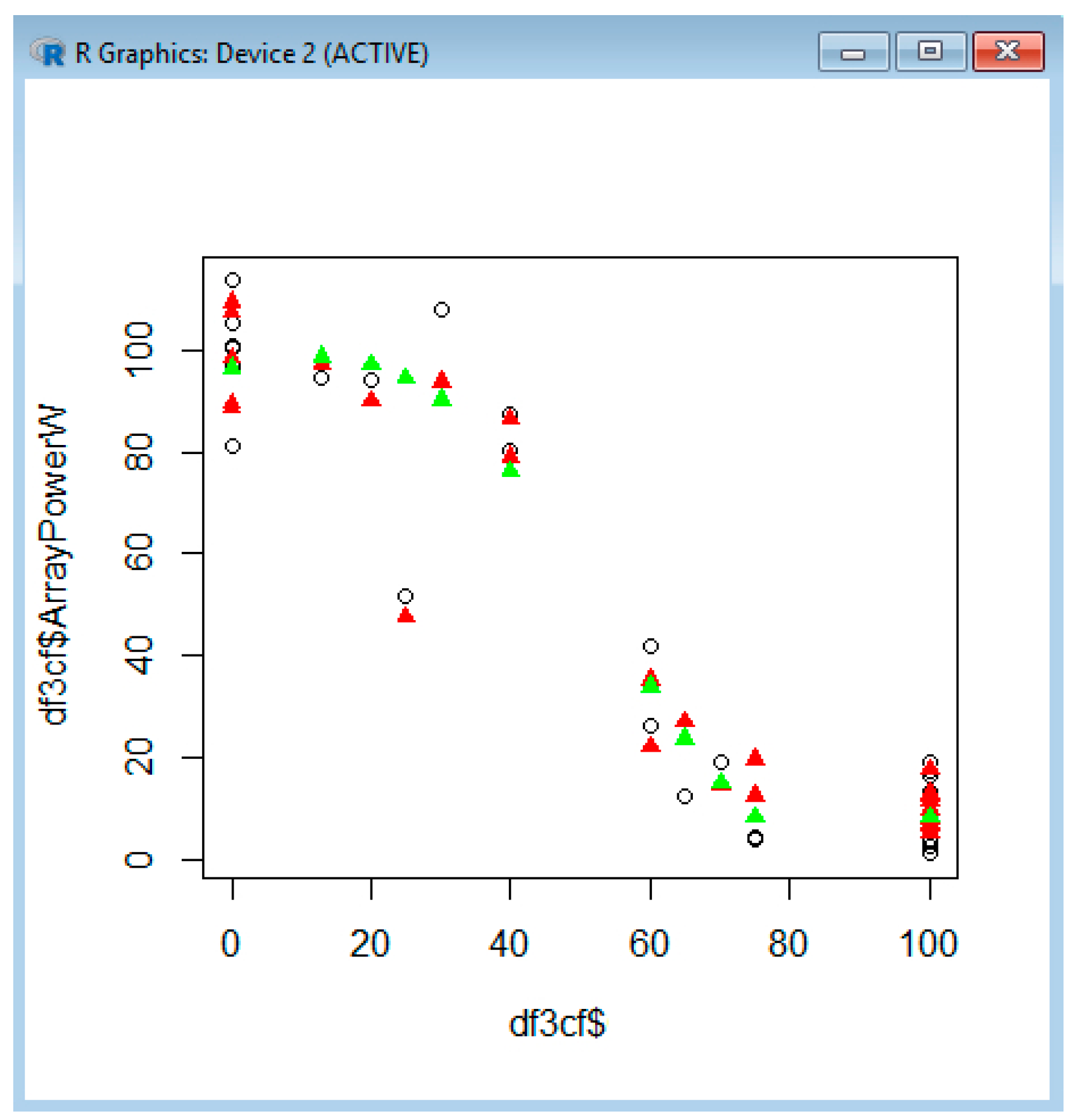
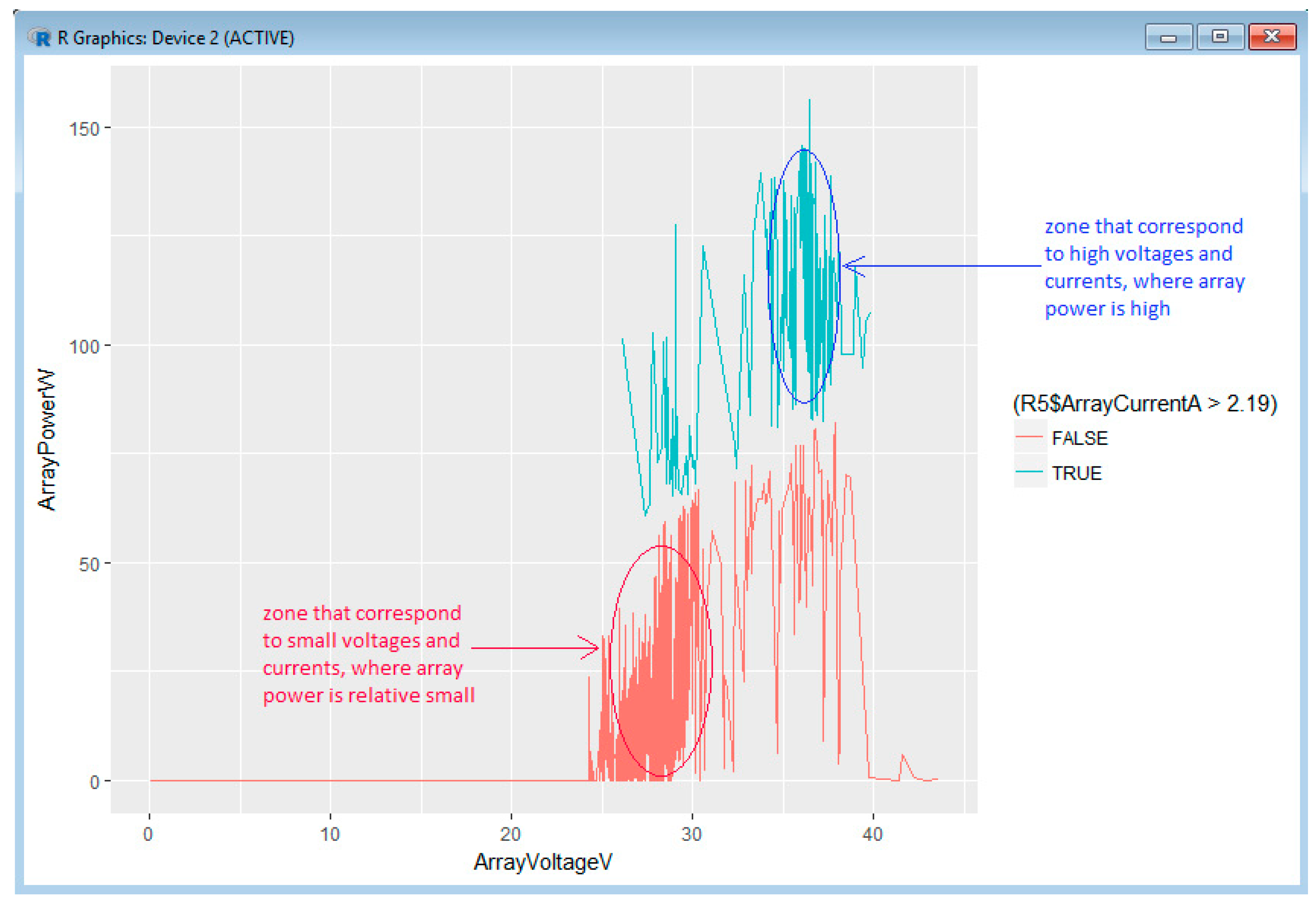
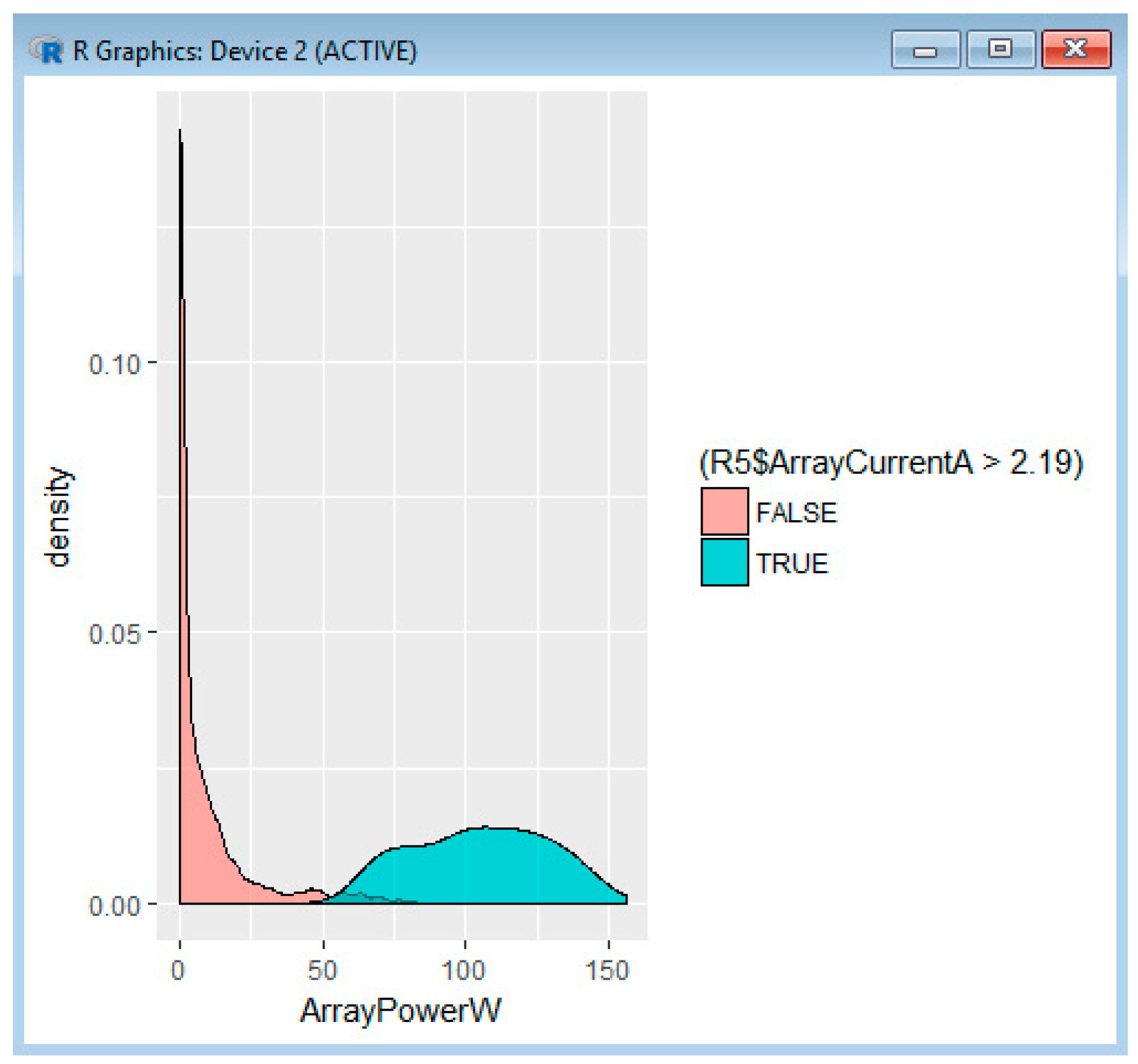
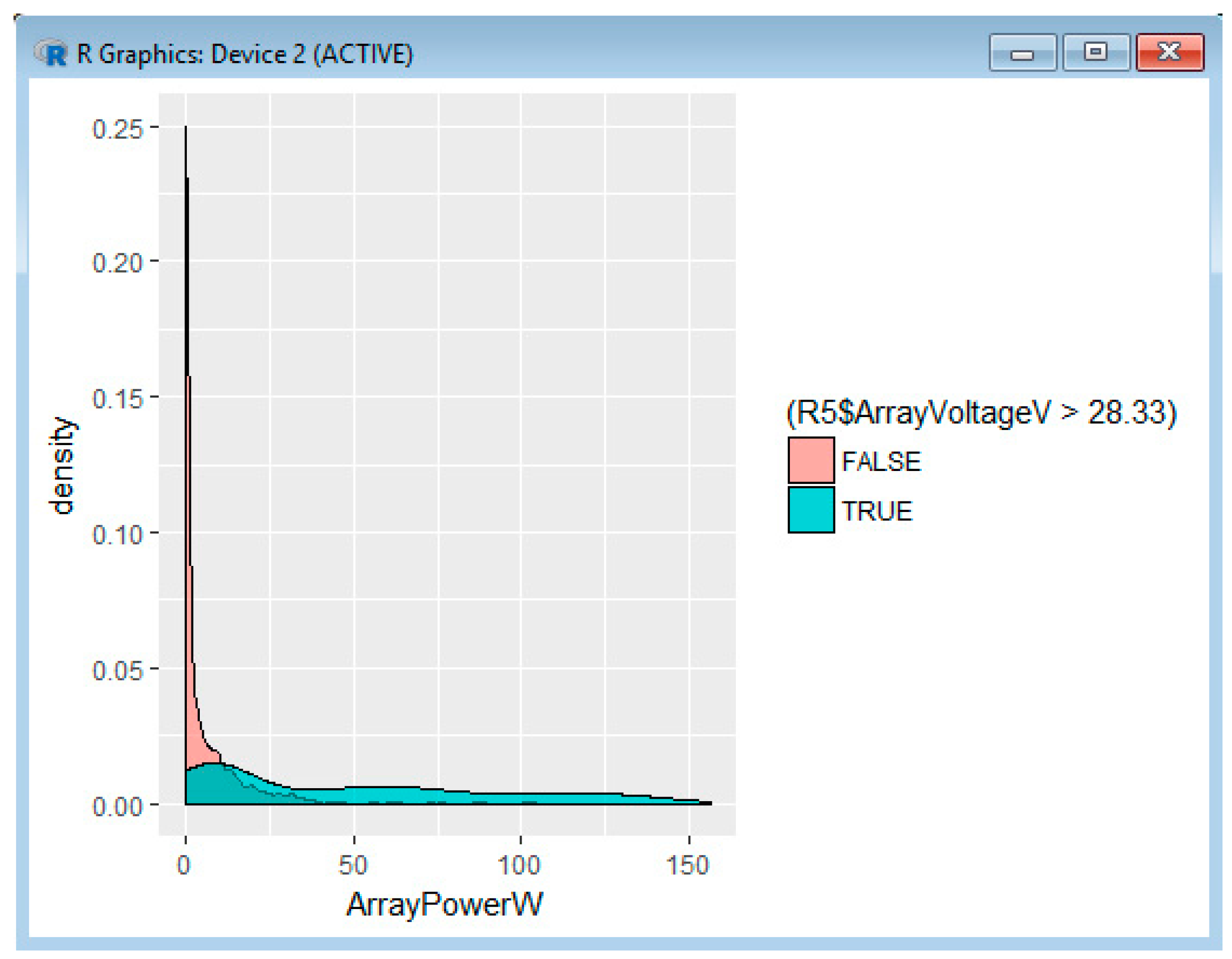
Example 4: Interpretation Related to the ArrayCurrentA, the ArrayVoltageV and the ArrayPowerW



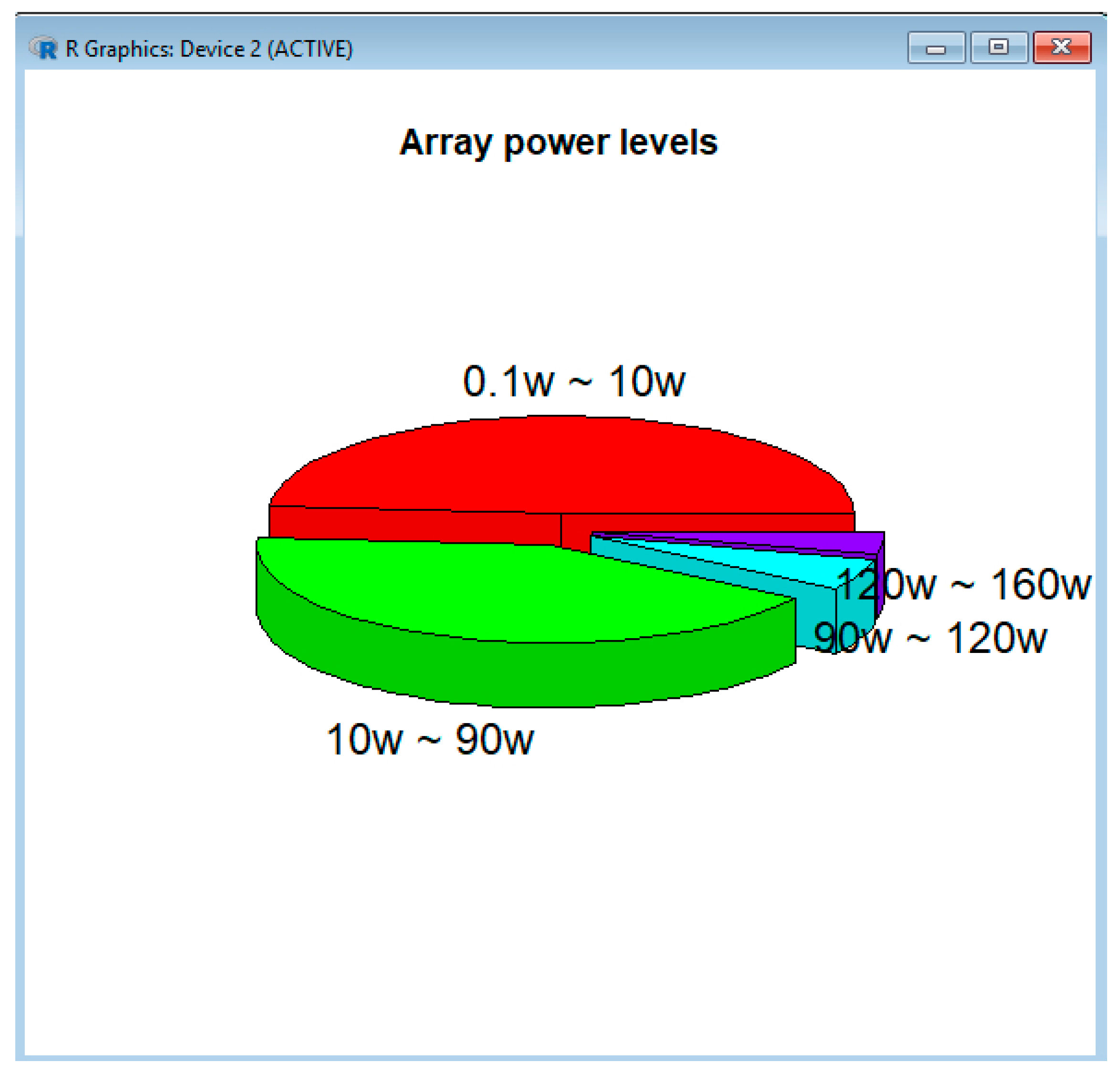
Example 5: A summary of the Generated Array Power Levels

References
- Jones, L.E. Renewable Energy Integration: Practical Management of Variability, Uncertainty, and Flexibility in Power Grids; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Woyte, A.; Richter, M.; Moser, D.; Reich, N.; Green, M.; Mau, S.; Beyer, H.G. Analytical Monitoring of Grid—Connected Photovoltaic Systems. Good Practices for Monitoring and Performance Analysis; Report IEA-PVPS T13-03:2014; IEA International Energy Agency: Brussels, Belgium, 2014. [Google Scholar]
- Erdinc, O. Optimization in Renewable Energy Systems: Recent Perspectives; Butterworth-Heinemann: Oxford, UK, 2017. [Google Scholar]
- Shyam, R.; Bharathi Ganesh, B.G.; Kumar, S.; Poornachandran, P.; Soman, K.P. Apache Spark a Big Data Analytics Platform for Smart Grid. Procedia Technol. 2015, 21, 171–178. [Google Scholar] [CrossRef]
- Ardakani, F.J.; Ardehali, M.M. Long-term electrical energy consumption forecasting for developing and developed economies based on different optimized models and historical data types. Energy 2014, 65, 452–461. [Google Scholar] [CrossRef]
- Energy Sector Management Assistance Program; Energy Analytics for Development. Big Data for Energy Access, Energy Efficiency, and Renewable Energy. ESMAP Knowledge Series 2017, 027. [Google Scholar]
- Spatti, D.H.; Liboni, L.H.B. Emerging Technologies for Renewable Energy Systems. In Smart Cities Technologies; Da Silva, I.N., Flauzino, R.A., Eds.; IntechOpen: Rijeka, Croatia, 2016. [Google Scholar]
- Yahyaoui, I.; Chaabene, M.; Tadeo, F. Energy management for photovoltaic irrigation with a battery bank. Int. J. Energy Optim. Eng. 2015, 4, 18–32. [Google Scholar] [CrossRef]
- Fonseca, J.G.D.; Oozeki, T.; Ohtake, H.; Shimose, K.I.; Takashima, T.; Ogimoto, K. Forecasting regional photovoltaic power generation—A comparison of strategies to obtain one-day-ahead data. Energy Procedia 2014, 57, 1337–1345. [Google Scholar]
- Funabashi, T. Integration of Distributed Energy Resources in Power Systems: Implementation, Operation and Control; Academic Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Diamantoulakis, P.D.; Kapinas, V.M.; Karagiannidis, G.K. Big Data Analytics for Dynamic Energy Management in Smart Grids. Big Data Res. 2015, 2, 94–101. [Google Scholar] [CrossRef]
- Pelland, S.; Remund, J.; Kleissl, J.; Oozeki, T.; De Brabandere, K. Photovoltaic and Solar Forecasting: State of the Art IEA PVPS. 2013, 14, 1–36. [Google Scholar]
- Breeze, P. Solar Power Generation; Elsevier Science: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Heller, P. The Performance of Concentrated Solar Power (CSP) Systems: Analysis, Measurement and Assessment; Woodhead Publishing: Sawston, UK, 2017. [Google Scholar]
- Kleissl, J. Solar Energy Forecasting and Resource Assessment; Academic Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Breeze, P. Wind Power Generation; . Elsevier Science: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Wu, Q.; Sun, Y. Modeling and Modern Control of Wind Power; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Tan, Y.K. Energy Harvesting Autonomous Sensor Systems: Design, Analysis, and Practical Implementation; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Salameh, Z. Renewable Energy System Design; Academic Press: Waltham, MA, USA, 2014. [Google Scholar]
- Zhou, K.; Fu, C.; Yang, S. Big data driven smart energy management: From big data to big insights. Renew. Sustain. Energy Rev. 2016, 56, 215–225. [Google Scholar] [CrossRef]
- Panda, S.K.; Jagadev, A.K.; Mohanty, S.N. Forecasting Methods in Electric Power Sector. Int. J. Energy Optim. Eng. 2018, 7, 1–21. [Google Scholar] [CrossRef]
- Boylan, J.E.; Goodwin, P.; Mohammadipour, M.; Syntetos, A.A. Reproducibility in forecasting research. Int. J. Forecast. 2015, 31, 79–90. [Google Scholar] [CrossRef]
- Bunn, D.W. Forecasting loads and prices in competitive power markets. Proc. IEEE 2000, 88, 163–169. [Google Scholar] [CrossRef]
- Catalão, J.P.S. Electric Power Systems: Advanced Forecasting Techniques and Optimal Generation Scheduling; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Open Data and Analytics for a Sustainable Energy Future. Available online: https://energydata.info/ (accessed on 11 November 2018).
- Gilliland, M.; Sglavo, U.; Tashman, L. Business Forecasting: Practical Problems and Solutions; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Gollapudi, S. Practical Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Daki, H.; el Hannani, A.; Aqqal, A.; Haidine, A.; Dahbi, A. Big Data management in smart grid: Concepts, requirements and implementation. J. Big Data 2017, 4, 13. [Google Scholar] [CrossRef]
- Hatziargyriou, N. Microgrids: Architectures and Control; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Khan, S.S. Modeling and Operating Strategies of Micro-Grids for Renewable Energy Communities. In Renewable and Alternative Energy: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2017; pp. 735–760. [Google Scholar]
- Prieto, M.J.; Pernía, A.M.; Nuño, F.; Díaz, J.; Villegas, P.J. Development of a wireless sensor network for individual monitoring of panels in a photovoltaic plant. Sensors 2014, 14, 2379–2396. [Google Scholar] [CrossRef] [PubMed]
- Al-dahoud, A. Remote Monitoring System using WSN for Solar Power Panels. In Proceedings of the 2014 First International Conference on Systems Informatics, Modelling and Simulation, Sheffield, UK, 29 April–1 May 2014. [Google Scholar]
- Martínez, M.A.; Andújar, J.M.; Enrique, J.M. Temperature measurement in PV facilities on a per-panel scale. Sensors 2014, 14, 13308–13323. [Google Scholar] [CrossRef]
- Santolin, E.A.; Junior, I.D.; Corte, V.D.; da Silva, J.C.C.; de Oliveira, V. Thermal Monitoring of Photovoltaic module using Optical Fiber Sensors. J. Microw. Optoelectron. Electromagn. Appl. 2016, 15, 333–348. [Google Scholar] [CrossRef]
- Kaur, A.; Datta, A. A novel algorithm for fast and scalable subspace clustering of high-dimensional data. J. Big Data 2015, 2, 17. [Google Scholar] [CrossRef]
- Fawzy, D.; Moussa, S.; Badr, N. The evolution of data mining techniques to big data analytics: An extensive study with application to renewable energy data analytics. Asian J. Appl. Sci. 2016, 4, 1–11. [Google Scholar]
- Papageorgas, P.; Piromalis, D.; Antonakoglou, K.; Vokas, G.; Tseles, D.; Arvanitis, K.G. Smart solar panels: In-situ monitoring of photovoltaic panels based on wired and wireless sensor networks. Energy Procedia 2013, 36, 535–545. [Google Scholar] [CrossRef]
- Güngör, V.Ç.; Hancke, G.P. Industrial Wireless Sensor Networks: Applications, Protocols, and Standards; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Khan, S.; Pathan, A.-S.K.; Alrajeh, N.A. Wireless Sensor Networks: Current Status and Future Trends; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- el Emary, I.M.M.; Ramakrishnan, S. Wireless Sensor Networks; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Nikolaidis, I.; Iniewski, K. Building Sensor Networks: From Design to Applications; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Solar Monitor User Guide, Basic Features. Available online: http://wiki.solarmonitor.cz/doku.php?id=en:sim:manual:popis:zakladni_vlastnosti (accessed on 11 November 2018).
- Solar Monitor User Guide, Picture of SM2-MU + SM2-BE Connection. Available online: http://wiki.solarmonitor.cz/doku.php?id=en:sim:manual:rozsirujici_moduly:sm2_be:studer (accessed on 11 November 2018).
- SMA Cluster Controller. Available online: https://www.sma.de/en/products/monitoring-control/sma-cluster-controller.html (accessed on 11 November 2018).
- Sugomori, Y.; Kaluza, B.; Soares, F.M.; Souza, A.M.F. Deep Learning: Practical Neural Networks with Java; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Rabl, T. Big Data Stream Processing; Presented at the Berlin Big Data Center: Berlin, Germany, 2017. [Google Scholar]
- Lars, G. Hbase: The Definitive Guide, 2e; O’Reilly Media: Sebastopol, CA, USA, 2018. [Google Scholar]
- Apache HBase. Available online: https://hbase.apache.org/ (accessed on 11 November 2018).
- Lars, G. Architecting Modern Data Platforms; O’Reilly Media: Sebastopol, CA, USA, 2018. [Google Scholar]
- HDFS Architecture Guide. Available online: https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html (accessed on 11 November 2018).
- Akhtar, S.M.F. Big Data Architects Handbook: A Guide to Building Proficiency in Tools and Systems Used by Leading Big Data Experts; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Apache Kafka Core Concepts. Available online: http://kafka.apache.org/11/documentation/streams/core-concepts (accessed on 11 November 2018).
- Dharmesh, K. Apache Mesos Essentials. Packt, 20 June 2015. [Google Scholar]
- Hindman, B.; Konwinski, A.; Zaharia, M.; Ghodsi, A.; Joseph, A.D.; Katz, R.H.; Shenker, S.; Stoica, I. Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center. NSDI 2011, 11, 22. [Google Scholar]
- Mesos Architecture. Available online: http://mesos.apache.org/documentation/latest/architecture/ (accessed on 11 November 2018).
- Apache Hadoop YARN. Available online: https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html (accessed on 11 November 2018).
- Jain, A. Mastering Apache Storm; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Gunarathne, T. Hadoop MapReduce v2 Cookbook; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Frampton, M. Mastering Apache Spark; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Apache Spark. Available online: https://spark.apache.org/ (accessed on 11 November 2018).
- Deshpande, T. Learning Apache Flink; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Apache Tez. Available online: https://hortonworks.com/apache/tez/ (accessed on 11 November 2018).
- Bell, J. Machine Learning: Hands-on for Developers and Technical Professionals; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn& TensorFlow; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Kafka, A Distributed Streaming Platform. Available online: https://kafka.apache.org (accessed on 11 November 2018).
- Pearsall, N. The Performance of Photovoltaic (PV) Systems: Modelling, Measurement and Assessment; Woodhead Publishing: Sawston, UK, 2016. [Google Scholar]
- Moten, L. Solar-Log. Available online: https://github.com/lewismoten/solar-log (accessed on 11 November 2018).
- Modbus Protocol. Available online: https://en.wikipedia.org/wiki/Modbus (accessed on 11 November 2018).
- Thottuvaikkatumana, R. Apache Spark 2 for Beginners; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Lesmeister, C. Mastering Machine Learning with R; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Lesmeister, C. Mastering Machine Learning with R–Second Edition; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Viswanathan, V.; Viswanathan, S.; Gohil, A.; Yu-Wei, C.D.C. R: Recipes for Analysis, Visualization and Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Bali, R.; Sarkar, D.; Lantz, B.; Lesmeister, C. R: Unleash Machine Learning Techniques; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Jaradat, M.; Jarrah, M.; Bousselham, A.; Jararweh, Y.; Al-Ayyoub, M. The internet of energy: Smart sensor networks and big data management for smart grid. Procedia Comput. Sci. 2015, 56, 592–597. [Google Scholar] [CrossRef]
- Kooijman, M. Building Wireless Sensor Networks Using Arduino; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| df3cb <- data.frame(df3b$ArrayPowerW, df3b$Ceiling.Metric.Value) | df3cc <- data.frame(df3b$ArrayPowerW, df3b$Temperature.Metric.Value) |
| names(df3cb)[1:2] = c(“ArrayPowerW”, “Ceiling.Metric.Value”) | names(df3cc)[1:2] = c(“ArrayPowerW”, “Temperature.Metric.Value”) |
| model_b <- svm(ArrayPowerW~Ceiling.Metric.Value, df3cb) | model_c <- svm(ArrayPowerW~Temperature.Metric.Value, df3cc) |
| pred_b <- predict(model_b, df3cb) | pred_c <- predict(model_c, df3cc) |
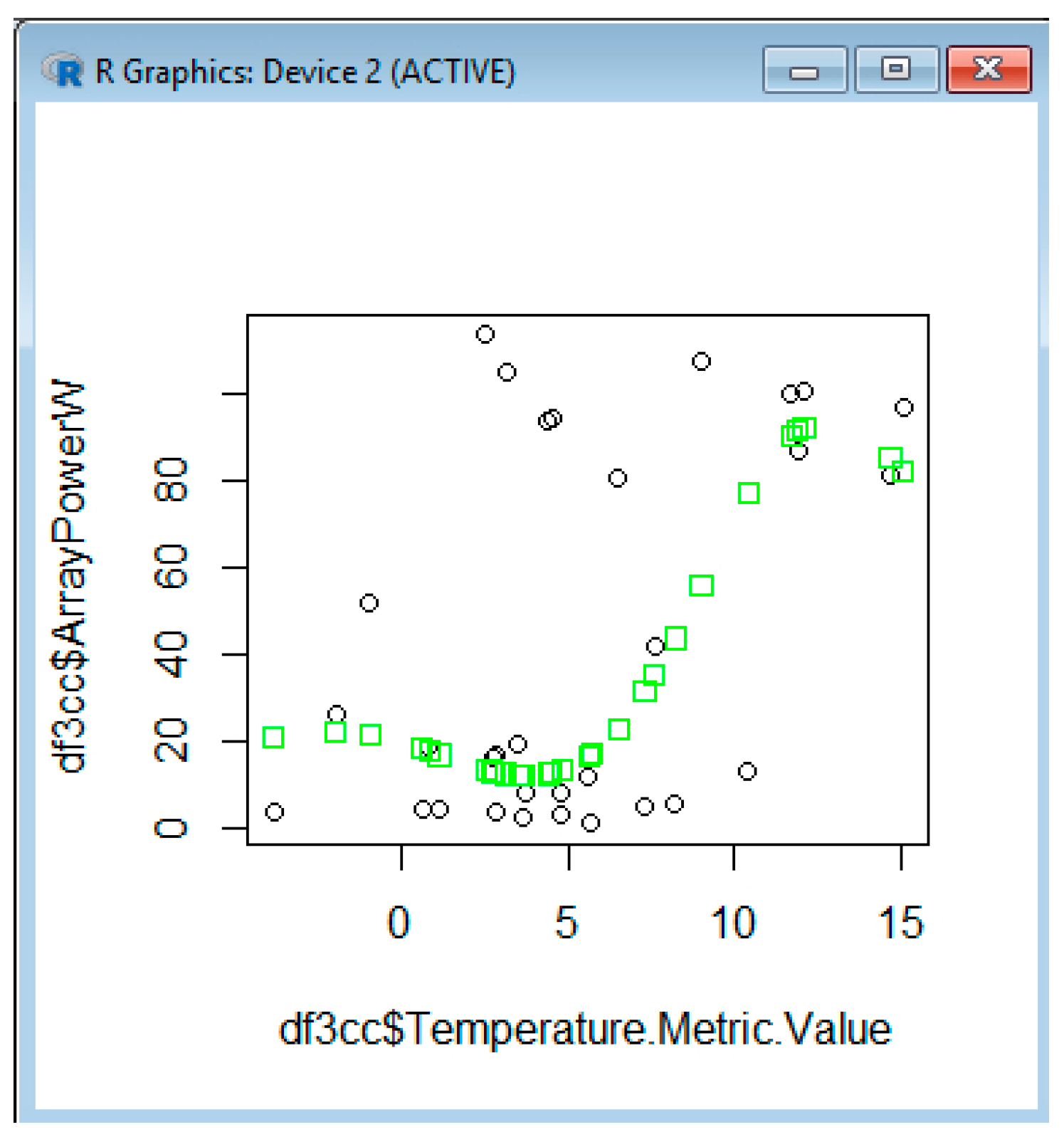
| plot(df3cb$Ceiling.Metric.Value, df3cb$ArrayPowerW) | plot(df3cc$Temperature.Metric.Value, df3cc$ArrayPowerW) |
| points(df3cb$Ceiling.Metric.Value, pred_b, col = “blue”, pch = 4) | points(df3cc$Temperature.Metric.Value, pred_c, col = “green”, pch = 0) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Preda, S.; Oprea, S.-V.; Bâra, A.; Belciu, A. PV Forecasting Using Support Vector Machine Learning in a Big Data Analytics Context. Symmetry 2018, 10, 748. https://doi.org/10.3390/sym10120748
Preda S, Oprea S-V, Bâra A, Belciu A. PV Forecasting Using Support Vector Machine Learning in a Big Data Analytics Context. Symmetry. 2018; 10(12):748. https://doi.org/10.3390/sym10120748
Chicago/Turabian StylePreda, Stefan, Simona-Vasilica Oprea, Adela Bâra, and Anda Belciu (Velicanu). 2018. "PV Forecasting Using Support Vector Machine Learning in a Big Data Analytics Context" Symmetry 10, no. 12: 748. https://doi.org/10.3390/sym10120748
APA StylePreda, S., Oprea, S.-V., Bâra, A., & Belciu, A. (2018). PV Forecasting Using Support Vector Machine Learning in a Big Data Analytics Context. Symmetry, 10(12), 748. https://doi.org/10.3390/sym10120748