Background Augmentation Generative Adversarial Networks (BAGANs): Effective Data Generation Based on GAN-Augmented 3D Synthesizing †


Abstract
1. Introduction
2. Related Work
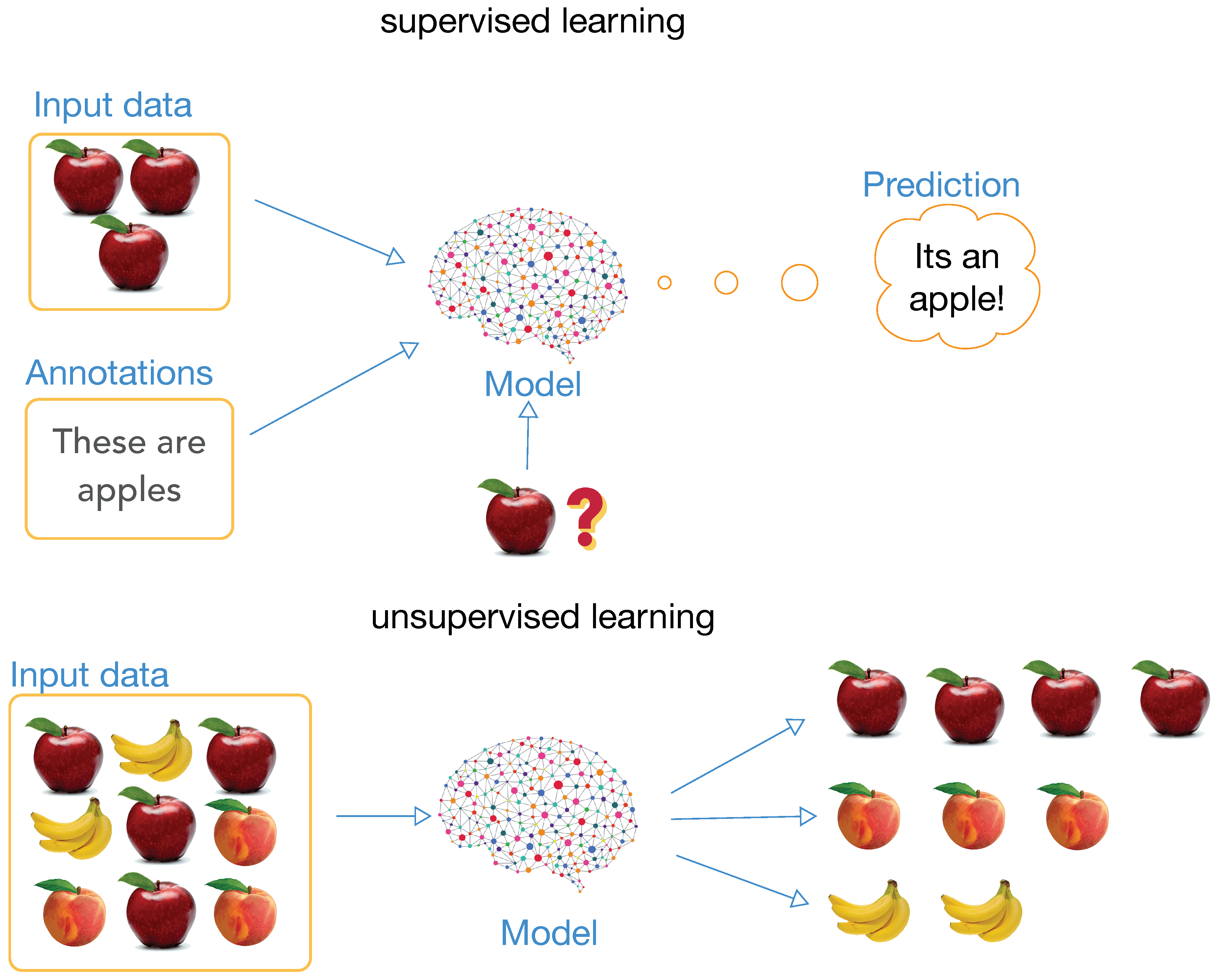
2.1. Generative Adversarial Networks
2.2. Conditional Generative Adversarial Networks
3. Materials and Methods
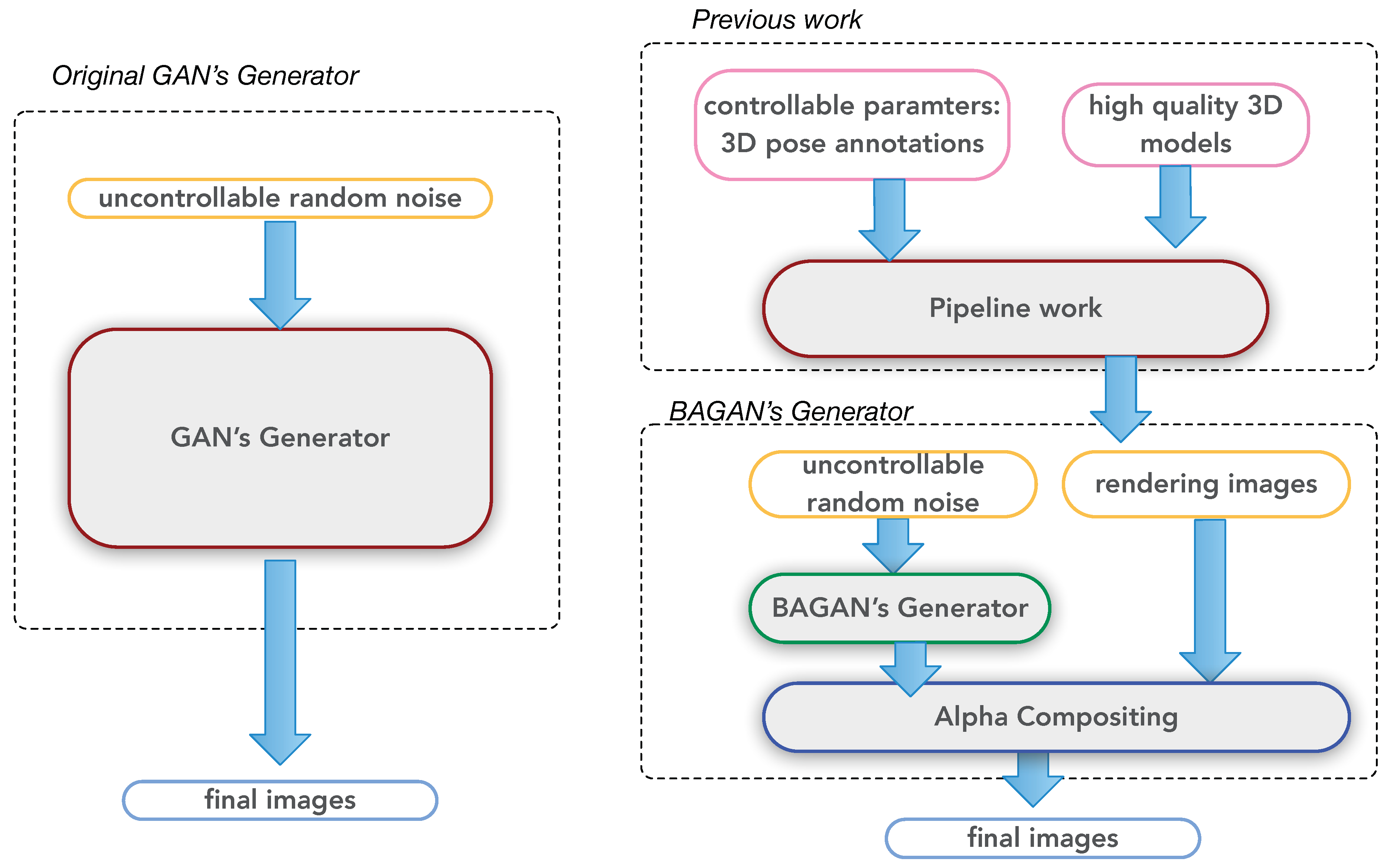
3.1. Previous Work: Synthetic Image Data from 3D Models
3.2. Background Augmentation Generative Adversarial Networks (BAGANs)
3.2.1. Importance of Augment the Synthesis Image’s Background
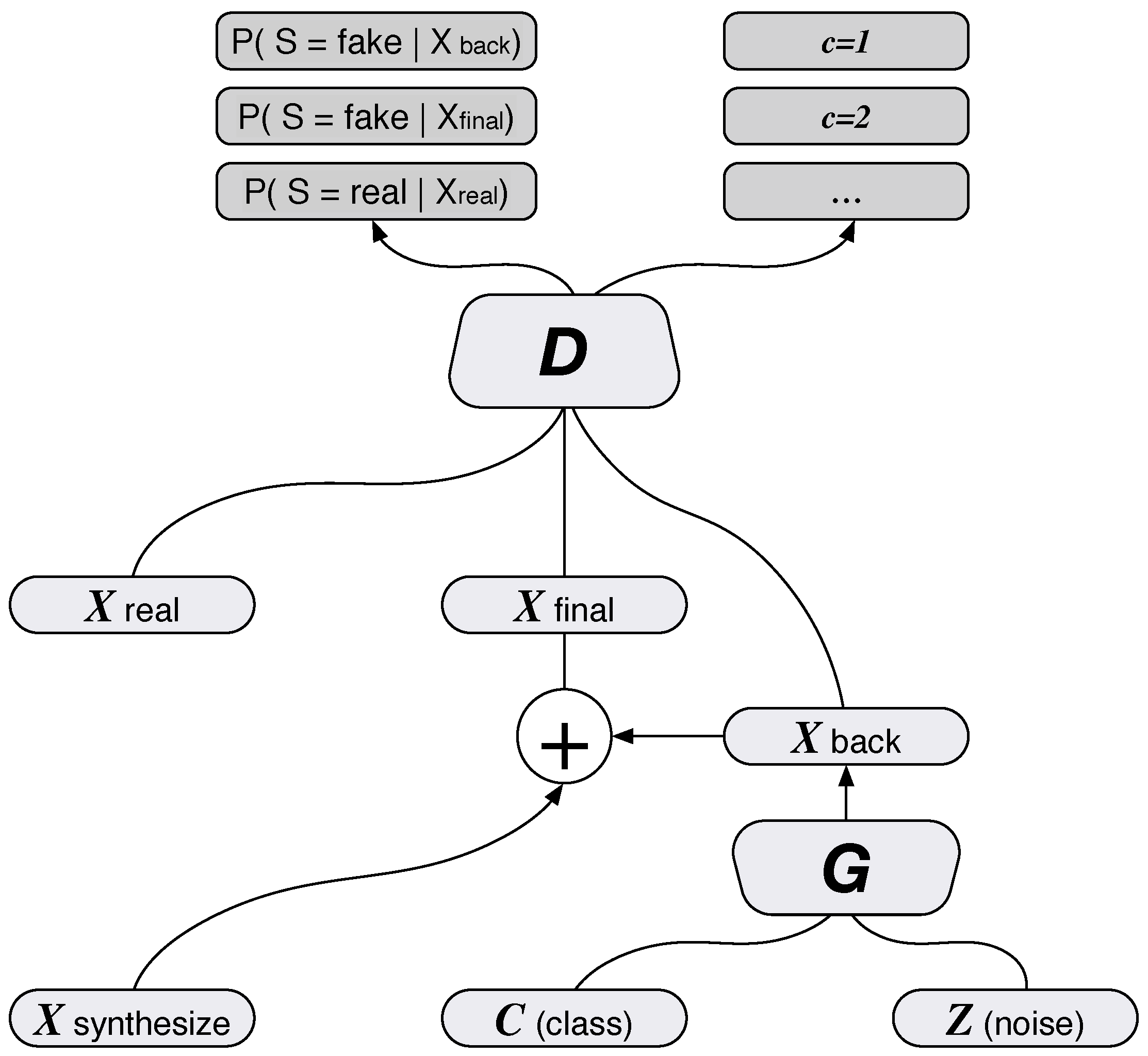
3.2.2. The Value Function of a BAGAN
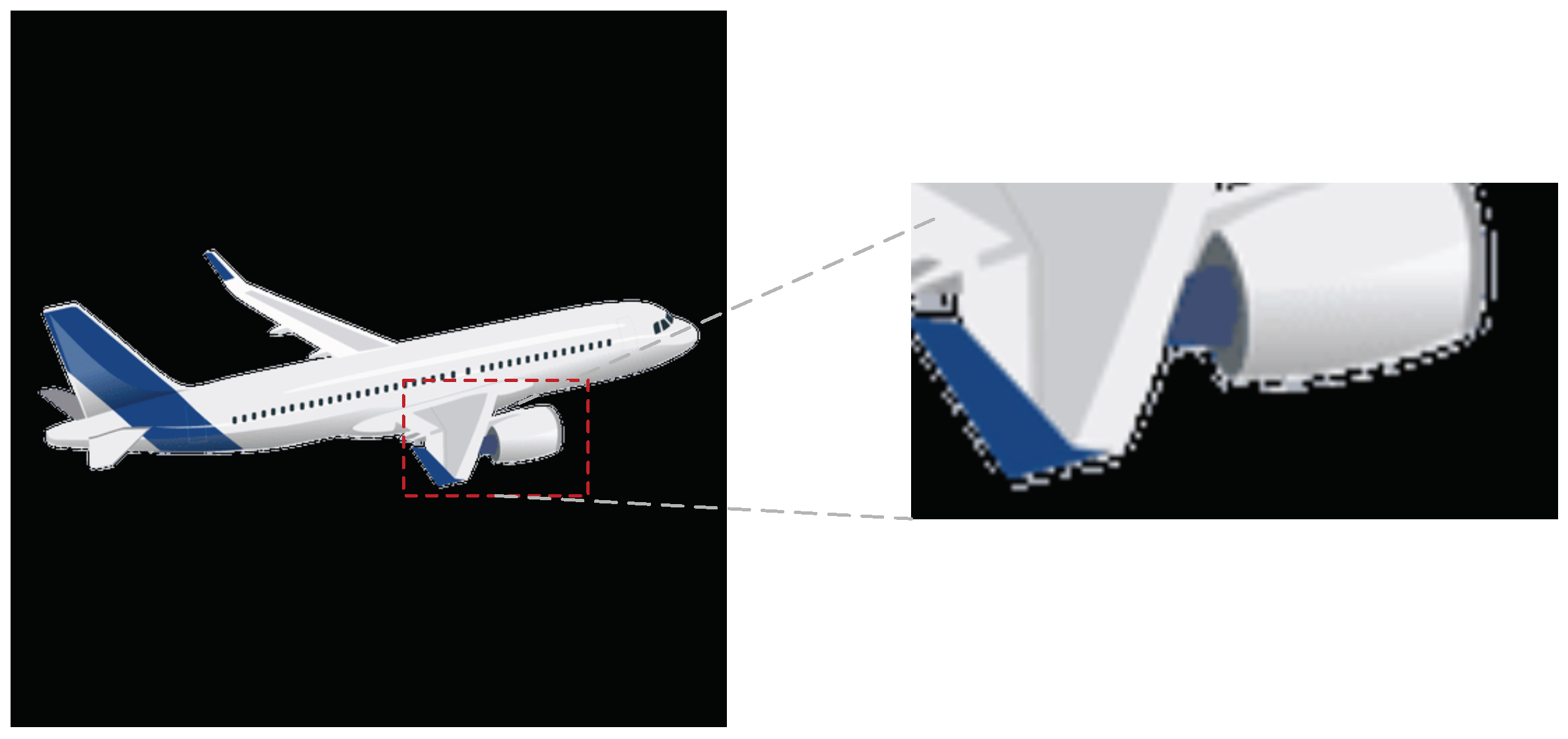
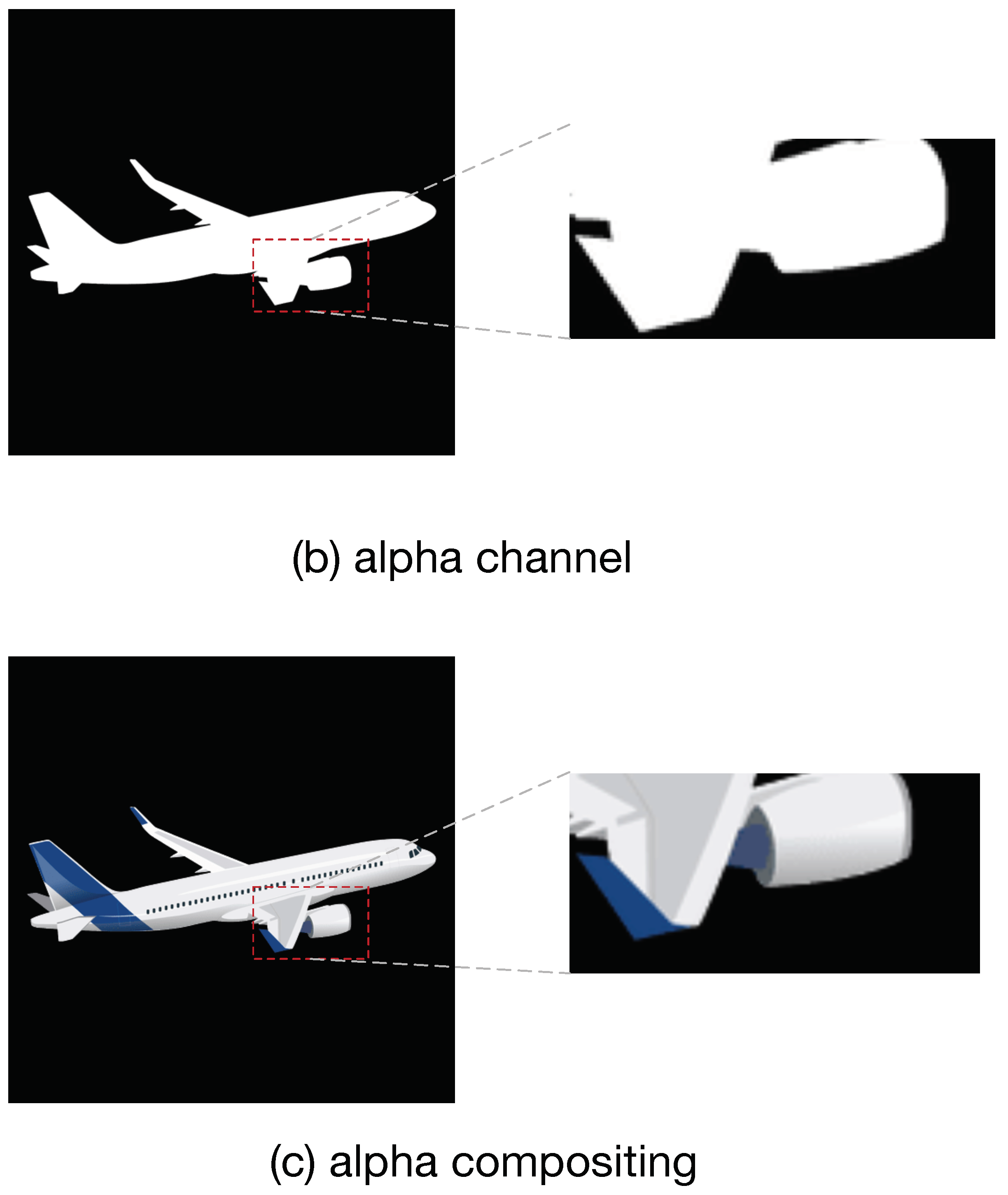
3.2.3. Composite Layer for Foreground Object Adding
| Algorithm 1 Optimal RGBA image resizing method. | ||
| Input: | ▹, Input foreground image (RGBA) | |
| Output: | ▹, Resized foreground image (RGBA) | |
| 1: | ||
| 2: | for 0 do | |
| 3: | for 0 do | |
| 4: | ▹ is RGB channels value; | |
| 5: | ▹ is alpha channels value | |
| 6: | if then | |
| 7: | ||
| 8: | ||
| 9: | end if | |
| 10: | end for | |
| 11: | end for | |
| 12: | = RESIZE() | |
| 13: | ||
| 14: | for 0 do | |
| 15: | for 0 do | |
| 16: | ▹ is RGB channels value; | |
| 17: | ▹ is alpha channels value | |
| 18: | if and then | |
| 19: | if then | |
| 20: | ||
| 21: | else | |
| 22: | ||
| 23: | end if | |
| 24: | ||
| 25: | end if | |
| 26: | end for | |
| 27: | end for | |
4. Results
4.1. Datasets
4.2. Evaluation Metrics
4.3. Comparison with Different Generative Models
4.3.1. BAGAN vs. ACGAN
4.3.2. BAGAN vs. Cycle-GAN
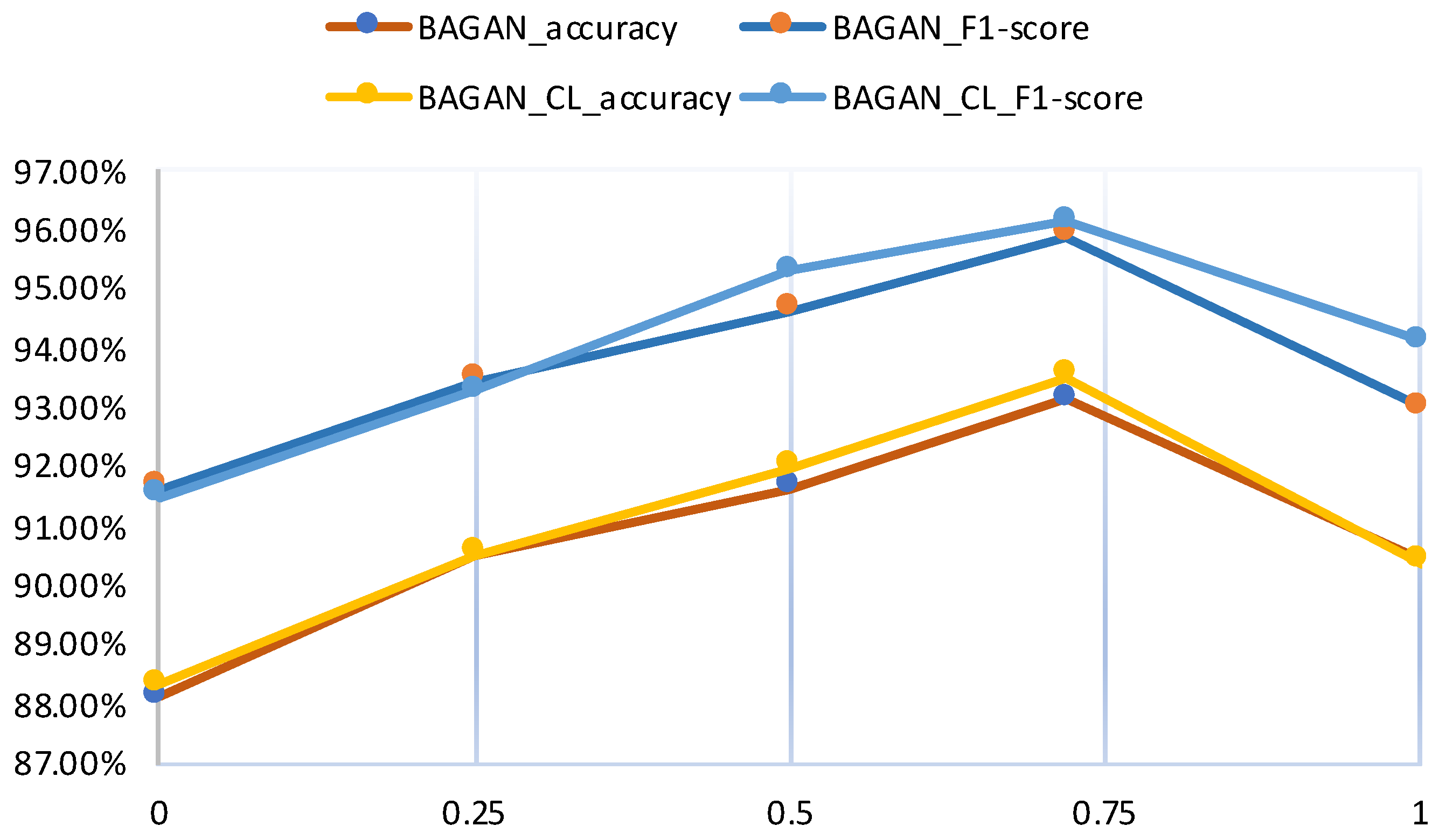
4.4. Lambda Parameters
- If is 0, the BAGAN will only consider the integrity of the background images (). After compositing the foreground and the background images, the BAGAN will fail to find a balance between and . Therefore, the generated background images look like random noise.
- If is 0.25, the BAGAN will try to find a balance between the background and the foreground. Figure 10 shows that the BAGAN achieved a much better background than that when is 0.
- If is 0.5, the generated backgrounds are more natural than and . This stems from the training balance between and .
- After tuning the , when its value is 0.72, the BAGAN generates the best backgrounds.
- If is 1, the BAGAN does not consider , so the generated backgrounds resemble noise images again.
4.5. Effect of the Alpha Compositing Layer
4.6. Classification Results of Different Training Data
5. Discussion
- Using 3D shapes can decrease the complex task of GANs in data synthesis.
- Designing a BAGAN makes synthesis images more natural.
- Using alpha compositing algorithms increases foreground edge appearance.
- Training visual data produced by our method enhances the classifier, with 93% accuracy.
- Wang [31] applied visual attention algorithms to video saliency detection. Adding the attention module may allow a GAN to produce an image background better.
- In light of stacked stages from networks (mentioned by Jaime [32]), manufacturing multi-stage networks is perhaps an adequate approach to fixing the problem of high-resolution images.
- Fusing the loss function of cycle–GAN image to image.
- Considering classification results, saliency object recognition [33] could be an alternative research direction.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HCI | human–computer interaction |
| GANs | generative adversarial networks |
| PCA | principal component analysis |
| ILSVRC | ImageNet Large Scale Visual Recognition Challenge |
References
- Richer, R.; Maiwald, T.; Pasluosta, C.; Hensel, B.; Eskofier, B.M. Novel human computer interaction principles for cardiac feedback using google glass and Android wear. In Proceedings of the 2015 IEEE 12th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Cambridge, MA, USA, 9–12 June 2015; pp. 1–6. [Google Scholar]
- Hong, J.I. Considering privacy issues in the context of Google glass. Commun. ACM 2013, 56, 10–11. [Google Scholar] [CrossRef]
- Evans, G.; Miller, J.; Pena, M.I.; Macallister, A.; Winer, E.H. Evaluating the Microsoft HoloLens through an augmented reality assembly application. Proc. SPIE 2017, 10197. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Jain, N.; Kumar, S.; Kumar, A.; Shamsolmoali, P.; Zareapoor, M. Hybrid deep neural networks for face emotion recognition. Pattern Recognit. Lett. 2018, 115, 101–106. [Google Scholar] [CrossRef]
- Wang, Z.; Lu, D.; Zhang, D.; Sun, M.; Zhou, Y. Fake modern Chinese painting identification based on spectral–spatial feature fusion on hyperspectral image. Multidimens. Syst. Signal Process. 2016, 27, 1031–1044. [Google Scholar] [CrossRef]
- Sun, M.; Zhang, D.; Ren, J.; Wang, Z.; Jin, J.S. Brushstroke based sparse hybrid convolutional neural networks for author classification of Chinese ink-wash paintings. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 626–630. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Tipping, M.E.; Bishop, C.M. Probabilistic Principal Component Analysis. J. R. Stat. Soc. Ser. B Stat. Methodol. 1999, 61, 611–622. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis With Auxiliary Classifier GANs. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from Simulated and Unsupervised Images through Adversarial Training. CVPR 2017, 2, 5. [Google Scholar]
- Zongker, D.E.; Werner, D.M.; Curless, B.; Salesin, D.H. Environment Matting and Compositing. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques; ACM Press/Addison-Wesley Publishing Co.: New York, NY, USA, 1999; pp. 205–214. [Google Scholar]
- Porter, T.; Duff, T. Compositing Digital Images. SIGGRAPH Comput. Graph. 1984, 18, 253–259. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. arXiv, 2017; arXiv:1701.04862. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv, 2017; arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5769–5779. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv, 2014; arXiv:1411.1784v1. [Google Scholar]
- Odena, A. Semi-Supervised Learning with Generative Adversarial Networks. arXiv, 2016; arXiv:1606.01583. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2172–2180. [Google Scholar]
- Xiang, Y.; Kim, W.; Chen, W.; Ji, J.; Choy, C.; Su, H.; Mottaghi, R.; Guibas, L.; Savarese, S. ObjectNet3D: A Large Scale Database for 3D Object Recognition. In European Conference Computer Vision (ECCV); Springer: Cham, Switzerland, 2016. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H. ShapeNet: An Information-Rich 3D Model Repository. arXiv, 2015; arXiv:1512.03012v1. [Google Scholar]
- Zhao, D.; Zheng, J.; Ren, J. Effective Removal of Artifacts from Views Synthesized using Depth Image Based Rendering. In Proceedings of the International Conference on Distributed Multimedia Systems, Vancouver, BC, USA, 31 August–2 September 2015; pp. 65–71. [Google Scholar]
- Smith, A.R.; Blinn, J.F. Blue Screen Matting. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques; ACM: New York, NY, USA, 1996; pp. 259–268. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. SUN database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–8 June 2010; pp. 3485–3492. [Google Scholar]
- Wang, Z.; Ren, J.; Zhang, D.; Sun, M.; Jiang, J. A Deep-Learning Based Feature Hybrid Framework for Spatiotemporal Saliency Detection inside Videos. Neurocomputing 2018, 287, 68–83. [Google Scholar] [CrossRef]
- Zabalza, J.; Ren, J.; Zheng, J.; Zhao, H.; Qing, C.; Yang, Z.; Du, P.; Marshall, S. Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging. Neurocomputing 2016, 185, 1–10. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Hu, X.; Guo, L.; Ren, J.; Wu, F. Background Prior-Based Salient Object Detection via Deep Reconstruction Residual. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1309–1321. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
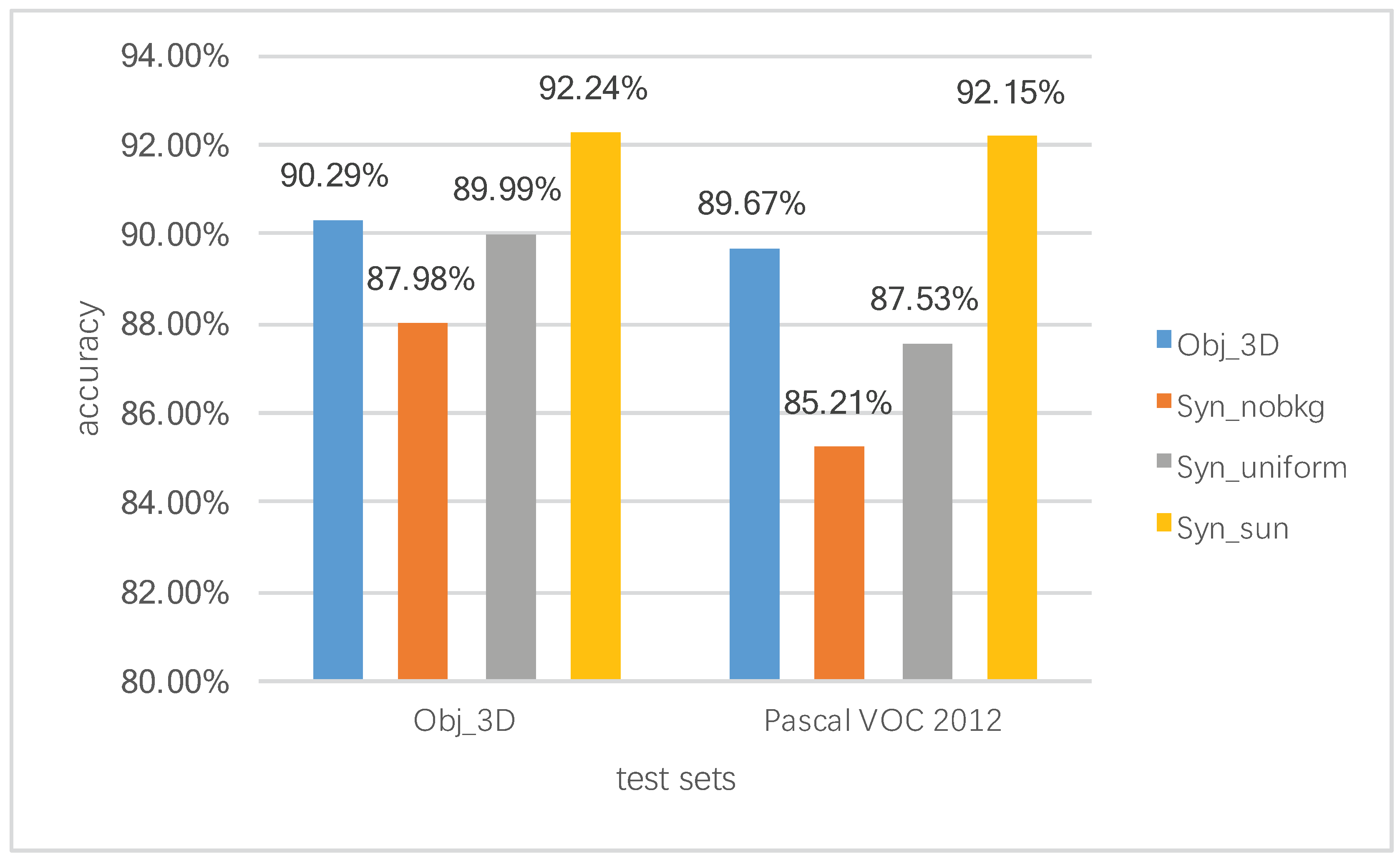{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trainingdata | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| BAGANs () | 88.12% | 92.06% | 91.67% | 91.63% |
| BAGANs-CL () | 88.32% | 92.06% | 91.67% | 91.51% |
| BAGANs () | 90.53% | 91.15% | 94.77% | 93.44% |
| BAGANs-CL () | 90.52% | 90.25% | 95.54% | 93.26% |
| BAGANs () | 91.64% | 94.65% | 94.58% | 94.62% |
| BAGANs-CL () | 91.97% | 96.03% | 94.55% | 95.28% |
| BAGANs () | 93.12% | 94.23% | 97.64% | 95.90% |
| BAGANs-CL () | 93.51% | 95.27% | 97.02% | 96.14% |
| BAGANs () | 90.42% | 91.54% | 94.53% | 93.01% |
| BAGANs-CL () | 90.39% | 92.22% | 96.509% | 94.12% |
| Trainingdata | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| No_bkg | 87.98% | 90.58% | 94.23% | 92.37% |
| Uniform_bkg | 89.99% | 91.80% | 95.25% | 93.50% |
| SUN_bkg | 92.24% | 93.65% | 96.19% | 94.90% |
| ObjNet_3D | 90.29% | 92.14% | 95.47% | 93.78% |
| Cycle_GANs | 73.64% | 77.52% | 82.17% | 79.78% |
| BAGANs () | 88.12% | 92.06% | 91.67% | 91.63% |
| BAGANs () | 90.53% | 91.15% | 94.77% | 93.44% |
| BAGANs () | 91.64% | 94.65% | 94.58% | 94.62% |
| BAGANs () | 93.12% | 94.23% | 97.64% | 95.90% |
| BAGANs () | 90.42% | 91.54% | 94.53% | 93.01% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Liu, K.; Guan, Z.; Xu, X.; Qian, X.; Bao, H. Background Augmentation Generative Adversarial Networks (BAGANs): Effective Data Generation Based on GAN-Augmented 3D Synthesizing. Symmetry 2018, 10, 734. https://doi.org/10.3390/sym10120734
Ma Y, Liu K, Guan Z, Xu X, Qian X, Bao H. Background Augmentation Generative Adversarial Networks (BAGANs): Effective Data Generation Based on GAN-Augmented 3D Synthesizing. Symmetry. 2018; 10(12):734. https://doi.org/10.3390/sym10120734
Chicago/Turabian StyleMa, Yan, Kang Liu, Zhibin Guan, Xinkai Xu, Xu Qian, and Hong Bao. 2018. "Background Augmentation Generative Adversarial Networks (BAGANs): Effective Data Generation Based on GAN-Augmented 3D Synthesizing" Symmetry 10, no. 12: 734. https://doi.org/10.3390/sym10120734
APA StyleMa, Y., Liu, K., Guan, Z., Xu, X., Qian, X., & Bao, H. (2018). Background Augmentation Generative Adversarial Networks (BAGANs): Effective Data Generation Based on GAN-Augmented 3D Synthesizing. Symmetry, 10(12), 734. https://doi.org/10.3390/sym10120734