Image Feature Matching Based on Semantic Fusion Description and Spatial Consistency


Abstract
1. Introduction
2. Related Work
2.1. Image Feature Extraction and Description Methods
2.2. Feature-Matching Methods
2.3. Object Detection Methods
3. Feature Description Method Based on Semantic Fusion
3.1. Object Detection on Images
3.2. ORB Feature Extraction
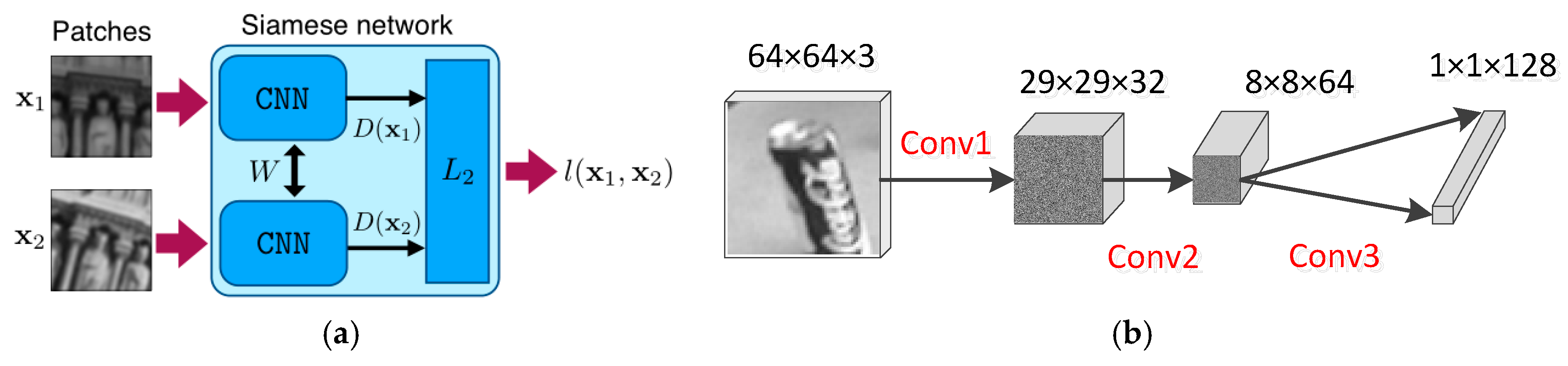
3.3. Semantic Fusion Description of Feature Point Based on Siamese Network
3.4. Weights Optimization Based on PSO
- Initialize randomly in range of [0,1] as particle swarm, which is satisfied with .
- For all these particles, means their historical optimal values, which are initialized by the initial values of particles, means the global optimal value of the particle swarm.
- The objection function is written as
- Define the iteration as 1000 and, for every iteration, the speed and locations of particles will be updated aswhere and means the speed and location of a particle in the m-th iteration, and means the updated speed and location in the next iteration, means the random number between 0 and 1.
4. Feature-Matching Algorithm Based on Feature Spatial Consistency
4.1. Object Spatial Consistency Based on SSD
4.2. Distance and Orientation Constraints within Object Spaces
- The distance constraint. On the basis of the correspondence of and , we can construct a set of relative distances , the elements in the set are the relative distances between the points in and their corresponding points in :and the relative distance between and , which is signed as , should satisfy the constraint that , and mean the minimum and maximum of .
- The orientation constraint. Calculate the orientation vectors of and , signed as and constructed as a set , the element in the set is written as:and the orientation vector between and , which is signed as , should satisfy the constraint that . The example is shown in Figure 8.
4.3. Feature Matching with Feature Spatial Consistency
5. Experiment Design and Result Analysis
5.1. Parameters Optimization of Feature Semantic Description
5.2. Feature Matching and Mismatch Removal
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.J.V. SURF: Speeded Up Robust Features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Part I. pp. 404–417. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G.R. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Proceedings of the Computer Vision-ECCV2006, 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Part I. pp. 430–443. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Proceedings of the Computer Vision-ECCV 2010, 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Part IV. pp. 778–792. [Google Scholar] [CrossRef]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; LeCun, Y.; Moore, C.; Säckinger, E.; Shah, R. Signature Verification Using A “Siamese” Time Delay Neural Network. IJPRAI 1993, 7, 669–688. [Google Scholar] [CrossRef]
- Harris, C.G.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the Alvey Vision Conference, AVC 1988, Manchester, UK, 31 August–2 September 1988; pp. 1–6. [Google Scholar] [CrossRef]
- Verdie, Y.; Yi, K.M.; Fua, P.; Lepetit, V. TILDE: A Temporally Invariant Learned DEtector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 5279–5288. [Google Scholar] [CrossRef]
- Lenc, K.; Vedaldi, A. Learning Covariant Feature Detectors. In Proceedings of the Computer Vision-ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Part III. pp. 100–117. [Google Scholar] [CrossRef]
- Brown, M.A.; Hua, G.; Winder, S.A.J. Discriminative Learning of Local Image Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 43–57. [Google Scholar] [CrossRef] [PubMed]
- Trzcinski, T.; Christoudias, C.M.; Lepetit, V. Learning Image Descriptors with Boosting. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 597–610. [Google Scholar] [CrossRef] [PubMed]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative Learning of Deep Convolutional Feature Point Descriptors. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 118–126. [Google Scholar] [CrossRef]
- Zbontar, J.; LeCun, Y. Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches. J. Mach. Learn. Res. 2016, 17, 2. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Chen, J.; Ma, J.; Yang, C.; Tian, J. Mismatch removal via coherent spatial relations. J. Electron. Imaging 2014, 23, 043012. [Google Scholar] [CrossRef]
- Caetano, T.S.; Caelli, T.; Schuurmans, D.; Barone, D.A.C. Graphical Models and Point Pattern Matching. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1646–1663. [Google Scholar] [CrossRef] [PubMed]
- Caetano, T.S.; McAuley, J.J.; Cheng, L.; Le, Q.V.; Smola, A.J. Learning Graph Matching. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1048–1058. [Google Scholar] [CrossRef] [PubMed]
- Cho, M.; Alahari, K.; Ponce, J. Learning Graphs to Match. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2013, Sydney, Australia, 1–8 December 2013; pp. 25–32. [Google Scholar] [CrossRef]
- Cho, M.; Sun, J.; Duchenne, O.; Ponce, J. Finding Matches in a Haystack: A Max-Pooling Strategy for Graph Matching in the Presence of Outliers. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; pp. 2091–2098. [Google Scholar] [CrossRef]
- Olson, C.F.; Huttenlocher, D.P. Automatic target recognition by matching oriented edge pixels. IEEE Trans. Image Process. 1997, 6, 103–113. [Google Scholar] [CrossRef] [PubMed]
- Gavrila, D.; Philomin, V. Real-Time Object Detection for “Smart” Vehicles. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 87–93. [Google Scholar] [CrossRef]
- Viola, P.A.; Jones, M.J. Rapid Object Detection using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Forsyth, D.A. Object Detection with Discriminatively Trained Part-Based Models. IEEE Comput. 2014, 47, 6–7. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision-ECCV 2016-14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I. pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Fu, C.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv, 2017; arXiv:1701.06659. [Google Scholar]
- Affine Covariant Features Database for Evaluating Feature Detector and Descriptor Matching Quality and Repeatability. Available online: http://www.robots.ox.ac.uk/~vgg/research/affine (accessed on 15 July 2017).
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, IJCAI’81, Vancouver, BC, Canada, 24–28 August 1981; pp. 674–679. [Google Scholar]
- A Benchmark for the Evaluation of RGB-D SLAM Systems. Available online: https://vision.in.tum.de/data/datasets/rgbd-dataset (accessed on 14 October 2017).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AUC | ORB + BRIEF | SIFT | Method in [12] | Ours |
|---|---|---|---|---|
| bikes sequence | 0.58 | 0.62 | 0.71 | 0.79 |
| bark sequence | 0.47 | 0.71 | 0.68 | 0.77 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Zhang, G. Image Feature Matching Based on Semantic Fusion Description and Spatial Consistency. Symmetry 2018, 10, 725. https://doi.org/10.3390/sym10120725
Zhang W, Zhang G. Image Feature Matching Based on Semantic Fusion Description and Spatial Consistency. Symmetry. 2018; 10(12):725. https://doi.org/10.3390/sym10120725
Chicago/Turabian StyleZhang, Wei, and Guoying Zhang. 2018. "Image Feature Matching Based on Semantic Fusion Description and Spatial Consistency" Symmetry 10, no. 12: 725. https://doi.org/10.3390/sym10120725
APA StyleZhang, W., & Zhang, G. (2018). Image Feature Matching Based on Semantic Fusion Description and Spatial Consistency. Symmetry, 10(12), 725. https://doi.org/10.3390/sym10120725