Comparison of Random Subspace and Voting Ensemble Machine Learning Methods for Face Recognition



Abstract
1. Introduction
1.1. Background
1.2. Research Motivations
1.3. Contribution
1.4. Organization
2. Literature Review
3. Materials and Methods
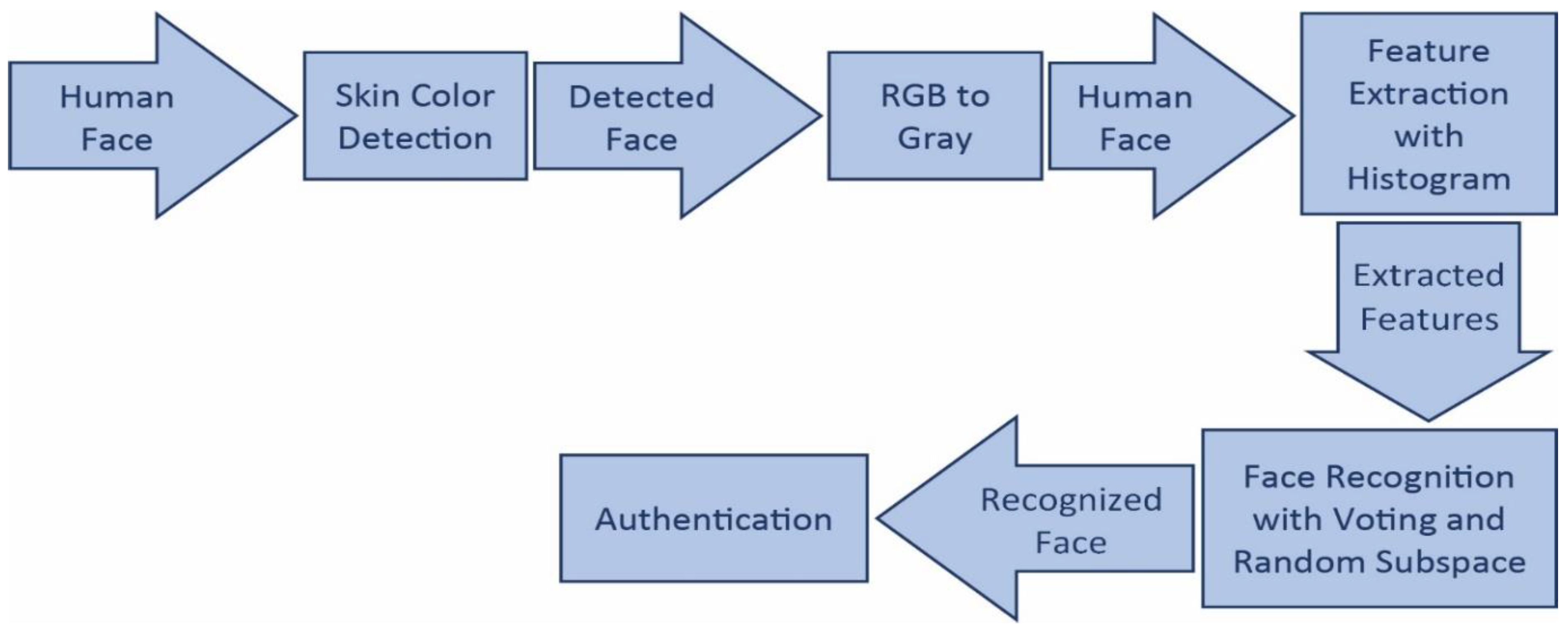
3.1. Face Detection
3.2. Facial Feature Extraction
3.3. Face Recognition
3.4. Classification Methods
3.4.1. Artificial Neural Networks (ANN)
3.4.2. k-Nearest Neighbor (k-NN)
3.4.3. Support Vector Machine (SVM)
3.4.4. Naïve Bayes (NB)
3.4.5. Classification and Regression Tree (CART)
3.4.6. C4.5 Decision Tree
3.4.7. REP Tree
3.4.8. AD Tree
3.4.9. LAD Tree
3.4.10. Random Tree Classifiers
3.4.11. Random Forests (RF)
3.4.12. Rotation Forest (RoF)
3.5. Ensemble Methods
3.5.1. Random Subspace Method
- Repeat for b = 1, 2, …, B:
- Choose an r-dimensional random subspace from the original p-dimensional feature space X.
- Build a classifier Cb(x) (with a decision boundary Cb(x) = 0) in .
- Aggregate classifiers Cb(x), b =1, 2, …, B, by utilizing majority voting for the final decision.
- Classifier: represents the base classifier to be applied. We applied 11 different classifiers such as ANN, k-NN, SVM, RF, C4.5, Random Tree, REP Tree, LAD Tree, NB, Rotation Forest, and CART.
- Numiterations: represents the number of repetitions to be applied. The best performance is achieved for a setting up to 10.
- Seed: represents the number seed to be applied randomly. The best performance is achieved with a seed = 1 in the implementation of the random subspace.
- Subspacesize: represents the size of each subspace. The best performance is achieved with a subspace = 0.5 in the implementation of the random subspace.
3.5.2. Voting
- Classifier: represents the base classifier to be combined with default classifier. We applied 11 different classifiers such as ANN, k-NN, SVM, RF, C4.5, Random Tree, REP Tree, LAD Tree, NB, Rotation Forest, and CART.
- Combinationrule: represents the combination rule to be applied. The best performance is achieved with an average of probabilities combination rule among others, such as: the product of probabilities, majority voting, minimum probability, maximum probability, and median combination rules.
- Seed: represents the number seed to be applied randomly. The best performance is achieved with a seed = 1 in the implementation of Voting.
4. Results and Discussion
4.1. Experimental Setup
4.2. Database Descriptions
4.3. Performance Evaluation Metrics
4.4. Experimental Results
4.4.1. Results for the FERET Database
4.4.2. Results for the KREMIC Database
4.5. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jain, A.K.; Nandakumar, K.; Ross, A. 50 years of biometric research: Accomplishments, challenges, and opportunities. Pattern Recognit. Lett. 2016, 79, 80–105. [Google Scholar] [CrossRef]
- Jain, A.K.; Ross, A.A.; Nandakumar, K. Introduction to Biometrics; Springer Science & Business Media: Basel, Switzerland, 2011; ISBN 978-0-387-77326-1. [Google Scholar]
- Sidek, K.A.; Mai, V.; Khalil, I. Data mining in mobile ECG based biometric identification. J. Netw. Comput. Appl. 2014, 44, 83–91. [Google Scholar] [CrossRef]
- Chihaoui, M.; Elkefi, A.; Bellil, W.; Ben Amar, C. A survey of 2D face recognition techniques. Computers 2016, 5, 21. [Google Scholar] [CrossRef]
- Vinay, A.; Shekhar, V.S.; Rituparna, J.; Aggrawal, T.; Murthy, K.B.; Natarajan, S. Cloud based big data analytics framework for face recognition in social networks using machine learning. Procedia Comput. Sci. 2015, 50, 623–630. [Google Scholar] [CrossRef]
- Tripathi, B.K. On the complex domain deep machine learning for face recognition. Appl. Intell. 2017, 47, 382–396. [Google Scholar] [CrossRef]
- Li, J.; Hao, W.; Zhang, X. Learning kernel subspace for face recognition. Neurocomputing 2015, 151, 1187–1197. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, Y.; Fang, Q.; Liang, Z.; Yang, F.; Zhan, S. Heterogeneous face recognition based on super resolution reconstruction by adaptive multi-dictionary learning. In Proceedings of the 10th Chinese Conference on Biometric Recognition, Tianjin, China, 13–15 November 2015; pp. 143–150. [Google Scholar]
- Chen, G.; Shao, Y.; Tang, C.; Jin, Z.; Zhang, J. Deep transformation learning for face recognition in the unconstrained scene. Mach. Vis. Appl. 2018, 29, 513–523. [Google Scholar] [CrossRef]
- Dai, K.; Zhao, J.; Cao, F. A novel decorrelated neural network ensemble algorithm for face recognition. Knowl.-Based Syst. 2015, 89, 541–552. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.D.; Li, F.Z. Kernel sparse representation-based classifier ensemble for face recognition. Multimed. Tools Appl. 2015, 74, 123–137. [Google Scholar] [CrossRef]
- Wang, S.J.; Chen, H.L.; Yan, W.J.; Chen, Y.H.; Fu, X. Face recognition and micro-expression recognition based on discriminant tensor subspace analysis plus extreme learning machine. Neural Process. Lett. 2014, 39, 25–43. [Google Scholar] [CrossRef]
- Bashbaghi, S.; Granger, E.; Sabourin, R.; Bilodeau, G.A. Dynamic ensembles of exemplar-svms for still-to-video face recognition. Pattern Recognit. 2017, 69, 61–81. [Google Scholar] [CrossRef]
- Odone, F.; Pontil, M.; Verri, A. Machine learning techniques for biometrics. In Handbook of Remote Biometrics; Springer: London, UK, 2009; pp. 247–271. [Google Scholar]
- Shen, L.; Bai, L.; Bardsley, D.; Wang, Y. Gabor feature selection for face recognition using improved adaboost learning. In Advances in Biometric Person Authentication; Springer: Berlin/Heidelberg, Germany, 2005; pp. 39–49. [Google Scholar]
- Zong, W.; Huang, G.B. Face recognition based on extreme learning machine. Neurocomputing 2011, 74, 2541–2551. [Google Scholar] [CrossRef]
- Kremic, E.; Subasi, A.; Hajdarevic, K. Face recognition implementation for client server mobile application using PCA. In Proceedings of the ITI 2012 34th International Conference on Information Technology Interfaces, Zagreb, Croatia, 25–28 June 2012; pp. 435–440. [Google Scholar]
- De-la-Torre, M.; Granger, E.; Radtke, P.V.; Sabourin, R.; Gorodnichy, D.O. Partially-supervised learning from facial trajectories for face recognition in video surveillance. Inf. Fusion 2015, 24, 31–53. [Google Scholar] [CrossRef]
- Han, S.; Meng, Z.; Khan, A.; Tong, Y. Incremental Boosting Convolutional Neural Network for Facial Action Unit Recognition. In Proceedings of the Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 109–117. [Google Scholar]
- Kremic, E.; Subasi, A. Performance of random forest and SVM in face recognition. Int. Arab J. Inf. Technol. 2016, 13, 287–293. [Google Scholar]
- Zhao, J.; Lv, Y.; Zhou, Z.; Cao, F. A novel deep learning algorithm for incomplete face recognition: Low-rank-recovery network. Neural Netw. 2017, 94, 115–124. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.G.; Lee, W.O.; Kim, K.W.; Hong, H.G.; Park, K.R. Performance Enhancement of Face Recognition in Smart TV Using Symmetrical Fuzzy-Based Quality Assessment. Symmetry 2015, 3, 1475–1518. [Google Scholar] [CrossRef]
- Wang, S.-Y.; Yang, S.-H.; Chen, Y.-P.; Huang, J.-W. Face Liveness Detection Based on Skin Blood Flow Analysis. Symmetry 2017, 12, 305. [Google Scholar] [CrossRef]
- Li, Y.; Lu, Z.; Li, J.; Deng, Y. Improving deep learning feature with facial texture feature for face recognition. Wirel. Pers. Commun. 2018, 103, 195–1206. [Google Scholar] [CrossRef]
- Yang, J.; Sun, W.; Liu, N.; Chen, Y.; Wang, Y.; Han, S. A novel multimodal biometrics recognition model based on stacked ELM and CCA methods. Symmetry 2018, 10, 96. [Google Scholar] [CrossRef]
- Sajid, M.; Shafique, T.; Manzoor, S.; Iqbal, F.; Talal, H.; Samad Qureshi, U.; Riaz, I. Demographic-assisted age-invariant face recognition and retrieval. Symmetry 2018, 10, 148. [Google Scholar] [CrossRef]
- Wang, W.; Yang, J.; Xiao, J.; Li, S.; Zhou, D. Face recognition based on deep learning. In Proceedings of the International Conference on Human Centered Computing, Phnom Penh, Cambodia, 27–29 November 2014; pp. 812–820. [Google Scholar]
- Mohammed, A.A.; Minhas, R.; Wu, O.J.; Sid-Ahmed, M.A. Human face recognition based on multidimensional PCA and extreme learning machine. Pattern Recognit. 2011, 10–11, 2588–2597. [Google Scholar] [CrossRef]
- Valenti, R.; Sebe, N.; Gevers, T.; Cohen, I. Machine learning techniques for face analysis. In Machine Learning Techniques for Multimedia; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Information Science and Statistics: Secaucus, NJ, USA, 2006. [Google Scholar]
- Salah, A.A. Insan ve bilgisayarda yüz tanima. In Proceedings of the International Cognitive Neuroscience Symposium, Marmaris, Turkey, 5–8 May 2007; Available online: http://www.academia.edu/2666478/%C4%B0NSAN_VE_B%C4%B0LG%C4%B0SAYARDA_Y%C3%9CZ_TANIMA (accessed on 1 October 2018).
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Al-Ghamdi, B.A.S.; Allaam, S.R.; Soomro, S. Recognition of human face by face recognition system using 3D. J. Inf. Commun. Technol. 2010, 4, 27–34. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Waltham, MA, USA, 2011. [Google Scholar]
- Zhang, Y.; Wu, L. Classification of fruits using computer vision and a multiclass support vector machine. Sensors 2012, 12, 12489–12505. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Dong, Z.; Wang, S.; Ji, G.; Yang, J. Preclinical diagnosis of magnetic resonance (MR) brain images via discrete wavelet packet transform with Tsallis entropy and generalized eigenvalue proximal support vector machine (GEPSVM). Entropy 2015, 17, 1795–1813. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Cambridge, MA, USA, 2016. [Google Scholar]
- Holmes, G.; Pfahringer, B.; Kirkby, R.; Frank, E.; Hall, M. Multiclass alternating decision trees. In Proceedings of the European Conference on Machine Learning, Skopje, Macedonia, 18–22 September 2002; pp. 161–172. [Google Scholar]
- Kalmegh, S. Analysis of WEKA data mining algorithm REP Tree, Simple CART and Random Tree for classification of Indian news. Int. J. Innov. Sci. Eng. Technol. 2015, 2, 438–446. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Grąbczewski, K. Meta-Learning in Decision Tree Induction; Springer: New York, NY, USA, 2014. [Google Scholar]
- Rodriguez, J.J.; Kuncheva, L.I.; Alonso, C.J. Rotation forest: A new classifier ensemble method. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1619–1630. [Google Scholar] [CrossRef] [PubMed]
- Saraswathi, D.; Srinivasan, E. An ensemble approach to diagnose breast cancer using fully complex-valued relaxation neural network classifier. Int. J. Biomed. Eng. Technol. 2014, 15, 243–260. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Skurichina, M.; Duin, R.P. Bagging, boosting and the random subspace method for linear classifiers. Pattern Anal. Appl. 2002, 5, 121–135. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Singh, S.K.; Chauhan, D.S.; Vatsa, M.; Singh, R. A robust skin color based face detection algorithm. J. Appl. Sci Eng. 2003, 6, 227–234. [Google Scholar]
- Kim, K.S.; Kim, G.Y.; Choi, H.I. Automatic face detection using feature tracker. In Proceedings of the International Conference on Convergence and Hybrid Information Technology, Daejeon, Korea, 28–29 August 2008; pp. 211–216. [Google Scholar]
- Phillips, P.J.; Moon, H.; Rizvi, S.A.; Rauss, P.J. The FERET evaluation methodology for face-recognition algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1090–1104. [Google Scholar] [CrossRef]
- Egan, J.P. Signal detection theory and {ROC} analysis. Psychol. Rec. 1975, 26, 567. [Google Scholar]
- Swets, J.A.; Dawes, R.M.; Monahan, J. Better decisions through science. Sci. Am. 2000, 283, 82–87. [Google Scholar] [CrossRef] [PubMed]
- Provost, F.J.; Fawcett, T. Analysis and visualization of classifier performance: Comparison under imprecise class and cost distributions. In Proceedings of the Third International Conference on Knowledge Discovery and Data Mining, Newport Beach, CA, USA, 14–17 August 1997; pp. 43–48. [Google Scholar]
- Provost, F.J.; Fawcett, T.; Kohavi, R. The case against accuracy estimation for comparing induction algorithms. In Proceedings of the Fifteenth International Conference on Machine Learning, Madison, WI, USA, 24–27 July 1998; pp. 445–453. [Google Scholar]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Viera, A.J.; Garrett, J.M. Understanding interobserver agreement: The kappa statistic. Fam. Med. 2005, 37, 360–363. [Google Scholar] [PubMed]
- Yang, Z.; Zhou, M. Kappa statistic for clustered physician–patients polytomous data. Comput. Stat. Data Anal. 2015, 87, 1–17. [Google Scholar] [CrossRef]
- Kepenekci, B. Face recognition using gabor wavelet transform. Ph.D. Thesis, The Middle East Technical University, Ankara, Turkey, 2001. [Google Scholar]
- Dong, Z.; Jing, C.; Pei, M.; Jia, Y. Deep CNN based binary hash video representations for face retrieval. Pattern Recognit. 2018, 81, 357–369. [Google Scholar] [CrossRef]
- Le, T.H.; Bui, L. Face recognition based on SVM and 2DPCA. arXiv, 2011; arXiv:11105404. [Google Scholar]
- Kar, A.; Bhattacharjee, D.; Nasipuri, M.; Basu, D.K.; Kundu, M. High performance human face recognition using gabor based pseudo hidden Markov model. Int. J. Appl. Evol. Comput. IJAEC 2013, 4, 81–102. [Google Scholar] [CrossRef]
- Chihaoui, M.; Bellil, W.; Elkefi, A.; Amar, C.B. Face recognition using HMM-LBP. In Proceedings of the International Conference on Hybrid Intelligent Systems, Marrakech, Morocco, 21–23 November 2016; pp. 249–258. [Google Scholar]


{kind=link}
| Accuracy (%) | F-measure | ROC Area | Kappa | |
|---|---|---|---|---|
| ANN | 98.75 | 0.986 | 0.999 | 0.987 |
| k-NN | 97.00 | 0.969 | 0.998 | 0.969 |
| SVM | 99.00 | 0.989 | 0.997 | 0.989 |
| RF | 99.25 | 0.991 | 0.998 | 0.992 |
| C4.5 | 90.50 | 0.903 | 0.997 | 0.902 |
| Random Tree | 94.75 | 0.947 | 0.995 | 0.946 |
| REP Tree | 94.75 | 0.944 | 0.997 | 0.946 |
| LAD Tree | 88.25 | 0.875 | 0.995 | 0.879 |
| Naïve Bayes | 98.75 | 0.986 | 0.998 | 0.987 |
| Rotation Forest | 90.50 | 0.903 | 0.996 | 0.989 |
| CART | 90.50 | 0.903 | 0.996 | 0.902 |
| Accuracy (%) | F-Measure | ROC Area | Kappa | |
|---|---|---|---|---|
| ANN | 98.75 | 0.986 | 0.999 | 0.987 |
| k-NN | 97.25 | 0.971 | 0.987 | 0.971 |
| SVM | 98.75 | 0.986 | 0.997 | 0.987 |
| RF | 99.25 | 0.989 | 0.998 | 0.989 |
| C4.5 | 75.00 | 0.748 | 0.873 | 0.743 |
| Random Tree | 68.75 | 0.686 | 0.840 | 0.979 |
| REP Tree | 59.50 | 0.583 | 0.891 | 0.584 |
| LAD Tree | 68.50 | 0.683 | 0.978 | 0.676 |
| Naïve Bayes | 98.75 | 0.986 | 0.997 | 0.987 |
| Rotation Forest | 96.50 | 0.964 | 0.997 | 0.968 |
| CART | 75.50 | 0.750 | 0.883 | 0.748 |
| Accuracy (%) | F-measure | ROC Area | Kappa | |
|---|---|---|---|---|
| ANN | 95.51 | 0.953 | 0.993 | 0.955 |
| k-NN | 95.38 | 0.954 | 0.984 | 0.953 |
| SVM | 90.51 | 0.901 | 0.994 | 0.901 |
| RF | 96.41 | 0.965 | 0.999 | 0.965 |
| C4.5 | 95.65 | 0.957 | 0.996 | 0.958 |
| Random Tree | 95.64 | 0.957 | 0.996 | 0.955 |
| REP Tree | 91.41 | 0.915 | 0.996 | 0.915 |
| LAD Tree | 83.84 | 0.830 | 0.992 | 0.831 |
| Naïve Bayes | 90.38 | 0.897 | 0.993 | 0.901 |
| Rotation Forest | 96.41 | 0.965 | 1 | 0.963 |
| CART | 91.02 | 0.911 | 0.991 | 0.908 |
| Accuracy (%) | F-measure | ROC Area | Kappa | |
|---|---|---|---|---|
| ANN | 92.69 | 0.923 | 0.983 | 0.925 |
| k-NN | 95.00 | 0.950 | 0.974 | 0.948 |
| SVM | 92.95 | 0.929 | 0.995 | 0.927 |
| RF | 96.79 | 0.968 | 0.999 | 0.967 |
| C4.5 | 84.23 | 0.841 | 0.928 | 0.838 |
| Random Tree | 86.28 | 0.862 | 0.930 | 0.859 |
| REP Tree | 73.85 | 0.738 | 0.932 | 0.731 |
| LAD Tree | 73.85 | 0.734 | 0.982 | 0.731 |
| Naïve Bayes | 90.64 | 0.899 | 0.991 | 0.903 |
| Rotation Forest | 94.87 | 0.949 | 0.997 | 0.947 |
| CART | 83.08 | 0.831 | 0.930 | 0.826 |
| The Study Reference | Feature Extraction Method | Classifier | Classification Accuracy |
|---|---|---|---|
| Kar et al. [63] | Gabor Wavelet | Hidden Markov Model | 81.25 |
| Chihaoui et al. [64] | Local Binary Pattern | Hidden Markov Model | 99.00 |
| Kepenekci [60] | Gabor Wavelet | ANN | 90.00 |
| Le and Bui [62] | 2D Principal Component Analysis (2DPCA | SVM | 95.10 |
| Le and Bui [62] | PCA | SVM | 85.20 |
| Le and Bui [62] | 2D Principal Component Analysis (2DPCA | KNN | 90.10 |
| Le and Bui [58] | PCA | KNN | 80.10 |
| Kremic and Subasi [20] | Histogram | SVM | 97.94 |
| Shen et al. [15] | Gabor | Adaboost | 95.50 |
| Dong et al. [61] | The Big Bang Theory | DCNN | 98.00 |
| Zhao et al. [21] | Low-rank-recovery network (LRRNet) | SVM | 98.31 |
| Proposed Method | Histogram | Voting and Random Subspace with Random Forest | 99.25 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yaman, M.A.; Subasi, A.; Rattay, F. Comparison of Random Subspace and Voting Ensemble Machine Learning Methods for Face Recognition. Symmetry 2018, 10, 651. https://doi.org/10.3390/sym10110651
Yaman MA, Subasi A, Rattay F. Comparison of Random Subspace and Voting Ensemble Machine Learning Methods for Face Recognition. Symmetry. 2018; 10(11):651. https://doi.org/10.3390/sym10110651
Chicago/Turabian StyleYaman, Mehmet Akif, Abdulhamit Subasi, and Frank Rattay. 2018. "Comparison of Random Subspace and Voting Ensemble Machine Learning Methods for Face Recognition" Symmetry 10, no. 11: 651. https://doi.org/10.3390/sym10110651
APA StyleYaman, M. A., Subasi, A., & Rattay, F. (2018). Comparison of Random Subspace and Voting Ensemble Machine Learning Methods for Face Recognition. Symmetry, 10(11), 651. https://doi.org/10.3390/sym10110651