1. Introduction
Fuzzing is a widely used security technique for discovering vulnerability in network protocol by sending a series of test files with random or fault data to software system implementing specific protocol and observing software exceptions to detect vulnerabilities within the protocol.
Currently, there exist mainly two kinds of fuzzing techniques, i.e., mutation-based and generation-based fuzzing [
1]. The former generates test files by injecting random or fault data into sample messages (message is the basic data unit exchanged between processes of application-layer protocol ), while the latter constructs fault-injected messages as test files based on specific protocol specification. The mutation-based fuzzing emits a fatal problem that too many fault-injected messages are required to maintain a high test coverage, such as FileFuzz (
http://www.securiteam.com/tools/5PP051FGUE.html) and SPIKEfile (
https://www.ee.oulu.fi/research/ouspg/SPIKEfile). However, the amount of fault-injected files is
, where
L is the power of sample message’s length, and it would take tremendously long time to handle so great amount of fault-injected test files especially when
L is large. Actually, a protocol’s software system parses inputs by considering their formats and treats any files which does not obey the rule of its format as invalid input, in which case a software system will throw an error and quit before it reaches the fault segment(s). Therefore, many of fault-injected test files are not necessary for successful fuzzing test. The generation-based fuzzing generates test files by considering the format of input messages, such as PROTOS (
https://www.ee.oulu.fi/roles/ouspg/Protos). One advantage of such fuzzing tools is that it reduces the number of test files greatly and introduces nearly no sacrifice on test coverage [
2]. However, one has to figure out the message formats and configure generation-based fuzzer accordingly. Currently, the message formats are mainly collected or analyzed in a manual way, which is a time-consuming and error-prone process. To address these issues, protocol reverse engineering [
3] is introduced to obtain protocol specification automatically. The protocol specification including message format a set of rules that describe or model a network protocol. Then a field-based fault-injected message generation procedure conducted by the message format is applied to create fuzzing test files.
Protocol message is treated as a byte sequence which could be divided into a sequence of fields. A keyword field usually holds a command, operator or state code of protocol, while a data field is variable subsequence whose content is always changeable, such as the value of some parameters of communication. Generally, message format is recovered by identifying all fields in byte sequences. However, it is hard to locate the boundary of fields and a great challenge to identify fields in message, since a priori information about them is usually not available. The byte sequence of protocol message is supposed to obey an underlying stochastic process in which different fields have their own distribution of symbols and change-points are the boundaries of fields. Apparently, each change-point implies an end point of one field and a start point of another field. With these assumption, our goal of field boundary detection is essentially the problem of multi-change-point detection. This problem can be addressed using change-point detection [
4] widely used in time series analysis. When change-points are localized successfully, messages are divided into field sequences. However, the type of fields are still uncertain. Thus, a further inference procedure, named position-based occurrence probability test analysis, is proposed to determine field type( keyword fields and data fields). Firstly, fields with approximate zero-probability distribution are classified as data fields. Then, the rest ones are further processed in a position-based statistic test. Specifically, a reference position would be selected for every field, and each field are tested by binomial test to make sure whether their positions are equal to the reference position with probability 1 given a significance level
. The fields passing these tests are chosen as keyword fields, while the rest ones are considered as uncertain fields.
2. Related Work
Recently, the security and privacy issues for Internet of Things have attracted a lot of research interests [
5,
6,
7,
8,
9,
10]. In particular, the analysis of applications and protocols in real-time network traffic monitoring is a fundamental and critical building block in network management and security systems for IoT infrastructures [
11,
12,
13,
14,
15]. In this part, we review the recent works in application-layer network protocol vulnerability analysis and detection.
Fuzzing helps protocol vulnerabilities detection to gain higher benefit-to-cost ratio with no or less increasing in computing complexity. It aims to reveal bugs in protocols which would be exploited by adversary to launch attack or activate their malicious code. Currently, research on network protocol fuzzing test is a heat topic in network security. AutoFuzz [
16] identified the variable parts of sample messages and fuzzes protocol implementation by sending messages with invalid symbols or messages. AspFuzz [
17] leveraged the accessible protocol specifications on RFCs (Request for Comments) to generate fault-injected messages for test files. Then, AspFuzz sent both anomalous and reordered messages to discover vulnerabilities. SecFuzz [
18] focused on fuzzing security protocol implementation, but it did not consider the specification of target protocol as well. Zhao et al. [
19] used regression finite state machine to infer a state transition diagram of protocol so as to reveal potential vulnerabilities in wireless protocols.
In recent years, a range of works about protocol reverse engineering [
20] have been published. Early in 2005, Marshall A. Beddoe held the protocol informatics project [
21] and applied bio-informatics algorithms to identify the fields in packets based on alignment algorithms. Cui et al. went further than Beddoe and presented Discoverer [
22] to recover protocol message format using both sequence aligning and recursively clustering algorithm. However, Discoverer need some a priori information about the delimiters used by protocol, such as space and comma, which is used to help tokenization, i.e., breaking message into token sequence. Recently, Tao et al. [
23] combines hierarchical clustering algorithm, multi-sequence alignment and Bayesian decision model to determine the field boundary of binary protocol in bit granularity. Chen et al. [
24] introduce deep learning algorithm to analyze mobile applications. Xiao et al. [
25] propose a method based on heuristic rule to reverse analysis of the incomplete flow. In our approach, we make no assumption about the delimiters. We treat the byte sequence of message as a stochastic process and detect field boundaries according to their statistical properties.
As a paralleled method to understand the unknown protocols, binary analysis-based techniques, such as Polyglot [
26], Tupni [
27], AutoFormat [
28], Prospex [
29] Dispatcher [
30] and so on, also draw much research attention. They are practical in some special scenarios where binary codes are available and executable in a specific sandbox-like environment. Moreover, binary analysis method would fail if programs make use of some confusion techniques like obfuscation to keep themselves away from being reverse-engineered.
As in many other security application domains [
31,
32,
33,
34,
35,
36], data mining and machine learning techniques have been widely adopted in the domain of IoT security and IoT traffic analysis. One of the key challenges is the data privacy problem, especially in collaborative and cloud-based learning scenarios. Several recent studies have proposed novel data privacy preserving approaches for addressing the problem [
37,
38,
39,
40,
41,
42].
3. Problem Formulation
Suppose that the alphabet used by protocol messages is defined as . A string is defined as a finite set of ordered letters in . That is ( ). All strings over alphabet forms a super set . As a basic data unit used by IoT protocol, protocol message m is essentially strings made up of a sequence of message fields. Thus, we mark message field as .
In this paper, a protocol message is assumed to be a byte sequence undergoing hidden statistical process, denoted as , whose statistical feature would shift on and on when the byte sequence goes from one message field to another. As passes from one field () to another (), the statistical characteristic would change significantly. Thus, a change-point would occur just in the boundary of two different message fields. Inspired by this observation, the problem of message field identification can be transformed to be a change-point detection issue in the statistical process undergone by protocol message.
Given a string , a q-length prefix of the last letter (i.e., ) in is marked as , while the set of such prefixes whose lengths are no longer than Q in is marked as . For instance, , , and .
The prefix conditional probability of
is defined as
Let
to be a
Q-order Markov process. Then, the likelihood of
given
is
where
and
.
Suppose that the byte sequence of protocol message obeys
Q-order Markov process, then Equation (
1) would be rewritten as follows.
where
is the weight of
. Essentially,
can be regarded as the importance of
for predicting the context of
.
The larger
q is, the more important it is for
in predicting the context of
. For instance, it is much more important for
than
to foresee that the context of “e” is “example” instead of “multiple”. As a result, the weight of
in this paper is defined as
Additionally,
is calculated by
where
is the frequency of
in training dataset
.
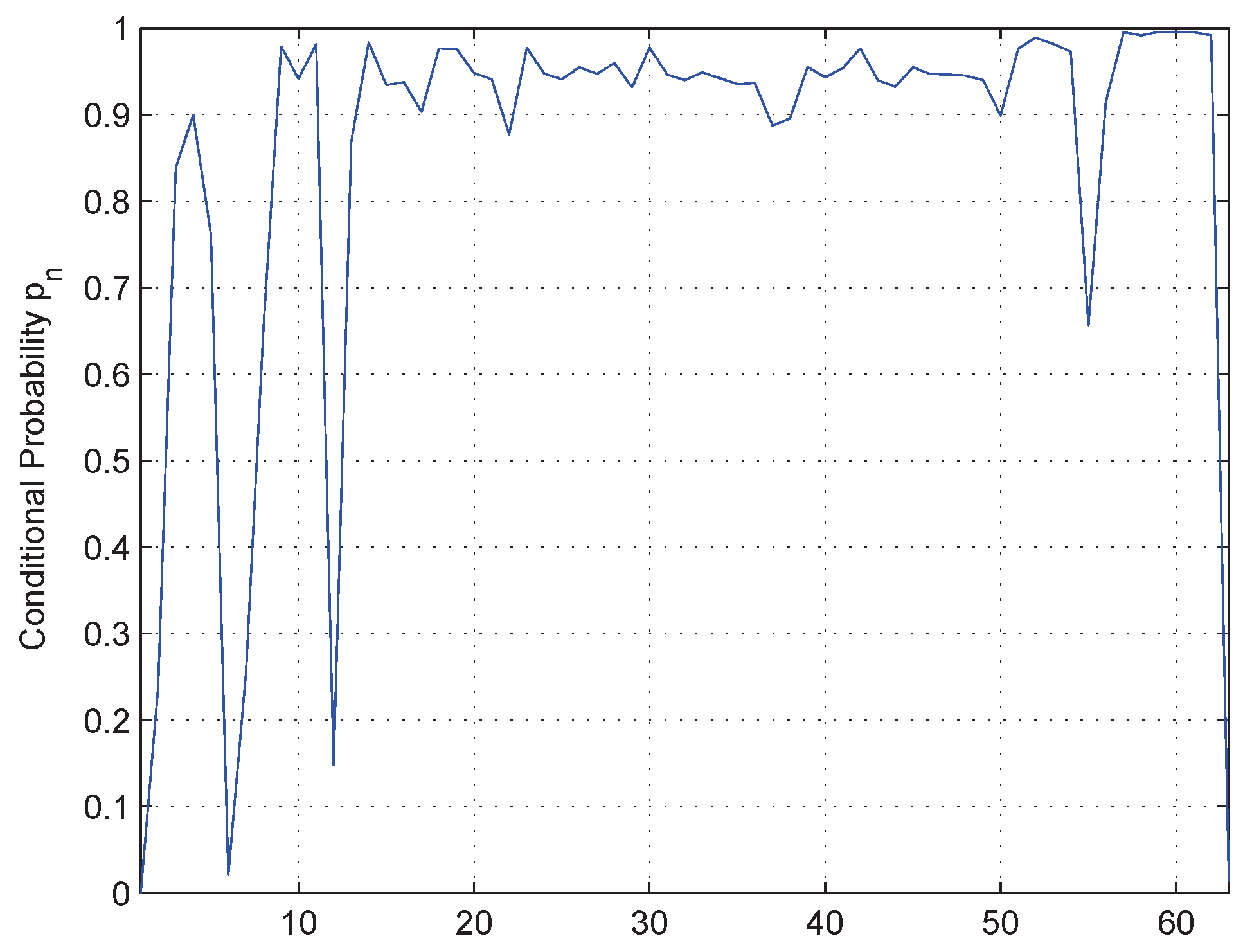
As shown in
Figure 1, the prefix conditional probability of
would be very high when
and
locate in the same field, otherwise it would be low.
3.1. Minmax Formulation for Field Detection
There exist mainly two formulations of change-point detecting problem: Bayesian formulation and minmax formulation. The Bayesian formulation [
43] assumes that the change-point
obeys a prior distribution which is known in prior, while the minmax formulation [
44] supposes that the change-point as well as its statistical distribution are unknown to us.
In this paper, the statistical distribution of change-points in protocol message is unknown. As a result, the change-point detection problem should be represented in minmax formulation. Page [
45] proposed a cumulative sum (CUSUM) algorithm to implement an optimal solution to minmax formulated problems. Accordingly, a CUSUM-LIKE algorithm is proposed to search fro multiple change-points in this paper. Since the statistic feature of message fields is unknown in prior, the likelihood ratio from post-change probability to pre-change probability, denoted as
cannot be calculated directly by
. Thus,
is replaced with a new metric in this paper as
Suppose
is a change-point in a message and
is the
n-th letter in the message. We assume that the post-change distribution of
is
, while the pre-change distribution of
is
, then prefix conditional probability of
, i.e.,
, would be much less than
, which results in a high and positive value of
. When
, if
and
locate in the same field, that is they obey the same distribution, so that
, where
is a small and positive value, given as a threshold. if
and
locate in different fields, that means
is also a change-point which should be detected before
. On the other hand, the value of
is likely to be bigger than the given threshold
when
. As a result, a detection indicator metric which could be regarded recursively for multi-change-point detection should be defined as:
The stopping condition can be set as
where
is a threshold of detection indicator.
3.2. Multi-Change-Point Detection
Since the problem of message field identification in this paper is actually a multi-change-point detection problem, the detection procedure has to be extended to a multi-round procedure presented in
Section 3.1 and called MultiCUSUM.
A variable
indicating the underlying state of
is defined as
Accordingly, the detection statistic is
where
is the initial condition in a new round of detection procedure started once the previous change-point has been found.
The stopping time in the
k-th iteration, denoted as
, is defined as
where
with
as the mean of
and
as the coefficient of
.
3.3. Message Segmenting Algorithm
A message segmenting algorithm, as shown in Algorithm 1, is proposed to segment protocol message
m into a set of message fields. In Algorithm 1, the message
m consists of a set of All messages associated with a specific protocol in
are concatenated one by one to form a new message
m according to their appearance time. Then, a
Q-depth suffix trie
is built to store sub-strings of
m with max length of
(line 1). The prefix conditional probability
is calculated according to Equation (
3) (line 2) to enable the multi-change-point detection procedures (MultiCUSUM()). The identified change-points are put into
(line 3).
| Algorithm 1 Message Segmenting Algorithm |
Input: Message
Output: Segment set - 1:
QSufTrie(m); # Creating Q-depth suffix trie - 2:
condProb(m,); # Compute the conditional probabilities: - 3:
MultiCUSUM(m,); # Change-point detection, is the change-point set - 4:
; # Reverse the message stream - 5:
QSufTrie(); - 6:
condProb(,); - 7:
MultiCUSUM(,); - 8:
- 9:
MsgSeg(m,);
|
Actually, not all change-points are not so sensitive to the prefix conditional probability of to be detected by the aforementioned procedure, instead they are more sensitive to the postfix conditional probability of which is essentially the prefix conditional probability in a special string that is the reverse-order of original message. Therefore, we reverse the letter order of m (i.e., ) and perform the same detection procedure again on to search for such type of change-points (line 4∼7) and put the results in .
Finally, the two sets of change-points are merged by and the message m is segmented into segments based on the change-points in (line 8∼9).
4. Inferring Message Fields
4.1. Occurrence Probability Analysis
To relief the burden of position-based statistic test analysis, a pre-processing called occurrence probability analysis is applied to filter out the obvious part of data fields whose occurrence probability is very low. Given a dataset and its size of M, and the occurrence probability of a string in , denoted as , is defined as the ratio between the amount of messages containing , denoted as , and the size of dataset.
The data field is variational and their occurrence probabilities of each value in a data field are always very small, which nearly approaches zero. Therefore, the data field can be found by searching for those string segments whose occurrence probabilities are statistically zero. In this paper, the occurrence probabilities of message segments is assumed to obey binomial distribution and the binomial test in the statistics field is considered to test whether the occurrence probability of each message segment is zero.
Let the hypothesis be
where
is a significance level.
The strings in
could be chosen as data fields according to
4.2. Position-Based Statistic Test Analysis
Apparently, a keyword field would frequently appear in many messages with similar function and its positions are also relatively stable. That means both frequency and position are important features for us to infer keyword fields from segment set . As a result, a position-based statistic test is introduced to select keyword fields from by testing the position of segment is fixed or quasi-fixed in messages.
Specifically, four kinds of positions of are considered in our scheme. That is
: the distance between the message head and the position of in the message.
: the distance between the message tail and the position of in the message.
: the distance between the head of a line which containing and the position of in that line.
: the distance between the tail of a line which containing and the position of in that line.
Let
and define the support rate of
, marked as
, as the number of
in
. Based on binomial test (see
Section 4.1), the keyword fields are chosen by
given
as the significance level.
Equation (
15) infers keywords whose positions are fixed by searching for segments satisfying
. It has good performance on those
which have one dominated position. For instance, “GET” in HTTP messages has one dominated position, i.e., in the head of a request message. However, some other keywords have more than one dominated position, and there are multiple peaks in
.
Aiming to address multi-peak issue, an algorithm (called MDL-PTA) based on the minimal description length (MDL) [
46] criteria is introduced to enable the position-based statistic test analysis, as shown in Algorithm 2.
k reference positions, , whose support rates are the first k top values in (line 5) are selected for each , and is divided into k clusters, , according to the distance between and reference position , (line 6).
The entropy of
is calculated through following equation:
The model complexity of
is
and the sum of description length of
is calculated in line 7, that is
The k-th model in the model set is represented as . The optimal model with minimal description length would be selected from (line 11). Apparently, the computation complexity would be very high if all models in are considered. Meanwhile, a keyword should not have lots of reference positions. As a result, only the top K models in are considered in Algorithm 2 (line 4∼10).
| Algorithm 2 MDL-PTA Algorithm |
Input:K, and
Output: true if is a keyword field, or false otherwise.- 1:
- 2:
GetPos(,) # Get positions of - 3:
- 4:
for i = 1 K do - 5:
TopK(,i) # Get reference positions - 6:
Cluster(,) # Cluster - 7:
CalDLen() # Compute the description length of - 8:
- 9:
- 10:
end for - 11:
minDLen() # Get the model with minimal description length - 12:
for alldo - 13:
res←TestPos( , ) # Check whether satisfies Eq. ( 19) - 14:
if res==true then - 15:
return true - 16:
end if - 17:
end for - 18:
return false
|
The optimal model chosen by the Algorithm 2 is
. For each reference position
in
, the following hypothesis is tested via binomial test:
where
and
.
The segment set passing hypothesis test is regarded as keyword set , and the rest ones are uncertain fields.
The inferred message fields would be further refined and some semantic information of message fields would be determined. Specifically, continuous segments of data (or uncertain) fields would be merged into a single segment which is data (or uncertain) field. Regular expressions representing some specific semantic information, such as IP address, File names, URLs, Timestamp and so on, are applied to match the message fields so that some semantic of message fields would be inferred.
5. Evaluation
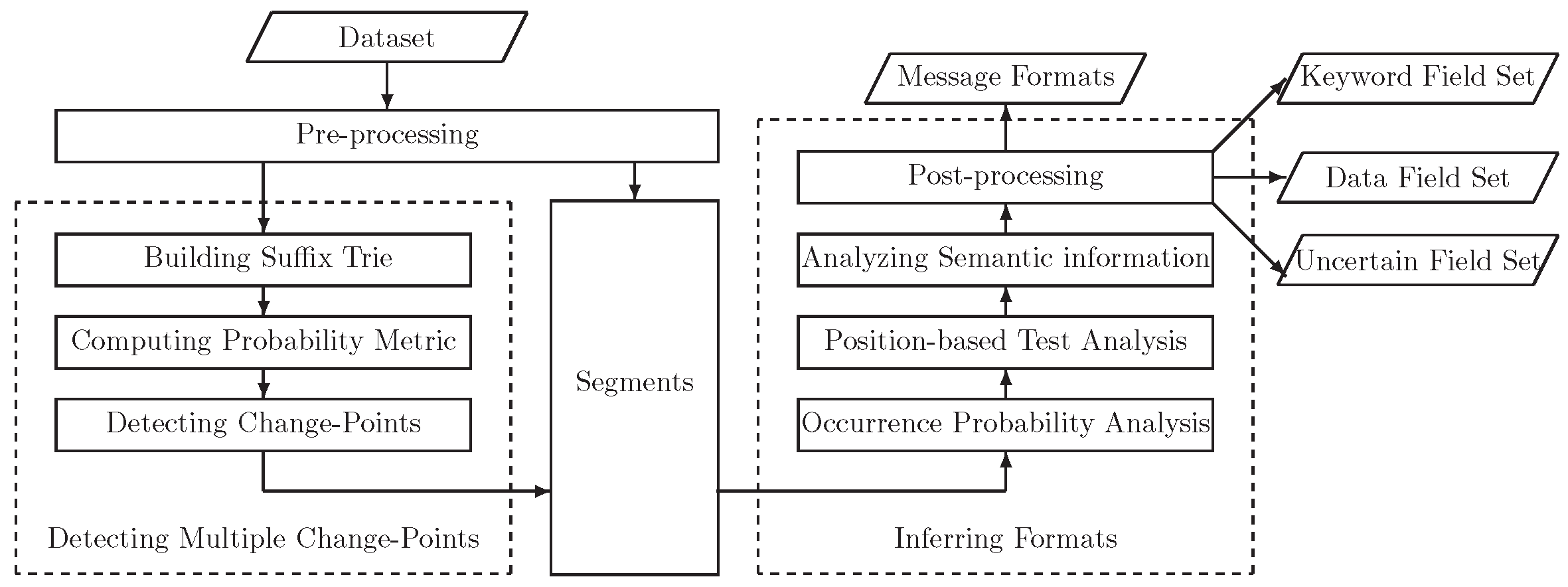
In this section, experiments are performed to evaluate the effectiveness of the proposed method. The experiments comprise of two parts: message segmentation evaluation and fuzzing test. The proposed message segmentation approach is implemented on a system called QCD-PInfer whose system architecture is shown in
Figure 2.
There are totally six typical protocols (HTTP, FTP, SMTP, POP, DNS and QQ) which are widely used in the application-layer are selected to test the effectiveness and efficiency of message segmentation. The recall and precision of keyword inference are shown in
Table 1 and
Table 2. Please note that, the ground truth of keywords are those keywords which are occurred in the test set. Both DNS and QQ are not taken into account for evaluating the quality of keyword set, since the two are binary protocols and there is no concept of keyword defined in binary protocol.
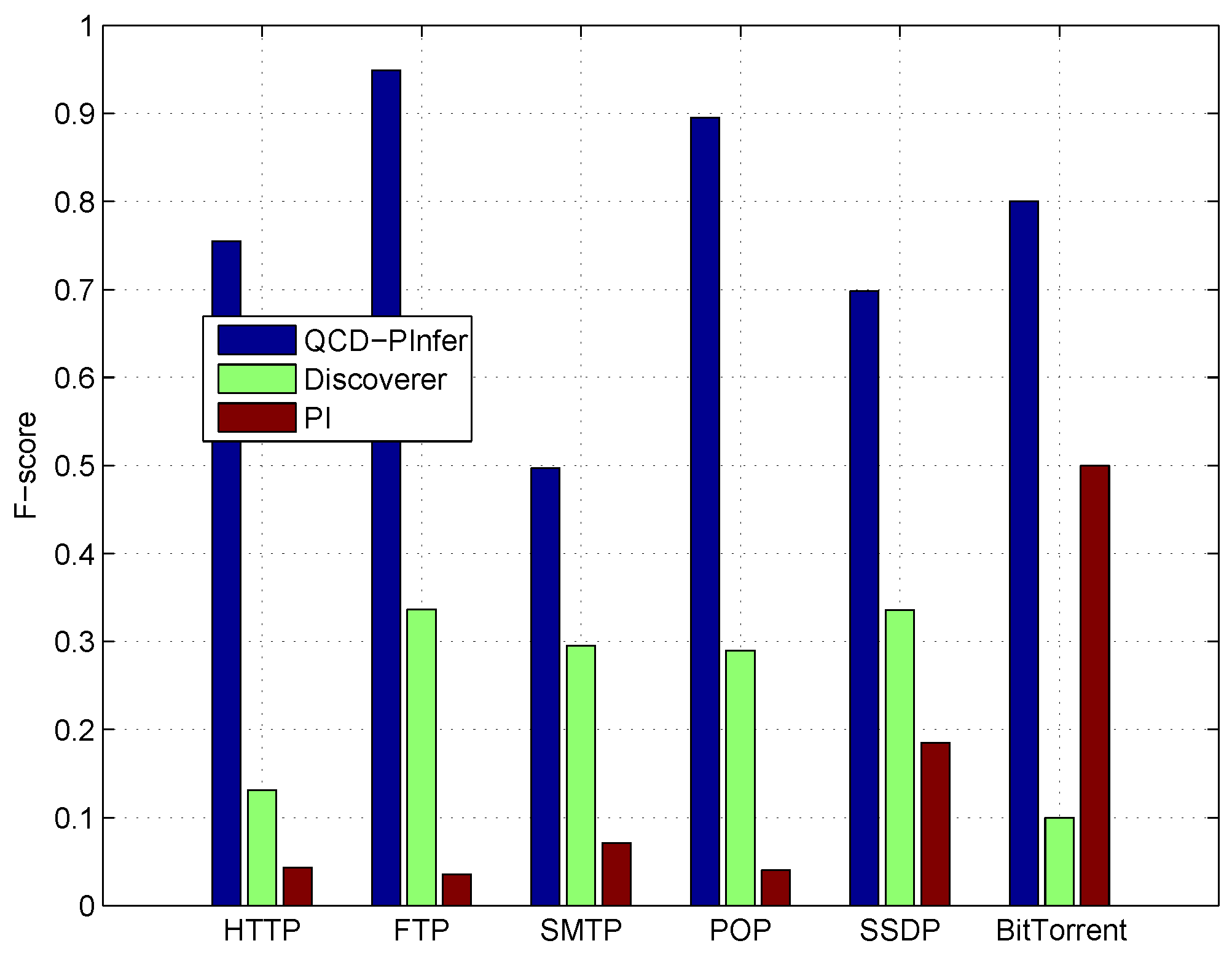
By comparison, QCD-PInfer has a higher recall rate than Discoverer and PI. In particular, PI’s recall rate is much low: the recall rates for HTTP, FTP, SMTP and POP are less than 10%.
Discoverer is prone to infer too many segments as keywords, so that its precision is much lower than that of the proposed system. Although PI’s recall rate is very low, its precision for HTTP and FTP is extremely high. However, PI’s precision for other protocols are still very low. It is worth mentioning that PI infers too few keywords, always less than 5 for all protocols being considered.
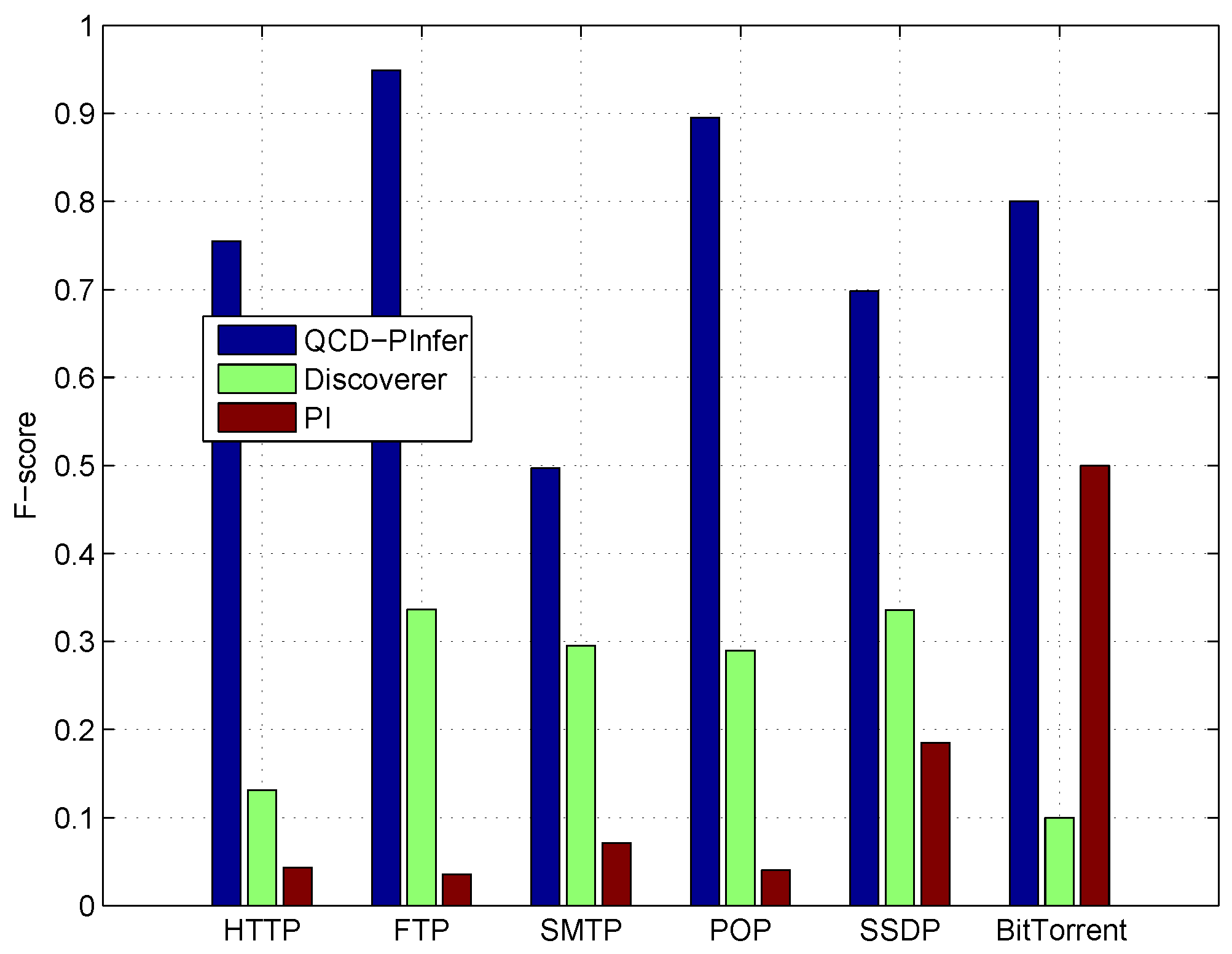
The F-scores of the experiment results are shown in
Figure 3. The proposed system has the highest F-score for all the six protocols, which means our method performs well in keyword inference.
In fuzzing test, QCD-PInfer is extended with fuzzing function to implement an automatic fuzzing tool (APREFuzz). APREFuzz can identify vulnerability in a system being tested which is designed to introduce information-centric network into IoT devices to enable their caching capability. The protocol used by target system under testing comprises of 5 type of messages responsible for sending interesting, distributing data, pushing data, responding with target data and responding with no answer, respectively.
Firstly, message fields are identified using QCD-PInfer system, and message format are reconstructed.
Secondly, test files are generated by inserting fault data into one field according to the message format. Please note that, for a real fuzz test, fault data may inserted into more than one field. However, as a proof-of-concept system, APREFuzz considers the scenarios with only one field being fault-injected currently. Actually, it is not difficult to extend the system to consider fault-injected in multiple fields. When inserting the fault data, keyword fields are only replacing with inferred keywords according to message formats, data fields would be replaced by random data, while uncertain fields would be replaced with either inferred keywords or random data. In our experiments, the uncertain fields are treated the same as data fields.
Finally, the target system are treated as a black box and supposed to be unknown to us. APREFuzz sends test files to target system file-by-file and monitors the reactive of target system via analyzing the response.
In our experiments, APREFuzz extracted 7 keyword fields and infers 7 data fields in the sample message. One data field is found that it contains only figures. The amount of inferred keywords is 12. We take 11 abnormal strings into account for inserting fault data into the data fields except the one containing only figures. For the special field that containing only figures, 21 boundary figures are used to be injected. As a result, the amount of fault-injected files generated by APREFuzz is 248 (=). On the other hand, FileFuzz generates (=) fault-injected files by replacing each byte with values from to . When test files are sent to target system, APREFuzz monitored one exception that the system fails to respond, while FileFuzz monitor none. The exceptions maybe indicates a vulnerability which would be leveraged to launch a DoS attack, or some attacks that would ruin the system’s availability. Actually, other tools are needed to analyze the exception deeply and figure out its type and impact. However, that work has surpassed the discussion scope concerned in this paper so that it will not be presented here.
6. Conclusions
The proposed method applies protocol reverse engineering approach to improve IoT protocol fuzzing performance by creating valid and effective test files based on protocol message format and reducing greatly the size of test files. It considers the statistical attributes of message fields to locate their boundaries by searching for change-points in the messages and reconstruct the message format. A CUSUM-LIKE algorithm is presented to address the problem of multi-change-point detection. Additional procedures including occurrence probability test and position test are further employed to classify the message segments into keyword fields, data fields and uncertain fields. The results show that the extracted message formats are useful for generating test files for network protocol fuzzing.
In the future, the proposed APREFuzz with enough improvement based on current version would be a practical and powerful tool to generate test files automatically for fuzzing test carried on IoT protocols or devices to reveal their hidden vulnerabilities. It also would contribute to strengthening the IoT security in effective and efficient way, and even to be a security tool for improving protocol fuzzing in many other types of network.
Author Contributions
Conceptualization, J.-Z.L. and J.C.; methodology, J.-Z.L.; software, J.-Z.L. and C.S.; validation, J.-Z.L., J.C., Y.L. and C.S.; formal analysis, C.S.; investigation, C.S.; resources, J.C.; data curation, Y.L.; writing—original draft preparation, J.-Z.L.; writing—review and editing, J.C. and C.S.; visualization, Y.L.; supervision, J.C.; project administration, J.C.; funding acquisition, J.C.
Funding
This research was funded by National Natural Science Foundation of China (Grant No.: 61702120, 61571141); Natural Science Foundation of Guangdong Province (Grant No.: 2017A030310591, 2014A030313637, 2015A030313672); Department of Education of Guangdong Province (Grant No.: YQ2015105, 2016GCZX006, 2016KQNCX091); Guangdong Provincial Application-oriented Technical Research and Development Special fund project (Grant No.: 2015B010131017); Guangdong Science and Technology Department (Grant No.: 2016A010120010, 2014A010103032, 2017A090905023); Science and Technology Program of Guangzhou (Grant No.: 201604016108).
Acknowledgments
The authors would also like to thank the anonymous reviewers for their valuable comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Munea, T.L.; Lim, H.; Shon, T. Network protocol fuzz testing for information systems and applications: A survey and taxonomy. Multimed. Tools Appl. 2016, 75, 14745–14757. [Google Scholar] [CrossRef]
- Kim, H.C.; Choi, Y.H.; Lee, D.H. Efficient file fuzz testing using automated analysis of binary file format. J. Syst. Archit. 2011, 57, 259–268. [Google Scholar] [CrossRef]
- Duchêne, J.; Le Guernic, C.; Alata, E.; Nicomette, V.; Kaâniche, M. State of the art of network protocol reverse engineering tools. J. Comput. Virol. Hacking Tech. 2018, 14, 53–68. [Google Scholar] [CrossRef]
- Aminikhanghahi, S.; Cook, D.J. A survey of methods for time series change point detection. Knowl. Inf. Syst. 2017, 51, 339–367. [Google Scholar] [CrossRef] [PubMed]
- Yan, H.; Li, X.; Wang, Y.; Jia, C. Centralized Duplicate Removal Video Storage System with Privacy Preservation in IoT. Sensors 2018, 18, 1814. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Zheng, X.; Tang, C. Lightweight distributed secure data management system for health internet of things. J. Netw. Comput. Appl. 2017, 89, 26–37. [Google Scholar] [CrossRef]
- Tan, Q.; Gao, Y.; Shi, J.; Wang, X.; Fang, B.; Tian, Z.H. Towards a Comprehensive Insight into the Eclipse Attacks of Tor Hidden Services. IEEE Internet Things J. 2018. [Google Scholar] [CrossRef]
- Wang, Z. A privacy-preserving and accountable authentication protocol for IoT end-devices with weaker identity. Future Gener. Comput. Syst. 2018, 82, 342–348. [Google Scholar] [CrossRef]
- Luo, E.; Bhuiyan, M.Z.A.; Wang, G.; Rahman, M.A.; Wu, J.; Atiquzzaman, M. PrivacyProtector: Privacy- Protected Patient Data Collection in IoT-Based Healthcare Systems. IEEE Commun. Mag. 2018, 56, 163–168. [Google Scholar] [CrossRef]
- Mao, Y.; Li, J.; Chen, M.R.; Liu, J.; Xie, C.; Zhan, Y. Fully secure fuzzy identity-based encryption for secure IoT communications. Comput. Stand. Interfaces 2016, 44, 117–121. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, G.; Liu, X.; Peng, T.; Wu, J. Achieving reliable and secure services in cloud computing environments. Comput. Electr. Eng. 2017, 59, 153–164. [Google Scholar] [CrossRef]
- Chen, Z.; Peng, L.; Gao, C.; Yang, B.; Chen, Y.; Li, J. Flexible neural trees based early stage identification for IP traffic. Soft Comput. 2017, 21, 2035–2046. [Google Scholar] [CrossRef]
- Meng, W.; Tischhauser, E.W.; Wang, Q.; Wang, Y.; Han, J. When Intrusion Detection Meets Blockchain Technology: A Review. IEEE Access 2018, 6, 10179–10188. [Google Scholar] [CrossRef]
- Zhou, Z.; Dong, M.; Ota, K.; Wang, G.; Yang, L.T. Energy-Efficient Resource Allocation for D2D Communications Underlaying Cloud-RAN-Based LTE-A Networks. IEEE Internet Things J. 2016, 3, 428–438. [Google Scholar] [CrossRef]
- Cai, J.; Wang, Y.; Liu, Y.; Luo, J.Z.; Wei, W.; Xu, X. Enhancing network capacity by weakening community structure in scale-free network. Future Gener. Comput. Syst. 2018, 87, 765–771. [Google Scholar] [CrossRef]
- Gorbunov, S.; Rosenbloom, A. AutoFuzz: Automated Network Protocol Fuzzing Framework. Int. J. Comput. Sci. Netw. Secur. 2010, 10, 239–245. [Google Scholar]
- Kitagawa, T.; Hanaoka, M.; Kono, K. AspFuzz: A state-aware protocol fuzzer based on application-layer protocols. In Proceedings of the IEEE Symposium on Computers and Communications, Riccione, Italy, 22–25 June 2010; pp. 202–208. [Google Scholar]
- Tsankov, P.; Dashti, M.T.; Basin, D. SecFuzz: Fuzz-testing security protocols. In Proceedings of the International Workshop on Automation of Software Test, Zurich, Switzerland, 2–3 June 2012; pp. 1–7. [Google Scholar]
- Zhao, J.; Chen, S.; Liang, S.; Cui, B.; Song, X. RFSM-Fuzzing a Smart Fuzzing Algorithm Based on Regression FSM. In Proceedings of the Eighth International Conference on P2p, Parallel, Grid, Cloud and Internet Computing, Compiegne, France, 28–30 October 2013; pp. 380–386. [Google Scholar]
- Narayan, J.; Shukla, S.K.; Clancy, T.C. A survey of automatic protocol reverse engineering tools. ACM Comput. Surv. (CSUR) 2016, 48, 40. [Google Scholar] [CrossRef]
- Beddoe, M.A. Network Protocol Analysis Using Bioinformatics Algorithms. 2004. Available online: http://www.4tphi.net/~awalters/PI/pi.pdf (accessed on 28 October 2018).
- Cui, W.; Kannan, J.; Wang, H.J. Discoverer: Automatic protocol reverse engineering from network traces. In Proceedings of the 16th USENIX Security Symposium on USENIX Security Symposium, Boston, MA, USA, 6–10 August 2007; USENIX Association: Berkeley, CA, USA, 2007; pp. 1–14. [Google Scholar]
- Tao, S.; Yu, H.; Li, Q. Bit-oriented format extraction approach for automatic binary protocol reverse engineering. IET Commun. 2016, 10, 709–716. [Google Scholar] [CrossRef]
- Zhengyang, C.; Bowen, Y.; Yu, Z.; Jianzhong, Z.; Jingdong, X. Automatic Mobile Application Traffic Identification by Convolutional Neural Networks. In Proceedings of the IEEE Trustcom/BigDataSE/SPA, Tianjin, China, 23–26 August 2016; pp. 301–307. [Google Scholar]
- Xiao, M.M.; Zhang, S.L.; Luo, Y.P. Automatic network protocol message format analysis. J. Intell. Fuzzy Syst. 2016, 31, 2271–2279. [Google Scholar] [CrossRef]
- Caballero, J.; Yin, H.; Liang, Z.; Song, D. Polyglot: Automatic extraction of protocol message format using dynamic binary analysis. In Proceedings of the 14th ACM conference on Computer and Communications Security, Alexandria, VA, USA, 29 October–2 Novemver 2007; ACM: New York, NY, USA, 2007; pp. 317–329. [Google Scholar]
- Cui, W.; Peinado, M.; Chen, K.; Wang, H.J.; Irun-Briz, L. Tupni: Automatic reverse engineering of input formats. In Proceedings of the 15th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 27–31 October 2008; ACM: New York, NY, USA, 2008; pp. 391–402. [Google Scholar]
- Lin, Z.; Jiang, X.; Xu, D.; Zhang, X. Automatic Protocol Format Reverse Engineering through Context-Aware Monitored Execution. NDSS 2008, 8, 1–15. [Google Scholar]
- Comparetti, P.; Wondracek, G.; Kruegel, C.; Kirda, E. Prospex: Protocol Specification Extraction. In Proceedings of the 2009 30th IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 17–30 May 2009; pp. 110–125. [Google Scholar]
- Caballero, J.; Poosankam, P.; Kreibich, C.; Song, D. Dispatcher: Enabling active botnet infiltration using automatic protocol reverse-engineering. In Proceedings of the 16th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 9–13 November 2009; ACM: New York, NY, USA, 2009; pp. 621–634. [Google Scholar]
- Meng, W.; Wang, Y.; Wong, D.S.; Wen, S.; Xiang, Y. TouchWB: Touch behavioral user authentication based on web browsing on smartphones. J. Netw. Comput. Appl. 2018, 117, 1–9. [Google Scholar] [CrossRef]
- Li, J.; Sun, L.; Yan, Q.; Li, Z.; Srisa-an, W.; Ye, H. Significant Permission Identification for Machine Learning Based Android Malware Detection. IEEE Trans. Ind. Inform. 2018. [Google Scholar] [CrossRef]
- Liu, Y.; Ling, J.; Liu, Z.; Shen, J.; Gao, C. Finger Vein Secure Biometric Template Generation Based on Deep Learning. Soft Comput. 2018, 22, 2257–2265. [Google Scholar] [CrossRef]
- Yuan, C.; Li, X.; Wu, Q.; Li, J.; Sun, X. Fingerprint Liveness Detection from Different Fingerprint Materials Using Convolutional Neural Network and Principal Component Analysis. CMC-Comput. Mater. Contin. 2017, 53, 357–371. [Google Scholar]
- Meng, W.; Jiang, L.; Wang, Y.; Li, J.; Zhang, J.; Xiang, Y. JFCGuard: Detecting juice filming charging attack via processor usage analysis on smartphones. Comput. Secur. 2018, 76, 252–264. [Google Scholar] [CrossRef]
- Chen, S.; Wang, G.; Yan, G.; Xie, D. Multi-imensional fuzzy trust evaluation for mobile social networks based on dynamic community structures. Concurr. Comput. Pract. Exp. 2017, 29, e3901. [Google Scholar] [CrossRef]
- Li, P.; Li, J.; Huang, Z.; Gao, C.Z.; Chen, W.B.; Chen, K. Privacy-preserving outsourced classification in cloud computing. Clust. Comput. 2017. [Google Scholar] [CrossRef]
- Li, P.; Li, J.; Huang, Z.; Li, T.; Gao, C.Z.; Yiu, S.M.; Chen, K. Multi-key privacy-preserving deep learning in cloud computing. Future Gener. Comput. Syst. 2017, 74, 76–85. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Y.; Chen, X.; Xiang, Y. Secure attribute-based data sharing for resource-limited users in cloud computing. Comput. Secur. 2018, 72, 1–12. [Google Scholar] [CrossRef]
- Gao, C.Z.; Cheng, Q.; Li, X.; Xia, S.B. Cloud-assisted privacy-preserving profile-matching scheme under multiple keys in mobile social network. Clust. Comput. 2018. [Google Scholar] [CrossRef]
- Luo, E.; Liu, Q.; Abawajy, J.H.; Wang, G. Privacy-preserving multi-hop profile-matching protocol for proximity mobile social networks. Future Gener. Comput. Syst. 2017, 68, 222–233. [Google Scholar] [CrossRef]
- Zhi Gao, C.; Cheng, Q.; He, P.; Susilo, W.; Li, J. Privacy-preserving Naive Bayes classifiers secure against the substitution-then-comparison attack. Inf. Sci. 2018, 444, 72–88. [Google Scholar]
- Shiryaev, A. On Optimum Methods in Quickest Detection Problems. Theory Probab. Appl. 1963, 8, 22–46. [Google Scholar] [CrossRef]
- Lorden, G. Procedures for Reacting to a Change in Distribution. Ann. Math. Stat. 1971, 42, 1897–1908. [Google Scholar] [CrossRef]
- Page, E.S. Continuous Inspection Schemes. Biometrika 1954, 41, 100–115. [Google Scholar] [CrossRef]
- Rissanen, J. Universal coding, information, prediction, and estimation. IEEE Trans. Inf. Theory 1984, 30, 629–636. [Google Scholar] [CrossRef]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}