1. Introduction
Blind source separation (BSS) considers the recovery of source signals from observed signals without knowing the recording environment. Recently, the use of BSS has become an active research area. If the number of source signals is less, equal or greater than the number of microphones, BSS can be classified as the overdetermined case [
1], the determined case [
2,
3], or the underdetermined case [
4,
5], respectively. In particular, in the natural environment, the mixing process is generally considered to be convolutive, i.e., the channel between each source and each microphone is modeled in a linear filter that represents multiple source-to-microphone paths because it considers the reverberation of the channel. Therefore, underdetermined convolutive BSS is a challenging problem in the field of BSS.
To address this underdetermined convolutive BSS problem, tensor decomposition shows great potential, because an interesting property of higher-order tensors is that their rank decomposition is unique. Additionally, parallel factor (PARAFAC) decomposition factorizes a tensor into a sum of component rank-one tensors, and the factor matrices refer to the combination of the vectors from the rank-one components. By singular value decomposition of a series of matrices, the parallel factorization problem is transformed into a joint matrix diagonalization problem, such that the PARAFAC analysis is solved [
6,
7]. Therefore, the PARAFAC method can be used to identify the mixing matrix in the underdetermined case, which has been proven usefully in a wide range of applications from sensor array processing to communication, speech and audio signal processing [
8,
9]. In the phase of source separation, source signals can be estimated by using the
-norm minimization method [
10] or the binary masking algorithm [
11]. However, these methods suffer from poor separation performance. To improve separation performance, we found out that the source model includes some specific information on the spectral structures of sources. Therefore, a better source model has the potential to improve the source separation performance.
In BSS, the non-negative matrix factorization (NMF) source model is usually applied on the speech/music power spectrogram, where the spectrogram is approximated by the product of two non-negative matrices, i.e., a basis matrix and an activation matrix. The basis matrix represents the repeating spectral patterns, and the activation matrix represents the presence of these patterns over time. Additionally, NMF aims to decompose a non-negative factor matrix into the product of two low-rank non-negative factor matrices [
12,
13]. The NMF model can be used to efficiently exploit the low-rank nature of the speech spectrogram and its dependency across the frequencies. In some NMF-based methods [
14,
15,
16,
17], non-negative matrix factor two-dimensional deconvolution is an effective machine learning method in audio source separation field. In particular, in the convolutive frequency-domain model, the well-known permutation alignment problem cannot be solved without using additional a priori knowledge about the sources or the mixing filters. However, the NMF source model implies a coupling of the frequency bands, and joint estimation of the source parameters and mixing coefficients, which frees us from the permutation problem. Furthermore, NMF is well suited to polyphony as it basically takes the source to be a sum of elementary components with characteristic spectral signatures. Therefore, NMF source model is able to improve the source separation performance.
Additionally, in order to obtain better source separation results, the estimated mixing matrix and NMF variables need to be updated using an optimization algorithm. In most BSS optimization algorithms, we found out that expectation-maximization (EM) algorithm [
18], which is a popular choice for Gaussian models, provided faster convergence. The EM algorithm is related to some multichannel source separation techniques by employing Gaussian mixture model as source models. However, it is very sensitive to initialization in source separation tasks. There had been some studies of parameter initialization of NMF to optimize separation performance [
19,
20]. Therefore, we try to take an optimization algorithm to improve the source separation performance.
In this paper, an alternative optimization algorithm is proposed to deal with the parameter initialization problem and improve separation performance. First, we employ tensor decomposition to detect the mixing matrix, and NMF is used to estimate the source spectrogram factors. Then these model parameters are updated using the EM algorithm. Meanwhile, the spatial images of source signals are estimated using Wiener filters constructed from the learned parameters. The time-domain sources can be obtained through inverse short-term Fourier transform (STFT) using an adequate overlap-add procedure with dual synthesis window. Thanks to the linearity of the inverse STFT, the reconstruction is conservation in the time-domain as well. Finally, a series of experimental results including synthetic instantaneous and convolutive music and speech source mixtures, as well as live real recordings, show that our improved algorithm outperforms the state-of-the-art baseline methods. We can highlight the main contributions of this article as follows.
(1) We propose an improved algorithm that combines tensor decomposition and advanced NMF to deal with the underdetermined linear BSS. The mixing matrix is estimated using tensor decomposition, and NMF is used to decompose the given spectrogram into several spectral bases and temporal activations. Then the mixing matrix, NMF variables, and noise components are updated by a series of iteration rules. The proposed algorithm combines the advantages of tensor decomposition and NMF, which is beneficial to improve the performance of source separation. Additionally, the improved algorithm can be extended to underdetermined convolutive BSS.
(2) We have demonstrated the superiority in the underdetermined linear and convolutive BSS cases. Additionally, in this paper we mainly consider the audio datasets, the proposed algorithm demonstrates the effectiveness and superiority compared with the state-of-the-art algorithms, which improves the source separation performance based on a series of simulation experiments.
The structure of the remaining of this paper is organized as follows.
Section 2 formulates the problem of the underdetermined blind source separation. In
Section 3, an optimization algorithm is presented based on tensor decomposition and NMF. Experimental results compared the source separation performance with the state-of-the-art techniques in various experimental settings are shown in
Section 4. Finally,
Section 5 summarizes our conclusion and the future work.
3. The Proposed Optimization Algorithm
In the following, we will propose a robust parameters initialization scheme using tensor decomposition and NMF to optimize the EM algorithm. First, the mixing matrix is estimated using tensor decomposition. Second, the state-of-the-art source separation algorithms are reviewed. Finally, the optimization algorithm is presented in detail.
3.1. Mixing Matrix Estimation Using Tensor Decomposition
Let us denote the
auto-correlation matrix as follows:
where
is the auto-correlation matrix of the source signal, the superscripts
denotes the complex conjugate transpose. For simplicity, we have dropped the noise terms. Let us divide the whole data block into P non-overlapping sub-blocks, which are indexed by
. Then the spatial covariance matrices of the observation satisfy
in which
is diagonal. The problem we want to solve is the estimation of
from the set
. The solution will be obtained by interpreting as a tensor decomposition. It can equivalently be written as PARAFAC decomposition of a third-order tensor
built by stacking the P matrices
one after each other along the third dimension. Each element of the tensor
is denoted by
, with
,
, and
. Define the matrix
whose element on the
p-th row and
i-th column, denoted
, is the
i-th diagonal element of
. Then we have
The PARAFAC decomposition (
13) of the tensor
is a decomposition
as a linear combination of a minimal number of rank-1 term:
where ∘ denotes the tensor outer product, the superscripts
denotes the complex conjugate,
and
are the column of
and
, respectively.
In this paper, we will use the following
matrix representation of
[
22,
23]
Then (
14) can be written in a matrix format as
where ⊙ denotes the Khatri-Rao product. As a result, its reduced-size SVD can be written as
where
,
is diagonal, and
. Then there exists a nonsingular matrix
, such that
where the columns of
are the vectors
(⊗ denotes the Kronecker product), which are the vectorized representations of the rank-1 matrices
. As a consequence, the mixing matrix
can be determined using some optimization algorithms. The standard way is by means of an alternating least squares (ALS) algorithm [
24]. To enhance the convergence of ALS algorithm, an exact line search method is also used [
25,
26,
27]. The discussion [
25] is limited to the real case and the complex case is addressed [
26,
27]. Additionally, the matrix
is to impose that has a Khatri-Rao structure. It was shown that
diagonalizes a set of symmetric matrices by congruence. For further details on the way these matrices are built [
28]. This tensor method is uniquely identifiable in certain underdetermined cases, thus proving uniqueness of the estimated mixing matrix.
3.2. Source Separation Using the Baseline Methods
Now the mixing matrix had been estimated using the above tensor decomposition method, we can separate the source signals using some state-of-the-art methods. In the following, we review two baseline methods for the source separation. One is complex
norm minimization method [
10], the other is binary masking method [
11].
3.2.1. Norm Minimization Method
The phases of the source STFT coefficients
are assumed to be uniformly distributed, while their magnitudes are modeled by
where the parameters
and
govern the shape and the variance of the prior, respectively.
is the gamma function. Therefore, the maximum a posterior source coefficients are given as follows:
where
is the
norm of the source
defined by
.
3.2.2. Binary Masking Method
We create the time-frequency mask corresponding to each source and produce the original source time-frequency representation. For instance, defining
which is the indicator function for the support of
. Then, we obtain the time-frequency representation of
from the mixture via
Therefore, the spectral basis and temporal code are estimated based on NMF of the source spectrogram estimates by using the outputs of the above source separation methods. Then the mixing matrix and the source spectrogram factors are updated jointly, the spatial images of all sources are obtained using the following optimization EM algorithm.
3.3. The Optimization EM Algorithm
Let
be the set of all parameters, where
is the
matrix with entries
,
is the
matrix with entries
,
is the
matrix with entries
,
is the noise covariance parameters. We derive an optimization EM algorithm, and the set
is defined as follows:
We select the following Minus Log-likelihood (ML) criterion:
Then the mixing matrix, noise covariance, and , will be updated by using the following two-step iteration.
• E-step: Conditional Expectations of Natural Statistics
The minimum mean square error estimates
of the source STFT are directly retrieved, and the spatial images of all source signals are obtained by using Wiener filtering, which is expressed as follows:
and the component estimates is
where
• M-step: Update of Parameters
In the linear instantaneous mixture case, the mixing matrix is real-valued. Therefore, we obtain the updated mixing matrix
and
where
• Normalize A, W, and H.
Finally, by conservativity of Wiener reconstruction the spatial images of the estimated sources and noise sum up to the original mixture in the STFT domain. Then the inverse STFT can be used to transform them to the time-domain due to the linearity of the STFT. The source separation algorithm in the linear mixture case is outlined in Algorithm 1.
| Algorithm 1: Proposed Algorithm for Underdetermined Linear BSS. |
• Underdetermined Linear Mixture Case ()
Step 1. Estimate the mixing matrix by using the time-domain tensor decomposition.
Step 2. Perform STFT on to get .
Step 3. Estimate the sources using (20) and detect the source spectrogram factors employing
the NMF method with (7).
Step 4. Initialize the updated matrix, the spectral basis, and temporal code, then update these
parameters using EM algorithm. i.e.,
repeat
(i). Update with (33) in the linear mixture case.
(ii). Alternately update and with (35).
until convergence
Step 5. Estimate by using Wiener filter of (28).
Step 6. Transform into time-domain to obtain through inverse STFT.
• end |
3.4. Convolutive Mixed Sources Case
The derivation of optimization EM algorithm for convolutive model is more complex since each mixing filter boils down to the combination of a delay so that the updated mixing matrix cannot be expressed using (
33) in the M-step. In the following, we consider the underdetermined multichannel convolutive mixture model, namely
in which
is the mixing system’s impulse response matrix at the time-lag
l, and
L denotes the maximum channel length. Then the convolutive mixtures can be decoupled into a series of linear instantaneous mixtures by applying STFT on consecutive time windows. Therefore, (
39) can be expressed as follows:
where
is the frequency component of the mixing filter
at frequency
f, and
,
are defined by the same way as in the linear instantaneous mixture model. In this case, the updated mixing matrix (
33) needs to be replaced by
In the convolutive mixture model, the mixing matrix is estimated in the Fourier domain. Therefore, the main difficulty is the need to deal with the permutation and scaling ambiguities. In our algorithm, the minimal distortion principle is used to compensate the scaling ambiguity, and K-mean clustering algorithm is employed to deal with the frequency-dependent permutation ambiguity problem. Finally, the source separation algorithm in the convolutive mixture case is outlined in Algorithm 2.
| Algorithm 2: Proposed Algorithm for Underdetermined Convolutive BSS. |
• Underdetermined Convolutive Mixture Case ()
Step 1. Perform STFT on to get
Step 2. Estimate the mixing matrix by using frequency-domain tensor decomposition.
Step 3. Estimate the sources using (22), and detect the source spectrogram factors employing
the NMF method with (7).
Step 4. Initialize the updated matrix, the spectral basis, and temporal code, then update these
parameters using EM algorithm. i.e.,
repeat
(i). Update with (41) in the convolutive mixture case.
(ii). Alternately update and with (35).
until convergence
Step 5. Estimate by using Wiener filter of (28).
Step 6. Transform into time-domain to obtain through inverse STFT.
• end |
4. Experiments
In this section, all the simulation experiments are conducted on a computer with Inter (R) Xeon (R) CPU E5-2630 v3 @ 2.40GHz, 32.00 GB memory under Ubuntu 15.04 operational system and the programs are coded by Matlab R2016b installed in a personal computer.
First, we describe the test datasets and evaluation criteria, and proceed with experiments including the music mixture signals and speech mixture signals. Based on these criteria, we select two models for further study, namely the linear instantaneous mixture model and convolutive mixture model. Second, we compare the proposed algorithm with the baseline algorithms over synthetic reverberant speech/music mixtures and the real-world speech/music mixtures. Finally, numerous simulation examples are shown to illustrate the performance of our proposed algorithm.
4.1. Datasets
We talk about four audio datasets, i.e., two synthetic stereo linear instantaneous mixture (Dataset A and Dataset B) and two convolutive mixture (Dataset C and Dataset D). In the linear instantaneous mixture case, Dataset A matches with the development dataset dev2 (
dev2-wdrums-inst-mix) of the 2008 Signal Separation Evaluation Campaign “under-determined speech and music mixtures” task development datasets (SiSEC’08) (
http://www.sisec.wiki.irisa.fr), which consists of one synthetic stereo mixture, including three musical sources with drums which consist of percussive instruments. Dataset B comes from the development dataset dev1 (
dev1-female3-inst-mix) of SiSEC’08 which consists of three speech mixtures.
In the convolutive mixture case, Dataset C comes from the music data with drums in dataset dev2 (dev2-wdrums-liverec-250ms-1m-mix), which has 250 ms of reverberation time with 1 m space between their microphones in the live real-recording environment. Dataset D is from the dataset dev1 (dev1-male3-synthconv-130ms-1m-mix) of the SiSEC’08 which has 130 ms of reverberation time with 1 m space between their microphones.
4.2. Source Signal Separation Evaluation Criteria
In order to evaluate our proposed algorithm in the blind audio source separation, we use several objective performance criteria [
29] which compare the reconstructed source signal images with the original ones. Now we define numerical performance criteria by computing energy ratios expressed in decibels (dB) from estimated source decomposition to global performance.
The criteria derive from the decomposition of an estimated source image as
where
is the true source image of source
on channel
.
and
are distinct error components representing distortion, interference, and artifacts in the channel
j, respectively. Therefore, these criteria are defined as follows:
The Signal to Distortion Ratio (SDR)
The Source Image to Spatial Distortion Ratio (ISR)
The Source to Interference Ratio (SIR)
The Source to Artifacts Ratio (SAR)
In our paper, we employ the above measures (SDR, ISR, SIR, SAR) to evaluate the performance of our proposed algorithm and compare with the baseline methods. Finally, a series of simulation results verify the competence of our proposed algorithm.
4.3. Algorithm Parameters
The proposed algorithm will be compared with the EM, MU algorithms [
16], and full-rank algorithm [
30]. In the linear instantaneous case, the initial values of the NMF parameters for the MU and EM algorithms are based on a mixing matrix estimate obtained with the method of Arberet et al. [
31]. In the convolutive case, the initial values are based on frequency-dependent complex-valued mixing matrix estimation [
32]. For verifying the effective of our proposed algorithm, we employ the time-domain tensor decomposition to estimate the linear mixing matrix and the frequency-domain tensor decomposition to estimate the convolutive mixing matrix. Additionally, we build the initialization of the source spectrogram estimation
and
based on EU-NMF, KL-NMF, and IS-NMF, respectively. The initial values for the NMF parameters
of a given source
i are calculated by applying the NMF algorithm to mono-channel power spectrogram of source.
Finally, we set the following parameters for our optimization algorithm, the number of components is
for every experiment. Furthermore, since the choice of the STFT window size and the number of iteration are rather important, so we use the STFT with the half-overlapping sine windows (typically a Hanning Window), these parameters are reported in
Table 1.
4.4. Underdetermined BSS in the Linear Instantaneous Case and Convolutive Mixture Case
In the first place, we consider underdetermined music mixtures and speech mixtures in the linear case, and compare our proposed algorithms (Tensor-EU, Tensor-KL, Tensor-IS) with the baseline algorithms (
min [
10], EM [
16], MU [
16]). Additionally, we run the EM and MU from 100 different random initializations (EM, MU), and select the average as the results for the tasks of underdetermined music and speech mixtures in the linear instantaneous case, respectively.
In the second place, we test the performance of our proposed algorithms in the realistic underdetermined convolutive mixture case. For example, music mixtures are the live recording dataset which are more complicated than the synthetic convolutive case, and the speech recorded in an indoor environment are often convolutive, due to multipath reflections. We compare our proposed algorithms with the methods [
11,
16,
30]. In addition, the separation result obtained with the EM and MU methods depends on the initial values, we conducted 100 trials with random initializations and selected the average as the results.
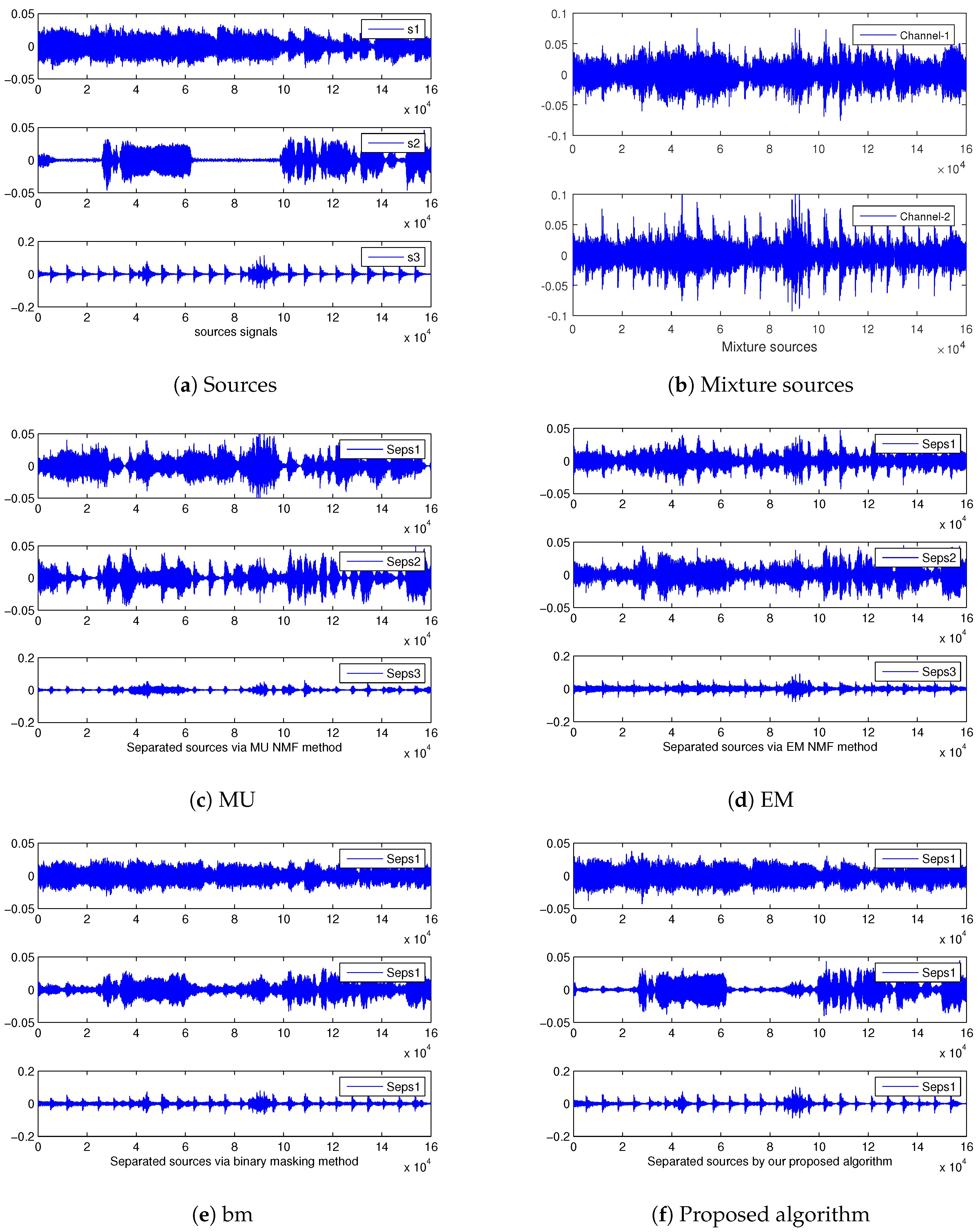
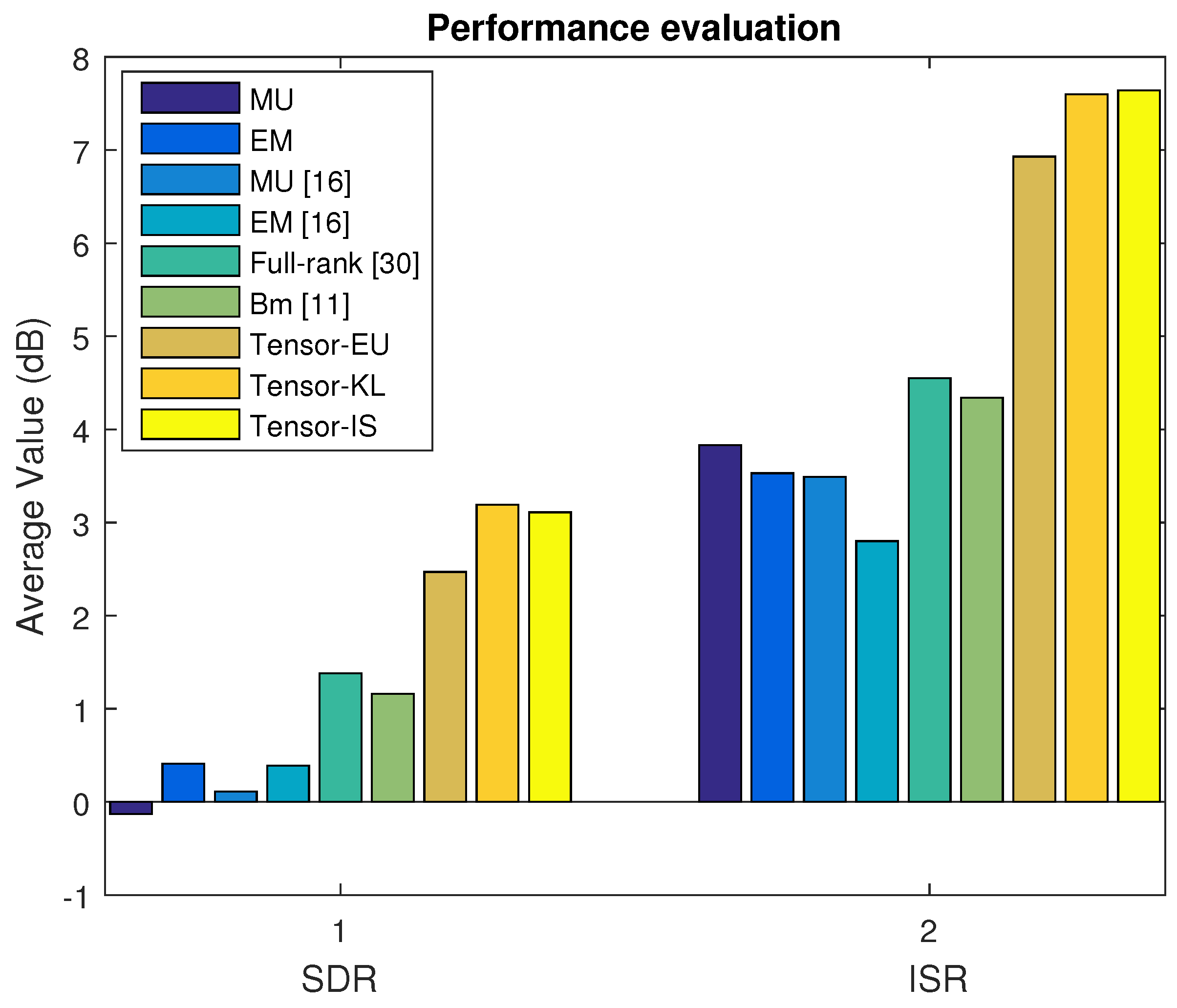
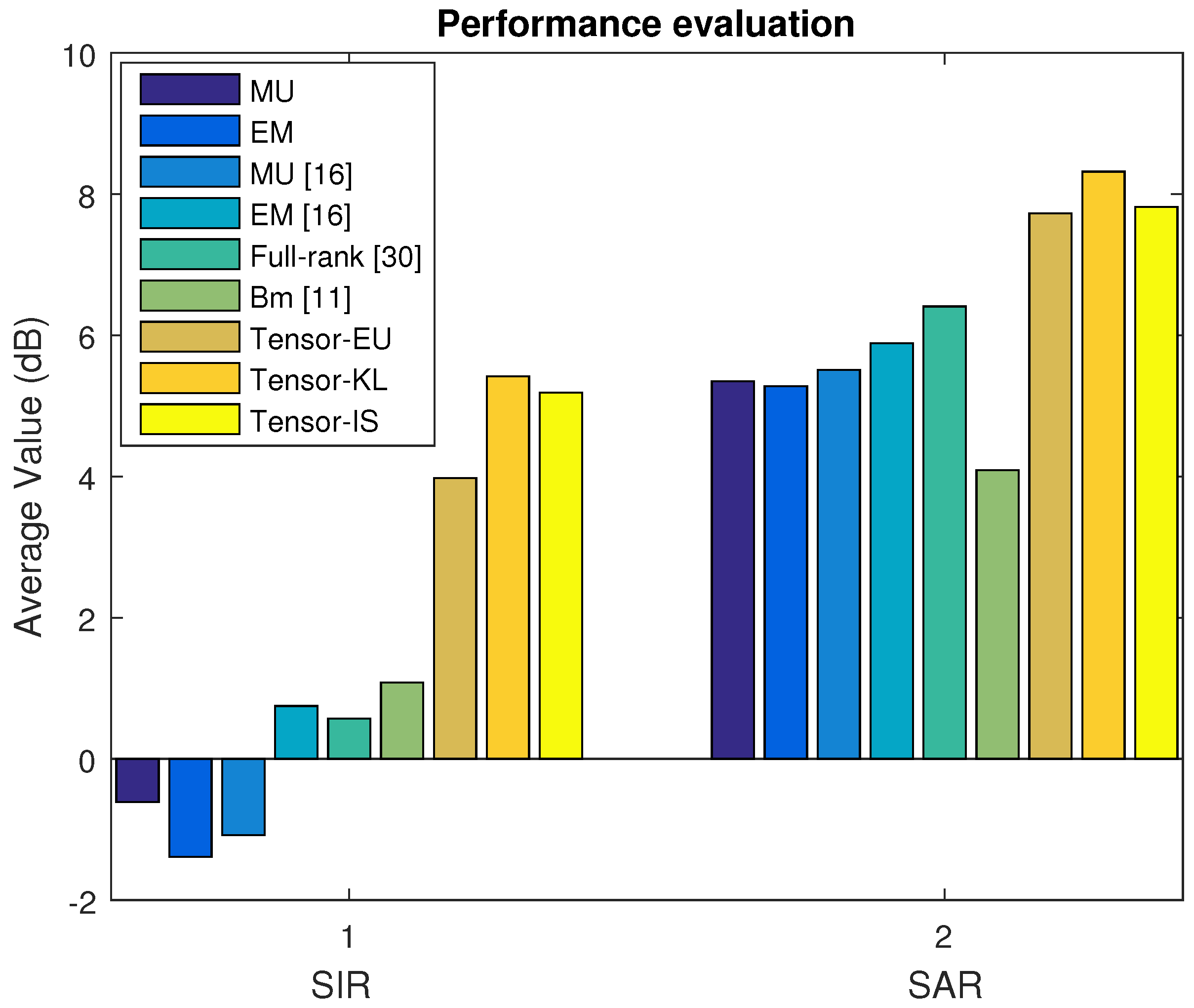
4.4.1. Music Signal Mixtures in the Linear Instantaneous Case
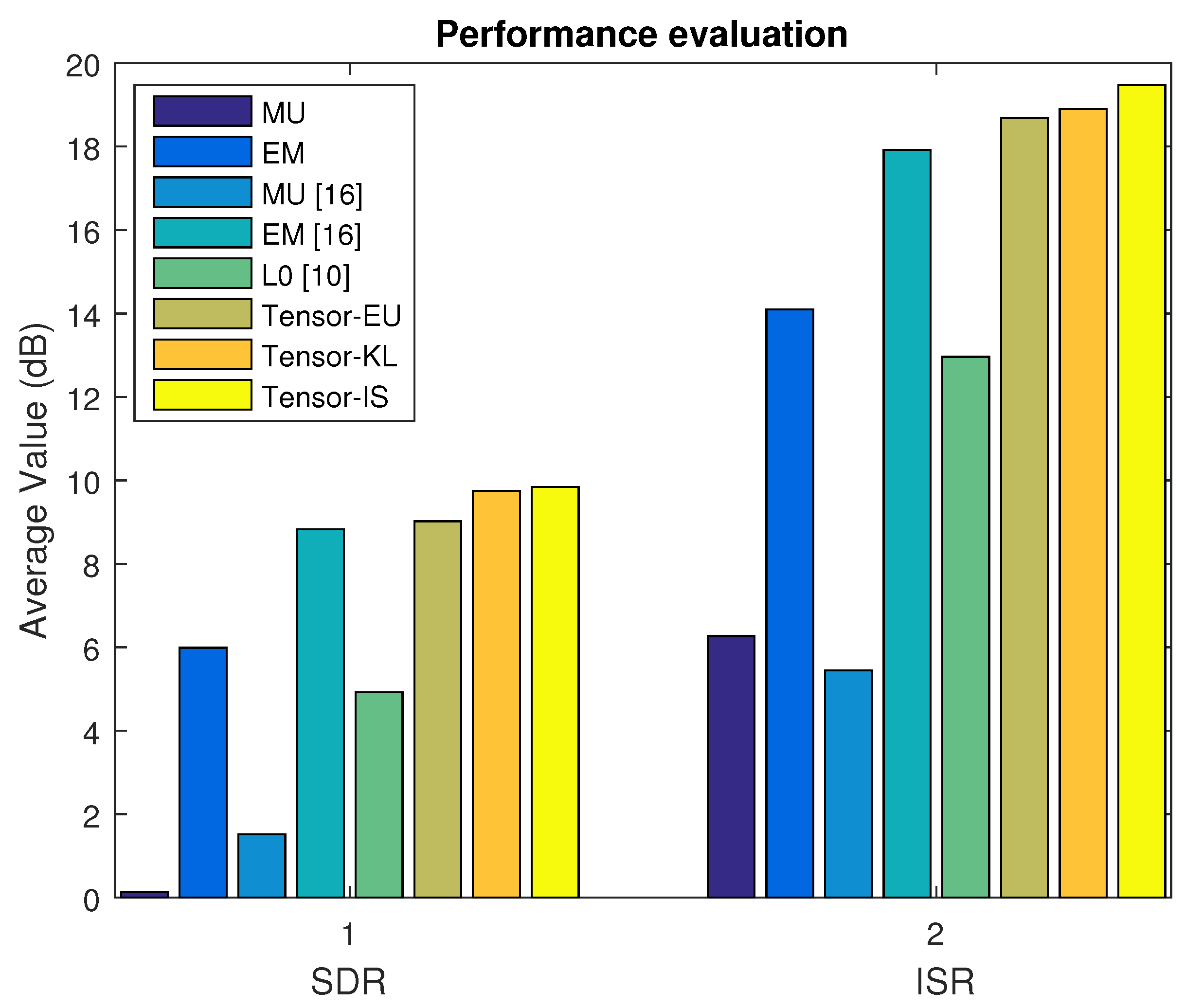
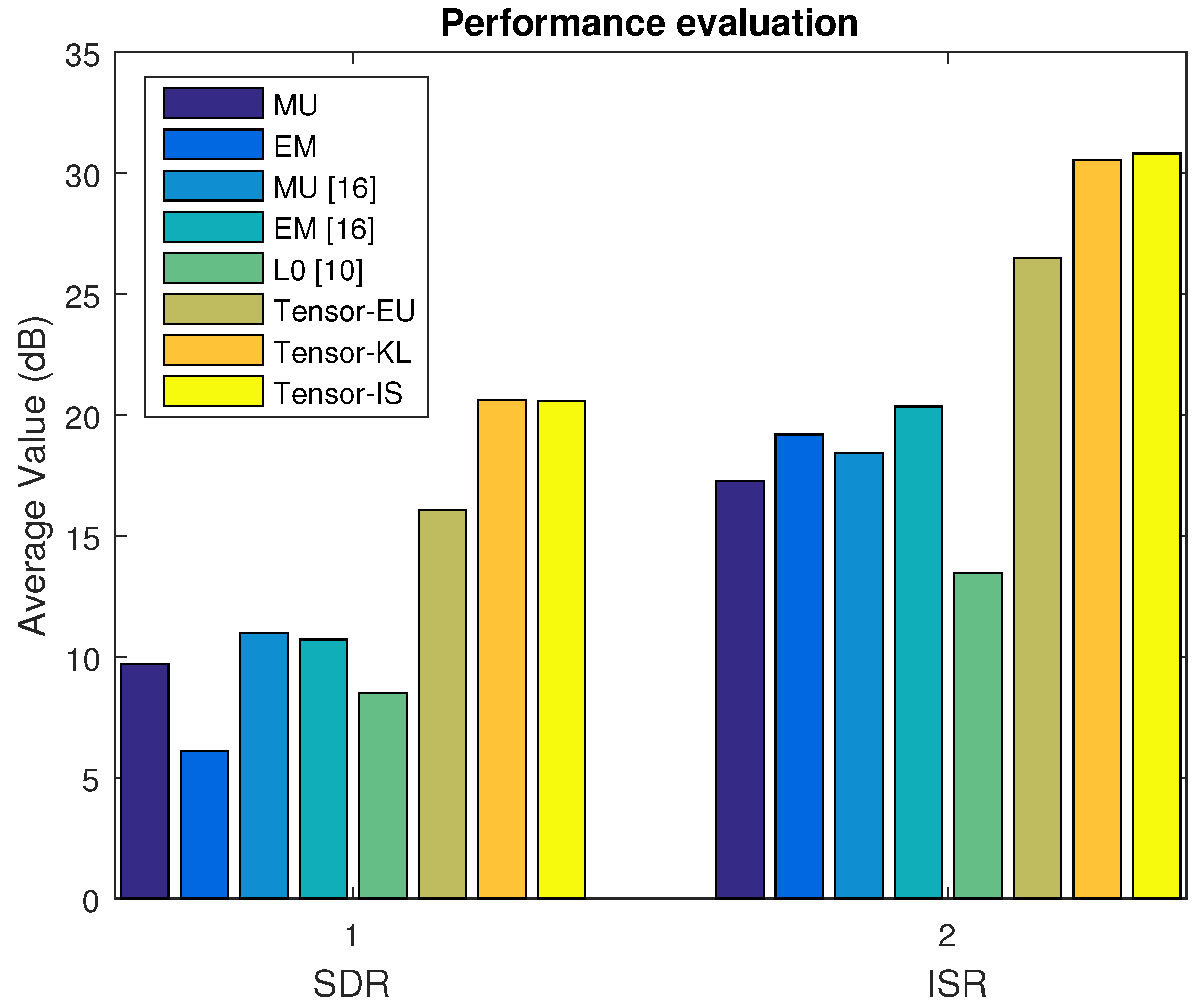
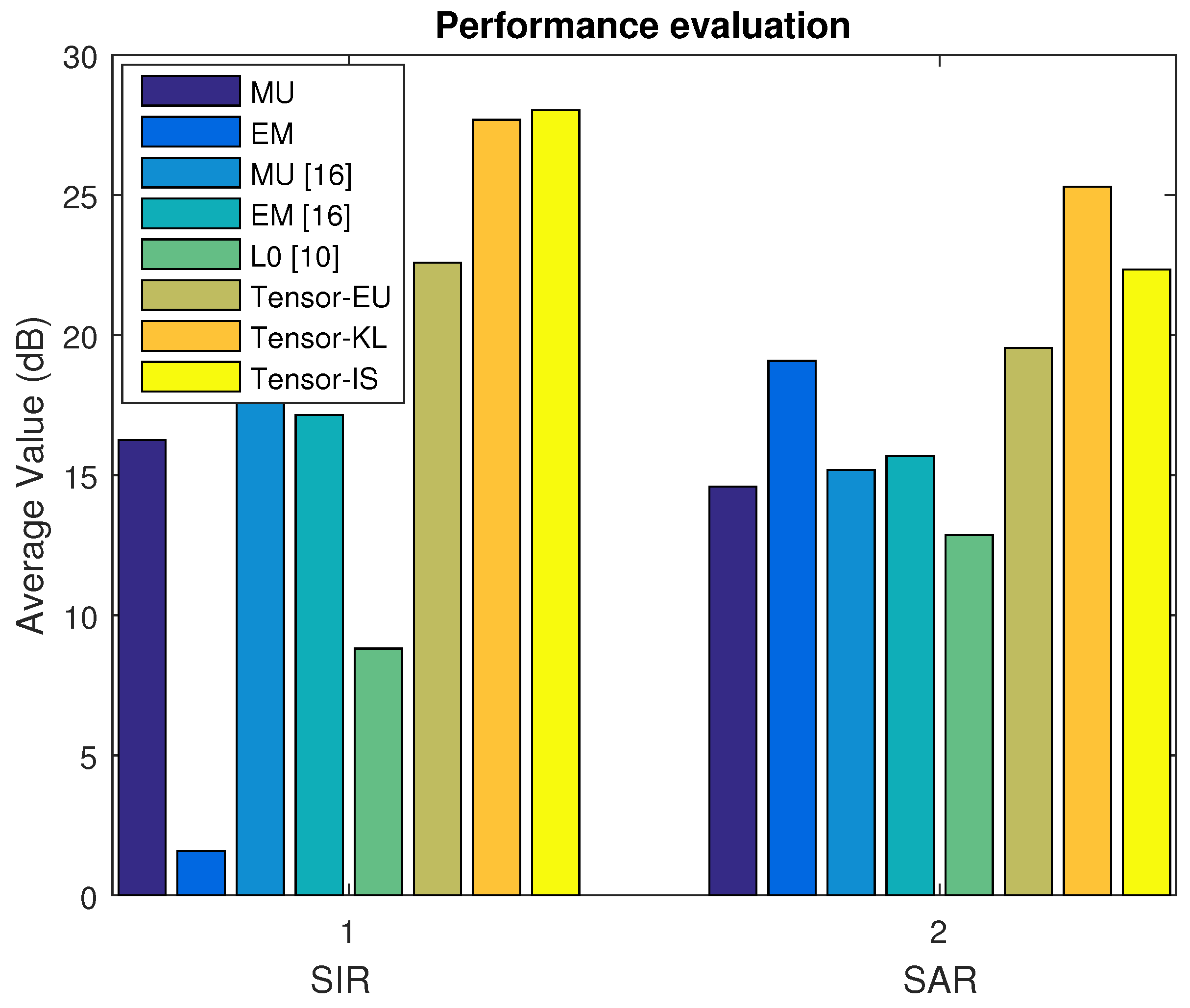
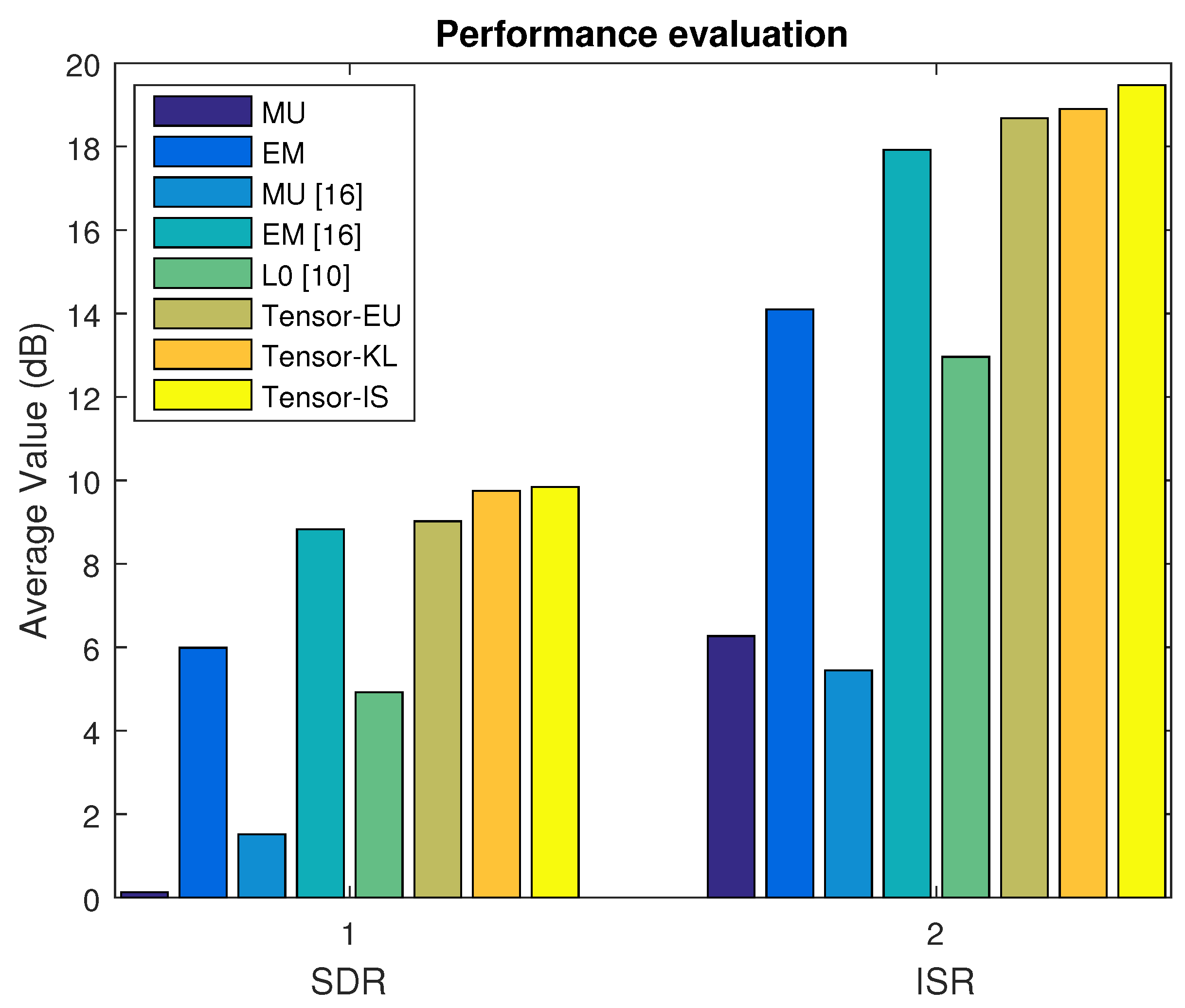
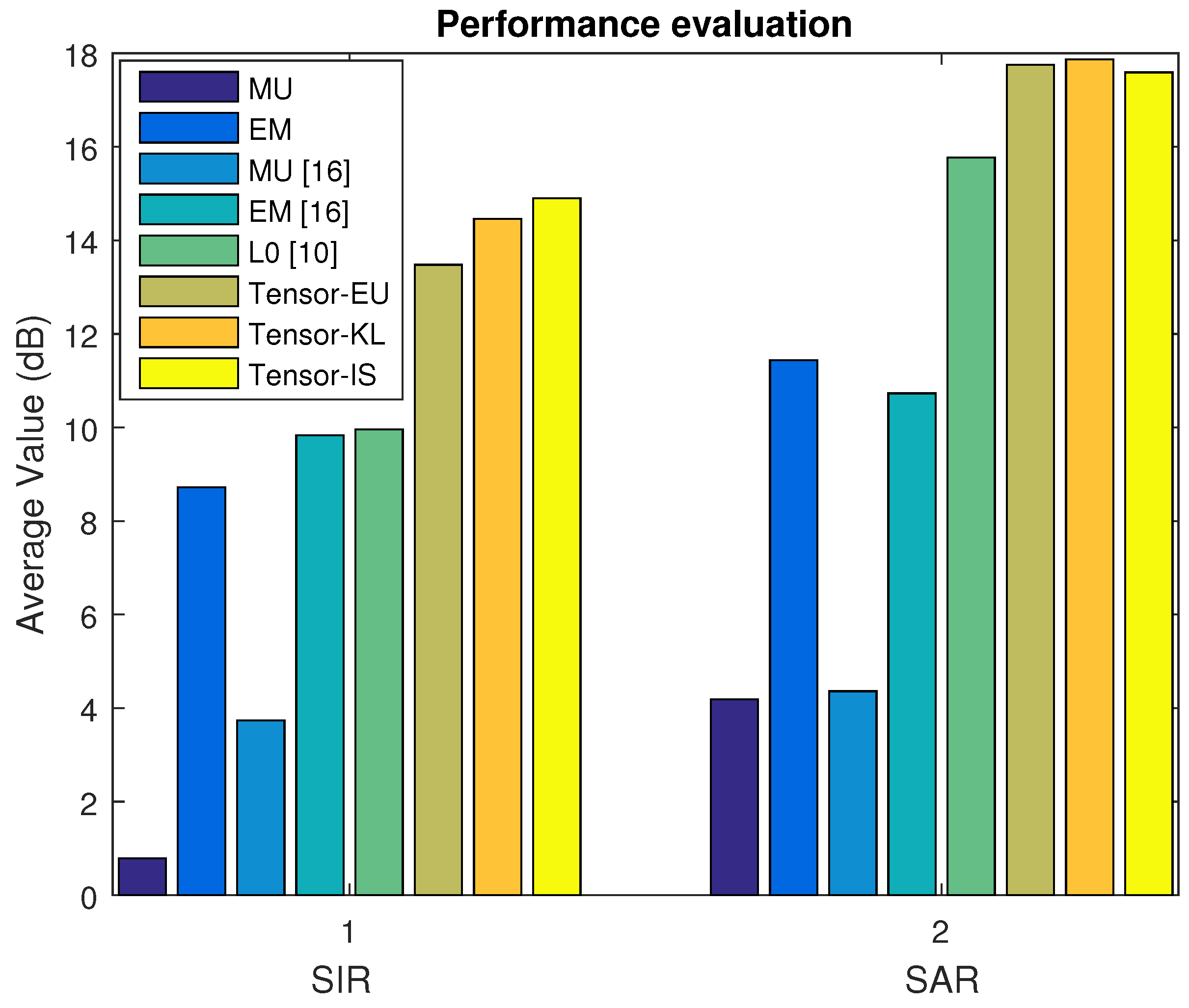
In Dataset A, we first select the music signal mixtures in the linear case. The average SDR, ISR, SIR, and SAR are depicted in
Figure 2 and
Figure 3 based on the MU, EM with the random initialization, MU [
16], EM [
16],
min [
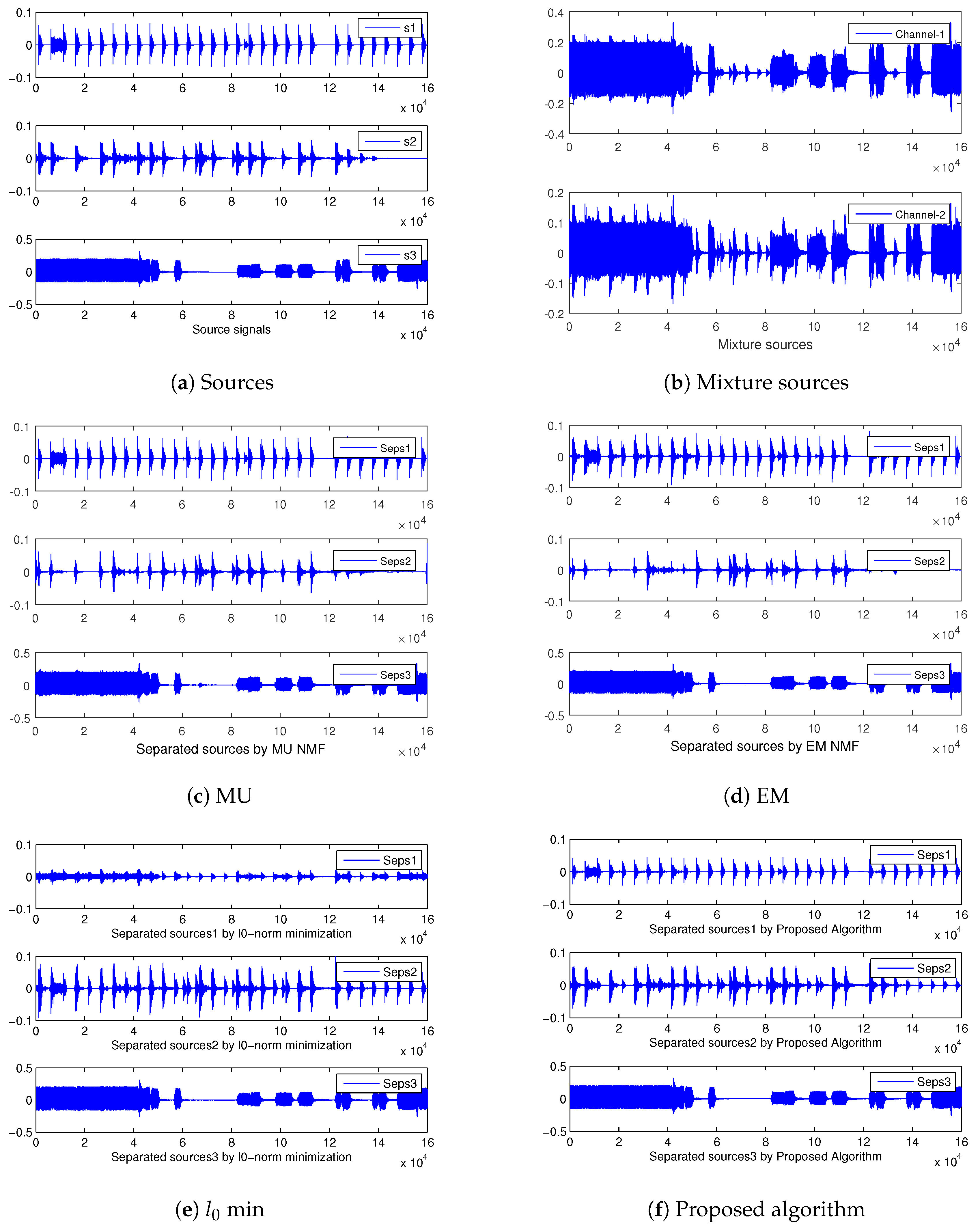
10], and our proposed algorithm (Tensor-EU, Tensor-KL, Tensor-IS). Finally, the waveforms of the estimated sources are shown in
Figure 4.
4.4.2. Speech Signal Mixtures in the Linear Instantaneous Case
In Dataset B, we select the speech signal mixtures in the linear instantaneous case. The average SDR, ISR, SIR, and SAR are depicted in
Figure 5 and
Figure 6 based on the MU, EM with the random initialization, MU [
16], EM [
16],
min [
10], and our proposed algorithm (Tensor-EU, Tensor-KL, Tensor-IS), respectively.
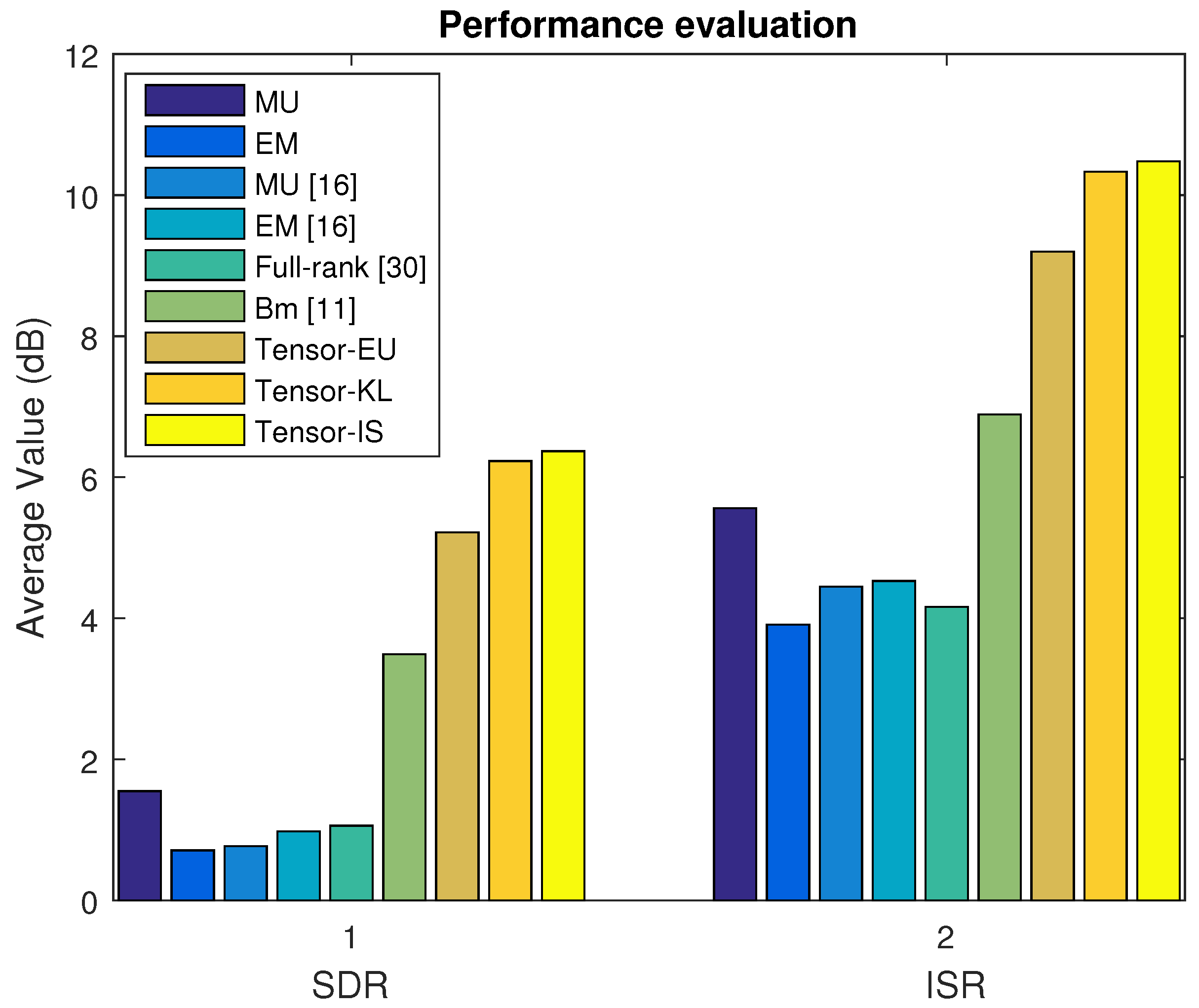
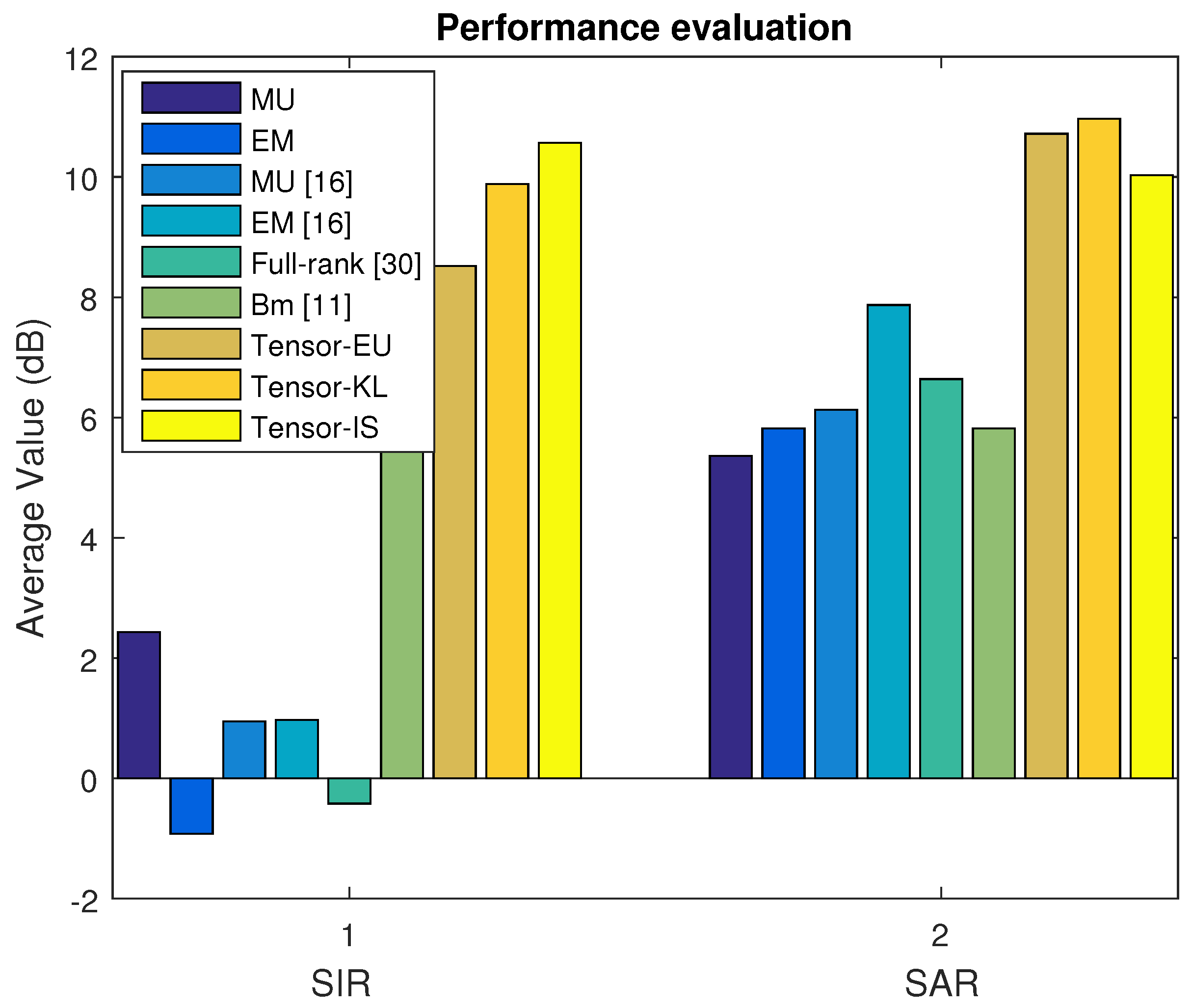
4.4.3. Music Signal Mixtures in the Convolutive Case
In Dataset C, we select the real live recording convolutive dataset which consists of vocal and musical instrument with drum. The average SDR, ISR, SIR, and SAR are depicted in
Figure 7 and
Figure 8 based on the MU, EM with the random initialization, MU [
16], EM [
16], Full-rank [
30], Bm [
11] and our proposed algorithm (Tensor-EU, Tensor-KL, Tensor-IS), respectively. Finally, the waveforms of the estimated sources are shown in
Figure 9.
4.4.4. Speech Signal Mixtures in the Convolutive Case
In Dataset D, we select the synthetic convolutive mixtures including three speech sources and two mixing channels. The average SDR, ISR, SIR, and SAR are depicted in
Figure 10 and
Figure 11 based on the MU, EM with the random initialization, MU [
16], EM [
16], Full-rank [
30], Bm [
11] and our proposed algorithm (Tensor-EU, Tensor-KL, Tensor-IS), respectively.
Discussion 1. According to the above experimental results of Dataset A, Dataset B, Dataset C, and Dataset D, it can be seen that our proposed algorithm can separate music signal mixtures and speech signal mixtures in the underdetermined linear and convolutive case. What is more, according to the average value of source separation results, it is also shown that our proposed algorithm outperforms the baseline algorithms.
4.5. The Runtime of All Algorithms
The corresponding runtimes of the algorithms are shown in
Table 2. It can be seen that the proposed algorithm takes more time than the MU and EM methods. It is mainly because the time consuming on estimation of mixing matrix based on tensor decomposition. However, compared with the full-rank algorithm, our proposed algorithm takes less time. Additionally, as for the source separation results, the proposed algorithms exhibit better separation performance than the compared algorithms. In our future work, it is still necessary to develop a better algorithm to reduce time cost.
5. Conclusions and Future Work
In this paper, we proposed an optimization underdetermined multichannel BSS algorithm based on tensor decomposition and NMF. Because the EM method is very sensitive to the parameter initialization, we first estimated the mixing matrix employing tensor decomposition; meanwhile, the source spectrogram factors were estimated using NMF source model, and produced an optimization parameter initialization scheme. Then the model parameters were updated using the EM algorithm. The spatial images of all sources were obtained in the minimum mean square error sense by multichannel Wiener filtering. The time-domain sources can be obtained through inverse STFT. Finally, a series of experimental results showcase that our proposed optimization algorithm improves the separation performance compared with the baseline algorithms.
In addition, there are some aspects that deserve further study. Firstly, the estimation of number of components of NMF model is an open topic. There have been some articles to solve this problem, such as the automatic order selection [
33], Information Theoretic Criteria [
34], and N-way Probabilistic Clustering [
35]. Secondly, the window length used in the STFT has been taken advantage to match the characteristics of audio signals, and different window lengths have different effects on the separation results. Furthermore, taking into account source or microphone motions [
36,
37], i.e., convolutive mixture corresponding to source-to-microphone channel that can change over time, is a challenging problem. Therefore, these problems would be the focus of our future work.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}