Local Importance Representation Convolutional Neural Network for Fine-Grained Image Classification

Abstract
1. Introduction
2. Related Work
2.1. Weak Supervised Classification Model
2.2. Lightweight Convolution Model
3. Approach
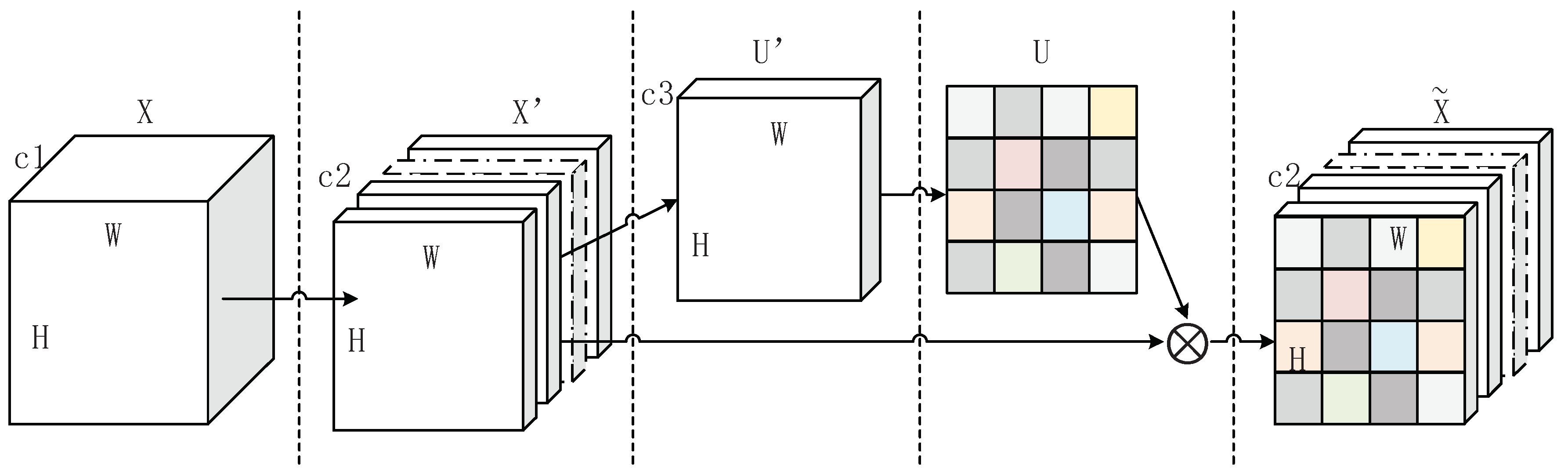
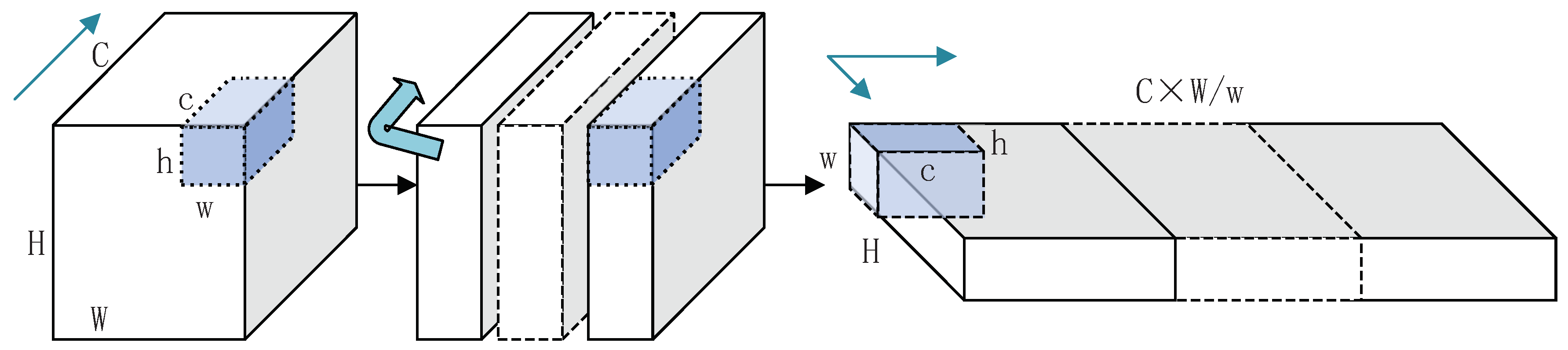
3.1. Local Importance Representation Convolution
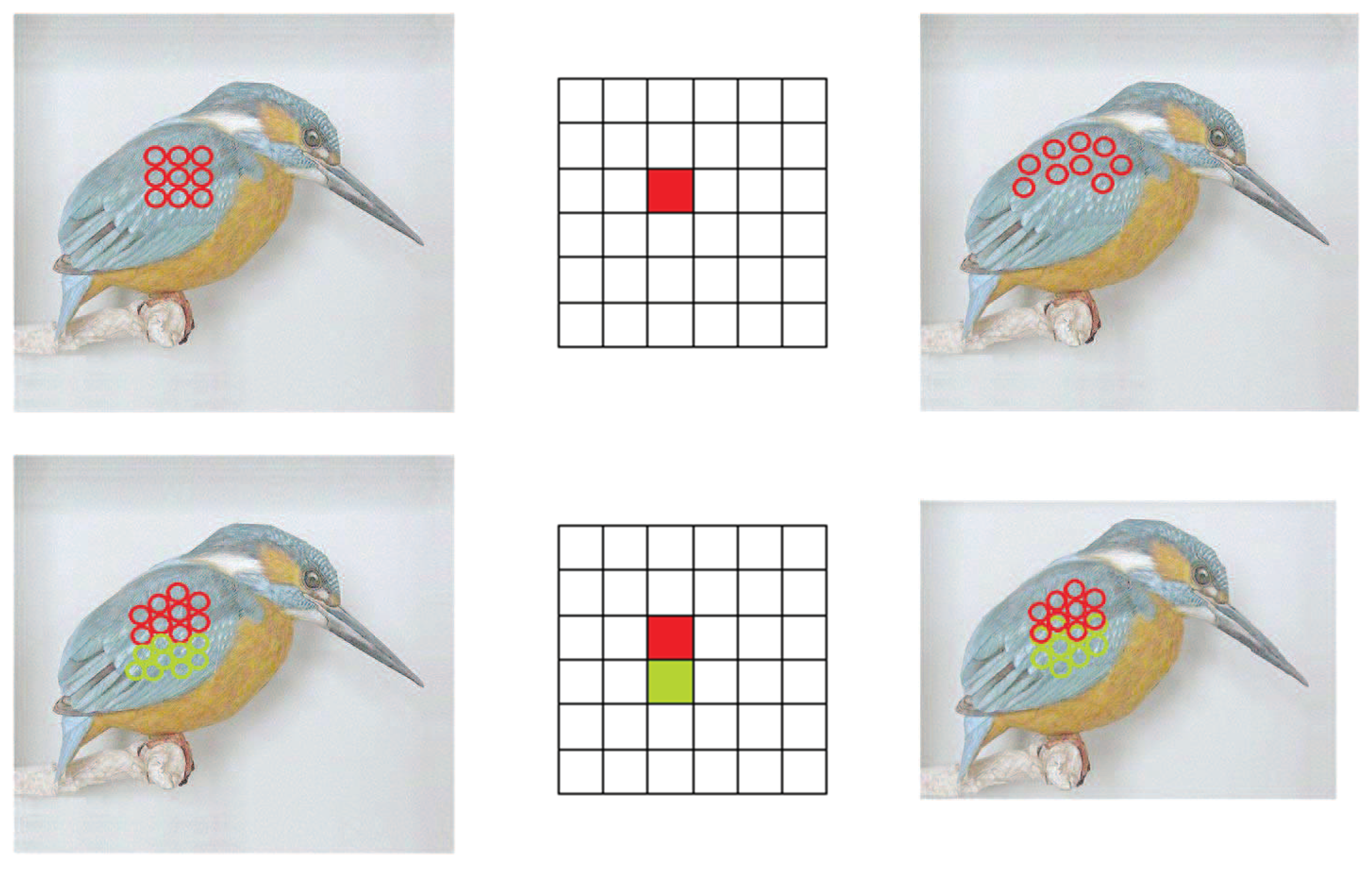
3.2. Super-Pixel Segmentation Convolution
- Generate K seed points on the input image. The distance of the adjacent seed points on the vertical axis and the horizontal axis are and :
- Calculate the gradient values for all pixels in the 3 × 3 neighborhood of the seed point, and move the seed point to the place where the gradient is the smallest.
- Calculate the distance D between each pixel in the 2 × 2 neighborhood of the seed point and the seed point. The computation formulae are:where l, a, b are from the CIELAB color space and x, y are from its position information, is the CIELAB color space color difference value, is the distance between pixels, i and j represent two pixels, m is the compact coefficient, and s is the maximum spatial distance within the class.
- Each super-pixel block is composed of k pixels, which are around the seed point and distances (D) between them are smallest. One pixel can belong to different super-pixels.
- Go back to Step 2 and perform multiple iteration optimizations. The number of iterations is I. We will get K super-pixels, and each super-pixel size is k.
- The convolution operation will be performed on each super-pixel, and the convolution stride is . That is to say, each convolution kernel is convolved only once for each super-pixel.
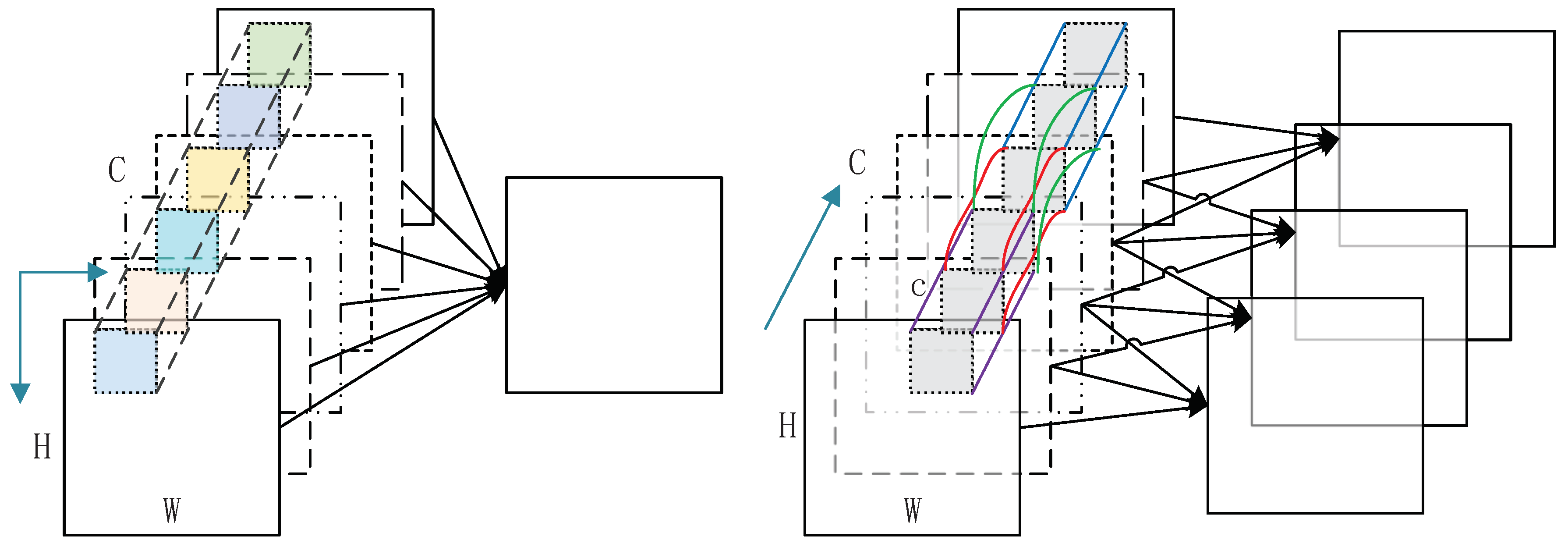
3.3. Channelwise Convolution
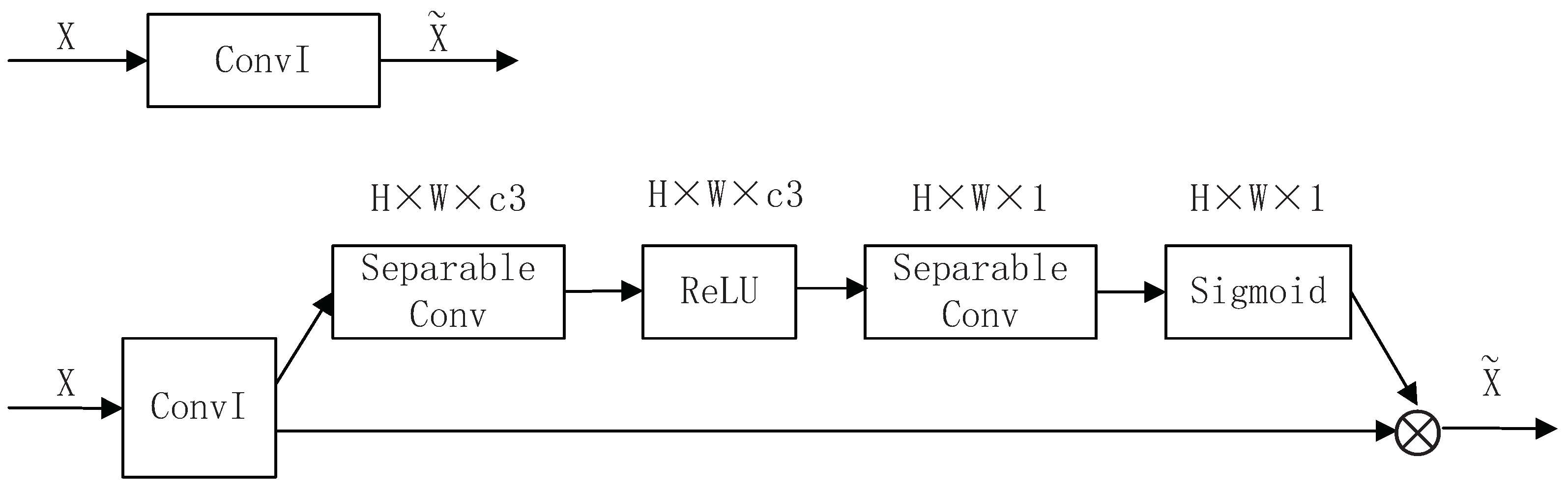
3.4. LIR-CNN Model
4. Experiments
4.1. LIR-CNN_V1
4.2. LIR-CNN_V2
4.3. LIR-CNN_V3
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Peng, Y.X.; He, X.T.; Zhao, J.J. Object-Part Attention Model for Fine-Grained Image Classification. IEEE Trans. Image Process. 2018, 27, 1487–1500. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Lian, J.; Fan, M.Q.; Zheng, Y.J. Deep Indicator for Fine-Grained Classification of Banana’s Ripening Stages. EURASIP J. Image Video Process. 2018, 1, 46. [Google Scholar] [CrossRef]
- Wei, X.S.; Xie, C.W.; Wu, J. Mask-CNN: Localizing Parts and Selecting Descriptors for Fine-Grained image Recognition. Pattern Recogn. 2018, 76, 704–714. [Google Scholar] [CrossRef]
- Koprowski, R.; Lanza, M.; Irregolare, C. Corneal Power Evaluation after Myopic Corneal Refractive Surgery Using Artificial Neural Networks. BioMed. Eng. Online 2016, 15, 121. [Google Scholar] [CrossRef] [PubMed]
- Tadeusiewicz, R. Neural Networks in Mining Sciences-General Overview and Some Representative Examples. Arch. Min. Sci. 2015, 60, 971–984. [Google Scholar] [CrossRef]
- Ganovska, B.; Molitoris, M.; Hosovsky, A.; Pitel, J. Design of the Model for the On-Line Control of the AWJ Technology Based on Neural Networks. Indian J. Eng. Mater. Sci. 2016, 23, 279–287. [Google Scholar]
- Dudczyk, J.; Matuszewski, J.; Wnuk, M. Applying the Relational Modelling and Knowledge Based Techniques to the Emitter Database Design. In Proceedings of the International Conference on Microwaves, Radar and Wireless Communications, Gdańsk, Poland, 20–22 May 2002; pp. 172–175. [Google Scholar]
- Dudczyk, J.; Kawalec, A.; Wnuk, M. Applying the Neural Networks to Formation of Radiation Pattern of Microstrip Antenna. In Proceedings of the International Radar Symposium, Wroclaw, Poland, 21–23 May 2008; pp. 99–102. [Google Scholar]
- Dudczyk, J.; Kawalec, A. Adaptive Forming the Beam Pattern of Microstrip Antenna with the Use of an Artificial Neural Network. Int. J. Antennas Propag. 2012, 2012, 388–392. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, G.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Donahue, J.; Girshick, R.; Darrell, T. Part-based R-CNNs for Fine-grained Category Detection. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2010; pp. 834–849. [Google Scholar]
- Lin, D.; Shen, X.Y.; Lu, C.W.; Jia, J.Y. Deep LAC: Deep localization, alignment and classification for fine-grained recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1666–1674. [Google Scholar]
- Xu, Z.; Huang, S.L.; Zhang, Y.; Tao, D.C. Augmenting Strong Supervision Using Web Data for Fine-Grained Categorization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2524–2532. [Google Scholar]
- Huang, S.L.; Xu, Z.; Tao, D.C.; Zhang, Y. Part-Stacked CNN for Fine-Grained Visual Categorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1173–1182. [Google Scholar]
- Simon, M.; Rodner, E. Neural Activation Constellations: Unsupervised Part Model Discovery with Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1143–1151. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; kavukcuogu, K. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Wang, D.Q.; Shen, Z.Q.; Shao, J.; Zhang, W.; Xue, X.Y.; Zhang, Z. Multiple Granularity Descriptors for Fine-Grained Categorization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2399–2406. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Q.; Zhang, G.D.; Hu, H.; Wei, Y.C. Deformable Convolutional Networks. arXiv, 2017; arXiv:1703.06211. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv, 2017; arXiv:1610.02357. [Google Scholar]
- Howard, A.G.; Zhu, M.L.; Chen, B.; Kalenichenko, D.; Wang, W.J.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv, 2017; arXiv:1704.04861. [Google Scholar]
- Sifre, L. Rigid-Motion Scattering for Image Classification. Ph.D. Thesis, Ecole Polytechnique, Paris, France, 2014. [Google Scholar]
- Berg, T.; Belhumeur, P.N. POOF: Part-Based One-vs.-One Features for Fine-Grained Categorization, Face Verification, and Attribute Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 955–962. [Google Scholar]
- Perronnin, F.; Sanchez, J.; Mensink, T. Improving the Fisher Kernel for Large-Scale Image Classification. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 143–156. [Google Scholar]
- Gajewski, J.; Valis, D. The Determination of Combustion Engine Condition and Reliability Using Oil Analysis by MLP and RBF Neural Networks. Tribol. Int. 2017, 115, 557–572. [Google Scholar] [CrossRef]
- Perronnin, F.; Sanchez, J.; Mensink, T. Neural Network Application for Emitter Identification. In Proceedings of the International Radar Symposium, Prague, Czech, 15–17 August 2017; pp. 1–8. [Google Scholar]
- Glowacz, A. Acoustic Based Fault Diagnosis of Three-Phase Induction Motor. Appl. Acoust. 2018, 137, 82–89. [Google Scholar] [CrossRef]
- Perronnin, F.; Sanchez, J.; Mensink, T. Object Detection and Recognition System Using Artificial Neural Networks and Drones. In Proceedings of the Signal Processing Symposium, Jachranka, Poland, 12–14 September 2017; pp. 1–5. [Google Scholar]
- Ma, B.Y.; Ban, X.J.; Huang, H.Y.; Chen, Y.L.; Liu, W.B.; Zhi, Y.H. Deep Learning-Based Image Segmentation for Al-La Alloy Microscopic Images. Symmetry 2018, 10, 107. [Google Scholar] [CrossRef]
- Zhang, L.; Cheng, Z.X.; Shen, Y.; Wang, D.Q. Palmprint and Palmvein Recognition Based on DCNN and A New Large-Scale Contactless Palmvein Dataset. Symmetry 2018, 10, 78. [Google Scholar] [CrossRef]
- Xiao, T.J.; Xu, Y.C.; Yang, K.Y.; Zhang, J.X.; Peng, Y.X.; Zhang, Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 842–850. [Google Scholar]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN Models for Fine-grained Visual Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1449–1457. [Google Scholar]
- Fu, J.L.; Zheng, H.L.; Mei, T. Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4476–4484. [Google Scholar]
- Zheng, H.L.; Fu, J.L.; Mei, T.; Luo, J.B. Learning Multi-Attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5219–5227. [Google Scholar]
- Wang, Y.M.; Morariu, V.I.; Davis, L.S. Learning a Discriminative Filter Bank within a CNN for Fine-grained Recognition. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 5209–5217. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 7132–7141. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceeding of the 32nd International Conference on Machine Learning, Lille, France, 6 July–11 July 2015; pp. 448–456. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inceptionv4, inception-resnet and the impact of residual connections on learning. arXiv, 2017; arXiv:1602.07261. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Xie, S.N.; Girshick, R.; Dollar, P.; Tu, Z.W.; He, K.M. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S.C. Network In Network. arXiv, 2014; arXiv:1312.4400. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Zhang, T.; Qi, G.J.; Xiao, B.; Wang, J.D. Interleaved Group Convolutions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4373–4382. [Google Scholar]
- Zhang, X.Y.; Zhou, X.Y.; Lin, M.X.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. arXiv, 2017; arXiv:1707.01083. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset. In Technical Repoert CNS-TR-2011-001; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-grained visual classification of aircraft. arXiv, 2013; arXiv:1306.5151. [Google Scholar]
- Krause, J.; Stark, M.; Jia, D.; Li, F.F. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 3–6 December 2013; pp. 554–561. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Convolution Layers | Fully Connected Layers | ||||||
|---|---|---|---|---|---|---|---|---|
| M-Net | conv1 | conv2 | conv3 | conv4 | conv5 | fc6 | fc7 | fc8 |
| D-Net | conv1_1 | conv2_1 | conv3_1 | conv4_1 | conv5_1 | fc6 | fc7 | fc8 |
| conv1_2 | conv2_2 | conv3_2 | conv4_2 | conv5_2 | fc6 | fc7 | fc8 | |
| conv3_3 | conv4_3 | conv5_3 | fc6 | fc7 | fc8 | |||
| Model | Accuracy (%) | △Params | ||
|---|---|---|---|---|
| Birds | Aircrafts | Cars | ||
| B-CNN | 84.1 | 83.9 | 91.3 | 0 |
| LIR-CNN_V1 ( = 1) | 84.2 | 84.4 | 91.1 | 0.03 M |
| LIR-CNN_V1 ( = 20) | 85.1 | 85.8 | 91.6 | 0.10 M |
| LIR-CNN_V1 ( = ) | 85.3 | 86.1 | 91.5 | 1.52 M |
| Model | Accuracy (%) | ||
|---|---|---|---|
| Birds | Aircrafts | Cars | |
| B-CNN | 84.1 | 83.9 | 91.3 |
| LIR-CNN_V1 | 85.3 | 86.1 | 91.5 |
| LIR-CNN_V2 (sp = 448) | 85.7 | 87.0 | 91.8 |
| LIR-CNN_V2 (sp = 224) | 85.4 | 87.0 | 91.7 |
| Model | Accuracy (%) | △Params | ||
|---|---|---|---|---|
| Birds | Aircrafts | Cars | ||
| B-CNN | 84.1 | 83.9 | 91.3 | 0 |
| LIR-CNN_V2 | 85.7 | 87.0 | 91.8 | 1.52 M |
| LIR-CNN_V3 (CC) | 85.3 | 86.4 | 91.6 | M |
| LIR-CNN_V3 (SC) | 84.8 | 85.3 | 91.2 | M |
| LIR-CNN_V3 (DC+CC) | 85.9 | 87.5 | 92.0 | M |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Wang, X.; Zhang, H. Local Importance Representation Convolutional Neural Network for Fine-Grained Image Classification. Symmetry 2018, 10, 479. https://doi.org/10.3390/sym10100479
Yang Y, Wang X, Zhang H. Local Importance Representation Convolutional Neural Network for Fine-Grained Image Classification. Symmetry. 2018; 10(10):479. https://doi.org/10.3390/sym10100479
Chicago/Turabian StyleYang, Yadong, Xiaofeng Wang, and Hengzheng Zhang. 2018. "Local Importance Representation Convolutional Neural Network for Fine-Grained Image Classification" Symmetry 10, no. 10: 479. https://doi.org/10.3390/sym10100479
APA StyleYang, Y., Wang, X., & Zhang, H. (2018). Local Importance Representation Convolutional Neural Network for Fine-Grained Image Classification. Symmetry, 10(10), 479. https://doi.org/10.3390/sym10100479