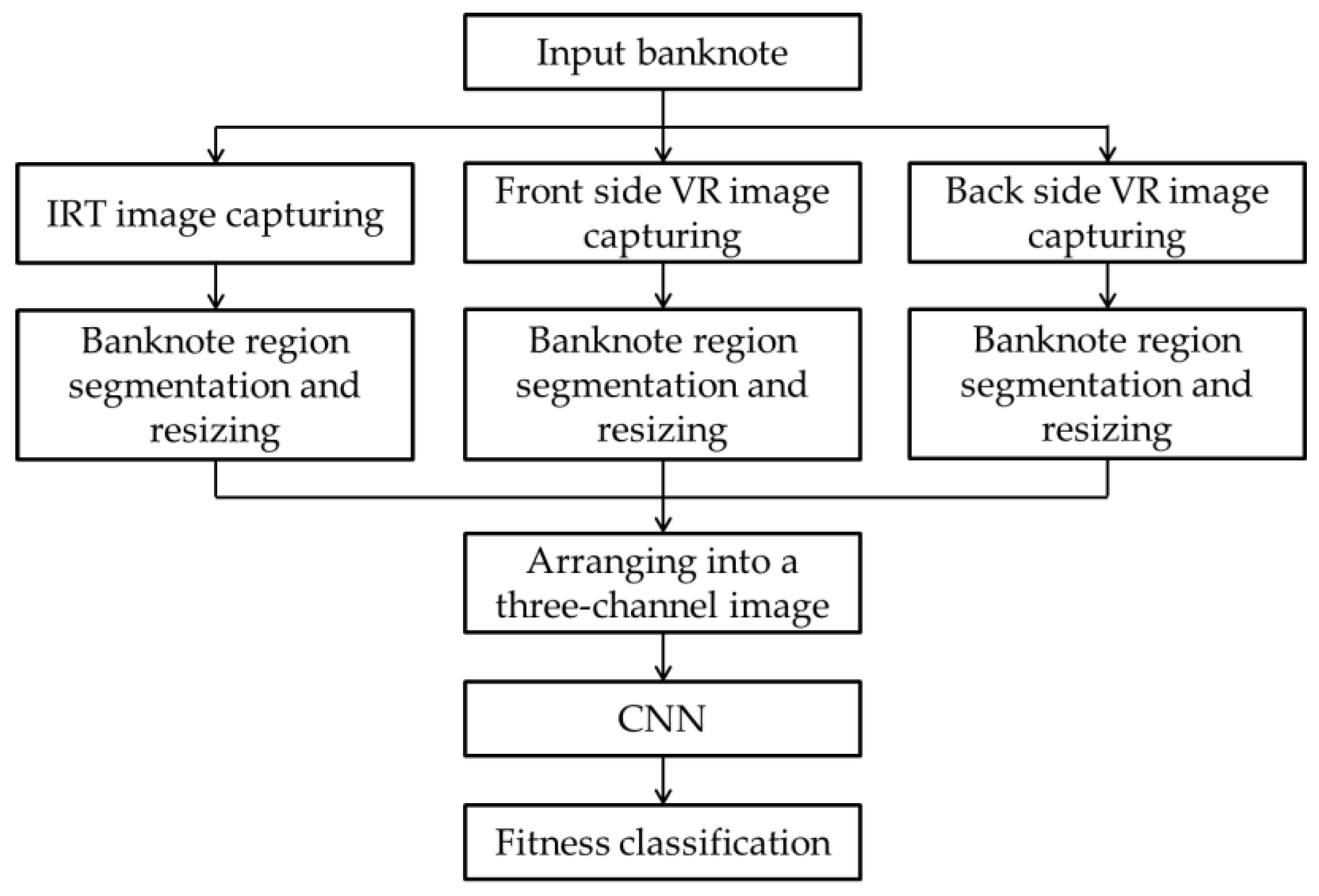
5.2. Training of CNN
For evaluating the performance of the proposed method, we conducted the experiments with a two-fold cross validation. The database was randomly divided into two subsets, one for training and another for testing, and the process was repeated with these two subsets swapped. The overall performance was measured based on the average of the obtained results from two trials.
In the first experiments for training the CNN, we trained the network model on each subset of the two-fold cross validation, and saved the trained models for testing in the remaining subsets of the next experiments. As the CNN models were trained from scratch, we performed data augmentation to increase the amount of data used in the training process for generalization and avoiding overfitting [
17]. The training data was expanded using the boundary cropping method [
2], i.e., the boundaries of the original image in the training subset was randomly cropped in the range of 1–7 pixels. This type of data augmentation has been widely used in previous research [
21]. With the various augmenting factors, the number of banknotes in each national currency and each class of fitness were increased to be relatively comparable, as shown in
Table 3. We performed the CNN training using MATLAB (MathWorks, Inc., Natick, MA, USA) [
27] on a desktop computer with the following configuration: Intel
® Core™ i7-3770K CPU @ 3.50 GHz [
28], 16 GB DDR3 memory, and NVIDIA GeForce GTX 1070 graphics card (1920 CUDA cores, 8 GB GDDR5 memory) [
29]. The training method is the stochastic gradient descend (SGD), in which the network weights are updated based on batches of data points at a time [
26], with the parameters set as follows: the training epoch number is 100, the learning rate is initialized at 0.01 and reduced with the factor of 0.1 at every 20 epochs, and the dropout factor
p in Equation (4) is set to 50%.
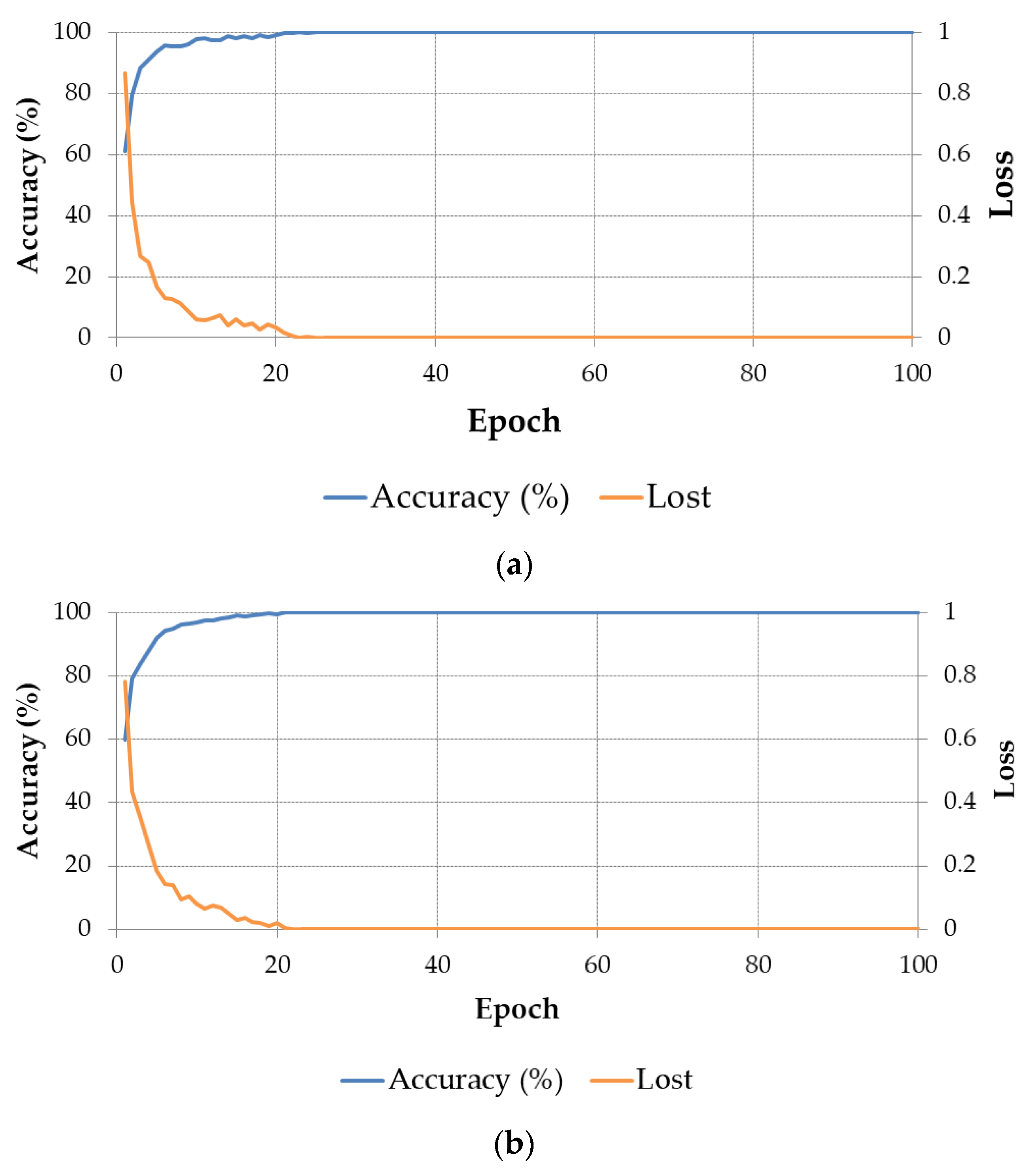
Figure 7 shows the graphs of accuracy and batch loss of the training process on the two subsets of training data in the two-fold cross-validation method.
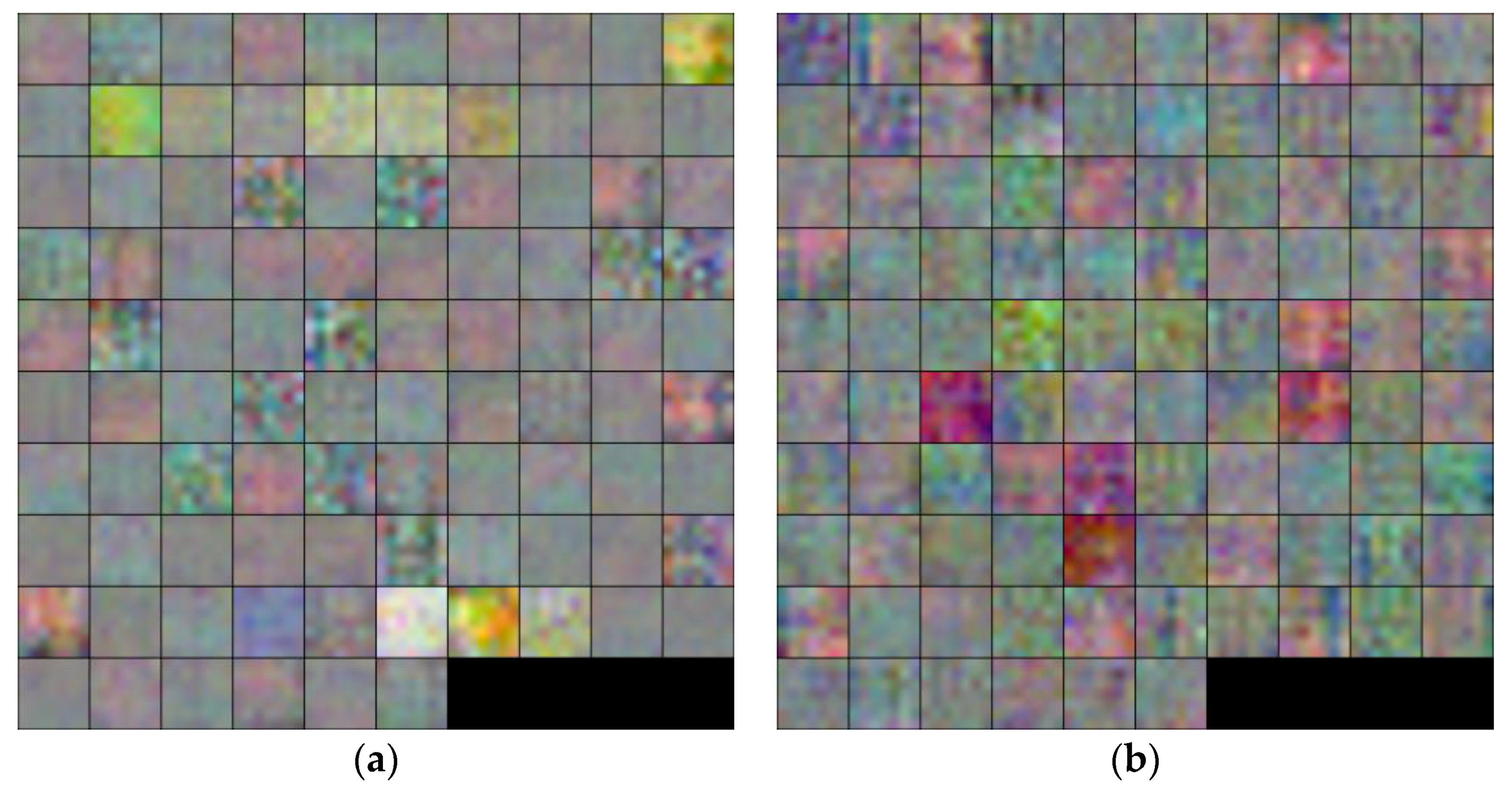
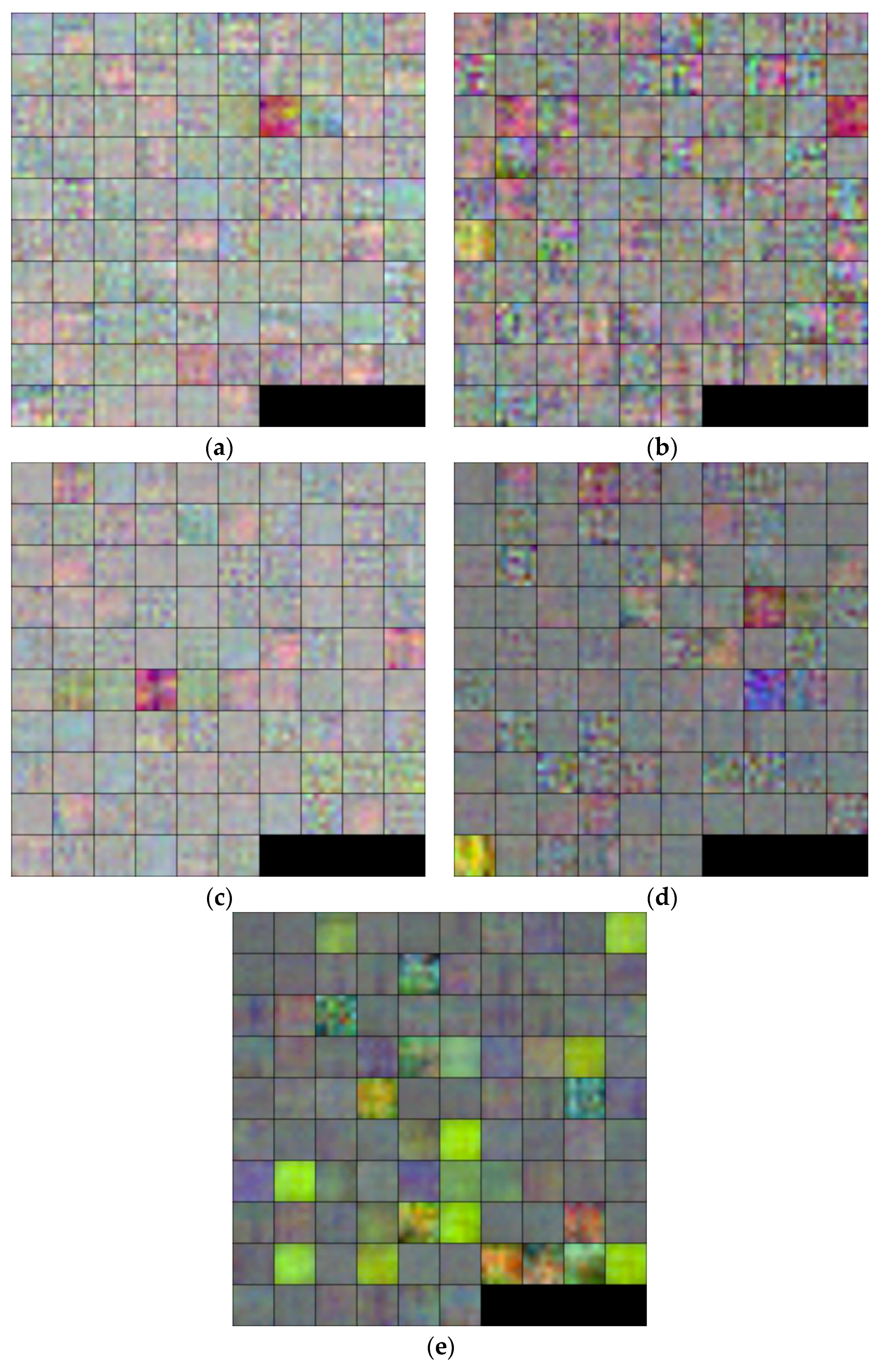
Figure 8 shows the trained filters in the first convolutional layer (L1) of the CNN models obtained by two training trials of the two-fold cross validation. The filters in the first layers were trained to extract the important low-, mid- and high-frequency features that reflect the fitness characteristics of a banknote on all the input image channels. Each filter in
Figure 8 was resized from 7 × 7 × 3 pixels, as shown in
Table 2, to five times larger, and scaled from the original real pixel values to the range of 0–255 by integer for visualization.
5.3. Testing of Proposed Method and Comparative Experiments
In the subsequent experiments, we performed the measurement of the classification accuracy on the remaining subsets against the training sets of the multinational banknote database. From the accuracies obtained by the two testing trials, we calculated the average accuracy as the ratio of the total accurately classified cases of the two subsets, and the total number of samples in the database [
2,
17]. In
Table 4, we show the confusion matrices of the classification accuracy of the experimental results using the proposed CNN-based method with two-fold cross validation on the multinational banknote fitness database.
As shown in
Table 4, the overall testing accuracy of the proposed method on the experimental database with merged currency types, denominations, and input directions of the banknotes is nearly 99%. These results proved that the proposed CNN-based method yields good fitness classification performance with the conditions of the multinational banknote dataset.
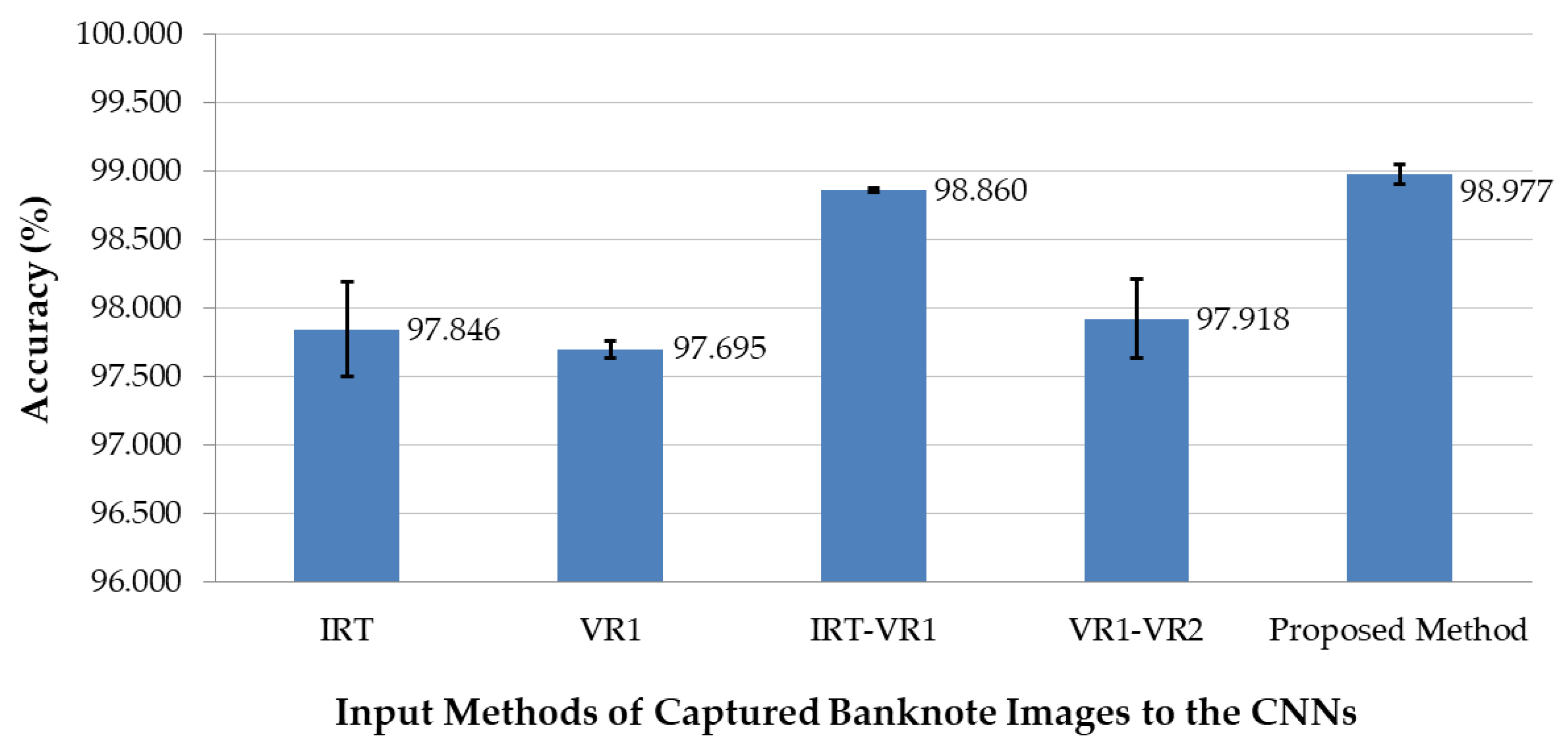
In the proposed method, we used the combination of images captured by various sensors per input banknote, in which one IRT and two VR images were used. In the next experiments, we investigated the optimality of the possible combinations of the captured images per banknote for inputting to the CNN models, as well as the effect of each type of image on the classification of the banknote fitness. Five cases were considered: using IRT images only (denoted by IRT), using VR images captured from the front side only (denoted by VR1), using two-channel input images of IRT and front side VR images (denoted by IRT-VR1), using two-channel input images of two VR images (denoted by VR1-VR2), and using three-channel input images of IRT and two VR images (the proposed method). In the multinational banknote database, the USD dataset consists of only one IRT and one VR image captured from the front side; therefore, the combination of IRT and reverse side VR images, which might be considered as IRT-VR2, is not considered. In the case of VR1-VR2, for the USD banknotes in the dataset, the VR image was duplicated into the two channels of the input image. We also used the CNN structure similar to the two-fold cross-validation for these comparative experiments. The results are shown in
Figure 9 with the average classification accuracy for each case of input image to the CNNs.
Among the methods for inputting banknotes to the CNNs, the proposed method of using the three-channel input comprising all the captured images yielded the best accuracy, because it can fully utilize the available captured information of the banknote for fitness classification, as shown in
Figure 9. Furthermore,
Figure 9 shows that the IRT images of the banknote reflect the most fitness information, expressed by the high classification accuracy in the cases that present IRT images.
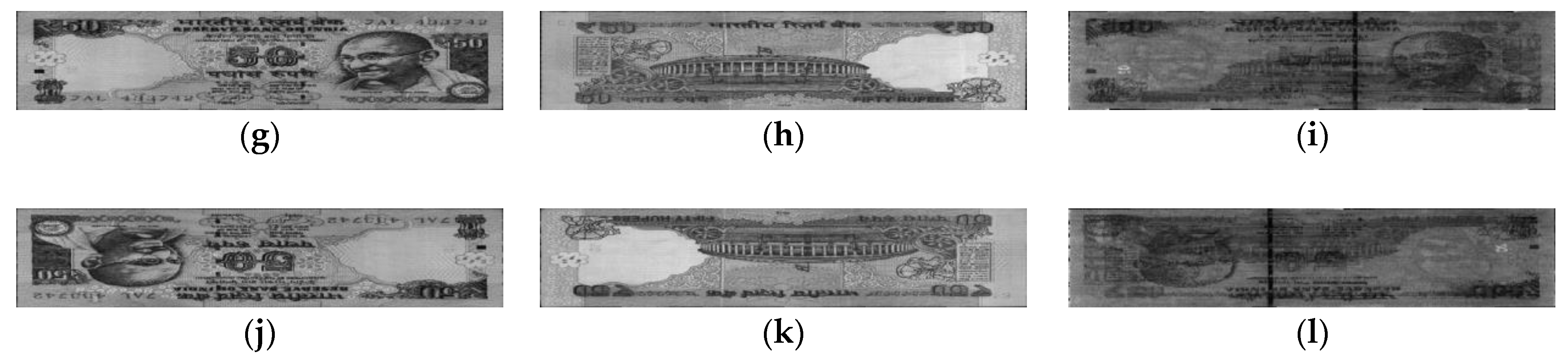
The examples of the correctly classified cases by our proposed method are shown in
Figure 10, including the captured images of the banknotes from the three national currencies of the database.
Figure 10 shows that the fitness levels in these examples are more clearly distinguished for the INR banknotes than those for KRW and USD. However, the IRT images of banknotes from different fitness levels are slightly more distinguishable than the VR images. This results in the relative high classification effect of the IRT images, as shown in the experimental results of
Figure 9. To adapt to the multinational banknote fitness system, the VR image of USD, or the Case 2 fitness, need to be duplicated to form the three-channel input image. This leads to insufficient information for fitness classification in this case, and results in the high error rate in the Case 2 fitness levels.
In
Figure 11,
Figure 12 and
Figure 13, we visualize the examples of feature maps at the outputs of the pooling layers in the CNN structure for the genuine acceptance cases shown in
Figure 10. There are three max pooling layers in the convolutional layers of L1, L2 and L5. At the output of these pooling layers of L1, L2 and L5, the numbers of feature maps’ channels are 96, 128 and 128, respectively, as shown in
Table 2. By visualizing the output feature maps, we can see in
Figure 11,
Figure 12 and
Figure 13 that the extracted features become more distinguishable over the stages of the convolutional layers among banknotes of the same national currency with different fitness classes. Banknote images responded differently to the filters of the first convolutional layer, and the output features of this L1 layer consist of many minor details, as shown in the left images of
Figure 11,
Figure 12 and
Figure 13. However, as the banknote features pass through the stages of the convolutional networks from L1 to L5, the noises are gradually reduced, and only the classification features are maintained before being input to the successive fully connected layers. In the Case 1 fitness examples of
Figure 11 and
Figure 12, the output features at the last layer (L5) consist of the patterns that their noticeability reduces from unfit to normal to fit input banknotes, because the high-pass filters in the first L1 layers, which are visualized in
Figure 8, tend to have more response to the details of the damage on the unfit banknote images than those on the normal and fit banknotes. These responses are maintained through max pooling layers to the last layers of the feature extraction part of the CNN. With the Case 2 fitness of USD, fitness levels of fit and unfit tend to be classified according to the brightness of the banknote images, since unfit banknote features at L5 have lower pixel values than that of the fit banknote, as shown in
Figure 13.
Figure 14 shows the examples of error cases that occurred in the testing process for each case of fitness levels. In some cases, the banknote region segmentation did not operate correctly, as shown in
Figure 14c,f. Consequently, the classification results were affected. The fit INR banknote in
Figure 14a was misclassified to normal, because it contained a reverse side VR image with slightly low contrast, and soiling on the upper part, which was visible but not as clear in the IRT and front side VR images. The soiling in the lower part of the VR image is also the reason for the fit banknote in
Figure 14e to be incorrectly recognized as unfit. In the case of normal fitness banknote in
Figure 14b, the brightness of the banknote images were not highly different from the fit banknotes; meanwhile, the tearing near the middle of the banknote was not clearly visible when being resized to be input to the CNN. The misclassification to unfit shown in
Figure 14d is a KRW banknote with normal fitness with a small tearing part that is visible by the IRT image, and the handwritten mark on the opposite side of the banknote is captured by the VR sensor.
To make a further comparison with an equal number of fitness levels, we conducted the experiments of multinational banknote fitness classification with the two fitness levels of fit and unfit on the three currency types (USD, KRW, and INR) in the database. Since the fitness levels of the banknotes in the database were determined by human experts based on the densitometer measurement values [
10], it is difficult to manually and subjectively reassign an additional level of normal for USD banknotes, as well as reassign the normal banknotes of INR and KRW into fit and unfit classes. As a result, we considered the experiments with the two fitness levels of fit and unfit cases. With the normal banknotes excluded from the INR and KRW datasets, we modified the CNN structure to have two outputs, corresponding to the two classes of fit and unfit of the three national currencies’ datasets. Experimental results of two-fold cross-validation of the two fitness levels classification for multiple currencies of INR, KRW and USD using the proposed CNN-based method are shown in
Table 5 in the form of confusion matrices. In
Table 6, we show the experimental results with average accuracy of each testing phase and overall testing results in
Table 5 separately for each national currency.
It can be seen from
Table 6 that the classification accuracies of INR and KRW were nearly 100% and the performance in the case of the USD dataset is the lowest among the three national currencies. The reason for the experimental results can be explained as follows. The data of the three fitness levels exists for the original INR and KRW databases. Therefore, without the data of normal banknotes from these databases, the possibility of overlap between the two classes of fit and unfit is lower than that among the three classes of fit, normal, and unfit. Whereas, the original USD dataset has two fitness levels, and the consequent possibility of overlap between classes is still maintained. Moreover, the third channel of input image in the case of USD is the duplication of the VR image in the second channel to adapt to the three-channel input of the CNN structure, resulting in the disparity of the fitness information in the input data between USD banknotes and the banknotes of the remaining currencies. This causes the lower accuracy in the case of USD compared to INR and KRW.
For confirming the generalization of the results of the proposed method, we conducted the additional experiments with a five-fold cross-validation method. That is, the database was randomly divided into five subsets, in which four subsets were used for training and the remainder was used for testing. These processes of training and testing are repeated five times with the alternated subsets, and we calculated the average testing accuracy.
Figure 15 shows the visualized filters in the first convolutional layer (L1) of the CNN models obtained by five training experiments. The visualization method is similar to that of
Figure 8. The confusion matrices of the experimental results with five-fold cross-validation using the proposed method are shown in
Table 7.
It can be seen from
Table 7 that the average classification accuracy of the five-fold cross-validation was slightly higher than that of the two-fold cross-validation using the proposed method, as shown in
Table 4, owing to the more intensive training tasks in the five-fold cross-validation compared to the two-fold cross-validation method.
In order to compare our method to the more complex network, we conducted comparative experiments with the ResNet model [
30]. In these experiments, we used the pretrained ResNet-50 model that was trained on the ImageNet database on MATLAB [
31] and conducted transfer learning [
32] with the following parameters: the first half number of the layers of ResNet-50 model is frozen while training, the number of training epochs was 10, and the learning rate was 0.001. The experimental results of two-fold cross-validation on the multinational banknote fitness database using ResNet-50 CNN structure are shown in
Table 8 in the form of confusion matrices.
It can be seen from
Table 8 that the results when using ResNet-50 were not as good as those of the proposed method in terms of lower average classification accuracy. This can be explained by the method for training the network models between the two methods. The ResNet model was pretrained with the ImageNet database, and we applied transfer learning on this model with the first half number of the layers frozen to reduce training time. Meanwhile, for the proposed CNN structure, we conducted training from scratch by our banknote image dataset, as the number of parameters is smaller than that of the ResNet model. As a result, the filters in the early layers of our proposed model are able to respond and select the details on banknote images that reflect the fitness characteristic of the banknote, such as stains, tearing or other damage. The overall classification accuracy was higher when using the proposed method than using the ResNet model.
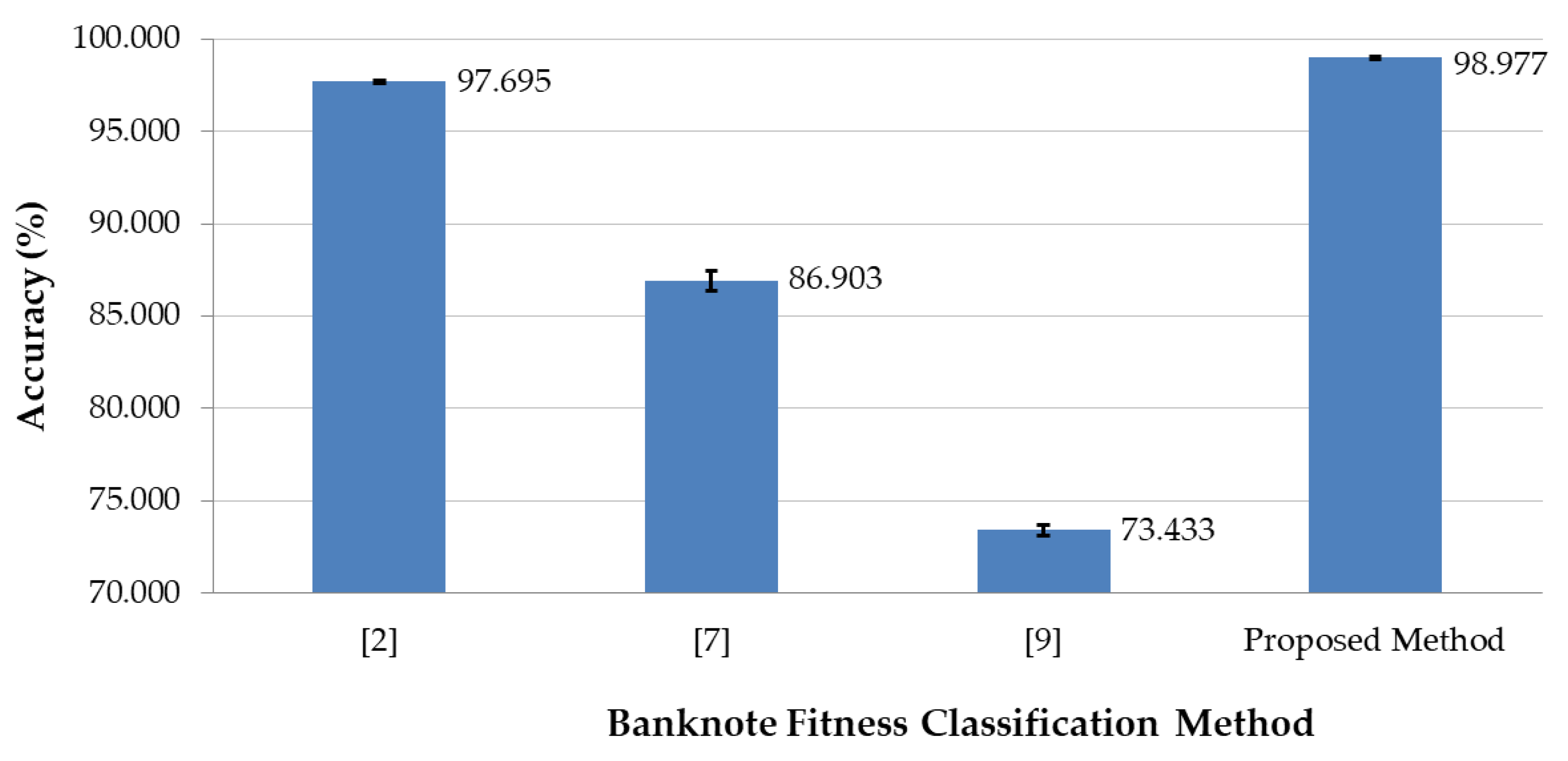
We also experimentally compared our proposed method to previous studies [
2,
7,
9]. The two-fold cross-validation method was also adopted in these comparative experiments. In the method proposed in [
2], the grayscale VR images of banknotes were used for the fitness classification by the CNN. This can be considered as equivalent to the VR1 experiment mentioned above. For the experiments using the method in [
7], we extracted the histogram features from the grayscale VR images of the banknotes and classified the fitness levels using a multilayered perceptron (MLP) network with 95 nodes in the input and hidden layers. Referring to [
9], we located the ROIs on the VR banknote images, performed Daubechies wavelet decomposition on the ROIs, and calculated the mean and standard variation values of the wavelet-transformed sub-bands. The means and standard variations were selected as the features to be classified for fitness levels by the SVM. The number of fitness classes in these three comparative experiments was maintained to that of the proposed method; consequently, we used the one-against-all training strategy for the SVM classifiers in the implementation of [
9]. For the comparative experiments using the DWT and SVM method [
9], the assumption of the prior knowledge of the currency type, denomination, and input direction of the banknote is required, as the ROI’s positions are different among the types of banknote images; meanwhile, in the cases of [
2,
7], we could conduct the comparative experiments with the multinational currency condition. The experiments with the previous fitness classification method were implemented in MATLAB [
33,
34].
Figure 16 shows the comparative experimental results of the proposed method to the previous study with the average classification accuracies of the two-fold cross-validation method.
As the method proposed in [
9] required the pre-classification of denomination and input direction of banknote images, we implemented the experiments using this DWT and SVM-based method with two-fold cross-validation separately on each type of banknote image. As a result, the classification accuracies were calculated separately according to the currency types, denominations and input directions of banknotes, and shown in
Table 9 for all the adopted methods. In the methods in [
2,
7] and the proposed method, the pre-classification of these categories was not required.
The experimental results in
Figure 16 show that the proposed method outperformed the methods of the previous studies, and in most of the cases of banknote types in
Table 9, the proposed method and the CNN-based method in [
2] outperformed the other methods in terms of higher average classification accuracy with two-fold cross validation. The reason for the comparative experimental results can be explained as follows. The histogram-based method of [
7] used only the brightness characteristic of the visible light banknote images, which were strongly affected by the illumination condition of the sensors, for the fitness levels determination. This consequently does not guarantee the reliability for the recognition of the other cases of degradation such as tearing or staining, which might occur sparsely on the banknote and are hardly represented by the brightness histogram characteristics. In the case of [
9], banknote fitness was classified by the features extracted from the ROIs that are the blank areas on the banknote images. This method is not effective for cases where damage or staining occurs on other areas of the banknotes. The most accurate recognition cases were the CNN-based methods of [
2] and the proposed method, in which the proposed method used the additional IRT images for the classification of the banknote fitness. The advantage of the CNN-based method is that both of the classifier’s parameters in the fully connected layers and the feature extraction stage’s parameters in the convolutional layers are trained with the training dataset. In addition, the proposed method used banknote images captured by various sensors of visible-light and near-infrared. Consequently, the appropriate features for the fitness classification of banknotes can be captured by the proposed system and extracted, as well as classified, by the CNN architecture to obtain the best accuracy, compared to the previous methods in the experiments shown in
Figure 16.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}