Nuclei, Primes and the Random Matrix Connection

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Summary
2. Introduction
2.1. Number Theory Preliminaries
2.2. Random Matrix Theory Preliminaries
2.3. Why Random Matrix Theory
3. Nuclear Physics History
3.1. Introduction
3.2. Nuclear Physics and Random Matrix Theory
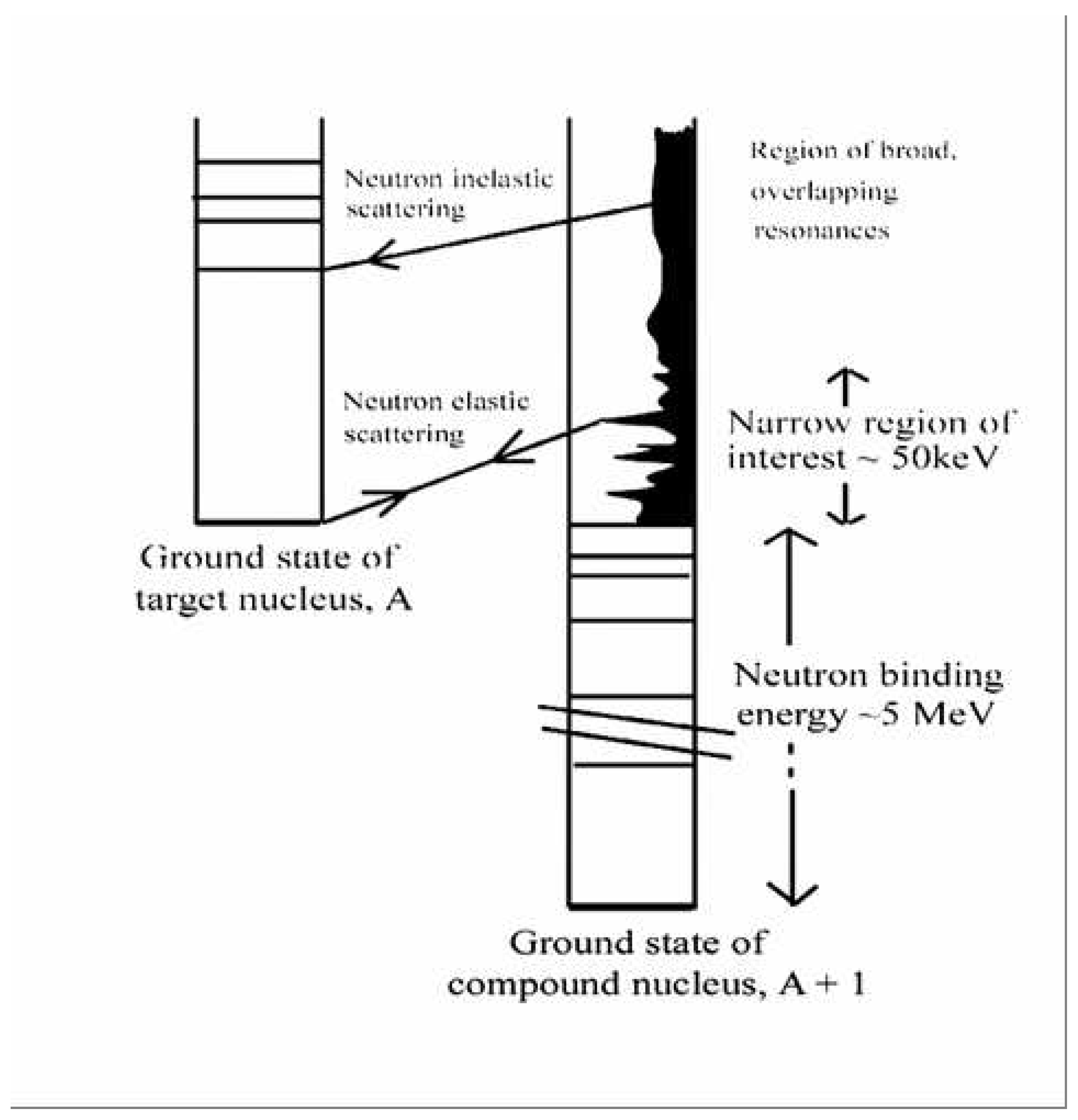
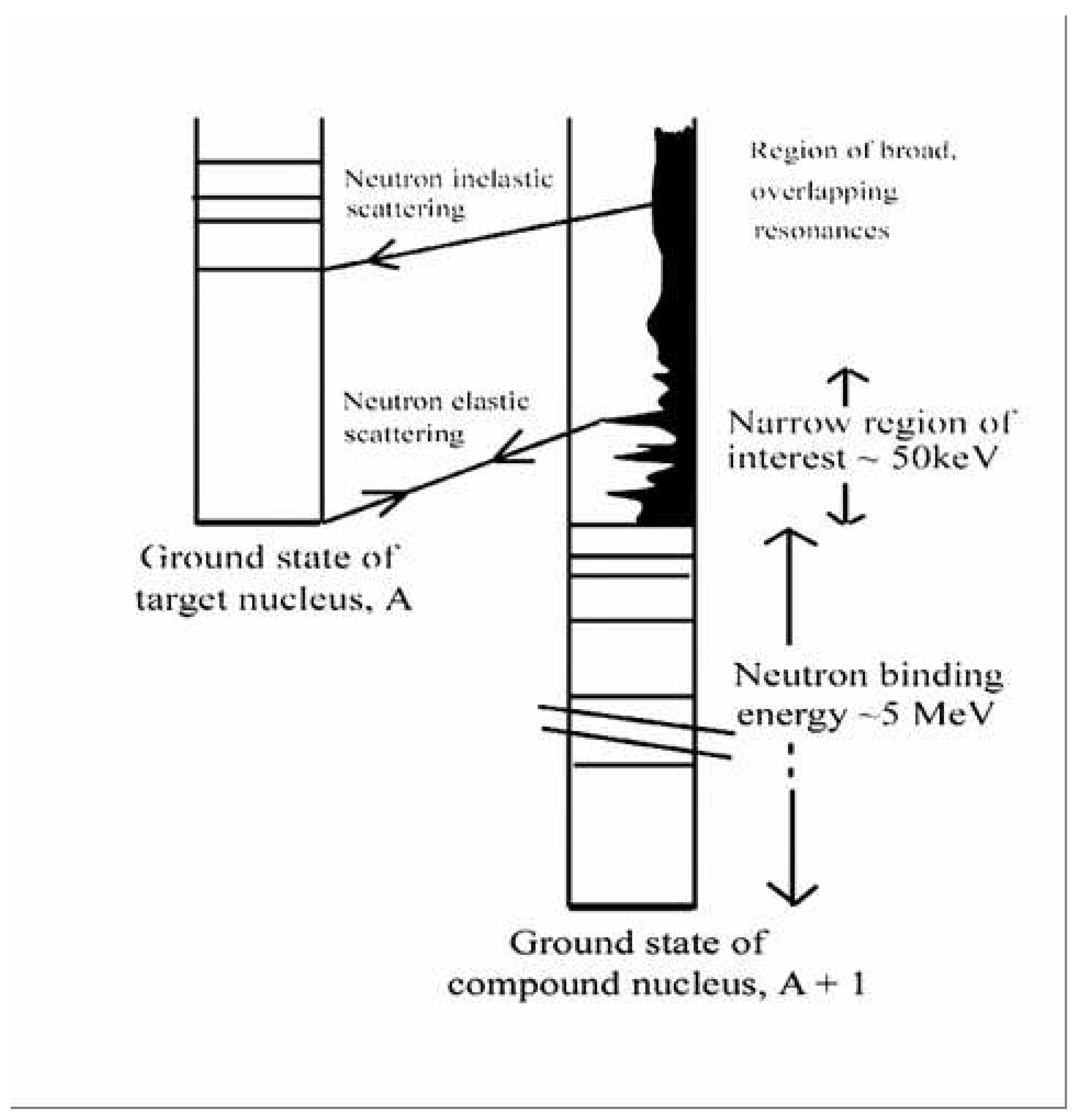
- Neutrons, with kinetic energies of a few electron-volts, excite states in compound nuclei at energies ranging from about 5 million electron-volts to almost 10 million electron-volts – typical neutron binding energies. Schematically, see Figure 2.
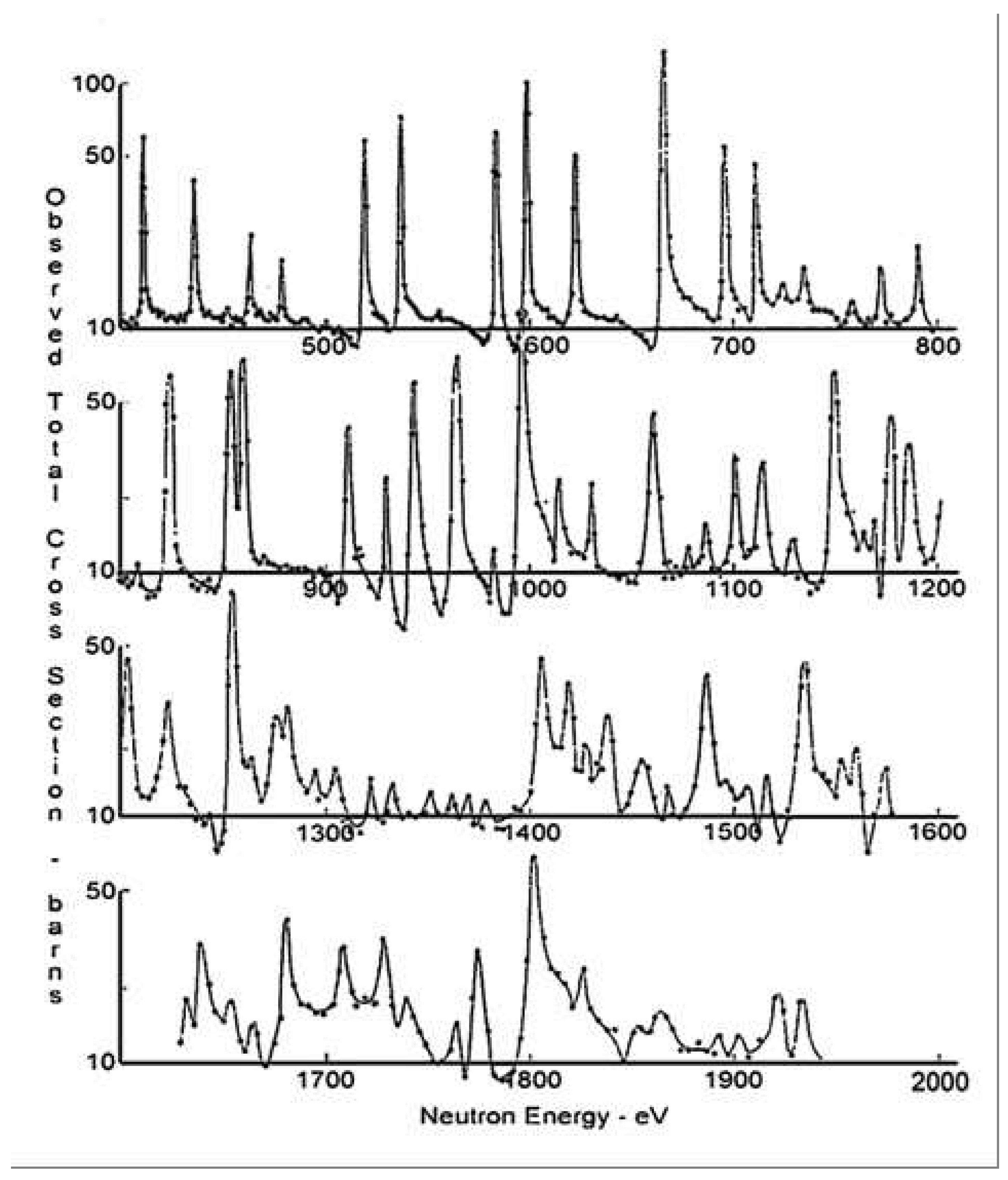
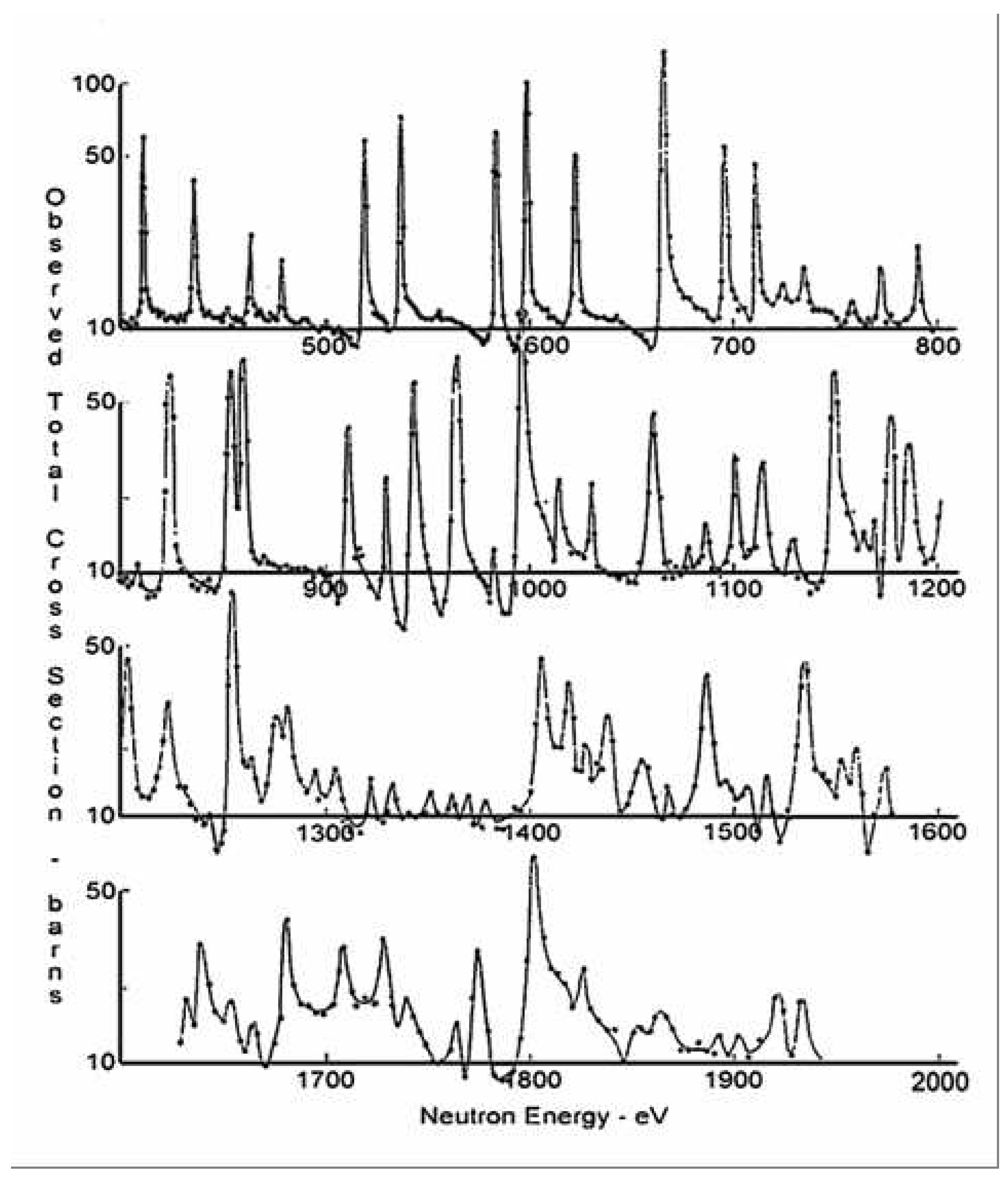
- Low-energy resonant states in heavy nuclei (mass numbers greater than about 100) have lifetimes in the range to seconds, and therefore they have widths of about 1 eV. The compound nucleus loses all memory of the way in which it is formed. It takes a relatively long time for sufficient energy to reside in a neutron before being emitted. This is a highly complex, statistical process. In heavy nuclei, the average spacing of adjacent resonances is typically in the range from a few eV to several hundred eV.
- Just above the neutron binding energy, the angular momentum barrier restricts the possible range of values of total spin of a resonance, J (J = I + i + l, where I is the spin of the target nucleus, i is the neutron spin, and l is the relative orbital angular momentum). This is an important technical point.
- The neutron time-of-flight method provides excellent energy resolution at energies up to several keV. (See Firk [53] for a review of time-of-flight spectrometers.)
- Doppler broadening of the resonance profile due to the thermal motion of the target nuclei; it is characterized by the quantity (eV), where A is the mass number of the target. If keV and , eV, a value that may be ten times greater than the natural width of the resonance.
- Resolution broadening of the observed profile due to the finite resolving power of the spectrometer. For a review of the experimental methods used to measure neutron total cross sections see Firk and Melkonian [54]. Lynn [55] has given a detailed account of the theory of neutron resonance reactions.
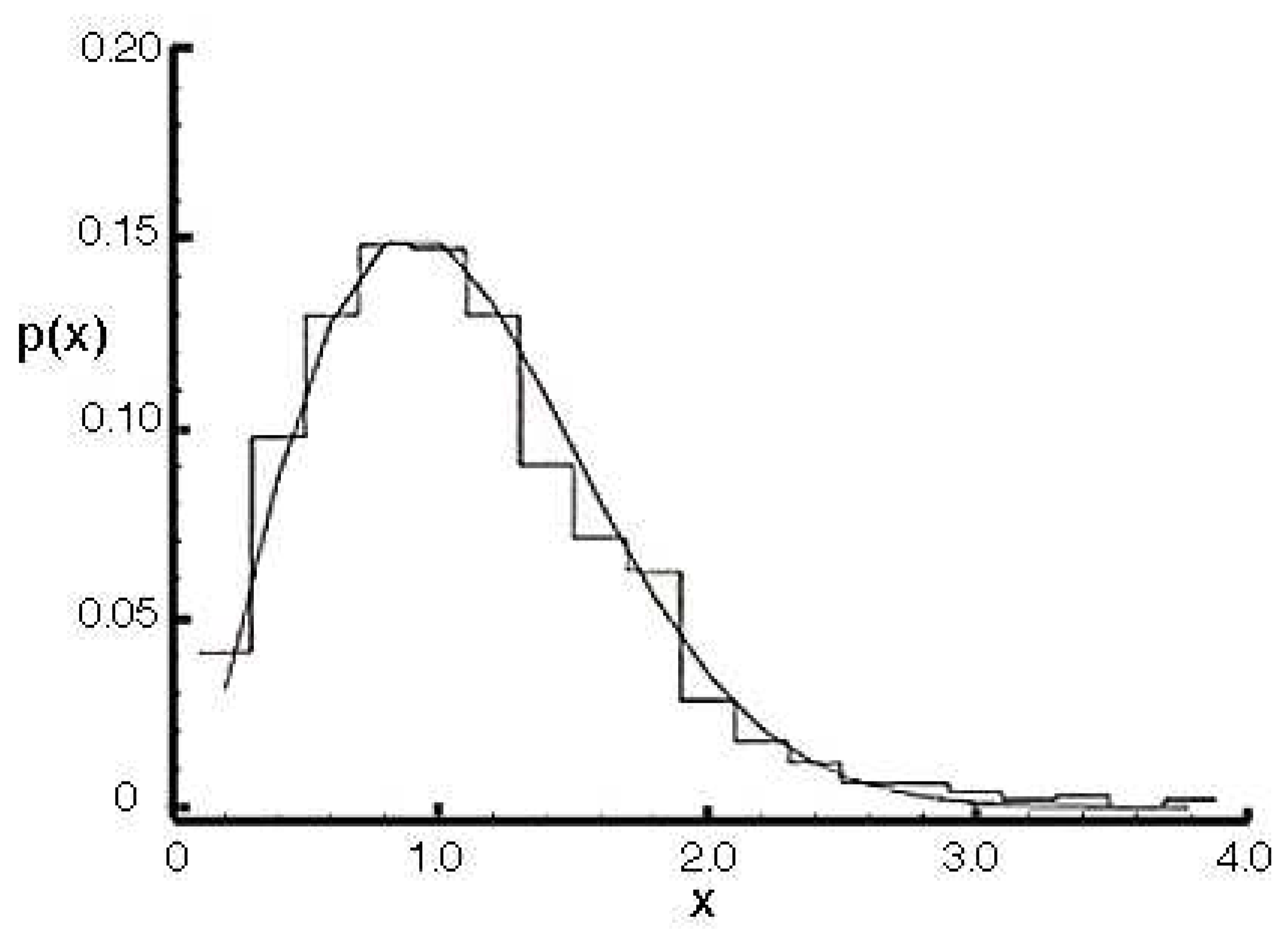
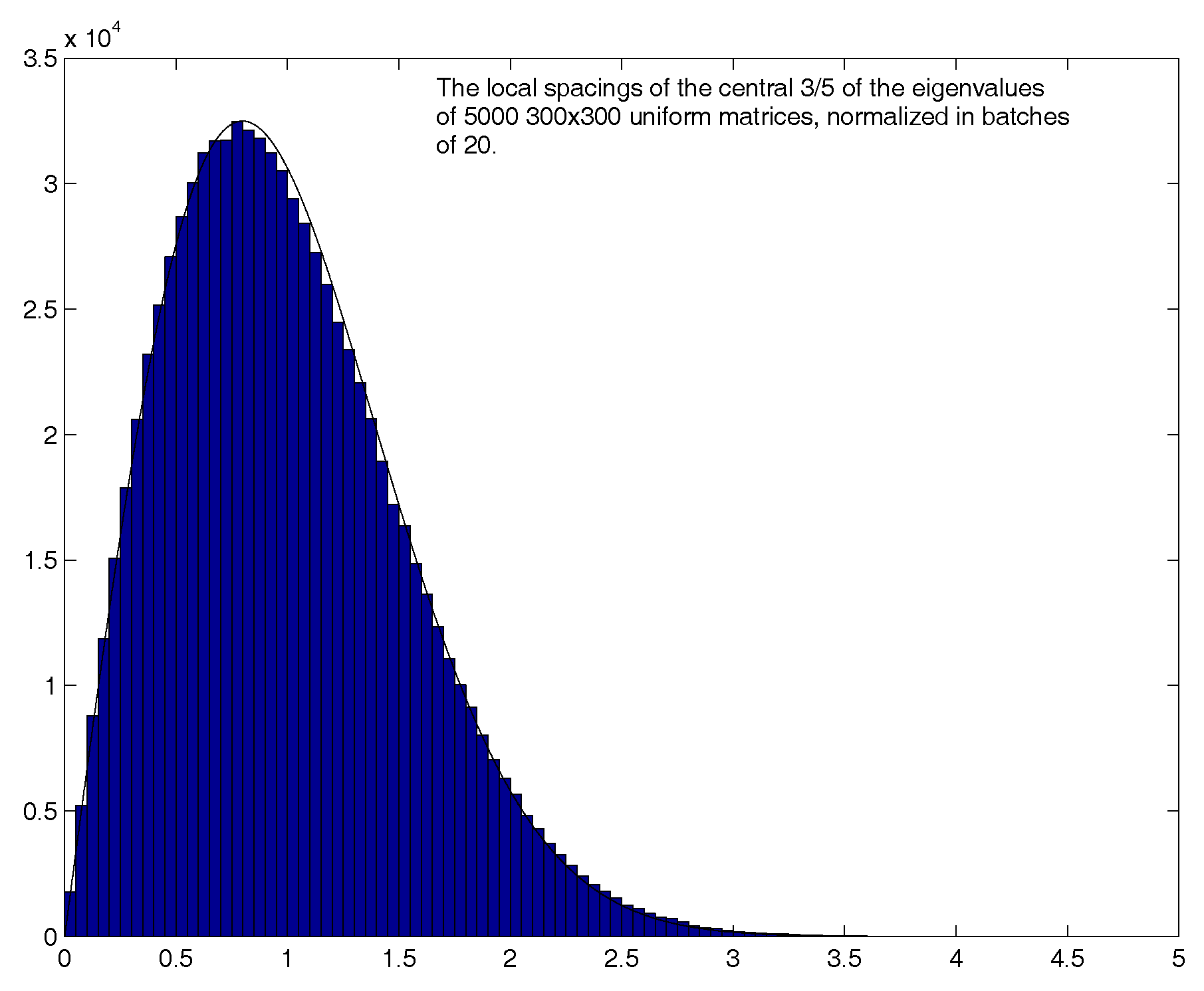
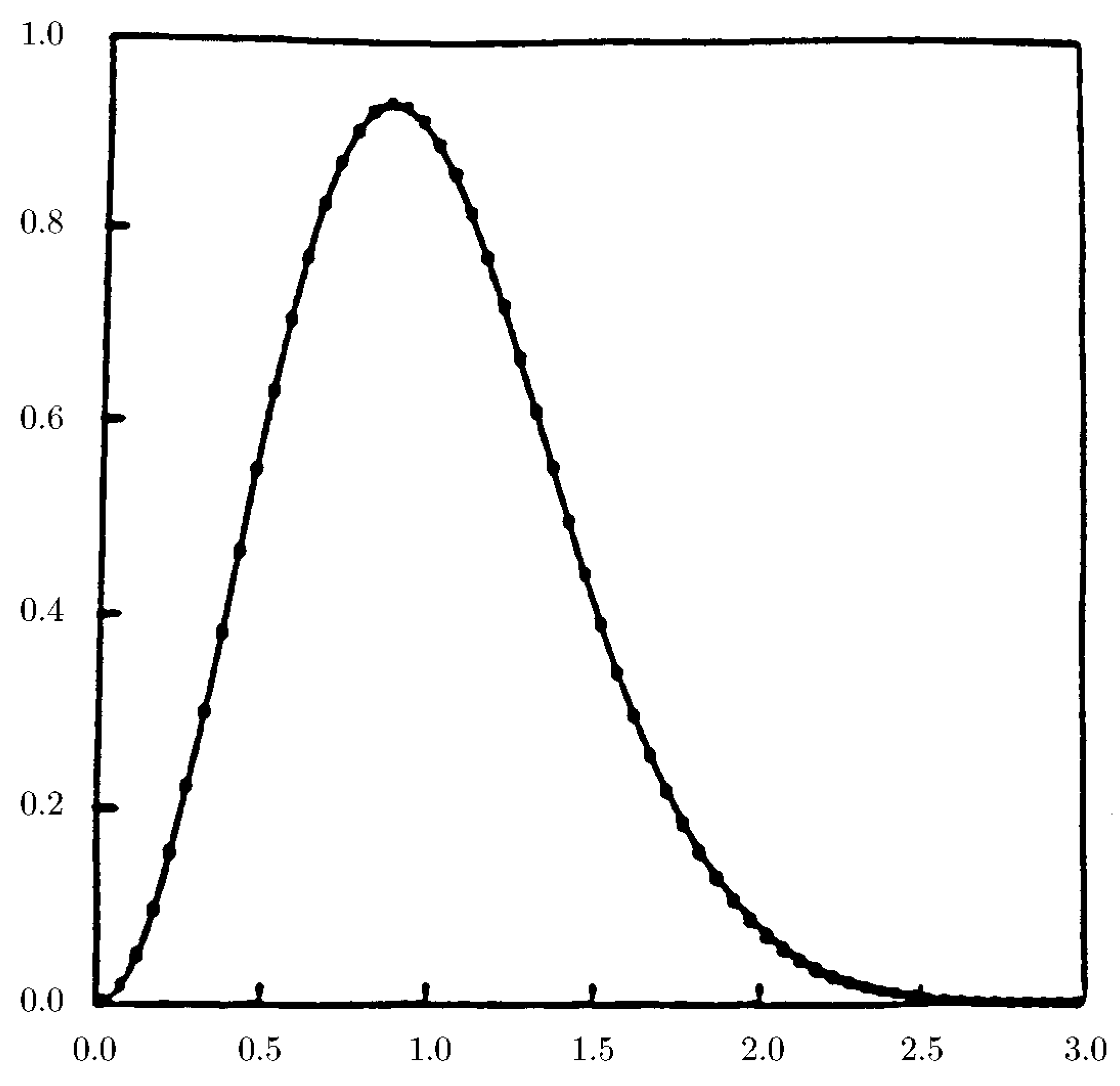
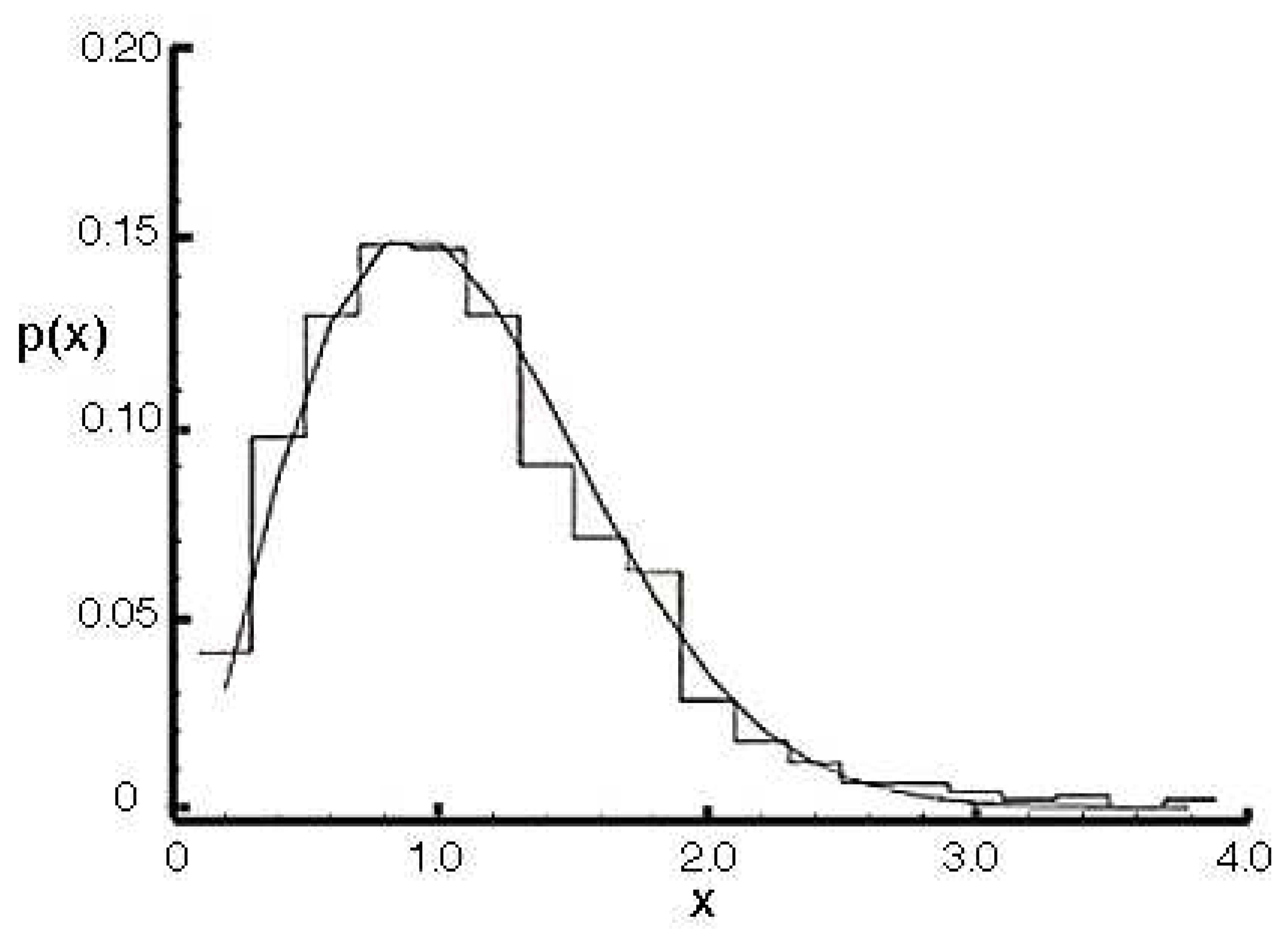
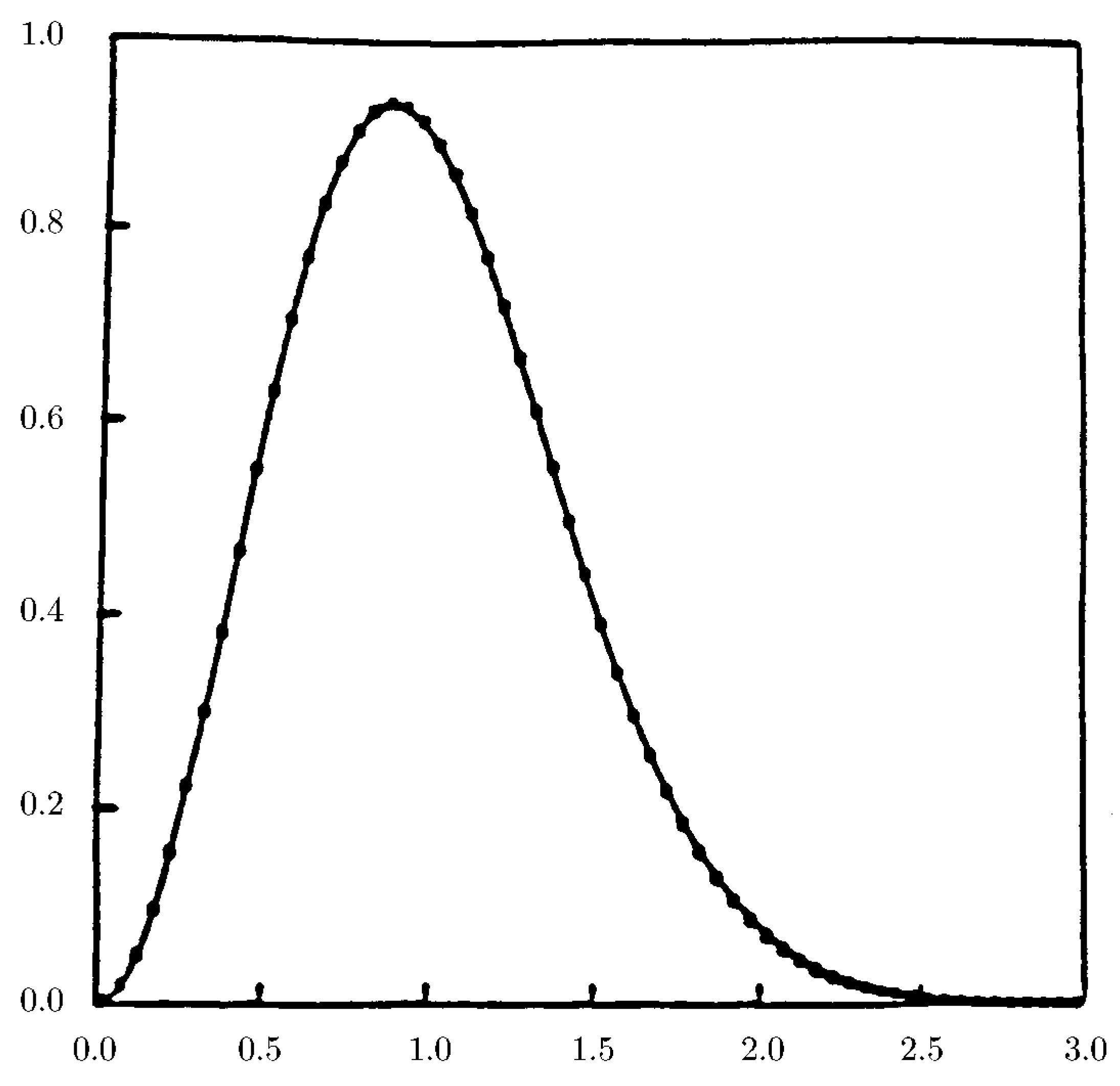
3.3. The Wigner Surmise
- the Poisson distribution;
- , the Rayleigh distribution;
- is approximately a normal distribution.33
3.4. Further Developments
- the Gaussian Othogonal Ensemble (GOE) for systems in which rotational symmetry and time-reversal invariance holds (the Wigner distribution): ;
- the Gaussian Unitary Ensemble (GUE) for systems in which time-reversal invariance does not hold (French et al. [31]): .
3.5. From Physics to Number Theory
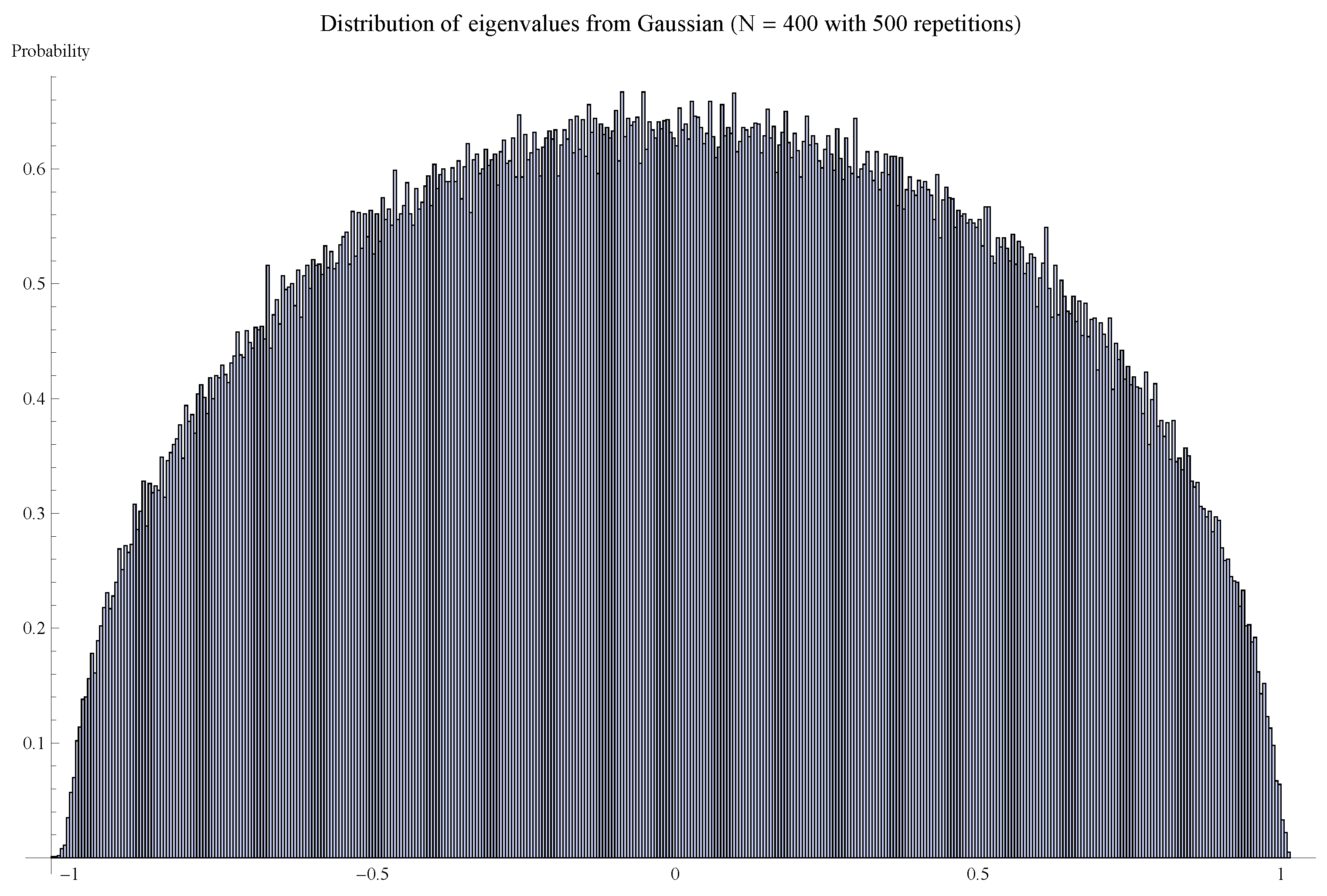
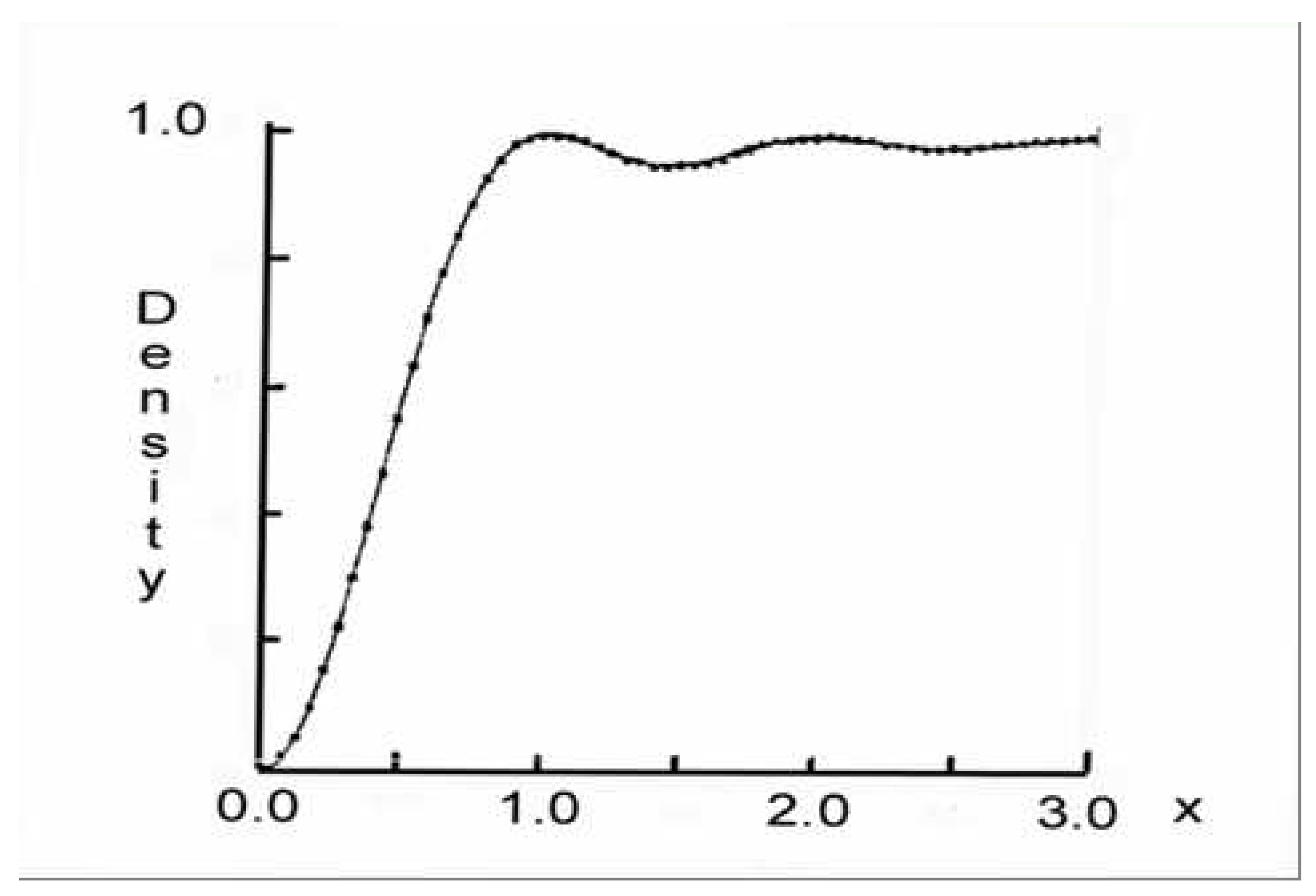
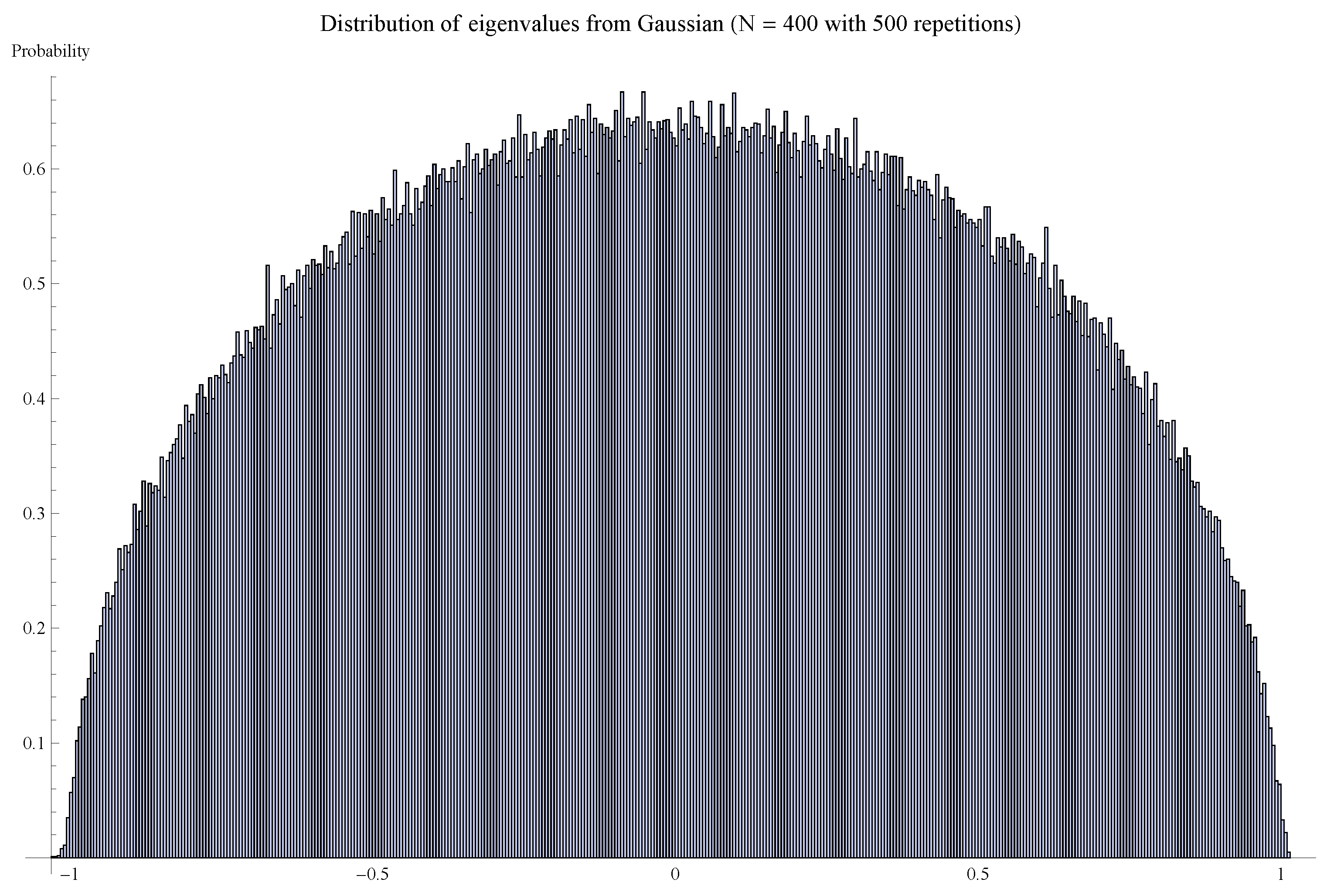
4. Wigner’s Semi-circle law
4.1. Wigner’s Semi-circle Law (Statement)
4.2. Wigner’s Semi-circle Law (Sketch of Proof)
- Determine the correct scale.
- Develop an explicit formula relating what we want to study to something we understand.
- Use an averaging formula to analyze the quantities above.
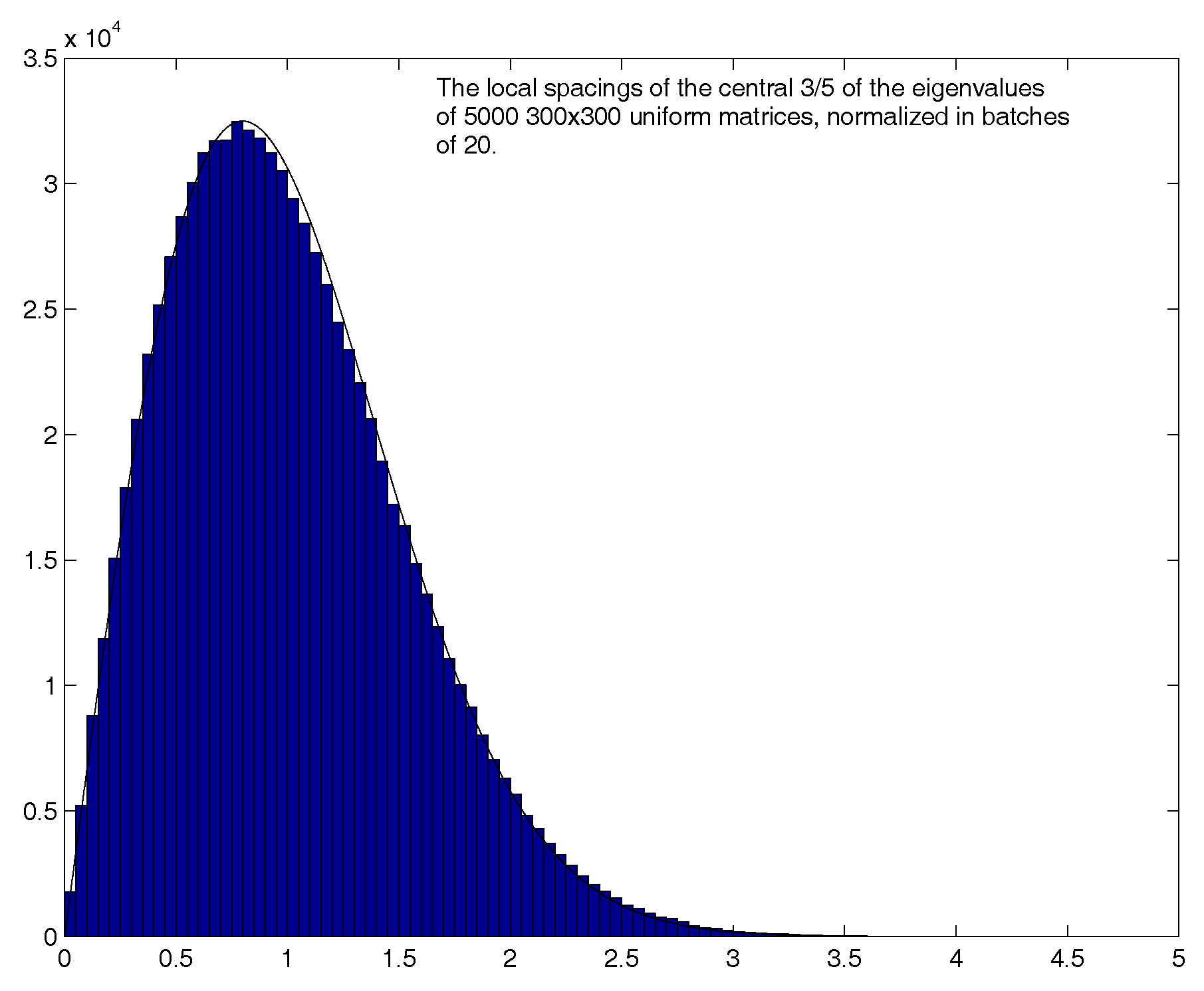
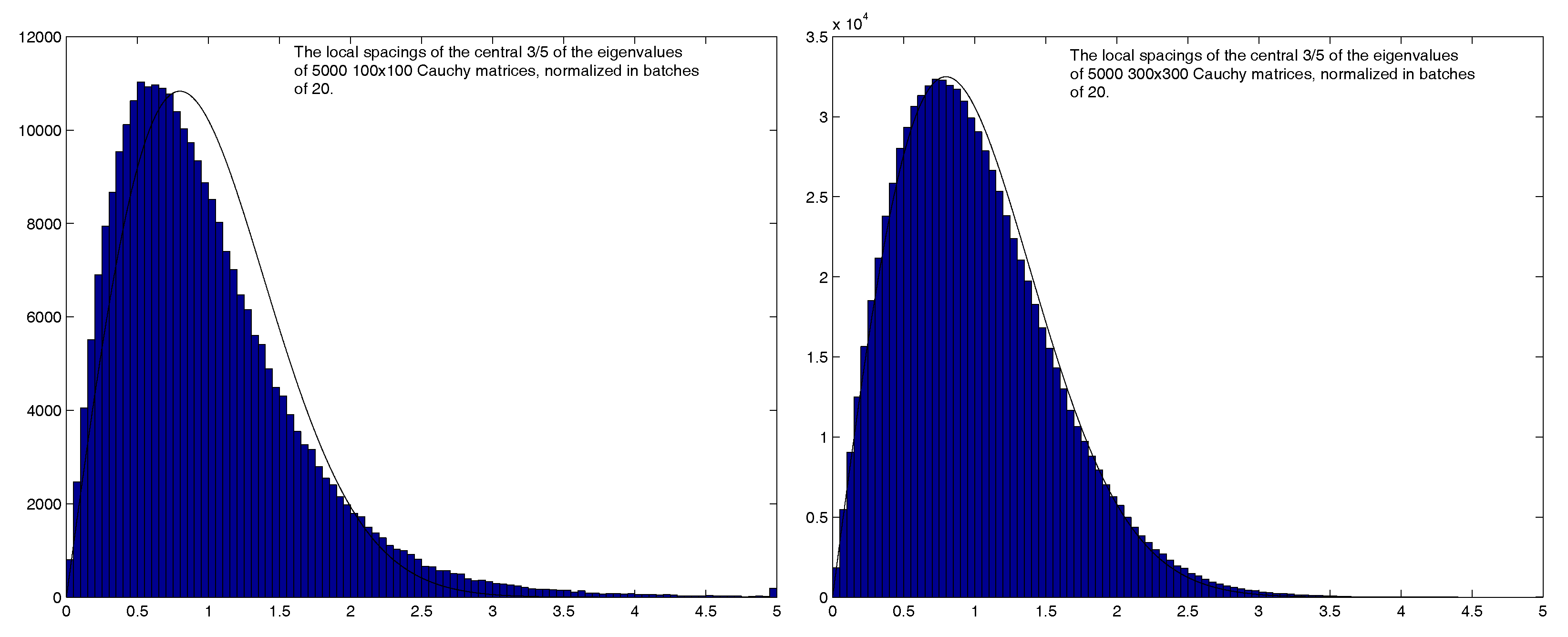
4.3. Additional statistics
5. From Random Matrix Theory to Number Theory
5.1. Preliminaries
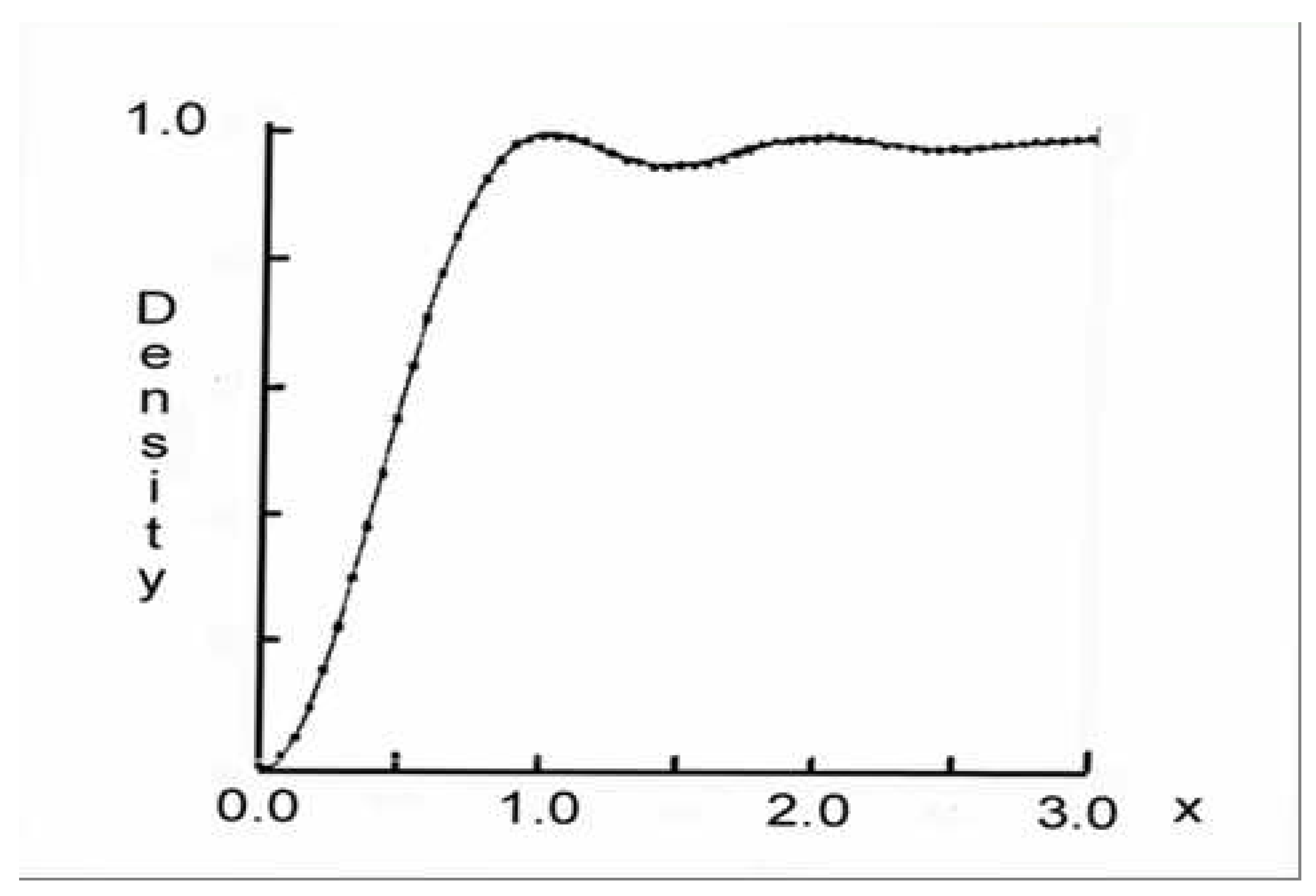
5.2. 1-level Density (Preliminaries)
- Cuspidal newforms: LetWe say f is a weight k holomorphic cuspform of level N ifwhere . As k or N tend to infinity, the behavior agrees with the scaling limit of orthogonal matrices.61
- Elliptic curves: Let be an elliptic curve over . For each we can specialize and get an elliptic curve . We can build an L-function, where is related to the number of solutions to . Our family is now with , and these families have orthogonal symmetry.
5.3. 1-level Density (Proofs)
5.4. Nuclear Physics Interpretation
5.5. Future avenues
- is 0 if the family has unitary symmetry, 1 if the family has symplectic symmetry and if the family has orthogonal symmetry;
- .
Acknowledgements
References
- Wishart, J. The generalized product moment distribution in samples from a normal multivariate population. Biometrika 1928, 20A, 32–52. [Google Scholar] [CrossRef]
- Wigner, E. Results and theory of resonance absorption. Gatlinburg Conference on Neutron Physics by Time-of-Flight, Oak Ridge, National Lab; Report No. ORNL–2309, 1957. Elsevier Science B.V, 2001. [Google Scholar]
- Montgomery, H. The pair correlation of zeros of the zeta function. In Analytic Number Theory, Proceedings of the Symposium on Pure Mathematicsm, Amer. Math. Soc.; Providence, 1973; pp. 181–193. [Google Scholar]
- Hayes, B. The spectrum of Riemannium. Am. Sci. 2003, 91, 296–300. [Google Scholar]
- Rockmore, D. Stalking the Riemann Hypothesis: The Quest to Find the Hidden Law of Prime Numbers; Pantheon: New York, USA, 2005. [Google Scholar]
- Conrey, J.B. Mathematics unlimited — 2001 and Beyond; Springer-Verlag: Berlin, 2001; L-Functions and random matrices; pp. 331–352. [Google Scholar]
- Conrey, J.B. The Riemann hypothesis. Notices of the AMS 2003, 50, 341–353. [Google Scholar]
- Forrester, P.J.; Snaith, N.C.; Verbaarschot, J.J.M. Developments in Random Matrix Theory. J. Phys. A 2003, 36, R1–R10. [Google Scholar] [CrossRef]
- Katz, N.; Sarnak, P. Zeros of zeta functions and symmetries. Bull. AMS 1999, 36, 1–26. [Google Scholar] [CrossRef]
- Keating, J.P.; Snaith, N.C. Random matrices and L-functions. J. Phys. A: Math. Gen. 2003, 36, 2859–2881. [Google Scholar] [CrossRef]
- Mehta, M.L. Random Matrices, 3rd ed.; Elsevier: San Diego, CA, USA, 2004. [Google Scholar]
- Hardy, G.H.; Wright, E. An Introduction to the Theory of Numbers, 5th ed.; Oxford Science Publications, Clarendon Press: Oxford, UK, 1995. [Google Scholar]
- Sloane, N.J.A. The On-Line Encyclopedia of Integer Sequences. Article A000945. available online at http://www.research.att.com/∼njas/sequences/A000945.
- Erdös, P. Démonstration élémentaire du théore#x2018;me sur la distribution des nombres premiers; Scriptum 1; Centre Mathe#x2018;matique: Amsterdam, 1949. [Google Scholar]
- Selberg, A. An Elementary Proof of the Prime Number Theorem. Ann. Math. 1949, 50, 305–313. [Google Scholar] [CrossRef]
- Miller, S.J.; Takloo-Bighash, R. An Invitation to Modern Number Theory; Princeton University Press: Princeton, NJ, USA, 2006. [Google Scholar]
- Davenport, H. Graduate Texts in Mathematics Series: Multiplicative Number Theory, 2nd ed.; revised by Montgomery, H.; Springer-Verlag: New York, USA, 1980; p. 74. [Google Scholar]
- Riemann, G.F.B. Über die Anzahl der Primzahlen unter einer gegebenen Grösse. Monatsber. Königl. Preuss. Akad. Wiss. Berlin 1859, 671–680, See [19] for an English translation. [Google Scholar]
- Edwards, H.M. Riemann’s Zeta Function; Dover Publications: New York, 1974. [Google Scholar]
- Lang, S. Graduate Texts in Mathematics: Complex Analysis; Springer-Verlag: New York, USA, 1999. [Google Scholar]
- Stein, E.; Shakarchi, R. Complex Analysis; Princeton University Press: Princeton, NJ, USA, 2003. [Google Scholar]
- Hadamard, J. Sur la distribution des zéros de la fonction ζ(s) et ses conséquences arithmétiques. Bull. Soc. math. France 1896, 24, 199–220, Reprinted in [115]. [Google Scholar] [CrossRef]
- De la Vallée Poussin, C.J. Recherches analytiques la théorie des nombres premiers. Ann. Soc. scient. Brux. 1896, 20, 183–256, Reprinted in [115]. [Google Scholar]
- Goldfeld, D. The Elementary proof of the Prime Number Theorem, An Historical Perspective. In Number Theory, New York Seminar 2003; Chudnovsky, D., Chudnovsky, G., Nathanson, M., Eds.; Springer-Verlag: New York, USA, 2004; pp. 179–192. [Google Scholar]
- Brody, T.; Flores, J.; French, J.; Mello, P.; Pandey, A.; Wong, S. Random-matrix physics: spectrum and strength fluctuations. Rev. Mod. Phys. 1981, 53, 385–479. [Google Scholar] [CrossRef]
- Derrien, H.; Leal, L.; Larson, N. Status of new evaluation of the neutron resonance parameters of 238U ORNL. PHYSOR 2004, Chicago, USA, 25–29 April, 2004; Amer. Nucl. Soc.: Illinois, USA, 2004; Available on CD-ROM. [Google Scholar]
- Dyson, F. Statistical theory of the energy levels of complex systems: I, II, III. J. Mathematical Phys. 1962, 3, 140–175. [Google Scholar] [CrossRef]
- Dyson, F. The threefold way. Algebraic structure of symmetry groups and ensembles in quantum mechanics. J. Mathematical Phys. 1962, 3, 1199–1215. [Google Scholar] [CrossRef]
- Firk, F.; Lynn, J.E.; Moxon, M. Parameters of neutron resonances in U238 below 1.8 keV. In Proceedings of the International Conference on Nuclear Structure, Kingston, Toronto, Aug 29 - Sep 3, 1960; University of Toronto Press: Toronto, 1960; pp. 757–759. [Google Scholar]
- Firk, F.; Reid, G.; Gallagher, J. High resolution neutron time- of-flight experiments using the Harwell 15 MeV linear electron accelerator. Nucl. Instr. 1958, 3, 309–315. [Google Scholar] [CrossRef]
- French, J.; Kota, V.; Pandey, A.; Tomosovic, S. Bounds on time-reversal non-invariance in the nuclear Hamiltonian. Phys. Rev. Lett. 1985, 54, 2313–2316. [Google Scholar] [CrossRef] [PubMed]
- Gaudin, M. Sur la loi limite de l’espacement des valeurs propres d’une matrice aléatoire. Nucl. Phys. 1961, 25, 447–458. [Google Scholar] [CrossRef]
- Harvey, J.; Hughes, D. Spacings of nuclear energy levels. Phys. Rev. 1958, 109, 471–479. [Google Scholar] [CrossRef]
- Haq, R.; Pandey, A.; Bohigas, O. Fluctuation properties of nuclear energy levels: do theory and experiment agree? Phys. Rev. 1982, 48, 1086–1089. [Google Scholar] [CrossRef]
- Hughes, D. Neutron Cross Sections; Pergamon Press: New York, USA, 1957. [Google Scholar]
- Mehta, M.L. On the statistical properties of level spacings in nuclear spectra. Nucl. Phys. 1960, 18, 395–419. [Google Scholar] [CrossRef]
- Mehta, M.L.; Gaudin, M. On the density of the eigenvalues of a random matrix. Nucl. Phys. 1960, 18, 420–427. [Google Scholar] [CrossRef]
- Statistical Theories of Spectra: Fluctuations; Porter, C. (Ed.) Academic Press: New York, USA, 1965. [Google Scholar]
- Wigner, E. On the statistical distribution of the widths and spacings of nuclear resonance levels. Proc. Cambridge Phil. Soc. 1951, 47, 790–798. [Google Scholar] [CrossRef]
- Wigner, E. Characteristic vectors of bordered matrices with infinite dimensions. Ann. of Math. 1955, 2, 548–564. [Google Scholar] [CrossRef]
- Wigner, E. Statistical Properties of real symmetric matrices. In Canadian Mathematical Congress Proceedings; University of Toronto Press: Toronto, 1957; pp. 174–184. [Google Scholar]
- Wigner, E. Characteristic vectors of bordered matrices with infinite dimensions. II. Ann. of Math. Ser. 2 1957, 65, 203–207. [Google Scholar] [CrossRef]
- Wigner, E. On the distribution of the roots of certain symmetric matrices. Ann. of Math. Ser. 2 1958, 67, 325–327. [Google Scholar] [CrossRef]
- Casella, G.; Berger, R. Statistical Inference, 2nd ed.; Duxbury Advanced Series: Pacific Grove, CA, 2002. [Google Scholar]
- Shohat, J.A.; Tamarkin, J.D. The Problem of Moments; AMS: Providence, RI, 1943. [Google Scholar]
- Simon, B. The classical moment problem as a self-adjoint finite difference operator. Adv. Math. 1998, 137, 82–203. [Google Scholar] [CrossRef]
- Baik, J.; Borodin, A.; Deift, P.; Suidan, T. A Model for the Bus System in Cuernevaca (Mexico). Math. Phys. 2005, 1–9. Online available at http://arxiv.org/abs/math/0510414.
- Krbalek, M.; Seba, P. The statistical properties of the city transport in Cuernavaca (Mexico) and Random matrix ensembles. J. Phys. A: Math. Gen 2000, 33, L229–L234. [Google Scholar] [CrossRef]
- Whittaker, E. A Treatise on the Analytical Dynamics of Particles and Rigid Bodies: With an Introduction to the Problem of Three Bodies; Cambridge University Press: Dover, New York, 1944. [Google Scholar]
- Reif, F. Fundamentals of Statistical and Thermal Physics; McGraw-Hill: New York, USA, 1965. [Google Scholar]
- Diaconis, P. “What is a random matrix?”. Notices Amer. Math. Soc. 2005, 52, 1348–1349. [Google Scholar]
- Diaconis, P. Patterns of Eigenvalues: the 70th Josiah Willard Gibbs Lecture. Bull. Amer. Math. Soc. 2003, 40, 155–178. [Google Scholar] [CrossRef]
- Firk, F. Neutron Time-of-Flight Spectrometers. In Detectors in Nuclear Science; Bromley, D.A., Ed.; Elsevier Science & Technology Books: North-Holland, Amsterdam, 1979; Volume 162, pp. 539–563. [Google Scholar]
- Firk, F.; Melkonian, E. Total Neutron Cross Section Measurements. In Experimental Neutron Resonance Spectroscopy; Harvey, J.A., Ed.; Academic Press: New York, USA, 1970; pp. 101–154. [Google Scholar]
- Lynn, J.E. The Theory of Neutron Resonance Reactions; The Clarendon Press: Oxford, UK, 1968. [Google Scholar]
- Rosen, J.; Desjardins, J.S.; Rainwater, J.; Havens, W., Jr. Slow neutron resonance spectroscopy I. Phys. Rev. 1960, 118, 687–697. [Google Scholar] [CrossRef]
- Desjardins, J.S.; Rosen, J.; Rainwater, J.; Havens, W., Jr. Slow neutron resonance spectroscopy II. Phys. Rev. 1960, 120, 2214–2224. [Google Scholar] [CrossRef]
- Garg, J.; Ranwater, J.; Peterson, J.; Havens, W., Jr. Neutron resonance spectroscopy III. Th 232 and U238. Phys. Rev. 1964, 134, 985–1009. [Google Scholar] [CrossRef]
- Gurevich, I.I.; Pevzner, M.I. Repulsion of nuclear levels. Physica 1956, 22, 1132. [Google Scholar] [CrossRef]
- Landau, L.; Smorodinski, Ya. Lektsii po teorii atomnogo yadra. Gos Izd. tex - teoreyicheskoi Lit. Moscow 1955, 92–94. [Google Scholar]
- Weibull, W. A statistical distribution function of wide applicability. J. Appl. Mech. Trans. 1951, 18, 293–297. [Google Scholar]
- Miller, S.J. A derivation of the Pythagorean Won-Loss Formula in baseball. Chance Magazine 2007, 20, 40–48. [Google Scholar] [CrossRef]
- Porter, C.; Rosenzweig, N. Repulsion of energy levels in complex atomic spectra. Phys. Rev. 1960, 120, 1698–1714. [Google Scholar]
- Bohigas, O.; Giannoni, M.; Schmit, C. Characterization of chaotic quantum spectra and universality of level fluctuation laws. Phys. Rev. Lett. 1984, 52, 1–4. [Google Scholar] [CrossRef]
- Alhassid, Y. The Statistical Theory of Quantum Dots. Rev. Mod. Phys. 2000, 72, 895–968. [Google Scholar] [CrossRef]
- Hardy, G.H. Sur les Zéros de la Fonction ζ(s) de Riemann. C. R. Acad. Sci. Paris 1914, 158, 1012–1014, Reprinted in [115]. [Google Scholar]
- Selberg, A. On the zeros of Riemann’s zeta-function. Skr. Norske Vid. Akad. Oslo I. 1942, 10, 1–59. [Google Scholar]
- Levinson, N. More than one-third of the zeros of Riemann’s zeta function are on σ = 1/2. Adv. In Math. 1974, 13, 383–436. [Google Scholar] [CrossRef]
- Conrey, J.B. More than two fifths of the zeros of the Riemann zeta function are on the critical line. J. Reine angew. Math. 1989, 399, 1–16. [Google Scholar]
- Stark, H.M. The Gauss Class-Number Problems. Clay Math. Proc. 2007, 7, 247–250. Online available at http://www.claymath.org/publications/Gauss Dirichlet/stark.pdf.
- Watkins, M. Class numbers of imaginary quadratic fields. Math. Comp. 2004, 73, 907–938. [Google Scholar] [CrossRef]
- Conrey, J.B.; Iwaniec, H. Spacing of Zeros of Hecke L-Functions and the Class Number Problem. Acta Arith 2002, 103, 259–312. [Google Scholar] [CrossRef]
- Goldfeld, D. The class number of quadratic fields and the conjectures of Birch and Swinnerton-Dyer. Ann. Scuola Norm. Sup. Pisa Cl. Sci. 3 1976, 4, 624–663. [Google Scholar]
- Gross, B.; Zagier, D. Heegner points and derivatives of L-series. Invent. Math. 1986, 84, 225–320. [Google Scholar] [CrossRef]
- Odlyzko, A. On the distribution of spacings between zeros of the zeta function. Math. Comp. 1987, 48, 273–308. [Google Scholar] [CrossRef]
- Odlyzko, A. The 1022-nd zero of the Riemann zeta function. Proceedings Conference on Dynamical, Spectral and Arithmetic Zeta-Function; van Frankenhuysen, M., Lapidus, M.L., Eds.; 2001. Online available at http://www.research.att.com/~amo/doc/zeta.html.
- Erdös, L.; Ramirez, J.A.; Schlein, B.; Yau, H.-T. Bulk Universality for Wigner Matrices. Preprint: http://arxiv.org/abs/0905.4176.
- Erdös, L.; Schlein, B.; Yau, H.-T. Wegner estimate and level repulsion for Wigner random matrices. Preprint: http://arxiv.org/abs/0905.4176.
- Tao, T.; Vu, V. From the Littlewood-Offord problem to the Circular Law: universality of the spectral distribution of random matrices. Bull. Amer. Math. Soc. 2009, 46, 377–396. [Google Scholar] [CrossRef]
- Tao, T.; Vu, V. Random matrices: universality of local eigenvalue statistics up to the edge. Comm. Math. Phys. Preprint: http://arxiv.org/PS cache/arxiv/pdf/0908/0908.1982v1.pdf.
- Grimmett, G.R.; Stirzaker, D.R. Probability and Random Processes, 3rd ed.; Oxford University Press, 2001. [Google Scholar]
- Feller, W. An Introduction to Probability Theory and Its Applications, 2nd ed.; John Wiley & Sons: New York, USA, 1971. [Google Scholar]
- Hammond, C.; Miller, S.J. Eigenvalue spacing distribution for the ensemble of real symmetric Toeplitz matrices. J. Theoret. Probab. 2005, 18, 537–566. [Google Scholar] [CrossRef]
- Massey, A.; Miller, S.J.; Sinsheimer, J. Eigenvalue spacing distribution for the ensemble of real symmetric palindromic Toeplitz matrices. J. Theor. Probab. 2007, 20, 637–662. [Google Scholar] [CrossRef]
- Rubinstein, M. Low-lying zeros of L-functions and random matrix theory. Duke Math. J. 2001, 109, 147–181. [Google Scholar] [CrossRef]
- Rudnick, Z.; Sarnak, P. Zeros of principal L-functions and random matrix theory. Duke Math. J. 1996, 81, 269–322. [Google Scholar] [CrossRef]
- Gao, P. N-level density of the low-lying zeros of quadratic Dirichlet L-functions. Ph.D. Dissertation, University of Michigan, Ann Arbor, MI, 2005. [Google Scholar]
- Stanley, R.P. Enumerative Combinatorics, ed. 2; Cambridge University Press: New York/Cambridge, 1999. [Google Scholar]
- Lehman, R. First order spacings of random matrix eigenvalues. Junior’s Thesis, Princeton University, Princeton, USA, 2001. [Google Scholar]
- McKay, B. The expected eigenvalue distribution of a large regular graph. Linear Algebra Appl. 1981, 40, 203–216. [Google Scholar] [CrossRef]
- Jakobson, D.; Miller, S.D.; Rivin, I.; Rudnick, Z. Eigenvalue spacings for regular graphs. In Emerging Applications of Number Theory, Vol. 109; Springer: New York, USA, 1999; pp. 317–327. [Google Scholar]
- Miller, S.J.; Novikoff, T.; Sabelli, A. The distribution of the second largest eigenvalue in families of random regular graphs. Exp. Mat. 2008, 17, 231–244. [Google Scholar] [CrossRef]
- Tracy, C.A.; Widom, H. Level-spacing distributions and the Airy kernel. Commun. Math. Phys. 1994, 159, 151–174. [Google Scholar] [CrossRef]
- Tracy, C.A.; Widom, H. On Orthogonal and Sympletic Matrix Ensembles. Commun. Math. Phys. 1996, 727–754. [Google Scholar] [CrossRef]
- Tracy, C.A.; Widom, H. Distribution functions for largest eigenvalues and their applications. In Proceedings of the ICM Vol. I, Beijing, China, Aug 20-28, 2002; Tatsien, L.I., Ed.; Higher Education Press: Beijing, China, 2002. [Google Scholar]
- Bryc, W.; Dembo, A.; Jiang, T. Spectral measure of large random Hankel, Markov and Toeplitz matrices. Ann. Probab. 2006, 34, 1–38. [Google Scholar] [CrossRef]
- Hejhal, D. On the triple correlation of zeros of the zeta function. Int. Math. Res. Notices 1994, 294–302. [Google Scholar]
- Katz, N.; Sarnak, P. Random Matrices, Frobenius Eigenvalues and Monodromy; AMS Colloquium Publications: Providence, RI, USA, 1999. [Google Scholar]
- Iwaniec, H.; Kowalski, E. Analytic Number Theory; AMS Colloquium Publications: Providence, RI, USA, 2004; Vol. 53. [Google Scholar]
- Miller, S.J. 1- and 2-level densities for families of elliptic curves: evidence for the underlying group symmetries. Compositio Mathematica 2004, 140, 952–992. [Google Scholar] [CrossRef]
- Hughes, C.; Miller, S.J. Low-lying zeros of L-functions with orthogonal symmetry. Duke Math. J. 2007, 136, 115–172. [Google Scholar] [CrossRef]
- Dueñez, E.; Miller, S.J. The low lying zeros of a GL(4) and a GL(6) family of L-functions. Compositio Mathematica 2006, 142, 1403–1425. [Google Scholar] [CrossRef]
- Fouvry, E.; Iwaniec, H. Low-lying zeros of dihedral L-functions. Duke Math. J. 2003, 116, 189–217. [Google Scholar] [CrossRef]
- Güloğlu, A. Low Lying Zeros of Symmetric Power L-Functions. Int. Math. Res. Not. 2005, 517–550. [Google Scholar] [CrossRef]
- Hughes, C.; Rudnick, Z. Linear statistics of low-lying zeros of L-functions. Q. J. Math. 2003, 54, 309–333. [Google Scholar] [CrossRef]
- Iwaniec, H.; Luo, W.; Sarnak, P. Low lying zeros of families of L-functions. Inst. Hautes Études Sci. Publ. Math. 2000, 91, 55–131. [Google Scholar] [CrossRef]
- Miller, S.J. Lower order terms in the 1-level density for families of holomorphic cuspidal newforms. Acta Arith. 2009, 137, 51–98. [Google Scholar] [CrossRef]
- Royer, E. Petits zéros de fonctions L de formes modulaires. Acta Arith. 2001, 99, 47–172. [Google Scholar] [CrossRef]
- Young, M. Low-lying zeros of families of elliptic curves. J. Amer. Math. Soc. 2006, 19, 205–250. [Google Scholar] [CrossRef]
- Conrey, J.B.; Gonek, S.M. High moments of the Riemann zeta-function. Duke Math. Jour. 2001, 107, 577–604. [Google Scholar]
- Conrey, J.B.; Ghosh, A. A conjecture for the sixth power moment of the Riemann zeta-function. Int. Math. Res. Not. 1998, 15, 775–780. [Google Scholar] [CrossRef]
- Conrey, J.B.; Farmer, D.W.; Keating, P.; Rubinstein, M.; Snaith, N. Integral moments of L-functions. Proc. London Math. Soc. 2005, 91, 33–104. [Google Scholar] [CrossRef]
- Keating, J.P.; Snaith, N.C. Random matrix theory and ζ(1/2+it). Commun. Math. Phys. 2000, 214, 57–89. [Google Scholar] [CrossRef]
- Keating, J.P.; Snaith, N.C. Random matrix theory and L-functions at s = 1/2. Commun. Math. Phys. 2000, 214, 91–110. [Google Scholar] [CrossRef]
- A Resource for the Afficionado and Virtuoso Alike. In The Riemann Hypothesis; Borwein, P.; Choi, S.; Rooney, B. (Eds.) CMS Books in Mathematics; Springer: New York, 2008. [Google Scholar]
- Conrey, J.B.; Farmer, D.W.; Zirnbauer, M.R. Autocorrelation of ratios of L-functions. 2007. Preprint: http://arxiv.org/abs/0711.0718.
- Conrey, J.B.; Farmer, D.W.; Zirnbauer, M.R. Howe pairs, supersymmetry, and ratios of random characteristic polynomials for the classical compact groups. Preprint: http://arxiv.org/abs/math-ph/0511024.
- Conrey, J.B.; Snaith, N.C. Applications of the L-functions Ratios Conjecture. Proc. London Math. Soc. 2007, 94, 594–646. [Google Scholar] [CrossRef]
- Dueñez, E.; Miller, S.J. The effect of convolving families of L-functions on the underlying group symmetries. In Proc. London Math. Soc.; London, United Kingdom, 2009; pp. 1–34. [Google Scholar]
- Fermigier, S. Étude expérimentale du rang de familles de courbes elliptiques sur ℚ. Exper. Math. 1996, 5, 119–130. [Google Scholar] [CrossRef]
- Frechet, M. Sur la loi de probabilite de l’ecart maximum. Ann. de la Soc. Polonaise de Mathematique 1927, 6, 93–116. [Google Scholar]
- Goes, J.; Jackson, S.; Miller, S.J.; Montague, D.; Ninsuwan, K.; Peckner, R.; Pham, T. A unitary test of the Ratios Conjecture. Preprint.
- Gonek, S.M.; Hughes, C.; Keating, J.P. A hybrid Euler-Hadamard product for the Riemann zeta function. Duke Math. J. 2007, 136, 507–549. [Google Scholar]
- Miller, S.J. Investigations of zeros near the central point of elliptic curve L-functions. Experim. Math. 2006, 15, 257–279, With an appendix by E. Dueñez. [Google Scholar] [CrossRef]
- Miller, S.J. A symplectic test of the L-Functions Ratios Conjecture. Int. Math. Res. Notices 2008. [Google Scholar] [CrossRef]
- Miller, S.J. An orthogonal test of the L-functions Ratios Conjecture. In Proceedings of the London Mathematical Society; Vol. 99, Part2; August 2009. [Google Scholar]
- Miller, S.J.; Montague, D. An Orthogonal Test of the L-functions Ratios Conjecture, II. Preprint.
- Montgomery, H.; Soundararajan, K. Beyond pair correlation. In Paul Erdös and His Mathematics, I (Vol. 11); Bolyai Society Mathematical Studies: Js Bolyai Math. Soc., Budapest, 2002; pp. 507–514. [Google Scholar]
- Ricotta, G.; Royer, E. Statistics for low-lying zeros of symmetric power L-functions in the level aspect. Preprint: http://arxiv.org/abs/math/0703760.
- Sarnak, P. Cambridge Trusts in Mathemetics: Some applications of modular forms; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Stopple, J. The quadratic character experiment. Exp. Math. 2009, 18, 193–200. [Google Scholar] [CrossRef]
- Wormald, N.C. Models of random regular graphs. In London Mathematical Society Lecture Note Series: Surveys in combinatorics (Canterbury); Cambridge University Press: Cambridge, UK, 1999; pp. 239–298. [Google Scholar]
- Young, M. Lower-order terms of the 1-level density of families of elliptic curves. Int. Math. Res. Not. 2005, 10, 587–633. [Google Scholar] [CrossRef]
| 1. | An integer is prime if the only positive integers that divide it are 1 and itself; if is not prime we say it is composite. The number 1 is neither prime nor composite, but instead is called a unit. |
| 2. | This property is called unique factorization, and is one of the most important properties of prime numbers. If 1 were considered a prime, then unique factorization would fail; for example, if 1 were prime then and would be two different factorizations of 1701. |
| 3. | The proof is by contradiction. Assume there are only finitely many primes. We label them , , ⋯, . Consider the number . Either this is a new prime not on our list, or it is composite. If it is composite, it must be divisible by some prime; however, it cannot be divisible by any prime on our list, as each of these give remainder 1. Thus m is either prime or divisible by a prime not on our list. In either case, our list was incomplete, proving that there are infinitely many primes. With a little bit of effort, one can show that Euclid’s argument proves there is a such that . The first few primes generated in this manner are 2, 3, 7, 43, 13, 53, 5, 6221671, 38709183810571, 139, 2801. A fascinating question is whether or not every prime is eventually listed (see [13]). |
| 4. | The notation means . |
| 5. | A complex number is of the form . We call x the real part and y the imaginary part; we frequently denote these by and , respectively. |
| 6. | Let . Then . The integral test from calculus states that this series converges if and only if converges, and this integral converges if . |
| 7. | To see this, use the geometric series formula (see Footnote 9) to expand as and note that occurs exactly once on each side (and clearly every term from expanding the product is of the form for some n. |
| 8. | We give two quick proofs of the importance of the Euler product by showing how it implies there are infinitely many primes. The first is as , which means there must be infinitely many primes as otherwise the product is finite. The second proof is to note is irrational; if there were only finitely many primes than the product would be rational. See for example [16] for details. |
| 9. | The subject of meromorphic continuation belongs to complex analysis. For the benefit of the reader who hasn’t seen this, we give a brief example that will be of use throughout this paper, namely the geometric series formula . Note that while the sum makes sense only when , is well-defined for all and agrees with the sum whenever . We say is a meromorphic continuation of the sum. |
| 10. | One proof is to use the Gamma function, . A simple change of variables gives = . Summing over n represents a multiple of as an integral. After some algebra we find =+, with . Using Poisson summation, we find , which yields =+ , from which the claimed functional equation follows. |
| 11. | Let f be a meromorphic function with only finitely many poles on an open set U which is bounded by a ‘nice’ curve . Thus at each point we have with . If we say f has a zero of order N. If we say f has a pole of order , and in this case we call the residue of f at (for clarity, we often denote this by ). If f does not have a pole at , then the residue is zero. Our assumption implies that there are only finitely many points where the residue is non-zero. The residue theorem states . One useful variant is to apply this to , which then counts the number of zeros of f minus the number of poles; another is to look at where is analytic, which we will do later when stating the explicit formula for the zeros of the Riemann zeta function. |
| 12. | Some care is required with this sum, as diverges. The solution involves pairing the contribution from with ; see for example [17]. |
| 13. | To see this, note , while the contribution from with is bounded by (this is because implies ). |
| 14. | Partial summation is the discrete analogue of integration by parts [16]. In our case, is equivalent to . |
| 15. | Note this is only true for zeros in the critical strip, namely ; for zeros outside the critical strip we can and do have zeros of not corresponding to zeros of because of poles of the Gamma function. |
| 16. | The Riemann Hypothesis is probably the most important mathematical aside ever in a paper. Riemann [18,19] wrote (translated into English; note when he talks about the roots being real, he’s writing the roots as , and thus is the Riemann Hypothesis): …and it is very probable that all roots are real. Certainly one would wish for a stricter proof here; I have meanwhile temporarily put aside the search for this after some fleeting futile attempts, as it appears unnecessary for the next objective of my investigation. Though not mentioned in the paper, Riemann had developed a terrific formula for computing the zeros of , and had checked (but never reported!) that the first few were on the critical line . His numerical computations were only discovered decades later when Siegel was looking through Riemann’s papers. |
| 17. | The prime number theorem is in fact equivalent to the statement that for any zero of . The prime number theorem was first proved independently by Hadamard [22] and de la Vallée Poussin [23] in 1896. Each proof crucially used results from complex analysis, which is hardly surprising given that Riemann had shown is related to the zeros of the meromorphic function . It was not until almost 50 years later that Erdös [14] and Selberg [15] obtained elementary proofs of the prime number theorem (in other words, proofs that did not use complex analysis, which was quite surprising as the prime number theorem was known to be equivalent to a statement about zeros of a meromorphic function). See [24] for some commentary on the history of elementary proofs. |
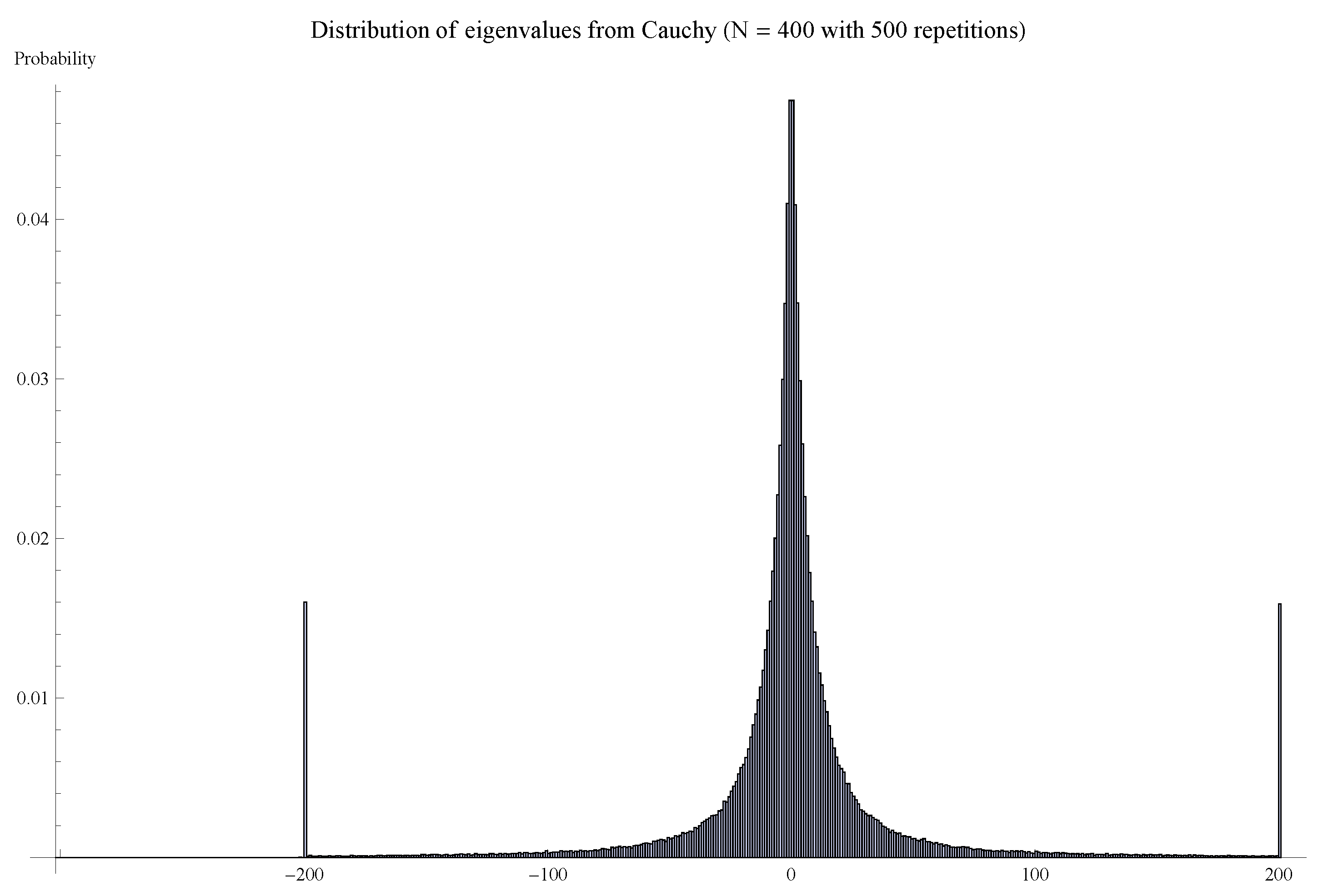
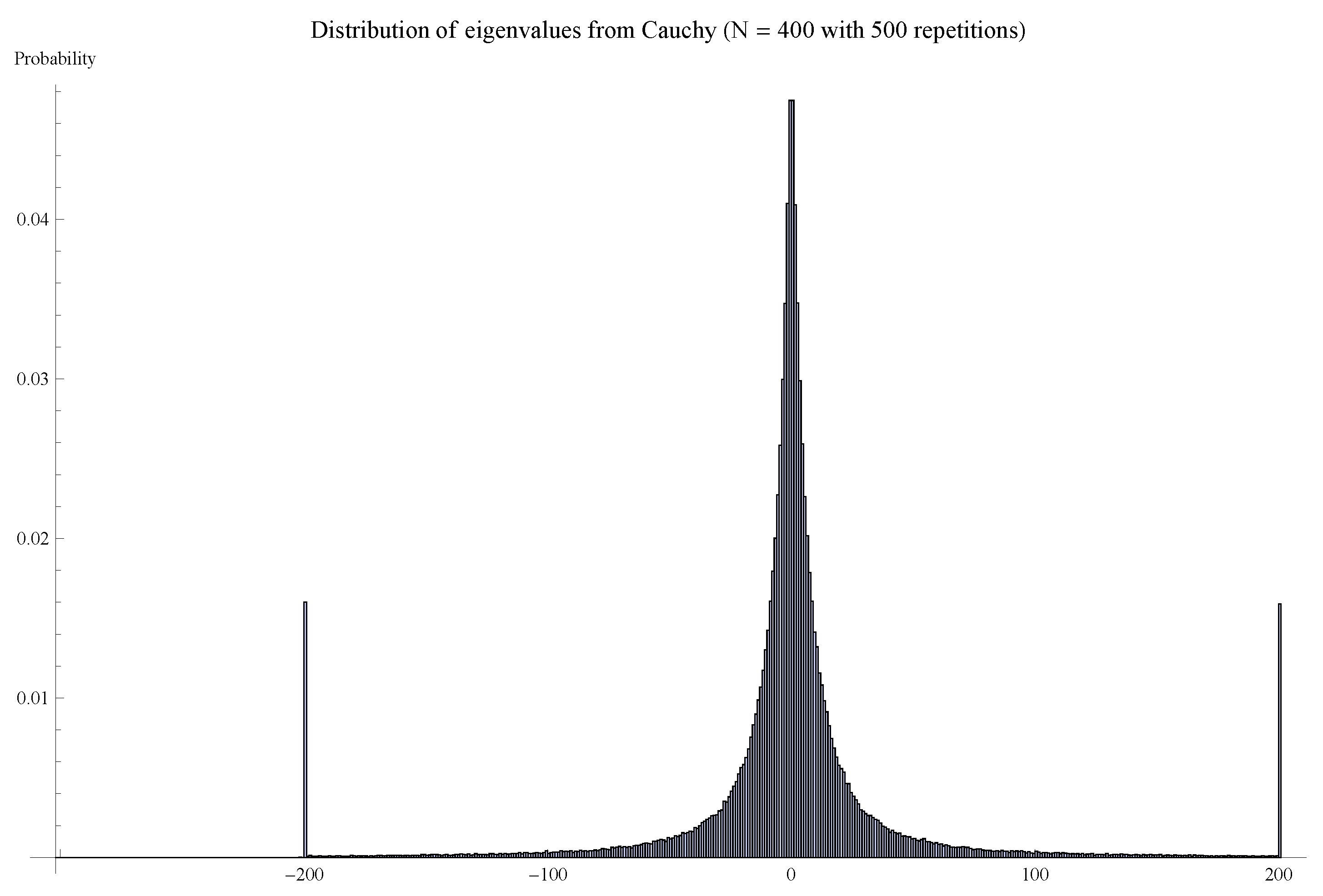
| 18. | By this we mean . If the integrand is not absolutely convergent, then the value could depend on how we tend to infinity. The standard example is the Cauchy distribution, . Note , and . |
| 19. | The reason is we can always adjust our probability distribution, in this case, to have mean 0 and variance 1 by simple translations and rescaling. For example, if the density p has mean and variance , then has mean 0 and variance 1. Thus the third moment (or the fourth if the third vanishes) are the first moments that truly show the ‘shape’ of the density. |
| 20. | For , consider and . For , the rth moment of and is . The reason for the non-uniqueness of moments is that the moment generating function does not converge in a neighborhood of the origin. See [44], Chapter 2. |
| 21. | The standard example is the function if and 0 otherwise. By using the definition of the derivative and L’Hopital’s rule, we see for all n, but clearly this function is non-zero if . Thus the radius of convergence is zero! This example illustrates how much harder real analysis can be than complex analysis. There if a function of a complex variable has even one derivative then it has infinitely many, and is given by its Taylor series in some neighborhood of the point. |
| 22. | We can consider the probability densities , where A is a probability density and . As almost all the probability (mass) is concentrated in a narrower and narrower band about the origin; we let be the limit with all the mass at one point. It is a discrete (as opposed to continuous) probability measure, with infinite density but finite mass. Note that acts like a unit point mass; however, instead of having its mass concentrated at the origin, it is now concentrated at . |
| 23. | As A is real symmetric, the eigenvalues are real (see Footnote 19) and thus this measure is well defined. |
| 24. | These ensembles have behavior that is often described by a parameter , which is 1 for real symmetric, 2 for complex Hermitian and 4 for symplectic matrices. |
| 25. | See [47,48]. We quote from [47] who quote from [48]: There is no covering company responsible for organizing the city transport. Consequently, constraints such as a time table that represents external influence on the transport do not exist. Moreover, each bus is the property of the driver. The drivers try to maximize their income and hence the number of passengers they transport. This leads to competition among the drivers and to their mutual interaction. It is known that without additive interaction the probability distribution of the distances between subsequent buses is close to the Poisonian distribution and can be described by the standard bus route model.... A Poisson-like distribution implies, however, that the probability of close encounters of two buses is high (bus clustering) which is in conflict with the effort of the drivers to maximize the number of transported passengers and accordingly to maximize the distance to the preceding bus. In order to avoid the unpleasant clustering effect the bus drivers in Cuernevaca engage people who record the arrival times of buses at significant places. Arriving at a checkpoint, the driver receives the information of when the previous bus passed that place. Knowing the time interval to the preceding bus the driver tries to optimize the distance to it by either slowing down or speeding up. The papers go on to show the behavior is well-modeled by random matrix theory (specifically, ensembles of complex Hermitian matrices)! |
| 26. | Explicitly, given two points with masses and and initial velocities and and located at and , we can describe how the system evolves in time given that gravity is the only force in play. |
| 27. | While there are known solutions for special arrangements of special masses, three bodies in general position is still open; see [49] for more details. |
| 28. | Whether or not Pluto will regain planetary status is an entirely different question. |
| 29. | This is reminiscent of the Central Limit Theorem. For example, if we average over all sequences of tossing a fair coin times, we obtain N heads, and most sequences of tosses will have approximately N heads, where approximately means deviations on the order of . |
| 30. | The first reference to this conjecture in the literature might not have been until 1973 by Montgomery [3]. |
| 31. | If v is an eigenvector with eigenvalue of a Hermitian matrix A (so with the complex conjugate transpose of A, then ; the first expression is while the last is , with non-zero. Thus , and the eigenvalues are real. This is one of the most important properties of Hermitian matrices, as it allows us to order the eigenvalues. |
| 32. | In fact, one of the authors has used Weibull distributions to model run production in major league baseball, giving a theoretical justification for Bill James’ Pythagorean Won-Loss formula [62]. |
| 33. | Obviously this Weibull cannot be a normal distribution, as they have very different decay rates for large x, and this Weibull is a one-sided distribution! What we mean is that for this Weibull is well approximated by a normal distribution which shares its mean and variance, which are (respectively) and . |
| 34. | Historically, Frechet introduced this distribution in 1927, and Nuclear Physicists often refer to the Weibull distribution as the Brody distribution [25]. |
| 35. | There is an interesting perspective to proving more than a third of the zeros lie on the critical line. As zeros off the line occur in complex conjugate pairs, proving more than a third of all non-trivial zeros lie on the line is equivalent to more than a half of all zeros with real part at least 1/2 are on the line! Thus, in this sense, a ‘majority’ of all zeros are on the critical line. |
| 36. | The class number measures how much unique factorization fails in the ring of integers of a finite extension of , and thus is an extremely important property of these fields. For example, has unique factorization, while does not (in the latter, note we can write 6 as either or , and none of these four numbers can be factored as without one of the two factors being a unit (the units are numbers in the ring whose norm is 1; in , these numbers are (in we would also have numbers such as , as ). The class number problem is to find all imaginary quadratic fields with a given class number; see [70,71] for more details and results. It turns out (see [72]) that if there are many small (relative to the average spacing) gaps between zeros of on the critical line, then there are terrific lower bounds for the class number; another connection between the class number and zeros of L-functions is through the work of Goldfeld [73] and Gross-Zagier [74]. |
| 37. | Of course, one has to invert these relations to find the eigenvalues! |
| 38. | |
| 39. | For example, imagine for all N we always had half the moments equal 0 and the other half equal ; then the average is but no measure is close to the system average. |
| 40. | Many of the papers in the field have large sections devoted to handling combinatorics; see for instance [83,85,86]. Interestingly, sometimes the combinatorics cannot be handled, and in [87] we believe the number theory and random matrix theory agree where both have been calculated, but we cannot do the combinatorics to prove this. |
| 41. | The proof is trivial if A is diagonal or upper diagonal, following by definition. As we only need this result for real symmetric matrices, which can be diagonalized, we only give the proof in this case. Let S be such that with diagonal. The claim follows from and . |
| 42. | With a little more work, we could calculate the variance of the average eigenvalue squared, using either the Central Limit Theorem or even Chebyshev’s Theorem (from probability). |
| 43. | This is similar in some sense to dimensional analysis arguments in physics, which detect parameter dependence but not the constants. For example, imagine a pendulum of mass m (in kilograms), length L (in meters) where the difference in rest height (when the pendulum is down) and the raised height (where it is at angle ) is meters. We assume the only force acting is gravity, with constant g (in meters per second squared). The period is how long (in seconds) it takes the pendulum to do a complete cycle, must be a function of m, L, and g; however, the only combinations of these quantities that give units of seconds are and ; thus the period must be a function of these two expressions. The correct answer turns out to be (at least for small initial displacements) approximately ; we are able to deduce the correct functional form, though the constants are beyond such analysis. |
| 44. | It is not hard to show the odd moments vanish by simple counting arguments. For the even moments, if the ’s are not matched in pairs then there is negligible contribution as . The proof follows by counting how many tuples there can be with a given matching, and then comparing that to (the proofs are somewhat easier if our distribution is even). For example, as we are assuming our distribution has zero mean, if ever there was an that was unmatched (so neither or occurs as the index in any other factor in the trace expansion, then the expectation of this term must vanish as each is drawn from a mean zero distribution. The number of valid pairings of the ’s (where everything is matched in pairs) is , which is the th moment of the standard normal; not ever matching contributes fully, though, and this is why the resulting moments are significantly smaller than the Gaussian’s. |
| 45. | The Catalan numbers are . They arise in a variety of combinatorial problems; see for example [88]. |
| 46. | If the ensemble of matrices had a different symmetry, the start of the proof proceeds as above but the combinatorics changes. For example, looking at Real Symmetric Toeplitz matrices (matrices constant along diagonals) leads to very different combinatorics (and in fact a different density of states than the semi-circle); see [83,84]. If we looked at d-regular graphs, the combinatorics differs again, this time involving local trees; see [90]. |
| 47. | A graph is d-regular if each vertex is connected to exactly d neighbors. |
| 48. | The Fourier transform of g is . |
| 49. | This means for any that (i.e., g and all its derivatives tend to zero faster than any polynomial). |
| 50. | We want (1) is symmetric; (2) for ; (3) rapidly as in the hyperplane ; see [86]. |
| 51. | The earliest occurrence was probably in Dirichlet’s work, who used L-functions attached to characters on to study primes in arithmetic progressions. Another example are elliptic curve L-functions, which (at least conjecturally) give information about the group of Mordell-Weil group of rational solutions of the elliptic curve. |
| 52. | This is because the zeros are tending to infinity. Thus, given any zero and any finite box, only finitely many zeros can be associated to it such that the required differences lie in the box. Therefore, this zero has negligible contribution in the limit as we are dividing by N. |
| 53. | For example, the Birch and Swinnerton-Dyer conjecture states the order of vanishing at the central point of an elliptic curve L-function equals the rank of the Mordell-Weil group of rational solutions of the elliptic curve; this is quite important information which we do not wish to discard! |
| 54. | These classical compact groups are much more natural random matrix ensembles. In our original formulation, we chose the matrix elements randomly and independently from some probability distribution p. What should we take for p? The GOE and GUE ensembles, where the entries are chosen from Gaussians, arise by imposing invariance on under orthogonal (respectively unitary) transformations; these are natural conditions to impose as the probability of a transformation should be independent of the coordinate system used to write it down. The classical compact groups come endowed with a natural probability, namely Haar measure. |
| 55. | The eigenvalues of a unitary matrix are of the form . To see this, let v be an eigenvector of U with eigenvalue . Note , which gives , so . Thus, similar to real symmetric and complex Hermitian matrices, we can parametrize the eigenvalues by a real quantity. |
| 56. | We use the normalization . The Fourier transform has many nice properties on the Schwartz space (see [21] for example). |
| 57. | These are very strong conditions, and most choices of will not satisfy these requirements. Fortunately there are many choices that do work, and these frequently encode information about arithmetically interesting problems. The most studied examples include Dirichlet L-functions, modular and Maass forms; see [99] for details. |
| 58. | For example, there are three flavors of orthogonal symmetry, and their 1-level densities are indistinguishable if the support of is contained in ; however, the 2-level densities of all three are distinguishable for arbitrarily small support [100]. Another example is in obtaining better decay rates for high vanishing at the central point in a family [101]. |
| 59. | This means we avoid the trivial character if n is relatively prime to m and 0 otherwise; this character gives rise to a simple modification of . |
| 60. | We could consider the related family of quadratic Dirichlet characters coming from a fundamental discriminant with ; this family agrees with the scaling limit of symplectic matrices. |
| 61. | There are actually three flavors of orthogonal groups. If all the signs of the functional equation are even, the corresponding group should be , and similarly if the signs are all odd. We refer the reader to the previously mentioned surveys for the details. |
| 62. | In fact, the case being studied here has the best averaging formula! For cuspidal newforms we have the Petersson formula, and for families of elliptic curves we can use periodicity in evaluating Legendre sums of cubic polynomials. In general, however, unless our family is obtained in some manner from a family such as one of these, we do not possess the needed averaging formula. |
| 63. | is the set where multiplication and addition are modulo m; for example, if , and then , so , while . The hardest step in proving that this is a group under multiplication is finding inverses; one way to accomplish this is with the Euclidean algorithm. |
| 64. | These properties mean , and . Further, though initially only defined on , we extend the definition to all of by setting . As , or for all . Thus has to be an root of unity. We see each of these roots gives rise to a character (one of which is the principal or trivial character); by multiplicativity once we know the character’s action on the generator we know it everywhere. |
| 65. | This is not surprising, as the above argument is quite crude, where we have inserted absolute values and thus lost the expected cancelation due to the terms having opposite sign. |
| 66. | This just asserts that any ‘nice’ L-function has all of its zeros in the critical strip having real part equal to 1/2. |
| 67. | If =, then is related to a product over primes of . It is conjectured that these functions have functional equations, satisfy the Riemann hypothesis, et cetera. The existence of the Rankin-Selberg convolution is known for just a few choices of the ’s. |
| 68. | There are several difficulties with the proofs in general, ranging from not knowing properties of the Rankin-Selberg convolution in general to not having a good averaging formula over general families. |
| 69. | A special case of this theorem was discovered by Dueñez-Miller in [102] in studies of a family of and a family of L-functions. The analysis there led to a disproof of a folklore conjecture that the theory of low-lying zeros of L-functions is equivalent to a theory of the distribution of signs of the functional equations in the family; see [102,119] for details. The key ingredient in the proofs is the universality of the second moments of the Satake parameters ; this is similar to the universality found by Rudnick and Sarnak [86] in the n-level correlations. The higher moments of the Satake parameters control the rate of convergence to the random matrix predictions. |
| 70. | Instead of attaching a symmetry constant, additionally one can attach a symmetry vector which incorporates other information, such as the rank of the family. |
| 71. | The search string was ’number theory and random matrix theory’. |
© 2009 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license http://creativecommons.org/licenses/by/3.0/.
Share and Cite
Firk, F.W.K.; Miller, S.J. Nuclei, Primes and the Random Matrix Connection. Symmetry 2009, 1, 64-105. https://doi.org/10.3390/sym1010064
Firk FWK, Miller SJ. Nuclei, Primes and the Random Matrix Connection. Symmetry. 2009; 1(1):64-105. https://doi.org/10.3390/sym1010064
Chicago/Turabian StyleFirk, Frank W. K., and Steven J. Miller. 2009. "Nuclei, Primes and the Random Matrix Connection" Symmetry 1, no. 1: 64-105. https://doi.org/10.3390/sym1010064
APA StyleFirk, F. W. K., & Miller, S. J. (2009). Nuclei, Primes and the Random Matrix Connection. Symmetry, 1(1), 64-105. https://doi.org/10.3390/sym1010064