Combined Use of Optical and Synthetic Aperture Radar Data for REDD+ Applications in Malawi


Abstract
1. Introduction
- (1)
- What is the added value of using time series data versus mono-temporal remote sensing data?
- (2)
- What is the added value of combining optical and SAR time series data?
- (3)
- Which of the two tested combination approaches (data-based vs. result-based) performs better?
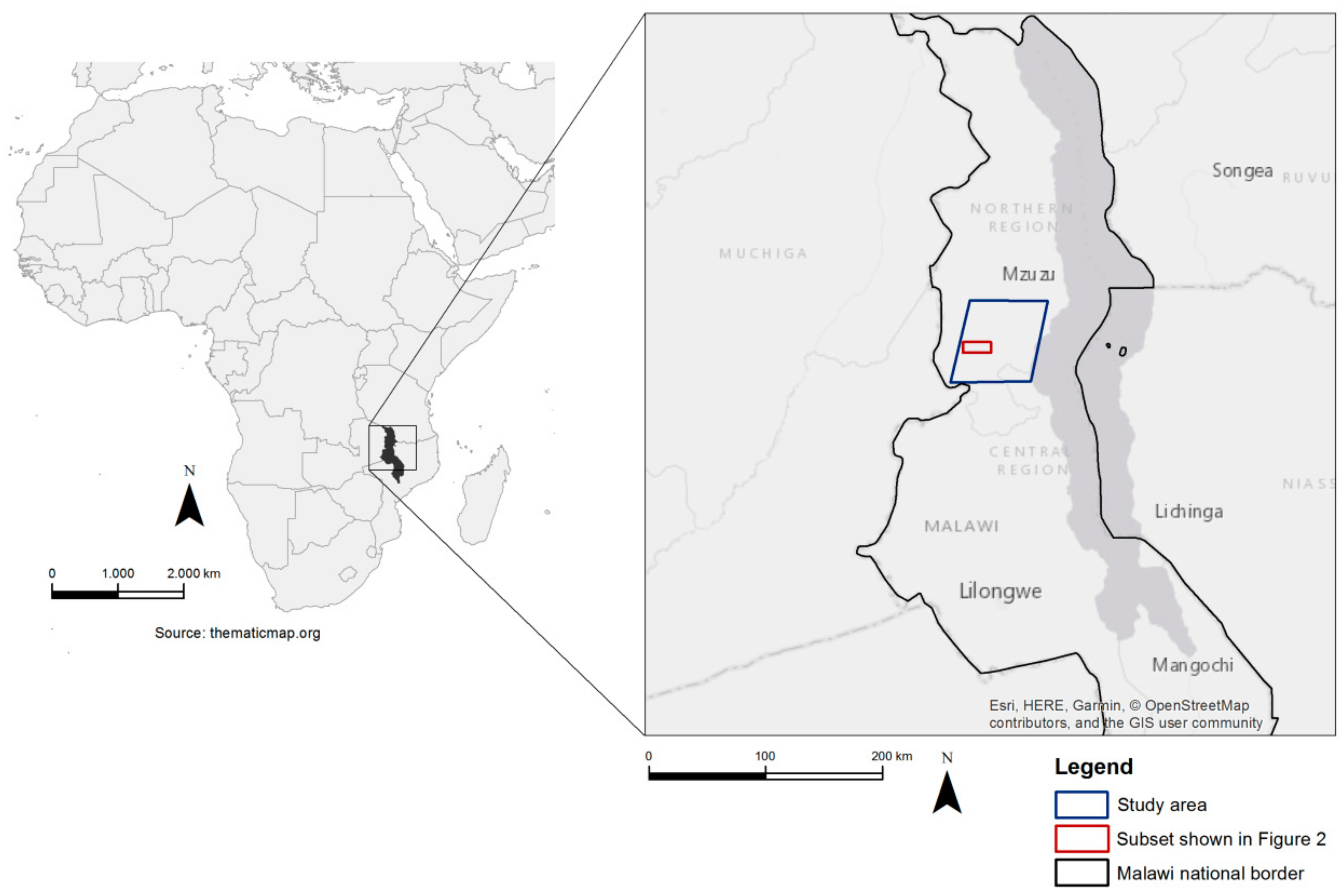
2. Study Area and Data
3. Methods
3.1. Pre-Processing Methods
3.2. Classification Methods for Mono-Temporal and Time-Series Data
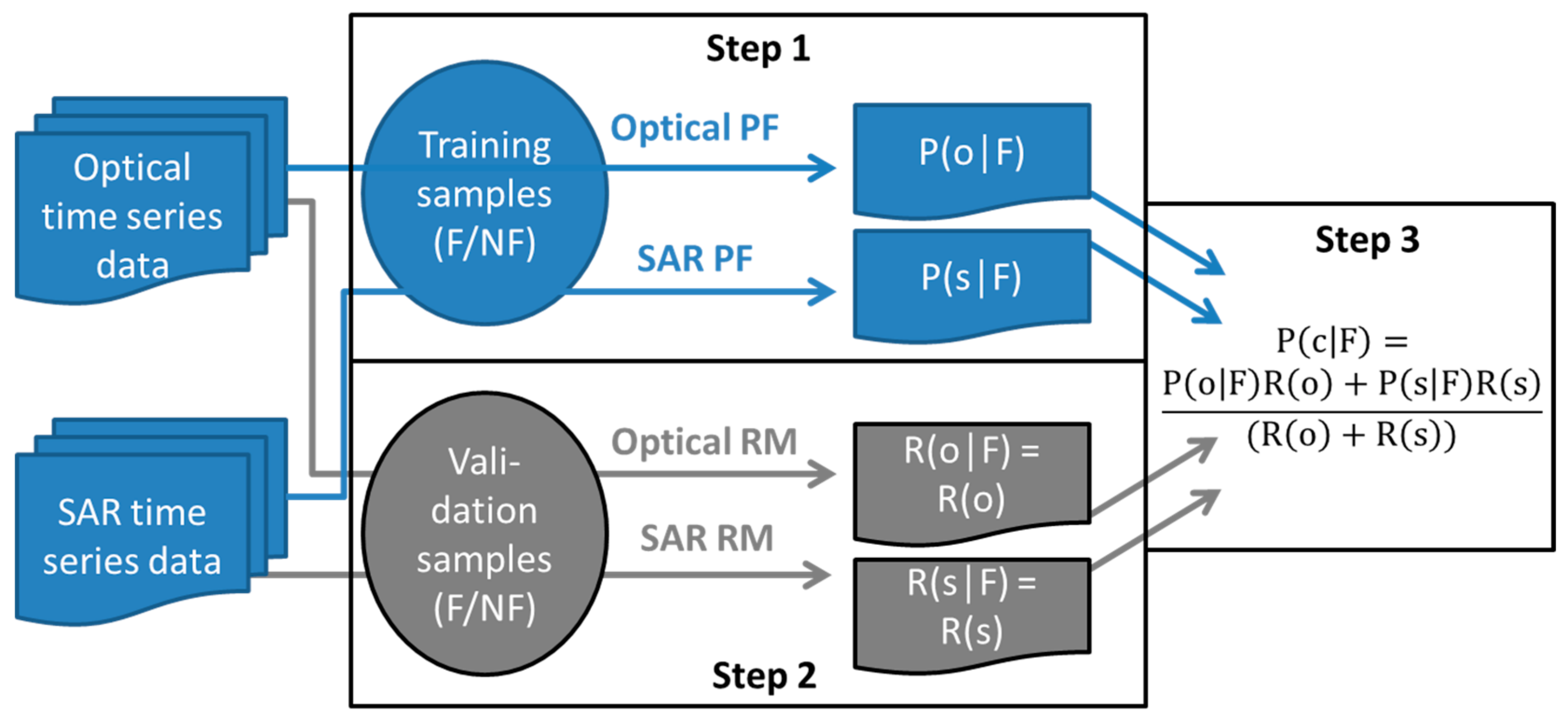
3.3. Methods for Combined Use of Optical and SAR Time Series Data
3.4. Validation Method
4. Results
4.1. Forest/Non-Forest Mapping and LC Classification: Optical Mono-Temporal Versus Optical Time Series Results
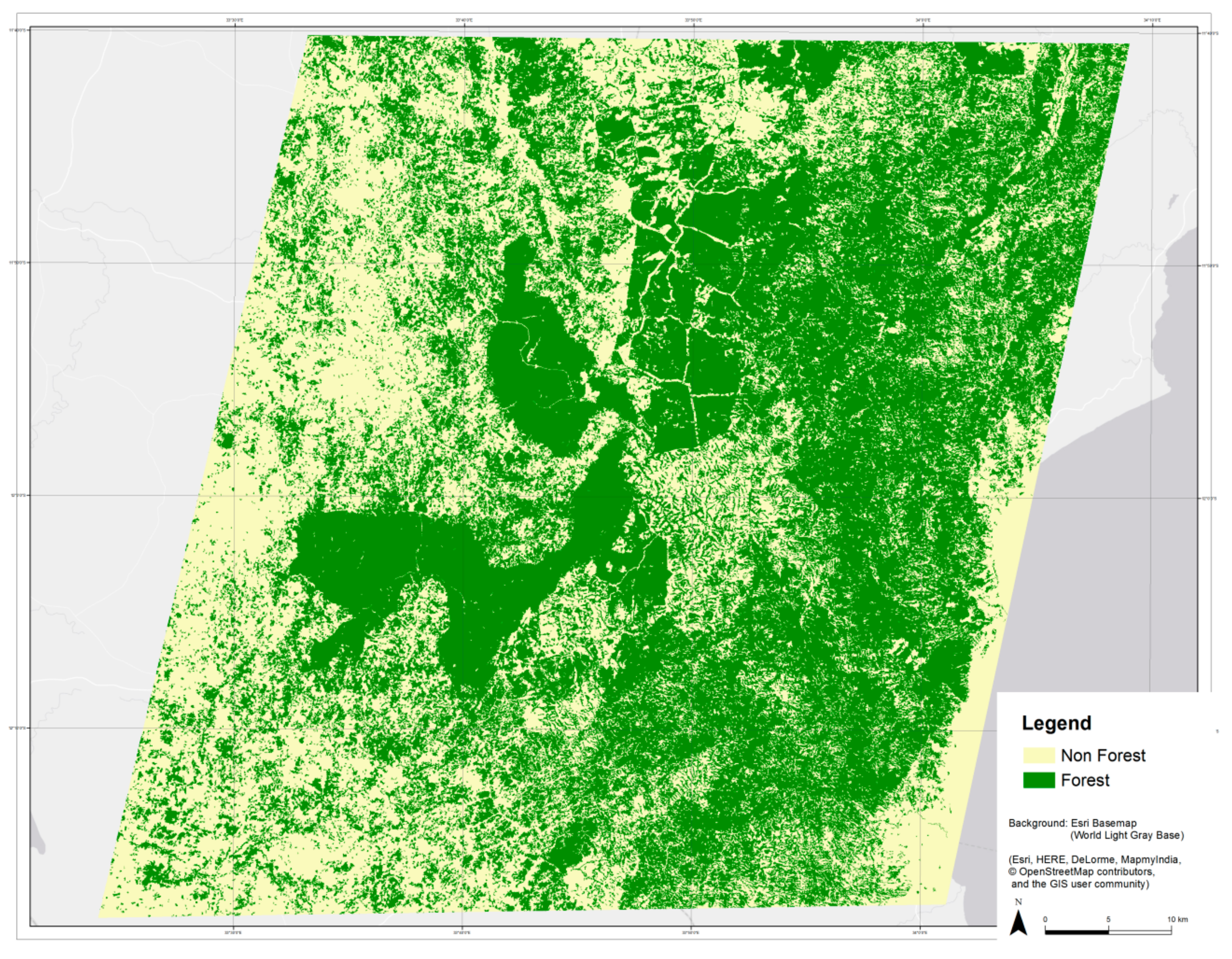
- Mono-temporal: Sentinel-2 image from 02.08.2016 (very good quality image, see Figure 2)
- Time series variant 1 (V1): 23.07.2016, 02.08.2016, 12.08.2016
- Time series variant 2 (V2): 26.12.2015, 02.08.2016, 12.08.2016, 10.11.2016
- Time series variant 3 (V3): 26.12.2015, 14.05.2016, 23.07.2016, 10.11.2016
- Time series variant 4 (V4): 26.12.2015, 14.05.2016, 23.07.2016, 02.08.2016, 12.08.2016, 10.11.2016
- Time series all: All optical images available for 2016 including those with low quality or high cloud cover.
4.2. Combination of SAR and Optical Time-Series Data Sets for FNF Maps
4.3. Combination of SAR and Optical Time-Series Data Sets for LC Maps
4.4. Comparison with Existing Products
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Parker, N.C.; Mitchell, A.; Trivedi, M. The Little REDD+ Book: An Updated Guide to Governmental and Non-Governmental Proposals for Reducing Emissions from Deforestation and Degradation, 2nd ed.; Global Canopy Foundation: Oxford, UK, 2009; p. 132. [Google Scholar]
- IPCC Good Practice Guidance for Land Use, Land-Use Change and Forestry (GPG-LULUCF). 2003. Available online: http://www.ipcc-nggip.iges.or.jp/public/gpglulucf/gpglulucf_contents.html (accessed on 8 October 2018).
- Pesaresi, M.; Corbane, C.; Julea, A.; Florczyk, A.; Syrris, V.; Soille, P. Assessment of the Added-Value of Sentinel-2 for Detecting Built-up Areas. Remote Sens. 2016, 8, 299. [Google Scholar] [CrossRef]
- Abdikan, S.; Sanli, F.B.; Ustuner, M.; Calò, F. Land Cover Mapping using Sentinel-1 SAR Data. Int. Archives Photogramm. Remote Sens. 2016, 41, 757–761. [Google Scholar] [CrossRef]
- Balzter, H.; Cole, B.; Thiel, C.; Schmullius, C. Mapping CORINE land cover from Sentinel-1A SAR and SRTM digital elevation model data using Random Forests. Remote Sens. 2015, 7, 14876–14898. [Google Scholar] [CrossRef]
- Antropov, O.; Rauste, Y.; Väänänen, A.; Mutanen, T.; Häme, T. Mapping forest disturbance using long time series of Sentinel-1 data: Case studies over boreal and tropical forests. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–12 July 2016; pp. 3906–3909. [Google Scholar] [CrossRef]
- Delgado-Aguilar, M.J.; Fassnacht, F.E.; Peralvo, M.; Gross, C.P.; Schmitt, C.B. Potential of TerraSAR-X and Sentinel 1 imagery to map deforested areas and derive degradation status in complex rain forests of Ecuador. Int. For. Rev. 2017, 19, 102–118. [Google Scholar] [CrossRef]
- Deutscher, J.; Gutjahr, K.; Perko, R.; Raggam, H.; Hirschmugl, M.; Schardt, M. Humid tropical forest monitoring with multi-temporal L-, C- and X-Band SAR data. In Proceedings of the 2017 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Bruges, Belgium, 27–29 June 2017. [Google Scholar]
- Dostálová, A.; Hollaus, M.; Milutin, I.; Wagner, W. Forest Area Derivation from Sentinel-1 Data. ISPRS Ann. Photogram. Remote Sens. Spat. Inf. Sci. 2016, 3, 227–233. [Google Scholar] [CrossRef]
- Haarpaintner, J.; Davids, C.; Storvold, R.; Johansen, K.; Ãrnason, K.; Rauste, Y.; Mutanen, T. Boreal Forest Land Cover Mapping in Iceland and Finland Using Sentinel-1A. In Proceedings of the Living Planet Symposium 2016, Prague, Czech Republic, 9–13 May 2016; Volume 740, p. 197, ISBN 978-92-9221-305-3. [Google Scholar]
- Pham-Duc, B.; Prigent, C.; Aires, F. Surface Water Monitoring within Cambodia and the Vietnamese Mekong Delta over a Year, with Sentinel-1 SAR Observations. Water 2017, 9, 366. [Google Scholar] [CrossRef]
- Plank, S.; Jüssi, M.; Martinis, S.; Twele, A. Mapping of flooded vegetation by means of polarimetric Sentinel-1 and ALOS-2/PALSAR-2 imagery. Int. J. Remote Sens. 2017, 38, 3831–3850. [Google Scholar] [CrossRef]
- Twele, A.; Cao, W.; Plank, S.; Martinis, S. Sentinel-1-based flood mapping: a fully automated processing chain. Int. J. Remote Sens. 2016, 37, 2990–3004. [Google Scholar] [CrossRef]
- Nguyen, D.B.; Wagner, W. European Rice Cropland Mapping with Sentinel-1 Data: The Mediterranean Region Case Study. Water 2017, 9, 392. [Google Scholar] [CrossRef]
- Tamm, T.; Zalite, K.; Voormansik, K.; Talgre, L. Relating Sentinel-1 Interferometric Coherence to Mowing Events on Grasslands. Remote Sens. 2016, 8, 802. [Google Scholar] [CrossRef]
- Mermoz, S.; Le Toan, T. Forest Disturbances and Regrowth Assessment Using ALOS PALSAR Data from 2007 to 2010 in Vietnam, Cambodia and Lao PDR. Remote Sens. 2016, 8, 217. [Google Scholar] [CrossRef]
- Mermoz, S.; Réjou-Méchain, M.; Villard, L.; Toan, T.L.; Rossi, V.; Gourlet-Fleury, S. Decrease of L-band SAR backscatter with biomass of dense forests. Remote Sens. Environ. 2015, 159, 307–317. [Google Scholar] [CrossRef]
- Sharma, R.C.; Hara, K.; Tateishi, R. High-Resolution Vegetation Mapping in Japan by Combining Sentinel-2 and Landsat 8 Based Multi-Temporal Datasets through Machine Learning and Cross-Validation Approach. Land 2017, 6, 50. [Google Scholar] [CrossRef]
- Shoko, C.; Mutanga, O. Examining the strength of the newly-launched Sentinel 2 MSI sensor in detecting and discriminating subtle differences between C3 and C4 grass species. ISPRS J. Photogram. Remote Sens. 2017, 129, 32–40. [Google Scholar] [CrossRef]
- Solano-Correa, Y.T.; Bovolo, F.; Bruzzone, L.; Fernández-Prieto, D. Spatio-temporal evolution of crop fields in Sentinel-2 Satellite Image Time Series. In Proceedings of the 2017 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Bruges, Belgium, 7–29 June 2017. [Google Scholar]
- Zhang, T.; Su, J.; Liu, C.; Chen, W.-H.; Liu, H.; Liu, G. Band Selection in Sentinel-2 Satellite for Agriculture Applications. In Proceedings of the 2017 23rd International Conference on Automation & Computing, Huddersfield, UK, 7–8 September 2017. [Google Scholar]
- Toming, K.; Kutser, T.; Laas, A.; Sepp, M.; Paavel, B.; Nges, T. First experiences in mapping lake water quality parameters with Sentinel-2 MSI imagery. Remote Sens. 2016, 8, 640. [Google Scholar] [CrossRef]
- Hirschmugl, M.; Deutscher, J.; Gutjahr, K.-H.; Sobe, C.; Schardt, M. Combined Use of SAR and Optical Time Series Data for Near Real-Time Forest Disturbance Mapping. In Proceedings of the 2017 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Bruges, Belgium, 7–29 June 2017. [Google Scholar]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First Experience with Sentinel-2 Data for Crop and Tree Species Classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Majasalmi, T.; Rautiainen, M. The potential of Sentinel-2 data for estimating biophysical variables in a boreal forest: A simulation study. Remote Sens. Lett. 2016, 7, 427–436. [Google Scholar] [CrossRef]
- Simonetti, D.; Marelli, A.; Rodriguez, D.; Vasilev, V.; Strobl, P.; Burger, A.; Soille, P.; Achard, F.; Eva, H.; Stibig, H.; et al. Sentinel-2 Web Platform for REDD+ Monitoring. 2017. Available online: https://www.researchgate.net/publication/317781159 (accessed on 9 October 2018).
- Sothe, C.; de Almeida, C.M.; Liesenberg, V.; Schimalski, M.B. Evaluating Sentinel-2 and Landsat-8 Data to Map Sucessional Forest Stages in a Subtropical Forest in Southern Brazil. Remote Sens. 2017, 9, 838. [Google Scholar] [CrossRef]
- Hirschmugl, M.; Haas, S.; Deutscher, J.; Schardt, M.; Siwe, R.; Haeusler, T. Investigating different sensors for degradation mapping in Cameroonian tropical forests. In Proceedings of the 33rd International Symposium on Remote Sensing of Environment (ISRSE), Stresa, Italy, 4–8 May 2009; Available online: https://www.researchgate.net/publication/228355394_REDD_PILOT_PROJECT_IN_CAMEROON_MONITORING_FOREST_COVER_CHANGE_WITH_EO_DATA (accessed on 9 October 2018).
- Joshi, N.; Baumann, M.; Ehammer, A.; Fensholt, R.; Grogan, K.; Hostert, P.; Jepsen, M.R.; Kuemmerle, T.; Meyfroidt, P.; Mitchard, E.T.; et al. A review of the application of optical and radar remote sensing data fusion to land use mapping and monitoring. Remote Sens. 2016, 8, 70. [Google Scholar] [CrossRef]
- Ali, J.; Khan, R.; Ahmad, N.; Maqsood, I. Random forests and decision trees. Int. J. Comput. Sci. Issues (IJCSI) 2012, 9, 272–278. [Google Scholar]
- Grinand, C.; Rakotomalala, F.; Gond, V.; Vaudry, R.; Bernoux, M.; Vieilledent, G. Estimating deforestation in tropical humid and dry forests in Madagascar from 2000 to 2010 using multi-date Landsat satellite images and the random forests classifier. Remote Sens. Environ. 2013, 139, 68–80. [Google Scholar] [CrossRef]
- Horning, N. Random Forests: An algorithm for image classification and generation of continuous fields data sets. In Proceedings of the International Conference on Geoinformatics for Spatial Infrastructure Development in Earth and Allied Sciences, Hanoi, Vietnam, 9–11 December 2010. [Google Scholar]
- Li, T.; Ni, B.; Wu, X.; Gao, Q.; Li, Q.; Sun, D. On random hyper-class random forest for visual classification. Neurocomputing 2016, 172, 281–289. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Briem, G.J.; Benediktsson, J.A.; Sveinsson, J.R. Multiple classifiers applied to multisource remote sensing data. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2291–2299. [Google Scholar] [CrossRef]
- Campos-Taberner, M.; García-Haro, F.J.; Camps-Valls, G.; Grau-Muedra, G.; Nutini, F.; Busetto, L.; Katsantonis, D.; Stavrakoudis, D.; Minakou, C.; Gatti, L.; et al. Exploitation of SAR and Optical Sentinel Data to Detect Rice Crop and Estimate Seasonal Dynamics of Leaf Area Index. Remote Sens. 2017, 9, 248. [Google Scholar] [CrossRef]
- Chen, B.; Xiao, X.; Li, X.; Pan, L.; Doughty, R.; Ma, J.; Dong, J.; Qin, Y.; Zhao, B.; Wu, Z.; et al. A mangrove forest map of China in 2015: Analysis of time series Landsat 7/8 and Sentinel-1A imagery in Google Earth Engine cloud computing platform. ISPRS J. Photogram. Remote Sens. 2017, 131, 104–120. [Google Scholar] [CrossRef]
- Notarnicola, C.; Asam, S.; Jacob, A.; Marin, C.; Rossi, M.; Stendardi, L. Mountain crop monitoring with multitemporal Sentinel-1 and Sentinel-2 imagery. In Proceedings of the 2017 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Bruges, Belgium, 7–29 June 2017. [Google Scholar]
- Chang, J.; Shoshany, M. Mediterranean shrublands biomass estimation using Sentinel-1 and Sentinel-2. In Proceedings of the Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–12 July 2016; pp. 5300–5303. [Google Scholar] [CrossRef]
- Reiche, J.; de Bruin, S.; Verbesselt, J.; Hoekman, D.; Herold, M. Near Real-time Deforestation Detection using a Bayesian Approach to Combine Landsat, ALOS PALSAR and Sentinel-1 Time Series. In Proceedings of the Living Planet Symposium 2016, Prague, Czech Republic, 9–13 May 2016. [Google Scholar]
- Reiche, J.; Hamunyela, E.; Verbesselt, J.; Hoekman, D.; Herold, M. Improving near-real time deforestation monitoring in tropical dry forests by combining dense Sentinel-1 time series with Landsat and ALOS-2 PALSAR-2. Remote Sens. Environ. 2018, 204, 147–161. [Google Scholar] [CrossRef]
- Verhegghen, A.; Eva, H.; Ceccherini, G.; Achard, F.; Gond, V.; Gourlet-Fleury, S.; Cerutti, P.O. The Potential of Sentinel Satellites for Burnt Area Mapping and Monitoring in the Congo Basin Forests. Remote Sens. 2016, 8, 986. [Google Scholar] [CrossRef]
- Erasmi, S.; Twele, A. Regional land cover mapping in the humid tropics using combined optical and SAR satellite data—A case study from Central Sulawesi, Indonesia. Int. J. Remote Sens. 2009, 30, 2465–2478. [Google Scholar] [CrossRef]
- Stefanski, J.; Kuemmerle, T.; Chaskovskyy, O.; Griffiths, P.; Havryluk, V.; Knorn, J.; Korol, N.; Sieber, A.; Waske, B. Mapping land management regimes in western Ukraine using optical and SAR data. Remote Sens. 2014, 6, 5279–5305. [Google Scholar] [CrossRef]
- Waske, B.; van der Linden, S. Classifying multilevel imagery from SAR and optical sensors by decision fusion. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1457–1466. [Google Scholar] [CrossRef]
- Zhang, H.; Lin, H.; Li, Y. Impacts of Feature Normalization on Optical and SAR Data Fusion for Land Use/Land Cover Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1061–1065. [Google Scholar] [CrossRef]
- Mueller-Wilm, U. Sentinel-2 MSI—Level-2A Prototype Processor Installation and User Manual. Available online: http://step.esa.int/thirdparties/sen2cor/2.2.1/S2PAD-VEGA-SUM-0001-2.2.pdf (accessed on 9 October 2018).
- Louis, J.; Charantonis, A.; Berthelot, B. Cloud Detection for Sentinel-2. In Proceedings of the ESA Living Planet Symposium 2016, Prague, Czech Republic, 9–13 May 2016. [Google Scholar]
- Gallaun, H.; Schardt, M.; Linser, S. Remote Sensing Based Forest Map of Austria and Derived Environmental Indicators. In Proceedings of the ForestSat Conference, Montpellier, France, 5–7 November 2007. [Google Scholar]
- Quegan, S.; Toan, T.L.; Yu, J.J.; Ribbes, F.; Floury, N. Multitemporal ERS analysis applied to forest mapping. IEEE Trans. Geosci. Remote Sens. 2000, 38, 741–753. [Google Scholar] [CrossRef]
- Trouvé, E.; Chambenoit, Y.; Classeau, N.; Bolon, P. Statistical and operational performance assessment of multitemporal SAR image filtering. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2519–2530. [Google Scholar] [CrossRef]
- OTB Development Team. The ORFEO Tool Box Software Guide Updated for OTB-6.4.0. 2018. Available online: https://www.orfeo-toolbox.org/packages/OTBSoftwareGuide.pdf (accessed on 9 October 2018).
- Quegan, S.; Le Toan, T. Analysing multitemporal SAR images. In Proceedings of the Anais IX Simposio Brasileiro de Sensoriamento Remoto, Santos, Brazil, 11–18 September 1998; pp. 1183–1194. Available online: https://www.researchgate.net/publication/43807289_Analysing_multitemporal_SAR_images (accessed on 9 October 2018).
- Reiche, J. Combining SAR and Optical Satellite Image Time Series for Tropical Forest Monitoring. Ph.D. Thesis, Wageningen University, Wageningen, NL, USA, 2015. [Google Scholar]
- Reiche, J.; de Bruin, S.; Hoekman, D.; Verbesselt, J.; Herold, M. A Bayesian Approach to Combine Landsat and ALOS PALSAR Time Series for Near Real-Time Deforestation Detection. Remote Sens. 2015, 7, 4973–4996. [Google Scholar] [CrossRef]
- Castel, T.; Beaudoin, A.; Stach, N.; Stussi, N.; Le Toan, T.; Durand, P. Sensitivity of space-borne SAR data to forest parameters over sloping terrain. Theory and experiment. Int. J. Remote Sens. 2001, 22, 2351–2376. [Google Scholar] [CrossRef]
- Van Zyl, J.J.; Chapman, B.D.; Dubois, P.; Shi, J. The effect of topography on SAR calibration. IEEE Trans. Geosci. Remote Sens. 1993, 31, 1036–1043. [Google Scholar] [CrossRef]
- Olson, M.; Wyner, A.J. Making Sense of Random Forest Probabilities: A Kernel Perspective. 2017. Available online: http://www-stat.wharton.upenn.edu/~maolson/docs/olson.pdf (accessed on 9 October 2018).
- McRoberts, R.E.; Tomppo, E.O.; Czaplewski, R.L. Sampling designs for national forest assessments. In Knowledge Reference for National Forest Assessments; FAO: Rome, Italy, 2015; pp. 23–40. [Google Scholar]
- Gallaun, H.; Steinegger, M.; Wack, R.; Schardt, M.; Kornberger, B.; Schmitt, U. Remote Sensing Based Two-Stage Sampling for Accuracy Assessment and Area Estimation of Land Cover Changes. Remote Sens. 2015, 7, 11992–12008. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Stehman, S.V.; Woodcock, C.E. Making better use of accuracy data in land change studies: Estimating accuracy and area and quantifying uncertainty using stratified estimation. Remote Sens. Environ. 2013, 129, 122–131. [Google Scholar] [CrossRef]
- Cartus, O.; Santoro, M.; Kellndorfer, J. Mapping forest aboveground biomass in the Northeastern United States with ALOS PALSAR dual-polarization L-band. Remote Sens. Environ. 2012, 124, 466–478. [Google Scholar] [CrossRef]
- Yu, Y.; Saatchi, S. Sensitivity of L-Band SAR Backscatter to Aboveground Biomass of Global Forests. Remote Sens. 2016, 8, 522. [Google Scholar] [CrossRef]
- Hamunyela, E.; Verbesselt, J.; Herold, M. Using spatial context to improve early detection of deforestation from Landsat time series. Remote Sens. Environ. 2016, 172, 126–138. [Google Scholar]
- Bach, H.; Friese, M.; Spannraft, K.; Migdall, S.; Dotzler, S.; Hank, T.; Frank, T.; Mauser, W. Integrative use of multitemporal rapideye and TerraSAR-X data for agricultural monitoring. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 3748–3751. [Google Scholar] [CrossRef]
- Bertoluzza, M.; Bruzzone, L.; Bovolo, F. Circular change detection in image time series inspired by two-dimensional phase unwrapping. In Proceedings of the 2017 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Bruges, Belgium, 7–29 June 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Bruzzone, L.; Bovolo, F.; Paris, C.; Solano-Correa, Y.T.; Zanetti, M.; Fernández-Prieto, D. Analysis of multitemporal Sentinel-2 images in the framework of the ESA Scientific Exploitation of Operational Missions. In Proceedings of the 2017 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Bruges, Belgium, 7–29 June 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Franklin, S.E.; Ahmed, O.S.; Wulder, M.A.; White, J.C.; Hermosilla, T.; Coops, N.C. Large Area Mapping of Annual Land Cover Dynamics Using Multitemporal Change Detection and Classification of Landsat Time Series Data. Can. J. Remote Sens. 2015, 41, 293–314. [Google Scholar] [CrossRef]
- Hütt, C.; Koppe, W.; Miao, Y.; Bareth, G. Best Accuracy Land Use/Land Cover (LULC) Classification to Derive Crop Types Using Multitemporal, Multisensor, and Multi-Polarization SAR Satellite Images. Remote Sens. 2016, 8, 684. [Google Scholar] [CrossRef]
- Addabbo, P.; Focareta, M.; Marcuccio, S.; Votto, C.; Ullo, S.L. Land cover classification and monitoring through multisensor image and data combination. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–12 July 2016; pp. 902–905. [Google Scholar] [CrossRef]
- Chen, B.; Li, X.; Xiao, X.; Zhao, B.; Dong, J.; Kou, W.; Qin, Y.; Yang, C.; Wu, Z.; Sun, R.; Lan, G.; Xie, G. Mapping tropical forests and deciduous rubber plantations in Hainan Island, China by integrating PALSAR 25-m and multi-temporal Landsat images. Int. J. Appl. Earth. Obs. Geoinf. 2016, 50, 117–130. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Marais-Sicre, C. Improved Early Crop Type Identification by Joint Use of High Temporal Resolution SAR and Optical Image Time Series. Remote Sens. 2016, 8, 362. [Google Scholar] [CrossRef]
- Yesou, H.; Pottier, E.; Mercier, G.; Grizonnet, M.; Haouet, S.; Giros, A.; Faivre, R.; Huber, C.; Michel, J. Synergy of Sentinel-1 and Sentinel-2 imagery for wetland monitoring information extraction from continuous flow of Sentinel images applied to water bodies and vegetation mapping and monitoring. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–12 July 2016; pp. 162–165. [Google Scholar] [CrossRef]
- Reiche, J.; Verbesselt, J.; Hoekman, D.; Herold, M. Fusing Landsat and SAR time series to detect deforestation in the tropics. Remote Sens. Environ. 2015, 156, 276–293. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | November | December |
|---|---|---|
| 2000 | 60 mm | 150 mm |
| 2001 | 0 mm | 3 mm |
| 2002 | 295 mm | 79 mm |
| 2003 | 21 mm | 124 mm |
| 2004 | 2 mm | 143 mm |
| 2005 | 7 mm | 43 mm |
| … | … | … |
| 2013 | 46 mm | 79 mm |
| 2014 | 36 mm | 20 mm |
| 2015 | 133 mm | 0 mm |
| 2016 | 0 mm | 34 mm |
| 2017 | 2 mm | 17 mm |
| Sensor | Acquisition Dates | Properties |
|---|---|---|
| Sentinel-1 A/B | 2016-04-28 | Interferometric wide swath mode 250 km swath Processing Level-1: GRD high resolution product: 20 m slant range × 22 m azimuth spatial resolution, 5 × 1 looks, pixel spacing: 10 m Polarization: dual polarization available but single VH polarization used only Orbit mode: ascending orbit data used only |
| 2016-10-01 | ||
| 2016-10-25 | ||
| 2016-11-18 | ||
| 2016-12-12 | ||
| 2017-01-05 | ||
| 2017-01-29 | ||
| 2017-02-10 | ||
| 2017-02-22 | ||
| 2017-03-06 | ||
| 2017-03-18 | ||
| 2017-03-30 | ||
| 2017-04-11 | ||
| 2017-04-23 | ||
| Sentinel-2 A/B | 2015-12-26 | Spectral bands used: Bands 2, 3, 4, 8 at 10 m spatial resolution Bands 5, 6, 7, 8a, 11 and 12 with original 20 m resolution resampled to 10 m resolution Level 1C data |
| 2016-01-05 | ||
| 2016-05-14 | ||
| 2016-07-23 | ||
| 2016-08-02 | ||
| 2016-08-12 | ||
| 2016-09-01 | ||
| 2016-09-11 | ||
| 2016-09-21 | ||
| 2016-10-11 | ||
| 2016-11-10 | ||
| 2016-12-10 | ||
| 2017-01-29 | ||
| 2017-02-08 | ||
| 2017-02-18 | ||
| Very high resolution (VHR) data from Google Earth | 2015–2017 | Spatial resolution 1 m or better; visible bands (red-green-blue) only |
| Forest/Non-Forest | Overall Accuracy | Kappa | Users’ Accuracy (UA) Forest | UA Forest Range ± | Producers’ Accuracy (PA) Forest | PA Forest Range ± |
|---|---|---|---|---|---|---|
| mono-temporal | 0.7590 | 0.53 | 92.94 | 2.01 | 65.13 | 1.95 |
| time-series V1 | 0.7965 | 0.59 | 88.72 | 2.32 | 74.16 | 2.14 |
| time-series V2 | 0.8026 | 0.59 | 80.72 | 2.55 | 86.73 | 2.24 |
| time-series V3 | 0.8343 | 0.66 | 86.29 | 2.32 | 84.98 | 2.17 |
| time-series V4 | 0.8364 | 0.66 | 85.91 | 2.33 | 85.91 | 2.15 |
| time-series all | 0.7911 | 0.58 | 88.09 | 2.26 | 76.37 | 2.12 |
| IPCC LC Classes | Overall Accuracy | Kappa |
|---|---|---|
| mono-temporal | 0.6775 | 0.44 |
| time-series V1 | 0.7153 | 0.51 |
| time-series V4 | 0.7375 | 0.54 |
| Forest/Non-Forest | Overall Accuracy | Kappa |
|---|---|---|
| Optical only | ||
| mono-temporal | 0.7590 | 0.53 |
| time-series V4 | 0.8364 | 0.66 |
| SAR only | ||
| VH time series 2016 | 0.6924 | 0.41 |
| Optical & SAR data-based combination | ||
| mono-temporal optical & SAR VH | 0.8319 | 0.65 |
| time-series V4 & SAR VH | 0.8526 | 0.70 |
| Optical & SAR result-based combination | ||
| mono-temporal optical & SAR VH | 0.8310 | 0.64 |
| time-series V4 & SAR VH | 0.8425 | 0.67 |
| Class Name (columns = Ground Truth; Rows = Mapped Class) | Forest | Non-Forest | Users Accuracy and Confidence Interval at 95% Confidence Level | |
|---|---|---|---|---|
| Forest | 842 | 15 | 857 | 98.25% ± 0.88 |
| Non-Forest | 68 | 554 | 622 | 89.07% ± 2.45 |
| Total | 910 | 569 | 1479 | |
| Producers Accuracy and Confidence Interval at 95% Confidence Level | 91.53% ± 1.74 | 97.69% ± 1.13 | Overall Accuracy: 94.08% CI: 92.87–95.29 | |
| IPCC LC Classes | Overall Accuracy | Kappa |
|---|---|---|
| Optical only | ||
| mono-temporal | 0.6775 | 0.44 |
| time-series V4 | 0.7375 | 0.54 |
| SAR only | ||
| VH time series 2016 | 0.6759 | 0.43 |
| Optical & SAR data-based combination | ||
| mono-temporal optical & SAR VH | 0.7870 | 0.60 |
| time-series V4 & SAR VH | 0.7780 | 0.60 |
| Forest/Non-Forest | Overall Accuracy | Kappa |
|---|---|---|
| Optical time-series V4 | 0.8364 | 0.66 |
| Data-based combination of time-series V4 & SAR VH | 0.8526 | 0.70 |
| Existing FNF maps | ||
| Global Forest Watch 1 | 0.7187 | 0.40 |
| CCI Land Cover (2016) | 0.7194 | 0.46 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hirschmugl, M.; Sobe, C.; Deutscher, J.; Schardt, M. Combined Use of Optical and Synthetic Aperture Radar Data for REDD+ Applications in Malawi. Land 2018, 7, 116. https://doi.org/10.3390/land7040116
Hirschmugl M, Sobe C, Deutscher J, Schardt M. Combined Use of Optical and Synthetic Aperture Radar Data for REDD+ Applications in Malawi. Land. 2018; 7(4):116. https://doi.org/10.3390/land7040116
Chicago/Turabian StyleHirschmugl, Manuela, Carina Sobe, Janik Deutscher, and Mathias Schardt. 2018. "Combined Use of Optical and Synthetic Aperture Radar Data for REDD+ Applications in Malawi" Land 7, no. 4: 116. https://doi.org/10.3390/land7040116
APA StyleHirschmugl, M., Sobe, C., Deutscher, J., & Schardt, M. (2018). Combined Use of Optical and Synthetic Aperture Radar Data for REDD+ Applications in Malawi. Land, 7(4), 116. https://doi.org/10.3390/land7040116