
Context-Specific Urban Optimisations Through Data-Driven Classification: A Perspective on Methods and Applications



Abstract
1. Introduction
2. Computational Framework: Structured Methodology and Analytical Workflow
2.1. Data Acquisition and Filtering
- The primary datasets (i.e., reference datasets) facilitate the classification of arbitrary urban areas into distinct typology classes through adaptive automated methodologies. We stimulate the application of open datasets accessible via open application programming interfaces (open APIs). These enable the automated acquisition of available data for arbitrary locations; however, after data collection, the implementation of appropriate data models and data integration is required.
- A curated array of additional datasets is utilised to extract relevant KPIs, with each dataset being tailored to the specific characteristics of the corresponding urban area type. The curation and selection process of these datasets is guided by their relevance and applicability to addressing the distinct urban challenges pertinent to each case study. The acquired and integrated data layers can be applied to the assessment of multi-domain KPIs, each potentially relevant to different urban settings.
2.1.1. Selection Criteria
- Open source opportunities.
- Data suitability to climate-related issues.
- Spatial and temporal coverage.
Open Source Opportunities
Data Suitability to Climate-Related Issues
Spatial and Temporal Coverage
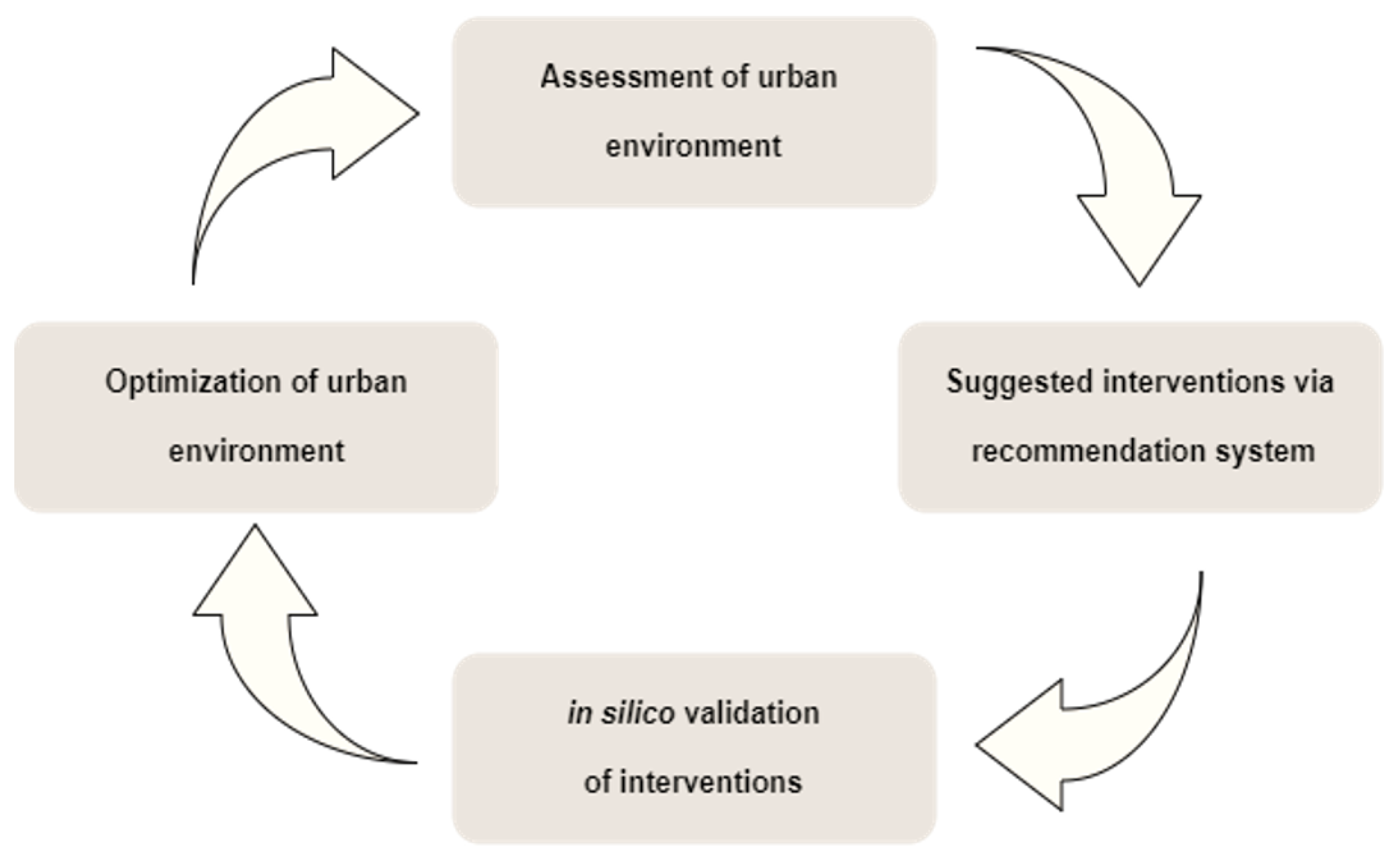
2.2. Urban Classification
2.3. Assessment of KPIs and Identification of Critical Points
2.4. Recommendation and Validation of Interventions to Optimise Urban Environments
3. Applicability Potential and Contextual Fitting
3.1. Reference Data Layers: Building Footprints, Population Counts and Land Use
3.2. Potential Auxiliary Data Layers
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | In this paper, the term analytical classification framework refers to a structured computational framework and methodological workflow. It integrates open source spatial data, analytics, and classification methods, and serves as a conceptual structure for organising the analysis. |
| 2 | European strategy for data: https://digital-strategy.ec.europa.eu/en/policies/strategy-data (accessed on 7 February 2025). |
| 3 | Copernicus: https://www.copernicus.eu/en (accessed on 19 February 2025). |
| 4 | European Environmental Agency: https://www.eea.europa.eu/en (accessed on 16 February 2025). |
| 5 | European Data Portal: https://data.europa.eu/en (accessed on 12 March 2025). |
| 6 | OpenAIRE: https://www.openaire.eu/ (accessed on 17 February 2025). |
| 7 | European Open Science Cloud: https://eosc.eu/eosc-about/ (accessed on 17 February 2025). |
| 8 | e.g., Geofabrik Downloads: https://download.geofabrik.de/; the Pyrosm API: https://pyrosm.readthedocs.io/en/latest/; Overpass API: http://overpass-api.de/ or QGIS: https://www.qgis.org/en/site/ plug-ins such as QuickOSM: https://plugins.qgis.org/plugins/QuickOSM/; OSMDownloader: https://plugins.qgis.org/plugins/OSMDownloader/ (all accessed on 7 February 2025). |
| 9 | Telraam: https://telraam.net/ (accessed on 7 February 2025). |
| 10 | sensor.community: https://sensor.community/en/ (accessed on 7 February 2025). |
| 11 | Mapillary: https://www.mapillary.com. |
| 12 | POIs primarily denote amenities and central functions, not necessarily related to genuine interest as the term might imply. |
| 13 | Statistical Office of the Republic of Slovenia. https://gis.stat.si/ (accessed on 7 February 2025). |
| 14 | Urban Atlas Land Cover, Land Use 2018. 10.2909/fb4dffa1-6ceb-4cc0-8372-1ed354c285e6 (accessed on 18 February 2025). |
| 15 | Urban Atlas Building Height 2012. https://land.copernicus.eu/en/products/urban-atlas/building-height-2012 (accessed on 12 February 2025). |
References
- Connections Between the Paris Agreement and the 2030 Agenda. 2021. Available online: https://www.sei.org/wp-content/uploads/2019/08/connections-between-the-paris-agreement-and-the-2030-agenda.pdf (accessed on 16 March 2025).
- United Nations. The 2030 Agenda for Sustainable Development. 2015. Available online: https://sdgs.un.org/sites/default/files/publications/21252030%20Agenda%20for%20Sustainable%20Development%20web.pdf (accessed on 16 March 2025).
- European Commission. The European Green Deal. 2019. Available online: https://www.esdn.eu/fileadmin/ESDN_Reports/ESDN_Report_2_2020.pdf (accessed on 16 March 2025).
- Angelakoglou, K.; Nikolopoulos, N.; Giourka, P.; Svensson, I.L.; Tsarchopoulos, P.; Tryferidis, A.; Tzovaras, D. A methodological framework for the selection of key performance indicators to assess smart city solutions. Smart Cities 2019, 2, 269–306. [Google Scholar] [CrossRef]
- Stavroulaki, I.; Pont, M.B. A systematic review of the scientific literature on the theme of multi-functional streets. In Proceedings of the IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2020; Volume 588, p. 052046. [Google Scholar]
- Rossi, A. The Architecture of the City; MIT Press: Cambridge, MA, USA, 1984. [Google Scholar]
- Aymonino, C. La formazione di un moderno concetto di tipologia edilizia. Rapp. Tra La Morfol. Urbana E La Tipol. Edil. Doc. Del Corso Di Caratter. Distrib. Degli Edif. Anno Accad. 1965, 1966, 12–51. [Google Scholar]
- Leupen, B. Design and Analysis; 010 Publishers: Rotterdam, The Netherlands, 1997. [Google Scholar]
- Perez, J.; Fusco, G.; Araldi, A.; Fuse, T. Building typologies for urban fabric classification: Osaka and Marseille case studies. In Proceedings of the International Conference on Spatial Analysis and Modeling (SAM), Kuala Lumpur, Malaysia, 24–25 April 2018. [Google Scholar]
- Petruccioli, A. (Ed.) Exoteric—Polytheistic—Fundamentalist Typology: Gleanings in the Form of an Introduction. In Typological Process and Design Theory; Harvard University and Massachusetts Institute of Technology: Cambridge, MA, USA, 1998. [Google Scholar]
- Whitehand, J.W.R. Recent advances in urban morphology. Urban Stud. 1992, 29, 619–636. [Google Scholar] [CrossRef]
- Pinho, P.; Oliveira, V. Cartographic analysis in urban morphology. Environ. Plan. B Plan. Des. 2009, 36, 107–127. [Google Scholar] [CrossRef]
- Dibble, J.; Prelorendjos, A.; Romice, O.; Zanella, M.; Strano, E.; Pagel, M.; Porta, S. On the origin of spaces: Morphometric foundations of urban form evolution. Environ. Plan. B Urban Anal. City Sci. 2019, 46, 707–730. [Google Scholar] [CrossRef]
- Sneath, P.H.A.; Sokal, R. The principles and practice of numerical classification. Numer. Taxon. 1973, 573, 190–199. [Google Scholar]
- Alverti, M.N.; Themistocleous, K.; Kyriakidis, P.C.; Hadjimitsis, D.G. A study of the interaction of human smart characteristics with demographic dynamics and built environment: The case of Limassol, Cyprus. Smart Cities 2020, 3, 48–73. [Google Scholar] [CrossRef]
- Hall, P. Cities of Tomorrow: An Intellectual History of Urban Planning and Design Since 1880; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- OpenStreetMap contributors. OpenStreetMap Data; Packt Publishing Ltd.: Mumbai, India, 2025. [Google Scholar]
- Biljecki, F.; Chow, Y.S.; Lee, K. Quality of crowdsourced geospatial building information: A global assessment of OpenStreetMap attributes. Build. Environ. 2023, 237, 110295. [Google Scholar] [CrossRef]
- Janež, M.; Verovšek, Š.; Zupančič, T.; Moškon, M. Citizen science for traffic monitoring: Investigating the potentials for complementing traffic counters with crowdsourced data. Sustainability 2022, 14, 622. [Google Scholar] [CrossRef]
- Yap, W.; Janssen, P.; Biljecki, F. Free and open source urbanism: Software for urban planning practice. Comput. Environ. Urban Syst. 2022, 96, 101825. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhang, Y.; Chang, K.; Brovelli, M.A. Assessing OSM building completeness for almost 13,000 cities globally. Int. J. Digit. Earth 2022, 15, 2400–2421. [Google Scholar] [CrossRef]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Brovelli, M.A.; Zamboni, G. A new method for the assessment of spatial accuracy and completeness of OpenStreetMap building footprints. ISPRS Int. J. Geo-Inf. 2018, 7, 289. [Google Scholar] [CrossRef]
- Huang, W.; Cui, L.; Chen, M.; Zhang, D.; Yao, Y. Estimating urban functional distributions with semantics preserved POI embedding. Int. J. Geogr. Inf. Sci. 2022, 36, 1905–1930. [Google Scholar] [CrossRef]
- Psyllidis, A.; Gao, S.; Hu, Y.; Kim, E.K.; McKenzie, G.; Purves, R.; Yuan, M.; Andris, C. Points of Interest (POI): A commentary on the state of the art, challenges, and prospects for the future. Comput. Urban Sci. 2022, 2, 20. [Google Scholar] [CrossRef] [PubMed]
- Yap, W.; Stouffs, R.; Biljecki, F. Urbanity: Automated modelling and analysis of multidimensional networks in cities. NPJ Urban Sustain. 2023, 3, 45. [Google Scholar] [CrossRef]
- Conzen, M.R.G. Alnwick, Northumberland: A study in town-plan analysis. Trans. Pap. (Inst. Br. Geogr.) 1960, 27, iii–122. [Google Scholar] [CrossRef]
- Talen, E. City Rules: How Regulations Affect Urban Form; Island Press: Washington, DC, USA, 2012. [Google Scholar]
- Fischel, W.A. The Economics of Zoning Laws: A Property Rights Approach to American Land Use Controls; JHU Press: Baltimore, MD, USA, 1987. [Google Scholar]
- McLaughlin, R.B. Land use regulation: Where have we been, where are we going? Cities 2012, 29, S50–S55. [Google Scholar] [CrossRef]
- Alexiou, A.; Singleton, A.; Longley, P.A. A classification of multidimensional open data for urban morphology. Built Environ. 2016, 42, 382–395. [Google Scholar] [CrossRef]
- Abrantes, P.; Rocha, J.; Marques da Costa, E.; Gomes, E.; Morgado, P.; Costa, N. Modelling urban form: A multidimensional typology of urban occupation for spatial analysis. Environ. Plan. B Urban Anal. City Sci. 2019, 46, 47–65. [Google Scholar] [CrossRef]
- Fan, Y.; Ding, X.; Wu, J.; Ge, J.; Li, Y. High spatial-resolution classification of urban surfaces using a deep learning method. Build. Environ. 2021, 200, 107949. [Google Scholar] [CrossRef]
- Liu, Y.; Lu, S.; Lu, X.; Wang, Z.; Chen, C.; He, H. Classification of urban hyperspectral remote sensing imagery based on optimized spectral angle mapping. J. Indian Soc. Remote Sens. 2019, 47, 289–294. [Google Scholar] [CrossRef]
- Kuras, A.; Brell, M.; Rizzi, J.; Burud, I. Hyperspectral and lidar data applied to the urban land cover machine learning and neural-network-based classification: A review. Remote Sens. 2021, 13, 3393. [Google Scholar] [CrossRef]
- Wang, J.; Huang, W.; Biljecki, F. Learning visual features from figure-ground maps for urban morphology discovery. Comput. Environ. Urban Syst. 2024, 109, 102076. [Google Scholar] [CrossRef]
- Yu, T.; Sützl, B.S.; van Reeuwijk, M. Urban neighbourhood classification and multi-scale heterogeneity analysis of Greater London. Environ. Plan. B Urban Anal. City Sci. 2023, 50, 1534–1558. [Google Scholar] [CrossRef]
- Serrano-Estrada, L.; Martí, P.; Bernabeu-Bautista, Á.; Huskinson, M. Mapping heritage engagement in historic centres through social media insights and accessibility analysis. Land 2024, 13, 1972. [Google Scholar] [CrossRef]
- Malah, A.; Bahi, H. Integrated multivariate data analysis for Urban Sustainability Assessment, a case study of Casablanca city. Sustain. Cities Soc. 2022, 86, 104100. [Google Scholar] [CrossRef]
- Blanco, L.; Alhamwi, A.; Schiricke, B.; Hoffschmidt, B. Data-driven classification of Urban Energy Units for district-level heating and electricity demand analysis. Sustain. Cities Soc. 2024, 101, 105075. [Google Scholar] [CrossRef]
- Amado, M.; Poggi, F. (Eds.) Chapter 7—Morphological Analysis. In Sustainable Energy Transition for Cities; Elsevier: Amsterdam, The Netherlands, 2022; pp. 89–122. [Google Scholar] [CrossRef]
- De Oliveira, R.; Carneiro, C.d.C.; De Almeida, F.; de Oliveira, B.; Nunes, E.; dos Santos, A. Multivariate air pollution classification in urban areas using mobile sensors and self-organizing maps. Int. J. Environ. Sci. Technol. 2019, 16, 5475–5488. [Google Scholar] [CrossRef]
- Grafius, D.R.; Corstanje, R.; Harris, J.A. Linking ecosystem services, urban form and green space configuration using multivariate landscape metric analysis. Landsc. Ecol. 2018, 33, 557–573. [Google Scholar] [CrossRef] [PubMed]
- Yu, B.; Wang, Z.; Mu, H.; Sun, L.; Hu, F. Identification of urban functional regions based on floating car track data and POI data. Sustainability 2019, 11, 6541. [Google Scholar] [CrossRef]
- Su, Y.; Zhong, Y.; Zhu, Q.; Zhao, J. Urban scene understanding based on semantic and socioeconomic features: From high-resolution remote sensing imagery to multi-source geographic datasets. ISPRS J. Photogramm. Remote Sens. 2021, 179, 50–65. [Google Scholar] [CrossRef]
- Liu, X.; He, J.; Yao, Y.; Zhang, J.; Liang, H.; Wang, H.; Hong, Y. Classifying urban land use by integrating remote sensing and social media data. Int. J. Geogr. Inf. Sci. 2017, 31, 1675–1696. [Google Scholar] [CrossRef]
- McKenzie, G.; Janowicz, K. The effect of regional variation and resolution on geosocial thematic signatures for points of interest. In Proceedings of the Societal Geo-Innovation: Selected Papers of the 20th AGILE Conference on Geographic Information Science; Springer: Berlin/Heidelberg, Germany, 2017; pp. 237–256. [Google Scholar]
- Andrade, R.; Alves, A.; Bento, C. POI mining for land use classification: A case study. ISPRS Int. J. Geo-Inf. 2020, 9, 493. [Google Scholar] [CrossRef]
- Huang, H.; Huang, J.; Chen, B.; Xu, X.; Li, W. Recognition of Functional Areas in an Old City Based on POI: A Case Study in Fuzhou, China. J. Urban Plan. Dev. 2024, 150, 04024001. [Google Scholar] [CrossRef]
- Xu, Y.; Jin, S.; Chen, Z.; Xie, X.; Hu, S.; Xie, Z. Application of a graph convolutional network with visual and semantic features to classify urban scenes. Int. J. Geogr. Inf. Sci. 2022, 36, 2009–2034. [Google Scholar] [CrossRef]
- Li, F.; Yigitcanlar, T.; Nepal, M.; Nguyen, K.; Dur, F. Machine learning and remote sensing integration for leveraging urban sustainability: A review and framework. Sustain. Cities Soc. 2023, 96, 104653. [Google Scholar] [CrossRef]
- Zhang, P.; Ghosh, D.; Park, S. Spatial measures and methods in sustainable urban morphology: A systematic review. Landsc. Urban Plan. 2023, 237, 104776. [Google Scholar] [CrossRef]
- Fleischmann, M.; Romice, O.; Porta, S. Measuring urban form: Overcoming terminological inconsistencies for a quantitative and comprehensive morphologic analysis of cities. Environ. Plan. B Urban Anal. City Sci. 2021, 48, 2133–2150. [Google Scholar] [CrossRef]
- Han, J.; Mo, N.; Cai, J.; Ouyang, L.; Liu, Z. Advancing the local climate zones framework: A critical review of methodological progress, persisting challenges, and future research prospects. Humanit. Soc. Sci. Commun. 2024, 11, 1–18. [Google Scholar] [CrossRef]
- Stewart, I.D.; Oke, T.R. Local Climate Zones for Urban Temperature Studies. Bull. Am. Meteorol. Soc. 2012, 93, 1879–1900. [Google Scholar] [CrossRef]
- Hazarika, M.; Nashrrullah, S.; Alam, M.; Chen, L.; van Westen, C.; Dwijananto, A.; Roxas, M. Building Footprint Maps. 2014. Available online: https://www.cdema.org/virtuallibrary/index.php/charim-hbook/data-management-book/5-elements-at-risk-data/5-2-building-footprint-maps (accessed on 16 March 2025).
- Microsoft. Global ML Building Footprints, 2025. Open Data Commons Open Database License (ODbL). Available online: https://gee-community-catalog.org/projects/msbuildings/ (accessed on 16 March 2025).
- Milojevic-Dupont, N.; Wagner, F.; Nachtigall, F.; Hu, J.; Brüser, G.B.; Zumwald, M.; Biljecki, F.; Heeren, N.; Kaack, L.H.; Pichler, P.P.; et al. EUBUCCO v0. 1: European building stock characteristics in a common and open database for 200+ million individual buildings. Sci. Data 2023, 10, 147. [Google Scholar] [CrossRef] [PubMed]
- Fleischmann, M. Momepy: Urban morphology measuring toolkit. J. Open Source Softw. 2019, 4, 1807. [Google Scholar] [CrossRef]
- Atwal, K.S.; Anderson, T.; Pfoser, D.; Züfle, A. Predicting building types using OpenStreetMap. Sci. Rep. 2022, 12, 19976. [Google Scholar] [CrossRef] [PubMed]
- Chen, R.; Yan, H.; Liu, F.; Du, W.; Yang, Y. Multiple global population datasets: Differences and spatial distribution characteristics. ISPRS Int. J. Geo-Inf. 2020, 9, 637. [Google Scholar] [CrossRef]
- Statistical Office of the Republic of Slovenia. GIS Application—Statistical Office of the Republic of Slovenia; Statistical Office of the Republic of Slovenia: Ljubljana, Slovenia, 2025.
- European Environment Agency. Urban Atlas Land Cover/Land Use 2018 (Vector), Europe, 6-Yearly, July 2021; European Environment Agency: Copenhagen, Denmark, 2021. [Google Scholar]
- European Environment Agency. Mapping Guide for a European Urban Atlas; European Environment Agency: Copenhagen, Denmark, 2011. [Google Scholar]
- Szatmári, D.; Kopecká, M.; Feranec, J. Accuracy Assessment of the Building Height Copernicus Data Layer: A Case Study of Bratislava, Slovakia. Land 2022, 11, 590. [Google Scholar] [CrossRef]
- Sohn, W.; Kim, J.H.; Li, M.H.; Brown, R.D.; Jaber, F.H. How does increasing impervious surfaces affect urban flooding in response to climate variability? Ecol. Indic. 2020, 118, 106774. [Google Scholar] [CrossRef]
- Barlacchi, G.; Lepri, B.; Moschitti, A. Land use classification with point of interests and structural patterns. IEEE Trans. Knowl. Data Eng. 2020, 33, 3258–3269. [Google Scholar] [CrossRef]
- Fan, J.; Thakur, G. Towards POI-based large-scale land use modeling: Spatial scale, semantic granularity, and geographic context. Int. J. Digit. Earth 2023, 16, 430–445. [Google Scholar] [CrossRef]
- Xu, Y.; Zhou, B.; Jin, S.; Xie, X.; Chen, Z.; Hu, S.; He, N. A framework for urban land use classification by integrating the spatial context of points of interest and graph convolutional neural network method. Comput. Environ. Urban Syst. 2022, 95, 101807. [Google Scholar] [CrossRef]
- Mullaney, J.; Lucke, T.; Trueman, S.J. A review of benefits and challenges in growing street trees in paved urban environments. Landsc. Urban Plan. 2015, 134, 157–166. [Google Scholar] [CrossRef]
- Copernicus Land Monitoring Service. Urban Atlas Street Tree Layer (STL) 2018. 2018. Available online: https://land.copernicus.eu/en/products/urban-atlas/street-tree-layer-stl-2018 (accessed on 18 March 2025).
- Copernicus Land Monitoring Service. Tree Cover Density 2018. 2018. Available online: https://land.copernicus.eu/en/products/high-resolution-layer-forests-and-tree-cover/tree-cover-density-2018-raster-10-m-100-m-europe-yearly (accessed on 18 March 2025).
- Copernicus Land Monitoring Service. Small Woody Features 2018. 2018. Available online: https://land.copernicus.eu/en/products/high-resolution-layer-small-woody-features/small-woody-features-2018 (accessed on 18 March 2025).
- Kopp, J.; Frajer, J.; Novotná, M.; Preis, J.; Dolejš, M. Comparison of ecohydrological and climatological zoning of the cities: Case study of the city of Pilsen. ISPRS Int. J. Geo-Inf. 2021, 10, 350. [Google Scholar] [CrossRef]
- Benjamin, K.; Luo, Z.; Wang, X. Crowdsourcing urban air temperature data for estimating urban heat island and building heating/cooling load in London. Energies 2021, 14, 5208. [Google Scholar] [CrossRef]
- Wu, J.; Liu, C.; Wang, H. Analysis of Spatio-temporal patterns and related factors of thermal comfort in subtropical coastal cities based on local climate zones. Build. Environ. 2022, 207, 108568. [Google Scholar] [CrossRef]
- Bochow, M.; Taubenböck, H.; Segl, K.; Kaufmann, H. An automated and adaptable approach for characterizing and partitioning cities into urban structure types. In Proceedings of the 2010 IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010; pp. 1796–1799. [Google Scholar]
- Lehner, A.; Blaschke, T. A generic classification scheme for urban structure types. Remote Sens. 2019, 11, 173. [Google Scholar] [CrossRef]
- Durst, N.J.; Sullivan, E.; Jochem, W.C. The spatial and social correlates of neighborhood morphology: Evidence from building footprints in five US metropolitan areas. PLoS ONE 2024, 19, e0299713. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Generic Urban Typology | Illustrative KPIs | Typical Intervention Levers |
|---|---|---|
| Low-rise residential fabric | ||
| (Dispersed/single-family dominant) |
|
|
| High-rise residential fabric | ||
| (Compact apartment blocks) |
|
|
| Non-residential & mixed-use activity zones | ||
| (Industrial, commercial, civic, or transport hubs) |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Verovšek, Š.; Moškon, M. Context-Specific Urban Optimisations Through Data-Driven Classification: A Perspective on Methods and Applications. Land 2025, 14, 1505. https://doi.org/10.3390/land14081505
Verovšek Š, Moškon M. Context-Specific Urban Optimisations Through Data-Driven Classification: A Perspective on Methods and Applications. Land. 2025; 14(8):1505. https://doi.org/10.3390/land14081505
Chicago/Turabian StyleVerovšek, Špela, and Miha Moškon. 2025. "Context-Specific Urban Optimisations Through Data-Driven Classification: A Perspective on Methods and Applications" Land 14, no. 8: 1505. https://doi.org/10.3390/land14081505
APA StyleVerovšek, Š., & Moškon, M. (2025). Context-Specific Urban Optimisations Through Data-Driven Classification: A Perspective on Methods and Applications. Land, 14(8), 1505. https://doi.org/10.3390/land14081505