1. Introduction
With the improvement of China’s infrastructure construction, the level of response to flood and waterlogging risk has been improved, and the population and property losses caused by flood have been significantly reduced. However, compared with Germany, Japan, and other countries, the proportion of population and economic losses caused by rain and flooding is still high [
1]. The sixth report of the United Nations Intergovernmental Panel on Climate Change pointed out that 9 of the 15 extreme tipping points of climate change have been exceeded, and the risk of flooding has increased worldwide [
2]. In recent years, China’s 800 mm iso-precipitation line has a northward trend, and rainfall in the north has begun to increase. However, the level of prevention and control of rainlogging in the north is relatively low, which greatly increases the uncertainty and harm of future rainlogging risk [
3]. The results show that the increase in the extreme precipitation index will be the most significant by the end of this century. Among them, the extreme precipitation index shows a significant increasing trend in Central China and Northeast China. The total annual precipitation shows an increasing trend in Central China and North China [
4]. According to the study of Yu Kongjian, the risk of rain and waterlogging in Huang-Huai region is at a high level in China due to flat terrain and dense population [
5]. The causes of urban flooding also include urbanization, climate change, land use, and ecology. In particular, the local microclimate formed by urban heat islands can also affect rainfall and urban flooding [
6]. Although China has also put forward measures to strengthen the construction of old urban areas, improve the drainage capacity, construct sponge cities and resilient cities, and other suggestions, the guidance of the overall policy for specific cases is still weak. For instance, large-scale fatal accidents caused by floods still occurred in Beijing and Zhengzhou [
7].
At present, the main research methods for assessing the risk of rain and waterlogging involve simulating runoff using SWMM [
8], HAC-RAS [
9], SWAT [
10], and other software. These simulation methods are capable of producing high-precision numerical results. However, numerical model simulations for large-scale areas with complex underlying surfaces are complicated and time-consuming. This makes it difficult to meet the aging requirements of rainstorm waterlogging and waterlogging prediction, while also significantly decreasing accuracy [
11]. However, the advantages of machine learning methods that can handle large amounts of data and require low data accuracy are very obvious [
12]. AI has a flexible mathematical structure and can simulate the complex nonlinear relationship between the input and output data features. This is difficult to describe using physical equations in hydrodynamic simulation research [
13]. The use of AI technology for disaster prevention and early warning is a new trend in recent years [
14]. For example, convolutional neural network (CNN) technology can be applied to deal with urban waterlogging [
15], CNN technology is most commonly used in image processing; Artificial neural network (ANN) is one of the most widely used technologies in artificial intelligence flood forecasting in the world. Although ANN is prone to overfitting, it has a strong ability to analyze and process the results of linear data, which can be used for predicting the depth of water accumulation. They simulate the brain’s problem-solving function through mathematical models inspired by neural processes [
16,
17]. Scholars have gradually applied machine learning methods to the prediction of rainstorm and waterlogging disasters. Machine learning methods include lasso regression [
18], SVM [
19], decision trees, random forests [
20], extreme gradient boosting (XGBoost) [
21], and deep learning based on artificial neural networks [
22]. Some machine learning models have similar counting principles, and their advantages and disadvantages can only be determined by comparing the simulation results. The learning characteristic factors include rainstorm intensity, rainfall duration, impervious rate, elevation, slope, topographic humidity index, distance from road, and drainage network density [
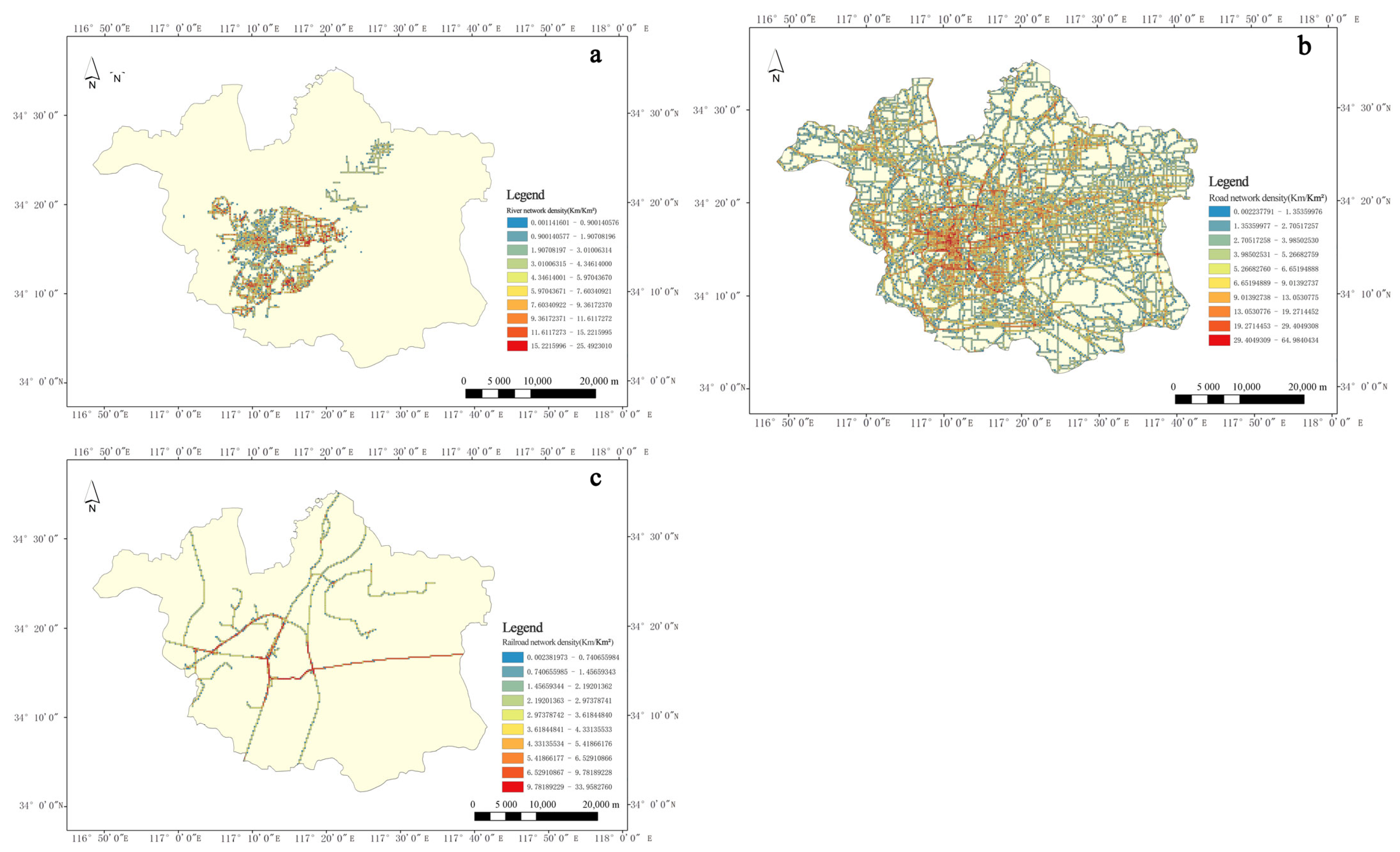
23,
24]. However, many relevant researches are used to put both disaster factors and disaster victims in the analysis of rain and waterlogging factors for machine learning simulation analysis [
25]. This is unreasonable to some extent, as the occurrence of waterlogging is an objective cause. Meanwhile, people, land, and buildings, as disaster-bearing bodies, are not the direct cause of waterlogging. The real-time dynamics of the current research data are relatively low, and the reliance on historical disaster data is high. Therefore, there may be insufficient adaptability of the model to extreme rainfall.
People are the participants of urban economic development and the object of urban service. Together, they constitute the foundation and main body of social production behavior [
26]. On the one hand, the acceleration of China’s urbanization process has led to the rapid expansion of urban population areas. On the other hand, it also intensifies the contradiction between population, resources, and environment [
27]. Human life safety is the most obvious disaster-bearing body, so the analysis of population distribution is a very important content in the study of exposure risk of flood and waterlogging [
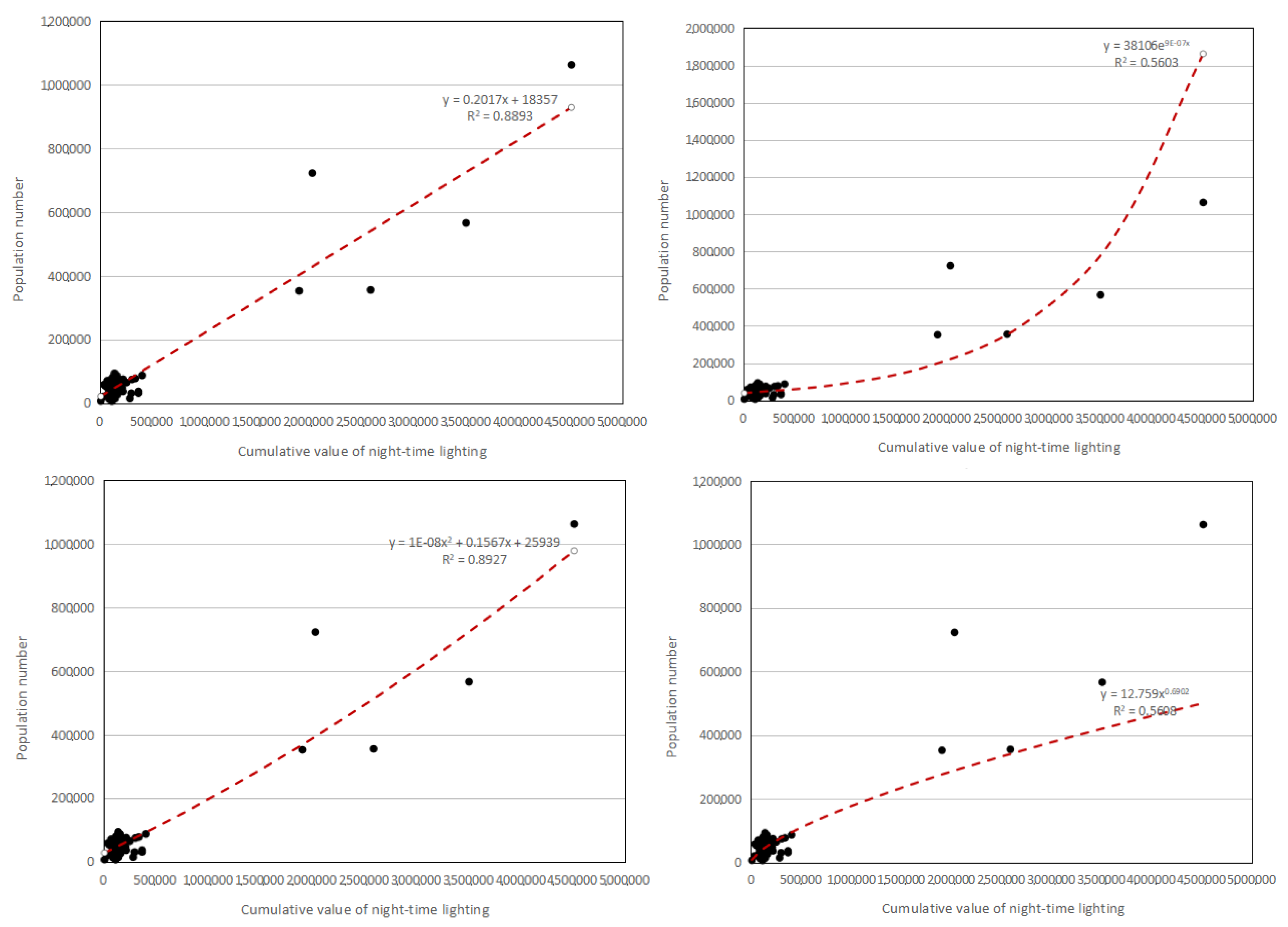
28].With the rapid development of remote sensing technology, night light data—capturing varying light intensities generated by cities, small-scale residential areas, and traffic flows—has become an effective indicator for monitoring human activities [
29,
30]. At present, this technology is widely used in urban and rural population distribution, disaster population statistics, and other fields [
31]. It uses brightness value to characterize the intensity of human activities. Related studies include socio-economic parameters, urban construction [
32], natural disasters, resources, and environment, etc., and can be used as a proxy variable for a variety of social and economic indicators [
33].
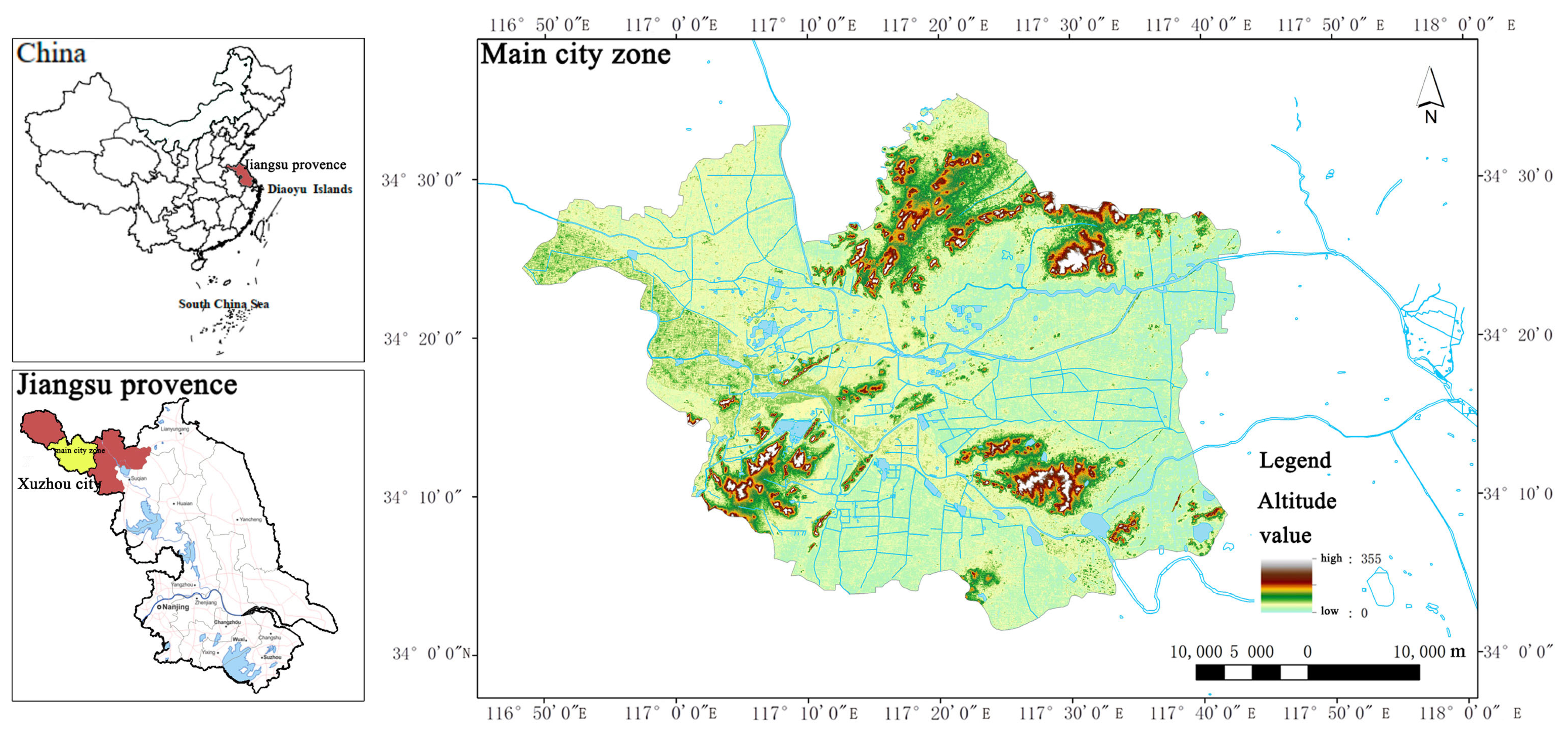
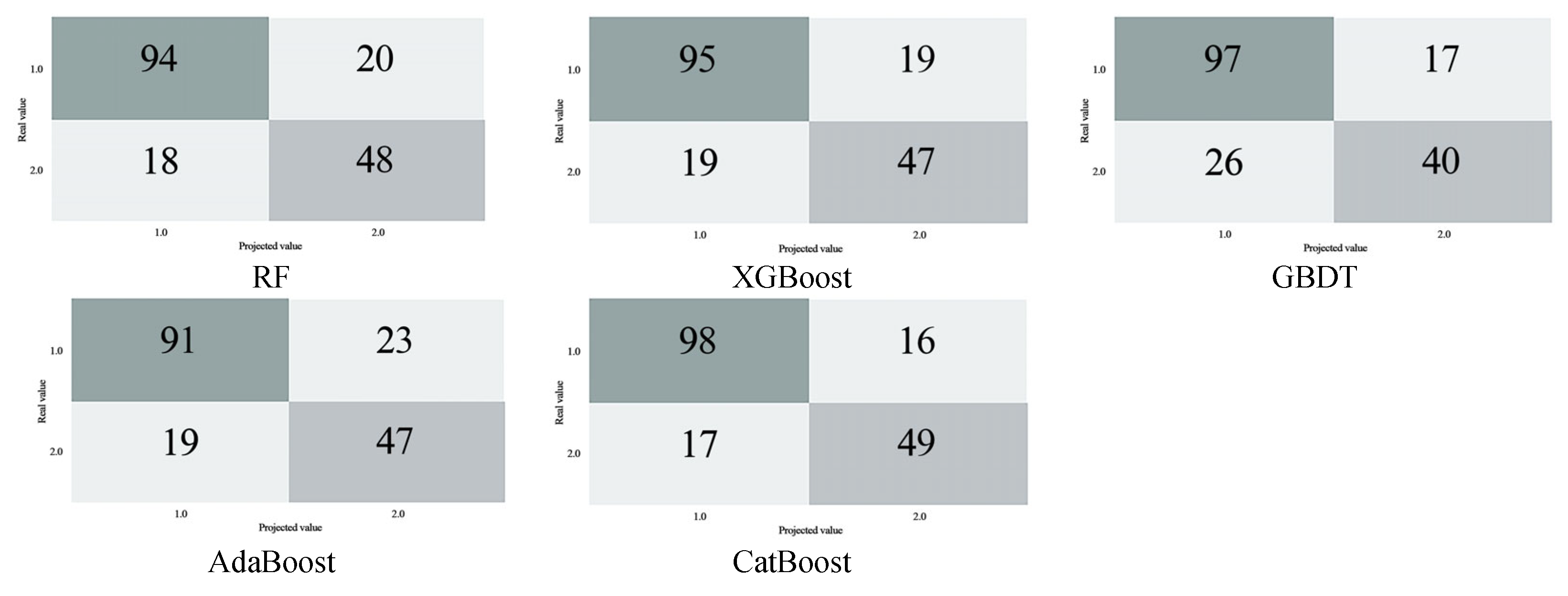
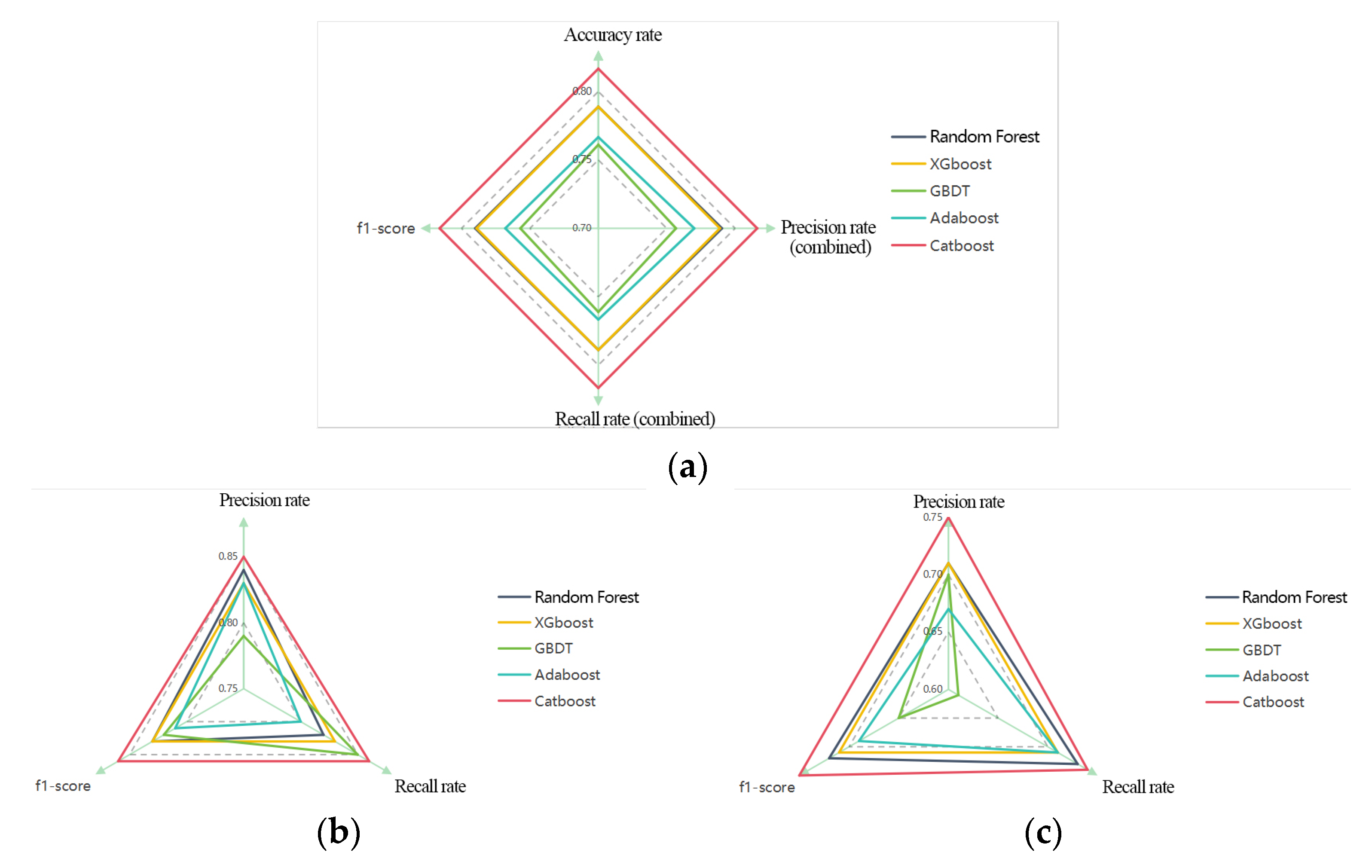
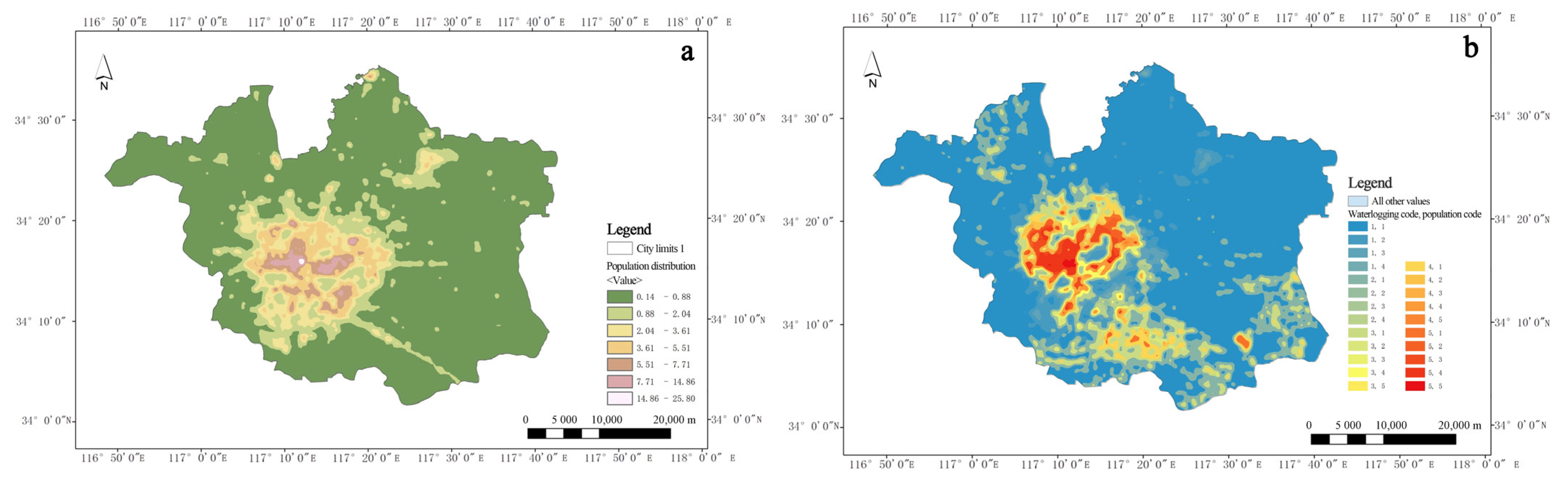
Therefore, this paper constructs a machine learning index system suitable for the assessment of rain and waterlogging in Huang-Huai region. Waterlogged and non-waterlogged were used as identification features. Five machine learning models were selected for verification. By comparing four indicators of machine learning output—accuracy rate, precision rate, recall rate, and F1-score—CatBoost demonstrated the best simulation effect. After that, nuclear density analysis was performed on the accumulation point area output by CatBoost model to obtain the accumulation risk level. The population distribution density is also analyzed based on the remote sensing light data at night. The result of waterlogging risk exposure can be obtained by coupling analysis of the two. We believe that this is of great benefit to guiding urban waterlogging control and promoting urban sustainable development of Xuzhou city in Huang-Huai area.
4. Discussion
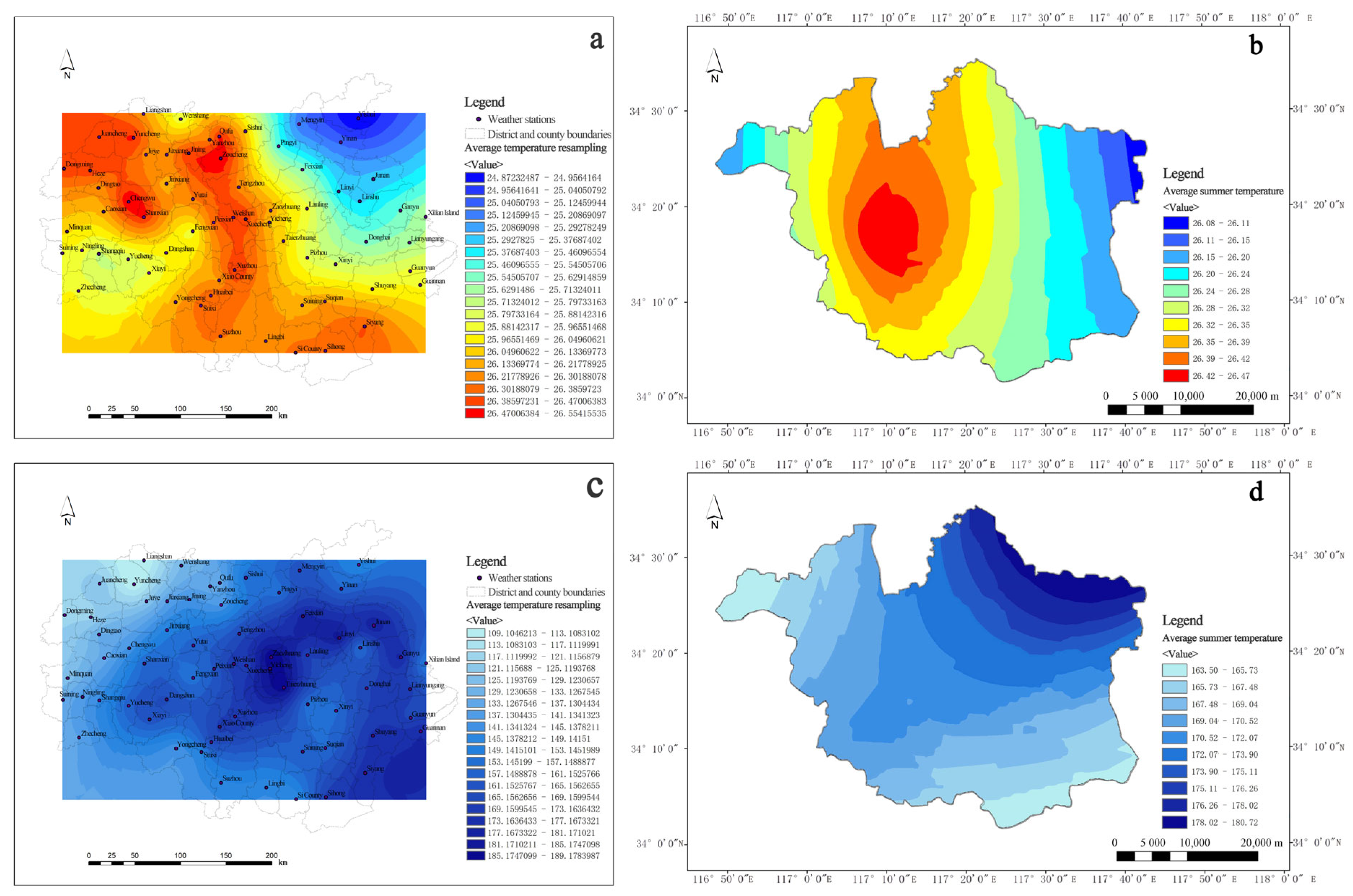
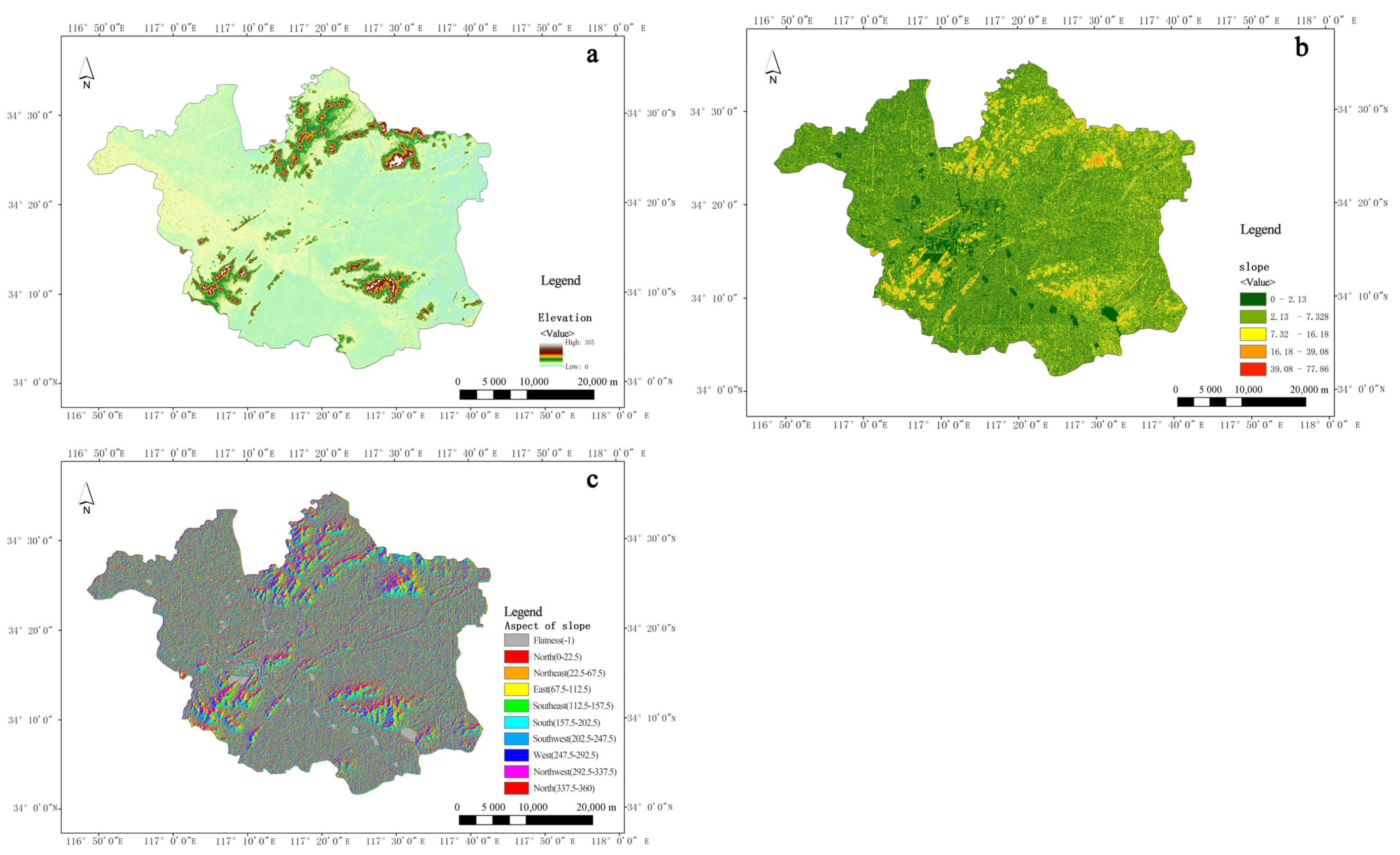
From the perspective of formation mechanism, climate, terrain, artificial surface, and natural surface work together to form water accumulation. The analysis results of the weights indicate that topography and climate play the most important influencing role in the formation of urban flooding. The intensity of heavy rain determines the occurrence of surface runoff. Topographic features affect the process of runoff convergence, which determines the probability of urban flooding formation. The characteristics of the natural surface and the artificial surface will have an impact on runoff and infiltration velocity. The above factors interact with each other and ultimately determine the formation of water accumulation.
This study provides a scientific basis for urban rain and waterlogging management in the Huang-Huai region, especially in the main city of Xuzhou. For the high-risk M5N5 and M5N4 areas (e.g., the old city and JiuLi Lake Wetland), it is recommended to prioritize the implementation of the “point-line-plane” integrated management strategy. Because high-risk areas are more vulnerable to rain and flooding and pose a greater threat to life safety. “Point-level” measures focus on the refined renovation of small and micro spaces, such as low-lying nodes, building ancillary facilities, and the storage and regulation facilities in old residential areas. Rain gardens, permeable pavements, green roofs, sunken tree pits, etc., can be renovated. The “line-level” measures focus on the improvement of the drainage system. Specifically, improvements can be made in rivers, waterways, and drainage corridors, such as repairing and widening rivers, upgrading rainwater networks, and laying drainage ditches along roadsides. At the “surface level”, measures should focus on ecological restoration of territorial space and zonal control of sponge cities. For instance, rivers and lakes should be connected through river networks and canals to enhance regulatory capabilities. In the zoning of sponge cities, the requirements for seepage and water storage indicators, as well as development restrictions should be strengthened. For medium-risk areas (e.g., M3N4, M4N3), community-level emergency response capacity should be strengthened, such as popularizing intelligent water level monitoring equipment in densely populated residential clusters and formulating graded evacuation plans. In addition, the “hidden risk areas” revealed by the research (such as the farmland runoff irrigation area in the south of the city) should prompt the planning department to break the status quo of urban-rural drainage system separation. Cross-regional deployment of stormwater resources is best achieved through integrated ditch-pipe network design. In the long run, the assessment of rainfall and waterlogging risk should be incorporated into the rigid constraints of territorial spatial planning, and the natural hydrological cycle should be gradually restored in conjunction with urban regeneration actions. Specific measures for these constraints can be to legalize the risk map or integrate the risk analysis process with the demarcation of the three zones and three lines. For instance, the area around Jiuli Lake Wetland can be designated as an ecological red line zone, prohibiting land reclamation from the lake. At the level of control detailed planning, indicators such as the total runoff control rate and the proportion of permeable area should be set. Thus, the urban area of Xuzhou ultimately achieves the collaborative goal of “reducing risks—optimizing space—enhancing resilience”. Countries such as Japan and the Netherlands have incorporated flood risks into their territorial spatial planning. China’s documents such as the “National Spatial Planning Law” and the “Guidelines for Sponge City Construction” explicitly state that flood risk assessment needs to be strengthened. Rigid constraints are a concrete manifestation of implementing the national strategy for disaster prevention and mitigation. At present, although China has also conducted evaluations of the carrying capacity of resources and the environment and the suitability of territorial space development. However, the rigid constraints on urban flooding in the evaluation content are too low. Raising the rigid defense standards can reduce a large amount of life and property losses every year. The old urban areas, which were developed earlier, are low-lying and prone to urban waterlogging. Promoting the prevention of urban flooding during urban renewal can achieve multiple benefits at once.
In the future, by integrating Internet of Things sensors, Geographic Information Systems (GIS), and real-time monitoring networks, machine learning models will be able to conduct dynamic modelling of urban water circulation systems, thereby optimizing rainwater runoff prediction, urban flooding risk assessment, and water resource scheduling strategies. For instance, the smart management and control platform for sponge cities established by Kunming collects multi-dimensional data through nearly 200 online monitoring stations. It uses machine learning algorithms to analyze rainwater volume, pollution load, and the operation status of pipe networks, achieving a transformation from “governance” to “intelligent management”, and significantly enhancing the efficiency of urban flood prevention and water resource utilization. This technological integration not only resolves the issue of data silos in traditional sponge city construction but also supports multi-scale system collaboration through simulation and optimization algorithms, such as balancing flood control and ecological demands at the basin scale, or precisely designing the storage and regulation capacity of rain gardens at the community scale.
5. Conclusions
The study achieves a refined assessment of the coupled relationship between rainfall and flooding risk and population exposure in Xuzhou City by constructing a machine learning-based analytical model. The following conclusions were obtained: Firstly, from the perspective of technical approach, the CatBoost model has significant advantages in feature processing and nonlinear relationship capture, and its 81.67% accuracy rate verifies its applicability in complex geographic environments; Secondly, the fusion strategy of multi-source data (e.g., nighttime lighting data inversion of population distribution, dynamic correction of topographic factors) provides high-resolution data support for the study, which compensates for the spatial and temporal limitations of the traditional statistical methods; Thirdly, in addition to common waterlogging points in built-up areas, the study also identifies a large number of waterlogging points in peri-urban and rural areas; Fourthly, population densities of areas with high-risk of waterlogging are generally high, and high-risk of waterlogging is shown in the old urban area, the northwestern section and the southern part of the city, all of which are characterized by high-risk, high exposure. However, there are also shortcomings in this paper. Firstly, the insufficient spatio-temporal resolution of the data makes it difficult to capture the local heavy rainfall and sudden changes in surface confluence caused by urban micro-topography, resulting in inaccurate predictions of urban waterlogging hotspots. Secondly, the existing models rely on static infrastructure parameters (such as drainage pipe networks) and do not integrate real-time sensor data (such as manhole cover water levels and pump station status), which weakens the response capability to emergencies such as pipe network blockages or equipment failures. Furthermore, the heterogeneity of multi-source data (such as the format differences of meteorological satellites and social media warnings) limits the dynamic fusion ability of the model, making it difficult to achieve minute-level coupling of “meteorology—hydrology—society” data. In the future, it is necessary to integrate high-resolution radar precipitation forecasting, IoT sensor networks, and reinforcement learning algorithms to construct a digital twin system that ADAPTS to the evolution of urban rain and flood.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}