1. Introduction
Drought is a multifaceted meteorological phenomenon that has an impact on agriculture, economy, ecosystems, and various other aspects [
1]. Over the past few decades, particularly since the 1990s, drought has become increasingly severe in most parts of the world. Central and northeastern regions have experienced noticeable drought trends, with some areas experiencing a yearly increase in drought coverage of 3.72%, surpassing the area of humid regions [
2]. Mishra et al. identified four distinct drought categories: meteorological, agricultural, hydrological, and socio-economic [
3,
4]. Drought presents significant challenges to ecosystems, agriculture, and economies, necessitating research to concentrate on prediction, assessment, and risk management. Traditional forecasting methods, such as ARIMA and hydrometeorological models, leverage historical data to identify drought patterns; however, they often fail to accurately capture multidimensional non-linear data structures. The advent of artificial intelligence offers transformative advances for drought prediction, with deep learning models such as LSTM, CNN, and Informer adept at extracting intricate spatiotemporal features from diverse data sources, thus markedly improving predictive accuracy. Despite these advancements, AI-based forecasting faces critical challenges, including its reliance on extensive datasets, limitations in predicting short-term and extreme drought events, and the need for more effective multi-source data integration and model optimization. Addressing these limitations in future research is imperative to improve the accuracy of drought prediction and provide scientifically robust information to support disaster prevention and mitigation efforts. This research aims to predict drought using the Informer model, emphasizing reduction in data noise and errors to enhance prediction accuracy and efficiency. Through the refinement of the model architecture and parameter optimization, this study sought to enhance the model’s capacity to capture critical drought characteristics, ultimately providing a more precise and effective tool for drought early warning and risk management.
Prior studies typically have employed a drought index for the accurate measurement of regional drought. This index is extensively utilized for assessing and analyzing drought conditions or its spatiotemporal attributes [
5,
6,
7]. Commonly utilized drought metrics used in studies are the Z index [
8,
9], Meteorological Drought Composite Index (CI), Palmer Drought Severity Index (PDSI), Standardized Precipitation Index (SPI), and Standardized Precipitation–Evapotranspiration Index (SPEI). The Palmer Drought Severity Index (PDSI) is a meteorological drought measure introduced by Palmer in 1965. It is used to analyze regional water balance by distinguishing between dry and wet periods [
10]. Nevertheless, the PDSI calculation heavily relies on meteorological station data at a specific location, which greatly hampers its capacity to evaluate drought conditions across different areas. The index is inadequate for regionalizing drought and is ineffective in monitoring short-term drought across various climate regions [
11]. The SPI utilizes long-term monthly precipitation data within a specific range and incorporates various time scales to measure the excess or deficiency in precipitation. This allows for the identification of drought and wet periods [
12,
13,
14,
15], as well as the determination of drought severity and duration in a particular region [
1]. The SPI is determined by analyzing long-term precipitation data for a specific location. The calculation process is straightforward and can be applied to various climate conditions. However, it does not take into account the impact of temperature [
16], wind speed, or other meteorological factors on evapotranspiration. Therefore, it is not suitable for analyzing the impact of climate change on evapotranspiration. The SPEI, a novel drought index introduced by Vicente-Serrano et al. in 2010, aims to overcome the constraints of the aforementioned drought indices [
1]. SPEI data comprise time series information that displays various temporal scales. Hence, we used the SPEI drought index in this study.
Drought forecasting is crucial in meteorology and plays a pivotal role in preventing, mitigating, and monitoring drought risks [
17]. Drought is a crucial concern in climate change and the management of water resources. Accurately predicting when and how droughts will occur is essential for agriculture, water resource planning, and disaster management [
18]. Forecasting approaches for time series data play a crucial role in predicting droughts [
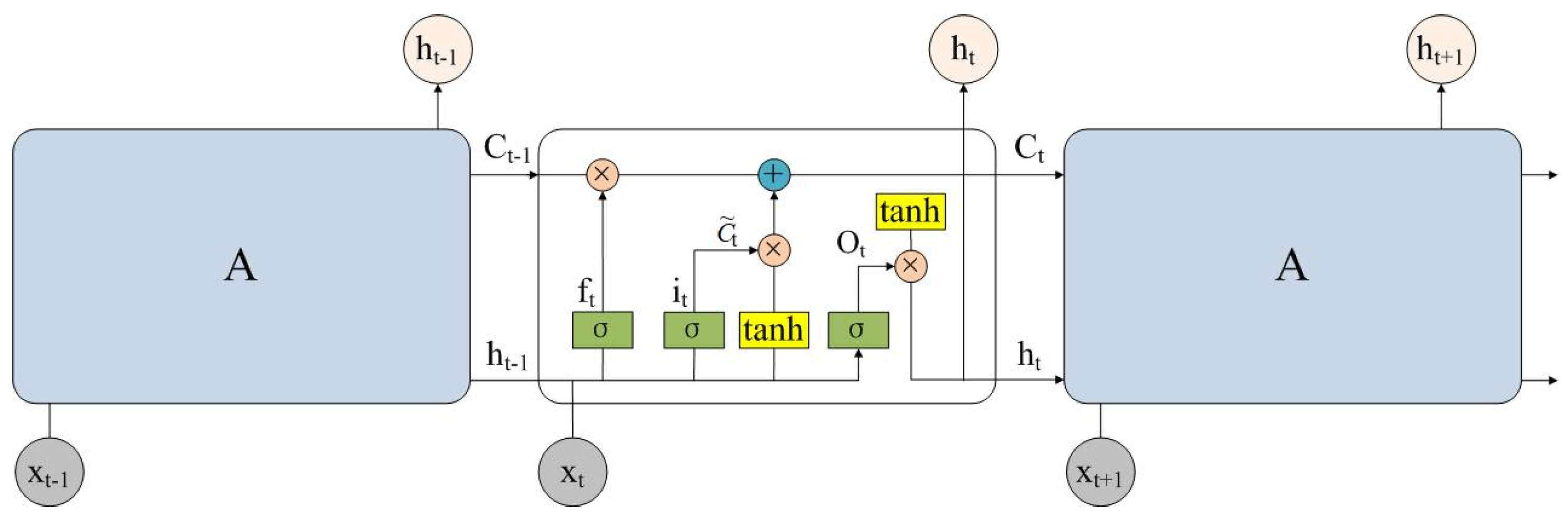
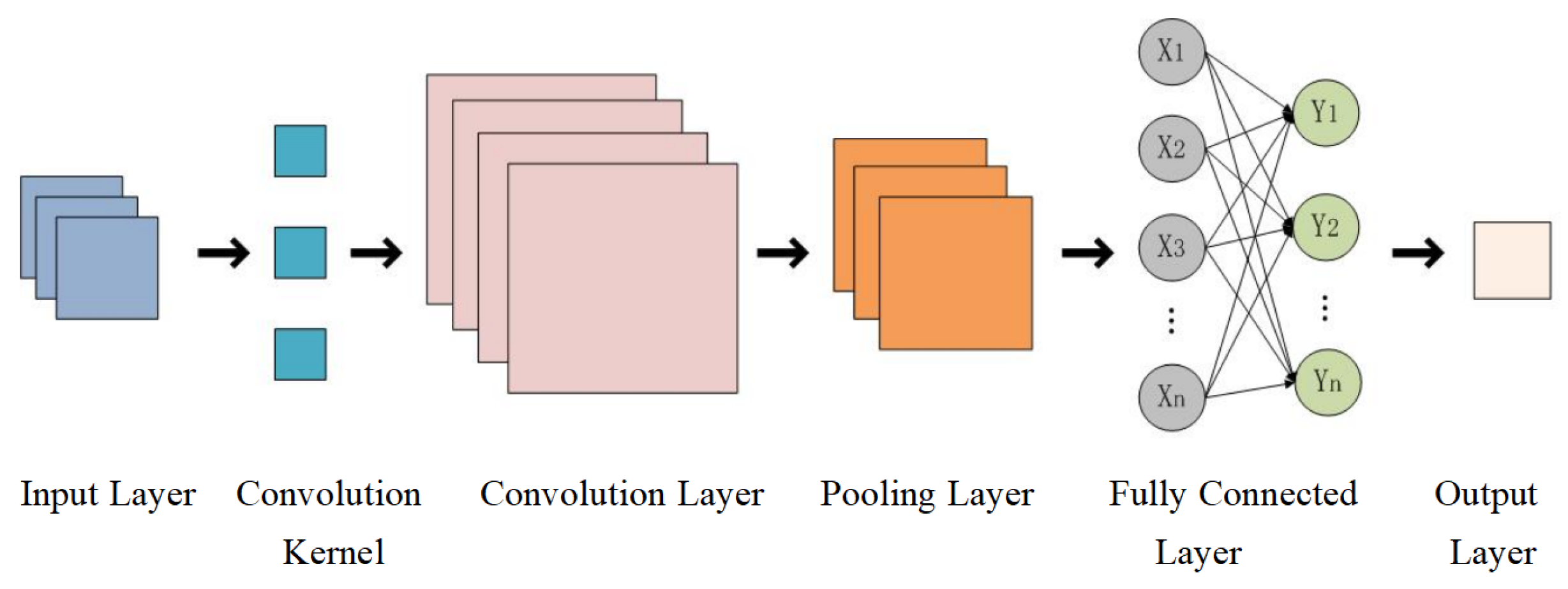
19]. Drought forecasting methods utilize mathematical models to predict the occurrence and intensity of future droughts using historical data and meteorological indicators. There are two main types of drought forecasting methods: statistical methods and machine learning methods. Mi et al. employed an ARIMA model, LSTM model, improved LSTM model (ILSTM), and ILSTM model with additional convolutional layers (CLSTM) to forecast forthcoming drought conditions in eight specific areas of China. The findings indicated that the CLSTM reduces the root mean square error by 0.09∼0.33, making it more appropriate for short-term regional drought and climate prediction [
20]. In their study on drought forecasting in the Talegan watershed, Tehran province, Iran, Nikbakht et al. discovered that the application of Support Vector Machines (SVMs) yielded more precise predictions during spring and fall [
21]. Over the past decade, hybrid models have been utilized to forecast various types of droughts [
22]. Ding et al. developed a Complementary Ensemble Empirical Mode Decomposition (CEEMD)-ARIMA model and a CEEMD-LSTM model to forecast drought in the Xinjiang region. The findings indicated that the CEEMD-ARIMA model achieved the highest accuracy in forecasting, and the hybrid model outperformed the individual models in accuracy across all time scales. However, there was still a lower accuracy in forecasting at shorter time scales [
23]. Xu et al. integrated the advantages of ARIMA and CEEMD to predict regional droughts in China. They discovered that the combined model yielded superior results compared to using a single model. However, the accuracy of short-term predictions remained relatively poor [
24]. Xu et al. conducted a comparative analysis of various forecasting models, including ARIMA, support vector regression (SVR), LSTM, ARIMA-SVR, least square SVR (LS-SVR), and ARIMA-LSTM, to predict the Standardized Precipitation–Evapotranspiration Index (SPEI) in China. The results indicated that the hybrid model had a higher accuracy in forecasting long-term SPEI, but a lower accuracy in forecasting short-term SPEI. Additionally, the ARIMA-LSTM model exhibited the highest accuracy in predicting the SPEI on the 6-, 12-, and 24-month scales, suggesting its suitability for long-term drought forecasting in China [
25]. Zhang et al. employed various forecasting models, including ARIMA, random forest (RF), recurrent neural network (RNN), LSTM, and convolutional long short-term memory (ConvLSTM), to predict short-term meteorological droughts. The study revealed that ConvLSTM effectively captures spatiotemporal information and outperforms other models in short-term drought forecasting. Specifically, ConvLSTM exhibited high accuracy in forecasting droughts within a time frame of 1–5 days [
26]. Shang et al. employed the Informer model to predict droughts in the Yangtze River Basin. The findings indicated that the Informer model outperforms LSTM and ARIMA in terms of forecasting accuracy. Nonetheless, despite some advancements in forecasting short-term droughts, the general precision of the predictions continues to be inadequate [
27].
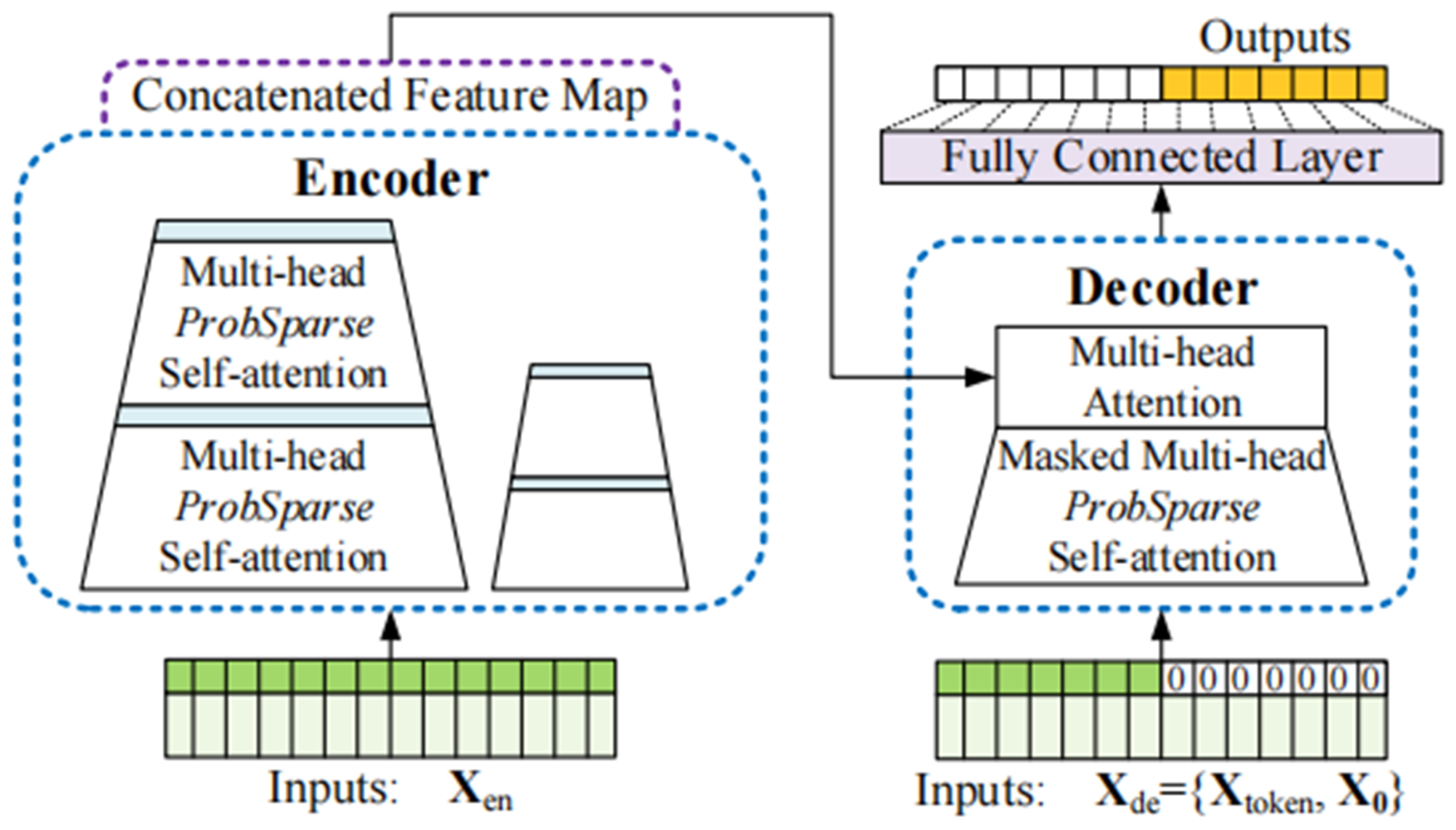
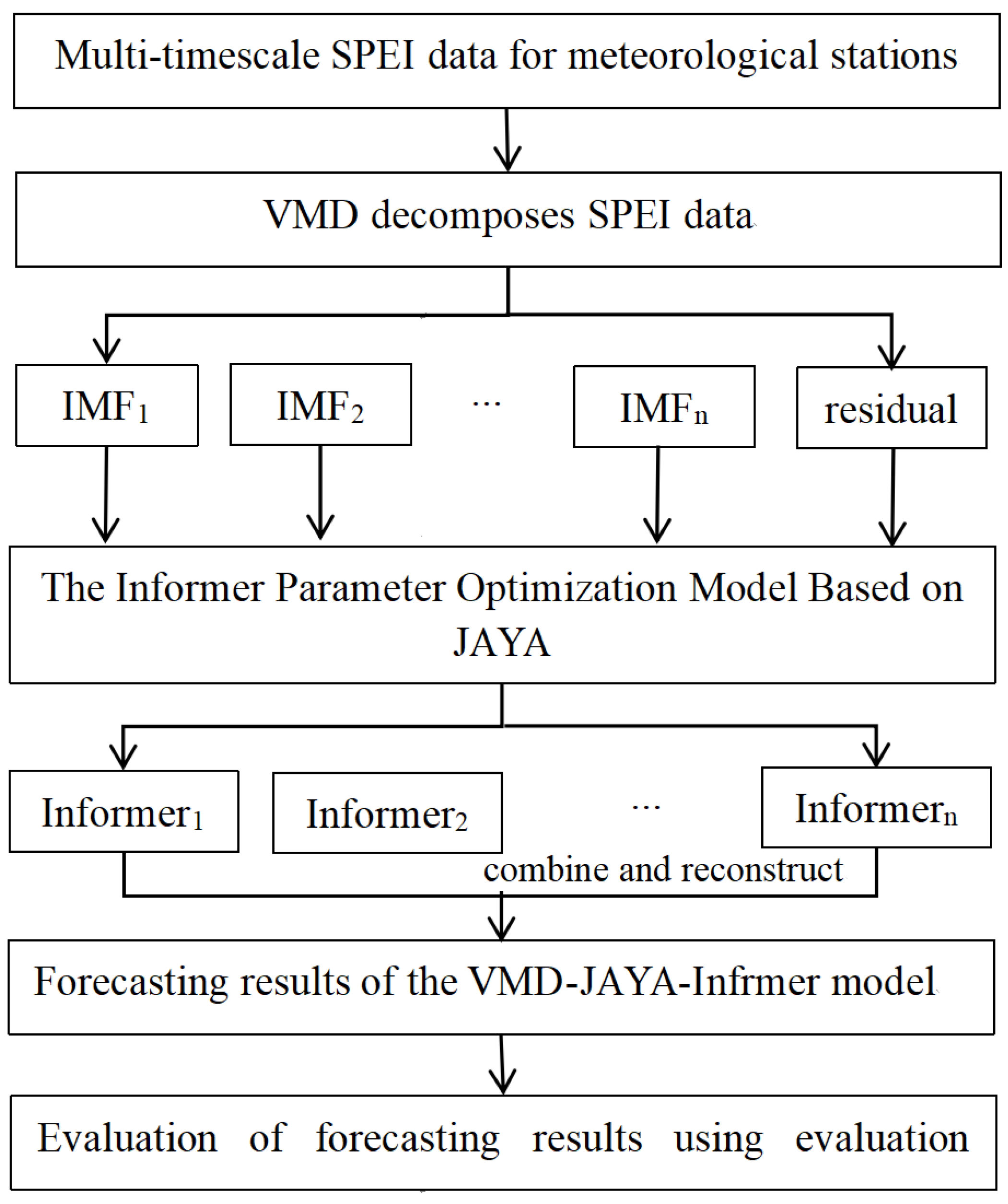
This work addresses the issue of low accuracy in predicting droughts on a short time scale, based on the scientific background provided above. While the Informer model excels at long-term forecasting, its accuracy in short-term forecasting can be influenced by factors such as excessive noise, seasonality, and periodicity. This study aims to enhance short-term forecasting by concentrating on the Songliao River Basin and integrating Variational Mode Decomposition (VMD) with the Jaya algorithm (JAYA) to improve the Informer model. The resulting model is referred to as VMD-JAYA-Informer. When comparing the predictions of VMD-JAYA-Informer with those of VMD-JAYA-LSTM, VMD-JAYA-ARIMA, and VMD-JAYA-CNN, the VMD-JAYA-Informer algorithm consistently exhibits superior accuracy in forecasting SPEI across all time scales. In this study, the SPEI data from four randomly chosen meteorological stations in the Songliao River Basin were verified.
4. Discussion
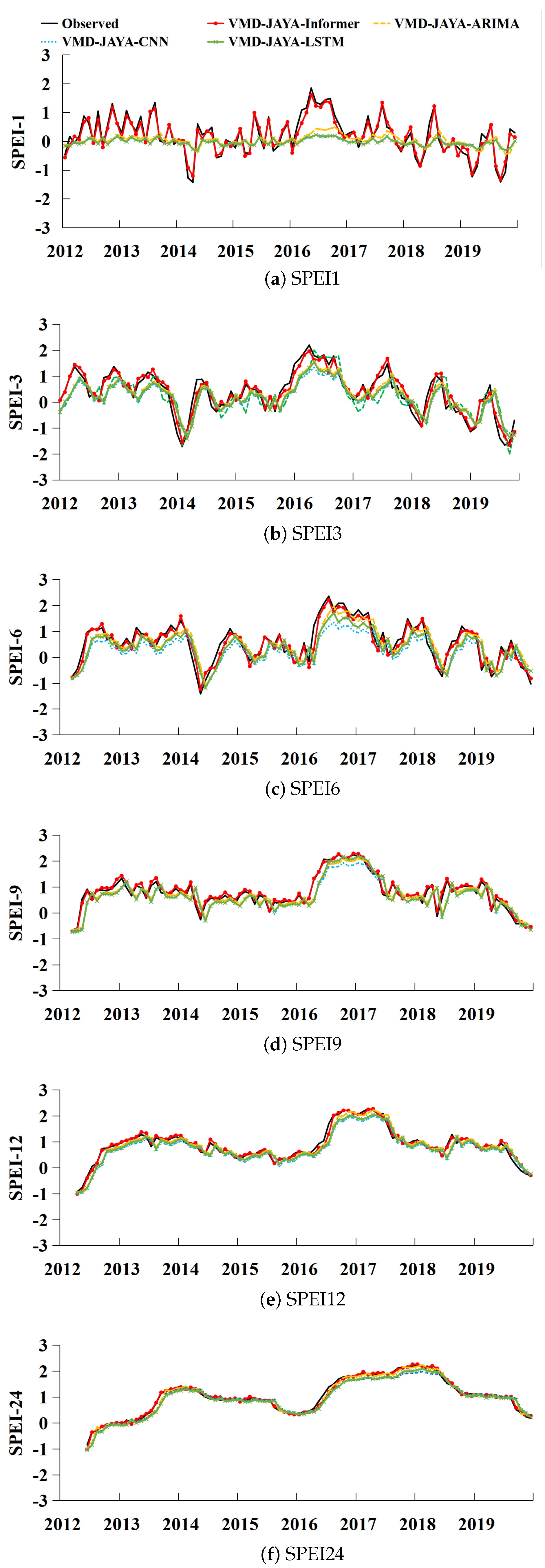
This study investigates the performance of SPEI prediction methods including the ARIMA, LSTM, CNN, and Informer models. To address the challenge of low prediction accuracy at shorter time scales, we proposed a VMD-JAYA-Informer model that integrates Variational Mode Decomposition (VMD) and JAYA optimization with the Informer model, effectively enhancing the Informer’s performance in drought prediction.
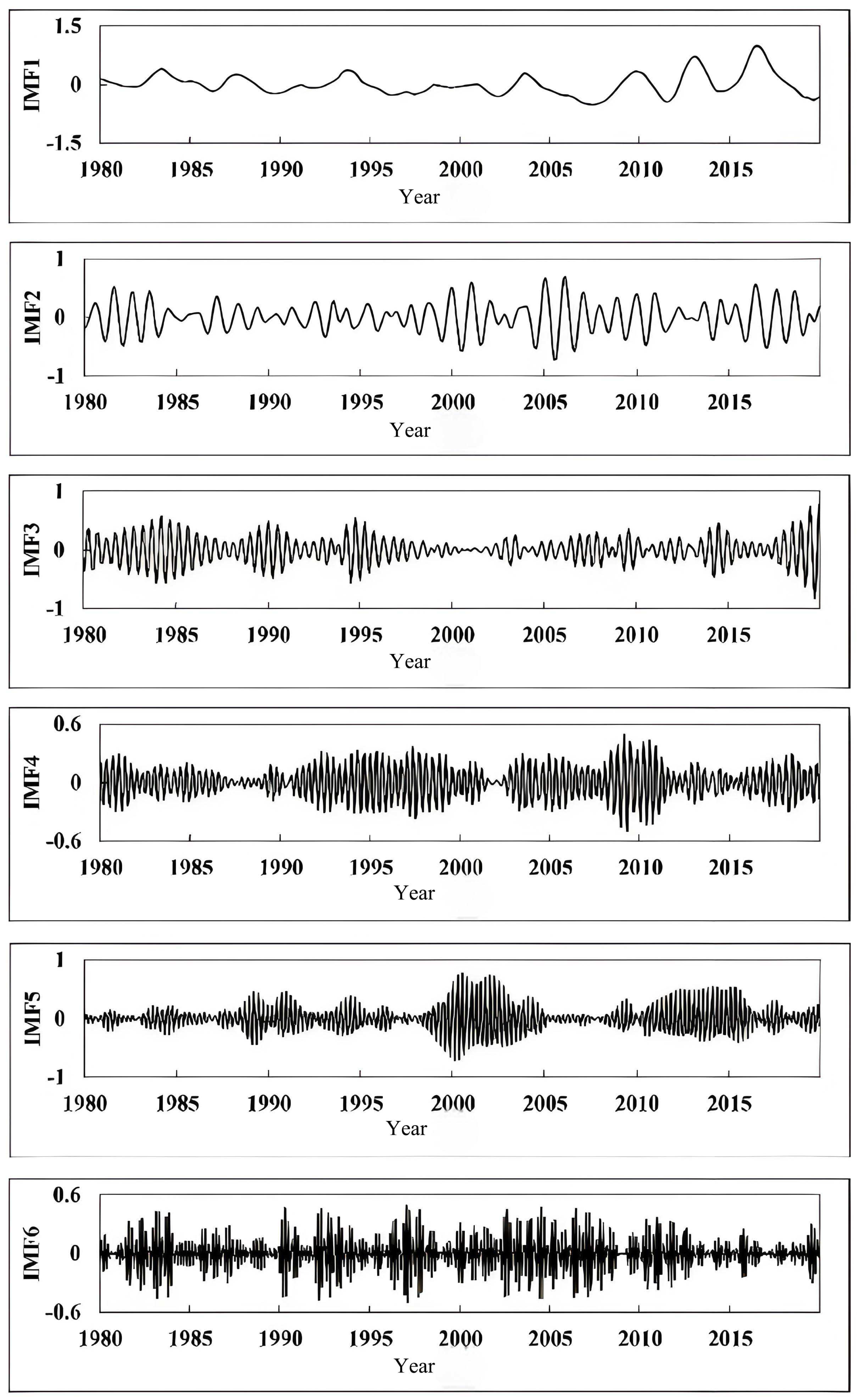
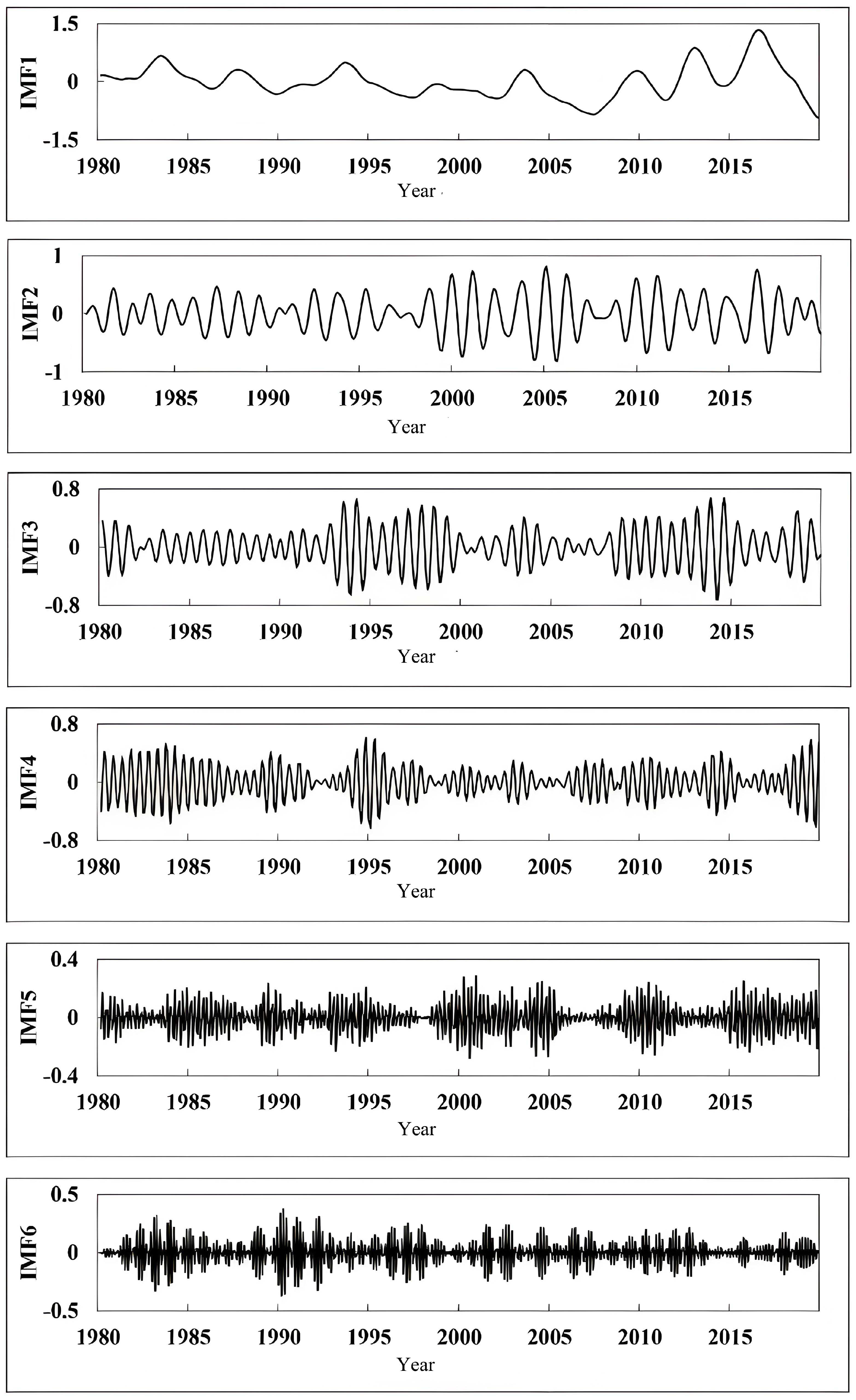
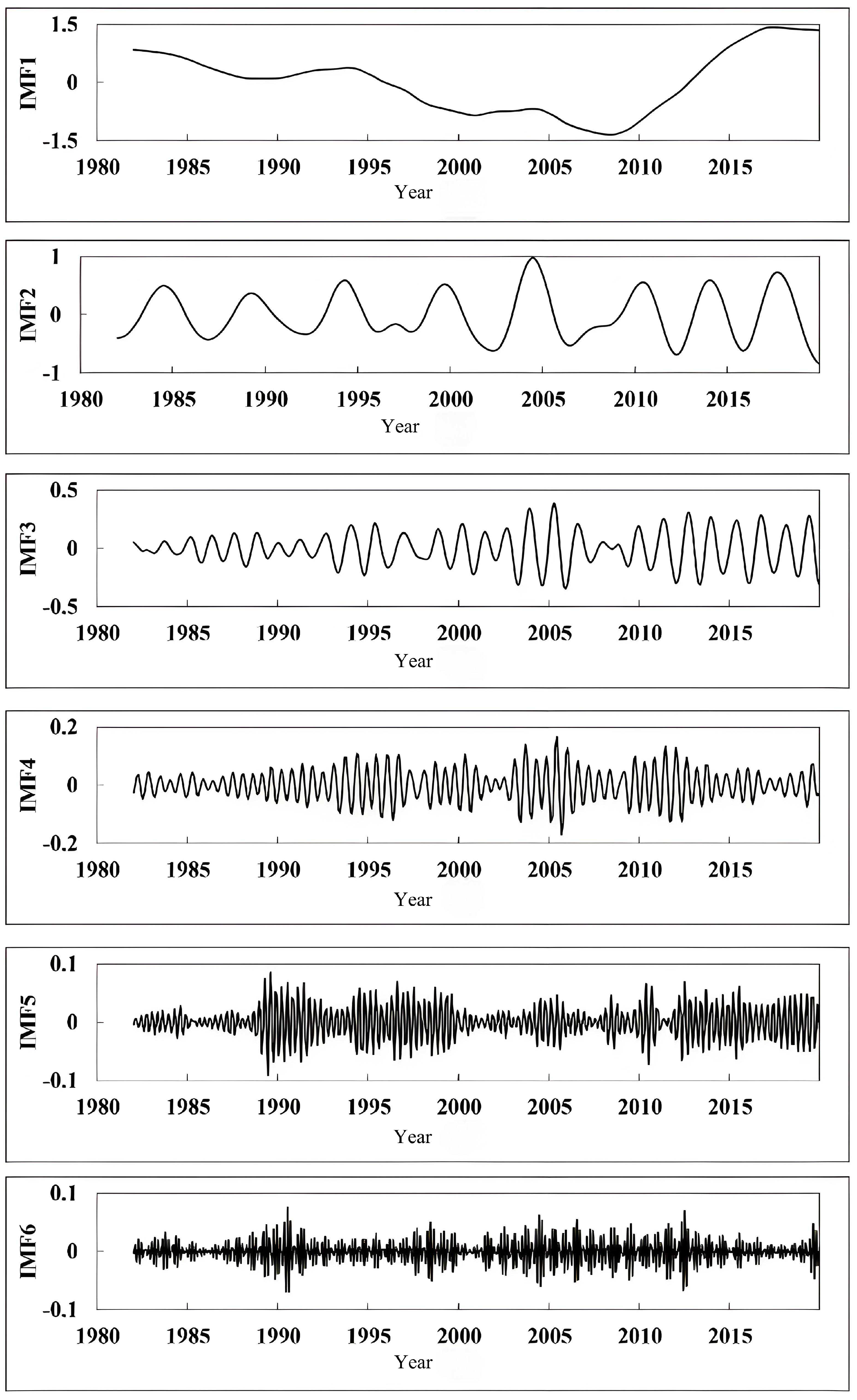
In this approach, VMD decomposes the SPEI time series into multiple temporal components. This approach reduces noise and captures SPEI’s oscillatory patterns with greater accuracy. The decomposed data are then predicted using the Informer model, further enhanced by the JAYA algorithm’s optimized parameter selection. This combination enables the model to attain enhanced predictive accuracy, particularly in short-term intervals and for extreme values, where it significantly outperforms the independent Informer model, especially in 1-month forecasts.
The enhanced precision of VMD-JAYA-Informer for short-term SPEI can be attributed to three main factors. First, the adaptive decomposition from VMD enables the breakdown of SPEI data into modal functions across varying frequencies, which reveals both local and global features across multiple time scales. This decomposition better represents SPEI’s periodic characteristics and provides a robust foundation for Informer to handle SPEI’s complex time series structure. Secondly, the JAYA optimization algorithm refines the Informer’s hyperparameters and weights, facilitating a more effective exploration of the parameter space and producing optimal parameter combinations that markedly enhance forecasting performance on SPEI data. Lastly, the Informer model’s multi-head self-attention mechanism effectively captures both short-term fluctuations and long-term dependencies in SPEI data. When optimized with VMD and JAYA, Informer utilizes the SPEI’s multi-scale information more effectively, resulting in enhanced prediction accuracy, especially for short-term and extreme values.
Our findings align with those of Ding et al. and Xu et al., who found that hybrid models generally outperform single models in drought prediction, particularly for shorter time intervals. Although the CEEMD-ARIMA model has demonstrated efficacy in drought forecasting, it continues to encounter challenges regarding short-term SPEI precision [
24,
25]. Similarly, Xu et al.’s ARIMA-LSTM hybrid model performs well for achieving long-term accuracy but faces limitations with short-term SPEI predictions [
26]. Shang et al. noted enhancements in forecasting precision with the Informer; however, deficiencies in short-term SPEI accuracy persisted [
28].
This study’s contributions are twofold. First, it applies the Informer model for drought prediction in the Songliao River Basin, and compares its performance with that of the ARIMA, LSTM, and CNN models. While all models exhibit reduced accuracy over shorter time scales, Informer consistently outperforms the others, demonstrating strong adaptability across different time frames. Second, by introducing the VMD-JAYA-Informer approach, this study addresses Informer’s short-term accuracy limitations and demonstrates its effectiveness in predicting extreme SPEI values, especially for 1-month forecasts.
This study indicates that VMD-JAYA-Informer improves SPEI forecasting accuracy for short time scales and implies that additional parameter optimization or data decomposition methods may further enhance its efficacy. Future research could explore the model’s applicability across various drought indices, potentially broadening its utility under diverse drought prediction scenarios.
5. Conclusions
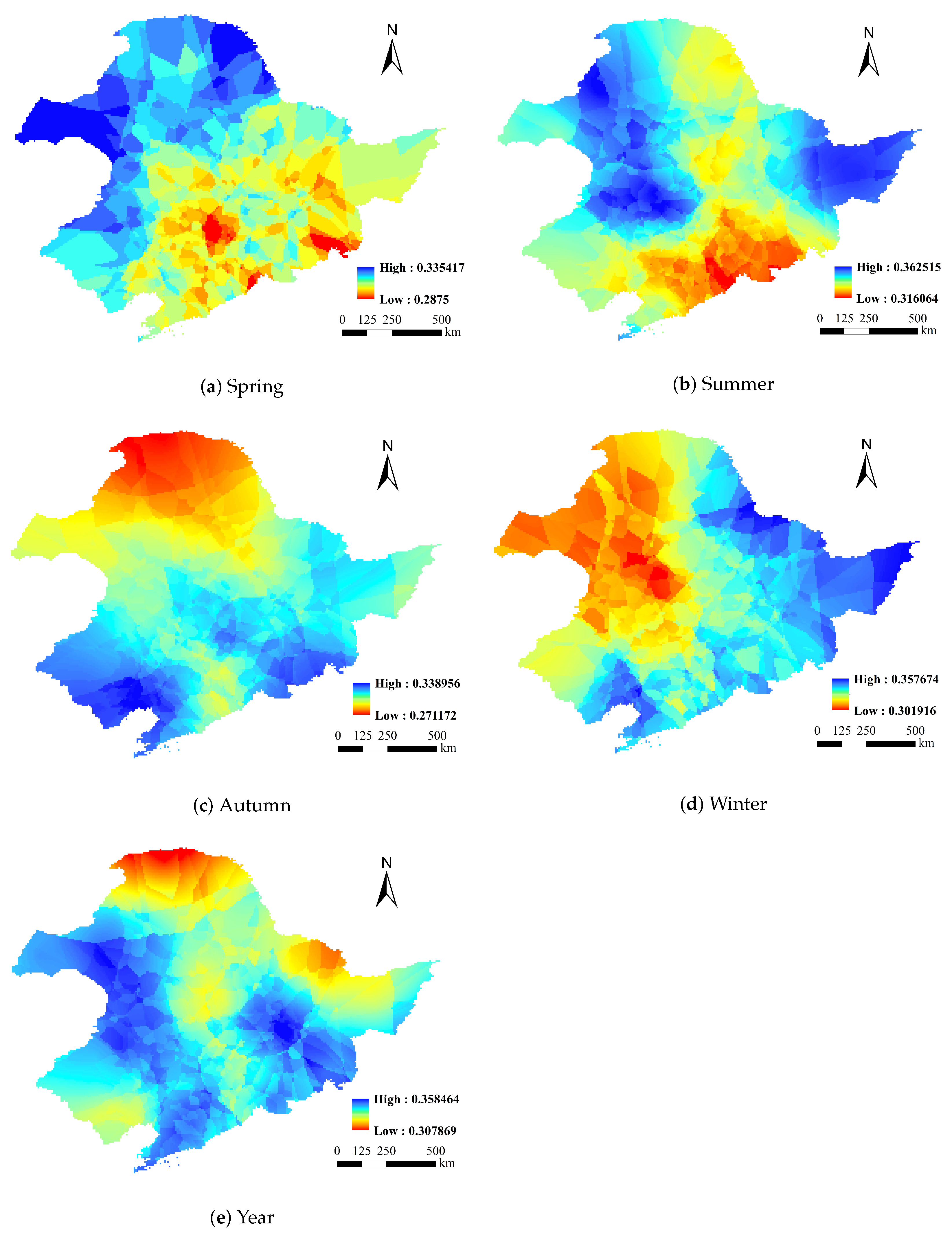
This study estimated the Standardized Precipitation–Evapotranspiration Index (SPEI) using meteorological data from the Songliao River Basin spanning the years 1980 to 2020 at multiple time scales. Additionally, we made predictions based on these calculations. To improve the Informer’s accuracy for short-time-scale SPEI predictions, a drought forecasting approach called VMD-JAYA-Informer was developed. This was achieved by comparing and analyzing the performance of ARIMA, LSTM, CNN, and Informer in drought forecasting. The primary focuses of this study are outlined as follows:
(1) The experimental findings demonstrate that when the time scale diminished, the forecasting ability of ARIMA, LSTM, CNN, and Informer also declined. However, Informer consistently outperformed ARIMA, LSTM, and CNN. As the time scale increased, the forecasting performance of ARIMA, LSTM, CNN, and Informer improved steadily. The NSE also gradually increased and reached its optimal value of 1. The RMSE and MAE exhibited the inverse trends. All four models achieved an optimal predicting performance over the 24-month time period. The NSE values were obtained: 0.9276, 0.8537, 0.9009, and 0.9395.
(2) However, due to the influence of weather changes, the SPEI at short time scales experiences greater fluctuations and is more challenging to predict. Consequently, the Informer model’s forecasting accuracy at short time scales has not yet reached the desired level. This study introduces VMD-JAYA-Informer, a method for drought prediction that aims to fix the Informer’s poor performance in SPEI prediction at short time scales. The results show that when it comes to predicting the SPEI at the 1-month time scale, VMD-JAYA-Informer outperforms the Informer and aligns better with the real data. It demonstrates that VMD-JAYA-Informer is more effective in accurately predicting the SPEI in short time periods. It also outperforms the Informer model in other time periods.
(3) For this study, we chose four meteorological stations in the Songliao River Basin at random to test the accuracy of the VMD-JAYA-Informer. The results indicate that the VMD-JAYA-Informer outperforms the Informer significantly when it comes to forecasting at the 1-month time scale. The NSE values for the four weather stations were obtained: 0.8663, 0.8765, 0.8822, and 0.8416, respectively. The VMD-JAYA-Informer demonstrates a higher prediction performance compared with Informer across several time scales, highlighting its broad applicability and high accuracy in drought prediction.



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}