
Evaluation of Maximum Entropy (Maxent) Machine Learning Model to Assess Relationships between Climate and Corn Suitability


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
2.1.1. Cropland Presence Data and Study Area
2.1.2. Factors Driving Crop Suitability

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Definition |
|---|---|
| Bio 01: Mean annual temperature | Annual Mean temperature |
| Bio 02: Mean diurnal range | Average difference between high and low daily temperature |
| Bio 03: Isothermality | Ratio of mean diurnal temperature range relative to seasonal range |
| Bio 04: Temperature seasonality | Temperature variation over a year by monthly average temperature |
| Bio 05: Max temp. of warmest month | Monthly mean of daily high temperatures for hottest month |
| Bio 06: Min temp. of coldest month | Monthly mean of daily low temperatures for coldest month |
| Bio 07: Temperature annual range | Bio 07 = Bio 05–Bio 06 |
| Bio 08: Mean temp. of wettest quarter | Average temperature for three months with most precipitation |
| Bio 09: Mean temp. of driest quarter | Average temperature for three months with least precipitation |
| Bio 10: Mean temp. of warmest quarter | Average temperature for three hottest months |
| Bio 11: Mean temp. of coldest quarter | Average temperature for three coldest months |
| Bio 12: Annual precipitation | Total annual precipitation |
| Bio 13: Precipitation of wettest month | Total precipitation for month with most precipitation |
| Bio 14: Precipitation of driest month | Total precipitation for month with least precipitation |
| Bio 15: Precipitation seasonality | Precipitation variation over a year by monthly total precipitation |
| Bio 16: Precipitation of wettest quarter | Total precipitation for three months with most precipitation |
| Bio 17: Precipitation of driest quarter | Total precipitation for three months with least precipitation |
| Bio 18: Precipitation of warmest quarter | Total precipitation for three hottest months |
| Bio 19: Precipitation of coldest quarter | Total precipitation for three coldest months |
| Slope | Gradient of land incline |
| Elevation | Elevation in meters |
| Root zone depth | Depth in which crops can extract water and nutrients effectively |
| Available water storage | Amount of water that soil can store for use by crops |
| Taxonomic order | 12 soils orders based on physical, chemical, and biological conditions |
2.2. Methods
2.2.1. Constructing and Setting Maxent Model
2.2.2. Comparing and Evaluating Maxent
Comparison with Other Method: Random Forest (RF)
OR
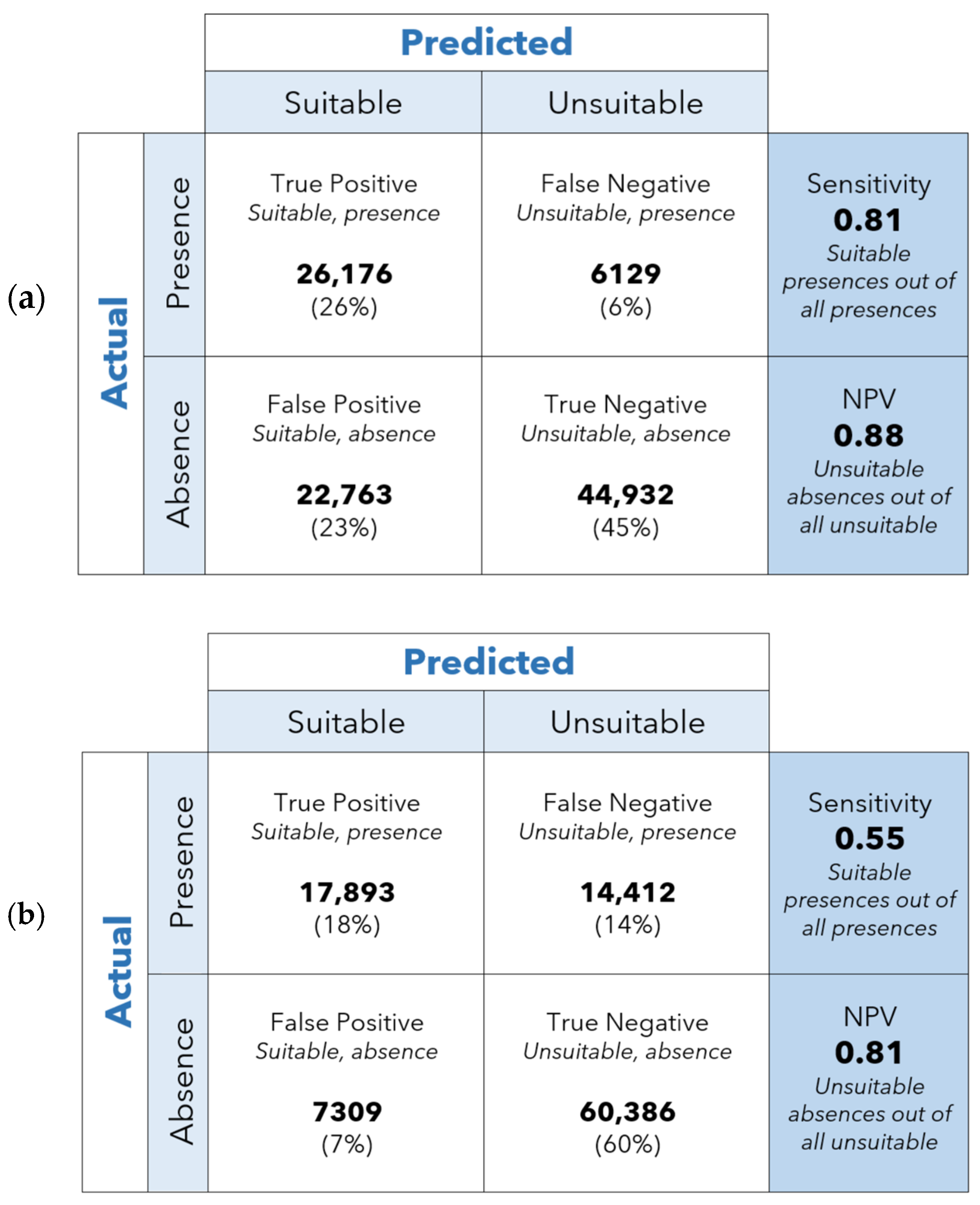
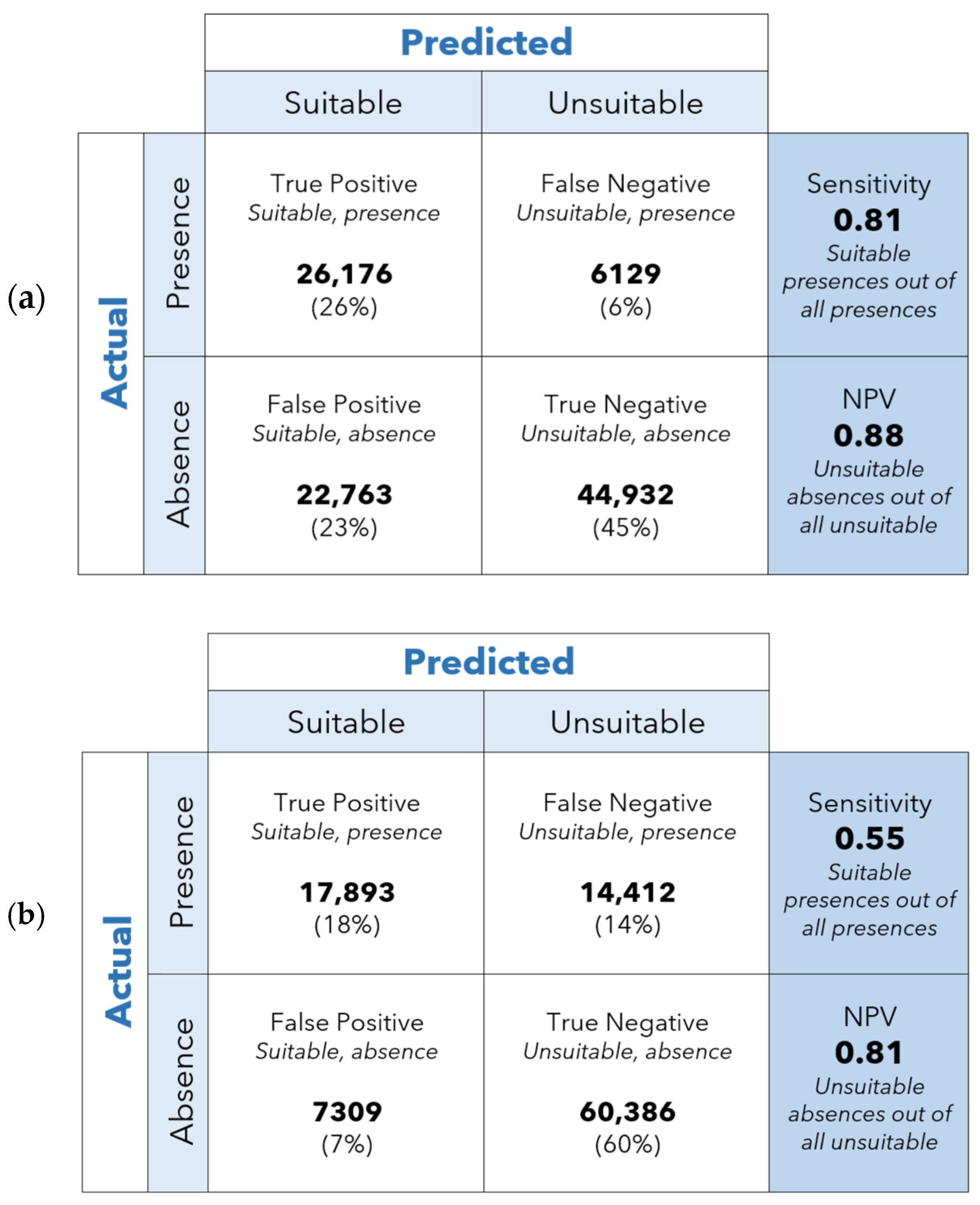
Sensitivity = [suitable, present]/[all presences]
OR
NPV = [unsuitable, absence]/[all unsuitable]
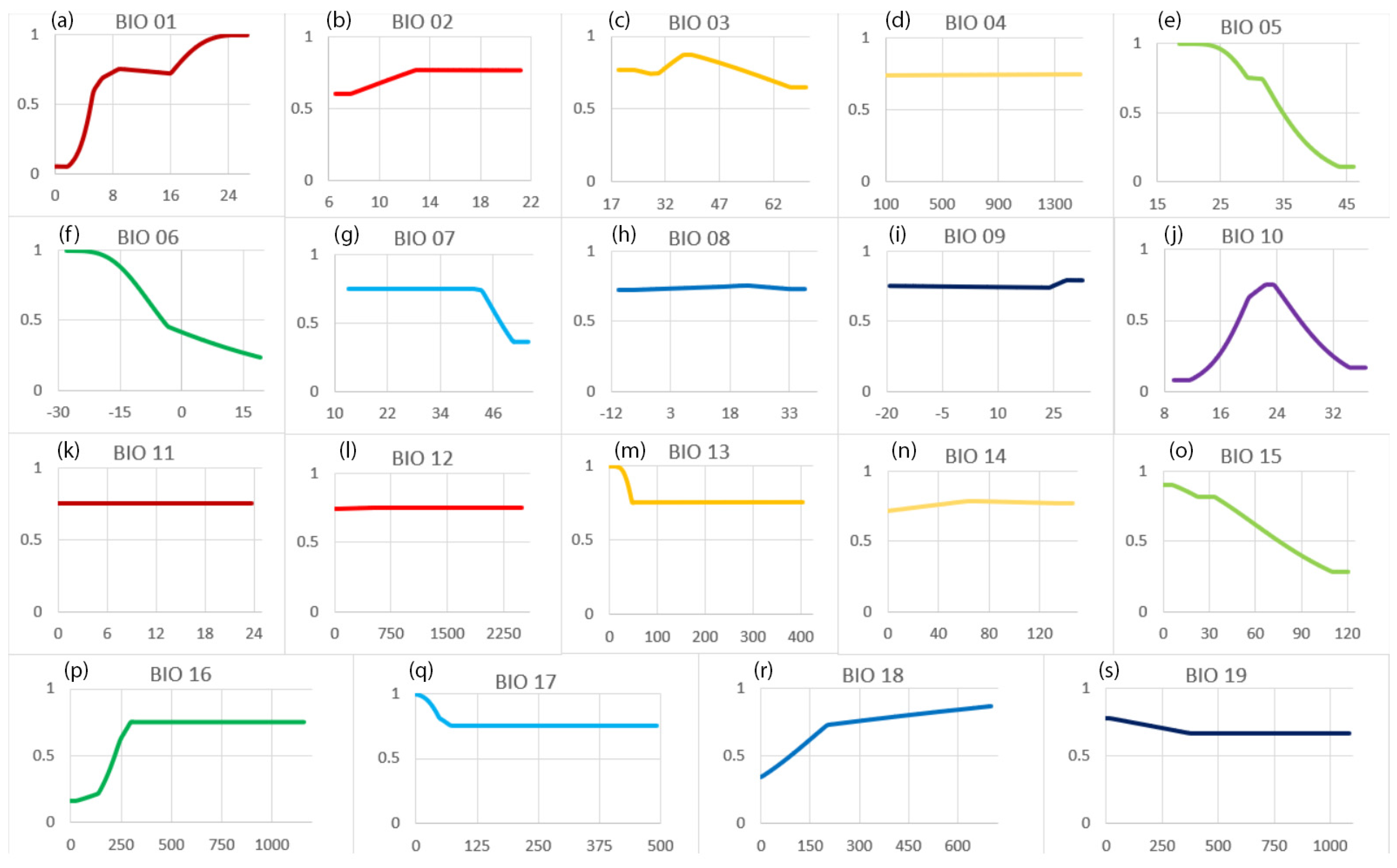
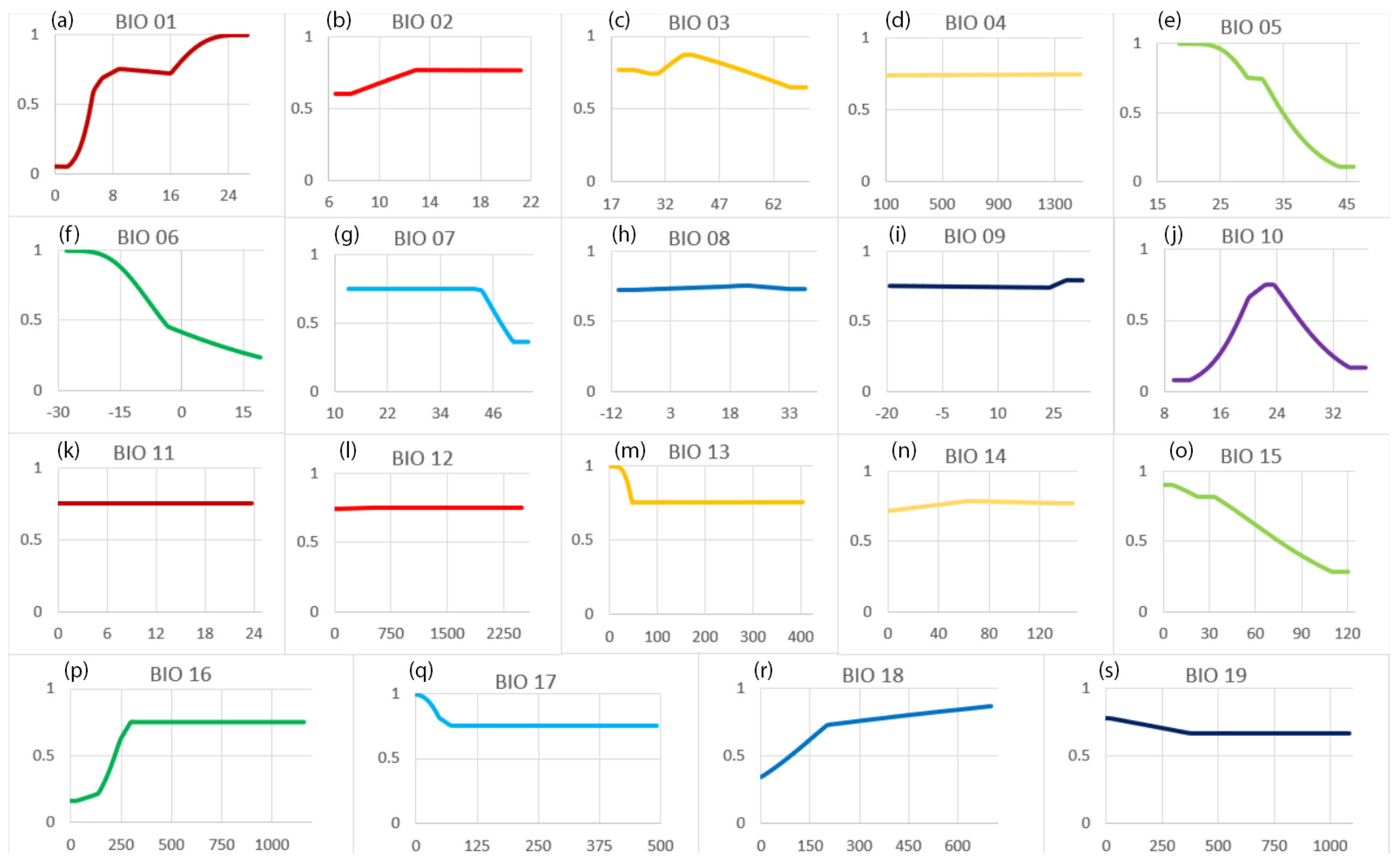
Using Response Curves to Compare to Literature
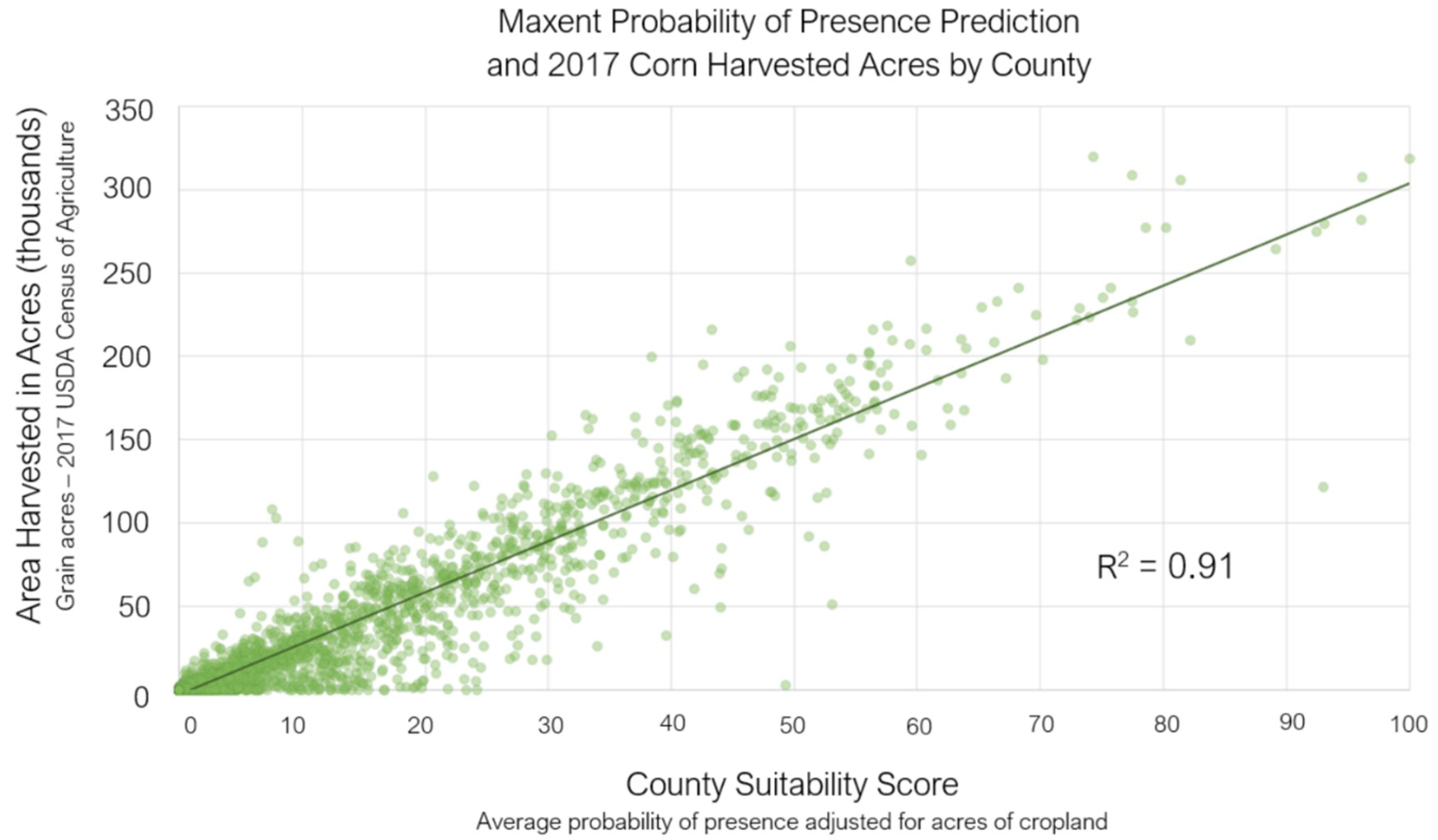
Comparison with Real Cultivation Data
3. Results and Discussion
3.1. Model Comparison: Evaluating the Results from RF and Maxent
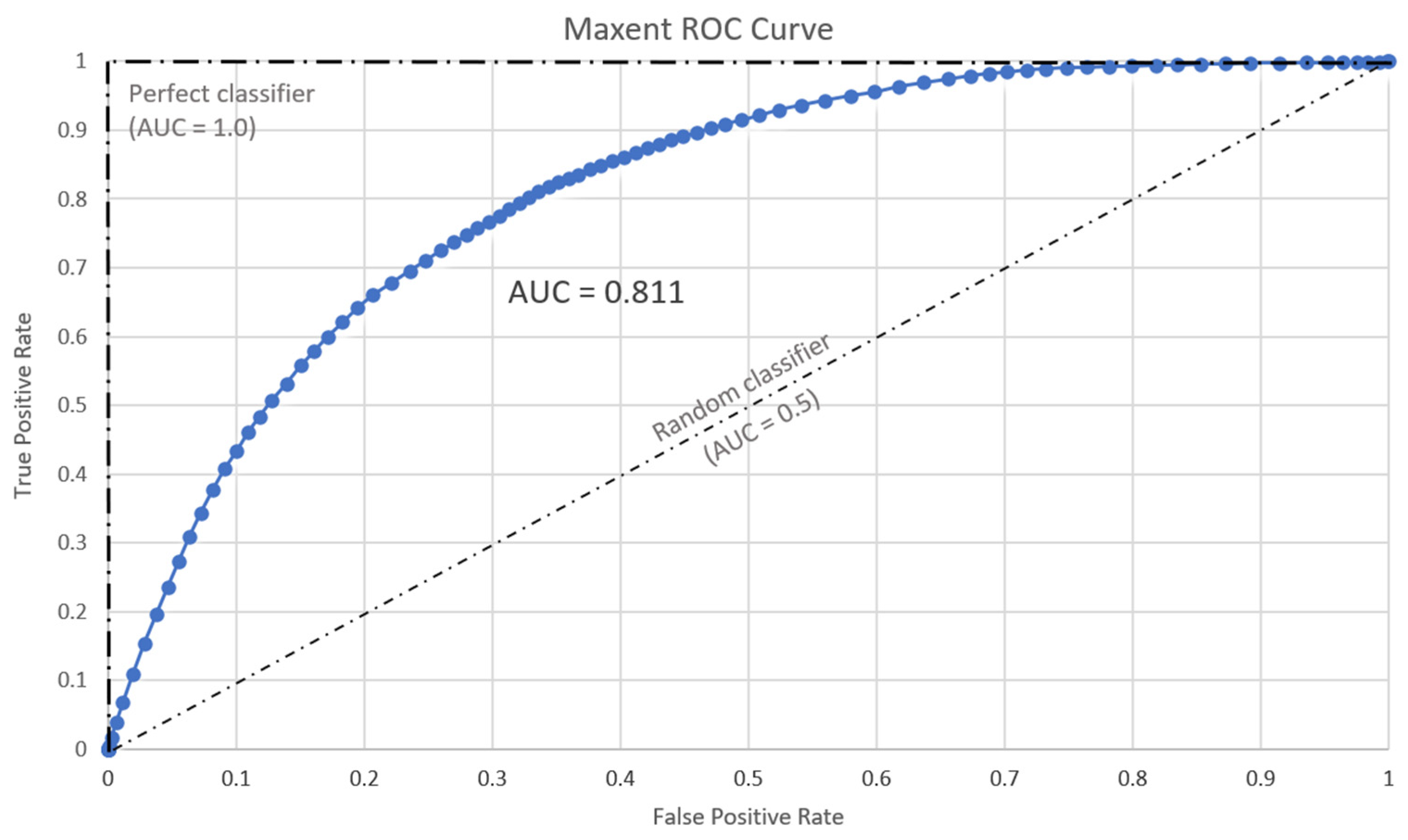
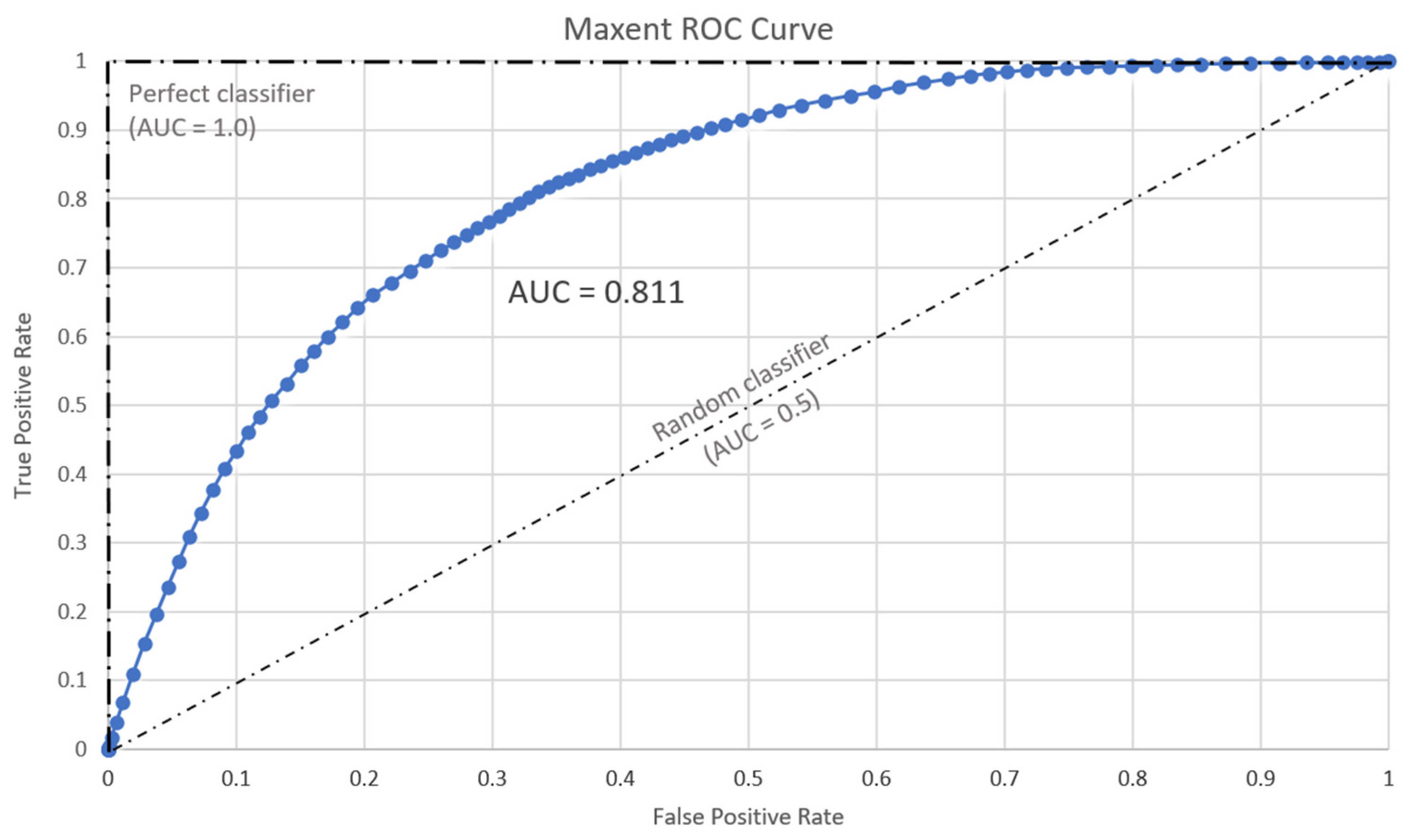
3.1.1. Statistical Evaluation
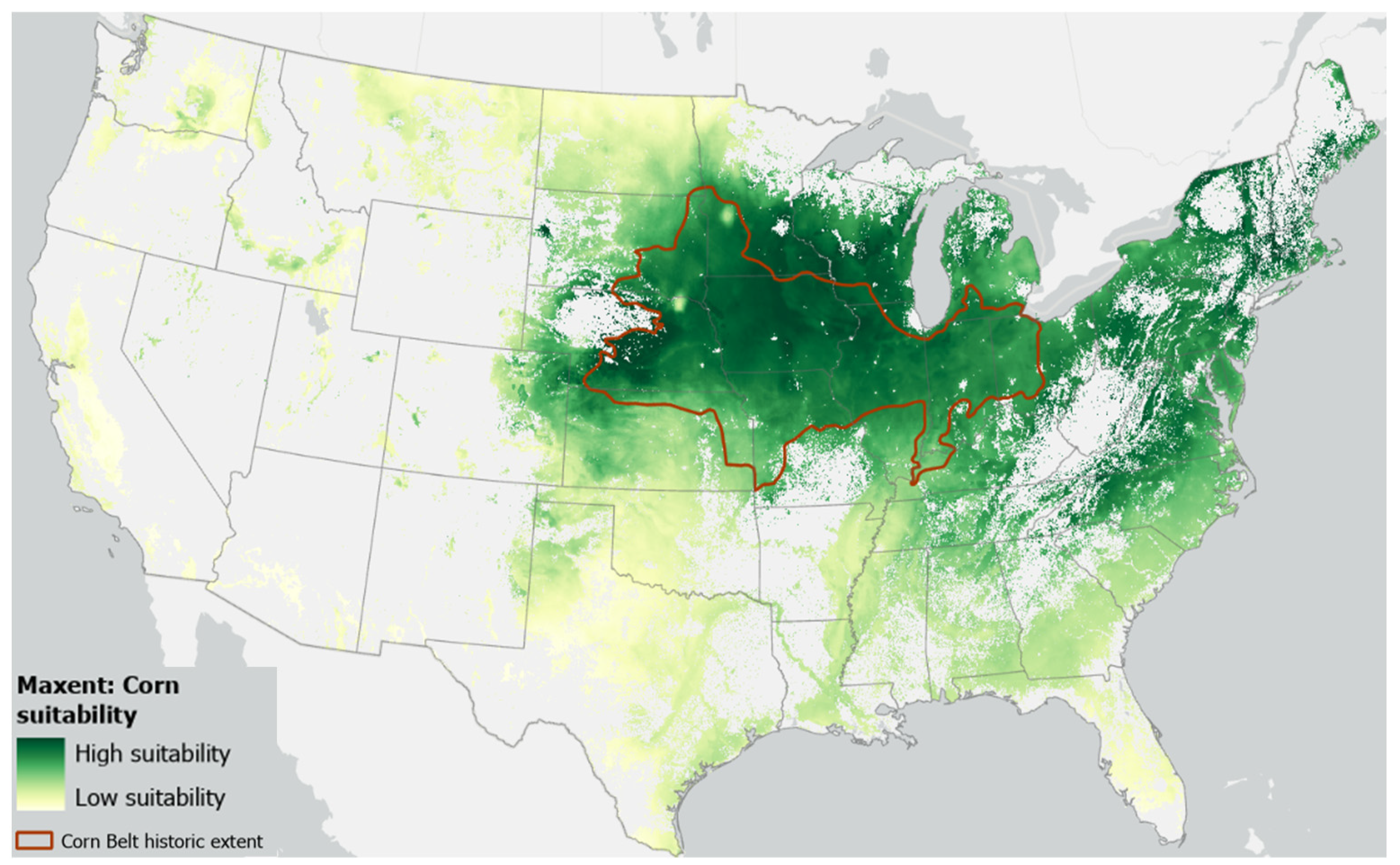
3.1.2. Visual Evaluation
3.2. Comparison with Existing Literature on Suitability Thresholds
| Variable | Name | Range | Max POP | Max POP Value | Min POP | Min POP Value | Trend | Interpretation |
|---|---|---|---|---|---|---|---|---|
| Bio 01 | Annual mean temperature | 0.95 | 1 | >24 | 0.05 | <2 | Positive | Suitability increases with temperature |
| Bio 05 | Max temperature of warmest month | 0.89 | 1 | <28 | 0.11 | >44 | Negative | Suitability decreases in areas prone to extreme summer heat |
| Bio 06 | Min temperature of coldest month | 0.76 | 1 | <−28 | 0.24 | >19 | Negative | High suitability corresponds with cold winters |
| Bio 10 | Mean temperature of warmest quarter | 0.67 | 0.75 | 23 | 0.08 | <12 | Quadratic | Corn prefers warm, not hot, summers |
| Bio 15 | Precipitation seasonality | 0.62 | 0.9 | <7 | 0.28 | >110 | Negative | Suitability increases with low rainfall variation |
| Bio 16 | Precipitation of wettest quarter | 0.58 | 0.75 | >297 | 0.17 | <50 | Positive | Corn prefers medium to high seasonal rainfall |
| Bio 18 | Precipitation of warmest quarter | 0.54 | 0.87 | >700 | 0.33 | <40 | Positive | Corn prefers rainy summers |
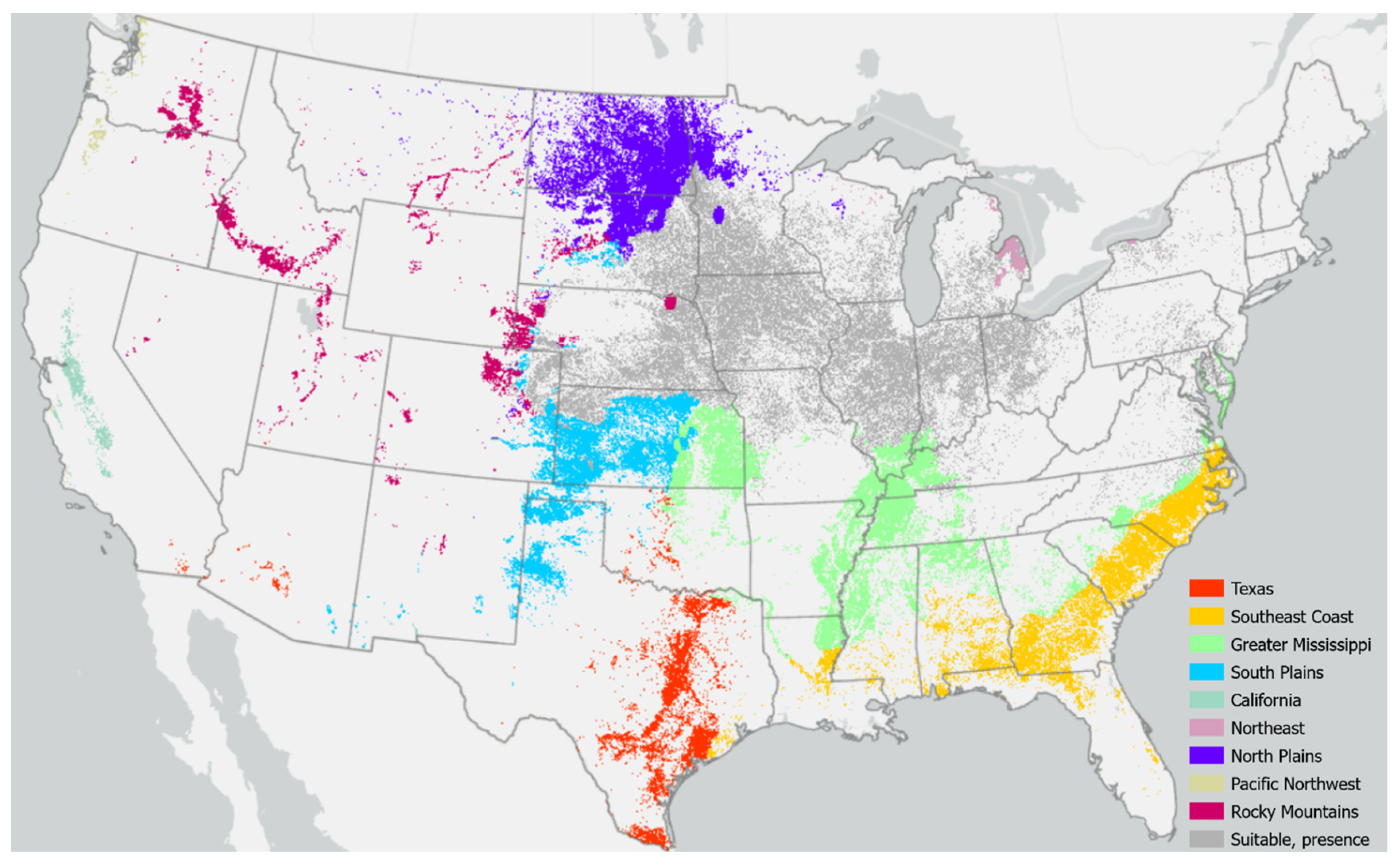
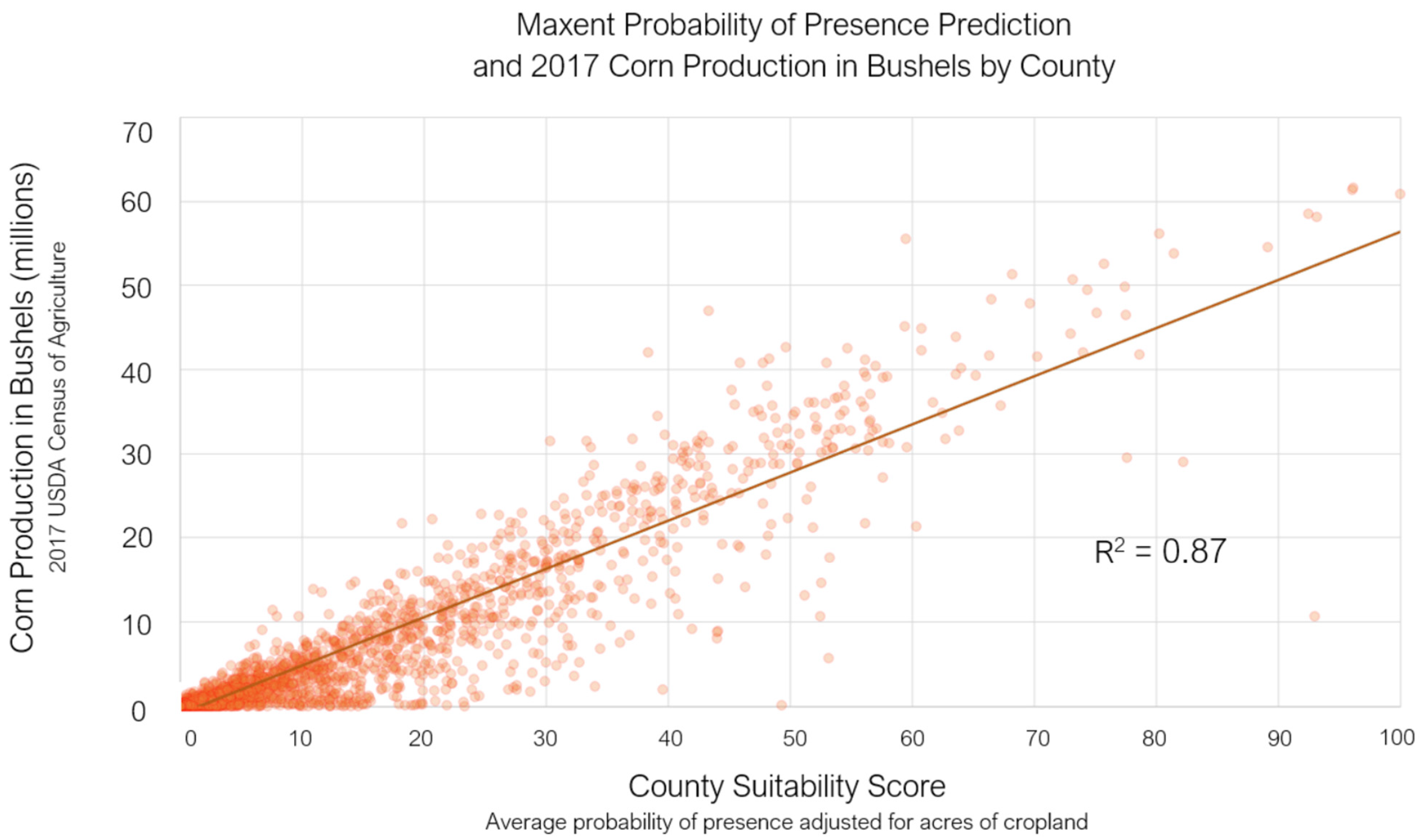
3.3. Comparison with Cultivation Data
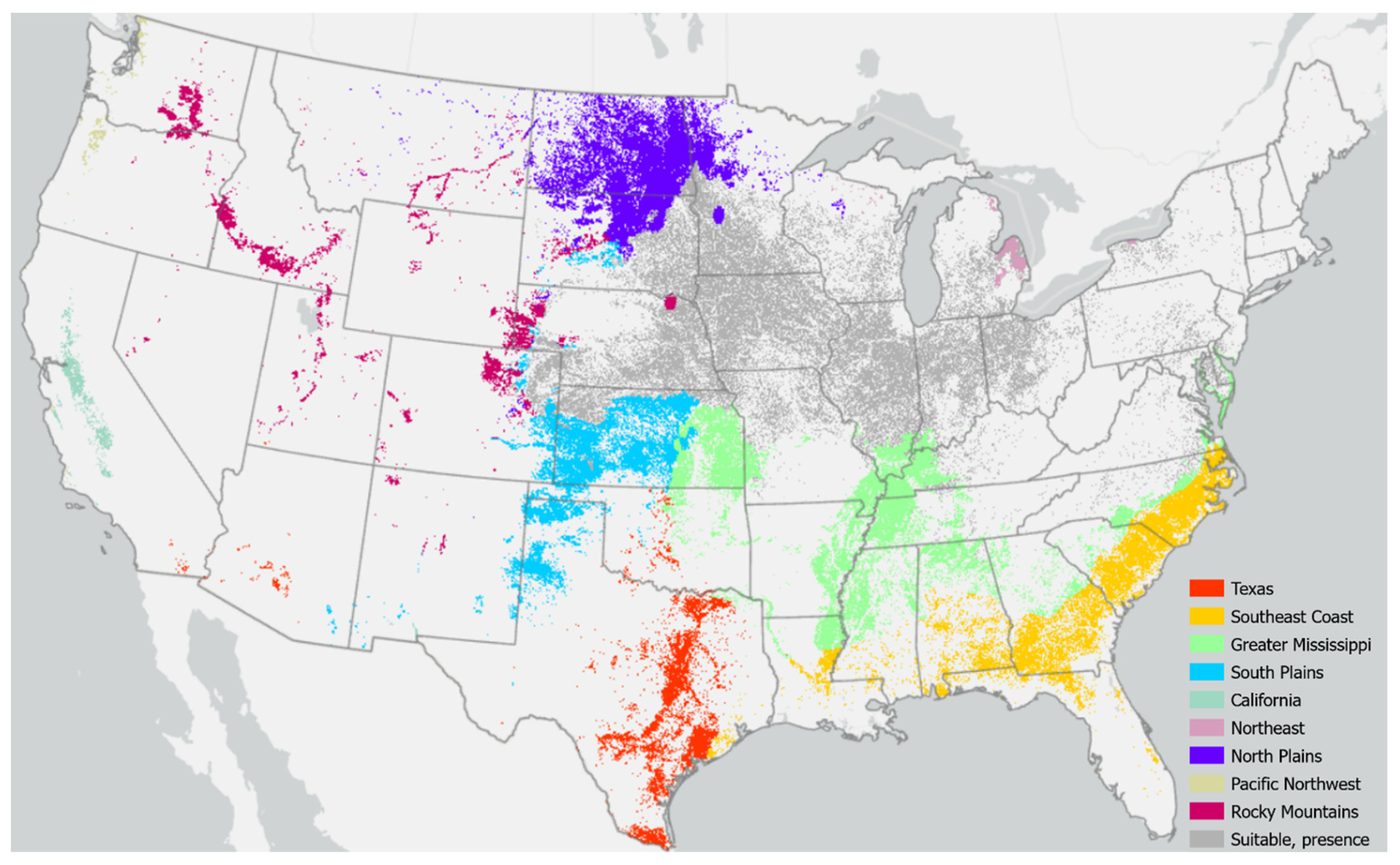
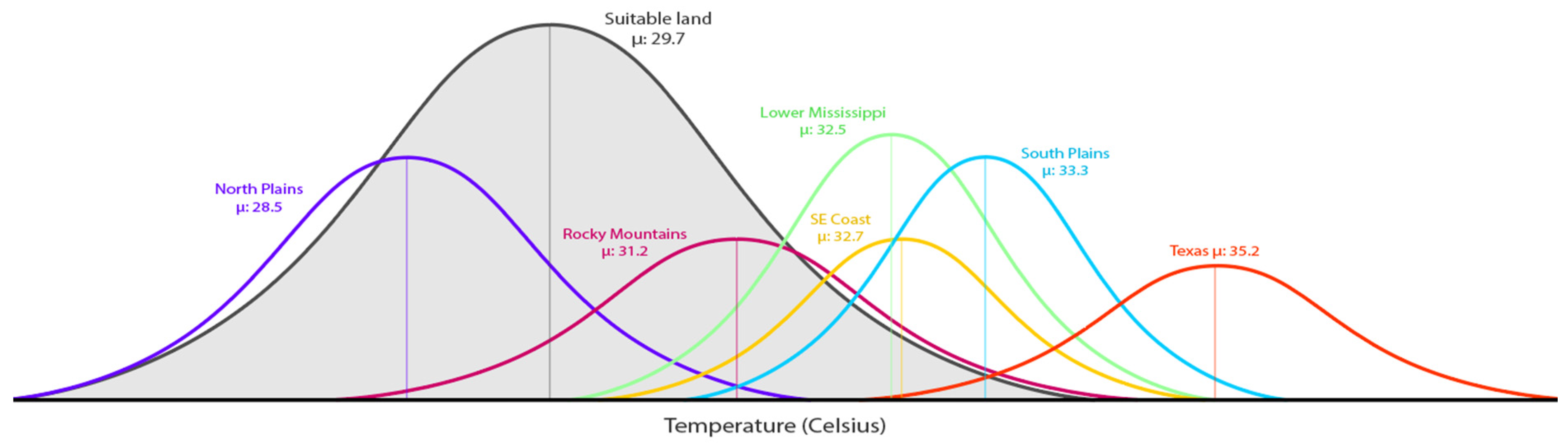
3.4. Application of Maxent: Risk and Necessary Adaptations
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vose, R.S.; Easterling, D.R.; Kunkel, K.E.; LeGrande, A.N.; Wehner, M.F. Temperature Changes in the United States. In Climate Science Special Report: Fourth National Climate Assessment; CreateSpace Independent Publishing Platform: Scotts Valley, CA, USA, 2017; Chapter 6; Volume I, pp. 1–470. [Google Scholar] [CrossRef]
- Diffenbaugh, N.S.; Davenport, F.V.; Burke, M. Historical warming has increased U.S. crop insurance losses. Environ. Res. Lett. 2021, 16, 084025. [Google Scholar] [CrossRef]
- Fick, S.E.; Hijmans, R.J. WorldClim 2: New 1-km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- Taylor, K.E.; Stouffer, R.J.; Meehl, G.A. An Overview of CMIP5 and the Experiment Design. Bull. Am. Meteorol. Soc. 2012, 93, 485–498. [Google Scholar] [CrossRef]
- Adams, R.M.; Rosenzweig, C.; Peart, R.M.; Ritchie, J.T.; McCarl, B.A.; Glyer, J.D.; Curry, R.B.; Jones, J.W.; Boote, K.; Allen, L.H. Global climate change and US agriculture. Nature 1990, 345, 219–224. [Google Scholar] [CrossRef]
- FAO. A Framework for Land Evaluation; Food and Agriculture Organization of the United Nations: Rome, Italy, 1976. [Google Scholar]
- Özkan, B.; Dengiz, O.; Turan, I.D. Site suitability analysis for potential agricultural land with spatial fuzzy multi-criteria decision analysis in regional scale under semi-arid terrestrial ecosystem. Sci. Rep. 2020, 10, 22074. [Google Scholar] [CrossRef] [PubMed]
- Malczewski, J. Multiple Criteria Decision Analysis and Geographic Information Systems. In Trends in Multiple Criteria Decision Analysis; Ehrgott, M., Figueira, J.R., Greco, S., Eds.; Springer: New York, NY, USA, 2010; pp. 369–395. [Google Scholar] [CrossRef]
- Yalew, S.G.; van Griensven, A.; Mul, M.L.; van der Zaag, P. Land suitability analysis for agriculture in the Abbay basin using remote sensing, GIS and AHP techniques. Model. Earth Syst. Environ. 2016, 2, 101. [Google Scholar] [CrossRef]
- Maleki, F.; Kazemi, H.; Siahmarguee, A.; Kamkar, B. Development of a land use suitability model for saffron (Crocus sativus L.) cultivation by multi-criteria evaluation and spatial analysis. Ecol. Eng. 2017, 106, 140–153. [Google Scholar] [CrossRef]
- Aliyu, M.; Shaba, H.A.; Dada, I.; Muhammad, B.A.; Baba, S.; Imhanfidon, O.J. Cropland Suitability Analysis. Int. J. Sci. Eng. Res. 2021, 12, 996–1001. [Google Scholar]
- El Baroudy, A. Mapping and evaluating land suitability using a GIS-based model. CATENA 2016, 140, 96–104. [Google Scholar] [CrossRef]
- Purnamasari, R.A.; Noguchi, R.; Ahamed, T. Land suitability assessments for yield prediction of cassava using geospatial fuzzy expert systems and remote sensing. Comput. Electron. Agric. 2019, 166, 105018. [Google Scholar] [CrossRef]
- Dedeoğlu, M.; Dengiz, O. Generating of land suitability index for wheat with hybrid system aproach using AHP and GIS. Comput. Electron. Agric. 2019, 167, 105062. [Google Scholar] [CrossRef]
- Kiliç, M.; Kaya, I. Investment project evaluation by a decision making methodology based on type-2 fuzzy sets. Appl. Soft Comput. 2015, 27, 399–410. [Google Scholar] [CrossRef]
- Williams, J.W.; Jackson, S.T. Novel climates, no-analog communities, and ecological surprises. Front. Ecol. Environ. 2007, 5, 475–482. [Google Scholar] [CrossRef]
- Fitzpatrick, M.C.; Hargrove, W. The projection of species distribution models and the problem of non-analog climate. Biodivers. Conserv. 2009, 18, 2255–2261. [Google Scholar] [CrossRef]
- Scherrer, D.; Esperon-Rodriguez, M.; Beaumont, L.J.; Barradas, V.L.; Guisan, A. National assessments of species vulnerability to climate change strongly depend on selected data sources. Divers. Distrib. 2021, 27, 1367–1382. [Google Scholar] [CrossRef]
- Akpoti, K.; Kabo-Bah, A.T.; Zwart, S.J. Agricultural land suitability analysis: State-of-the-art and outlooks for integration of climate change analysis. Agric. Syst. 2019, 173, 172–208. [Google Scholar] [CrossRef]
- Franklin, J. Species distribution models in conservation biogeography: Developments and challenges. Divers. Distrib. 2013, 19, 1217–1223. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R. Species Distribution Models: Ecological Explanation and Prediction Across Space and Time. Annu. Rev. Ecol. Evol. Syst. 2009, 40, 677–697. [Google Scholar] [CrossRef]
- Buckley, L.B.; Urban, M.C.; Angilletta, M.J.; Crozier, L.G.; Rissler, L.J.; Sears, M.W. Can mechanism inform species’ distribution models? Ecol. Lett. 2010, 13, 1041–1054. [Google Scholar] [CrossRef]
- Olesen, J.E.; Bindi, M. Consequences of climate change for European agricultural productivity, land use and policy. Eur. J. Agron. 2002, 16, 239–262. [Google Scholar] [CrossRef]
- Estes, L.D.; Bradley, B.A.; Beukes, H.; Hole, D.G.; Lau, M.; Oppenheimer, M.G.; Schulze, R.; Tadross, M.A.; Turner, W.R. Comparing mechanistic and empirical model projections of crop suitability and productivity: Implications for ecological forecasting. Glob. Ecol. Biogeogr. 2013, 22, 1007–1018. [Google Scholar] [CrossRef]
- Evans, T.G.; Diamond, S.E.; Kelly, M.W. Mechanistic species distribution modelling as a link between physiology and conservation. Conserv. Physiol. 2015, 3, cov056. [Google Scholar] [CrossRef] [PubMed]
- Cuddington, K.; Fortin, M.-J.; Gerber, L.R.; Hastings, A.; Liebhold, A.; O’Connor, M.; Ray, C. Process-based models are required to manage ecological systems in a changing world. Ecosphere 2013, 4, 1–12. [Google Scholar] [CrossRef]
- Yao, F.; Tang, Y.; Wang, P.; Zhang, J. Estimation of maize yield by using a process-based model and remote sensing data in the Northeast China Plain. Phys. Chem. Earth Parts A/B/C 2015, 87–88, 142–152. [Google Scholar] [CrossRef]
- Rougier, T.; Lassalle, G.; Drouineau, H.; Dumoulin, N.; Faure, T.; Deffuant, G.; Rochard, E.; Lambert, P. The Combined Use of Correlative and Mechanistic Species Distribution Models Benefits Low Conservation Status Species. PLoS ONE 2015, 10, e0139194. [Google Scholar] [CrossRef]
- Feng, L.; Wang, H.; Ma, X.; Peng, H.; Shan, J. Modeling the current land suitability and future dynamics of global soybean cultivation under climate change scenarios. Field Crop. Res. 2021, 263, 108069. [Google Scholar] [CrossRef]
- Gao, Y.; Zhang, A.; Yue, Y.; Wang, J.; Su, P. Predicting Shifts in Land Suitability for Maize Cultivation Worldwide Due to Climate Change: A Modeling Approach. Land 2021, 10, 295. [Google Scholar] [CrossRef]
- Ishikawa, Y.; Yamazaki, D. Global high-resolution estimation of cropland suitability and its comparative analysis to actual cropland distribution. Hydrol. Res. Lett. 2021, 15, 9–15. [Google Scholar] [CrossRef]
- Møller, A.; Mulder, V.; Heuvelink, G.; Jacobsen, N.; Greve, M. Can We Use Machine Learning for Agricultural Land Suitability Assessment? Agronomy 2021, 11, 703. [Google Scholar] [CrossRef]
- Cantelaube, P.; Terres, J.-M. Seasonal weather forecasts for crop yield modelling in Europe. Tellus A Dyn. Meteorol. Oceanogr. 2005, 57, 476–487. [Google Scholar] [CrossRef]
- Thenkabail, P.S.; Teluguntla, P.G.; Xiong, J.; Oliphant, A.; Congalton, R.G.; Ozdogan, M.; Gumma, M.K.; Tilton, J.C.; Giri, C.; Milesi, C.; et al. Global Cropland-Extent Product at 30-m Resolution (GCEP30) Derived from Landsat Satellite Time-Series Data for the Year 2015 Using Multiple Machine-Learning Algorithms on Google Earth Engine Cloud; US Geological Survey Professional Paper 1868; U.S. Geological Survey: Reston, VA, USA, 2021. [CrossRef]
- Yu, X.; Tao, X.; Liao, J.; Liu, S.; Xu, L.; Yuan, S.; Zhang, Z.; Wang, F.; Deng, N.; Huang, J.; et al. Predicting potential cultivation region and paddy area for ratoon rice production in China using Maxent model. Field Crop. Res. 2021, 275, 108372. [Google Scholar] [CrossRef]
- Wisz, M.S.; Hijmans, R.J.; Li, J.; Peterson, A.T.; Graham, C.H.; Guisan, A.; NCEAS Predicting Species Distributions Working Group. Effects of sample size on the performance of species distribution models. Divers. Distrib. 2008, 14, 763–773. [Google Scholar] [CrossRef]
- Elith, J.; Graham, C.H. Do they? How do they? WHY do they differ? On finding reasons for differing performances of species distribution models. Ecography 2009, 32, 66–77. Available online: https://www.jstor.org/stable/30244651 (accessed on 4 April 2022). [CrossRef]
- Phillips, S.J.; Anderson, R.P.; Schapire, R.E. Maximum entropy modeling of species geographic distributions. Ecol. Model. 2006, 190, 231–259. [Google Scholar] [CrossRef]
- Ovalle-Rivera, O.; Läderach, P.; Bunn, C.; Obersteiner, M.; Schroth, G. Projected Shifts in Coffea arabica Suitability among Major Global Producing Regions Due to Climate Change. PLoS ONE 2015, 10, e0124155. [Google Scholar] [CrossRef] [PubMed]
- Ramirez-Cabral, N.Y.Z.; Kumar, L.; Shabani, F. Global alterations in areas of suitability for maize production from climate change and using a mechanistic species distribution model (CLIMEX). Sci. Rep. 2017, 7, 5910. [Google Scholar] [CrossRef] [PubMed]
- Shabani, F.; Kumar, L.; Ahmadi, M. A comparison of absolute performance of different correlative and mechanistic species distribution models in an independent area. Ecol. Evol. 2016, 6, 5973–5986. [Google Scholar] [CrossRef] [PubMed]
- USDA NASS. CropScape and Cropland Data Layers. US Department of Agriculture, National Agriculture Statistics Service. Available online: https://www.nass.usda.gov/Research_and_Science/Cropland/sarsfaqs2.php (accessed on 5 April 2022).
- Dempsey, J. New Census of Agriculture Shows Decline in Number of America’s Farms, Farmers, and Farmland; American Farmland Trust: Washington, DC, USA, 2019; Available online: https://farmland.org/new-census-of-agriculture-shows-decline-in-number-of-americas-farms-farmers-and-farmland/ (accessed on 18 August 2022).
- Läderach, P.; Martinez-Valle, A.; Schroth, G.; Castro, N. Predicting the future climatic suitability for cocoa farming of the world’s leading producer countries, Ghana and Côte d’Ivoire. Clim. Chang. 2013, 119, 841–854. [Google Scholar] [CrossRef]
- Kogo, B.K.; Kumar, L.; Koech, R.; Kariyawasam, C.S. Modelling Climate Suitability for Rainfed Maize Cultivation in Kenya Using a Maximum Entropy (MaxENT) Approach. Agronomy 2019, 9, 727. [Google Scholar] [CrossRef]
- USDA NCSS. Soil Taxonomy: A Basic System of Soil Classification for Making and Interpreting Soil Surveys, 2nd ed.; US Department of Agriculture, Natural Resources Conservation Service: Washington, DC, USA, 1999.
- O’Donnell, M.S.; Ignizio, D.A. Bioclimatic Predictors for Supporting Ecological Applications in the Conterminous United States; Data Series 691; U.S. Geological Survey: Reston, VA, USA, 2012. Available online: https://pubs.usgs.gov/ds/691/ds691.pdf (accessed on 10 August 2022).
- Phillips, S.J.; Dudík, M. Modeling of species distributions with Maxent: New extensions and a comprehensive evaluation. Ecography 2008, 31, 161–175. [Google Scholar] [CrossRef]
- O’Neil, G.L.; Goodall, J.L.; Watson, L.T. Evaluating the potential for site-specific modification of LiDAR DEM derivatives to improve environmental planning-scale wetland identification using Random Forest classification. J. Hydrol. 2018, 559, 192–208. [Google Scholar] [CrossRef]
- Everingham, Y.; Sexton, J.; Skocaj, D.; Inman-Bamber, G. Accurate prediction of sugarcane yield using a random forest algorithm. Agron. Sustain. Dev. 2016, 36, 27. [Google Scholar] [CrossRef]
- Burchfield, E.K. Shifting cultivation geographies in the Central and Eastern US. Environ. Res. Lett. 2022, 17, 054049. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- USDA NASS. Census of Agriculture 2017; US Department of Agriculture, National Agriculture Statistics Service: Washington, DC, USA, 2017. Available online: www.nass.usda.gov/AgCensus (accessed on 18 August 2022).
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2009, 31, 651–666. [Google Scholar] [CrossRef]
- USDA BAE. Generalized Types of Farming in the United States; Agricultural Information Bulletin No. 3; US Department of Agriculture, Bureau of Agricultural Economics: Washington, DC, USA, 1950.
- Guisan, A.; Zimmermann, N.E. Predictive habitat distribution models in ecology. Ecol. Model. 2000, 135, 147–186. [Google Scholar] [CrossRef]
- Feng, X.; Park, D.S.; Walker, C.; Peterson, A.T.; Merow, C.; Papeş, M. A checklist for maximizing reproducibility of ecological niche models. Nat. Ecol. Evol. 2019, 3, 1382–1395. [Google Scholar] [CrossRef]
- Warwell, M.V.; Rehfeldt, G.E.; Crookston, N.L. Modeling Species’ Realized Climatic Niche Space and Predicting Their Response to Global Warming for Several Western Forest Species with Small Geographic Distributions. In Advances in Threat Assessment and Their Application to Forest and Rangeland Management; Pye, J.M., Rauscher, H.M., Sands, Y., Lee, D.C., Beatty, J.S., Eds.; General Technical Report PNW-GTR-802; US Department of Agriculture, Forest Service, Pacific Northwest and Southern Research Stations: Portland, OR, USA, 2010; Volume 802, pp. 171–182. Available online: https://www.fs.usda.gov/treesearch/pubs/37041 (accessed on 3 May 2022).
- USDA. Climate and Man: Yearbook of Agriculture 1941; US Department of Agriculture: Washington, DC, USA, 1941.
- Bird, I.F.; Cornelius, M.J.; Keys, A.J. Effects of Temperature on Photosynthesis by Maize and Wheat. J. Exp. Bot. 1977, 28, 519–524. [Google Scholar] [CrossRef]
- Hu, Q.; Buyanovsky, G. Climate Effects on Corn Yield in Missouri. J. Appl. Meteorol. 2003, 42, 1626–1635. [Google Scholar] [CrossRef]
- Mearns, L.O.; Katz, R.; Schneider, S.H. Extreme High-Temperature Events: Changes in their probabilities with Changes in Mean Temperature. J. Clim. Appl. Meteorol. 1984, 23, 1601–1613. Available online: https://www.jstor.org/stable/26181141 (accessed on 1 May 2022). [CrossRef]
- Shaw, R.H. Climate Requirement; Wiley: Hoboken, NJ, USA, 2015; pp. 609–638. [Google Scholar]
- Neild, R.E.; Newman, J.E. Growing Season Characteristics and Requirements in the Corn Belt. In National Corn Handbook; NCH-40; Purdue University: West Lafayette, IN, USA, 1990; Available online: https://www.extension.purdue.edu/extmedia/NCH/NCH-40.html (accessed on 2 May 2022).
- Huang, C.; Duiker, S.W.; Deng, L.; Fang, C.; Zeng, W. Influence of Precipitation on Maize Yield in the Eastern United States. Sustainability 2015, 7, 5996–6010. [Google Scholar] [CrossRef]
- Baum, M.E.; Archontoulis, S.V.; Licht, M.A. Planting Date, Hybrid Maturity, and Weather Effects on Maize Yield and Crop Stage. Agron. J. 2019, 111, 303–313. [Google Scholar] [CrossRef]
- Zhang, N.; Qu, Y.; Song, Z.; Chen, Y.; Jiang, J. Responses and sensitivities of maize phenology to climate change from 1971 to 2020 in Henan Province, China. PLoS ONE 2022, 17, e0262289. [Google Scholar] [CrossRef] [PubMed]
- USDA NASS. Usual Planting and Harvesting Dates for US Field Crops; US Department of Agriculture, National Agricultural Statistics Service: Washington, DC, USA, 1997. Available online: https://swat.tamu.edu/media/90113/crops-typicalplanting-harvestingdates-by-states.pdf (accessed on 2 May 2022).
- Elmore, R.; Rees, J. Windows of Opportunity for Corn Planting: Data from Across the Corn Belt; CropWatch, University of Nebraska: Lincoln, NE, USA, 2019; Available online: https://cropwatch.unl.edu/2019/corn-planting-windows-across-corn-belt (accessed on 2 May 2022).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fitzgibbon, A.; Pisut, D.; Fleisher, D. Evaluation of Maximum Entropy (Maxent) Machine Learning Model to Assess Relationships between Climate and Corn Suitability. Land 2022, 11, 1382. https://doi.org/10.3390/land11091382
Fitzgibbon A, Pisut D, Fleisher D. Evaluation of Maximum Entropy (Maxent) Machine Learning Model to Assess Relationships between Climate and Corn Suitability. Land. 2022; 11(9):1382. https://doi.org/10.3390/land11091382
Chicago/Turabian StyleFitzgibbon, Abigail, Dan Pisut, and David Fleisher. 2022. "Evaluation of Maximum Entropy (Maxent) Machine Learning Model to Assess Relationships between Climate and Corn Suitability" Land 11, no. 9: 1382. https://doi.org/10.3390/land11091382
APA StyleFitzgibbon, A., Pisut, D., & Fleisher, D. (2022). Evaluation of Maximum Entropy (Maxent) Machine Learning Model to Assess Relationships between Climate and Corn Suitability. Land, 11(9), 1382. https://doi.org/10.3390/land11091382