1. Introduction
The Karakoram Range is characterized by extreme-altitude remote areas and hosts very large glaciers, such as the Siachen, Masherbrum, Panmah, Baltoro, Biafo, Chogo Lungma, Batura, Hispar and Rimo glaciers. These glaciers account for nearly 3% of the total global ice reserves outside Greenland and Antarctica [
1,
2]. The state and fate of these glaciers are important global climate change indicators.
The rivers draining the southern slopes of the Karakoram Range carry meltwater from these glaciers and snow-covered areas and feed the Upper Indus River, which impounds water at Tarbela Reservoir at the outlet of the Upper Indus Basin (UIB). Tarbela is the origin of the western branch of the extensive Indus Irrigation System and serves hydropower production. Snow and ice accumulation during the Monsoon season and melting during the summer months are the drivers behind runoff generation [
3,
4,
5,
6,
7,
8]. The current and future states of the Karakoram glaciers have serious implications on water availability at the reservoir. During the last decade, glacier mass balance analysis has become the focus of numerous investigations [
9,
10,
11], which aim at estimating possible glacier mass imbalances due to climatic change in the UIB mountain ranges. Several of these studies rely heavily on satellite altimetry [
12,
13] or space-borne gravimetry [
14] for glacier mass balance estimation, while the analyses based on a hydrological mass balance [
15] are very few.
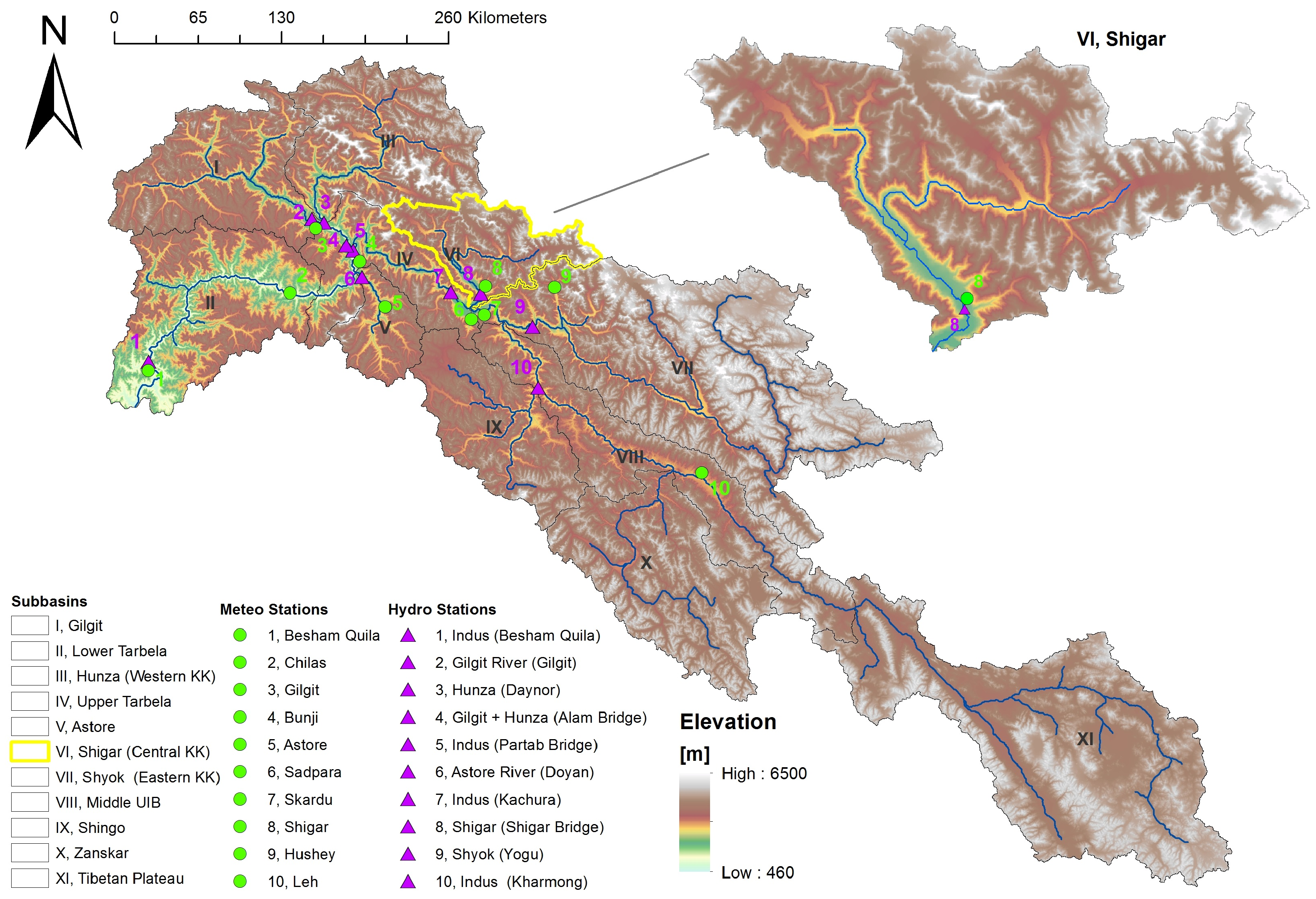
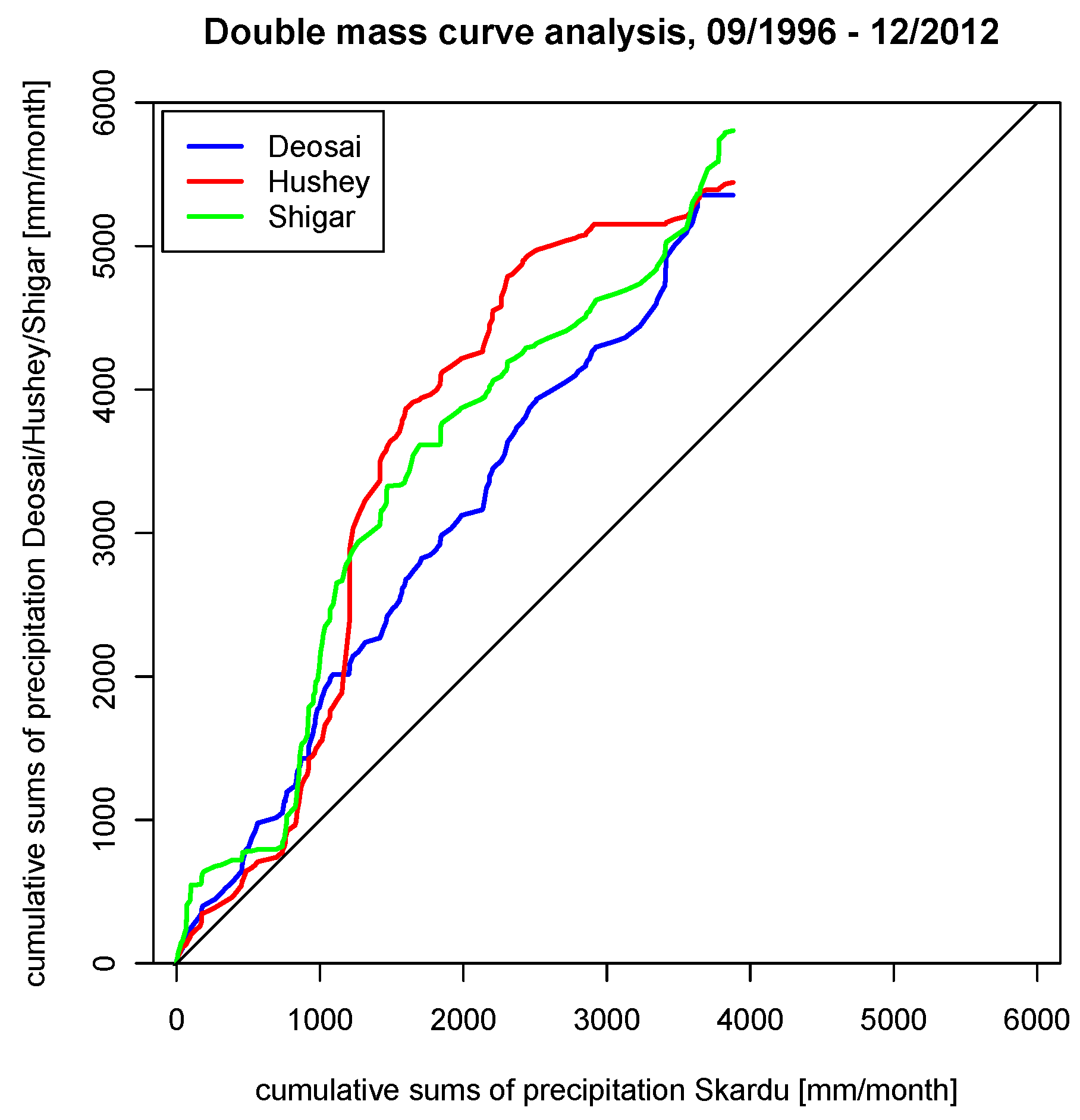
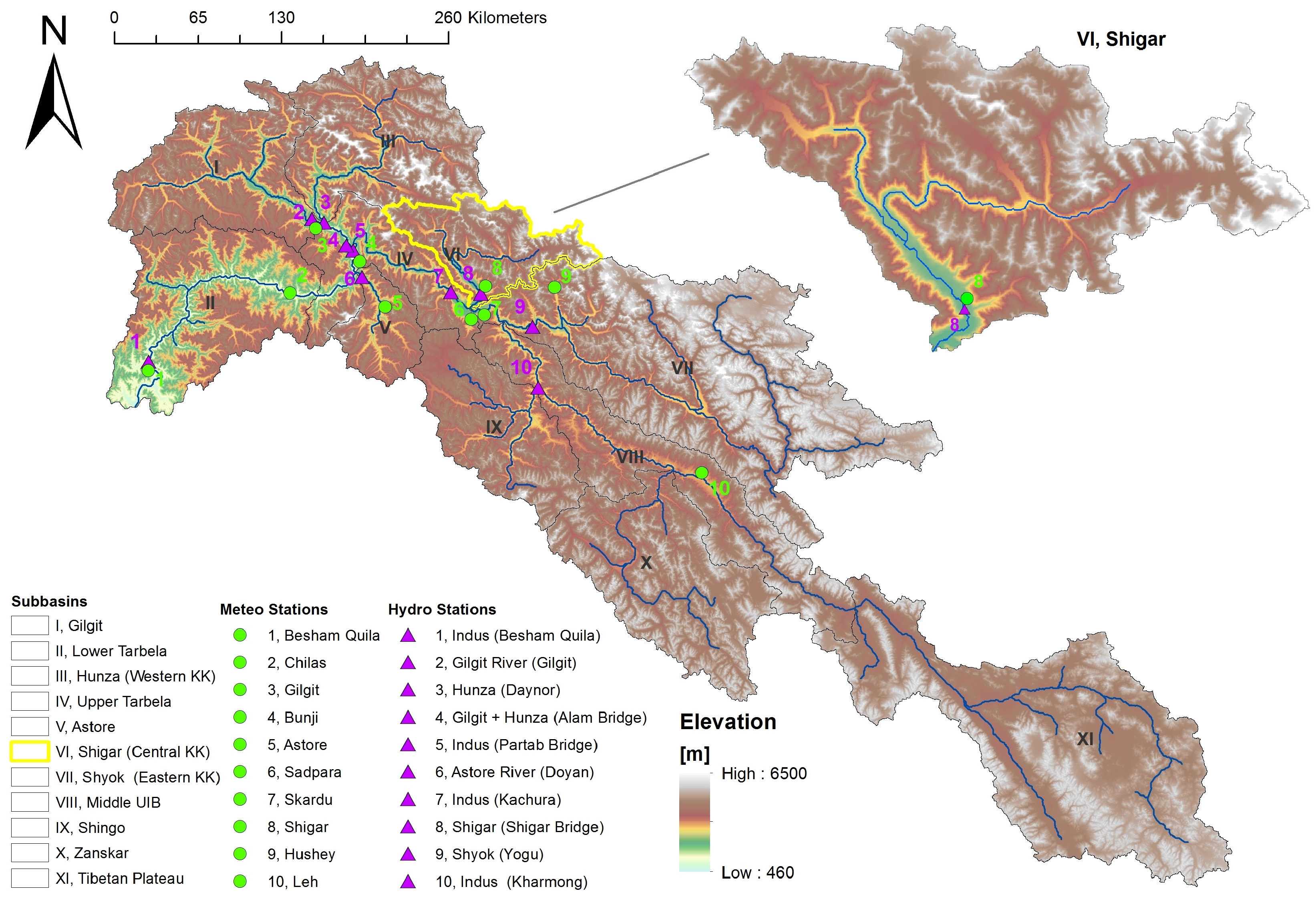
One of the principal factors hampering the hydro-glaciological analysis of this system is the inherent scarcity of ground observations needed for the validation of water balance analysis. As shown in
Figure 1, the UIB is monitored by a very sparse network of precipitation, temperature and flow gauging stations with respect to its size (165,000 km
), which precludes the elaboration of reliable spatial maps of meteorological forcing across the basin necessary for hydro-glaciological mass balance studies. Moreover, precipitation and temperature are elevation dependent and, thus, characterized by strong spatial gradients over the steep surface relief. For this reason, precipitation and temperature products, which are generally derived by spatial interpolation of observations at valley stations, tend to systematically underestimate the actual meteorological variables, thus enhancing the risk of erroneous hydrological balance estimates. For example, studies of area-averaged precipitation for UIB derived from Climate Research Unit (CRU) TS3.21 [
16] or the Global Precipitation Climatology Centre (GPCC) [
17] precipitation analysis products have been shown [
18,
19] to underestimate mean annual precipitation in the UIB by approximately a factor of two.
Satellite-observed precipitation is an alternative to spatially-interpolated
in situ observations. The main advantage offered by satellite measurements is the coverage of large areas and their repeatability in time. Nevertheless, satellite observations require validation against ground observations, as they may be strongly biased. For example, high-altitude applications of the TRMM 3B43 product for the wet season in the Peruvian [
20] and Ecuadorian Andes [
21] indicate precipitation underestimation in the order of 50%.
In view of the above-mentioned difficulties of precipitation estimation for the region of interest, the only viable alternative options for sourcing spatially- and temporally-continuous precipitation data for vast and poorly-gauged basins are atmospheric reanalyses [
22]. Reanalysis data are obtained by performing runs of Global Circulation Models (GCM) at pre-defined spatial resolutions, whereby prognostic atmospheric state variables, such as temperature, wind speed, pressure and water vapor observed on the land surface or from satellites, are used to correct model simulations by means of data assimilation [
23]. Through the adoption of variational principles [
24] or stochastic methods [
25], the atmospheric model output is adjusted so as to minimize the difference between computed variables and observations at selected time steps and measurement points. Depending on the specific reanalysis project, the atmospheric models are run over several consecutive decades, starting from the 1950s or earlier, until the present. Data assimilation has undergone progressive improvement from 1979 onwards, when satellite observations became more continuously available.
The additional benefits of using a group of atmospheric reanalyses for precipitation and temperature estimation in poorly-gauged areas arise from the simultaneous availability of multiple independent predictions, effectively an ensemble of estimators of the true atmospheric variables. Reanalyses are re-forecasts (in meteorology, also known as hindcasts) of past weather, which are inherently uncertain. A multi-model ensemble offers the possibility to quantify the Predictive Uncertainty (PU) [
26,
27] of the reanalysis output. Predictive uncertainty is the quantitative assessment of the predictive capability of one or multiple forecasting models to correctly estimate an observed predictand. The concept of PU applies to precipitation, temperature or any variable (re-)forecast by atmospheric reanalysis. In this context, a recent application has been presented [
28] in which consistent datasets of Land Surface Temperature (LST) were generated and data gaps closed with respective uncertainty estimates by combining multiple satellite LST estimates with LST reanalyses in a Bayesian framework. Missing data were filled with the aid of the National Centre of Environmental Prediction (NCEP) Climate Forecast System Reanalysis (CFSR) product [
29] by using reanalyzed LST as the predictor.
In the present application, we apply similar concepts to a different, albeit parallel setting. The unknown predictands are spatial averages of mean monthly precipitation and temperature in a poorly-gauged basin in Central Karakoram, UIB. The only supporting observations are daily precipitation and temperature observations from a single nearby ground station. The estimates of the predictand are given by series of atmospheric reanalysis data produced by independent models.
The main goals of this study are: (1) to assess the predictive uncertainty of the ensemble of atmospheric model outputs in predicting selected forcing variables; (2) to investigate to what extent the uncertainty in predicting the variable can be contained by including multiple model predictions; and (3) to perform educated gap-filling of missing ground observations. For this purpose, we adopt the Model-Conditional Processor (MCP) [
30,
31], which we calibrate using
in situ observations. The proposed approach constitutes a systematic procedure of combining multiple atmospheric predictor variables in poorly-gauged basins to gain added information on a predictand. The specific Karakoram application presented here aims at obtaining educated guesses of basin average monthly precipitation and temperature, which can be used for improved hydrological mass balance studies, as opposed to just using unprocessed reanalyses unrelated to
in situ data. As we are actually aggregating multiple model output cells to basin average variables at monthly time steps, we prefer to separate the proposed approach from statistical downscaling of GCM output to local scales [
32]. While the study area we have chosen is poorly monitored and
in situ observations are sparse, the methodology remains generally valid and is expected to deliver increasingly less uncertain results if ground observations become denser.
A recent study [
33], which uses glacier mass balances in the UIB to inversely determine high-altitude precipitation, performed an uncertainty analysis on precipitation. Monte Carlo analysis was applied to an assumed vertical precipitation gradient model of spatially-interpolated
in situ observations (APHRODITE, [
34]) with prior assumptions on the statistical properties of the gradient model parameters. Such an approach requires the statistical properties and, thus, the uncertainty of precipitation to be assumed beforehand. We use reanalyses instead, which are bias-corrected and combined by weighting them on the basis of how they correlate with deterministic observations. The conceptual advantage of the latter approach is the absence of any need for making prior assumptions on the statistical properties of variables and the uncertainty, as these are a direct outcome of the Bayesian processing, as we show below.
The present contribution is structured as follows: In
Section 2, we describe the study site and the data used, then we give a brief overview of the Bayesian methods of uncertainty assessment that are relevant in the context of this study.
Section 3 is devoted to presenting the application of the Model-Conditional Processor (MCP) to Shigar Basin and
Section 4 to discussing the results. The implementation details of the processor are reported in the
Appendix.
5. Conclusions
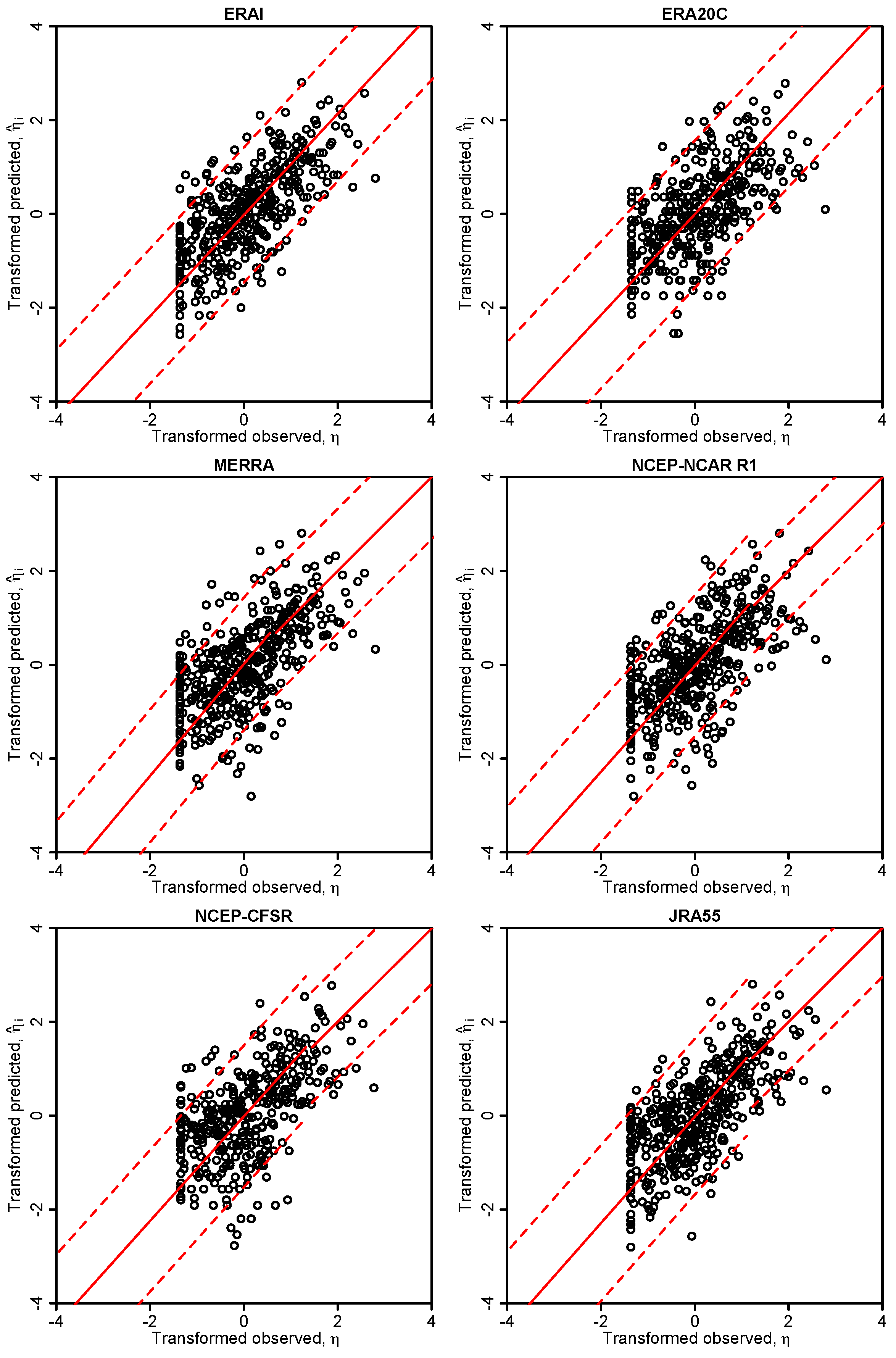
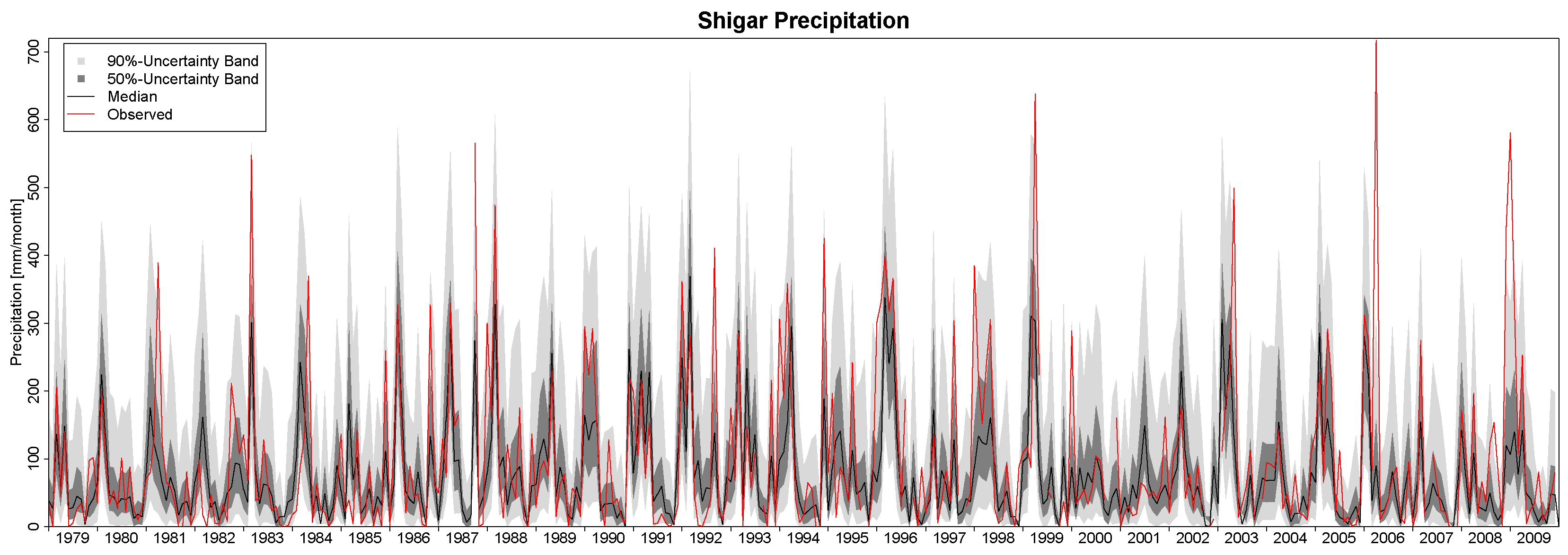
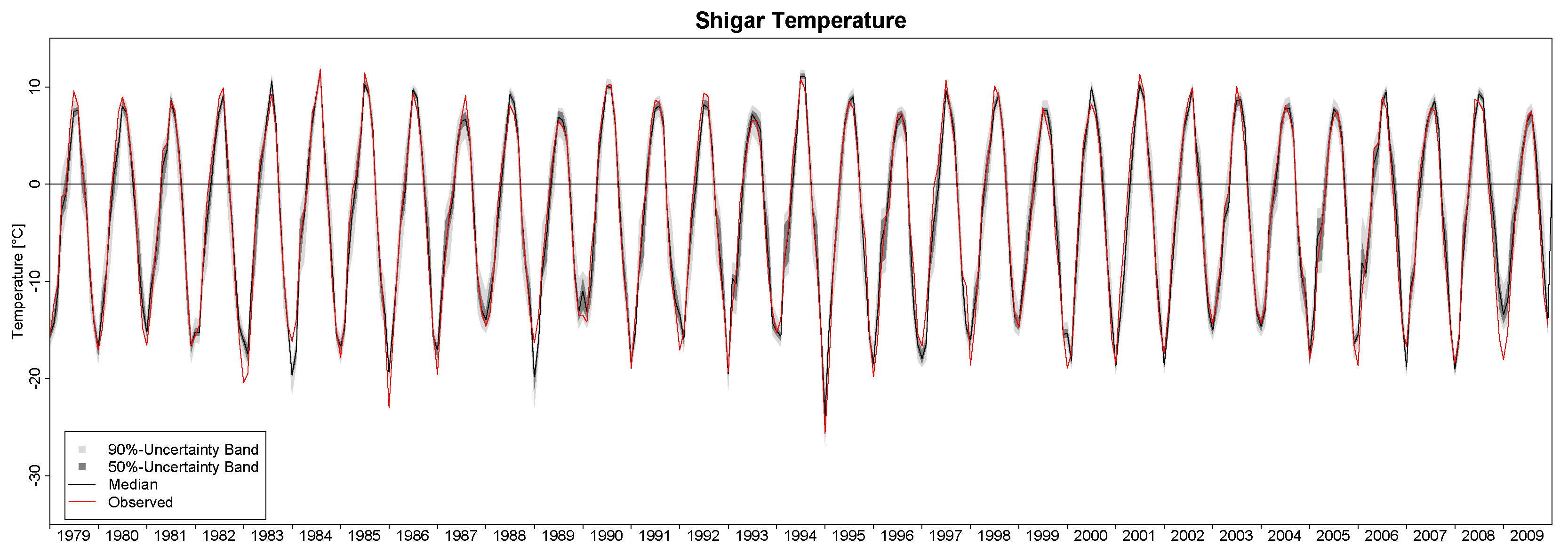
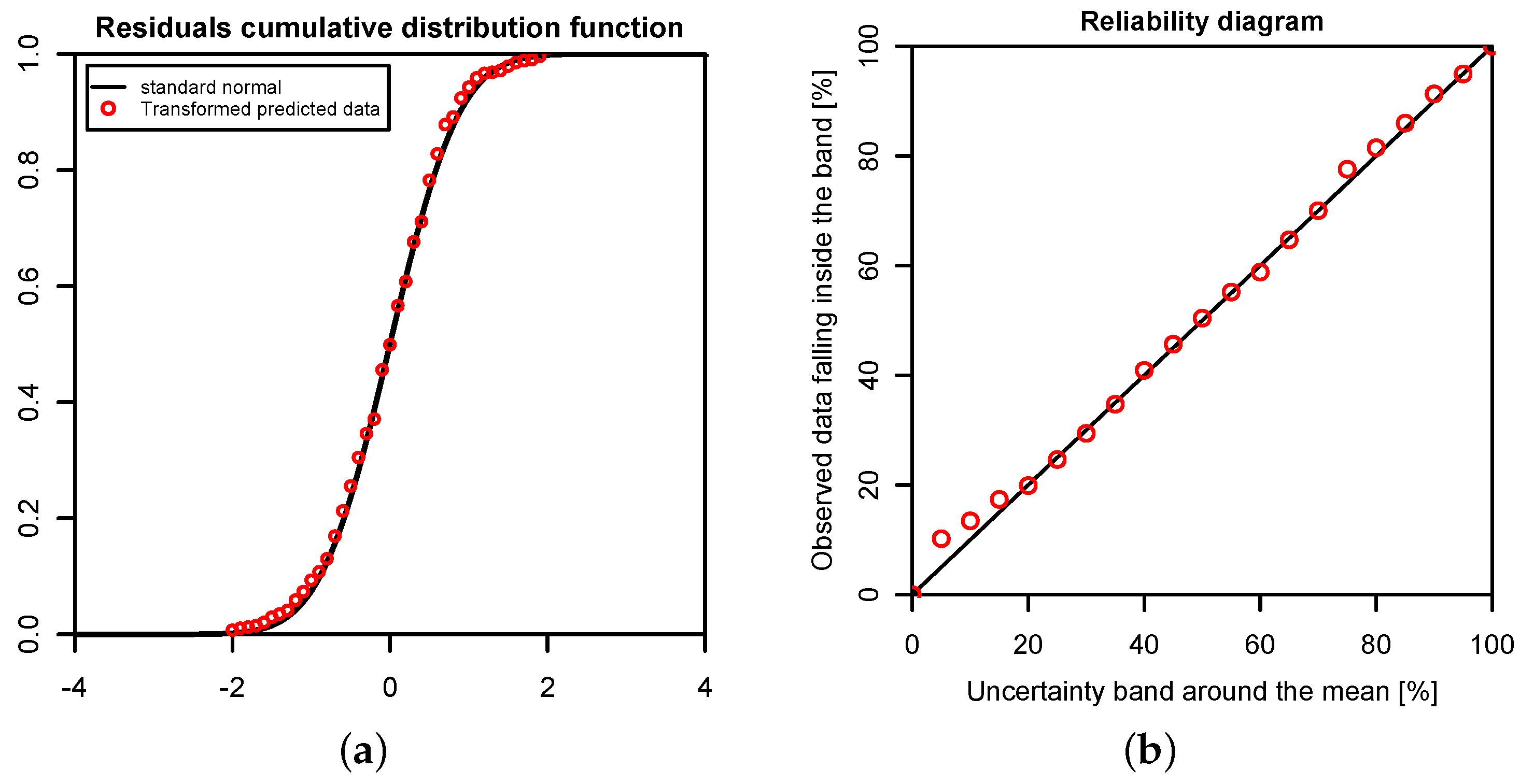
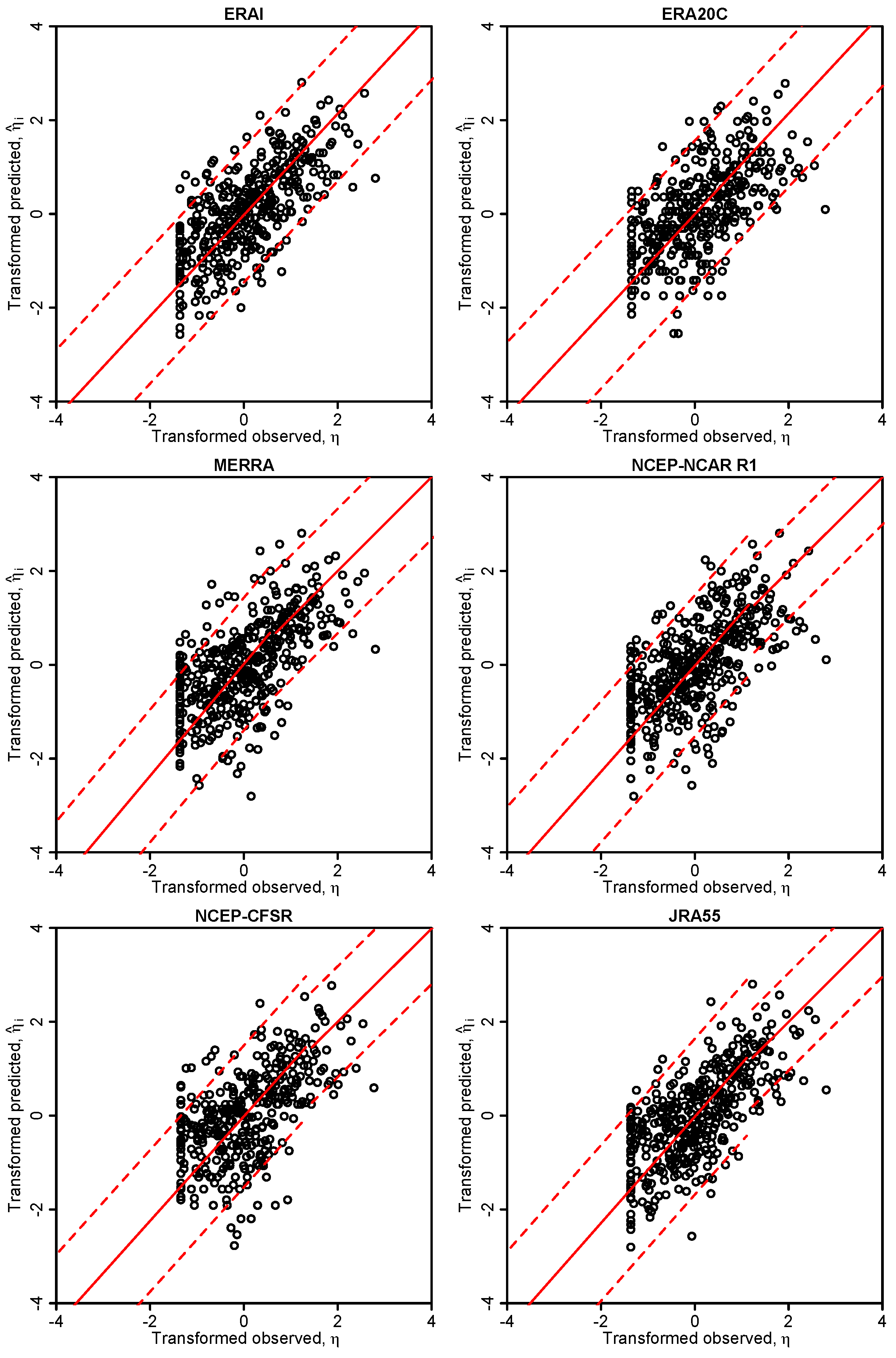
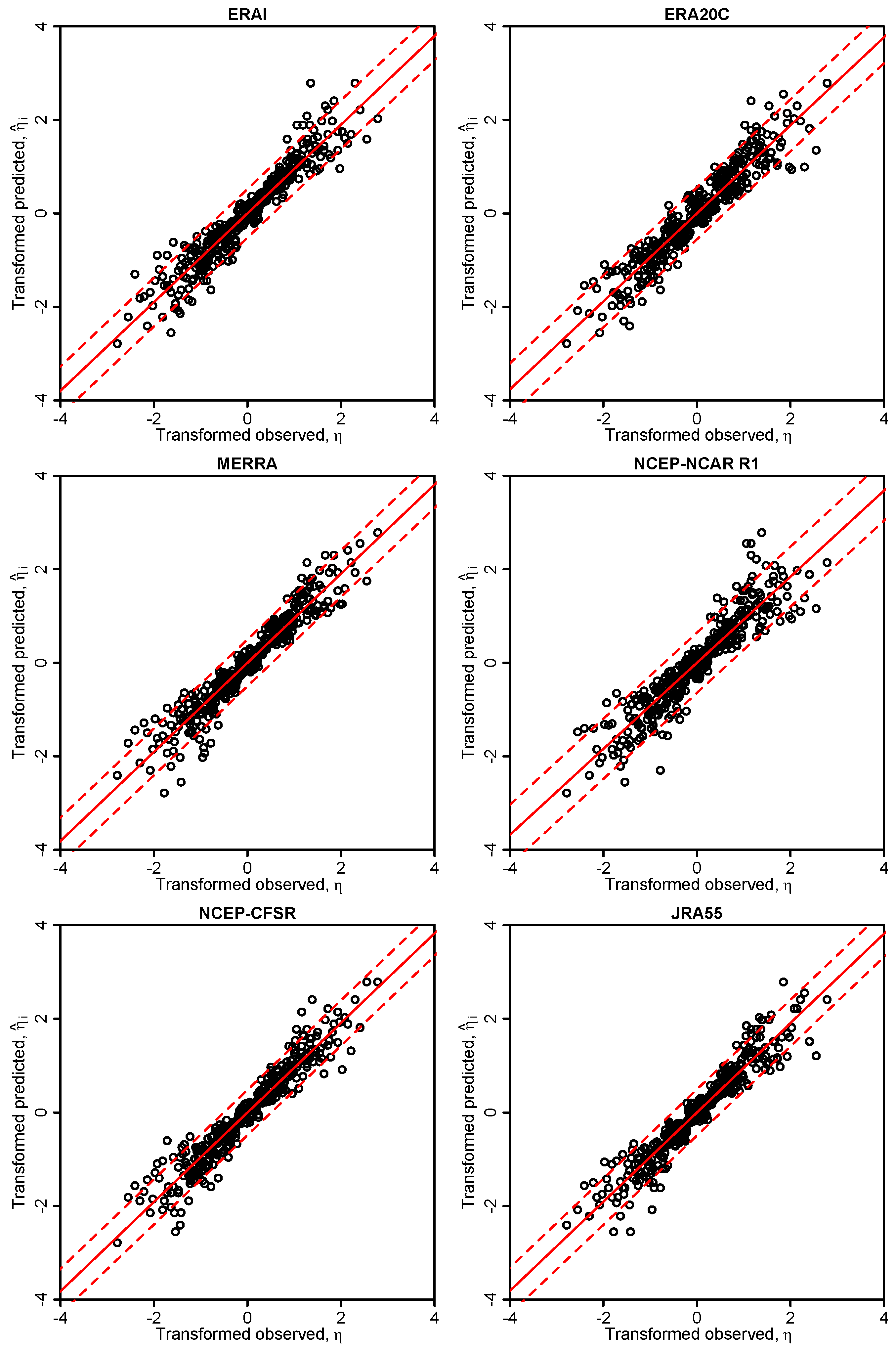
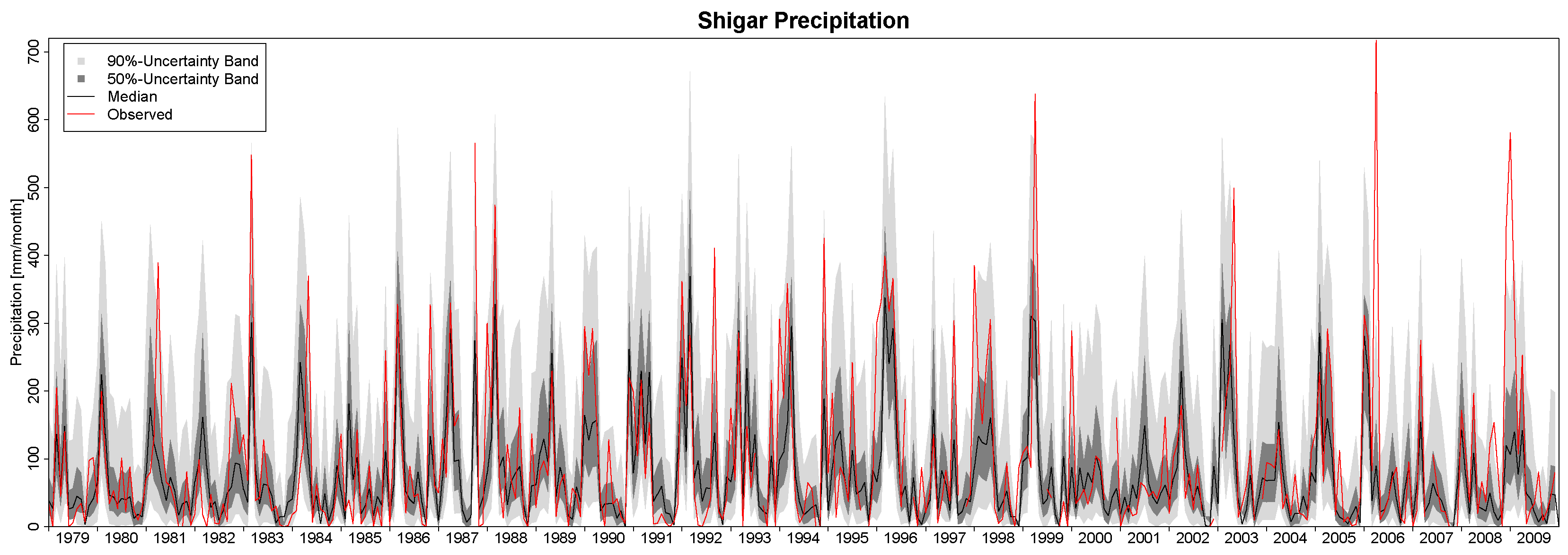
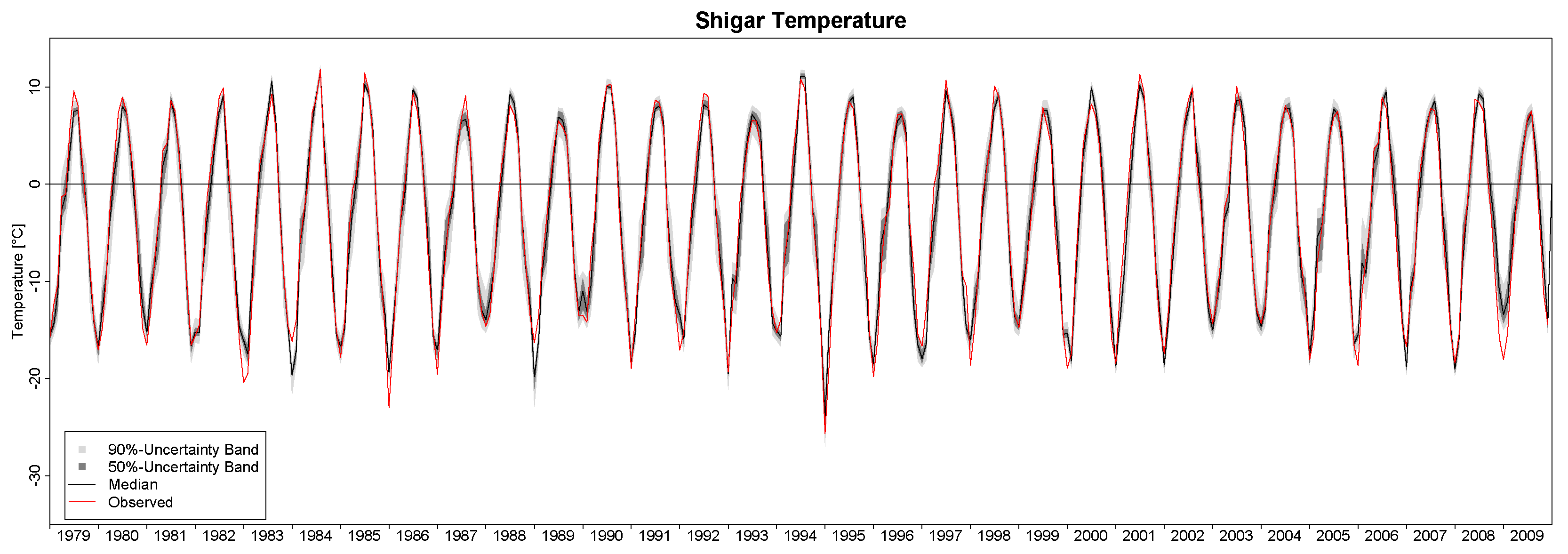
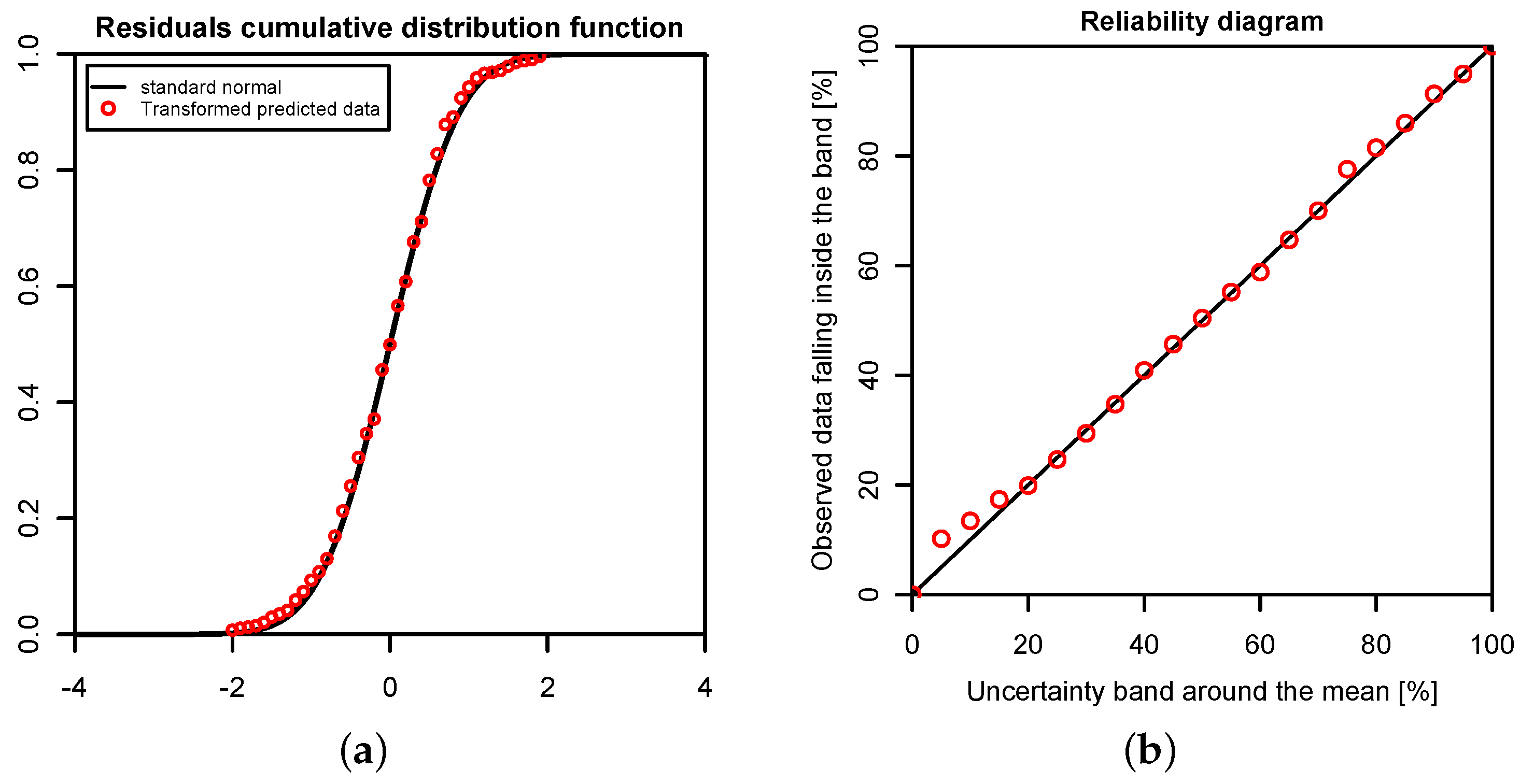
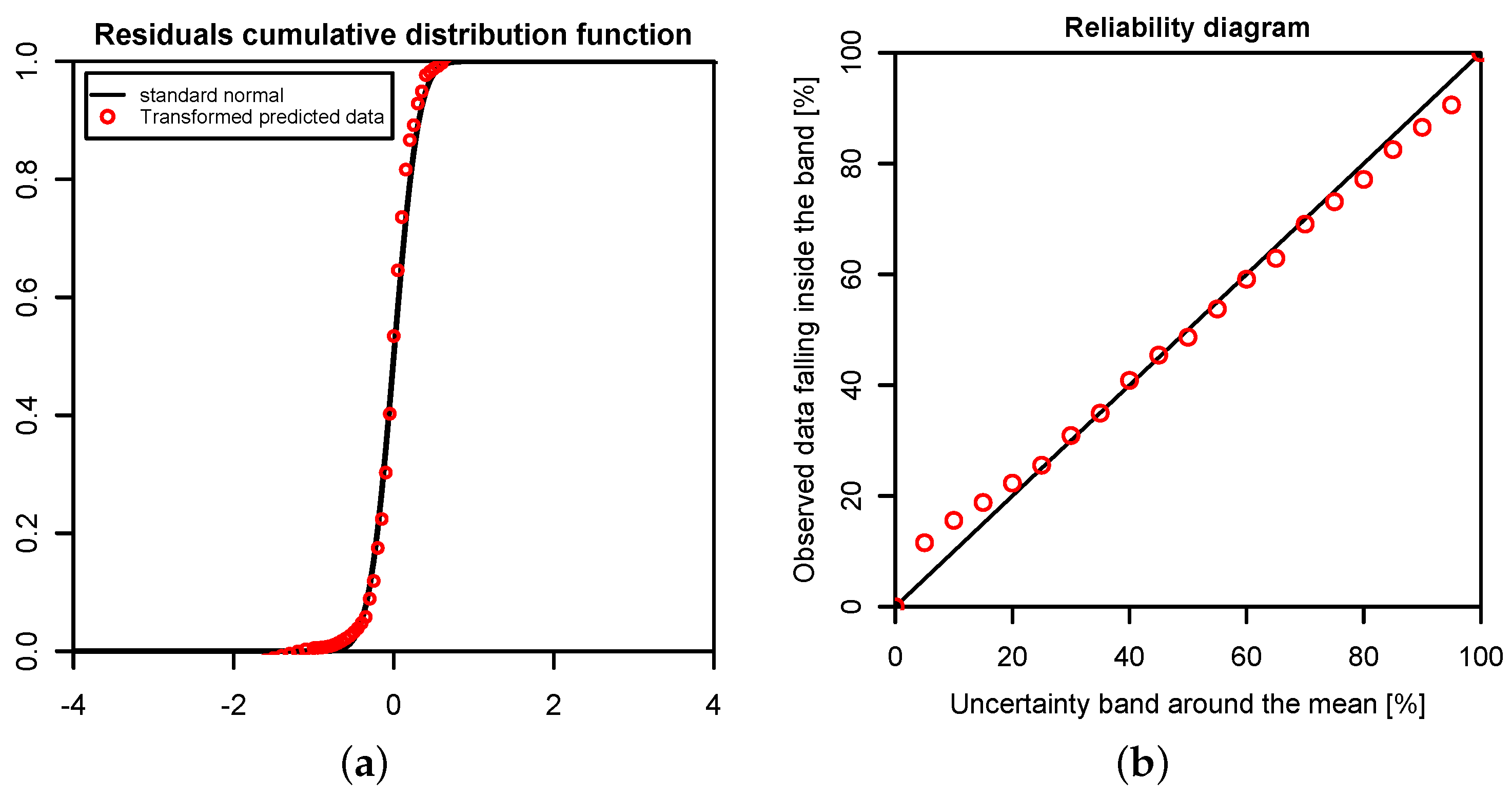
In this study, we have applied the Bayesian paradigm for prediction to quantitatively assess the uncertainty of precipitation and temperature estimates in a poorly-gauged basin in Central Karakoram by a six-member ensemble of independent reanalysis outputs. To this end, the Bayesian Model-Conditional Processor (MCP) has been used to estimate the predictive uncertainty for two meteorological variables required in regional hydro-glaciological mass balance analysis. The processor has been conditioned on monthly precipitation and temperature observations at a single observing station located in the proximity of the basin, which were mapped to the elevation of the basin centroid via an empirical scaling relationship and the adiabatic lapse rate. The reanalysis predictions were elaborated with the processor to remove the bias due to the different reference elevations of the atmospheric model
vs. basin centroid elevation and to weight them according to their correlation with observations. The results show that the combination of the model predictions in the processing leads to a considerable reduction of the predictive uncertainty and an improved signal-to-noise ratio. The gain is more pronounced for temperature than for precipitation. Already, the use of a single reanalysis model, conditioned on observations, leads to noticeable improvements, but maximum benefit is obtained by the Bayesian combination of multiple independent predictions, six in our case. It needs to be emphasized that the combined result is only as good as the conditioning observations. Nevertheless, the obtained mean annual precipitation values summarized in
Table 5 allow for a meaningful closure of the water balance. The continuous series of mean monthly precipitation and temperature and their variance can be used for specifying the uncertainty of atmospheric forcing in regional hydrological mass balance studies.
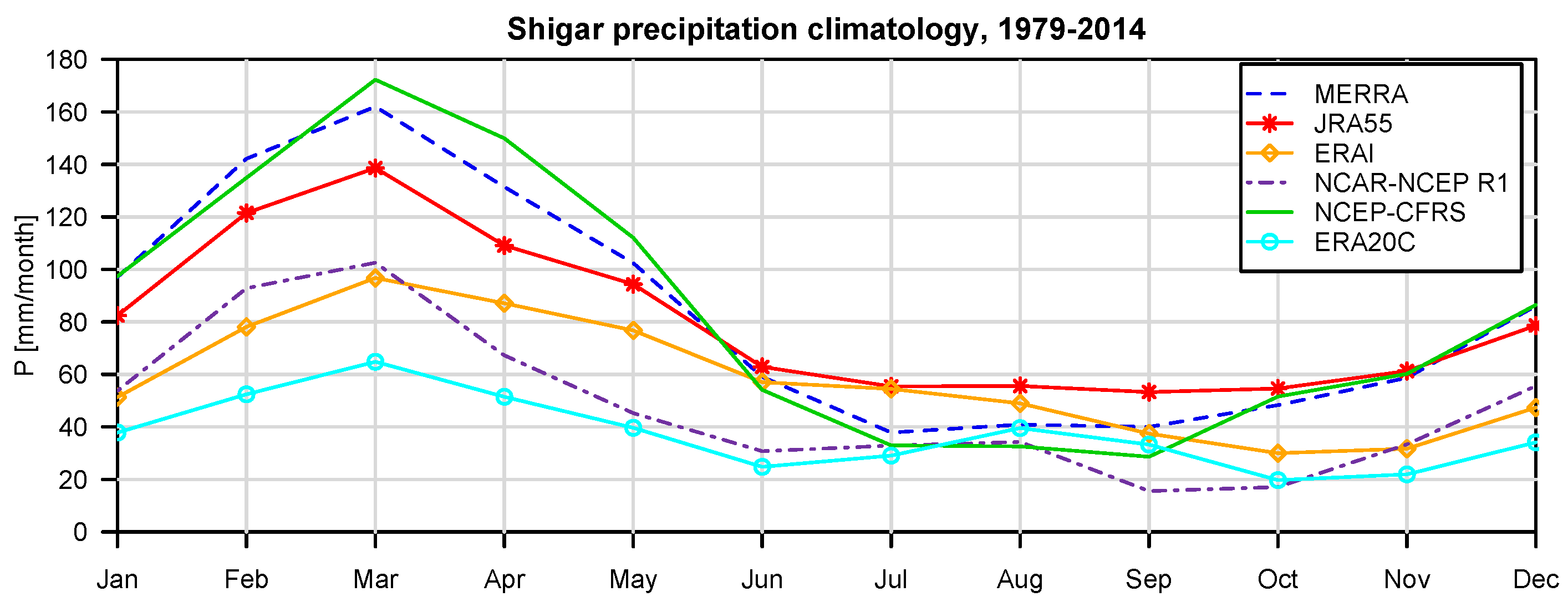
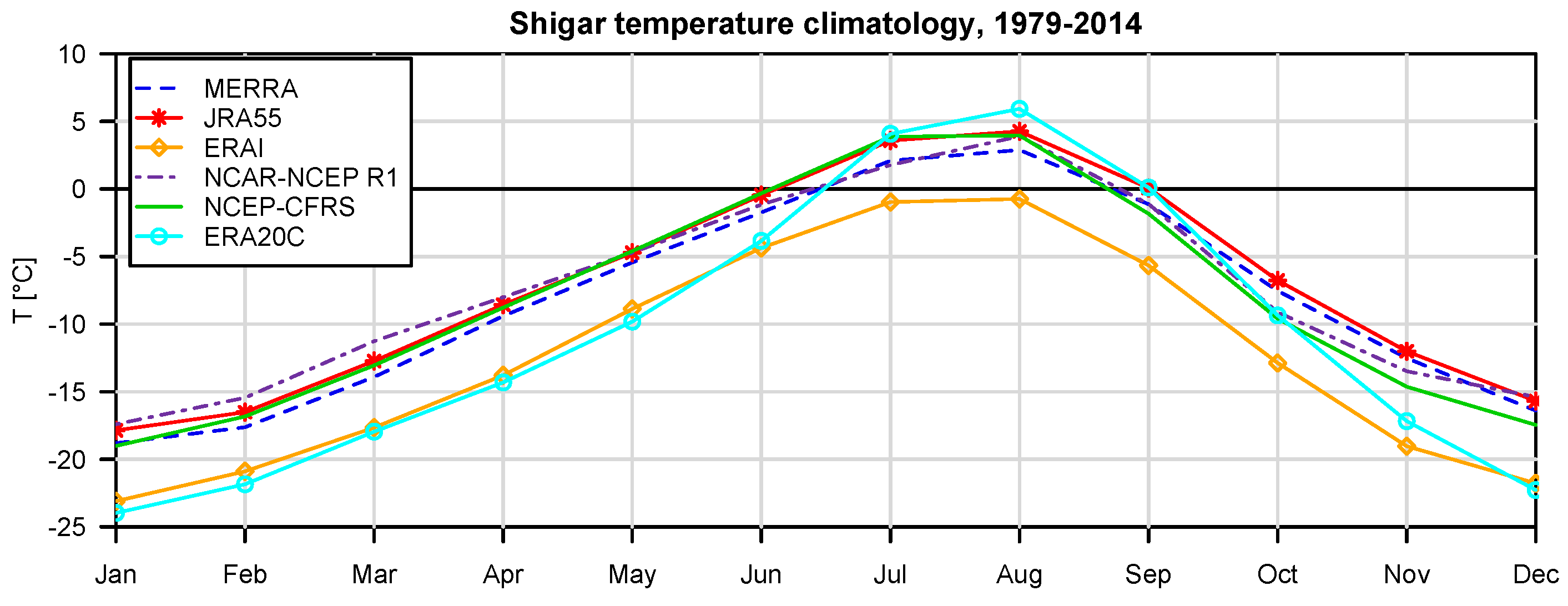
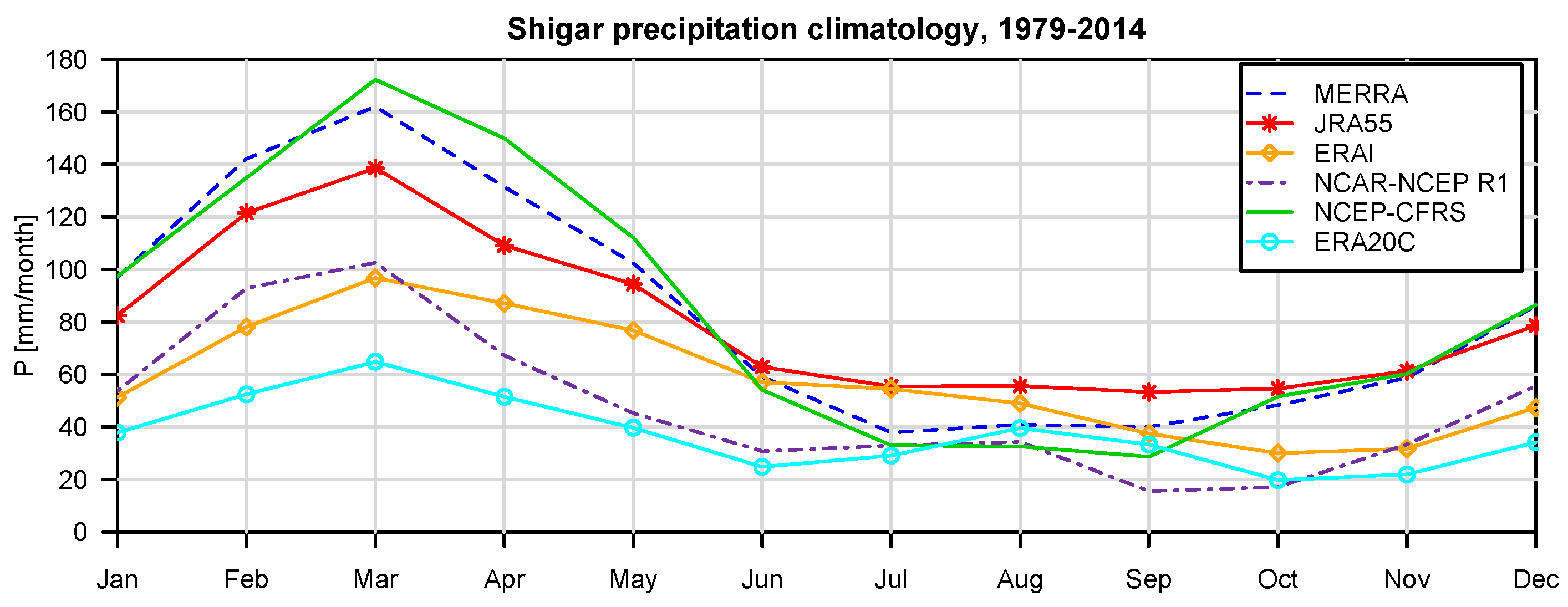
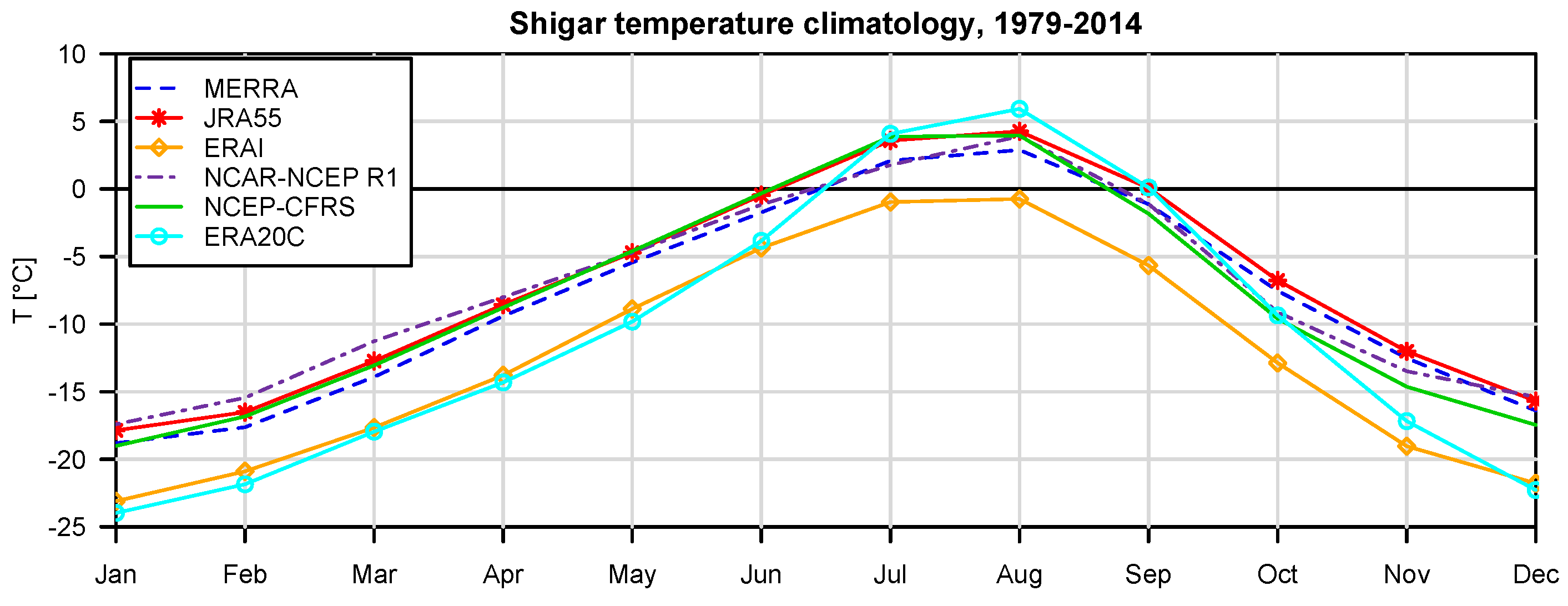
For the specific study region, which is characterized by extreme topographic relief and temperature excursions, there is a considerable difference in predictive capability between individual reanalysis products; JRA55 and NCEP-CFSR perform best for temperature, while JRA55 and ERA INTERIM outperform for precipitation. In general, the predictions of monthly precipitation, a diagnostic variable, are much more uncertain than those of temperature, a prognostic quantity. The study suggests that the use of reanalysis data for precipitation with sub-monthly resolution is to be considered as not adequate for hydrological studies in the region of interest. Future improvement of the sub-grid cloud and precipitation schemes in the atmospheric models are necessary for these products to become useful for applications with sub-monthly temporal resolution. The MCP also provides a solid conceptual basis for probabilistic reconstruction of missing observations and delivers the least uncertain atmospheric forcing data for poorly-gauged basins from atmospheric reanalysis data given conditioning observations.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}