1. Introduction
The use of remote sensing technology, namely, optical remote sensing images, is becoming important in the extraction of water bodies due to its wide coverage, abundant information, and fast update rate. Remote sensing imageries provide efficient and accurate data on water bodies, offering significant assistance for related research and applications [
1]. Water body extraction technology is founded on the capacity to identify, classify, and retrieve data pertaining to water bodies from remote sensing methods. This procedure utilizes technologies and knowledge from various domains, such as image processing, pattern recognition, geographic information systems, and others [
2]. Water bodies typically exhibit distinct spectral and spatial properties, such as reflectivity, texture, shape, etc. By analyzing and using these attributes, we may efficiently gather information about water bodies. In recent years, the progress in computer and remote sensing technologies has resulted in notable improvements in water body extraction technology [
3].
The water body index and image classification method are the two main conventional techniques employed for extracting water bodies from high-resolution optical remote sensing images. Several scholars have developed a variety of indicators for extracting information about water bodies. McFeeter proposed using the Normalized Differential Water Index (NDWI) for the green and near-infrared bands [
4]. Nevertheless, the presence of buildings causes substantial interference with NDWI, hence posing difficulties in accurately identifying water bodies in such areas. In order to overcome the limitations of the NDWI, Xu et al. proposed the Modified Normalized Differential Water Index (MNDWI) [
5], which replaces the near-infrared band with the short-wave infrared band in NDWI [
5]. Yan et al. introduced the Enhanced Water Index (EWI) by merging NDWI and MNDWI [
6]. Feyisa et al. developed the Automated Water Extraction Index (AWEI) [
7] to reduce noise in mountainous and urban regions. Zhang et al. [
8] combined a suspended particulate matter concentration and water index to reveal the multi-scale variation pattern of the surface water area in the Yellow River Basin. They used various bands (1, 2, 4, 5, and 7) of Landsat 5 TM. Other, less prevalent water indices encompass the shadow water index, pseudo-NDWI, Gaussian NDWI, MNDWI, and the new water index. However, the majority of water index techniques are unsuitable due to the limited number of spectral bands found in high-resolution images, often consisting of only four bands: blue, green, red, and near infrared.
In order to overcome the shortcomings of the water index method and make use of the spatial information of high-resolution optical remote sensing images, various image classification methods have been proposed. Image classification performs water extraction by combining spectral, shape, and texture features and using various classifiers in machine learning. Commonly used classifiers include decision tree [
9], random forest [
10], support vector machine [
11,
12,
13], etc. Although image taxonomies can make use of a variety of features to achieve better results than water index methods, they require these features to be manually constructed for specific water extraction tasks. This will greatly reduce the efficiency and prolong the extraction time. In addition, the application scope of these artificially constructed features is limited, and it is difficult to extract water bodies in different regions [
14].
Convolutional Neural Networks (CNNs) [
15] have gained popularity in the fields of semantic segmentation, object identification, and scene categorization due to their ability to efficiently learn multiple layers of automated features. Water body extraction is a specific task in semantic segmentation that is commonly addressed by CNN models [
16]. Chen et al. introduced an adaptive water extraction pooling layer [
17] to reduce the loss of features during pooling. Most existing methods fail to meet the extraction requirements of water bodies of different sizes [
18]. In addition, as features are extracted sequentially, the size of the feature map will decrease, potentially leading to the omission of small water bodies with subtle characteristics, resulting in biased outcomes. Thus, it is necessary to employ multi-layer and multi-scale characteristics in order to address these challenges. Multi-layer features refer to features that have been extracted from different convolutional neural network (CNN) layers [
19,
20]. Several multi-scale feature extraction modules have been developed as a result of semantic segmentation, such as Spatial Pyramid Pooling (SPP), Pyramid Pooling Module (PPM) in PSPNet [
21], and Atrous Spatial Pyramid Pooling (ASPP) in DeepLabv2. Unfortunately, data loss occurs due to the absence of multi-layer settings in these multi-scale feature extraction modules, which primarily execute pooling on feature maps. And Sun et al. [
22] improved the Deeplabv3+ network to extract water bodies and attempted to combine DEM data with remote sensing image data to extract small water bodies [
23]. Cao et al. [
24] extracted water bodies from high-resolution remote sensing images by enhancing Unet networks and multi-scale information fusion. Yan et al. [
25] used a novel water body extraction method to automate water body extraction from Landsat 8 OLI images. Cheng et al. [
26] proposed a water body extraction method based on spatial partitioning and feature decoupling. Zhao et al. [
27] proposed an unsupervised water body extraction method by combining the estimated probabilities of historical, neighboring, and neighborhood prior information using Bayesian model averaging. Chen et al. [
28] refined the feature information by introducing dynamic semantic kernels to achieve high-precision extraction of lake water bodies. Mishra et al. [
29] used principal component analysis to fuse panchromatic and infrared bands to classify the fused images into surface types. Wang et al. [
30,
31] incorporated a mixed-domain attention mechanism into the decoder structure to fully exploit the spatial and channel features of small water bodies in the image.
Traditional water extraction methods, such as the threshold method, spectral index method, object-oriented method, and machine learning classification method, mainly rely on manual statistical features and expert experience, which may not be effective in dealing with complex backgrounds or diverse water bodies. In addition, traditional methods often struggle to achieve a high degree of automation, which increases the complexity and time cost of operations. Interference factors such as shadows and buildings can also limit the accuracy of water extraction, and traditional methods may not be flexible and accurate enough in dealing with these interferences. Deep learning methods can automatically learn and extract useful features from input data without the need for manual feature selection and extraction, greatly improving the efficiency and accuracy of water extraction. Deep learning models can learn complex features and the intrinsic laws of water bodies by training on large amounts of data, thus having good generalization ability to unknown data. Furthermore, deep learning models have strong robustness to noise and interference, and can handle water extraction tasks in complex backgrounds. Deep learning models have transferability and can be applied to water extraction tasks in different regions and data sources. Moreover, with the continuous development of technology, deep learning models can be continuously optimized and expanded to meet more complex water extraction needs.
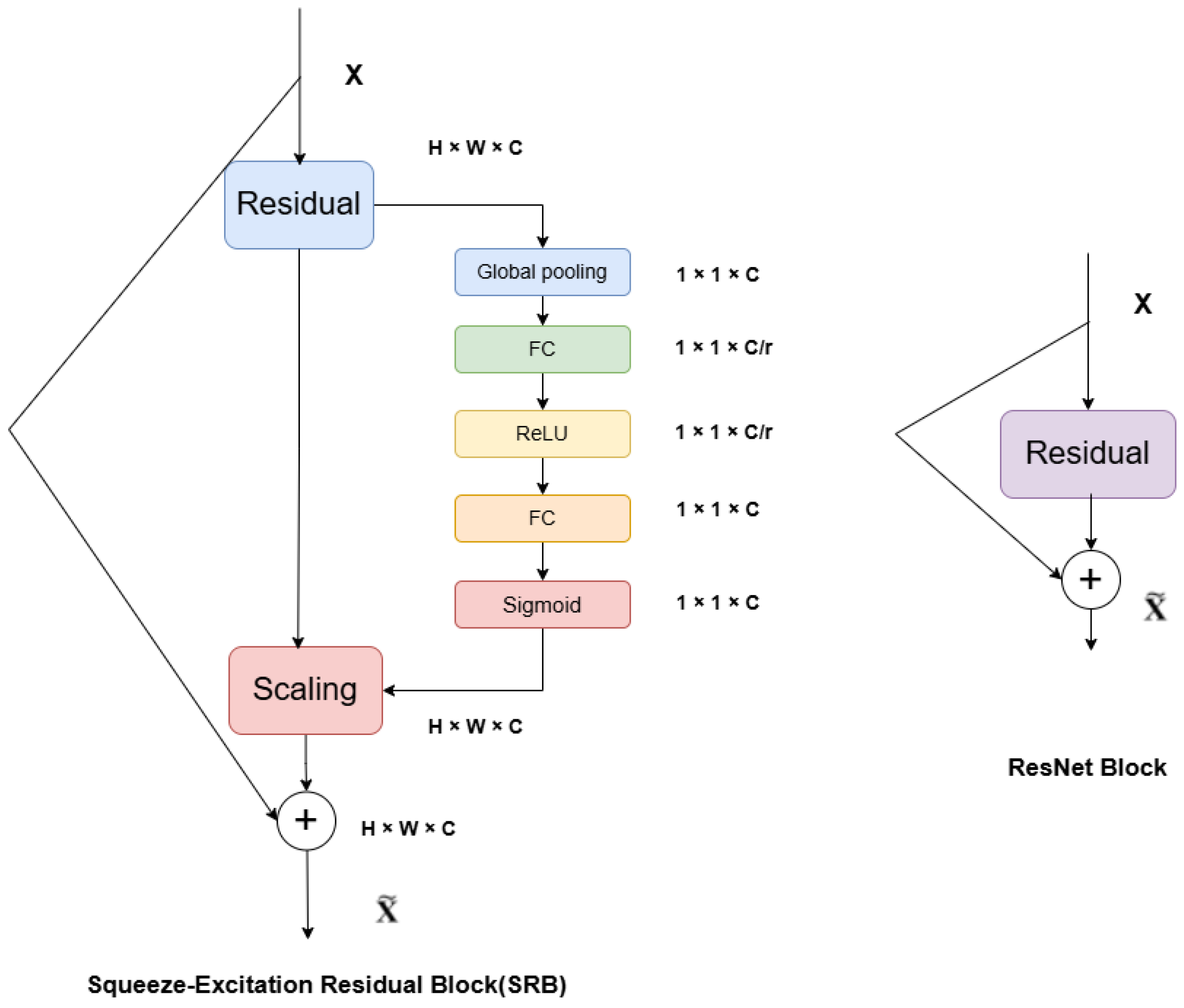
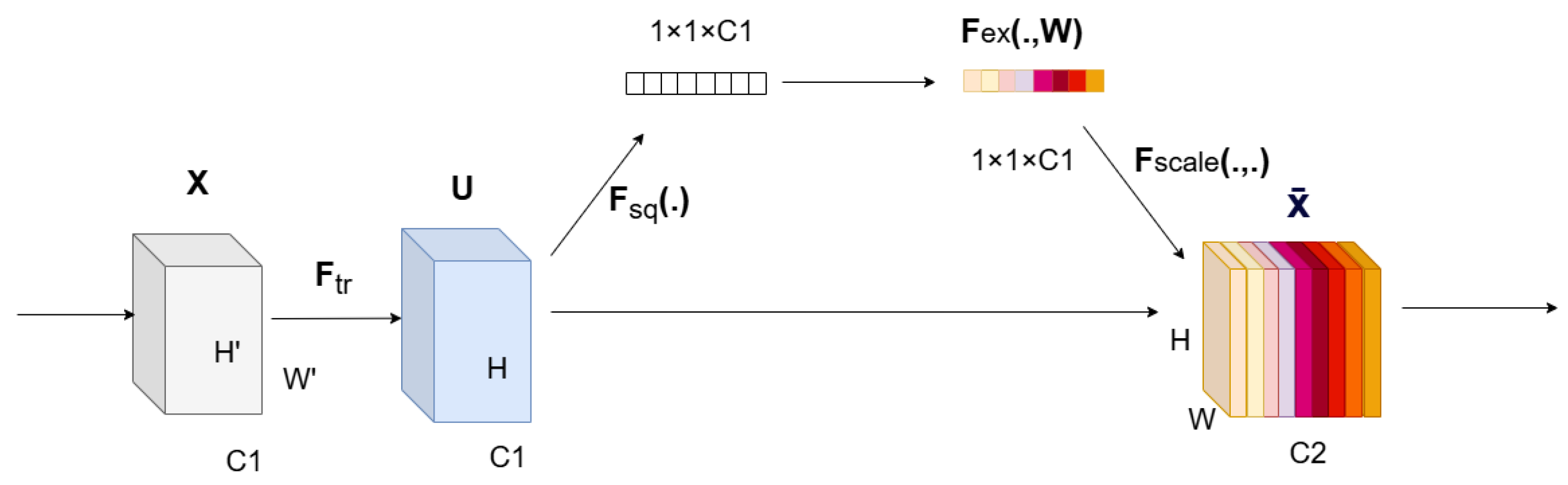
In light of this, the current study constructs a feature extraction network that utilizes the Unet’s multi-scale feature architecture and jumping structure [
32] to extract water body features at several layers and scales. The water body extraction task involves only two categories: background and water body. To ensure a balanced representation of positive and negative data during training, the W-Dice loss function is incorporated. To be more precise, the model minimizes unnecessary computation usage while accurately extracting the crucial information from the data by combining the optimization guidance of the loss function with the focusing ability of the attention mechanism [
33]. This enhances the model’s cognitive process and augments the precision of its predictions. The W-Dice loss function offers a distinct optimization objective for the model, while the SE channel attention mechanism effectively captures the complex relationships among several channels in remote sensing images. To achieve the desired outcomes, this combination enables the model to consistently improve its performance and optimize the utilization of river features in remote sensing images [
34].
The main contents of this paper are as follows:
- (1)
The down-sampling approach integrates the SE attention mechanism with a residual structure, and learns the jumping structure of the Unet for multi-scale feature extraction and compensation. This enhances the capability to extract the characteristics of small water bodies, including rivers, lakes, and reservoirs.
- (2)
In order to enhance the model’s generalization and to ensure that both positive and negative samples are given equal importance, the W-Dice loss function is incorporated into the loss calculation during the training phase.
- (3)
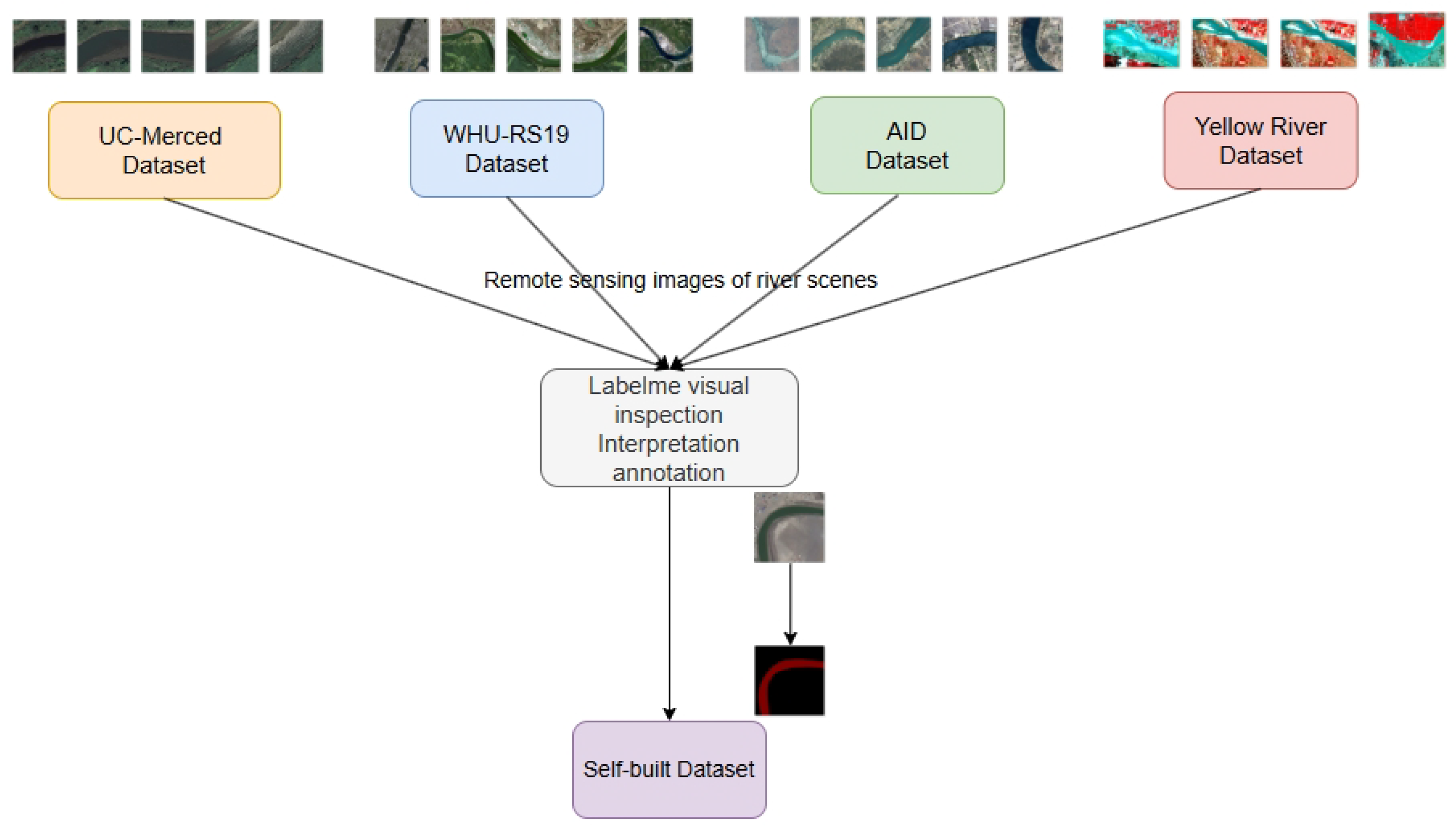
The enhanced network model is compared and evaluated with semantic segmentation networks like PSPNet and Deeplabv3+ on both a self-built remote sensing image dataset and another public remote sensing interpretation dataset. The effectiveness of water body extraction is assessed using the mIoU as a crucial metric.
4. Discussion
This paper proposes the SE-ResUnet method for water extraction from satellite images. This method uses Unet’s skipping structure for multi-scale feature extraction and compensation, the SE attention mechanism with residual structure for down-sampling, and the W-Dice loss function for loss calculation during training [
35]. We conducted numerous performance comparison experiments and ablation studies on two datasets. The experiments demonstrated that, while adjusting the imbalance between water bodies and background distribution in some sample data, we can effectively acquire the semantic information of the river center and marginal water bodies in high-resolution remote sensing images.
The performance of SE-ResUnet was evaluated by comparing it with other semantic segmentation networks, such as Unet, PSPNet, HRNet, and Deeplabv3+. The evaluation was conducted using a self-built dataset and a publicly available remote sensing interpretation water body dataset. The comparison results demonstrated that SE-ResUnet shows superior water body extraction performance. The mIoU, OA, and F1-score of SE-ResUnet are improved by 0.38%, 0.12%, and 0.08%, respectively, on the generated dataset, while that on the public remote sensing dataset showed enhancements of 0.63%, 0.26%, and 0.25%, respectively, when compared with the original Unet. Based on the results displayed in
Figure 10 and
Figure 11, SE-ResUnet was able to effectively extract target water bodies from those images containing spectral noise and other shadow interference, while fully extracting water bodies that are challenging to identify at the river’s edge and center. The edge and ground truth also matched very well. The ablation study results, depicted in
Figure 8 and
Figure 9, indicate a significant imbalance in the distribution of positive and negative samples between the water body and background in narrow rivers. Additionally, the SE-ResUnet model performs effectively on these specific test sets. The smoothness of the extracted water body’s edge indicates that the SE channel attention mechanism with residual structure is more effective in capturing the relationship between different channels, especially the information at the image edge. However, solely using the W-Dice loss function is not enough to adequately supervise and focus on the features across channels. The comparison results and ablation study findings on the two datasets suggest that the weighted loss function can enhance the model’s generalization, and help the SE-ResUnet model perform end-to-end water body extraction from multi-resolution remote sensing satellite images.
Our ablation experiment verified the feasibility of combining an attention mechanism and weighted loss function to optimize water extraction tasks, and achieved good experimental results on the two datasets used in the paper experiment. In the future, we will consider conducting experiments on more remote sensing image datasets and tasks to expand the application scope of this optimization strategy.
At the same time, it should be noted that there is still room for further experimentation with the Resnet backbone network selected by our proposed model. Additionally, the number and types of datasets are still limited, and there are not enough ways to enhance the data. This may result in poor generalization of our model on other datasets. However, based on our experimental results, our optimization strategy has shown good performance.
Despite achieving a good segmentation performance on Dataset1 and Dataset2, our suggested SE-ResUnet method still has significant limitations that will direct our future studies. First, there are a lot of parameters in the Unet model that are introduced into the SE attention mechanism, which means that training and deployment will be very expensive. We intend to use model pruning and distillation approaches to lower the model’s complexity and processing requirements in order to increase efficiency in our follow-up research. The paper by Pandey et al. [
43] includes a list of other performance metrics that we will attempt to use in other models to describe model performance and training effectiveness. Second, the left single CNN structure is not sensitive enough to fine features, especially when dealing with water body boundaries. The main reason is that this mode is an encoder-decoder network, which might result in less smooth water body boundary lines. Finally, a parameter is introduced to achieve a balance between the cross-entropy loss and Dice loss when computing the objective function using the W-Dice loss function. However, it is important to note that this parameter is not trained automatically. Due to the expense of training time, the experiment achieves its nearly optimal water extraction effect at a value of 0.5 after multiple manual adjustments. Subsequently, we can attempt to fine-tune it to the hyper-parameter of the network, and through the utilization of the training data, it will autonomously learn to reach a parameter threshold that is nearly optimal. Ozdemir et al. [
44] used the automatic mask generator method of SAM to segment images and zero shot classification of fragments using CLIP. The proposed method accurately depicts water bodies under complex environmental conditions. In the future, combining SAM with massive remote sensing image data to complete segmentation and extraction tasks will be a research direction.


 and
and 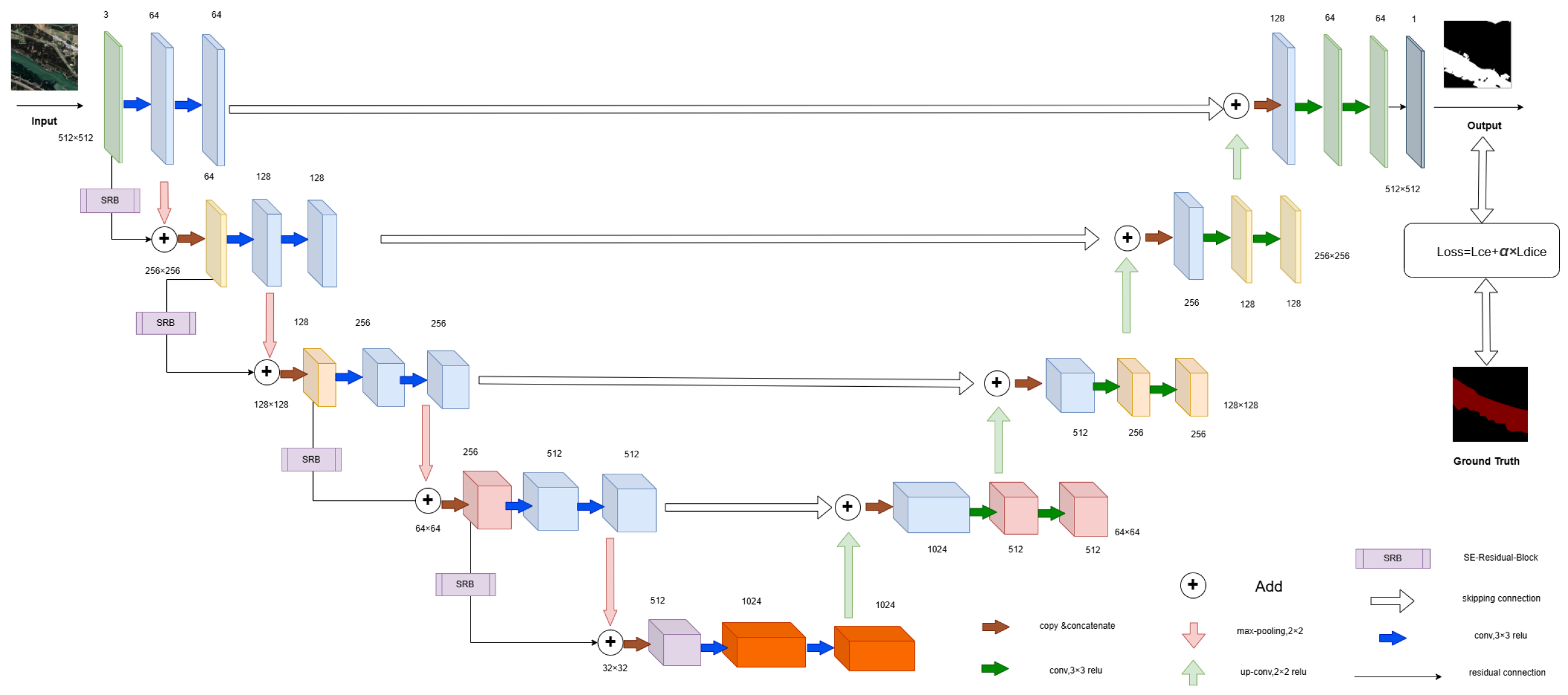








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}