
A Review of Water Quality Forecasting and Classification Using Machine Learning Models and Statistical Analysis


Abstract
1. Introduction
- Systematically categorise and compare machine learning and statistical models (including regression, classification, hybrid, and ensemble approaches) used in water quality prediction;
- Benchmark model performance using common evaluation metrics such as RMSE, R2, accuracy, and F1-score to assess predictive capability;
- Assess the limitations, applicability, and interpretability of these models in the context of Malaysia’s environmental and regulatory requirements;
- Highlight statistical analysis techniques such as residual analysis and PCA that complement machine learning methods in model validation and optimisation;
- Identify current research gaps and propose future directions for the integration of artificial intelligence (AI) and data-driven decision-making in sustainable water quality management.
2. Water Quality Monitoring
3. Water Quality Conditions and Standards
3.1. Comparison of Water Quality Standards (WQSs) Globally
3.2. Water Conditions in Malaysia
3.3. The National Water Quality Index (NWQI) in Malaysia
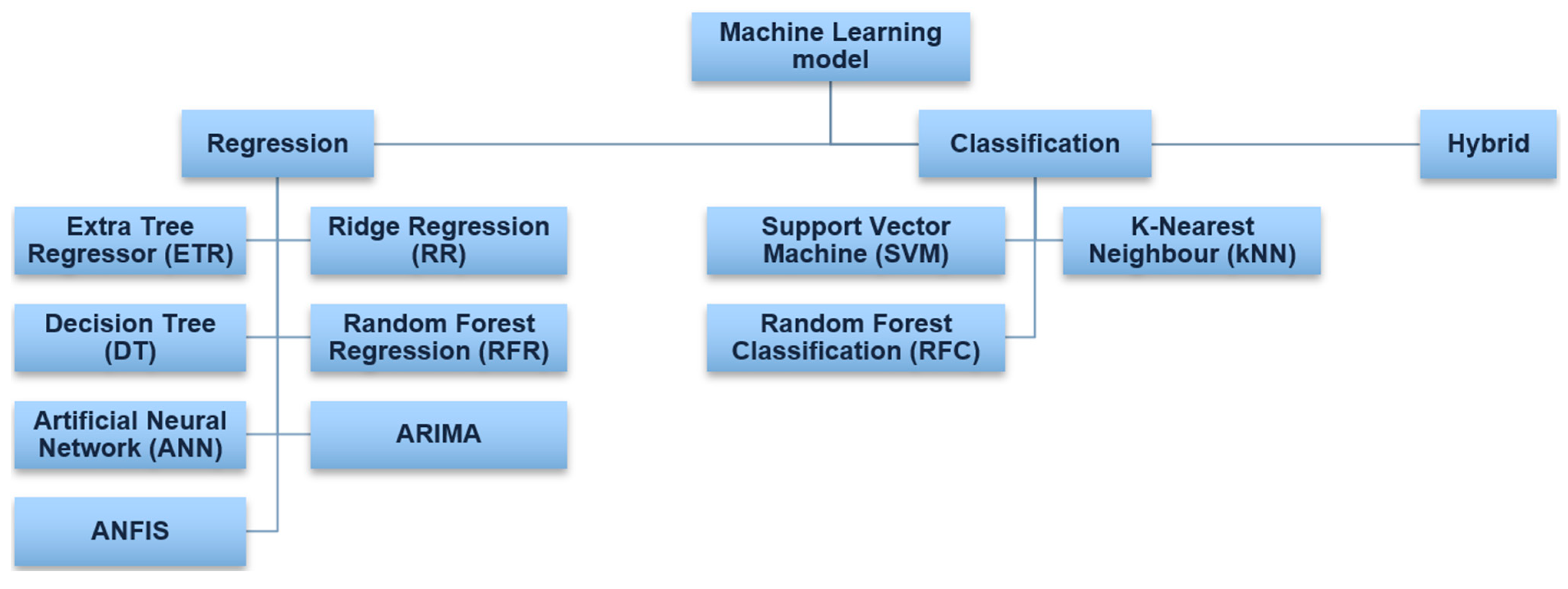
4. Machine Learning Models for Water Quality Forecasting and Classification
4.1. Forecasting-Based Water Quality Management
4.2. Regression-Based Prediction Models
4.2.1. Extra Tree Regressor (ETR)
4.2.2. Ridge Regression (RR)
4.2.3. Decision Tree (DT)
4.2.4. Random Forest Regression (RFR)
4.2.5. Artificial Neural Networks (ANNs)
4.2.6. Autoregressive Integrated Moving Average (ARIMA)
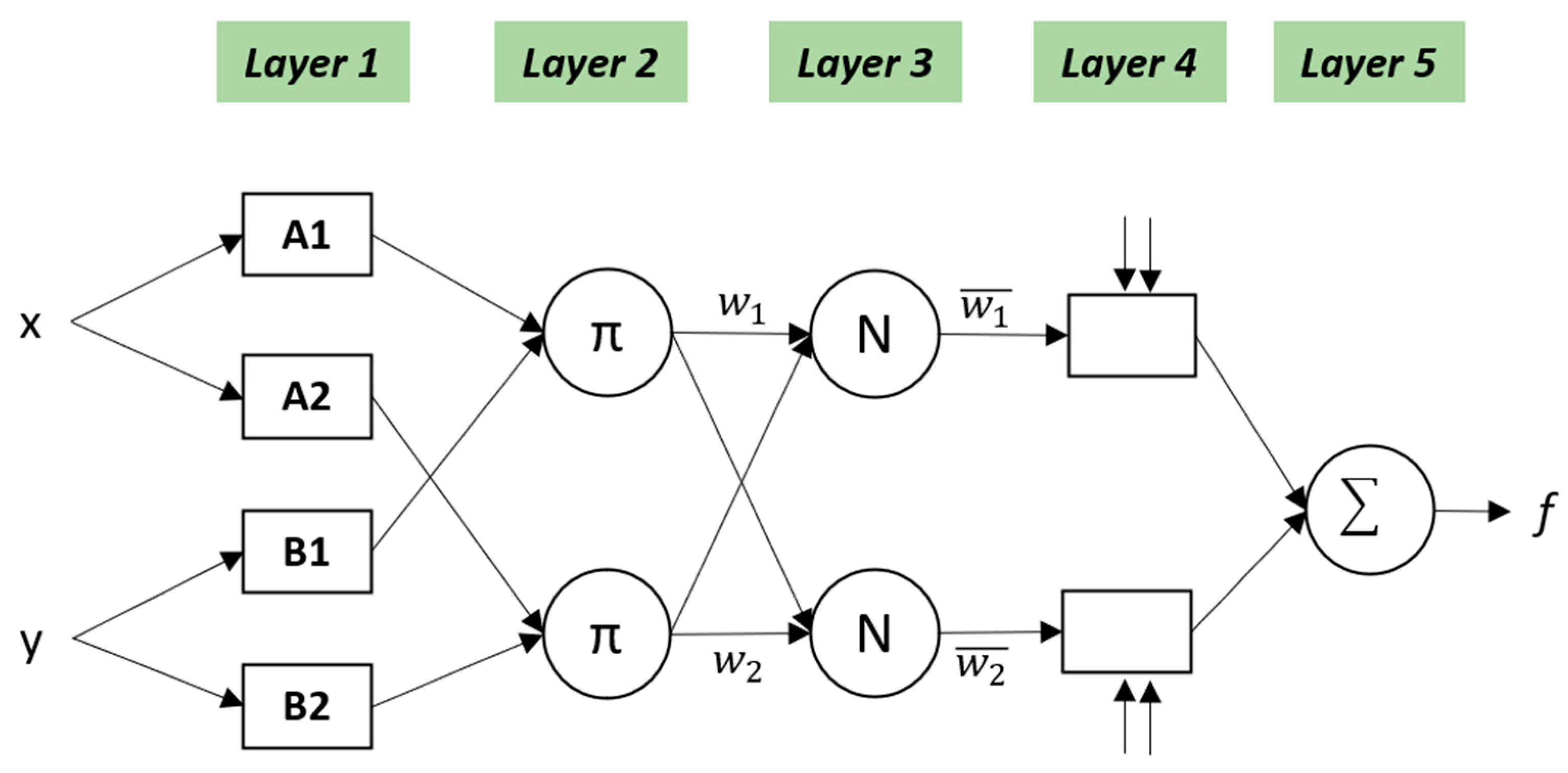
4.2.7. Adaptive Neuro-Fuzzy Inference System (ANFIS)
4.3. Classification-Based Prediction Models
4.3.1. Support Vector Machines (SVMs)
4.3.2. K-Nearest Neighbours (KNNs)
4.3.3. Random Forest Classification (RFC)
4.4. Hybrid Machine Learning Models
4.5. Model Benchmarking and Comparative Performance Evaluation
4.6. Small-Scale Implementation Using Malaysian Water Quality Data
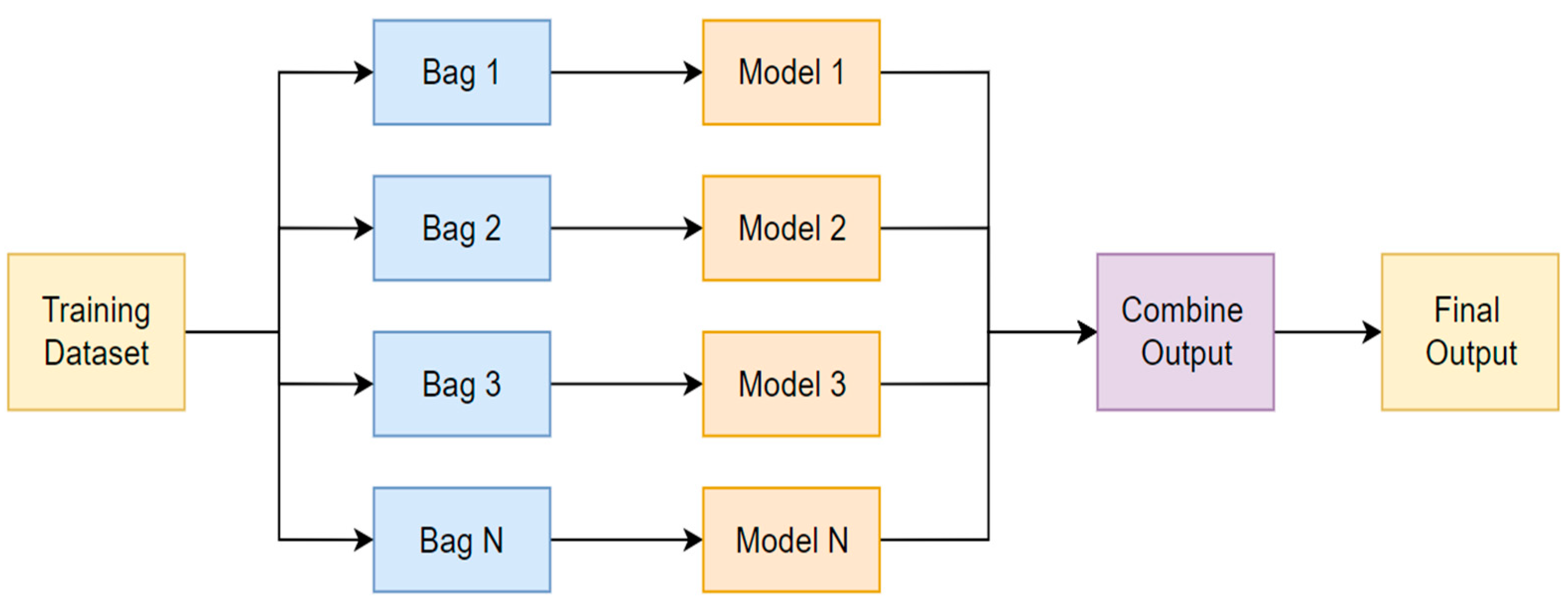
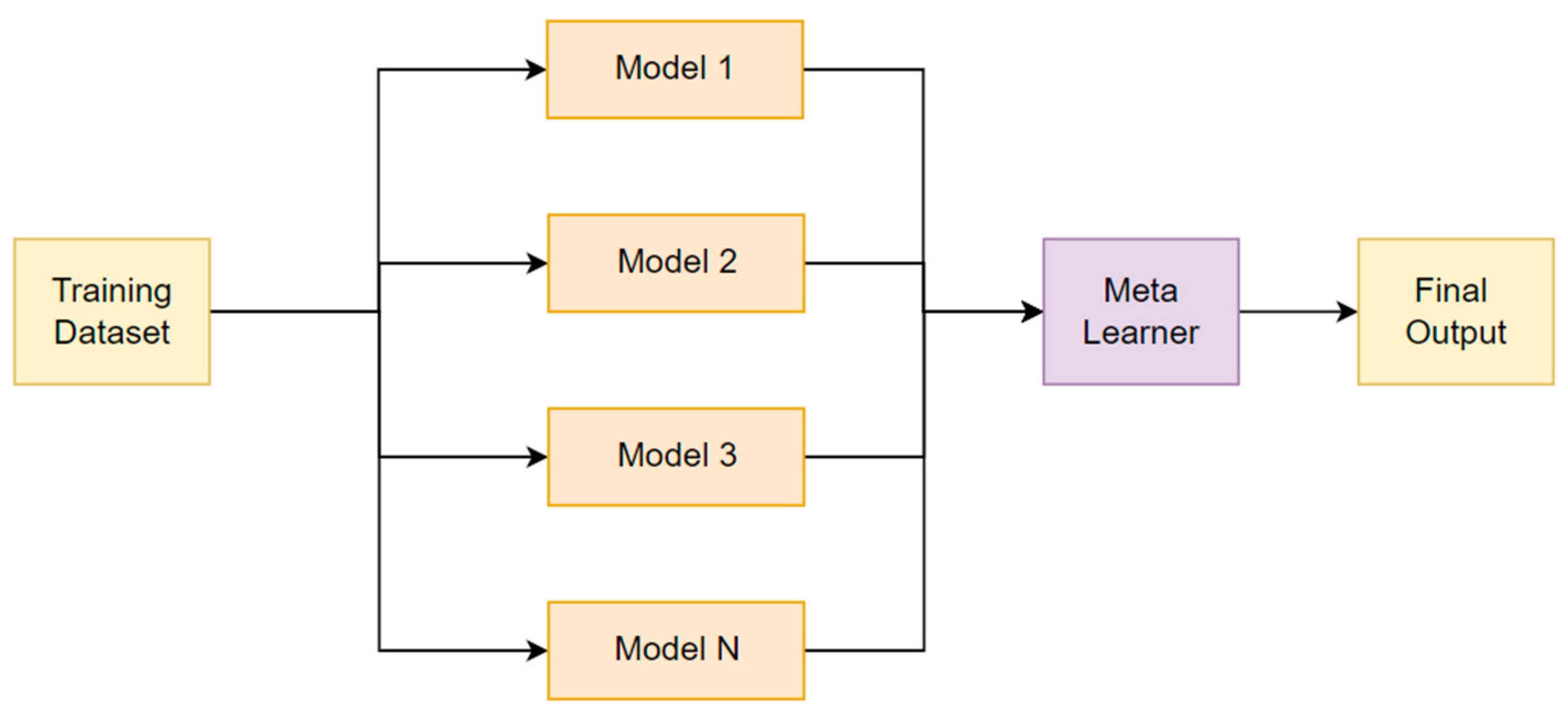
5. Ensemble Learning Methods
5.1. Bagging Method
5.2. Boosting Method
5.3. Stacking Method
6. Statistical Analysis of Water Quality
6.1. Residual Analysis
6.2. Diagnostic and Assumption Tests
6.3. Feature Importance
6.4. Learning Curve Analysis
6.5. Principal Component Analysis (PCA)
7. Challenges in Machine Learning-Based WQI Modelling and Limitations in Current Studies
7.1. Interpretability, Data Availability, and Complexity of Machine Learning Models
7.2. Cost–Benefit Considerations in Resource-Limited Settings
7.3. Practical Concerns: Data Privacy, Sensor Calibration, and Infrastructure Gaps
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Munteanu, C.; Teoibas-Serban, D.; Iordache, L.; Balaurea, M.; Blendea, C.D. Water intake meets the Water from inside the human body—Physiological, cultural, and health perspectives—Synthetic and Systematic literature review. Balneo PRM Res. J. 2021, 12, 196–209. [Google Scholar] [CrossRef]
- Angelakis, A.N.; Valipour, M.; Choo, K.-H.; Ahmed, A.T.; Baba, A.; Kumar, R.; Toor, G.S.; Wang, Z. Desalination: From Ancient to Present and Future. Water 2021, 13, 2222. [Google Scholar] [CrossRef]
- World Health Organization. Drinking-Water. Available online: https://www.who.int/news-room/fact-sheets/detail/drinking-water (accessed on 7 June 2024).
- He, C.; Liu, Z.; Wu, J.; Pan, X.; Fang, Z.; Li, J.; Bryan, B.A. Future global urban water scarcity and potential solutions. Nat. Commun. 2021, 12, 4667. [Google Scholar] [CrossRef]
- Kumar, S. The Looming Threat of Water Scarcity. Vital Signs 2013, 20, 96–100. [Google Scholar] [CrossRef]
- TayyabZahid, A.M.; Munir, A.; Falk, M.; Muazim, M.; Umair, M.; Qasim, S.; Khan, D.G. Chronic Effect of Heavy Metal Exposure on Poultry Health and Performance. Biol. Times 2024, 3, 1–2. [Google Scholar]
- Limburg, K.E. Deoxygenation—Coming to a water body near you. Front. Ecol. Environ. 2024, 22, e2812. [Google Scholar] [CrossRef]
- Mutono, N.; Wright, J.; Mutembei, H.; Muema, J.; Thomas, M.; Mutunga, M.; Thumbi, S.M. The nexus between improved water supply and water-borne diseases in urban areas in Africa: A scoping review protocol. AAS Open Res. 2020, 3, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Park, J.; Kim, K.T.; Lee, W.H. Recent Advances in Information and Communications Technology (ICT) and Sensor Technology for Monitoring Water Quality. Water 2020, 12, 510. [Google Scholar] [CrossRef]
- Ghiță, S.; Stanciu, I.; Sabău, A. Assessment of the Quality of the Aquatic Environment in the Areas Bordering the Development of Fishing Activities. J. Mar. Technol. Environ. 2023, 2, 32–37. [Google Scholar] [CrossRef]
- Nagothu, S.K.; Sri, P.B.; Anitha, G.; Vincent, S.; Kumar, O.P. Advancing aquaculture: Fuzzy logic-based water quality monitoring and maintenance system for precision aquaculture. Aquac. Int. 2025, 33, 32. [Google Scholar] [CrossRef]
- Nasution, S.F.; Harmadi, H.; Suryadi, S.; Widiyatmoko, B. Development of River Flow and Water Quality Using IOT-based Smart Buoys Environment Monitoring System. J. ILMU Fis. Univ. Andalas 2023, 16, 1–12. [Google Scholar] [CrossRef]
- Dewangan, S.K.; Toppo, D.N.; Kujur, A. Investigating the Impact of pH Levels on Water Quality: An Experimental Approach. Int. J. Res. Appl. Sci. Eng. Technol. 2023, 11, 756–759. [Google Scholar] [CrossRef]
- Dada, M.A.; Majemite, M.T.; Obaigbena, A.; Daraojimba, O.H.; Oliha, J.S.; Nwokediegwu, Z.Q.S. Review of smart water management: IoT and AI in water and wastewater treatment. World J. Adv. Res. Rev. 2024, 21, 1373–1382. [Google Scholar] [CrossRef]
- Abuzir, S.Y.; Abuzir, Y.S. Machine learning for water quality classification. Water Qual. Res. J. 2022, 57, 152–164. [Google Scholar] [CrossRef]
- Yan, X.; Zhang, T.; Du, W.; Meng, Q.; Xu, X.; Zhao, X. A Comprehensive Review of Machine Learning for Water Quality Prediction over the Past Five Years. J. Mar. Sci. Eng. 2024, 12, 159. [Google Scholar] [CrossRef]
- Sahu, P.; Londhe, S.N.; Kulkarni, P.S. Modelling water quality parameters using model tree, random forest, and non-linear regression for Mula-Mutha River, Pune, India. Environ. Monit. Assess. 2024, 196, 1047. [Google Scholar] [CrossRef]
- Jude, P.S.V.; Brighty, S.P.S.; Gandhi, R.R.; Balamurguan, K.; Krishnakumar, R. Water Quality Prediction Using Random Forest Algorithm. In Proceedings of the 2nd International Conference on Futuristic Technologies (INCOFT), Joondalup, Australia, 24–26 November 2023; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- Li, Z.; Fantke, P. Toward harmonizing global pesticide regulations for surface freshwaters in support of protecting human health. J. Environ. Manag. 2022, 301, 113909. [Google Scholar] [CrossRef] [PubMed]
- Graham, D.J.; Bierkens, M.F.P.; van Vliet, M.T.H. Impacts of droughts and heatwaves on river water quality worldwide. J. Hydrol. 2024, 629, 130590. [Google Scholar] [CrossRef]
- Mitchell, E.J.; Frisbie, S.H. A comprehensive survey and analysis of international drinking water regulations for inorganic chemicals with comparisons to the World Health Organization’s drinking-water guidelines. PLoS ONE 2023, 18, e0287937. [Google Scholar] [CrossRef] [PubMed]
- Tyurina, I.A.; Ya, L.-S.; Manaeva, E.S. Legislation of the countries of the European Region on the drinking water quality management (overview). Vodosnabzhenie Sanit. Teh. 2022, 10, 14–22. [Google Scholar] [CrossRef]
- Hendrayana, H.; Riyanto, I.A.; Nuha, A. River water quality variability in the young volcanic areas in Java, Indonesia. J. Degrad. Min. Lands Manag. 2023, 10, 4467–4478. [Google Scholar] [CrossRef]
- Van Winckel, T.; Cools, J.; Vlaeminck, S.E.; Joos, P.; Van Meenen, E.; Borregán-Ochando, E.; Steen, K.V.D.; Geerts, R.; Vandermoere, F.; Blust, R. Towards harmonization of water quality management: A comparison of chemical drinking water and surface water quality standards around the globe. J. Environ. Manag. 2021, 298, 113447. [Google Scholar] [CrossRef]
- Wang, X.; Xu, X.Q.; Gao, C.H.; Li, L.H.; Liu, Y.; Zhang, N.; Xia, Y.; Fang, X.; Zhang, X.G. Assessing the drinking water quality in the Inner Mongolia Autonomous Region from 2014 to 2018. J. Water Health 2022, 20, 610–619. [Google Scholar] [CrossRef]
- Karmakar, B.; Singh, M.K. Assessment of water quality status of water bodies using water quality index and correlation analysis in and around industrial areas of west District, Tripura, India. Nat. Environ. Pollut. Technol. 2021, 20, 551–559. [Google Scholar] [CrossRef]
- Enea, A.; Hapciuc, O.-E.; Iosub, M.; Minea, I.; Romanescu, G. Water quality assessment in three mountainous watersheds from Eastern Romania (Suceava, Ozana and Tazlau rivers). Environ. Eng. Manag. J. 2017, 16, 605–614. Available online: https://eemj.eu/index.php/EEMJ/article/view/3211 (accessed on 2 November 2024). [CrossRef]
- DOE. National Water Quality Standards and Water Quality Index—Department of Environment. Available online: https://www.doe.gov.my/en/national-river-water-quality-standards-and-river-water-quality-index/ (accessed on 12 April 2024).
- Goi, C.L. The river water quality before and during the Movement Control Order (MCO) in Malaysia. Case Stud. Chem. Environ. Eng. 2020, 2, 100027. [Google Scholar] [CrossRef]
- Yeoh, R.S.Y.; Wong, K.Y. Water’s role in ensuring food security: An analysis of Malaysia from 1991 to 2020. In Proceedings of the 12th International Conference on Business, Accounting, Finance and Economics (BAFE 2024), Kampar, Malaysia, 23 October 2024. [Google Scholar]
- Najah, A.; Teo, F.Y.; Chow, M.F.; Huang, Y.F.; Latif, S.D.; Abdullah, S.; Ismail, M.; El-Shafie, A. Surface water quality status and prediction during movement control operation order under COVID-19 pandemic: Case studies in Malaysia. Int. J. Environ. Sci. Technol. 2021, 18, 1009–1018. [Google Scholar] [CrossRef]
- Alberti, G.; Zanoni, C.; Magnaghi, L.R.; Biesuz, R. Low-cost, disposable colourimetric sensors for metal ions detection. J. Anal. Sci. Technol. 2020, 11, 30. [Google Scholar] [CrossRef]
- Bernama 29 Polluted Rivers Identified in 2022|MalaysiaNow. 2023. Available online: https://www.malaysianow.com/news/2023/06/13/29-polluted-rivers-identified-in-2022 (accessed on 21 August 2023).
- Bernama—WST 2040 to Boost Malaysia’s GDP and Water Sector Growth—DPM Fadillah. Bernama. 2024. Available online: https://www.bernama.com/tv/news.php?id=2357799 (accessed on 30 October 2024).
- Sakke, N.; Jafar, A.; Dollah, R.; Asis, A.H.B.; Mapa, M.T.; Abas, A. Water Quality Index (WQI) Analysis as an Indicator of Ecosystem Health in an Urban River Basin on Borneo Island. Water 2023, 15, 2717. [Google Scholar] [CrossRef]
- Mamat, N.; Razali, S.F.M.; Hamzah, F.B. Enhancement of water quality index prediction using support vector machine with sensitivity analysis. Front. Environ. Sci. 2023, 10, 1061835. [Google Scholar] [CrossRef]
- Fadzillah, N.; Salim, A.; Kasmin, H. Study on the Water Quality Index (WQI) of Parit Besar River in Batu Pahat. J. Adv. Environ. Solut. Resour. Recovery 2022, 2, 8–14. [Google Scholar] [CrossRef]
- Kamarudin, M.K.A.; Wahab, N.A.; Jalil, N.A.A.; Sunardi; Saad, M.H.M. Water quality issues in water resources management at Kenyir Lake, Malaysia. J. Teknol. 2020, 82, 1–11. [Google Scholar] [CrossRef]
- Encinas, C.; Ruiz, E.; Cortez, J.; Espinoza, A. Design and implementation of a distributed IoT system for the monitoring of water quality in aquaculture. In Proceedings of the 2017 Wireless Telecommunications Symposium, Chicago, IL, USA, 26–28 April 2017; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- De Zuane, J. Handbook of Drinking Water Quality; Wiley: Hoboken, NJ, USA, 1996. [Google Scholar] [CrossRef]
- Division, E.S. Drinking Water Quality Standard Malaysia; Ministry of Health Malaysia: Putrajaya, Malaysia, 2016. [Google Scholar]
- Al-Tameemi, H.J.; Jabbar, M. BOD: COD Ratio as Indicator for Wastewater and Industrial Water Pollution. Int. J. Spec. Educ. 2022, 3, 2164–2171. Available online: https://www.researchgate.net/publication/362053527_BOD_COD_Ratio_as_Indicator_for_Wastewater_and_Industrial_Water_Pollution (accessed on 22 April 2024).
- Liu, Y.Z.; Chen, Z. Prediction of biochemical oxygen demand with genetic algorithm-based support vector regression. Water Qual. Res. J. 2023, 58, 87–98. [Google Scholar] [CrossRef]
- Mekaoussi, H.; Heddam, S.; Bouslimanni, N.; Kim, S.; Zounemat-Kermani, M. Predicting biochemical oxygen demand in wastewater treatment plant using advance extreme learning machine optimized by Bat algorithm. Heliyon 2023, 9, e21351. [Google Scholar] [CrossRef]
- Qi, M.; Han, Y.; Zhao, Z.; Li, Y. Integrated determination of chemical oxygen demand and biochemical oxygen demand. Pol. J. Environ. Stud. 2021, 30, 1785–1794. [Google Scholar] [CrossRef]
- Adjovu, G.E.; Stephen, H.; James, D.; Ahmad, S. Measurement of Total Dissolved Solids and Total Suspended Solids in Water Systems: A Review of the Issues, Conventional, and Remote Sensing Techniques. Remote Sens. 2023, 15, 3534. [Google Scholar] [CrossRef]
- Wu, J.; Wang, Z. A Hybrid Model for Water Quality Prediction Based on an Artificial Neural Network, Wavelet Transform, and Long Short-Term Memory. Water 2022, 14, 610. [Google Scholar] [CrossRef]
- Shams, M.Y.; Elshewey, A.M.; El-kenawy, E.S.M.; Ibrahim, A.; Talaat, F.M.; Tarek, Z. Water quality prediction using machine learning models based on grid search method. Multimed. Tools Appl. 2024, 83, 35307–35334. [Google Scholar] [CrossRef]
- Fang, P.; Wang, Y.; Zhao, Y.; Kang, J. Analysis of Prediction Confidence in Water Quality Forecasting Employing LSTM. Water 2025, 17, 1050. [Google Scholar] [CrossRef]
- Abushandi, E. Water Quality Assessment and Forecasting Along the Liffey and Andarax Rivers by Artificial Neural Network Techniques Toward Sustainable Water Resources Management. Water 2025, 17, 453. [Google Scholar] [CrossRef]
- Chen, J.; Wei, X.; Liu, Y.; Zhao, C.; Liu, Z.; Bao, Z. Deep Learning for Water Quality Prediction—A Case Study of the Huangyang Reservoir. Appl. Sci. 2024, 14, 8755. [Google Scholar] [CrossRef]
- Li, B.; Sun, F.; Lian, Y.; Xu, J.; Zhou, J. A Variational Mode Decomposition—Grey Wolf Optimizer—Gated Recurrent Unit Model for Forecasting Water Quality Parameters. Appl. Sci. 2024, 14, 6111. [Google Scholar] [CrossRef]
- Sukkuea, A.; Akkajit, P.; Suwannarat, K.; Foithong, P.; Afsarimanesh, N.; Alahi, E.E. AI-Driven Time Series Forecasting of Coastal Water Quality Using Sentinel-2 Imagery: A Case Study in the Gulf of Thailand. Water 2025, 17, 1798. [Google Scholar] [CrossRef]
- Li, Q.; He, J.; Mu, D.; Liu, H.; Li, S. Dissolved Oxygen Modeling by a Bayesian-Optimized Explainable Artificial Intelligence Approach. Appl. Sci. 2025, 15, 1471. [Google Scholar] [CrossRef]
- Bin Shahid, S.; Rifat, H.R.; Uddin, A.; Islam, M.; Mahmud, Z.; Sakib, K.H.; Roy, A. Hypertuning-Based Ensemble Machine Learning Approach for Real-Time Water Quality Monitoring and Prediction. Appl. Sci. 2024, 14, 8622. [Google Scholar] [CrossRef]
- Verma, N.; Bhardwaj, D.; Scholar, M.T. Research Paper on Analysing impact of Various Parameters on Water Quality Index. Int. J. Adv. Res. Comput. Sci. 2017, 8, 2496–2498. [Google Scholar]
- Malek, N.H.A.; Yaacob, W.F.W.; Nasir, S.A.M.; Shaadan, N. Prediction of Water Quality Classification of the Kelantan River Basin, Malaysia, Using Machine Learning Techniques. Water 2022, 14, 1067. [Google Scholar] [CrossRef]
- Chinnappan, C.V.; William, A.D.J.; Nidamanuri, S.K.C.; Jayalakshmi, S.; Bogani, R.; Thanapal, P.; Syed, S.; Venkateswarlu, B.; Masood, J.A.I.S. IoT-Enabled Chlorine Level Assessment and Prediction in Water Monitoring System Using Machine Learning. Electronics 2023, 12, 1458. [Google Scholar] [CrossRef]
- Bentley, C.; Junqueira, T.; Dove, A.; Vriens, B. Mass-Balance Modeling of Metal Loading Rates in the Great Lakes. Environ. Res. 2022, 205, 112557. [Google Scholar] [CrossRef]
- Haghnazar, H.; Cunningham, J.A.; Kumar, V.; Aghayani, E.; Mehraein, M. COVID-19 and urban rivers: Effects of lockdown period on surface water pollution and quality—A case study of the Zarjoub River, north of Iran. Environ. Sci. Pollut. Res. 2022, 29, 27382–27398. [Google Scholar] [CrossRef]
- Ma, J.; Ding, Y.; Cheng, J.C.P.; Jiang, F.; Xu, Z. Soft detection of 5-day BOD with sparse matrix in city harbor water using deep learning techniques. Water Res. 2020, 170, 115350. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Seo, Y.; Kim, S.; Ghorbani, M.A.; Samadianfard, S.; Naghshara, S.; Kim, N.W.; Singh, V.P. Can Decomposition Approaches Always Enhance Soft Computing Models? Predicting the Dissolved Oxygen Concentration in the St. Johns River, Florida. Appl. Sci. 2019, 9, 2534. [Google Scholar] [CrossRef]
- Pu, F.; Ding, C.; Chao, Z.; Yu, Y.; Xu, X. Water-Quality Classification of Inland Lakes Using Landsat8 Images by Convolutional Neural Networks. Remote Sens. 2019, 11, 1674. [Google Scholar] [CrossRef]
- Kumar, V.; Sharma, A.; Kumar, R.; Bhardwaj, R.; Thukral, A.K.; Rodrigo-Comino, J. Assessment of heavy-metal pollution in three different Indian water bodies by combination of multivariate analysis and water pollution indices. Hum. Ecol. Risk Assess. 2018, 26, 1–16. [Google Scholar] [CrossRef]
- Chen, L.; Wu, T.; Wang, Z.; Lin, X.; Cai, Y. A novel hybrid BPNN model based on adaptive evolutionary Artificial Bee Colony Algorithm for water quality index prediction. Ecol. Indic. 2023, 146, 109882. [Google Scholar] [CrossRef]
- Fang, Z.; Wang, Y.; Peng, L.; Hong, H. Predicting flood susceptibility using LSTM neural networks. J. Hydrol. 2021, 594, 125734. [Google Scholar] [CrossRef]
- Im, Y.; Song, G.; Lee, J.; Cho, M. Deep Learning Methods for Predicting Tap-Water Quality Time Series in South Korea. Water 2022, 14, 3766. [Google Scholar] [CrossRef]
- Trach, R.; Trach, Y.; Kiersnowska, A.; Markiewicz, A.; Lendo-Siwicka, M.; Rusakov, K. A Study of Assessment and Prediction of Water Quality Index Using Fuzzy Logic and ANN Models. Sustainability 2022, 14, 5656. [Google Scholar] [CrossRef]
- Zhou, M.; Zhang, Y.; Wang, J.; Shi, Y.; Puig, V. Water Quality Indicator Interval Prediction in Wastewater Treatment Process Based on the Improved BES-LSSVM Algorithm. Sensors 2022, 22, 422. [Google Scholar] [CrossRef]
- Ghazwani, M.; Begum, M.Y. Computational intelligence modeling of hyoscine drug solubility and solvent density in supercritical processing: Gradient boosting, extra trees, and random forest models. Sci. Rep. 2023, 13, 1–11. [Google Scholar] [CrossRef]
- Hoque, J.M.Z.; Nor, N.A.; Alelyani, S.; Mohana, M.; Hosain, M. Improving Water Quality Index Prediction Using Regression Learning Models. Int. J. Environ. Res. Public Health 2022, 19, 13702. [Google Scholar] [CrossRef]
- Alvarez, V.F.; Salazar, D.G.; Figueroa, C.; Corrales, J.C.; Casanova, J.F. Estimation of Water Turbidity in Drinking Water Treatment Plants Using Machine Learning Based on Water and Meteorological Data. Environ. Sci. Proc. 2023, 25, 89. [Google Scholar] [CrossRef]
- Hasrod, T.; Nuapia, Y.B.; Tutu, H. Comparison of individual and ensemble machine learning models for prediction of sulphate levels in untreated and treated Acid Mine Drainage. Environ. Monit. Assess. 2024, 196, 1–27. [Google Scholar] [CrossRef]
- Sudhakara, B.; Priyadarshini, R.; Bhattacharjee, S.; Kamath, S.S.; Pruthviraj, U.; Gangadharan, K.V.; Ghosh, S.K. Spatio-Temporal Analysis and Modeling of Coastal Areas for Water Salinity Prediction. In Proceedings of the 2023 IEEE International Students’ Conference on Electrical, Electronics and Computer Science, SCEECS, Bhopal, India, 18–19 February 2023; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- Nasaruddin, N.; Ahmad, A.; Zakaria, S.F.; Ul-Saufie, A.Z.; Osman, M.S. Predicting Kereh River’s Water Quality: A comparative Study of Machine Learning Models. Environ. Behav. Proc. J. 2023, 8, 213–219. [Google Scholar] [CrossRef]
- Abirami, K.; Radhakrishna, P.C.; Venkatesan, M.A. Water Quality Analysis and Prediction using Machine Learning. In Proceedings of the 2023 12th IEEE International Conference on Communication Systems and Network Technologies (CSNT), Bhopal, India, 8–9 April 2023; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2023; pp. 241–245. [Google Scholar] [CrossRef]
- Abbas, F.; Cai, Z.; Shoaib, M.; Iqbal, J.; Ismail, M.; Ullah, A. Uncertainty Analysis of Predictive Models for Water Quality Index: Comparative Analysis of XGBoost, Random Forest, SVM, KNN, Gradient Boosting, and Decision Tree Algorithms. Artif. Intell. Mach. Learn. 2024; in press. [Google Scholar] [CrossRef]
- Jena, P.; Rahaman, S.M.; DasMohapatra, P.K.; Barik, D.P.; Patra, D.S. Surface Water Quality Assessment, Prediction & Modelling of River Daya in Odisha. Res. Sq. 2022; in press. [Google Scholar] [CrossRef]
- Gai, R.; Yang, J. Summary of Water Quality Prediction Models Based on Machine Learning. In Proceedings of the 2021 IEEE 23rd International Conference on High Performance Computing & Communications; 7th International Conference on Data Science & Systems; 19th International Conference on Smart City; 7th International Conference on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Haikou, China, 20–22 December 2021; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2021; pp. 2338–2343. [Google Scholar] [CrossRef]
- Zhang, H.; Ren, X.; Chen, S.; Xie, G.; Hu, Y.; Gao, D.; Tian, X.; Xiao, J.; Wang, H. Deep optimization of water quality index and positive matrix factorization models for water quality evaluation and pollution source apportionment using a random forest model. Environ. Pollut. 2024, 347, 123771. [Google Scholar] [CrossRef]
- Swetha, P.; Rasheed, A.H.K.P.; Harigovindan, V.P. Random Forest Regression based Water Quality Prediction for Smart Aquaculture. In Proceedings of the 4th International Conference on Computing and Communication Systems (I3CS), Shillong, India, 16–18 March 2023; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- Tejaswi, T.; Manoj, C.; Naidu, P.V.D.; Santhosh, T.; Akhil, P.V.S.; Ganesan, V. Nexus of Water Quality prediction by ANN. In Proceedings of the 2022 International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES), Chennai, India, 15–16 July 2022; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Mohammed, R.; Al-Obaidi, B. Treatability influence of municipal sewage effluent on surface water quality assessment based on Nemerow pollution index using an artificial neural network. IOP Conf. Ser. Earth Environ. Sci. 2021, 877, 012008. [Google Scholar] [CrossRef]
- Hasnan, M.I.; Jaffar, A.; Thamrin, N.M.; Misnan, M.F.; Yassin, A.I.M.; Ali, M.S.A.M. NARX-based water quality index model of Air Busuk River using chemical parameter measurements. Indones. J. Electr. Eng. Comput. Sci. 2021, 23, 1663–1673. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, J.; Tan, W.; Lan, H.; Zhang, S.; Xiao, K.; Wang, L.; Lin, H.; Sun, G.; Guo, P. Application of Time Serial Model in Water Quality Predicting. Comput. Mater. Contin. 2023, 74, 67–82. [Google Scholar] [CrossRef]
- Lokman, A.; Ramasamy, R.K.; Ting, C.Y. Scheduling and Predictive Maintenance for Smart Toilet. IEEE Access 2023, 11, 17983–17999. [Google Scholar] [CrossRef]
- Zafra-Mejía, C.A.; Rondón-Quintana, H.A.; Urazán-Bonells, C.F. ARIMA and TFARIMA Analysis of the Main Water Quality Parameters in the Initial Components of a Megacity’s Drinking Water Supply System. Hydrology 2024, 11, 10. [Google Scholar] [CrossRef]
- Ibrahim, H.; Yaseen, Z.M.; Scholz, M.; Ali, M.; Gad, M.; Elsayed, S.; Khadr, M.; Hussein, H.; Ibrahim, H.H.; Eid, M.H.; et al. Evaluation and Prediction of Groundwater Quality for Irrigation Using an Integrated Water Quality Indices, Machine Learning Models and GIS Approaches: A Representative Case Study. Water 2023, 15, 694. [Google Scholar] [CrossRef]
- Shah, S.M.H.; Yaseen, M.A.; Abba, S.I.; Lawal, D.U.; Aliyu, F.; Al-Qadami, W.H.H.; Mustaffa, Z.; Pande, C.B.; Sammen, S.S.; Aliundi, I.H. Treated Wastewater Assessment to Optimize Agricultural Water Reuse in Al-Qatif Region Saudi Arabia Using Hybrid Machine Learning Techniques. Water Sci. Technol. 2024; in press. [Google Scholar] [CrossRef]
- Khan, M.S.I.; Islam, N.; Uddin, J.; Islam, S.; Nasir, M.K. Water quality prediction and classification based on principal component regression and gradient boosting classifier approach. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 4773–4781. [Google Scholar] [CrossRef]
- Adizue, U.L.; Tura, A.D.; Isaya, E.O.; Farkas, B.Z.; Takács, M. Surface quality prediction by machine learning methods and process parameter optimization in ultra-precision machining of AISI D2 using CBN tool. Int. J. Adv. Manuf. Technol. 2023, 129, 1375–1394. [Google Scholar] [CrossRef]
- Nair, J.P.; Vijaya, M.S. River Water Quality Prediction and index classification using Machine Learning. J. Phys. Conf. Ser. 2022, 2325, 012011. [Google Scholar] [CrossRef]
- Zhou, S.; Song, C.; Zhang, J.; Chang, W.; Hou, W.; Yang, L. A Hybrid Prediction Framework for Water Quality with Integrated W-ARIMA-GRU and LightGBM Methods. Water 2022, 14, 1322. [Google Scholar] [CrossRef]
- Sarma, A.; Shiney, O.J. An Analysis on the Techniques for Water Quality Prediction from Remotely Sensed data. In Proceedings of the IEEE International Conference on Recent Trends in Electronics and Communication: Upcoming Technologies for Smart Systems (ICRTEC 2023), Mysore, India, 10–11 February 2023; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- Shamsuddin, I.I.S.; Othman, Z.; Sani, N.S. Water Quality Index Classification Based on Machine Learning: A Case from the Langat River Basin Model. Water 2022, 14, 2939. [Google Scholar] [CrossRef]
- Lilhore, U.K.; Singh, R.I. Water Quality Prediction Using Hybrid Classification Model. In Proceedings of the International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), Tenerife, Spain, 19–21 July 2023; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- AlZubi, A.A. IoT-based automated water pollution treatment using machine learning classifiers. Environ. Technol. 2024, 45, 2299–2307. [Google Scholar] [CrossRef]
- Maulani, J.; Sari, M. Komparasi Metode K-Nearest Neighbor (Knn) Dengan Support Vector Machine (Svm) Terhadap Tingkat Akurasi Klasifikasi Kualitas Air. Smart Comp Jurnalnya Orang Pint. Komput. 2023, 12, 430–435. [Google Scholar] [CrossRef]
- Yang, Q.; Li, Y.; Gao, J. An effective model based on machine learning for water quality prediction after desalination. In Proceedings of the International Conference on Electronic Information Engineering and Data Processing (EIEDP 2023), Nanchang, China, 17–19 March 2023; Volume 12700, pp. 810–814. [Google Scholar] [CrossRef]
- Pardeshi, S.; Gandre, P.; Poojari, N.; Pansare, S.; Alte, B. Water Quality Analysis from Satellite Images. In Proceedings of the 2023 International Conference on Data Science and Network Security (ICDSNS), Tiptur, India, 28–29 July 2023; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- Abumohsen, M.; Owda, A.Y.; Owda, M.; Abumihsan, A. Hybrid machine learning model combining of CNN-LSTM-RF for time series forecasting of Solar Power Generation. E-Prime Adv. Electr. Eng. Electron. Energy 2024, 9, 100636. [Google Scholar] [CrossRef]
- Ahmed, R.; Sreeram, V.; Mishra, Y.; Arif, M.D. A review and evaluation of the state-of-the-art in PV solar power forecasting: Techniques and optimization. Renew. Sustain. Energy Rev. 2020, 124, 109792. [Google Scholar] [CrossRef]
- Le, T. Enhancing Predictive Capabilities of Arima Models by Hybridization—A Case Study on Omxh25 Index. Master’s Thesis, LUT University, Lappeenranta, Finland, 2024. [Google Scholar]
- Harini, R.S.S.; Amudha, V.; Lakshmi, S.V. Deep Ensemble-based Water Quality Index Prediction and Classification using Randomized Low-Rank Approximation. In Proceedings of the 2023 2nd International Conference on Augmented Intelligence and Sustainable Systems (ICAISS), Trichy, India, 23–25 August 2023; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2023; pp. 434–439. [Google Scholar] [CrossRef]
- Enriquez, L.; Saldarriaga, J.; Berardi, L.; Laucelli, D.; Giustolisi, O. Using artificial intelligence models to support water quality prediction in water distribution networks. IOP Conf. Ser. Earth Environ. Sci. 2023, 1136, 012009. [Google Scholar] [CrossRef]
- Li, Y.; Li, X.; Xu, C.; Tang, X. Dissolved Oxygen Prediction Model for the Yangtze River Estuary Basin Using IPSO-LSSVM. Water 2023, 15, 2206. [Google Scholar] [CrossRef]
- Jo, J.; Kwak, C.; Kim, J.; Kim, S. Deriving Optimal Analysis Method for Road Surface Runoff with Change in Basin Geometry and Grate Inlet Installation. Water 2022, 14, 3132. [Google Scholar] [CrossRef]
- Onga, L.; Kattel-Salusoo, E.; Trapido, M.; Preis, S. Oxidation of Aqueous Dexamethasone Solution by Gas-Phase Pulsed Corona Discharge. Water 2022, 14, 467. [Google Scholar] [CrossRef]
- Saba, E.; Kalwar, I.H.; Unar, M.A.; Memon, A.L.; Pirzada, N. Fuzzy Logic-Based Identification of Railway Wheelset Conicity Using Multiple Model Approach. Sustainability 2021, 13, 10249. [Google Scholar] [CrossRef]
- Zeng, Y.; Xu, W.; Wang, H.; Zhao, D.; Ding, H. Nitrogen and Phosphorus Removal Efficiency and Denitrification Kinetics of Different Substrates in Constructed Wetland. Water 2022, 14, 1757. [Google Scholar] [CrossRef]
- Basack, S.; Goswami, G.; Dai, Z.H.; Baruah, P. Failure-Mechanism and Design Techniques of Offshore Wind Turbine Pile Foundation: Review and Research Directions. Sustainability 2022, 14, 12666. [Google Scholar] [CrossRef]
- Sanchez, R.; Rodriguez, L. Transboundary Aquifers between Baja California, Sonora and Chihuahua, Mexico, and California, Arizona and New Mexico, United States: Identification and Categorization. Water 2021, 13, 2878. [Google Scholar] [CrossRef]
- Latha, C.B.C.; Jeeva, S.C. Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques. Inform. Med. Unlocked 2019, 16, 100203. [Google Scholar] [CrossRef]
- Tanuku, S.R.; Kumar, A.A.; Somaraju, S.R.; Dattuluri, R.; Reddy, M.V.K.; Jain, S. Liver Disease Prediction Using Ensemble Technique. In Proceedings of the 8th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 25–26 March 2022; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2022; pp. 1522–1525. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M.; Malik, A.K.; Tanveer, M.; Suganthan, P.N. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2021, 115, 105151. [Google Scholar] [CrossRef]
- Mahajan, P.; Uddin, S.; Hajati, F.; Moni, M.A. Ensemble Learning for Disease Prediction: A Review. Healthcare 2023, 11, 1808. [Google Scholar] [CrossRef] [PubMed]
- Sarmah, U.; Borah, P.; Bhattacharyya, D.K. Ensemble Learning Methods: An Empirical Study. SN Comput. Sci. 2024, 5, 924. [Google Scholar] [CrossRef]
- Ramesh, D.; Katheria, Y.S. Ensemble method based predictive model for analyzing disease datasets: A predictive analysis approach. Health Technol 2019, 9, 533–545. [Google Scholar] [CrossRef]
- Mienye, I.D.; Sun, Y. A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects. IEEE Access 2022, 10, 99129–99149. [Google Scholar] [CrossRef]
- Verma, A.K.; Pal, S.; Kumar, S. Comparison of skin disease prediction by feature selection using ensemble data mining techniques. Inform. Med. Unlocked 2019, 16, 100202. [Google Scholar] [CrossRef]
- Jaiyeoba, O.; Ogbuju, E.; Yomi, O.T.; Oladipo, F. Development of a Model to Classify Skin Diseases using Stacking Ensemble Machine Learning Techniques. J. Comput. Theor. Appl. 2024, 2, 22–38. [Google Scholar] [CrossRef]
- Umamaheswari, K.; Madhumathi, R. Predicting Crop Yield Based on Stacking Ensemble Model in Machine Learning. In Proceedings of the 8th International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC 2024), Kirtipur, Nepal, 3–5 October 2024; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2024; pp. 1831–1836. [Google Scholar] [CrossRef]
- Wu, Y.; Xia, Z.; Feng, Z.; Huang, M.; Liu, H.; Zhang, Y. Forecasting Heart Disease Risk with a Stacking-Based Ensemble Machine Learning Method. Electronics 2024, 13, 3996. [Google Scholar] [CrossRef]
- Singh, N.; Singh, P. A Stacked Generalization Approach for Diagnosis and Prediction of Type 2 Diabetes Mellitus. Adv. Intell. Syst. Comput. 2020, 990, 559–570. [Google Scholar] [CrossRef]
- Sidek, L.M.; Mohiyaden, H.A.; Marufuzzaman, M.; Noh, N.S.M.; Heddam, S.; Ehteram, M.; Kisi, O.; Sammen, S.S. Developing an ensembled machine learning model for predicting water quality index in Johor River Basin. Environ. Sci. Eur. 2024, 36, 67. [Google Scholar] [CrossRef]
- Nguyen, H.D.; Phan, T.T.H. Investigating Ensemble Learning Methods for Predicting Water Quality Index. Lect. Notes Data Eng. Commun. Technol. 2023, 188, 3–12. [Google Scholar] [CrossRef]
- Rahman, A.; Syeed, M.M.M.; Karim, M.R.; Fatema, K.; Khan, R.H.; Uddin, M.F. An optimized ensemble ML-WQI model for reliable water quality prediction by minimizing the eclipsing and ambiguity issues. Appl. Water Sci. 2025, 15, 1–27. [Google Scholar] [CrossRef]
- Schreiber, S.G.; Schreiber, S.; Tanna, R.N.; Roberts, D.R.; Arciszewski, T.J. Statistical tools for water quality assessment and monitoring in river ecosystems—A scoping review and recommendations for data analysis. Water Qual. Res. J. 2022, 57, 40–57. [Google Scholar] [CrossRef]
- Statswork. Applications of Statistical Analyses on Water Quality Data and Its Recent Research Trends. Pioneer Statistical Consulting. Available online: https://statswork.com/blog/applications-of-statistical-analyses-on-water-quality-data-and-its-recent-research-trends/ (accessed on 13 November 2023).
- Fu, L.; Wang, Y.-G. Statistical Tools for Analyzing Water Quality Data. 2012. Available online: www.intechopen.com (accessed on 26 May 2025).
- Benko, Ľ.; Munkova, D.; Munk, M.; Benkova, L.; Hajek, P. The use of residual analysis to improve the error rate accuracy of machine translation. Sci. Rep. 2024, 14, 9293. [Google Scholar] [CrossRef] [PubMed]
- Soleimani, F.; Hajializadeh, D. Bridge seismic hazard resilience assessment with ensemble machine learning. Structures 2022, 38, 719–732. [Google Scholar] [CrossRef]
- Wang, X.; Mazumder, R.K.; Salarieh, B.; Salman, A.M.; Shafieezadeh, A.; Li, Y. Machine Learning for Risk and Resilience Assessment in Structural Engineering: Progress and Future Trends. J. Struct. Eng. 2022, 148, 03122003. [Google Scholar] [CrossRef]
- Ohaegbulem, E.U.; Iheaka, V.C. On Remedying the Presence of Heteroscedasticity in a Multiple Linear Regression Modelling. Afr. J. Math. Stat. Stud. 2024, 7, 225–261. [Google Scholar] [CrossRef]
- Yulia, Y.; Helvira, R.; Tunisa, J. Impact Analysis of Inflation, ROA, FDR, and Financing on Non-Performing Financing in Indonesian Islamic Banks. Dinar J. Ekon. Dan Keuang. Islam 2024, 11, 222–235. [Google Scholar] [CrossRef]
- Saariniemi, J. Case-study: Twitter Data Analysis by Linear Regression Modelling. 2023. Available online: https://lutpub.lut.fi/handle/10024/166121 (accessed on 17 October 2024).
- Wang, W.; Melnyk, L.; Kubatko, O.; Kovalov, B.; Hens, L. Economic and Technological Efficiency of Renewable Energy Technologies Implementation. Sustainability 2023, 15, 8802. [Google Scholar] [CrossRef]
- Zheng, Z.; Yang, Y.; Zhou, J.; Gu, F. Research on Time Series Data Prediction Based on Machine Learning Algorithms. In Proceedings of the 2024 IEEE 2nd International Conference on Control, Electronics and Computer Technology, ICCECT 2024, Jilin, China, 26–28 April 2024; pp. 680–686. [Google Scholar] [CrossRef]
- Qu, X.; Zhao, F.; Gao, L.; Zhang, Z. The application of machine learning regression algorithms and feature engineering in practical application. In Proceedings of the 2022 10th International Conference on Information Systems and Computing Technology, ISCTech 2022, Guilin, China, 28–30 December 2022; pp. 259–263. [Google Scholar] [CrossRef]
- Zheng, Z.; Yuan, J.; Yao, W.; Kwan, P.; Yao, H.; Liu, Q.; Guo, L. Fusion of UAV-Acquired Visible Images and Multispectral Data by Applying Machine-Learning Methods in Crop Classification. Agronomy 2024, 14, 2670. [Google Scholar] [CrossRef]
- Catav, A.; Fu, B.; Zoabi, Y.; Meilik, A.L.W.; Shomron, N.; Ernst, J.; Sankararaman, S.; Gilad-Bachrach, R. Marginal Contribution Feature Importance—An Axiomatic Approach for Explaining Data. In Proceedings of the 38th International Conference on Machine Learning, Online, 18–24 July 2021; Volume 139, p. 1324. Available online: https://pmc.ncbi.nlm.nih.gov/articles/PMC8460841/ (accessed on 17 November 2024).
- Framling, K. Feature Importance versus Feature Influence and What It Signifies for Explainable AI. Commun. Comput. Inf. Sci. 2023, 1901, 241–259. [Google Scholar] [CrossRef]
- Oukhouya, H.; El Himdi, K. A comparative study of ARIMA, SVMs, and LSTM models in forecasting the Moroccan stock market. Int. J. Simul. Process Model. 2023, 20, 125–143. [Google Scholar] [CrossRef]
- Verma, V.K.; Kumar, V. Optimization of Regression algorithms using Learning curve in WSN. In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering, ICACITE 2021, Greater Noida, India, 4–5 March 2021; pp. 379–382. [Google Scholar] [CrossRef]
- Hannula, O.; Hällberg, V.; Meuronen, A.; Suominen, O.; Rautiainen, S.; Palomäki, A.; Hyppölä, H.; Vanninen, R.; Mattila, K. Self-reported skills and self-confidence in point-of-care ultrasound: A cross-sectional nationwide survey amongst Finnish emergency physicians. BMC Emerg. Med. 2023, 23, 23. [Google Scholar] [CrossRef]
- Liu, H.; Yang, S.; Qi, F.; Wang, S. Learning to Rank Normalized Entropy Curves with Differentiable Window Transformation. 2023. Available online: https://arxiv.org/abs/2301.10443v1 (accessed on 17 November 2024).
- Lu, J.; Gu, J.; Han, J.; Xu, J.; Liu, Y.; Jiang, G.; Zhang, Y. Evaluation of Spatiotemporal Patterns and Water Quality Conditions Using Multivariate Statistical Analysis in the Yangtze River, China. Water 2023, 15, 3242. [Google Scholar] [CrossRef]
- Ma, X.; Wang, L.; Yang, H.; Li, N.; Gong, C. Spatiotemporal Analysis of Water Quality Using Multivariate Statistical Techniques and the Water Quality Identification Index for the Qinhuai River Basin, East China. Water 2020, 12, 2764. [Google Scholar] [CrossRef]
- Camargo, A. PCAtest: Testing the statistical significance of Principal Component Analysis in R. PeerJ 2022, 10, e12967. [Google Scholar] [CrossRef]
- Brereton, R.G. Principal components analysis with several objects and variables. J. Chemom. 2023, 37, e3408. [Google Scholar] [CrossRef]
- Krzyśko, M.; Nijkamp, P.; Ratajczak, W.; Wołyński, W.; Wenerska, B. Spatio-temporal principal component analysis. Spat Econ. Anal. 2024, 19, 8–29. [Google Scholar] [CrossRef]
- Mohammed, A.H.; Ashour, M.A.H. Improving the efficiency measurement index using principal component analysis (PCA). Int. J. Health Sci. 2022, 6, 6584–6600. [Google Scholar] [CrossRef]
- Haryati, A.E.; Sugiyarto. Clustering with Principal Component Analysis and Fuzzy Subtractive Clustering Using Membership Function Exponential and Hamming Distance. In Proceedings of the 5th International Conference on Information Technology and Digital Applications (ICITDA 2020), Yogyakarta, Indonesia, 13–14 November 2020; IOP Conference Series: Materials Science and Engineering. IOP Publishing Ltd.: Bristol, UK, 2021; Volume 012019, p. 1077. [Google Scholar] [CrossRef]
- Abalasei, M.E.; Toma, D.; Teodosiu, C. Monitoring and Evaluation of Water Quality from Chirita Lake, Romania. Water 2025, 17, 1844. [Google Scholar] [CrossRef]
- Padilla-Mendoza, C.; Torres-Bejarano, F.; Campo-Daza, G.; González-Márquez, L.C. Potential of Sentinel Images to Evaluate Physicochemical Parameters Concentrations in Water Bodies—Application in a Wetlands System in Northern Colombia. Water 2023, 15, 789. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, C.; Xie, H.; Li, Y.; Zhu, C.; Liu, M. Carbon Accounting and Carbon Emission Reduction Potential Analysis of Sponge Cities Based on Life Cycle Assessment. Water 2023, 15, 3565. [Google Scholar] [CrossRef]
- Korchagin, S.; Grigoriev, S.; Nguyen, H.V.; Byeon, H. Prediction of Parkinson’s Disease Depression Using LIME-Based Stacking Ensemble Model. Mathematics 2023, 11, 708. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | Parameters Assessed | Clarification Levels |
|---|---|---|
| Global [24] | Drinking and surface water | Varies across regions |
| Indonesia [23] | PI and WQI | WQI shows “excellent”; PI indicates pollution |
| China [25] | Microbiological, fluoride, nitrate | 89% compliance overall |
| India [26] | BOD, Total Coliform | High pollution in industrial zone |
| United States/Canada [24] | Drinking and surface water safety | Flexible, risk-based approach |
| Europe [27] | WQI, pollutant concentration | Excellent and poor class |
| Malaysia [28] | Six physicochemical parameters | Class I to V |
| Parameter | Unit | Class | ||||
|---|---|---|---|---|---|---|
| I | II | III | IV | V | ||
| AN | mg/L | <0.1 | 0.1–0.3 | 0.3–0.9 | 0.9–2.7 | >2.7 |
| BOD | mg/L | <1 | 1–3 | 3–6 | 6–12 | >12 |
| COD | mg/L | <10 | 10–25 | 25–50 | 50–100 | >100 |
| DO | mg/L | >7 | 5–7 | 3–5 | 1–3 | <1 |
| pH | - | >7.0 | 6.0–7.0 | 5.0–6.0 | <5.0 | >5.0 |
| TSS | mg/L | <25 | 25–50 | 50–150 | 150–300 | >300 |
| WQI | >92.7 | 76.5–92.7 | 51.9–76.5 | 31.0–51.9 | <31.0 | |
| Ref. | Modelling Techniques | Advantages | Disadvantages | Data Size | Water Parameters |
|---|---|---|---|---|---|
| [49] | Long Short-Term Memory (LSTM) | High accuracy in predicting water quality indicators across multiple basins. | Model tuning details are limited, reducing reproducibility. | Dataset size is not stated but covers three rivers. | AN, BOD, COD, DO, pH, and total phosphorus (TP). |
| [50] | Artificial Neural Networks (ANNs) | Employs a novel Absorption Characteristics Recognition (ACR) algorithm, delivering optimal regression performance. | The ACR method lacks detailed performance benchmarks regarding computational cost and robustness. | 200 spectral readings. | TP, COD, turbidity, total nitrogen (TN), chlorophyll. |
| [53] | AI-driven Time Series (SVM and ARIMA) with Satellite Imagery | The hybrid framework combining Sentinel-2 imagery with SVM and ARIMA models increased spatial data coverage. | ARIMA is less optimal for non-seasonal parameters; limited subsurface insight. | Dataset size is not stated. | Chlorophyll, Secchi Depth, Trophic State Index. |
| [51] | Deep Learning (LTSF-Linear Model) | Linear model baseline outperformed ARIMA, LSTM, and Informer, reducing MSE and MAE by 8.55% and 10.51%. | Limited to three parameters, restricting applicability to more complex multi-parameter models. | Hourly measurements from January 2022 to July 2023 | pH, turbidity, DO. |
| [58] | Proposed chlorine level assessment using IoT system and machine learning. | The random forest model achieved high accuracy with an F1-score of 0.89 for chlorine level classification. | Lacks comparison with more diverse models. | Dataset size is not stated. | Residual chlorine. |
| [59] | Proposed mass balance model to monitor the water quality at the river. | Provides a robust benchmark with 18,000 scenarios across varied network types. | Limited to chlorine dynamics; not evaluated for other water quality parameters. | 18,000 simulation cases. | Chlorine concentration. |
| [60] | Case study on the effect of lockdown period on surface water pollution and quality. | Uses advanced AI (deep learning, ensemble) to directly predict WQI and water quality classes. | Details on data volume and parameter list are not fully disclosed. | 33,612 samples. | BOD, COD, DO, turbidity, heavy metals (e.g., Pb, Zn). |
| [61] | Predicted the BOD using data from New York Harbor waters. | RMSE was 11.5–17.2% lower than regular matrix-completion approaches and 19.2–25.2% lower than classic machine learning models. | Deep models require extensive data to perform well. | 32,323 samples. | BOD, pH, DO, temperature. |
| [62] | Predicted DO concentration using different water quality parameters. | Best hybrid reduces RMSE by 80% from standalone MLP. | A small dataset size may limit broad applicability. | 232 samples. | Chlorine, TDS, pH, temperature. |
| [63] | Proposed water quality classification using Landsat8 images by CNN. | CNN provided superior classification over traditional ML approaches. | Temporal mismatch between satellite capture and sampling, plus weather variability. | 481 samples. | DO, TN, TP, COD and Ammonium |
| [64] | Proposed the assessment of heavy-metal pollution in water to detect Pb, Cu, and Zn. | CNNs showed strong potential in mapping chlorophyll-a concentration from satellite data. | Deep learning models perform best with large, labelled datasets. | Dataset size is not stated. | Chlorophyll. |
| [65] | Proposed prediction river WQI for river pollution prevention and management. Algorithm comparison with PSO, GA, LSTM, and SVM. | Hybrid adaptive evolutionary artificial bee colony–backpropagation neural network (AEABC–BPNN) searches more reliably for global optima. | Combining evolutionary algorithms with neural networks adds architectural and training complexity. | Dataset size is not stated. | pH, turbidity, nutrients. |
| [44] | Prediction of biochemical oxygen demand with GA-based SVR to ensure the quality of water. | SVR optimised via genetic algorithm (GA) outperformed linear regression and MLP, indicating effective feature-selection and parameter tuning. | Reliance on past data and GA tuning might restrict generalizability to new water bodies. | Dataset size is not stated. | AN, TP, TN, pH, DO, COD. |
| [66] | Proposed dissolved oxygen prediction at rivers using PCA, LSSVM, and improve PSO. | Best model (Gradient Boost) scored R2 ≈ 1.00 and MAE ≈ 0.08, robust across two WWTP datasets. | While tested across two plants, many models may need recalibration for other regions. | Dataset size is not stated. | Flow rate, COD, pH, AN, TSS. |
| [67] | Proposed water quality prediction model by using ARIMA, LSTM, GRU, and SCINet algorithms. | Utilises state-of-the-art deep learning to model complex temporal patterns. | Limited parameter scope: only three water quality indicators excluding others like microbial or chemical contaminants. | 47,448 samples. | pH, turbidity, residual chloride. |
| [68] | Study assessment and prediction of water quality index using fuzzy logic and ANN models. | Hybrid modelling approach combines fuzzy logic with ANNs, blending interpretability and adaptive prediction. | Dataset specifics unclear, making it difficult to evaluate robustness or representativeness. | Dataset size is not stated. | pH, DO, TSS, nutrients. |
| [69] | Proposed water quality indicator prediction for wastewater using improve Bald Eagle Search and least-square support vector machine. | Goes beyond point estimates, providing ranges for BOD and AN, enhancing operational safety and risk assessment. | Designed for wastewater effluent; may not generalise to other water systems without recalibration. | Dataset size is not stated. | BOD, AN. |
| Model | RMSE | MAE | R2 |
|---|---|---|---|
| ETR [66] | 1.55 | 0.69 | 0.99 |
| RR [107] | 0.05 | 0.04 | 0.96 |
| DT [66] | 2.76 | 1.19 | 0.97 |
| RFR [66] | 1.71 | 0.74 | 0.99 |
| ANN [108] | 0.08 | 0.06 | 0.98 |
| ANFIS [109] | 0.14 | 0.09 | 0.97 |
| ARIMA [110] | 301.99 | 220.14 | - |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| RFC [111] | 98.2 | 0.98 | 0.98 | 0.98 |
| KNN [112] | 97.4 | 0.97 | 0.98 | 0.97 |
| SVM [111] | 97.9 | 0.98 | 0.98 | 0.98 |
| Ref. | Method | Advantages | Disadvantages | Data Size | Water Parameters |
|---|---|---|---|---|---|
| [154] | PCA | In-depth analysis, including national legal compliance and enhancing relevance for management. | Limited to a single lake; results may not generalise to other water bodies. | 5-year period (2020–2024). | Temperature, turbidity, pH, conductivity, total alkalinity, total hardness |
| [54] | Feature Importance (using SHAP) | Uses SHAP for feature contributions, providing insight into key drivers. | Model accuracy declines over longer forecasting horizons (though still R2 > 0.75 up to 30 days). | Dataset size is not stated. | DO, temperature |
| [155] | Residual Analysis | Achieved high empirical model fits (R2: DO = 0.948, NO3 = 0.858, TP = 0.779). | Based on one-day sampling at 17 sites, limits temporal representativeness. | Dataset size is not stated. | TSS, turbidity, DO, nitrate, TP |
| [156] | Diagnostic and Assumption Test (Durbin–Watson) | Provides actionable insights with sensitivity analysis (e.g., impacts of rainfall, materials, transport). | Does not evaluate direct water quality parameters. | Dataset size is not stated. | No water-quality analytes |
| [157] | Learning Curve Analysis | Compares 7 machine learning models, with ensemble Gradient Boosting delivering highest accuracy | Focus on water quality classification, not continuous concentration estimation. | Dataset from 2005 to 2020. | DO, BOD, AN, pH, TSS, COD |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lokman, A.; Ismail, W.Z.W.; Aziz, N.A.A. A Review of Water Quality Forecasting and Classification Using Machine Learning Models and Statistical Analysis. Water 2025, 17, 2243. https://doi.org/10.3390/w17152243
Lokman A, Ismail WZW, Aziz NAA. A Review of Water Quality Forecasting and Classification Using Machine Learning Models and Statistical Analysis. Water. 2025; 17(15):2243. https://doi.org/10.3390/w17152243
Chicago/Turabian StyleLokman, Amar, Wan Zakiah Wan Ismail, and Nor Azlina Ab Aziz. 2025. "A Review of Water Quality Forecasting and Classification Using Machine Learning Models and Statistical Analysis" Water 17, no. 15: 2243. https://doi.org/10.3390/w17152243
APA StyleLokman, A., Ismail, W. Z. W., & Aziz, N. A. A. (2025). A Review of Water Quality Forecasting and Classification Using Machine Learning Models and Statistical Analysis. Water, 17(15), 2243. https://doi.org/10.3390/w17152243