
Prediction of Inland Excess Water Inundations Using Machine Learning Algorithms


Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data
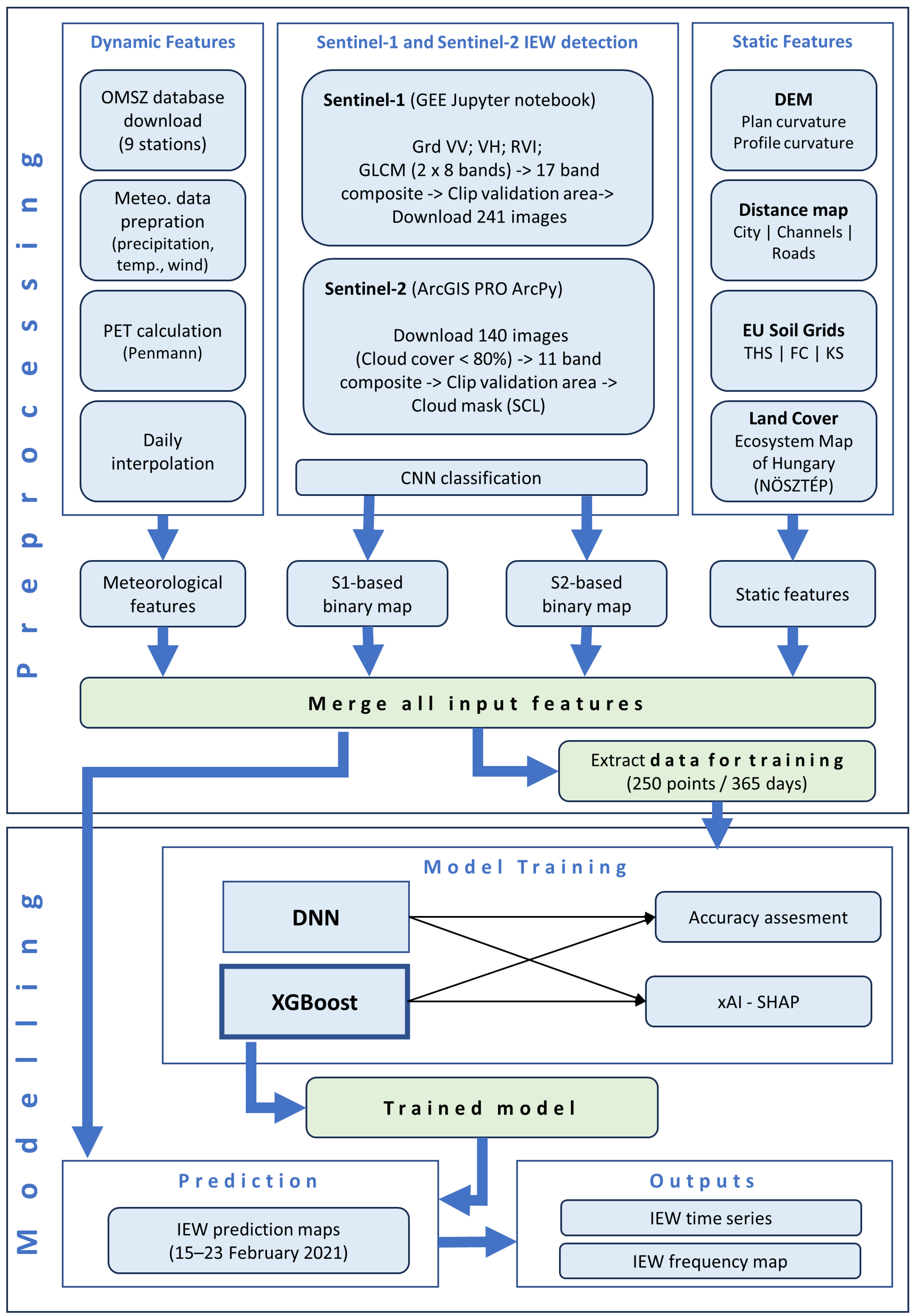
2.3. Methodology
2.3.1. Data Preparation
- Sentinel-1 data preparation
- Sentinel-2 data preparation
- Meteorological data
- Static data
2.3.2. Water Classification Using Convolutional Neural Network Satellite Data
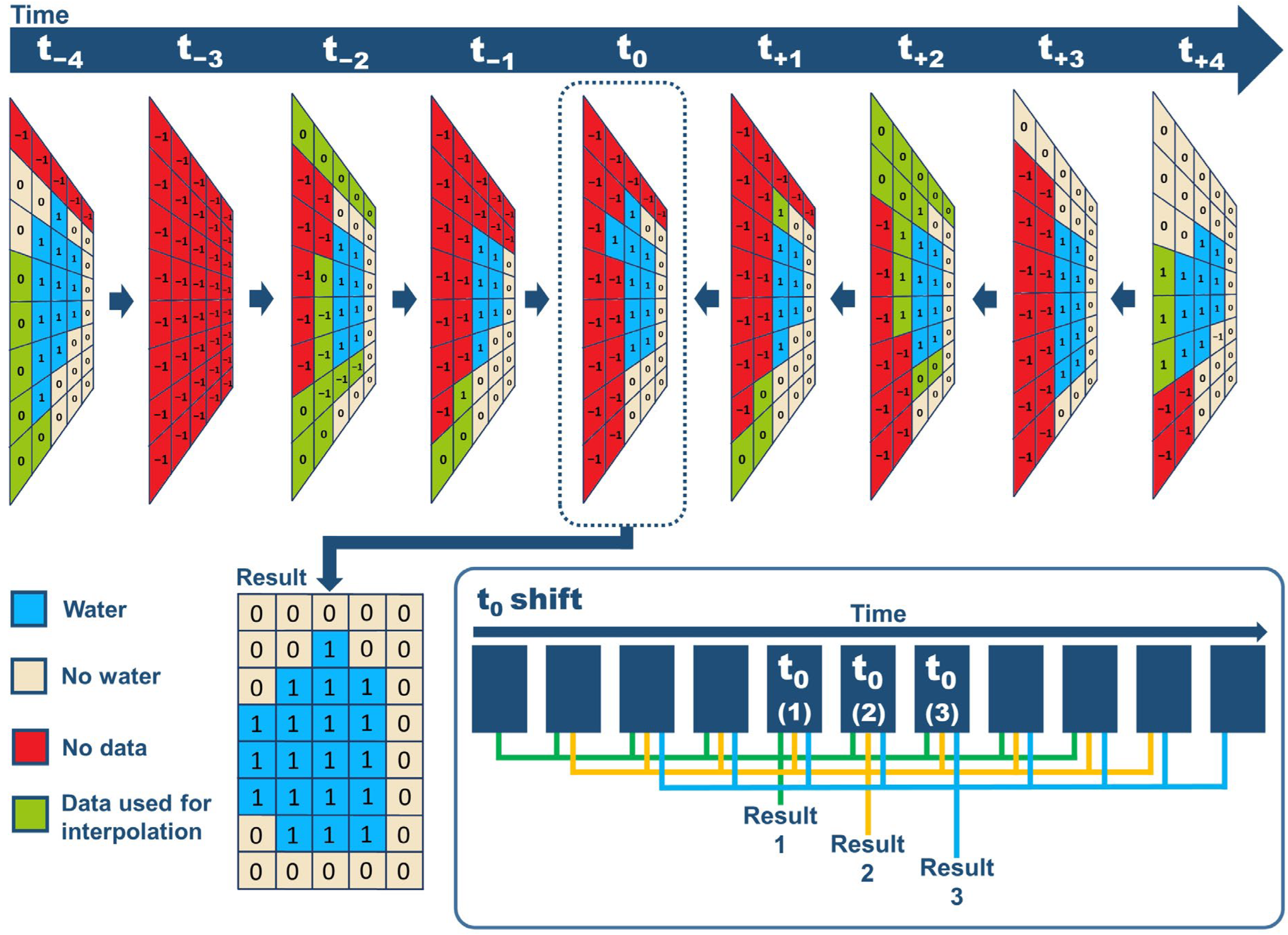
2.3.3. Water Time Series and Generation of IEW Inundation History
2.3.4. Training of Prediction Models
2.4. Prediction and Forecast with the Trained Model
3. Results
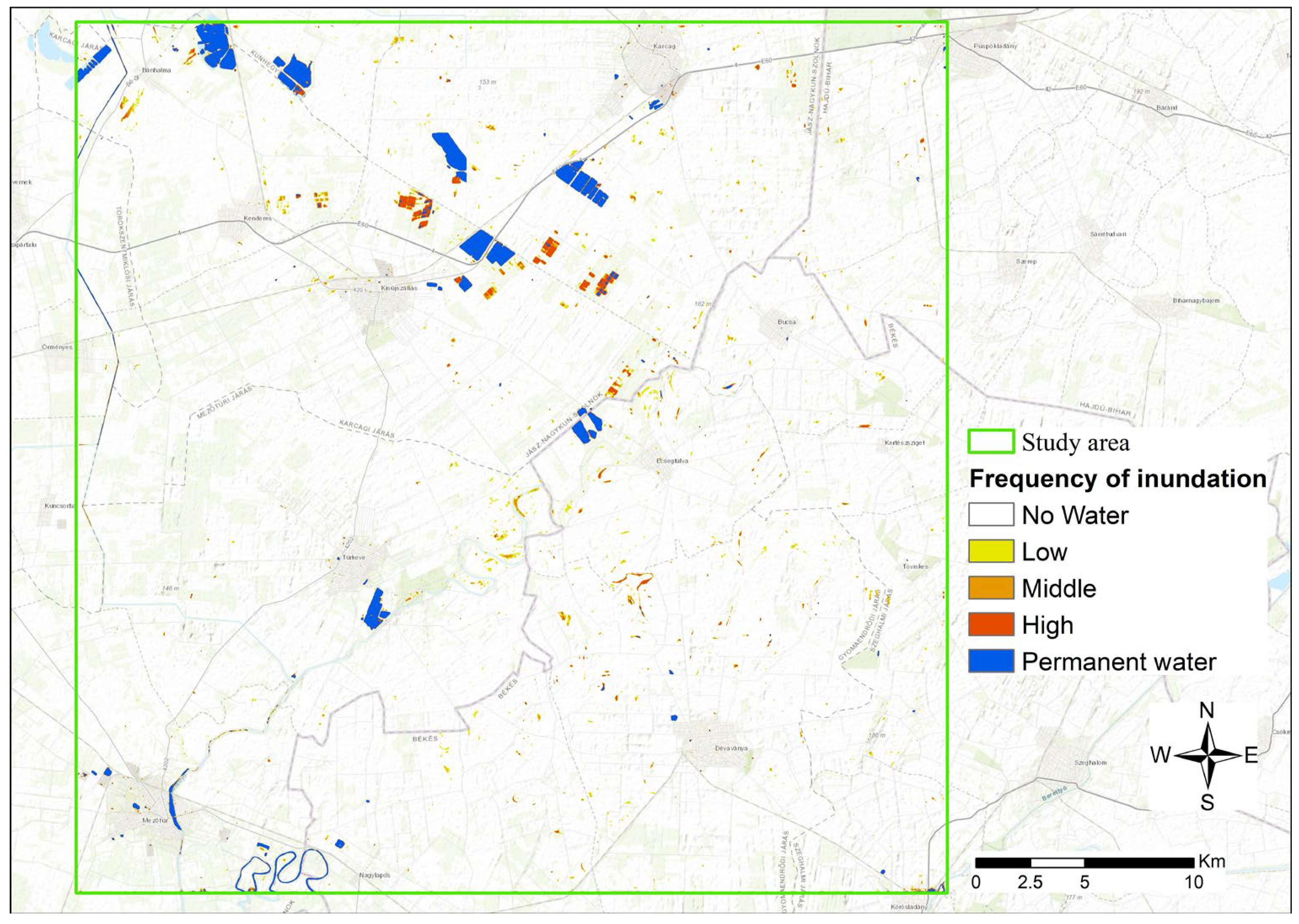
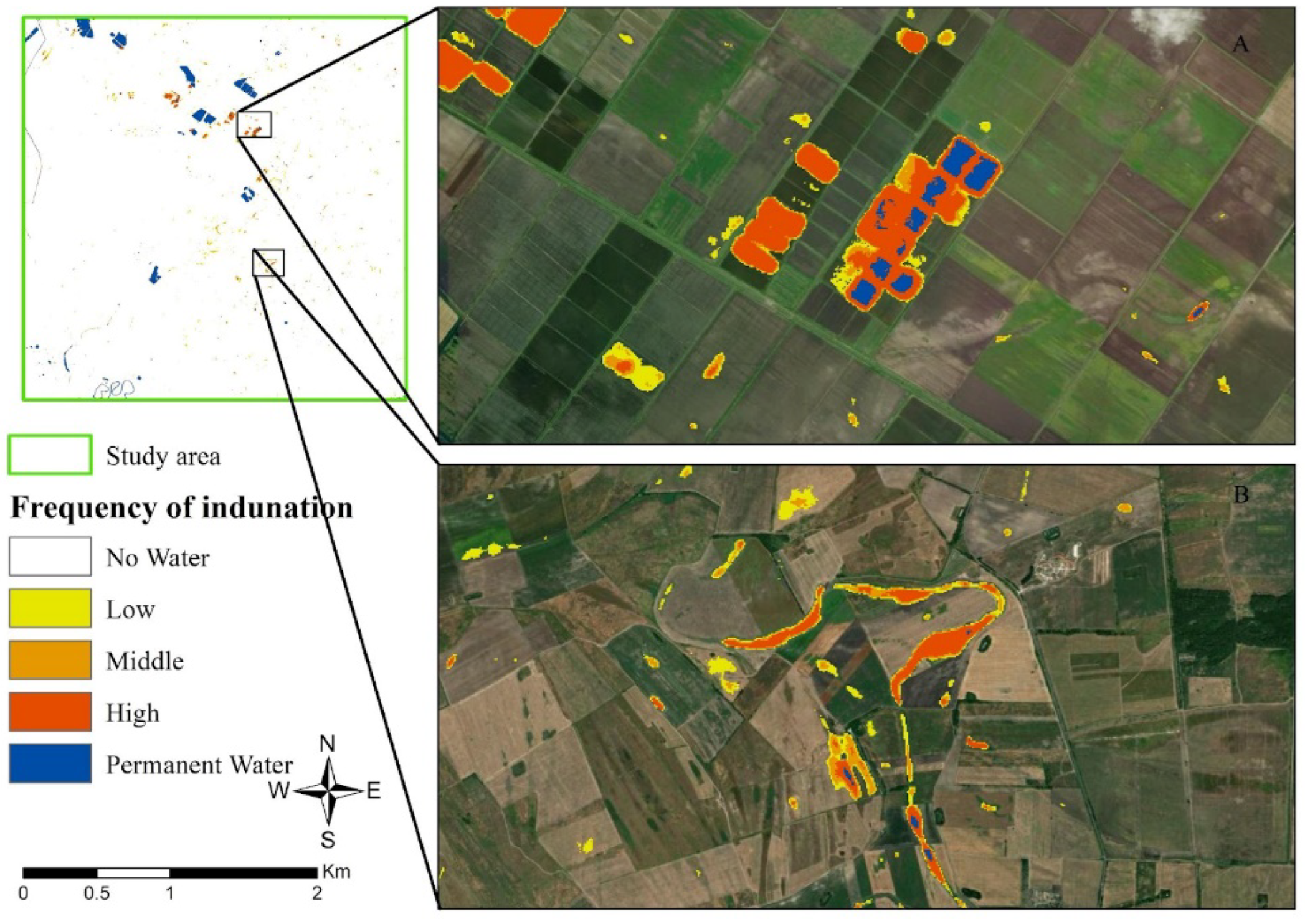
3.1. IEW Inundation Time Series
3.2. Training of Prediction Model
3.3. Results of the Inundation Prediction
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dunka, S.; Fejér, L.; Vágás, I. A Verítékes Honfoglalás: A Tisza-Szabályozás Története [The Sweaty Conquest: The History of the Tisza Regulation]; MKVM: Budapest, Hungary, 1996; p. 12. (In Hungarian) [Google Scholar]
- Pálfai, I. A belvíz definíciói [Definitions of inland excess water]. Vízügyi Közlemények 2001, 83, 376–392. (In Hungarian) [Google Scholar]
- Hungarian Central Statistical Office. Available online: https://www.ksh.hu/stadat_files/mez/hu/mez0008.html (accessed on 3 March 2024).
- Pálfai, I. Az Alföld belvíz-veszélyeztetettségi térképe [Excess water risk and dought sensitivity of the Great Plain]. Vízügyi közlemények 1994, 76, 278–290. (In Hungarian) [Google Scholar]
- Bozán, C.; Takács, K.; Körösparti, J.; Laborczi, A.; Túri, N.; Pásztor, L. Integrated spatial assessment of inland excess water hazard on the Great Hungarian Plain. Land Degrad. Dev. 2018, 29, 4373–4386. [Google Scholar] [CrossRef]
- IPCC. Climate Change 2023: Synthesis Report. Contribution of Working Groups I, II and III to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change; Core Writing Team, Lee, H., Romero, J., Eds.; IPCC: Geneva, Switzerland, 2023; pp. 35–115. [Google Scholar] [CrossRef]
- Mezősi, G.; Meyer, B.C.; Loibl, W.; Aubrecht, C.; Csorba, P.; Bata, T. Assessment of regional climate change impacts on Hungarian landscapes. Reg. Environ. Change 2013, 13, 797–811. [Google Scholar] [CrossRef]
- Bartholy, J.; Pongrácz, R.; Pieczka, I.; Torma, C.S. Dynamical downscaling of projected 21st century climate for the Carpathian Basin. In Climate Change—Research and Technology for Adaptation and Mitigation; Blanco, J.A., Kheradmand, H., Eds.; Intech: Rijeka, Croatia, 2011; pp. 3–22. ISBN 978-953-307-621-8. [Google Scholar] [CrossRef]
- Kuti, L.; Kerék, B.; Vatai, J. Problem and prognosis of excess water inundation based on agrogeological factors. Carpth. J. Earth Environ. Sci. 2006, 1, 5–18. [Google Scholar]
- Jong, P.; Hobma, F. Rights and responsibilities in Dutch land-use planning aimed at flood protection and prevention of waterlogging. In Proceedings of the 6th International Conference of the International Academic Association on Planning, Law and Property Rights, Belfast, UK, 7–10 February 2012. [Google Scholar]
- Bíró, T. Amikor sok víz van a területen–Belvíz [When there is a lot of water in the area—Inland excess water]. Magy. Tudomány 2017, 178, 1216–1227. (In Hungarian) [Google Scholar] [CrossRef]
- Thyll, S.; Bíró, T. A belvíz-veszélyeztetettség térképezése. Hidrológiai Közlemények 1999, 81, 709–717. [Google Scholar]
- Kozma, Z.; Jolánkai, Z.; Kardos, M.K.; Muzelák, B.; Koncsos, L. Adaptive water management-land use practice for improving ecosystem services—A Hungarian Modelling Case Study. Period. Polytech. Civ. Eng. 2022, 66, 256–268. [Google Scholar] [CrossRef]
- Pálfai, I. Belvizek és aszályok Magyarországon: Hidrológiai tanulmányok [Excess water and drought in Hungary: Hydrological studies]; Közlekedési Dokumentációs Kft: Budapest, Hungary, 2004; 99p, ISBN 963-552-382-3. (In Hungarian) [Google Scholar]
- Pásztor, L.; Körösparti, J.; Bozán, C.; Laborczi, A.; Takács, K. Spatial risk assessment of hydrological extremities: Inland excess water hazard, Szabolcs-Szatmár-Bereg County, Hungary. J. Maps 2015, 11, 636–644. [Google Scholar] [CrossRef]
- Laborczi, A.; Bozan, C.; Körösparti, J.; Szatmari, G.; Kajari, B.; Turi, N.; Kerezsi, G.; Pasztor, L. Application of hybrid prediction methods in spatial assessment of inland excess water hazard. ISPRS Int. J. Geo-Inf. 2020, 9, 268. [Google Scholar] [CrossRef]
- Tobak, Z.; Szatmári, J.; Van Leeuwen, B. Small Format Aerial Photography—Remote Sensing Data Acquisition for Environmental Analysis. J. Environ. Geogr. 2008, 3, 21–26. [Google Scholar] [CrossRef]
- Balázs, B. Belvizes területek felmérése geoinformatikai módszerekkel [Survey of Inland Excess Water using geoinformatics methods]. In Geoinformatika és Domborzatmodellezés: A HunDEM 2009 és a GeoInfo 2009 Konferencia és Kerekasztal Válogatott Tanulmányai; Hegedűs, A., Ed.; Miskolci Egyetem: Miskolc, Hungary, 2010; pp. 1–10. (In Hungarian) [Google Scholar]
- Bangira, T.; Iannini, L.; Menenti, M.; Van Niekerk, A.; Vekerdy, Z. Flood extent mapping in the Caprivi floodplain using sentinel-1 time series. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5667–5683. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, S.J.; Henderson, D.; Howard, E.R.; Hubbard, W.; Jackel, D.L. Handwritten Digit Recognition with a Back-Propagation Network. In Advances in Neural Information Processing Systems 2 (NIPS 1989); Touretzky, D., Ed.; Morgan Kaufmann: Denver, CO, USA, 1990; Volume 2, pp. 396–403. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Giulia, C.; De Fioravante, P.; Dichicco, P.; Congedo, L.; Marchetti, M.; Munafò, M. Land Cover Mapping with Convolutional Neural Networks Using Sentinel-2 Images: Case Study of Rome. Land 2023, 12, 879. [Google Scholar] [CrossRef]
- Yichen, L.; James, T.; Schillaci, C.; Lipani, A. Snow Detection in Alpine Regions with Convolutional Neural Networks: Discriminating Snow from Cold Clouds and Water Body. GIScience Remote Sens. 2022, 59, 1321–1343. [Google Scholar] [CrossRef]
- Simón Sánchez, A.-M.; González-Piqueras, J.; de la Ossa, L.; Calera, A. Convolutional Neural Networks for Agricultural Land Use Classification from Sentinel-2 Image Time Series. Remote Sens. 2022, 14, 5373. [Google Scholar] [CrossRef]
- Kajári, B.; Bozán, C.; Van Leeuwen, B. Monitoring of Inland Excess Water Inundations Using Machine Learning Algorithms. Land 2023, 12, 36. [Google Scholar] [CrossRef]
- Jiang, W.; He, G.; Long, T.; Ni, Y.; Liu, H.; Peng, Y.; Lv, K.; Wang, G. Multilayer Perceptron Neural Network for Surface Water Extraction in Landsat 8 OLI Satellite Images. Remote Sens. 2018, 10, 755. [Google Scholar] [CrossRef]
- Devi, M.S.; Chib, S. Classification of Satellite Images Using Perceptron Neural Network. Int. J. Comput. Intell. Res. 2019, 15, 1–10. [Google Scholar]
- Bravo-López, E.; Fernández Del Castillo, T.; Sellers, C.; Delgado-García, J. Landslide Susceptibility Mapping of Landslides with Artificial Neural Networks: Multi-Approach Analysis of Backpropagation Algorithm Applying the Neuralnet Package in Cuenca, Ecuador. Remote Sens. 2022, 14, 3495. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Li, Y.; Zeng, H.; Zhang, M.; Wu, B.; Zhao, Y.; Yao, X.; Cheng, T.; Qin, X.; Wu, F. A county-level soybean yield prediction framework coupled with XGBoost and multidimensional feature engineering. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103269. [Google Scholar] [CrossRef]
- Wang, M.; Li, Y.; Yuan, H.; Zhou, S.; Wang, Y.; Ikram, R.M.A.; Li, J. An XGBoost-SHAP approach to quantifying morphological impact on urban flooding susceptibility. Ecol. Indic. 2023, 156, 111137. [Google Scholar] [CrossRef]
- Lundberg, M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef]
- Conners, R.W.; Trivedi, M.M.; Harlow, C.A. Segmentation of a high-resolution urban scene using texture operators. Comput. Vis. Graph. Image Process. 1984, 25, 273–310. [Google Scholar] [CrossRef]
- Allagwail, S.; Gedik, O.S.; Rahebi, J. Face Recognition with Symmetrical Face Training Samples Based on Local Binary Patterns and the Gabor Filter. Symmetry 2019, 11, 157. [Google Scholar] [CrossRef]
- Csorba, P. Magyarország Kistájai; Meridián Táj-és Környezetföldrajzi Alapítvány: Debrecen, Hungary, 2021; ISBN 978-963-89712-4-1. [Google Scholar]
- Bihari, Z.; Babolcsai, G.; Bartholy, J.; Ferenczi, Z.; Gerhátné Kerényi, J.; Haszpra, L.; Homokiné Ujváry, K.; Kovács, T.; Lakatos, M.; Németh, Á.; et al. Éghajlat. In Magyarország Nemzeti Atlasza: Természeti Környezet; Kocsis, K., Ed.; Magyar Tudományos Akadémia, Csillagászati és Földtudományi Kutatóközpont, Földrajztudományi Intézet: Budapest, Hungary, 2018; pp. 58–69. ISBN 978-963-9545-56-4. [Google Scholar]
- Vári, Á.; Tanács, E.; Tormáné Kovács, E.; Kalóczkai, Á.; Arany, I.; Czúcz, B.; Bereczki, K.; Belényesi, M.; Csákvári, E.; Kiss, M.; et al. National Ecosystem Services Assessment in Hungary: Framework, Process and Conceptual Questions. Sustainability 2022, 14, 12847. [Google Scholar] [CrossRef]
- Tóth, B.; Weynants, M.; Pásztor, L.; Hengl, T. 3D soil hydraulic database of Europe at 250 m resolution. Hydrol. Process. 2017, 31, 2662–2666. [Google Scholar] [CrossRef]
- Lechner Knowledge Center. Available online: https://lechnerkozpont.hu/oldal/domborzatmodell (accessed on 3 March 2024).
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- van Leeuwen, B.; Tobak, Z.; Kovács, F. Sentinel-1 and -2 Based near Real Time Inland Excess Water Mapping for Optimized Water Management. Sustainability 2020, 12, 2854. [Google Scholar] [CrossRef]
- Szigarski, C.; Jagdhuber, T.; Baur, M.; Thiel, C.; Parrens, M.; Wigneron, J.-P.; Piles, M.; Entekhabi, D. Analysis of the Radar Vegetation Index and Potential Improvements. Remote Sens. 2018, 10, 1776. [Google Scholar] [CrossRef]
- Nasirzadehdizaji, R.; Balik Sanli, F.; Abdikan, S.; Cakir, Z.; Sekertekin, A.; Ustuner, M. Sensitivity Analysis of Multi-Temporal Sentinel-1 SAR Parameters to Crop Height and Canopy Coverage. Appl. Sci. 2019, 9, 655. [Google Scholar] [CrossRef]
- Kupidura, P. The Comparison of Different Methods of Texture Analysis for Their Efficacy for Land Use Classification in Satellite Imagery. Remote Sens. 2019, 11, 1233. [Google Scholar] [CrossRef]
- Mullissa, A.; Vollrath, A.; Odongo-Braun, C.; Slagter, B.; Balling, J.; Gou, Y.; Gorelick, N.; Reiche, J. Sentinel-1 SAR Backscatter Analysis Ready Data Preparation in Google Earth Engine. Remote Sens. 2021, 13, 1954. [Google Scholar] [CrossRef]
- Vremec, M.; Collenteur, R. PyEt—A Python package to estimate potential and reference evapotranspiration. In Proceedings of the EGU General Assembly 2021, Online, 19–30 April 2021; p. EGU21-15008. [Google Scholar] [CrossRef]
- Ponce, V.M. Engineering Hydrology: Principles and Practices; Prentice Hall: Englewood Cliffs, NJ, USA, 1989; Volume 640, Available online: http://ponce.sdsu.edu/330textbook_hydrology_chapters.html (accessed on 29 June 2022).
- Kajári, B.; Van Leeuwen, B. Sentinel-1 és Sentinel-2 felvételek belvízveszélyeztetettségi idősoros elemzése konvolúciós neurális hálózatokkal [Sentinel-1 and Sentinel-2 based time series analysis of inland excess water hazard using convolutional neural networks]. Geodézia És Kartográfia 2024. Available online: https://edit.elte.hu/xmlui/static/pdf-viewer-master/external/pdfjs-2.1.266-dist/web/viewer.html?file=https://edit.elte.hu/xmlui/bitstream/handle/10831/107835/GK.76.2024.1.2-DOI.pdf?sequence=1&isAllowed=y (accessed on 25 April 2024). [CrossRef]
- Kajári, B.; Bozán, C.; van Leeuwen, B. Belvízelöntés Detektálása Sentinel-1-es Műhold Felvételeken GLCM Textúrák és Konvolúciós Neurális Hálózat Segítségével [Inland Excess Water Detection Based on Sentinel-1 Satellite Images Using GLCM Textures and Convolutional Neural Network]; Abriha-Molnár, V.É., Ed.; Az Elmélet és Gyakorlat Találkozása a Térinformatikában XIV: Theory Meets Practice in GIS Debrecen; Debreceni Egyetemi Kiadó: Debrecen, Hungary, 2023; pp. 93–101. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 1 December 2023).
- O’Brien, R.M. A caution regarding rules of thumb for variance inflation factors. Qual. Quant. Int. J. Methodol. 2007, 41, 673–690. [Google Scholar] [CrossRef]
- Dong, J.; Zeng, W.; Wu, L.; Huang, J.; Gaiser, T.; Srivastava, A.K. Enhancing short-term forecasting of daily precipitation using numerical weather prediction bias correcting with XGBoost in different regions of China. Eng. Appl. Artif. Intell. 2023, 117, 105579. [Google Scholar] [CrossRef]
- Ma, M.; Zhao, G.; He, B.; Li, Q.; Dong, H.; Wang, S.; Wang, Z. XGBoost-based method for flash flood risk assessment. J. Hydrol. 2021, 598, 126382. [Google Scholar] [CrossRef]
- Abedi, R.; Costache, R.; Shafizadeh-Moghadam, H.; Pham, Q.B. Flash-flood susceptibility mapping based on XGBoost, random forest and boosted regression trees. Geocarto Int. 2021, 37, 5479–5496. [Google Scholar] [CrossRef]
- van Houdt, G.; Mosquera, C.; Nápoles, G. A review on the long short-term memory model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Abdi, A.M. Land cover and land use classification performance of machine learning algorithms in a boreal landscape using Sentinel-2 data. GIScience Remote. Sens. 2019, 57, 1–20. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
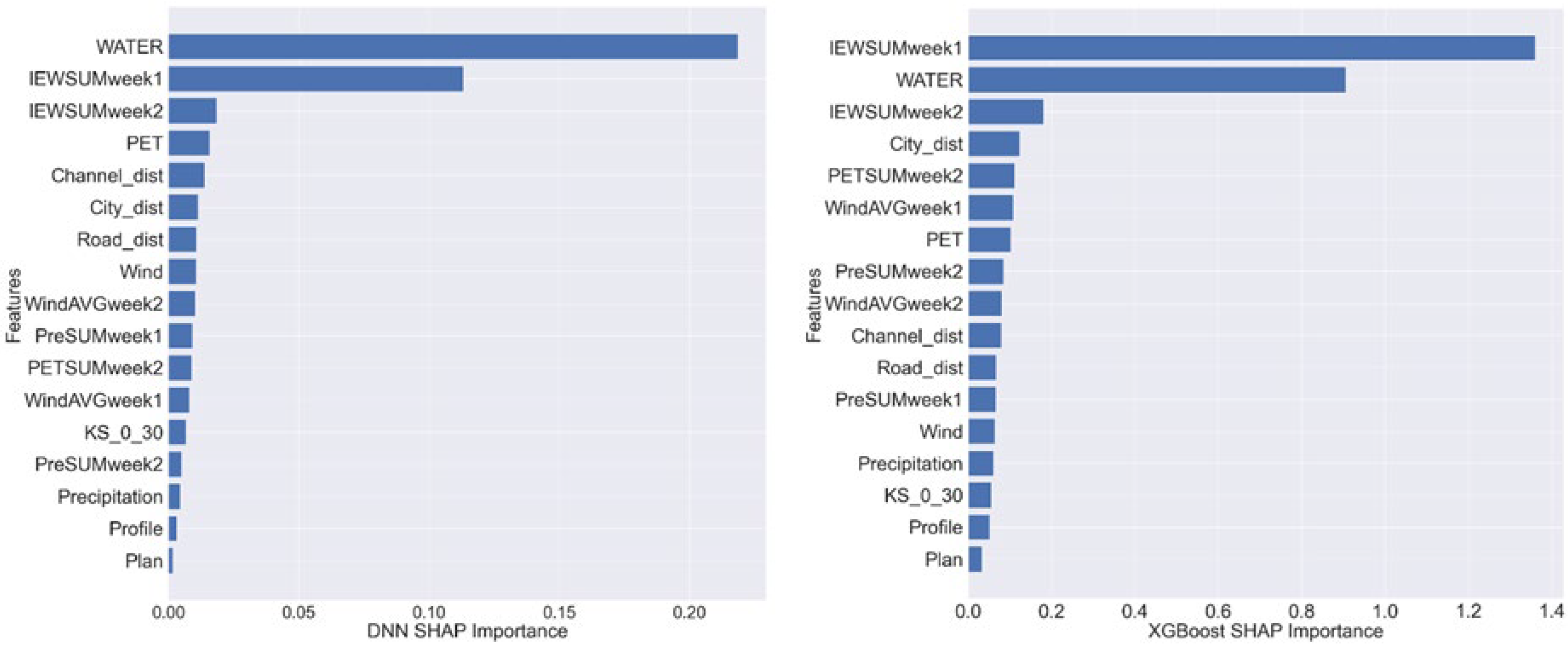
| Feature Name | Description | Minimum Value | Maximum Value | Mean Value | |
|---|---|---|---|---|---|
| 1 | WATER | Number of water pixels in satellite-derived water maps within a distance of 50 m (or 9 × 9 kernel) from center pixel at t−1 | 0.00 | 69 * | 16.62 |
| 2 | IEWSUMweek1 | Number of days with water detected at a pixel in satellite-derived water maps between t−1 and t−7 | 0.00 | 7 | 1.92 |
| 3 | IEWSUMweek2 | Number of days with water detected at a pixel in satellite-derived water maps between t−8 and t−15 | 0.00 | 7 | 1.90 |
| 4 | Precipitation | Daily precipitation in mm on t0 | 0.00 | 95.46 | 1.80 |
| 5 | PET | Daily potential evapotranspiration in mm on t0 | 0.00 | 8.16 | 2.58 |
| 6 | Wind | Average daily wind speed in meters per second t0 | 0.00 | 7.30 | 2.23 |
| 7 | PreSUMweek1 | Sum of precipitation between t0 and t−6 | 0.00 | 151.64 | 12.90 |
| 8 | PreSUMweek2 | Sum of precipitation between t−7 and t−14 | 0.00 | 151.64 | 12.90 |
| 9 | PETSUMweek1 | Sum of evapotranspiration between t0 and t−6 | 0.59 | 47.45 | 18.05 |
| 10 | PETSUMweek2 | Sum of evapotranspiration between t−7 and t−14 | 0.59 | 47.45 | 18.05 |
| 11 | WindAVGweek1 | Average wind speed between t0 and t−6 | 0.11 | 4.89 | 2.22 |
| 12 | WindAVGweek2 | Average wind speed between t−7 and t−14 | 0.11 | 4.89 | 2.22 |
| 13 | Road_dist | Distance from pixel to nearest road class pixel in meters | 0.00 | 1564.16 | 281.50 |
| 14 | City_dist | Distance from pixel to nearest urban class pixel in meters | 0.00 | 8489.08 | 3344.08 |
| 15 | Channel_dist | Distance from pixel to nearest channel class pixel in meters | 0.00 | 1697.29 | 285.67 |
| 16 | Profile | Profile curvature in meters | −0.04 | 0.21 | 0.00 |
| 17 | Plane | Plane curvature in meters | −0.25 | 0.13 | 0.00 |
| Slope | Slope in degrees, this feature was removed ** | 0.00 | 0.11 | 5.22 | |
| 18 | FC_0_30 | Average field capacity between 0 and 30 cm deep (in cm3 cm−3) | 32.50 | 40.25 | 36.26 |
| 19 | FC_30_60 | Average field capacity between 30 and 60 cm deep (in cm3 cm−3) | 30.50 | 39.50 | 34.89 |
| 20 | KS_0_30 | Average saturated hydraulic conductivity between 0 and 30 cm deep (in cm day−1) | 1361.50 | 4964.75 | 2895.95 |
| 21 | KS_30_60 | Average saturated hydraulic conductivity between 30 and 60 cm deep (in cm day−1) | 468.00 | 5015.50 | 3774.94 |
| 22 | THS_0_30 | Average saturated water content between 0 and 30 cm deep (in cm3 cm−3) | 47.75 | 51.75 | 49.39 |
| 23 | THS_30_60 | Average saturated water content between 30 and 60 cm deep (in cm3 cm−3) | 45.50 | 49.50 | 47.27 |
| 24 | LU | Land use classes | Three most predominant classes: 2100—arable land, 3400—closed grassland on compacted soil, and 6100—open water | ||
| Input Data (# of Features) | t−8…−15 | t−1…−7 | t−1 | tn |
|---|---|---|---|---|
| Static features (6) | x | Prediction | ||
| Surrounding water (1) | x | |||
| Water history (2) | x | x | ||
| Meteorological data (8) | x | x | ||
| Metric | DNN | XGBoost |
|---|---|---|
| Overall Accuracy | 0.84 | 0.85 |
| Cohen’s Kappa | 0.68 | 0.70 |
| Sensitivity | 0.86 | 0.87 |
| Precision | 0.83 | 0.84 |
| F1 score | 0.84 | 0.85 |
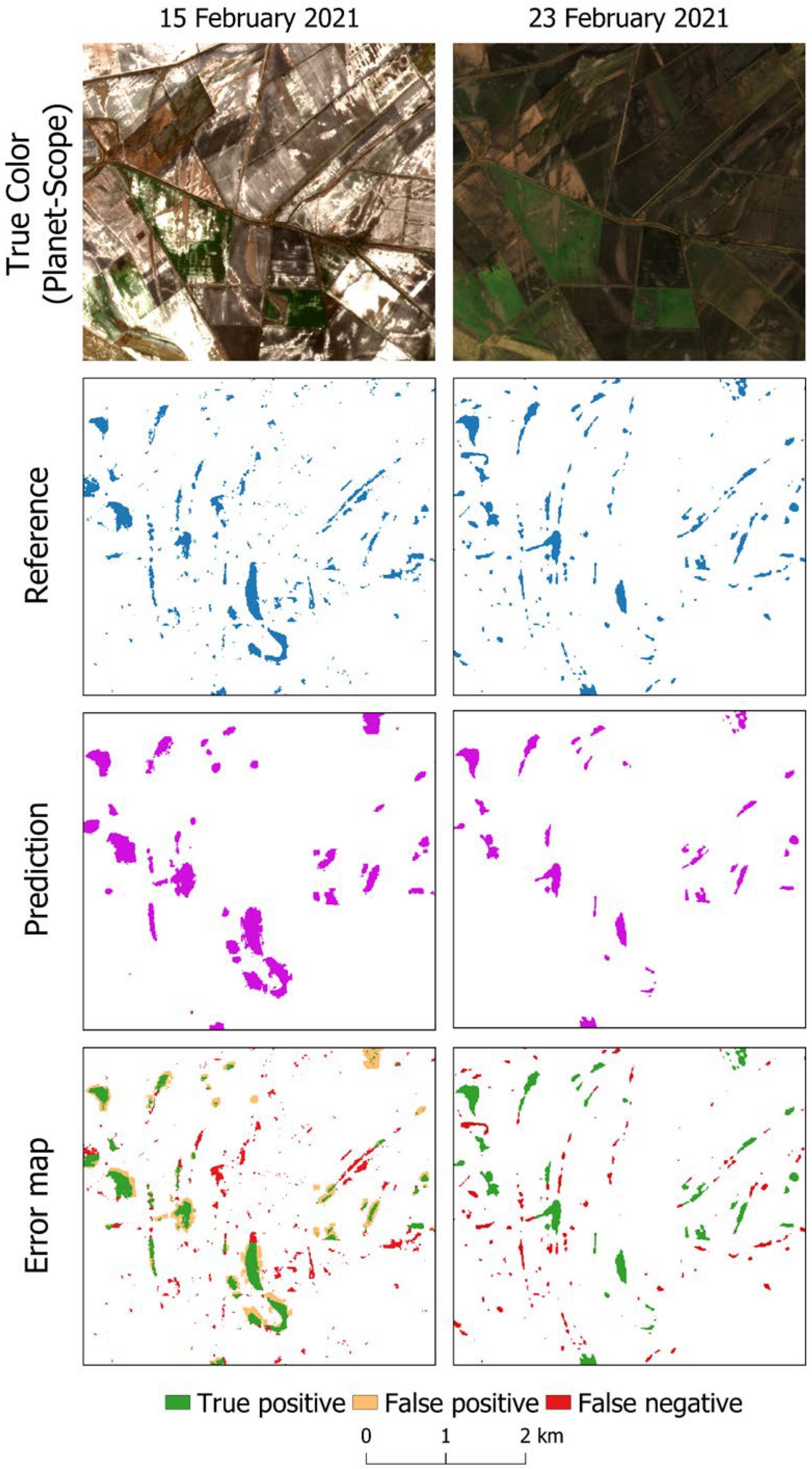
| 15/02/2021 | Reference | |||||
|---|---|---|---|---|---|---|
| Pixel | Water | No Water | Total | Overall Accuracy | 0.97 | |
| Prediction | Water | 265,531 | 257,641 | 523,172 | Precision | 0.51 |
| No Water | 154,736 | 15,322,092 | 15,476,828 | Kappa | 0.55 | |
| Total | 420,267 | 15,579,733 | 16,000,000 | F1 score | 0.56 | |
| 23/02/2021 | Reference | |||||
| Pixel | Water | No Water | Total | Overall Accuracy | 0.98 | |
| Prediction | Water | 466,232 | 1081 | 467,313 | Precision | 1.00 |
| No Water | 387,091 | 15,145,596 | 15,532,687 | Kappa | 0.69 | |
| Total | 853,323 | 15,146,677 | 16,000,000 | F1 score | 0.71 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kajári, B.; Tobak, Z.; Túri, N.; Bozán, C.; Van Leeuwen, B. Prediction of Inland Excess Water Inundations Using Machine Learning Algorithms. Water 2024, 16, 1267. https://doi.org/10.3390/w16091267
Kajári B, Tobak Z, Túri N, Bozán C, Van Leeuwen B. Prediction of Inland Excess Water Inundations Using Machine Learning Algorithms. Water. 2024; 16(9):1267. https://doi.org/10.3390/w16091267
Chicago/Turabian StyleKajári, Balázs, Zalán Tobak, Norbert Túri, Csaba Bozán, and Boudewijn Van Leeuwen. 2024. "Prediction of Inland Excess Water Inundations Using Machine Learning Algorithms" Water 16, no. 9: 1267. https://doi.org/10.3390/w16091267
APA StyleKajári, B., Tobak, Z., Túri, N., Bozán, C., & Van Leeuwen, B. (2024). Prediction of Inland Excess Water Inundations Using Machine Learning Algorithms. Water, 16(9), 1267. https://doi.org/10.3390/w16091267