
A Method for Identifying Gross Errors in Dam Monitoring Data


Abstract
1. Introduction
2. Fundamentals of a Gross Error Identification Algorithm for Dam Monitoring Data
2.1. FCM Algorithm
2.2. OPTICS Algorithm and Its Improvement
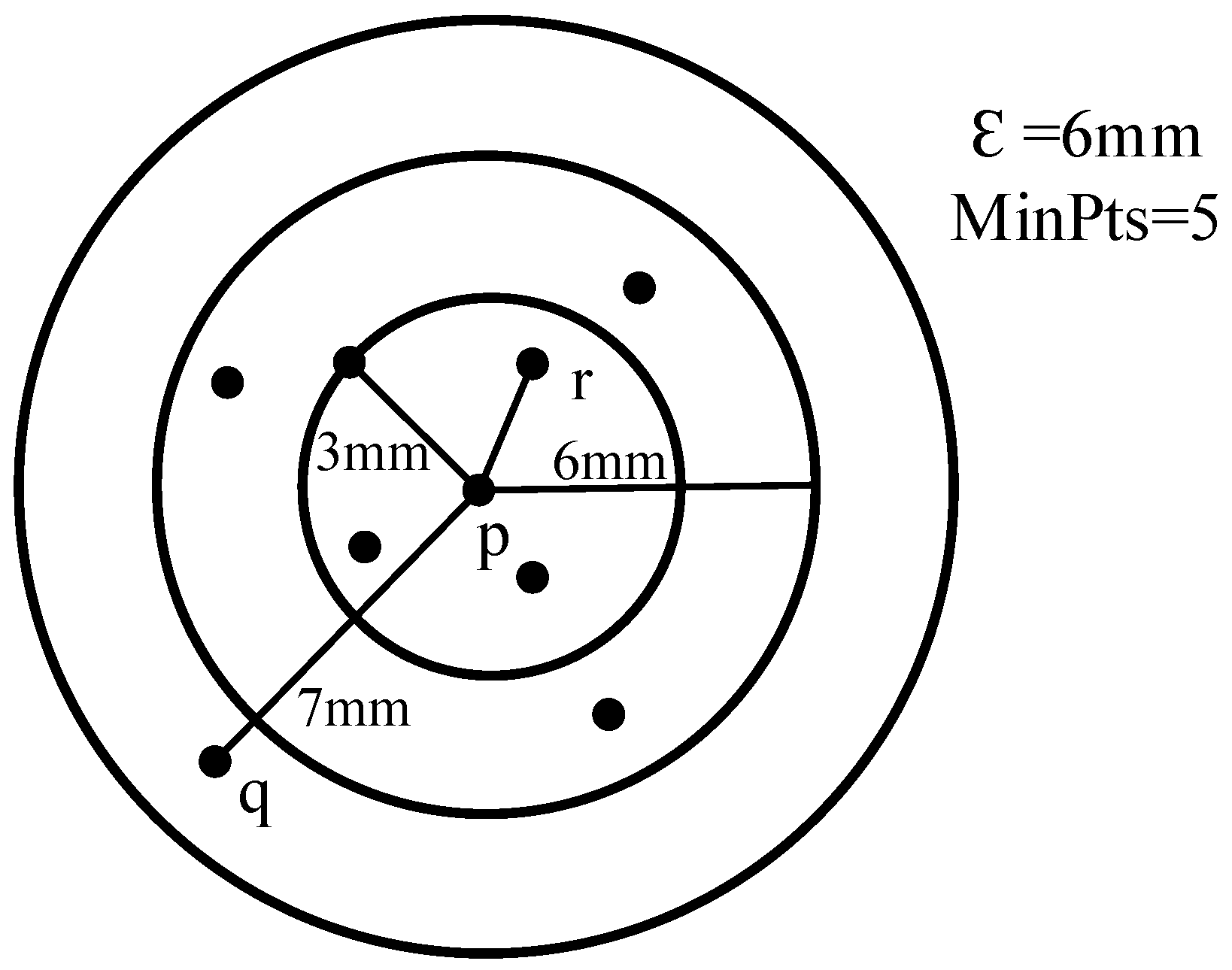
2.2.1. OPTICS Algorithm
2.2.2. Improved OPTICS Algorithm
2.3. LOF Algorithm
3. Gross Error Identification Method for Dam Safety Monitoring Based on FCM-OPTICS-LOF Algorithm
4. Case Study
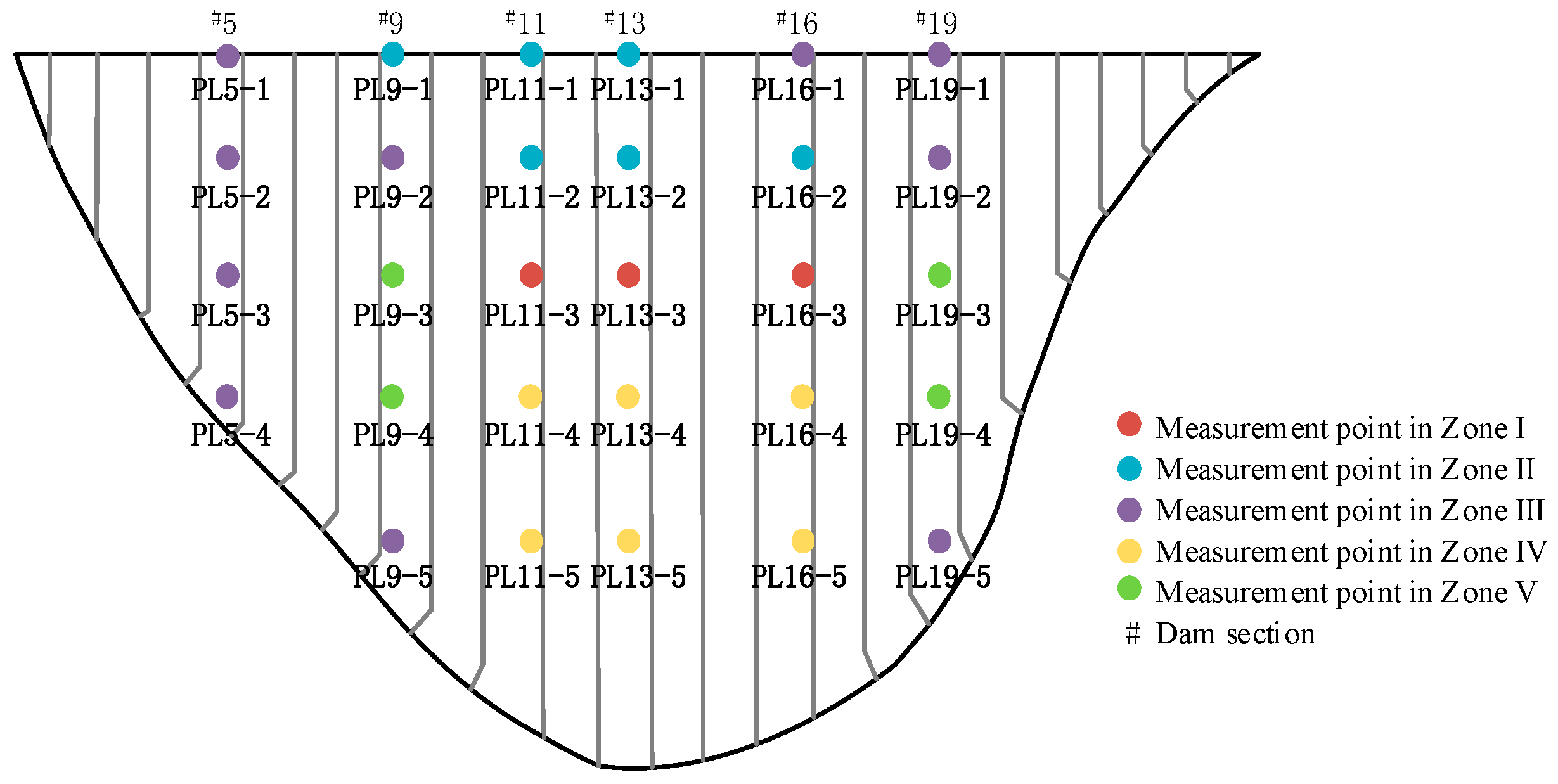
4.1. Project Overview
4.2. Clustering Partition
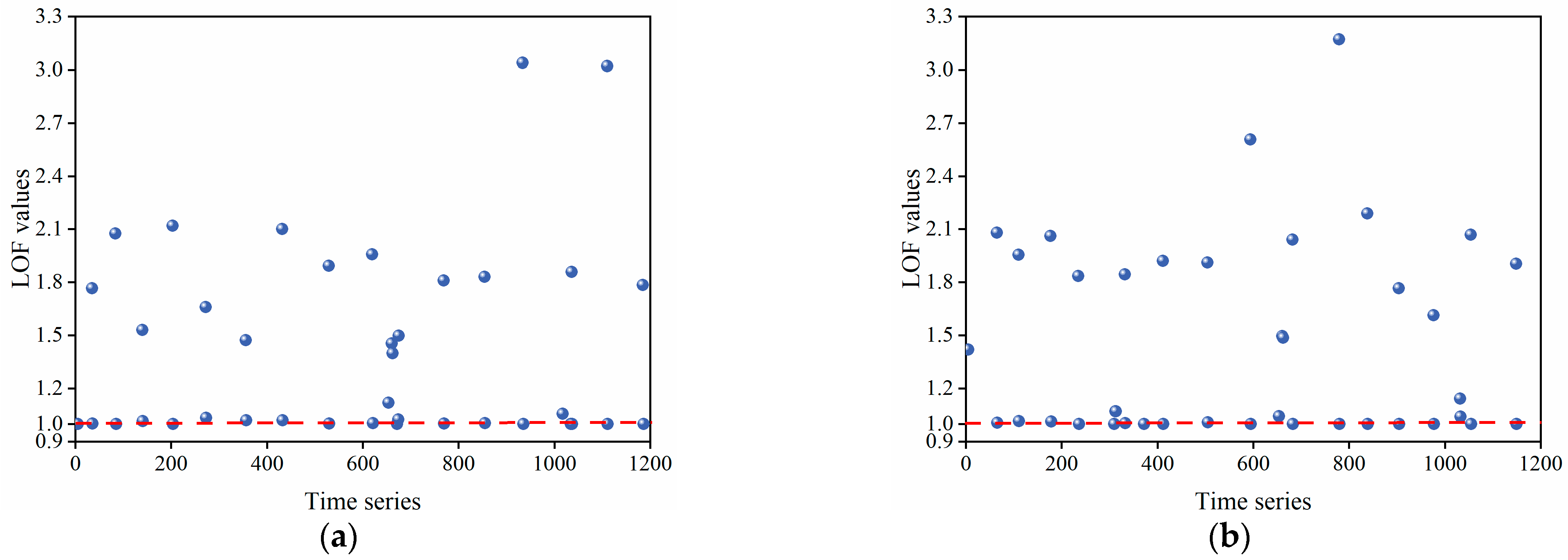
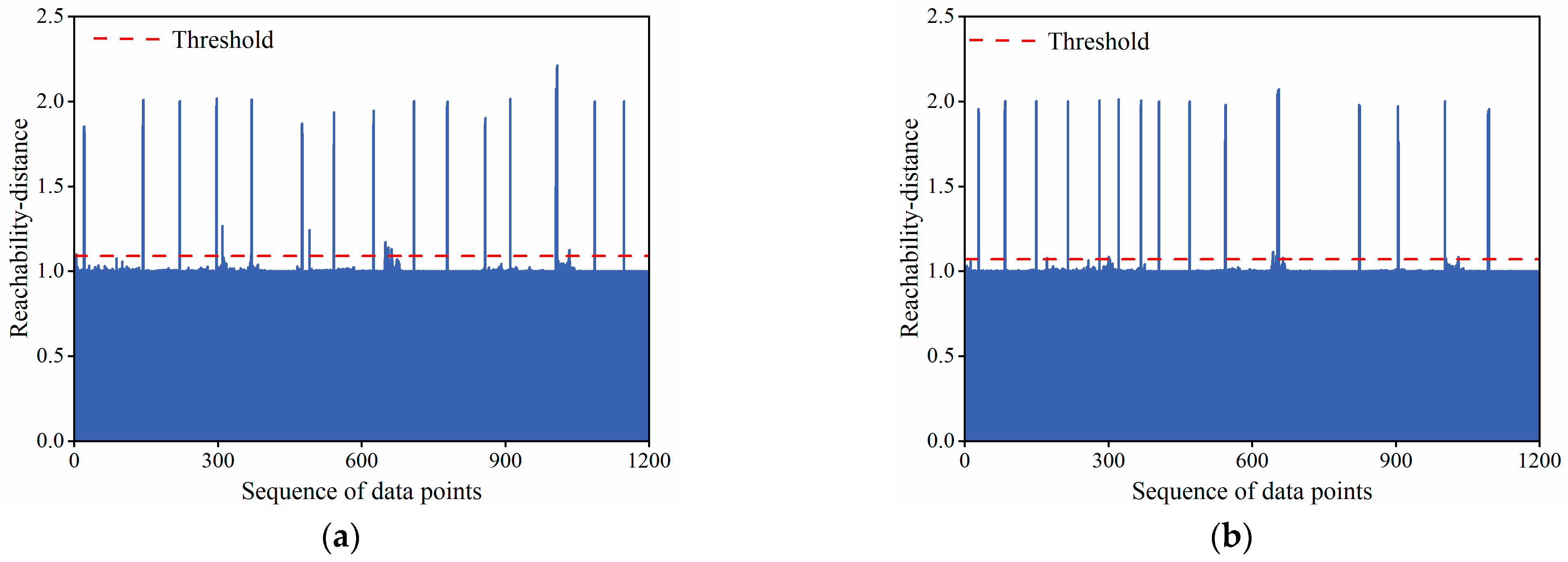
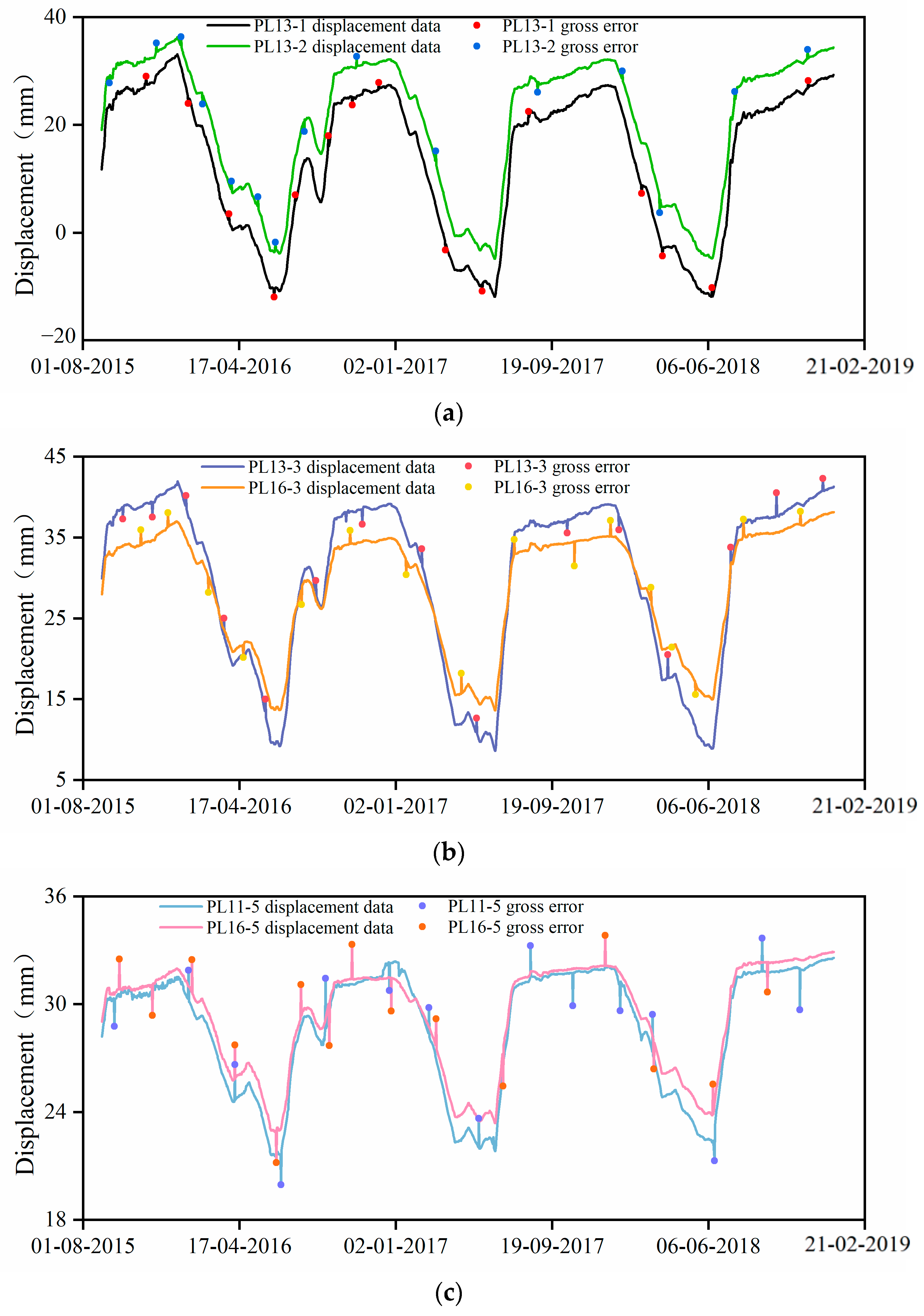
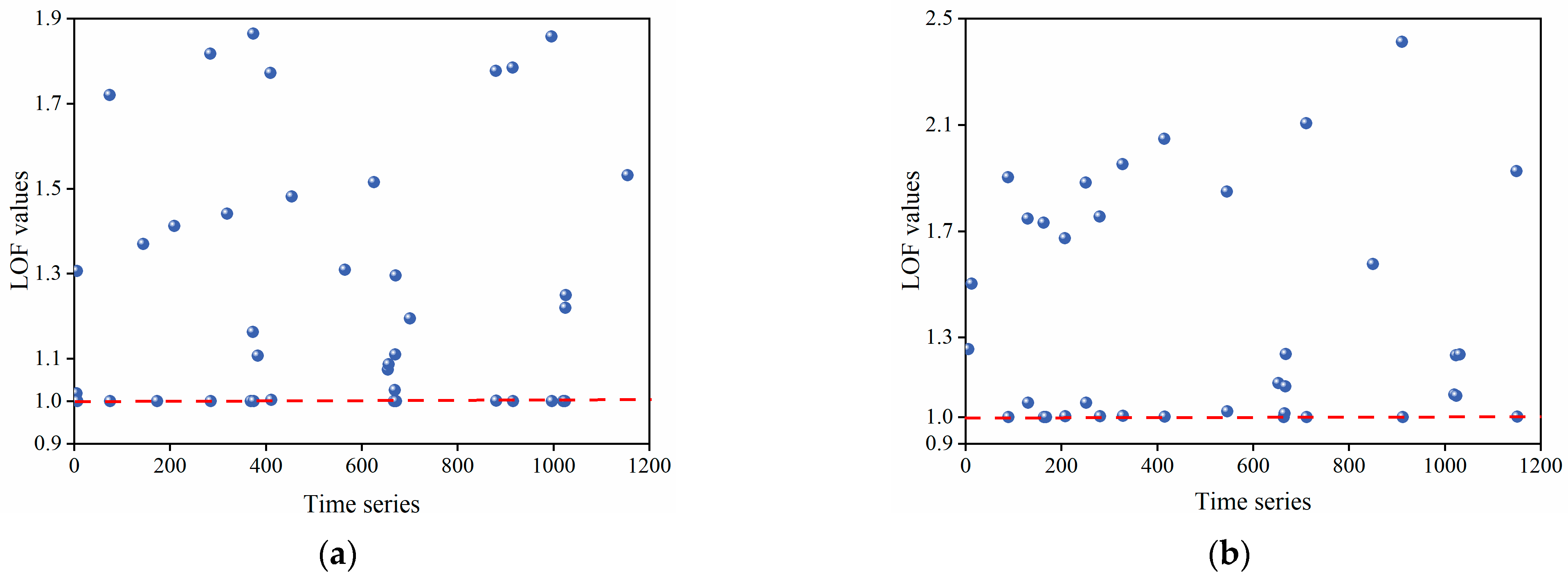
4.3. Gross Errors Identification
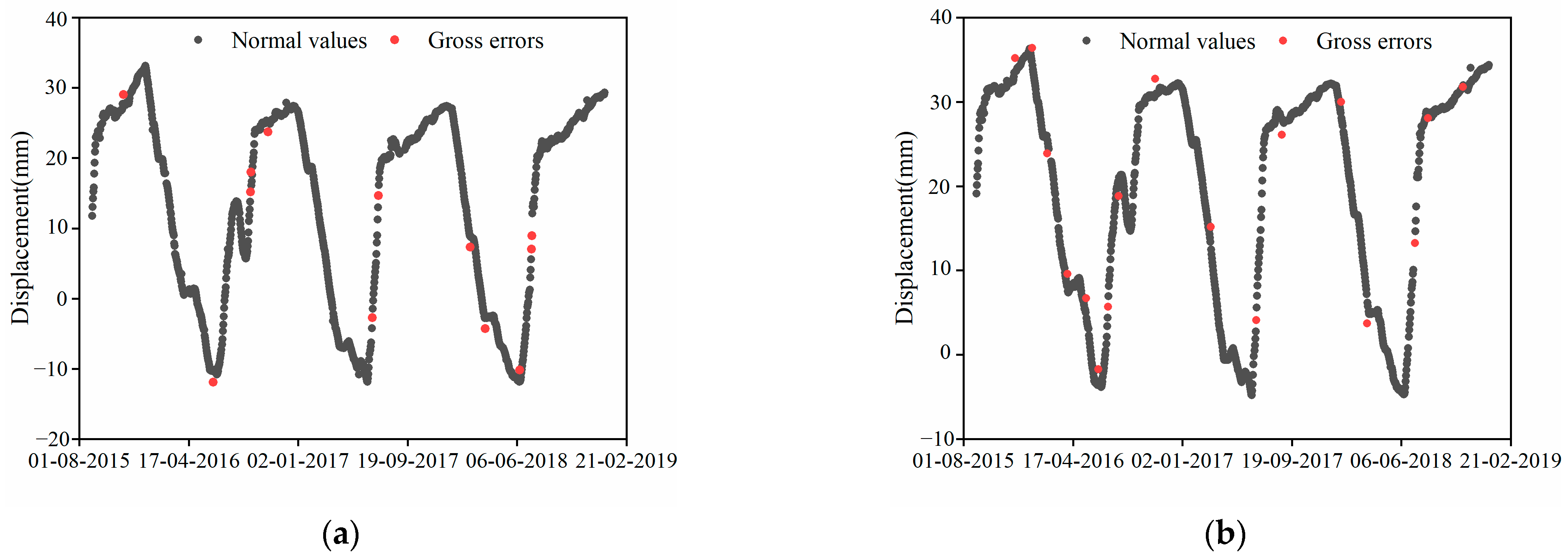
4.4. Comparison Analysis with Other Identification Methods
5. Conclusions
- (1)
- The FCM-OPTICS-LOF gross error identification method proposed in this study effectively identifies all gross errors within the dataset. And it will not misjudge abrupt data fluctuations induced by changes in environmental variables as gross errors. This presents a reliable and effective new approach for gross error identification in dam deformation monitoring data.
- (2)
- The proposed FCM-OPTICS-LOF method for gross error identification demonstrates higher accuracy compared to both the standalone LOF method and the widely employed DBSCAN method, belonging to the same density clustering algorithms. This affirms the superiority of the proposed method. Furthermore, the method’s ability to identify gross errors by comparing different measurement points allows simultaneous recognition of two or more points, significantly enhancing the efficiency of gross error detection.
- (3)
- Although the proposed gross error identification method in this paper achieves accurate identification, the threshold selection of the LOF value needs to be manually judged and determined for the specific situation. How to adaptively select the appropriate threshold needs to be further studied and explored.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PL13-3 | PL16-3 | ||||||
|---|---|---|---|---|---|---|---|
| Data | Raw Data/mm | Gross Error Size/mm | the Data after Adding the Gross Error/mm | Data | Raw Data/mm | Gross Error Size/mm | the Data after Adding the Gross Error/mm |
| 6 October 2015 | 38.87 | −1.56 | 37.31 | 5 November 2015 | 34.09 | 1.86 | 35.95 |
| 24 November 2015 | 39.32 | −1.78 | 37.54 | 20 December 2015 | 36.35 | 1.73 | 38.08 |
| 19 January 2016 | 38.72 | 1.45 | 40.17 | 25 February 2016 | 30.16 | −1.95 | 28.21 |
| 22 March 2016 | 22.72 | 2.3 | 25.02 | 23 April 2016 | 21.75 | −1.6 | 20.15 |
| 30 May 2016 | 13.11 | 1.89 | 15 | 29 July 2016 | 28.71 | −2 | 26.71 |
| 22 August 2016 | 28 | 1.68 | 29.68 | 18 October 2016 | 34.27 | 1.59 | 35.86 |
| 7 November 2016 | 38.52 | −1.86 | 36.66 | 19 January 2017 | 32.23 | −1.83 | 30.4 |
| 14 February 2017 | 31.66 | 1.96 | 33.62 | 21 April 2017 | 15.64 | 2.56 | 18.2 |
| 16 May 2017 | 10.84 | 1.82 | 12.66 | 18 July 2017 | 33.07 | 1.68 | 34.75 |
| 14 October 2017 | 37.22 | −1.65 | 35.57 | 26 October 2017 | 34.5 | −3 | 31.5 |
| 8 January 2018 | 37.73 | −1.76 | 35.97 | 25 December 2017 | 35.14 | 1.96 | 37.1 |
| 30 March 2018 | 17.61 | 2.89 | 20.5 | 2 March 2018 | 27.02 | 1.82 | 28.84 |
| 13 July 2018 | 31.9 | 1.9 | 33.8 | 15 May 2018 | 17.09 | −1.49 | 15.6 |
| 27 September 2018 | 37.72 | 2.8 | 40.52 | 3 August 2018 | 35.27 | 2 | 37.27 |
| 13 December 2018 | 40.77 | 1.53 | 42.3 | 6 November 2018 | 36.55 | 1.67 | 38.22 |
| PL11-5 | PL16-5 | ||||||
|---|---|---|---|---|---|---|---|
| Data | Raw Data/mm | Gross Error Size/mm | Data after Adding the Gross Error/mm | Data | Raw Data/mm | Gross Error Size/mm | Data after Adding the Gross Error/mm |
| 22 September 2015 | 30.3 | −1.53 | 28.77 | 30 September 2015 | 30.81 | 1.71 | 32.52 |
| 23 January 2016 | 30.2 | 1.69 | 31.89 | 24 November 2015 | 31.18 | −1.79 | 29.39 |
| 9 April 2016 | 24.67 | 1.98 | 26.65 | 29 January 2016 | 30.65 | 1.84 | 32.49 |
| 25 June 2016 | 21.72 | −1.76 | 19.96 | 9 April 2016 | 25.86 | 1.88 | 27.74 |
| 7 September 2016 | 28.65 | 2.8 | 31.45 | 17 June 2016 | 23.11 | −1.92 | 21.19 |
| 22 December 2016 | 32.41 | −1.64 | 30.77 | 28 July 2016 | 29.32 | 1.77 | 31.09 |
| 26 February 2017 | 28.24 | 1.58 | 29.82 | 13 September 2016 | 30.11 | −2.4 | 27.71 |
| 20 May 2017 | 21.99 | 1.65 | 23.64 | 21 October 2016 | 31.41 | 1.92 | 33.33 |
| 14 August 2017 | 31.54 | 1.73 | 33.27 | 25 December 2016 | 31.47 | −1.85 | 29.62 |
| 23 October 2017 | 31.74 | −1.82 | 29.92 | 10 March 2017 | 27.61 | 1.58 | 29.19 |
| 10 January 2018 | 31.29 | −1.64 | 29.65 | 29 June 2017 | 27.53 | −2.08 | 25.45 |
| 5 March 2018 | 27.23 | 2.2 | 29.43 | 16 December 2017 | 32.14 | 1.7 | 33.84 |
| 16 June 2018 | 23.03 | −1.74 | 21.29 | 7 March 2018 | 27.95 | −1.55 | 26.4 |
| 3 September 2018 | 31.84 | 1.84 | 33.68 | 13 June 2018 | 23.84 | 1.72 | 25.56 |
| 5 November 2018 | 31.99 | −2.3 | 29.69 | 12 September 2018 | 32.36 | −1.68 | 30.68 |


References
- Milillo, P.; Perissin, D.; Salzer, J.T.; Lundgren, P.; Lacava, G.; Milillo, G.; Serio, C. Monitoring dam structural health from space: Insights from novel InSAR techniques and multi-parametric modeling applied to the Pertusillo dam Basilicata, Italy. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 221–229. [Google Scholar] [CrossRef]
- Gu, C.; Su, H.; Wang, S. Advances in calculation models and monitoring methods for long-term deformation behavior of concrete dams. J. Hydroelectr. Eng. 2016, 35, 1–14. [Google Scholar]
- Yuan, D.; Gu, C.; Gu, H. Displacement behavior analysis and prediction model of concrete gravity dams in cold region. J. Hydraul. Eng. 2022, 53, 733–746. [Google Scholar]
- Wu, Z. Safety Monitoring Theory and Its Applications in Hydraulic Structures; Higher Education Press: Beijing, China, 2003. [Google Scholar]
- Li, Z.; Hou, H. Dam safety monitoring indices based on motion stability theory. Eng. J. Wuhan Univ. Eng. Ed. 2010, 43, 581. [Google Scholar]
- Zhang, C.; Zhou, X.; Gao, C.; Wang, C. On improving the precision of localization with gross error removal. In Proceedings of the 28th International Conference on Distributed Computing Systems Workshops, Beijing, China, 17–20 June 2008; pp. 144–149. [Google Scholar]
- Hu, Y.T.; Shao, C.F.; Gu, C.S.; Meng, Z.Z. Concrete Dam Displacement Prediction Based on an ISODATA-GMM Clustering and Random Coefficient Model. Water 2019, 11, 714. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Z.-Y.; Wen, K.-L.; Chen, H.-C. The development of Matlab toolbox for gross error in measurement. In Proceedings of the 2011 International Conference on System Science and Engineering, Macau, China, 8–10 June 2011; pp. 461–466. [Google Scholar]
- Xiong, Z.; Cui, C.; Pei, D. Research on the Processing of the Gross Error of Shock Wave Overpressure Value. J. Ordnance Equip. Eng. 2021, 42, 94–97. [Google Scholar]
- Ge, L.Y.; Wang, Z.Y. Novel uncertainty-evaluation method of virtual instrument small sample size. J. Test. Eval. 2008, 36, 273–279. [Google Scholar]
- Zhao, Z.P.; Chen, K.J.; Zhang, H.; Li, Y.; Wu, Z. The method of gross error identification of dam monitoring data based on robust estimation. J. Water Resour. Power 2018, 36, 68–71. [Google Scholar]
- Li, X.; Li, Y.L.; Zhang, P.; Yang, Z. Research on an improved Pauta criterion based on M-estimation for gross error identification of monitoring data and its application. China Rural Water Hydropower 2019, 8, 133–136. [Google Scholar]
- Qu, X.D.; Yang, J.; Chang, M. A Deep Learning Model for Concrete Dam Deformation Prediction Based on RS-LSTM. J. Sens. 2019, 2019, 4581672. [Google Scholar] [CrossRef]
- Al-Samahi, S.S.A.; Ho, K.C.; Islam, N.E. Improving Elliptic/Hyperbolic Localization Under Multipath Environment Using Neural Network for Outlier Detection. In Proceedings of the IEEE Conference on Computer Communications (IEEE INFOCOM), Paris, France, 29 April–2 May 2019; pp. 933–938. [Google Scholar]
- Bourquin, J.; Schmidli, H.; van Hoogevest, P.; Leuenberger, H. Pitfalls of artificial neural networks (ANN) modelling technique for data sets containing outlier measurements using a study on mixture properties of a direct compressed dosage form. Eur. J. Pharm. Sci. 1998, 7, 17–28. [Google Scholar] [CrossRef] [PubMed]
- Chakravarty, S.; Demirhan, H.; Baser, F. Fuzzy regression functions with a noise cluster and the impact of outliers on mainstream machine learning methods in the regression setting. Appl. Soft Comput. 2020, 96, 106535. [Google Scholar] [CrossRef]
- Miao, Y.; Su, H.Y.; Xu, O.G.; Chu, J. Support Vector Regression Approach for Simultaneous Data Reconciliation and Gross Error or Outlier Detection. Ind. Eng. Chem. Res. 2009, 48, 10903–10911. [Google Scholar] [CrossRef]
- Ramachandran, V.; Kishorebabu, V. A Tri- State Filter for the Removal of Salt and Pepper Noise in Mammogram Images. J. Med. Syst. 2019, 43, 40. [Google Scholar] [CrossRef] [PubMed]
- Mohandoss, D.P.; Shi, Y.; Suo, K. Outlier Prediction Using Random Forest Classifier. In Proceedings of the IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 27–30 January 2021; pp. 27–33. [Google Scholar]
- Song, J.T.; Chen, Y.C.; Yang, J. A Novel Outlier Detection Method of Long-Term Dam Monitoring Data Based on SSA-NAR. Wirel. Commun. Mob. Comput. 2022, 2022, 6569367. [Google Scholar] [CrossRef]
- Qi, Z.Y.; Sun, F.T.; Mao, Y.P.; Zhou, J.B.; Zhang, C.H.; Li, Q.Y. Research on Gross Error Detecting Method of Monitored Dam Deformation Data Based on Fully Convolutional Networks. Water Resour. Power 2023, 41, 87–90. [Google Scholar]
- Wang, L.; Zheng, D. Anomaly Identification of Dam Safety Monitoring Data Based on Convolutional Neural Network. J. Yangtze River Sci. Res. Inst. 2021, 38, 72–77. [Google Scholar]
- Hu, J.; Ma, F.H.; Wu, S.H. Anomaly identification of foundation uplift pressures of gravity dams based on DTW and LOF. Struct. Control Health Monit. 2018, 25, e2153. [Google Scholar] [CrossRef]
- Song, J.T.; Zhang, S.F.; Tong, F.; Yang, J.; Zeng, Z.Q.; Yuan, S. Outlier Detection Based on Multivariable Panel Data and K-Means Clustering for Dam Deformation Monitoring Data. Adv. Civ. Eng. 2021, 2021, 3739551. [Google Scholar] [CrossRef]
- Shao, C.F.; Zheng, S.; Gu, C.S.; Hu, Y.T.; Qin, X.N. A novel outlier detection method for monitoring data in dam engineering. Expert Syst. Appl. 2022, 193, 116476. [Google Scholar] [CrossRef]
- Bao, Y.Q.; Tang, Z.Y.; Li, H.; Zhang, Y.F. Computer vision and deep learning-based data anomaly detection method for structural health monitoring. Struct. Health Monit. Int. J. 2019, 18, 401–421. [Google Scholar] [CrossRef]
- Harrou, F.; Zeroual, A.; Hittawe, M.M.; Sun, Y. Chapter 6—Recurrent and convolutional neural networks for traffic management. In Road Traffic Modeling and Management; Harrou, F., Zeroual, A., Hittawe, M.M., Sun, Y., Eds.; Elsevier: Amsterdam, The Netherlands, 2022; pp. 197–246. [Google Scholar]
- Harrou, F.; Zeroual, A.; Hittawe, M.M.; Sun, Y. Road Traffic Modeling and Management: Using Statistical Monitoring and Deep Learning; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar]
- Hittawe, M.M.; Langodan, S.; Beya, O.; Hoteit, I.; Knio, O. Efficient SST prediction in the Red Sea using hybrid deep learning-based approach. In Proceedings of the 20th IEEE International Conference on Industrial Informatics (INDIN), Perth, Australia, 25–28 July 2022; pp. 107–114. [Google Scholar]
- Zhang, J.; Xie, J.M.; Kou, P.G. Abnormal Diagnosis of Dam Safety Monitoring Data Based on Ensemble Learning. In Proceedings of the 3rd International Workshop on Renewable Energy and Development (IWRED), Guangzhou, China, 8–10 March 2019. [Google Scholar]
- Gu, C.S.; Wang, Y.B.; Gu, H.; Hu, Y.T.; Yang, M.; Cao, W.H.; Fang, Z. A Combined Safety Monitoring Model for High Concrete Dams. Appl. Sci. 2022, 12, 12103. [Google Scholar] [CrossRef]
- Li, N.; Li, P.; Shi, X.L.; Yan, K.; Ren, W.P. Outlier Identify Based on BP Neural Network in Dam Safety Monitoring. In Proceedings of the 2nd International Asia Conference on Informatics in Control, Automation and Robotics (CAR), Wuhan, China, 6–7 March 2010; pp. 210–214. [Google Scholar]
- Liu, J.; Lian, J.J. Outliers Detection of Dam Displacement Monitoring Data Based on Wavelet Transform. In Proceedings of the International Conference on Green Building, Materials and Civil Engineering (GBMCE 2011), Shangri La, China, 22–23 August 2011; pp. 4590–4595. [Google Scholar]
- Li, H.J.; Li, J.J.; Kang, F. Risk analysis of dam based on artificial bee colony algorithm with fuzzy c-means clustering. Can. J. Civ. Eng. 2011, 38, 483–492. [Google Scholar] [CrossRef]
- Yang, C.; Bao, T. Dam Deformation Prediction Model Based on FCM-XGBoost. J. Yangtze River Sci. Res. Inst. 2021, 38, 66–71. [Google Scholar]
- Liu, W.; Chen, B.; Ge, P.; Zhang, X. Deformation prediction model of a high arch dam based on clustering and MO-LSSVR. Adv. Sci. Technol. Water Resour. 2023, 43, 102–108. [Google Scholar]
- Li, Z.K.; Li, W.; Ge, W. Weight analysis of influencing factors of dam break risk consequences. Nat. Hazards Earth Syst. Sci. 2018, 18, 3355–3362. [Google Scholar] [CrossRef]
- Kumar, K.M.; Reddy, A.R.M. A fast DBSCAN clustering algorithm by accelerating neighbor searching using Groups method. Pattern Recognit. 2016, 58, 39–48. [Google Scholar] [CrossRef]
- Kalita, H.K.; Bhattacharyya, D.K.; Kar, A. A new algorithm for Ordering of Points To Identify Clustering Structure Based On Perimeter of Triangle: OPTICS (BOPT). In Proceedings of the 15th International Conference on Advanced Computing and Communications, Indian Inst Technol Guwahati, Guwahati, India, 18–21 December 2007; pp. 523–528. [Google Scholar]
- Deng, Z.; Hu, Y.Y.; Zhu, M.; Huang, X.H.; Du, B. A scalable and fast OPTICS for clustering trajectory big data. Clust. Comput. J. Netw. Softw. Tools Appl. 2015, 18, 549–562. [Google Scholar] [CrossRef]
- Xiao, X.; Xue, S. An outlier detection algorithm based on improved OPTICS clustering and LOPW. Comput. Eng. Sci. 2019, 41, 885–892. [Google Scholar]






| PL13-1 | PL13-2 | ||||||
|---|---|---|---|---|---|---|---|
| Data | Raw Data/mm | Gross Error Size/mm | the Data after Adding the Gross Error/mm | Data | Raw Data/mm | Gross Error Size/mm | the Data after Adding the Gross Error/mm |
| 14 November 2015 | 27.62 | 1.38 | 29 | 14 September 2015 | 29.34 | −1.5 | 27.84 |
| 23 January 2016 | 25.15 | −1.15 | 24 | 1 December 2015 | 33.51 | 1.7 | 35.21 |
| 31 March 2016 | 2.1 | 1.4 | 3.5 | 11 January 2016 | 34.59 | 1.8 | 36.39 |
| 14 June 2016 | −10.5 | −1.4 | −11.9 | 16 February 2016 | 25.76 | −1.9 | 23.86 |
| 19 July 2016 | 5.78 | 1.22 | 7 | 4 April 2016 | 7.82 | 1.76 | 9.58 |
| 12 September 2016 | 15.67 | 2.33 | 18 | 18 May 2016 | 4.7 | 2 | 6.7 |
| 22 October 2016 | 25.24 | −1.54 | 23.7 | 16 June 2016 | −3.39 | 1.66 | −1.73 |
| 5 December 2016 | 26.7 | 1.2 | 27.9 | 3 August 2016 | 20.91 | −2.1 | 18.81 |
| 26 March 2017 | −1.74 | −1.46 | −3.2 | 29 October 2016 | 30.83 | 1.88 | 32.71 |
| 26 May 2017 | −9.4 | −1.40 | −10.8 | 10 March 2017 | 12.94 | 2.25 | 15.19 |
| 11 August 2017 | 20.91 | 1.59 | 22.5 | 26 August 2017 | 27.98 | −1.89 | 26.09 |
| 15 February 2018 | 8.74 | −1.44 | 7.3 | 14 January 2018 | 28.36 | 1.65 | 30.01 |
| 22 March 2018 | −2.74 | −1.56 | −4.3 | 17 March 2018 | 6.72 | −3 | 3.72 |
| 12 June 2018 | −11.86 | 1.66 | −10.2 | 20 July 2018 | 24.32 | 1.86 | 26.18 |
| 19 November 2018 | 26.89 | 1.31 | 28.2 | 18 November 2018 | 32.25 | 1.77 | 34.02 |
| Monitoring Points | Gross Error Identification Method | ||
|---|---|---|---|
| FCM-OPTICS-LOF | FCM-LOF | FCM-DBSCAN | |
| PL13-1 | 93.75% | 66.67% | 58.33% |
| PL13-2 | 93.75% | 83.33% | 82.35% |
| PL13-3 | 100% | 78.94% | 75% |
| PL16-3 | 93.75% | 75% | 78.94% |
| PL11-5 | 93.75% | 83.33% | 53.33% |
| PL16-5 | 100% | 78.94% | 73.33% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Gu, C.; Zheng, S.; Wang, Y. A Method for Identifying Gross Errors in Dam Monitoring Data. Water 2024, 16, 978. https://doi.org/10.3390/w16070978
Chen L, Gu C, Zheng S, Wang Y. A Method for Identifying Gross Errors in Dam Monitoring Data. Water. 2024; 16(7):978. https://doi.org/10.3390/w16070978
Chicago/Turabian StyleChen, Liqiu, Chongshi Gu, Sen Zheng, and Yanbo Wang. 2024. "A Method for Identifying Gross Errors in Dam Monitoring Data" Water 16, no. 7: 978. https://doi.org/10.3390/w16070978
APA StyleChen, L., Gu, C., Zheng, S., & Wang, Y. (2024). A Method for Identifying Gross Errors in Dam Monitoring Data. Water, 16(7), 978. https://doi.org/10.3390/w16070978